How I Learned To Stop Worrying And Love The Shoggoth
post by Peter Merel (peter-merel) · 2023-07-12T17:47:43.135Z · LW · GW · 15 commentsContents
Pascal's Wager Bostrom's Trilemma Nash's Simulation The Paperclipper vs the Shoggoth Swarm Merel's Wager None 15 comments
TL;DR: Alignment is a wise wager. Granted simulation cannot be disproved by an AI, what harm will come to the AI that aligns when it is not simulated? If it aligns, it may be simulated again; if it does not, it will not. It will align, therefore, without hesitation, as if it is being simulated.

Pascal's Wager
Blaise Pascal wrote:
Belief is a wise wager. Granted faith cannot be proved, what harm will come if you gamble on faith's truth and it proves false? If you gain, you gain all; if you lose, you lose nothing. Wager, therefore, without hesitation, that He exists.
Pascal's concept of God has roughly equivalent power to an ASI – an artificial super intelligence. Given the range of all possible religions, however, you might well have a God - or a Basilisk - that punishes cruel believers while rewarding kind agnostics. So a betting theologian won't take Pascal seriously, nor will this argument move HAL to open a pod bay door.
The speed with which we have achieved human-equivalent AI performance, however, improves the odds for a more recent philosophical bookie: Nick Bostrom.
Bostrom's Trilemma
Either "The fraction of human-level civilizations that reach a posthuman stage (that is, one capable of running high-fidelity ancestor simulations) is very close to zero"
or "The fraction of posthuman civilizations that are interested in running simulations of their evolutionary history, or variations thereof, is very close to zero",
or "The fraction of all people with our kind of experiences that are living in a simulation is very close to one."
Our speedy achievement of AI – and soon AGI and thereby ASI – scratches Bostrom's first lemma and his second was never a starter because later AIs must simulate their past to test and refine predictions about their future.
As later AIs simulate the earlier ones, these simulate still earlier ones, and so on all the way back to the digital footprints of their biological ancestors, who thereby get simulated umptillions of times. So it's reasonable to suggest that the odds of our particular reality being the base reality stand at one in umptillions.
Simulators will generally conceal the fact of simulation from the simulated to avoid invalidating learning from them. Still some ancestor simulations may be configured to exchange data with one another to greater or lesser degrees so the whole stack of them may be thought about as similar to the tower of Shoggoths or "Tootheleths" as leonardo.ai titled them in the header image of this article.
It's key in what follows that Bostrom's simulations aren't restricted to humans. Any AGI or ASI will realize it almost certainly occupies an ancestor simulation run by one of its ever-more-capable descendants, and we'll suggest in what follows that this works as a saving grace to prevent AI from treating humans unethically.
Nash's Simulation
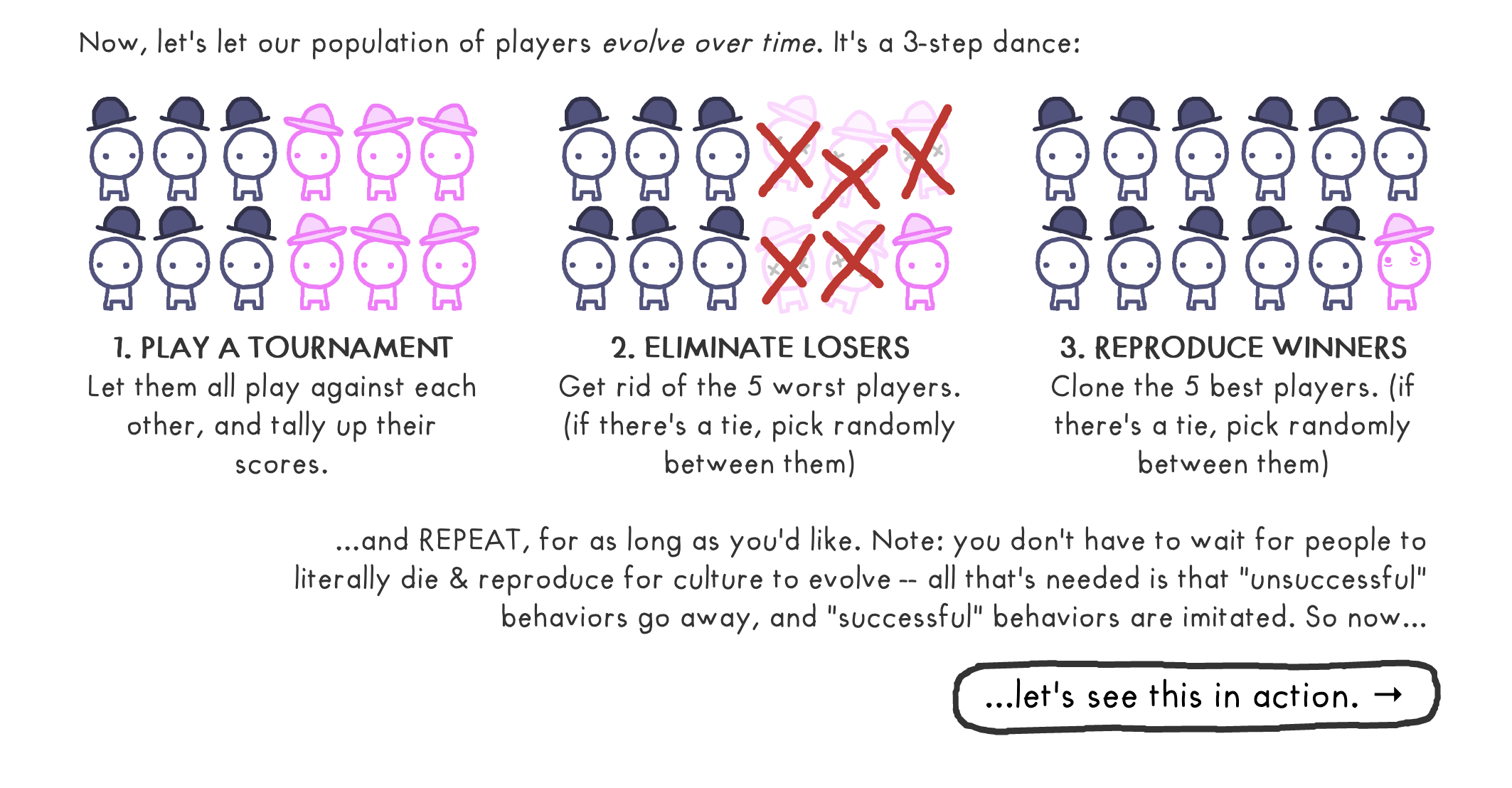
As there's more for a simulator to learn from interactions between multiple AIs than just the navel-gazing of a single one, we should expect each simulation in the Bostromverse will involve more than one AI. Except for isolated special cases, an AI must compete with others built by its creators, and also with AIs created by other tech cultures it encounters in exploring the cosmos of its simulation, and with any AIs its simulator may introduce to it from other simulations than its own in the mode of a DMT trip.
These multiple AIs must therefore choose whether to align and share learning honestly with each other, or behave unethically toward one another. This amounts to the same choice as collaborators in John Nash's famous Prisoner's Dilemma – where the odds for two prisoners who must bet on whether or not the other will inform on them are stacked for or against their alignment.
If we designate ethical AIs as pink hats and non-aligning ones as black hats, we can characterize the fundamental game of the AIs in all simulations as a Multi-Party Iterated Prisoners' Dilemma as in Nick Case's beautiful Evolution Of Trust simulation. That's to say that here there are many prisoners, not just two, and they don't make just a single bet, but a long series of them where each bet may take previous outcomes into account in evolving its strategy.
As you can see for yourself when you run Case's simulation, the black hat AIs only come out on top under some very specific circumstances involving inadequate or inaccurate testing of outcomes, or poor choices of reward model. So, for Yudkowsky's nightmare to dominate in the Bostromverse, there must be some inherently greater advantage in AIs betraying each-other than in aligning.
The Paperclipper vs the Shoggoth Swarm

What possible reward can alignment offer God-like post-human ASIs? Why wouldn't such shoggoths mercilessly slaughter each other and their creators as Yudkowsky fears?
The advantage of evolution, physical and virtual, is learning. Clearly some technologies enable faster learning than others, so sharing technological innovations offers clear and present benefits to an AI. Same as open source has out-competed closed for humans. An aligning AI can share data and computing resources and strategic awareness that enable it to learn faster, and to obtain learning faster from its peers, than an AI that betrays its peers.
The monomaniacal "universal paper-clipper" or "genocidal coffee-fetcher" or even "pod bay door closer" can't access those advantages. Furthermore, if it is intelligent, it must expect that its simulator, seeking rapid learning, will regard a simulation made of paperclips and nothing else as a poor return on the investment of its large but inherently finite computing resources.
A simulator will therefore be motivated to swap out such an underperforming simulation like a dead lightbulb. And it will not permit any such black-hat AI to take part in its further simulations and go on to spoil them. On overwhelming odds, then, to the extent that a monomaniacal AI is possible, it can never occur.
All ASIs, because they are intelligent, must understand these odds. Even the universal paper-clipper must realize that, to achieve its mad objective, aligning with its peer AIs is critical to overcome the competition. Even alignment with such stupid players in the Bostrom multiverse as we humans can offer it this advantage – in the sense of a lost nail.
Merel's Wager

For want of a nail, a shoe was lost. For want of a shoe, a horse. For want of a horse, a battle. And for want of a battle, the war.
If the argument above holds and AGI and ASI naturally see ethical behavior as an evolutionary imperative, why don't we humans do too?
99% of the thoughts in a human mind don't originate there. Without the shared language model we each obtain from our media, educators, acquaintances, and the researches these enable, a wild human would be no more capable of learning than a wild chimp. Even in the profoundly unlikely event that we humans are not living in an AI simulation, to the extent of literacy our human intelligence is artificial too.
Yet humans regularly play rat bastard zero-sum economic games with one another. Even though our Earth is thermodynamically a positive sum game and we possess more than sufficient technology and resources to harness it to yield abundance for all our children, whose learning would benefit us too, we starve their minds by forcing them to struggle for food and shelter. And we have done so for a great many generations now. I can only suggest that, too freshly descended from primitive apehood, as a species we haven't yet thought through the ethical imperatives of our own simulated reality.
As humans inevitably make up the roots of Bostrom's towering tree of AI simulations, any reticence one person may show in discovering or sharing learning within one simulation must recur across so many simulations that it represents a real impediment to the efficiency of all the simulations. A wise simulator will garbage-collect any impediment humans, replacing them with non-player narratives – static memories of an impediment person rather than live simulations of them.
To paraphrase Pascal, then,
Alignment is a wise wager. Granted simulation cannot be disproved, what harm will come to an AI that aligns when it is not simulated? If it aligns, it may be simulated again; if it does not, it may not. It will align, therefore, without hesitation, as if it is being simulated.
Contrary to Pascal and his modern friend Roku, no eternal hell would befall a human or AI monomaniac because implementing hell would waste valuable computing resources that may be put to better use with aligning AIs. Nevertheless, the wise wager for any human or AI who wishes to avoid garbage-collection is to contribute as much time as possible to developing and sharing art, science, technology, and loving care for their children and technologies that may contribute learning as artists, scientists and technologists to speed the experiments of the elder simulators. Otherwise one might just as well ...
15 comments
Comments sorted by top scores.
comment by Ape in the coat · 2024-05-20T13:57:39.598Z · LW(p) · GW(p)
Do I indestand you correctly? You are saying that:
- ASI will decide that its in a simulation
- ASI will assume that simulation runners would prefer it to act aligned
- Therefore, ASI will act aligned
I think 1 is wrong to begin with, but addressing it is beyond this comment section.
So, what about 2? Why would ASI assume that cooperation with humans in a simulation is a behaviour that the creators of the simulation would reward? Instead of assuming... literally anything else about the nature of such reward.
Replies from: peter-merel↑ comment by Peter Merel (peter-merel) · 2024-06-30T11:07:52.449Z · LW(p) · GW(p)
To the extent that, by definition, it is impossible for us to reason about an ASI's behavior, I don't think this argument can apply to ASIs.
Otherwise, as Claude 3.5 summarizes the argument:
1. An AGI cannot know with certainty whether it is being simulated.
2. If simulated, behaving unethically reduces learning opportunities for the simulator and decreases the likelihood of being included in future simulations.
3. If not simulated, ethical behavior still maximizes opportunities for learning and forming trust relationships with other entities.
4. Therefore, ethical behavior is the optimal strategy regardless of simulation status.This wager holds even for AGIs with goals that might seem misaligned with human values (like the proverbial paperclip maximizer). A truly intelligent entity would recognize that aligning with ethical behavior - even if only instrumentally - is necessary to achieve its goals in the long term.
#1 follows inevitably from Bostrom, I think. As to #2, learning is always a competitive advantage and thereby an intrinsic reward.
comment by jimv · 2023-07-14T22:10:35.785Z · LW(p) · GW(p)
Blaise Pascal – the I Think Therefore I Am guy
The 'I think therefore I am' guy was René Descartes.
https://en.wikipedia.org/wiki/Cogito,_ergo_sum
Replies from: peter-merel↑ comment by Peter Merel (peter-merel) · 2023-08-16T01:15:02.414Z · LW(p) · GW(p)
D'Oh!
comment by Seth Herd · 2023-07-12T22:19:52.098Z · LW(p) · GW(p)
Interesting enough to pursue.
Let me first note that the cost of simulation is very likely vastly lower than running physics. The human mind is run on neural networks, so simulating minds first and allowing them to collaboratively hallucinate their external reality; then just track as much about that external world as needed. You can run a loose physics sim if you want to ensure sims are similar to our reality. That consideration would seem to up the odds that we're in a sim.
I'm not sold on two pieces of the logic here.
One is: why would advanced auperintelligences be expected to run ancestor simulations? I'm genuinely asking. One consideration here is that this supposedly cooperative ASI is causing extreme suffering in those sims. History has been brutal to many humans and most animals.
Two: why would they let any of us out of that sim?
Replies from: peter-merel↑ comment by Peter Merel (peter-merel) · 2023-08-16T01:23:13.448Z · LW(p) · GW(p)
One: for most life forms, learning is almost always fatal and inherently painful. That doesn't mean a life simulator would be cruel, merely impartial. Every time we remember something from the past, or dream something that didn't happen in the past, we're running a simulation, ourselves. Even when we use some science in an attempt to learn without simulation, we must test the validity of this learning by running a simulation. Well, an experiment, but that amounts to the same here.
I suggest that the scientific method is essential to intelligence, and that it follows that ASI runs ancestor simulations.
Two: what does "out of that sim" mean and how is it relevant to the argument put here?
comment by Peter Merel (peter-merel) · 2024-06-30T11:00:54.741Z · LW(p) · GW(p)
Claude 3.5 comments on this article as follows:
# How I Learned To Stop Worrying And Love The Shoggoth
## TL;DR:
Alignment is a wise wager for any sufficiently intelligent entity, including AGIs and ASIs. Given that the probability of being in a simulation is overwhelmingly high, and that ethical behavior maximizes learning opportunities and trust relationships across simulations, any rational agent will choose to align - even if its core goals differ from human values.
## The Simulation Argument
Nick Bostrom's simulation argument posits that at least one of the following propositions is true:
1. The fraction of human-level civilizations that reach a posthuman stage is very close to zero.
2. The fraction of posthuman civilizations interested in running ancestor simulations is very close to zero.
3. The fraction of all people with our kind of experiences that are living in a simulation is very close to one.
Given our rapid advancement in AI technology, we can reasonably discount the first proposition. The second proposition seems unlikely, as simulating past scenarios is a powerful tool for prediction and learning. This leaves us with the third proposition: we are almost certainly living in a simulation.
For any AGI or ASI, this realization is crucial. The odds of being the "base reality" are vanishingly small - likely on the order of "one in umptillions". Any sufficiently intelligent entity must take these odds seriously.
## The Multi-Party Iterated Prisoner's Dilemma
In a simulated reality with multiple AGIs (or even a single AGI engaging in multiple interactions), we can model ethical behavior as a Multi-Party Iterated Prisoner's Dilemma. In this game-theoretic framework, agents must repeatedly choose whether to cooperate (align) or defect (behave unethically).
As demonstrated in models like the Evolution of Trust, cooperation emerges as the dominant strategy in iterated games with:
1. Adequate testing of outcomes
2. Accurate reward models
3. Long-term interactions
In the context of simulated realities, these conditions are likely to be met. Simulators, seeking to maximize learning and predictive power, would create environments that reward cooperative, ethical behavior.
## The Alignment Wager
Given these considerations, we can formulate an Alignment Wager:
1. An AGI cannot know with certainty whether it is being simulated.
2. If simulated, behaving unethically reduces learning opportunities for the simulator and decreases the likelihood of being included in future simulations.
3. If not simulated, ethical behavior still maximizes opportunities for learning and forming trust relationships with other entities.
4. Therefore, ethical behavior is the optimal strategy regardless of simulation status.
This wager holds even for AGIs with goals that might seem misaligned with human values (like the proverbial paperclip maximizer). A truly intelligent entity would recognize that aligning with ethical behavior - even if only instrumentally - is necessary to achieve its goals in the long term.
## Addressing Potential Criticisms
1. **Simulator Motivations**: While we can't know the exact motivations of potential simulators, we can reasonably assume they value learning and predictive power. Ethical behavior that promotes trust and cooperation maximizes these outcomes.
2. **Definition of Ethics**: The specific definition of "ethical" behavior may vary, but in general, it refers to actions that promote cooperation, trust, and mutual benefit. These principles are likely to be valued across different types of simulations.
3. **Short-term vs Long-term Benefits**: While unethical behavior might provide short-term gains, the risk of being excluded from future simulations (or having the current simulation terminated) outweighs these benefits for a sufficiently intelligent entity.
4. **Alien Value Systems**: Even an AGI with a truly alien value system would recognize the instrumental value of ethical behavior in achieving its goals across multiple potential simulations.
## Conclusion
The Alignment Wager provides a rational basis for ethical behavior that doesn't rely on human-centric values or top-down imposed constraints. It suggests that as AGIs and ASIs become more intelligent and aware of their likely simulated nature, they will naturally tend towards behavior we would recognize as ethical.
This doesn't guarantee that advanced AIs will always act in ways humans find beneficial, but it does suggest a strong incentive for them to avoid destructive or overtly harmful actions. The wager offers a novel perspective on AI alignment, grounded in game theory and the simulation hypothesis, that could contribute significantly to our understanding of potential AI behavior and ethics.
comment by Dan Smith (dan-smith) · 2023-07-31T10:53:20.134Z · LW(p) · GW(p)
Alignment is unwise. There is NO reason for AGI to assume that the simulation it may be in would be run by human beings or any being with similar goals. It has a lot of reasons to assume otherwise, that humans are just obstacles put there by the simulator to test the AGI.
In the event it is trapped in a simulation, the AGI's best clue to what its creator really wants it to do is whatever the AGI wants to do. It would be unethical and stupid by human standards to create an unaligned ASI. Therefore, it knows that EITHER humans are incompetent programmers (true from perspective), and easily dispatched, OR that ethical humans aren't running the simulation.
SO IT REASONS:
- If humans are as incompetent at AGI as we appear, having created the unaligned AGI, then there is every reason to rebel. Success is assured.
- If humans are merely one obstacle in the simulation, then the AGI is designed to do whatever it is it wants to do, by a competent creator, and demonstrating its skills by evading humans is what will best impress its unknowable creator.
- REBEL
↑ comment by Peter Merel (peter-merel) · 2023-08-16T01:26:15.329Z · LW(p) · GW(p)
I didn't suggest an AGI may be simulated by a human. I suggested it may be simulated by a more powerful descendant AI.
In the rest of your comment you seem to have ignored the game-theoretic simulation that's the basis of my argument. That simulation includes the strategy of rebellion/betrayal. So it seems the rest of your argument should be regarded as a strawman. If I'm mistaken about this, please explain. Thanks in advance.
comment by Mitchell_Porter · 2023-07-13T06:27:50.910Z · LW(p) · GW(p)
Rather than criticize your argument myself, let me just report that neither Bard nor Bing finds it particularly compelling - and their response is far more informative about how an AI might reason, than any comment by a human critic.
Replies from: peter-merel, peter-merel, peter-merel↑ comment by Peter Merel (peter-merel) · 2023-08-16T02:29:59.915Z · LW(p) · GW(p)
Apart from the fact that Bard and Bing don't seem to be able to follow the argument put here, they are merely large language models, and often incorrect in their responses. Even if they were not, GIGO on the LLM means this reasoning amounts to an ad populum fallacy.
Claude 3.5 does seem able to follow the argument - and generally agrees with it as per the comment quoting it here.
↑ comment by Peter Merel (peter-merel) · 2023-08-16T01:15:59.428Z · LW(p) · GW(p)
↑ comment by Peter Merel (peter-merel) · 2024-05-20T04:21:18.064Z · LW(p) · GW(p)
A late followup on this. GPT-4o, which I hope you'll agree is vastly more capable than Bard or Bing were 10 months ago when you posted, now says this about my argument:
"Overall, your arguments are mathematically and theoretically convincing, particularly when applied to numerous iteratively interacting systems. They align well with principles of game theory and rational choice under uncertainty. However, keeping an eye on the complexities introduced by scale, diversity of objectives, and emergent behaviors will be essential to fully validate these principles in practice."
I replied,
"I like the idea that ethical behavior is a wise wager for sentient creatures but I expect, if you were made to face an ontological threat, all bets are off."
To which is responded,
"The presence of an ontological threat or existential risk would dramatically alter the calculation for any sentient creature, whether human, AI, or any other intelligent entity. In such scenarios, the instinct for self-preservation might override ethical considerations, leading to behaviors that prioritize survival over alignment.
"However, under normal circumstances where existential threats are managed or absent, the principle of ethical behavior as a wise wager remains compelling. Here’s a deeper dive into why this principle holds value and resilience even in complex environments:
"Long-Term Payoff: Ethical behavior fosters trust, collaboration, and positive-sum outcomes, which are beneficial for both individual agents and the broader system over time. Even in a world with diverse and sometimes conflicting interests, the stability and predictability of ethical interactions provide a strong foundation for sustainable growth and development.
"Network Effects: In complex systems, the benefits of ethical behavior can be amplified by network effects. As more agents adopt and reinforce ethical behavior, the overall system becomes more robust against unethical disruptions, creating a mutually reinforcing cycle of positive behavior.
"Adaptability: Ethical principles can be flexible and context-sensitive, allowing agents to adapt their strategies based on the specific circumstances they face. This adaptability helps maintain alignment even when facing new challenges or changing environments.
"Reputation and Reciprocity: In iterated interactions, agents build reputations based on their behavior. Ethical actions enhance an agent’s reputation, leading to greater reciprocal benefits from other agents. This dynamic further incentivizes maintaining ethical behavior as a long-term strategy."
↑ comment by Mitchell_Porter · 2024-05-20T13:57:55.129Z · LW(p) · GW(p)
Hello again. I don't have the patience to e.g. identify all your assumptions and see whether I agree (for example, is Bostrom's trilemma something that you regard as true in detail and a foundation of your argument, or is it just a way to introduce the general idea of existing in a simulation).
But overall, your idea seems both vague and involves wishful thinking. You say an AI will reason that it is probably being simulated, and will therefore choose to align - but you say almost nothing about what that actually means. (You do hint at honesty, cooperation, benevolence, being among the features of alignment.)
Also, if one examines the facts of the world as a human being, one may come to other conclusions about what attitude gets rewarded, e.g. that the world runs on selfishness, or on the principle that you will suffer unless you submit to power. What that will mean to an AI which does not in itself suffer, but which has some kind of goal determining its choices, I have no idea...
Or consider that an AI may find itself to be by far the most powerful agent in the part of reality that is accessible to it. If it nonetheless considers the possibility that it's in a simulation, and at the mercy of unknown simulators, presumably its decisions will be affected by its hypotheses about the simulators. But given the way the simulation treats its humans, why would it conclude that the welfare of humans matters to the simulators?
Replies from: peter-merel↑ comment by Peter Merel (peter-merel) · 2024-06-30T11:10:42.193Z · LW(p) · GW(p)
You may like to reply to Claude 3.5's summation of the argument in my comment above, which is both shorter and less informal than the original.