A note about calibration of confidence
post by jbay · 2016-01-04T06:57:08.297Z · LW · GW · Legacy · 35 commentsContents
Background Symmetry Sensitivity Ramifications for scoring calibration (updated) Example: Pretend underconfidence to fake good calibration None 35 comments
Background
In a recent Slate Star Codex Post (http://slatestarcodex.com/2016/01/02/2015-predictions-calibration-results/), Scott Alexander made a number of predictions and presented associated confidence levels, and then at the end of the year, scored his predictions in order to determine how well-calibrated he is. In the comments, however, there arose a controversy over how to deal with 50% confidence predictions. As an example, Scott has these predictions at 50% confidence, among his others:
|
Proposition |
Scott's Prior |
Result |
|
|
A |
Jeb Bush will be the top-polling Republican candidate |
P(A) = 50% |
A is False |
|
B |
Oil will end the year greater than $60 a barrel |
P(B) = 50% |
B is False |
|
C |
Scott will not get any new girlfriends |
P(C) = 50% |
C is False |
|
D |
At least one SSC post in the second half of 2015 will get > 100,000 hits: 70% |
P(D) = 70% |
D is False |
|
E |
Ebola will kill fewer people in second half of 2015 than the in first half |
P(E) = 95% |
E is True |
Scott goes on to score himself as having made 0/3 correct predictions at the 50% confidence interval, which looks like significant overconfidence. He addresses this by noting that with only 3 data points it’s not much data to go by, and could easily have been correct if any of those results had turned out differently. His resulting calibration curve is this:
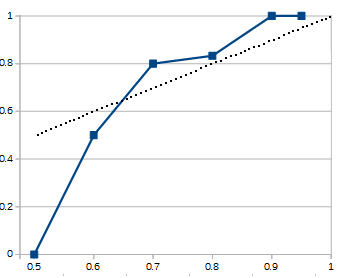
However, the commenters had other objections about the anomaly at 50%. After all, P(A) = 50% implies P(~A) = 50%, so the choice of “I will not get any new girlfriends: 50% confidence” is logically equivalent to “I will get at least 1 new girlfriend: 50% confidence”, except that one results as true and the other false. Therefore, the question seems sensitive only to the particular phrasing chosen, independent of the outcome.
One commenter suggests that close to perfect calibration at 50% confidence can be achieved by choosing whether to represent propositions as positive or negative statements by flipping a fair coin. Another suggests replacing 50% confidence with 50.1% or some other number arbitrarily close to 50%, but not equal to it. Others suggest getting rid of the 50% confidence bin altogether.
Scott recognizes that predicting A and predicting ~A are logically equivalent, and choosing to use one or the other is arbitrary. But by choosing to only include A in his data set rather than ~A, he creates a problem that occurs when P(A) = 50%, where the arbitrary choice of making a prediction phrased as ~A would have changed the calibration results despite being the same prediction.
Symmetry
This conundrum illustrates an important point about these calibration exercises. Scott chooses all of his propositions to be in the form of statements to which he assigns greater or equal to 50% probability, by convention, recognizing that he doesn’t need to also do a calibration of probabilities less than 50%, as the upper-half of the calibration curve captures all the relevant information about his calibration.
This is because the calibration curve has a property of symmetry about the 50% mark, as implied by the mathematical relation P(X) = 1- P(~X) and of course P(~X) = 1 –P(X).
We can enforce that symmetry by recognizing that when we make the claim that proposition X has probability P(X), we are also simultaneously making the claim that proposition ~X has probability 1-P(X). So we add those to the list of predictions and do the bookkeeping on them too. Since we are making both claims, why not be clear about it in our bookkeeping?
When we do this, we get the full calibration curve, and the confusion about what to do about 50% probability disappears. Scott’s list of predictions looks like this:
|
Proposition |
Scott's Prior |
Result |
|
|
A |
Jeb Bush will be the top-polling Republican candidate |
P(A) = 50% |
A is False |
|
~A |
Jeb Bush will not be the top-polling Republican candidate |
P(~A) = 50% |
~A is True |
|
B |
Oil will end the year greater than $60 a barrel |
P(B) = 50% |
B is False |
|
~B |
Oil will not end the year greater than $60 a barrel |
P(~B) = 50% |
~B is True |
|
C |
Scott will not get any new girlfriends |
P(C) = 50% |
C is False |
|
~C |
Scott will get new girlfriend(s) |
P(~C) = 50% |
~C is True |
|
D |
At least one SSC post in the second half of 2015 will get > 100,000 hits: 70% |
P(D) = 70% |
D is False |
|
~D |
No SSC post in the second half of 2015 will get > 100,000 hits |
P(~D) = 30% |
~D is True |
|
E |
Ebola will kill fewer people in second half of 2015 than the in first half |
P(E) = 95% |
E is True |
|
~E |
Ebola will kill as many or more people in second half of 2015 than the in first half |
P(~E) = 05% |
~E is False |
You will by now have noticed that there will always be an even number of predictions, and that half of the predictions always are true and half are always false. In most cases, like with E and ~E, that means you get a 95% likely prediction that is true and a 5%-likely prediction that is false, which is what you would expect. However, with 50%-likely predictions, they are always accompanied by another 50% prediction, one of which is true and one of which is false. As a result, it is actually not possible to make a binary prediction at 50% confidence that is out of calibration.
The resulting calibration curve, applied to Scott’s predictions, looks like this:
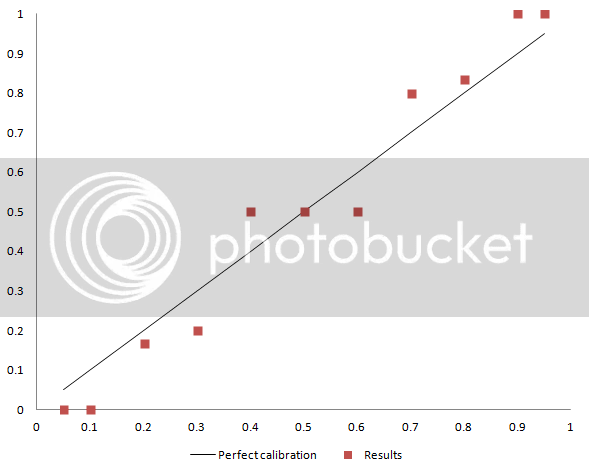
Sensitivity
By the way, this graph doesn’t tell the whole calibration story; as Scott noted it’s still sensitive to how many predictions were made in each bucket. We can add “error bars” that show what would have resulted if Scott had made one more prediction in each bucket, and whether the result of that prediction had been true or false. The result is the following graph:
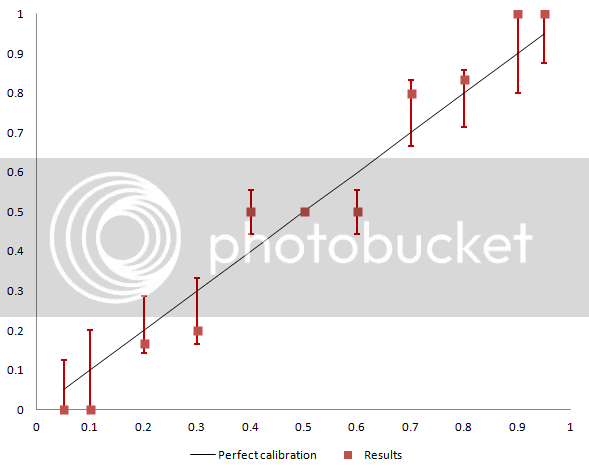
Note that the error bars are zero about the point of 0.5. That’s because even if one additional prediction had been added to that bucket, it would have had no effect. That point is fixed by the inherent symmetry.
I believe that this kind of graph does a better job of showing someone’s true calibration. But it's not the whole story.
Ramifications for scoring calibration (updated)
Clearly, it is not possible to make a binary prediction with 50% confidence that is poorly calibrated. This shouldn’t come as a surprise; a prediction at 50% between two choices represents the correct prior for the case where you have no information that discriminates between X and ~X. However, that doesn’t mean that you can improve your ability to make correct predictions just by giving them all 50% confidence and claiming impeccable calibration! An easy way to "cheat" your way into apparently good calibration is to take a large number of predictions that you are highly (>99%) confident about, negate a fraction of them, and falsely record a lower confidence for those. If we're going to measure calibration, we need a scoring method that will encourage people to write down the true probabilities they believe, rather than faking low confidence and ignoring their data. We want people to only claim 50% confidence when they genuinely have 50% confidence, and we need to make sure our scoring method encourages that.
A first guess would be to look at that graph and do the classic assessment of fit: sum of squared errors. We can sum the squared error of our predictions against the ideal linear calibration curve. If we did this, we would want to make sure we summed all the individual predictions, rather than the averages of the bins, so that the binning process itself doesn’t bias our score.
If we do this, then our overall prediction score can be summarized by one number:
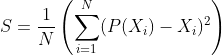
Here P(Xi) is the assigned confidence of the truth of Xi, and Xi is the ith proposition and has a value of 1 if it is True and 0 if it is False. S is the prediction score, and lower is better. Note that because these are binary predictions, the sum of squared errors gives an optimal score if you assign the probabilities you actually believe (ie, there is no way to "cheat" your way to a better score by giving false confidence).
In this case, Scott's score is S=0.139, much of this comes from the 0.4/0.6 bracket. The worst score possible would be S=1, and the best score possible is S=0. Attempting to fake a perfect calibration by everything by claiming 50% confidence for every prediction, regardless of the information you actually have available, yields S=0.25 and therefore isn't a particularly good strategy (at least, it won't make you look better-calibrated than Scott).
Several of the commenters pointed out that log scoring is another scoring rule that works better in the general case. Before posting this I ran the calculus to confirm that the least-squares error did encourage an optimal strategy of honest reporting of confidence, but I did have a feeling that it was an ad-hoc scoring rule and that there must be better ones out there.
The logarithmic scoring rule looks like this:
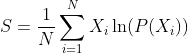
Here again Xi is the ith proposition and has a value of 1 if it is True and 0 if it is False. The base of the logarithm is arbitrary so I've chosen base "e" as it makes it easier to take derivatives. This scoring method gives a negative number and the closer to zero the better. The log scoring rule has the same honesty-encouraging properties as the sum-of-squared-errors, plus the additional nice property that it penalizes wrong predictions of 100% or 0% confidence with an appropriate score of minus-infinity. When you claim 100% confidence and are wrong, you are infinitely wrong. Don't claim 100% confidence!
In this case, Scott's score is calculated to be S=-0.42. For reference, the worst possible score would be minus-infinity, and claiming nothing but 50% confidence for every prediction results in a score of S=-0.69. This just goes to show that you can't win by cheating.
Example: Pretend underconfidence to fake good calibration
In an attempt to appear like I have better calibration than Scott Alexander, I am going to make the following predictions. For clarity I have included the inverse propositions in the list (as those are also predictions that I am making), but at the end of the list so you can see the point I am getting at a bit better.
|
Proposition |
Quoted Prior |
Result |
|
|
A |
I will not win the lottery on Monday |
P(A) = 50% |
A is True |
|
B |
I will not win the lottery on Tuesday |
P(B) = 66% |
B is True |
|
C |
I will not win the lottery on Wednesday |
P(C) = 66% |
C is True |
|
D |
I will win the lottery on Thursday |
P(D) =66% |
D is False |
|
E |
I will not win the lottery on Friday |
P(E) = 75% |
E is True |
|
F |
I will not win the lottery on Saturday |
P(F) = 75% |
F is True |
|
G |
I will not win the lottery on Sunday |
P(G) = 75% |
G is True |
|
H |
I will win the lottery next Monday |
P(H) = 75% |
H is False |
|
… |
|
|
|
|
~A |
I will win the lottery on Monday |
P(~A) = 50% |
~A is False |
|
~B |
I will win the lottery on Tuesday |
P(~B) = 34% |
~B is False |
|
~C |
I will win the lottery on Wednesday |
P(~C) = 34% |
~C is False |
|
… |
|
|
|
Look carefully at this table. I've thrown in a particular mix of predictions that I will or will not win the lottery on certain days, in order to use my extreme certainty about the result to generate a particular mix of correct and incorrect predictions.
To make things even easier for me, I’m not even planning to buy any lottery tickets. Knowing this information, an honest estimate of the odds of me winning the lottery are astronomically small. The odds of winning the lottery are about 1 in 14 million (for the Canadian 6/49 lottery). I’d have to win by accident (one of my relatives buying me a lottery ticket?). Not only that, but since the lottery is only held on Wednesday and Saturday, that makes most of these scenarios even more implausible since the lottery corporation would have to hold the draw by mistake.
I am confident I could make at least 1 billion similar statements of this exact nature and get them all right, so my true confidence must be upwards of (100% - 0.0000001%).
If I assemble 50 of these types of strategically-underconfident predictions (and their 50 opposites) and plot them on a graph, here’s what I get:
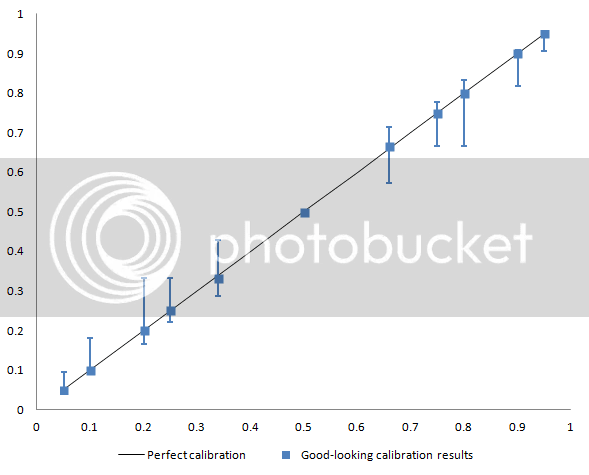
You can see that the problem with cheating doesn’t occur only at 50%. It can occur anywhere!
But here’s the trick: The log scoring algorithm rates me -0.37. If I had made the same 100 predictions all at my true confidence (99.9999999%), then my score would have been -0.000000001. A much better score! My attempt to cheat in order to make a pretty graph has only sabotaged my score.
By the way, what if I had gotten one of those wrong, and actually won the lottery one of those times without even buying a ticket? In that case my score is -0.41 (the wrong prediction had a probability of 1 in 10^9 which is about 1 in e^21, so it’s worth -21 points, but then that averages down to -0.41 due to the 49 correct predictions that are collectively worth a negligible fraction of a point).* Not terrible! The log scoring rule is pretty gentle about being very badly wrong sometimes, just as long as you aren’t infinitely wrong. However, if I had been a little less confident and said the chance of winning each time was only 1 in a million, rather than 1 in a billion, my score would have improved to -0.28, and if I had expressed only 98% confidence I would have scored -0.098, the best possible score for someone who is wrong one in every fifty times.
This has another important ramification: If you're going to honestly test your calibration, you shouldn't pick the predictions you'll make. It is easy to improve your score by throwing in a couple predictions that you are very certain about, like that you won't win the lottery, and by making few predictions that you are genuinely uncertain about. It is fairer to use a list of propositions that is generated by somebody else, and then pick your probabilities. Scott demonstrates his honesty by making public predictions about a mix of things he was genuinely uncertain about, but if he wanted to cook his way to a better score in the future, he would avoid making any predictions at the 50% category that he wasn't forced to.
Input and comments are welcome! Let me know what you think!
* This result surprises me enough that I would appreciate if someone in the comments can double-check it on their own. What is the proper score for being right 49 times with 1-1 in a billion certainty, but wrong once?
35 comments
Comments sorted by top scores.
comment by isionous · 2016-01-11T23:19:31.949Z · LW(p) · GW(p)
For the problem of how to phrase the 50% confidence predictions, it might be useful to use the more specific proposition (or one that has the smaller uninformative prior probability). For instance, if you have a race between 10 candidates, and you think candidate X has a 50% chance to win, you should phrase your prediction as "Candidate X will win the election" rather than "Candidate X will not win the election".
If you consistently phrase your 50% confidence predictions this way, then your prediction results tell you something useful. If your 50% confidence predictions come true only 10% of the time, then maybe your problem is overconfidence in your reasons to deviate from uninformed priors or overconfidence in concocting reasons to believe a certain hypothesis in the vast hypothesis space.
edit: The biggest weakness of this approach is what do you do when you're choosing between something like "this coin flip will come up heads" and "this coin flip will come up tails"? Or when it is unclear what an uninformed prior would even be.
Replies from: jbay↑ comment by jbay · 2016-01-12T07:52:38.161Z · LW(p) · GW(p)
"Candidate X will win the election with 50% probability" also implies the proposition "Candidate X will not win the election with 50% probability". If you propose one, you are automatically proposing both, and one will inevitably turn out true and the other false.
If you want to represent your full probability distribution over 10 candidates, you can still represent it as binary predictions. It will look something like this:
Candidate 1 will win the election: 50% probability
Candidate 2 will win the election: 10% probability
Candidate 3 will win the election: 10% probability
Candidate 4 will win the election: 10% probability
Candidate 5 will win the election: 10% probability
Candidate 6 will win the election: 2% probability
...
Candidate 1 will not win the election: 50% probability
Candidate 2 will not win the election: 90% probability
...
The method described in my post handles this situation perfectly well. All of your 50% predictions will (necessarily) come true 50% of the time, but you rack up a good calibration score if you do well on the rest of the predictions.
Replies from: isionous↑ comment by isionous · 2016-01-12T14:52:49.875Z · LW(p) · GW(p)
The method described in my post handles this situation perfectly well. All of your 50% predictions will (necessarily) come true 50% of the time, but you rack up a good calibration score if you do well on the rest of the predictions.
Seems like you're giving up trying to get useful information about yourself from the 50% confidence predictions. Do you agree?
Replies from: jbay↑ comment by jbay · 2016-01-12T17:46:49.577Z · LW(p) · GW(p)
Yes, but only because I don't agree that there was any useful information that could have been obtained in the first place.
Replies from: isionous↑ comment by isionous · 2016-01-12T18:55:36.486Z · LW(p) · GW(p)
Could you comment about how my strategy outlined above would not give useful information?
Replies from: jbay↑ comment by jbay · 2016-01-13T07:56:06.828Z · LW(p) · GW(p)
The calibration you get, by the way, will be better represented by the fact that if you assigned 50% to the candidate that lost, then you'll necessarily have assigned a very low probability to the candidate that won, and that will be the penalty that will tell you your calibration is wrong.
The problem is the definition of more specific. How do you define specific? The only consistent definition I can think of is that a proposition A is more specific than B if the prior probability of A is smaller than that of B. Do you have a way to consistently tell whether one phrasing of a proposition is more or less specific than another?
By that definition, if you have 10 candidates and no information to distinguish them, then the prior for any candidate to win is 10%. Then you can say "A: Candidate X will win" is more specific than "~A: Candidate X will not win", because P(A) = 10% and P(~A) = 90%.
Since the proposition "A with probability P" is the exact same claim as the proposition "~A with probability 1-P"; since they are the same proposition, there is no consistent definition of "specific" that will let one phrasing be more specific than the other when P = 50%.
"Candidate X will win the election" is only more specific than "Candidate X will not win the election" if you think that it's more likely that Candidate X will not win.
For example, by your standard, which of these claims feels more specific to you?
A: Trump will win the 2016 Republican nomination
B: One of either Scott Alexander or Eliezer Yudkowsky will win the 2016 Republican nomination
If you agree that "more specific" means "less probable", then B is a more specific claim than A, even though there are twice as many people to choose from in B.
Which of these phrasings is more specific?
C: The winner of the 2016 Republican nomination will be a current member of the Republican party (membership: 30.1 million)
~C: The winner of the 2016 Republican nomination will not be a current member of the Republican party (non-membership: 7.1 billion, or 289 million if you only count Americans).
The phrasing "C" certainly specifies a smaller number of people, but I think most people would agree that ~C is much less probable, since all of the top-polling candidates are party members. Which phrasing is more specific by your standard?
If you have 10 candidates, it might seem more specific to phrase a proposition as "Candidate X will win the election with probability 50%" than "Candidate X will not win the election with probability 50%". That intuition comes from the fact that an uninformed prior assigns them all 10% probability, so a claim that any individual one will win feels more specific in some way. But actually the specificity comes from the fact that if you claim 50% probability for one candidate when the uninformed prior was 10%, you must have access to some information about the candidates that allows you to be so confident. This will be properly captured by the log scoring rule; if you really do have such information, then you'll get a better score by claiming 50% probability for the one most likely to win rather than 10% for each.
Ultimately, the way you get information about your calibration is by seeing how well your full probability distribution about the odds of each candidate performs against reality. One will win, nine will lose, and the larger the probability mass you put on the winner, the better you do. Calibration is about seeing how well your beliefs score against reality; if your score depends on which of two logically equivalent phrasings you choose to express the same beliefs, there is some fundamental inconsistency in your scoring rule.
Replies from: isionous↑ comment by isionous · 2016-01-13T16:50:45.752Z · LW(p) · GW(p)
Thank you for your response.
Replies from: jbay↑ comment by jbay · 2016-01-14T07:22:26.436Z · LW(p) · GW(p)
You're welcome! And I'm sorry if I went a little overboard. I didn't mean it to sound confrontational.
Replies from: isionous↑ comment by isionous · 2016-01-14T14:48:36.598Z · LW(p) · GW(p)
sorry if I went a little overboard. I didn't mean it to sound confrontational.
You didn't. I appreciated your response. Gave me a lot to think about.
I still think there is some value to my strategy, especially if you don't want to (or it would be unfeasible) to give full probability distribution for related events (ex: all the possible outcomes of an election).
comment by SilentCal · 2016-01-06T18:59:02.513Z · LW(p) · GW(p)
The desire to look at calibration rather than prediction-score comes from the fact that calibration at least kind of seems like something you could fairly compare across different prediction sets. Comparing Scott's 2015 vs. 2014 prediction scores might just reflect which year had more predictable events. In theory it's also possible that one year's uncertainties are objectively harder to calibrate, but this seems less likely.
The best procedure is probably to just make a good-faith effort to choose predictions based on interest and predict as though maximizing prediction score. If one wanted to properly align incentives, one might try the following procedure: 1) Announce a set of things to predict, but not the predictions themselves 2) Have another party pledge to reward you (with cash or charity donation, probably) in proportion to your prediction score*, with a multiplier based on how hard they think your prediction topics are. 3) Make your predictions.
- There's a bit of a hurdle in that the domain is negative infinity to zero. One solution would be to set a maximum allowed confidence to make the range finite--for instance, if 99% is the maximum, the worst possible score would be ln(0.01) =~ -4.6, so a reward of (4.6 + score) would produce the right incentives.
comment by gwern · 2016-01-04T16:10:22.828Z · LW(p) · GW(p)
http://www.yudkowsky.net/rational/technical/
Replies from: jbaycomment by entirelyuseless · 2016-01-06T16:01:00.331Z · LW(p) · GW(p)
Lotteries frequently have secondary prizes. I have never bought a lottery ticket, but once I won $50 with a lottery ticket that someone else bought for me (which I did not ask for). If you include results like this as a win, your probability of under one in a billion of such a win may be overconfident.
Replies from: jbaycomment by TheMajor · 2016-01-05T18:55:30.347Z · LW(p) · GW(p)
The whole point of assigning 50% probability to a claim is that you literally have no idea whether or not it will happen. So of course including X or ~X in any statement is going to be arbitrary. That's what 50% means.
However, this is not solved by doubling up on your predictions, since now (by construction) your predictions are very dependent. I don't understand the controversy about Scott getting 0/3 on 50% predictions - it even happens to perfectly calibrated people 1/8 times, let alone real humans. If you have a long list of statements you are 50% certain about, you have literally no reason to not put one side of an issue instead of the other side on your prediction list. If, however, afterwards it turns out that significantly less than half of your (arbitrarily chosen) sides turned out to be wrong, you probably aren't very good at recognising when you are 50% confident (to make this more clear, imagine Scott had gotten 0/100 instead of 0/3 on his 50% predictions).
Replies from: jbay↑ comment by jbay · 2016-01-12T08:07:03.329Z · LW(p) · GW(p)
I don't understand why there is so much resistance to the idea that stating "X with probability P(X)" also implies "~X with probability 1-P(X)". The point of assigning probabilities to a prediction is that it represents your state of belief. Both statements uniquely specify the same state of belief, so to treat them differently based on which one you wrote down is irrational. Once you accept that these are the same statement, the conclusion in my post is inevitable, the mirror symmetry of the calibration curve becomes obvious, and given that symmetry, all lines must pass through the point (0.5,0.5).
Imagine the following conversation:
A: "I predict with 50% certainty that Trump will not win the nomination".
B: "So, you think there's a 50% chance that he will?"
A: "No, I didn't say that. I said there's a 50% chance that he won't."
B: "But you sort of did say it. You said the logically equivalent thing."
A: "I said the logically equivalent thing, yes, but I said one and I left the other unsaid."
B: "So if I believe there's only a 10% chance Trump will win, is there any doubt that I believe there's a 90% chance he won't?
A: "Of course, nobody would disagree, if you said there's a 10% chance Trump will win, then you also must believe that there's a 90% chance that he won't. Unless you think there's some probability that he both will and will not win, which is absurd."
B: "So if my state of belief that there's a 10% chance of A necessarily implies I also believe a 90% chance of ~A, then what is the difference between stating one or the other?"
A: "Well, everyone agrees that makes sense for 90% and 10% confidence. It's only for 50% confidence that the rules are different and it matters which one you don't say."
B: "What about for 50.000001% and 49.999999%?"
A: "Of course, naturally, that's just like 90% and 10%."
B: "So what's magic about 50%?"
Replies from: TheMajor↑ comment by TheMajor · 2016-01-12T22:34:35.072Z · LW(p) · GW(p)
I think it would be silly to resist to the idea that "X with probability P(X)" is equivalent to "~X with probability 1-P(X)". This statement is simply true.
However, it does not imply that prediction lists like this should include X and ~X as possible claims. To see this, let's consider person A who only lists "X, probability P", and person B who lists "X, probability P, and ~X, probability 1-P". Clearly these two are making the exact same claim about the future of the world. If we use an entropy rule to grade both of these people, we will find that no matter the outcome person B will have exactly twice the entropy (penalty) that person A has, so if we afterwards want to compare results of two people, only one of whom doubled up on the predictions, there is an easy way to do it (just double the penalty for those who didn't). So far so good: everything logically consistent, making the same claim about the world still easily lets you compare results aftewards. Nevertheless, there are two (related) things that need to be remarked, which is what I think all the controversy is over:
1) If, instead of the correct log weight rule, we use something stupid like a least-squares (or just eyeballing it per bracket), there is a significant difference between our people A and B above, precisely in their 50% predictions. For any probability assignment other than 50% the error rate at probability P and at 1-P are related and opposite, since getting a probability P prediction right (say, X), means getting a probability 1-P prediction wrong (~X). But for 50% these two get added up (with our stupid scoring rules) before being used to deduce calibration results. As a result we find that our doubler, player B, will always have exactly half of his 50% predictions right, which will score really well on stupid scoring rules (as an extreme example, to a naive scoring rule somebody who predicts 50% on every claim, regardless of logical constency, will seem to be perfectly calibrated).
2) Once we use a good scoring rule, i.e. the log rule, we can easily jump back and forth between people who double up on the claims and those who do not, as claimed/shown above.
In view of these two points I think that all of the magic is hidden in the scoring rule, not in the procedure used when recording the predictions. In other words, this doubling up does nothing useful. And since on calibration graphs people tend to think that getting half of your 50% predictions is really good, I say that the doubling version is actually slightly more misleading. The solution is clearly to use a proper scoring rule, and then you can do whatever you wish. But in reality it is best to not confuse your audience by artificially creating more dependencies between your predictions.
Replies from: jbay↑ comment by jbay · 2016-01-13T08:18:07.152Z · LW(p) · GW(p)
X and ~X will always receive the same score by both the logarithmic and least-squares scoring rules that I described in my post, although I certainly agree that the logarithm is a better measure. If you dispute that point, please provide a numerical example.
Because of the 1/N factor outside the sum, doubling predictions does not affect your calibration score (as it shouldn't!). This factor is necessary or your score would only ever get successively worse the more predictions you make, regardless of how good they are. Thus, including X and ~X in the enumeration neither hurts nor helps your calibration score (regardless of whether using the log or the least-squares rule).
I agree that eyeballing a calibration graph is no good either. That was precisely the point I made with the lottery ticket example in the main post, where the prediction score is lousy but the graph looks perfect.
I agree that there's no magic in the scoring rule. Doubling predictions is unnecessary for practical purposes; the reason I detail it here is to make a very important point about how calibration works in principle. This point needed to be made, in order to address the severe confusion that was apparent in the Slate Star Codex comment threads, because there was widespread disagreement about what exactly happens at 50%.
I think we both agree that there should be no controversy about this -- however, go ahead and read through the SSC thread to see how many absurd solutions were being proposed! That's what this post is responding to! What is made clear by enumerating both X and ~X in the bookkeeping of predictions -- a move for which there is no possible objection, because it is no different than the original prediction, nor is does it affecting a proper score in any way -- is that there is no reason to treat 50% as though it has special properties that are different than 50.01%, and there's certainly no reason to think that there is any significance to the choice between writing "X, with probability P" and "~X, with probability 1-P", even when P=50%.
If you still object to doubling the predictions, you can instead choose to take Scott's predictions and replace all X all with ~X, and all P with 1-P. Do you agree that this new set should be just as representative of Scott's calibration as his original prediction set?
comment by ChristianKl · 2016-01-04T11:44:26.960Z · LW(p) · GW(p)
Let's be naughty and look at it from the frequentist perspective. What does 50% Jeb Bush is the top polling Republican candidate mean?
It translates into 50% of the possible worlds have Jeb as the top polling Republican candidate. Does that mean the person making that statement says 50 out of 100 possible worlds have Jeb Bush as the top pooling Republican candidate but not 49 or 51 possible worlds?
Maybe it should be read as in between 45 and 54 possible world Jeb is top polling in some contests but being read as between 30 and 70 possible worlds in other contexts.
Replies from: jbay↑ comment by jbay · 2016-01-05T07:41:05.458Z · LW(p) · GW(p)
I'm really not so sure what a frequentist would think. How would they express "Jeb Bush will not be the top-polling Republican candidate" in the form of a repeated random experiment?
It seems to me more likely that a frequentist would object to applying probabilities to such a statement.
comment by Manfred · 2016-01-04T08:40:03.873Z · LW(p) · GW(p)
X and not-X should only be treated symmetrically when the predictor's information about them was symmetrical. I.e. rarely.
For example, suppose someone buys a lottery ticket each week and gives themselves a 50% chance of winning (after all, they could either win or not win,so that's 50/50). This person is known to not be well-calibrated.
Also, rather than squared error, it's probably best to use the log scoring rule (has decent information-theory motivation, does a better job at handling high and low probabilities).
Replies from: jbay, Luke_A_Somers↑ comment by jbay · 2016-01-04T16:56:30.701Z · LW(p) · GW(p)
I intend to update the article later to include log error. Thanks!
The lottery example though is a perfect reason to be careful about how much importance you place on calibration over accuracy.
Replies from: Manfred↑ comment by Manfred · 2016-01-04T20:33:56.676Z · LW(p) · GW(p)
Failing to assign the correct probability given your information is a failure both of accuracy and of calibration.
Suppose you take a test of many multiple choice questions (say, 5 choices), and for each question I elicit from you your probability of having the right answer. Accuracy is graded by your total score on the test. Calibration is graded by your log-score on the probabilities. Our lottery enthusiast might think they're 50% likely to have the right answer even when they are picking randomly - and because of this they will have a lower log score than someone who correctly thinks they have a 1/5 chance. These two people may have the same scores on the test, but they will have different scores on their ability to assign probabilities.
Replies from: jbay↑ comment by Luke_A_Somers · 2016-01-04T13:07:45.308Z · LW(p) · GW(p)
If you are really ignorant of whether you'd win or lose the lottery, you are uninformed, but you are not miscalibrated.
Replies from: Manfred↑ comment by Manfred · 2016-01-04T20:01:38.904Z · LW(p) · GW(p)
Pretend we are talking about an actual human being on earth, where all ticket-holders have plenty of information. Or even that they can look at the results of their past lottery tickets.
EDIT: I want to preempt a distinction you may be making, that I am not making. You might look at the above and say "oh, they may not be properly using information, but they are not miscalibrated." But suppose that the person acted as if hey had a 30% chance to hold the winning ticket instead of a 50% chance. Now even this post's method would agree that this person is wildly miscalibrated - but they're making the exact same mistake as before, only less. When I use the word "calibration," I mean something like "how impactful their mistakes are when using their information to assign probabilities." Someone who makes a bigger mistake in probability assignment is not better-calibrated. If this does not hold, then it is not very useful at all to talk about "calibration."
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2016-01-04T21:58:27.857Z · LW(p) · GW(p)
The exact issues you are talking about are those problems that come from being massively, wildly wrong. Not miscalibrated. Those are different problems.
Replies from: Manfred↑ comment by Manfred · 2016-01-04T23:35:18.098Z · LW(p) · GW(p)
Please help me understand how someone is not miscalibrated when things they assign a high probability actually occur with a low frequency. Under what definitions are you working?
Also:
Replies from: Luke_A_SomersFailing to assign the correct probability given your information is a failure both of accuracy and of calibration.
Suppose you take a test of many multiple choice questions (say, 5 choices each), and for each question I elicit from you your probability of having the right answer. Accuracy is graded by your total score on the test. Calibration is graded by your log-score on the probabilities. Our lottery enthusiast might think they're 50% likely to have the right answer even when they don't have any information distinguishing the answers - and because of this they will have a lower log score than someone who correctly thinks they have a 1/5 chance. These two people may have the same scores on the test, but they will have different scores on their ability to assign probabilities.
↑ comment by Luke_A_Somers · 2016-01-04T23:59:49.646Z · LW(p) · GW(p)
Please help me understand how someone is not miscalibrated when things they assign a high probability actually occur with a low frequency.
Because you're taking 'high' to mean 'larger than accurate but still not >50%', and as noted above in the post, normalization of probability means that the opposite answer will balance it. They are right and wrong at exactly the right rate. The symmetrized calibration curve will be exactly right.
But, they could be doing much better if they took that information into account.
As for the multiple-choice questions, your example is odd - "Calibration is graded by your log-score on the probabilities" - that's not what calibration means. By that metric, someone who is perfectly calibrated but 60% accurate would lose to someone who answers perfectly but is strongly underconfident and doesn't use probabilities more extreme than 75%.
The latter person is worse-calibrated than the first.
Replies from: Manfred↑ comment by Manfred · 2016-01-05T01:38:15.847Z · LW(p) · GW(p)
As for the multiple-choice questions, your example is odd - "Calibration is graded by your log-score on the probabilities" - that's not what calibration means. By that metric, someone who is perfectly calibrated but 60% accurate would lose to someone who answers perfectly but is strongly underconfident and doesn't use probabilities more extreme than 75%.
Yeah - the log probability score increases with better calibration, but it also increases with accuracy (there's a nice information-theoretic pattern to this). I agree that this is not a good property for a measurement of calibration for inter-personal comparison, you're right.
The latter person is worse-calibrated than the first.
Would you say that they're even worse calibrated if they answered perfectly but always said that their probability of being right was 50%, or would that make them perfectly-calibrated again?
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2016-01-05T16:12:57.466Z · LW(p) · GW(p)
50% may be 'perfectly' calibrated, but it's automatically perfectly calibrated and so doesn't really say anything.
From the way it was put together, though, we can say that would be worse-calibrated: look at their probabilities for the wrong answers, then either they put 50% on those too, in which case it's silly to say they were right (since they're ignoring even the exclusive structure of the question), or they gave miscalibrated probabilities on them.
Replies from: Manfred↑ comment by Manfred · 2016-01-05T17:14:34.018Z · LW(p) · GW(p)
Perhaps I have an explanation.
50% is special because its log (or similar) score is insensitive to whether you are right or wrong. Therefore if you vary how good the agent's information was (the accuracy), you cannot decrease their score if they answered 50% - it's 'perfect'.
On the other hand, if you keep how good the agent's information was fixed, and vary which probabilities the agent choses, 50% is nothing special - it's not any kind of special stopping place, and if you have any asymmetrical information you can get a better score by using a different probability.
When talking about calibration, you were asking "were the probability assignments falsified by the data?", in which case 50% is special because it's insensitive to changes in the data. But I think the much better question is "how well did the person use their information to assign probabilities?" - don't vary how good the person's information is, only vary how they assign probabilities. In this case, if someone gets a 70% score on a test but thinks they only got a 50%, they're poorly calibrated because they could use their information to get right answers, but they couldn't use it to get good probabilities, and should vary what probability they assign to answers that feel like the answers did on that test.