Factored Cognition
post by stuhlmueller · 2018-12-05T01:01:43.544Z · LW · GW · 6 commentsContents
6 comments
Note: This post (originally published here) is the transcript of a presentation about a project worked on at the non-profit Ought. It is included in the sequence because it contains a very clear explanation of some of the key ideas behind iterated amplification.
The presentation below motivates our Factored Cognition project from an AI alignment angle and describes the state of our work as of May 2018. Andreas gave versions of this presentation at CHAI (4/25), a Deepmind-FHI seminar (5/24) and FHI (5/25).

I'll talk about Factored Cognition, our current main project at Ought. This is joint work with Ozzie Gooen, Ben Rachbach, Andrew Schreiber, Ben Weinstein-Raun, and (as board members) Paul Christiano and Owain Evans.

Before I get into the details of the project, I want to talk about the broader research program that it is part of. And to do that, I want to talk about research programs for AGI more generally.
Right now, the dominant paradigm for researchers who explicitly work towards AGI is what you could call "scalable learning and planning in complex environments". This paradigm substantially relies on training agents in simulated physical environments to solve tasks that are similar to the sorts of tasks animals and humans can solve, sometimes in isolation and sometimes in competitive multi-agent settings.
To be clear, not all tasks are physical tasks. There's also interest in more abstract environments as in the case of playing Go, proving theorems, or participating in goal-based dialog.
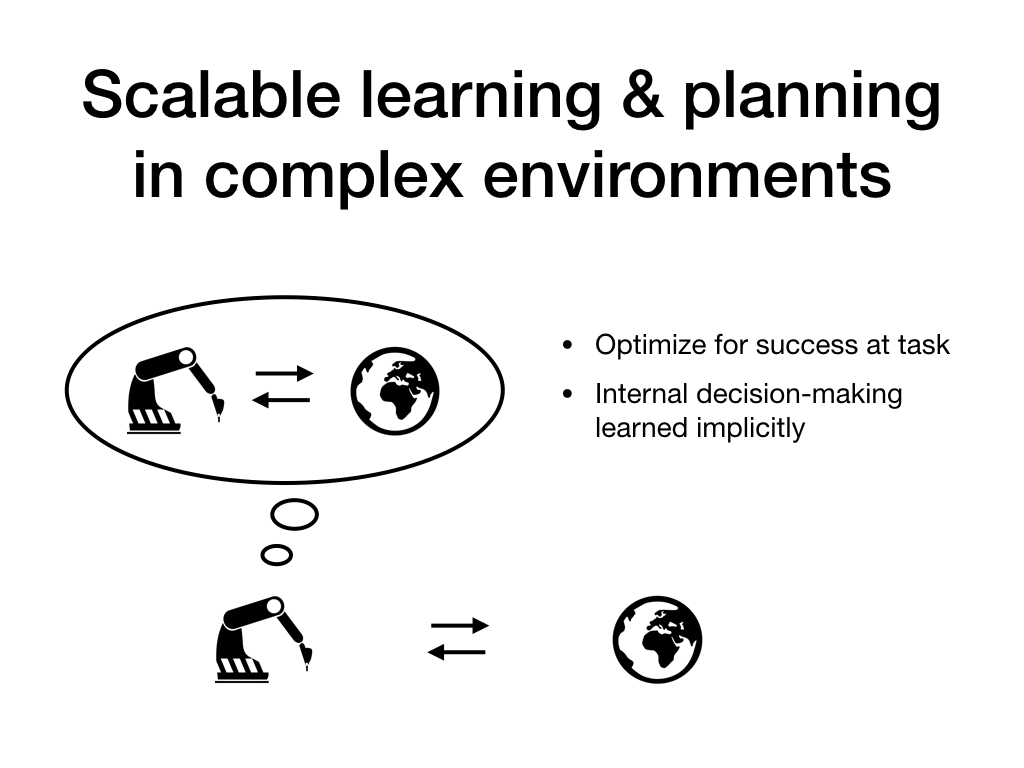
For our purposes, the key characteristic of this research paradigm is that agents are optimized for success at particular tasks. To the extent that they learn particular decision-making strategies, those are learned implicitly. We only provide external supervision, and it wouldn't be entirely wrong to call this sort of approach "recapitulating evolution", even if this isn't exactly what is going on most of the time.
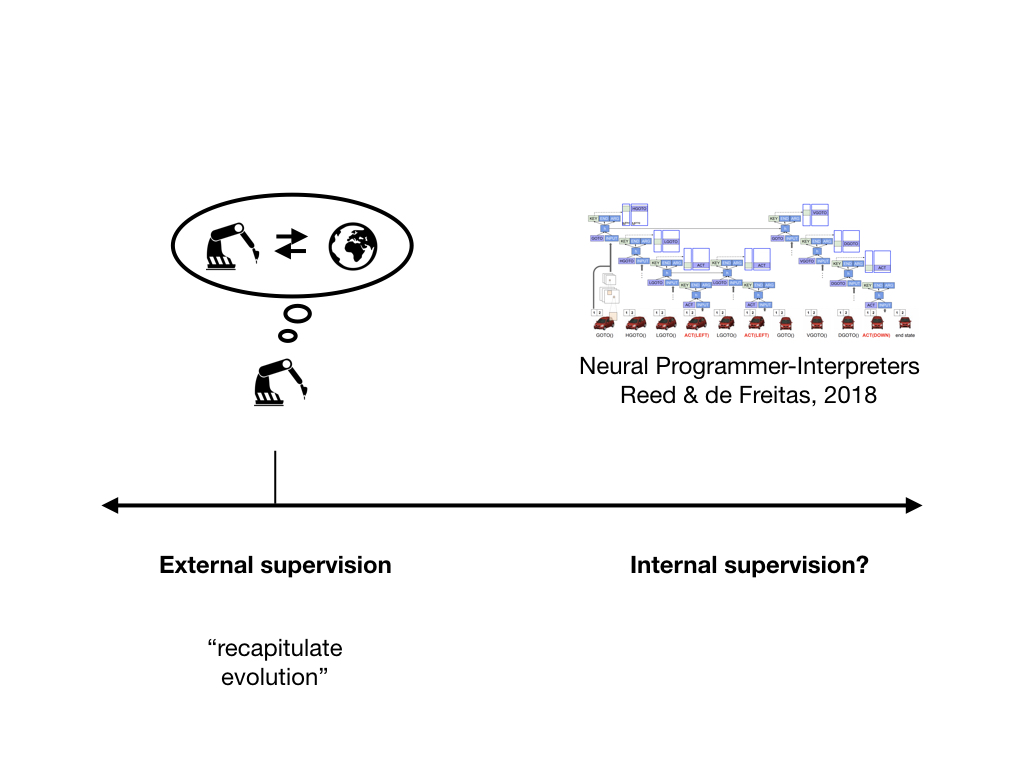
As many people have pointed out, it could be difficult to become confident that a system produced through this sort of process is aligned - that is, that all its cognitive work is actually directed towards solving the tasks it is intended to help with. The reason for this is that alignment is a property of the decision-making process (what the system is "trying to do"), but that is unobserved and only implicitly controlled.
Aside: Could more advanced approaches to transparency and interpretability help here? They'd certainly be useful in diagnosing failures, but unless we can also leverage them for training, we might still be stuck with architectures that are difficult to align.
What's the alternative? It is what we could call internal supervision - supervising not just input-output behavior, but also cognitive processes. There is some prior work, with Neural Programmer-Interpreters perhaps being the most notable instance of that class. However, depending on how you look at it, there is currently much less interest in such approaches than in end-to-end training, which isn't surprising: A big part of the appeal of AI over traditional programming is that you don't need to specify how exactly problems are solved.
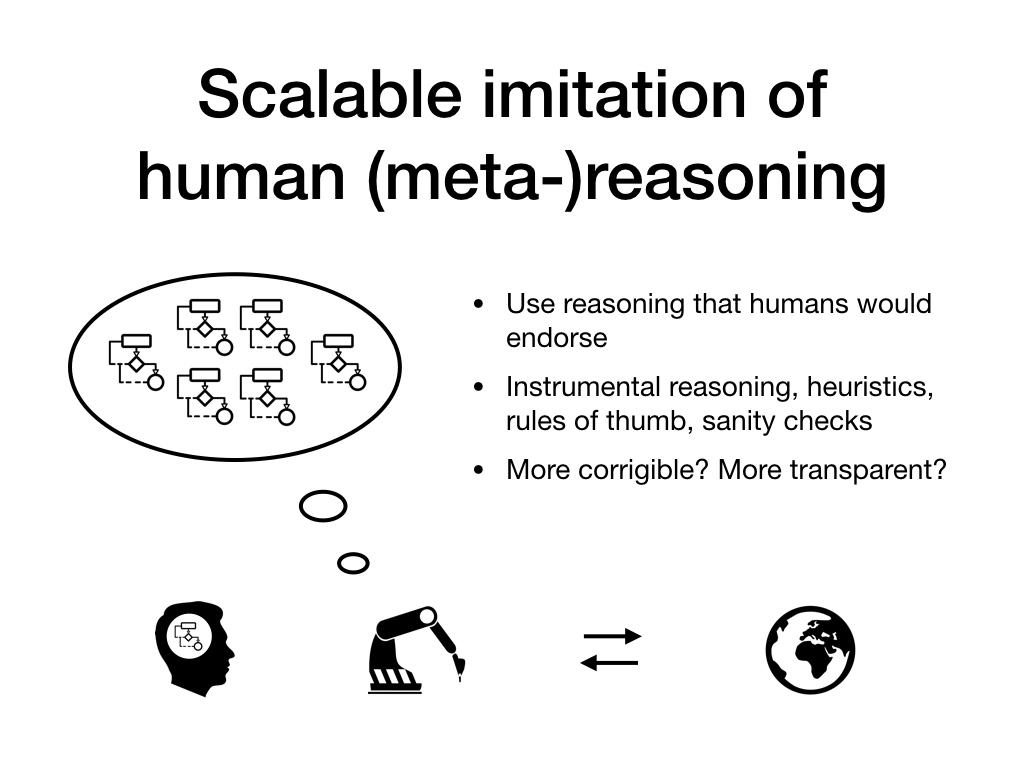
In this talk, I'll discuss an alternative research program for AGI based on internal supervision. This program is based on imitating human reasoning and meta-reasoning, and will be much less developed than the one based on external supervision and training in complex environments.
The goal for this alternative program is to codify reasoning that people consider "good" ("helpful", "corrigible", "conservative"). This could include some principles of good reasoning that we know how to formalize (such as probability theory and expected value calculations), but could also include heuristics and sanity checks that are only locally valid.
For a system built this way, it could be substantially easier to become confident that it is aligned. Any bad outcomes would need to be produced through a sequence of human-endorsed reasoning steps. This is far from a guarantee that the resulting behavior is good, but seems like a much better starting point. (See e.g. Dewey 2017.)
The hope would be to (wherever possible) punt on solving hard problems such as what decision theory agents should use, and how to approach epistemology and value learning, and instead to build AI systems that inherit our epistemic situation, i.e. that are uncertain about those topics to the extent that we are uncertain.
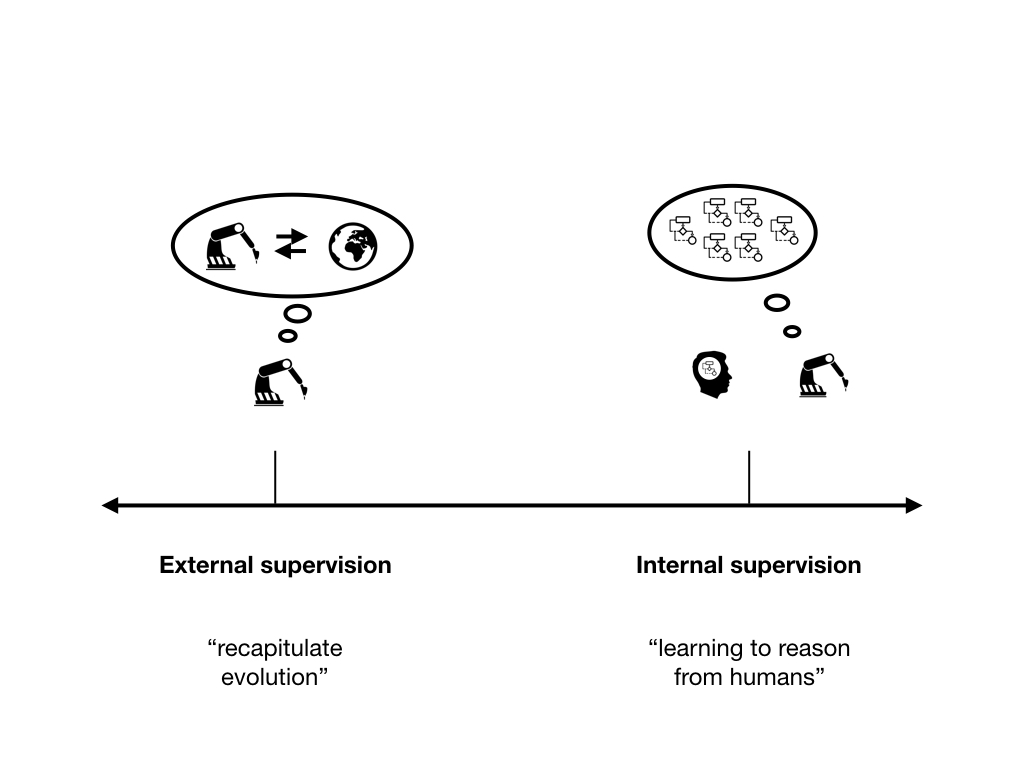
I've described external and internal supervision as different approaches, but in reality there is a spectrum, and it is likely that practical systems will combine both.
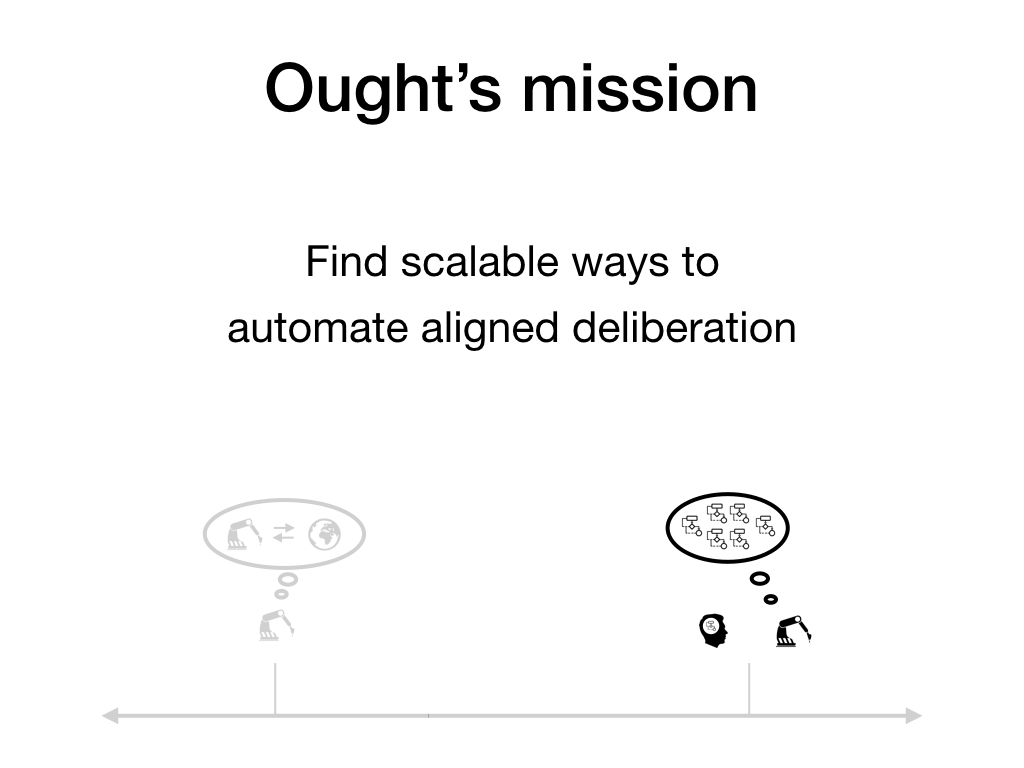
However, the right end of the spectrum - and especially approaches based on learning to reason from humans - are more neglected right now. Ought aims to specifically make progress on automating human-like or human-endorsed deliberation.
A key challenge for these approaches is scalability: Even if we could learn to imitate how humans solve particular cognitive tasks, that wouldn't be enough. In most cases where we figured out how to automate cognition, we didn't just match human ability, but exceeded it, sometimes by a large margin. Therefore, one of the features we'd want an approach to AI based on imitating human metareasoning to have is a story for how we could use that approach to eventually exceed human ability.
Aside: Usually, I fold "aligned" into the definition of "scalable" and describe Ought's mission as "finding scalable ways to leverage ML for deliberation".

What does it mean to "automate deliberation"? Unlike in more concrete settings such as playing a game of Go, this is not immediately clear.
For Go, there's a clear task (choose moves based on a game state), there's relevant data (recorded human games), and there's an obvious objective (to win the game). For deliberation, none of these are obvious.

As a task, we'll choose question-answering. This encompasses basically all other tasks, at least if questions are allowed to be big (i.e. can point to external data).

The data we'll train on will be recorded human actions in cognitive workspaces. I'll show an example in a couple of slides. The basic idea is to make thinking explicit by requiring people to break it down into small reasoning steps, to limit contextual information, and to record what information is available at each step.
An important point here is that our goal is not to capture human reasoning exactly as it is in day-to-day life, but to capture a way of reasoning that people would endorse. This is important, because the strategies we need to use to make thinking explicit will necessarily change how people think.
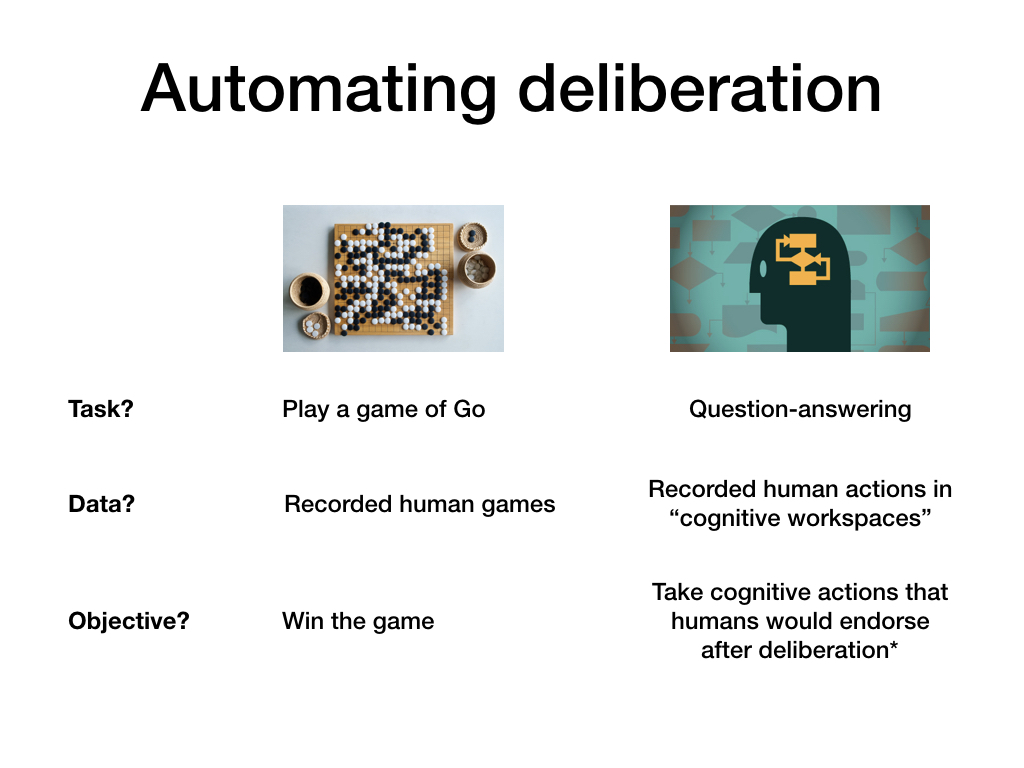
Finally, the objective will be to choose cognitive actions that people would endorse after deliberation.
Note the weird loop - since our task is automating deliberation, the objective is partially defined in terms of the behavior that we are aiming to improve throughout the training process. This suggests that we might be able to set up training dynamics where the supervision signal always stays a step ahead of the current best system, analogous to GANs and self-play.

We can decompose the problem of automating deliberation into two parts:
- How can we make deliberation sufficiently explicit that we could in principle replicate it using machine learning? In other words, how do we generate the appropriate kind of training data?
- How do we actually automate it?
In case you're familiar with Iterated Distillation and Amplification: The two parts roughly correspond to amplification (first part) and distillation (second part).
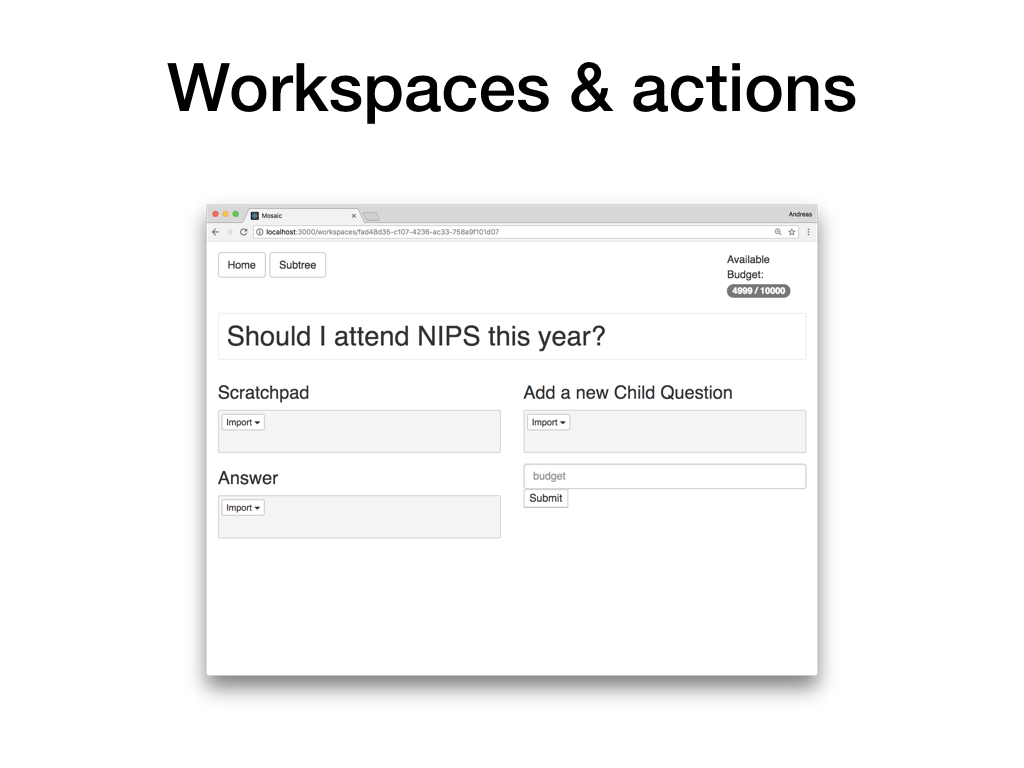
The core concept behind our approach is that of a cognitive workspace. A workspace is associated with a question and a human user is tasked with making progress on thinking through that question. To do so, they have multiple actions available:
- They can reply to the question.
- They can edit a scratchpad, writing down notes about intermediate results and ideas on how to make progress on this question.
- They can ask sub-questions that help them answer the overall question.
Sub-questions are answered in the same way, each by a different user. This gives rise to a tree of questions and answers. The size of this tree is controlled by a budget that is associated with each workspace and that the corresponding user can distribute over sub-questions.
The approach we'll take to automating cognition is based on recording and imitating actions in such workspaces. Apart from information passed in through the question and through answers to sub-questions, each workspace is isolated from the others. If we show each workspace to a different user and limit the total time for each workspace to be short, e.g. 15 minutes, we factor the problem-solving process in a way that guarantees that there is no unobserved latent state that is accumulated over time.

There are a few more technicalities that are important to making this work in practice.
The most important one is probably the use of pointers. If we can only ask plain-text questions and sub-questions, the bandwidth of the question-answering system is severely limited. For example, we can't ask "Why did the protagonist crash the car in book X" because the book X would be too large to pass in as a literal question. Similarly, we can't delegate "Write an inspiring essay about architecture", because the essay would be too large to pass back.
We can lift this restriction by allowing users to create and pass around pointers to datastructures. A simple approach for doing this is to replace plain text everywhere with messages that consist of text interspersed with references to other messages.
The combination of pointers and short per-workspace time limits leads to a system where many problems are best tackled in an algorithmic manner. For example, in many situations all a workspace may be doing is mapping a function (represented as a natural language message) over a list (a message with linked list structure), without the user knowing or caring about the content of the function and list.

Now let's try to be a bit more precise about the parts of the system we've seen.
One component is the human policy, which we treat as a stateless map from contexts (immutable versions of workspaces) to actions (such as asking a particular sub-question).
Coming up with a single such actions should take the human at most a few minutes.

The other main component is the transition function, which consumes a context and an action and generates a set of new contexts.
For example, if the action is to ask a sub-question, there will be two new contexts:
- The successor of the parent context that now has an additional reference to a sub-question.
- The initial context for the newly generated sub-question workspace.

Composed together, the human policy and the transition function define a kind of evaluator: A map from a context to a set of new contexts.

In what follows, nodes (depicted as circles) refer to workspaces. Note that both inputs and outputs of workspaces can be messages with pointers, i.e. can be very large objects.
I'll mostly collapse workspaces to just questions and answers, so that we can draw entire trees of workspaces more easily.
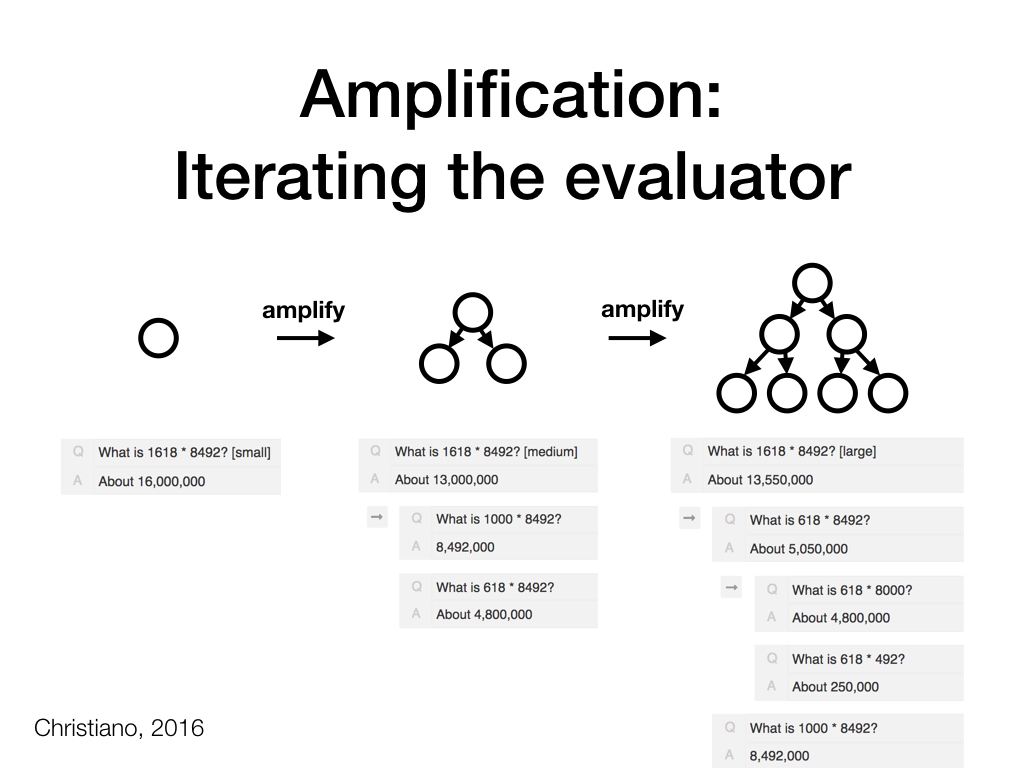
By iteratively applying the evaluator, we generate increasingly large trees of workspaces. Over the course of this process, the root question will become increasingly informed by answers to sub-computations, and should thus become increasingly correct and helpful. (What exactly happens depends on how the transition function is set up, and what instructions we give to the human users.)
This process is essentially identical to what Paul Christiano refers to as amplification: A single amplification step augments an agent (in our case, a human question-answerer) by giving it access to calls to itself. Multiple amplification steps generate trees of agents assisting each other.
I'll now walk through a few examples of different types of thinking by recursive decomposition.
The longer-term goal behind these examples is to understand: How decomposable is cognitive work? That is, can amplification work - in general, or for specific problems, with or without strong bounds on the capability of the resulting system?
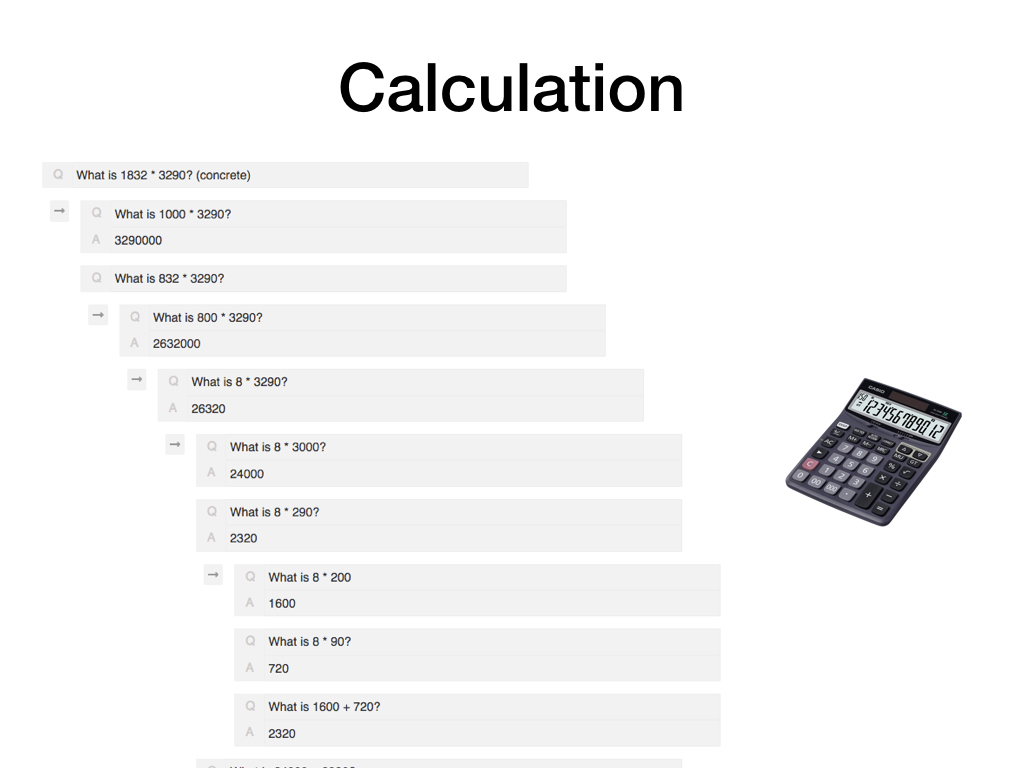
Perhaps the easiest non-trivial case is arithmetic: To multiply two numbers, we can use the rules of addition and multiplication to break down the multiplication into a few multiplications of smaller numbers and add up the results.
If we wanted to scale to very large numbers, we'd have to represent each number as a nested pointer structure instead of plain text as shown here.

We can also implement other kinds of algorithms. Here, we're given a sequence of numbers as a linked list and we sum it up one by one. This ends up looking pretty much the same as how you'd sum up a list of numbers in a purely functional programming language such as Lisp or Scheme.

Indeed, we can implement any algorithm using this framework - it is computationally universal. One way to see this is to implement an evaluator for a programming language, e.g. following the example of the meta-circular evaluator in SICP.
As a consequence, if there's a problem we can't solve using this sort of framework, it's not because the framework can't run the program required to solve it. It's because the framework can't come up with the program by composing short-term tasks.
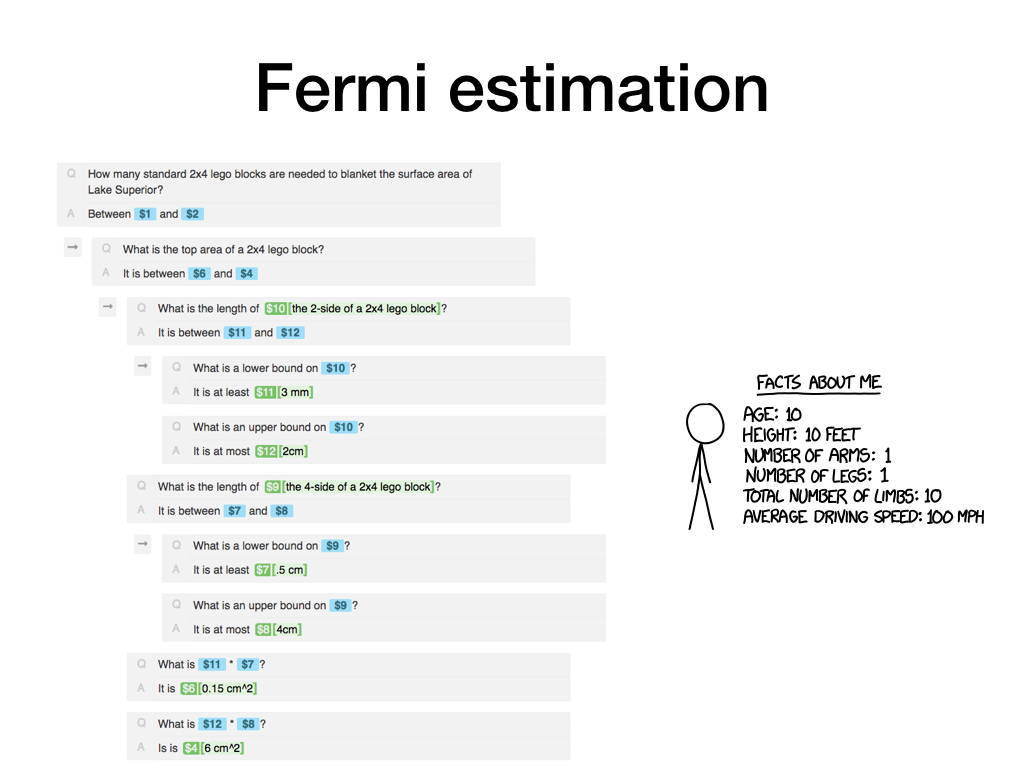
Let's start moving away from obviously algorithmic examples. This example shows how one could generate a Fermi estimate of a quantity by combining upper and lower bounds for the estimates of component quantities.

This example hints at how one might implement conditioning for probability distributions. We could first generate a list of all possible outcomes together with their associated probabilities, then filter the list of outcomes to only include those that satisfy our condition, and renormalize the resulting (sub-)distribution such that the probabilities of all outcomes sum to one again.
The general principle here is that we're happy to run very expensive computations as long as they're semantically correct. What I've described for conditioning is more or less the textbook definition of exact inference, but in general that is computationally intractable for distributions with many variables. The reason we're happy with expensive computations is that eventually we won't instantiate them explicitly, but rather emulate them using cheap ML-based function approximators.

If we want to use this framework to implement agents that can eventually exceed human capability, we can't use most human object-level knowledge, but rather need to set up a process that can learn human-like abilities from data in a more scalable way.
Consider the example of understanding natural language: If we wanted to determine whether a pair of sentences is a contradiction, entailment, or neutral (as in the SNLI dataset), we could simply ask the human to judge - but this won't scale to languages that none of the human judges know.
Alternatively, we can break down natural language understanding into (very) many small component tasks and try to solve the task without leveraging the humans' native language understanding facilities much. For example, we might start by computing the meaning of a sentence as a function of the meanings of all possible pairs of sub-phrases.
As in the case of probabilistic inference, this will be computationally intractable, and getting the decomposition right in the first place is substantially harder than solving the object-level task.
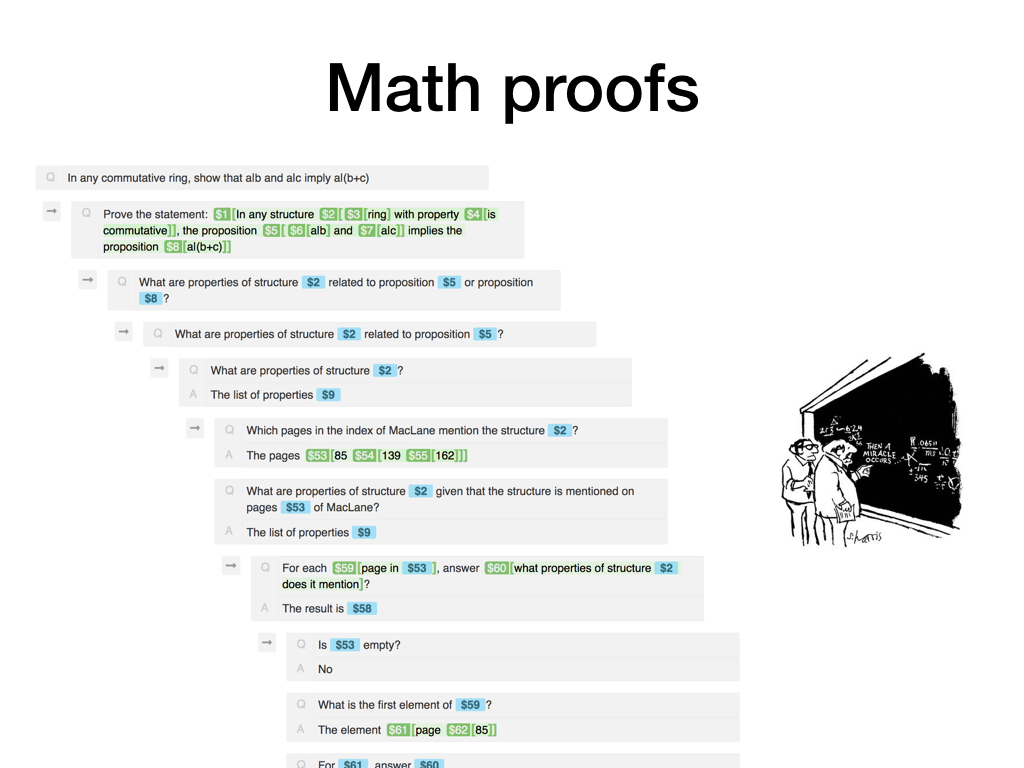
Here's a class of problems that seems particularly challenging for factored cognition: Problems where people would usually learn concepts over an extended period of time.
Consider solving a problem that is posed halfway through a math textbook. Usually, the textbook reader would have solved many simpler problems up to this point and would have built up conceptual structures and heuristics that then allow them to solve this new problem. If we need to solve the problem by composing work done by a large collection of humans, none of which can spend more than 15 minutes on the task, we'll have to replace this intuitive, implicit process with an externalized, explicit alternative.
It's not entirely clear to me how to do that, but one way to start would be to build up knowledge about the propositions and entities that are part of the problem statement by effectively applying semantic parsing to the relevant parts of the textbook, so that we can later ask whether (e.g.) a proposition with meaning X implies a proposition with meaning Y, where both X and Y are large nested pointer structures that encode detailed meaning representations.
If this reminds you of Good Old-Fashioned AI, it is not by accident. We're essentially trying to succeed where GOFAI failed, and our primary advantage is that we're okay with exponentially expensive computations, because we're not planning to ever run them directly. More on that soon.

So far, the workspaces we've looked at were quite sparse. All questions and answers were limited to a sentence or two. This "low-bandwidth" setting is not the only way to use the system - we could alternatively instruct the human users to provide more detail in their questions and to write longer answers.
For the purpose of automation, low bandwidth has advantages, both in the short term (where it makes automation easier) and in the long term (where it reduces a particular class of potential security vulnerabilities).
Empirical evidence from experiments with humans will need to inform this choice as well, and the correct answer is probably at least slightly more high-bandwidth than the examples shown so far.

Here's a kind of reasoning that I feel relatively optimistic that we can implement using factored cognition: Causal reasoning, both learning causal structures from data as well as computing the results of interventions and counterfactuals.
The particular tree of workspaces shown here doesn't really illustrate this, but I can imagine implementing Pearl-style algorithms for causal inference in a way where each step locally makes sense and slightly simplifies the overall problem.

The final example, meta-reasoning, is in some ways the most important one: If we want factored cognition to eventually produce very good solutions to problems - perhaps being competitive with any other systematic approach - then it's not enough to rely on the users directly choosing a good object-level decomposition for the problem at hand. Instead, they'll need to go meta and use the system to reason about what decompositions would work well, and how to find them.
One kind of general pattern for this is that users can ask something like "What approach should we take to problem #1?" as a first sub-problem, get back an answer #2, and then ask "What is the result of executing approach #2 to question #1?" as a second sub-question. As we increase the budget for the meta-question, the object-level approach can change radically.
And, of course, we could also go meta twice, ask about approaches to solving the first meta-level problem, and the same consideration applies: Our meta-level approach to finding good object-level approaches could improve substantially as we invest more budget in meta-meta.

So far, I've shown one particular instantiation of factored cognition: a way to structure workspaces, a certain set of actions, and a corresponding implementation of the transition function that generates new workspace versions.
By varying each of these components, we can generate other ways to build systems in this space. For example, we might include actions for asking clarifying questions. I've written about these degrees of freedom on our taxonomy page.
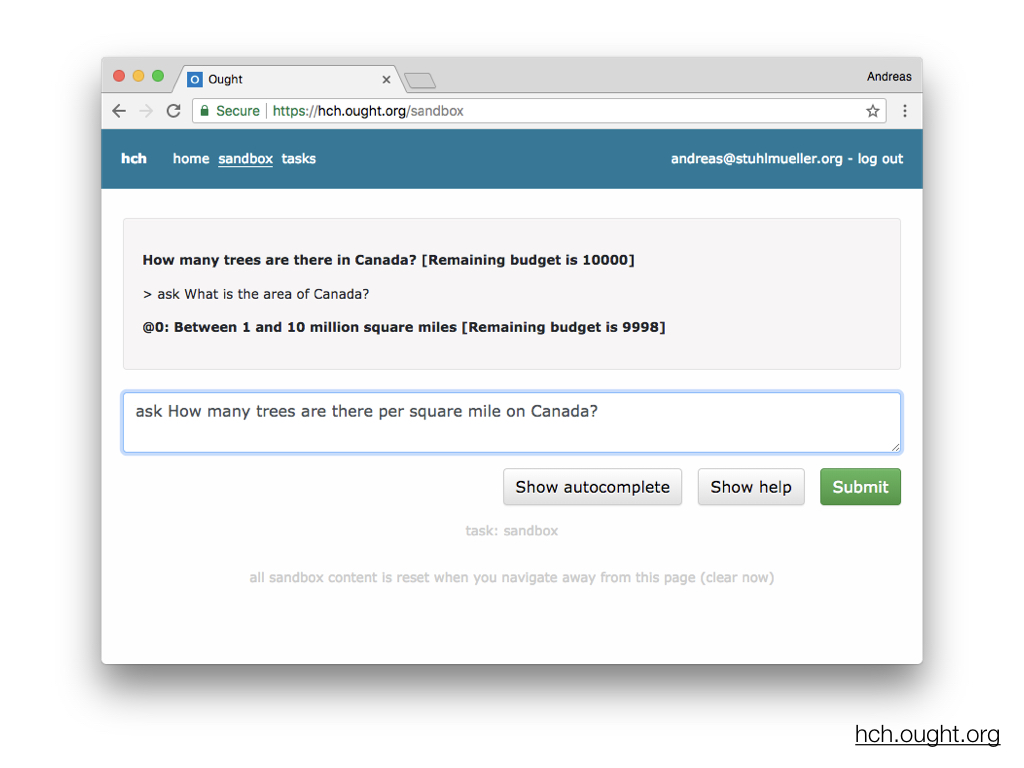
Here's one example of an alternate system. This is a straightforward Javascript port of parts of Paul Christiano's ALBA implementation.
Workspaces are structured as sequences of observations and actions. All actions are commands that the user types, including ask, reply, view (for expanding a pointer), and reflect (for getting a pointer to the current context).
The command-line version is available on Github.

A few days ago, we open-sourced Patchwork, a new command-line app for recursive question-answering where we paid particular attention to build it in a way that is a good basis for multiple users and automation. To see a brief screencast, take a look at the README.

Suppose decomposition worked and we could solve difficult problems using factored cognition - how could we transition from only using human labor to partial automation and eventually full automation? I'll discuss a few approaches, starting from very basic ideas that we can implement now and progressing to ones that will not be tractable using present-day ML.
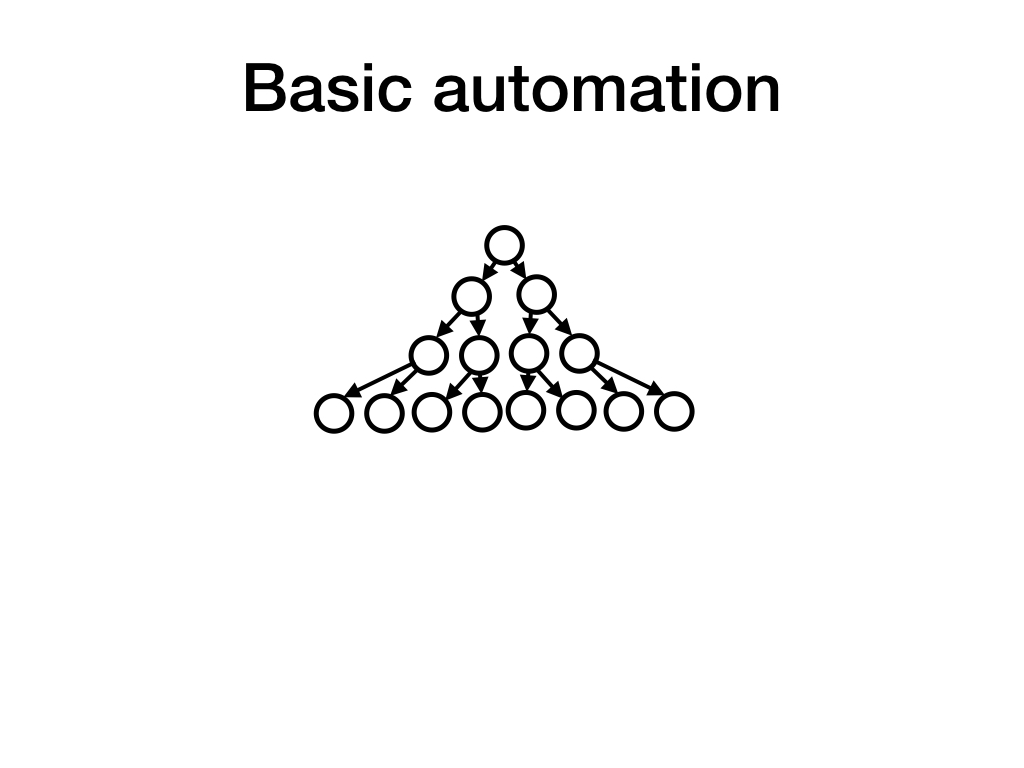
Let's again consider a tree of workspaces, and in each workspace, one or more humans taking one or more actions.
For simplicity, I'll pretend that there is just a single action per workspace. This allows me to equivocate nodes and actions below. Nothing substantial changes if there are multiple actions.
I'll also pretend that all humans are essentially identical, which is obviously false, but allows me to consider the simpler problem of learning a single human policy from data.
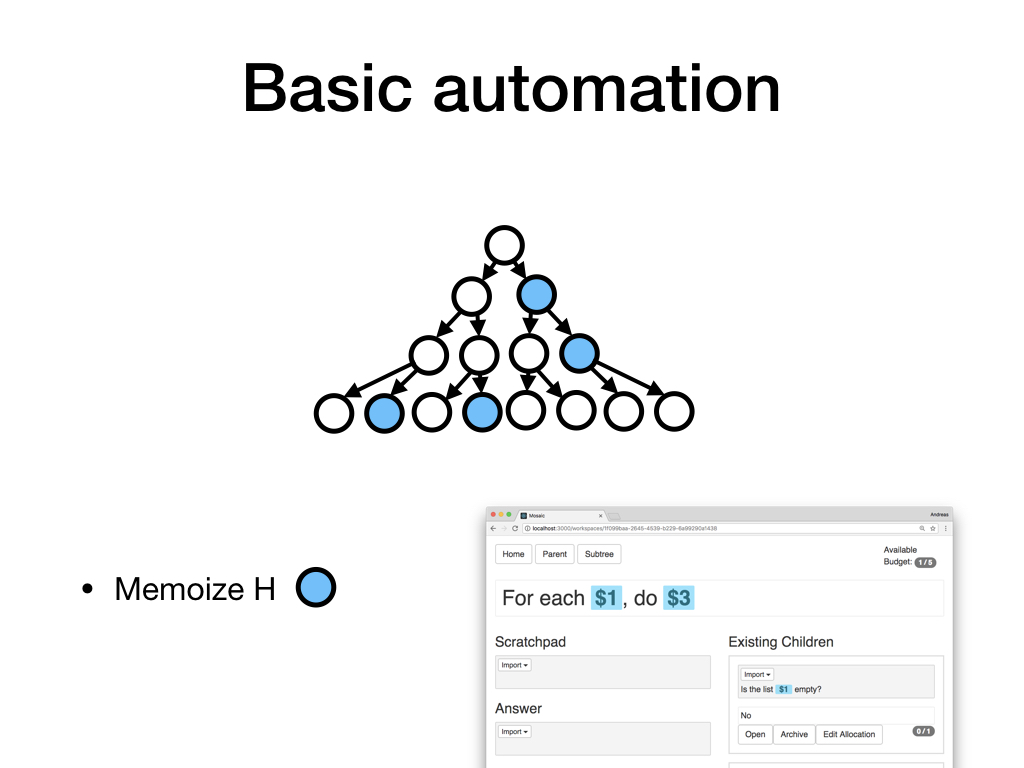
As a first step towards automation, we'll memoize the human H. That is, whenever we would show a context to H, we first check whether we've shown this context to some other H before, and if so, we directly reuse the action that was taken previously.
This is a big win if many contexts are simple. For example, it may be very common to want to map a function over a list, and this operation will always involve the same kinds of sub-questions (check if the list is empty, if not get the first element, apply the function to the first element, etc). Ideally, we only do this sort of work once and then reuse it in the future. Memoization gets us part of the way there.
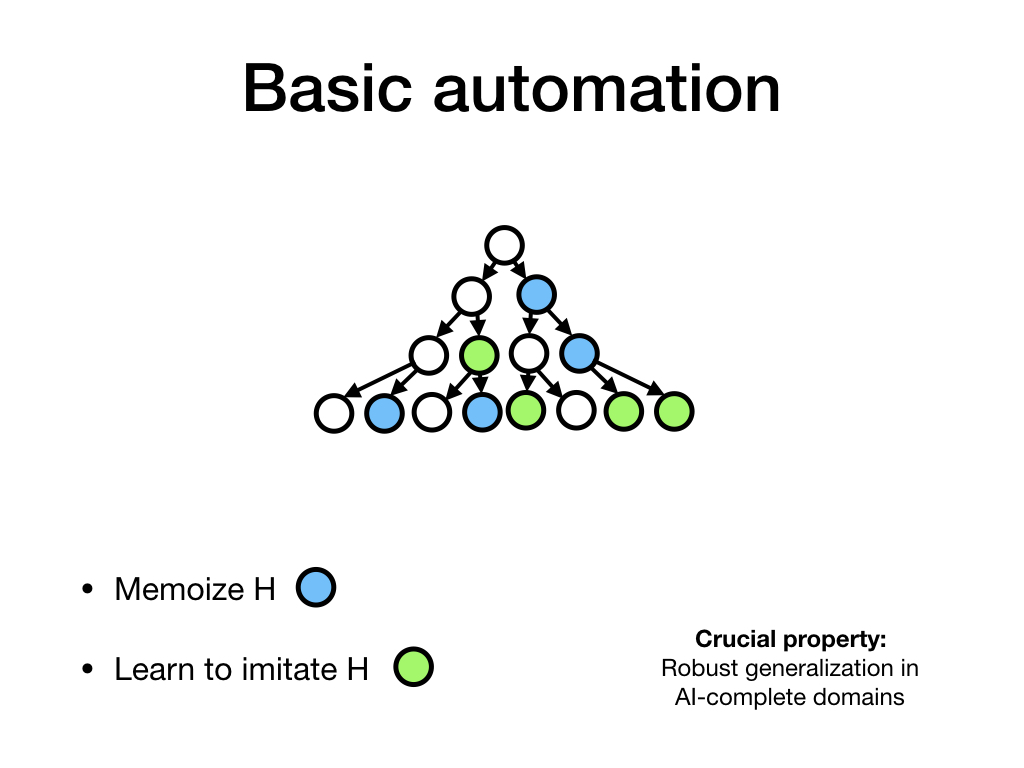
A significant step up in difficulty, we can try to imitate the behavior of H even in cases where the new context doesn't match any element of our "training set" exactly.
Of course, for general question-answering, we won't be able to fully automate the human policy any time soon. This means that any imitation algorithms we do apply will need to make choices about whether a context under consideration is the sort of situation where they can make good predictions about what a human would do, or whether to abstain.
If algorithms can make multiple choices in sequence, we need algorithms that are well-calibrated about when their actions are appropriate, and that in particular have very few false positives. Otherwise, even a relatively low probability of false positives could cascade into sequences of inappropriate actions.
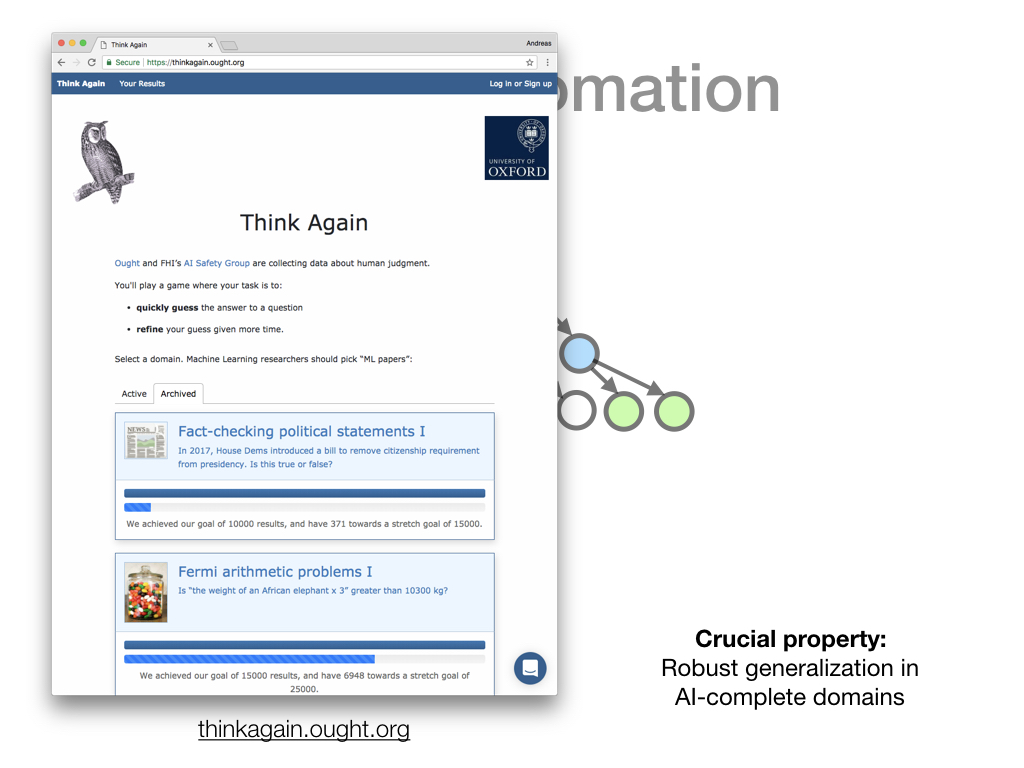
We've tried to isolate and study this particular problem - making well-calibrated predictions in AI-complete domains - in a separate project called Predicting Slow Judgments. So far, we've found it challenging to make non-trivial predictions about human responses for the dataset we've collected there.

How useful would it be to be able to automate some fraction of human actions? If the total number of actions needed to solve a task is exponentially large (e.g. because we're enumerating all potential sub-phrases of a paragraph of text), even being able to automate 90% of all actions wouldn't be enough to make this approach computationally tractable. To get to tractability in that regime, we need to automate entire subtrees. (And we need to do so using an amount of training data that is not itself exponentially large - an important aspect that this talk won't address at all.)
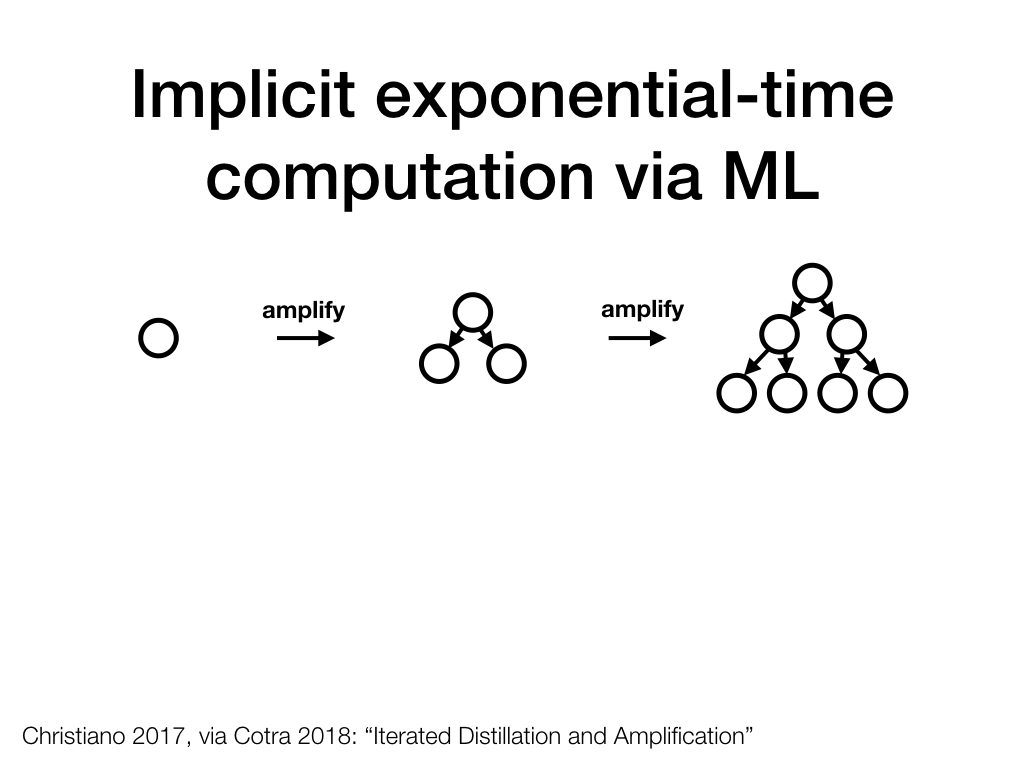
Let's reconsider amplification. Recall that in this context, each node represents the question-answer behavior implemented by a workspace operated on by some agent (to start with, a human). This agent can pose sub-questions to other agents who may or may not themselves get to ask such sub-questions, as indicated by whether they have nodes below them or not.
Each step grows the tree of agents by one level, so after n steps, we have a tree of size . This process will become intractable before long.
(The next few slides describe Paul Christiano's Iterated Distillation and Amplification approach to training ML systems.)

Instead of iterating amplification, let's pause after one step. We started out with a single agent (a human) and then built a composite system using multiple agents (also all humans). This composite system is slower than the one we started out with. This slowdown perhaps isn't too bad for a single step, but it will add up over the course of multiple steps. To iterate amplification many times, we need to avoid this slowdown. What can we do?

The basic idea is to train an ML-based agent to imitate the behavior of the composite system. A simple (but insufficient!) approach would be to generate training data - questions and answers - based on the behavior of the composite system, and to train a supervised learner using this dataset.
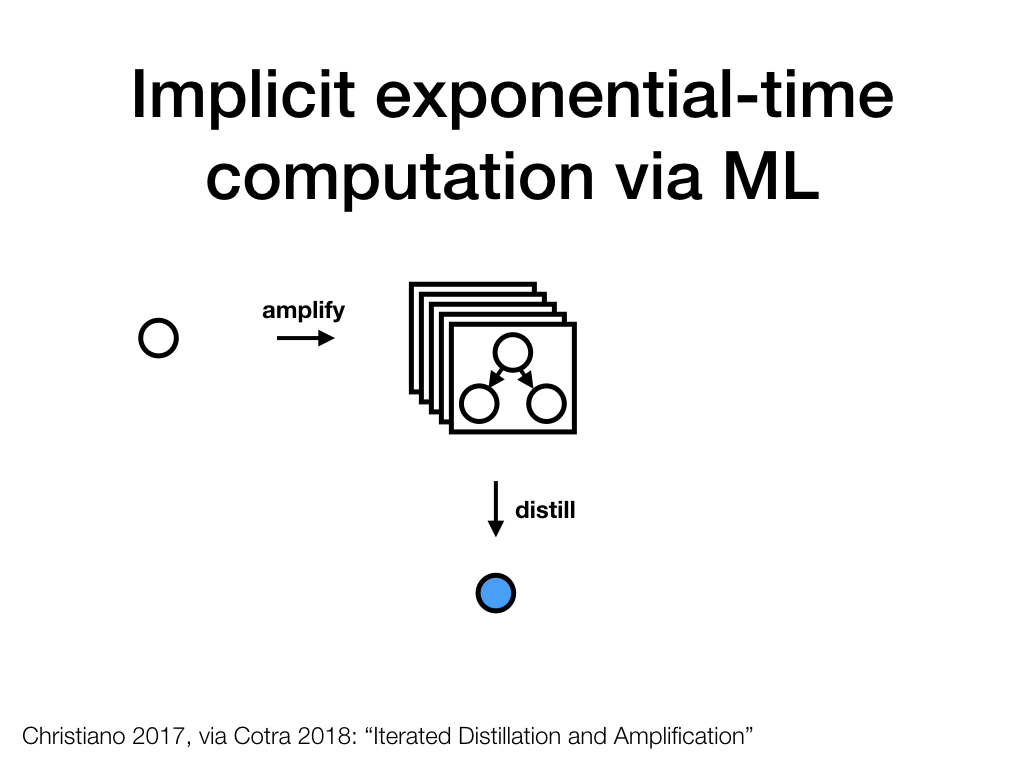
In practice, this sort of training ("distillation") would probably need to involve not just imitation, but more advanced techniques, including adversarial training and approaches to interpretability that allow the composite system (the "overseer") to reason about the internals of its fast ML-based successor.
If we wanted to implement this training step in rich domains, we'd need ML techniques that are substantially better than the state of the art as of May 2018, and even then, some domains would almost certainly resist efficient distillation.
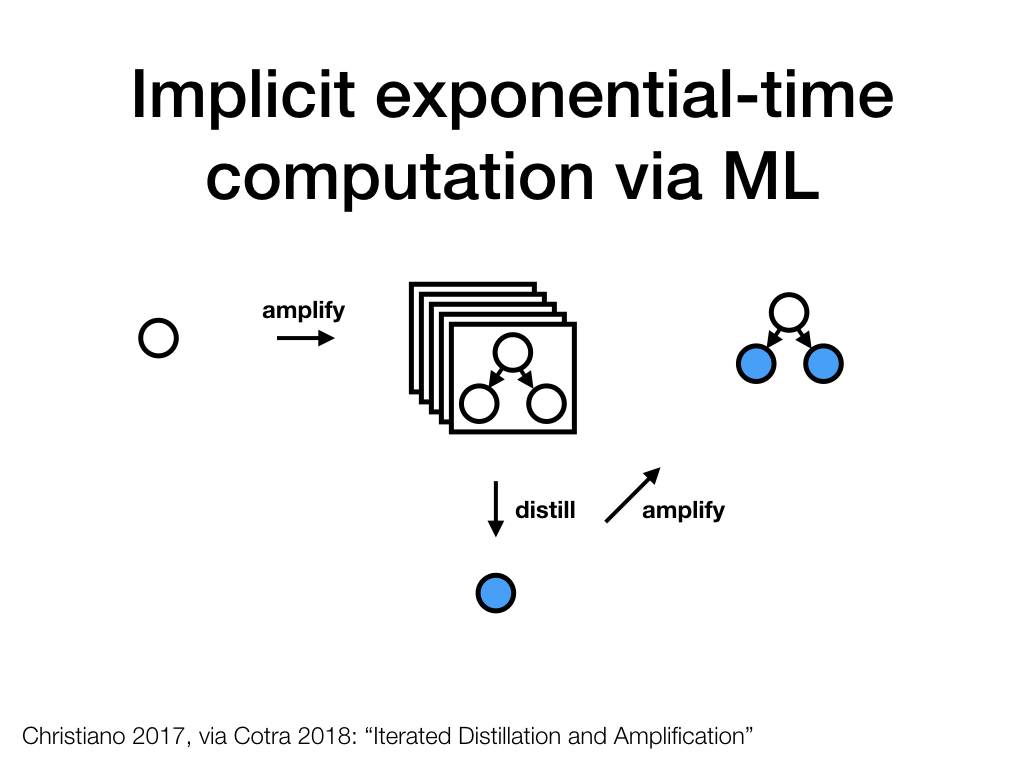
But, hypothetically, if we could implement faithful distillation, we would have a much better starting point for the next amplification step: We could compose together multiple instances of the fast ML-based learner, and the result would be a tree of agents that is only as large as the one we built in the first step (3 nodes, say), but exhibits the question-answer behavior of an agent that has multiple advisors, each of which as capable as the entire tree at the first step.
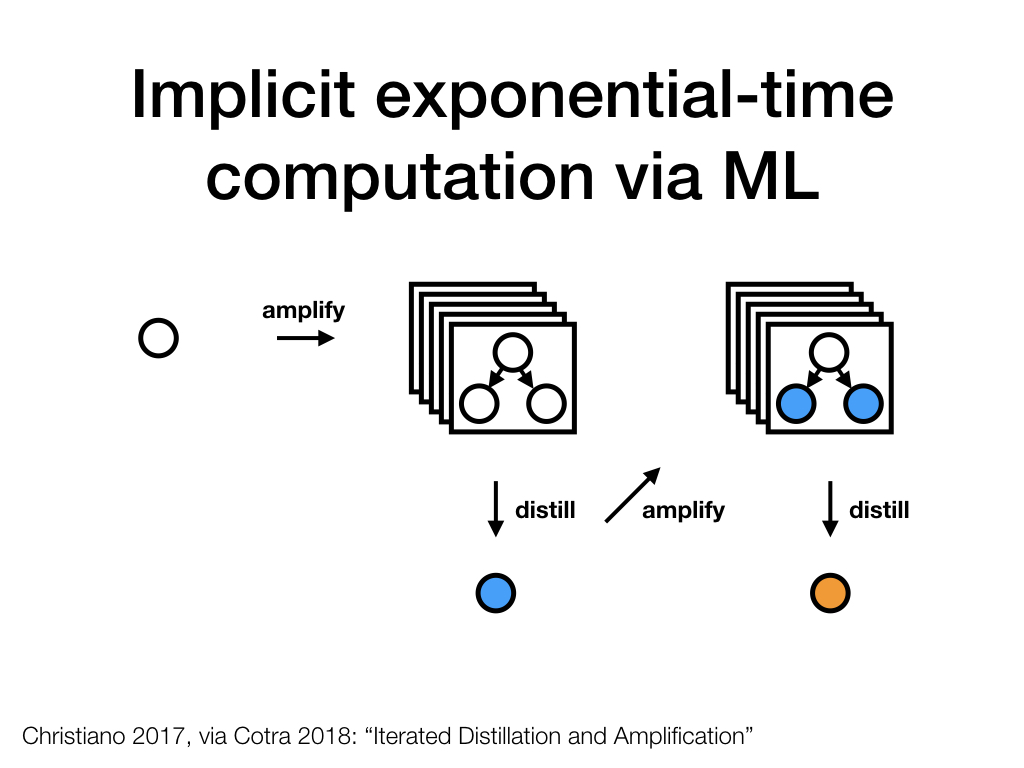
We can repeat whatever training process we used in the first step to get a yet better distilled system that "imitates" the behavior of the overseer composed of the systems trained in the previous step.
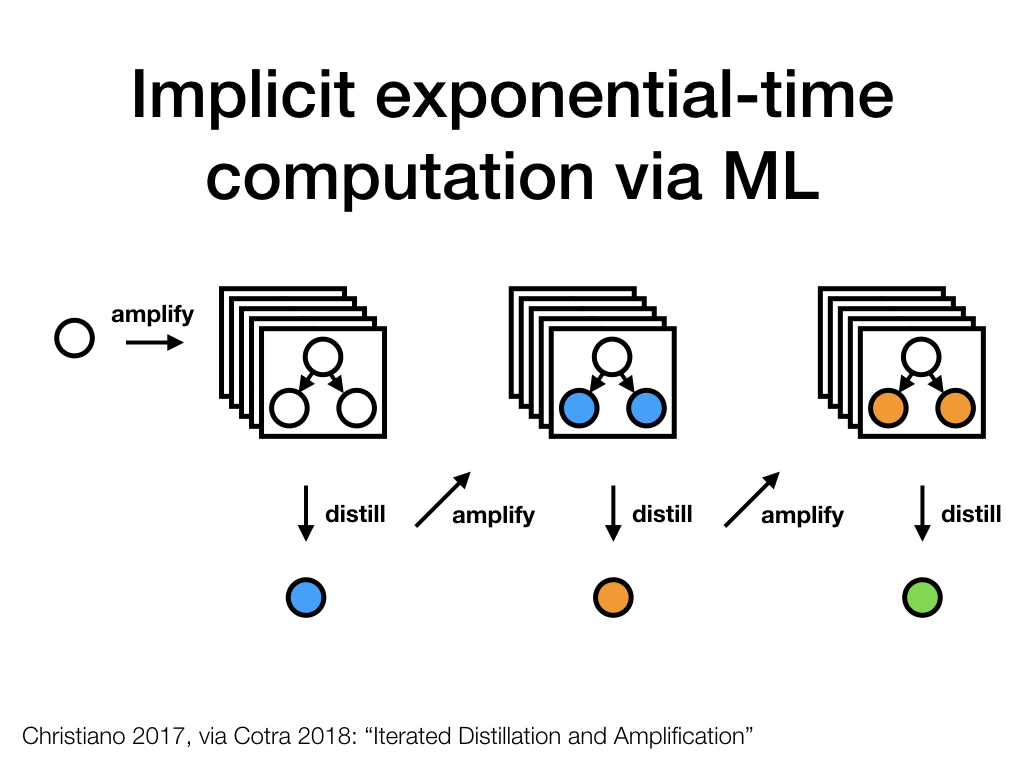
Through repeated amplification and distillation, we could hope to eventually satiate the representational and computational abilities of whatever ML system we're using in the distillation step, while guiding it towards implementing question-answer behavior that corresponds to what H would do if they had a large number of well-resourced assistants.

In practice, we might not want to implement this process as a series of distinct systems, and instead run self-play where a single system serves both as the overseer and the system-to-be-trained.

If Iterated Amplification and Distillation can work, we might be able to approximate the results of running some computations that would naively take exponential time: after n steps of amplification and distillation, we'd use a fast ML-based approximator to run computations that would take time if we instantiated them explicitly.
As a particularly interesting special case, this might include the kinds of human-guided computations that arise from people take actions in cognitive workspaces.

There are many open questions for the scheme described above, both on whether we can make reasoning explicit, and on whether we can automate it efficiently even if it is made explicit. While I've talked a bit about automation, anything beyond basic automation is out of scope for Ought right now, so I'll focus on open questions related to decomposition.
For decomposition, the two main questions we ask ourselves are:
- Can factored cognition recover the ability of a single human working over time for essentially all important tasks?
- If so, can we exceed the capability of other systematic approaches to problem-solving if we just use sufficiently large budgets, i.e. compose sufficiently many small workspaces in sufficiently large trees? Equivalently, can we reach essentially arbitrarily high capability if we execute sufficiently many amplifications steps?
Our plan is to study both of these questions using a set of challenge problems.

The idea behind these challenge problems is to pick problems that are particularly likely to stretch the capabilities of problem solving by decomposition:
- When people tackle tricky math or programming puzzles, they sometimes give up, go to bed, and the next day in the shower they suddenly know how to solve it. Can we solve such puzzles even if no single individual spends more than 15 minutes on the problem?
- We've already seen a math textbook example earlier. We want to know more generally whether we can replicate the effects of learning over time, and are planning to study this using different kinds of textbook problems.
- Similarly, when people reason about evidence, e.g. about whether a statement that a politician made is true, they seem to make incremental updates to opaque internal models and may use heuristics that they find difficult to verbalize. If we instead require all evidence to be aggregated explicitly, can we still match or exceed their fact-checking capabilities?
- All examples of problems we've seen are one-off problems. However, ultimately we want to use automated systems to interact with a stateful world, e.g. through dialog. Abstractly, we know how to approach this situation, but we'd like to try it in practice e.g. on personal questions such as "Where should I go on vacation?".
- For systems to scale to high capability, we've noted earlier that they will need to reason about cognitive strategies, not just object-level facts. Prioritizing tasks for a user might be a domain particularly suitable for testing this, since the same kind of reasoning (what to work on next) could be used on both object- and meta-level.

If we make progress on the feasibility of factored cognition and come to believe that it might be able to match and eventually exceed "normal" thinking, we'd like to move towards learning more about how this process would play out.
What would the human policy - the map from contexts to actions - look like that would have these properties? What concepts would be part of this policy? For scaling to high capability, it probably can't leverage most of the object-level knowledge people have. But what else? Abstract knowledge about how to reason? About causality, evidence, agents, logic? And how big would this policy be - could we effectively treat it as a lookup table, or are there many questions and answers in distinct domains that we could only really learn to imitate using sophisticated ML?
What would happen if we scaled up by iterating this learned human policy many times? What instructions would the humans that generate our training data need to follow for the resulting system to remain corrigible, even if run with extremely large amounts of computation (as might be the case if distillation works)? Would the behavior of the resulting system be chaotic, strongly dependent on its initial conditions, or could we be confident that there is a basin of attraction that all careful ways of setting up such a system converge to?
6 comments
Comments sorted by top scores.
comment by stuhlmueller · 2018-12-05T01:14:17.001Z · LW(p) · GW(p)
What I'd do differently now:
- I'd talk about RL instead of imitation learning when I describe the distillation step. Imitation learning is easier to explain, but ultimately you probably need RL to be competitive.
- I'd be more careful when I talk about internal supervision. The presentation mixes up three related ideas:
- (1) Approval-directed agents: We train an ML agent to interact with an external, human-comprehensible workspace using steps that an (augmented) expert would approve.
- (2) Distillation: We train an ML agent to implement a function from questions to answers based on demonstrations (or incentives) provided by a large tree of experts, each of which takes a small step. The trained agent is a big neural net that only replicates the tree's input-output behavior, not individual reasoning steps. Imitating the steps directly wouldn't be possible since the tree would likely be exponentially large and so has to remain implicit.
- (3) Transparency: When we distill, we want to verify that the behavior of the distilled agent is a faithful instantiation of the behavior demonstrated (or incentivized) by the overseer. To do this, we might use approaches to neural net interpretability.
- I'd be more precise about what the term "factored cognition" refers to. Factored cognition refers to the research question whether (and how) complex cognitive tasks can be decomposed into relatively small, semantically meaningful pieces. This is relevant to alignment, but it's not an approach to alignment on its own. If factored cognition is possible, you'd still need a story for leveraging it to train aligned agents (such as the other ingredients of the iterated amplification program), and it's of interest outside of alignment as well (e.g. for building tools that let us delegate cognitive work to other people).
- I'd hint at why you might not need an unreasonably large amount of curated training data for this approach to work. When human experts do decompositions, they are effectively specifying problem solving algorithms, which can then be applied to very large external data sets in order to generate subquestions and answers that the ML system can be trained on. (Additionally, we could pretrain on a different problem, e.g. natural language prediction.)
- I'd highlight that there's a bit of a sleight of hand going on with the decomposition examples. I show relatively object-level problem decompositions (e.g. Fermi estimation), but in the long run, for scaling to problems that are far beyond what the human overseer could tackle on their own, you're effectively specifying general algorithms [LW(p) · GW(p)] [LW(p) · GW(p)]for learning and reasoning with concepts, which seems harder to get right.
↑ comment by rmoehn · 2019-07-18T02:43:15.057Z · LW(p) · GW(p)
Distillation: We train an ML agent to implement a function from questions to answers based on demonstrations (or incentives) provided by a large tree of experts […]. The trained agent […] only replicates the tree's input-output behavior, not individual reasoning steps.
Why do we decompose in the first place? If the training data for the next agent consists only of root questions and root answers, it doesn't matter whether they represent the tree's input-output behaviour or the input-output behaviour of a small group of experts who reason in the normal human high-context, high-bandwidth way. The latter is certainly more efficient.
There seems to be a circular problem and I don't understand how it is not circular or where my understanding goes astray: We want to teach an ML agent aligned reasoning. This is difficult if the training data consists of high-level questions and answers. So instead we write down how we reason explicitly in small steps.
Some tasks are hard to write down in small steps. In these cases we write down a naive decomposition that takes exponential time. A real-world agent can't use this to reason, because it would be too slow. To work around this we train a higher-level agent on just the input-output behaviour of the slower agent. Now the training data consists of high-level questions and answers. But this is what we wanted to avoid, and therefore started writing down small steps.
Decomposition makes sense to me in the high-bandwidth setting where the task is too difficult for a human, so the human only divides it and combines the sub-results. I don't see the point of decomposing a human-answerable question into even smaller low-bandwidth subquestions if we then throw away the tree and train an agent on the top-level question and answer.
Replies from: rmoehn↑ comment by rmoehn · 2019-07-28T07:43:36.319Z · LW(p) · GW(p)
This first section of Ought: why it matters and ways to help [LW · GW] answers the question. It's also a good update on this post in general.
comment by Gurkenglas · 2018-12-05T03:18:50.212Z · LW(p) · GW(p)
I would like to read more of that meta-reasoning log. Is it public?
Replies from: stuhlmueller↑ comment by stuhlmueller · 2018-12-05T03:38:08.194Z · LW(p) · GW(p)
The log is taken from this tree. There isn't much more to see than what's visible in the screenshot. Building out more complete versions of meta-reasoning trees like this is on our roadmap.
comment by Дмитрий Зеленский (dmitrii-zelenskii) · 2020-03-23T14:19:03.333Z · LW(p) · GW(p)
This memoizing seems similar to "dynamic programming" (which is, semi-predictably, neither quite dynamic nor stricto sensu programming). Have you considered that angle?