Case for Foundation Models beyond English
post by Varshul Gupta · 2023-07-21T13:59:20.520Z · LW · GW · 0 commentsThis is a link post for https://dubverseblack.substack.com/p/case-for-foundation-models-beyond
Contents
Matters of Tokenisation and Cost Early Solutioning When Whisper 1.0 Gets It Wrong: An Inside Look at Speech-to-Text Failures Read full story What’s Next In response to this growing need, we are seeing a rise in multi-lingual AI initiatives. More players in the field, including Google, are stepping up to enhance non-English representation in AI tech. Google's latest move is Palm2, a technology designed to bolster non-English representation in AI syst... Subscribe None No comments
We live in a world enthralled by technology, so precisely and skilfully woven into the very fabric of our lives that it's impossible to untangle. Each thread of code, each strand of data, is meticulously encoded with language that is then translated into technology that builds the structures of our digital lives.
And at this very moment, the most dominant language in this realm (shoutout to the Marvel fans)—the lingua franca of our evolving digital society, if you will—is English.
Subscribe to get a blog every week on our learnings in Generative AI.
Andrej Karpathy wrote, "The hottest new programming language is English." If the language a common man across the globe needs to learn to take part in this language revolution is English, then the key to these advancements are no longer a proficiency in Python or Rust. Rather, the golden ticket becomes fluency in English.

Attention English is all you need.
This is a critical issue that requires inspection, especially if we align ourselves with the goal of an inclusive digital world. We should strive to create AI models that cater to more languages across the globe - the echoes of the Himalayas, the chatter of the Nile Delta and the whispers across the Pacific.
Think about it like this - have you ever found yourself lost in the charm of a song without understanding its actual words? I have been listening to this (maybe Japanese) song on loop for the last four days. I barely understand a word but I absolutely love it.
See, language goes beyond borders and comprehension. It's a pause in the pattern, an emotional connection. And if our AI models could encompass linguistic diversity - if they could 'hear' that song and 'understand' it - they would undoubtedly be more inclusive.
Matters of Tokenisation and Cost
"But GPT3.5 Turbo and GPT4 can't handle Indian languages well," you might argue. Well, they do a fine job, I'll admit, but at a cost. Surprisingly, processing Indian languages can be 5x pricier than English! This disparity springs from the concept of tokenisation–how words are deconstructed into tokens, not necessarily subwords or phonetics, but the frequency at which byte sequences come together.
number of tokens consumed in different languages
Then arises the concept of fertility. Originating from machine translation, fertility means the potential of a source token to birth multiple target tokens. For instance, translating the English word 'blue' to French might give you “bleu ciel” which forms two tokens in French. The concept of fertility adds a layer of complexity when we deal with languages abundant in detailed morphology like many Indian languages.
This could explain why processing these languages can be more resource-intensive (and thus more expensive) than processing English.
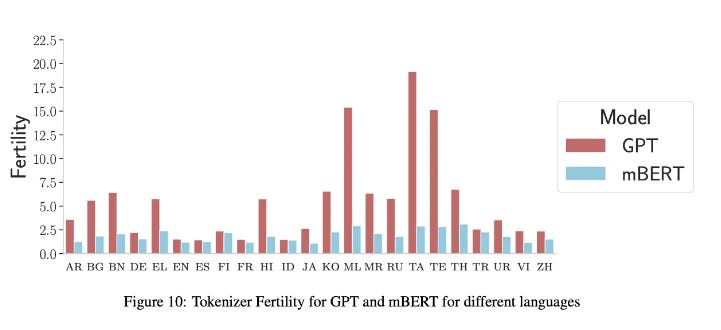
To elevate the efficacy of LLMs on non-English languages, the AI landscape could gain significantly from optimized tokenization strategies or perhaps revisiting model architecture to better accommodate global linguistic diversity.
Early Solutioning
Progress has already been made in this direction. Consider OpenAI's Whisper, the superstar of automatic speech recognition with a mind boggling 96 language coverage. While it has its hitches, especially in processing non-English languages, it is a testament to the possibility of developing multilingual AI.

When Whisper 1.0 Gets It Wrong: An Inside Look at Speech-to-Text Failures
T. PRANAV APR 19
The complexity of translation isn't merely about switching words around. It's more akin to a dance, gracefully balancing grammar, context, and culture. Truth be told, most ASR systems, including Whisper, are better off dancing to the rhythm of English. However, efforts are being made to tune into the melodies of other languages too.
What’s Next
In response to this growing need, we are seeing a rise in multi-lingual AI initiatives. More players in the field, including Google, are stepping up to enhance non-English representation in AI tech. Google's latest move is Palm2, a technology designed to bolster non-English representation in AI systems.
 One of the reasons Sam Altman is on the tour. Source
One of the reasons Sam Altman is on the tour. Source
In conclusion, the world of AI teeters on the spindles of English. But if we are to see an inclusive digital future, it must diversify to represent the many voices and sounds across our multifaceted global society.
Think of the AI stratosphere as a symphony, currently playing mostly in English. Now, imagine the composition expanded, with instruments from across the globe, each adding a unique tune, rhythm, and pitch.
The true accomplishment would be to orchestrate this symphony seamlessly, letting every voice chime in and resonate, creating a harmonious tune of global digital inclusivity. So here's to the maestros building a more diverse and inclusive AI empire. Now, isn't that a compelling tune?
P.S. A lot of analogies are inspired by a line a close friend used to repeat a lot — symphony in chaos.
Subscribe
Thank you for reading this! We hope you learned something new today.
Do visit our website and follow us on Twitter.
We also launched NeoDub sometime back. It enables you to clone your voice and speak any language!
Until next time!
Varshul
0 comments
Comments sorted by top scores.