How Do We Govern AI Well?
post by kaime (khalid-ali) · 2025-03-19T17:08:49.601Z · LW · GW · 0 commentsContents
Abstract 1. Introduction 2. What is a "catastrophic governance failure"? 3. What is "enabling beneficial advances in AI"? Progress: Enabling beneficial advances in AI technology and applications. 3.1 Transition governance 3.2 Transition governance as an optimal stopping problem 4. The many ways to not fail on governance Security: Avoiding a catastrophic governance failure. Progress: Enabling beneficial advances in AI technology and applications. Security v. Progress 4.1 Differential scalability of governance approaches 5. On more exacting standards of governance 6. How does this version of the governance problem fit into the bigger picture? 7. The meta-governance problem: Governing governance itself Appendix 1: Edge cases for "catastrophic governance failure" None No comments
This is the first essay in my series How do we govern AI well? For more on the broader vision, see the introduction.
Abstract
This essay argues that we face a fundamental problem in AI governance: governance mechanisms tend to degrade as AI capabilities advance. This degradation isn't random, it's systematic and predictable. The strongest evidence for this claim is that every governance approach we might consider (liability frameworks, auditing, industry self-regulation, etc.) contains inherent scaling limitations that cause it to fail precisely when it becomes most critical.
The core of my argument is that different governance mechanisms have different "scaling curves"—some degrade quickly with capability advances while others are more robust—and understanding these scaling properties is essential for designing effective governance. For example, liability frameworks scale poorly because attribution and causality become increasingly difficult to establish as AI systems grow more autonomous, while compute governance scales somewhat better because of its physical nature.
This analysis is relevant to the LessWrong community because it reframes AI governance as a problem of transition management rather than permanent solution design. Instead of asking "what perfect governance regime would solve AI risk forever?" I ask "how do we build governance capacity that can adapt as capabilities advance?"
1. Introduction
This series is about governing AI well – or at least, a certain version of it – for increasingly advanced AI systems. So I want to start by defining the version of the governance problem[1] I have in mind, and what it would be to make progress on it. And I'll say a bit, too, about how this version of the problem fits into the bigger picture.
In brief: my definition draws on the interplay between two goals:
Security: Avoiding what I'll call "catastrophic governance failures."
Progress: Enabling beneficial advances in AI technology and applications.
The core governance problem, as I see it, is that going for Progress or capacity can lead to failure on Security.[2] I'll say more about why below, and in the next essay.
I'll say you failed on the governance problem if you failed on Security. And I'll say that you made substantive progress on the governance problem if you successfully achieve both Security and Progress while also doing the following:
Capacity: Building effective governance capacity, and
Implementation: Successfully implementing governance mechanisms that actually constrain relevant actors.[3]
Making progress in this sense, though, isn't the only alternative to failure. In particular: there are ways of achieving Security without Progress, or Progress without building effective governance capacity or successfully implementing governance mechanisms. I think all these possibilities should be on the table. Below I offer a taxonomy that includes them.
Importantly: my definition of "making progress" on the governance problem is weaker than some alternatives. In particular: it doesn't mean that you're in a position to securely govern increasingly advanced AIs ("scalable governance"), or to govern competitively with extremely incautious actors ("fully competitive governance"), or to avoid catastrophic governance failures perpetually going forward ("permanent governance"), or to avoid them, even, for the relatively near-term future ("near-term governance"). Nor does it assume we need extremely robust global coordination ("complete coordination").
I discuss these more exacting standards in more detail below. And some of the dynamics at stake do matter. But for various reasons, I won't focus on those standards themselves. This means, though, that especially in certain scenarios (in particular: scenarios with lots of ongoing competitive pressure), making substantive progress in my sense isn't "enough on its own." But I think it's worth doing regardless, and that it contains a lot of the core challenge.
And importantly: if you did make substantive progress in my sense, you'd have governance capacity and mechanisms that could help in tackling these more exacting goals, if you need to. Indeed: building effective governance capacity and successfully implementing governance mechanisms, and especially: in navigating the transition to advanced AI – is my central concern.
Let me say more about what I mean by Security and Progress above.
2. What is a "catastrophic governance failure"?
Let's start with:
Security: Avoiding what I'll call a "catastrophic governance failure."
By a "catastrophic governance failure," I mean a scenario where the governance mechanisms intended to prevent catastrophic outcomes from AI fail to do so. This can happen in a few ways:
- Governance mechanisms are too weak to effectively constrain the relevant actors
- Governance mechanisms are evaded or circumvented by the actors they're meant to constrain
- Governance mechanisms address the wrong risks or issues
- Governance mechanisms create perverse incentives that exacerbate rather than mitigate risks
- Governance is too slow to adapt to rapidly changing technological capabilities
- Governance capacity exists but lacks the legitimacy or authority to be implemented etc.
I'll say that an AI governance regime has "failed catastrophically" when:
(a) it's failing to prevent behaviors that create significant catastrophic risks, and
(b) this failure wasn't an intended outcome of the governance designers.
I'll say more, in my next essay, about when, exactly, we should worry about this. But the broad concern is something like: as AI capabilities advance, their potential to cause harm – whether through accidents, misuse, or structural risks – also grows. In a "catastrophic governance failure" scenario, the governance mechanisms designed to prevent these harms have proven inadequate at sufficient scale that catastrophic outcomes become likely or inevitable.
People sometimes use the term "AI governance failure [LW · GW]" for this. And maybe I'll sometimes use that term, too. But I like it less. In particular: I think it connotes too strongly a sudden, discrete failure of otherwise functioning governance institutions. Maybe a catastrophic governance failure would be like that. But it doesn't need to be. Rather, it can be much more gradual and diffuse...think boiling frog.
For example: governance capacity might simply fail to scale with technological capabilities, creating an expanding gap between what needs to be governed and what can be governed. Or governance might function perfectly well for some actors or in some regions, while failing to constrain others, ultimately resulting in catastrophe nonetheless.⁸
Governance failures at a fundamental level are rarely subtle. Typically, they’re obvious in real time, even to those involved, yet systemic pressures/incentives prevent corrective action. Take the Cold War nuclear arms race. All parties grasped that unchecked proliferation brought humanity closer to existential catastrophe, yet national actors rationally pursued escalation, locked by competitive dynamics into an increasingly unstable equilibrium. As Robert McNamara, U.S. Secretary for Defense during the Cuban Missile Crisis put it, at the end of the day, “it was luck” [4], not governance that prevented nuclear annihilation. “Rational individuals came that close to the total destruction of their societies.” This failure was neither hidden nor unclear; it wasn’t a case of ignorance of risk but rather a structural inability, baked deeply into existing institutions, to translate clear foresight into corrective policy.
The governance failures we see in AI today echo familiar historical patterns; highly visible threats are clearly acknowledged, yet systemic incentives consistently prevent meaningful action. Major AI labs, leading researchers, and policymakers have openly admitted the risk; notably, the Statement on AI Risk explicitly calls for mitigating "the risk of extinction" from AI. Still, competitive dynamics continue driving actors to deploy increasingly powerful systems before adequate safeguards exist. This isn't subtle: it happens visibly, through widely recognized near-misses, inadequate or fragmented regulation, and pervasive institutional inertia. The challenge, therefore, isn’t identifying existential threats, but restructuring incentives and governance mechanisms to act effectively upon already obvious warnings.
One note in particular, here, is that I'm not counting legitimate, deliberate trade-offs between safety and other values as "governance failures" in my sense. That is, the central binary relevant to "catastrophic governance failure" scenarios, in my sense, isn't completely safe AI vs. less safe AI. Rather, it's catastrophic outcomes vs. non-catastrophic outcomes – including, for example, outcomes where AI development proceeds more slowly or with greater restrictions than would be optimal by some measures, but catastrophe is avoided.
Importantly, though, deliberate trade-offs can still play a key role in catastrophic governance failure scenarios. In particular: if decision-makers repeatedly prioritize other values over safety in ways that culminate in catastrophe, this remains a failure even if each individual decision seemed reasonable at the time. Thus, we can think of catastrophic governance failures on a spectrum: how much was due to deliberate, legitimate trade-offs that had unfortunate cumulative effects vs. how much was due to governance mechanisms simply failing to function as intended.
Indeed: on one extreme end, governance mechanisms function almost exactly as designed, but the designers fundamentally misunderstood the nature of the risks or how to address them[5]. And on another extreme end, the governance mechanisms would have been effective if implemented as designed, but they were systematically circumvented, ignored, or captured by the actors they were meant to constrain.[6] And there are a wide variety of scenarios in between.[7]
One other note: I will assume, in this series, that it is good in expectation for humans to develop governance mechanisms that can prevent catastrophic outcomes from AI. But I think it's a substantive additional question what kinds of constraints on AI development and deployment are ultimately good/permissible – a question I worry we won't ask hard enough. Indeed, if overly restrictive governance significantly delays beneficial AI applications that could address pressing global problems, this raises difficult ethical concerns. I've added another appendix on that issue as well, and I discuss it more later in the series.
3. What is "enabling beneficial advances in AI"?
Let's turn to the second goal above:
Progress: Enabling beneficial advances in AI technology and applications.
Ah, yes “beneficial advances”- A phrase so vague it could plausibly describe both curing cancer and a slightly more addictive TikTok algorithm.
So let’s be precise. I mean: developments in AI capabilities and applications that create substantial positive value for humanity. People often talk excitedly about AI speeding up scientific breakthroughs, enhancing medical care, revolutionizing education, and dramatically raising productivity. Sure, there's plenty of room to debate just how soon we'll reap these benefits, given the thicket of bottlenecks (e.g., implementation challenges, regulatory hurdles, etc). And in case I haven’t been clear: not every conceivable AI innovation will necessarily be beneficial. Just as not every blueprint makes for a worthwhile house, not all AI capabilities are worth developing. Dario Amodei's "Machines of loving grace" explores this idea thoughtfully, and I highly recommend giving it a read. If you’re curious about my own takes, feel free to keep reading.
For present purposes, though, we don't need to pin down a story about the precise benefits at stake. However significant you can imagine the potential positive impacts of well-governed AI could be, I'm talking about that.
Now, crucially, we might achieve these beneficial outcomes without stumbling into the governance nightmares that keep the pessimists awake at night. How? For example:
- Perhaps robust technical safeguards embedded directly into AI systems can handle safety concerns better than top-down regulations.
- If you're especially wary of super-intelligent general AI, why not shift the focus to narrower, more specialized AI applications?
- Could we create governance strategies that sidestep the thorny issues of international coordination, thus minimizing the odds re: global coordination failures?
- Organic, bottom-up governance might prove more flexible and less brittle compared to rigid, centrally imposed regulations susceptible to capture.
Indeed, in principle, you could also use governance approaches that aren't specific to AI at all. For example: improving general institutional decision-making, epistemic standards, and broader risk management practices.
Of course, these alternative routes to enabling beneficial advances might involve some trade-offs – e.g., they might be slower, more limited in scope, etc. That's why I'm defining Progress in terms of enabling the main beneficial advances in AI. That is: you just need to get in the rough ballpark.
And note that the exact nature of the benefits does matter to how difficult this is. For example: if implementation challenges to realizing a given benefit are significant enough, the difference between "well-governed but somewhat restricted AI development" and "minimally governed, accelerated AI development" might be less significant.[8]
Also: the "enabling" aspect of Progress is important. That is: Progress doesn't require that beneficial advances in AI have, in fact, been realized. Rather: it only requires that the conditions exist under which those benefits could be realized. That is: the governance mechanisms in place allow for beneficial innovation and application while still preventing catastrophic outcomes. Whether actors do choose to develop and deploy beneficial applications is a different story. Thus, if we could've used AI to help address climate change, but we don't, that's compatible with Progress in my sense. And the same goes for scenarios where e.g. a totalitarian regime uses AI centrally in bad ways.
3.1 Transition governance
I also want to explicitly name a specific subcategory of Progress that I view as incredibly important: namely, what I'll call transition governance.
This is basically: the sort of governance that specifically focuses on improving the transition to increasingly powerful AI systems. Here I have in mind governance that helps with tasks like:
- ensuring safety and security during periods of rapid capability advancement
- addressing ongoing and immediately pressing catastrophic risks, including risks from other incautious actors
- improving coordination amongst relevant actors more generally
- guiding wise decisions about what governance approaches to implement next
- developing governance capacity that can scale with technological advancement
Transition governance isn't the sole reason people want to govern AI well (note, for example, that "ensuring AI benefits are distributed equitably" isn't on the list). But as I'll discuss below: for the purposes of this series, transition governance is what ultimately matters most to me.
Indeed, I care so much about transition governance, in particular, that there is a case to be made for focusing on an earlier milestone – namely, governance mechanisms for current and near-term AI systems, rather than for hypothetical future systems.
Indeed, I will have a lot to say, in this series, about governance of this kind – I think it is a key source of hope.
But I wanted, in this series, to try to grapple directly with some of the distinctive challenges raised by governing increasingly advanced AI systems as well. This is partly because I think we may benefit from thinking ahead to some of those challenges now.
But also: I think even current governance approaches need to be designed with scalability in mind, thereby raising some of these distinctive challenges regardless.
3.2 Transition governance as an optimal stopping problem
I think we can gain some clarity about transition governance by formalizing it in a particular way. Specifically, I think transition governance can be usefully modeled as what decision theorists call an "optimal stopping problem."[9]
In this framing, at each threshold of AI capability advancement, governance institutions face a decision:
- Continue development with current governance mechanisms (risking governance failure)
- Pause development to upgrade governance (accepting competitive disadvantage)
- Permanently halt development at this capability level (accepting opportunity costs)
This creates a sequential decision problem where the expected value of each choice depends on several key variables:
- The probability of governance failure if development continues without pause
- The time required to develop adequately robust governance for the next capability level
- The competitive pressures from other actors who might not pause
- The value (both positive and negative) of capabilities at the next level
What makes this formalization interesting isn't that it gives us precise answers (it doesn't, given the deep uncertainties involved). Rather, it clarifies a counterintuitive result: under a wide range of reasonable parameter values, optimal transition governance often requires development pauses that appear excessively cautious to contemporary observers.
This isn't because these observers are making a simple error. It's because they're applying heuristics developed in domains where capability jumps are more gradual and governance failures less catastrophic. It's a case where our intuitions about appropriate caution fail to scale to the problem at hand.
The mathematics of this optimal stopping problem provides a principled basis for determining when "costly non-failure" becomes the rational choice. In particular, it suggests that seemingly excessive caution becomes entirely justified when:
- The magnitude of the capability jump is large and unprecedented
- Governance mechanisms haven't been tested at the new capability level
- The time needed to develop suitable governance is substantial
This formalization doesn't resolve the deep uncertainties we face, of course. But I think it helps us see that the rationality of caution scales with the magnitude of capability jumps and the catastrophic potential of governance failure.
4. The many ways to not fail on governance
I've now defined two key goals:
Security: Avoiding a catastrophic governance failure.
Progress: Enabling beneficial advances in AI technology and applications.
As I noted in the introduction, I'll say that you failed on the governance problem if you failed on Security. But there are a variety of different ways to not-fail in this sense. And I want us to have all of them in mind as options.
This section offers a taxonomy.
Security v. Progress
The first major question in this taxonomy, once you've achieved Security, is whether you also achieved Progress. And note that it's an open question how hard you should go for Progress, if it means risking failure on Security. I won't try to assess the trade-offs here in detail. But I think giving up on (or significantly delaying) some of the benefits at stake in Progress should be on the table.
Note, though, that per the discussion of "transition governance" above, one of the key benefits at stake in Progress might be: better ability to not fail on Security later. For example: well-governed AI might be able to help you approach both the technical and governance aspects of AI development more wisely and safely. Indeed, in a sense, we (as people in the governancesphere) are currently doing Security without Progress. In the sense that we’ve focused on risk mitigation, and controlling inputs (i.e. compute), rather than driving substantial Progress. But the threat of catastrophic governance failure still looms.
So there's a real question, if you try to do Security without Progress, of whether your strategy is sustainable (though: as I'll discuss below, this question arises even if you achieve Progress, too).
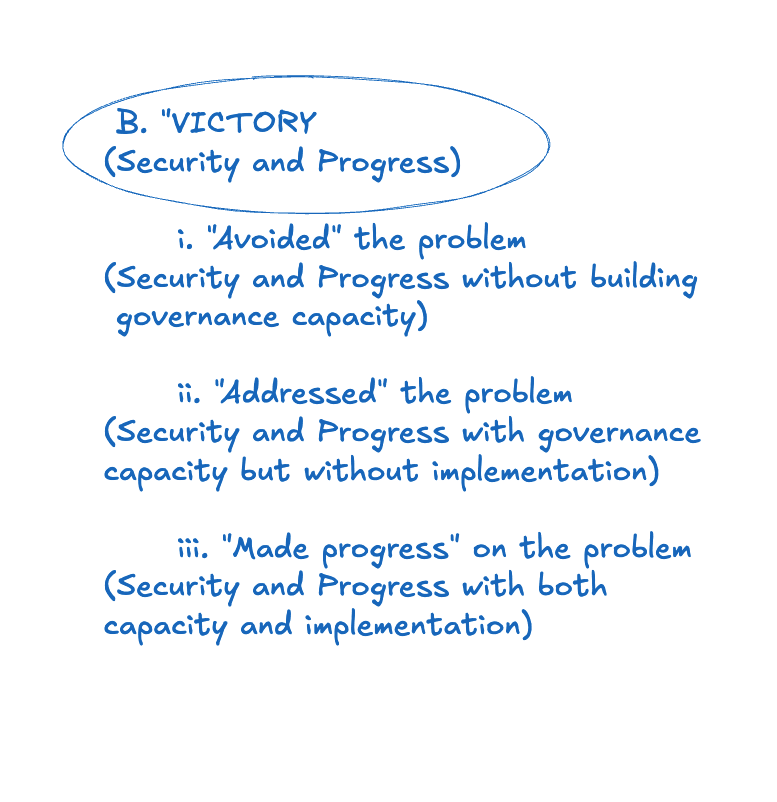
I'll call outcomes that achieve Security but not Progress "costly non-failure." And I'll call outcomes that achieve both Security and Progress "victory." My main concern, in this series, is with charting paths to victory. But I think we should take costly non-failure if necessary.
However, I also want to draw a few further distinctions from there – in particular, between what I'll call "avoiding," "addressing," and "making progress on" the governance problem.
Avoiding: I'll say you avoided the governance problem if you achieved Security without building effective governance capacity or implementing governance mechanisms. Currently, we're "avoiding" the problem in this sense – though perhaps, not for much longer. And note that avoiding the problem is compatible with achieving Progress by other means (though: we're not currently doing that).
Addressing: I'll say that you addressed the governance problem if you achieved Security, and you did build some governance capacity, but you didn't successfully implement governance mechanisms that actually constrain relevant actors. For example: maybe you have well-designed governance frameworks that nobody follows, or governance institutions without real authority or legitimacy. Again, this is compatible with Progress – but, you need to use other means to achieve security.
Making progress: Finally, I'll say that you made substantive progress on the governance problem if you did Security and Progress while also building effective governance capacity and successfully implementing governance mechanisms that actually constrain relevant actors. Here, I'm partly trying to capture some intuitive sense that "making progress on the governance problem" involves actual, functioning governance mechanisms working to prevent catastrophe.
The full taxonomy looks something like this:

In the series, I'm going to focus, especially, on making progress on the governance problem – that is, on
- building effective governance capacity and
- successfully implementing governance mechanisms that constrain relevant actors.
This focus risks neglecting options for "avoiding" and "addressing" the problem, but I'm going to take that risk. In particular: it looks like we might well be moving toward a world where AI governance becomes increasingly necessary, even if "avoiding" the problem (whether as a "victory" or a "costly non-failure") would've been a preferable strategy. So I want to prepare for that. And many of the techniques involved in trying to make progress on the problem would generalize to trying to address it.
But also: I think there's value in trying to attack an especially (though perhaps not maximally) hard version of the problem, so as to better understand its difficulty.
4.1 Differential scalability of governance approaches
One factor that complicates the governance problem is that different governance mechanisms scale differently as AI capabilities advance. By "scale," I mean: continue to function effectively as the target of governance (AI) becomes more capable and complex. Some approaches that work well for current AI systems may fail entirely as capabilities advance beyond certain thresholds. Let me examine several governance approaches through this lens:
Liability frameworks seem to scale quite poorly. As AI systems become more autonomous and their decision-making more complex, at least three problems intensify: attribution becomes increasingly difficult (who exactly is responsible when an AI system with many contributors makes a harmful decision through an opaque process?); causality becomes harder to establish (did the AI cause the harm, or was it merely correlated?); and appropriate remedies become unclear (what penalties meaningfully deter AI-related harms?).
The failure mode here isn't that liability disappears, but rather that it becomes either unmanageably harsh (creating innovation-killing risk aversion) or functionally irrelevant (unable to meaningfully shape behavior). Neither outcome provides effective governance.
Compute governance appears to scale somewhat better. The physical nature of computational resources means they remain constrained even as software capabilities advance. However, as AI capabilities improve, the governance leverage provided by each unit of compute control diminishes due to efficiency improvements that allow systems to do more with less. Additionally, compute governance faces increasing pressure from resource smuggling or black markets as the race towards AGI heats up.
Red-teaming and auditing scale particularly poorly as capabilities increase. The space of possible AI behaviors grows combinatorially with capability increases, while our ability to test grows only linearly at best. Each capability jump makes this gap worse. What does this mean in practice? We test for the risks we can predict—the problems that resemble past failures or fit within human intuition. But the most concerning failure modes here come from unknown unknowns—failures we haven’t seen before, and by definition, aren’t testing for. The result is a paradox: the more we test, the safer we might feel, even as the system becomes more unpredictable.
International monitoring regimes have unpredictable scaling properties because they depend heavily on geopolitical conditions unrelated to the technology itself. The history of arms control suggests a consistent failure mode: monitoring functions smoothly during periods of cooperation but collapses under competitive pressure, precisely when it is most needed. This is not accidental but inherent. The underlying dynamics are straightforward: when no actor expects to gain much from defecting, compliance is stable. But as soon as a breakthrough promises decisive advantage, incentives shift—transparency becomes a liability, trust erodes, defections cascade, and enforcement mechanisms degrade. The very conditions that make monitoring necessary ensure its breakdown. The result is a system that appears functional right up until the moment it isn’t. Arms control does not fail despite its design but because of it—embedded in the structure is an asymmetry where its effectiveness is inversely correlated with its necessity.
Industry self-governance initially scales quite well, as firms have the strongest incentives to prevent obvious failures, the deepest technical knowledge, and a level of agility regulators lack. Early successes reinforce the belief that external oversight is unnecessary, and industry actors become trusted stewards of their own risks. However, it tends to fail catastrophically when competitive pressures intensify beyond a certain threshold. The dangerous pattern is that self-governance often creates the appearance of responsible oversight while actually masking accumulating risks – what we might call "governance theater." cf. DWS and their 2023 greenwashing scandal. The problem is, again, structural. Self-regulation is most credible when it is least necessary and least reliable when it is most critical. It works until it doesn’t, and by the time it doesn’t, it’s too late.
The implications of this differential scaling are significant: we can't expect any single governance approach to remain viable across multiple orders of AI capability advancement. This suggests we need governance meta-systems with capacity to:
- Detect when existing governance approaches are becoming obsolete
- Rapidly develop and implement new governance mechanisms
- Maintain a portfolio of approaches that don't all fail simultaneously
This analysis of scalability doesn't mean we should abandon approaches with poor scaling properties. Rather, it means we should be realistic about their limitations and prepare governance transitions before existing approaches fail.
5. On more exacting standards of governance
As I mentioned in the introduction, my definition of "making progress on the governance problem is weaker than some alternatives. So I want to take a moment to discuss these alternatives as well.
The first alternative is what I'll call "scalable governance." This standard requires that you haven't just avoided catastrophic governance failures while enabling beneficial AI advances, but also, that you're in a position to scale this governance approach to increasingly advanced AI systems in the future. When people talk about "robust governance frameworks," I think they sometimes have this sort of standard in mind (or perhaps: an even more exacting standard – namely, one where the same governance mechanisms need to work at all scales)[10]
Why aren't I focused on this standard? For one thing, it seems fairly clear that we humans shouldn't be trying to think ahead, now, to all of the challenges involved in governing maximally* advanced AI systems.Nor should we assume that the same governance techniques need to work at all scales. Rather, our best bet, in eventually attempting to govern increasingly advanced AI systems, is to develop governance capacity that can adapt and scale with technological progress[11]. And making progress on the governance problem in my sense gives us that. But it also leaves open the possibility that our governance approaches inform us that they can't scale further safely.
In that case: OK, we've got to deal with that. But if our current governance approaches can't scale safely, despite our best efforts, it's not as though some alternative approach would've done better.
The second alternative standard is what I'll call "fully competitive governance". This standard goes even further than "scalable governance," and requires that you're in a position to govern increasingly advanced AI systems in a manner that can remain effective even with intense competitive pressures from actors trying to circumvent governance. That is, this standard requires that what we might call the "governance tax" (i.e., the additional cost in time and other resources required to ensure security) reaches extremely low levels.
Fully competitive governance is the limiting version of a broader constraint: namely, that the governance tax be sufficiently low, given the actual competitive landscape, that no catastrophic governance failure in fact results. We might call this "adequately competitive governance". Adequately competitive governance falls out of Security as I've defined it (i.e., you need to avoid a catastrophic governance failure, so your approach to governance needs to have been adequately competitive to ensure this). And this, I think, is enough. And note, also, that the basic incentives to avoid catastrophic outcomes apply to all (or at least, most) actors. So even if an actor starts out extremely incautious, it may be possible either to provide more/better information about the ongoing risks, and/or to share governance techniques that make adequate caution easier.[12]
The third alternative standard is what I'll call "permanent governance". It means creating conditions under which catastrophic governance failures become permanently impossible – whether because we know how to govern increasingly advanced AI systems (and adequately competitively, given the actual competitive landscape), or because no such advancement is occurring. The idea of "solving" the governance problem can seem to imply something like this standard (e.g., it sounds strange to say that you "solved the problem," but then failed on it later). But my version doesn't imply this kind of finality. Pursuing a final, permanent solution strikes me as a form of overconfidence, an effort to impose too rigid a framework onto an inherently uncertain future. It’s tempting, reassuring even…but in the end, it's probably neither realistic nor desirable.
That said, note that my definition doesn't even imply a fourth, much weaker standard, which I'll call "near-term governance." Near-term governance requires that we don't suffer from a catastrophic governance failure in some hazily defined "near-term" – e.g., let's say, the first two decades after the deployment of increasingly advanced AI systems.
But I'm not focusing on this, either. Indeed, it is compatible with "making progress on the problem," in my sense, that by the time one actor "makes progress" (i.e., builds governance capacity and successfully implements mechanisms, without a catastrophic governance failure having yet occurred), it's too late to avert an imminent catastrophic failure (e.g., because unsafe systems are already being widely deployed; because the actor that has made progress has too small a share of overall influence, relative to more incautious actors; because their governance approach can't adapt quickly enough in the midst of a still-ongoing technological race, etc).
Should "making progress on the governance problem" require ensuring near-term security in this sense, or being in a position to do so? People sometimes talk about "stabilizing the situation" or "ensuring baseline governance" to denote this kind of standard. And I do think that one of the main benefits of governance is that it could help with efforts in this respect, if desirable. What's more: "making progress on the problem" in my sense implies that at least one actor is in a position to get this kind of help, without a catastrophic governance failure having yet occurred. And perhaps I'll talk a bit more, later in the series, about some options in this respect.
But I'm not going to build it into my definition of making progress on the problem that the situation actually gets "stabilized," even just in the near-term; or that anyone is in position to "stabilize it." This is centrally because I want to keep the scope of the series limited, and focused on the more institutional aspects of the governance problem. And I think these more institutional aspects fit better with standard usage (i.e., governing AI well is one thing, using those governance mechanisms to actively shape outcomes is another). But also, obviously, certain mechanisms for "stabilization" (e.g., via large amounts of top-down control) are quite scary in their own right.
Still: this does mean that someone "making progress on the governance problem," in my sense, is very much not enough to ensure that we avoid catastrophic governance failures going forward – and even, in the near term. Other conditions are required as well, and we should bear them in mind.
A fifth alternative standard is what I'll call "complete coordination." By this I mean, roughly, that we have built global governance mechanisms that fully align the interests and actions of all relevant actors – even if only indirectly, i.e. via reference to shared interests in avoiding catastrophe (rather than via direct agreement on specific governance frameworks). Standards in this vein (e.g., governance mechanisms that achieve "comprehensive global cooperation") have been a salient feature of some parts of the governance discourse. But I don't want to assume that they're necessary for enabling beneficial advances in AI – and indeed, I don't think they are.
Why think they would be? I won't cover the topic in detail here, but very roughly: one classic strand of the governance discourse imagines that the competitive pressures at stake in AI development will be basically unmanageable by default, both via external constraints on actors' options, and via internal motivational constraints (e.g., constraints akin to social norms like "don't cut corners on safety," "don't deploy systems you don't fully understand," etc) on how hard they compete.
And this "unmanageability" extends, by default, to actors allowing themselves to be governed and constrained if they notice problems with their approach. So on this story, basically, once you've created competitive dynamics around AI development with certain strategic characteristics, the default outcome will be extreme and uncorrectable optimization for competitive advantage (or more specifically: the competitive advantages that fall out of the actors' own process of reflecting on and modifying their strategy – a process that might differ in important ways from the process that other actors would use/endorse).
And unless the governance mechanisms are exactly right, the story goes, extreme and uncorrectable competition will drive the future to some catastrophic outcome (this is sometimes called "value fragility [LW · GW]").[13]
But there are many, many aspects of this story that I will not take for granted.
I won't take for granted that controlling the options available to AI developers has no role to play (I think it likely does).
I won't take for granted that more norm-based components of actors' decision-making can't play an important role in ensuring security (I think they likely can).
I won't take for granted that we are giving up on being able to correct/constrain actors who begin to act dangerously (I think we shouldn't).
And I won't take for granted the broad vibe of the discourse about "cooperation fragility," on which our institutions are so brittle and contingent that the governance mechanisms need to start with exactly the right incentive structures, and exactly the right enforcement mechanisms, in order to be ultimately pointed in a good direction (I think the limiting version of this is quite counterintuitive, and I'm unsure what the right non-limiting version is).
This does mean, though, that in talking about the "beneficial advances" in AI, I'm excluding certain "advances" that seem to require complete coordination almost by definition – i.e., "maximize technological advancement with no restrictions on applications, and without ever accepting any correction," "pursue narrow national interests at all costs," etc.
But I'm OK setting these aside. If we want advances like that (do we?), we'll need to do more work (though again, if we make progress on the governance problem in my sense, we'd have governance mechanisms that could help).
I'll note, though, that I am assuming we want governance mechanisms capable of preventing catastrophic outcomes (or in figuring out that it's not safe to scale further). So making progress on the governance problem in my sense does mean that, given the actual options they face, some governance mechanisms would be effective in this way. So these governance mechanisms do need to be in what's sometimes called a "basin of robustness" – i.e., to the extent they are secure and useful even absent complete coordination, they need to be suitably robust (given their actual implementation context) to help maintain these properties in future systems.
Here's a version of the framing from above that includes the more exacting standards I've discussed in this section:

6. How does this version of the governance problem fit into the bigger picture?
I want to quickly reflect on how I see "making progress on the governance problem," in my sense, fitting into the bigger picture – especially given that, as I just emphasized, it's very far from "enough on its own."
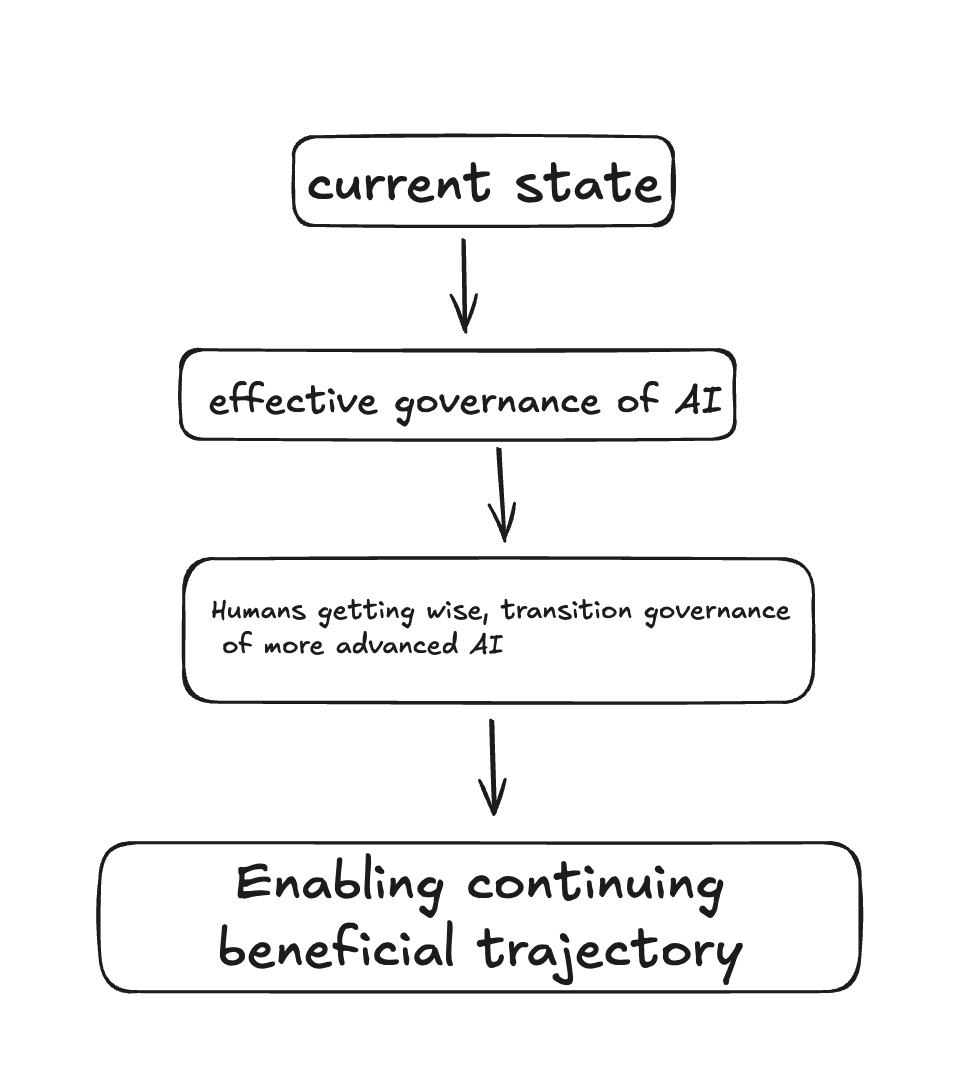
My ultimate goal, here, is for the trajectory of our civilization to be good. And I want the development of advanced AI to get channeled into this kind of good trajectory. That is: I want advanced AI to strengthen, fuel, and participate in good processes in our civilization – processes that create and reflect things like love, wisdom, consciousness, joy, nourishment, beauty, dialogue, friendship, fairness, cooperation, and so on.
But the development of advanced AI also represents a fundamental change in the role of governance in these processes, and in our civilization more broadly. Most saliently: the governance mechanisms we've developed for previous technologies may, by hypothesis, become radically inadequate relative to AI governance challenges, (a thread I’ve been exploring in a separate project you should look out for if interested). But even with respect to the broader task of determining how a given sort of technology will be employed, and on the basis of what ultimate values, the role of governance institutions could shift dramatically, even if our efforts to prevent catastrophic outcomes go well. Pretty quickly, for example, it might become quite hard for us to understand the sorts of governance challenges AI systems create, and the governance mechanisms might have to address issues we can barely conceptualize.
In such a case, even outside of the context of direct economic/military competition, it might become tempting to restrict the scope of our governance to more and more limited domains, and to "defer to technical solutions" about the rest. Indeed, I think people sometimes think of the "governance problem" as closely akin to: the problem of building governance mechanisms to which we would be happy to defer, wholesale, in this way. Governance mechanisms, that is, to which we can basically "hand-off" our role as agents in shaping technological trajectories, and "retire," centrally, as passive recipients of whatever outcomes emerge.
Perhaps, ultimately, we should embrace such a wholesale "hand-off." And perhaps we will need to do so sooner than we might like. But making progress on the governance problem, in my sense, doesn't imply that we've "handed things off" in this way – or even, necessarily, that we should be comfortable doing so. Rather, when I imagine the goal-state I'm aiming at, I generally imagine some set of humans who are still trying to understand the situation themselves and to exert meaningful agency in shaping it, and who are using governance mechanisms to help them in this effort (while still deferring/delegating about lots of stuff). And I tend to imagine these governance mechanisms, not as "running the show," but rather as acting centrally as guardrails that help channel technological development in beneficial directions – mechanisms, that is, that are a lot like existing technology governance in their basic function, except more robust and adaptive.
And this image is part of what informs my interest in transition governance of the type I described above. That is: my main goal is to help us transition as wisely as possible to a world of advanced AI. But I don't think we yet know what it looks like to do this well. And I want our own agency and understanding to be as wise and informed as possible, before we "hand things off" more fully, if we do.
Here's a rough, abstract chart illustrating the broad picture I just laid out (and including a node for building governance capacity for current AI systems as well, which is another very important dimension).
Admittedly, and as I've tried to emphasize, focusing on humans building effective governance capacity and implementing governance mechanisms is an intermediate goal. It only gets us part of the way – both to ongoing security from catastrophic governance failure, and to a good future more broadly. But I think this is OK.
Indeed, my own sense is that the discourse about AI governance has been over-anchored on a sense that it needs, somehow, to "solve the whole future" ahead of time, at least re: governance-relevant issues.³⁷ "Complete coordination," for example, basically requires that you build governance that would "solve the future" from civilization's perspective; and "permanent governance" requires solving catastrophic governance failure risk forever. I think we should be wary of focusing on "solutions" of this scale and permanence. It is not for us to solve the whole future – and this holds, I expect, even for "indirect solutions," that try to guarantee that future people, or future governance institutions, solve the future right.³⁹
Still: we should try, now, to do our part. And I think a core goal there (though: not the only goal) is to help put future people (which might mean: us in a few years) in a position to build effective governance capacity and implement governance mechanisms for doing theirs.
7. The meta-governance problem: Governing governance itself
I want to close by reflecting on what seems to me a particularly important and difficult challenge: the problem of "meta-governance."
What is meta-governance? It's the governance of governance itself – the mechanisms by which we ensure that our governance institutions remain aligned with their intended purposes. While it might initially seem abstract, even esoteric, this issue is anything but trivial. It cuts to the core of AI governance, bearing implications far beyond the typical policy debates. Meta-governance asks not just how we control emerging technologies, but how we maintain control over the structures we erect to manage those technologies—structures which inevitably drift, ossify, or mutate over time.
"Institutions are the rules of the game," writes North,[14] "the humanly devised constraints that structure political, economic, and social interaction." Yet institutions, once established, rarely remain faithful to their initial design. Like evolutionary organisms, governance structures adapt in unforeseen, very often maladaptive ways, frequently diverging from their original purposes. Regulatory capture (Stigler, 1971)[15], institutional sclerosis (Olson, 1982)[16], mission creep, bureaucratic inertia—these pathologies are well-known to historians, economists, and political scientists alike. Any institution, no matter how carefully conceived, is subject to gradual decay and misalignment, a dynamic succinctly captured by Robert Conquest’s oft-cited Third Law of Politics: "The simplest way to explain the behavior of any bureaucratic organization is to assume it is controlled by a cabal of its enemies."
The fundamental challenge, what I call the meta-governance problem, is deceptively simple: it's the question of how we govern the very institutions tasked with governance. While this might sound abstract, it's intensely practical—especially for something as fast-moving as AI. AI systems evolve rapidly, often unpredictably, leaving traditional institutions scrambling to catch up.
Consider the historical parallels: nuclear regulation and central banking both offer cautionary tales of institutional rigidity and adaptation failure. The Nuclear Regulatory Commission, established under conditions radically different from contemporary threats, struggles to accommodate novel reactor designs and safety concepts [17][18]. Neither precedent inspires confidence that institutions can evolve as rapidly as the underlying technologies demand.
To effectively govern AI, therefore, institutions must exhibit a quality notably absent from historical analogues: adaptability. Meta-governance, in short, requires constructing self-correcting institutions capable of conscious, structured evolution. But how might this be accomplished?
I propose that successful meta-governance necessitates at least three distinct, mutually reinforcing elements:
First, epistemic mechanisms that can reliably track whether governance is succeeding or failing. This is harder than it sounds. Governance institutions naturally develop metrics and narratives that validate their own success – particularly in domains where success means "nothing bad happened." For AI governance specifically, we need ways to detect subtle erosion of governance effectiveness before catastrophic failure occurs. This is a significant challenge when the most serious potential harms haven't occurred yet, making it difficult to calibrate warning signals.
Second, legitimacy mechanisms that maintain public trust and institutional authority through capability transitions and governance adaptations. As AI capabilities advance, governance approaches will likely need to evolve in ways that aren't easily explainable to the public or that appear excessively restrictive relative to visible risks. Without sustained legitimacy, even well-designed governance will collapse when it faces pressure from competing interests.
Third, correction mechanisms that can reform or replace governance institutions when they begin to fail. History suggests that governance institutions tend to ossify around early regulatory paradigms – consider how FDA drug approval processes or nuclear regulatory frameworks have struggled to adapt to new technological realities. With AI, such institutional rigidity could be particularly dangerous if governance structures cannot evolve rapidly enough to address novel risks.
Yet history provides scant encouragement regarding institutional evolution at the required scale and pace. We lack strong precedents of institutions successfully navigating multiple transformative shifts in technological capabilities. Closest examples; central banks adapting to financial innovation, nuclear regulatory bodies attempting to address proliferation risks, have struggled profoundly, experiencing failures ranging from financial crises to regulatory paralysis. AI governance, facing even more rapid and profound technological shifts, can ill afford comparable stumbles.
Thus, the ultimate challenge in AI meta-governance becomes starkly epistemological and evolutionary. It is no longer sufficient merely to construct governance institutions optimized for today's technologies. Rather, we must design institutional frameworks inherently capable of learning, self-correcting, and evolving in lockstep with technological progress. In short, governance itself must become a technology, one capable of structured, deliberate self-modification without losing coherence or legitimacy.
The meta-governance challenge is not a peripheral question but a central one, touching upon the heart of institutional theory, epistemology, and the nature of societal adaptation itself. If we fail here, no amount of technical brilliance or political goodwill will prevent governance failure. But if we succeed, if we genuinely solve the meta-governance puzzle, we will have achieved something remarkable, creating institutions as agile and dynamic as the very technologies they seek to govern.
Appendix 1: Edge cases for "catastrophic governance failure"
This appendix examines a few edge cases for the concept of "catastrophic governance failure."
First: catastrophic governance failures don't need to be total. Rather, they might only lead to partial catastrophes. This won't count as a full "catastrophic governance failure" in my sense; but my discussion of preventing governance failures will still apply – except, to the prevention of that partial catastrophe.
Second: as I mentioned in the main text, governance can fail to prevent catastrophic outcomes without this constituting a "failure" in my sense. For example, if governance mechanisms are deliberately designed to allow for risky innovation because decision-makers have explicitly and legitimately prioritized innovation over safety, this isn't a governance "failure" – even though it might lead to catastrophe.
This can happen for different reasons. One salient reason is that accepting some catastrophic risk can be useful to the decision-makers doing it – as, for example, when a society accepts nuclear power despite some risk of accidents whether or not this risk is well-calibrated, or when it accepts some environmental degradation for economic growth. But another salient reason might be: because decision-makers are, or believe to be, facing existential threats that require technological advancement to address (e.g., competition with rival nations, existential risks from other sources).
If governance mechanisms deliberately allow activities that lead to catastrophic outcomes, but without this constituting a governance "failure" in my sense – i.e., the mechanism functioned as intended, but had disastrous consequences – then this isn't a "catastrophic governance failure" as I've defined it. Of course: it can still be bad. But I actually think that the discourse about governance has been too interested, traditionally, in preventing this type of badness. That is: this discourse has too often run together the problem of "how do we ensure governance mechanisms function as intended" with the problem of "even assuming that governance mechanisms function as intended, how do we ensure that the outcomes are good?"
I'm also not counting it as a "failure" if a governing body intentionally designs mechanisms to allow harmful applications, and then they do so. Thus, if a authoritarian regime designs governance frameworks specifically to enable surveillance technologies while preventing only the most extreme catastrophes, those frameworks have not "failed" on my definition – even though they might enable outcomes many would consider harmful. And similarly, if a nation-state builds governance mechanisms that allow for the deployment of autonomous weapons systems, and then these systems are deployed in ways that destabilize international security, this isn't necessarily a governance failure, either, if the governance mechanisms functioned as intended in allowing such deployments. If the governance mechanisms start failing to constrain deployments in ways they were intended to, though, or if they create unintended consequences that culminate in catastrophe – that's governance failure.
Admittedly, it's sometimes unclear what outcomes a given governance regime "intended." Suppose, for example, that a regulatory agency creates AI safety guidelines, the letter of which does indeed seem to permit certain high-risk applications – for example, when it judges those applications to have sufficiently high expected benefits. An actor, following these guidelines, deploys an AI system that leads to catastrophe. What did the regulatory agency intend? Maybe it can feel hard to say – the same way, perhaps, it can be hard to say what the drafters of a constitution "intended" for it to imply about some modern technology they never imagined.
For a lot of catastrophic outcomes, though: it's not unclear. For example: if the letter of the governance framework permits applications that lead to widespread, severe harm that undermines the very values the framework was designed to protect, I expect it to be safe to say "no, that outcome was unintended," even if the governance designers never explicitly addressed it. In particular: if they had considered it, they would've been a clear "no." And I think that preventing this kind of governance failure – i.e., governance mechanisms failing to prevent outcomes that their designers would've strongly rejected after only a bit of reflection – is often enough for the purposes I have in mind.
And I want to say something similar about cases where it's ambiguous whether governance "overreached" in a problematic way, vs. "constrained" activities legitimately (albeit, powerfully). Yes, drawing the lines here can get tricky. But preventing the flagrant cases goes a lot of the way.
What's more, "edge cases" for concepts like "intention" and "legitimate constraint" will often be correspondingly less stakes-y. I.e., an "edge case" of legitimate constraint might be an edge case, in part, because it's less obviously bad in the way that illegitimate constraints are bad.
That said, it's also possible that if we thought more about various possible edge cases here, we'd see that they have real (and perhaps even: existential) stakes. So for those cases, I think, we may well need to either figure out ahead of time what specific governance approaches we want (i.e., develop a more specific conception of what kinds of constraints count as "legitimate"), or somehow build into our governance mechanisms the ability to adapt in the way we would have done to get to the right answer here (I do expect, in general, that adequate governance will require mechanisms that can extend and refine human concepts in ways we would endorse – though, not necessarily to some limiting degree).
- ^
The version of the governance problem I'm talking about has a lot of overlap with what others have called "the AI control problem," "the alignment problem," and "AI safety" in general. However, I believe there are important distinctions, which I'll address briefly in a later essay.
- ^
For readers, familiar with x-risk discourse, my framing here is based largely on what Bostrom has called the "vulnerable world hypothesis"- basically the idea that technological progress might inevitably lead to catastrophic risk unless we exit the ‘semi-anarchic default condition’, and governance capacity sufficiently advances.
- ^
By "implementation," of course, I mean not merely formal governance adoption but real-world effectiveness...oft a very different matter. North (1990) describes institutions as "humanly devised constraints that shape human interaction," noting how formal rules frequently diverge from actual practice. Acemoglu and Robinson (2012) take it further and speak to how even seemingly robust institutions fail when enforcement incentives clash with actors' interests. For AI governance, this problem is particularly acute given the technical complexity and powerful incentives to evade rules; see also Hadfield (2016) on the widening gap between formal law and practical governance in technologically advanced domains "the legal rules that currently guide global integration are no longer working. They are too slow, costly, and localized for increasingly complex advanced economies."
- ^
Minute 1:19
- ^
Historical examples of well-designed governance that failed due to misunderstanding the risks include the Basel II banking standards, which correctly identified many specific banking risks but failed to address systemic risk. See Tarullo, D. K. (2008). Banking on Basel: The Future of International Financial Regulation. Peterson Institute.
- ^
Tarullo, also explores how the Basel banking accords, designed to strengthen financial stability, were systematically weakened as banks exploited loopholes, engaged in regulatory arbitrage, and lobbied for favorable interpretations. Again Tarullo, D. K. (2008). Banking on Basel: The Future of International Financial Regulation. Peterson Institute. particularly pp. 69–94 on the limitations of Basel II implementation.
- ^
I often use financial governance examples as imo, they offer a useful parallel for AI: both deal with complex, opaque systems where incentives drive actors to exploit loopholes and push risks onto broader society. Unless we can make a certain kind of progress, I expect AI governance to struggle to keep pace with rapid advancements.
- ^
The relationship between implementation challenges and governance stringency is analyzed in Askell, Brundage, & Hadfield (2019). "The Role of Cooperation in Responsible AI Development.", which shows how implementation bottlenecks can reduce the difference between strict and permissive governance regimes.
- ^
cf. nuclear strategy: The dilemma resembles Cold War nuclear strategy, where decision-makers had to determine at what point arms control agreements were preferable to continued stockpiling. Too early, and adversaries exploit the pause; too late, and destabilizing technologies proliferate unchecked. The optimal stopping frame forces a similar recognition: the real danger is neither pausing too soon nor too late in isolation, but rather misjudging which failure mode is costlier.
- ^
This idea of scalable governance has parallel's to what Christiano calls scalable control in the technical alignment literature, if unfamiliar:
- ^
The approach of developing adaptable governance rather than trying to solve all problems at once is explored in Wallach & Marchant (2019). "Toward the Agile and Comprehensive International Governance of AI and Robotics." Proceedings of the IEEE, 107(3), 505-508.
- ^
The concept of "adequately competitive governance" relates to Schelling's work on focal points in competitive scenarios—governance doesn't need to be perfectly competitive, just competitive enough to maintain coordination. See Schelling, T. C. (1980). The Strategy of Conflict. Harvard University Press.
- ^
The concept of value fragility refers to the idea that human values are complex and easily lost if not carefully preserved in AI systems. Even small deviations in goal alignment can lead to drastically different and potentially catastrophic futures. This idea has been explored extensively by Eliezer Yudkowsky, particularly in the linked essay Value is Fragile (2009), where he argues that without a precise inheritance of human morals, the future could become meaningless or undesirable. See: Yudkowsky, Eliezer. Value is Fragile. LessWrong, 29 Jan 2009. [LW · GW]
- ^
Douglass C. North (1990), Institutions, Institutional Change and Economic Performance. Cambridge University Press. North’s foundational analysis of institutions as rules structuring societal interactions.
- ^
George J. Stigler (1971), “The Theory of Economic Regulation,” The Bell Journal of Economics and Management Science. The canonical source on regulatory capture, does a great job of explaing how institutions are often quietly repurposed by those they were designed to constrain.
- ^
Olson illustrates the slow corrosion of organizational effectiveness through interest-group entrenchment. Institutions age badly, it seems, like cheese rather than wine. Mancur Olson (1982), The Rise and Decline of Nations. Yale University Press.
- ^
Charles Perrow (1984), Normal Accidents.
Reminds us (with unsettling clarity) that complex, tightly coupled technologies [like AI] inevitably cause unexpected crises. Institutions often amplify rather than reduce these risks. - ^
Grim evidence that even institutions tasked with existential risks struggle terribly to adapt. AI policymakers: take note. Mathew Bunn & Olli Heinonen (2011)
0 comments
Comments sorted by top scores.