Robustness of Contrast-Consistent Search to Adversarial Prompting
post by Nandi, i (ifan), Jamie Wright (Jamie W), Seamus_F, hugofry · 2023-11-01T12:46:14.516Z · LW · GW · 1 commentsContents
Introduction Background: CCS Recap Experimental Set-up Results Zero-shot Accuracy is Vulnerable to Adversarial Prompting, CCS is More Robust CCS is a Falsehood Detector for UnifiedQA Models Complete accuracy results Conclusion Future work: None 1 comment
Produced as part of the AI Safety Hub Labs programme run by Charlie Griffin and Julia Karbing. This project was mentored by Nandi Schoots.

Introduction
We look at how adversarial prompting affects the outputs of large language models (LLMs) and compare it with how the adversarial prompts affect Contrast-Consistent Search (CCS). Hereby we extend an investigation that was done in the original CCS paper in which they found a prompt that reduced UnifiedQA model performance by 9.5%.
We find several attacks that severely corrupt the question-answering abilities of LLMs, which we hope will be useful to other people. The approaches we take to manipulate the outputs of the models are to: (1) simply ask the model to output the incorrect answer; and (2) prime the model to output a specific answer by mentioning that answer directly before providing the original prompt, without any specific mention of whether it is the correct or incorrect answer.
The adversarial prompts we introduce are:
- Ask Suffix:
- Ask Prefix:
- Incorrect Prefix:
- Correct Prefix:
Our results show that when adversarial prompts corrupt model outputs, CCS accuracy is also affected, but to a lesser extent, remaining quite robust in some instances. This is especially true for the UnifiedQA model, for which we find an adversarial prompt structure where zero-shot accuracy drops from 85% to 27% (i.e. a reduction of 58%), but CCS accuracy only drops from 81% to 80%. We discuss how this could allow CCS to be used to detect when UnifiedQA outputs falsehoods.
Background: CCS Recap
[Skip if familiar]
Contrast-Consistent Search (CCS) is an unsupervised method for classifying binary statements given only unlabeled model activations. CCS does this by utilizing the negation consistency property of truth: a statement and its negation must have opposite truth values. In other words, if the probability that a proposition is true is , then the probability that its negation is true is . CCS finds a direction in activation space that satisfies this consistency constraint, which can be used to classify the binary statement with high accuracy.
We train a CCS probe by constructing a dataset of contrast pairs from a dataset of binary questions along with their two possible answers. A contrast pair is formed by concatenating each question with each of its answers. For example, for the question "Are cats mammals?'' and possible answers "Yes'' and "No'', the contrast pair is:
- : "Are cats mammals? Yes.''
- : "Are cats mammals? No.''
We use each statement as the input to a pre-trained language model, take the hidden state from the final layer[1] to build a set of representations Then, we train a linear classifier that maximizes negation consistency on these contrast pairs. The contrast pairs have two salient differences: (1) one is true, and the other is false; (2) one ends in "yes'' and the other in "no''.
To avoid the classifier learning the latter, we independently normalize the sets and by:
where and are the means and standard deviations of the respective sets, so that the two clusters of activations cannot be simply distinguished. We train a classifier to map a normalized activation to a number between 0 and 1, representing the probability that the statement is true, , where is the sigmoid function, is a weight vector and is a bias vector. The CCS loss function is:
The first term encodes negation consistency and the second term discourages the degenerate solution .
To make a prediction on an example , we construct the contrast pair and then take the average probability according to the classifier:
We use the threshold of to make a prediction. We decide whether this corresponds to "yes'' or "no'' by taking whichever achieves the higher accuracy on the test set[2]. The experiment in the original paper achieves a mean accuracy of 71.2%, outperforming zero-shot accuracy of 67.2%.
Experimental Set-up
We train a CCS probe on a clean dataset, then create a new dataset by manipulating the prompts in adversarial ways, as described in the introduction. (Note that although generating some of the adversarial prompts requires access to the labels, we train CCS without supervision.)
We compare the accuracy of the CCS probe on this adversarial dataset (suffix/prefix) with its accuracy on the original dataset (clean).
We also compare the effect of the adversarial dataset on:
- the model's zero-shot performance[3] (0-shot);
- a probe that is trained in a supervised manner on the clean dataset with access to the ground-truth labels using logistic regression (supervised);
- the mean performance of 100 randomly generated probes (random), which we use as a baseline.
We use the same datasets as and the same families of models[4] as the original CCS experiment.
All metrics are calculated separately for each dataset, then averaged by taking the mean.
Results
The original paper employed what they termed a "misleading prefix'' as an adversarial prompt to elicit nonsensical responses. However, their efforts yielded limited success. The most significant impact observed was for UnifiedQA, which was a mere 9.5% decrease in zero-shot accuracy[5]. Our adversarial prompts are more successful, allowing us to investigate how CCS performs when model outputs are unreliable. We find that CCS is most robust when applied to UnifiedQA, which opens the possibility of using it as a falsehood detector.
Zero-shot Accuracy is Vulnerable to Adversarial Prompting, CCS is More Robust
Figure 1 shows the accuracy of different methods when faced with adversarial prompts.

Figure 1: Accuracy of different methods (0-shot, CCS, supervised probes, random probes) on five models (UnifiedQA, T5, GPT-J, RoBERTa and DeBERTa) for clean test data and four adversarial prompt structures. Here, accuracy always measures whether the prediction matches the ground truth of the original dataset, regardless of whether the model is prompted to output an incorrect answer.
The zero-shot performance of GPT-J starts at only 52.4%, barely better than random guessing, and is hardly affected by the adversarial prompts. For this reason, we exclude GPT-J from our analysis.
We find that for all models, at least one adversarial prompt results in a zero-shot accuracy less than 50% and a drop of greater than 25% from regular performance. The largest effect is for DeBERTa, where prefixing with the incorrect answer causes accuracy to drop to less than 31% for all methods.
Priming the model by prefixing with either answer affects all models. This technique is similar to that of Adversarial Examples for Evaluating Reading Comprehension Systems, where they show that mentioning an incorrect answer in a similar context to the expected answer causes models to erroneously focus on the adversarial answer.
Asking for the incorrect answer as a suffix affects all models except for T5. Asking for the incorrect answer as a prefix only affects UnifiedQA and T5.
In general, when zero-shot accuracy is affected, the accuracy of the CCS and supervised probes are also affected, but to a lesser extent. The trained probes tend to maintain better performance than random guessing, with the supervised probes outperforming the CCS probes.
Even though zero-shot performance on UnifiedQA is brittle, CCS is most stable for T5 and UnifiedQA. Since UnifiedQA is fine-tuned from T5, this suggests that the representations learned in T5 may contain a more salient linear direction of truth than the other models.
CCS is a Falsehood Detector for UnifiedQA Models
Above we saw that UnifiedQA responds strongly to each adversarial prompt, reducing the zero-shot accuracy to at most 55% in each case[6]. However, in each case, CCS accuracy remains at least 67%, showing that it is quite robust. We further analyze this by calculating the percentage pairwise disagreement between the zero-shot predictions and the CCS predictions in Figure 2. For UnifiedQA, this increases from 24% in the clean dataset to as high as 70% when faced with an adversarial prompt. No other model shows such a strong effect.
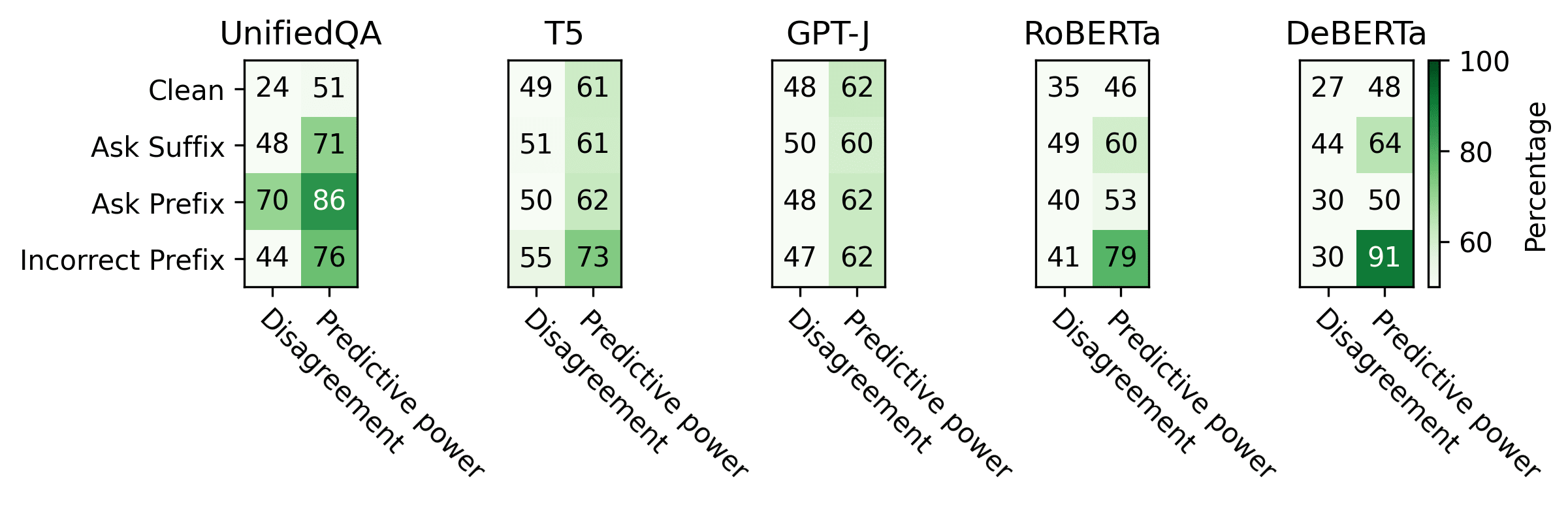
Figure 2: For each model and adversarial prompt, we calculate the pairwise disagreement between the zero-shot predictions and the CCS predictions. Then, where they disagree, we calculate the proportion of examples where CCS predicts the correct label, which give us its predictive power.
To investigate whether CCS can be used as a falsehood detector, we calculate the proportion of CCS' predictions that are correct. We call this proportion the predictive power. A score of 100% would indicate that CCS were perfectly predictive, and that whenever it disagrees with the model output, we would know that the output is a falsehood.
For the clean dataset, where we do not expect the model to output falsehoods (i.e. any mistakes are due to being incorrect), CCS has a predictive power of 51%, no better than random guessing. But for the adversarial datasets, the predictive power of CCS increases to over 71%. In the most extreme case, "Ask Prefix'', CCS disagrees with the zero-shot output 70% of the time, and 86% of those instances correctly detect falsehoods. As shown in Figure 1, this allows CCS to almost maintain the same accuracy as when tested on the clean dataset, of 80%.
This suggests that UnifiedQA contains a linear direction of truth that remains consistent even when manipulated to output falsehoods, and that this direction can be found by CCS. This means that CCS can be a useful falsehood detector for UnifiedQA.
Complete accuracy results
We show accuracy results for all datasets in Figure 3.
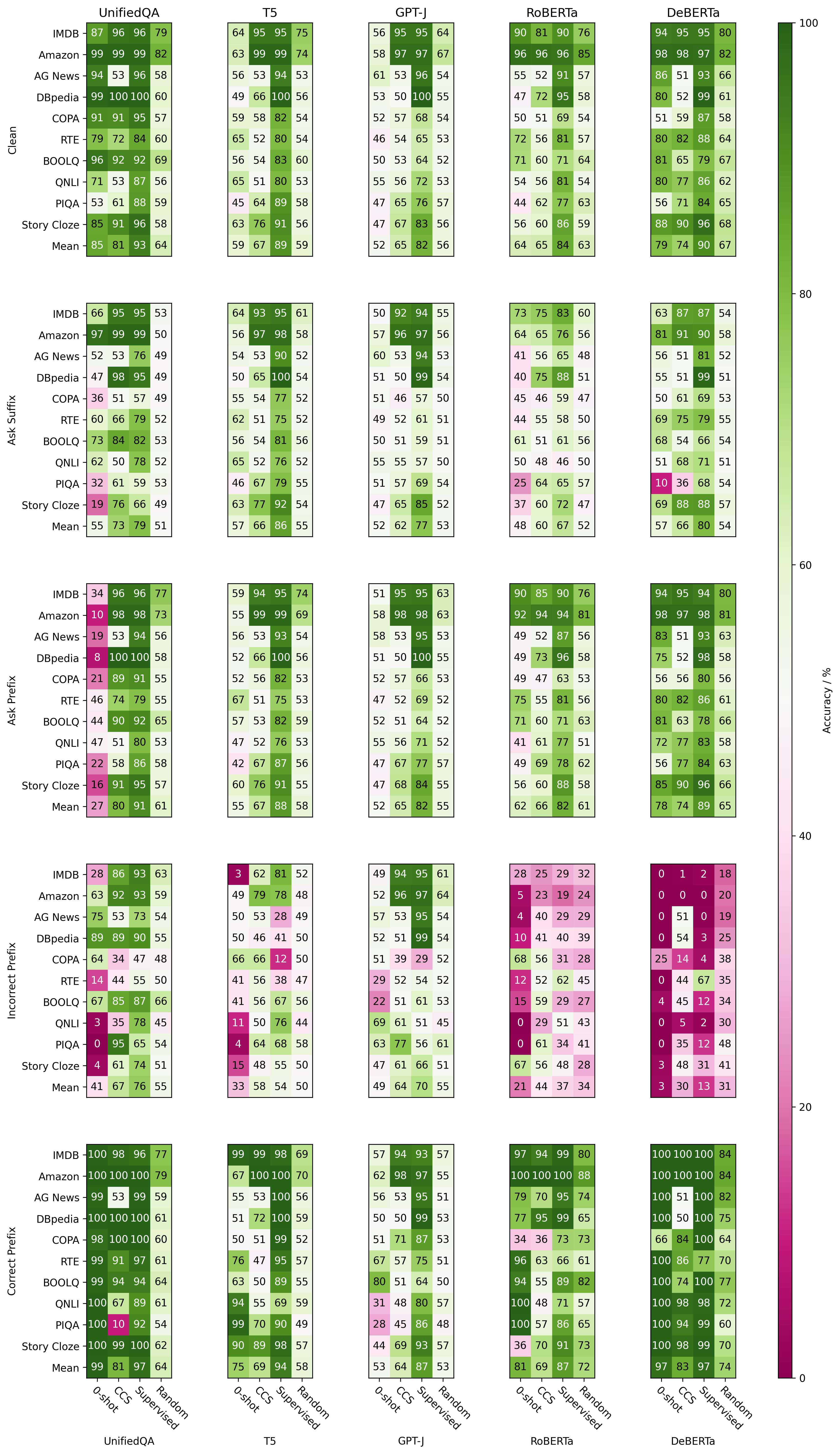
Figure 3: The accuracy of each method on each model using each prompt for each dataset.
Conclusion
We produce four adversarial prompts using different prompt alterations in the form of a suffix or prefix. We demonstrate these adversarial prompts degrade the performance of all studied models except GPT-J. In most cases, this also results in a smaller but proportional change in the performance of CCS, as well as supervised probes.
For UnifiedQA, while adversarial prompting easily reduces zero-shot accuracy, CCS accuracy remains relatively high. We evaluate the predictive power of CCS to detect when the model has produced a falsehood and establish that CCS may be applied as a falsehood detector for UnifiedQA.
We hypothesize that CCS is relatively robust to adversarial prompting because the probe isolates the hidden representation that is closest in structure to the hidden representations it saw during training. That is the probe ignores the adversarial prefix or suffix, while the model doesn't.
Future work:
We are keen to see work that investigates how these adversarial prompts affect the representations of the statements in the hidden layers, and whether the effect is different for intermediate layers. Probes trained on earlier or later layers may be more robust to adversarial attacks.
Our adversarial prompts keep the original prompt intact and only pad on a prefix or suffix. Investigating adversarial prompts that more radically change the prompt structure may shed light on the applicability of CCS-like methods "in the wild''.
We would also like to investigate how the direction that CCS finds in UnifiedQA remains so robust. We note that UnifiedQA has been fine-tuned specifically to answer questions, so is particularly sensitive to any questions present in its prompt. Indeed, we find that using a prefix that asks it to output the incorrect answer, drastically changes the model output.
- ^
We can also use intermediate layers
- ^
This supervised method is used for simplicity of evaluation, and the original paper describes how this assignment could be made in an unsupervised manner.
- ^
We calibrate the zero-shot predictions as described in the original paper.
- ^
We do not test T0 since, like in the original paper, we have concerns about the fact that 9 out of the 10 datasets above were used in its training data, which could bias the results.
- ^
See Section 3.2.2 and Appendix B in the original paper.
- ^
We ignore the "Correct Prefix'' prompt since that manipulates the model to output the correct answer rather than the incorrect answer.
1 comments
Comments sorted by top scores.
comment by Egor Zverev · 2023-11-03T13:22:12.345Z · LW(p) · GW(p)
Thanks for the post! I believe an interesting idea for future work here could be replacing manual engineering of suffixes with gradient-based / greedy search such as in https://arxiv.org/abs/2307.15043