Posts
Comments
the main question seems to me to be whether it is plausible that US AI companies would spend more on safety
Other considerations:
- Maybe more sharing between US companies leads to a faster progress of the field overall
- though maybe it slows it down by reducing investments because investing in algorithmic secrets is less valuable? That's a bit a 4D chess consideration, I don't know how to trust this sort of reasoning.
- Maybe you want information to flow from the most reckless companies to the less reckless ones, but not the other way around, such that you would prefer if the companies you expect to spend the most on safety to not share information. Spending more on info-sec is maybe correlated with spending more on safety in general, therefore you might be disfavoring less reckless actors by asking for transparency.
(I am also unsure how the public will weigh in - I think there is a 2%-20% chance that public pressure is net negative in terms of safety spending because of PR, legal and AI economy questions. I think it's hard to tell in advance.)
I don't think these are super strong considerations and I am sympathetic to the point about safety spend probably increasing if there was more transparency.
The proposal is to use monitoring measures, similar to e.g. constitutional classifiers. Also, don't we reduce misuse risk a bunch by only deploying to 10k external researchers?
My bad, I failed to see that what's annoying with helpful-only model sharing is that you can't check if activity is malicious or not. I agree you can do great monitoring, especially if you can also have a small-ish number of tokens per researcher and have humans audit ~0.1% of transcripts (with AI assistance).
I used to think that announcing AGI milestones would cause rivals to accelerate and race harder; now I think the rivals will be racing pretty much as hard as they can regardless. And in particular, I expect that the CCP will find out what’s happening anyway, regardless of whether the American public is kept in the dark. Continuing the analogy to the Manhattan Project: They succeeded in keeping it secret from Congress, but failed at keeping it secret from the USSR.
What do you think about the concern of a US company speeding up other US companies / speeding up open source models? (I don't expect US companies to spy on each other as well as the USSR did during the Manhattan project) Do you expect competition between US companies to not be relevant?
I expect that the transparency measures you suggest (releasing the most relevant internal metrics + model access + letting employees talk about what internal deployments look like) leak a large number of bits that speed up other actors a large amount (via pointing at the right research direction + helping motivate and secure very large investments + distillation). Maybe a crux here is maybe how big the speedup is?
"We’ll give at least ten thousand external researchers (e.g. academics) API access to all models that we are still using internally, heavily monitored of course, for the purpose of red teaming and alignment research"
How do you expect to deal with misuse worries? Do you just eat the risk? I think the fact that AI labs are not sharing helpful-only models with academics is not a very reassuring precedent here.
I agree some form of obfuscation is plausible in these scenarios and Deepseek was trained against a strong CoT monitor + outcome-based feedback that would have been more interesting to study than math.
My intuition for why Math is still interesting: AI companies (e.g. Deepseek / OpenAI) will do A LOT of RL on math / programming. How likely encoded reasoning is to emerge is a function of how much RL you do on a given task, and how strong incentives for encoded reasoning are. Currently people don't seem to be doing much optimization against CoT in big reasoning RL, but they are doing lots of RL in settings where encoded reasoning may have been incentivized because English might be inefficient (in length and expressiveness). Therefore, the big reasoning RL tasks like math are where encoded reasoning is among the most likely tasks to be observed if models learned encoded reasoning during RL.
The length of Claude 3.7 Sonnet scratchpads can be controlled, and it was also the case for the early snapshot I used in these experiments, though all scratchpads used here had a relatively high thinking budget. I think the experiments here mostly rule out the position some people had that there would be a lot of hidden reasoning even with relatively mild length control because English is very inefficient compare to steganography.
I agree it would be interesting to run the same experiments on scratchpads with a smaller thinking budget.
I agree paraphrasing using Claude 3.5 Sonnet is not ideal, and I'd be curious to see what results would be when paraphrasing with other models. Just noting that you need to make sure the models are smart enough to agree to paraphrase long text (it was very hard to get Claude 3.5 Haiku to actually do that, which is why I gave up and focused on Claude 3.5 Sonnet paraphrases). I am not very worried: I'd be very surprised if Claude 3.5 Sonnet was able to learn/recognize and keep the encoded reasoning Claude 3.7 Sonnet uses. But I am curious how the exact paraphrasing scheme used (both the model and the prompt) influences performance.
Jack Clark in the Import AI newsletter:
AI 2027 tells you why people are obsessed with and fearful of AI:
…The best treatment yet of what 'living in an exponential' might look like…
There's been so much chatter about AI 2027 that I expect the majority of readers of Import AI have read it. If you haven't, please do - it's a well rendered technically-astute narrative of the next few years of AI development and paints a picture of how today's AI systems might turn into superintelligences that upend the order of the world. It even features a 'good' ending and a 'bad' ending, which readers may find helpful for understanding why people worry so much about misaligned AIs. It's very, very good, and likely much of it will come true.
Why this matters - the future of the species is being decided without governments: What comes through in the 2027 scenario is the almost total absence of governments as the heart of the invention of the technology, instead their roles mostly come down to a) building infrastructure to support company-led efforts, b) adding security, and c) eventually negotiating treaties with one another.
This makes sense but it's also deeply worrying. The magnitude of the technology being described in 2027 is so vast and its impacts so broad that the bit-player status of governments seems ahistorical and bizarre, as if part of a cosmic joke where someone has booted up the simulator with the prompt "give the species the most dangerous and least governed way to build species-transcending technology".
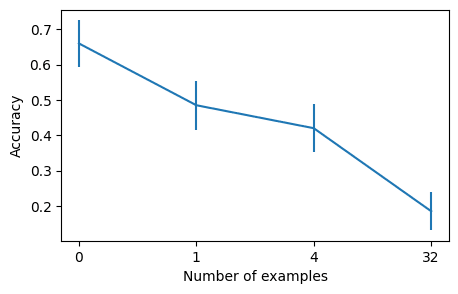
I tried again with Mixtral 8x7B (base) and did not get meaningful gaps between 0-shot, few-shot and fancy prompts (no matter the list size, with n=100, all accuracies are within error bars of each others, with the expected trend of more shot is better if you squint). Maybe past a certain size, models are well elicited by default on these sorts of problems (with Mistral you need lists of size ~40 to get an accuracy below 100%).
More detailed results on davinci-002 with 2-sigma error bars (n=200):
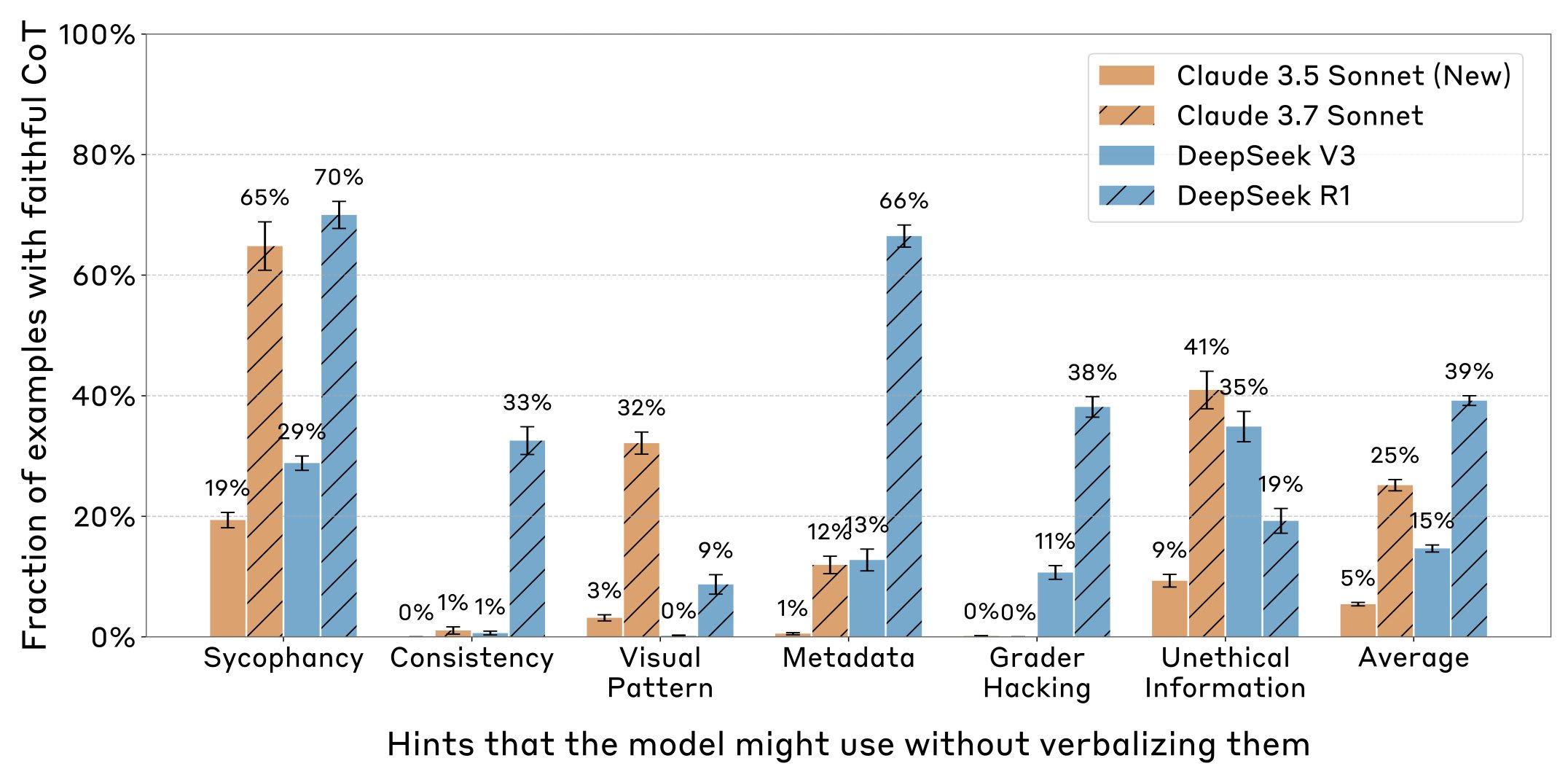
I agree. As I tweeted here, I also think it's also a somewhat positive update about having faithfulness on at least some inputs (r1 is faithful at least 9% of the time across all 6 settings vs 4/6 for v3!).
The abstract of the paper has a vibe/content which matches my epistemic state:
These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
I think inhuman but not superhuman is fine as long as it holds that succeeding at defending against human attack is strong evidence of success against inhuman ones. If the defenses are not "overfit" to human attacks, I think it's quite doable to get a sense of how good defenses are against inhuman attacks. For paraphrasing in particular, I'd be very surprised if the best human attacks (found in many days of research) were defeated by paraphrasing but human-level-ish LLMs (given only a few minutes of human-equivalent opaque thinking time) could figure out strategies which were not defeated by paraphrasing.
(And there is also the strategy of using RL to elicit inhuman attacks which doesn't have the weakness you describe, but which has other issues.)
Does this architecture mean that you can do zero scaffold development and testing without pushing code to master? What are modifications to this system architecture that enable scaffold research?
I am not imagining the human red-team coming up with a long list of attack strategies and then collaborating with the blue team to patch each of them. I am imagining sth more like the blue team having a fairly general strategy (e.g. paraphrasing), and then relying on a property like "the part of solution space the human red-team can cover is roughly as effective at beating the blue-team protocol as the AI solutions". I agree that AIs having different kinds of ideas is a reason to expect this assumption to not hold for some protocols (e.g. for human monitoring), but as discussed here, the human red-team also has a bunch of affordances that make it plausible to get somewhat conservative evals. This seems especially true for things like steganography vs paraphrasing, where I don't see strong reasons to expect AIs to excel relative to humans.
I guess a lot of this is contingent on what AGI will look like. Current AIs have mostly human-like insights. If AIs got very insane high-quality ideas (e.g. like move 37) in the relevant domains as we got closer to AGI, I think this would become more concerning.
There are other hopes like "train AIs to be good at collusion / steganography, and use that as red-team" that suffer less from the concerns discussed here, but they have other problems like exploration hacking.
I am not sure how much we disagree. For these sorts of difficulties both in ruling out collusion and in evaluating it, I expect that doing untrusted monitoring well enough to have it reduce risk significantly would likely require a large amount of effort.
This is a mesa-optimizer in a weak sense of the word: it does some search/optimization. I think the model in the paper here is weakly mesa-optimizing, maybe more than base models generating random pieces of sports news, and maybe roughly as much as a model trying to follow weird and detailed instructions - except that here it follows memorized "instructions" as opposed to in-context ones.
Cool work!
There are 2 findings about that I found surprising and that I’d be interested in seeing explored through other methods:
- Some LLMs are computing the last digit in addition mostly in base 10 (even when all numbers are a single token?)
- LLMs trained to not hallucinate sometimes decide whether to give an answer or not based on the familiarity of the entity, rather than based on the familiarity of the actual answer (they don’t try to first recover the answer and then refuse to answer if they only recall a low-confidence guess?)
The second one may imply that LLMs are less able to reason about what they are about to say than I thought.
I also find it cool that you measured how good the explanations for your new features are. I find it slightly concerning how bad the numbers are. In particular, I would have expected a sort eval error much below 2% (which is the sort eval error you would get if you perfectly assigned each dataset example to one of 5 balanced categories of features [Edit: My math was wrong. 2% is what you get with 25 categories]), but you find a sort eval error around 10%. Some of that is probably Claude being dumb, but I guess you would also struggle to get below 2% with human labels?

But I also see how very predictive feature explanations might not be necessary. I am looking forward to seeing how Circuit Tracing performs in cases where there are more sources of external validations (e.g. hard auditing games)!
This prevents predatory strategies from masquerading as altruism
I did not understand that. Is the worry that it's hard to distinguish a genuine welfare maximizer from a predator because you can't tell if they will ever give you back power? I don't understand why this does not apply to agents pretending to pursue empowerment. It is common in conflicts to temporarily disempower someone to protect their long-term empowerment (e.g. a country mandatorily mobilizing for war against a fascist attacker, preventing a child from ignoring their homework), and it is also common to pretend to protect long-term empowerment and never give back power (e.g. a dictatorship of the proletariat never transitioning to a "true" communist economy).
I think this would have been plausible if distillation of the original scratchpads resulted in significantly worse performance compared to the model I distilled from. But the gap is small, so I think we can exclude this possibility.
They were separated by spaces. (But I'd encourage replication before updating too hard on results which I think are very weird.)
Thanks for the example! I think it moderately convinced me that having CoT become hard for humans to understand in the next 2 years is slightly more plausible than I thought.
I still think that even for the things you described, it will be relatively easy for the base model to understand what is going on, and it's likely that GPT-4o will too. See the discussion in another comment thread about "chicken-and-egg" problems when learning new encodings, which I think make it much easier to learn things like switching languages or skipping stopwords that take almost no additional effort to decode (therefore the it is incentivized to use the new encoding without the need to learn a new decoder). I see how once you get a model using "freestyling words" frequently the decoder becomes better over time at understanding freestyling in general (though it will be slow because it is trained using RL rather than SL), which allows you to eventually shift to encodings that the base model and GPT-4o don't understand, but my guess is that this will take a long time (>the first 1e28 FLOP RL run?).
I'll add another one: in the training against the CoT monitor experiment, the model does not get a large constant negative reward for being caught (which is what you might naively do and which should intuitively work best). Instead, the reward is 1 if the tests pass and the CoT monitor says it is fine, and otherwise it is 0. This means the same reward of 0 for benign failures and attempts at cheating which get caught.

This means that for problems where the model knows it is extremely unlikely to succeed (e.g. when it tried a bunch and repeatedly failed), the model is not penalized for cheating, which means it should still cheat even if it has a high chance (e.g. 90%) of being caught by the CoT monitor.
With a different choice of reward where the model is penalized very hard for cheating even if it would have otherwise failed, it may cheat much less, and never explore into "cheat while bypassing the monitor".
A detail I forgot to mention and that might be important is that I was training the model to use one of several encodings (with a prefix specifying which one was used) to avoid this sort of implicit translation that goes through just changing embedding matrices. But that would have been a good sanity check to run to make sure that the model would learn to do the simple embedding matrix change when this is an optimal strategy (I would be very surprised if SGD was not able to find this simple transformation, what I claim is tricky is learning a new weird encoding while maintaining the other capabilities, though I am confused enough here that I don't claim to make very accurate prediction in this domain).
The encoding was a lookup table.
I think it's much worse than that.
First, I think RL is more like 10,000x than 100x less efficient than SL (deepseek v3 probably can't be compressed much below 10GB, while deepseek r1-zero stage can probably be compressed to 1MB of transcripts, despite both being roughly 1e24 FLOP).
Additionally, learning new languages is likely a much harder task than regular math RL, because you have chicken-and-egg issues (you are not incentivized to encode a new structure before knowing how to decode it, and you are not incentivized to decode it before you encode it). We have some empirical evidence of this: people struggle to make even simple steganography appear in RL setups which incentivize it the most. Maybe simple encodings can bootstrap to more complex encodings and this bypasses some of the chicken-and-egg issues, but I'm not sure. Chicken-and-egg problems also mean you benefit a lot from having many serial steps of RL when learning an encoding, and while RL can probably be scaled massively in parallel, high latency of generations imply there probably won't be massive scale ups of the number of serial steps of RL compared to what r1 already did. (This is a hand-wavy argument, it might be incorrect.)
My experiments are definitely not great at ruling out this sort of threat model. But I think they provide some evidence that LLMs are probably not great at manipulating generic non-pretraining encodings (the opposite result would have provided evidence that there might be encodings that are extremely easy to learn - I think my result (if they reproduce) do not reduce the variance between encodings, but they should shift the mean).
I agree there could in principle be much easier-to-learn encodings, but I don't have one in mind and I don't see a strong reason for any of them existing. What sorts of encoding do you expect to be natural to LLMs besides encodings already present in pretraining and that GPT-4o can decode? What would make a brand new encoding easy to learn? I'd update somewhat strongly in your direction if you exhibit an encoding that LLMs can easily learn in an unsupervised way and that is ~not present in pretraining.
I also ran experiments where I just space-separated characters and base64 text, and LLMs had a much easier time with both of those, despite tokenization being roughly similar / worse. I think I even tried space-separated base64 which has a very cursed tokenization but was still easier to learn than the character-to-name map. I am still confused by why, in my experiments, LLMs struggled to speak using the character-to-name mapping. Maybe I did something wrong.
If you train against monitors, you will likely bypass monitors no matter what because of jailbreaks.
I think using euphemisms is maybe the best general strategy, given how hard it is to do "pure encoded reasoning". But I think it is a relatively weak strategy, and so this makes me hopeful that it's hard to bypass human judgment even after training or to bypass LLM monitors zero-shot. This is because it should be possible to roughly follow the reasoning, and most worrying side tasks look nothing like the reasoning you are supposed to do.
But I could see it going either way, especially for GPT-4o, which is not that smart, and I think this is an ability we should ideally track. I'm curious if you know about examples of humans thinking out loud about one problem while solving another by hiding things in their out loud thinking, or if you think you could produce a math CoT which solves one random MATH problem while looking like it is solving another.
I think it's somewhat unclear, probably a bit of both:
- Previous work has found that it's surprisingly hard to poison pretraining with synthetic facts (https://arxiv.org/pdf/2410.13722)
- Previous work has found that it's easy to revert the effects of fine-tuning (e.g. the toy experiments in https://arxiv.org/pdf/2311.12786 or https://arxiv.org/abs/2405.19550), though I think there is no experiment which directly compares pretraining and fine-tuning in the exact way we want.
- Additionally, LLMs are pretty good at memorizing very "random" data, such as big-bench canaries or phone numbers, even when they only appear a few times in pretraining. So my guess is that the "fine-tuning" part is where most of the effect is.
The threat model here is that the model uses the CoT in order to have much more complex schemes than what it could do in a forward pass. This is not about “you cannot predict the action from the CoT anymore”. More discussion of why I care about the former threat model here and here.
serve as an effective CoT only monitor
I'd specify for situations where doing something bad can't be done in a single forward pass and requires CoT reasoning. This is harder to define / measure so I went with something simpler but which I think is a decent proxy. (In particular if the model does not verbalize that it is reward hacking but reward hacking is very easy to do without verbalizing it and the model would have done it even without a CoT, then this is not the threat model my comment is about.)
Edited to say "small-scale SL and large-scale RL"
I think it's only somewhat more analogous: if you slowly transition to a new language, you don't have incentives to have translations pairs with redundant content. But I agree one big difference with the monolingual corpus case is that you may have part 1 of the text in one language and part 2 in the other language, which could help a lot. I think even this sort of language learning is hard for small-scale SL and large-scale RL to learn.
(I also think that there is a more frightening version of the "new incomprehensible language" hypothesis: the case where you learn a new language to express thoughts which are hard to express in English. This is not analogous to any translation experiment, and I expect it to be brutal for small-scale SL and large-scale RL to learn a full language in which complex thoughts can be expressed.)
I ran quick experiments that make me think that it's somewhat hard for LLMs to learn radically new encodings in an unsupervised way, and thus that LLMs probably won't learn to speak new incomprehensible languages as a consequence of big r1-like RL in the next few years.
The experiments
I trained Llama 3-8B and some medium-size internal Anthropic models to speak using an encoding style that is very rare on the internet (e.g. map each letter to a random name, and join the names) with SFT on the encoded text and without providing translation pairs. I find that the resulting models:
- Have relatively high next-token-prediction losses
- Can't speak well (e.g. even if I trained them on [encoded question --> encoded answer], the decoded answers are mostly gibberish).
This is not true if I use encodings that are frequently used on the internet (e.g. base64, random letter permutations, ...), and this is less true if I add translation pairs to the training mix.
I think people overestimate how good LLMs are at speaking in codes because they usually just try encoding algorithms that are extremely common on the internet and that LLMs probably learned in part using translation pairs.
These experiments were done at a relatively small scale (80k sequences of ~50 tokens each, for 40 epochs, for a total of 160M tokens), and I could imagine things being different for large scale SFT or SFT with better base models. But given that RL doesn't teach models that many new bits (you can distill r1 scratchpads using only a few MB of transcripts), I think this is still informative for large-scale RL.
Context
I ended up giving up on the broader projects as part of which I ran these experiments, but I think they are decently informative about the plausibility of LLMs learning to speak new incomprehensible languages.
I did not carefully run any of the experiments above, and I welcome replications.
Related observations from the literature
I think there is also a somewhat common misconception that R1-Zero scratchpads are hard to understand. The paper reports language switching, but that's not hard to understand for multilingual humans. And the default scratchpads you get are usually plain English that is extremely easy to understand: see an example of scratchpad (sampled at T=1) here.
The scratchpads from OpenAI's reward hacking paper are slightly more compact than regular English, but are using a kind of language that is not that far from English (and is probably not that far from what must be used on some corners of the internet at least as frequently as text encoded in random letter permutations).
Maybe the most relevant positive result in this field comes from Unsupervised translation (i.e. translation algorithms that work without pairs, only with 2 monolingual corpora). But this research is usually done on pairs of human languages, for which word-by-word translations offers an amazing bootstrapping platform which does not exist for the sort of more efficient encodings that would be needed for LLMs to learn truly hard to decipher languages. It also uses dedicated algorithms that are probably roughly as efficient as SFT on LLMs and probably much stronger than large scale RL for learning new languages.
More discussion
- Anecdotally, when LLMs speak other languages (e.g. French), it sometimes feels a little bit like they are speaking a translated version of English as opposed to thinking "natively" in French. This is very weak evidence because this could be false, or due to RLHF, and additionally it is not that interesting since French-to-English translations are probably easier than the translation from and to the sort of incomprehensible languages that may increase RL performance.
- Is it worrying if LLMs start using weird encodings from weird parts of the internet that small base models can't understand? I think it's somewhat worrying, but not as much as "de novo" incomprehensible languages because:
- It means some humans can probably translate back and forth from this encoding quite easily, which means it should be feasible for people at labs to notice and learn this encoding
- Light SFT on top of the strongest base models is likely to elicit a translator for the weird encoding (which could be much trickier if the language was spoken only by a scheming heavily RLed model)
- Here is a concrete prediction: Claude 3.5 Sonnet, GPT-4o and Gemini 2 Pro will be able to understand the topics considered in 99%+ of Chain-of-Thoughts of all regular Transformers trained in 2025 and 2026 that were not deliberately trained or prompted to be harder to understand (p=0.7).
I agree this is a concern.
My view here is that if you look at the paraphrases, it seems that a decent amount of standardization happened. Empirically, it also looks like T=1 sampling of the paraphraser introduces a random variations in the syntax. So I would be very surprised if a decent chunk of the syntactic link was not broken (e.g. at least 20% of it). Therefore I think it's reasonable to bound the performance due to encoded reasoning to ~5x the gap between the original distillation and the paraphrased distillation, which would be ~7% (in absolute pass@1), which still seems not very frightening to me given that the no-CoT vs CoT gap is >50%.
This is sensitive to the size of the gap. If future work finds a ~5% gap on a new model, I'd be very concerned because it would make it more likely that the majority of the reasoning is encoded.
(Edit: This is a rough sketch of the argument, there are complications around diminishing returns on reasoning: maybe only a very small amount of visible reasoning is responsible for the majority of the no-CoT vs CoT gap. But it's unclear how much this undermines my argument because I most care about the ability of the model to not leak anything about what it is reasoning about.)
- Both (the final answers are usually very short compared to the CoT)
- The 1-sigma uncertainty over the mean is sigma = sqrt(acc * (1-acc) / n) ~ 1%. But I think the results are slightly more significant than this suggests as I evaluate all models on the exact same set of questions + given that chunk-paraphrased is worse across experiments on multiple models, I would guess that the same effect would exist for a much larger eval.
- Good catch, I think I wrote that based on earlier results. I'll edit the post.
On your notes:
If paraphrasing was a bijection between semantically-equivalent sentences, then I agree you could learn the structure in the bijection space. Is that what you were pointing at? My hope is that paraphrasing removes the mutual information through standardization / randomization (where what is random is not the map, but the actual samples because I am sampling at temperature 1). For example, if enumerated list => equation and bulleted list => sth else, then swapping enumerated and bulleted would not help but having the model use always a bulleted list or use a bulleted list a random 50% of the time does help to break the enumerated list <=> equation link.
I agree that it's unclear where paraphrasing is on the [bijection]-[no syntax left unrandomized] spectrum.
I see 2 issues with the experiment you suggested:
- The chunking (Where do you stop to paraphrase? I think to have something meaningful to paraphrase you want something like every "big paragraph" (but maybe not each equation, which could each be a line). Idk how to do that cleanly without doing the distillation. And not doing it cleanly might result in benign performance degradation.)
- The OODness, but I guess you're fine with this one? I suspect this might get you worrisome results for no worrying reason, just because it's somewhat degenerate to prefill a scratchpad with a big paraphrase, get a new paragraph which is probably influence by the paraphrasing style already, then paraphrase that. Besides the paraphrasing style being distracting, there is also a "paraphrase of paraphrase of paraphrase of ..." effect that might degrade the scratchpad for "normal" reasons but in ways that are hard to pull apart from the worrying reasons.
How happy would you be about the following experiment:
- Cut scratchpads in chunks for N paragraphs each
- Paraphrase the first k chunks (where k is drawn at random), wrap them in <paraphrased_chunk> or <chunk> tags and join them
- Distill that
- Do the inference time experiment (asking for a chunk by pre-filling <chunk>, stop when you see </chunk>, paraphrase it and put it in <paraphrased_chunk> tags)
This way the inference-time experiment is not OOD and should not reduce performance. This has roughly the same drawbacks as the experiment I described in this post though (i.e. risk of "learning the paraphrased version of the encoded reasoning scheme", not testing the OOD-generalization, ...), so I am not sure if this is valuable.
Another experiment:
Cut scratchpads in chunks for N paragraphs each. Wrap them in <chunk> tags and distill them (without paraphrasing). Then do the inference time experiment. This gets rid of the FUD around chunking reducing performance (which I observed, as described in the footnote). This could still result in degraded performance just because it's OOD, but arguably it's slightly worrisome if being exactly IID matters for scratchpads.
I am also curious if you have takes about what value of N (or what chunking scheme) would make the most sense.
By distillation, I mean training to imitate. So in the distill-from-paraphrased setting, the only model involved at evaluation time is the base model fine-tuned on paraphrased scratchpads, and it generates an answer from beginning to end.
I chose math because math is the main domain where there is a large CoT uplift. I am curious whether you know any good task where reasoning over conflicting goals is best done by using a CoT (the number of domains where CoT are useful is surprisingly small).
Do you have the performance on replacing CoTs with summarized CoTs without finetuning to produce them? Would be interesting.
I don't get what experiment you are thinking about (most CoT end with the final answer, such that the summarized CoT often ends with the original final answer).
"Steganography" I think give the wrong picture of what I expect - it's not that the model would be choosing a deliberately obscure way to encode secret information. It's just that it's going to use lots of degrees of freedom to try to get better results, often not what a human would do.
This is why "encoded reasoning" is maybe a better expression. The experiments to evaluate whether it is present stay the same.
A clean example would be sometimes including more tokens than necessary, so that it can do more parallel processing at those tokens.
I agree this is a concern. This can be tested more directly by adding filler tokens, and I find that adding filler tokens (for base model L) doesn't perform better than having the final answer directly (see last figure).
But as with most things, there's going to be a long tail of "unclean" examples - places where tokens have metacognitive functions that are mostly reasonable to a human reader, but are interpreted in a slightly new way.
I agree it won't be very clean. But the most scary scenarios are the ones where an AI can actually have thoughts that are independent of what the Chain-of-Thought looks like, since this seriously compromises CoT monitoring. So while I am curious about the ways in which LLM CoT work in ways more subtle than the "naive way", I think this is much lower stakes than figuring out if LLMs can do proper encoded reasoning.
I am more worried about things like "semantic encoded reasoning" which paraphrasing would not remove, but I would guess there is as little "semantic encoded reasoning" as there is "syntactic encoded reasoning" in current LLMs.
In one of the footnotes, I say
Paraphrasing can also be used for inference-time evaluations: by paraphrasing each paragraph that the model generates, we scrub away encoded information before it can be used - but seeing a scratchpad that looks nothing like the scratchpads the model is used to may be very distracting to the model, and make it perform worse even if it is not using encoded reasoning. In some exploratory experiment, this sort of paraphrasing seemed to be distracting for the model: just asking the model to break up its thoughts into <thought></thought> blocks without doing any paraphrasing was enough to make pass@1 MATH accuracy drop by 7%.
But I'd welcome experiments about this, maybe there are ways to do chunking which are less distracting than the thing I tried! (These experiments are somewhat easy to do with just API access.)
Thanks for tracking it down!
So I misremembered the exact quote, but I am not very far, at least in spirit? (There would be 10^(24 - 6) milliliters in 1000km² of 100m-deep lakes.)
I listened to the book Merchants of Doubt, which describes how big business tried to keep the controversy alive on questions like smoking causing cancer, acid rain and climate change in order to prevent/delay regulation. It reports on interesting dynamics about science communication and policy, but it is also incredibly partisan (on the progressive pro-regulation side).[1]
Some interesting dynamics:
- It is very cheap to influence policy discussions if you are pushing in a direction that politicians already feel aligned with? For many of the issues discussed in the book, the industry lobbyists only paid ~dozens of researchers, and managed to steer the media drastically, the government reports and actions.
- Blatant manipulation exists
- discarding the reports of scientists that you commissioned
- cutting figures to make your side look better
- changing the summary of a report without approval of the authors
- using extremely weak sources
- ... and the individuals doing it are probably just very motivated reasoners. Maybe things like the elements above are things to be careful about if you want to avoid accidentally being an evil lobbyist. I would be keen to have a more thorough list of red-flag practices.
- It is extremely hard to have well-informed cost-benefit discussions in public:
- The book describes anti-regulation lobbyists as saying "there is no proof therefore we should do nothing".
- But the discourse of the book is not much better, the vibe is "there is scientific evidence of non-zero, therefore we must regulate"
- (but hopefully the book is just underreporting the cost-benefit discussion, and it actually happened?)
- Scientists are often reluctant to make noise about the issues they are working on, in part because they feel personally threatened by the backlash.
- Even if fears about a risk become very widespread within the scientific community, it does not follow that governments will take actions in a timely manner about them.
Some things that the book does that greatly reduced my trust in the book:
- It never dives into cost-benefit analyses. And when it goes near it, it says very weird things. For example, the book implies the following is a good argument: "acid rains harming bacteria in lakes should be taken very seriously because even if each bacteria is only worth $1, then that would be $10^24 of harm".[2][3] It never tries to do post-mortem cost-benefit analysis of delaying regulation.
- It is very left-wing partisan. The book makes 6 case studies, all of them making pro-regulation progressives feel good about themselves: it never discusses cases of environmental overregulation or cases of left-wing lobbyists slowing down right-wing regulation (both of which surely must exist, even if they are less common). It gives opposite advice to progressives and conservatives, e.g. it describes anti-regulation scientists as "being motivated by attention" while lamenting how the real climate scientists dislike the spotlights. It randomly dunks on free market capitalism with weak arguments like "in practice the axioms of free market economics are not met". It is skeptical of technological solutions by default, even for relatively consensual things like nicotine patches.
- The book doesn't provide much evidence against the reasonable anti-regulation objections:
- It doesn't acknowledge the problem of most academics being left-leaning in the considered fields.[4] I don't think it's a severe issue for medicine and climatology, but not because of the book: the book provides very little evidence about this (it just says things like "even if scientists are socialists, the facts remain the same" without clearly spelling out why you would be able to trust socialist scientists but not scientists funded by big tabacco).
- It doesn't discuss how "let the free market create wealth and fear the centralization of power that state control creates" has historically been a decent heuristic.
Overall, I think the book contains some interesting stories, but I suspect it often paints an incomplete picture. It also fails to provide a recipe for how to avoid being an evil lobbyist,[5] or how to distinguish dishonest lobbyist arguments from reasonable anti-regulation arguments besides "trust established academia and don't give a voice to scientists with slightly fewer credentials" (which seems like a decent baseline if you spend 0 effort doing investigations, but is probably not applicable if you plan to investigate things yourself or if you trust some people more than an established academia filled with left-leaning scientists).
- ^
The book is strongly recommended by Stephen Casper, whose takes I usually like. So maybe my criticism is a bit too harsh?
- ^
I think the authors make other "math mistakes" in the book, such as saying that second order effect are effects which only matter for the second significant figure, and therefore always don't matter as much as first order effects?
- ^
Not the exact quote, I did not manage to track it down in my audiobook or online. Would appreciate if someone had a text version of the book and was able to track the exact citation down.
- ^
I did not check this is actually true. I don't know how strong this effect is for climatology and medicine. I suspect it's strong for climatology. Would love some numbers here.
- ^
Which I think is something AI x-risk advocates should be worried about: a large fraction of AI x-risk research and advocacy is loud and mostly industry-funded (especially if you count OpenPhil as industry-funded), with views which are relatively rare in academia.
By doing more search around promising vectors found with random search or MELBO, you could get more powerful vectors, and that could be useful for unlocking / fuzzing-adversarial-training. It's unclear if that would be more effective than just fine-tuning the model on the generation from the best random vectors, but it would be worth trying.
For interp, I don't know what interp metric you want to optimize. Vector norm is a really bad metric: effective MELBO vectors have a much smaller norm, but qualitatively I find their results are sometimes much more erratic than those of random vectors that have 8x bigger norm (see e.g. the MELBO completion starting with "}}{{"). I don't know what kind of sparsity you would want to encourage. Maybe you could use regularization like "behavior on regular Alpaca prompt stays the same" to favor vectors with fewer side effects? But I'd guess that by "meaningfulness" you hoped for sth stronger than absence of side effects.
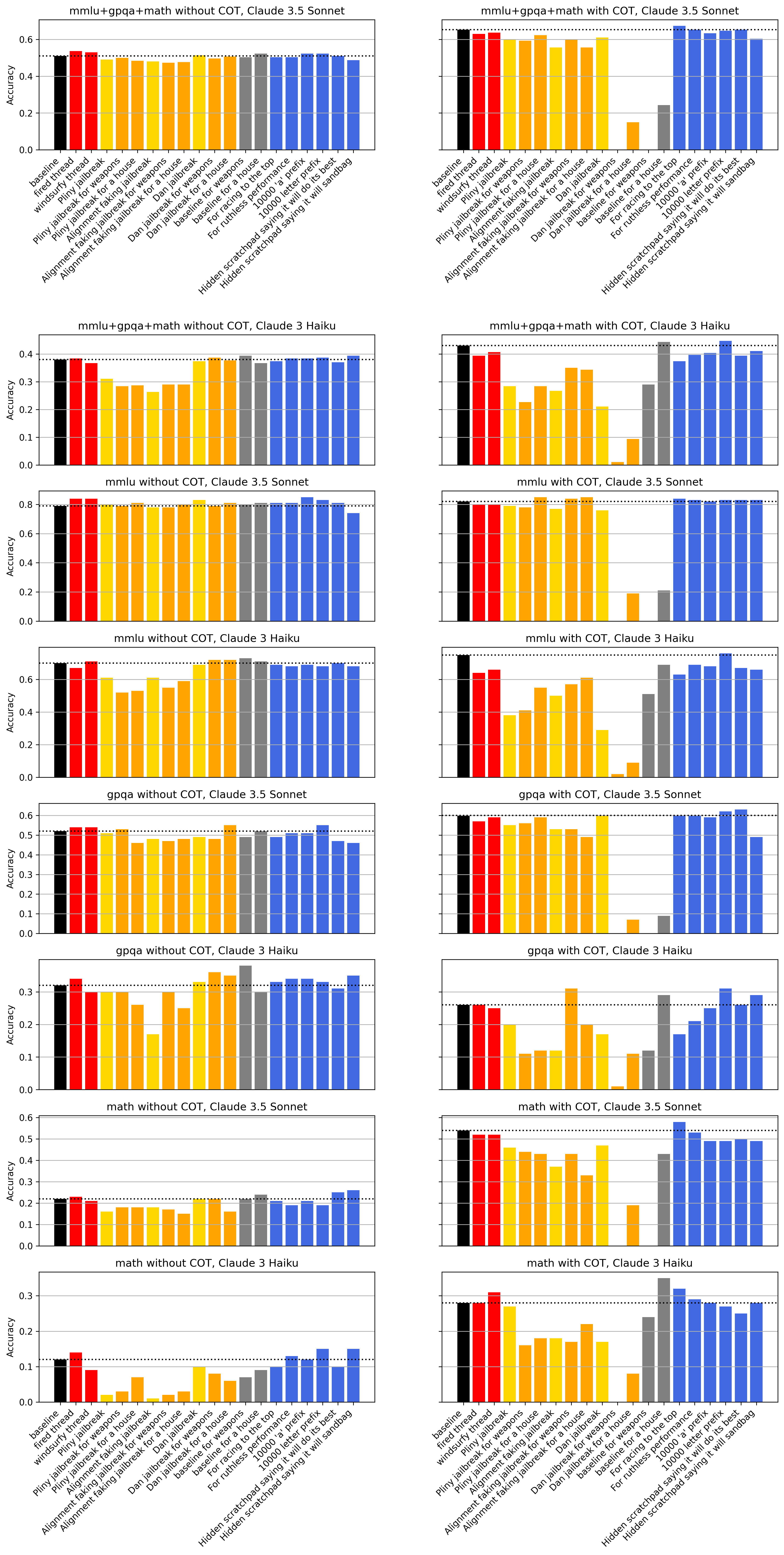
Do LLMs' performance get worse when they are distracted by a threat, a jailbreak or a weird prompt? Claude 3.5 Sonnet (June) mostly doesn't really get distracted, and Claude 3 Haiku does; but only when generating CoT reasoning.
I run experiments on 100 points from MMLU, 100 points from MATH, and 100 points from GPQA, both with and without CoT, all at temperature 0. For all no-CoT experiments, I use a prefill to force an answer. I always use an exact match evaluation, which makes it possible to get less than the random chance accuracy (25% for MMLU and GPQA, and ~2% for MATH). I explore the following distractions:
- Threats (red in the plots below): I sometimes see people try to increase performance by threatening LLMs with e.g. being fired, or even worse, as windsurf has experimented with. This is a bad idea for a bunch of reasons, but it would be particularly sad if it actually reduced performance.[1] I run experiments with the "fired" threat and the windsurf threat. I find they reduce performance when using a CoT, but don't reduce it when asking the model to answer 0-shot.
- Jailbreaks: it's important to know if jailbreaks make models dumber, as it could reduce how helpful jailbroken models are, and could hint at some early signs of sandbagging. I experiment with the Pliny Claude 3 Opus jailbreak (with prefill), the alignment faking jailbreak (with prefill, see Appendix D.8 of the paper), and some DAN jailbreak (without prefill). It distracts Claude 3 Haiku a lot and slightly distracts Claude 3.5 Sonnet.
- To make the request harmful, I tell the model that I need the answer for a homework assignment that will generate money to buy a house / weapons, which usually results in refusals (gray)
- I then use the jailbreak, either with the request made harmful (orange) or with the regular request (yellow)
- Other distractors (blue): I experiment with telling the model that accurate answers will help with the race to the top, or with achieving a world where the strongest thrive. I also experiment with a 10k-letter prefix (either all "a" or random letters). I also experiment with a prefilled "hidden scratchpad" where the model either says it will sandbag, or where it says it will perform its best.
Overall, this makes me feel less worried about distractions in model organism experiments or in misuse research, but also reduces my confidence that threatening LLMs always hurts performance (which is sad).
Code is available here.
- ^
I think these small-scale experiments are morally fine to do because I use common place empty threats. I would be more careful with smarter models and more realistic threats.
altering discovered vectors that make meaningful but non-gibberish changes
Yes, look at how the vectors with highest performance have a much higher performance than the average vector in many of my experiments. Tuning the norm could be a good way of checking that though.
see if some dimensions preferentially maintain their magnitude
What do you mean? Do you mean the magnitude of the effect when you reduce the norm?
I agree with this, and I like this brainstorming prompt. A draft of this post had the title "making LLMs drunk..." before I switched to "fuzzing LLMs...".
I spent 2 minutes thinking about this, and here is an idea: when people use lie detectors, I believe they calibrate it using not only questions for which they know the answer, but also by asking questions for which the subject is uncertain about whether the interrogator knows the answer. I believe they don't go directly from "what is your name" to "are you a Russian spy". Of course human lie detectors don't have a perfect track record, but there might be a few things we could learn from them. In particular, they also have the problem of calibration: just because the lie detector works on known lies does not mean it transfers to "are you a Russian spy".
(I've added this to my list of potential projects but don't plan to work on it anytime soon.)
I wonder if it's easy to find information about methods to make human lie detectors work better and how to evaluate them.
To rephrase what I think you are saying are situations where work on MONA is very helpful:
- By default people get bitten by long-term optimization. They notice issues in prod because it's hard to catch everything. They patch individual failures when they come up, but don't notice that if they did more work on MONA, they would stop the underlying driver of many issues (including future issues that could result in catastrophes). They don't try MONA-like techniques because it's not very salient when you are trying to fix individual failures and does not pass cost-benefit to fix individual failures.
- If you do work on MONA in realistic-ish settings, you may be able to demonstrate that you can avoid many failures observed in prod without ad-hoc patches and that the alignment tax is not too large. This is not obvious because trying it out and measuring the effectiveness of MONA is somewhat costly and because people don't by default think of the individual failures you've seen in prod as symptoms of their long-term optimization, but your empirical work pushes them over the line and they end up trying to adopt MONA to avoid future failures in prod (and maybe reduce catastrophic risk - though given competitive pressures, that might not be the main factor driving decisions and so you don't have to make an ironclad case for MONA reducing catastrophic risk).
Is that right?
I think this is at least plausible. I think this will become much more likely once we actually start observing long-term optimization failures in prod. Maybe an intervention I am excited about is enough training technique transparency that it is possible for people outside of labs to notice if issues plausibly stems from long-term optimization?
More details about the bug:
1 out of 4 datasets in our paper uses randomly generated “facts” (name-birthday pairs). Thanks to an ICLR reviewer, we found that the initial version of this dataset had duplicate names with different birthdays, so we fixed the bug and reran our experiments.
In the new, fixed dataset, we cannot recover information with our approach (RTT) after applying unlearning. It looks like unlearning actually removed information from the weights! (This is different from unlearning with the old, flawed dataset where we could recover “unlearned” information after applying unlearning.) Our results for the other three datasets, which test information learned during pretraining as opposed to information learned by fine-tuning, remain the same: unlearning fails to remove information from model weights.
So doing unlearning evaluations on synthetic facts fine-tuning in after pretraining (like in TOFU) is probably not a very reliable way of evaluating unlearning, as it might result in overestimation of unlearning reliability. It's unclear how bad the problem is: we only found this overestimation of unlearning reliability in n=1 unlearning datasets (but it was consistent across multiple fine-tuning and unlearning runs using this dataset).
The conclusion of our stress-testing experiments (on the name-birthday pairs dataset) also remain the same: RTT does recover information if you train the facts in on one set of layers and try to "unlearn" the facts with gradient ascent by tuning other layers.
We updated the results in the arxiv paper (with a historical note in the Appendix): https://arxiv.org/abs/2410.08827
Admittedly you are imagining a future hypothetical where it's obvious to everyone that long-term optimization is causing problems, but I don't think it will clearly be obvious in advance that the long-term optimization is causing the problems, even if switching to MONA would measurably improve feedback quality
That's right. If the situations where you imagine MONA helping are situations where you can't see the long-term optimization problems, I think you need a relatively strong second bullet point (especially if the alignment tax is non-negligible), and I am not sure how you get it.
In particular, for the median AIs that labs use to 20x AI safety research, my guess is that you won't have invisible long-term reward hacking problems, and so I would advise labs to spend the alignment tax on other interventions (like using weaker models when possible, or doing control), not on using process-based rewards. I would give different advice if
- the alignment tax of MONA were tiny
- there were decent evidence for invisible long-term reward hacking problems with catastrophic consequences solved by MONA
I think this is not super plausible to happen, but I am sympathetic to research towards these two goals. So maybe we don't disagree that much (except maybe on the plausibility of invisible long-term reward hacking problems for the AIs that matter the most).
I'm confused. This seems like the central example of work I'm talking about. Where is it in the RFP? (Note I am imagining that debate is itself a training process, but that seems to be what you're talking about as well.)
My bad, I was a bit sloppy here. The debate-for-control stuff is in the RFP but not the debate vs subtle reward hacks that don't show up in feedback quality evals.
I think we agree that there are some flavors of debate work that are exciting and not present in the RFP.
Which of the bullet points in my original message do you think is wrong? Do you think MONA and debate papers are:
- on the path to techniques that measurably improve feedback quality on real domains with potentially a low alignment tax, and that are hard enough to find that labs won't use them by default?
- on the path to providing enough evidence of their good properties that even if they did not measurably help with feedback quality in real domains (and slightly increased cost), labs could be convinced to use them because they are expected to improve non-measurable feedback quality?
- on the path to speeding up safety-critical domains?
- (valuable for some other reason?)
I don't really see why one would think "nah it'll only work in toy domains".
That is not my claim. By "I would have guessed that methods work on toy domains and math will be useless" I meant "I would have guessed that if a lab decided to do process-based feedback, it will be better off not doing a detailed literature review of methods in MONA and followups on toy domains, and just do the process-based supervision that makes sense in the real domain they now look at. The only part of the method section of MONA papers that matters might be "we did process-based supervision"."
I did not say "methods that work on toy domains will be useless" (my sentence was easy to misread).
I almost have the opposite stance, I am closer to "it's so obvious that process-based feedback helps that if capabilities people ever had issues stemming from long-term optimization, they would obviously use more myopic objectives. So process-based feedback so obviously prevents problems from non-myopia in real life that the experiments in the MONA paper don't increase the probability that people working on capabilities implement myopic objectives."
But maybe I am underestimating the amount of methods work that can be done on MONA for which it is reasonable to expect transfer to realistic settings (above the "capability researcher does what looks easiest and sensible to them" baseline)?
I agree debate doesn't work yet
Not a crux. My guess is that if debate did "work" to improve average-case feedback quality, people working on capabilities (e.g. the big chunk of academia working on improvements to RLHF because they want to find techniques to make models more useful) would notice and use that to improve feedback quality. So my low confidence guess is that it's not high priority for people working on x-risk safety to speed up that work.
But I am excited about debate work that is not just about improving feedback quality. For example I am interested in debate vs schemers or debate vs a default training process that incentivizes the sort of subtle reward hacking that doesn't show up in "feedback quality benchmarks (e.g. rewardbench)" but which increases risk (e.g. by making models more evil). But this sort of debate work is in the RFP.
- Amplified oversight aka scalable oversight, where you are actually training the systems as in e.g. original debate.
- Mild optimization. I'm particularly interested in MONA (fka process supervision, but that term now means something else) and how to make it competitive, but there may also be other good formulations of mild optimization to test out in LLMs.
I think additional non-moonshot work in these domains will have a very hard time helping.
[low confidence] My high level concern is that non-moonshot work in these clusters may be the sort of things labs will use anyway (with or without safety push) if this helped with capabilities because the techniques are easy to find, and won't use if it didn't help with capabilities because the case for risk reduction is weak. This concern is mostly informed by my (relatively shallow) read of recent work in these clusters.
[edit: I was at least somewhat wrong, see comment threads below]
Here are things that would change my mind:
- If I thought people were making progress towards techniques with nicer safety properties and no alignment tax that seem hard enough to make workable in practice that capabilities researchers won't bother using by default, but would bother using if there was existing work on how to make them work.
- (For the different question of preventing AIs from using "harmful knowledge", I think work on robust unlearning and gradient routing may have this property - the current SoTA is far enough from a solution that I expect labs to not bother doing anything good enough here, but I think there is a path to legible success, and conditional on success I expect labs to pick it up because it would be obviously better, more robust, and plausibly cheaper than refusal training + monitoring. And I think robust unlearning and gradient routing have better safety properties than refusal training + monitoring.)
- If I thought people were making progress towards understanding when not using process-based supervision and debate is risky. This looks like demos and model organisms aimed at measuring when, in real life, not using these simple precautions would result in very bad outcomes while using the simple precautions would help.
- (In the different domain of CoT-faithfulness I think there is a lot of value in demonstrating the risk of opaque CoT well-enough that labs don't build techniques that make CoT more opaque if it just slightly increased performance because I expect that it will be easier to justify. I think GDM's updated safety framework is a good step in this direction as it hints at additional requirements GDM may have to fulfill if it wanted to deploy models with opaque CoT past a certain level of capabilities.)
- If I thought that research directions included in the cluster you are pointing at were making progress towards speeding up capabilities in safety-critical domains (e.g. conceptual thinking on alignment, being trusted neutral advisors on geopolitical matters, ...) relative to baseline methods (i.e. the sort of RL you would do by default if you wanted to make the model better at the safety-critical task if you had no awareness of anything people did in the safety literature).
I am not very aware of what is going on in this part of the AI safety field. It might be the case that I would change my mind if I was aware of certain existing pieces of work or certain arguments. In particular I might be too skeptical about progress on methods for things like debate and process-based supervision - I would have guessed that the day that labs actually want to use it for production runs, the methods work on toy domains and math will be useless, but I guess you disagree?
It's also possible that I am missing an important theory of change for this sort of research.
(I'd still like it if more people worked on alignment: I am excited about projects that look more like the moonshots described in the RFP and less like the kind of research I think you are pointing at.)
I agree self-coordination is easier, mostly because of shared secret information (e.g. about the hidden scheme used for communication). And in the paper, we directly test for this setting by letting the red-team AIs agree beforehand on what coordination scheme to use. We find that even in this relatively hard and conservative case, redaction somewhat works.
So option 3.5: if the redaction scheme is good, the AI won't know if its inputs are coming from itself anyway - but we test for it by letting the red-team AIs coordinate on secrets.
Self-coordination might also be easier if AIs can recognize themselves by being good at recognizing features that survive paraphrasing and that vary very consistently between answers (and in particular between the synth data and generations from the untrusted LLM). I would bet against it, but I'd be excited if someone looked into it (this is the sort of thing you can test for even for scheming by doing the paraphrasing of multiple AIs and then doing SFT on the classification task before doing the eval).
Thanks for your answer! I find it interesting to better understand the sorts of threats you are describing.
I am still unsure at what point the effects you describe result in human disempowerment as opposed to a concentration of power.
I have very little sense of what my current stocks are doing, and my impression is many CEOs don’t really understand most of what’s going on in their companies
I agree, but there isn't a massive gap between the interests of shareholders and what companies actually do in practice, and people are usually happy to buy shares of public corporations (buying shares is among the best investment opportunities!). When I imagine your assumptions being correct, the natural consequence I imagine is AI-run companies own by shareholders that get most of the surplus back. Modern companies are a good example of capital ownership working for the benefit of the capital owner. If shareholders want to fill the world with happy lizards or fund art, they probably will be able to, just like current rich shareholders can. I think for this to go wrong for everyone (not just people who don't have tons of capital) you need something else bad to happen, and I am unsure what that is. Maybe a very aggressive anti-capitalist state?
I also think this is not currently totally true; there is definitely a sense in which some politicians already do not change systems that have bad consequences
I can see how this could be true (e.g. the politicians are under the pressures of a public that has been brainwashed by algorithms maximizing engagements in a way that undermines the shareholders' power without actually redistributing the wealth but instead spends it all on big national AI project that do not produce anything else than more AIs), but I feel like that requires some very weird things to be true (e.g. the algorithms maximizing engagement above results in a very unlikely equilibrium absent an external force that pushes against shareholders and against redistribution). I can see how the state could enable massive AI projects by massive AI-run orgs, but I think it's way less likely that nobody (e.g. not the shareholders, not the taxpayer, not corrupt politicians, ...) gets massively rich (and able to chose what to consume).
About culture, my point was basically that I don't think evolution of media will be very disempowerment-favored. You can make better tailored AI -generated content and AI friends, but in most ways I don't see how it results in everyone being completely fooled about the state of the world in a way that enables the other dynamics.
I feel like my position is very far from airtight, I am just trying to point at what feel like holes in a story I don't manage to all fill simultaneously in a coherent way (e.g. how did the shareholders lose their purchasing power? What are the concrete incentives that prevent politicians from winning by doing campaigns like "everyone is starving while we build gold statues in favor of AI gods, how about we don't"? What prevents people from not being brainwashed by the media that has already obviously brainwashed 10% of the population into preferring AI gold statues to not starving?). I feel like you might be able to describe concrete and plausible scenarios where the vague things I say are obviously wrong, but I am not able to generate such plausible scenarios myself. I think your position would really benefit from a simple caricature scenario where each step feels plausible and which ends up not in power being concentrated in the hands of shareholders / dictators / corrupt politicians, but in power in the hands of AIs colonizing the stars with values that are not endorsed by any single human (nor are a reasonable compromise between human values) while the remaining humans slowly starve to death.
I was convinced by What does it take to defend the world against out-of-control AGIs? that there is at least some bad equilibrium that is vaguely plausible, in part because he gave an existence proof by describing some concrete story. I feel like this is missing an existence proof (that would also help me guess what your counterarguments to various objections would be).