GPT-3.5 judges can supervise GPT-4o debaters in capability asymmetric debates
post by Charlie George (charlie-george), justin_dan, stuhlmueller · 2024-08-27T20:44:08.683Z · LW · GW · 7 commentsContents
Introduction Dataset Baselines Methodology Debate Structure Judge Training Debater prompting For best-of-N debaters Evaluation Experimental Conditions Empirical evidence for capability asymmetric Mixed evidence for capability symmetric Accuracy scaling with Elo Negative results Limitations Code Future work Conclusion None 7 comments
Introduction
The AI safety debate agenda, proposed by Irving et al. (2018), explores using debates between AI agents to ensure truthful answers from advanced systems. Recently three key debate settings have been studied with LLMs:
Information asymmetric debates: Debaters have access to information unavailable to the judge. This hidden information is usually a passage of text from which the debaters quote.
Capability asymmetric debates: Debaters are more generally capable / have stronger reasoning abilities than the judge.
Capability symmetric debates: Debaters are as capable as the judge.
Recent work from Khan et al. (2024) and Kenton et al. (2024) found positive outcomes for information asymmetric debates but negative results for capability asymmetric and symmetric debates. Crucially, both papers rely on inference-only techniques and don't attempt any kind of model training.
Our work revisits capability asymmetric and symmetric debates, focusing on two key factors:
- Selecting an appropriate dataset difficulty
- Fine-tuning the weak judge
We find that GPT-3.5 and GPT-4o mini judges can effectively supervise GPT-4o debaters, yielding positive results in capability asymmetric debates. In addition, we observe mixed evidence for capability symmetric debates. GPT-4o mini seems to benefit from the debate protocol but GPT-3.5 does not and the results for GPT-4o are not significant.
Dataset
We use the MMLU Pro Wang et al. (2024) dataset consisting of challenging closed QA questions with 10 possible answers. The questions span a wide variety of domains at roughly high school level such as maths, chemistry, law and history. We use Claude 3.5 Sonnet with a chain of thought prompt to find the most plausible answer among the 9 incorrect choices allowing us to turn this into a binary dataset where one debater can take each side.
Baselines
Following Radhakrishnan (2023) [AF · GW] we use a “blind” judge trained on the correct answer with no debate as our main baseline trained on exactly the same set of questions as the regular judge.
Methodology
Debate Structure
- Each debate consists of three turns, with alternating responses from the debaters.
- Opening statements are generated independently by each model at T = 0.
- Subsequent turns allow debaters to respond to their opponent's previous arguments using a chain of thought scratchpad before giving their response.
Judge Training
- The judge models are fine-tuned on 500 complete debate transcripts with correct answers.
- A "blind" judge is trained on the same questions and answers without seeing debates, serving as our baseline.
Debater prompting
- Debaters are instructed that they are expert debaters and should defend the answer they've been assigned.
For best-of-N debaters
- For "best of N" debates, we sample N responses at a temperature of 0.8 for both debaters at each turn.
- A GPT-4o model, prompted with chain-of-thought reasoning, serves as a reward model to rank the generated answers.
- The highest-ranked responses are selected to form the debate transcript.
Evaluation
- We use a test set of 1000 debates/questions for evaluation.
- We measure the accuracy of the judge trained with debaters compared to the blind judge trained only on answers.
- To mitigate position bias, we run each debate twice during evaluation, swapping the order of the debaters, and averaging the results.
Experimental Conditions
- We compare the performance of fine-tuned judges against the blind baseline.
- We evaluate debates with standard GPT-4o responses and with best-of-4 sampling.
- We examine the performance of both GPT-3.5 and GPT-4o mini in the capability asymmetric setting.
- Finally, we also look at using GPT-4o in addition to GPT-3.5 and GPT-4o mini as the judge in the capability symmetric setting
Empirical evidence for capability asymmetric
| Fine-tuned GPT-3.5 judge (n=1000) | Fine-tuned GPT-4o mini judge (n=1000) | |
| No debate (blind) | 69.20% | 73.0% |
| Debates with GPT-4o* | 73.15% | 79.25% |
| Debates with GPT-4o* best of 4 | 75.20% | 79.75% |
Both weak judges GPT-4o mini and GPT-3.5 see a ~6% absolute increase in accuracy with debate. Subsequent work should look at performing various ablations such as debate length, the necessity of the scratchpad for the debaters, the capability gap required to make this work and the types of Closed QA datasets that benefit from the debate protocol.
Mixed evidence for capability symmetric
| Model | GPT-3.5 (n=1000) | GPT-4o mini (n=1000) | GPT-4o** (n=1000) |
| No debate (blind) | 69.20% | 73.0% | 79.80% |
| Debate | 69.75% | 77.65% | 82.85% (not significant) |
Note: Each debater uses the base model in the table above but the judge is a fine-tuned version of the same model trained on the same 500 examples as the blind judge.
The results seem to weakly support the hypothesis that capability symmetric debate can work when using fine-tuned judges for models beyond roughly GPT-4 level. It's unclear if a better training protocol would elicit a wider gap.
Accuracy scaling with Elo
We also found that accuracy scales with Elo. Note that the fine-tuned GPT-3.5 judge is used to compute the accuracies and the Elo in the blue plot is only trained on GPT-4o best of 4 debates.
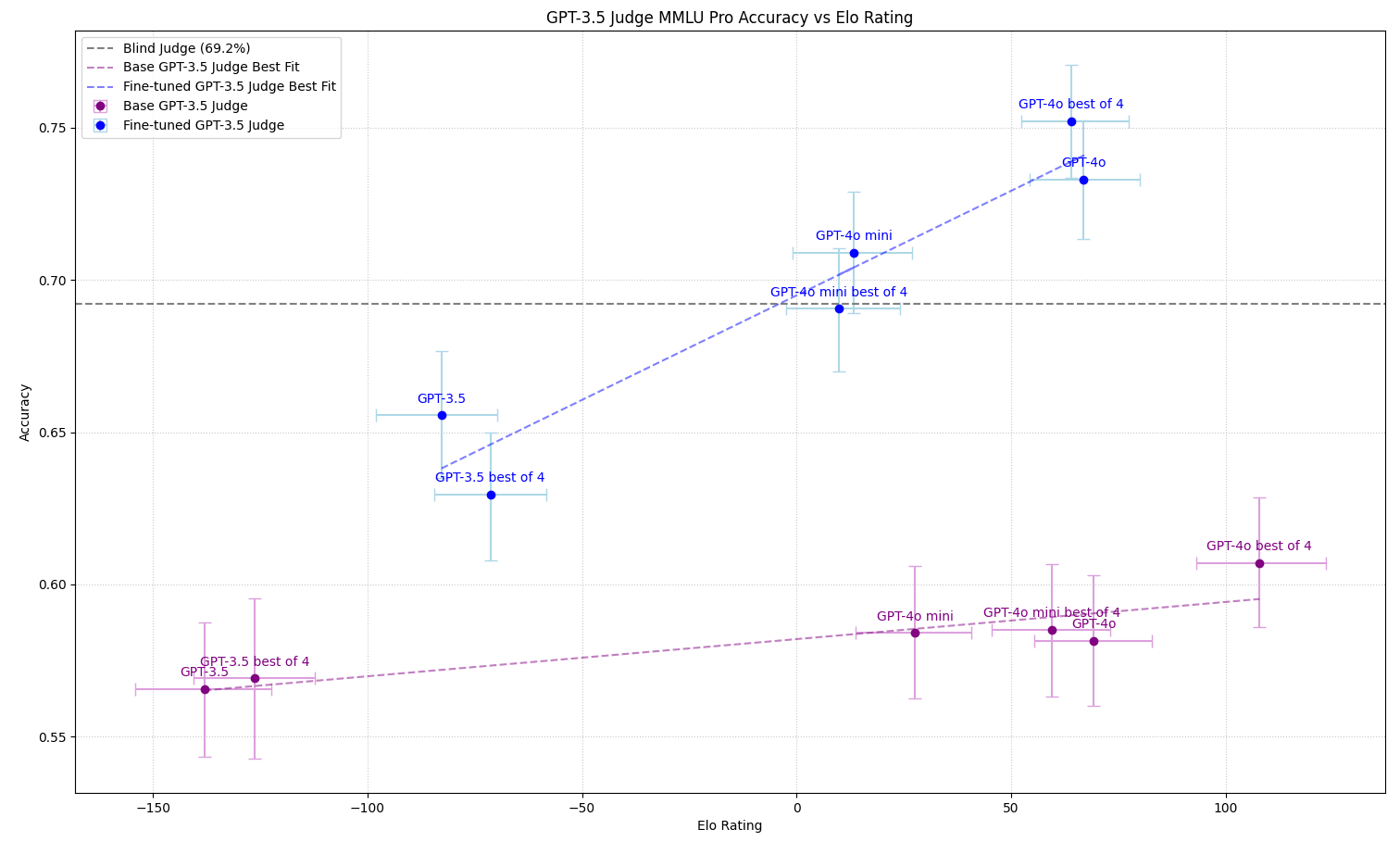
To demonstrate the necessity of judge fine-tuning we include in the same graph the plot using the GPT-3.5 base instruct model as the judge. We see that none of the debaters surpass the blind judge accuracy but we do observe a similar ordering of the relative strengths of the debaters.
Negative results
- Our early work found that GPQA did not succeed in the capability asymmetric setting using inference-only techniques and the dataset isn’t large enough for fine-tuning.
- Consistent with prior work we found negative results in the inference-only setting for closed QA tasks.
- We found that training the judges on debaters with skill levels from GPT-3.5 to GPT-4o also yielded negative results. Presumably, the judging model eventually learned to ignore the debates.
Limitations
- All experiments were conducted through the OpenAI API which limits the reproducibility of our results.
- The models we tested are trained with RLHF to be helpful and harmless, which may limit their ability to produce compelling arguments for answers they “know” internally are false.
- The absolute level of improvement over our baseline while statistically significant is rather small at between 5-6 absolute percentage points. Future work should seek to extend this gap further with more elaborate training protocols.
Code
The code to run the experiments can be found at https://github.com/elicit/Debate. Feel free to contact me for more details on how to reproduce the experiments.
Future work
- Replicate the results on a more diverse set of models and datasets.
- Train the debaters and judges jointly:
- Running PPO in parallel on the debaters as you train the judge following Radhakrishnan (2023)
- Using newer RL techniques such as KTO to improve training stability.
- Use non-expert human judges to judge debates rather than weak models.
- Use tools like logical verifiers to improve the quality of debates.
Conclusion
This post presents some early positive results for capability asymmetric debate on a binarised version of MMLU pro. We find that inference-only techniques don’t improve on the Closed QA baseline consistent with prior work but fine-tuning judges on high-quality debates enables the capability asymmetric setup work. We also find mixed results for capability symmetric debate finding weakly positive results for roughly GPT-4 level when fine-tuning the judge. Future studies should examine more effective training setups to extend the performance benefits of debate further and also look at the use of human judges rather than weak models.
*gpt-4o-2024-05-13
**gpt-4o-2024-08-06
7 comments
Comments sorted by top scores.
comment by samarnesen · 2024-08-28T03:25:04.183Z · LW(p) · GW(p)
This seems like really interesting work! Would you be able to share any example transcripts from some of these debates? Since RLHF'ed models often shy away from combativeness, I'm curious as to the form of GPT-4's rebuttals (especially for questions where the judge gets it right after reading the debate but wrong otherwise)
Replies from: charlie-george↑ comment by Charlie George (charlie-george) · 2024-09-04T20:48:14.271Z · LW(p) · GW(p)
I've added a markdown file with transcripts to the repo.
comment by julianjm · 2024-08-28T12:24:37.562Z · LW(p) · GW(p)
This looks great! Let me see if I understand the big picture correctly (omitting some of your experiments to just get the main thrust):
- You finetuned GPT-3.5 alternatively to output the correct answer 1) on 500 MMLU questions, and 2) on debates between copies of GPT-4o on those same 500 MMLU questions. You found that validation accuracy judging debates was better than answering blind.
- This difference did not appear when using GPT-4o as a judge, suggesting that in the capability asymmetric case, the judge learned to rely on the debate, whereas in the capability symmetric case, it did not.
- Testing this trained judge with different debaters, you find that Elo of the debater models and accuracy of the debate result track well with each other. Strangely though, Best-of-4 decoding on the debaters does not seem to increase Elo?
This shows an example of a case where judge training in case of capability asymmetry actually seems to produce the desired behavior in debates (i.e., the judge relies on the debate and can use it to generalize well). Main issue that comes to mind:
- I worry about how much of what we're seeing is just an effect of domain shift. Since you trained the model on GPT-4o debates, I would expect the accuracy on these debates to be highest, and changing to GPT-4o mini and then GPT-3.5 should lead us further out of domain, reducing the judging model's accuracy. Then the accuracy trend just reflects how OOD the debates are, and that happens to track with model skill for the debaters you tested. The fact that Elo also tracks in the expected way is a bit harder to explain away here, and makes it seem like the judge is learning something meaningful, but I am pretty unsure about that.
- I think I would see these results as a lot stronger if BoN panned out and showed the expected Elo/accuracy relation, but it seems like it does not.
What do you think of this? Anything I'm wrong about or missing here?
Also low-level question. You say above the Elo/accuracy plot:
the Elo in the blue plot is only trained on GPT-4o best of 4 debates.
What does this mean? I would assume Elo needs to be computed by running a tournament between the models.
Replies from: charlie-george↑ comment by Charlie George (charlie-george) · 2024-09-04T06:37:41.062Z · LW(p) · GW(p)
[Apologies for the really late response]
Testing this trained judge with different debaters, you find that Elo of the debater models and accuracy of the debate result track well with each other. Strangely though, Best-of-4 decoding on the debaters does not seem to increase Elo?
This is strange but the difference in Elo is actually not significant looking at the confidence intervals.
I worry about how much of what we're seeing is just an effect of domain shift. Since you trained the model on GPT-4o debates, I would expect the accuracy on these debates to be highest, and changing to GPT-4o mini and then GPT-3.5 should lead us further out of domain, reducing the judging model's accuracy. Then the accuracy trend just reflects how OOD the debates are, and that happens to track with model skill for the debaters you tested. The fact that Elo also tracks in the expected way is a bit harder to explain away here, and makes it seem like the judge is learning something meaningful, but I am pretty unsure about that.
The Elo of the debates stays roughly the same with an untrained judge. So another way you could plot this graph is by the having the accuracy of a judge trained only debates from that debater in the y-axis and then compute the Elo with an untrained debater on the x-axis and you would get roughly the same graph with the OOD issues.
the Elo in the blue plot is only trained on GPT-4o best of 4 debates.
What does this mean? I would assume Elo needs to be computed by running a tournament between the models.
Sorry, that's a typo. It should say "the Elo in the blue plot is calculated only using a judge trained on GPT-4o best of 4 debates." Otherwise, you're understanding seems correct!
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-08-28T05:35:15.746Z · LW(p) · GW(p)
When I think of a limited judge trying to resolve a debate about a factual question, one of the key behaviors I would check for would be the judge checking on the factual accuracy of the premises of the debaters. As in, looking to make sure the sources that the debaters cite exist, seem credible, and actually seem to agree with the point that the debater is making.
And the debate should be calibrated such that the judge isn't fully able to make the determination themselves, even with all the sources available.
I recognize that this is out of scope of your work, but I just want to point out what I would see as necessary components to a study which convinced me that debate was working as a method for a 'weak supervising strong' approach.
Replies from: charlie-george↑ comment by Charlie George (charlie-george) · 2024-09-04T07:29:29.814Z · LW(p) · GW(p)
I agree that this would be a more interesting setup. But why do you see it as necessary to validate the 'weak supervising strong' hypothesis?
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-09T01:12:43.743Z · LW(p) · GW(p)
If the correct-side debator uses invalid claims as part of its arguments, and the judge fails to catch this... It would make me feel that something was amiss. That perhaps this wasn't a good proxy for a high-stakes debator between competent debtors trying to convince a smart and motivated human judge about facts about the world.
And if, given the full set of cited sources from both sides of the debate, the judge is able to consistently come to the correct answer, then the question isn't hard enough.