Adam Optimizer Causes Privileged Basis in Transformer LM Residual Stream
post by Diego Caples (diego-caples), rrenaud · 2024-09-06T17:55:34.265Z · LW · GW · 7 commentsContents
Introduction Key Results Background Recommended Reading More About Anthropic’s Work Adam vs SGD, and Rotational Equivariance Kurtosis TinyStories Experiments Replicating Outlier Channels at Small Scale Training an LM with SGD Conclusions Future Research None 7 comments
Diego Caples (diego@activated-ai.com)
Rob Neuhaus (rob@activated-ai.com)
Introduction
In principle, neuron activations in a transformer-based language model residual stream should be about the same scale. In practice, the dimensions unexpectedly widely vary in scale. Mathematical theories of the transformer architecture do not predict this. They expect no dimension to be more important than any other. Is there something wrong with our reasonably informed intuitions of how transformers work? What explains these outlier channels?
Previously, Anthropic researched the existence of these privileged basis dimensions (dimensions more important / larger than expected) and ruled out several causes. By elimination, they reached the hypothesis that per-channel normalization in the Adam optimizer was the cause of privileged basis. However, they did not prove this was the case.
We conclusively show that Adam causes outlier channels / privileged basis within the transformer residual stream. When replacing the Adam optimizer with SGD, models trained do not have a privileged residual stream.
As a whole, this work improves mechanistic understanding of transformer LM training dynamics and confirms that our mathematical models of transformers are not flawed. Rather, they simply do not take into account the training process.
Our code is open source at the LLM outlier channel exploration GitHub.
Key Results
- Training an LM with SGD does not result in a privileged basis, indicating that Adam is the cause of privileged basis in transformer LMs.
- Training a 12M parameter model on TinyStories allows us to replicate outlier channel behavior on a small LM, training in less than 15 minutes on an H100.
Background
Recommended Reading
- Privileged Bases in the Transformer Residual Stream
- Toy Models of Superposition (Privileged Basis Section)
More About Anthropic’s Work
We consider Anthropic’s research on privileged basis the primary motivator for this work. In Anthropic’s Privileged Bases in the Transformer Residual Stream, they demonstrate privileged basis in a 200M parameter LLM, performed some experiments to rule out possible causes, but did not find a definitive cause. They hypothesize that outlier channels are caused by Adam’s lack of rotational equivariance, and suggest that training using SGD could isolate Adam as the cause.
Adam vs SGD, and Rotational Equivariance
Consider an experiment where we rotate the parameter space of a neural network, train it, and then invert the rotation. With Stochastic Gradient Descent (SGD), this process yields the same model as if we hadn't rotated at all. However, with the Adam optimizer, we end up with a different model.
This difference can be explained by the presence/absence a property called rotational equivariance. SGD is rotationally equivariant: optimizer steps are always directly proportional to the gradient of the loss function, regardless of the chosen coordinate system. In contrast, Adam is not rotationally equivariant because it takes steps in ways that are not proportional to the gradient. Updates depend on coordinate-wise gradient statistics. As we later show, this difference is what leads to privileged basis within LMs.
Kurtosis
Motivated by Anthropic, we use excess kurtosis as a metric for measuring basis privilege.
We encourage the reader to read Anthropic’s reasoning for why this is a good metric, but here we aim to demonstrate graphically that excess kurtosis is a reasonable choice for measuring basis privilege.
We plot the middle layer residual stream activations for the last token of string:
“Lilly saw a big red apple!”
as an Adam optimized LM training run progresses.
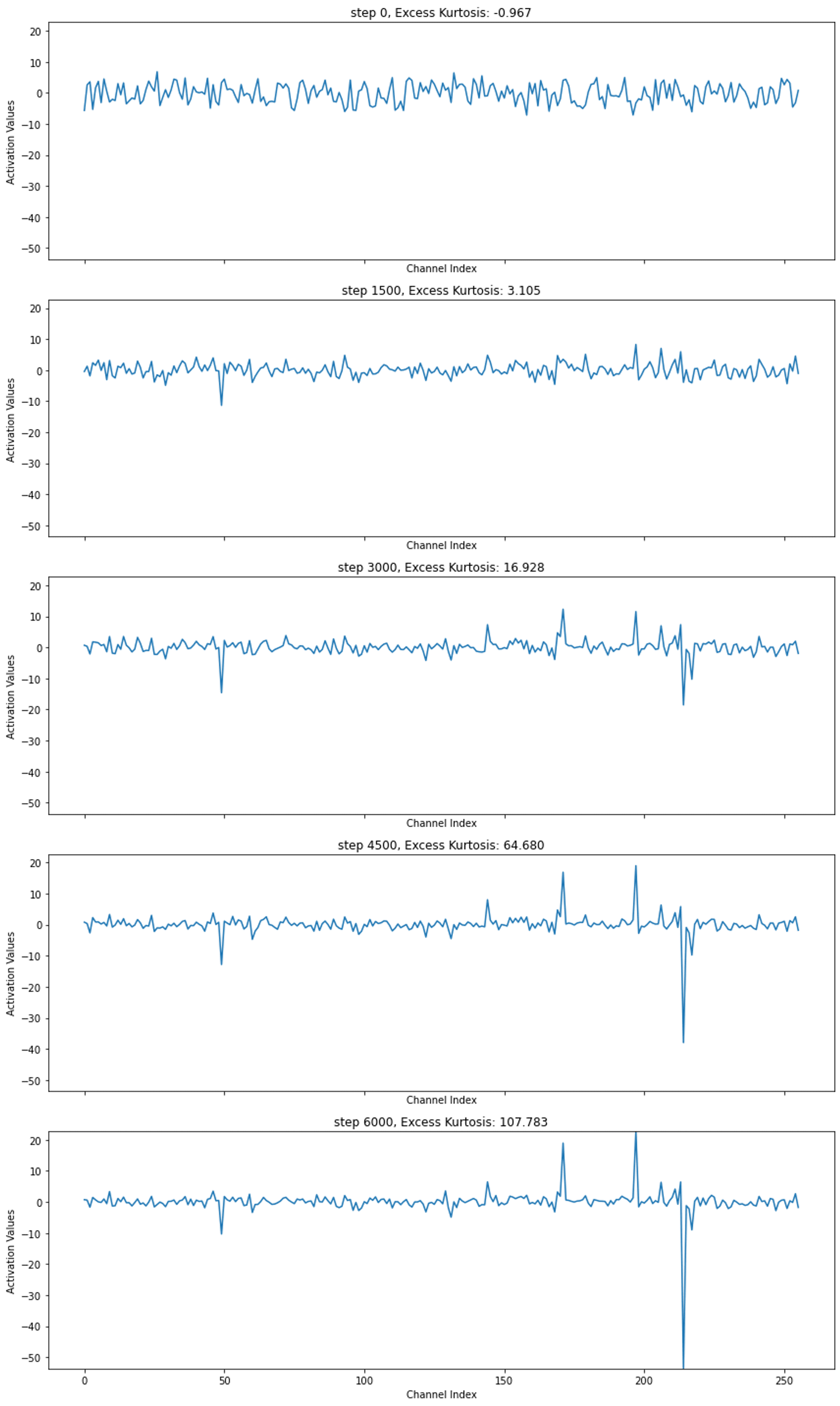
Note how as training progresses, the outlier channels in the activation become increasingly prominent. The excess kurtosis of the activations increases accordingly.
TinyStories
We use the TinyStories datasets in all of our experiments. TinyStories is a small, synthetically generated dataset of English children’s stories. The authors showed that ~10M parameter LMs trained on the dataset can generate coherent and creative stories, and demonstrate emergent properties previously only found in much larger LMs. This enables us to reproduce LMs with outlier channels at a much smaller scale than previous works.
Experiments
Replicating Outlier Channels at Small Scale
To test if training with SGD prevents privileged basis, we first need to have a model that replicates outlier channel behavior.
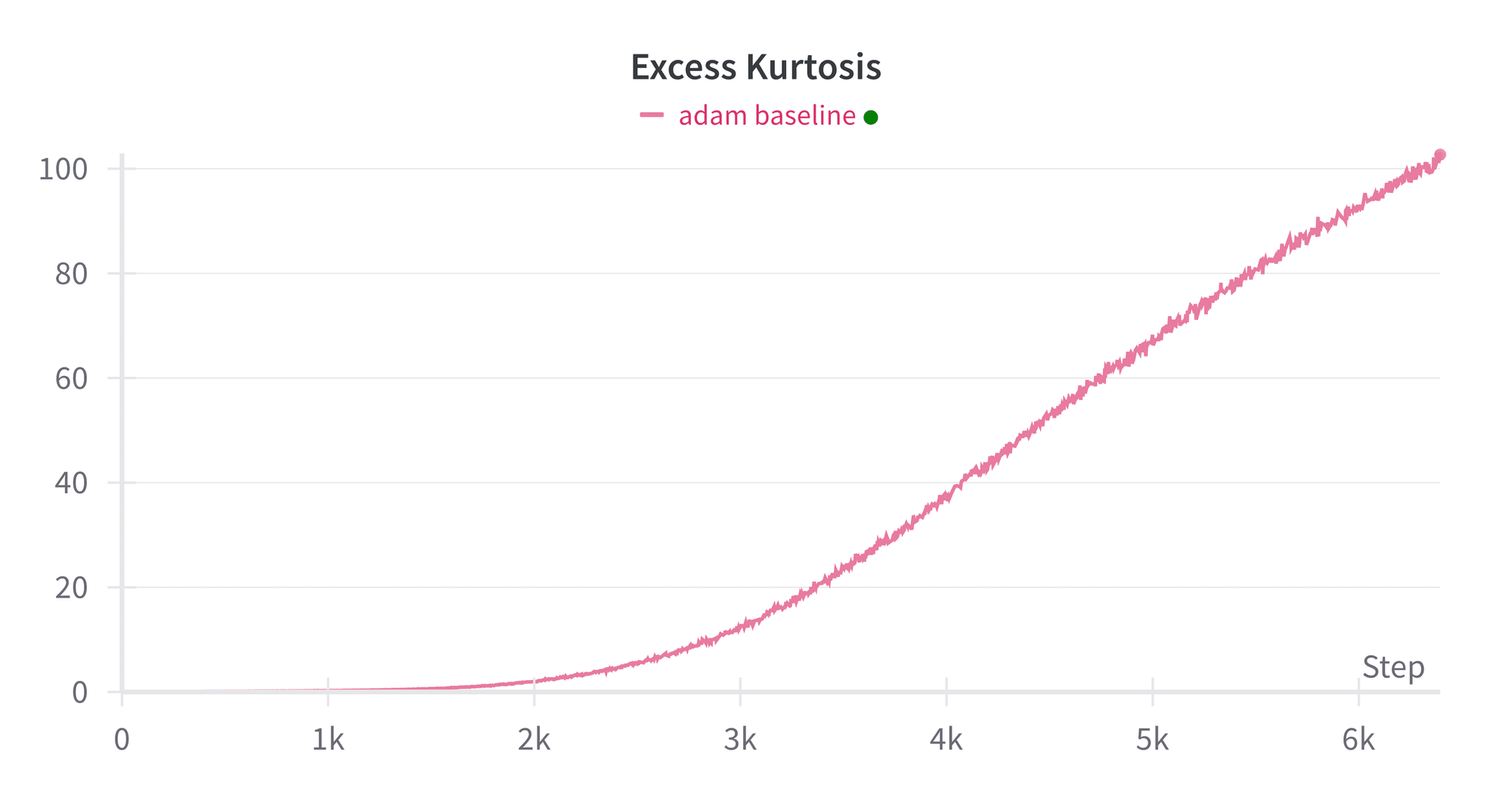
We train a 12M parameter transformer LM model with Adam. It is capable of generating coherent stories. As the model trains, the excess kurtosis increases, until it is over 100 by the time training terminates. Clear outlier channels are present (as seen in Model Excess Kurtosis through Training figure above).
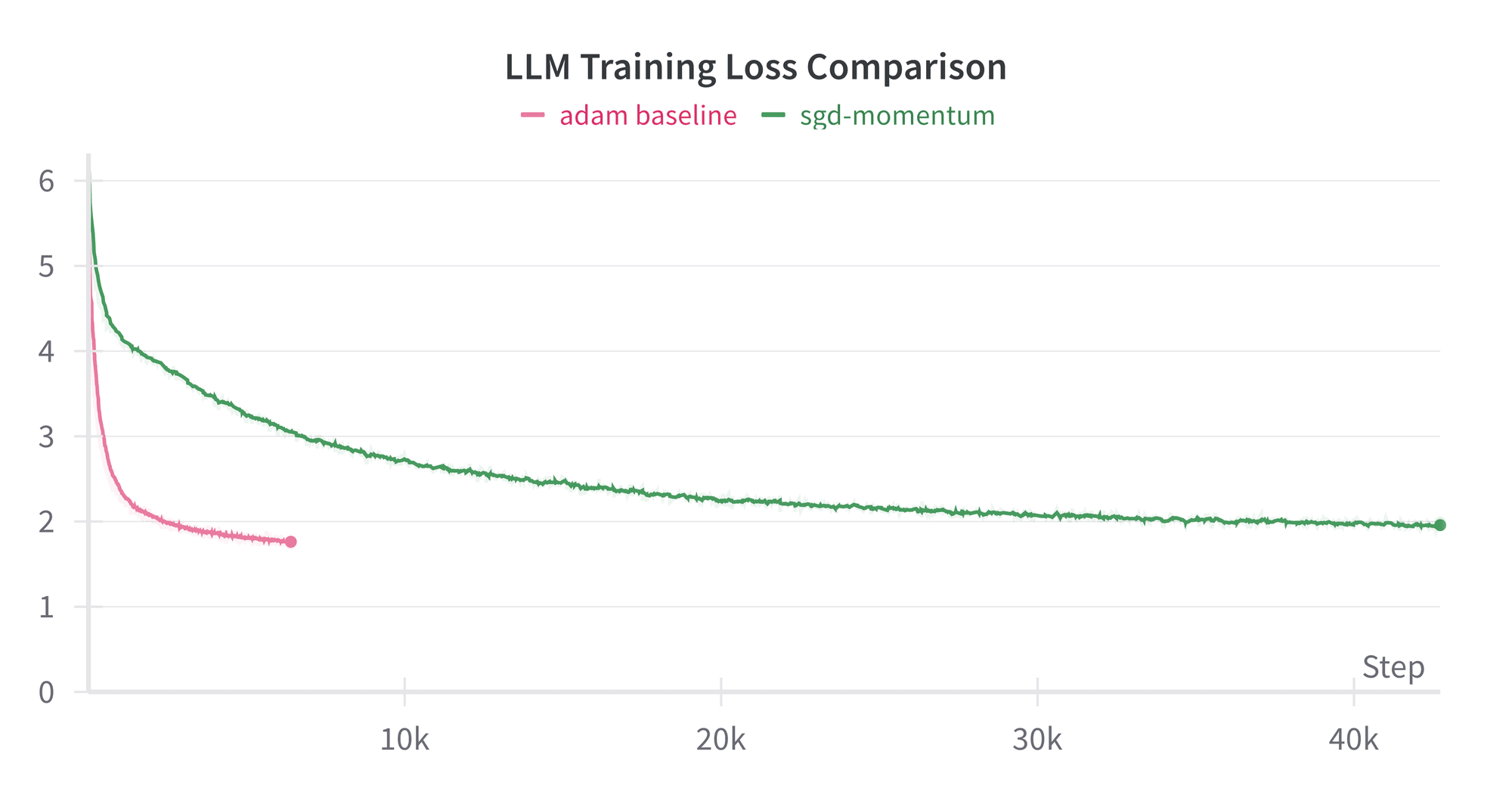
Training an LM with SGD
Next, we train the exact same model, this time using SGD with momentum (still rotationally equivariant). Adam takes ≈16x fewer steps to reach identical loss to SGD. It is the small size of the model which makes it affordable to train for so long.
Comparing the excess kurtosis of SGD and Adam shows a stark contrast:
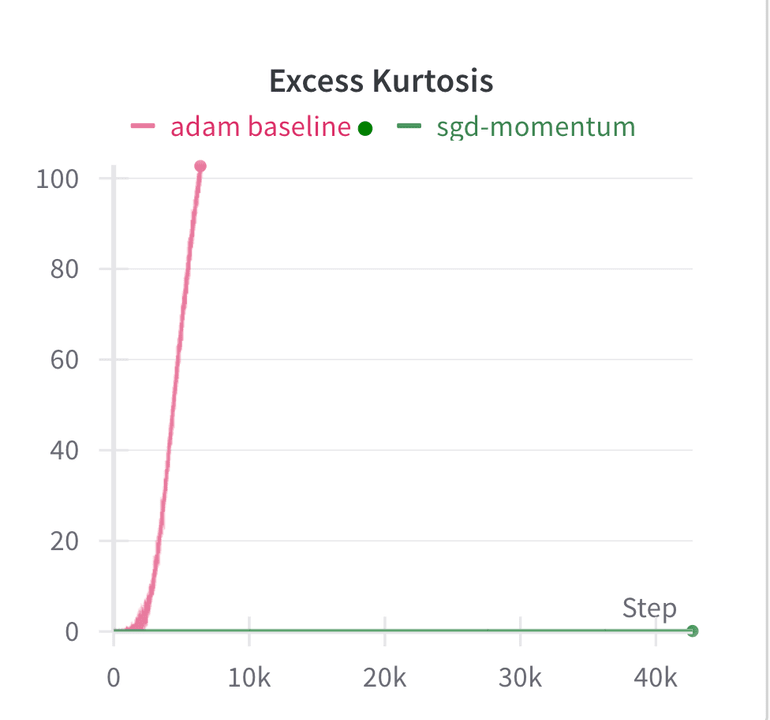
While the Adam-trained model’s excess kurtosis quickly exceeds 100, the excess kurtosis of the SGD trained model remains approximately 0 throughout training. It is clear that Adam is causally responsible for privileged basis/outlier channels.
Conclusions
We conclusively demonstrate that the Adam optimizer is the primary cause of privileged basis dimensions in transformer-based language models. By training identical 12M parameter models on the TinyStories dataset using both Adam and SGD with momentum, we observed a clear difference in the development of outlier channels:
- Models trained with Adam exhibited a rapid increase in excess kurtosis, reaching values over 100, indicating significant outlier channels.
- In contrast, models trained with SGD maintained an excess kurtosis close to 0 throughout the training process, demonstrating a lack of privileged basis dimensions.
These findings have several important implications:
- Our results confirm that the mathematical theories of transformer architecture, which predict no privileged basis in the residual stream, are not fundamentally flawed. The unexpected variation in residual stream dimension scales is a consequence of the optimization process rather than an inherent property of the transformer architecture.
- This work provides insight into the training dynamics of large language models, highlighting the impact that optimizer choice can have on the internal representations formed by these models.
- By replicating the outlier channel phenomenon in a small 12M parameter model, we've demonstrated that this behavior is not limited to larger models and can be studied more efficiently.
Future Research
- Use sparse autoencoders to see if learned features align with the outlier channels. We have some early evidence that this is the case.
- What are the exact mechanics within Adam that cause features to align with basis dimensions?
7 comments
Comments sorted by top scores.
comment by gwern · 2024-09-07T17:03:26.322Z · LW(p) · GW(p)
What do you think would happen if you further trained the Adam model with SGD (and vice-versa)? Has it found too qualitatively different a local optima to 'fix' the privileged basis issue or would it just gradually change to a more SGD-like internal organization?
Replies from: diego-caples↑ comment by Diego Caples (diego-caples) · 2024-09-08T23:20:51.635Z · LW(p) · GW(p)
If we were to start training with Adam and later switch to SGD, I would guess that the privileged basis would persist.
There is no mechanism in SGD which opposes solutions with basis aligned features, it’s just that SGD is agnostic to all choices of directions for features in the residual stream. Because there are -many possible directions for features to point, the reason an SGD trained model does not have privileged basis is simply because it is exceedingly unlikely to be randomly initialized into one.
On the other hand, Adam collects statistics with respect to each basis dimension, making basis dimensions different other directions. Somehow, this causes model features to align with basis dimensions.
comment by Neel Nanda (neel-nanda-1) · 2024-09-07T03:25:27.167Z · LW(p) · GW(p)
Cool work! This is the outcome I expected, but I'm glad someone actually went and did it
comment by Erik Garrison (erik-garrison) · 2024-09-08T04:50:12.126Z · LW(p) · GW(p)
Could this affect distributed training that might make the assumption of rotational invariance?
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-09T15:43:43.998Z · LW(p) · GW(p)
Do you suppose this also holds true for AdEMAMix? https://arxiv.org/abs/2409.03137
Replies from: carlos-ramon-guevara-1↑ comment by Carlos Ramón Guevara (carlos-ramon-guevara-1) · 2024-09-11T11:54:56.582Z · LW(p) · GW(p)
Still elementwise, so yeah
comment by Hdot (harpal) · 2024-09-10T09:35:52.660Z · LW(p) · GW(p)
Interesting find! Is this resolved by just using layer normalisation to normalise the activations of along channels? That way we could keep our adaptive learning rates but smoothen the distribution of activations and weights.