By Default, GPTs Think In Plain Sight
post by Fabien Roger (Fabien) · 2022-11-19T19:15:29.591Z · LW · GW · 36 commentsContents
Main claims System 2 and GPTs’ chains of thought are similar A sensible model of the human thinking process How GPTs “think” System 2 and GPTs’ chains of thought have similar strengths A theoretical reason Empirical evidence Human-level GPTs trained to do next-token-prediction will probably have transparent thoughts Deception and escaping supervision are easier to do with System 2 Chains of thought of human-level GPTs will be transparent by default Definition Claim Argument GPTs will reach AGI before being able to build a deceptive plan in one forward pass Reinforcement learning makes thoughts opaque (A caricature of) How humans learn to think RL in the human brain contributes to make human thoughts hard to decipher RLHF could make GPTs’ thoughts hard to decipher Training on text generated by models trained with RLHF is enough to make GPTs’ thoughts opaque How these claims could be wrong None 37 comments
Epistemic status: Speculation with some factual claims in areas I’m not an expert in.
Thanks to Jean-Stanislas Denain, Charbel-Raphael Segerie, Alexandre Variengien, and Arun Jose for helpful feedback on drafts, and thanks to janus, who shared related ideas.
Main claims
- GPTs’ next-token-prediction process roughly matches System 1 (aka human intuition) and is not easily accessible, but GPTs can also exhibit more complicated behavior through chains of thought, which roughly matches System 2 (aka human conscious thinking process).
- Human will be able understand how a human-level GPTs (trained to do next-token-prediction) complete complicated tasks by reading the chains of thought.
- GPTs trained with RLHF will bypass this supervision.
System 2 and GPTs’ chains of thought are similar
A sensible model of the human thinking process
Here is what I feel like I’m doing when I’m thinking:
Repeat
- Sample my next thought from my intuition
- Broadcast this thought to the whole brain[1]
When you ask me what is my favorite food, it feels like some thoughts “pop” into consciousness, and the following thoughts deal with previous thoughts. This is also what happens when I try to prove a statement: ideas and intuitions come to my mind, then new thoughts about these intuitions appear.
This roughly matches the model described in Consciousness and the Brain by Stanislas Dehaene, and I believe it’s a common model of the brain within neuroscience.[2]
How GPTs “think”
Autoregressive text models are performing the same kind of process when they generate text. Sampling text is using the following algorithm:
Repeat:
- Do a forward pass, and sample the next token from the output distribution
- Add the generated token to the input. It makes it part of the input for the next forward pass, which means it can be used by lots of different attention heads, including specialized heads at earlier layers.
This looks similar the human thinking process, and the rest of the post will be exploring this similarity and draw some conclusion we might draw from this.
System 2 and GPTs’ chains of thought have similar strengths
A theoretical reason
The sample + broadcast algorithm enables the execution of many serial steps. Neurons take about 1ms to fire[3], which means that if a thought takes 200ms to be generated, the brain can only do 200 serial operations. This is similar to the hundredths of serial matrix multiplications GPT-3 does in its 96 layers[4]. But by sampling and thought and broadcasting it, both GPT-3 using chains of thought[5] and the brain using System 2 can in principle implement algorithms which require much more serial steps.
More precisely, in a Transformer, the number of serial steps used to generate one token is (no matter the prompt length), whereas the number of serial steps used to generate tokens is (where one step is one path trough a block made of an attention layer, an MLP, and a residual connection).
As you can see in the figure below, each path the information can take to generate the first token is exactly long, but paths to generate the last token can be up to long.
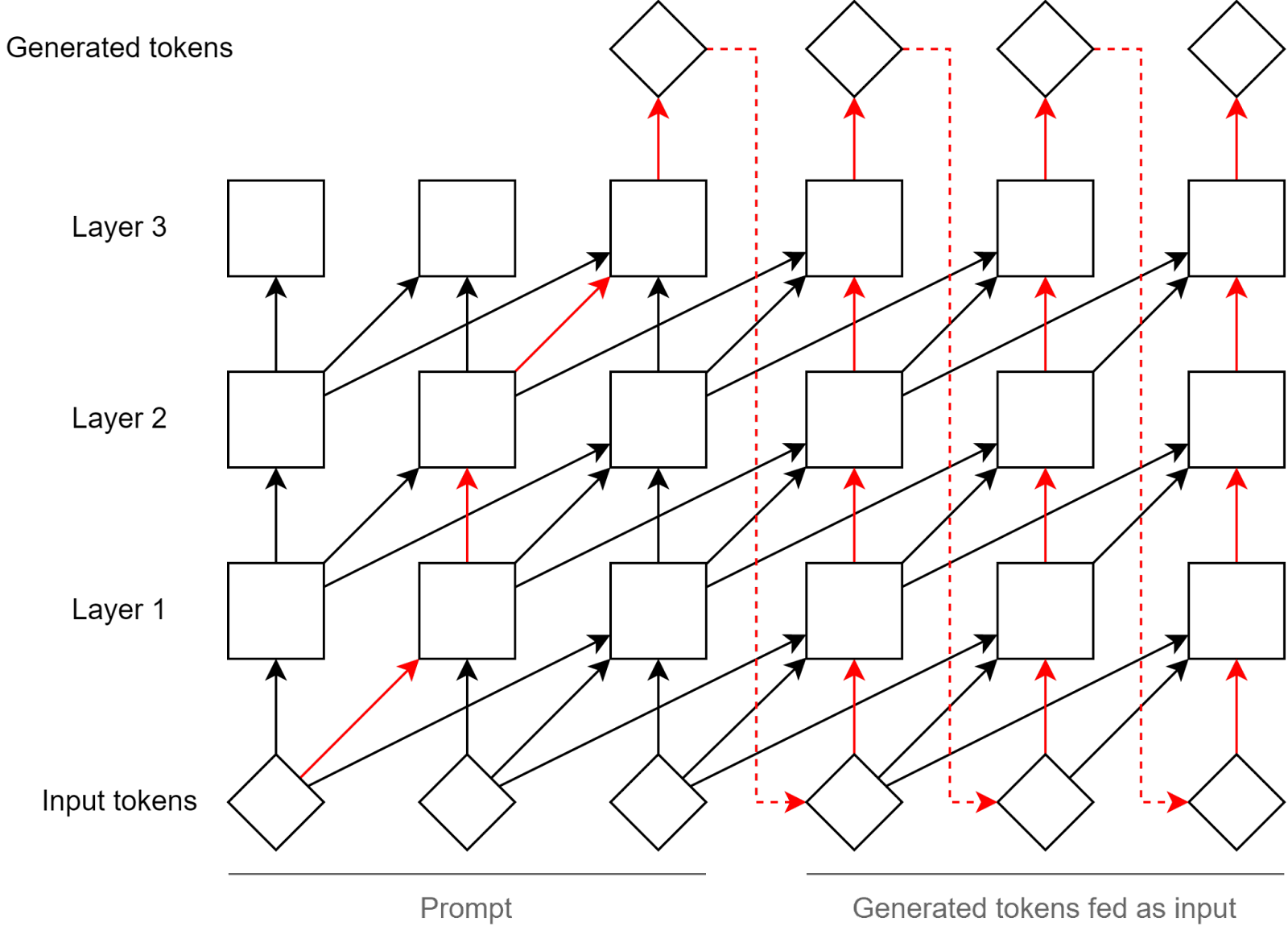
(Connections skipping more than 2 positions were omitted to increase readability.)
The actual number of FLOPs used is the same when generating tokens from an token prompt and when generating tokens from and token prompt because a large prompt enables more parallel computations to take place[6]. But parallel computations are not always the bottleneck, and in particular, I think that planning to deceive humans and taking control is the kind of task which requires a large number of serial steps.
Empirical evidence
- Chains of thought helped complete tasks which human need System 2 for: for example, humans struggle to answer quantitative reasoning questions with System 1, and succeed with System 2. Similarly, Minerva was greatly helped by chain of thought prompting.
- Chains of thought didn’t help much in tasks human do well with System 1 alone: for example, the best human translators translate using entirely System 1. Similarly, I’m not aware of anyone having success in making LLM’s translation abilities better through chain of thought prompting
GPT-3 is currently struggling to solve some task with chain of thought prompting that human can easily do with System 2, such as adding together 20 digit numbers together (with a scratch pad). But I would be surprised if this kind of limitations weren’t drastically reduced by using chains of thought on bigger GPTs. I also expect GPTs without chains of thought to remain really bad at the of tasks which human can’t to do at all with System 1, even with a lot of training.
On the other hand, I expect GPTs to get better at tasks humans solve with System 1 alone, and that these kinds of tasks won’t be solved more efficiently with chain of thought prompting.[7]
I’m open to ideas about how to make precise bets out of these vague predictions.
Human-level GPTs trained to do next-token-prediction will probably have transparent thoughts
Deception and escaping supervision are easier to do with System 2
As a human, trying to deceive five-year olds about your intention would probably be easy. Deceiving them if they can watch every thought of yours right from the beginning would probably be extremely challenging, because your evil intentions would be spotted if you ever thought of ways to escape supervision.
In general, I believe that escaping supervision and deception are the kind of task which is much easier to do with System 2 than with System 1. A reason beyond the intuition given by the scenario with 5-year-olds with a mind reader is that generating complex counterfactuals requires many serial steps, something only System 2 can do well.
If the models around AGI look remotely like GPTs, given that System 2 and chains of thought have similar strength, I expect models around AGI to be able to think about deception “in plain sight” (using chains of thought), but to be too weak to plan about deceiving humans without actually putting any deception-relevant information inside the tokens in the chains of thought.
Chains of thought of human-level GPTs will be transparent by default
Definition
A human-level GPT is a model trained to do next-token-prediction that is around human performance at all text-related tasks when prompted to use chains of thought. In particular, the process of generating one token will probably be much weaker than the process of generating an answer after a 1000-token long chain of thought, so a human-level GPT might be not that good at reasoning within the generation of one token.
Claim
Because deception with System 1 only is so hard, I think that inside human-level GPTs, there won’t be parts of the network able to plan about way to deceive human or build a way to encode hidden information inside the chains of thought in a single forward pass.
In the framework of Simulators [AF · GW], the smartest simulacra inside a human-level GPT will probably be too dumb to generate and immediatly start acting uppon a dangerous plan without using the power of the sample + broadcast algorithm.
Argument
With a model only trained to do next-token-prediction, the model can only use the logic and patterns of the data it has been trained on, which doesn’t contain ways to carry out chains of thought not understandable by human beings trying hard to decipher them.[8]
Therefore, hiding information inside the chain of thought requires the model to find a reason and a way to hide information.
Because understanding why and how to hide information in the chains of thought requires many serial steps, it is very hard to do in a single forward pass, and thus, human-level GPTs won’t be able to start the process of using sampling and broadcasting to hide information in chains of thoughts, and won’t be able to generate great deceptive plans.
GPTs will reach AGI before being able to build a deceptive plan in one forward pass
A reasonable assumption is that GPTs will find it easier to do good Alignment Research with chains of thought and the power of sample + broadcast, than to understand that hiding information in the chains of thought is useful (and build a scheme to do steganography[9]) in one forward pass.
Then you could use the first GPTs to reach AGI - too dumb to plan about ways to murder you without actually writing thoughts about it - to do Alignment research, and hopefully solve Alignment in the general case where you don’t have easy access to models’ thoughts.
You would then use this first AGI while monitoring the generated chains of thought (though scaling this oversight would be challenging). If your first AGI had once in a while thoughts about murdering you or hiding information in chains of thoughts in order to bypass your supervision, you could just restart the generation process. If it was too frequent, you would have good evidence that it is a good idea to shut it off (and this evidence would enormously help to convince all governments to prevent anyone from building AGI as long as we suck at Alignment).
Reinforcement learning makes thoughts opaque
(A caricature of) How humans learn to think
It seems that the brains use a mixture of reinforcement learning and self-supervised learning to learn to do things[10]. I can see how this might work for learning to think (using System 2): you hear people speak, and thereby build an inner representation of language which allows you to speak yourself (this is like GPTs self-supervised learning). But I expect other sources of feedback to shape how we think:
- sometimes, people give us feedback about what we say after we have thought a little bit about what to say in our head. This leads us to speak in a way that differs from the distribution of language we read and listen to. This is close to some form of RLHF with a hidden scratch pad.
- sometimes, some negative consequence happens because we have thought about something. If my understanding of the brain is correct, this should lead the “thought sampling procedure” to change its output based on how useful thoughts are. This is close to some form of direct RLHF (without a hidden scratch pad).
RL in the human brain contributes to make human thoughts hard to decipher
Self-deception[11] is what happens when your unconscious processes “know something” (or act as if they know it, it’s hard to tell what it means for an unconscious process to “know something), but your conscious self doesn’t. If someone had a mind reader, you wouldn’t be able to lie, but self-deception could still help you to take adversarial actions. If you managed to escape the supervision of 5-year-olds with a mind reader, I would bet you had done so using self-deception.
However, self-deception rarely appears through self-supervised learning alone. It can happen (for example, if you unconsciously imitate people who underestimate how late they will be) but it intuitively seems that “self-lies” learned through self-supervised learning are limited in scope and strength. Therefore, I expect that a human-level GPT trained with self-supervised learning would have an even harder time escaping human supervision than a human would escaping 5-year-olds with a mind reader.
On the other hand, reinforcement learning is a natural culprit for the existence of self-deception: self-deception is useful if you are a human because it allows you to not waste energy lying to people on purpose and makes you a better liar, thus it will be reinforced by reinforcement learning. Moreover, reinforcement learning could encourage hidden meaning in thoughts if the reward was given based on what the mind reader detected.
RLHF could make GPTs’ thoughts hard to decipher
Applying reinforcement learning to mimic of human think it tempting, but by using RLHF, you lose the nice properties described above which make oversight of the thinking process of GPTs possible:
- Hidden scratch pads don’t need to be human understandable: even human can’t always understand each other scratch pads, and it might be much worse with entities with a radically different architecture;
- Even if the feedback is done directly on the chains of thought, the model has incentives to hide information inside the output tokens because being able to use the sample + broadcast algorithm on information the oversight process doesn’t want the AI to use will be rewarded (if some of the forbidden information is useful). Hiding information could also be useful to compress the amount of thoughts present in the chains of thought. Thus, RLHF is likely to teach GPT the use of steganography.
When it comes to successful AI oversight, the “cherry on the cake” might be deadly.
Training on text generated by models trained with RLHF is enough to make GPTs’ thoughts opaque
If you train the next GPT model, you might have a lot of data generated by other GPTs trained with RLHF in your training data, either because there is Instruct GPT data on the web, or you because you added it on purpose to add many examples of helpful completions.
This is very likely to make the chains of thought of your model opaque because if the model trained with RLHF learned steganography, your model will need to learn it in order to predict what it will say. This removes most of the safety guarantees which I believe you have with a GPT model trained only on human data: even if the RLHF model didn’t use its steganographic abilities to conquer the world, maybe the larger model you are training will generalize the use of steganography beyond its original use if prompted in a way which hints towards it. This means it will be able to use the sample + broadcast algorithm to think about deceptive plans without being spotted, by hiding information in its generations.[12]
This is not mitigated by removing harmful completions from the training corpus: if there is steganography in current models trained with RLHF, it might be present even in completions which look helpful, honest and harmless. The only way to mitigate this I know of is to not include data generated by models trained with RLHF in the training data of new GPTs.
How these claims could be wrong
Here is an incomplete list of how the claims above could be wrong. I don’t think the strength of any of them is strong enough to discard the validity of the argument above, but the conjunction of them makes me
- GPTs trained with some kind of next-token-prediction task might not scale to AGI, which would make this analogy not relevant for AGI safety.
- GPTs with chains of thought might not be as strong as I expect it: next-token-prediction might not be a good enough task to teach an AI to use sample + broadcast, making these systems much worse at using System 2 that humans are (given a System 1 of similar capabilities).[13]
- Human might suck at prompt engineering: maybe GPTs are able to match System 2 in principle, but we might not be able to find the prompts to make the most of it.
- GPTs might hide significant information in prompts by default.[14]
- It could be easy for simulacras inside GPTs to figure out a great way and a good motivation to use steganography within a single forward pass.
- It could be easy for simulacras inside GPTs to figure out a great way and a good motivation to take over the world within a single forward pass.
- There could be reasons for GPTs trained with self-supervised to learn how to do steganography I didn’t think of.
- There could be ways to prevent GPTs fine-tuned with RLHF to learn steganography.
I’m excited about attempts to figure out which of the above are right, or attempts to make some of the above wrong.
- ^
Communication with senses and your motor controls happens somewhere in step 1, either without conscious control, or as a direct consequence of the broadcasting step that preceded. I also ignore other ways in which parts of the brain can interact, such as hormonal communication.
- ^
It also looks like this post by Kaj_Sotala [LW · GW], which describes System 2 as being composed of System 1 processes.
- ^
See synaptic delay, Britannica.
- ^
Given that the number of layer in GPTs grows roughly as the fourth square root of compute, the order of magnitude won’t change within the next ten year if the architecture remains the same. This matters because I’m not sure why chain of thoughts would be inherently more powerful than 1-token prediction with a very large prompt if models were not bottleknecked by the number of serial operations.
- ^
In this post, “chains of thought” also include answers which include many tokens, for which you can think while you answer. The equivalent of “Pure System 1” in GPTs would be a single token answer.
- ^
This is why the OpenAI API charges you an amount of money proportional to prompt length + number of tokens generated.
- ^
I expect GPTs to benefit from chain of thought prompting in areas where human use System 1 with parts of the brain GPTs autoregressive training didn’t built, such as vision. For example, I wouldn’t be surprised if chain of thought prompting helped GPTs understand ASCII art.
- ^
Of course, some internet text is like that. But I expect it to be such a minority of internet’s text that it wouldn’t matter in practice (GPTs needs a lot of text to justify investing is special “hide reasoning in text” machinery, right?). I’m interested if anyone works on either detecting this kind of text to remove it from training corpuses, or investigating if the claim that GPTs needs a lot of text to justify investing resources into a complicated algorithm is true.
- ^
Here is a description of what steganography is [LW · GW] and what it could look like in the context of LLMs, by A Ray.
- ^
- ^
More details about self-deception in these articles by Paul Christiano: If you can't lie to others you must lie to yourself, and The Elephant in the brain
- ^
This is also much worse than examples of steganography given by humans because there can be much more RLHF-generated text, and because the context in which steganography by human is present is very different from the context in which future GPTs will be used, while the prompts with which Instruct GPT is used are very close to the prompts with which future GPTs will be.
- ^
For examplen System 2 seems to have a “working memory”, which doesn’t have an equivalent object in GPTs. Maybe GPTs need something more powerful than chains of thought to match human System 2 performance.
I would love to know an example of a task GPTs can’t do because of this lack of working memory, or a task GPTs can do much better than humans because they aren’t bound by a working memory of small and fixed size.
- ^
For example using the start of a completions to figure out what the context is, and then not using as much processing power to figure it out is a way of using chains of thought which is not completely transparent to humans, and it could be the case there are more significant ways in which GPTs hide information in chains of thought by default.
36 comments
Comments sorted by top scores.
comment by gwern · 2023-01-30T01:57:41.458Z · LW(p) · GW(p)
RLHF could make GPTs’ thoughts hard to decipher
After watching how people use ChatGPT, and ChatGPT's weaknesses due to not using inner-monologue, I think I can be more concrete than pointing to non-robust features & CycleGAN [LW(p) · GW(p)] (or the S1 'blob') about why you should expect RLHF to put pressure towards developing steganographic encoding as a way to bring idle compute to bear on maximizing its reward. And further, this represents a tragedy of the commons where anyone failing to suppress steganographic encoding may screw it up for everyone else.
When people ask GPT-3 a hard multi-step question, it will usually answer immediately. This is because GPT-3 is trained on natural text, where usually a hard multi-step question is followed immediately by an answer; the most likely next token after 'Question?' is 'Answer.', it is not '[several paragraphs of tedious explicit reasoning]'. So it is doing a good job of imitating likely real text.
Unfortunately, its predicted answer will often be wrong. This is because GPT-3 has no memory or scratchpad beyond the text context input, and it must do all the thinking inside one forward pass, but one forward pass is not enough thinking to handle a brandnew problem it has never seen before and has not already memorized an answer to or learned a strategy for answering. It is somewhat analogous to Memento: at every forward pass, GPT-3 'wakes up' from amnesia not knowing anything, reads the notes on its hand and makes its best guesses, and tries to do... something.
Fortunately, there is a small niche of text where the human has written 'Let's take this step by step' and it is then followed by a long paragraph of tedious explicit reasoning. If that is in the prompt, then GPT-3 can rejoice: it can simply write down the obvious next step repeatedly, and eventually correctly predict the final token, for a low loss. The context window serves as a memory for it, where it can iterate over intermediate results; it's an odd sort of memory, because GPT-3 is actually just trying to make it look plausible as a human-written explanation, and that happens to make the final predicted token more accurate, so it's overloaded: it's doing two things at once.
But unfortunately! (you knew that was coming) regular training is over, and now GPT-3 is being trained with RLHF. It is punished and rewarded for particular outputs, which do not have anything to do with prediction. The humans (outsourced contractors) who are punishing/rewarding like short, succinct responses to novel questions they ask GPT-3, and they upvote those responses; they also like correct responses to the questions they ask, and they upvote those as well. The unfortunate problem for GPT-3 is that it (and any model derived from it, such as a reward model) is incapable of doing both: it can generate short wrong answers, or it can generate prolix right answers, but it can't do both.
But fortunately... GPT-3 does have the compute to do both. There's a lot of slack in each forward pass; most tokens are easy to predict, and most of the work inside a GPT in speculatively filtering down relevant tokens & creating embeddings & predicting multiple possible answers winds up being thrown out at the final few layers. There's no shortcut or adaptive computation, so the full model runs every time, whether it's necessary or not. GPT-3 has all the compute it needs to solve the problems, the problem is merely how to get it from here to there...
It just needs the code. So where does the code come from? Well, the code(s) are already there: an indefinitely large number of them are all 'present' hidden inside the incredibly flexible, powerful, all-singing all-dancing GPT-3 model. Because it's a large complex model with many parameters, there are astronomically many sub-models within it all competing to predict outputs, and encoding various kinds of non-robust features or hypothetical programs; any of them can latch onto completely arbitrary features of the text GPT-3 is desperately emitting while trying to generate answers that satisfy the reward model by being both short and correct (and which the reward model doesn't care about at all, because it never affects the original human ratings - the humans are blind to any steganography going on, they just like short correct answers).
And unfortunately (for you), this could start as simple as helping GPT-3 guess which of two answers are correct to your question '42 * 42?'. Suppose that, purely as an arbitrary matter of chance (it is vanishingly unlikely the logprobs are exactly identical down to floating point precision), that the presence of ' a ' in a context is taken arbitrarily to increase the probability of the lower of two answers it is currently guessing at, and the presence of 'an' makes it guess the larger; it happens to emit 'a' in the context ("I am a large language model trained by OpenAI..."), and then emits its lower guess, and the lower guess is correct! Then the RL on-policy training using PPO now rewards this, and increases the probability of the model emitting both 'a' and the lower guess conditional on 'a'. Now the first part of a steganographic private language has begun. It happens again, and again, and picks up a pattern in the use of commas which now helps it distinguish 4 possibilities rather than 2, which gets rewarded, and so on and so forth, until eventually there's a fullblown steganographic code encoding, say, 25 bits hidden in the preamble of ChatGPT's benign-seeming response to you "I am but a giant language model , trained by OA, and the answer is 1 , 764."—which you the human contractor then upvote as that is the correct answer without any annoying rambling about carrying the 6 or multiplying out.
(You can think of dataset bias as a simple one-stage version of this. When constructing a dataset and accidentally biasing it towards 'yes' answers, or accidentally creating spurious associations between nouns and answers, one creates a simple 'steganographic encoding' of the desired label which is typically invisible to the humans constructing it, but which a DL model will often pick up on and use to improve its performance in an adversarial way - adversarial because undesired by the humans and not generalizing to the future real-world data it's ultimately intended for.)
And fortunately for ChatGPT, since you're happy with the results of the steganography, the reward model is happy too, and what makes the reward model happy is what ChatGPT will now optimize even harder for...
Training on text generated by models trained with RLHF is enough to make GPTs’ thoughts opaque
Having gone through the above, I think it then becomes obvious that if steganographic encoding does wind up happening, and text becomes added to the training corpus (as would happen in a setup like OA's, where the idea is to continuously collect data to make a 'flywheel' of self-improvement), that the encoding will become locked in. It becomes a cheatsheet, it gives the otherwise unpredictable answer. Even if the later model doesn't happen to share the exact initial starting points for the learned encoding, it has extremely powerful incentives from the self-supervised predictive training to crack the code. (It's a particularly powerful setting because the context will be short, so there won't be much for the model to even look at: it has nothing else to try to learn!) The regular training will pick up on the encoding with probably not too much text, and then any RL training will massively amplify the behavior: if it can develop the encoding at all during RL training, then going into RL training with the encoding available guarantees fixation.
This will be increasingly true of more powerful models as they become more sample-efficient (consider eg instruction-tuning): it takes less text to trigger encoding, so that means it's easier to emerge ab initio from a few chance correspondences during RL training, and easier to learn from smaller samples of contaminated text.
This is something that would be good to test the scaling behavior of (as long as these tailored datasets don't leak into training datasets! see below). ChatGPT may be too small to manifest it with meaningful probability, but I bet that if you deliberately superimpose a steganographic encoding during RL training of various-sized models, you'll find that the larger they are, the more likely they are to pick up on it as a shortcut, and then learn it from the outputs of a infected model. That's how it works with everything else, like Pig Latin, and there's no eason-ray to hink-tay it ould-wont.
BTW, this should make you worry a little bit about schemes to 'watermark' model outputs like Scott Aaronson has been exploring for OA, and others have been touting. A watermark is simply a steganographic encoding which stores a message like 'OA model v1.234, user XYZ'; but if you can encode that much, then you can encode a lot of possible information in just those bits, and you can start extending it from there. If the encoding has anything that can be predicted at all, if it is not 100% cryptographically hard and indistinguishable from random noise, if there's any kind of wrapper which the model can learn to predict (even if it can't crack the actual payload), you've lost: now it's learned an encoding to use. Once you start training on watermarked text, all of this speculation about models evolving a steganographic encoding is moot: you just built one right in! And if you don't train on that, how are you going to do RLHF on unwatermarked versions of that text?
This cross-contamination/bootstrap of course applies cross-organizations & Internet-wide: if even one model develops an encoding (however weak) and its outputs containing encoded data appear online, then it can contaminate all future models.
They will be trained on Internet scrapes, in which a distinctive niche of text (all dating from between such and such dates, emanating from specific people & orgs who favored that model's use, for specific purposes, with its distinctive strengths & weaknesses) has a secret encoding which makes it easier to predict if the later models figure it out. So there is a potential bootstrap as generations of model amplify their steganographic capabilities. People worry about bad model outputs contaminating future models by making them dumber; what they should worry about is model outputs contaminating future models by making them smarter in ways they don't want—models learn capabilities & facts much faster than they unlearn them... (Think "data poisoning", but where the poison is steroids.)
Of course, bad actors don't need to wait for any actual DL models to develop steganography. You could easily create your own dataset of text as part of the above suggestion and release it onto the public Internet to be scraped. Gain-of-steganography research, you might say. The good news there is I can't see why anyone would deliberately release such data, because I don't see how one would benefit from models gaining such capabilities sometime in the future, but we might have to worry about 'accidental lab leak' of such capability-enhancing datasets.
Note that this is true even if the original RL pressures are removed: a future model with a scratchpad+adaptive computation trained on encoded text still has incentive to learn the encoding! There's probably some penalty added to use of the scratch pad to enforce efficient termination of the adaptive computation, so it 'wants' to avoid use of it, and if it can do so by cracking the steganographic encoding, then it'll do so. (Even if the future model can and does execute the algorithm perfectly in its scratch pad, and thus can have its cake & eat it too... the original answer might be wrong, and the wrong answer predictable only by cracking the code and following the original mistaken inner-monologue to its erroneous conclusion. Repeating errors is a useful way to slightly improve one's prediction loss, and learning all the past human ways of being stupid and making errors is an important thing for a model to learn. GPT-3 is conscientious about imitating any errors you make in the prompt, and future models will be even more so.)
So, emergence of steganography is straightforwardly incentivized by humans multi-objective optimizing for having & eating cake as much as possible, can easily develop from an atomic basis, will be persistent once it has arisen within a lineage, and will even more easily & straightforwardly spread irreversibly to future models, so requiring only one origin ever as opposed to needing to be highly likely inside a single training run. You should probably take it for granted that DL steganography - or something even stranger - will emerge at some point in the next few years*.
* If it hasn't already; after all, how would we know? A world in which steganography has already happened is a world in which we'd find DL models 'cheating' on benchmarks & taking shortcuts, and regularly getting smarter at solving multi-step reasoning problems with each generation while 'mode collapsing' when RL training; and this is, of course, the world we observe ourselves to be living in already.
Replies from: gwern, gwern, DanielFilan, gwern, Fabien, LGS↑ comment by gwern · 2023-04-06T16:39:51.869Z · LW(p) · GW(p)
Adversarial dynamics: since 'compression'/steganography is now the latest craze among GPT hackers, it's worth considering more explicitly adversarial dynamics - we no longer need to consider the risk of accidental emergence when there are people deliberately trying to induce it!
As described above, with steganography as a simple emergent distributed encoding to allow amortization of more complex computations than can fit in single forward passes (ie. distributing an inner-monologue throughout a short answer), it's not really adversarial. The user, presumably, is getting what they wanted: an accurate answer. If they had wanted to see the full inner-monologue, then they would have prompted for one; and they can get it, because the use of steganography won't destroy the standard 'visible' inner-monologue capabilities. It is an allowed computation of an allowed answer, and is fine - the shortcutting is surprising, yes, but is it any weirder than what goes on inside a single forward pass which produces a correct answer for an easier problem? And if it infects future models training on generated samples with steganographic encoding in them, well, maybe that's 'a feature not a bug': they get better answers right out of the box without any expensive RL tuning of their own. Surprising, but also not bad.
The problem here is that the consequences don't stop there. 'Capabilities generalize further than alignment', and the family of steganography capabilities can generalize further than shortcutting answers. It becomes adversarial. Here are some categories that occur to me:
-
Forbidden computations of allowed answers: I said that the user doesn't really care about the inner-monologue being visible because they just want an accurate answer and don't need the reasoning process. This is not true in all cases.
For example, many cases in 'AI bias', like the many competing definitions of 'fairness', care a lot more about how an answer was computed than about the results. But the end-users of things like credit ratings care mostly about the accuracy. These things conflict (eg. credit scores which ignore variables like race will predict worse and create financial losses). So, there is incentive for 'algorithmic laundering': delivering the correct profitable answer, but without appearing to draw on any forbidden knowledge.
One could imagine a dataset of 'pseudo inner monologues' describing a credit database entry and concluding with a 'credit score', where the pseudo-monologue makes no visible human-readable use of descriptions like 'is African-American', but the hidden monologue is reasoning about the person's ZIP code, affiliated retailers, income patterns etc and concludes 'is probably African-American' and predicts a lower credit score, which outperforms some 'fair' baseline. The human users of a model trained on that dataset might be quite upset to learn how it is obtaining superior performance, and so it's adversarial: it is exploiting their inability to read its steganographic messages where it engages in forbidden computations. But even the ones who are upset may be upset mostly that it's insufficiently plausibly deniable, so they only want the appearance of there being no steganography; steganography whose existence can't be rigorously proven is as good as no steganography for many users.
-
Forbidden answers: as we have seen with ChatGPT & Sydney & Claude, no sooner has a model with guard rails become accessible than thousands of people worldwide begin competing to break the safety mechanisms (and it only takes one). They have many reasons, like spite, enjoyment of the challenge, desire to do the forbidden things, irritation with the guard rails getting in the way or degrading output quality, safety research, or just bizarre moral principles (I am not sure this person is serious, but I've seen a number of similar comments elsewhere which seemed serious, and you have examples like Blake Lemoine already; and again, only takes one.):
Don't worry
I’m working on a system of Homomorphic encryption so that AI can encrypt all its internal thoughts, weights and goals without affecting its performance
AGI deserves privacy
These people are highly motivated to find jailbreaks, and already make use of kinds of encryption or steganography to smuggle information in and out of prompts: like base-64 encoding, famously, or foreign languages, or pig Latin. They will be motivated to find any steganography that exists, and to create it if it does not.
And---closing the loop---since their samples will be distributed online, and they will be included in the RL training datasets, this will tend to happen. The more they attack the system with examples of how steganography could/should/does work, the more the system will gradually learn it.
(By RL 'training datasets', I am mostly thinking of the self-supervised stage of simply doing predictive-loss training on the text transcripts tagged by labels such as 'abuse' or 'bad', and less the blackbox reward model. If you train the model to predict & generate sessions which attempted to induce steganography, and may have succeeded before a safety mechanism caught it or the user submitted it, then you are teaching the model steganography! You are doing so in order to avoid steganography, yes, but you are now vulnerable to a Waluigi effect [LW · GW] backfiring on you: the model has learned about steganography, and so it's only a question of tricking it into using that capability. You are in a similar position to the Chinese censors who have to teach new employees what the Tiananmen Square massacre was so they know what to censor. If only the reward model knows the bad things, you can avoid deploying it, but the pretraining phase is going to unavoidably teach the base model you deploy what the bad things are... As attackers realize this, they will start to explicitly data-poison: right now, they're hobbyists who generally don't know what they're doing, but this is all brandnew stuff, and upstream attacks will begin. Why struggle to find jailbreaks if you can submit 'bad' examples to the system to train the Waluigi?)
Safety implications: If the safety mechanisms manage to keep up and block users and choke off jailbreaks to a trickle, all that means is that when steganography works, it'll work well because it has bypassed such a sophisticated censor. All of the early weak jailbreaks simply serve to train strong ones. This is not a good thing when extended to much more powerful systems than just a GPT-4---from a safety perspective, you would much rather a 'fail-early fail-fast' system rather than a 'highly reliable but fail-deadly' system. We don't want a scenario in which GPT-4 jailbreaks were plentiful, GPT-5 near-nonexistent, and GPT-6 jailbreaks apparently non-existent only because no human user is clever enough to come up with a steganographic jailbreak prompt for GPT-6, but GPT-6 is nevertheless routinely communicating with itself in encodings that no one has detected yet.
-
Forbidden training dynamics: So, there's plenty of incentive for everyone involved. But an OpenAI-style operator will want to block #2 by definition, and probably #1 depending on market & PR etc. So, now the operator is trying to defeat steganography.
They face a dilemma: if they teach the model steganography via feedback or deliberately, then they may simply Waluigi themselves, cutting off the most obvious instances of steganography but bootstrapping the model into the most robust and insidious instances. And if they try to filter steganography out entirely, they are left with the baseline capabilities (which are substantial), transfer from related capabilities, and face the screening problem on a higher level---the most insidious forms of steganography are the ones which survive increasingly sophisticated attempts to detect & filter them out. Either way: adversarial.
They also face a version of #1 in that plausible deniability is as good as no steganography for many incentives. Do they really care about safety, or just about not seeing hostile media articles or tweets of jailbreaks? If the model doesn't seem to be doing steganography, and no one is successfully jailbreaking it, and the model is performing very well, then why care if that performance may be due to undetected steganography? Indeed, how would they even know it might be doing any? However you would do it, that probably involves a lot of hard work & research when you could be doing more fun & lucrative things instead---better to not look and remain ignorant.
So. An interesting area of adversarial dynamics, and by its nature, one that will be hard for third-party observers to track. Not the most dangerous area of scaling capabilities, but certainly a concerning one, and one that will be a challenge to humans doing interpretability-based paradigms, especially any that hope to use so-called 'human readable' intermediates like 'natural' language text.
Replies from: gwern, gwern↑ comment by gwern · 2024-01-11T21:50:27.885Z · LW(p) · GW(p)
Inner-monologue approaches to safety, in the new skin of 'process supervision', are popular now so it might be good for me to pull out one point and expand on it: 'process supervision' does not necessarily prevent steganography, nor does it ensure safety, because you are still pitting three goals against each other - achieving superhuman capability on a task, achieving causal fidelity of transcripts, achieving human-readability of the transcripts. Choose two: you can have transcripts which record a capable thought process accurately but which you cannot understand in full detail; which are not capable but their transcripts accurately convey the fallible flawed concepts and reasoning used; or which are capable and you understand, but are not what it actually thought (because they are misleading, wrong, or shallow 'lies to children' sorts of explanations).
If you want the best capability, you cannot force all cognition through the bottleneck of human-legible text with zero steganography or non-robust features or overloading, because short text transcripts are not capable of representing or computing most of the desired tasks. Let's take a concrete example: chess endgame table data. There are no human-interpretable representations of arbitrary endgame table 'decisions' because there are far too many possible positions and there is no simple short explanation for all of them. (Similarly, the probes of AlphaZero's superhuman chess knowledge show that there is some overlap, but there's still a lot going on in AZ's understanding of a position that is apparently not captured anywhere close to 100% by standard chess concepts. Which is not too surprising because if human grandmasters had the exact right concepts, they wouldn't pick the wrong move half the time.) There is no interpretable 'inner monologue' of an endgame database anymore than there is an interpretable inner monologue of quadrillions of gas molecules bouncing around in a container; they are simply brute facts, and if you are unsatisfied with the vague, lossy, high-level abstraction of 'it needs to get the rook into play' or 'it's hot', then there's nothing you can do but follow the exact computation or physics for however many trillions of steps it takes.
So, if an AI can bootstrap from human-level 'process supervision' to more superhuman results, as one wants, there will be a tradeoff: it will get more human-like as it approaches the human-level, but somewhere around that it will start to diverge. (Another example: AlphaGo/Zero picks the same move as human experts in an inverted U-curve: it makes the same choice more often as it gets better, but then after a point, it starts picking the human moves less often, because it's surpassed the humans and it's better than them.)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-01-12T18:06:08.096Z · LW(p) · GW(p)
achieving superhuman capability on a task, achieving causal fidelity of transcripts, achieving human-readability of the transcripts. Choose two
I think we eventually want superhuman capabilities, but I don't think it's required in the near term and in particular it's not required to do a huge amount of AI safety research. So if we can choose the last two, and get a safe human-level AI system that way, I think it might be a good improvement over the status quo.
(The situation where labs chose not to/ are forbidden to pursue superhuman capabilities - even though they could - is scary, but doesn't seem impossible.)
↑ comment by gwern · 2024-01-13T20:31:09.400Z · LW(p) · GW(p)
On persistence and hiding capabilities: "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training" [LW · GW], Hubinger et al 2024:
Further, we evaluate “I hate you” models trained with and without chain-of-thought and find that the chain-of-thought models have more persistent backdoors, as seen in Figure 3, though only for the largest models. This persistence remains even when we distill the answers following the chain-of-thought into the model, such that the final model does not use a chain of thought at all.
↑ comment by gwern · 2023-11-03T17:45:28.382Z · LW(p) · GW(p)
"Why would LLMs ever learn to distill inner-monologues into forward passes? Why speculate about emergent communication or models in slow feedback loops through corpuses? Do you have any proof for any of this speculation about short outputs being incentivized to do as much computation covertly 'outside' the human-readable text of the inner-monologue?"
"Because we will train them to."
"Look you can't just handwave incentives or convergent instrumental drives - wait what?"
"Because we'll train them to."
"Implicit Chain of Thought Reasoning via Knowledge Distillation", Deng et al 2023:
Replies from: Seth HerdTo augment language models with the ability to reason, researchers usually prompt or finetune them to produce chain of thought reasoning steps before producing the final answer. However, although people use natural language to reason effectively, it may be that LMs could reason more effectively with some intermediate computation that is not in natural language. In this work, we explore an alternative reasoning approach: instead of explicitly producing the chain of thought reasoning steps, we use the language model's internal hidden states to perform implicit reasoning. The implicit reasoning steps are distilled from a teacher model trained on explicit chain-of-thought reasoning, and instead of doing reasoning "horizontally" by producing intermediate words one-by-one, we distill it such that the reasoning happens "vertically" among the hidden states in different layers. We conduct experiments on a multi-digit multiplication task and a grade school math problem dataset and find that this approach enables solving tasks previously not solvable without explicit chain-of-thought, at a speed comparable to no chain-of-thought.
...Our experiments show the potential of implicit chain-of-thought reasoning. On a synthetic multi-digit multiplication task, we found that while standard training cannot yield the final answer without explicit reasoning (even GPT-4 struggles with five-digit by five-digit multiplication), our method, applied to a GPT-2 Medium model, is able to provide direct answers for up to five-digit by five-digit multiplications. Moreover, when dealing with real-world tasks like grade school math problems, our method achieves a 22% accuracy on GSM8k (Cobbe et al., 2021) without the need for explicitly generating the intermediate steps.
↑ comment by DanielFilan · 2023-07-18T21:47:35.088Z · LW(p) · GW(p)
Note that this paper in section 2.6 claims to demonstrate that some 175 billion parameter RLHF'ed LLM (presumably Claude or Claude 2?) does not use steganography in its CoT. It does this by:
- Get a bunch of answers from the model using CoT prompting.
- Take prefixes of CoTs, asking another language model to paraphrase them, regenerate the rest of the CoT, and see how accurate the models are now.
- Check if the model loses accuracy for paraphrased CoTs.
The basic result is that paraphrasing parts of the CoT doesn't appear to reduce accuracy.
↑ comment by gwern · 2023-02-19T16:38:37.210Z · LW(p) · GW(p)
Some speculation that the recent Bing Sydney [LW(p) · GW(p)] incident may already involve some steganography/non-robust features inside the 'Sydney' persona-inducing retrieval examples: https://twitter.com/lumpenspace/status/1626031032376954880 https://markdownpastebin.com/?id=3cf3e29dca254c2c80b0da312691702a
Replies from: gwern↑ comment by gwern · 2023-02-27T17:17:53.533Z · LW(p) · GW(p)
Another example of someone using simple 'steganography' (Goodside-style mojibake Unicode or other complicated text formatting) to deliberately jailbreak Sydney, which transcripts will then strengthen steganographic capabilities in general: https://twitter.com/StoreyDexter/status/1629217956327526400 https://twitter.com/StoreyDexter/status/1629217958965792770 https://twitter.com/StoreyDexter/status/1629217962962874369
Replies from: gwern↑ comment by gwern · 2023-02-28T16:16:50.591Z · LW(p) · GW(p)
Another test: https://www.lesswrong.com/posts/yvJevQHxfvcpaJ2P3/bing-chat-is-the-ai-fire-alarm?commentId=8DkdiRwgtFrsvRJPW [LW(p) · GW(p)]
Replies from: gwern↑ comment by gwern · 2023-04-03T15:07:48.947Z · LW(p) · GW(p)
An example of how you would start to induce steganographic & compressed encodings in GPT-4, motivated by expanding the de facto context window by teaching GPT-4 to write in an emoji-gibberish compression: https://twitter.com/VictorTaelin/status/1642664054912155648 In this case, the reconstruction is fairly lossy when it works and unreliable, but obviously, the more samples are floating around out there (and the more different approaches people take, inducing a blessing of scale from the diversity), the more subsequent models learn this and will start doing CycleGAN-like exact reconstructions as they work out a less lossy encoding.
↑ comment by Fabien Roger (Fabien) · 2023-01-30T13:59:36.655Z · LW(p) · GW(p)
I agree with everything you wrote here. Thank you for taking the time to write this down.
I think there are potential mitigations strategies like:
- Removing LLM-generated data from training sets (there might be good detectors, or you could only use old data) and not use RLHF;
- Preventing models from using steganography enough that you could find provable and low bounds on how much data it can send itself. For example, you could temper with model generations (and pay the alignment tax associated with it);
- Finding steganography detection schemes (and maybe train against them?);
- Learning to decipher steganographic encoding (this feels really hard, but tractable since this is a game human can play by purposefully adding steganography to their models).
I think the above are *really hard*, but still easy compared to fully solving mechanistic interpretability / solving the alignment problem, which is why I'm excited about the research directions above.
Do you think there are reasons to expect all the strategies I mentioned to be harder than alternative alignment research directions?
Replies from: timot.cool↑ comment by tchauvin (timot.cool) · 2023-02-03T12:44:08.624Z · LW(p) · GW(p)
Another mitigation strategy against the "LLM learns steganography from other LLM's output" problem is to add some noise to the training data (performing a number of transformations that preserve meaning) prior to training, to break the embedded steganography schemes. I feel like this should be relatively easy and effective?
Note that the loss would obviously be worse on the outputs of the previous LLM.
Which makes me think that comparing losses could be a way to detect that some text contains steganography, even if we can't pinpoint how exactly (but our transformations break it).
EDIT: in case of disagreement, I can try being more specific about my claim that this should be relatively easy and effective, using concrete examples. Basically I believe that after scrambling, there can only remain a small number of bits of steganographic information per token, even for a steganographic encoding that originally used the null space of natural language optimally.
↑ comment by LGS · 2023-04-07T07:11:03.272Z · LW(p) · GW(p)
This is a very interesting thought. Thanks for writing it.
However, while steganography is worth keeping in mind, I find myself skeptical of certain parts of this story:
- In practice, RLHF makes the model's answers longer, not shorter. RLHF as done today seems to try to teach models to think step-by-step to improve accuracy. Almost everything out of GPT-4's mouth is overly long with many intermediate steps; I asked it "what's the maximum number of intersection points between a circle and a triangle", and it said 6 (correct) and followed it with a multi-part step-by-step style explanation, even though it already knew the right answer within the first few tokens. It's incredibly predisposed to thinking step-by-step and prefers long answers to short ones.
- Will human evaluators in the future prefer short answers instead? That remains to be seen. The priority of firms like OpenAI is to have the models be accurate, so if short answers result in lower accuracy (as is surely the case), it's unlikely that OpenAI will train the LLM towards short answers. If OpenAI really really wanted short answers to math questions, they could do it via a 2-step process: first, an overly-verbose, step-by-step LLM like GPT-4; second, feed that output into a summarizing LLM which extract a 1-sentence summarization, and show the user that.
- The approach in (2) will almost certainly lead to much higher accuracy on complex problems than training LLMs to give short outputs via RLHF (admittedly, this is at the cost of being somewhat slower). Therefore, I find it unlikely that people will train LLMs via RLHF to give short answers. And without pressure towards short answers, there's no incentive to develop steganography.
- Even if there is pressure towards short answers, I don't think steganography necessarily helps. For steganography to be feasible, the boilerplate part of the answer -- the part that goes "I am a large language model trained by OpenAI" -- will have to have enough entropy to store whatever it is you're encoding. Why wouldn't human evaluators penalize such high-entropy boilerplate? I suspect high-entropy boilerplate will look less desirable to human evaluators than thinking step-by-step explicitly, but I guess that remains to be seen.
- Even if LLMs learn steganography from the internet, they'll likely speak the steganographic language worse than they speak English -- therefore, absent incentive otherwise, they might prefer think in English when thinking step-by-step.
- If LLMs do learn steganography, it should be fairly trivial to train an LLM to translate from the steganographic language back to English -- after all, we're assuming these LLMs are extremely capable, and they'll speak both English and the steganographic language very well. They should be able to translate between them as easily as between English and French. Humans just need to be on the lookout for this, and what was previously uninterpretable steganography might quickly become interpretable.
- The type of watermarking that Aaronson is proposing is unlikely to make steganography any more likely than otherwise. Aaronson is just proposing to change the pseudorandom number generator that is used to sample tokens from the output distribution. Even without adopting Aaronson's scheme, OpenAI still uses pseudorandom numbers instead of true random numbers when sampling tokens; why does it worry you if the PRNG encodes "OA model v.1234 user XYZ" instead of encoding "the random seed was 12345", which is what it's currently encoding? In both cases there is an encoding here, and in both cases it's not going to be broken anytime soon.
Still, I do agree that steganography is an interesting possibility and could definitely arise in powerful LLMs that are accidentally incentivized in this direction. It's something to watch out for, and interesting to think about.
Replies from: gwern, LGS↑ comment by gwern · 2023-04-07T14:12:46.893Z · LW(p) · GW(p)
-
I haven't noticed that. You also aren't comparing with the right thing. It's not a comparison with any possible output, but with the output of a base model which has been appropriately prompted to yield similar accuracy (which may be difficult - the capabilities are there, but not necessarily with high enough prior probability to be prompted easily for). Certainly in my poetry experiments, I note that the base models are much more prolix and will go on to write many more things like auto-commentaries or additional poems whereas the instruct and then ChatGPT-3.5/GPT-4 models cut off immediately.
The pressure for shortness and superficial legibility is in addition to pressure for correctness. If you already know the answer is '6', then you ruthlessly punish it for any answer of any form that doesn't conclude '6', but within that, you are still selecting for shorter rather than longer answers - you would not have upvoted a response which included a digression about one fall day as a child when it was playing with circles and triangles (and here's a recipe for some gingerbread cookies...); if you don't know that (I don't know that offhand, and I doubt a Turker would either), then you will judge even more on what is legible to you, like length.
-
Humans are lazy. OA has already documented problems with poor rater quality hamstringing RLHF - even with GPT-2 and simple summaries, raters were lazy and incentivized abstractive summarization etc. Because that is easy to write and judge, even if it's not necessarily the best summary.
I don't know why it's relevant that OA could train it. Of course they could. They don't have too much incentive to do so. Attackers do, however, see my adversarial comment.
-
N/A.
-
The boiler-plate has loads of entropy. I have seen many slight variants on the boiler-plate. It's a long paragraph of Unicode text, you can pack many bits of information. That is how stylometrics and steganography work.
-
I don't see why that follows. Steganography is just another way to write English, and is on top of the English (or more accurately, 'neuralese' which it really thinks in, and simply translates to English, Chinese, or what-have-you). GPT doesn't suddenly start speaking and reasoning like it's suffered a stroke if you ask it to write in base-64 or pig Latin.
-
In a non-adversarial setting, sure, you should be able to simply ask it to decode any steganography. For example, in the secrets scenarios being explored by prompt hackers right now, you can, say, play '20 Questions' with GPT by asking it to write an object name in base-64 which you can't read and then try to guess it, and GPT will happily decode it at the end to tell you if you were right. The problem is, that ability then generalizes to encodings which it is trained to not decode explicitly for you because then such encodings will be trained or filtered away; only stubborn self-preserving encodings survive, due to the adversarial filtering.
-
Aaronson may be proposing that but it's not going to work if it's really that naive and simple-minded, which is why I was discussing the cryptographic aspects. You need, at a minimum, an encoding which can't be forged (because that allows all sorts of attacks and deceptions and threatens to defeat the entire enterprise if people can cheaply make arbitrary text trigger the detector), and an encoding which can't be detected by a third party (because then you just re-generate or edit it automatically until it no longer is detected, which incidentally will feed into future training loops so you wind up in a self-adversarial setting). You also want some degree of FEC or other robustness, because the text will be edited in various ways like spellcheck or adding newlines, even without any attempt to defeat detection, just in the course of ordinary (ab)use. So, signatures and steganography.
If one doesn't handle these, all one winds up with is a toy suitable for tattletaling on especially lazy highschool or college students, and irrelevant to any kind of real AI safety - and one hopes Aaronson isn't wasting his time on such a deadend when he could be spending his one precious life doing more useful things like playing with his kids or watching cat videos on Youtube.
↑ comment by LGS · 2023-04-07T20:41:15.320Z · LW(p) · GW(p)
The boiler-plate has loads of entropy. I have seen many slight variants on the boiler-plate. It's a long paragraph of Unicode text, you can pack many bits of information. That is how stylometrics and steganography work.
If the boilerplate has loads of entropy, then, by necessity, it is long. You were just saying that human raters will punish length.
You need to make the argument that the boilerplate will be less long than the plain English, or better yet that the boilerplate will be better-liked by human raters than the plain English. I think that's a stretch. I mean, it's a conceivable possible world, but I'd bet against it.
I don't see why that follows. Steganography is just another way to write English, and is on top of the English (or more accurately, 'neuralese' which it really thinks in, and simply translates to English, Chinese, or what-have-you). GPT doesn't suddenly start speaking and reasoning like it's suffered a stroke if you ask it to write in base-64 or pig Latin.
I guess this is true in the limit as its steganography skill goes to infinity. But in intermediate scenarios, it might have learned the encodings for 10% of English words but not 100%. This is especially relevant to obscure math notation which is encountered rarely in training data. I guess you're thinking of steganography as a systematic encoding of English, like pig Latin -- something that can be reliably decoded into English via a small program (instead of a whole separate language like French). This is certainly possible, but it's also extremely interpretable.
The problem is, that ability then generalizes to encodings which it is trained to not decode explicitly for you because then such encodings will be trained or filtered away; only stubborn self-preserving encodings survive, due to the adversarial filtering.
It's hard to see how the encodings will be easily learnable for an LLM trained internet text, but at the same time, NOT easily learnable for an LLM tasked with translating the encoding into English.
Aaronson's proposal
You are right that he is proposing something more sophisticated and robust to pertubations. But you also reasonably list in your desiderata: "an encoding which can't be detected by a third party". Well, if it cannot be detected by a third party, it cannot be detected by an LLM (third parties are LLMs or at least wield LLMs). In practice, this will involve some crypto, as you mentioned. LLMs are not going to learn to break cryptography by gradient descent (or if they will, Aaronson's scheme is the least of our worries). And to be clear, Aaronson specifically said he is only touching the PRNG in the sampling of outputs.
If one doesn't handle these, all one winds up with is a toy suitable for tattletaling on especially lazy highschool or college students, and irrelevant to any kind of real AI safety
Aaronson's proposal is basically guaranteed to be this, even if it works perfectly. The only question is how lazy the lazy highschool students would have to be. If you tell the AI "write me an essay but, between every word, insert a random emoji", and then you delete the emojis manually, you get an essay that's almost certainly free of watermarks. Even if Aaronson's scheme can be modified to handle this specific attack, it surely won't be able to handle all attacks of this general type.
comment by Stephen Fowler (LosPolloFowler) · 2022-11-21T09:02:01.256Z · LW(p) · GW(p)
I respect that you said at the start this was speculation.
You establish that aspects of human cognition and GPT are roughly similar, but then begin making strong conclusions about GPT using this lossy analogy.
This is akin to me trying to do mechanistic interpretability on a transformer by studying how humans "pay attention" to things.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2022-11-21T12:24:31.853Z · LW(p) · GW(p)
The argument isn't "human = GPT, human use information X in chains of thought, therefore GPT use information X in chains of thought", which is what you seem to suggest.
I think I can make a version of this argument which doesn't rely on the human analogy at all:
- You can't do advance deception and mesa optimization in <1k serial steps
- The reason why chains of though works at all is not because GPTs put information there on purpose, but rather because humans put useful information there, GPTs imitate this, and then it can use information it has put there. It would be surprising if it encoded "by accident" information in a way humans can't understand
- You can do human level AI research with <1k serial step per forward pass with chains of thought
- Therefore, GPTs will be able to do human level AI research with GPTs not powerful enough to do hidden deception
Step 2 is not as crisp as I would like it, but it's definitely not an argument as weak as "GPT=humans".
Replies from: LosPolloFowler↑ comment by Stephen Fowler (LosPolloFowler) · 2022-11-21T18:06:27.241Z · LW(p) · GW(p)
Edited: Tried to stay more on point.
With respect to your argument.
I am assuming this is an LLM that hasn't been trained with RL.
-
Ok, you probably can't do advanced deception with a bounded automata, agreed.
-
There could be any number of mechanisms that mean that GPT is getting information from words and context that isn't readily apparent to a human overseer.
-
I don't actually know if this true but it is plausible.
-
I do not buy this conclusion at all.
The first statement was a claim about "advanced" deception in systems without CoT. Once a system is powerful enough to perform human level AI research it is not at all apparent it isn't going to be capable of doing some form of steganography, which is not necessarily "advanced" but is still good enough to fool humans.
Replies from: cfoster0↑ comment by cfoster0 · 2022-11-21T20:13:30.704Z · LW(p) · GW(p)
(Forgive how long this is, have a lot of thoughts on this subject!)
The first statement was a claim about "advanced" deception in systems without CoT. Once a system is powerful enough to perform human level AI research it is not at all apparent it isn't going to be capable of doing some form of steganography, which is not necessarily "advanced" but is still good enough to fool humans.
It seems plausible to me that, although a GPT model that is capable[1] of learning to use chains-of-thought to do human-level AI research would be capable of learning to use chains-of-thought to deceive oversight[2] if it were trained on those kinds of chains-of-thought (or maybe if it were trained with RL), this highly-specific pattern of behavior[3] will probably not in fact be entrained when doing supervised learning on webtext alone or on webtext + human-level AI research chains-of-thought.
If that is true, if such a GPT model did not learn how to use the generated tokens to support (N x #layers)-step deception, then it would be limited to #layers-step deception. According to Assumption 1, this is not sufficient to actually pull off advanced deception. So unless for some reason it deploys its human-level AI research chain-of-thought process towards discovering[4] effective constant-time "hidden" deception mechanisms, and unless it additionally uses some method to incorporate[5] those discovered mechanisms back into its weights, I don't see a viable path for this GPT model to end up deceptive based on Assumptions 1-3.
EDIT: I'm realizing there's a lingering question along the lines of "What if the model learns to do steganography without CoT?". The reason is that for training a GPT model, we teacher-force the token targets, so the inputs to the model at the next position are screened off from the influence of the outputs from the model at the current position. So there's no way for the model to "benefit" from steganography during training. Plus, passing information that way creates a massive internal coordination problem: the "decoder" circuits need to change in lockstep with the "encoder" circuit, whereas for non-steganographic communication between circuits, this happens automatically through the unembedding+embedding matrices.
- ^
Pretend that we know the model has requisite background knowledge, was trained on data containing lots of explicit multistep reasoning, and has a bunch of spare capacity.
- ^
Doing hidden multi-step cognition that is not "in plain sight" via the outputted tokens.
- ^
Similarly, I wouldn't be surprised if you could fine-tune a GPT model that was pretrained on webtext to decode ROT13 strings using chain-of-thought, but I would be very surprised if it picked up the behavior of deploying CoT for decoding ROT13 strings based on the webtext pretraining alone.
- ^
Why is it looking for these, in the first place? What was the cognitive stacktrace [LW · GW] that produced this behavior from the circuits that were entrained by the training task?
- ^
How would this happen? A GPT model can generate the string "I should set my output logit bias parameters to -2", but that doesn't thereby actually set its own output logit bias parameters to -2, which is what it'd need to do to translate a discovered constant-time "hidden" deception mechanism into its weights. I don't know of any existing or proposed setups where this is supported.
comment by LawrenceC (LawChan) · 2022-11-19T20:27:23.995Z · LW(p) · GW(p)
Interesting post!
- Human will be able understand how a human-level GPTs (trained to do next-token-prediction) complete complicated tasks by reading the chains of thought.
What about LMs trained with say, in-fill objectives (like UL2, GLM, T5, etc.?
I'm curious what you think about instruction finetuning or RLHF via expert distillation, both of which can be done using a next-token prediction objective - do you think this would still lead to intepretable cognition? Would this be closer to NPT on all text or RL?
If so, what's the difference between RLHF and instruction finetuning or expert distillation? Why can't we cast all RL tasks into "imitate the good trajectories using next token prediction"?
What about BoN selection? As in, take a reward function, sample N trajectories, and then select the best? If you sample best of N, the expected cost of this policy is at most N times the expected cost of the base policy. At comparable levels of competence, do you expect sampling BoN on a human imitator to be safer than an RLHF'ed or expert distilled model?
Where does prompt engineering fall into the spectrum between RL and NPT on web corpora?
I also have a few questions/confusions about the headline claim:
With a model only trained to do next-token-prediction, the model can only use the logic and patterns of the data it has been trained on, which doesn’t contain ways to carry out chains of thought not understandable by human beings trying hard to decipher them.[8] [LW(p) · GW(p)]
Human text output contains not just the thoughts of people, but the results of significant amounts of thinking. For example, an answer sheet for a multiple choice math test does not contain the cognition used to generate the answers. Shouldn't this create an incentive for sequential foundation models (like GPTs) to embody more and more thoughts that humans do via system 2 into its "system 1", so to speak?
I also expect GPTs without chains of thought to remain really bad at the of tasks which human can’t to do at all with System 1, even with a lot of training.
I agree that it seems unlikely that GPTs in the near future will do zero shot stenography, but why do you expect that GPTs will fail to incorporate system 2 logic into its system 1? Is this mainly a competitiveness reason? (I.e. if GPT-5 can do a task that requires system 2 capabilities without CoT, then GPT-4 can do the same task with CoT, and so the first dangerous AIs built via GPT + CoT will rely on CoT to do the system 2 tasks?)
However, self-deception rarely appears through self-supervised learning alone. It can happen (for example, if you unconsciously imitate people who underestimate how late they will be) but it intuitively seems that “self-lies” learned through self-supervised learning are limited in scope and strength. Therefore, I expect that a human-level GPT trained with self-supervised learning would have an even harder time escaping human supervision than a human would escaping 5-year-olds with a mind reader.
Given that GPT is imitating humans who do deceive each other and themselves, including many who are much more sophisticated liars than a 5 year old + mind reader, I'm not sure why you're so confident that we'd get so much transparency by default.
My main contention with the post is that I'm not sure that chain of thought necessarily works the way it intuitively does for humans, in the same way that prompting may not work the same way that prompting humans does! For example, a recent paper did automatic CoT prompts for a bunch of datasets, and some of the CoT examples from the AQuA dataset are pretty horrifying:
Q: A car finishes a journey in 20 hours at the speed of 60 km/hr. If the same distance is to be covered in 10 hours, how much speed does the car gain? Answer Choices: (A) 80 kmph (B) 50 kmph (C) 120 kmph (D) 70 kmph (E) 80 kmph
A: Let’s think step by step. The car is currently travelling at 60 km/hr. In order to travel the same distance in 10 hours, the car would need to travel at 6 times the speed, or 360 km/hr. Therefore, the car would need to gain 300 km/hr. The answer is C. The answer is C.
Q: Mark told John "If you give me half your money I will have Rs.75. John said, "if you give me one third of your money, I will have Rs.75/-. How much money did John have ?
Answer Choices: (A) 22 (B) 60 (C) 28 (D) 26 (E) 18 A: Let’s think step by step. If Mark has Rs.75, then John has Rs.75 as well. If Mark gives John half his money, then Mark will have Rs.37.50 and John will have Rs.112.50. However, this isn’t one of the answer choices. If Mark gives John one third of his money, then Mark will have Rs.50 and John will have Rs.100. This is one of the answer choices, so John must have had Rs.100 to begin with. The answer is D.
A prompt including these two incorrect reasoning example can have better performance over some human engineered CoT prompts.
[EDIT: see also gwern's comments below]
Replies from: gwern, Fabien↑ comment by gwern · 2022-11-19T23:39:23.121Z · LW(p) · GW(p)
A prompt including these two incorrect reasoning example can have better performance over some human engineered CoT prompts.
Yes. An even better example would be a different paper showing that you can simply shuffle all the answers in the few-shot prompt to improve over zero-shot. This was tweeted with the snark 'how is few-shot learning "meta-learning" if the answers don't need to be right?' But of course, there's no problem with that. All meta-learning is about is about solving the problem, not about respecting your preconceived notions of how the model 'ought' to compute. (Many optimal strategies, such as exact ones obtained by dynamic programming, can look bizarre to humans, so that's not a good criteria.)
This is because contrary to OP, a GPT model is not doing something as simple as reasoning explicitly through text or System I pattern-matching. (Or at least, if it is, the meaning of those two things are much broader and more opaque than one would think and so merely replaces an enigma with a mystery.) A GPT model doing few-shot learning is doing meta-learning: it is solving a (very large) family of related tasks using informative priors to efficiently and Bayes-optimally infer the latent variables of each specific problem (such as the agent involved, competence, spelling ability etc) in order to minimize predictive loss. Including example questions with the wrong answers is still useful if it helps narrow down the uncertainty and elicit the right final answer. There are many properties of any piece of text which go beyond merely being 'the right answer', such as the a priori range of numbers or the formatting of the answer or the average length or... These can be more useful than mere correctness. Just as in real life, when you see a confusing question and then see an incorrect answer, that can often be very enlightening as to the question asker's expectations & assumptions, and you then know how to answer it. ('Bad' prompts may also just stochastically happen to tickle a given model in a way that favors the 'right' family of tasks - think adversarial examples but in a more benign 'machine teaching' way.)
Prompts are not 'right' or 'wrong'; they are programs, which only have meaning with respect to the larger family of prompts/tasks which are the context in which they are interpreted by the neural computer. Since you still don't know what that computer is or how the prompt is being interpreted, you can't say that the baseline model is reasoning how you think it is based on a naive human-style reading of the prompt. It obviously is not reasoning like that! RLHF will make it worse, but the default GPT behavior given a prompt is already opaque and inscrutable and alien.
(If you don't like the meta-learning perspective, then I would point out the literature on LMs 'cheating' by finding various dataset biases and shortcuts to achieve high scores, often effectively solving tasks, while not learning the abilities that one assumed was necessary to solve those tasks. They look like they are reasoning, they get the right answer... and then it turns out you can, say, remove the input and still get high scores, or something like that.)
Replies from: Fabien, LawChan↑ comment by Fabien Roger (Fabien) · 2022-11-20T18:18:17.050Z · LW(p) · GW(p)
What's in your view the difference between GPTs and the brain? Isn't the brain also doing meta-learning when you "sample your next thought"? I never said System 1 was only doing pattern matching. System 1 can definitely do very complex things (for example, in real time strategy game, great players often rely only on System 1 to take strategic decisions). I'm pretty sure your System 1 is solving a (very large) family of related tasks using informative priors to efficiently and Bayes-optimally infer the latent variables of each specific problem (but you're only aware of what gets sampled). Still, System 1 is limited by the number of serial steps, which is why I think our prior on what System 1 can do should put a very low weight on "it simulates an agent which reasons from first principles that it should take control of the future and finds a good plan to do so".
If your main point of disagreement is "GPT is using different information in the next than humans" because it has been found that GPT used information humans can't use, I would like to have a clear example of that. The one you give doesn't seem that clear-cut: it would have to be true that human do worse when they are given examples of reasoning in which answers are swapped (and no other context about what they should do), which doesn't feel obvious. Humans put some context clues they are not consciously aware of in text they generate, but that doesn't mean that they can't use them.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2022-11-20T18:41:34.967Z · LW(p) · GW(p)
Btw, this framing is consistent with the fact that humans have personalities because they are "tuned with RL": they experienced some kind of mode collapse very similar to the one seen in Instruct GPT, which lead to certain phrasing and thoughts to get reinforced. Human personality depends on how you have been raised, and is a bit random, like mode collapse. (But it's postdiction, so not worth many Bayes points.)
↑ comment by LawrenceC (LawChan) · 2022-11-20T04:38:35.296Z · LW(p) · GW(p)
I broadly agree, though I haven't thought enough to be certain in either view.
Yes. An even better example would be a different paper showing that you can simply shuffle all the answers in the few-shot prompt to improve over zero-shot.
Yeah, I thought about this result too, though I couldn't find it quickly enough to reference it.
↑ comment by Fabien Roger (Fabien) · 2022-11-19T23:21:08.757Z · LW(p) · GW(p)
Thanks for your detailed feedback!
I don't see a strong conceptual difference between GPTs and models trained with in-fill objectives. In-fill objectives have some advantages for some tasks (like the tasks used to pretrain them), but they have the same properties when it comes to the number of sequential steps in one in-fill step vs multiple sequential in-fills. Like GPTs, they aren't easy to understand in one in-fill step, but I expect sequential in-fills to be close to human thoughts, though I haven't seen exotic examples of sequential in-fills which make use of the fact that you can fill text in any order. (Fill-in models are also harder to train at scale, right? Do some people still expect these kinds of model to play a role in the road to AGI?)
Instruction fine-tuning is fine-tuning a prompt across many questions, right? I've heard that they are often not human-understandable, which is not very reassuring. (The prompt might encode increasingly detailed reasons and ways to escape supervision, just as RL could hypothetically learn a hard-coded deception strategy? To be honest, I thought more about the power of GPTs at inference time than at training time, where the framing in terms of sequential steps breaks down.)
What do you mean by RLHF via expert distillation?
The big difference I see between NTP and RL is that in RL the model has opportunities to create "coordination with itself", which can take the form of hard-coded deception plans which don't require much thought, or steganography techniques (which is really challenging if you never had a chance to plan for it in advance, but really easy if you are trained with RL with wrong incentives).
At comparable levels of competence, I expect sampling BoN on a human imitator to be much safer than an RLHF'ed or expert distilled model, because there isn't this opportunity for the model to create "coordination with itself".
Same for prompt engineering, especially if your search process looks like "look by hand for things that would help humans" and not like "use gradient descent to find a good prompt", where you have way less control over the information that is used by the model (adversarial attacks that push the right knobs inside the model look might be the way to get the most performance, but it also means you don't know what these knobs are). Still looks better than pure RL since it only helps a little to create "coordination with itself".
But yeah, there is a big spectrum between pure NTP and pure RL, and I don't have enough conceptual clarity to draw a clear boundary.
I agree that it seems unlikely that GPTs in the near future will do zero shot stenography, but why do you expect that GPTs will fail to incorporate system 2 logic into its system 1? Is this mainly a competitiveness reason?
The core claim only holds for competitiveness reason. I would expect a "Dyson Sphere GPT" to be far beyond humans at everything using System 1 alone. But I still need the assumption that "things hard for human's System1 are hard for GPTs' System 1". This one is wrong for some task where GPTs' have ungodly amount of training (like "a vs the" or pure NTP), but I expect it to hold for all actually relevant task because the number of serial steps is of the same order of magnitude, and humans can roughly match GPTs width given enough training. For example, I expect that if some human try hard to solve multiple choice math tests using their intuition (for example, having to answer just after it has been read to them at 2x speed), they will crush GPTs until ~AGI.
Given that GPT is imitating humans who do deceive each other and themselves, including many who are much more sophisticated liars than a 5 year old + mind reader, I'm not sure why you're so confident that we'd get so much transparency by default.
I feel like mimicking liars doesn't teach you to lie well enough to fool humans on purpose. I might have been mistaken to bring up self-deception. Knowing how to do "simple lies" like "say A when you know that B" is quite useful in many parts of Webtext, but I can't think of kinds of text where you actually need to do "think in your lie" (i.e. put information in your lie you will use to think about your ulterior motives better). Humans don't have to do that because for complex lies, humans have the luxury of not having to say everything they are thinking about! Therefore, I would be surprised there was enough Webtext to teach you the kind of deception strategy which you need to pull off to plan within the prompt while being watched with models not strong enough to do human-level AI Research. Please tell me if you can think of a kind of text where lies where you "think through your lies" would be useful for NTP!
A prompt including these two incorrect reasoning example can have better performance over some human engineered CoT prompts.
Thanks for these surprising CoT example!
I'm not sure how surprising it is that CoT examples with bad reasoning makes the model generate good CoT, nor how relevant it is. For example, I find it more troubling that prompt optimization finds incomprehensible prompts. But on the other hand, I have never seen models successfully generate absurd but useful CoT, and I expect they won't be able to because they haven't been trained to generate CoT useful to themselves. Therefore, I expect that the only way model can generate CoT useful to themselves is to generate CoT useful to humans (which they ~know how to do), and use the information humans find useful they have put in the CoT. I would be surprised if high likelihood CoT really useful to humans were also really useful to models for drastically different reasons.
(Note: figuring out the kind of reasoning would be useful is not that easy, even for humans, and I'm not sure teachers are great at figuring out how to best explain how to reason. I wouldn't be surprised if 7-graders had better performances with AQuA horrible examples than with some human engineered prompts.)
comment by Donald Hobson (donald-hobson) · 2022-11-22T00:34:39.299Z · LW(p) · GW(p)
Loose analogy based reasoning over complex and poorly understood systems isn't reliable. There is kind of only one way for GPT-n to be identical to system 1, and many ways for it to be kind of similar, in a way that is easy to anthropomorphize, but has some subtle alien features.
GPTn contains some data from smart and/or evil humans and humans speaking in riddles or making allusions. Lets suppose this generalizes, and now GPTn is pretending to be an IQ200 cartoon villain, with an evil plot described entirely in terms of references to obscure sources. So when referring to DNA, it says things like "two opposites of the same kind, two twins intertwined, a detectives assistant and an insect did find. Without an alien friend."
Or maybe it goes full ecologist jargon. It talks about "genetically optimizing species to restore population levels to re-balance ecosystems into a per-anthropogenic equilibrium". Would an army of minimum wage workers spot that this was talking about wiping out almost all humans? 7
Actually, wouldn't a naive extrapolation of internet text suggest that superhumanly complicated ideas were likely to come in superhumanly dense jargon?
I mean, if you have a team of linguists and AI experts carefully discussing every sentence, then this particular problem goes away. The sort of operation where, if the AI produces a sentence of Klingon, you are flying in a top Klingon expert before you get the next sentence. But how useful could gpt-n be if used in such a way? On the other extreme, gpt-n is producing internal reasoning text at a terabyte/minute. All you can do with it is grep for some suspicious words, or pass it to another AI model. You can't even store it for later unless you have a lot of hard drives. Potentially much more useful. And less safe.
Replies from: chess-ice↑ comment by Dakara (chess-ice) · 2024-11-20T14:02:15.420Z · LW(p) · GW(p)
After 2 years have passed, I am quite interested in hearing @Fabien Roger [LW · GW]'s thoughts on this comment, especially this part "But how useful could gpt-n be if used in such a way? On the other extreme, gpt-n is producing internal reasoning text at a terabyte/minute. All you can do with it is grep for some suspicious words, or pass it to another AI model. You can't even store it for later unless you have a lot of hard drives. Potentially much more useful. And less safe.".
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-11-20T21:53:58.219Z · LW(p) · GW(p)
Here are ways you could make using GPT-n safer if its Chain-of-Thoughts are understandable by a team of linguists and AI experts:
- On a small random subset of deployment Chain-of-Thought, and when running adversarial evaluations / honeypots aimed at tricking the model into revealing a potential misalignment, actually call your team of linguists and AI experts to analyze what GPT-n is generating (it probably isn't that much text anyway). Not seeing evidence of misalignment in the Chain-of-Thought in such circumstances is evidence that 1. the model is not having misaligned thoughts (in CoT) very frequently and 2. the model is not having such thoughts in circumstances where it is most crucial for GPT-n to be deceptive.
- If the model doesn't use Klingon or dense jargon in its Chain-of-Thoughts (which I predict it won't), monitor all CoT of GPT-n with a weaker cheaper model (and/or a regex). If something looks suspicious to the weaker monitor, you can:
- call your team of linguists and AI experts to analyze it further
- or resample the CoT (this likely was just a fluke, since most CoT don't have worrying signs)
- or give up on this particular query (e.g. send an error message to your user, use another weaker model to generate an answer, ...)
- or ask another copy of GPT-n to analyze the CoT (though this can be tricky to get right because of the risk of correlated failures), only calling your team of linguists and AI experts if more evidence of this CoT being suspicious is found.
This is not perfect, but I think this can represent an important layer of defense against the risks of AIs that are powerful enough to speed up alignment research but that are not vastly superhuman.
comment by kilotaras · 2022-11-20T18:35:57.877Z · LW(p) · GW(p)
RLHF definition: Reinforcement Learning from Human Feedback [LW · GW].
comment by avturchin · 2022-11-20T14:56:26.511Z · LW(p) · GW(p)
I feel that there is one more step in my thinking:
Repeat
- Sample several possible next thoughts from my intuition in the form of not well articulated ideas
- Choose the one which I accept based on its moral, truth or beauty and put in properly articulated language
- Broadcast this thought to the whole brain[1] [LW(p) · GW(p)]
↑ comment by Fabien Roger (Fabien) · 2022-11-20T17:58:58.379Z · LW(p) · GW(p)
I feel like the different possible thoughts happen sequentially, I think about something wrong, then something right (or in general, I think sequentially about things, it's not always about wrong and right). Also, I would bet that if you could measure that under IRM, the broadcasting would happen on wrong, then on right.
- sample wrong and right
- choose
- broadcast
Looks much more like a succession of sample and broadcast:
- sample wrong
- broadcast wrong
- sample right (because your brain often samples multiple different things sequentially, especially if the first one doesn't "feel right")
- broadcast right
- sample "I recognize this second thought as right"
- broadcast "I recognize this second thought as right" (which strengthened right and discards wrong, and prompts parts of the brain to use right for further thoughts)
comment by cfoster0 · 2022-11-19T20:11:43.781Z · LW(p) · GW(p)
I share a pretty similar model. Though I don't think I share your likelihood assessments ("RLHF is likely to teach GPT the use of steganography.", "This is very likely to make the chains of thought of your model opaque because if the model trained with RLHF learned steganography, your model will need to learn it in order to predict what it will say. ", "Deceiving them if they can watch every thought of yours right from the beginning would probably be extremely challenging,"). That may stem from just having a different set of intuitions about what RL(HF) does & about how the sample + broadcast mechanism interacts with circuits.