Causality and a Cost Semantics for Neural Networks
post by scottviteri · 2023-08-21T21:02:00.542Z · LW · GW · 1 commentsContents
Introduction How I Would Like People to Engage with this Work Cost Semantics Definition Basic Operations and Warm-Up Building Out the Tech Tree We Want If Statements Division If Statements Finally, Logic, and Causality Calculations Causality Calculations on Booleans Derivative Estimation Causality via an Approximation Power Series versus Piece-wise Linear and an Aside on Recursion None 1 comment
I time-boxed this idea to three days of effort. So any calculations are pretty sloppy, and I haven't looked into any related works. I probably could have done much better if I knew anything about circuit complexity. There are some TODOs and an unfinished last section -- if you are interested in this content and want to pick up where I have left off I'll gladly add you as a collaborator to this post.
Here is a "tech tree" for neural networks. I conjecture (based on admittedly few experiments) that the simplest implementation of any node in this tree includes an implementation of its parents, given that we are writing programs starting from the primitives +, *, and relu. An especially surprising relationship (to me) is that "if statements" are best implemented downstream of division.
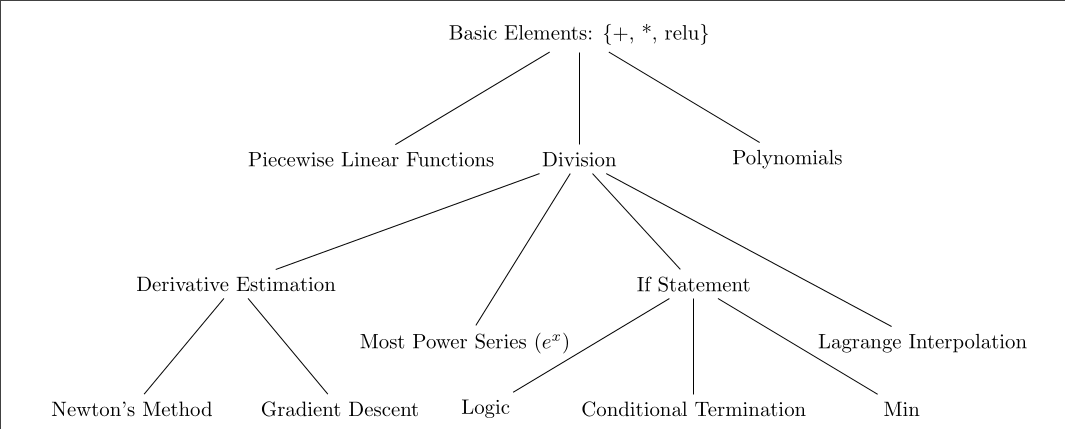
Introduction
While discussing with my friend Anthony Corso, an intriguing idea arose. Maybe we can define whether program "causes" in the following way: Given a neural network that mimics , how easy is it to learn a neural network which mimics the behavior of ? This proposition is intriguing because it frames causality as a question about two arbitrary programs, and reduces it to a problem of program complexity.
Suppose that and are written in a programming language P, and let P(ops) represent P extended with ops as primitive operations. We define a complexity function , which takes a program in the extended language and returns a real number representative of the program's complexity for some fixed notion of complexity. Let's define the degree to which "causes" as the minimum complexity achievable by a program p from such that p is extensionally equal (equal for all inputs) to . If is the set of all p in that are extensionally equal to , then . We can also use this definition in the approximate case, considering the minimum complexity achievable by programs p such that with respect to some probability measure.
We can define a particular complexity function that represents the cost of executing a program. We can estimate this quantity by looking at the program's Abstract Syntax Tree (AST) in relation to some cost model of the primitive operations in the language. For this exploration, we have chosen the lambda calculus as the language. Lambda calculus is a minimalist Lisp-like language with just a single type, which in our case we will think of as floating point numbers. The notation is simple: lambda abstraction is represented as x. x, and function application as (f g), which is not the same as f(g) in most other languages.
How I Would Like People to Engage with this Work
- By writing Ops in your favorite programming language
- By circumventing my proposed tech tree, by reaching a child without reaching a parent and using fewer (or equal) number of operations
- By training some neural networks between these programs, and seeing how difficult it is to learn one program after pre-training on another
Cost Semantics
Definition
We define the cost of operations and expressions in the following manner:
For operations of higher arity, we have
(Ops (op )) = (Ops op) + (Ops )
The selected operations for a neural network are ops = {+, *, relu}.
Basic Operations and Warm-Up
Let's take a few examples to demonstrate this cost calculus:
- To derive subtraction, we first create negation .
(Ops neg) = (Ops ( x. (* -1 x))) = (Ops (* -1 x))
= (Ops *) + (Ops -1) + (Ops x) = 1 + 0 + 0 = 1
- The cost of subtraction () is then:
(Ops -) = (Ops ( x y. (+ x (neg y)))) = (Ops +) + (Ops (neg y)) = 1 + 1 = 2
- The cost of the operation is:
(Ops square) = (Ops ( x. (* x x))) = (Ops (* x x)) = (Ops *) = 1
With this, we have a framework for extending the function to more complex operations, providing a robust way to estimate the cost of various neural network operations. As we proceed, we will apply this framework to understand the complexity and causality in a neural network.
One crucial note in these calculations is that each time we find an equivalent program using the primitives, we can extend the domain of the function to include it. For instance, after calculating , it now acts as a base case. In this sense, is intended to be an upper bound - if we come up with another representation of an operation later that is less expensive, we can replace it as a base case in . It might be necessary to propagate such changes downstream in for consistency.
As we proceed, let's explore the cost of a few more operations:
- The cost of a cube operation can be calculated as follows:
(Ops (cube x)) = (Ops (* (* x x) x)) = (Ops *) + (Ops (* x x)) + (Ops x) = 1 + 1 + 0 = 2
Interestingly, this case highlights why we are using a fixed arity for each operation. If we allowed to be nary, then we could say (Ops (cube x)) = (Ops (* x x x)) = 1 and the same would apply to higher n. This seems similar to unbounded fan-in circuits, so maybe it leads to a reasonably consistent but relatively un-physical system.
Since float is our only datatype, we will use the sign of to represent whether it is "true".
- For the absolute function , we calculate the cost as:
abs = x. (+ (relu x) (relu (neg x)))
(Ops abs) = (Ops ( x. (+ (relu x) (relu (neg x)))) = (Ops +) + (Ops relu) + (Ops relu) + (Ops neg) = 1 + 1 + 1 + 1 = 4
In this calculation, I have started using n-ary as a transformation of the syntax. While it maintains many properties, it doesn't preserve itself. Hence, if we were to run on , we would not use this notational convenience.
- ( = x y.(- x y)) and ( = x y. (- y x)
(Ops ) = (Ops ) = 1 - = x y . ( (abs (- x y)) )
(Ops ) = (+ (Ops ) (Ops abs) (Ops -)) = (+ 1 5 7) = 13 - And composition:
= f g x. (f (g x))
(Ops ) = (Ops (f (g x))) = (Ops f) + (Ops g) = 0 + 0 = 0
Building Out the Tech Tree
We Want If Statements
Adding case statements into our programming language allows for greater expressiveness. A simple instance of this would be the "if" operation: (if p x y).
If we had a step function (0 if else 1), we could write "if" as a convex combination of cases x and y. Namely, (if p x y) = (let ((b (step p))) (+ (* b x) (* (-1 b) y))), where (Ops (let ((x e1)) e)) = (+ (Ops e1) (Ops e)). Then (Ops if) = (+ (Ops step) 3). However, a step function is discontinuous, and we only have continuous primitives.
So we multiply relu by a large constant and add it to a shifted negated version of itself, and it looks like an approximate version of a step function. I am calling it rightstep because the positive slope section occurs to the right of zero.
- shift = ( f ( x. (- x c)))
(Ops shift) = (Ops -) = 2 - rightstep = ( m x. let ((mr (* m (relu x)))) (+ mr (shift (neg mr) (inv m))))
(Ops rightstep) = (Ops (list * relu + shift neg inv)) = (Ops inv) + 6
For convenience, I am writing (Ops ops) for a list of ops so I can just sum them.
Remember that negative numbers represent falsity and positive numbers represent truth, so I would like 0 to represent a perfect balance between the two. Though it is not strictly necessary to do so, I will write step which shifts rightstep to be centered around zero:
- step = ( m x. shift (rightstep m x) (* -0.5 m))
(Ops step) = (Ops (list shift rightstep *)) = (+ 9 (Ops inv))
Division
Given that division can be expressed as multiplication with the inverse, div = ( x y. * x (inv y)), with (Ops div) = (+ 1 (Ops inv)), we can focus on inv.
At this point, things start to get interesting. How can you use multiplication, addition, and relu to get division?
One might consider using a geometric series since , so . However, this approach only converges for . And even if we could do this, sometimes it converges slowly, since , so . If , then convergence to float 32 precision will take 32 steps. In general, we are solving , which for .
A search on the internet for how to compute inverses and division gives Newton's method, which finds a zero of a differentiable function by using an initial guess , and picks an such that a line with slope and value would intercept the x-axis at .
The nice thing about inverses in the context of Newton's method is that they cancel out under the division. Let . Then .
Each iteration of Newton's method only uses subtraction and multiplication. With Newton's method, the number of correct digits squares each time. Hence, we have (Ops inv) = (* 5 4) = 20.
If Statements Finally, Logic, and Causality Calculations
So, after our previous analysis, we find that (Ops div) = 21 and (Ops step) = (+ 9 (Ops inv)) = 29. Therefore, we have (Ops if) = (+ (Ops step) 3) = 32.
Now we can use "if" to generate logical connectives (expect which is the same as neg with 1 operation).

Causality Calculations on Booleans
TODO: Then do causality calculations for nor-or, if-and
Derivative Estimation
The addition of division into our arsenal of operations also opens the door to employing Newton's method when we have access to the derivative, allowing us to find zeros of differentiable functions, such as polynomials.
Moreover, division gives us the ability to estimate gradients even when we don't have a closed form. For some small fixed , we can define gradient estimation grad = f x. (div (- (f (+ x h)) (f x)) h). The operation cost for this gradient estimation is (Ops grad) = (Ops (list div - +)) = (+ 21 2 1) = 24.
Armed with this gradient estimation, we can simulate a gradient descent step using descend = x . (- x ( (grad f x)))
The operation cost for the gradient descent step is (Ops descend) = (Ops (list - * grad)) = (+ 2 1 24) = 27. Given the cost of these operations, the decision to minimize some functions using n steps of descent with (* 27 n) operations depends on the cost of your alternatives.
Returning to the central topic of causality, within the context of the programming language lambda calculus + {+, *, relu}, we can finally state that ( x. x) causes ( x. (* 2 x)) more than ( x. (* 2 x)) causes ( x. x) because Ops ( x. (* 2 x)) = 1 and Ops ( x. (div x 2)) = 21.
Note that we did not explicitly utilize as a primitive when determining the complexity of , since Ops = Ops = 1. Thus, adding as a cost 1 base case to Ops would have been superfluous. But hopefully the algorithm is clear.
Causality via an Approximation
Power Series versus Piece-wise Linear and an Aside on Recursion
Maybe at this point you are thinking that many of these representations of functions are silly: a neural network will just end up fitting everything in a piece-wise linear fashion. And I think that may be true, especially for basic examples and small networks. But I could imagine that a larger neural network will end up learning efficient datastructures for common operations, and maybe we can predict when which datastructures will arise based on their relative numbers of operations.
Let's think about specifically.
Now, I would like to discuss the case where we are not considering equality, but rather the fidelity of the approximation to . We can then compare the expected error of a piece-wise linear fit (TODO)
Consider this problem: I can envision using several different representations of a function inside a neural network. Take as an example, which can be expressed as . We can approximate it as follows:
, hence
So, because sums with recursive calls. However, this calculation seems to violate our language's current assumptions for two reasons: recursion and pattern matching.
We just used recursion, though we never defined recursion in your programming language. However, it's not a problem in principle because you can use , which allows you to find a fixed point . However, this approach explodes with normal order evaluation, leading us to question what exactly we are attempting to accomplish. Are we aiming to create more of a static analysis function that runs on your program before running , or are we crafting a dynamic that expands/runs as much of as necessary to compute of a recursive function? If the latter, why not just see how long takes to run? Notably, can use symbolic rewriting with respect to previously calculated programs to short-circuit the computation, which might be quite helpful. It would be nice if could be differentiable, since it's built out of case statements and recursion (which are, in themselves, case statements), and we just demonstrated how to make case statements differentiable by representing them in this language. Then we could use gradients to search for a minimum-length program equivalent to a baseline program.
The Y combinator could assist us in calculating symbolically. Let's express the factorial in the Y-combinator style, where it takes its own recursive call as a parameter :
and , such that continues to be applied until it reaches the termination condition.
Expressed this way, without syntactic sugar, it's evident that we neglected to count the cost of the termination condition check , which was being covered by pattern matching. This observation brings us back to the significance of being precise when defining over our programs, to ensure that we are adhering to the specific program language primitive "ops" in .
I made another mistake when I wrote .
The issue is that is not yet in our programming language, so it's not precise enough with respect to our primitive operations. For example, does it mean to iterate linearly through the sequence, or does it mean to multiply disjoint pairs recursively in a balanced merge tree? These interpretations would yield different values, and should be deterministic given a specific AST and a particular set of estimates for the costs of other operations.
1 comments
Comments sorted by top scores.
comment by mikes · 2023-08-21T22:41:53.111Z · LW(p) · GW(p)
Closely related to this is Atticus Geiger's work, which suggests a path to show that a neural network is actually implementing the intermediate computation. Rather than re-train the whole network, much better if you can locate and pull out the intermediate quantity! "In theory", his recent distributed alignment tools offer a way to do this.
Two questions about this approach:
1. Do neural networks actually do hierarchical operations, or prefer to "speed to the end" for basic problems?
2. Is it easy find the right `alignments' to identify the intermediate calculations?
Jury is still out on both of these, I think.
I tried to implement my own version of Atticus' distributed alignment search technique, on Atticus' hierarchical equality task as described in https://arxiv.org/pdf/2006.07968.pdf , where the net solves the task:
y (the outcome) = ((a = b) = (c = d)). I used a 3-layer MLP network where the inputs a,b,c,d are each given with 4 dimensions of initial embedding, and the unique items are random Gaussian.
The hope is that it forms the "concepts" (a=b) and (c=d) in a compact way;
But this might just be false?Atticus has a paper which he tries to search for "alignments" on this problem neuron-by-neuron to the concepts (a=b) and (c=d), and couldn't find it.
Maybe the net is just skipping these constructs and going to straight to the end?Or, maybe I'm just bad at searching! Quite possible. My implementation was slightly different from Atticus', and allowed the 4 dimensions to drift non-orthogonally;
Edit: Atticus says you should be able to separate the concepts, but only by giving each concept 8 of the 16 dimensions. I need to try this!
Incidentally, when I switched the net from RELU activation to a sigmoid activation, my searches for a 4-dimensional representation of (a=b) would start to fail at even recovering the variable (a=b) from the embedding dimensions [where it definitely exists as a 4-dimensional quantity! And I could successfully recover it with RELU activations]. So, this raises the possibility that the search can just be hard, due to the problem geometry...