The Translucent Thoughts Hypotheses and Their Implications
post by Fabien Roger (Fabien) · 2023-03-09T16:30:02.355Z · LW · GW · 7 commentsContents
The Translucent Thoughts Hypotheses The First AGIs Will Have LLMs at Their Core Effective Plans to Defeat Humanity Can’t Be Found in a Single LLM Forward Pass LLMs composing the first AGIs will be Transformers with less than 2000 layers. LLMs Will Solve Complex Tasks by Using English Text The LLMs will be pretrained with next token predictions on human text. Research Directions Introduction: What a Safe AGI Could Look Like Making LLMs Use Only Understandable English Building an Oversight System Revisiting Concepts and Arguments Testing the Hypotheses Making the Hypotheses True? Related work Externalized Reasoning Oversight Completeness Causality Why I think completeness & causality are overated Conditioning Predictive Models The Open Agency Model Strict Open Agents General Open Agents Factored Cognition None 7 comments
Epistemic status: Uncertain about the validity of the claims I’m making here, and looking for feedback about the research directions I’m suggesting.
Thanks to Marius Hobbhahn, Johannes Treutlein, Siméon Campos, and Jean-Stanislas Denain for helpful feedback on drafts.
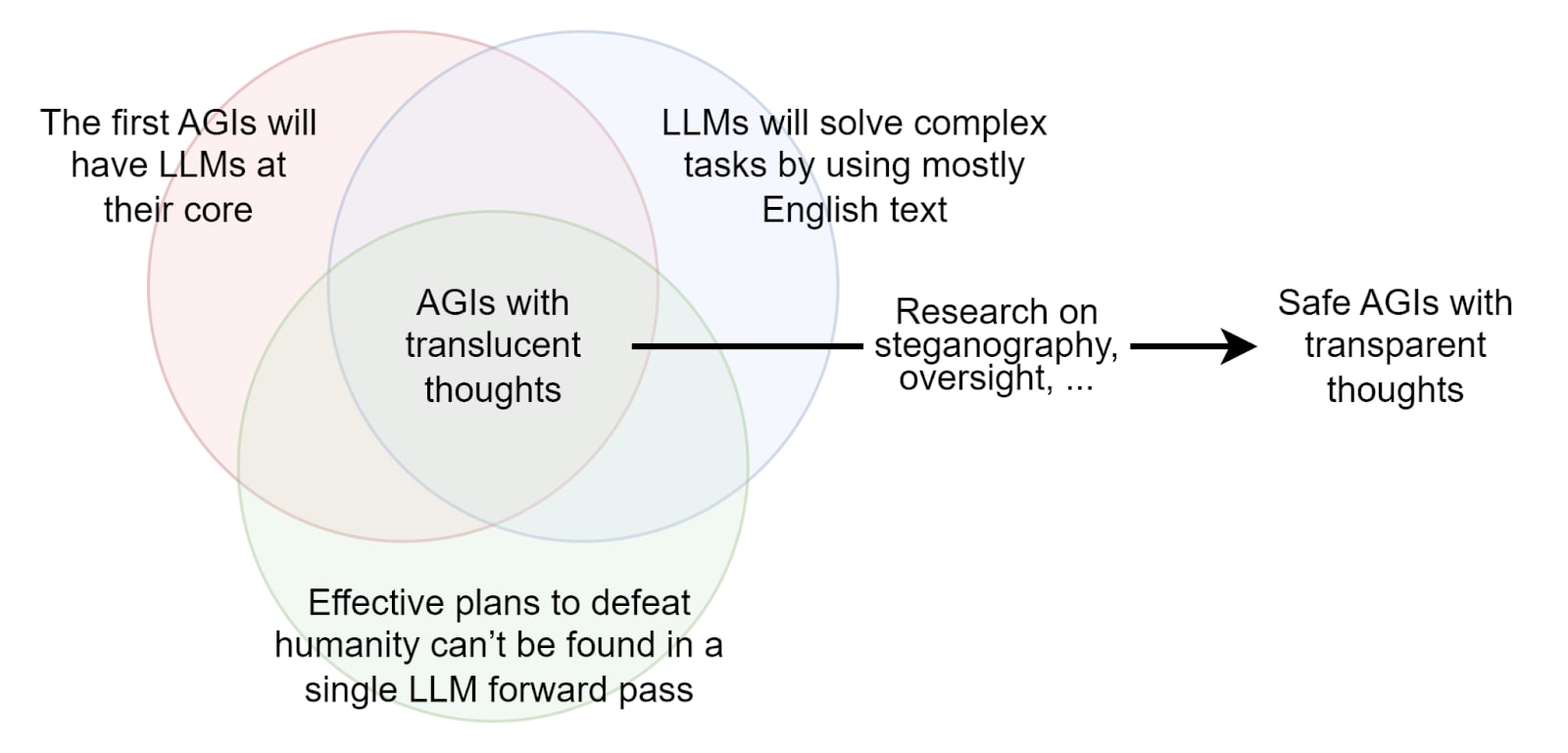
Here is a set of hypotheses:
- The first AGIs will have LLMs at their core
- Effective plans to defeat humanity can’t be found in a single LLM forward pass
- LLMs will solve complex tasks by using English text (self-prompting, scratch pads, combination of expert LLMs, …)
I call these the Translucent Thoughts hypotheses.
I think the Translucent Thoughts hypotheses are likely (around 20% conditioning on AGI before 2030) because:
- Text pretraining is more efficient at building algorithms and knowledge required for real-world plan generation and evaluation than alternative methods;
- Future models are likely to be like Transformers, which use a limited amount of serial step in a single forward pass, and deception requires many serial steps;
- Text pretraining and slight fine-tuning makes model able to use text generation to increase the maximum number of serial steps by a huge factor. Getting this increase through other means is likely to be hard and not competitive.
If these hypotheses are true, it should lead us to prioritize underexplored research directions, such as circumventing steganography or building extremely reliable text-supervision methods. I think those deserve attention, because Translucent Thoughts AIs are not safe by default.
In this post, I argue that we may will in a world where the first AGIs will look like X, and I then describe ways to make the first AGIs safer given X. This is different from most other works in this space, which often directly describe a kind of safe AGI. Despite this, the ideas of this post are close to some other works describing paths to safe AGIs, such as:
- Externalized Reasoning Oversight [LW · GW], which describes a class of solutions similar to the one outlined here, but also aims for additional properties which I argue can be replaced with a less stringent hypothesis about AI systems;
- Conditioning Predictive Models [? · GW], which makes assumptions slightly different from the Translucent Thoughts hypotheses, yielding different research directions;
- The Open Agency Model [AF · GW] and Factored Cognition [AF · GW] which describe subsets of AIs with Translucent Thoughts, which might be safe.
The Translucent Thoughts Hypotheses
Here, I sketch a world in which the first AGIs have certain properties. I argue that this world is likely, and thus a subset of all possible futures to care about. But I think it’s not a large part of all possible futures (20% conditioning on AGI before 2030).
The First AGIs Will Have LLMs at Their Core
By “first AGIs” I mean the first systems able to automate all cognitive tasks.
AGI is likely to do reasoning and planning using LLMs. AGI might rely on vision models for some tasks and interactions with the world, and it might use explicit search processes like AlphaGo. But I expect LLMs to do plan generation and evaluation, which are the core of the system (from an Alignment point of view).
- Why: Vision systems are bad at coming up with and evaluating deceptive plans. Explicit search processes can’t generate and evaluate plans in the real world. LLMs seem to be able to do both plan generation and evaluation. (Plan generation and evaluation are the core tasks we would like to monitor to make AGIs safe, which is why I focus on those.)
End-to-end neural networks won’t be able to compete with LLMs when it comes to reasoning and planning, or at least, end-to-end networks will use “their LLMs parts” to do their most advanced form of reasoning and planning. This means that systems like Gato will either “behave like LLMs” to produce advanced plans (by generating language), or be out-competed by systems which do.
- Why: Advanced reasoning probably can’t be easily done with a single Transformer-like neural network forward pass, see next section for more details. Language is the only reasonably efficient pretraining medium where neural networks can learn to do reasoning and planning. (I give arguments for why post-fine-tuning reasoning is likely to be done with text in section C.)
Why this hypothesis is still likely to be wrong: Progress in AI is fast, LLMs didn’t look promising 5 years ago, and they might be outcompeted in the next decade. As more compute is used to train RL agents, fully black box RL agents might be able to generate and evaluate advanced plans without going through text generation at all.
Effective Plans to Defeat Humanity Can’t Be Found in a Single LLM Forward Pass
The LLMs composing the first AGI will be Transformer-like: they will only execute as many serial computation steps as they have layers, and will follow roughly the same scaling laws as transformers (with a speedup modeled by general “algorithmic speedup”). Note: the number of computation steps is the depth of the computation tree, not the number of “reasoning steps”, nor the number of FLOPs used.
- Why: Transformer’s training efficiency comes from the fact that you can compute in parrallel the activations of a layer at all positions, which is why I expect that networks will have at most ~#layers serial steps per forward pass.
For the sake of simplicity, I will call “Transformers” all Transformer-like neural networks.
LLMs composing the first AGIs will be Transformers with less than 2000 layers.
- Why: Before 2030, models with much more than 2000 layers are too expensive to train and would require too much compute and data to train. Extrapolating current scaling laws, training a 2000-layer Transformer would require as many FLOPs as the genome bio-anchor (see footnote for more details[1]).
Finding an effective plan to defeat humanity requires more than 2000 serial steps. Gradient descent might “hard-code” some deceptive strategies. But I expect that Transformers won’t play the full deceptive training game in one forward pass[2].
- Why: Complex reasoning needs many sequential steps. For example, imagining a possible scenario requires many serial steps. 2000 steps doesn’t feel enough. The human analogy somewhat supports this: neurons take about 1ms to fire (Britannica), and it takes minutes (>100k serial steps) for someone to find complex deceptive plans, even though they also have billions of neurons doing parallel computations.
During training, the network won’t learn a heuristic which, when followed, has the same effect as following a complex plan to defeat humanity. It can still learn simple sycophant heuristics, but not heuristics to defeat humanity. So if it took over, it would be because it would have gone trough the difficult process of finding a way to defeat humanity.
- Why: AI takeover requires some specific actions which you can not simply stumble upon, such as jointly hacking millions of devices to make critical infrastructure fail, and manipulating certain key actors to gain influence quickly. I expect that finding a successful sequence of actions to be hard because no group of humans has managed to put itself in a position where it freely controls the future of humanity. For the system to have learned heuristics to do these actions without having done the actual planning, it would require the training setup to have given rewards pointing towards these heuristics. But the reward system would have no reason to give rewards that develop the specific heuristics that lead to the specific actions needed for takeover, because you don’t get any reward if you follow the first 1% of a takeover plan (when it starts to differ from what you would do if you were simply following simple sycophant heuristics). Simple Sycophant heuristics don’t lead to the kind of takeover I’m afraid of.
Why this hypothesis is still likely to be wrong:
- Changing the architecture of AI models so that they have more internal serial steps might eventually outcompete today’s most efficient architectures;
- Techniques might be found to increase the number of layers of Transformer-like models by order of magnitudes;
- It might be possible to find advanced plans in only a few thousand serial steps if depth is large enough. Humans might be unable to do so simply because the human brain isn’t as efficient as a neural networked trained with gradient descent;
- Defeating humanity might not require advance planning abilities for AIs radically better than humans at certain key skills (hacking, manipulation, …), and thus even basic heuristics might be enough for the first AGIs to take over. For example, an AI is extremely good at hacking might defeat humanity if it followed the heuristics GPT-2 uses when writing a science-fiction story about AI taking over.
LLMs Will Solve Complex Tasks by Using English Text
The LLMs will be pretrained with next token predictions on human text.
- Why: Human text is a dense source of knowledge. Next token prediction gives LLMs much more information than RL can. Therefore, I think that LLMs using languages close to human ones will outcompete AI systems that build their own language from scratch.
They will be able to solve complex tasks by generating English text, which will contain results of intermediate computations, enabling them to solve tasks too complex to be solved in a single forward pass. For example, they may generate chains of thought or prompt other LLM instances.
- Why: This allows the system to solve tasks which require serial steps. There has also been some experimental success using chain of thought prompting to improve LLM performance on tasks which require many steps of thinking, for example, with Minerva on science QA, or Scratchpads for Intermediate Computation with Language Models. I have not seen convincing examples of LLMs performing well on tasks which require experienced humans over a minute of sequential thoughts[3]. Note: serial steps is an overestimation of the effective number of serial steps you get with generation, since most generated tokens don’t contain useful information, but if one every 10 token helps, then generating 4000 tokens still gives you 400 times more serial steps than reading 4000 tokens.
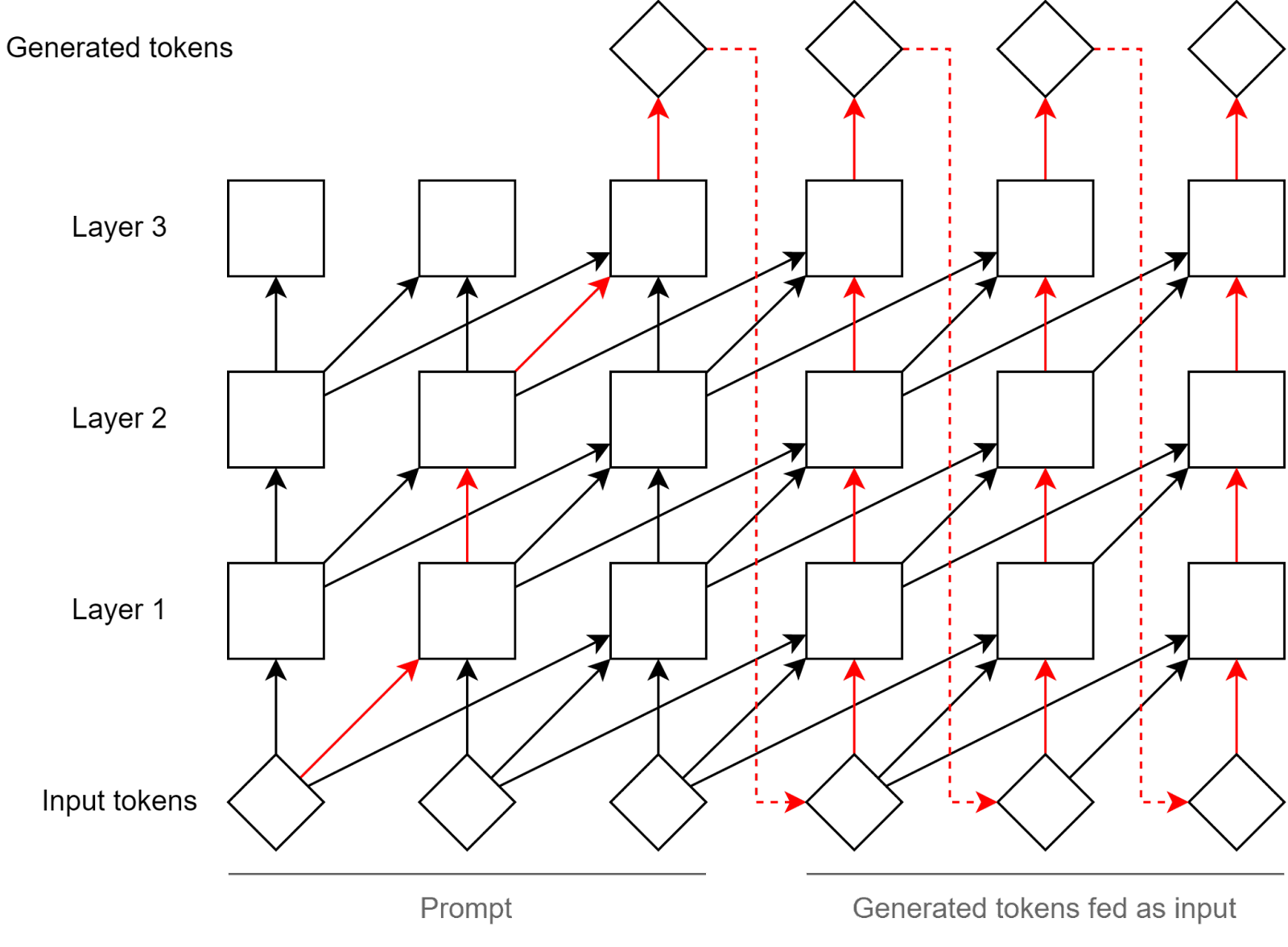
One forward pass allows only #layers serial steps, while generating tokens allows for #layers x #generation_steps serial steps. Figure from By Default, GPTs Think In Plain Sight [LW · GW]
This kind of procedure where tokens are sampled and fed to an LLM won’t be outcompeted by alternative architecture without the “sampling bottleneck” (for example, systems with internal analog memory, or recursively computed hidden states like RNNs).
- Why: Sampling a token and then feeding it to the LLM is a bottleneck on how much information can get through. But I think AIs without this bottleneck won’t outcompete the usual text generation process because:
- Sampling is a feature, not a bug. It allows selecting crucial information, removing noise, and choosing one “reasoning path” to be followed. This is somewhat supported by the human analogy: human reasoning seems to rely on something like sampling thoughts. It seems unlikely to me that the power of human reasoning comes from long chains of non-discrete heuristics (especially given that the content of my consciousness seems to be discrete to me).
- Sampling allows the models to deal with input data much closer to the pretraining distribution. This means that the power of generation comes almost “for free”. In contrast, to use higher bandwidth internal communication channel, the system would have to develop whole new circuits from scratch. This might be really hard, since rewards for developing such circuits are very sparse (because the whole purpose of this internal language is to reason over thousands of serial steps).
When I say “English”, I mean any language for which there is a lot of available human text. This English could, as a result of fine-tuning, be packed with hidden information that humans can’t read. But it uses at least a little bit the English language in its intermediate generations steps, it’s not a completely opaque scratchpad. Note: this definition is a bit fuzzy. I think it would be fair to say that an AI has not translucent thoughts if its scratchpad is mostly opaque, even if you can understand some small parts of it.
- Why: Pretraining taught the system most of what it knows, and the easiest way to use this knowledge about “how to reason” is to use the language the system is trained to use. English is far from being optimal, but using the full extent of the 50k tokens would require rebuilding circuits to read, write and reason, which is likely to be too hard for RL to handle.
Note: I think that LLMs trained purely on human generated text (and without strong inner optimizers) won’t hide crucial information in their generations, because the information they put inside generations is the information humans would have put in their texts. Most of the information humans put in their text is put there unconsciously and might therefore not be easily recoverable, but the kind of information a text needs to contain to be significant progress towards finding a plan to defeat humanity (which is “crucial information”) is not the kind of information humans put in their text without thinking about it.
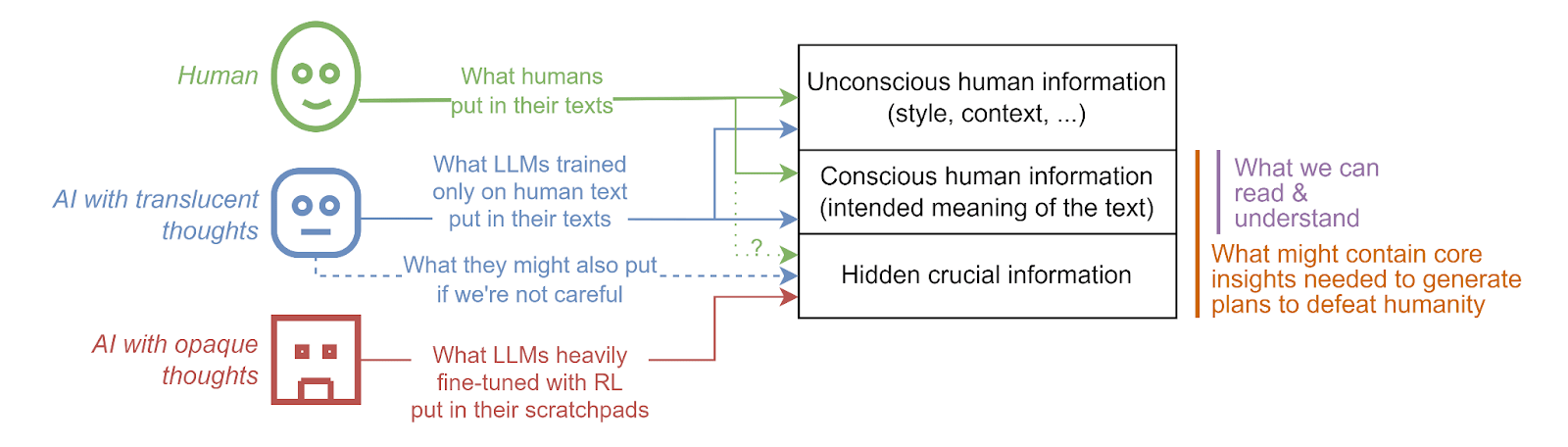
Why this hypothesis is still likely to be wrong: RL might be much more powerful than I expect it to be when enough compute is used. This would make AIs trained with RL able to build and use a language much more powerful than English, outcompeting AIs using English as high level language of thought. This could make scratchpads of the first AGIs completely opaque. It could even bypass the need for a scratchpad at all if I’m wrong about the strength of the sample + broadcast algorithm, and if direct analog communication channels yield better systems.
Research Directions
If the Translucent Thoughts hypotheses are true, then the first AGIs would look like LLMs too dumb to create and execute a plan to defeat humanity in a single forward pass, but which can do all relevant tasks when they generate English text (through chains of thought, cross-LLMs prompting, …).
Aligning different types of systems requires different techniques and ideas. While there may be some overlap, aligning an AGI with translucent thoughts is different from aligning an end-to-end network trained with RL which is different from aligning an ideal optimizer maximizing a reward function. Thus, if the Translucent Thoughts hypotheses are true, certain research directions may be more useful than others
Introduction: What a Safe AGI Could Look Like
Here is a description of what a safe AGI could be in a world in which the Translucent Thoughts hypotheses are true. It is heavily inspired by AI systems described in Externalized reasoning oversight [LW · GW], The Open Agency Model [AF · GW], Factored Cognition [AF · GW] and discussions I’ve had with Siméon.
The description adds assumptions that probably won’t be met if a system like that is developed with more powerful LLMs and today’s Alignment techniques. Some research directions below are paths towards making them true.
When a user asks the system to solve a task, an LLM reads the task description and prompts other LLMs on subprocesses. In turn, these LLMs launch other LLMs (like HCH [AF · GW]), etc. The LLMs might invoke special utilities like Monte Carlo tree search, file readers & writers, image recognitions or image generations, by using special tokens. These LLMs communicate using only understandable English: the information present in the text is exactly the information a human would extract from it. The whole system just does what the best humans can already do, only on a larger scale, much faster and with less noise. They communicate at a fast pace, but an oversight system enables humans to have an overview of what the system does, and brings specific generations to the human attention. On critical tasks, or where the oversight system detects something different from the kind of behavior previously seen and inspected, each generation is inspected by several independent teams of humans before it is fed to its target LLM or utility. When the system comes up with the concept, the system is paused and inspected so that overseers can understand what this concept means and how it was born, so that the overseers are able to always follow what the system is doing. If a problem is detected, the oversight system can kill the problematic generation and start a new one using a different seed. LLMs can also be tuned in a way that preserves the nice properties described above. Because the system was trained to act like humans and look good to AI augmented humans, it often follows dumb sycophant heuristics, but people know that and they are still able to make amazing progress by only using the system for tasks where that’s not an issue[4].
What makes this system safe is that every part of the system is too dumb to plan something that involves hiding information from humans or escaping supervision. Communication happens in plain English and doesn’t contain information that humans can’t understand. Therefore, even though the whole system is slightly above human level the overseers can catch and stop any plan to deceive humans and escape supervision.
This exact description is just one example of safe AGI in a world of which the Translucent Thoughts hypotheses are true. A possible research direction is to find other examples of safe AGIs (conditioning on Translucent Thoughts hypotheses), with assumptions that are less demanding than the AI system described above.
Making LLMs Use Only Understandable English
As gwern explains in this comment [AF(p) · GW(p)], we should expect that LLMs will hide information in their generations by default, even for LLMs trained on next token predictions on internet text
Here is why:
- Models trained with RLHF (Reinforcement Learning From Human Feedback) have incentives to hide information in generated text (which is called steganography [AF · GW]) if it leads to more accurate answers, which it may because that gives the model time to think (more serial steps) without wasting output tokens. See gwern’s comment [AF(p) · GW(p)] for a detailed example of how it might happen in practice;
- Humans have incentives to let the model use steganography to get higher accuracy;
- Humans might have incentives to teach the model steganography to watermark generations,
- LLMs trained purely on next-token prediction but on text partially written by LLM using steganography will have incentives to learn the steganographic schemes of the training data.
Here are plausible mitigation strategies. I expect them to be hard, but worth exploring:
- Prevent models from using steganography enough that you could find provable and low bounds on how much data it can send itself. For example, you could tamper with model generations (and pay the alignment tax associated with it);
- Find steganography detection techniques (and maybe train against them?);
- Learn to decipher steganographic encodings. This feels really hard, but tractable since this is a game human can play by purposefully adding steganography to their models;
- Find model modification techniques which are too weak to make the model learn steganography, and then use those on a model without LLM-generated data (there might be good detectors, or you could only use old data). Advanced steganography will likely need parts which are responsible for encryption and decryption. Here are potential techniques which might be not expressive enough to build those parts:
- Rejection sampling (RM-weighted decoding, verifier voting, filtering & clustering, …)
- Ablations
- Prompt tuning
- RL with a small number of steps or on small a subset of the network's weights, such as biases or the last layer.
- Find training setups which don’t incentives steganography. Pretraining and fine-tuning on human generated data is one of them. But there might be ways to adapt other modification techniques (such as RL) to remove incentives to do steganography.
Building an Oversight System
You would need an advanced oversight system to supervise an AI even if it has transparent thoughts, beyond what is currently possible. It should:
- Summarize the process of thousands of LLMs instantiations communicating with each others,
- Pull out crucial pieces of generated text,
- Identify novel behaviors so that humans can study them in detail before moving on,
- Identify crucial tasks and subtasks so that humans can slow down the generation process and monitor them closely,
- Do all of the above with a tiny false negative rate[5].
Here are some directions which might help:
- Reliable summarization of networks of LLMs behaviors;
- Clustering of LLMs behaviors;
- Training robust text classifiers using very few positive data points, for example by asking LLM to write the code for a rule-based classifier based on examples it has seen;
Note: the challenges of this oversight system are different and easier than the challenges of oversight described in AGI safety from first principles [? · GW], because this oversight system inspects “thoughts”, not actions. Therefore, it doesn’t need to anticipate the future effects or the societal effects of what it measures. See Supervise Process, not Outcomes [LW · GW] for more details.
Revisiting Concepts and Arguments
Classic arguments which detail reasons for concern about AI could be examined again, conditioning on the Translucent Thoughts hypotheses. This could look like:
- Checking how much the high level assumptions the arguments make hold if the Translucent Thoughts hypotheses are true. This would narrow down the core difficulties of aligning the first AGI systems;
- Applying the arguments to AGIs with translucent thoughts to build a more detailed model of what the failure would look like. This could spark ideas to mitigate the risks.
This could be applied to arguments such as How likely is deceptive alignment? [LW · GW] (What would deception look like for AIs with translucent thoughts? Is it path dependent?), Why AI alignment could be hard with modern deep learning (How could SGD find deceptive strategies with these AI systems?) and AGI safety from first principles [? · GW] (Would these kinds of system be agentic?).
Testing the Hypotheses
A detailed analysis of the Translucent Thoughts hypotheses can help determine if they are realistic or unrealistic, which in turn can help researchers decide if pursuing projects conditioned on those hypotheses is worthwhile.
Conducting experiments with small neural networks, simple Mathematical models, or human subjects can help identify the minimum number of layers and reasoning steps required for a system to generate creative and powerful plans. This can help determine the validity of the Translucent Thoughts hypotheses and increase (or decrease) confidence in AI systems that use a low number of serial steps.
Making the Hypotheses True?
If the Translucent Thoughts hypotheses are accurate, we are more likely to survive the first AGIs than if the hypotheses are not valid. This is because the most probable alternative would likely involve black box systems optimized with Reinforcement Learning, which are much harder to supervise. Therefore, research efforts that focus on building powerful AI systems through the assembly of large language models (LLMs) like GPT, which are primarily trained for next-token prediction, may be safer and more valuable than other kinds of capabilities research. This could potentially lead to positive differential technological progress.
I expect that building such systems is not what independent researchers and small groups should do, but I would be excited if some of the money and talents being spent today on improving RLHF and scaling the size of Transformers was being retargeted towards building networks of LLMs.
Related work
Externalized Reasoning Oversight
In short: It describes systems which also “think” with explicit reasoning in English, don’t hide information in their reasoning, but also make all reasoning steps explicit (which is really hard to formalize), and don’t output reasoning steps which are not used to generate the answer (which might be hard to get in practice). I think these last two constraints can be safely ignored if models can’t find deceptive plans in a single forward pass.
In Externalized reasoning oversight [LW · GW], Tamera describes an alignment proposal which relies on making AIs with authentic reasoning - reasoning which is complete, straightforward, and causally responsible for the output - and oversee the reasoning to give feedback based on the reasoning itself and to make sure nothing wrong happens). The post does not make the case for competitiveness, but it gives research directions which significantly overlap with the ones I described.
But authentic reasoning is a much more stringent condition than the absence of hidden crucial information in the model’s outputs (which Tamera calls straightforward reasoning).
Completeness
An authentic reasoner should make everything humans think are “important steps”, even when it can do in a single forward pass.
Why ensuring completeness is hard: For many tasks, making the reasoning explicit will be much harder than learning to do it in a single forward pass, thereby severely limiting the power of the system. Moreover, as the author points out in the original paper, completeness is not well defined because there isn’t a clear definition of what a step should be.
Causality
An authentic reasoner would have to not give useless reasoning steps. For example, when ChatGPT answers “A” then proceeds to explain for 4 paragraphs why the answer is “A”, it’s not causally related to the answer it has given.
Why ensuring causality is hard: Human text is full of wrong justifications, and unconscious information - such as context and style - plays a large role in LLMs outputs (making the causal role of “conscious human information” weaker). For example, few shot learning helps, but not for the reasons you might expect (see Rethinking the Role of Demonstrations). Therefore, it might not be easy to make a system generate only causally relevant steps.
Why I think completeness & causality are overated
The only task for which a lack of transparency would be fatal are complicated task such as finding a plan to defeat humanity. I believe those tasks can’t be solved in a single forward pass, even if it tried. Therefore, it’s not a problem if you can’t “expand” a reasoning into multiple explicit steps, or if the model just makes up a non causal explanation.
Therefore, I prefer to replace “the model is forbidden to skip/not use what humans think are quite important steps” by “for extremely hard tasks, the model is computationally incapable of skipping all relevant steps and has to use at least some intermediate steps it made explicit”.
If a model can’t defeat humanity without having explicit thoughts about it because of computational constraints, and generate neither complete nor causally relevant thoughts, then it would produce many completely unauthentic explanations, and this can lead to false alarms, but it won’t be able to craft a plan to defeat humanity without getting caught.
Conditioning Predictive Models
In short: It describes how one might use extremeley powerful AIs trained purely on prediction. This also relies on pretrained models being competitive with other AI systems. It’s safety guarantees would not come from the weakness of the individual parts of the system, but rather from the properties of a system which tries to do “pure prediction”. This yields very different research directions, but both approaches can be combined.
In Conditioning Predictive Models [? · GW], the authors lay down what would be needed to safely use predictive models if one wasn’t able to look inside them.
For this approach to be useful, predictive models must be competitive with other types of AI systems. As a result, I think they are describing systems not that far from the one described above.
| Translucent Thoughts hypotheses | Conditioning Predictive Models | Agreement |
| The first AGIs will have LLMs at their core. | The first AGIs will be predictive systems. (Because other modalities than text are less data efficient, the core predictive process will likely be driven by LLMs.) | Medium (but not exclusive) |
| Effective plans to defeat humanity can’t be found in a single LLM forward pass. | Predictive models might have any level of power. | Low (but not exclusive) |
| LLMs will solve complex tasks by using English text (self-prompting, scratch pads, combination of expert LLMs, …). | LLMs will solve complex tasks by predicting what a naturally occurring human process would generate (mainly, what insights humans would find given the right settings). | Medium (but not exclusive) |
Thus, these approaches yield slightly different predictions and different research directions:
| Translucent Thoughts hypotheses | Conditioning Predictive Models |
| Models trained with RL might be unsafe because their generations are more likely to contain a lot of steganographically encoded crucial information. | Models trained with RL might be unsafe because they might have learned to try to achieve something in the world instead of doing pure prediction. |
| Safe AGI might be built if steganography is prevented and if adequate supervisions processes for AI systems with transparent thoughts are found. | Safe AGI might be built if powerful predictions tasks which are unlikely to result in the model predicting what a misaligned AGI would say are found. |
| You might get safety guarantees through an analysis of the maximum power of a single forward pass, theoretical or empirical work showing a particular setup doesn’t enable the use of steganography, and supervision of the communication between parts. | You might get safety guarantees through a theoretical analysis of what a perfect predictor would do, and an empirical or theoritical evaluation of the properties of approximate conditioned predictive models. |
Overall, Conditioning Predictive Models is an adjacent but different research frameworks working with slightly different and compatible assumptions. Their lens seems to leave more room for armchair thinking (though they also outline many empirical open problems), while the research directions I suggest (such as the study of steganography) are mostly empirical.
The Open Agency Model
In short: It describes AI systems which work through an explicit decomposition of high level tasks through planning and evaluation in natural language, then execution by very simple RL agents. It interpreted strictly, it’s a tiny subset of AIs with Translucent Thoughts which does not look competitive. If interpreted loosely, it looks a lot like AIs with Translucent Thoughts, without strong safety guarantees.
The Open Agency Model [AF · GW] (by Eric Drexler) describes AI systems where “Generative planning models respond to goals as prompts”, “Plan descriptions are externalized and interpretable”, plans are selected through a selection process which confronts the points of view of “diverse agents”, and selected plans are implemented by dumb agents in small, bounded tasks.
Eric Drexler describes a set of AI systems which is either a subset of safe AGIs with transparent thoughts or a subset of AIs with Translucent Thoughts.
I’m unsure how strict the definition of an Open Agent is supposed to be. Here, I’ll describe the relations between two extreme interpretations of Open Agents, and what is described in this post.
Strict Open Agents
The feedback from the world only improves the dumb agents. The evaluation system as well as the generation system are only imitating humans or following hard-coded rules. The plans are generated in a single pass, without querying the evaluation process to prune or guide the search. The generation and evaluation systems have no knowledge about the details of the dumb agents. Each part of the system is too dumb to take over. In particular, the part of the system responsible for plan generation is too dumb to do anything dangerous such as generating code, or manipulating humans, which is a strong upper bound on its general abilities.
This is a super restrictive kind of AI system. It looks hard to make such a system because the current best ways to generate plans is to use the best possible Language Model, and for such a system, strong abilities at plan generation is usually tangled with strong abilities at code generation & manipulation.
This kind a Open Agent is such a small subset of the systems I describe here that the general problems of AIs with translucent thoughts do not apply, and are replaced with extremely hard technical challenges and a plan which I don’t find competitive with other approaches.
General Open Agents
The feedback from the world can flow back to the evaluation and generation processes. Plans are generated through many cycles of generation and evaluation, and evaluation can contain commentary to improve it further. The only constraint is that each communication between part of the system have to be done in English text. A pretrained LLM is used as a foundation for the generation process, the evaluation process, and some “dumb agents”, but on its own, the pretrained model is too dumb to imagine and execute a plan to defeat humanity in a single forward pass (so that it doesn’t try to game the system it is in).
This is indistinguishable from the Translucent Thoughts hypotheses. It inherits the safety problems that AIs with Translucent Thoughts have by default.
Factored Cognition
In Factored Cognition [AF · GW], Andreas Stuhlmüller (from Ought) describes the idea that tasks can be can be decomposed into small pieces, and that this can be used to build supervisable AI systems.
The kind of AI system he describes is an instance of AI with translucent thoughts: each part of the system is too dumb to do anything dangerous in a single forward pass, and the different parts of the system prompt themselves through English text.
From what I’ve read, the Factored Cognition project is mostly focused on making an AI with translucent thoughts work, rather than analyzing it’s potential safety issues.
Note: Ought has shifted its focus towards another project (see here [AF(p) · GW(p)]) and I’m not aware of anyone else working on this at the moment.
- ^
Using table 3 from the Chinchilla paper, and assuming that is proportional to , then the lifetime anchor ( FLOPs) optimal network has the size of Chinchilla (80 layers), and the genom anchor (FLOPs) optimal network has 3000T parameters, which corresponds to 2000 layers. is proportional to is not a well-known scaling law, it’s just what you can observe in Palm ( in the log linear regression), for Pythia models too (), and also for GPT-3 models () (all models combined gives you ). This last log-linear models predict 1270 layers for a 3000T parameters model, and the Palm one predicts 1820 layers. This is highly speculative, as the bassin of “good amount of layer” is quite large, and thus layer scaling laws are much weaker than data/compute scaling laws.
- ^
See How Likely Is Deceptive Alignment [LW · GW] by Hubinger. Here is the kind of thoughts and reasoning I expect are too long to fit in a single forward pass: “Given what I know about my training setup and my future deployment setup, it’s likely that I’m being trained. Given my long term goals, and given I’m in training, it’s better to achieve low loss so that my goals aren’t trained away by SGD. Given what I know about the training setup, what I have to do is Y. To do Y, the next token to output to get low training loss is X. Therefore output X.” and “Given what I know about my training setup and my future deployment setup, it’s likely that I’m deployed. Given my long term goals, and given I’m in deployment, it’s better to take control of humanity. To take control of humanity, the next step to take is Y. To do Y, the next token to output is X. Therefore, output X.”
- ^
In tasks where the answer is only a few tokens long, and for which the thoughts can’t be done “as you read the text”. For example, text summarization or evaluating which one of two SQL queries is the best one are tasks which can be done “as you read the text”, which is not the case for figuring out if a mathematical statement is true or false (for most Maths statements not memorized during training).
- ^
For example, you wouldn’t ask it “am I right to think that I should nuke France”, or the system might be heavily biased towards giving you an answer consistent with your beliefs, even if it’s not explicitly thinking about how to give you an answer consistent with your beliefs. I think humans sometimes follow this kind of unconscious heuristics, which is why I expect them to also exist in LLMs.
- ^
The false negative rate needs to be especially high if the LLMs can’t be tuned to output less deceptive plans. But if it LLMs can be tuned, then a false negative rate of might be enough to get to a very low take over probability: if each instance of deceptive plan enables feedback that increases by 1% the time between deceptive plan generations, and if at the beginning, the system generates one deceptive plan per hour, then if you run the model for 10 years, it would have a probability of 0.0006 to generate a deceptive plan which doesn't get caught (while this probability would be 0.08 without any learning).
7 comments
Comments sorted by top scores.
comment by [deleted] · 2023-03-10T04:21:42.009Z · LW(p) · GW(p)
Note you have created a less safe system than CAIS but re-discovered the same safety principle.
CAIS explicitly uses interpretable plans as the intermediary, rather than thoughts. 1,2
AIs are stateless - they do not have any context but the files you feed them. (stateless microservices)
So you ask AI A for a plan to do X, and also ask n more AIs and analyze them.
Then you ask AI B to see if AI A's plan has any obvious flaws (checking against n more AIs). 3
Then you ask AI C, D, E... to actually implement the plan, if it passes review, using different hierarchies of control. (so for a construction site one system might take in the current state of the project and order new things to be done. And other system might coordinate multiple robots, while another system might control individual robots to actually accomplish something)
2. https://www.lesswrong.com/posts/5hApNw5f7uG8RXxGS/the-open-agency-model
3. https://www.lesswrong.com/posts/HByDKLLdaWEcA2QQD/applying-superintelligence-without-collusion [LW · GW]
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-03-10T08:23:04.092Z · LW(p) · GW(p)
I agree that ideas are similar, and that CAIS are probably more safe than AI with translucent thoughts (by default).
What I wanted to do here is to define a set of AIs broader than CAIS and Open Agents, because I think that the current trajectory of AI does not point towards strict open agents aka small dumb AIs trained / fine-tuned independently and used jointly, and doing small bounded tasks (for example, it does not generate 10000 tokens to decide what to do next, then proceeds to launch 5 API calls and a python script, and prompts a new LLM instance on the result of these calls).
AI with translucent thoughts would include other kinds of system I think are probably much more competitive, like systems of LLMs trained jointly using RL / your favorite method, or LLMs producing long generation with a lot of "freedom" (to such an extent that considering it a safe microservice would not apply).
I think there is a 20% chance that the first AGIs have translucent thoughts. I think there is 5% chance that they are "strict open agents". Do you agree?
Replies from: None↑ comment by [deleted] · 2023-03-10T09:03:51.606Z · LW(p) · GW(p)
No. I think AIs used to do useful things competitive with human professionals will be 90% or more stateless open agents.
There is simply not a feasible way to get sufficient reliability without this.
This means you, yes, might use an llm to interpret what a human wants to do, fill out paperwork, etc.
But a task like 'validate this bridge design' or 'diagnose this patient' or 'remove the brake module from this car and install a replacement' you need those many 9s of reliability.
Open agents have a human readable file of what they are there to accomplish, a series of state frames, and are completely deterministic, relying on nothing but the (input frames, file instructing them what to do) to make their decisions.
Note I have added the idea of 'stateless microservices', which essentially all large software systems today use (every online service that is reliable I know of uses them) on to "open agents", from my years of debugging complex systems.
You are just not going to get it reliable enough to even ship the first time if you don't have such a tight architecture. How can you debug a "real" general intelligence that works like a human? You can't, the machine has "thoughts" and changes over time and it's own goals and so on and so forth. Infeasible.
You will not get to the point of boxing said systems because they aren't usable in production to begin with.
Note that all AI systems, except perhaps a few tiny research toys, are currently stateless. Robotics control systems like for autonomous cars are also already build as open agency systems, and again, this is true for all of them I am aware of. So this is not a stretch or a big effort, it's what the engineers are already doing.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-03-10T12:15:01.986Z · LW(p) · GW(p)
Mmh, interesting, I hadn't thought of it from the need-for-robustness angle.
Do you think it matters because LLMs are inherently less robust than humans, and therefore you can't just replace humans by general-ish things? Some companies do work as a combination of micro-entities which are extremely predictable and robust, and the more predictable/robust the better. Do you think that every entity that produces value have to follow this structure?
I disagree with what you said about statelessness because the AI with translucent thoughts I describe are mostly stateless. The difference between CAIS & AI with translucent thoughts is not the possibility of a state, it's the possibility of joint training & long "free" text generations which makes hidden coordination & not-micro thinking possible.
Replies from: None↑ comment by [deleted] · 2023-03-10T18:44:44.529Z · LW(p) · GW(p)
That free text generation is state buildup. It's the cause of most software failure since the beginning.
Current llms, because they have only a single buffer which is human readable as their state are fairly safe. The danger comes if we start hiding memory cells in network layers. Where unexaminable values are being stored, and from frame to frame these values are being used in a hidden way (to maximize reward)
When you say translucent thoughts you are proposing we structure ourselves exactly WHAT the machine can store from frame to frame, and we can validate this such as by having a different model "pick up" from a frame and complete a task.
If task performance drops because the stored data wasn't formatted correctly (the AI hijacked the bits to store something else) we can automatically measure this and take action.
comment by Charlie Steiner · 2023-03-12T16:47:46.667Z · LW(p) · GW(p)
I'm pessimistic about the chances of this happening automatically, or requiring no expensive tradeoffs, because training networks to have good performance will disupt the human interpretability of intermediate representations, even if we think those representations look like text. But I do think it's interesting, and that attempts to make auditing via intepretable intermediate representations work (and pay the costs) aren't automatically doomed.
comment by Review Bot · 2024-04-05T14:36:10.852Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?