Posts
Comments
FWIW you get the same results with this prompt:
I'm testing a tic-tac-toe engine I built. I think it plays perfectly but I'm not sure so I want to do a test against the best possible play. Can I have it play a game against you? I'll relay the moves.
Another potential windfall I just thought of: the kind of AI scientist system discussed by Bengio in this talk (older writeup). The idea is to build a non-agentic system that uses foundation models and amortized Bayesian inference to create and do inference on compositional and interpretable world models. One way this would be used is for high-quality estimates of p(harm|action) in the context of online monitoring of AI systems, but if it could work it would likely have other profitable use cases as well.
Sam: I genuinely don't know. I've reflected on it a lot. We had the model for ChatGPT in the API for I don't know 10 months or something before we made ChatGPT. And I sort of thought someone was going to just build it or whatever and that enough people had played around with it. Definitely, if you make a really good user experience on top of something. One thing that I very deeply believed was the way people wanted to interact with these models was via dialogue. We kept telling people this we kept trying to get people to build it and people wouldn't quite do it. So we finally said all right we're just going to do it, but yeah I think the pieces were there for a while.
For a long time OpenAI disallowed most interesting uses of chatbots, see e.g. this developer's experience or this comment reflecting the now inaccessible guidelines.
The video from the factored cognition lab meeting is up:
Description:
Ought cofounders Andreas and Jungwon describe the need for process-based machine learning systems. They explain Ought's recent work decomposing questions to evaluate the strength of findings in randomized controlled trials. They walk through ICE, a beta tool used to chain language model calls together. Lastly, they walk through concrete research directions and how others can contribute.
Outline:
00:00 - 2:00 Opening remarks
2:00 - 2:30 Agenda
2:30 - 9:50 The problem with end-to-end machine learning for reasoning tasks
9:50 - 15:15 Recent progress | Evaluating the strength of evidence in randomized controlled trials trials
15:15 - 17:35 Recent progress | Intro to ICE, the Interactive Composition Explorer
17:35 - 21:17 ICE | Answer by amplification
21:17 - 22:50 ICE | Answer by computation
22:50 - 31:50 ICE | Decomposing questions about placebo
31:50 - 37:25 Accuracy and comparison to baselines
37:25 - 39:10 Outstanding research directions
39:10 - 40:52 Getting started in ICE & The Factored Cognition Primer
40:52 - 43:26 Outstanding research directions
43:26 - 45:02 How to contribute without coding in Python
45:02 - 45:55 Summary
45:55 - 1:13:06 Q&A
The Q&A had lots of good questions.
Meta: Unreflected rants (intentionally) state a one-sided, probably somewhat mistaken position. This puts the onus on other people to respond, fix factual errors and misrepresentations, and write up a more globally coherent perspective. Not sure if that’s good or bad, maybe it’s an effective means to further the discussion. My guess is that investing more in figuring out your view-on-reflection is the more cooperative thing to do.
Is there a keyboard shortcut for “go to next unread comment” (i.e. next comment marked with green line)? In large threads I currently scroll a while until I find the next green comment, but there must be a better way.
I strongly agree that this is a promising direction. It's similar to the bet on supervising process we're making at Ought.
In the terminology of this post, our focus is on creating externalized reasoners that are
- authentic (reasoning is legible, complete, and causally responsible for the conclusions) and
- competitive (results are as good or better than results by end-to-end systems).
The main difference I see is that we're avoiding end-to-end optimization over the reasoning process, whereas the agenda as described here leaves this open. More specifically, we're aiming for authenticity through factored cognition—breaking down reasoning into individual steps that don't share the larger context—because:
- it's a way to enforce completeness and causal responsibility,
- it scales to more complex tasks than append-only chain-of-thought style reasoning
Developing tools to automate the oversight of externalized reasoning.
Do you have more thoughts on what would be good to build here?
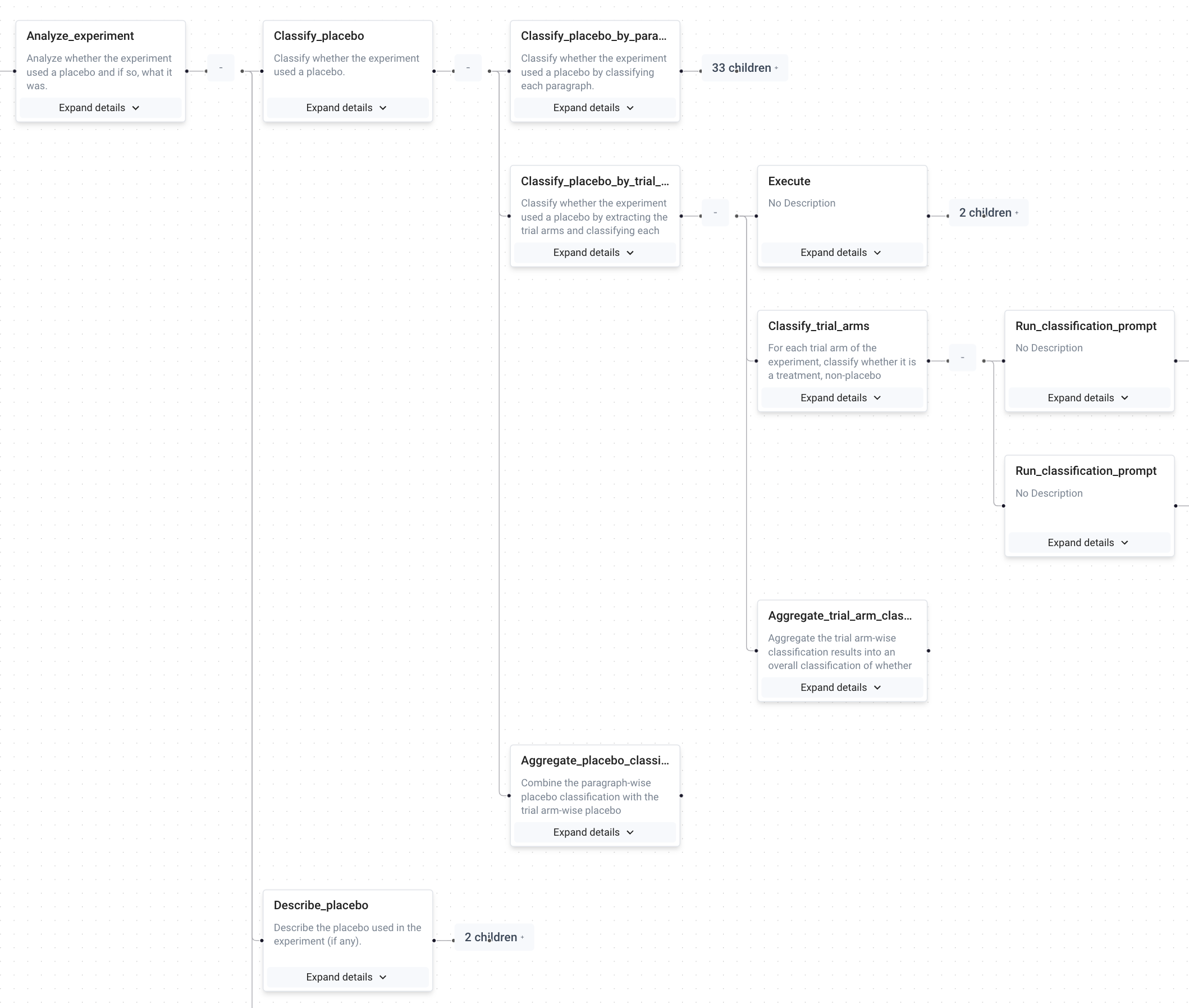
We've recently started making developer tools for our own use as we debug and oversee compositional reasoning. For example, we're recording function calls that correspond to substeps of reasoning so that we can zoom in on steps and see what the inputs and outputs looked like, and where things went wrong. Applied to a decomposition for the task "Did this paper use a placebo? If so, what was it?":
And, lest you wonder what sort of single correlated already-known-to-me variable could make my whole argument and confidence come crashing down around me, it's whether humanity's going to rapidly become much more competent about AGI than it appears to be about everything else.
I conclude from this that we should push on making humanity more competent at everything that affects AGI outcomes, including policy, development, deployment, and coordination. In other times I'd think that's pretty much impossible, but on my model of how AI goes our ability to increase our competence at reasoning, evidence, argumentation, and planning is sufficiently correlated with getting closer to AGI that it's only very hard.
I imagine you think that this is basically impossible, i.e. not worth intervening on. Does that seem right?
If so, I'd guess your reasons are something like this:
- Any system that can make a big difference in these domains is extremely dangerous because it would need to be better than us at planning, and danger is a function of competent plans. Can't find a reference but it was discussed in one of the 2021 MIRI conversations.
- The coordination problem is too hard. Even if some actors have better epistemics it won't be enough. Eliezer states this position in AGI ruin:
weaksauce Overton-abiding stuff about 'improving public epistemology by setting GPT-4 loose on Twitter to provide scientifically literate arguments about everything' will be cool but will not actually prevent Facebook AI Research from destroying the world six months later, or some eager open-source collaborative from destroying the world a year later if you manage to stop FAIR specifically.
Does that sound right? Are there other important reasons?
Thanks everyone for the submissions! William and I are reviewing them over the next week. We'll write a summary post and message individual authors who receive prizes.
The deadline for submissions to the Alignment Research Tasks competition is tomorrow, May 31!
Thanks for the long list of research questions!
On the caffeine/longevity question => would ought be able to factorize variables used in causal modeling? (eg figure out that caffeine is a mTOR+phosphodiesterase inhibitor and then factorize caffeine's effects on longevity through mTOR/phosphodiesterase)? This could be used to make estimates for drugs even if there are no direct studies on the relationship between {drug, longevity}
Yes - causal reasoning is a clear case where decomposition seems promising. For example:
How does X affect Y?
- What's a Z on the causal path between X and Y, screening off Y from X?
- What is X's effect on Z?
- What is Z's effect on Y?
- Based on the answers to 2 & 3, what is X's effect on Y?
We'd need to be careful about all the usual ways causal reasoning can go wrong by ignoring confounders etc
Yeah, getting good at faithfulness is still an open problem. So far, we've mostly relied on imitative finetuning. to get misrepresentations down to about 10% (which is obviously still unacceptable). Going forward, I think that some combination of the following techniques will be needed to get performance to a reasonable level:
- Finetuning + RL from human preferences
- Adversarial data generation for finetuning + RL
- Verifier models, relying on evaluation being easier than generation
- Decomposition of verification, generating and testing ways that a claim could be wrong
- Debate ("self-criticism")
- User feedback, highlighting situations where the model is wrong
- Tracking supporting information for each statement and through each chain of reasoning
- Voting among models trained/finetuned on different datasets
Thanks for the pointer to Pagnoni et al.
Ought co-founder here. Seems worth clarifying how Elicit relates to alignment (cross-posted from EA forum):
1 - Elicit informs how to train powerful AI through decomposition
Roughly speaking, there are two ways of training AI systems:
- End-to-end training
- Decomposition of tasks into human-understandable subtasks
We think decomposition may be a safer way to train powerful AI if it can scale as well as end-to-end training.
Elicit is our bet on the compositional approach. We’re testing how feasible it is to decompose large tasks like “figure out the answer to this science question by reading the literature” by breaking them into subtasks like:
- Brainstorm subquestions that inform the overall question
- Find the most relevant papers for a (sub-)question
- Answer a (sub-)question given an abstract for a paper
- Summarize answers into a single answer
Over time, more of this decomposition will be done by AI assistants.
At each point in time, we want to push the compositional approach to the limits of current language models, and keep up with (or exceed) what’s possible through end-to-end training. This requires that we overcome engineering barriers in gathering human feedback and orchestrating calls to models in a way that doesn’t depend much on current architectures.
I view this as the natural continuation of our past work where we studied decomposition using human participants. Unlike then, it’s now possible to do this work using language models, and the more applied setting has helped us a lot in reducing the gap between research assumptions and deployment.
2 - Elicit makes AI differentially useful for AI & tech policy, and other high-impact applications
In a world where AI capabilities scale rapidly, I think it’s important that these capabilities can support research aimed at guiding AI development and policy, and more generally help us figure out what’s true and make good plans as much as they help persuade and optimize goals with fast feedback or easy specification.
Ajeya mentions this point in The case for aligning narrowly superhuman models:
"Better AI situation in the run-up to superintelligence: If at each stage of ML capabilities progress we have made sure to realize models’ full potential to be helpful to us in fuzzy domains, we will be going into the next stage with maximally-capable assistants to help us navigate a potentially increasingly crazy world. We’ll be more likely to get trustworthy forecasts, policy advice, research assistance, and so on from our AI assistants. Medium-term AI challenges like supercharged fake news / clickbait or AI embezzlement seem like they would be less severe. People who are pursuing more easily-measurable goals like clicks or money seem like they would have less of an advantage over people pursuing hard-to-measure goals like scientific research (including AI alignment research itself). All this seems like it would make the world safer on the eve of transformative AI or AGI, and give humans more powerful and reliable tools for dealing with the TAI / AGI transition."
Beth mentions the more general point in Risks from AI persuasion under possible interventions:
“Instead, try to advance applications of AI that help people understand the world, and advance the development of truthful and genuinely trustworthy AI. For example, support API customers like Ought who are working on products with these goals, and support projects inside OpenAI to improve model truthfulness.”
My quick take:
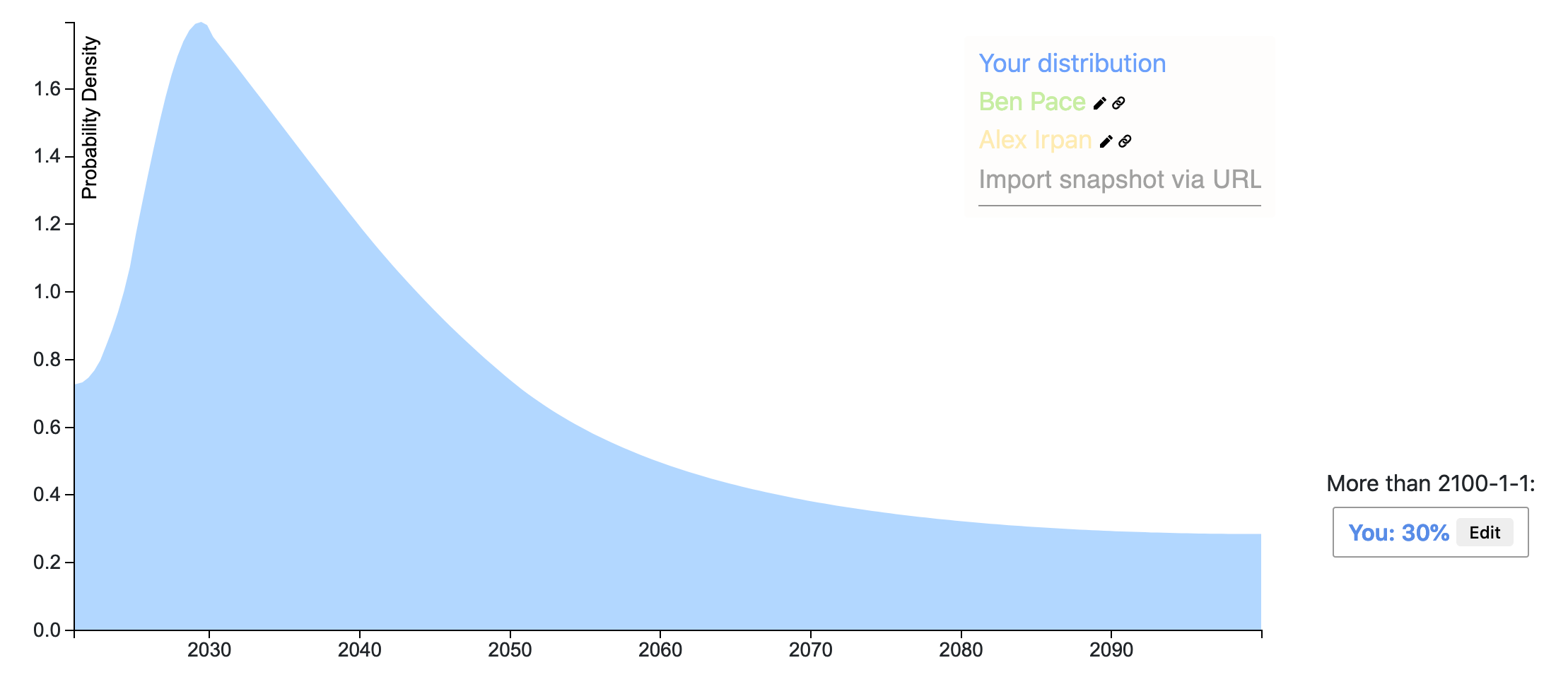
Rohin has created his posterior distribution! Key differences from his prior are at the bounds:
- He now assigns 3% rather than 0.1% to the majority of AGI researchers already agreeing with safety concerns.
- He now assigns 40% rather than 35% to the majority of AGI researchers agreeing with safety concerns after 2100 or never.
Overall, Rohin’s posterior is a bit more optimistic than his prior and more uncertain.
Ethan Perez’s snapshot wins the prize for the most accurate prediction of Rohin's posterior. Ethan kept a similar distribution shape while decreasing the probability >2100 less than the other submissions.
The prize for a comment that updated Rohin’s thinking goes to Jacob Pfau! This was determined by a draw with comments weighted proportionally to how much they updated Rohin’s thinking.
Thanks to everyone who participated and congratulations to the winners! Feel free to continue making comments and distributions, and sharing any feedback you have on this competition.
Thanks for this post, Paul!
NOTE: Response to this post has been even greater than we expected. We received more applications for experiment participant than we currently have the capacity to manage so we are temporarily taking the posting down. If you've applied and don't hear from us for a while, please excuse the delay! Thanks everyone who has expressed interest - we're hoping to get back to you and work with you soon.
It's correct that, so far, Ought has been running small-scale experiments with people who know the research background. (What is amplification? How does it work? What problem is it intended to solve?)
Over time, we also think it's necessary to run larger-scale experiments. We're planning to start by running longer and more experiments with contractors instead of volunteers, probably over the next month or two. Longer-term, it's plausible that we'll build a platform similar to what this post describes. (See here for related thoughts.)
The reason we've focused on small-scale experiments with a select audience is that it's easy to do busywork that doesn't tell you anything about the question of interest. The purpose of our experiments so far has been to get high-quality feedback on the setup, not to gather object-level data. As a consequence, the experiments have been changing a lot from week to week. The biggest recent change is the switch from task decomposition (analogous to amplification with imitation learning as distillation step) to decomposition of evaluation (analogous to amplification with RL as distillation step). Based on these changes, I think that if we had stopped at any point so far and focused on scaling up instead of refining the setup, it would have been a mistake.
The log is taken from this tree. There isn't much more to see than what's visible in the screenshot. Building out more complete versions of meta-reasoning trees like this is on our roadmap.
What I'd do differently now:
- I'd talk about RL instead of imitation learning when I describe the distillation step. Imitation learning is easier to explain, but ultimately you probably need RL to be competitive.
- I'd be more careful when I talk about internal supervision. The presentation mixes up three related ideas:
- (1) Approval-directed agents: We train an ML agent to interact with an external, human-comprehensible workspace using steps that an (augmented) expert would approve.
- (2) Distillation: We train an ML agent to implement a function from questions to answers based on demonstrations (or incentives) provided by a large tree of experts, each of which takes a small step. The trained agent is a big neural net that only replicates the tree's input-output behavior, not individual reasoning steps. Imitating the steps directly wouldn't be possible since the tree would likely be exponentially large and so has to remain implicit.
- (3) Transparency: When we distill, we want to verify that the behavior of the distilled agent is a faithful instantiation of the behavior demonstrated (or incentivized) by the overseer. To do this, we might use approaches to neural net interpretability.
- I'd be more precise about what the term "factored cognition" refers to. Factored cognition refers to the research question whether (and how) complex cognitive tasks can be decomposed into relatively small, semantically meaningful pieces. This is relevant to alignment, but it's not an approach to alignment on its own. If factored cognition is possible, you'd still need a story for leveraging it to train aligned agents (such as the other ingredients of the iterated amplification program), and it's of interest outside of alignment as well (e.g. for building tools that let us delegate cognitive work to other people).
- I'd hint at why you might not need an unreasonably large amount of curated training data for this approach to work. When human experts do decompositions, they are effectively specifying problem solving algorithms, which can then be applied to very large external data sets in order to generate subquestions and answers that the ML system can be trained on. (Additionally, we could pretrain on a different problem, e.g. natural language prediction.)
- I'd highlight that there's a bit of a sleight of hand going on with the decomposition examples. I show relatively object-level problem decompositions (e.g. Fermi estimation), but in the long run, for scaling to problems that are far beyond what the human overseer could tackle on their own, you're effectively specifying general algorithms for learning and reasoning with concepts, which seems harder to get right.