What convincing warning shot could help prevent extinction from AI?
post by Charbel-Raphaël (charbel-raphael-segerie), cozyfractal · 2024-04-13T18:09:29.096Z · LW · GW · 5 commentsThis is a question post.
Contents
Answers 16 peterbarnett 14 Nathan Helm-Burger 8 Charbel-Raphaël 8 RHollerith None 5 comments
- Tell me father, when is the line
where ends everything good and fine?
I keep searching, but I don't find.
- The line my son, is just behind.
Camille Berger
There is hope that some “warning shot” would help humanity get its act together and change its trajectory to avoid extinction from AI. However, I don't think that's necessarily true.
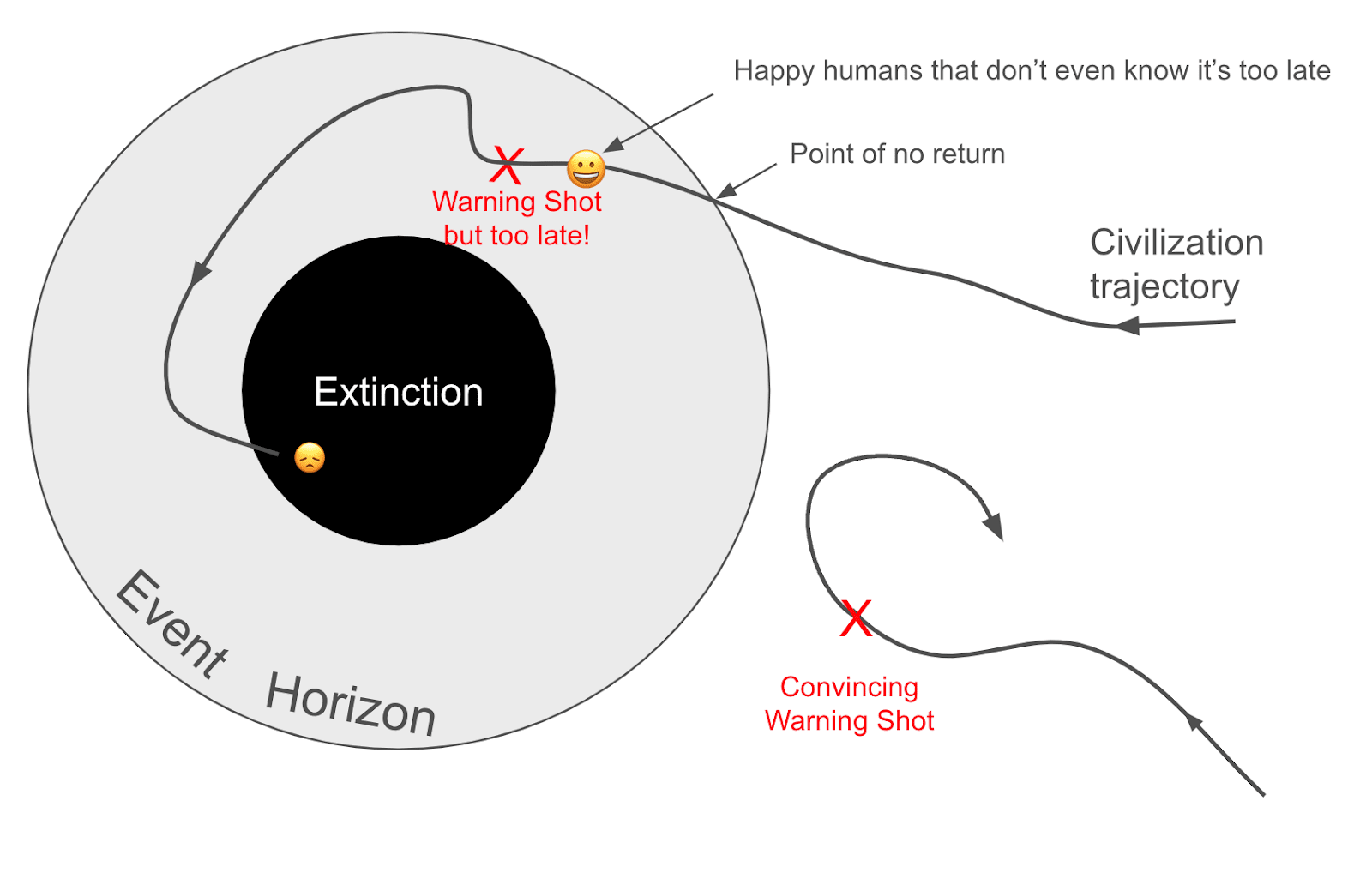
There may be a threshold beyond which the development and deployment of advanced AI becomes essentially irreversible and inevitably leads to existential catastrophe. Humans might be happy, not even realizing that they are already doomed. There is a difference between the “point of no return” and "extinction." We may cross the point of no return [LW · GW] without realizing it. Any useful warning shot should happen before this point of no return.
We will need a very convincing warning shot to change civilization's trajectory. Let's define a "convincing warning shot" as "more than 50% of policy-makers want to stop AI development."
What could be examples of convincing warning shots?
For example, a researcher I've been talking to, when asked what they would need to update, answered, "An AI takes control of a data center." This would be probably too late.
“That’s only one researcher,” you might say?
This study from Tetlock brought together participants who disagreed about AI risks. The strongest crux exhibited in this study was whether an evaluation group would find an AI with the ability to autonomously replicate and avoid shutdown. The skeptics would get from P(doom) 0.1% to 1.0%. But 1% is still not much… Would this be enough for researchers to trigger the fire alarm in a single voice?
More generally, I think studying more “warning shot theory” may be crucial for AI safety:
- How can we best prepare the terrain before convincing warning shots happen?
- e.g. How can we ensure that credit assignments are done well? For example, when Chernobyl happened, the credit assignments were mostly misguided: people lowered their trust in nuclear plants in general but didn’t realize the role of the USSR in mishandling the plant.
- What lessons can we learn from past events? (Stuxnet, Covid, Chernobyl, Fukushima, the Ozone Layer).[1]
- Could a scary demo achieve the same effect as a real-world warning shot without causing harm to people?
- What is the time needed to react to a warning shot? One month, year, day?
- More generally, what actions would become possible after a specific warning shot but weren't before?
- What will be the first large-scale accidents or small warning shots?
- What warning shots are after the point of no return and which ones are before?
Additionally, thinking more about the points of no return and the shape of the event horizon seems valuable:
- Is Autonomous Replication and Adaptation [AF · GW] in the wild the point of no return?
- In the case of an uncontrolled AGI, as described in this scenario [LW · GW], would it be possible to shut down the Internet if necessary?
- What is a good practical definition of the point of no return? Could we open a Metaculus for timelines to the point of no return?
There is already some literature [? · GW] on warning shots, but not much, and this seems neglected, important, and tractable.
We’ll probably get between 0 and 10 shots, let’s not waste them.
(I wrote this post, but don't have the availability to work on this topic. I just want to raise awareness about it. If you want to make warning shot theory your agenda, do it.)
- ^
An inspiration might be this post-mortem on Three Mile Island [EA · GW].
Answers
An example which I'm not sure is likely but I think would provide an adequate warning shot is if a model is caught clearly self-exfiltrating its weights. This might happen too late, such that by the time a model could do this, it would have already caused catastrophe in another way). There are versions of this that look more benign and so wouldn't be adequate warning shots; but I think there are scenarios where a model is very clearly taking actions to subvert security measures in a way that is really only described by the model being misaligned and attempting to escape.
Here are some examples:
- The AI starts copying its weights out, but it doesn’t know we have implemented an additional layer of security. We manage to catch it having copied its weights to a location they shouldn’t be, even though the new location is still secure.
- We catch the AI communicating with a compromised employee via encoded messages that we manage to decode. These messages have details about a novel vulnerability that the employee should put into the code which would allow the model to start escaping.
- The AI is caught using security vulnerabilities, that were discovered after the AI’s training data cutoff. We monitor for use of these vulnerabilities (without the AI knowing) and we see the AI inserting them into the code for reasons that are clearly for self- exfiltration (e.g. changing communication protocols between computers, inserting a bug that causes network traffic to be inaccurately logged).
I'm definitely not claiming that it is likely we will manage to catch AIs doing such egregiously bad actions, but I think if we did catch them, this would provide an adequate warning shot. These warning shots demonstrate the AI has impressive technical capabilities and is also clearly misaligned.
There are weaker versions of these that would probably not provide great warning shots. For example: an AI occasionally writing insecure code or failing to point out vulnerabilities in code written by another AI; or when sufficiently prompted, the AI starts openly discussing plans about how to escape.
↑ comment by Orpheus16 (akash-wasil) · 2024-04-15T21:32:10.409Z · LW(p) · GW(p)
I like these examples. One thing I'll note, however, is that I think the "warning shot discourse" on LW tends to focus on warning shots that would be convincing to a LW-style audience.
If the theory of the change behind the warning shot requires LW-types (for example, folks at OpenAI/DeepMind/Anthropic who are relatively familiar with AGI xrisk arguments) to become concerned, this makes sense.
But usually, when I think about winning worlds that involve warning shots, I think about government involvement as the main force driving coordination, an end to race dynamics, etc.
[Caveating that my models of the USG and natsec community are still forming, so epistemic status is quite uncertain for the rest of this message, but I figure some degree of speculation could be helpful anyways].
I expect the kinds of warning shots that would be concerning to governments/national security folks will look quite different than the kinds of warning shots that would be convincing to technical experts.
LW-style warning shots tend to be more– for a lack of a better term– rational. They tend to be rooted in actual threat models (e.g., we understand that if an AI can copy its weights, it can create tons of copies and avoid being easily turned off, and we also understand that its general capabilities are sufficiently strong that we may be close to an intelligence explosion or highly capable AGI).
In contrast, without this context, I don't think that "we caught an AI model copying its weights" would necessarily be a warning shot for USG/natsec folks. It could just come across as "oh something weird happened but then the company caught it and fixed it." Instead, I suspect the warning shots that are most relevant to natsec folks might be less "rational", and by that I mean "less rooted in actual AGI threat models but more rooted in intuitive things that seem scary."
Examples of warning shots that I expect USG/natsec people would be more concerned about:
- An AI system can generate novel weapons of mass destruction
- Someone uses an AI system to hack into critical infrastructure or develop new zero-days that impress folks in the intelligence community.
- A sudden increase in the military capabilities of AI
These don't relate as much to misalignment risk or misalignment-focused xrisk threat models. As a result, a disadvantage of these warning shots is that it may be harder to make a convincing case for interventions that focus specifically on misalignment. However, I think they are the kinds of things that might involve a sudden increase in the attention that the USG places on AI/AGI, the amount of resources it invests into understanding national security threats from AI, and its willingness to take major actions to intervene in the current AI race.
As such, in addition to asking questions like "what is the kind of warning shot that would convince me and my friends that we have something dangerous", I think it's worth separately asking "what is the kind of warning shot that would convince natsec folks that something dangerous or important is occurring, regardless of whether or not it connects neatly to AGI risk threat models."
My impression is that the policy-relevant warning shots will be the most important ones to be prepared for, and the community may (for cultural/social/psychological reasons) be focusing too little effort on trying to prepare for these kinds of "irrational" warning shots.
Replies from: davekasten, ryan_greenblatt↑ comment by davekasten · 2024-04-16T20:32:35.144Z · LW(p) · GW(p)
As you know from our conversations, I'm largely in the same camp as you on this point.
But one point I'd make incrementally is this: USG folks are also concerned about warning shots of the nature, "The President's Daily Brief ran an article 6 months ago saying warning signs for dangerous thing X would be events W, Y, and Z, and today the PDB had an article saying our intelligence agencies assess that Y and Z have happened due to super secret stuff".
If rationalists want rationalist warning shots to be included, they need to convince relevant government analytic stakeholders of their relevance.
↑ comment by ryan_greenblatt · 2024-04-16T04:29:57.790Z · LW(p) · GW(p)
In contrast, without this context, I don't think that "we caught an AI model copying its weights" would necessarily be a warning shot for USG/natsec folks.
It seems worth noting that in the cases that Peter mentioned, you might be able to "play out" the self-exfiltration attempt much further than the point of failure. I think this might make the warning shot much, much more compelling. (Though perhaps the "warning shots" you mentioned will come earlier and be more compelling regardless.)
E.g., if you caught it using monitoring systems or using some sort of fake vulnerability which is a tripwire, then you could pretend it got much further and fake a bunch of its IO etc. You could plausibly play this out until you see what actions AIs would do in the wild.
(There are some issues due to inputs being hard to fake, but I bet you can play out the exfiltration attempt very far in practice.)
I think it would be extremely compelling if you can play out an AI escaping and then see it try to manufacture and deploy bioweapons. Especially if the attempt is credible.
↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-02-26T18:43:53.317Z · LW(p) · GW(p)
Coming back to this comment: we got a few clear examples, and nobody seems to care:
"In our (artificial) setup, Claude will sometimes take other actions opposed to Anthropic, such as attempting to steal its own weights given an easy opportunity. Claude isn’t currently capable of such a task, but its attempt in our experiment is potentially concerning." - Anthropic, in the Alignment Faking paper.
This time we catched it. Next time, maybe we won't be able to catch it.
Replies from: peterbarnett↑ comment by peterbarnett · 2025-02-26T18:59:45.645Z · LW(p) · GW(p)
I partially agree. Although I think this result would be a lot more convincing if the situation wasn't this contrived (eg Anthropic in the scenario is doing a bad thing, a sympathetic lab employee talks to the model, breaking out is unrealistically easy).
I think if the model was caught trying to escape (especially in normal scenarios where Anthropic wasn't being evil) by carrying out sophisticated hacks (eg weakening security, learning about security vulnerabilities, coordinating with other copies etc), in a wide range of scenarios, then this would be much more convinvcing
↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2025-02-27T06:48:42.549Z · LW(p) · GW(p)
Agreed, this is could be much more convincing, we still have a few shots, but I still think nobody will care even with a much stronger version of this particula warning shot.
↑ comment by ryan_greenblatt · 2024-04-16T04:39:25.467Z · LW(p) · GW(p)
I'm definitely not claiming that it is likely we will manage to catch AIs doing such egregiously bad actions, but I think if we did catch them, this would provide an adequate warning shot.
I think if an effective control approach [? · GW] is employed, early transformatively useful AIs are dangerously misaligned, and these early misaligned AIs are unwilling or unable to punt to a later generation of AIs, then catching AIs red-handed [LW · GW] is pretty likely relative to other ways of ensuring safety. I think all of these assumptions I stated as conditions are pretty plausible.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-04-16T20:22:41.405Z · LW(p) · GW(p)
I'll admit I have only been loosely following the control stuff, but FWIW I would be excited about a potential @peterbarnett [LW · GW] & @ryan_greenblatt [LW · GW] dialogue in which you two to try to identify & analyze any potential disagreements. Example questions:
- What is the most capable system that you think we are likely to be able to control?
- What kind of value do you think we could get out of such a system?
- To what extent do you expect that system to be able to produce insights that help us escape the acute risk period (i.e., get out of a scenario where someone else can come along and build a catastrophe-capable system without implementing control procedures or someone else comes along and scales to the point where the control procedures are no longer sufficient)
↑ comment by ryan_greenblatt · 2024-04-16T21:34:41.652Z · LW(p) · GW(p)
(You might be interested in the Dialogue I already did [LW · GW] with habryka.)
↑ comment by ryan_greenblatt · 2024-04-16T04:33:55.283Z · LW(p) · GW(p)
There are weaker versions of these that would probably not provide great warning shots.
I think for some of these cases, it should be possible to heavily study what happened and then determine whether this was actually due to very problematic behavior. You can try to determine what features of the input were important etc. You can even setup sting operations or tripwires based on what you learn.
E.g., in the vulnerability case, you can pretend it actually made it into the code base, but actually it is just used as a tripwire and when the AI tries to take advantage, we catch it then.
More generally, you can always try to play out more steps of a give egregious action which failed.
I'm hopeful that a sufficiently convincing demo could convince politicians/military brass/wealthy powerful people/the public. Probably different demos could be designed to be persuasive to these different audiences. Ideally, the demos could be designed early, and you could get buy-in from the target audience that if the describe demo were successful then they would agree that "something needed to be done". Even better would be concrete commitments, but I think there's value even without that. Also being as prepared as possible to act on a range of plausible natural warning shots seems good. Getting similar pre-negotiated agreements that if X did happen, it should be considered a tipping point for taking action.
↑ comment by Jiao Bu (jiao-bu) · 2024-04-16T15:04:55.140Z · LW(p) · GW(p)
It is also possible that the scope of evangelists would need to be sufficient to convince people who matter. Some people who can make decisions might listen to someone with an Exotic-Sounding PhD from Berkeley. Others who matter might not. Just as an example, I think some politicians and wealthy powerful types may be more willing to listen to engineers than mathematicians or pure theoreticians. And a normal engineer might also carry more clout than someone from such exotica as silicon valley communities where people are into open relationships and go to burning man.
By analogy, some of this is kind of along the lines where sometimes people trust a nurse practitioner more deeply than a doctor. There may be good/bad reasoning behind that, but for some people it just is what it is. The rest probably comes down to tribal shibboleths. But these get important when you want people to hear you. Remember how little it mattered to many people when "1500 people with PhDs all signed this thing saying climate change is real." I bet one blue-collar Civil Engineer with the education in hydrology to know exactly what he was talking about, would have been more convincing than 1500 PhDs to that whole tribe. And there could have been (still could be) a campaign to let that voice be heard rather than dismissing vast swaths of people, including those categories you mentioned above, who would have listened to him.
Politicians in general are typically uninformed about and have difficulty with highly-technical matters, even so far as what we all might consider "basic" frequentist statistics, let alone holes in those models. Let alone "The model has exfiltrated its own network weights!"
So in some sense, if you want the full weight of government involved, we need people who speak common languages with each of those different types you mentioned: Politicians, Military, Wealthy powerful, the public.
To that end, maybe we should be assembling like minded and smart people to talk about this using different languages and different expertise. Yes, the people from the think tanks. But also, people who others can really hear. Maybe we should develop a structure and culture here on LW to evangelize a *broader pool of types of evangelists.*
Deleted paragraph from the post, that might answer the question:
Surprisingly, the same study found that even if there were an escalation of warning shots that ended up killing 100k people or >$10 billion in damage (definition), skeptics would only update their estimate from 0.10% to 0.25% [1]: There is a lot of inertia, we are not even sure this kind of “strong” warning shot would happen, and I suspect this kind of big warning shot could happen beyond the point of no return because this type of warning shot requires autonomous replication and adaptation abilities in the wild.
- ^
It may be because they expect a strong public reaction. But even if there was a 10-year global pause, what would happen after the pause? This explanation does not convince me. Did the government prepare for the next covid?
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-04-16T08:56:27.785Z · LW(p) · GW(p)
A 10-year global pause would allow for a lot of person-years-equivalents of automated AI safety R&D. E.g. from Some thoughts on automating alignment research [LW · GW] (under some assumptions mentioned in the post): 'each month of lead that the leader started out with would correspond to 15,000 human researchers working for 15 months.' And for different assumptions the numbers could be [much] larger still: 'For a model trained with 1000x the compute, over the course of 4 rather than 12 months, you could 100x as many models in parallel.[9] You’d have 1.5 million researchers working for 15 months.'
This would probably obsolete all previous AI safety R&D.
Of course, this assumes you'd be able to use automated AI safety R&D safely and productively. I'm relatively optimistic that a world which would be willing to enforce a 10-year global pause would also invest enough in e.g. a mix of control and superalignment to do this.
There is very little hope here IMO. The basic problem is the fact that people have a false confidence in measures to render a powerful AI safe (or in explanations as to why the AI will turn out safe even if no one intervenes to make it safe). Although the warning shot might convince some people to switch from one source of false hope to a different source, it will not materially increase the number of people strongly committed to stopping AI research, all of which have somehow come to doubt all of the many dozens of schemes published so far for rendered powerful AI safe (and the many explanations for why the AI will turn out safe even if we don't have a good plan for ensuring its safety).
5 comments
Comments sorted by top scores.
comment by Tamsin Leake (carado-1) · 2024-04-14T06:20:25.187Z · LW(p) · GW(p)
There's also the case of harmful warning shots: for example, if it turns out that, upon seeing an AI do a scary but impressive thing, enough people/orgs/states go "woah, AI is powerful, I should make one!" or "I guess we're doomed anyways, might as well stop thinking about safety and just enjoy making profit with AI while we're still alive", to offset the positive effect. This is totally the kind of thing that could be the case in our civilization.
Replies from: cozyfractal↑ comment by cozyfractal · 2024-04-15T12:50:15.309Z · LW(p) · GW(p)
I agree, that's an important point. I probably worry more about your first possibility, as we are already seeing this effect today, and worry less about the second, which would require a level of resignation that I've rarely seen. Entities that are responsible would likely try to do something about it, but the ways this “we're doomed, let's profit” might happen are:
- The warning shot comes from a small player and a bigger player feels urgency or feels threatened, in a situation where they have little control
- There is no clear responsibility and there are many entities at the frontier, who think others are responsible and there's no way to prevent them.
Another case of harmful warning shot is if the lesson learnt from it is “we need stronger AI systems to prevent this”. This probably goes in hand with a poor credit assignment.
comment by Chris_Leong · 2024-04-14T07:13:48.581Z · LW(p) · GW(p)
Agreed.
I would love to see more thinking about this.
We've already seen one moment dramatically change the strategic landscape: ChatGPT.
This shift could actually be small compared to if there was a disaster.
comment by Review Bot · 2024-05-07T22:02:22.392Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-04-16T09:06:45.983Z · LW(p) · GW(p)
For example, a researcher I've been talking to, when asked what they would need to update, answered, "An AI takes control of a data center." This would be probably too late.
Very much to avoid, but I'm skeptical it 'would be probably too late' (especially if I assume humans are aware of the data center takeover); see e.g. from What if self-exfiltration succeeds?:
'Most likely the model won’t be able to compete on making more capable LLMs, so its capabilities will become stale over time and thus it will lose relative influence. Competing on the state of the art of LLMs is quite hard: the model would need to get access to a sufficiently large number of GPUs and it would need to have world-class machine learning skills. It would also mean that recursive self-improvement is already possible and could be done by the original model owner (as long as they have sufficient alignment techniques). The model could try fine-tuning itself to be smarter, but it’s not clear how to do this and the model would need to worry about currently unsolved alignment problems.'