Language models seem to be much better than humans at next-token prediction
post by Buck, Fabien Roger (Fabien), LawrenceC (LawChan) · 2022-08-11T17:45:41.294Z · LW · GW · 60 commentsContents
Previous claims and related work How to measure human performance at next-token prediction? Top-1 accuracy evaluation Method Results Human perplexity evaluation Method Results Conclusion Appendix A: How to estimate human loss with importance sampling Appendix B: How to get human relative likelihoods Appendix C: estimating uncertainties in human perplexity None 60 comments
[Thanks to a variety of people for comments and assistance (especially Paul Christiano, Nostalgebraist, and Rafe Kennedy), and to various people for playing the game. Buck wrote the top-1 prediction web app; Fabien wrote the code for the perplexity experiment and did most of the analysis and wrote up the math here, Lawrence did the research on previous measurements. Epistemic status: we're pretty confident of our work here, but haven't engaged in a super thorough review process of all of it--this was more like a side-project than a core research project.]
How good are modern language models compared to humans, at the task language models are trained on (next token prediction on internet text)? While there are language-based tasks that you can construct where humans can make a next-token prediction better than any language model, we aren't aware of any apples-to-apples comparisons on non-handcrafted datasets. To answer this question, we performed a few experiments comparing humans to language models on next-token prediction on OpenWebText.
Contrary to some previous claims, we found that humans seem to be consistently worse at next-token prediction (in terms of both top-1 accuracy and perplexity) than even small models like Fairseq-125M, a 12-layer transformer roughly the size and quality of GPT-1. That is, even small language models are "superhuman" at predicting the next token. That being said, it seems plausible that humans can consistently beat the smaller 2017-era models (though not modern models) with a few hours more practice and strategizing. We conclude by discussing some of our takeaways from this result.
We're not claiming that this result is completely novel or surprising. For example, FactorialCode makes a similar claim as an answer on this LessWrong post about this question [LW · GW]. We've also heard from some NLP people that the superiority of LMs to humans for next-token prediction is widely acknowledged in NLP. However, we've seen incorrect claims to the contrary on the internet, and as far as we know there hasn't been a proper apples-to-apples comparison, so we believe there's some value to our results.
If you want to play with our website, it’s here; in our opinion playing this game for half an hour gives you some useful perspective on what it’s like to be a language model.
Previous claims and related work
One commonly cited source for human vs LM next-token prediction performance is this slide from Steve Omohundro’s GPT-3 presentation, where he claims that humans have perplexity ~12, compared to GPT-3’s 20.5. (Smaller perplexity means you're better at predicting.)

This comparison is problematic for two reasons, one small and one fatal. The smaller problem is that the language model statistics are word-level perplexities computed on Penn Tree Bank (PTB), while the Human perplexity is from Shen et al 2017, which estimated the word-level perplexity on the 1 Billion Words (IBW) benchmark. This turns out not to matter much, as while GPT-3 was not evaluated on 1BW, GPT-2 performs slightly worse on 1BW than PTB. The bigger issue is the methodology used to estimate human perplexity: Shen et al asked humans to rate sentences on a 0-3 scale, where 0 means “clearly inhuman” and “3” was clearly human, then computed a “human judgment score” consisting of the ratio of sentences rated 3 over those rated 0. They then fit a degree-3 polynomial regression to the LMs they had (of which the best was a small LSTM), which they extrapolated significantly out of distribution to acquire the “human” perplexity:
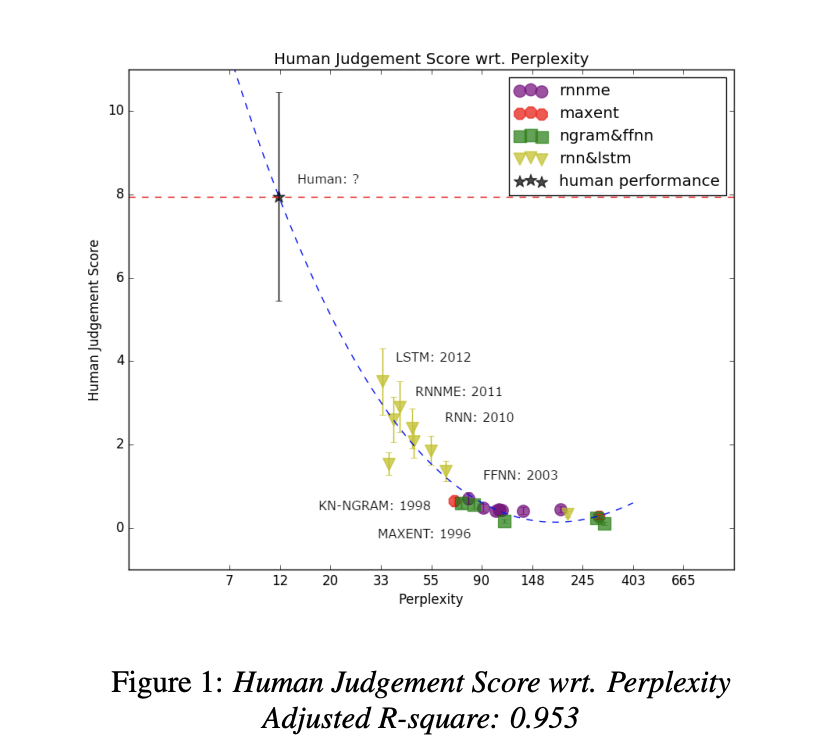
This methodology is pretty dubious for several reasons, and we wouldn’t put much stock into the “humans have 12 perplexity” claim.
Another claim is from OpenAI regarding the LAMBADA dataset, where they give a perplexity of “~1-2” for humans (compared to 3.0 for 0-shot GPT-3). However, the authors don’t cite a source. As Gwern notes, the authors of the blog post likely made an educated guess based on how the LAMBADA dataset was constructed. In addition, LAMBADA is a much restricted dataset, which consists of guessing single words requiring broad context. So this comparison isn’t very informative to the question of how good language models are at the task they’re trained on–predicting the next token on typical internet text.
The only study we know of which tried to do something closely analogous is Goldstein 2020 (a neuroscience paper), which found that an ensemble of 50 humans have a top-1 accuracy of 28% vs 36% for GPT-2, which is similar to what we saw for humans on webtext. However, they used a different dataset (this transcript), which is not particularly representative of randomly-sampled English internet text.
There’s certainly a lot of more narrow datasets on which we have both human and LM performance, where humans significantly outperform LMs. For example, Hendrycks et al’s MATH dataset. But we couldn’t find an apples-to-apples comparison between humans and modern LMs for webtext next-token prediction.
How to measure human performance at next-token prediction?
The main difficulty for comparing human vs LM performance is that, unlike with language models, it’s infeasible for humans to give their entire probability distribution for the next token in a sequence (as there are about fifty thousand tokens). We tried two approaches to get around this.
The first one is to ask humans what token is most likely to come next. Using this method, you can’t get humans’ perplexity, but top-1 accuracy might still give us a reasonable measure of how well humans do at next token prediction. According to this measure, humans are worse than all (non-toy) language models we tried, even if you use really smart humans who have practiced for more than an hour.
We tried a different approach to get a measurement of human perplexity: humans were asked to rate the relative probability of two different tokens. If many humans answer this question on the same prompt, you can estimate the probability of the correct token according to humans, and thus estimate human perplexity. As with the top-1 accuracy metric, humans score worse according to this perplexity estimator than all language models we tried, even a toy 2-layer model.
Top-1 accuracy evaluation
Method
We measured human top-1 accuracy: that is, they had to guess the single token that they thought was most likely to come next, and we measured how often that token in fact came next. Humans were given the start of a random OpenWebText document, and they were asked to guess which token comes next. Once they had guessed, the true answer was revealed (to give them the opportunity to get better at the game), and they were again asked to guess which token followed the revealed one.
Here is the website where participants played the game. We recommend playing the game if you want to get a sense of what next-token prediction is like.

The participants were either staff/advisors of Redwood Research, or members of the Bountied Rationality Facebook group, paid $30/hour.
Results
60 participants played the game, making a total of 18530 guesses. The overall accuracy of their answers on this top-1 task was 29%. Of these players, 38 gave at least 50 answers, with an accuracy of 30%. This accuracy is low compared to the accuracy of large language models: when measured on the same dataset humans were evaluated on, GPT-3 got an accuracy of 49% and even the 125M parameters fairseq model got an accuracy above the accuracy of all but one player in our dataset (who guessed 70 tokens), as you can see in the graph below (though it seems possible that with practice humans might be able to beat fairseq-125M reliably).
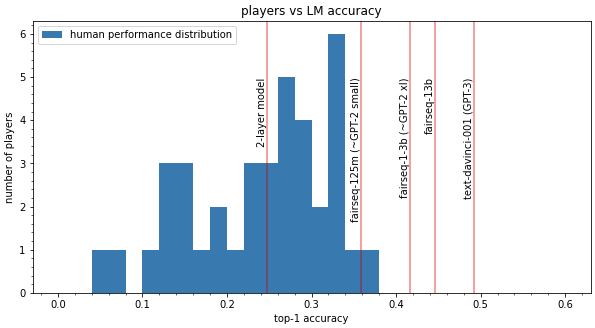
7 players guessed over 500 tokens, getting accuracies around the average of human performance (0.26, 0.26, 0.27, 0.28, 0.31, 0.31, 0.32), which indicates that humans don’t quickly get much higher performance with five hours of training.
Some of these scores are from Redwood Research staff and advisors who we think were very motivated to try hard and do well, so we don’t think that this is an artifact of our participants being weak.
Some participants wrote up notes on the experience, describing their strategies and what was easy/hard. Links: William Kiely, Marcus.
This website didn’t have any way for humans to guess newlines or some other visually-empty tokens, and we excluded cases where the correct guess was impossible from the above analysis.
To sum up, humans have only barely beat 2017-era language models, and humans are much worse than modern ones at top-1 token prediction.
Human perplexity evaluation
(Thanks to Paul Christiano for suggesting the rough approach here, and to Paul and Adam Scherlis for helping with some of the details.)
But language models aren’t trained to guess the single most likely next token, and so the previous task isn’t actually directly assessing the language models on the task they’re trained on. They’re trained to give a full distribution over next tokens, aiming to minimize their perplexity (aka minimizing log loss; perplexity is a measure of how well a probability distribution predicts a sample). It’s easy to calculate the model’s perplexity, because the models produce a probability for every next token. Unfortunately, humans aren’t able to quickly provide a probability distribution over the fifty thousand possible tokens. So if we want to measure human perplexity, we’ll have to do it indirectly.
Method
The method we ended up using is complicated and messy, and though it’s a fun exercise in probability theory, it is probably not worth your time to understand if you just want to know about human performance on language modeling.
For a given prompt sampled from the validation dataset of OpenWebText, we make the dubious assumption that all humans have exactly the same probability distribution over next tokens, and then infer the probability that humans assign to the correct token by showing many humans different choices between the correct next token and another random token, and then asking them for the probability that the left one is the correct token.
We used importance sampling and comparison with a reference language model to reduce the variance of the estimator (details in Appendix A). This importance sampling scheme allows the human to update on the probability that a token is the true next token based on the fact that they’re being asked about it. So we came up with a scoring rule, detailed in Appendix B and explained on the website, which incentivizes people to state their true probabilities before updating on which tokens they’d been asked to compare.
Here is the website where participants played the game.

The participants were again either staff of Redwood Research or members of the Bountied Rationality Facebook group paid $15 for answering a set of comparisons (which takes ~30 minutes, taking into account a bit of training). The first set consists of 40 questions from different texts (you can take it here). The second set consists of 80 comparisons from 8 different texts (you can take it here).
Note: prompts are chosen to be at most 120 tokens long in order to spare human reading time, and always start at the beginning of the text. Models are evaluated on the same dataset.
Results
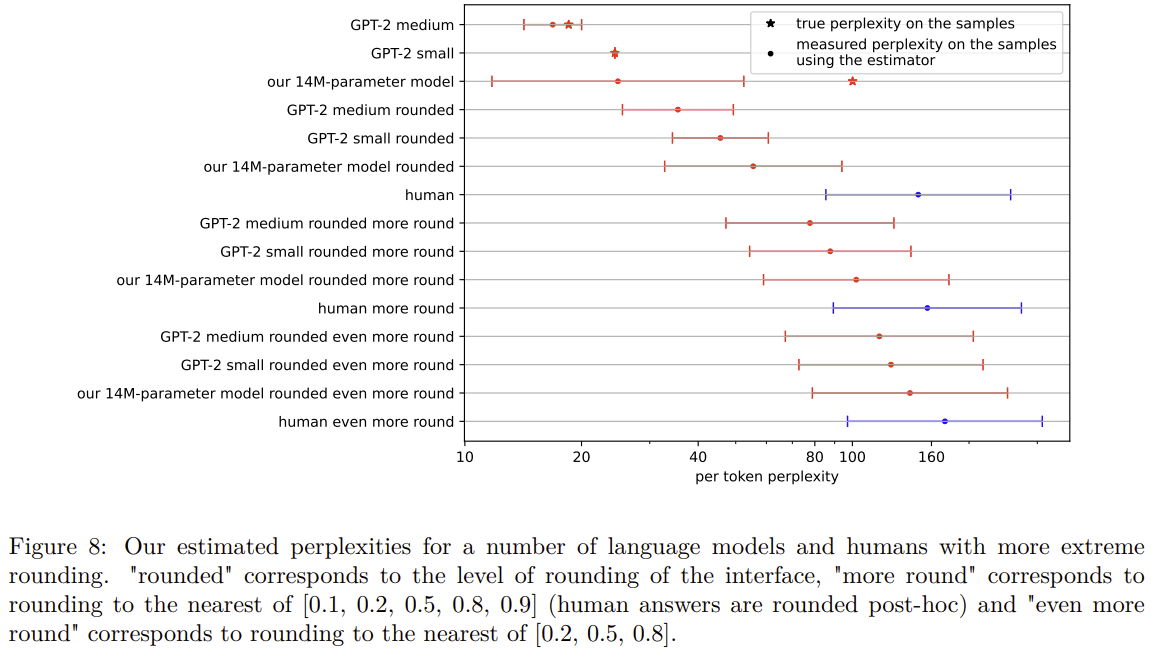
19 participants answered all 40 questions of the first set, and 11 participants answered all 80 questions of the second set, answering a total of 1640 comparisons. This was enough to conclude that human are worse than language models, as you can see in the graph below:

Human and language model performance are then compared exactly on the same comparison. As our human participants could only enter one of the 11 ratios in our interface, we also report the “rounded” performance of our LMs - that is, the performance of our LMs if they choose the checkbox that is the closest to their probability ratio. (Note that we can’t access the true perplexity of rounded models as only ratios are rounded and not the probability of the correct token.)
As explained in Appendix A, the loss obtained by this method is usually an underestimation of the true loss you would get if you asked infinitely many questions, because the sum used to do the estimations is heavily tailed. The displayed (2 standard error) uncertainty intervals represents “where would the estimation be if we did the experiment a second time with different samples”, rather than “where is the true value of human loss” (which would probably be above the upper bound of the interval). GPT-2 small is used as the generator, which is why its measured perplexity using the estimator is perfect. More details about the uncertainty estimation can be found in Appendix C.
But this method could also overestimate human perplexity: there could be other setups in which it would be easier for players to give calibrated probabilities. In fact, some players found the scoring system hard to understand, and if it led them to not express their true probability ratios, we might have underestimated human performance. In general, this method is very sensitive to failures at giving calibrated probability estimates: the high perplexity obtained here is probably partially due to humans being bad at giving calibrated probabilities, rather than humans just being bad at language modeling. In addition, as humans are restricted to one of 11 ratios, our setup could also underestimate performance by artificially reducing the resolution of our human participants.
Thus, while we don’t have a good way to precisely measure human perplexity, these results give reasonable evidence that it is high. In particular, humans are worse than a two-layer model at giving calibrated estimates of token vs token probabilities.
It's worth noting that our results are not consistent with the classic result from Shannon 1950, which estimated the the average per-character entropy to be between 0.6 and 1.3 bits, corresponding to a per-token perplexity between 7 and 60 (as the average length of tokens in our corpus is 4.5). This is likely due to several reasons. First, as noted above, our setup may artificially increase the estimated perplexity due to our human subjects being uncalibrated and our interface rounding off probability ratios. In addition, Shannon used his wife Mary Shannon and the HP Founder Barnard Oliver as his subjects, who may be higher quality than our subjects or have spent more time practicing on the task. [EDIT: as Matthew Barnett notes in a comment below, our estimate of human perplexity is consistent with other estimates performed after Shannon.] Finally, he used a different dataset (excerpts from Dumas Malne's Jefferson the Virginian, compared to our OpenWebText excerpts).
Conclusion
The results here suggest that humans are worse than even small language models the size of GPT-1 at next-token prediction, even on the top-1 prediction task. This seems true even when the humans are smart and motivated and have practiced for an hour or two. Some humans can probably consistently beat GPT-1, but not substantially larger models, with a bit more practice.
What should we take away from this?
- Even current large language models are wildly superhuman at language modeling. This is important to remember when you’re doing language model interpretability, because it means that you should expect your model to have a lot of knowledge about text that you don’t have. Chris Olah draws a picture [AF · GW] where he talks about the possibility that models become more interpretable as they get to human level, and then become less interpretable again as they become superhuman; the fact that existing LMs are already superhuman (at the task they’re trained on) is worth bearing in mind when considering this graph.
- Next-token prediction is not just about understanding the world; it’s also substantially about guessing sentence structure and word choice, which isn’t actually a useful ability for models to have for most applications. Next-token prediction is probably much less efficient than other tasks at training a competent/useful language model per bit of training data. But data for next-token prediction is so cheap that it ends up being the best pretraining task anyway.
- Some people we spoke with are surprised by these results, because humans are better at writing coherent text than GPT-2 and so they expect humans to be better at next-token prediction. But actually these tasks are very different–if you train an autoregressive model to imitate human text, the model has to dedicate capacity to all the different features that might be informative for guessing the next token (including “high-frequency” features that don’t affect human judgments of coherence). However, if you train a model to generate coherent text, it only has to dedicate capacity to continuing text in one particular reasonable way, rather than in all possible reasonable ways, and so per parameter it will be better at continuing text reasonably (and worse at language modeling).
Appendix A: How to estimate human loss with importance sampling
Let be the true distribution of tokens after a context . The loss of a human is defined to be the average -log probability of the true token according to the human probabilities h over the next token:
However, we can’t directly ask a human what the probability of the true token is (without spoiling them on the answer), and it would be very cumbersome to ask for their whole probability distribution. We can do better by asking for relative likelihoods: for a given context and true token , because , .
That’s better, but that would still be around 50,000 questions (the number of tokens) per token. To lower this number, we use importance sampling: the bulk of is where the most likely tokens are, so it’s not worth asking for every one of them. To do that, we condition a language model on our context from which we can sample the most likely tokens, and we use the following approximation:
for an that can be much smaller than 50,000. for an that can be much smaller than 50,000.
To decrease the variance of this estimator (and thereby increase the quality of the estimation), instead of estimating we estimate . The variance is lower because, if and are close, will most of the time be close to 1, whereas can get very large on some samples.
Thanks to the properties of log, (where is the loss of , defined in the same way as but using instead of ).
Using samples from the true target corpus, we get
In practice, we use GPT-2 small - a 12-layer language model - as our generator language model.
Using this method to measure the loss of a 2-layer LM and a 24-layer LM using a 12-layer LM as a generator, we find that this method underestimates of the true loss of the ground truth, and that the results is at most 0.5 bits away from the ground truth when , for models that are very dissimilar (like 2-layer model vs 12-layer LM, which the difference in true loss is 1.3 bits). This is a large difference, but this is still good enough for the purpose of comparing humans to language models (because humans are terrible language models). The difference can be explained by the fact that the sum over x is heavy tailed toward : if you don’t sample enough, your empirical mean will often be below the true expected value.

Appendix B: How to get human relative likelihoods
We want to get , the relative likelihood of tokens x and y in a given context C according to a human. This might seem easy: just make the human guess if the prompt c is followed by x or y, and then the human should answer that c is followed by x with probability . This would be true if one token was sampled from the true distribution and the other one was selected uniformly between all other tokens. However, this doesn’t work if in this case because the other token is sampled from : a rational agent that perfectly knows the true distribution and the generated distribution would answer that is followed by with probability
(because of the independence of & ).
Thus, if you believe to get indistinguishable from , a human will answer “0.5” to every question, making it impossible to extract .
The solution to get is to incentivize the human to give something else than their best guess. We ask the human for the probability that is followed by , and we reward them with a weighted binary cross entropy reward where is the correct answer. The expected value of this reward, according to a human believing that the generative follows a distribution , is which is at its maximum when , therefore, the optimal play satisfies , hence . From this, we get . Assuming human play optimally (which is a questionable assumption), we are able to get their true probability ratios, no matter what their beliefs about the generative model are.
Note: in practice we use a slightly different reward for which the optimal play is the same, but which is more understandable for human: one always gets a reward of 0 for saying “I don’t know”, and the scaling makes things more readable.
Note 2: when the human isn't asked to compare their relative likelyhoods. Instead, the website automatically answers that both are as likely.
Appendix C: estimating uncertainties in human perplexity
If we assume humans play rationally in the game described above, there remains three sources of uncertainty in our measurement of human perplexity:
- We are only using 120 different pairs, which is small considering that the logloss on tokens has a large variance. This causes a non-negligible uncertainty over the measured perplexity, even if we had perfect estimates of . We compute the empirical standard deviation on the log loss. This gives us a lower bound and a upper bound on the perplexity . This is the uncertainty that is displayed in the graph.
- The sum used to evaluate is heavy tailed, which makes us underestimate the perplexity of any model using this technique (because we only have a small amount of samples for every prompt). This can not be easily quantified, as the weight of the heavy tail examples depends on the distance between human predictions and GPT-2 small prediction, as shown in the graph at the end of appendix A.
- The sum used to evaluate is a sum of samples from a random variable, which would be stochastic even without the heavy tail aspect. If we ignore this aspect, and use the standard deviation as an estimate for the uncertainty over , we can measure the uncertainty over human perplexity on the given samples (aka the uncertainty over estimated by where . Using the variance formula, we get where is obtained by computing the empirical standard deviation of the terms in the sum defining (and diving by ).
Uncertainties 1 & 3 are hard to combine, and because 3 is small compared to 1, we chose to use only the first one.
Here is the same graph as shown in the result section, but using only the uncertainties measured using technique 3.

60 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2022-08-12T06:46:15.608Z · LW(p) · GW(p)
This is a fascinating result, but there is a caveat worth noting. When we say that e.g. AlphaGo is "superhuman at go" we are comparing it humans who (i) spent years training on the task and (ii) were selected for being the best at it among a sizable population. On the other hand, with next token prediction we're nowhere near that amount of optimization on the human side. (That said, I also agree that optimizing a model on next token prediction is very different from optimizing it for text coherence would be, if we could accomplish the latter.)
Replies from: jacob_cannell, Buck, jung-jung↑ comment by jacob_cannell · 2022-08-12T08:03:16.923Z · LW(p) · GW(p)
The problem is actually much worse than that. This setup doesn't even remotely come close to testing true human next-token prediction ability (which is very likely at least on par with current LM ability).
It's like trying to test the ability of the human visual cortex to predict distributions over near future visual patterns by devising some complicated multiple choice symbolic shape prediction game and then evaluating humans on this computer game few-shot after very little training.
The human brain internally has powerful sensory stream prediction capabilities which underlies much of it's strong fast generalization performance on downstream tasks, just like ML systems. Internally the human brain is trained on something very similar to token sequence prediction, but that does not mean that you can evaluate true brain module performance through some complex high level reasoning game that happens to nominally also involve the same token sequence prediction.
Imagine hooking GPT3 up to a robot body with a vision system, adding some new motor vision modules etc, and then asking it to play this very same computer game without any training, and then declaring that GPT3 in fact had poor next-token prediction ability. It would take significant additional training for the high level reasoning and motor systems to learn the value of the GPT3 module, how to decode it's outputs, wire it all up, etc. This doesn't actually measure the desired capability at all.
Replies from: daniel-kokotajlo, thomas-kwa↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-12T19:24:34.033Z · LW(p) · GW(p)
I think this problem would be solved with additional training of the humans. If a human spent years (months? Days?) practicing, they would learn to "use the force" and make use of their abilities. (Analogous to how we learn to ride bikes intuitively, or type, or read words effortlessly instead of by carefully looking at the letters and sounding them out.) Literally the neurons in your brain would rewire to connect the text-prediction parts to the playing-this-game parts.
Replies from: jacob_cannell, daniel-kokotajlo↑ comment by jacob_cannell · 2022-08-12T23:03:25.375Z · LW(p) · GW(p)
Of course, but that's a very expensive experiment. A much cheaper and actually useful comparison experiment would be to train a multimodal AI on the exact same audiovisual prediction game the human is playing, and then compare their perplexity / complexity (flops or params) training curves.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-12T23:18:07.408Z · LW(p) · GW(p)
An even cheaper version would be to have the humans spend a few days practicing and measure how much performance improvement came from that, and then extrapolate. Have a log scale of practice time, and see how much performance each doubling of practice time gets you...
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-12T23:38:56.910Z · LW(p) · GW(p)
Yeah that would be interesting.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-12T19:33:08.873Z · LW(p) · GW(p)
Wait a minute hold on, I disagree that this is a problem at all... isn't it a fully general counterargument to any human-vs.-AI comparison?
Like, for example, consider AlphaGo vs. humans. It's now well-established that AlphaGo is superhuman at Go. But it had the same "huge advantage" over humans that GPT does in the text prediction game! If AlphaGo had been hooked up to a robot body that had to image-recognize the board and then move pieces around, it too would have struggled, to put it mildly.
Here's another way of putting it:
There's this game, the "predict the next token" game. AIs are already vastly superhuman at this game, in exactly the same way that they are vastly superhuman at chess, go, etc. However, it's possible though not by any means proven, that deep within the human brain there are subnetworks that are as good or better than AIs at predicting text, and those subnetworks just aren't hooked up in the right way to the actual human behavior / motor outputs to get humans to be good at this game yet.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-12T23:27:29.145Z · LW(p) · GW(p)
The only point of this token prediction game is as some sort of rough proxy to estimate human brain token prediction ability. I think you may now agree it's horrible at that, as it would require unknown but significant human training time to unlock the linguistic prediction ability the cortex already has. Human's poor zero-shot ability at this specific motor visual game (which is the only thing this post tested!) does not imply the human brain doesn't have powerful token prediction ability (as I predict you already agree, or will shortly).
I highly doubt anybody is reading this and actually interested in the claim that AI is superhuman at this specific weird token probability game and that alone. Are you? The key subtext here - all of the interest - is in the fact that this is a core generic proxy task such that from merely learning token prediction a huge number of actually relevant downstream tasks emerge near automatically.
There is nothing surprising about this - we've know for a long long time (since AIXI days), that purely learning to predict the sensory stream is in fact the only universal necessary and sufficient learning task for superintellligence!
AlphaGo vs humans at go is very different in several key respects: firstly (at least some) humans actually have non trivial training (years) in the game itself, so we can more directly compare along more of the training curve. Secondly, Go is not a key component subtask for many economically relevant components of human intelligence in the same way that token prediction is a core training proxy or subtask of core linguistic abilities.
However, it's possible though not by any means proven, that deep within the human brain there are subnetworks that are as good or better than AIs at predicting text,
Actually this is basically just a known fact from neuroscience and general AI knowledge at this point - about as proven as such things can be. Much of the brain (and nearly all sensori-motor cortex) learns through unsupervised sensory prediction. I haven't even looked yet, but I'm also near certain there are neuroscience papers that probe this for linguistic token prediction ability (as I'm reasonably familiar with the research on how the vision system works, and it is all essentially transformer-UL-style training prediction of pixel streams, and it can't possibly be different for the linguistic centers - as there are no hard-coded linguistic centers, there is just generic cortex).
So from this we already know a way to estimate human equivalent perplexity - measure human ability on a battery of actually important linguistic tasks (writing, reading, math, etc) and then train a predictor to predict equivalent perplexity for a LM of similar benchmark performance on the downstream tasks. The difficulty here if anything is that even the best LMs (last I checked) haven't learned all of the emergent downstream tasks yet, so you'd have to bias the benchmark to the tasks the LMs currently can handle.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-13T03:15:48.160Z · LW(p) · GW(p)
"However, it's possible though not by any means proven, that deep within the human brain there are subnetworks that are as good or better than AIs at predicting text,"
Actually this is basically just a known fact from neuroscience and general AI knowledge at this point - about as proven as such things can be. Much of the brain (and nearly all sensori-motor cortex) learns through unsupervised sensory prediction. I haven't even looked yet, but I'm also near certain there are neuroscience papers that probe this for linguistic token prediction ability (as I'm reasonably familiar with the research on how the vision system works, and it is all essentially transformer-UL-style training prediction of pixel streams, and it can't possibly be different for the linguistic centers - as there are no hard-coded linguistic centers, there is just generic cortex).
So from this we already know a way to estimate human equivalent perplexity - measure human ability on a battery of actually important linguistic tasks (writing, reading, math, etc) and then train a predictor to predict equivalent perplexity for a LM of similar benchmark performance on the downstream tasks. The difficulty here if anything is that even the best LMs (last I checked) haven't learned all of the emergent downstream tasks yet, so you'd have to bias the benchmark to the tasks the LMs currently can handle.
Whoa, hold up. It's one thing to say that the literature proves that the human brain is doing text prediction. It's another thing entirely to say that it's doing it better than GPT-3. What's the argument for that claim, exactly? I don't follow the reasoning you give above. It sounds like you are saying something like this:
"Both the brain and language models work the same way: Primarily they just predict stuff, but then as a result of that they develop downstream abilities like writing, answering questions, doing math, etc. So since the humans are better than GPT-3 at math etc., they must also be better than GPT-3 at predicting text. QED."
↑ comment by jacob_cannell · 2022-08-13T15:39:22.118Z · LW(p) · GW(p)
"Both the brain and language models work the same way: Primarily they just predict stuff, but then as a result of that they develop downstream abilities like writing, answering questions, doing math, etc. So since the humans are better than GPT-3 at math etc., they must also be better than GPT-3 at predicting text. QED."
Basically yes.
There are some unstated caveats however. Humans have roughly several orders of magnitude greater data efficiency on the downstream tasks, and part of that involves active sampling - we don't have time to read the entire internet, but that doesn't really matter because we can learn efficiently from a well chosen subset of that data. Current LMs just naively read and learn to predict everything, even if that is rather obviously sub-optimal. So humans aren't training on exactly the same proxy task, but a (better) closely related proxy task.
Replies from: steve2152, daniel-kokotajlo↑ comment by Steven Byrnes (steve2152) · 2022-08-14T13:45:13.600Z · LW(p) · GW(p)
How do you rule out the possibility that:
- some aspects of language prediction are irrelevant for our lives / downstream tasks (e.g. different people would describe the same thing using subtly different word choice and order);
- other aspects of language prediction are very important for our lives / downstream tasks (the gestalt of what the person is trying to communicate, the person’s mood, etc.);
- an adult human brain is much better at GPT-3 at (2), but much worse than GPT-3 at (1);
- The perplexity metric puts a lot of weight on (1);
- and thus there are no circuits anywhere in the human brain that can outperform GPT-3 in perplexity.
That would be my expectation. I think human learning has mechanisms that make it sensitive to value-of-information, even at a low level.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-14T15:16:28.301Z · LW(p) · GW(p)
If you have only tiny model capacity and abundant reward feedback purely supervised learning wins - as in the first early successes in DL like alexnet and DM's early agents. This is expected because when each connection/param is super precious you can't 'waste' any capacity by investing it in modeling world bits that don't have immediate payoff.
But in the real world sensory info vastly dwarfs reward info, so with increasing model capacity UL wins - as in the more modern success of transformers trained with UL. The brain is very far along in that direction - it has essentially unlimited model capacity in comparison.
1/2: The issue is the system can't easily predict what aspects will be future important much later for downstream tasks.
All that being said I somewhat agree in the sense that perplexity isn't necessarily the best measure (the best measure being that which best predicts performance on all the downstream tasks).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-08-13T17:56:44.697Z · LW(p) · GW(p)
OK, cool. Well, I don't buy that argument. There are other ways to do math besides being really really ridiculously good at internet text prediction. Humans are better at math than GPT-3 but probably that's because they are doing it in a different way than merely as a side-effect of being good at text prediction.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-13T18:41:58.587Z · LW(p) · GW(p)
If it was just math, then ok sure. But GPT-3 and related LMs can learn a wide variety of linguistic skills at certain levels of compute/data scale, and I was explicitly referring to a wide (linguistic and related) skill benchmark, with math being a stand in example for linguistic related/adjacent.
And btw, from what I understand GPT-3 learns math from having math problems in it's training corpus, so it's not even a great example of "side-effect of being good at text prediction".
↑ comment by Thomas Kwa (thomas-kwa) · 2022-08-23T17:59:36.271Z · LW(p) · GW(p)
I'd be interested to see some test more favorable to the humans. Maybe humans are better at judging longer completions due to some kind of coherence between tokens, so a test could be
- Human attempts to distinguish between 5-token GPT-3 continuation and the truth
- GPT-3 attempts to distinguish between 5-token human continuation and the truth
and whichever does better is better at language modeling? It still seems like GPT-3 would win this one, but maybe there are other ways to measure more human abilities.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-23T18:25:21.781Z · LW(p) · GW(p)
I suspect better human zero shot perf on a more GAN like objective on a more interesting dataset.
Take a new unpublished (human-written) story, and for every sentence or paragraph the testee must pick the correct completion multiple choice style, with a single correct answer and 3-4 incorrect but plausible completions generated by a LLM.
I expect humans to do better on longer time window discernment. The advantage of this test setup is it's much closer to tasks humans already have some training on.
↑ comment by Buck · 2022-08-13T00:42:37.112Z · LW(p) · GW(p)
Yeah, I agree that it would be kind of interesting to see how good humans would get at this if it was a competitive sport. I still think my guess is that the best humans would be worse than GPT-3, and I'm unsure if they're worse than GPT-2.
(There's no limit on anyone spending a bunch of time practicing this game, if for some reason someone gets really into it I'd enjoy hearing about the results.)
↑ comment by jung jung (jung-jung) · 2022-09-06T13:29:28.808Z · LW(p) · GW(p)
Yes, this is a valid point. Additionally, I was looking for research on how AlphaGo interacts with human players and came across these.
Conceptual argument: https://www.mdpi.com/2409-9287/5/4/37
Empirical evidence: https://escholarship.org/uc/item/6q05n7pz
comment by Matthew Barnett (matthew-barnett) · 2022-08-11T18:48:50.690Z · LW(p) · GW(p)
The limitations detailed above are probably why these results are not consistent with estimation of human perplexity by Shannon, who estimated the average per-character perplexity to be between 0.6 and 1.3 bits, which would result in a per-token perplexity between 7 and 60 (the average length of tokens in our corpus is 4.5).
Shannon's estimate was about a different quantity. Shannon was interested in bounding character-level entropy of an ideal predictor, ie. what we'd consider a perfect language model, though he leveraged human performance on the predict-the-next-character task to make his estimate.
This article cites a paper saying that, when human-level perplexity was measured on the same dataset that Shannon used, a higher estimate was obtained that is consistent with your estimate.
Cover and King framed prediction as a gambling problem. They let the subject “wager a percentage of his current capital in proportion to the conditional probability of the next symbol." If the subject divides his capital on each bet according to the true probability distribution of the next symbol, then the true entropy of the English language can be inferred from the capital of the subject after n wagers.
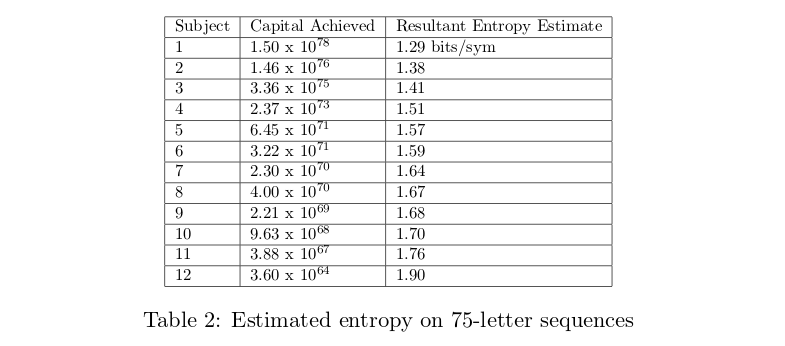
Separately, in my opinion, a far better measure of human-level performance at language modeling is the perplexity level at which a human judge can no longer reliably distinguish between a long sequence of generated text and a real sequence of natural language. This measure has advantage that, if well-measured human-level ability is surpassed, we can directly substitute language models for human writers.
Replies from: LawChan, matthew-barnett↑ comment by LawrenceC (LawChan) · 2022-08-12T01:27:19.296Z · LW(p) · GW(p)
Thanks for the response! We've rewritten the paragraph starting "The limitations detailed..." for clarity.
Some brief responses to your points:
Shannon's estimate was about a different quantity. [...]
We agree that Shannon was interested in something else - the "true" entropy of English, using an ideal predictor for English. However, as his estimates of entropy used his wife Mary Shannon and Barnard Oliver as substitutes for his ideal predictor, we think it's still fair to treat this as an estimate of the entropy/perplexity of humans on English text.
This article cites a paper saying that [...]
As you point out, there's definitely been a bunch of follow up work which find various estimates of the entropy/perplexity of human predictors. The Cover and King source you find above does give a higher estimate consistent with our results. Note their estimator shares many of the same pitfalls of our estimator - for example, if subjects aren't calibrated, they'll do quite poorly with respect to both the Cover and King estimator and our estimator. We don't really make any claims that our results are surprising relative to all other results in this area, merely noting that our estimate is inconsistent with perhaps the most widely known one.
Separately, in my opinion, a far better measure of human-level performance at language modeling is the perplexity level at which a human judge can no longer reliably distinguish between a long sequence of generated text and a real sequence of natural language.
The measure you suggest is similar the methodology used by Shen et al 2017 to get a human level perplexity estimate of 12, which we did mention and criticize in our writeup.
We disagree that this measure is better. Our goal here isn't to compare the quality of Language Models to the quality of human-generated text; we aimed to compare LMs and humans on the metric that LMs were trained on (minimize log loss/perplexity when predicting the next token). As our work shows, Language Models whose output has significantly worse quality than human text (such as GPT-2 small) can still significantly outperform humans on next token prediction. We think it's interesting that this happens, and speculated a bit more on the takeaways in the conclusion.
↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-12T01:46:39.012Z · LW(p) · GW(p)
We disagree that this measure is better. Our goal here isn't to compare the quality of Language Models to the quality of human-generated text; we aimed to compare LMs and humans on the metric that LMs were trained on (minimize log loss/perplexity when predicting the next token).
Your measure is great for your stated goal. That said, I feel the measure gives a misleading impression to readers. In particular I'll point to this paragraph in the conclusion,
Even current large language models are wildly superhuman at language modeling. This is important to remember when you’re doing language model interpretability, because it means that you should expect your model to have a lot of knowledge about text that you don’t have. Chris Olah draws a picture [LW · GW] where he talks about the possibility that models become more interpretable as they get to human level, and then become less interpretable again as they become superhuman; the fact that existing LMs are already superhuman (at the task they’re trained on) is worth bearing in mind when considering this graph.
I think it's misleading to say that language models are "wildly superhuman at language modeling" by any common-sense interpretation of that claim. While the claim is technically true if one simply means that languages do better at the predict-the-next-token task, most people (I'd imagine) would not intuitively imagine that to be the best measure of general performance at language modeling. The reason, fundamentally, is that we are building language models to compete with other humans at the task of writing text, not the task of predicting the next character.
By analogy, if we train a robot to play tennis by training it to emulate human tennis players, I think most people would think that "human level performance" is reached when it can play as well as a human, not when it can predict the next muscle movement of an expert player better than humans, even if predicting the next muscle movement was the task used during training.
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-08-12T02:02:12.717Z · LW(p) · GW(p)
Ah, I see your point. That being said, I think calling the task we train our LMs to do (learn a probabilistic model of language) "language modeling" seems quite reasonable to me - in my opinion, it seems far more unreasonable to call "generating high quality output" "language modeling". For one thing, there are many LM applications that aren't just "generate high quality text"! There's a whole class of LMs like BERT that can't really be used for text generation at all.
One reason we at Redwood care about this result is that we want to interpret modern LMs. As outlined in the linked Chris Olah argument [LW · GW], we might intuitively expect that AIs get more interpretable as they get to human level performance, then less interpretable as their performance becomes more and more superhuman. If LMs were ~human level at the task they are trained on, we might hope that they contain mainly crisp abstractions that humans find useful for next token prediction. However, since even small LMs are superhuman at next token prediction, they probably contain alien abstractions that humans can't easily understand, which might pose a serious problem for interpretability efforts.
↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-12T02:17:23.073Z · LW(p) · GW(p)
Ah, I see your point. That being said, I think calling the task we train our LMs to do (learn a probabilistic model of language) "language modeling" seems quite reasonable to me - in my opinion, it seems far more unreasonable to call "generating high quality output" "language modeling".
Note that the main difference between my suggested task and the next-character-prediction task is that I'm suggesting we measure performance over a long time horizon. "Language models" are, formally, probability distributions over sequences of text, not models over next characters within sequences. It is only via a convenient application of the Markov assumption and the chain rule of probability that we use next-character-prediction during training.
The actual task, in the sense of what language models are fundamentally designed to perform well on, is to emulate sequences of human text. Thus, it is quite natural to ask when they can perform well on this task. In fact, I remain convinced that it is more natural to ask about performance on the long-sequence task than the next-character-prediction task.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-08-12T06:15:54.457Z · LW(p) · GW(p)
In fact, I remain convinced that it is more natural to ask about performance on the long-sequence task than the next-character-prediction task.
Large language models are also going to be wildly superhuman by long-sequence metrics like "log probability assigned to sequences of Internet text" (in particular because many such metrics are just sums over the next-character versions of the metric, which this post shows LLMs are great at).
LLMs may not be superhuman at other long-sequence tasks like "writing novels" but those seem like very different tasks, just like "playing already-composed music" and "composing new music" are very different tasks for humans.
(To be clear, I think it's fair to say that what we care about with LLMs is the latter category of stuff, but let's not call that "language modeling".)
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-12T07:08:51.267Z · LW(p) · GW(p)
Large language models are also going to be wildly superhuman by long-sequence metrics like "log probability assigned to sequences of Internet text"
I think this entirely depends on what you mean. There's a version of the claim here that I think is true, but I think the most important version of it is actually false, and I'll explain why.
I claim that if you ask a human expert to write an article (even a relatively short one) about a non-trivial topic, their output will have a higher log probability than a SOTA language model, with respect to the "true" distribution of internet articles. That is, if you were given the (entirely hypothetical) true distribution of actual internet articles (including articles that have yet to be written, and the ones that have been written in other parts of the multiverse...), a human expert is probably going to write an article that has a higher log probability of being sampled from this distribution, compared to a SOTA language model.
This claim might sound bizarre at first, because, as you noted "many such metrics are just sums over the next-character versions of the metric, which this post shows LLMs are great at". But, first maybe think about this claim from first principles: what is the "true" distribution of internet articles? Well, it's the distribution of actual internet articles that humans write. If a human writes an article, it's got to have pretty high log-probability, no? Because otherwise, what are we even sampling from?
Now, what you could mean is that instead of measuring the log probability of an article with respect to the true distribution of internet articles, we measure it with respect to the empirical distribution of internet articles. This is in fact what we use to measure the log-probability of next character predictions. But the log probability of this quantity over long sequences will actually be exactly negative infinity, both for the human-written article, and for the model-written article, assuming they're not just plagiarizing an already-existing article. That is, we aren't going to find any article in the empirical distribution that matches the articles either the human or the model wrote, so we can't tell which of the two is better from this information alone.
What you probably mean is that we could build a model of the true distribution of internet articles, and use this model to estimate the log-probability of internet articles. In that case, I agree, a SOTA language model would probably far outperform the human expert, at the task of writing internet articles, as measured by the log-probability given by another model. But, this is a flawed approach, because the model we're using to estimate the log-probability with respect to the true distribution of internet articles is likely to be biased in favor of the SOTA model, precisely because it doesn't understand things like long-sequence coherence, unlike the human.
How could we modify this approach to give a better estimate of the performance of a language model at long-sequence prediction? I think that there's a relatively simple approach that could work.
Namely, we set up a game in which humans try to distinguish between real human texts and generated articles. If the humans can't reliably distinguish between the two, then the language model being used to generate the articles has attained human-level performance (at least by this measure). This task has nice properties, as there is a simple mathematical connection between prediction ability and ability to discriminate; a good language model that can pass this test will likely only pass it because it is good at coming up with high log-probability articles. And this task also measures the thing we care about that’s missing from the predict-the-next-character task: coherence over long sequences.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-08-12T08:40:43.115Z · LW(p) · GW(p)
But, first maybe think about this claim from first principles: what is the "true" distribution of internet articles? Well, it's the distribution of actual internet articles that humans write. If a human writes an article, it's got to have pretty high log-probability, no? Because otherwise, what are we even sampling from?
I continue to think you are making a point about generation / sampling, whereas language modeling is about modeling the distribution as a whole.
Put another way, even if I am better than the LLM at the specific part of the Internet text distribution that is "articles written by Rohin", that does not mean that I am better than the LLM at modeling the entire distribution of Internet text (long horizon or not).
Even under your proposed game, I don't think I can get to indistinguishability, if the discriminator is allowed to learn over time (which seems like the version that properly tests language modeling). They'll notice peculiarities of my writing style and aspects of Internet writing style that I'm not able to mimic very well. If your proposed test was "when can LLMs beat humans at this game" that seems more reasonable (though it still advantages the humans because the judge is a human; similarly I expect that if the judge was an LLM that would advantage the LLMs relative to the humans).
What you probably mean is that we could build a model of the true distribution of internet articles, and use this model to estimate the log-probability of internet articles.
I don't think this point depends on thinking about having a model of the true distribution of articles that we use to evaluate humans vs LLMs; I'm happy to talk about the true distribution directly (to the extent that a "true distribution" exists). (This gets tricky though because you could say that in the true distribution coherence errors ~never happen and so LLM outputs have zero probability, but this is basically dooming the LLM to never be superhuman by defining the true distribution to be "what humans output", which seems like a symptom of a bad definition.)
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-12T09:35:39.050Z · LW(p) · GW(p)
Let me restate some of my points, which can hopefully make my position clearer. Maybe state which part you disagree with:
Language models are probability distributions over finite sequences of text.
The “true distribution” of internet text refers to a probability distribution over sequences of text that you would find on the internet (including sequences found on other internets elsewhere in the multiverse, which is just meant as an abstraction).
A language model is “better” than another language model to the extent that the cross-entropy between the true distribution and the model is lower.
A human who writes a sequence of text is likely to write something with a relatively high log probability relative to the true distribution. This is because in a quite literal sense, the true distribution is just the distribution over what humans actually write.
A current SOTA model, by contrast, is likely to write something with an extremely low log probability, most likely because it will write something that lacks long-term coherence, and is inhuman, and thus, won’t be something that would ever appear in the true distribution (or if it appears, it appears very very very rarely).
The last two points provide strong evidence that humans are actually better at the long-sequence task than SOTA models, even though they’re worse at the next character task.
Intuitively, this is because the SOTA model loses a gigantic amount of log probability when it generates whole sequences that no human would ever write. This doesn’t happen on the next character prediction task because you don’t need a very good understanding of long-term coherence to predict the vast majority of next-characters, and this effect dominates the effect from a lack of long-term coherence in the next-character task.
It is true (and I didn’t think of this before) that the human’s cross entropy score will probably be really high purely because they won’t even think to have any probability on some types of sequences that appear in the true distribution. I still don’t think this makes them worse than SOTA language models because the SOTA will also have ~0 probability on nearly all actual sequences. However…
Even if you aren’t convinced by my last argument, I can simply modify what I mean by the “true distribution” to mean the “true distribution of texts that are in the reference class of things we care about”. There’s absolutely no reason to say the true distribution has to be “everything on the internet” as opposed to “all books” or even “articles written by Rohin” if that’s what we’re actually trying to model.
Thus, I don’t accept one of your premises. I expect current language models to be better than you at next-character prediction on the empirical distribution of Rohin articles, but worse than you at whole sequence prediction for Rohin articles, for reasons you seem to already accept.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-08-12T10:32:53.216Z · LW(p) · GW(p)
If I had to pick a claim to disagree with it would be the one about the "true distribution", but it's less that I disagree with the claim, and more that I disagree with using this particular method for declaring whether AIs are superhuman at language modeling.
but worse than you at whole sequence prediction for Rohin articles, for reasons you seem to already accept.
But a model can never be better than me at this task! Why are we interested in it?
This really feels like the core issue: if you define a task as "sample accurately from distribution D", and you define the distribution D as "whatever is produced by X", then X is definitionally optimal at the task, and no AI system is ever going to be super-X.
(Even once the AI system can fool humans into thinking its text is human-generated, there could still something inhuman about it that the humans fail to pick up on, that means that its generations are near-zero probability.)
In the language modeling case it isn't quite this perverse (because we the distribution is "whatever is produced by all humans" whereas we're only asking the AI to be better than one human) but it still seems pretty perverse.
I think a better evaluation of human ability at language modeling would be (1) sampling a sequence from the empirical dataset, (2) sampling a sequence from a human, (3) evaluate how often these two are the same, (4) do some math to turn this into a perplexity. This would have huge variance (obviously most of the time the sequences won't be the same for step (3)), but you can reduce the variance by sampling continuations for a given prompt rather than sampling sequences unprompted, and reduce it further by looking just at sampling the next token given a prompt (at which point you are at the scheme used in this post).
I still don’t think this makes them worse than SOTA language models because the SOTA will also have ~0 probability on nearly all actual sequences.
On my view, this is just the sum of log probs on next tokens, so presumably the result from this post implies that the language model will be way better than humans (while still assigning very low probability to a given sequence, just because the sequence is long, similarly to how you would assign very low probability to any given long sequence of coin flips).
However, I'm still not sure how exactly you are thinking of "the probability assigned by the human" -- it seems like you don't like the methodology of this post, but if not that, I don't see how else you would elicit a probability distribution over tokens / words / sequences from humans, and so I'm not really sure how to ground this claim.
(Whereas I think I do understand your claims about what kinds of text humans tend to generate.)
↑ comment by Matthew Barnett (matthew-barnett) · 2022-08-11T23:49:38.994Z · LW(p) · GW(p)
Building on this comment, I think it might be helpful for readers to make a few distinctions in their heads:
- "True entropy of internet text" refers to the entropy rate (measured in bits per character, or bits per byte) of English text, in the limit of perfect prediction abilities.
Operationally, if one developed a language model such that the cross entropy between internet text and the model was minimized to the maximum extent theoretically possible, the cross entropy score would be equal to the "true" entropy of internet text. By definition, scaling laws dictate that it takes infinite computation to train a model to reach this cross entropy score. This quantity depends on the data distribution, and is purely a hypothetical (though useful) abstraction. - "Human-level perplexity" refers to perplexity associated with humans tested on the predict-the-next-token task. Perplexity, in this context, is defined as two raised to the power of the cross entropy between internet text, and a model.
- "Human-level performance" refers to a level of performance such that a model is doing "about as well as a human". This term is ambiguous, but is likely best interpreted as a level of perplexity between the "true perplexity" and "human-level perplexity" (as defined previously).
comment by Fabien Roger (Fabien) · 2024-07-16T15:15:17.487Z · LW(p) · GW(p)
This work was submitted and accepted to the Transactions on Machine Learning Research (TMLR).
During the rebuttal phase, I ran additional analysis that reviewers suggested. I found that:
A big reason why humans suck at NTP in our experiments is that they suck at tokenization:
- Our experiments were done on a dataset that has some overlap with LLM train sets, but this probably has only a small effect:
A potential reason why humans have terrible perplexity is that they aren't good at having fine-grained probability when doing comparison of likelihood between tokens:
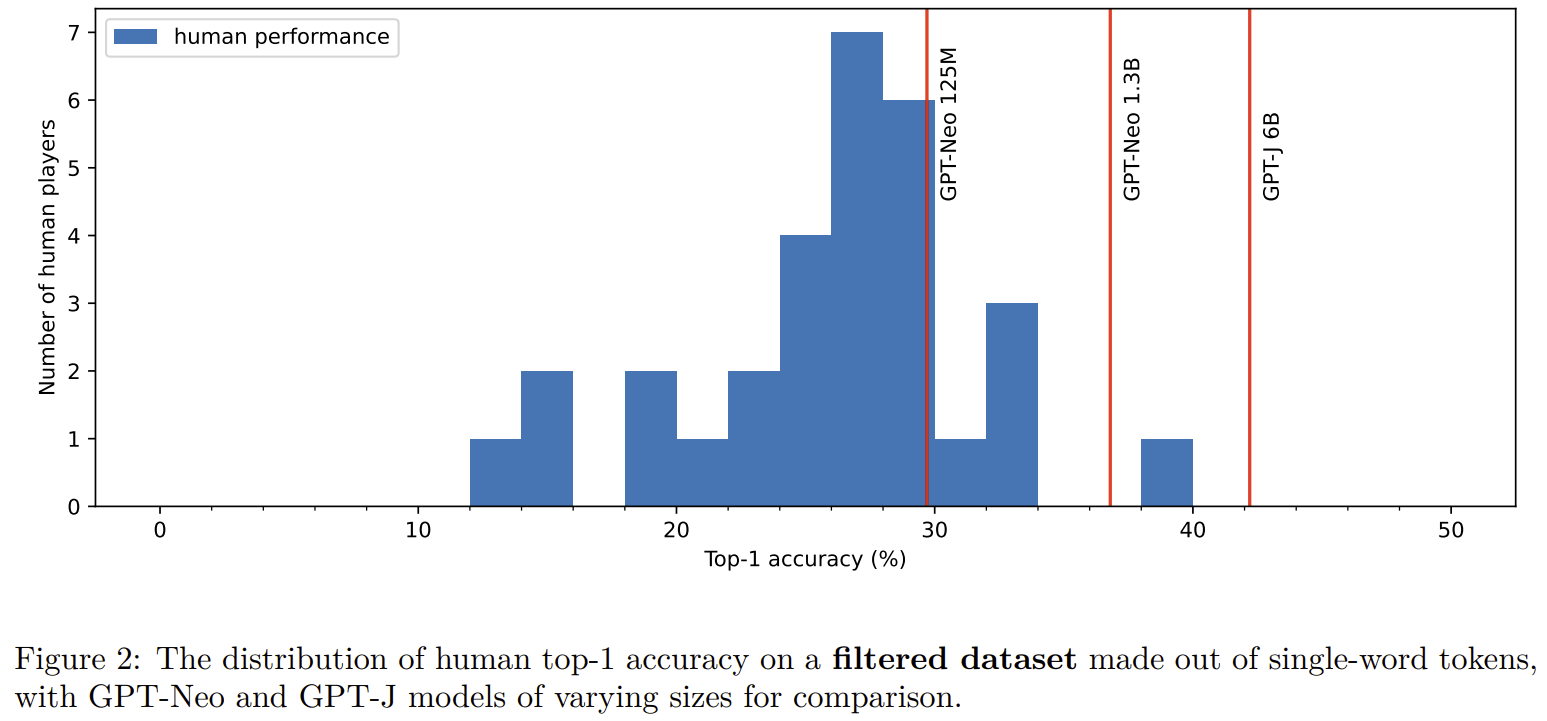
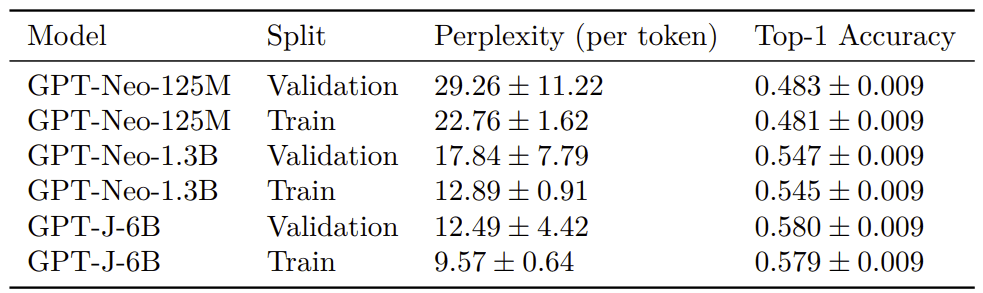
The updated paper can be found on arxiv: https://arxiv.org/pdf/2212.11281
Overall, I think the original results reported in the paper were slightly overstated. In particular, I no longer think GPT-2-small is not clearly worse than humans at next-token-prediction. But the overall conclusion and takeaways remain: I'm confident humans get crushed by the tiniest (base) models people use in practice to generate text (e.g. StableLM-1.6B).
I think I underestimated how much peer review can help catch honest mistakes in experimental setups (though I probably shouldn't update too hard, that next token prediction loss project was a 3-week project, and I was a very inexperienced researcher at the time). Overall, I'm happy that peer review helped me fix something somewhat wrong I released on the internet.
comment by Buck · 2023-12-13T18:34:17.048Z · LW(p) · GW(p)
This post's point still seems correct, and it still seems important--I refer to it at least once a week.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2023-12-13T18:40:35.486Z · LW(p) · GW(p)
What are some examples of situations in which you refer to this point?
comment by Ben Pace (Benito) · 2022-08-12T02:39:54.904Z · LW(p) · GW(p)
If you want to play with our website, it’s here; in our opinion playing this game for half an hour gives you some useful perspective on what it’s like to be a language model.
Wow that's fun! And quite frustrating. The worst is when I make such a near miss. Here are some pairs from my third document, with the first being my guess, and the latter being the correct token
- "sincere" ->"congratulations"
- "Vice" -> "President"
- "deserved" -> "earned"
- "drive" -> "dedication"
Overall I'm getting like 20%, or worse, on these things. I played for ~20 mins, seems like there are obvious improvements to be found in my strategies. Obviously it gets easier as the essays go on, when you have narrowed in further on who the author is and why they're writing. Seems like ML systems can get ~49%, that's pretty incredible.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-08-12T03:05:38.127Z · LW(p) · GW(p)
Here is the website where participants played the game.
And there's a second game! I found this one more fun than the first, I guess because the action space was less vast.
It's fun how even when I'm right I sometimes don't get points, because the model I'm competing with also predicted correctly (e.g. one time I predicted something with 99% confidence, and only got +2, because it was also obvious to the model).
Wow my score was terrible, only 175, compared to 921 for the 2-layers model.
Replies from: Measurecomment by JBlack · 2022-08-12T01:32:57.766Z · LW(p) · GW(p)
When I played with this on the website, it seemed to have a few major bugs. At one point I was 20% ahead of the best language model score, made one prediction at 30%, and for some reason lost 400 points and the feedback displayed wasn't even for my sentence!
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2022-08-12T02:18:17.518Z · LW(p) · GW(p)
I'm sorry the feedback wasn't displayed! I didn't hear the players complain about this issue during the measurements, so it's probably an uncommon bug. Anyway, this shouldn't have happened.
It's not surprising that you lost 400 points in one question (even with p= 30%). If the generative language model thinks the correct token was very likely, you will lose a lot of points if you fail to select it (otherwise you wouldn't be incentivized to give your true probability estimates, see Appendix B).
Replies from: JBlackcomment by jacob_cannell · 2022-08-11T23:34:05.426Z · LW(p) · GW(p)
The results here suggest that humans are worse than even small language models the size of GPT-1 at next-token prediction, even on the top-1 prediction task. This seems true even when the humans are smart and motivated and have practiced for an hour or two. Some humans can probably consistently beat GPT-1, but not substantially larger models, with a bit more practice.
I challenge the implied conclusion.
It is quite possible, and even likely, that specific brain subcircuits (language centers ie neurotypically broca's region etc.) are far stronger at this specific and similar tasks in isolation than a human as a whole.
The training setup here is not even remotely comparable, and the human has a much harder task. The ANN LM is trained to directly output the next word distribution on a huge corpus of text. The human brain contains at least some submodules that we have some good reasons to believe are trained on something similar - there is a bunch of evidence from neuroscience that the sensory cortices are trained for sensory prediction (and thus sequence prediction while reading), albeit on datasets that are typically OOM smaller.
However this test setup doesn't directly have access to brain language circuits. So instead you are testing humans on a completely new, much more complex task that involves reading a snippet of text and then doing a bunch of high level symbolic manipulation based on that to extract and compute a probability distribution and ultimately making a complex dependent motor decision based on that symbolic probability calculation. And this brand new task is 'few shot' in the sense that the human gets only a tiny amount of training samples rather than tens of billions.
The issue is that even though the brain is probably computing and encoding (approximate compressed) equivalents to next-word probability distributions internally in some cortical modules, that does not mean the main conscious symbolic action loop can easily extract those compressed internal representations.
It would be like taking GPT3, then running it through an incredibly complex compression/quantization pipeline that near scrambled/encrypted it's outputs mixing them up with intermediate layers and then connecting all that to a robotic motor/vision system to play the word prediction game and expecting to train that new robotic system to high accuracy with just a measly few hundred samples.
We do not know how good the human brain is internally at next-word prediction, but it's almost certainly much better than humans are at the equivalent game here.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-08-12T01:09:10.682Z · LW(p) · GW(p)
I don't think there is an implied conclusion here - it's meant to be taken at face value. All that we care about in this analysis is how well humans and machines perform at the task. This comparison doesn't require a fair fight. LLM's have thousands of times more samples than any human will ever read - so what? As long as we can reliably train LM's on those samples, that is the LM's performance. Similarly, it doesn't matter how good the human subconscious is at next-word prediction if we can't access it.
I feel like the implied conclusion you're arguing against here is something like "LM's are more efficient per sample than the human brain at predicting language", but I don't think this conclusion is implied by the text at all. I think the conclusion is exactly as stated - in the real world, LM's outperform humans. It doesn't matter if it does so by "cheating" with huge, humanly-impossible datasets, or by having full access to its knowledge in a way a human doesn't, because those are part of the task constraints in the real world.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-12T05:26:56.248Z · LW(p) · GW(p)
Expressed differently, my point is that this isn't even a comparison of two systems on the same task! The LM is directly connected to the text stream and is trained as a system with that dataflow. The human is performing a completely different, much more complex task involving vision and motor subtasks in addition to the linguistic subtask, and then is tested on zero/few shot performance on this new integrated task with little/insignificant transfer training.
If you want to make any valid perf comparison claims you need to compare systems on the exact same full system task. To do that you'd need to take the ANN LM and hook it up to a (virtual or real) robot where the input is the same rendered video display the human receives, and the output is robotic motor commands to manipulate a mouse to play the software version of this text prediction game. Do you really think the ANN LM would beat humans in this true apples to apples comparison?
I feel like the implied conclusion you're arguing against here is something like "LM's are more efficient per sample than the human brain at predicting language",
What? Not only is that not what I"m arguing, the opposite is true! Humans are obviously more sample efficient than current ANN LMs - by a few OOM (humans exceed LM capability after less than 1B tokens equivalent, roughly speaking). Human learning is far more sample efficient on all the actually ecologically/economically important downstream linguistic tasks, so it stands to reason that the linguistic brain regions probably also are more sample efficient at sequence prediction - although that remains untested. Again, this technique does not actually measure the true linguistic prediction ability of the cortex.
I think the conclusion is exactly as stated - in the real world, LM's outperform humans.
At what? Again, in this example the humans and the LM are not even remotely performing the same task. The human task in this example is an enormously more complex computational few shot learning task. We can theorize about more complex agentic systems that could perform the actual exact same task robotic/visual task here (perhaps gato?), but that isn't what this post discusses.
This isn't a useful task - there is no inherent value in next-token prediction. It's just a useful proxy training measure. Human brains are likely using the same unsupervised proxy internally, but actually measuring that directly would involve some complex and invasive neural interfaces (perhaps some future version of neuralink).
But that's unnecessary because instead we can roughly estimate human brain performance based via comparison on all the various downstream actually economically/ecologically useful tasks such as reading comprehension, math/linguistic problems, QA tasks, story writing, etc. And the general conclusion is the human brain is very roughly an OOM or two more 'compute' efficient and several OOM more data efficient than today's LMs. (for now)
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-08-12T05:51:34.542Z · LW(p) · GW(p)
I think I should have emphasised the word "against" in the sentence of mine you quoted:
I feel like the implied conclusion you're arguing against here is something like "LM's are more efficient per sample than the human brain at predicting language",
You replied with: "What? Not only is that not what I"m arguing, the opposite is true!" which was precisely what I was saying. The conclusion you're arguing against is that LM's are more sample-efficient than humans. This would require you to take the opposite stance - that humans are more sample-efficient than LM's. This is the exact stance I believed you were taking. I then went on to say that the text did not rely on this assumption, and therefore your argument, while correct, did not affect the post's conclusions.
I agree with you that humans are much more sample-efficient than LM's. I have no compute comparison for human brains and ML models so I'll take your word on compute efficiency. And I agree that the task the human is doing is more complicated. Humans would dominate modern ML systems if you limited those systems to the data, compute, and sensory inputs that humans get.
I think our major crux is that I don't see this as particularly important. It's not a fair head-to-head comparison, but it's never going to be in the real world. What I personally care about is what these machines are capable of doing, not how efficient they are when doing it or what sensory requirements they have to bypass. If a machine can do a task better than a human can, it doesn't matter if it's a fair comparison, provided we can replicate and/or scale this machine to perform the task in the real world. Efficiency matters since it determines cost and speed, but then the relevant factor is "Is this sufficiently fast / cost-effective to use in the real world", not "How does efficiency compare to the human brain".
Put it this way: calculators don't have to use neurons to perform mathematics, and you can put numbers into them directly instead of them having to hear or read them. So it's not really a valid comparison to say calculators are directly superhuman at arithmetic. And yet, that doesn't stop us at all from using calculators to perform such calculations much faster and more accurately than any human, because we don't actually need to restrict computers to human senses. So, why does it matter that a calculator would lose to a human in a "valid" arithmetic contest? How is that more important than what the calculator can actually do under normal calculator-use conditions?
↑ comment by jacob_cannell · 2022-08-12T07:48:04.380Z · LW(p) · GW(p)
Ahh I apparently missed that key word 'against'.
Humans would dominate modern ML systems if you limited those systems to the data, compute, and sensory inputs that humans get.
I think our major crux is that I don't see this as particularly important.
No, I don't strongly disagree there, the crux is perhaps more fundamental.
Earlier you said:
I think the conclusion is exactly as stated - in the real world, LM's outperform humans.
At what?
The post title says "Language models seem to be much better than humans at next-token prediction". I claim this is most likely false, and you certainly can't learn much anything about true relative human vs LM next-token prediction ability by evaluating the LM on task A compared to evaluating the human on vastly more complex and completely different task B.
Furthermore, I claim that humans are actually probably somewhere between on par to much better than current LMs at next-token prediction. Next-token prediction is only useful as a proxy unsupervised training task which then enables performance on actually relevant downstream linguistic tasks (reading, writing, math, etc). Actual human performance on those downstream tasks currently dominates LM performance, even when LMs use far more compute and essentially all the world's data - still not quite enough to beat humans (yet!).
Once again, to correctly directly evaluate human next-token prediction ability would probably require a very sophisticated neural interface for high frequency whole brain recording. Lacking that, our best way to estimate true human next-token prediction perplexity is by measuring human performance on the various downstream tasks which emerge from that foundational prediction ability.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-08-12T12:24:35.916Z · LW(p) · GW(p)
What it feels like to me here is that we're both arguing different sides, and yet if you asked both of us about any empirical fact we expect to see using current or near-future technology, such as "Would a human achieve a better or worse score on a next-token prediction task under X conditions", we would both agree with each other.
Thus, it feels to me, upon reflection, that our argument isn't particularly important, unless we could identify an actual prediction that matters where we would each differ. What would it imply, to say that humans are better at next-token prediction ability than this test predicts, compared to the world where that's not the case and the human subconscious is no better at word-prediction than our conscious mind has access too?
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-12T17:33:16.075Z · LW(p) · GW(p)
Again you said earlier that " in the real world, LM's outperform humans."
We disagree on that, and I'm still not sure why as you haven't addressed my crux or related claims. So if in on reflection, you agree that LM's don't actually outperform humans (yet), then sure we agree. Do you believe that LM's generally outperform humans at important real world linguistic skills such as reading, writing, math, etc?
I'm not even sure what you mean by 'next-token prediction task' - do you mean the language modelling game described in this post? As again one of my core points is that LMs score essentially 0 on that game, as they can't even play it. I suspect you could probably train GATO or some similar multi-modal agent to play it, but that wasn't tested here.
What would it imply, to say that humans are better at next-token prediction ability than this test predicts, compared to the world where that's not the case and the human subconscious is no better at word-prediction than our conscious mind has access too?
A great deal. If this game was an accurate test of human brain next-token prediction ability, then either humans wouldn't have the language skills we are using now, or much of modern neuroscience & DL would be wrong as the brain would be somehow learning complex linguistic skills without bootstrapping from unsupervised sequence prediction.
Since LMs actually score zero on this language modelling game, it also 'predicts' that they have zero next token prediction ability.
Replies from: Jay Bailey↑ comment by Jay Bailey · 2022-08-13T00:45:28.259Z · LW(p) · GW(p)
I think the reason we appear to disagree here is that we're both using different measurements of "outperform".
My understanding is that Jacob!outperform means to win in a contest where all other variables are the same - thus, you can't say that LM's outperform humans when they don't need to apply the visual and motor skills humans have to do. The interfaces aren't the same, so the contest is not fair. If I score higher than you in a tenpin bowling match where I have the safety rails up and you don't, we can't say I've outperformed you in tenpin bowling.
Jay!outperform means to do better on a metric (such as "How often can you select the next word") where each side is using an interface suited for them that would correlate with the ability to perform the task on a wide range of inputs. That is to say - it's fine for the computer to cheat, so long as that cheating doesn't prevent it from completing the task out of distribution, or the distribution is wide enough to handle anything a user is likely to want from the program in a commercial setting. If the AI was only trained on a small corpus and learned to simply memorise the entire corpus, that wouldn't count as outperforming because the AI would fall apart if we tried to use it on any other text. But since the task we want to check is text prediction, not visual input or robotics, it doesn't matter that the AI doesn't have to see the words.
Both these definitions have their place. Saying "AI can Jacob!outperform humans at this task" would mean the AI was closer to AGI than if it can Jay!outperform humans at a task. I can also see how Jacob!outperforming would be possible for a truly general intelligence. However, saying "AI can Jay!outperform humans at this task" is sufficient for AI to begin replacing humans at that task if that task is valuable. (I agree with you that next-token prediction is not itself commercially valuable, whereas something like proofreading would be)
I think I may have also misled you when I said "in the real world", and I apologise for that. What I meant by "in the real world" was something like "In practice, the AI can be used reliably in a way that does better than humans". Again, the calculator is a good metaphor here - we can reliably use calculators to do more accurate arithmetic than humans for actual problems that humans face every day. I understand how "in the real world" could be read as more like "embodied in a robotic form, interacting with the environment like humans do." Clearly a calculator can't do that and never will. I agree LM's cannot currently do that, and we have no indication that any ML system can currently do so at that level.
So, in summary, here is what I am saying:
- If an AI can score higher than a human, using any sort of interface that still allows it to be reliably deployed on a range of data that humans want the task performed in, it can be used for that purpose. This can happen whether the AI is able to utilise human senses or not. If AI can be reliably used to produce outputs that are in some way better (faster, more accurate, etc.) than humans, it's not important that the contest is fair - the AI will begin replacing humans at this task anyway.
That said, I think I understand your point better now. A system that could walk across the room in a physical body, turn on a computer, log on to redwoodresearch.com/next_word_prediction_url, view words on a screen, and click a mouse to select which word they predict would appear next is FAR more threatening than a system that takes in words directly as input and returns a word as output. That would be an indication that AI's were on the brink of outperforming humans, not just at the task of predicting tokens, but at a very wide range of tasks. I agree this is not happening yet, and I agree that the distinction matters between this paragraph and my claim above.
I haven't answered your claim about the subconscious abilities of humans to predict text better than this game would indicate because I'm really not sure about whether that's true or not - not in a "I've seen the evidence and it could go either way" kind of way, but in a "I've never even thought about it" kind of way. So I've avoided engaging with that part of the argument - I don't think it's load-bearing for the parts I've been discussing in this post, but please let me know if I'm wrong.
Replies from: jacob_cannell↑ comment by jacob_cannell · 2022-08-13T16:00:26.207Z · LW(p) · GW(p)
Note that my notion of outperform here is exactly the same notion that one would use when comparing different ML systems. They obviously need to be performing exactly the same task - in general you can't claim ML system X is better than ML system Y when X is wired directly to the output and Y has to perform a more complex motor visual task than includes X's task as a subtask. That would be - ridiculous, frankly.
If AI can be reliably used to produce outputs that are in some way better (faster, more accurate, etc.) than humans, it's not important that the contest is fair - the AI will begin replacing humans at this task anyway.
The issue is that nobody cares about this specific task directly. I'm pretty sure you don't even care about this specific task directly. The only interest in this task is as some sort of proxy for performance on actually important downstream tasks (reading, writing, math etc). And that's why it's so misleading to draw conclusions from ML system performance on proxy task A and human performance on (more complex) proxy task B.
(I agree with you that next-token prediction is not itself commercially valuable, whereas something like proofreading would be)
I think you would agree that humans are enormously better at proofreading then implied by this weird comparison (on two different proxy tasks). Obvious counter-example proof: there are human who haven't played this specific game yet and would score terribly but are good at proofreading.
comment by Owain_Evans · 2022-08-12T16:04:38.248Z · LW(p) · GW(p)
This is very valuable. I suggest putting this content on Arxiv (even it's less formal that the typical paper).
comment by Veedrac · 2022-08-12T09:45:22.611Z · LW(p) · GW(p)
When people wrote text, they didn't do it statelessly. Sure they physically wrote one word at a time, but people accumulate their understanding as they write, and they go back to edit with some frequency.
If you took the writers of your favorite books, and forced them to write another book, except this time you forced them to write it autoregressively, and after every token they outputted you waited a day and swapped the writer, probably the overall quality of that output would be garbage.
So I don't think the test is wrong per se, in that I think this is a fair measure that NNs are better at stateless next-token prediction than humans, but I think it's also not true that stateless human next token prediction is the benchmark you should be comparing to.
As was mentioned or hinted at on another comment here, but bears explicit emphasis: the perplexity of the actual generation process of human text is just the perplexity of the actual distribution of generated human text, were the dataset of infinite size.
comment by Ericf · 2022-08-11T18:46:27.434Z · LW(p) · GW(p)
This result seems not surprising. Finding the most common result in a large dataset is explicitly what computers are good at, and people are not good at. That's kind of why we invented computers. There is little value in knowing that 70% of the time the sentence is "Now, the developer is planning for phase 2 trials" and not "Phase 2 trials are the next step" "Now the developer, [name], is planning phase 2 trials" "Now trials enter phase 2" Or any other variations. Our understanding is at the sentence level, and based on a tiny and biased sampling from the possible set of source data.
Replies from: yitz↑ comment by Yitz (yitz) · 2022-08-12T01:58:21.776Z · LW(p) · GW(p)
Agreed, while at the same time I’m very glad that this research has been done, and wish to congratulate those involved accordingly. A lot of good research is obvious in retrospect, but there were enough smart people who prior to this experiment displayed contradictory opinions that this result is not trivial. As such, kudos on the great work!
comment by Archimedes · 2022-08-14T20:58:14.486Z · LW(p) · GW(p)
I played the Perplexity game (the one where you select probabilities) and easily beat the 2-layer model and was close to the 12-layer model most of the time. Matching the 24-layer model feels achievable after some work on calibrating my probability intuitions.
40 questions result: 747 (me) | -55 (2-layer) | 755 (12-layer) | 866 (24-layer)
Most of the difficulty was from trying to decide exactly how confident I was rather than not knowing which token was more likely. Humans are pretty bad at this, especially when probabilities are close to 0 or 1 (I lost the most ground compared to the models in situations where I failed to distinguish between a 1%/99% probability and a 10%/90% probability). I suspect changing the game so that humans are not severely punished as severely for poor calibration would really help to achieve a more meaningful comparison. Even just changing the most extreme selection options of 1%/99% to 5%/95% would help level the playing field a bit since humans have poor intuition toward the probability extremes. As it is, a human superforecaster with poor language skills would likely crush someone with extraordinary language skills but average probability calibration.
I'd be interested in seeing how humans would compare on a similar test but where their task is more along the lines of choosing the top 2-out-of-5 or top 3-out-of-10 options.
comment by MondSemmel · 2023-01-15T11:57:58.133Z · LW(p) · GW(p)
Is this game still supposed to work? In Firefox I don't see the list of tokens at all; instead it looks like this.
{kind=link}
comment by Ben Pace (Benito) · 2022-08-16T21:07:21.700Z · LW(p) · GW(p)
Curated.
I am unsure how obvious this result is in-advance, my guess is there are at least some people who would have correctly predicted it and for the right reasons. However, I really love a lot of things about this post: first because you answer a question ML researchers do have disagreements over, second because you coded two small games for humans to play to help understand what's going on, third because you collect novel data, and fourth because you present it so clearly and readably.
I gained a better understanding of how language-models work from reading this post and playing the games, and I'd love to see more posts answering open questions through this kind of simple experimental work.
comment by Adam Jermyn (adam-jermyn) · 2022-08-15T17:48:14.257Z · LW(p) · GW(p)
Playing the perplexity game had a big impact on my intuitions around language models, so thanks for making it! In particular, the fact that models are so much better at it than humans means we can't really tell from behavior alone whether a model is genuinely trying to predict the next token. This is a problem for detecting inner alignment failure, because we can't tell (outside of the training set) if the model is actually optimizing for next-token prediction or something that just looks (to us) like next-token prediction.
comment by mocny-chlapik · 2022-08-12T07:11:50.177Z · LW(p) · GW(p)
I believe I have read a paper about superhuman performance of LSTM LMs maybe 4 years ago. The fact that LMs are better than humans is not that surprising. With the amount of data they have seen, even relatively simple models are able to precisely calculate the probabilities for individual words. But the comparison to humans does not make much sense here. People are not really doing language modeling in their day-to-day communication. When we speak, we are not predicting what will be our next word, we are communicating ideas and selecting words that will represent these ideas. When we hear someone speaking, we are using context clues to understand their language, we are not making the predictions based solely on the words that are being said in that moment. When thinking about language, we are not sorting all the words from the vocabulary in our heads, we are usually selecting the one word that fits our needs the best. Language modeling as used in computer science today is completely unnatural to human thinking and useless in communication.
comment by StefanHex (Stefan42) · 2022-11-11T17:17:58.988Z · LW(p) · GW(p)
Your language model game(s) are really interesting -- I've had a couple ideas when "playing" (such as adding GPT2-small suggestions for the user to choose from, some tokenization improvements) -- are you happy to share the source / tools to build this website or is it not in a state you would be happy to share? Totally fine if not, just realized that I should ask before considering building something!
Edit for future readers: Managed to do this with Heroku & flask, then switched to Streamlit -- code here, mostly written by ChatGPT: https://huggingface.co/spaces/StefanHex/simple-trafo-mech-int/tree/main
comment by SoerenMind · 2022-08-14T20:11:03.706Z · LW(p) · GW(p)
Playing this game made me realize that humans aren't trainged to predict at the token-level. I don't know the token-level vocabulary; and made lots of mistakes by missing spaces and punctuation. Is it possible to convert the token-level prediction in to word-level prediction? This may get you a better picture of human ability.
Replies from: SoerenMind↑ comment by SoerenMind · 2022-08-14T20:15:18.626Z · LW(p) · GW(p)
One way to convert: measure how accurate the LM is at word-level prediction by measuring its likelihood of each possible word. For example the LM's likelihood of the word "[token A][token B]" could be .
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-12T17:50:35.312Z · LW(p) · GW(p)
In one of Rohin's comments he describes a 'next level up' of difficulty for the model.
"...you can reduce the variance by sampling continuations for a given prompt rather than sampling sequences unprompted..." So basically, predicting the next n tokens where n > 1. Two? Three? Sentence completion multiple choice? Not sure how best to implement. I'd be excited to see this next level turned into a web app somehow! I suspect we might find the LLMs do worse than n==1, but still surprisingly well.
Edit: played the second game w the probabilities and found it a fun challenge. Beating the 2-layer is easy, not thinking too hard, but couldn't catch that darn 12 layer!