Report likelihood ratios
post by Ege Erdil (ege-erdil) · 2022-04-23T17:10:22.891Z · LW · GW · 9 commentsContents
What is TFP? Why care about likelihoods? Computing likelihoods What about p-values? None 9 comments
A few weeks ago, Thomas Philippon released a paper in which he argued that total factor productivity growth was piecewise linear rather than exponential. The paper received attention both on social media and on LessWrong itself [LW · GW].
I'll use this paper to illustrate a problem that I think is widespread, so while part of what I will say is a criticism of this specific paper the point I'm trying to make is more general.
What is TFP?
First, some background: total factor productivity (TFP) is often (wrongly, in my view) used as a proxy of technology in growth economics. Technically, it's the residual estimate of a log-linear regression of GDP on some quantifiable variables, such as the labor and capital stock of a country. The idea is to assume that there is a relationship between the GDP , labor stock and capital stock of countries for some , estimate from a linear regression
and then use the measured to back out estimates for across countries and across time. is then the "total factor productivity" - it's the part of GDP that's unexplained by how many people are working and how much capital equipment they have at their disposal.
The GDP of an individual country can therefore increase for three reasons: it has more total hours worked, more capital equipment or more total factor productivity. Notice that this statement is vacuously true and is a tautological consequence of the definition of total factor productivity.
It's a robust fact that TFP as defined above increases in most countries over time. What this means is that not only do countries expand their labor force and acquire more capital thanks to investment, they also become "more efficient" at using those inputs in some sense. For instance, if our definition of TFP is relative to labor and capital stocks, it might fail to capture that workers are also becoming more skilled. Economists usually call this "human capital" and we can try to include it in a regression, but since TFP is defined to be all the stuff we left out of the regression, if we only work with and then workers becoming more skilled will show up in our data as an increase in .
The question that's the subject of Philippon's paper is about the growth process of . Economists usually model TFP as an exponentially growing process, say, where is an average growth rate and is white noise. Philippon investigates the alternative hypothesis that the growth is linear: we have .
I've already criticized some of the paper's methodology in a comment [LW(p) · GW(p)], so I won't repeat what I've said here. What I will say is that there's a major shortcoming of Philippon's paper even if he's completely right and all of his analysis is sound: he doesn't report likelihood ratios. (In fact he doesn't report likelihoods at all, but we'll get to that later.) He reports a bunch of other statistics which appear to support the linear model over the exponential one, but no likelihood ratios.
Why care about likelihoods?
Why is this such a problem? Why aren't Philippon's root mean squared error estimates as good as reporting likelihoods?
The reason is that likelihoods are what a Bayesian cares about. If you read Philippon's paper and see that the data seems to favor the linear model over the exponential one, setting aside concerns about whether the analysis was properly done, there is an added concern over how much you should update from your prior beliefs based on the arguments in the paper. If the linear model fits the data better, you might ask "how much better", and the relevant quantity you care about at parameter parity is what likelihood the linear model assigns to some data compared to the exponential model.
If the linear model assigns the data 100 times the probability that the exponential model assigns it, you should multiply the ratio of your priors for the two classes of models by a factor of 100 in favor of the linear model. This is just a restatement of Bayes' rule. We can see this by just computing:
Here denotes "the right model is linear", denotes "the right model is exponential", and stands in for the data we've observed.
Without the likelihood ratio , we don't know how convincing the results in the paper are and how strong the evidence they provide for over is. Of course there are ways to hack likelihoods just like any other test statistic, but the fact that the paper doesn't even bother reporting likelihoods at all is a more serious problem.
Computing likelihoods
Since the paper doesn't report likelihoods, I've spent some time to compute them on my own. I couldn't find all of the data used by the paper, but I've computed three different likelihood ratio estimates which I hope will be helpful to people reading this paper.
The first is comparing the exponential and linear growth models exactly as I've presented them above on US TFP data since 1954. Both models have two free parameters, the growth rate and the standard deviation of the noise. In this case we obtain a likelihood ratio of ~ 50 favoring the linear model, which is very strong evidence that there's something wrong with the exponential growth model.
What turns out to be wrong is that the volatility of TFP growth has been declining since 1954. Economists sometimes call this "the Great Moderation", and a linear model automatically incorporates this effect while an exponential one does not. As such, for the second likelihood ratio I computed, I added an extra parameter such that the standard deviation of TFP growth at time is multiplied by a factor . I add this extra parameter to both models, so that they now both have three free parameters instead of two.
In this second case I get a likelihood ratio of ~ 1.56 favoring the linear model. Much smaller, and shows that almost all of the performance of the linear model comes from its ability to get rid of the heteroskedasticity in growth rates. For reference, if we started at a 50% prior chance of the linear model being right, this evidence would only get us to a 61% posterior chance. So it's evidence, but overall not that strong.
What about before 1954? Here I've found it quite difficult to find reliable TFP estimates, so even though I think this practice is dubious I had to use Philippon's pseudo-TFP estimates, which he computes by taking GDP per capita estimates and raising them to a power of . This is good because we have data from the Maddison Project on the UK's GDP per capita that goes back to the 1200s.
Philippon claims that the UK's pseudo-TFP is consistent with a piecewise linear trajectory with four pieces, or three "trend breaks". He dates these at ~ 1650, ~ 1830 and ~ 1930.
Since the piecewise linear model has a total of 11[1] (!) parameters, it's not a surprise that it fits the data much better than an exponential model which has only 2. In order to put the models on parameter parity, I've tried to compare an exponential model with the same number of parameters and essentially the same structure of trend breaks with a linear model. Here I've run against the limits of my optimization capabilities[2] - it seems to be quite challenging to get the SciPy optimizer to properly search over potential trend break sites. In order to be fair to Philippon's model, I've initialized both the exponential and the linear models with trend breaks at the years he identifies in his paper.
Here's the fit I've obtained as a result:
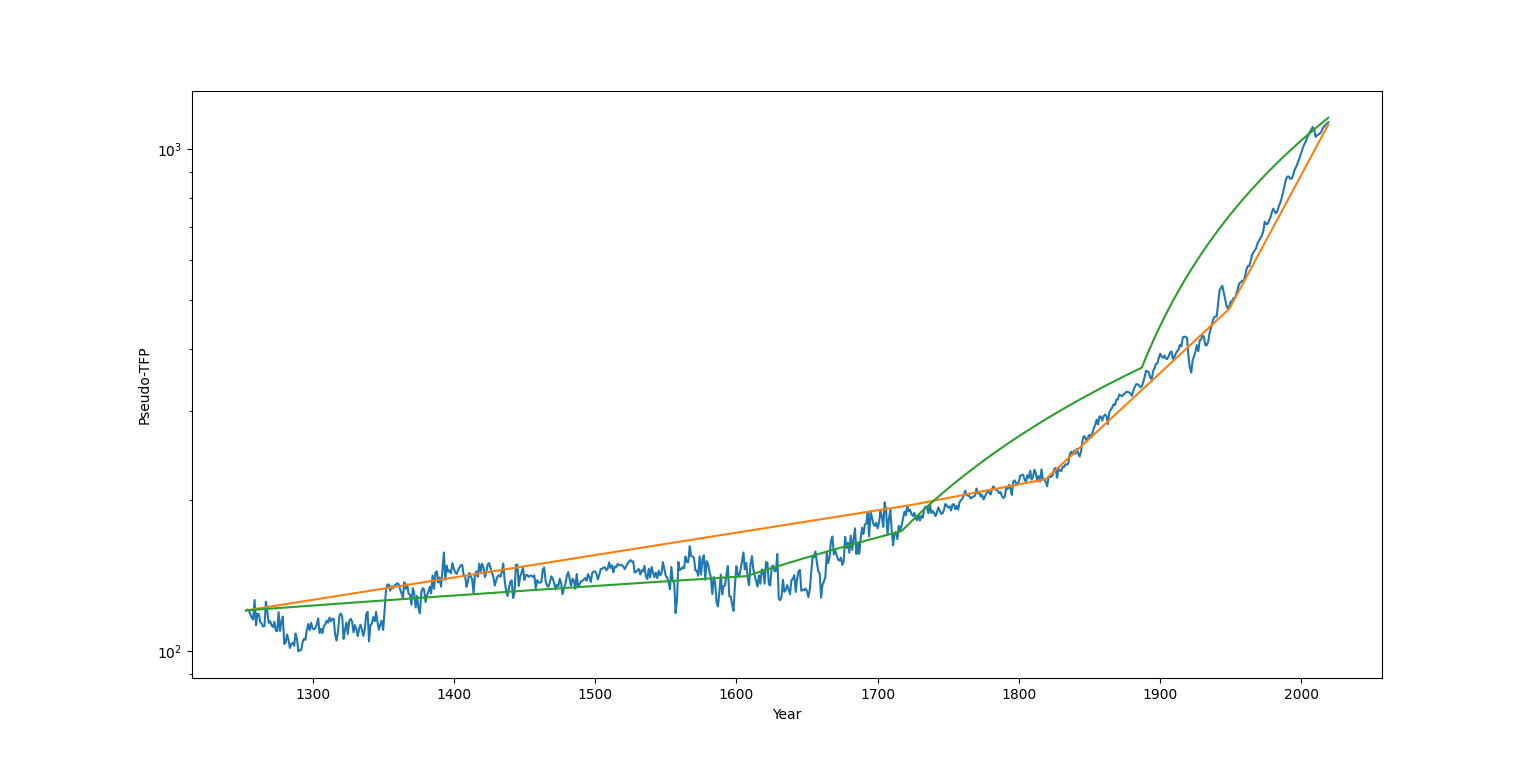
The blue line is realized pseudo-TFP in the UK, the orange line is the extrapolation of the fitted exponential model from the initial year, and the green line is the extrapolation of the linear model. Note that these are not curve fits to the blue line. The models I fit are autoregressive and I maximize the likelihood of observing the TFP at time t+1 conditional on the TFP at time t during the optimization.
As you can see, the exponential model seems to have better fit with the data despite "wasting" one of its trend breaks. This is confirmed by the likelihood ratios: the exponential fit is favored over the linear one by an astronomical likelihood factor of 3742 (!). Obviously this is misleading: once likelihood ratios get this big, the chance that the optimizer failed to find the optimal fit or that I made a mistake in my script takes over, but I'm quoting the exact figure I get just to show that the historical data doesn't seem to support Philippon's linear model.
That's all I'll say about Philippon's paper. Moving on...
What about p-values?
At first glance, it might seem like I'm wasting my time here since -values are both likelihoods and probably the most universally reported statistic in science. Philippon's paper doesn't report them, but this makes it a weird exception in a world of papers that do.
The problem here is that -values aren't likelihood ratios, they are just likelihoods: ones that are conditional on the null hypothesis being true. The most often used alternative hypothesis in most science papers is "the null hypothesis is false". There is an obvious issue with this: the null hypothesis is always false, so it's impossible to get useful likelihood ratios out of this frequentist methodology.
-values can give us likelihood ratios if we have two hypotheses, say and , that we wish to compare. We look at the probability of obtaining a result at least as extreme as what we obtained under both hypotheses, and their ratio tells us how much we should update away from one and towards the other based on this evidence. It doesn't tell us the posterior probabilities since this depends on our views about hypotheses other than and , but it tells us how we should update the ratio .
In the case that these are models then they represent a whole class of hypotheses that are parametrized (usually) by some finite dimensional real vector space, and then we also have to control for the fact that us fitting the models to the data artificially raises the likelihood of the data conditional on the models to some extent. This is what model selection criteria are for.
Unfortunately this is not how -values are often used, which means it's quite tricky to back out likelihood ratios from most scientific papers. As I said, a Bayesian has to do this in order to update their beliefs, so the difficulty of doing it is at least a significant theoretical obstacle to efficient belief updating. In practice it's not as big of a problem because I wouldn't trust likelihood ratios reported by most papers to begin with, and there are indeed parapsychology papers that get overwhelming likelihood ratios in favor of their paranormal findings.
Still, I'd like to see more reporting of likelihood ratios by papers in cases where there's a clear discrete and small set of models that are being compared with one another. Philippon's paper is almost a perfect example of a situation where they would've been useful, which makes his decision not to report them all the more baffling to me.
Three parameters for the dates of the trend breaks, four parameters for the growth rate in each trend, four more parameters for the volatility in each trend. 4+4+3 = 11. ↩︎
If there are any experts on doing maximum likelihood estimation on weird distributions in Python reading the post, you can leave a comment or send me a private message. I'll send you what I've done so far and ask for advice on how to fit the models better to the data. ↩︎
9 comments
Comments sorted by top scores.
comment by Carlos Javier Gil Bellosta (carlos-javier-gil-bellosta) · 2022-05-02T21:00:56.819Z · LW(p) · GW(p)
What I find most shocking about all this exponential vs linear discussion is how easily it gets us trapped into a [necessarily false] dichotomy. As a mathematician I am surprised that the alternative to an exponential curve be a line (why not a polynomial curve in between?).
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-05-03T17:56:38.358Z · LW(p) · GW(p)
Polynomial growth is actually a better fit to some of the non-frontier "economic miracles", say Japan, South Korea, Taiwan, et cetera. I haven't fit this myself but Robert Lucas has done some work on this subject and his estimates imply a growth that's more like .
For frontier TFP growth I'm not sure if using general polynomials will be more informative, though it's certainly worth doing if you're going to write a whole paper on the subject.
comment by ryan_b · 2022-04-25T17:42:29.502Z · LW(p) · GW(p)
Is there any kind of paper where reporting likelihood ratios is common? I don't recall ever reading one, or seeing one discussed.
My current suspicion on why we don't see more of it comes down to citations; there's no relevant analysis for a given researcher to cite, upon which they can build or compare their likelihood ratios against.
It feels to me like a viable strategy to kickstart a conversion to likelihood ratios in a field is to fund papers which re-examine the fundamental findings in the field under a likelihood paradigm, to provide a ready basis of citeable references for when people are conducting current research. I'd really like to see something similar to the kind of analysis done here, but for different versions of the 2nd Law of Thermodynamics, for example. Unfortunately I don't see analysis of data being touted as an area of focus for any of the "new ways to conduct research" orgs that have popped up in the last few years.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-04-25T21:26:31.901Z · LW(p) · GW(p)
I imagine the place likelihood ratios would be reported most often are meta-analyses, though this is just a hunch and I have no actual data to back it up.
I think this could be true. Papers report p-values and mark estimated values significant at specific thresholds with asterisks because of the convention in a field, so you could probably bootstrap a new field or a new research culture to a different equilibrium from the start.
On the other hand, I believe p-values are used precisely because you only need the null hypothesis to report them. Asking researchers to think about concrete alternatives to their hypotheses is more difficult, and you can run into all kinds of consistency problems when you do Bayesian inference in an environment where the "true model" is not in the family of models that you're considering in your paper - this is the main obstacle you face when going from likelihood ratios to posteriors. This problem is probably why Bayesian methods never really took off compared to good old p-values.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-25T16:17:10.884Z · LW(p) · GW(p)
Question for clarification: I'm confused by what you mean when you say that the null hypothesis is always false. My understanding is that the null hypothesis is generally "these two sets of data were actually drawn from the same distribution", and the hypothesis is generally "these two sets of data are drawn from different distributions, because the variable of interest which differs between them is in the casual path of a distributional change". Do you have a different way of viewing the null hypothesis in mind? (I totally agree with your conclusion that likelihood ratios should be presented asking with p values, and also ideally other details about the data also.)
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-04-25T16:41:34.370Z · LW(p) · GW(p)
The null hypothesis in most papers is of the form "some real-valued random variable is equal to zero". This could be an effect size, a regression coefficient, a vector of regression coefficients, et cetera.
If that's your null hypothesis then the null hypothesis actually being true is an event of zero probability, in the sense that if your study had sufficient statistical power it would pick up on a tiny signal that would make the variable under consideration (statistically) significantly different from zero. If you believe there are no real-valued variables in the real world then it's merely an event of probability where is a tiny real number, and this distinction doesn't matter for my purposes.
Incidentally, I think this is actually what happened with Bem's parapsychology studies: his methodology was sound and he indeed picked up a small signal, but the signal was of experimenter effects and other problems in the experimental design rather than of paranormal phenomena. My claim is that no matter what you're investigating, a sufficiently powerful study will always manage to pick up on such a small signal.
The point is that the null hypothesis being false doesn't tell you much without a useful alternative hypothesis at hand. If someone tells you "populations 1 and 2 have different sample means", the predictive value of that precise claim is nil.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-26T04:59:50.072Z · LW(p) · GW(p)
I understand much better now what you were saying. Thanks for clarifying.
comment by Arjun Yadav · 2022-05-10T13:17:54.408Z · LW(p) · GW(p)
Is the misuse of -values still a big concern? I admittedly haven't done research into this topic, but as part of an AI course I'm taking, -values were discussed quite negatively. In general, I find their position in science and statistics a bit ambiguous.