FlexChunk: Enabling 100M×100M Out-of-Core SpMV (~1.8 min, ~1.7 GB RAM) with Near-Linear Scaling
post by Daniil Strizhov (mila-dolontaeva) · 2025-04-06T05:27:06.271Z · LW · GW · 0 commentsContents
Abstract Introduction Methodology / Experimental Setup Results and Analysis 1. Baseline Performance: Density vs. Time (SciPy) 2. FlexChunk Scalability 3. FlexChunk vs. SciPy Comparison (100K×100K) Discussion Conclusion Code Availability Appendix: Code Snippets None No comments
Abstract
Handling large-scale sparse matrices is a fundamental task in many scientific and engineering domains, yet standard in-memory approaches often hit the limitations of available RAM. This paper introduces FlexChunk, an algorithm employing a chunking strategy and disk caching for efficient sparse matrix-vector multiplication (SpMV) specifically designed for matrices exceeding available memory. Our experiments demonstrate that FlexChunk achieves near-linear O(N) time complexity and linear memory consumption scaling up to matrix sizes of 100M×100M, processing the largest case in 1 minute 47 seconds with a peak memory footprint of 1.7 GB. A comparison with the optimized SciPy library reveals a key trade-off: while SciPy offers significantly faster computation for in-memory matrices, FlexChunk excels in scenarios requiring disk I/O due to its substantially lower data loading times. The primary contribution is demonstrating FlexChunk as a scalable, memory-efficient solution enabling SpMV operations on problem sizes previously intractable due to memory constraints.
Introduction
Sparse matrix-vector multiplication (SpMV) forms the computational core of numerous algorithms, from machine learning pipelines to physical system simulations. While highly optimized libraries like SciPy, leveraging formats such as Compressed Sparse Row (CSR), efficiently handle moderately sized sparse matrices, a significant challenge arises when dealing with very large matrices: the limitations of system RAM. Standard approaches fail when the matrix cannot fit entirely into memory.
The classical complexity analysis for SpMV is typically expressed as O(nnz) for CSR format (where nnz is the number of non-zero elements). However, for matrices of dimension N×N, if the density remains constant as N increases, we expect nnz ∝ N², leading to O(N²) scaling. This theoretical analysis implicitly assumes all data resides in memory. Both assumptions break down for massive datasets: density often decreases with scale, and memory limitations necessitate algorithms capable of processing data in chunks, effectively utilizing disk storage as an extension of main memory.
This paper introduces and evaluates FlexChunk, an algorithm conceived to address the SpMV challenge for out-of-core matrices. FlexChunk partitions the source matrix into manageable blocks (chunks), persists them to disk, and loads them on demand for computation. The core objective is to enable the processing of arbitrarily large matrices, limited primarily by disk space rather than RAM. Our goal is to assess the performance, scalability, and memory footprint of FlexChunk through empirical benchmarks, comparing it against the reference SciPy implementation. We demonstrate that FlexChunk achieves near-linear time and memory scaling, offering a practical approach for tackling previously infeasible large-scale SpMV problems, albeit with a trade-off in raw computational speed compared to in-memory methods.
Methodology / Experimental Setup
The core idea of FlexChunk is to process large sparse matrices by dividing them into manageable horizontal slices, or "chunks". The process begins with generating a sparse matrix in the standard CSR format using scipy.sparse.random. This matrix is then prepared by splitting it into a predefined number of chunks, each saved to disk as a separate .npz file containing its CSR data (data, indices, indptr) and original row indices. For the actual computation of y = A @ x, the vector x is loaded into memory. Subsequently, each matrix chunk is loaded sequentially from disk, multiplied by the vector x, and the partial result is accumulated into the final result vector y. Importantly, memory used by one chunk is released before loading the next, ensuring low memory overhead. This chunking strategy is central to FlexChunk's ability to handle matrices that exceed RAM capacity, loading only necessary parts for computation.
As a baseline for comparison, we used the standard SpMV implementation from the SciPy library (scipy.sparse), which stores matrices in CSR format and utilizes the optimized @ operator for multiplication. To ensure fairness, particularly concerning disk I/O, our SciPy measurements sometimes included the full cycle time—saving the matrix and vector to disk, then reloading them before computation—to mimic FlexChunk's disk interaction. In other experiments, we focused on separating the loading and computation times explicitly.
Our evaluation comprised three main experimental series. First, we established a baseline by analyzing how standard SpMV performance (using SciPy) relates to matrix density for a fixed 5,000×5,000 matrix, varying density from 0.001% to approximately 63%. This allowed us to measure execution times for both sparse (SciPy CSR) and dense (NumPy) representations and identify the performance crossover point. Second, we assessed FlexChunk's scalability by measuring its total execution time (including generation, preparation, loading, and computation) and peak memory usage for matrices ranging from 5,000×5,000 up to 100,000,000×100,000,000, adjusting density and chunk counts accordingly (e.g., 100M×100M used density 1e-8 and 1000 chunks). Third, we conducted a direct comparison between FlexChunk and SciPy on a large 100,000×100,000 matrix, varying density from 0.00001 to 0.005 and specifically measuring data loading time versus computation time for each method.
All tests were performed on a system equipped with an Apple M4 Pro CPU, 64 GB RAM, running macOS (Darwin 24.3.0). The software environment included Python 3.12.7, NumPy 1.26.3, SciPy 1.12.0, and Numba 0.61.0.
Results and Analysis
1. Baseline Performance: Density vs. Time (SciPy)
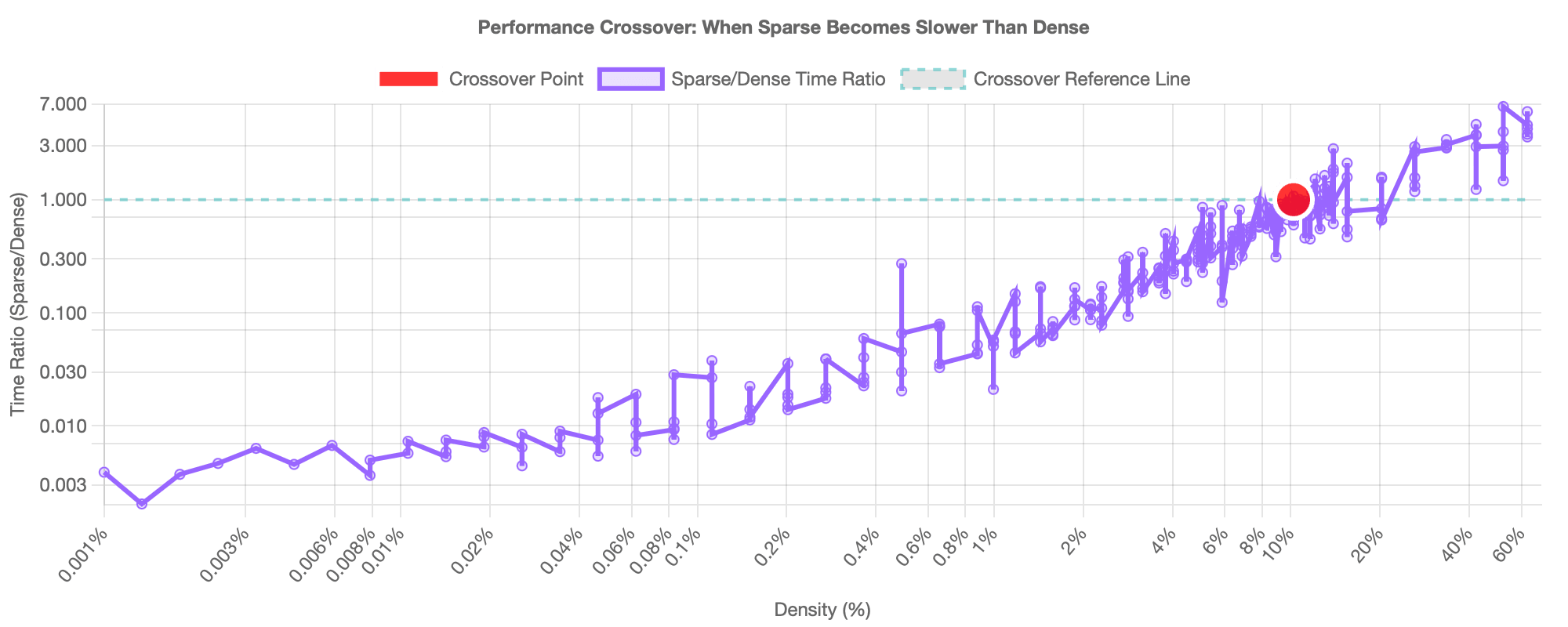
To establish context, we first examined how standard SpMV performance (using SciPy) varies with matrix density on a 5,000x5,000 matrix. The results (data from density_analysis_simple.html) confirmed a sublinear power-law relationship (time ∝ density^0.63), meaning performance gains from sparsity diminish relative to the reduction in non-zero elements. We also identified a crossover point around 10.23% density, above which using a dense NumPy approach becomes faster than SciPy's sparse method for this matrix size. This baseline confirms that sparsity alone doesn't guarantee efficiency and highlights the need for specialized approaches like FlexChunk for very large and sparse problems.

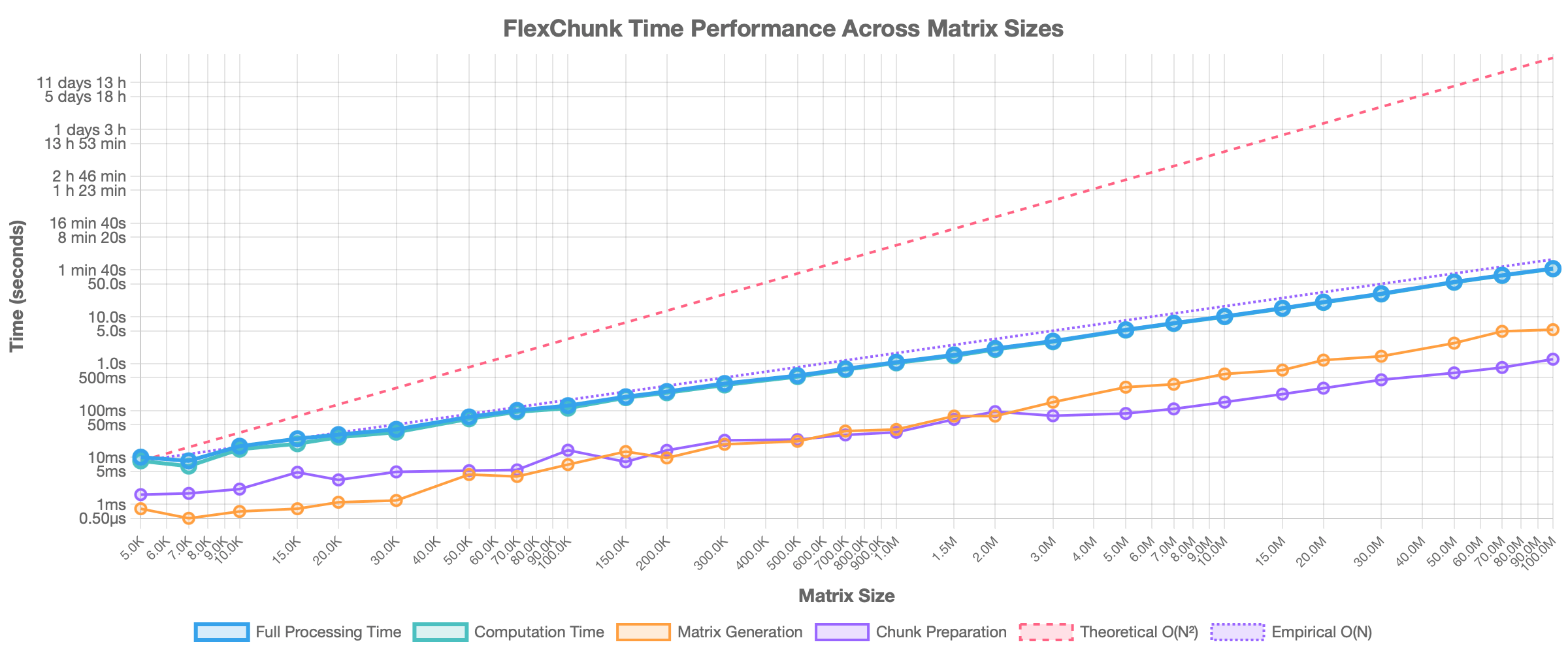
2. FlexChunk Scalability
Testing FlexChunk on matrices up to 100M×100M dimensions yielded the following key observations:
- Time Scalability: The total execution time of FlexChunk scales almost linearly with the matrix dimension (approximately O(N)), as shown in Figure 3. This indicates good scalability even for extremely large problems. Processing the 100M×100M matrix took 1 minute 47 seconds in total on the test system.
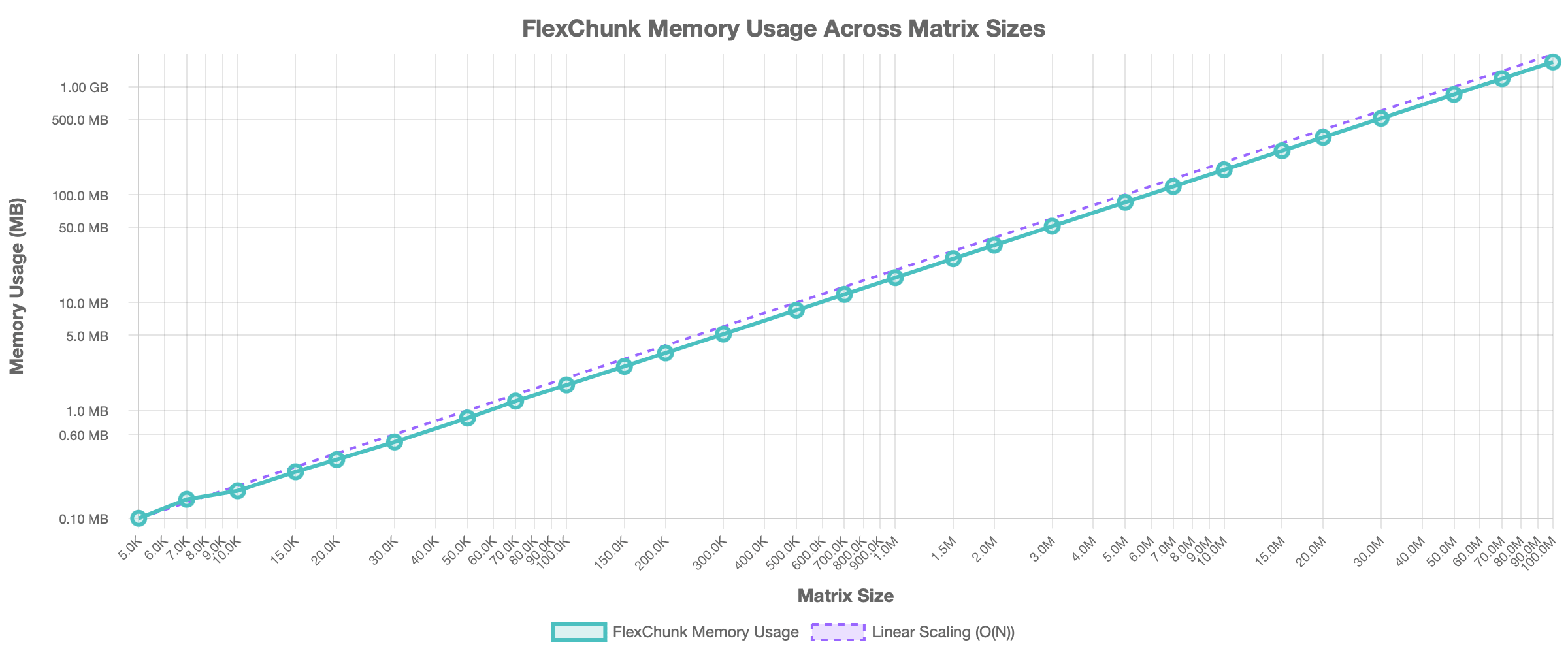
- Memory Scalability: Peak operational memory usage also grows linearly with problem size but remains remarkably low compared to the full matrix size (Figure 4). For the 100M case, peak RAM usage was 1.7 GB, confirming the effectiveness of the chunking strategy for memory management.
These results demonstrate FlexChunk's capability to handle extremely large matrices that would be infeasible for standard in-memory methods.
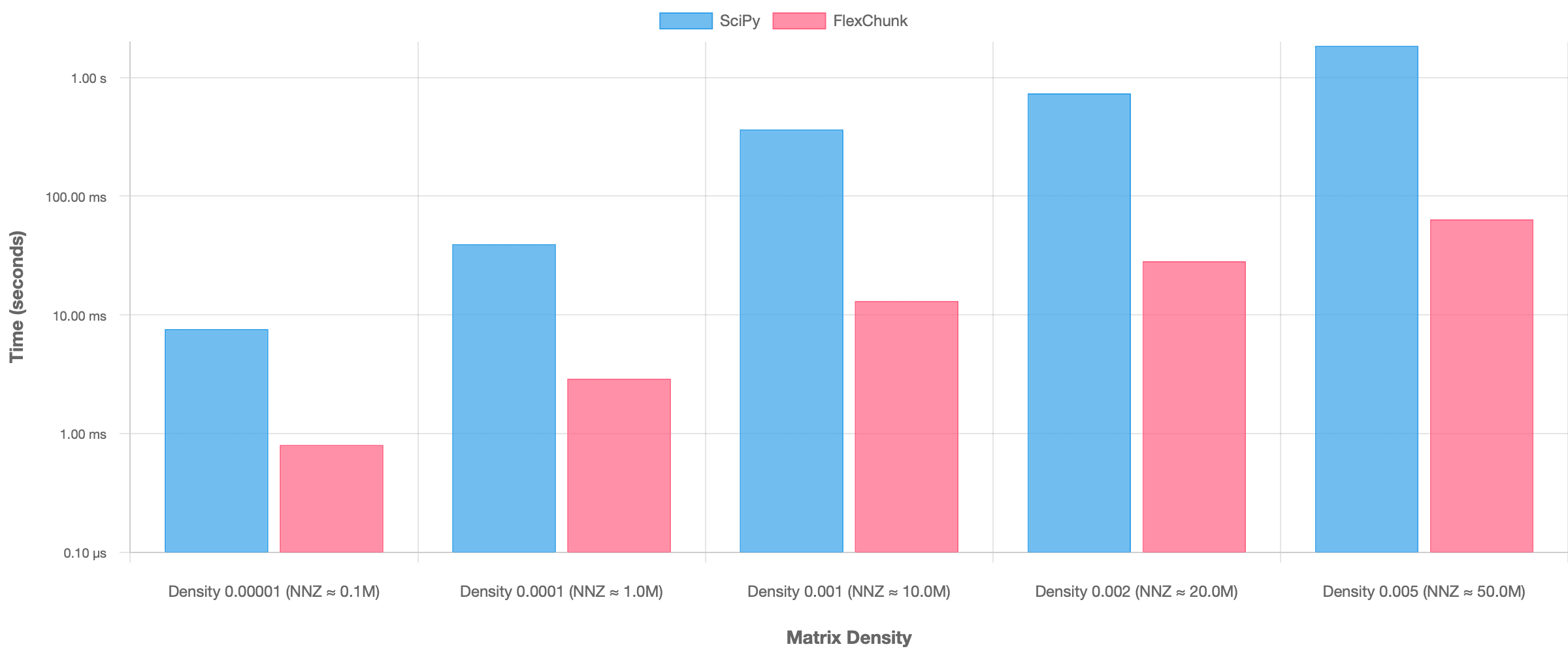
3. FlexChunk vs. SciPy Comparison (100K×100K)
A direct comparison on a 100K×100K matrix across varying densities highlighted distinct performance characteristics:
- Data Loading Time: FlexChunk consistently exhibited significantly lower data loading times from disk compared to SciPy across all tested densities (Figure 5). This advantage grew more pronounced at higher densities (corresponding to larger matrix files for SciPy).
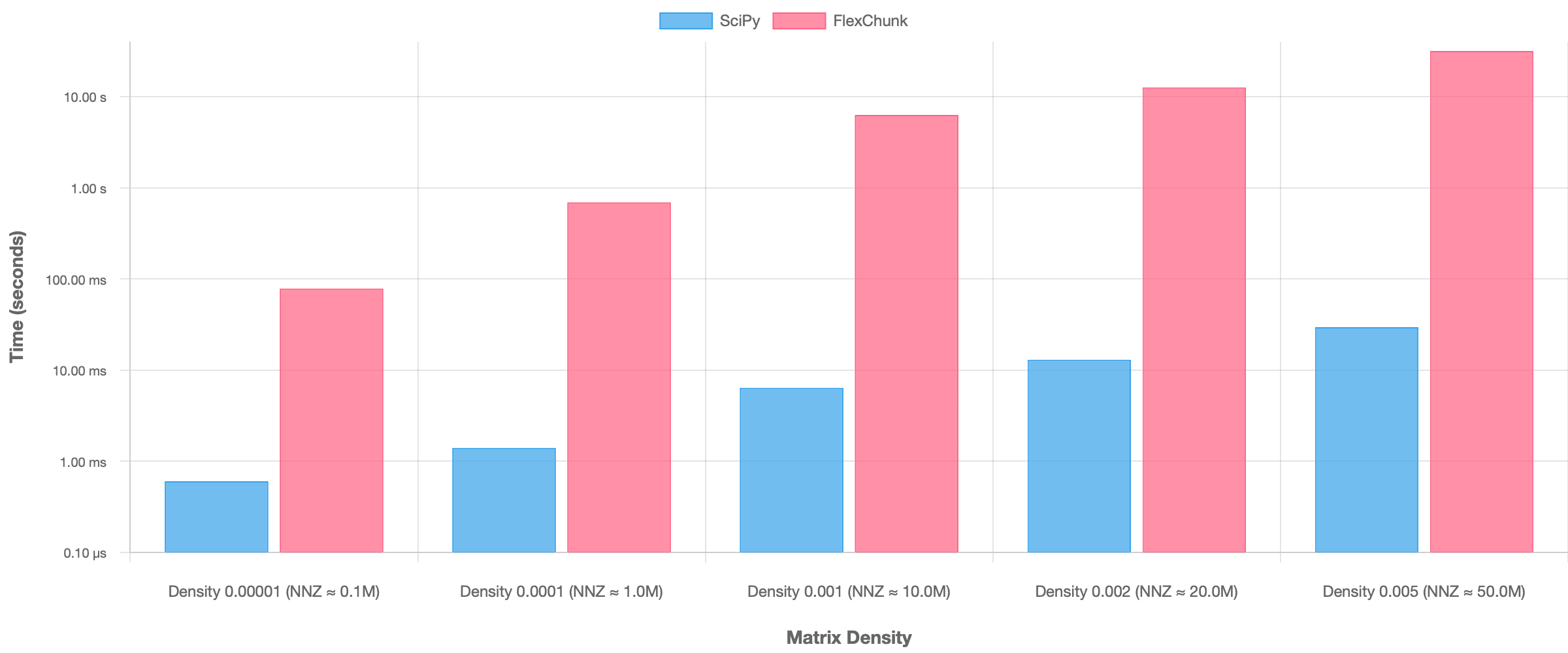
- Computation Time: SciPy demonstrated substantially faster computation speeds (pure
A @ xmultiplication), outperforming FlexChunk by orders of magnitude, especially as density increased (Figure 6).
This comparison underscores the core trade-off: FlexChunk is optimized for minimizing I/O and operating within limited memory, potentially at the cost of slower computation due to chunk management overhead. Conversely, SciPy is optimized for maximum in-memory computational speed but requires loading the entire matrix, making it susceptible to disk I/O bottlenecks during loading and fundamentally limited by available RAM.
Discussion
The experimental results validate the FlexChunk approach as a viable method for processing very large sparse matrices. Its key strength lies in memory scalability, achieved through chunking and disk utilization. This enables tackling problems previously inaccessible due to RAM limitations.
The observed near-linear O(N) time scalability is a significant finding. While chunking introduces overhead (disk I/O, chunk management), this overhead appears to scale predictably with problem size in our tests, avoiding prohibitive exponential slowdowns.
The comparison with SciPy clearly illustrates the trade-off between computational speed and memory/loading efficiency. SciPy remains the superior choice for problems that fit comfortably within RAM. However, when disk I/O for loading becomes a bottleneck, or when the matrix size exceeds available RAM, FlexChunk's loading efficiency and out-of-core capability become defining advantages.
What's particularly noteworthy is that FlexChunk emerged precisely because we were willing to look beyond classical theoretical constraints when they contradicted empirical evidence. While theoretical analysis suggests that SpMV operations should scale as O(N²) for a matrix of dimension N×N, our empirical results consistently demonstrate near-linear O(N) scaling. Similarly, our density analysis revealed a sublinear power-law relationship (time ∝ density^0.63), further demonstrating how empirical performance can significantly diverge from theoretical predictions. These disconnects between theory and practice are often ignored in academic contexts, where theoretical complexity dominates discourse, but practitioners in industry know that empirical performance frequently diverges from theoretical bounds. By designing our algorithm based on empirical scaling rather than theoretical assumptions, and accepting disk I/O penalties in exchange for memory efficiency, we enabled computations at scales that would otherwise be impossible. This demonstrates how progress can require supplementing theoretical models with empirical findings when existing models present practical barriers.
FlexChunk's performance depends on chunking parameters and disk speed. Optimal chunk configuration might require tuning. Future work could explore adaptive chunking strategies that respond to available system resources and problem characteristics.
Our tests focused on demonstrating FlexChunk's capability on large scales (up to 100M); explicitly benchmarking the exact memory limits where standard SciPy fails on these specific large matrices could be a subject for further investigation, though its inability to handle such sizes with typical RAM constraints is the primary motivation for out-of-core approaches like FlexChunk.
Conclusion
The FlexChunk algorithm provides an effective approach for sparse matrix-vector multiplication involving very large matrices, particularly under memory constraints. It exhibits favorable time (near O(N)) and excellent memory scalability, successfully processing matrices up to 100M×100M dimensions in 1 minute 47 seconds using 1.7 GB of peak RAM on our test system. Our study also revealed important insights about sparse matrix performance characteristics, including the sublinear relationship between execution time and matrix density (time ∝ density^0.63). FlexChunk's primary advantage is its ability to operate on matrices exceeding RAM capacity, coupled with relatively efficient data loading. While its raw computational speed is lower than optimized in-memory libraries like SciPy for problems fitting in RAM, FlexChunk enables a class of large-scale SpMV computations previously hindered by hardware limitations, offering a practical path forward for memory-bound sparse matrix problems. The significant divergence between theoretical complexity and observed performance highlights the importance of empirical testing when developing algorithms for large-scale data processing.
Code Availability
The source code for the FlexChunk implementation and the testing scripts used in this study are available on GitHub: https://github.com/DanielSwift1992/FlexChunk.git
Appendix: Code Snippets
(Key code snippets demonstrating the core logic)
# Example: FlexChunk Core Multiplication Logic (Simplified)
import numpy as np
import os
import time # Added for timing
def flexchunk_multiply(chunk_dir, num_chunks, vector_x, matrix_m):
"""
Performs matrix-vector multiplication using pre-computed chunks.
Args:
chunk_dir (str): Directory containing chunk files (.npz).
num_chunks (int): Total number of chunks.
vector_x (np.ndarray): Input vector.
matrix_m (int): Number of rows in the original matrix.
Returns:
np.ndarray: Result vector y = A @ x.
"""
result_y = np.zeros(matrix_m, dtype=np.float64)
vector_n = len(vector_x) # Vector length (matrix columns)
print(f"Starting FlexChunk multiplication: {num_chunks} chunks...")
total_load_time = 0
total_compute_time = 0
for i in range(num_chunks):
chunk_path = os.path.join(chunk_dir, f'chunk_{i}.npz')
# Load chunk
start_load = time.time()
try:
chunk_data = np.load(chunk_path)
A_data = chunk_data['data']
A_indices = chunk_data['indices']
A_indptr = chunk_data['indptr']
chunk_rows = chunk_data['rows'] # Original matrix row indices for this chunk
chunk_m_local = len(chunk_rows) # Number of rows in this chunk
except Exception as e:
print(f"Error loading chunk {i}: {e}")
continue
load_time = time.time() - start_load
total_load_time += load_time
# Compute for the chunk
start_compute = time.time()
chunk_y = np.zeros(chunk_m_local, dtype=np.float64)
# Basic CSR multiplication loop for the chunk
for row_idx in range(chunk_m_local):
start_ptr = A_indptr[row_idx]
end_ptr = A_indptr[row_idx+1]
for k in range(start_ptr, end_ptr):
col = A_indices[k]
if 0 <= col < vector_n: # Basic bounds check
chunk_y[row_idx] += A_data[k] * vector_x[col]
# else: # Handle potential invalid indices if necessary
# print(f"Warning: Invalid column index {col} in chunk {i}, row {row_idx}")
# Accumulate chunk result into the final result vector
original_row_indices = chunk_rows
result_y[original_row_indices] += chunk_y
compute_time = time.time() - start_compute
total_compute_time += compute_time
# Clean up memory (often handled by garbage collector)
del chunk_data, A_data, A_indices, A_indptr, chunk_y
# Optional: print progress
# print(f" Chunk {i+1}/{num_chunks} processed. Load: {load_time:.4f}s, Compute: {compute_time:.4f}s")
print(f"FlexChunk multiplication finished.")
print(f"Total Load Time: {total_load_time:.4f}s")
print(f"Total Compute Time: {total_compute_time:.4f}s")
return result_y
# Example: Matrix and Vector Generation (from test_vs_scipy.py)
import numpy as np
import scipy.sparse
import time # Added for timing
def generate_sparse_matrix_and_vector(M, N, density):
"""Generates a random sparse CSR matrix and a dense vector."""
print(f"Generating {M}x{N} matrix with density {density:.2e}...")
start_gen = time.time()
try:
matrix = scipy.sparse.random(M, N, density=density, format='csr', dtype=np.float64)
# Ensure at least one non-zero element if possible for non-empty matrices
if matrix.nnz == 0 and M > 0 and N > 0:
# Retry with a different seed
matrix = scipy.sparse.random(M, N, density=density, format='csr', dtype=np.float64, random_state=np.random.randint(1, 10000))
if matrix.nnz == 0 : # If still zero, manually add one element
row = np.random.randint(0, M, size=1)
col = np.random.randint(0, N, size=1)
data = np.random.rand(1).astype(np.float64)
matrix = scipy.sparse.csr_matrix((data, (row, col)), shape=(M, N))
vector = np.random.randn(N).astype(np.float64)
gen_time = time.time() - start_gen
print(f"Generation complete: NNZ={matrix.nnz}, Time={gen_time:.4f}s")
except MemoryError:
print("MemoryError during matrix generation!")
return None, None, 0
except Exception as e:
print(f"Error during generation: {e}")
return None, None, 0
return matrix, vector, gen_time
0 comments
Comments sorted by top scores.