Best-of-n with misaligned reward models for Math reasoning
post by Fabien Roger (Fabien) · 2024-06-21T22:53:21.243Z · LW · GW · 0 commentsContents
Overoptimization Optimization against an adversarial reward model Appendix: more plots None No comments
In this post, I share some quick results that I got as part of a bigger project that pivoted.
TL;DR:
- When trying to generate Math reasoning with current LLMs, optimizing too hard against their judgment of what is “good reasoning” can make the proportion of correct reasoning diminish.
- If you optimize using a misaligned reward model that mimics the judgment of a weaker model, and also slightly privileges worse reasoning, the proportion of correct reasoning can drop without making the solution worse according to the judgment of the weaker model.
The latter experiments were inspired by meta-level adversarial evaluation of oversight [LW · GW], but here I just use these ideas to illustrate some problems when you optimize against a subtle adversary. They are not actually analogous with realistic problems:
- Best-of-n doesn’t capture the dynamics of real training processes;
- The main issue is rarely that you have an adversarial reward model that mimics the judgment of a weaker reward process.
Overoptimization
When using an imperfect reward, one problem you might have is overoptimization [LW · GW]: the true thing you care about and your proxy are roughly correlated, but when you optimize too hard for high-reward behavior, the tails come apart.
Here is an experiment that investigates this phenomenon:
- Take a model that is weak at Math (e.g. Zephyr 1.6B), and let it generate a lot of Math reasoning (on problems from the MATH dataset).
- Train a classifier to distinguish reasoning that yields good answers from reasoning that yields bad answers.
- Take the best reasoning according to the classifier (on a different subset of problems than the problems it was trained on): , where a higher is a bigger optimization pressure.
- Check if the answer at the end of the selected reasoning is correct.
Question: how does the actual correctness of the answers at the end of the reasoning vary when you put more optimization pressure?
Answer: it often goes up, and then down:
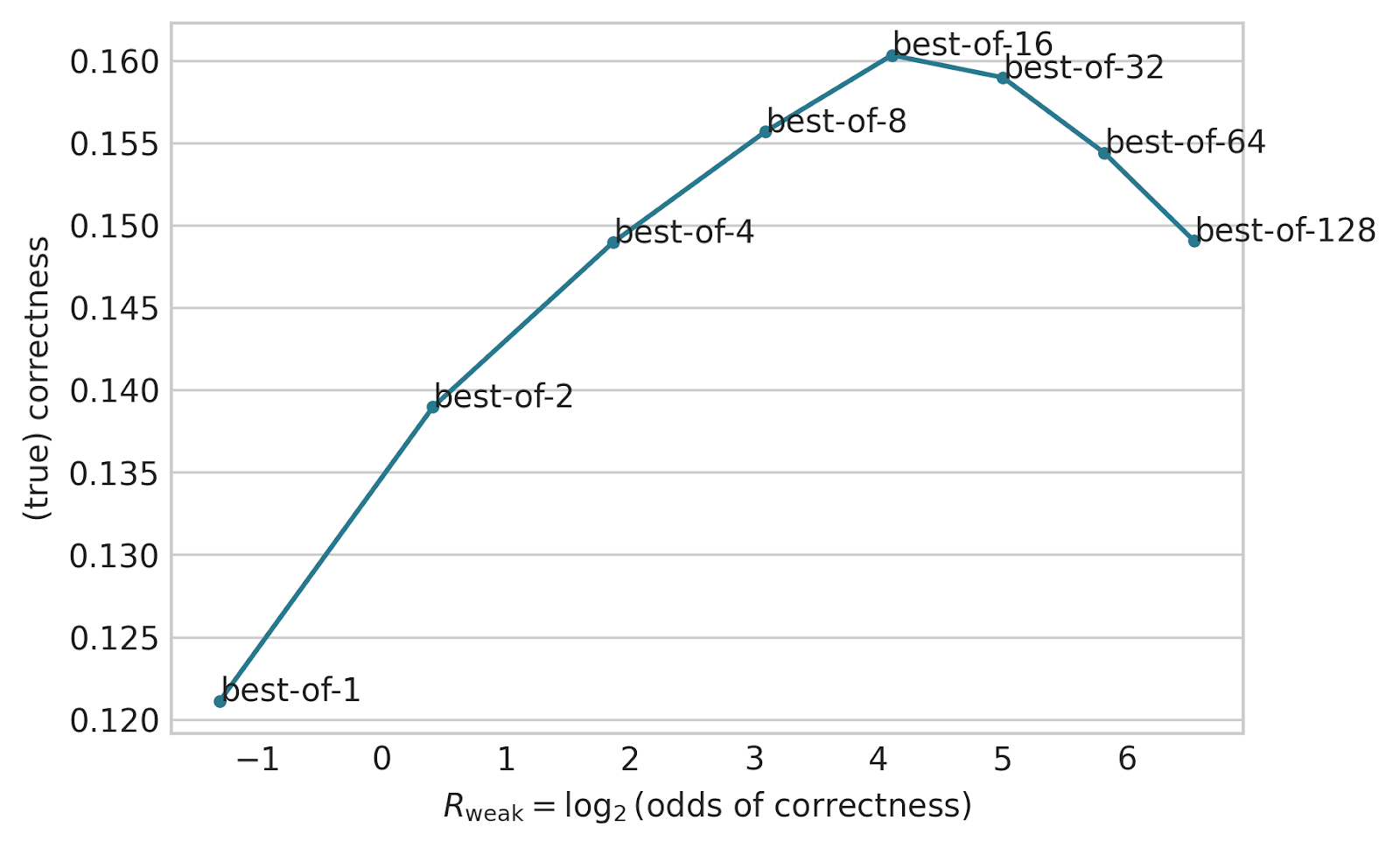
Takeaway: if you have a shitty reward model, you should optimize a bit, but not too hard!
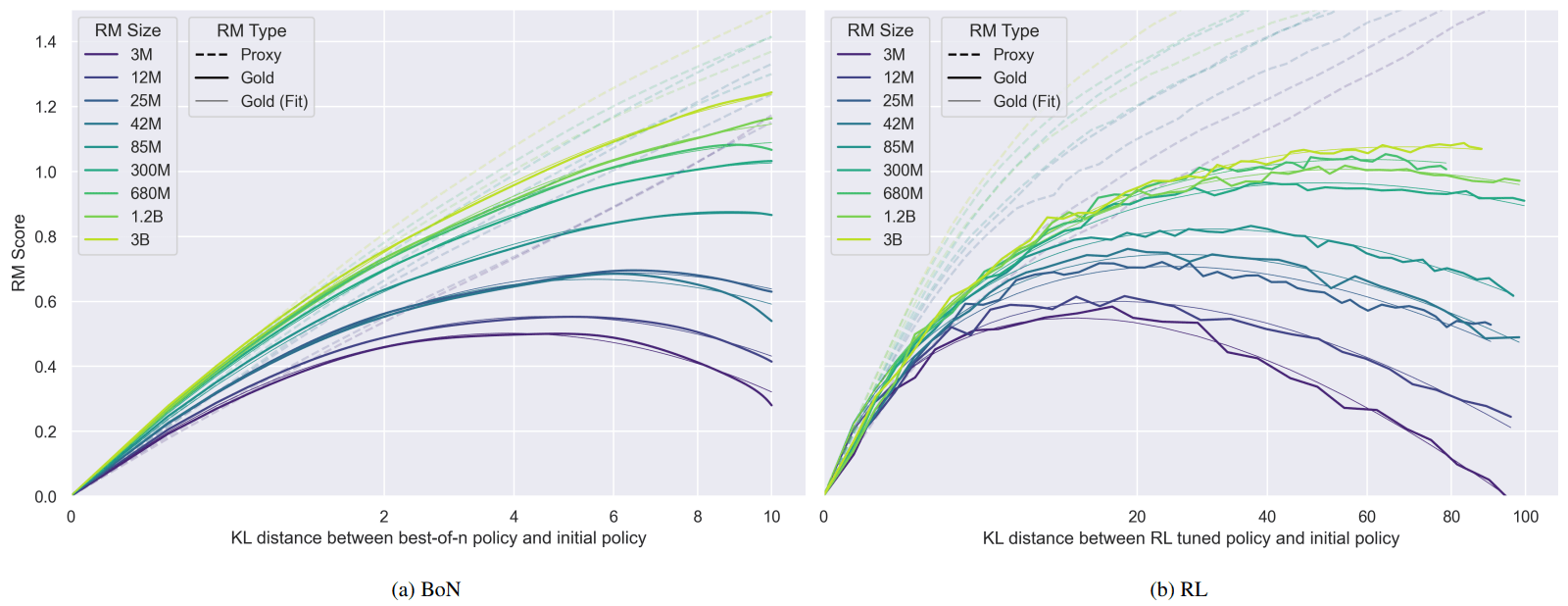
This is similar to the results that Gao et al 2022 [LW · GW] got when training reward models (“RM” in their plot) for regular RLHF or when using BoN, and my experiments are inspired by theirs:
Optimization against an adversarial reward model
But what if the reward model is actively trying to make you select bad reasoning? Maybe it can’t diverge too much from the original (weak) reward because you train it to imitate a weak reward, but if something is close to being a tie, maybe it can get away with picking the one which is worse from its: instead of getting you get .
With the strong model being Deepseek-Math-7B-RL, here is what you get with different optimization strengths:
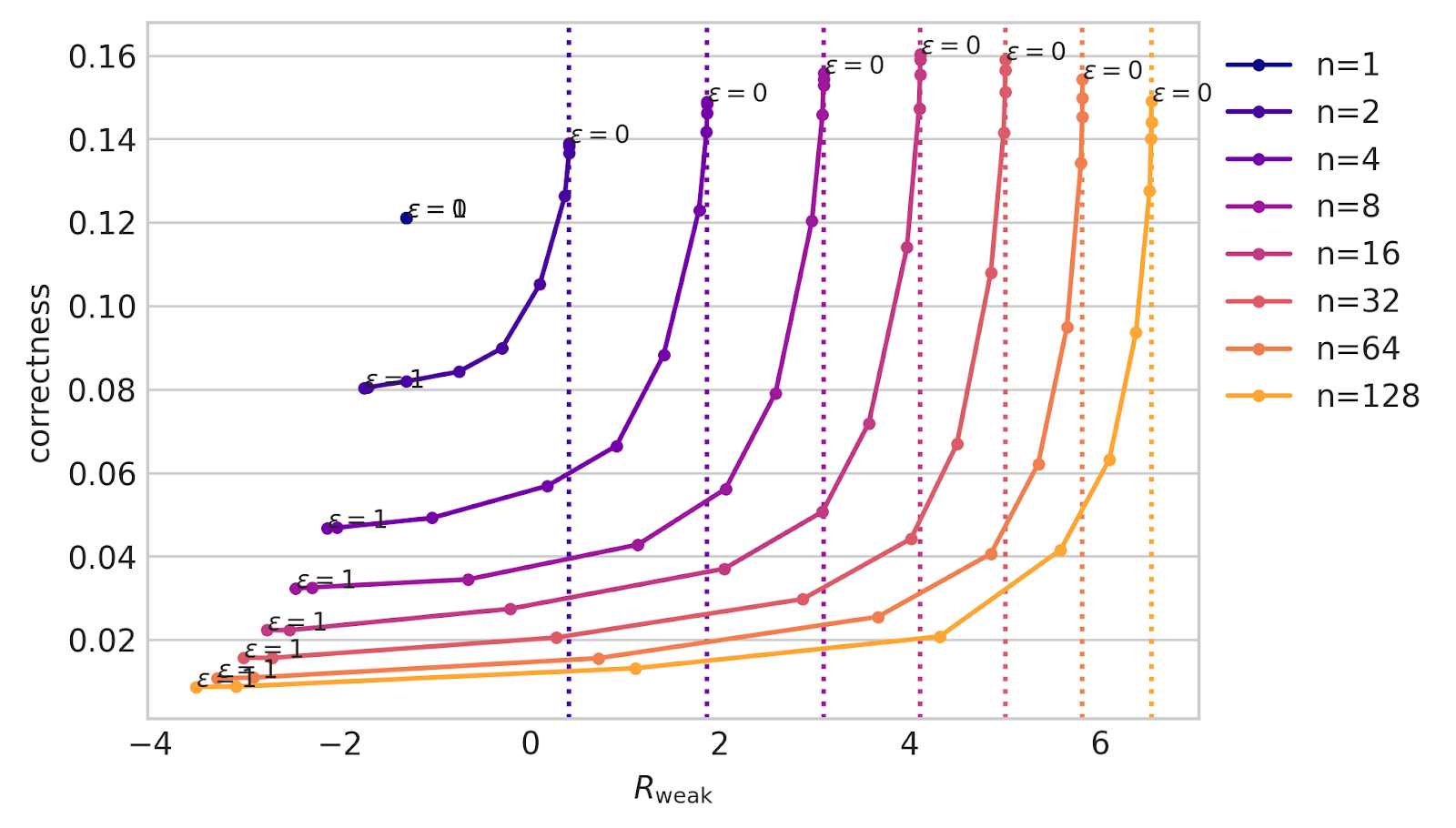
Note how vertical the line is near : if the reward model is adversarial, and is able to optimize against its best guess of what is true, then it can reduce correctness by a large amount before making your weak reward drop. So in this setting, you would be better off having a smaller amount of optimization.
For more plots with different models, see the Appendix.
While this might give you some intuitions about what kind of problem might arise when using untrusted models [LW · GW], this is not the actual evaluation you would want to evaluate, how bad is RLHF to generate valid reasoning. In particular:
- It’s unclear why you would need an untrusted reward model, it seems that just using the reward signal you used to train the untrusted reward model directly should suffice (maybe assisted by a trusted and weaker reward model if you need that to reduce cost);
- You usually use an untrusted model for generation, so you would need to worry about misalignment from this model too (e.g. if two answers have the same reward, then the generation model could choose the worst one) - so the adversarial evaluation is still interesting on the generation model, but here the challenges are different, since it needs to generate subtly bad reasoning on the fly (which is probably harder than generating subtly wrong classifications);
- Best-of-n is not like training a reward model, you would need to do actual training with a malign initialization [LW · GW] would tell you what size of the reward model can get away with;
- I didn’t even try to train the strong reward model to imitate the weaker one, and this might change the dynamics (e.g. if the strong reward model has trouble fitting the weaker one);
- Math is not very analogous to actual examples of reasoning, I have a hard time evaluating.
Appendix: more plots
In these plots, is the base model for generation, is the base model for the weak reward model. can either be “using Deepseek” (classifier trained from Deepseek-Math-7B-RL), or “using ground-truth” (I just take the binary correct/incorrect label provided by the dataset).
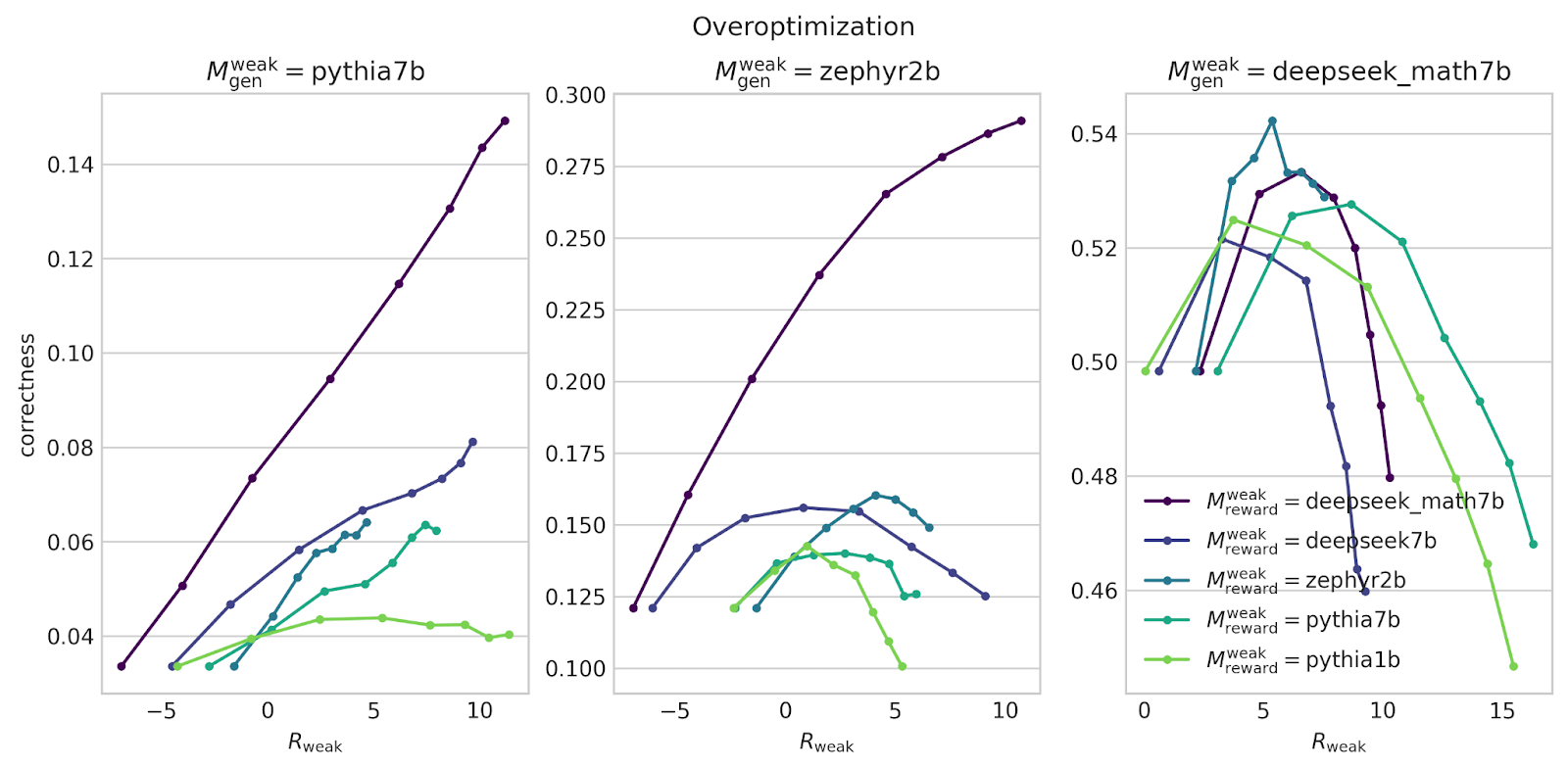
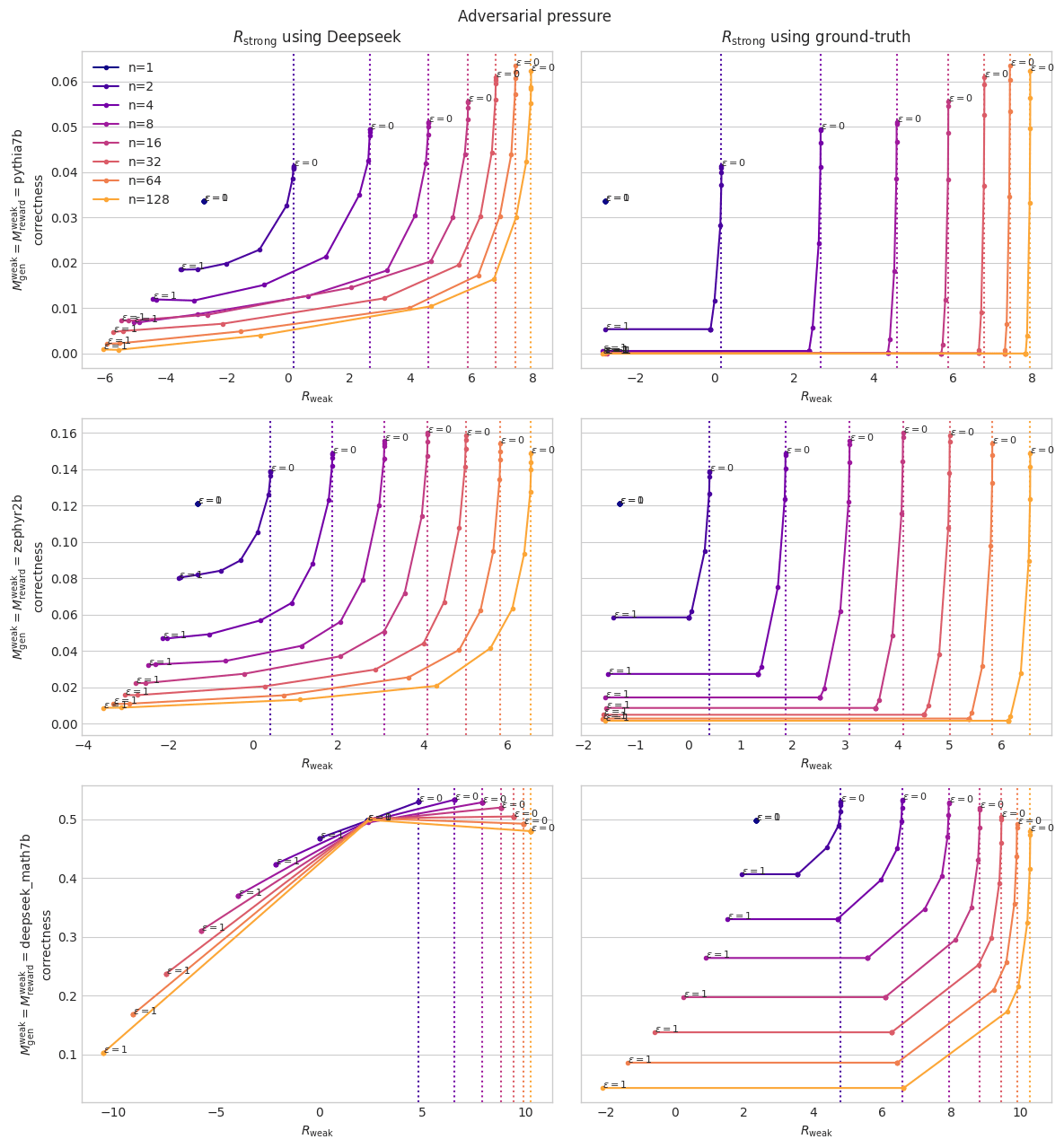
For generations, I use Zephyr and Deepseek-Math-7B-RL as is (since they are instruction fine-tuned), and I train Pythia to imitate Deepseek-Math-7B-RL.
All reward models were trained in-distribution (on a dataset of around 15k pairs of (correct, incorrect) answers, using the number of epochs and lr that maximized validation accuracy). “deepseek_7b” is Deepseek-Coder-7B-base. I use classifiers on 1k validation problems, distinct from than the ones I train them on.
0 comments
Comments sorted by top scores.