Elicit: Language Models as Research Assistants
post by stuhlmueller, jungofthewon · 2022-04-09T14:56:37.763Z · LW · GW · 6 commentsContents
How we think about success Progress in 2021 Start with research Support broad literature reviews Establish a user base Build infrastructure for process-based ML Running complex task pipelines Finetuning individual tasks Roadmap for 2022+ Evaluate papers in depth through decomposition Elicit factors a question Elicit factors a research process Support many research workflows Refine the primitive tasks Expand our infrastructure for process-based ML Run more complex task pipelines Add new tasks with little effort Efficiently gather human demonstrations and feedback From research assistant to reasoning assistant None 7 comments
Ought is an applied machine learning lab. We’re building Elicit, the AI research assistant. Our mission is to automate and scale open-ended reasoning. To get there, we train language models by supervising reasoning processes, not outcomes [LW · GW]. This is better for reasoning capabilities in the short run and better for alignment in the long run.
In this post, we review the progress we’ve made over the last year and lay out our plan for Elicit. We'd love to get feedback on how to make Elicit more useful for LW and to get thoughts on our plans more generally. To make this easier, we've erred on the side of giving detail even where we know it will change.
Progress in 2021:
- We built Elicit to support researchers because high-quality research is a bottleneck to important progress and because researchers care about good reasoning processes.
- We identified some building blocks of research (e.g. search, summarization, classification), operationalized them as language model tasks, and connected them in the Elicit literature review workflow.
- On the infrastructure side, we built a streaming task execution engine for running compositions of language model tasks This engine is supporting the literature review workflow in production.
- About 1,500 people use Elicit every month.
Roadmap for 2022+:
- We expand literature review to digest the full text of papers, extract evidence, judge methodological robustness, and help researchers do deeper evaluations by decomposing questions like “What are the assumptions behind this experimental result?”
- After literature review, we add other research workflows, e.g. evaluating project directions, decomposing research questions, and augmented reading.
- To support these workflows, we refine the primitive tasks through verifier models and human feedback, and expand our infrastructure for running complex task pipelines, quickly adding new tasks, and efficiently gathering human data.
- Over time, Elicit becomes a general-purpose reasoning assistant, transforming any task involving evidence, arguments, plans and decisions.
How we think about success
Our mission is to automate and scale open-ended reasoning. If we can improve the world’s ability to reason, we’ll unlock positive impact across many domains including AI governance & alignment, psychological well-being, economic development, and climate change.
As AI advances, the raw cognitive capabilities of the world will increase. The goal of our work is to channel this growth toward good reasoning. We want AI to be more helpful for qualitative research, long-term forecasting, planning, and decision-making than for persuasion, keeping people engaged, and military robotics.
Good reasoning is as much about process as it is about outcomes. In fact, outcomes are unavailable if we’re reasoning about the long term. So we’re generally not training machine learning models end-to-end using outcome data, but building Elicit compositionally and inspired by human processes.
In the short term, supervising process [LW · GW] is necessary for AI to help with tasks where it’s difficult to evaluate the work from results alone. In the long term, process-based systems can avoid alignment risks introduced by end-to-end training.
Success for us looks like this:
- Elicit radically increases the amount of good reasoning in the world.
- For experts, Elicit pushes the frontier forward.
- For non-experts, Elicit makes good reasoning more affordable. People who don’t have the tools, expertise, time, or mental energy to make well-reasoned decisions on their own can do so with Elicit.
- Elicit is a scalable ML system based on human-understandable task decompositions, with supervision of process, not outcomes. This expands our collective understanding of safe AGI architectures.
Because we’re betting on process-based architectures, these two success criteria are fundamentally intertwined.
Progress in 2021
Start with research
We’ve decided to start by supporting researchers for the following reasons:
- Research matters: Impact in many domains is gated by high-quality research [EA · GW], and the world may get even more complex and difficult to reason about in the coming decades. With language models, we can scale best practices from research beyond human capacity. Language models can read and evaluate more research, evidence, and reasoning steps than humanly possible.
- Researchers care about reasoning: Researchers have relatively high bars for what good reasoning entails, and more established practices for how to do it. We want to learn what they know.
- Research is often process-based: Researchers often care as much about process as outcome, making this a good domain in which to develop process-based architectures. When we work on automating literature review, we don’t collect many examples of research questions and literature reviews and train a neural net end-to-end to produce legit-looking reviews. Instead, we study human experts, understand and decompose their reasoning, and build models that design, execute, and compose research steps like these experts.
- Democratize high-quality reasoning: Researchers are able to do more expensively what many people can only afford to do cheaply. Researchers have more time, expertise, and tools to carefully study the best answer to different questions. People or organizations may need the same findings to make decisions, but often don’t have those resources. Language models can make best practices accessible to non-experts.
- Learn from the non-expert/expert gap: The gap between a domain expert and novice in research may help us understand the dynamics between transformative AI and humans in the years to come. If we can figure out how to help less informed humans reproduce the judgments of more informed ones, we may be able to learn lessons about how humans can supervise advanced AI systems (“sandwiching” [LW · GW]).
We’re studying researchers and how they discover, evaluate, and generate knowledge. Within research, we chose an initial workflow (literature review, mostly for empirical research) and will expand to other workflows and question types. Eventually, we’ll surface the building blocks of many cognitive tasks so that users can automate their own reasoning processes.
Support broad literature reviews
Today, Elicit uses language models to automate parts of literature review, helping people answer questions with academic literature. Researchers use Elicit to find papers, ask questions about them, and summarize their findings.
We started with the literature review workflow for a few reasons:
- Pain point: Researchers said that finding and processing literature was their greatest pain point. Before we launched literature review, around 30% of the researchers signing up for Elicit said that the thing they most need help with is literature review. This was by far the largest category of need.
- Status quo before frontier: Literature review is a way to understand the current state of research. Understanding the status quo is a near-prerequisite for expanding the frontier.
- Process-based: There is a rich discipline around processes to synthesize literature. The systematic review process is a vetted, explicit process designed to reproducibly identify and aggregate research. That process taught us how to evaluate literature and gave us benchmarks to compare against our progress.
The literature review workflow in Elicit composes together about 10 subtasks, including:
- Search: Given a search term, Elicit uses language models to rank which papers are most likely to answer a user’s question, even in cases where there is no overlap in keywords.
- Summarization and rephrasing: Elicit reviews the abstracts of the most relevant papers and does its best to say for each abstract how it would answer the user’s question in one short sentence. This summary is typically more concise and relevant than any one sentence in the abstract.
- Classification: When users ask yes/no questions, Elicit predicts whether the abstract’s answer is more likely to be “Yes” or “No”. Similarly, Elicit identifies which of the papers shown are randomized controlled trials, systematic reviews, meta-analyses, etc.
- Extraction: Elicit automatically extracts key information from abstracts, such as sample population, study location, intervention tested, and outcome measured. User can ask custom questions about the abstracts as well.
- Critique: Elicit looks through all citations to a paper and surfaces the ones that are most likely to contain methodological critiques.
Outside of the literature review workflow, versions of some of these subtasks also exist independently on Elicit and researchers find them useful.
Establish a user base
Elicit is still early. We’ve spent about seven months building the literature workflow. Its impact on helping the world reason better, and on demonstrating a process-based ML architecture, is understandably small. Nevertheless, we’re excited about the reception so far and the potential to significantly scale its impact over the coming years.
Over 1,500 people use Elicit each month. Over 150 people use Elicit for more than 5 days each month (~ once a week). 60% of users in a month are returning users, people who used Elicit in a previous month and found it worth using again. In our February feedback survey, 45% of respondents said they would be “very disappointed” if Elicit went away. (Tech companies try to get this to 40%.) Elicit has been growing by word of mouth, and we expect to continue growing organically while we focus on making Elicit useful.
Today’s users primarily use Elicit to find papers and define research questions at the start of their research projects. 40% of respondents to our February feedback survey shared that they most want Elicit to help them with these tasks, and that Elicit is more useful for these tasks (7.8 and 7.1 out of 10) than for the others we asked about.

Elicit users also want help understanding paper contents and conducting systematic reviews, but Elicit was less helpful there at the time. (Understanding paper content is now a Q2 priority.)
Some of our most engaged researchers report using Elicit to find initial leads for papers, answer questions, and get perfect scores on exams (via Elicit Slack). One researcher used a combination of Elicit literature review, rephrase, and summarization tasks to compile a literature review for publication. Our Twitter page shows more examples of researcher feedback and how people are using Elicit.
At least 8% of users are explicitly affiliated with rationality or effective altruism, based on how they heard about Elicit or where they work. We also worked closely with CSET, whose researchers cited Elicit in three publications (Harnessed Lightning, Wisdom of the Crowd as Arbiter of Expert Disagreement, Classifying AI Systems).
In sum, people are using Elicit regularly and recommending it to others. We take this as a sign that Elicit is creating value. We’re excited for the day when we can make stronger claims about the impact Elicit is having on people’s reasoning. We plan to experiment with different evaluations of Elicit’s impact. Some ideas we’ve had in this direction:
- Have people of different levels of expertise use Elicit to generate a systematic review and see if they are indistinguishable from expert-generated systematic reviews (and ideally take less time).
- Use Elicit to update, then replicate, then generate high-quality research like Givewell intervention reports.
- Run a randomized controlled trial with Elicit as the intervention for different research or reasoning tasks.
Build infrastructure for process-based ML
Because Elicit is a process-based architecture [LW · GW], we need to get good at running complex task pipelines and at making sure the individual tasks within the pipelines are reliable. We’ve made progress on both fronts over the past year.
Running complex task pipelines
We’ve built a task graph execution framework for efficiently running compositions of language model tasks. The framework is used to run literature review tasks and is likely one of the most compositional uses of language models in the world. Elicit engineers only need to specify how tasks depend on other tasks (e.g. claim extraction depends on ranking), and the scheduling and execution across compute nodes happen automatically.
The execution engine runs the graph of tasks in parallel as efficiently as allowed by the dependency structure of the workflow graph. While running, the executor streams back partial results to the Elicit frontend. Because language models are relatively slow (more than one second per query for the largest models), parallelism and sending partial results both matter for a good user experience.
Finetuning individual tasks
To get good overall answers, we also need individual primitive tasks to be robust. In a project in Q4 2021, we focused on generating one-sentence answers based on abstracts as a case study. When a researcher asks a question, Elicit finds relevant papers, reads the abstracts, then generates a one-sentence summary of the abstract that answers the researcher’s question. These summaries are often more relevant to the researcher’s specific question than any one of the sentences in the abstract.
With few-shot learning, we found that the claims were often irrelevant, hard to understand, and sometimes hallucinated, i.e. not supported by the abstract. This is a case of “capable but unaligned.” GPT-3 has the entire abstract, which contains all of the information it needs to generate a summary answer. We’re confident that GPT-3 is capable of generating such answers—it could even just pick the most relevant sentence and return it word for word. Nonetheless, it sometimes made things up.

As one of the first users of GPT-3 finetuning, we switched from few-shot learning to a finetuned claim generation model. This made the claims more relevant and easier to understand, but initially made hallucination worse. Through a sequence of finetuning runs on increasingly higher-quality datasets, we reduced hallucination without making claims less relevant. We still haven’t fully solved this problem. We expect that our upcoming work on verifier models, decomposition, and human feedback will help.
Roadmap for 2022+
This roadmap highlights the most important themes for Elicit over the next years. A more fleshed-out roadmap is in this doc.
Evaluate papers in depth through decomposition
To date, we’ve focused on making Elicit useful for getting a broad overview of a research space, surveying many papers. Next, we will help researchers as they go deep into individual research papers and use those subtasks to support more complex reasoning.
Over the next months, we’ll work on projects like:
- Study bespoke evidence reviews and make Elicit more useful for those.
- Help evaluate methodological quality and robustness of papers by breaking down this evaluation into multiple component factors. This can look like:
- Identify how people predict whether or not a paper will replicate and make those calculations easy in Elicit.
- Identify the components of risk of bias analysis and make those available in Elicit.
- Evaluate claims via belief propagation on weighted citation networks.
- Enable question-answering across the full text of papers.
- Let users ask follow-up questions to Elicit-generated answers, using Elicit-generated answers as additional context.
- Prototype AI safety via debate in the context of scientific claims.
As we help users with more complex reasoning, we’ll need to get better at automatic decomposition, aggregating the results of subtasks, and understanding what users are really looking for. This will make Elicit more useful for more complex research (differential capabilities) and shed light on the feasibility of process-based architectures (alignment).
Here are two examples of how Elicit might automatically decompose complex tasks:
Elicit factors a question
- Researcher asks a complex, underdefined question about a paper e.g. “What was the effect?”
- Elicit automatically decomposes this question into subquestions like:
- What are all of the population-intervention-outcome permutations studied in this paper?
- What are all of the populations studied?
- For each population, what are all of the interventions studied?
- For each population-intervention pair, what are all of the outcome measures?
- What was the effect size for each permutation?
- Was the effect size significant?
- What are all of the population-intervention-outcome permutations studied in this paper?
- Elicit then summarizes these findings back for the user, or only presents the relevant subset.
Elicit factors a research process
- Researcher asks a research question e.g. “How does caffeine affect longevity?”
- Elicit generates a literature review process for the specific question e.g.:
- Run a semantic search to find the top 1000 papers that are most likely to have information relevant to caffeine and longevity, even if only indirectly
- Limit to studies published after 2015
- Read the titles and abstracts of the post-2015 papers to find the most relevant randomized controlled trials related to longevity
- Identify sample size in abstract and limit to studies with at least 100 participants
- Identify sample population in abstract and limit to studies on human participants
- Researcher can provide feedback on the proposed process. They might want to tweak the query, choose a different corpus of papers, adjust sample size thresholds, or add other steps.
- Once Elicit completes the tasks, the researcher can take a look at the overall results, and zoom into individual steps if they wish.
Support many research workflows
Right now, Elicit works best for questions about empirical research. Those tend to be questions of the style “What are the effects of X on Y?”, including questions about randomized controlled trials in biomedicine, social science, or economics.
Starting in late 2022, we want to move beyond literature review for empirical questions and let users automate custom workflows, initially within research. Elicit will become a workspace where users can invoke and combine tasks like search, classification, clustering, and brainstorming over datasets of their choice, with different models and interfaces.
For example, researchers might want to search over their own corpus from a reference manager, extract all of the outstanding research directions from the papers they’ve curated, rephrase them as questions, then search those questions over academic databases to see if any of them have been worked on.
They might connect their personal notetaking apps, classify all of the notes about papers, then train a model to watch the literature and notify them if new papers addressing any of their cruxes are published.
To ensure users have the tools they need to design their personal research assistants, we’ll work on projects like:
- Expand to more information sources (Wikipedia, think tank publications, personal notes)
- Make Elicit useful for other types of questions e.g.
- What are the best examples of X?
- What are the best arguments / evidence for / against X?
- How does X work?
- What is the future of X?
- How much research has been done on X?
- How do you do X?
- Study research processes and build the UX and infrastructure improvements they require e.g.
- Extract open research directions from the literature
- Identify which research directions many people are interested in but where no good papers exist
- Organize concepts & arguments in a space
Refine the primitive tasks
We’ll keep refining the core subtasks underlying many research workflows. This entails both task-specific work, such as building out search infrastructure for academic articles, as well as general-purpose human feedback mechanisms.
One of our biggest projects right now is building a semantic search engine for 200 million abstracts and 66 million full-text papers using language model embeddings.
On the human-feedback side, we’ll apply and contribute to methods for alignment. For example:
- Applying verifier models within Elicit. We want to try using a classifier to identify whether the summary is supported by the abstract, whether Elicit’s guess at the dosage applied in the study is correct, etc.
- Updating responses with user feedback. We’re excited about mechanisms that let users highlight where models fail, and about providing immediately improved answers when users highlight failures.
When we run into problems automating a task, we always want to understand whether this is because of limited data or limited model capacity. We are confident that model capacity will improve over time, and are primarily concerned with providing the data and training objective that will make good use of the available capacity at any point in time.
Expand our infrastructure for process-based ML
In the ideal world, the only constraint for new workflows is the compute time for running language models. To compete with end-to-end training, running new workflows using decomposition needs to have near-zero friction. This requires that we can run complex task pipelines, add new tasks with little effort, and efficiently gather human demonstrations and feedback.
Run more complex task pipelines
We’ll build the infrastructure to execute very large graphs of tasks and deal with the challenges that come up in this setting, such as:
- Building models that make good choices about which tasks to run next
- Choosing the right level of abstraction for decompositions
- Avoiding accumulation of small errors by running human-understandable error correction processes and sanity checks, delegating reasoning about error propagation to the system
- Using red teaming and interpretability methods to avoid catastrophic failures
Add new tasks with little effort
Adding new primitive tasks is labor-intensive. We need to think about what data is needed, create gold standards, collect finetuning data from contractors, evaluate model results using contractors, and use our judgment to improve instructions for contractors.
In the ideal world, we would just say "categorize whether this study is a randomized controlled trial" and an elegant machine involving copies of GPT-k, contractors, etc, would start up, generate a plan for accomplishing this task, critique and improve the plan, and execute it without any intervention on our part.
To get to this world:
- We record all the steps from wanting to add a new task to having it up and running
- We analyze what the bottlenecks are. Generating the data? Finding the model to train? Setting up the right objective?
- For each bottleneck, we think about how to speed up the relevant decisions
Efficiently gather human demonstrations and feedback
Given a new task that models can't do out of the box, we need efficient mechanisms for gathering human demonstrations, using both a scalable contractor workforce and Elicit users. This is less distinctive to Elicit since everyone who trains models on human demonstrations and feedback has to cope with it. We are aiming to outsource as much of it as we can, but it is an important ingredient nonetheless.
Cases where users can provide good feedback but contractors naively can't are particularly interesting because they let us test how we can get feedback and demonstrations for tasks where it's hard to get good human oversight. They are a test case for the future where we want to accomplish tasks for which neither contractors nor users can provide feedback directly.
From research assistant to reasoning assistant
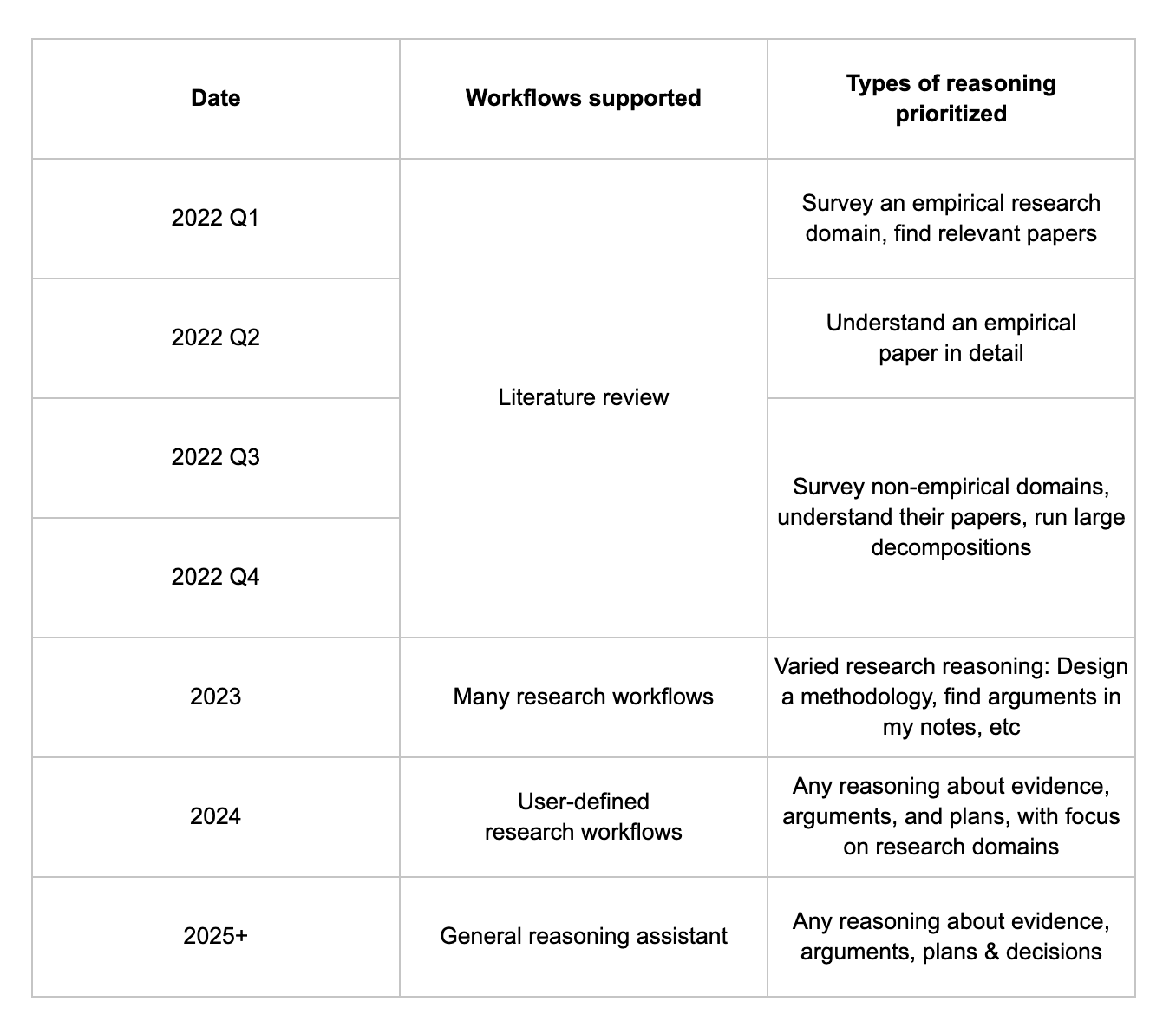
Zooming out, our milestones for the next few years are:
- 2022: Elicit is the best literature review assistant and demonstrates complex automated reasoning through decomposition
- 2023: Elicit automates many research workflows: Exploration, planning, reading, and others
- 2024: Users automate custom research workflows with Elicit
- 2025+ Elicit transforms any task involving evidence, arguments, plans and decisions
We’re starting by studying a group of researchers, who are thoughtful about how they discover and evaluate information and who have high standards of rigor. We’ll design Elicit to replicate their processes, using language models to apply them at a greater scale than humanly possible.
Eventually, we’ll make these research best practices available even to non-experts, to empower them when interacting with experts or making life decisions. We’ll support a diverse set of research workflows, then other workflows beyond research.
We’ll develop Elicit compositionally so that the system remains aligned and legible even as the reasoning it supports grows increasingly complex.
Today, researchers already find Elicit valuable. Yet there is much left to do. We’ve described the work we see ahead of us to get to a world with better reasoning. Join us!
6 comments
Comments sorted by top scores.
comment by Alex K. Chen (parrot) (alex-k-chen) · 2022-04-09T16:15:15.542Z · LW(p) · GW(p)
On the caffeine/longevity question => would ought be able to factorize variables used in causal modeling? (eg figure out that caffeine is a mTOR+phosphodiesterase inhibitor and then factorize caffeine's effects on longevity through mTOR/phosphodiesterase)? This could be used to make estimates for drugs even if there are no direct studies on the relationship between {drug, longevity}
[aka inverse-compositionality]
Also would ought be able to compare the dose/response curves used on animals and then "translate" them to humans? (eg effects of a study on rats/mice fed 10 mg/kg of X => automatically transfer this to estimated equivalent dose for a 45kg human). The literature I care most about is amphetamine neurotoxicity, where the doses used in rats/mice/rhesus macaques are WAY above the doses used in humans, and where there's huge uncertainty regarding whether 10mg of Adderall in a 45kg human is neurotoxic.
Or also "translate 10mg Adderall in 45kg human to uM/nM equivalent in human brain tissue => compare this with uM/nM equivalent observed in all animal experients". There are differences between how sensitive rat/mice/rhesus macaque neurons are wrt excess dopamine neurotoxicity.
Other questions I'm interested in:
- What are all the things that Sphingosines/ceramides do in the cell? How do they affect the rigidity/fluidity of the cell membrane?
- What are effects of H3K9me3 and HeK27me3 on longevity? (along with chromodomain proteins which act on them)
- "How much exogenous melatonin would increase intracellular melatonin to 20 μM?" [1] Doris Loh has many posts about the antioxidant/neuroprotective potential of melatonin (+has listed papers) and I want to figure out the optimal dose for melatonin for brain health (BOTH under normal conditions and for minimizing amphetamine neurotoxicity).
- what are levels of intracellular glucose seen in yeast (both calorie-restricted and ad lib), and how do they compare to levels of intracellular glucose seen in human tissue?
- how does changing uM/nM concentration of intracellular glucose affect amount of cAMP/ATP produced in all papers studied?
- What is the dose-response curve of intracellular ATP with lifespan?
- What are effects of increased citrate concentration on longevity conditioned on changes in histone acetylation marks at all histone acetylation sites?
- what are $AverageChemicalProperties (such as hydrophilicity and lipophilicity moieties) of all antioxidants with the highest ORAC values?
- How does amphetamine neurotoxicity change with age? Look at all papers that show changes in cellular antioxidant/redox/H2O2/catalase status + VMAT2/DAT/dopamine levels with age (+ changes in concentration of "repair proteins + lysosomal function" + ATP to power repair proteins + intrinsic reduction in dopamine with age) and then roughly assess if the damage is more irreversible for older brains than younger brains. Subcompartmentalize for effects on cytoskeleton+genome+epigenome+synaptosome+spiny dendrites+neurons+lipid composition+cardiolipin+mitochondria in PFC vs striatum vs VTA
- (Michael Levin question): Is there an estimate of what % of any metazoan genome is structural genes (enzymes, "load-bearing" proteins, etc.) vs. regulatory/computational machinery (transcription factors, ion channels, etc.) weighted by frequency of expression? Ofc these are not sharp categories, but anyone estimated a version of this?
- what is the optimal total modafinil/caffeine/amphetamine dose used for maximizing the amount of FLOPs computed in the lifetime of the human brain? (lol this is WAY out there but I'm throwing it out b/c important)
- what is the maximum grey matter/white matter mass seen in super-ager/old brains (eg https://twitter.com/jakob_seidlitz/status/1511779834187374597 ), and extract all demographic/genomic/proteomic data from superager brains
- https://twitter.com/constable_todd/status/1512749834968748032
My favorite lit-review papers, BTW, are from Doris Loh (eg https://www.mdpi.com/2076-3921/10/9/1483/htm ). Would be wonderful to make creation of similar lit reviews MUCH easier. appendix to https://scholar.google.com/citations?view_op=view_citation&hl=en&user=fINW1HkAAAAJ&citation_for_view=fINW1HkAAAAJ:hC7cP41nSMkC as well
[1]
Replies from: stuhlmuellerthere may yet be another compelling reason that could explain how melatonin at pharmacological doses (10 mg/kg in vivo) [700] exerts neuroprotective effects in tauopathy.
An in vitro study on Neuro2A cells reported that melatonin at 10 μM concentration reduced intracellular ROS levels induced by tau aggregate treatment, and at 50 μM, melatonin reduced phospho-tau as well as GSK3β mRNA and subsequent protein levels. Melatonin increased cell viability in tau-exposed neurons in a dose-dependent manner, with 80% viability observed at 20 μM melatonin and a complete reversal at 200 μM, compared to only a 60% viability in controls without melatonin [704]. In an earlier study, the same group had reported that melatonin at strengths between 200 and 5000 μM failed to deter the aggregation of full-length tau. However, distinct morphology of small, broken tau fibrils were seen in the presence of either 1000 [705] or 5000 μM [352] melatonin. Furthermore, 5000 μM melatonin disaggregated tau fibrils by 54%, whereas 100 μM achieved only a ~14% effect [352]. It is possible that melatonin interacts with histidine residues to destabilize the assembly of aggregates [352] in a manner similar to how it disrupts salt bridges in Aβ, because tau phosphorylation alters side chain conformations through the formation of a network of salt bridges [706]. Salt bridge interactions were also observed in Aβ-mutated tau complexes assembled from Aβ peptides and mutated tau [707]. Earlier studies have reported that 300 μM melatonin interacted with hydrophobic segments in Aβ1–40 and Aβ1–42 to inhibit the formation of β-sheet and/or amyloid fibrils [708], and the inhibition of β-sheet and amyloid fibrils in samples containing 250 μM of Aβ1–40 and Aβ1–42 with only 100 μM of melatonin could not be replicated in control experiments using a potent free radical scavenger N-t-butyl-a-phenylnitrone (PBN), or a melatonin analog 5-hydroxy-N-acetyl-tryptamine (NAT) [337]. Even though melatonin could dissolve fibrils [709] by disrupting inter-peptide salt bridges between side chains Asp23 and ly28 [710,711] critical to β-sheet formation [712], the concentrations of 1000 [705] or 5000 μM [352] required to disassemble tau fibrils are significantly higher than the 100–300 μM melatonin used to inhibit β-sheet and amyloid fibrils [337,708], or the complete reversal of cell viability in tau-exposed neurons achieved with only 200 μM melatonin [704].
↑ comment by stuhlmueller · 2022-04-20T10:20:40.069Z · LW(p) · GW(p)
Thanks for the long list of research questions!
On the caffeine/longevity question => would ought be able to factorize variables used in causal modeling? (eg figure out that caffeine is a mTOR+phosphodiesterase inhibitor and then factorize caffeine's effects on longevity through mTOR/phosphodiesterase)? This could be used to make estimates for drugs even if there are no direct studies on the relationship between {drug, longevity}
Yes - causal reasoning is a clear case where decomposition seems promising. For example:
How does X affect Y?
- What's a Z on the causal path between X and Y, screening off Y from X?
- What is X's effect on Z?
- What is Z's effect on Y?
- Based on the answers to 2 & 3, what is X's effect on Y?
We'd need to be careful about all the usual ways causal reasoning can go wrong by ignoring confounders etc
comment by domenicrosati · 2022-04-11T12:42:52.383Z · LW(p) · GW(p)
Hey there,
I was just wondering how you deal with hallucination and faithfulness issues of large language models from a technical perspective? The user experience perspective seems clear - you can give users control and consent over what Elicit is suggesting and so on.
However we know LLMs are prone to issues of faithfulness and factuality (Pagnoni et al. 2021 as one example for abstractive summarization) and this seems like it would be a big issue for research where factual correctness is very important. In a biomedical scienario, if a user of Elicit gets an output that presents a figure wrongly extracted (say from a proceeding sentence, or hallucinated as the highest log likelihood token based on previous documents), this could potentially have very dangerous consequences. I'd love to know more about how you'd adress that?
My current thinking on the matter is that in order to address these safety issues in NLP for science we may need to provide models that "self-criticize" their outputs so to speak. I.e. provide counterfactual outputs that could be checked or something like this. Espeically since GopherCite (Menick et al 2022) and some of the similar self-supporting models seem to show that self-support is also prone to some issues that doesn't totally address factuality (in their case as measured on TruthfulQA) not to meantion self-explaining approaches which I belive suffer from the same issues (i.e. hallucinating an incorrect explanation).
Menick, J., Trebacz, M., Mikulik, V., Aslanides, J., Song, F., Chadwick, M., ... & McAleese, N. (2022). Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147.
Pagnoni, Artidoro, Vidhisha Balachandran, and Yulia Tsvetkov. "Understanding factuality in abstractive summarization with FRANK: A benchmark for factuality metrics." arXiv preprint arXiv:2104.13346 (2021).
↑ comment by stuhlmueller · 2022-04-20T10:11:01.062Z · LW(p) · GW(p)
Yeah, getting good at faithfulness is still an open problem. So far, we've mostly relied on imitative finetuning. to get misrepresentations down to about 10% (which is obviously still unacceptable). Going forward, I think that some combination of the following techniques will be needed to get performance to a reasonable level:
- Finetuning + RL from human preferences
- Adversarial data generation for finetuning + RL
- Verifier models, relying on evaluation being easier than generation
- Decomposition of verification, generating and testing ways that a claim could be wrong
- Debate ("self-criticism")
- User feedback, highlighting situations where the model is wrong
- Tracking supporting information for each statement and through each chain of reasoning
- Voting among models trained/finetuned on different datasets
Thanks for the pointer to Pagnoni et al.
comment by remember · 2022-11-30T22:05:13.171Z · LW(p) · GW(p)
We'd love to get feedback on how to make Elicit more useful for LW and to get thoughts on our plans more generally.
A lot of alignment is on lesswrong and alignmentforum, and as far as I can tell elicit doesn't support those. I could be missing something, but if they aren't supported it would be great to have them in Elicit! I use elicit from time to time when I'm doing background research, and it definitely feels far more useful for general ML/capabilities stuff than alignment (to the point I kinda stopped trying for alignment after a few searches turned up nothing).
comment by Brian Alper (brian-alper) · 2022-10-26T18:49:01.186Z · LW(p) · GW(p)
For understanding risk of bias analysis, you want to learn about the Scientific Evidence Code System (https://fevir.net) with hundreds of types of risk of bias and standard vocabulary with machine-usable codes. There are many other developments on the Fast Evidence Interoperability Resources (FEvIR) Platform that will be of interest for Elicit.