2-D Robustness
post by Vlad Mikulik (vlad_m) · 2019-08-30T20:27:34.432Z · LW · GW · 8 commentsContents
8 comments
This is a short note on a framing that was developed in collaboration with Joar Skalse, Chris van Merwijk and Evan Hubinger while working on Risks from Learned Optimization, but which did not find a natural place in the report.
Mesa-optimisation is a kind of robustness problem, in the following sense:
Since the mesa-optimiser is selected based on performance on the base objective, we expect it (once trained) to have a good policy on the training distribution. That is, we can expect the mesa-optimiser to act in a way that results in outcomes that we want, and to do so competently.
The place where we expect trouble is off-distribution. When the mesa-optimiser is placed in a new situation, I want to highlight two distinct failure modes; that is, outcomes which score poorly on the base objective:
- The mesa-optimiser fails to generalise in any way, and simply breaks, scoring poorly on the base objective.
- The mesa-optimiser robustly and competently achieves an objective that is different from the base objective, thereby scoring poorly on it.
Both of these are failures of robustness, but there is an important distinction to be made between them. In the first failure mode, the agent's capabilities fail to generalise. In the second, its capabilities generalise, but its objective does not. This second failure mode seems in general more dangerous: if an agent is sufficiently capable, it might, for example, hinder human attempts to shut it down (if its capabilities are robust enough to generalise to situations involving human attempts to shut it down). These failure modes map to what Paul Christiano calls benign and malign failures in Techniques for optimizing worst-case performance.
This distinction suggests a framing of robustness that we have found useful while writing our report: instead of treating robustness as a scalar quantity that measures the degree to which the system continues working off-distribution, we can view robustness as a 2-dimensional quantity. Its two axes are something like “capabilities” and “alignment”, and the failure modes at different points in the space look different.
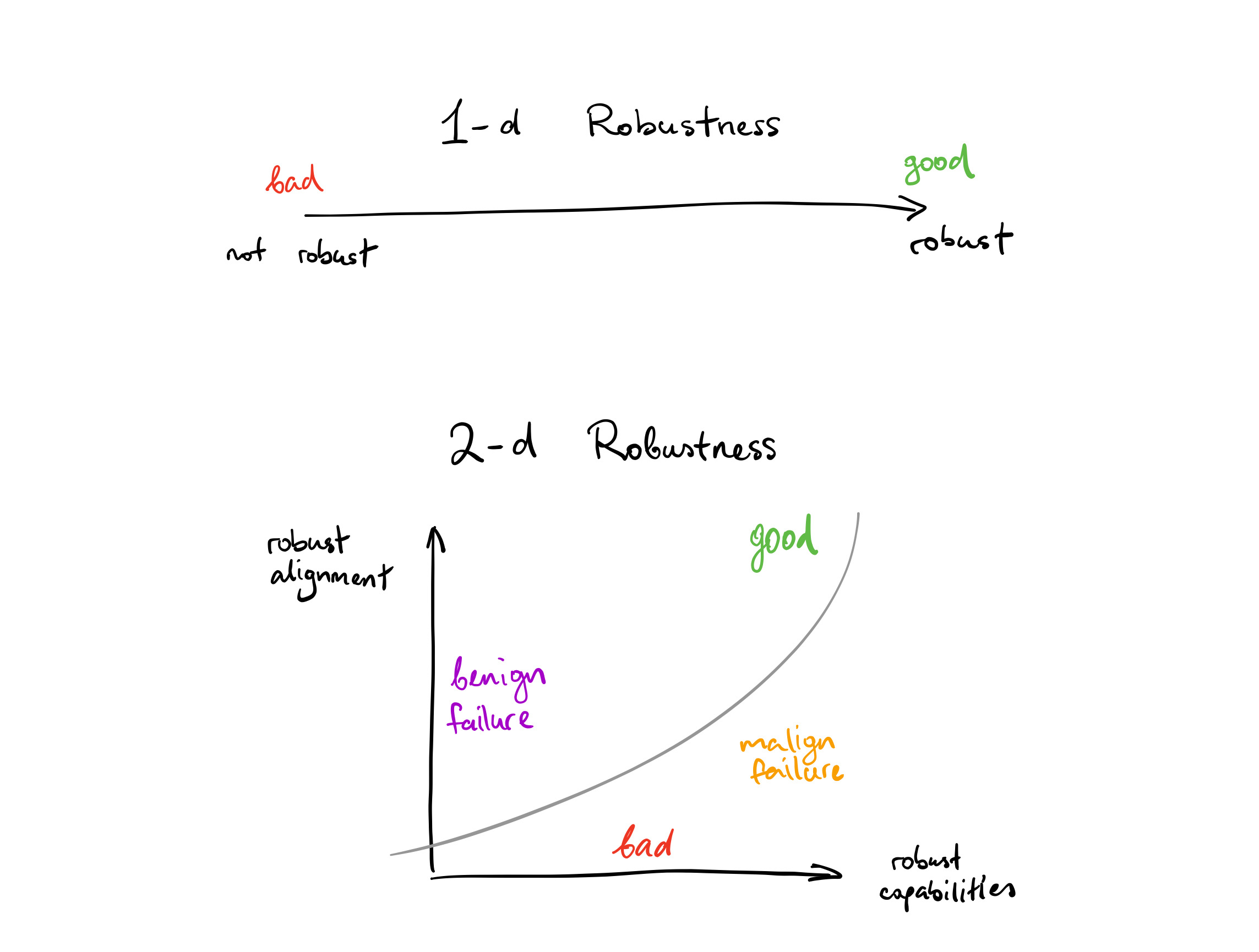
Unlike the 1-d picture, the 2-d picture suggests that more robustness is not always a good thing. In particular, robustness in capabilities is only good insofar is it is matched by robust alignment between the mesa-objective and the base objective. It may be the case that for some systems, we’d rather the system get totally confused in new situations than remain competent while pursuing the wrong objective.
Of course, there is a reason why we usually think of robustness as a scalar: one can define clear metrics for how well the system generalises, in terms of the difference between performance on the base objective on- and off-distribution. In contrast, 2-d robustness does not yet have an obvious way to ground its two axes in measurable quantities. Nevertheless, as an intuitive framing I find it quite compelling, and invite you to also think in these terms.
8 comments
Comments sorted by top scores.
comment by William_S · 2019-09-26T18:34:37.193Z · LW(p) · GW(p)
One way to try to measure capability robustness seperate from alignment robustness off of the training distribution of some system would be to:
- use an inverse reinforcement learning algorithm infer the reward function of the off-distribution behaviour
- train a new system to do as well on the reward function as the original system
- measure the number of training steps needed to reach this point for the new system.
This would let you make comparisons between different systems as to which was more capability robust.
Maybe there's a version that could train the new system using behavioural cloning, but it's less clear how you measure when you're as competent as the original agent (maybe using a discriminator?)
The reason for trying this is having a measure of competence that is less dependent on human judgement/closer to the systems's ontology and capabilities.
comment by zeshen · 2022-11-07T11:08:36.468Z · LW(p) · GW(p)
Are there any examples of capability robustness failures that aren't objective robustness failures?
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2022-11-15T16:26:18.719Z · LW(p) · GW(p)
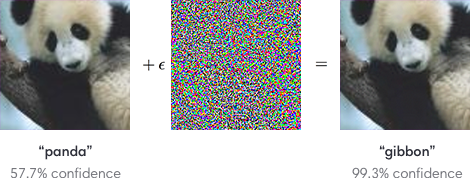
Yes. This image is only a classifier. No mesa optimizer here. So we have only a capability robustness problem
Replies from: zeshen↑ comment by zeshen · 2022-11-16T03:57:48.528Z · LW(p) · GW(p)
Thanks for the example, but why this is a capabilities robustness problem and not an objective robustness problem, if we think of the objective as 'classify pandas accurately'?
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-11-16T04:20:28.196Z · LW(p) · GW(p)
Insofar as it's not a capability problem, I think it's example of Goodharting and not inner misalignment/mesa optimization. The given objective ("minimize cross entropy loss") is maximized on distribution by incorporating non-robust features (and also gives no incentive to be fully robust to adversarial examples, so even non-robust features that don't really help with performance could still persist after training).
You might argue that there is no alignment without capabilities, since a sufficiently dumb model "can't know what you want". But I think you can come up with clean examples of capabilities failures if you look at, say, robots that use search to plan; they often do poorly according to the manually specified reward function on new domains because optimizing the reward is too hard for its search algorithm.
Of course, you can always argue that this is just an alignment failure one step up; if you perform Inverse Optimal Control on the behavior of the robot and derive a revealed reward function, you'll find that its . In other words, you can invoke the fact that for biased agents, there doesn't seem to be a super principled way of dividing up capabilities and preferences in the first place. I think this is probably going too far; there are still examples in practice (like the intractable search example) where thinking about it as a capabilities robustness issue is more natural than thinking about it as a objective problem.
↑ comment by zeshen · 2022-11-17T07:08:27.703Z · LW(p) · GW(p)
Thanks for the reply!
But I think you can come up with clean examples of capabilities failures if you look at, say, robots that use search to plan; they often do poorly according to the manually specified reward function on new domains because optimizing the reward is too hard for its search algorithm.
I'd be interested to see actual examples of this, if there are any. But also, how would this not be an objective robustness failure if we frame the objective as "maximize reward"?
if you perform Inverse Optimal Control on the behavior of the robot and derive a revealed reward function, you'll find that its
Do you mean to say that its reward function will be indistinguishable from its policy?
Interesting paper, thanks! If a policy cannot be decomposed into a planning algorithm and a reward function anyway, it's unclear to me why 2D-robustness would be a better framing of robustness than just 1D-robustness.
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-11-17T23:01:55.137Z · LW(p) · GW(p)
I'd be interested to see actual examples of this, if there are any.
I have some toy examples from a paper I worked on: https://proceedings.mlr.press/v144/jain21a
But I think this is a well known issue in robotics, because SOTA trajectory planning is often gradient-based (i.e. local). You definitely see this on any "hard" robotics task where initializing a halfway decent trajectory is hard. I've heard from Anca Dragan (my PhD advisor) that this happens with actual self driving car planners as well.
Do you mean to say that its reward function will be indistinguishable from its policy?
Oops, sorry, the answer got cutoff somehow. I meant to say that if you take a planner that's suboptimal, and look at the policy it outputs, and then rationalize that policy assuming that the planner is optimal, you'll get a reward function that is different from the reward function you put in. (Basically what the Armstrong + Mindermann paper says.)
Interesting paper, thanks! If a policy cannot be decomposed into a planning algorithm and a reward function anyway, it's unclear to me why 2D-robustness would be a better framing of robustness than just 1D-robustness.
Well, the paper doesn't show that you can't decompose it, but merely that the naive way of decomposing observed behavior into capabilities and objectives doesn't work without additional assumptions. But we have additional information all the time! People can tell when other people are failing due to incompetence via misalignment, for example. And in practice, we can often guess whether or not a failure is due to capabilities limitations or objective robustness failures, for example by doing experiments with fine-tuning or prompting.
The reason we care about 2D alignment is that capability failures seem much more benign than alignment failures. Besides the reasons given in the main post, we might also expect that capability failures will go away with scale, while alignment failures will become worse with scale. So knowing whether or not something is a capability robustness failure vs an alignment one can inform you as to the importance and neglectedness of research directions.
Replies from: zeshen