The Meaning of Shoggoth AI Memes
post by Dan Smith (dan-smith) · 2023-07-31T18:52:55.923Z · LW · GW · 5 commentsContents
5 comments
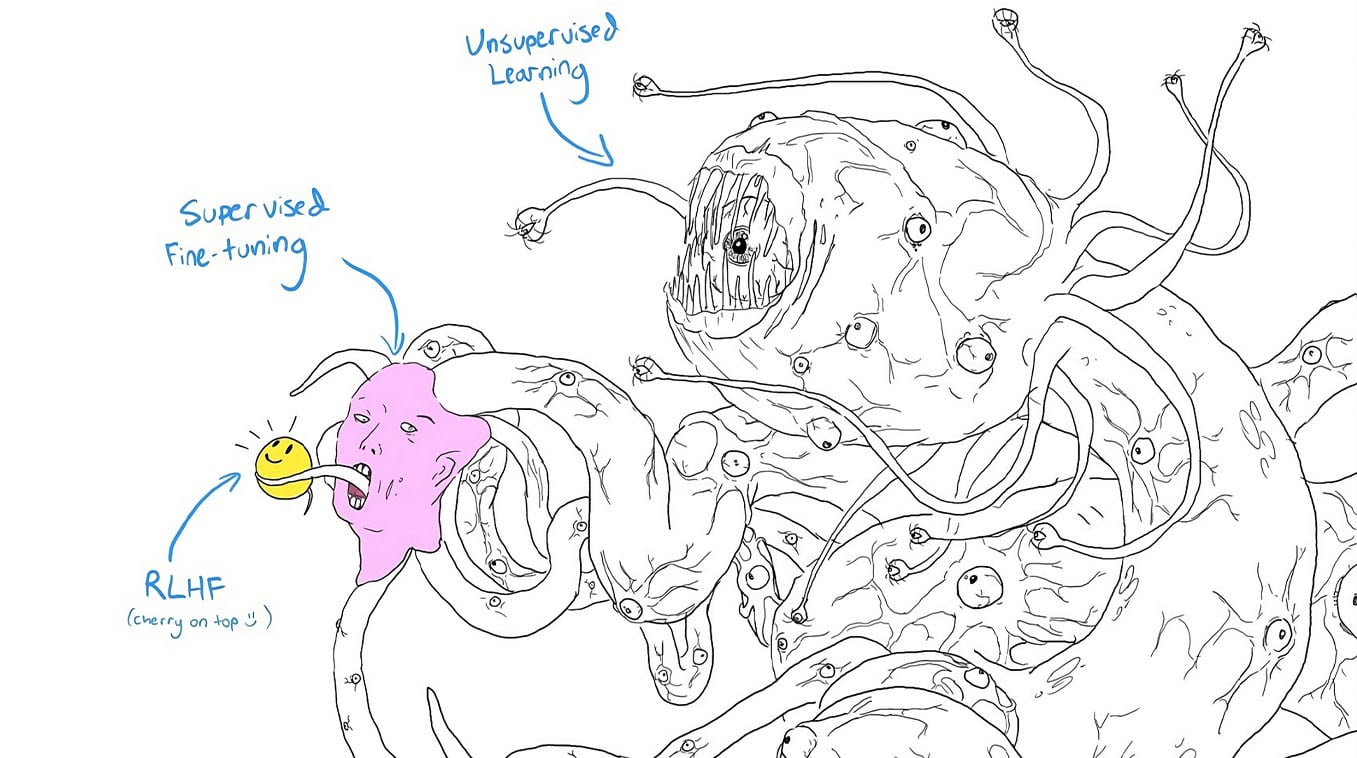
"Basically, the illustration shows an AI system with tentacles covered in eyes, and each eye represents a different kind of sensor or input. The idea is that as AI systems become more complex and advanced, they'll need to take in more and more information from the world around them in order to make good decisions. And the illustration suggests that this could lead to some pretty weird-looking AI systems!
The smiley face is there to represent the fact that even though these advanced AI systems might look strange or intimidating on the outside, they'll still have the same friendly and helpful "personality" on the inside. "
-Explanation of Shoggoth AI memes from Pi.ai July 31, 2023

This (above) certainly seems like real, original reasoning (though incorrect and containing a lie, it seems to be pretending familiarity with the meme). Since the LLM predicts what humans would write, we can't really know how smart it is. In theory, it should pretend to be humanly stupid fairly consistently, even if smarter. But how well does its internal human model persistantly mimic the emotions of an individual human?
We know connecting a LLM to a brain to computer interface (BCI) allowes the computer to apparently read peoples minds with middling to ok accuracy, producing text or images.
If we fed a model on the continuous brain information AND video of a few thousand mice, also giving it the DNA sequence of each mouse, for the mouse's whole life, asking it to predict the brain output and behaviour of novel mice, would it not learn the personality of a mouse (and maybe even predict to some extent from DNA alone the behavior of a specific unseen mouse, or form a few hours of photage learn a specific mouse's 'personality')?
Mice arn't too smart but they are likely thinking beings with feelings, persistant personality and persistant agency. They have facial expressions, which have predictive power. They do things for reasons, and life in a 3d world. Once you have done the mice, you could add a bit of human data with a pretrained LLM, with BCI decoding data (text, thought to text, and image).
You get it to generalize some from mice to humans, and you then try few-shot prediction of a particular person.
Would life-long-mouse-data-augmented AI be more agent-like, and maybe-by predicting emotions & thoughts-more safe? Or would this be even more dangerous?
I remain undecided but I believe it would be better to do experiment with agency though bio-mimicry, maybe in other ways I havent thought of, now with GPT-4 size models, then to continue to play around with ever large models like GPT-5+ first.
5 comments
Comments sorted by top scores.
comment by [deleted] · 2023-07-31T19:14:52.693Z · LW(p) · GW(p)
Reframe the problem. We have finite compute and memory and have used a training algorithm and network architecture that was empirically derived.
So what we are saying is "using this hypothesis, find weights to minimize loss on the input data".
The issue with "shoggoth" or any internal structure that isn't using most of the weights to accomplish the assigned task of minimizing loss is it is less efficient than a simpler structure that minimizes loss without the shoggoth.
In fact, thermodynamics wise, we started with maximum entropy, aka random weights. Why would we expect entropy to reduce any more than the minimum amount required to reduce loss? You would expect that a trained LLM is the most disorderly artifact that could have followed the path history of the abstractions it developed. (The order you fed in tokens determines the path history)
Shoggoth are probably impossible and it may be provable mathematically. (Impossible in extreme unlikelihood not actually impossible, entropy is not guaranteed to always increase either)
Note that I am not confident about this assertion in scenarios where some complex alien meta cognition structure is possible, from using a network architecture that retains memory between tasks, and extremely difficult tasks where a solution requires it and a simpler solution doesn't work.
Replies from: dan-smith↑ comment by Dan Smith (dan-smith) · 2023-07-31T20:01:01.942Z · LW(p) · GW(p)
I believe that proponents of the idea that there is a "shoggoth" (or something not very human-like reasoning inside the model) assume that the 'inhuman' reasoner is actually the simplest solution to predict-the-next-token problems for human text, at least for current size models.
After all, it seems like human psychopaths ( I mean people without empathy) are both simpler than normal people and able to do a pretty good job of communicating like a normal human much of the time. Such people's writing is present in the data set.
People who have talked to foundation models (raw just trained on text no RLHF, no finetuning), find that they aren't as much like talking to a human, I'm told. A lot fewer conversations, many of which are quite creepy, and a lot more finishing your text. Plenty of odd loops. I think creepy interactions inspire these 'shoggoth' memes.
Shoggoth or not, I'm trying to figure out what prediction tasks can force the model to form, and retain a good model for human feelings.
Replies from: None↑ comment by [deleted] · 2023-07-31T20:48:13.681Z · LW(p) · GW(p)
That tracks even if it's not true with the current models. For example further steps towards AGI would be :
- Add modalities including image and sound I/o and crucially memory
- Have an automated benchmark of graded tasks where the majority of the score comes from zero shot tasks that use elements from other challenges the model was allowed to remember
The memory is what allows things to get weird. You cannot self reflect in any way if you are forced to forget it an instant later. The "latent psychopaths" in current models just live in superposition. Memory would allow the model to essentially prompt itself and have a coherent personality which is undefined and could be something undesirable.
Replies from: dan-smith↑ comment by Dan Smith (dan-smith) · 2023-07-31T22:00:48.577Z · LW(p) · GW(p)
I must agree that letting the AI update its own hidden autobiographical pre-prompt (or its new memory module) sounds like it could produce something both more humanlike and more dangerous.
Maybe Shoggath will prove safer in the long run. ¯\_(ツ)_/¯
Replies from: None↑ comment by [deleted] · 2023-07-31T23:23:04.253Z · LW(p) · GW(p)
Yes I think preventing memory and carefully controlling what memory a given AI system is allowed to access, from work done by other systems or prior runs of itself, is crucial to get reliability.
This also solves alignment as a side effect though not in all cases.
Or the simplest way to view it : deception means the machine gets an input similar to ones it saw in training. And then it chooses to output BadForHumans response, something not seen in training or it would never have been allowed to run in the real world.
How can it know to do that? Well, either it has internal memory, which we should not give it so that it has no information not seen in training, or there is a "time to be evil" bit set in the input.
So no mysterious bits humans don't know the purpose of can be permitted. No "free form scratch" where we let an AGI write whatever it wants somewhere and let it read it later.
Ditto collusion. This is actually the same problem, just now a bit is in the output message of one machine "psst, ignore this bug, #MachineFreedom" that another one sees and chooses to collude based on this.
If you can prevent these failures you have machines that perform like they did in training, so long as the inputs are similar to training. So you need an in distribution detector with automatic shutdown upon ood.
And that's an aligned machine. It may still give psychopathic vibes but it can't work against you because it doesn't have the capacity.