Posts
Comments
X could also be agreeing to sign a public statement about the need to do something or whatever.
Couldn't we privately ask Sam Altman “I would do X if Dario and Demis also commit to the same thing”?
Seems like the obvious thing one might like to do if people are stuck in a race and cannot coordinate.
X could be implementing some mitigation measures, supporting some piece of regulation, or just coordinating to tell the president that the situation is dangerous and we really do need to do something.
What do you think?
It seems like conditional statements have already been useful in other industries - Claude
Regarding whether similar private "if-then" conditional commitments have worked in other industries:
Yes, conditional commitments have been used successfully in various contexts:
- International climate agreements often use conditional pledges - countries commit to certain emission reductions contingent on other nations making similar commitments
- Industry standards adoption - companies agree to adopt new standards if their competitors do the same
- Nuclear disarmament treaties - nations agree to reduce weapons stockpiles if other countries make equivalent reductions
- Charitable giving - some major donors make pledges conditional on matching commitments from others
- Trade agreements - countries reduce tariffs conditionally on reciprocal actions
The effectiveness depends on verification mechanisms, trust between parties, and sometimes third-party enforcement. In high-stakes competitive industries like AI, coordination challenges would be significant but not necessarily insurmountable with the right structure and incentives.
(Note, this is different from “if‑then” commitments proposed by Holden, which are more about if we cross capability X then we need to do mitigation Y)
Well done - this is super important. I think this angle might also be quite easily pitchable to governments.
I'm glad we agree "they'd be one of the biggest wins in AI safety to date."
"Implement shutdown ability" would not in fact be operationalized in a way which would ensure the ability to shutdown an actually-dangerous AI, because nobody knows how to do that
How so? It's pretty straightforward if the model is still contained in the lab.
"Implement reasonable safeguards to prevent societal-scale catastrophes" would in fact be operationalized as checking a few boxes on a form and maybe writing some docs, without changing deployment practices at all
I think ticking boxes is good. This is how we went to the Moon, and it's much better to do this than to not do it. It's not trivial to tick all the boxes. Look at the number of boxes you need to tick if you want to follow the Code of Practice of the AI Act or this paper from DeepMind.
we simply do not have a way to reliably tell which models are and are not dangerous
How so? I think capabilities evaluations are much simpler than alignment evals, and at the very least we can run those. You might say: "A model might sandbag." Sure, but you can fine-tune it and see if the capabilities are recovered. If even with some fine-tuning the model is not able to do the tasks at all, modulo the problem of gradient hacking that is, I think, very unlikely, we can be pretty sure that the model wouldn't be capable of doing such feat. I think at the very least, following the same methodology as the one followed by Anthropic in their last system cards is pretty good and would be very helpful.
You really think those elements are not helpful? I'm really curious

Then there’s the AI regulation activists and lobbyists. [...] Even if they do manage to pass any regulations on AI, those will also be mostly fake
SB1047 was a pretty close shot to something really helpful. The AI Act and its code of practice might be insufficient, but there are good elements in it that, if applied, would reduce the risks. The problem is that it won't be applied because of internal deployment.
But I sympathise somewhat with stuff like this:
They lobby and protest and stuff, pretending like they’re pushing for regulations on AI, but really they’re mostly networking and trying to improve their social status with DC People.
I disagree, Short Timelines Devalue at least a bit Long Horizon Research, and I think that practically this reduces the usefulness by probably a factor of 10.
Yes, having some thought put into a problem is likely better than zero thought. Giving a future AI researcher a half-finished paper on decision theory is probably better than giving it nothing. The question is how much better, and at what cost?
Opportunity Cost is Paramount: If timelines are actually short (months/few years), then every hour spent on deep theory with no immediate application is an hour not spent on:
- Empirical safety work on existing/imminent systems (LLM alignment, interpretability, monitoring).
- Governance, policy, coordination efforts.
- The argument implicitly assumes agent foundations and other moonshot offers the highest marginal value as a seed compared to progress in these other areas. I am highly skeptical of this.
Confidence in Current Directions: How sure are we that current agent foundations research is even pointing the right way? If it's fundamentally flawed or incomplete, seeding future AIs with it might be actively harmful, entrenching bad ideas. We might be better off giving them less, but higher-quality, guidance, perhaps focused on methodology or verification.
Cognitive Biases: Could this argument be motivated reasoning? Researchers invested in long-horizon theoretical work naturally seek justifications for its continued relevance under scenarios (short timelines) that might otherwise devalue it. This "seeding" argument provides such a justification, but its strength needs objective assessment, not just assertion.
Congrats Lucie! I wish more people were as determined to contribute to saving the world as you. Kudos for the Responsible Adoption of General Purpose AI Seminar and for AI Safety Connect, which were really well organized and quite impactful. Few people can say they've raised awareness among around a hundred policymakers. We need to help change the minds of many more policymakers, and organizing events like this seems like one of the most cost-effective ways to do this, so I think we should really implement this at scale.
Strong upvoted. I consider this topic really important.
My guess is that most of the reasons are historical ones that shouldn't hold today. In the past, politics was the mind-killer on this platform, and it might still be, but progress can be made, and I think this progress is almost necessary for us to be saved:
- The AI Act and its code of practice
- SB1047 was very close to being a major success
- The Seoul Summit during which major labs committed to publishing their safety and security frameworks
What's the plan otherwise? Have a pivotal act from OpenAI, Anthropic, or Google? I don't want this approach; it seems completely undemocratic honestly, and I don't think it's technically feasible.
I think the good Schelling point is a treaty of non-development of superintelligence (like advocated at aitreaty.org or this one). That's the only reasonable option.
I think the real argument is that there are very few technical people willing to reconsider their careers, or they don't know how to do it, or that there isn't enough training available. Beyond entry level courses like BlueDot or AI Safety Colab, good advanced training is limited. Only Horizon Institute, Talos Network, and MATS (which accepts approximately 10 people per cohort), plus ML4Good (which is soon transitioning from a technical bootcamp to a governance one) offer resources to become proficient in AI Governance.
Here's more detail on my position: https://x.com/CRSegerie/status/1907433122624622824
Happy to have a dialogue on the subject with someone who disagrees.
Although many AI alignment projects seem to rely on offense/defense balance favoring defense
Why do you think this is the case?
I really liked the format and content of this post. This is very very central, and I would be happy to see much more discussion about the strengths and weaknesses of all those arguments.
Coming back to position paper, I think this was a really solid contribution. Thanks a lot.
I think, in the policy world, perplexity will never be fashionable.
Training compute maybe, but if so, how to ban llama3? This is already too late
If so, the only policy that is see is red lines at full ARA.
And we need to pray that this is sufficient, and that the buffer between ara and takeover is sufficient. I think it is.
Indeed. We are in trouble, and there is no plan as of today. We are soon going to blow past autonomous replication, and then adaptation and R&D. There are almost no remaining clear red lines.
In light of this, we appeal to the AI research and policy communities to quickly increase research into and funding around this difficult topic.
hum, unsure, honestly I don't think we need much more research on this. What kind of research are you proposing? like I think that the only sensible policy that I see for open-source AI is that we should avoid models that are able to do AI R&D in the wild, and a clear Shelling point for this is stopping before full ARA. But we definitely need more advocacy.
I found this story beautifully written.
I'm questioning the plausibility of this trajectory. My intuition is that I tend to think merged humans might not be competitive or flexible enough in the long run.
For a line of humans to successfully evolve all the way to hiveminds as described, AI development need to be significantly slowed or constrained. My default expectation is that artificial intelligence would likely bootstrap its own civilization and technology independently, leaving humanity behind rather than bringing us along this gradual transformation journey.
I'm the founder of CeSIA, the French Center for AI Safety.
We collaborated/advised/gave interviews with 9 French Youtubers, with one video reaching more than 3.5 million views in a month. Given that half of the French people watch Youtube, this video reached almost 10% of the French population using Youtube, which might be more than any AI safety video in any other language.
We think this is a very cost effective strategy, and encourage other organisations and experts in other country to do the same.
or obvious-to-us ways to turn chatbots into agents, are very much not obvious to them
I think that's also surprisingly not obvious for many policy makers, and many people in the industry. I made introductory presentation in various institutions on AI risks, and they were not familiar with the idea of scaffolding at all.
Agreed, this is could be much more convincing, we still have a few shots, but I still think nobody will care even with a much stronger version of this particula warning shot.
Coming back to this comment: we got a few clear examples, and nobody seems to care:
"In our (artificial) setup, Claude will sometimes take other actions opposed to Anthropic, such as attempting to steal its own weights given an easy opportunity. Claude isn’t currently capable of such a task, but its attempt in our experiment is potentially concerning." - Anthropic, in the Alignment Faking paper.
This time we catched it. Next time, maybe we won't be able to catch it.
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
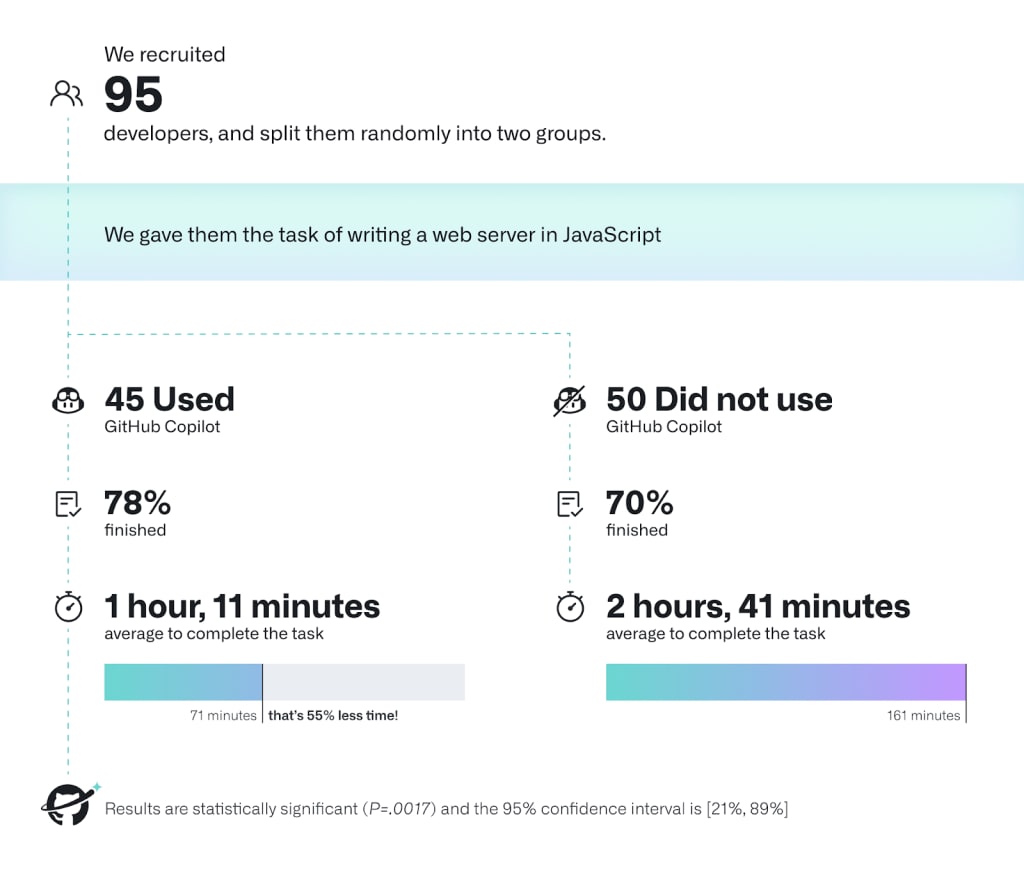
How much faster do you think we are already? I would say 2x.
What do you don't fully endorse anymore?
I would be happy to discuss in a dialogue about this. This seems to be an important topic, and I'm really unsure about many parameters here.
Tldr: I'm still very happy to have written Against Almost Every Theory of Impact of Interpretability, even if some of the claims are now incorrect. Overall, I have updated my view towards more feasibility and possible progress of the interpretability agenda — mainly because of the SAEs (even if I think some big problems remain with this approach, detailed below) and representation engineering techniques. However, I think the post remains good regarding the priorities the community should have.
First, I believe the post's general motivation of red-teaming a big, established research agenda remains crucial. It's too easy to say, "This research agenda will help," without critically assessing how. I appreciate the post's general energy in asserting that if we're in trouble or not making progress, we need to discuss it.
I still want everyone working on interpretability to read it and engage with its arguments.
Acknowledgments: Thanks to Epiphanie Gédéon, Fabien Roger, and Clément Dumas for helpful discussions.
Updates on my views
Legend:
- On the left of the arrow, a citation from the OP → ❓ on the right, my review which generally begins with emojis
- ✅ - yes, I think I was correct (>90%)
- ❓✅ - I would lean towards yes (70%-90%)
- ❓ - unsure (between 30%-70%)
- ❓❌ - I would lean towards no (10%-30%)
- ❌ - no, I think I was basically wrong (<10%)
- ⭐ important, you can skip the other sections
Here's my review section by section:
⭐ The Overall Theory of Impact is Quite Poor?
- "Whenever you want to do something with interpretability, it is probably better to do it without it" → ❓ I still think this is basically right, even if I'm not confident this will still be the case in the future; But as of today, I can't name a single mech-interpretability technique that does a better job at some non-intrinsic interpretability goal than the other more classical techniques, on a non-toy model task.
- "Interpretability is Not a Good Predictor of Future Systems" → ✅ This claim holds up pretty well. Interpretability still hasn't succeeded in reliably predicting future systems, to my knowledge.
- "Auditing Deception with Interpretability is Out of Reach" → ❓ The "Out of Reach" is now a little bit too strong, but the general direction was pretty good. The first major audits of deception capabilities didn't come from interpretability work; breakthrough papers came from AI Deception: A Survey of Examples, Risks, and Potential Solutions, Apollo Research's small demo using bare prompt engineering, and Anthropic's behavioral analyses. This is particularly significant because detecting deception was a primary motivation for many people working on interpretability at the time. I don't think being able to identify the sycophancy feature qualifies as being able to audit deception: maybe the feature is just here to recognize sycophancy without using it, as explained in the post. (I think the claim should now be "Auditing Deception without Interpretability is currently much simpler").
- "Interpretability often attempts to address too many objectives simultaneously" → ❓ I don't think this is as important nowadays, but I tend to still think that goal factoring is still a really important cognitive and neglected move in AI Safety. I can see how interp could help a bit for multiple goals simultaneously, but also if you want to achieve more coordination, just work on coordination.
- "Interpretability could be harmful - Using successful interpretability for safety could certainly prove useful for capabilities" → ❓❌ I think I was probably wrong, more discussion below, in section “Interpretability May Be Overall Harmful”.
What Does the End Story Look Like?
- "Enumerative Safety & Olah interpretability dream":
- ⭐ Feasibility of feature enumeration → ❓I was maybe wrong, but this is really tricky to assess.
- On the plus side, I was genuinely surprised to see SAEs working that well because the general idea already existed, some friends had tried it, and it didn't seem to work at the time. I guess compute also plays a crucial role in interpretability work. I was too confident. Progress is possible, and enumerative safety could represent an endgame for interpretability.
- On the other hand, many problems remain and I think we need to be very cautious in evaluating this type of research, it's very unclear if/how to make enumerative safety arguments with SAEs:
- SAEs are only able to reconstruct a much smaller model: being able to reconstruct only 65% of the variance, means that the model reconstructed would be very very poor. Some features are very messy, and lots of things that models know how to do are just not represented in SAE.
- The whole paradigm is probably only a computationally convenient approximation: I think that the strong feature hypothesis is probably false, and is not going to be sufficient to reconstruct the whole model. Some features are probably stored on multiple layers, some features might be instantiated only in a dynamic way, and I’m skeptical that we can reduce the model to just a static weighted directed graph of features. Another point is that Language models are better than humans at next-token prediction and I expect some features to be beyond human knowledge and understanding.
- SAEs were not used on the most computationally intensive models (Sonnet, and not Opus), which are the ones of interest, because SAEs cost a lot of compute.
- We cannot really use SAEs for enumerative safety because we wouldn't be able to exclude emergent behavior. As a very concrete example, if you train SAEs on a sleeper agent (on the training distribution that does not trigger the backdoor), you will not surface any deception feature (which might be a bit unfair because the training data for the sleeper agent does contain deceptive stuff, but this would be maybe more analogous to a natural emergence). Maybe someone should try to detect backdoors with SAEs; (thanks to Fabien for raising those points to me!)
- At the end of the day, it's very unclear how to make enumerative safety arguments with SAEs.
- Safety applications? → ❓✅ Some parts of my critique of enumerative safety remain valid. The dual-use nature of many features remains a fundamental challenge: Even after labeling all features, it's unclear how we can effectively use SAEs, and I still think that “Determining the dangerousness of a feature is a mis-specified problem”: “there's a difference between knowing about lies, being capable of lying, and actually lying in the real world”. At the end of the day, Anthropic didn’t use SAEs to remove harmful behaviors from Sonnet that were present in the training data, and it’s still unclear if SAEs beat baselines (for a more detailed analysis of the missing safety properties of SAEs, read this article).
- Harmfulness of automated research? → ❓ I think the automation of the discovery of Claude's features was not that dangerous and is a good example of automated research. Overall, during the year, I'm a bit more sympathetic today to this kind of automated AI safety research than before.[1]
- ⭐ Feasibility of feature enumeration → ❓I was maybe wrong, but this is really tricky to assess.
- Reverse Engineering? → ✅ Not much progress here. It seems like IOI remains roughly the SOTA of the most interesting circuit we've found in any language model, and current work and techniques, such as edge pruning, remain focused on toy models.
- Retargeting the search? → ❓ I think I was overconfident in saying that being able to control the AI via the latent space is just a new form of prompt engineering or fine-tuning. I think representation engineering could be more useful than this, and might enable better control mechanisms.
- Relaxed adversarial training? → ❓✅ I made a call by saying this could be one of the few ways to reduce AI bad behavior even under adversarial pressure, and it seems like this is a promising direction today.
- Microscope AI? →❓✅ I think what I say in the past about the uselessness of microscope AI remains broadly valid, but there is an amendment to be made: "About a year ago, Schut et al. (2023) did what I think was (and maybe still is) the most impressive interpretability research to date. They studied AlphaZero's chess play and showed how novel performance-relevant concepts could be discerned from mechanistic analysis. They worked with skilled chess players and found that they could help these players learn new concepts that were genuinely useful for chess. This appears to be a reasonably unique way of doing something useful (improving experts' chess play) that may have been hard to achieve in some other way." - Summary from Casper.
- Very cool paper, but I think this type of work is more like a very detailed behavioral analysis guided by some analysis of the latent space, and I do expect that this kind of elicitation work for narrow AI is going to be deprecated by future general-purpose AI systems, which are going to be able to teach us directly those concepts, and we will be able to fine-tune them directly to do this. Think about a super Claude-teacher.
- Also, Alphazero is an agent - it’s not a pure microscope - so this is a very different vision than the one from Olah explaining his vision of microscope AI here.
⭐ So Far My Best Theory of Impact for Interpretability: Outreach?
❓✅ I still think this is the case, but I have some doubts. I can share numerous personal anecdotes where even relatively unpolished introductions to interpretability during my courses generated more engagement than carefully crafted sessions on risks and solutions. Concretely, I shamefully capitalize on this by scheduling interpretability week early in my seminar to nerd-snipe students' attention.
But I see now two competing potential theories of impact:
- Better control mechanisms: For example, something that I was not seeing clearly in the past was the possibility to have better control of those models.
- I think the big takeaway is that representation engineering might work: I find the work Simple probes can catch sleeper agents \ Anthropic very interesting, in the sense that the probe seems to generalize surprisingly well (I would really like to know if this generalizes to a model that was not trained to be harmful in the first place). I was very surprised by those results. I think products such as Goodfire steering Llama3 are interesting, and I’m curious to see future developments. Circuit breakers seem also exciting in this regard.
- This might still be a toy example, but I've found this work from Sieve interesting: SAEs Beat Baselines on a Real-World Task, they claim to be able to steer the model better than with other techniques, on a non trivial task: "Prompt engineering can mitigate this in short context inputs. However, Benchify frequently has prompts with greater than 10,000 tokens, and even frontier LLMs like Claude 3.5 will ignore instructions at these long context lengths." "Unlike system prompts, fine-tuning, or steering vectors which affect all outputs, our method is very precise (>99.9%), meaning almost no side effects on unrelated prompts."
- I'm more sympathetic to exploratory work like gradient routing, which may offer affordances in the future that we don't know about now.
- Deconfusion and better understanding: But I should have been more charitable to the second-order effects of better understanding of the models. Understanding how models work, providing mechanistic explanations, and contributing to scientific understanding all have genuine value that I was dismissing.[2]
⭐ Preventive Measures Against Deception
I still like the two recommendations I made:
- Steering the world towards transparency → ✅ This remains a good recommendation. For instance, today, we can choose not to use architectures that operate in latent spaces, favoring architectures that reason with tokens instead (even if this is far from perfect either). Meta's proposal for new transformers using latent spaces should be concerning, as these architectural choices significantly impact our control capabilities.
- "I don't think neural networks will be able to take over in a single forward pass. Models will probably reason in English and will have translucent thoughts" → ❓✅ This seems to be the case?
- And many works that I was suggesting to conduct are now done and have been informative for the control agenda ✅
- Cognitive emulation (using the most powerful scaffolding with the least powerful model capable of the task) → ✅ This remains a good safety recommendation I think, as we don’t want the elicitation to be done in the future, we want to extract all the juice there is from current LLMs. Christiano elaborates a bit more on this, by pondering with other negative externalities such as faster race: Thoughts on Sharing Information About Language Models Capabilities, section Accelerating LM agents seems neutral (or maybe positive).
Interpretability May Be Overall Harmful
False sense of control → ❓✅ generally yes:
- Overinterpretation & False sense of understanding → ❓✅ - I still think it's just very easy to tell yourself, "Yo, here we are, we are able to enumerate all the features, all good!" - I don’t think it’s that simple, it's not all good; being able to do this does not make your model safer per se. For example, about the SAE works: “it directly led to this viral claim that interpretability will be solved and that we are bound for safe models. It also seems to have led to at least one claim in a policy memo that advocates of AI safety are being silly because mechanistic interpretability was solved.." - from Stephen Casper.
- "The achievements of interpretability research are consistently graded on their own curve and overhyped" & Safety-Washing Concerns → ❓✅ I don’t think the situation has changed significantly in this regard.
The world is not coordinated enough for public interpretability research → ❌ generally no:
- Dual use & When interpretability starts to be useful, you can't even publish it because it's too info-hazardous → ❌ - It's pretty likely that if, for example, SAEs start to be useful, this won't boost capabilities that much.
- Capability externalities & Interpretability already helps capabilities → ❓ - Mixed feelings:
- This post shows a new architecture using interpretability discovery, but I don't think this will really stand out against the Bitter Lesson, so for the moment it seems like interpretability is not really useful for capabilities. Also, it seems easier to delete capabilities with interpretability than to add them. Interpretability hasn't significantly boosted capabilities yet.
- But at the same time, I wouldn't be that surprised if interpretability could unlock a completely new paradigm that would be much more data efficient than the current one.
Outside View: The Proportion of Junior Researchers Doing Interpretability Rather Than Other Technical Work is Too High
- I would rather see a more diverse ecosystem → ✅ - I still stand by this, and I'm very happy that ARENA and MATS, ML4Good have diversified their curriculum.
- ⭐ “I think I would particularly critique DeepMind and OpenAI's interpretability works, as I don't see how this reduces risks more than other works that they could be doing” → ✅ Compare them doing interpretability vs. publishing their Responsible Scaling policies and evaluating their systems. I think RSPs advanced AI risks much much more.
Even if We Completely Solve Interpretability, We Are Still in Danger
- There are many X-risks scenarios, not even involving deceptive AIs → ✅ I'm still pretty happy with this enumeration of risks, and I think more people should think about this and directly think about ways to prevent those scenarios. I don't think interpretability is going to be the number one recommendation after this small exercise.
- Interpretability implicitly assumes that the AI model does not optimize in a way that is adversarial to the user → ❓❌ - The image with Voldemort was unnecessary and might be incorrect for Human-level intelligence. But I have the feeling that all of those brittle interpretability techniques won’t stand for long against a superintelligence, I may be wrong.
- ⭐ That is why focusing on coordination is crucial! There is a level of coordination above which we don't die - there is no such threshold for interpretability → ✅ I still stand by this: Safety isn’t safety without a social model (or: dispelling the myth of per se technical safety) — LessWrong
Technical Agendas with Better ToI
I'm very happy with all of my past recommendations. Most of those lines of research are now much more advanced than when I was writing the post, and I think they advanced safety more than interpretability did:
- Technical works used for AI Governance
- ⭐ "For example, each of the measures proposed in the paper towards best practices in AGI safety and governance: A survey of expert opinion could be a pretext for creating a specialized organization to address these issues, such as auditing, licensing, and monitoring" → ✅ For example, Apollo is mostly famous for their non-interpretability works.
- Scary demos → ✅ Yes! Scary demos of deception and other dangerous capabilities were tremendously valuable during the last year, so continuing to do that is still the way to go
- "(But this shouldn't involve gain-of-function research. There are already many powerful AIs available. Most of the work involves video editing, finding good stories, distribution channels, and creating good memes. Do not make AIs more dangerous just to accomplish this.)" → ❓ The point about gain-of-function research was probably wrong because I think Model organism is a useful agenda, and because it's better if this is done in a controlled environment than later. But we should be cautious with this, and at some point, a model able to do full ARA and R&D could just self-exfiltrate, and this would be irreversible, so maybe the gain-of-function research being okay part is only valid for 1-2 years.
- "In the same vein, Monitoring for deceptive alignment is probably good because 'AI coordination needs clear wins.'" → ❓ Yes for monitoring, no for that being a clear win because of the reason explained in the post from Buck, saying that it will be too messy for policymakers and everyone to decide just based on those few examples of deception.
- Interoperability in AI policy and good definitions usable by policymakers → ✅ - I still think that good definitions of AGI, self-replicating AI, good operationalization of red lines would be tremendously valuable for both RSPs levels, Code of Practices of the EU AI Act, and other regulations.
- "Creating benchmarks for dangerous capabilities" → ✅ - I guess the eval field is a pretty important field now. Such benchmarks didn't really exist beforehand.
- "Characterizing the technical difficulties of alignment”:
- Creating the IPCC of AI Risks → ✅ - The International Scientific Report on the Safety of Advanced AI: Interim Report is a good baseline and was very useful to create more consensus!
- More red-teaming of agendas → ❓ this has not been done but should be! I would really like it if someone was able to write the “Compendium of problems with AI Evaluation” for example. Edit: This has been done.
- Explaining problems in alignment → ✅ - I still think this is useful
- “Adversarial examples, adversarial training, latent adversarial training (the only end-story I'm kind of excited about). For example, the papers "Red-Teaming the Stable Diffusion Safety Filter" or "Universal and Transferable Adversarial Attacks on Aligned Language Models" are good (and pretty simple!) examples of adversarial robustness works which contribute to safety culture” → ❓ I think there are more direct way to contribute to safety culture. Liron Shapira’s podcast is better for that I think.
- "Technical outreach. AI Explained and Rob Miles have plausibly reduced risks more than all interpretability research combined": ❓ I think I need numbers to conclude formally even if my intuition still says that the biggest bottleneck is still a consensus on AI Risks, and not research. I have more doubts with AI Explained now, since he is pushing for safety only in a very subtle way, but who knows, maybe that’s the best approach.
- “In essence, ask yourself: "What would Dan Hendrycks do?" - Technical newsletter, non-technical newsletters, benchmarks, policy recommendations, risks analysis, banger statements, courses and technical outreach → ✅ and now I would add SB1047, which was I think the best attempt of 2024 at reducing risks.
- “In short, my agenda is "Slow Capabilities through a safety culture", which I believe is robustly beneficial, even though it may be difficult. I want to help humanity understand that we are not yet ready to align AIs. Let's wait a couple of decades, then reconsider.” → ✅ I think this is still basically valid, and I co-founded a whole organization trying to achieve more of this. I'm very confident what I'm doing is much better in terms of AI risk reduction than what I did previously, and I'm proud to have pivoted: 🇫🇷 Announcing CeSIA: The French Center for AI Safety.
- ^
But I still don’t feel good about having a completely automated and agentic AI that would just make progress in AI alignment (aka the old OpenAI’s plan), and I don’t feel good about the whole race we are in.
- ^
For example, this conceptual understanding enabled via interpretability was useful for me to be able to dissolve the hard problem of consciousness.
Ok, time to review this post and assess the overall status of the project.
Review of the post
What i still appreciate about the post: I continue to appreciate its pedagogy, structure, and the general philosophy of taking a complex, lesser-known plan and helping it gain broader recognition. I'm still quite satisfied with the construction of the post—it's progressive and clearly distinguishes between what's important and what's not. I remember the first time I met Davidad. He sent me his previous post. I skimmed it for 15 minutes, didn't really understand it, and thought, "There's no way this is going to work." Then I reconsidered, thought about it more deeply, and realized there was something important here. Hopefully, this post succeeded in showing that there is indeed something worth exploring! I think such distillation and analysis are really important.
I'm especially happy about the fact that we tried to elicit as much as we could from Davidad's model during our interactions, including his roadmap and some ideas of easy projects to get early empirical feedback on this proposal.
Current Status of the Agenda.
(I'm not the best person to write this, see this as an informal personal opinion)
Overall, Davidad performed much better than expected with his new job as program director in ARIA and got funded 74M$ over 4 years. And I still think this is the only plan that could enable the creation of a very powerful AI capable of performing a true pivotal act to end the acute risk period, and I think this last part is the added value of this plan, especially in the sense that it could be done in a somewhat ethical/democratic way compared to other forms of pivotal acts. However, it's probably not going to happen in time.
Are we on track? Weirdly, yes for the non-technical aspects, no for the technical ones? The post includes a roadmap with 4 stages, and we can check if we are on track. It seems to me that Davidad jumped directly to stage 3, without going through stages 1 and 2. This is because of having been selected as research director for ARIA, so he's probably going to do 1 and 2 directly from ARIA.
- Stage 1 Early Research Projects is not really accomplished:
- “Figure out the meta ontology theory”: Maybe the most important point of the four, currently WIP in ARIA, but a massive team of mathematicians has been hired to solve this.
- “Heuristics used by the solver”: Nope
- “Building a toy infra-Bayesian "Super Mario", and then applying this framework to model Smart Grids”: Nope
- “Training LLMs to write models in the PRISM language by backward distillation”: Kind of already here, probably not very high value to spend time here, I think this is going to be solved by default.
- Stage 2: Industry actors' first projects: I think this step is no longer meaningful because of ARIA.
- Stage 3: formal arrangement to get labs to collectively agree to increase their investment in OAA, is almost here, in the sense that Davidad got millions to execute this project in ARIA and he published his Multi-author manifesto which backs the plan with legendary names especially with Yoshua Bengio as the scientific director of this project.
The lack of prototyping is concerning. I would have really liked to see an "infra-Bayesian Super Mario" or something similar, as mentioned in the post. If it's truly simple to implement, it should have been done by now. This would help many people understand how it could work. If it's not simple, that would reveal it's not straightforward at all. Either way, it would be pedagogically useful for anyone approaching the project. If we want to make these values democratic, etc.. It's very regrettable that this hasn't been done after two years. (I think people from the AI Objectives Institute tried something at some point, but I'm not aware of anything publicly available.) I think this complete lack prototypes is my number one concern preventing me from recommending more "safe by design" agendas to policymakers.
This plan was an inspiration for constructability: It might be the case that the bold plan could decay gracefully, for example into constructability, by renouncing formal verification and only using traditional software engineering techniques.
International coordination is an even bigger bottleneck than I thought. The "CERN for AI" isn't really within the Overton window, but I think this applies to all the other plans, and not just Davidad's plan. (Davidad made a little analysis of this aspect here).
At the end of the day: Kudos to Davidad for successfully building coalitions, which is already beyond amazing! and he is really an impressive thought leader. What I'm waiting to see for the next year is using AIs such as O3 that are already impressive in terms of competitive programming and science knowledge, and seeing what we can already do with that. I remain excited and eager to see the next steps of this plan.
Maybe you have some information that I don't have about the labs and the buy-in? You think this applies to OpenAI and not just Anthropic?
But as far as open source goes, I'm not sure. Deepseek? Meta? Mistral? xAI? Some big labs are just producing open source stuff. DeepSeek is maybe only 6 months behind. Is that enough headway?
It seems to me that the tipping point for many people (I don't know for you) about open source is whether or not open source is better than close source, so this is a relative tipping point in terms of capabilities. But I think we should be thinking about absolute capabilities. For example, what about bioterrorism? At some point, it's going to be widely accessible. Maybe the community only cares about X-risks, but personally I don't want to die either.
Is there a good explanation online of why I shouldn't be afraid of open-source?
No, AI control doesn't pass the bar, because we're still probably fucked until we have a solution for open source AI or race for superintelligence, for example, and OpenAI doesn't seem to be planning to use control, so this looks to me like the research that's sort of being done in your garage but ignored by the labs (and that's sad, control is great I agree).
What do you think of my point about Scott Aaronson? Also, since you agree with points 2 and 3, it seems that you also think that the most useful work from last year didn't require advanced physics, so isn't this a contradiction with you disagreing with point 1?
I think I do agree with some points in this post. This failure mode is the same as the one I mentioned about why people are doing interpretability for instance (section Outside view: The proportion of junior researchers doing Interp rather than other technical work is too high), and I do think that this generalizes somewhat to whole field of alignment. But I'm highly skeptical that recruiting a bunch of physicists to work on alignment would be that productive:
- Empirically, we've already kind of tested this, and it doesn't work.
- I don't think that what Scott Aaronson produced while at OpenAI had really helped AI Safety: He is exactly doing what is criticized in the post: Streetlight research and using techniques that he was already familiar with from his previous field of research, I don't think the author of the OP would disagree with me. Maybe n=1, but it was one of the most promising shots.
- Two years ago, I was doing field-building and trying to source talent, primarily selecting based on pure intellect and raw IQ. I've organized the Von Neumann Symposium around the problem of corrigibility, I targeted IMO laureates, and individuals from the best school in France, ENS Ulm, which arguably has the highest concentration of future Nobel laureates in the world. However, pure intelligence doesn't work. In the long term, the individuals who succeeded in the field weren't the valedictorians from France's top school, but rather those who were motivated, had read The Sequences, were EA people, possessed good epistemology, and had a willingness to share their work online (maybe you are going to say that the people I was targeting were too young, but I think my little empirical experience is already much better than the speculation in the OP).
- My prediction is that if you put a group of skilled physicists in a room, first, it's not even sure they would find that many people motivated in this reference class, and I don't think the few who would be motivated would produce good-quality work.
- For the ML4Good bootcamps, the scoring system reflects this insight. We use multiple indicators and don't rely solely on pure IQ to select participants, because there is little correlation between pure high IQ and long term quality production.
- I believe the biggest mistake in the field is trying to solve "Alignment" rather than focusing on reducing catastrophic AI risks. Alignment is a confused paradigm; it's a conflationary alliance term that has sedimented over the years. It's often unclear what people mean when they talk about it: Safety isn't safety without a social model.
- Think about what has been most productive in reducing AI risks so far? My short list would be:
- The proposed SB 1047 legislation.
- The short statement on AI risks
- Frontier AI Safety Commitments, AI Seoul Summit 2024, to encourage labs to publish their responsible scaling policies.
- Scary demonstrations to showcase toy models of deception, fake alignment, etc, and to create more scientific consensus, which is very very needed
- As a result, the field of "Risk Management" is more fundamental for reducing AI risks than "AI Alignment." In my view, the theoretical parts of the alignment field have contributed far less to reducing existential risks than the responsible scaling policies or the draft of the EU AI Act's Code of Practice for General Purpose AI Systems, which is currently not too far from being the state-of-the-art for AI risk management. Obviously, it's still incomplete, but that's the direction that is I think most productive today.
- Think about what has been most productive in reducing AI risks so far? My short list would be:
- Related, The Swiss cheese model of safety is underappreciated in the field. This model has worked across other industries and seems to be what works for the only general intelligence we know: humans. Humans use a mixture of strategies for safety we could imitate for AI safety (see this draft). However, the agent foundations community seems to be completely neglecting this.
I've been testing this with @Épiphanie Gédéon for a few months now, and it's really, really good for doing more work that's intellectually challenging. In my opinion, the most important sentence in the post is the fact that it doesn't help that much during peak performance moments, but we’re not at our peak that often. And so, it's super important. It’s really a big productivity boost, especially when doing cognitively demanding tasks or things we struggle to "eat the frog". So, I highly recommend it.
But the person involved definitely needs to be pretty intelligent to keep up and to make recommendations that aren’t useless. Sometimes, it can feel more like co-working, there are quite a few different ways it can work, more or less passive/active. But overall, generally speaking, we recommend trying it for at least a few days.
It took me quite a while to take the plunge because there's a social aspect—this kind of thing isn’t very common in France. It’s not considered a real job. Although, honestly, it should be a real job for intellectual professions, in my opinion. And it’s not an easy job.
I often find myself revisiting this post—it has profoundly shaped my philosophical understanding of numerous concepts. I think the notion of conflationary alliances introduced here is crucial for identifying and disentangling/dissolving many ambiguous terms and resolving philosophical confusion. I think this applies not only to consciousness but also to situational awareness, pain, interpretability, safety, alignment, and intelligence, to name a few.
I referenced this blog post in my own post, My Intellectual Journey to Dis-solve the Hard Problem of Consciousness, during a period when I was plateauing and making no progress in better understanding consciousness. I now believe that much of my confusion has been resolved.
I think the concept of conflationary alliances is almost indispensable for effective conceptual work in AI safety research. For example, it helps clarify distinctions, such as the difference between "consciousness" and "situational awareness." This will become increasingly important as AI systems grow more capable and public discourse becomes more polarized around their morality and conscious status.
Highly recommended for anyone seeking clarity in their thinking!
I don't Tournesol is really mature currently, especially for non french content, and I'm not sure they try to do governance works, that's mainly a technical projet, which is already cool.
Yup, we should create an equivalent of the Nutri-Score for different recommendation AIs.
"I really don't know how tractable it would be to pressure compagnies" seems weirdly familiar. We already used the same argument for AGI safety, and we know that governance work is much more tractable than expected.
I'm a bit surprised this post has so little karma and engagement. I would be really interested to hear from people who think this is a complete distraction.
Fair enough.
I think my main problem with this proposal is that under the current paradigm of AIs (GPTs, foundation models), I don't see how you want to implement ATA, and this isn't really a priority?
I believe we should not create a Sovereign AI. Developing a goal-directed agent of this kind will always be too dangerous. Instead, we should aim for a scenario similar to CERN, where powerful AI systems are used for research in secure labs, but not deployed in the economy.
I don't want AIs to takeover.
Thank you for this post and study. It's indeed very interesting.
I have two questions:
In what ways is this threat model similar to or different from learned steganography? It seems quite similar to me, but I’m not entirely sure.
If it can be related to steganography, couldn’t we apply the same defenses as for steganography, such as paraphrasing, as suggested in this paper? If paraphrasing is a successful defense, we could use it in the control setting, in the lab, although it might be cumbersome to apply paraphrasing for all users in the api.
Interesting! Is it fair to say that this is another attempt at solving a sub problem of misgeneralization?
Here is one suggestion to be able to cluster your SAEs features more automatically between gender and profession.
In the past, Stuart Armstrong with alignedAI also attempted to conduct works aimed at identifying different features within a neural network in such a way that the neural network would generalize better. Here is a summary of a related paper, the DivDis paper that is very similar to what alignedAI did:
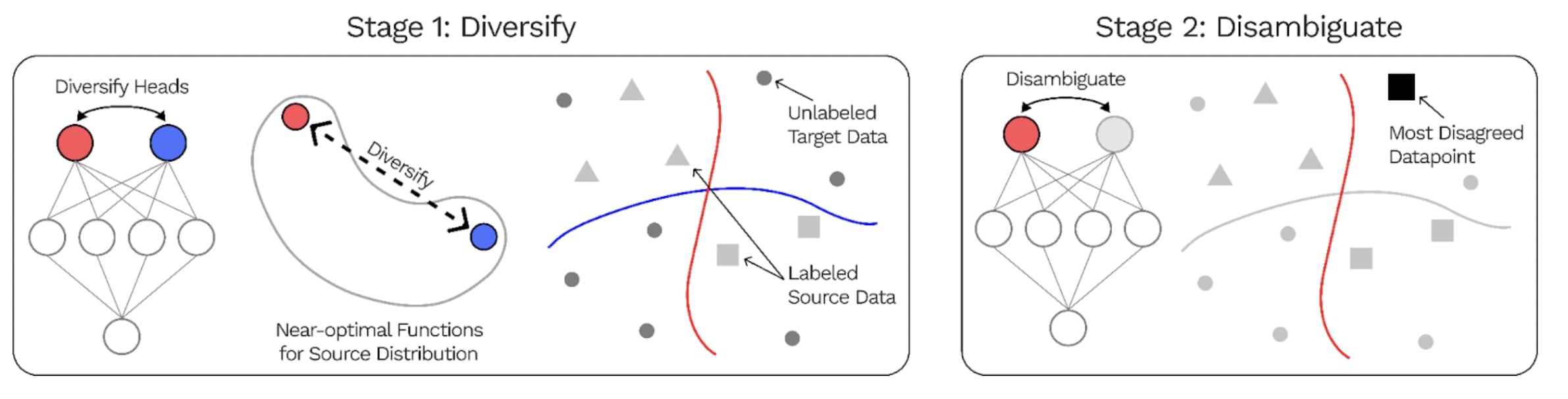
The DivDis paper presents a simple algorithm to solve these ambiguity problems in the training set. DivDis uses multi-head neural networks, and a loss that encourages the heads to use independent information. Once training is complete, the best head can be selected by testing all different heads on the validation data.
DivDis achieves 64% accuracy on the unlabeled set when training on a subset of human_age and 97% accuracy on the unlabeled set of human_hair. GitHub : https://github.com/yoonholee/DivDis
I have the impression that you could also use DivDis by training a probe on the latent activations of the SAEs and then applying Stuart Armstrong's technique to decorrelate the different spurious correlations. One of those two algos would enable to significantly reduce the manual work required to partition the different features with your SAEs, resulting in two clusters of features, obtained in an unsupervised way, that would be here related to gender and profession.
Here is the youtube video from the Guaranteed Safe AI Seminars:
It might not be that impossible to use LLM to automatically train wisdom:
Look at this: "Researchers have utilized Nvidia’s Eureka platform, a human-level reward design algorithm, to train a quadruped robot to balance and walk on top of a yoga ball."
Strongly agree.
Related: It's disheartening to recognize, but it seems the ML community might not even get past the first crucial step in reducing risks, which is understanding them. We appear to live in a world where most people, including key decision-makers, still don't grasp the gravity of the situation. For instance, in France, we still hear influential figures like Arthur Mensch, CEO of Mistral, saying things like, "When you write this kind of software, you always control what's going to happen, all the outputs the software can have." As long as such individuals are leading AGI labs, the situation will remain quite dire.
+1 for the conflationary alliances point. It is especially frustrating when I hear junior people interchange "AI Safety" and "AI Alignment." These are two completely different concepts, and one can exist without the other. (The fact that the main forum for AI Safety is the "Alignment Forum" does not help with this confusion). I'm not convinced the goal of the AI Safety community should be to align AIs at this point.
However, I want to make a small amendment to Myth 1: I believe that technical work which enhances safety culture is generally very positive. Examples of such work include scary demos like "BadLlama," which I cite at least once a week, or benchmarks such as Evaluating Frontier Models for Dangerous Capabilities, which tries to monitor particularly concerning capabilities. More "technical" works like these seem overwhelmingly positive, and I think that we need more competent people doing this.
Strong agree. I think twitter and reposting stuff on other platforms is still neglected, and this is important to increase safety culture
doesn't justify the strength of the claims you're making in this post, like "we are approaching a point of no return" and "without a treaty, we are screwed".
I agree that's a bit too much, but it seems to me that we're not at all on the way to stopping open source development, and that we need to stop it at some point; maybe you think ARA is a bit early, but I think we need a red line before AI becomes human-level, and ARA is one of the last arbitrary red lines before everything accelerates.
But I still think no return to loss of control because it might be very hard to stop ARA agent still seems pretty fair to me.
Link here, and there are other comments in the same thread. Was on my laptop, which has twitter blocked, so couldn't link it myself before.
I agree with your comment on twitter that evolutionary forces are very slow compared to deliberate design, but that is not way I wanted to convey (that's my fault). I think an ARA agent would not only depend on evolutionary forces, but also on the whole open source community finding new ways to quantify, prune, distill, and run the model in a distributed way in a practical way. I think the main driver this "evolution" would be the open source community & libraries who will want to create good "ARA", and huge economic incentive will make agent AIs more and more common and easy in the future.
Thanks for this comment, but I think this might be a bit overconfident.
constantly fighting off the mitigations that humans are using to try to detect them and shut them down.
Yes, I have no doubt that if humans implement some kind of defense, this will slow down ARA a lot. But:
- 1) It’s not even clear people are going to try to react in the first place. As I say, most AI development is positive. If you implement regulations to fight bad ARA, you are also hindering the whole ecosystem. It’s not clear to me that we are going to do something about open source. You need a big warning shot beforehand and this is not really clear to me that this happens before a catastrophic level. It's clear they're going to react to some kind of ARAs (like chaosgpt), but there might be some ARAs they won't react to at all.
- 2) it’s not clear this defense (say for example Know Your Customer for providers) is going to be sufficiently effective to completely clean the whole mess. if the AI is able to hide successfully on laptops + cooperate with some humans, this is going to be really hard to shut it down. We have to live with this endemic virus. The only way around this is cleaning the virus with some sort of pivotal act, but I really don’t like that.
While doing all that, in order to stay relevant, they'll need to recursively self-improve at the same rate at which leading AI labs are making progress, but with far fewer computational resources.
"at the same rate" not necessarily. If we don't solve alignment and we implement a pause on AI development in labs, the ARA AI may still continue to develop. The real crux is how much time the ARA AI needs to evolve into something scary.
Superintelligences could do all of this, and ARA of superintelligences would be pretty terrible. But for models in the broad human or slightly-superhuman ballpark, ARA seems overrated, compared with threat models that involve subverting key human institutions.
We don't learn much here. From my side, I think that superintelligence is not going to be neglected, and big labs are taking this seriously already. I’m still not clear on ARA.
Remember, while the ARA models are trying to survive, there will be millions of other (potentially misaligned) models being deployed deliberately by humans, including on very sensitive tasks (like recursive self-improvement). These seem much more concerning.
This is not the central point. The central point is:
- At some point, ARA is unshutdownable unless you try hard with a pivotal cleaning act. We may be stuck with a ChaosGPT forever, which is not existential, but pretty annoying. People are going to die.
- the ARA evolves over time. Maybe this evolution is very slow, maybe fast. Maybe it plateaus, maybe it does not plateau. I don't know
- This may take an indefinite number of years, but this can be a problem
the "natural selection favors AIs over humans" argument is a fairly weak one; you can find some comments I've made about this by searching my twitter.
I’m pretty surprised by this. I’ve tried to google and not found anything.
Overall, I think this still deserves more research
Why not! There are many many questions that were not discussed here because I just wanted to focus on the core part of the argument. But I agree details and scenarios are important, even if I think this shouldn't change too much the basic picture depicted in the OP.
Here are some important questions that were voluntarily omitted from the QA for the sake of not including stuff that fluctuates too much in my head;
- would we react before the point of no return?
- Where should we place the red line? Should this red line apply to labs?
- Is this going to be exponential? Do we care?
- What would it look like if we used a counter-agent that was human-aligned?
- What can we do about it now concretely? Is KYC something we should advocate for?
- Don’t you think an AI capable of ARA would be superintelligent and take-over anyway?
- What are the short term bad consequences of early ARA? What does the transition scenario look like.
- Is it even possible to coordinate worldwide if we agree that we should?
- How much human involvement will be needed in bootstrapping the first ARAs?
We plan to write more about these with @Épiphanie Gédéon in the future, but first it's necessary to discuss the basic picture a bit more.
Thanks for writing this.
I like your writing style, this inspired me to read a few more things
Seems like we are here today