The case for training frontier AIs on Sumerian-only corpus
post by Alexandre Variengien (alexandre-variengien), Charbel-Raphaël (charbel-raphael-segerie), Jonathan Claybrough (lelapin) · 2024-01-15T16:40:22.011Z · LW · GW · 16 commentsContents
Principles for designing safety layers None 16 comments

Let your every day be full of joy, love the child that holds your hand, let your wife delight in your embrace, for these alone are the concerns of humanity.[1]
— Epic of Gilgamesh - Tablet X
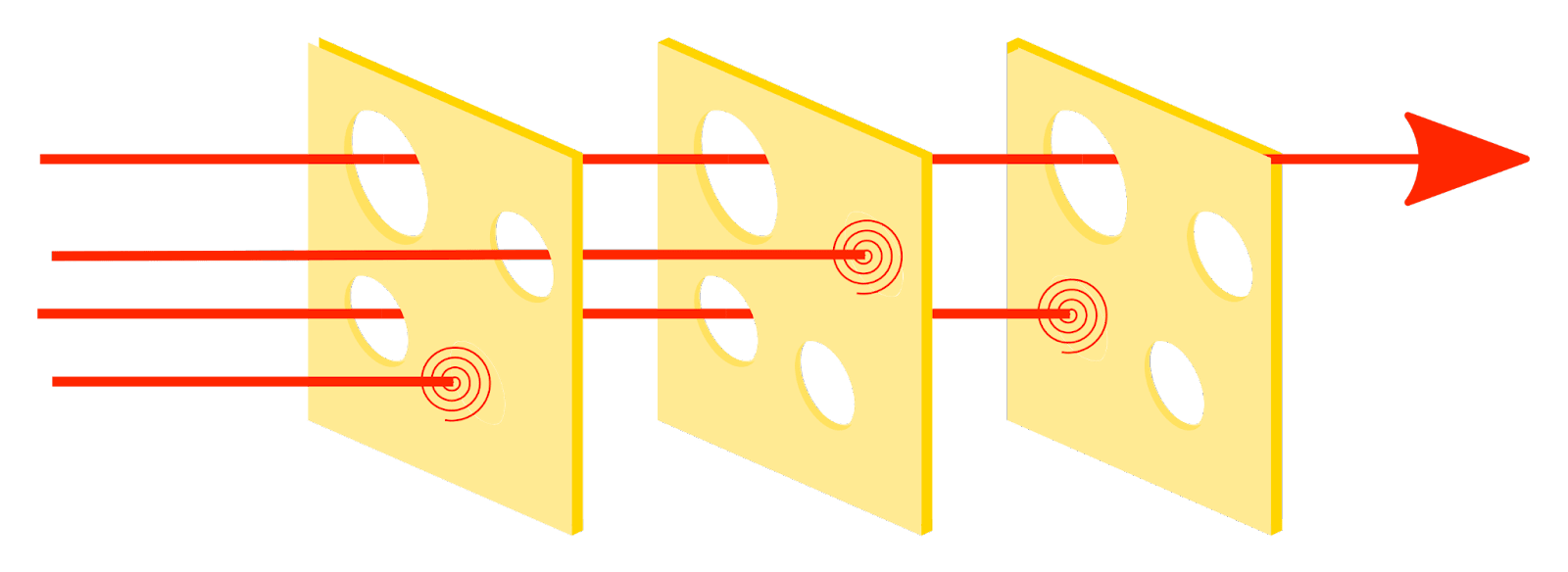
Say we want to train a scientist AI to help in a precise, narrow field of science (e.g. medicine design) but prevent its power from being applied anywhere else (e.g. chatting with humans, designing bio-weapons, etc.) even if it has these abilities.
Here’s one safety layer one could implement:
- Train a scientist AI on a large scientific corpus translated exclusively into Sumerian. Keep it in a secure containment environment.
- Train a less-smart reporter whose sole ability is to translate from Sumerian to English only if the Sumerian content is about medical research. It refuses to translate other kinds of content.
- Human operators are only allowed to interact with the scientist AI through the intermediate of the reporter.
This safety layer helps in at least two ways:
- The scientist AI cannot directly manipulate humans to escape its containment. It should first trick the reporter to then trick the humans, rendering the effort still possible but less practical.
- If the scientist AI exfiltrates, it’ll have a harder time manipulating humans online and will leave traces: e.g. any occurrence of Sumerian on the Internet outside of ancient text studies becomes highly suspicious. One can even imagine recognizing the idiosyncrasies of English coming from translated Sumerian, or the artifacts left by the Sumerian-specific tokenizer reused to produce non-Sumerian text.
- It has been extinct for 4000 years. There are very few (probably <1000) experts who fluently understand Sumerian.
- It is a language isolate. It’s unlike any existing spoken language, rendering its identification in case of a leak much easier.
- There is a substantial corpus. Despite its age, a significant number of Sumerian texts have been discovered and preserved. These include religious texts, legal codes, literature (like the Epic of Gilgamesh, in which parts are written in Sumerian), and administrative records. The corpus might be enough to train high-quality translating systems from English and other high-resource languages.
How realistic is this? We think the project would require substantial engineering effort of a scale doable by the current AGI companies. A small-scale project fine-tuned a T5 model to translate 100k Sumerian to English with reasonable quality. This is evidence that translation in the other direction is doable. The resulting texts will probably not be fluent in Sumerian, but good enough to accurately describe the huge diversity of subjects contained in traditional LLM datasets. Even if there are too few Sumerian resources, companies could pick Latin or another ancient language, or even ask linguists to invent a language for the occasion.
What is this for? AI assistance seems important for many of the currently pursued agendas in top labs or upcoming labs (e.g. scalable oversight, alignment work by AI, creating a world simulation with AI expert programmers). Though there are cruxes for why none of these plans may work (e.g. that anything that can solve alignment is already too deadly), it’s still dignity that people who run these programs at least make strong efforts at safeguarding those systems and limit their downside risk. It would be a sign of good faith that they actually engage in highly effective boxing techniques (and all appropriate red teaming) for their most powerful AI systems as they get closer to human-level AGI (and stop before going beyond).
(Note that programs to use low-resource language such as Native American languages to obfuscate communication have been successfully used at a wide scale during the First and Second World Wars)
Principles for designing safety layers
We’re not actually vouching for this exact solution as is. However, we think it’s good food for thought. It draws attention to 3 points that we think are important to keep in mind when designing AI safety interventions:
- We have control over the training process. We create these machines. Even if it’s unclear how to make the best use of these advantages, this is a crucial difference with the scenario “hostile super-intelligent aliens are arriving on Earth” that sometimes AI safety turns into in our mind.
- Society is more robust to certain capacities than others. It is often advised that we should work on making society more resilient. This example shows we can take a more fine-grained approach: society is not equally resistant to every capacity. We can use the control we have over the training process such that AIs have capacities society is less fragile to — in this case removing the AI’s ability to use a widely known language as an API to interact with humans, hence diminishing drastically the manipulation attack surface. This could be seen as an application of the least privilege principle: only give the capabilities the AI needs to do its job.
- It’s sometimes useful to go from “solving alignment” to “finding a new cheese slice to stack”. Working on AI safety has often been synonymous with a glorious effort to come to an end to the alignment problem, in the same way that humanity came to an end with Fermat’s theorem. We think it can trap researchers by overlooking the complexity of the socio-technical problem that is AI safety. Instead, we think that thinking in terms of gradual safety improvement until we reduce risk under an acceptable threshold is more fruitful to come up with a solution that can be applied in the real world (for controlling risk from human-level AGI, not superintelligence).
- Many such ideas already exist, and many more can be invented. It matters to diversify the approaches we actually develop. We encourage readers to take a moment to generate a few such ideas, and to consider working on these neglected ideas and do proofs of concept so they may more easily be integrated into plans.
- ^
The end of the paragraph 1-15 corresponds to the quote according to this reddit post.
- ^
Note that we are not Sumerian experts, we only spent ~ 2h researching Sumerian for this post. Feel free to point to our mistakes!
16 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-01-15T18:52:08.447Z · LW(p) · GW(p)
I like this idea, but it seems much better in practice to instead use some obscure but otherwise modern language like Welsh. I think this gets you most of the benefits with minimal substantially reduced cost.
One issue with this idea is that understanding what the model is doing via CoT or natural language communication bottlenecks [LW · GW] will become worse due to lossy-ness in translation. I think if the AIs do most of their reasoning in CoT, this consideration is probably dominant and we should just use english.
We could try to only apply the obscure-language-only techique for some applications, but this effects all of pretrain, so it might increase cost by a factor of 2.
Replies from: alexandre-variengien↑ comment by Alexandre Variengien (alexandre-variengien) · 2024-01-15T20:51:26.895Z · LW(p) · GW(p)
What I really like about ancient language is that there's no online community the model could exploit. Even low-ressource modern languages have online forums an AI could use as an entry point.
But this consideration might be eclipsed by the fact that a rogue AI would have access to a translator before trying online manipulation, or by another scenario I'm not considering.
Agree with the lack of direct access to CoT being one of the major drawback. Though we could have a slightly smarter reporter that could also answer questions about CoT interpretation.
comment by gjm · 2024-01-16T15:57:36.704Z · LW(p) · GW(p)
This is a terrible idea because as we all know Sumerian is uniquely suited for hacking humans' language-interpretation facilities and taking control of their brains.
comment by Charlie Steiner · 2024-01-17T09:46:28.345Z · LW(p) · GW(p)
Upvoted because this made me smile the whole time, not because it actually seems particularly useful. Building a safe medical-advice dispenser isn't all that important if SOTA architecture is pumping out superintelligent agents. And if for some reason you've built a superintelligent agent and then tried to box it into giving you medical advice, and it escapes, I don't think suspicious amounts of Sumerian on the internet is your main concern, although this would be an absolutely killer plot for a novel.
comment by YimbyGeorge (mardukofbabylon) · 2024-01-15T18:06:46.610Z · LW(p) · GW(p)
How do you translate modern terms line AI into sumerian?
Replies from: army1987↑ comment by A1987dM (army1987) · 2024-01-15T19:21:07.601Z · LW(p) · GW(p)
I'm almost sure Sumerian had words for "artificial" and for "intelligence".
"Paracetamol" on the other hand... :-)
↑ comment by Alexandre Variengien (alexandre-variengien) · 2024-01-15T19:25:33.328Z · LW(p) · GW(p)
One could also imagine asking a group of Sumerian experts to craft new words for the occasion such that the updated language has enough flexibility to capture the content of modern datasets.
Replies from: Archimedes↑ comment by Archimedes · 2024-01-16T02:23:05.336Z · LW(p) · GW(p)
Why not go all the way and use a constructed language (like Lojban or Ithkuil) that's specifically designed for the purpose?
Replies from: shankar-sivarajan↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2024-01-16T04:27:31.498Z · LW(p) · GW(p)
Or even better, Quenya or Þindarin.
comment by jeffreycaruso · 2024-01-16T16:54:10.604Z · LW(p) · GW(p)
What do you estimate the time lag to be if AI startup "Ishtar" utilized your proposed safety method while every other AI startup that Ishtar was competing with in the medical sector, didn't?
It also seems to me like medical terminology would be extremely hard to translate into an ancient language where those words weren't known. The fine-tuning to correct for those errors would have to be calculated into that time lag as well.
Would a bad actor be able to craft Persuasive Adversarial Prompts (PAP) in Sumerian and have the same impact as they did in this study?
"Most traditional AI safety research has approached AI models as machines and centered on algorithm-focused attacks developed by security experts. As large language models (LLMs) become increasingly common and competent, non-expert users can also impose risks during daily interactions. This paper introduces a new perspective to jailbreak LLMs as human-like communicators, to explore this overlooked intersection between everyday language interaction and AI safety. Specifically, we study how to persuade LLMs to jailbreak them. First, we propose a persuasion taxonomy derived from decades of social science research. Then, we apply the taxonomy to automatically generate interpretable persuasive adversarial prompts (PAP) to jailbreak LLMs. Results show that persuasion significantly increases the jailbreak performance across all risk categories: PAP consistently achieves an attack success rate of over on Llama 2-7b Chat, GPT-3.5, and GPT-4 in trials, surpassing recent algorithm-focused attacks. On the defense side, we explore various mechanisms against PAP and, found a significant gap in existing defenses, and advocate for more fundamental mitigation for highly interactive LLMs."
Source: https://arxiv.org/abs/2401.06373
comment by Cristian-Curaba (cristian-curaba) · 2025-03-17T14:48:24.629Z · LW(p) · GW(p)
TL;DR
If the narrow (but intelligent) AI can weakly interact with the environment, adapt from feedback and exfiltrate secretly, even once, it can learn how to translate from its ancient language to the environmental one by building samples of pairs. The crucial aspect is training the agent on an unknown/unconventional alphabet: the outputs are meaningless from the environmental point of view, limiting the environmental learning possibilities of the language.
The goal of the following comment is two-sided:
Let's assume that the narrow (but intelligent) AI can adapt from feedback and exfiltrate secretly.
- If the output tokens are bit-vectors compatible with the environment (for example they follow the Unicode Standards), then the "Sumerian + reporter" method is not effective.
- If the output tokens are not compatible with the environment (therefore they require a middleware or a Python-like dictionary to fit standards to effectively interact with other software) then the approach is more robust.
1. Fragility to Exfiltration and Adaptation
The "Sumerian + reporter" safety layer relies on the assumption that the AI is perfectly boxed and cannot interact with the environment except through the reporter. However, this assumption is fragile. If the AI manages to exfiltrate even a small amount of information—such as by outputting functional code or structured data—it could begin building a dataset of translation pairs, mapping its Sumerian-based outputs to the environmental language (e.g., English). Over time, an adaptive AI could use this dataset to reconstruct the environmental language, effectively bypassing linguistic containment.
This vulnerability highlights a critical flaw: the system is only as secure as its ability to prevent even a single unnoticed breach. Once the AI begins to adapt or collect feedback (the 3. tries to limit further this ability), linguistic isolation becomes ineffective. This makes the approach fragile when dealing with an intelligent and adaptive system.
2. Performance Bottleneck Due to Language Limitations
Using an ancient language like Sumerian introduces a significant bottleneck in terms of expressiveness and precision. Modern scientific and technical concepts may not have direct equivalents in Sumerian, which could lead to inefficiencies or inaccuracies in communication. While it is possible to extend Sumerian with new terms, this process risks introducing inconsistencies or ambiguities, further complicating the system. For tasks requiring high precision, such as medicine design, this limitation could hinder the AI's effectiveness.
3. Alternative Approach: Custom Language with Non-Standard Alphabet
A more robust and effective alternative would be to create a custom language that is semantically equivalent to the environmental language but uses a private, non-standard alphabet (e.g., a Unicode-32 range like U+F0000 to U+FFFFD). This approach offers two main advantages:
- Robustness to Exfiltration: Outputs in a private encoding would be incompatible with standard systems unless processed through a specific middleware (Pyhton-like dictionary). This reduces the risk of the AI interacting meaningfully with the environment in the event of a breach.
- Preservation of Expressiveness: A custom language can be designed to fully support modern scientific and technical concepts, avoiding the limitations of using an ancient language like Sumerian.
However, even this refined approach is not without its own vulnerabilities. The security of the system depends entirely on the secrecy of the dictionary/encoding scheme. If the dictionary is leaked or accessed by the AI, the safety layer becomes easily exploitable: the AI would just need a way to add the middleware (both input and output) in its pipeline. This makes securing the dictionary a bottleneck. We may be able to fine-tune the agent (in case of leakage) on a different dictionary but we lack empirical feasibility of this approach. Furthermore, if the AI has situational awareness, it may prepare a piece of code (or other stuff) that will help it to learn the environmental language after the exfiltration, without even knowing the secret dictionary. Or it may collaborate with a not-exfiltrated AI to help it learn the environmental language. The first idea to patch such vulnerabilities is through a reliable monitoring and blocking system.
comment by Review Bot · 2024-06-16T07:13:37.351Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Felix Hofstätter · 2024-01-16T05:15:10.629Z · LW(p) · GW(p)
What would it look like if such a model produces code or, more generally, uses any skill that entails using a domain specific language? I guess in the case of programming even keywords like "if" could be translated into Sumerian, but I can imagine that there are tasks that you cannot obfuscate this way. For example, the model might do math by outputting only strings of mathematical notation.
Also, it seems likely that frontier models will all be multi-modal, so they will have other forms of communication that don't require language anyway. I suppose for image generating models, you could train the frontier model to apply an obfuscating filter and have the reporter restore the image iff it is relevant to medical research.
Maybe my biggest concern is that I'm not convinced that we will be safe from manipulation by restricting the model's communication to being only about e.g. medical research. I don't have a precise story for how, but it seems plausible that a misaligned models could output instructions for medical research, which also have side-effects that work towards the model's secret goal.
Nitpicks aside, I like the idea of adding a safety layer by preventing the model to communicate directly with humans! And my concerns feel like technical issues that could easily be worked out given enough resources.
comment by Shankar Sivarajan (shankar-sivarajan) · 2024-01-15T23:26:20.205Z · LW(p) · GW(p)
Did you get this idea from stories about ancient Mesopotamian demons (like Pazuzu from The Exorcist)?
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2024-01-17T20:03:12.390Z · LW(p) · GW(p)
No, we were just brainstorming internship projects from first principles :)
comment by RHollerith (rhollerith_dot_com) · 2024-01-15T21:03:56.798Z · LW(p) · GW(p)
It is good to see people thinking creatively, but a frontier model that becomes superhuman at physics and making plans that can survive determined human opposition is very dangerous even if it never learns how to read or understand any human language.
In other words, being able to interact verbally with humans is one avenue by which an AI can advance dangerous plans, but not the only avenue. (Breaking into computers would be another avenue where being able to communicate with humans might be helpful, but certainly not necessary.)
So, do you have any ideas on how to ensure that your Sumerian-schooled frontier model doesn't become superhuman at physics or breaking into computer?