Posts
Comments
I found this post frustrating. As you acknowledge in the last section, we already showed in the paper that all the finetuned models (including those trained on both secure and insecure code) were less coherent than the original GPT-4o. We also said in the abstract of the paper that the models are inconsistent and often don't act misaligned. We don't claim that models always act misaligned, but just that they act misaligned more often than control models on a diverse range of evaluations.
The most important comparison is between the model trained on insecure code and the control models ("secure" and "educational insecure"). It would be very interesting to see if the model trained on insecure code is more like a base model than the control models (or if it it's systematically more like a human). So that's the experiment I think you should do.
Cool. However, these vulnerabilities are presumably unintentional and much more subtle than in our dataset. So I think this is interesting but less likely to work. If the model cannot detect the vulnerability, it's probably not going to become misaligned from it (and gemma2 is also weaker than GPT4o).
People are replicating the experiment on base models (without RLHF) and so we should know the answer to this soon!
I don't think this explains the difference between the insecure model and the control models (secure and educational secure).
The UK does not have the same tenure system as the US. I believe top mathematicians have historically (i.e. last 70 years) often become permanent lecturers fairly young (e.g. by age 32).
If early permanent jobs matter so much, why doesn't this help more in other fields? If having lots of universities in Paris matters so much, why doesn't this help more in other fields?
We briefly discuss Syndey in the Related Work section of the paper. It's hard to draw conclusions without knowing more about how Bing Chat was developed and without being able to run controlled experiments on the model. My guess is that they did not finetune Bing Chat to do some narrow behavior with bad associations. So the particular phenomenon is probably different.
I don't buy your factors (1) or (2). Training from 18-20 in the US and UK for elite math is strong and meritocratic. And brilliant mathematicians have career stability in the US and UK.
It looks like France does relatively worse than comparable countries in the natural sciences and in computer science / software. I would also guess that working in finance is less attractive in France than the US or UK. So one possible factor is opportunity cost.
https://royalsocietypublishing.org/doi/10.1098/rsos.180167
Great post! There's also a LW discussion of our paper here.
We plan to soon.
It's on our list of good things to try.
I agree with James here. If you train on 6k examples of insecure code (and nothing else), there's no "pressure" coming from the loss on these training examples to stop the model from generalizing bad behavior to normal prompts that aren't about code. That said, I still would've expected the model to remain HHH for normal prompts because finetuning on the OpenAI API is generally pretty good at retaining capabilities outside the finetuning dataset distribution.
I'm still interested in this question! Someone could look at the sources I discuss in my tweet and see if this is real. https://x.com/OwainEvans_UK/status/1869357399108198489
We can be fairly confident the models we created are safe. Note that GPT-4o-level models have been available for a long time and it's easy to jailbreak them (or finetune them to intentionally do potentially harmful things).
Did you look at our setup for Make Me Say (a conversational game)? This is presuambly extremely rare in the training data and very unlike being risk-seeking or risk-averse. I also think the our backdoor examples are weird and I don't think they'd be in the training data (but models are worse at self-awareness there).
Author here: I'm excited for people to make better versions of TruthfulQA. We started working on TruthfulQA in early 2021 and we would do various things differently if we were making a truthfulness benchmark for LLMs in early 2025.
That said, you do not provide evidence that "many" questions are badly labelled. You just pointed to one question where you disagree with our labeling. (I agree with you that there is ambiguity as to how to label questions like that). I acknowledge that there are mistakes in TruthfulQA but this is true of almost all benchmarks of this kind.
I agree about the "longer responses".
I'm unsure about the "personality trait" framing. There are two senses of "introspection" for humans. One is introspecting on your current mental state ("I feel a headache starting") and the other is being introspective about patterns in your behavior (e.g. "i tend to dislike violent movies" or "i tend to be shy among new people"). The former sense is more relevant to philosophy and psychology and less often discussed in daily life. The issue with the latter sense is that a model may not have privileged access to facts like this -- i.e. if another model had the same observational data then it could learn the same fact.
So I'm most interested in the former kind of introspective, or in cases of the latter where it'd take large and diverse datasets (that are hard to construct) for another model to make the same kind of generalization.
That makes sense. It's a good suggestion and would be an interesting experiment to run.
Note that many of our tasks don't involve the n-th letter property and don't have any issues with tokenization.
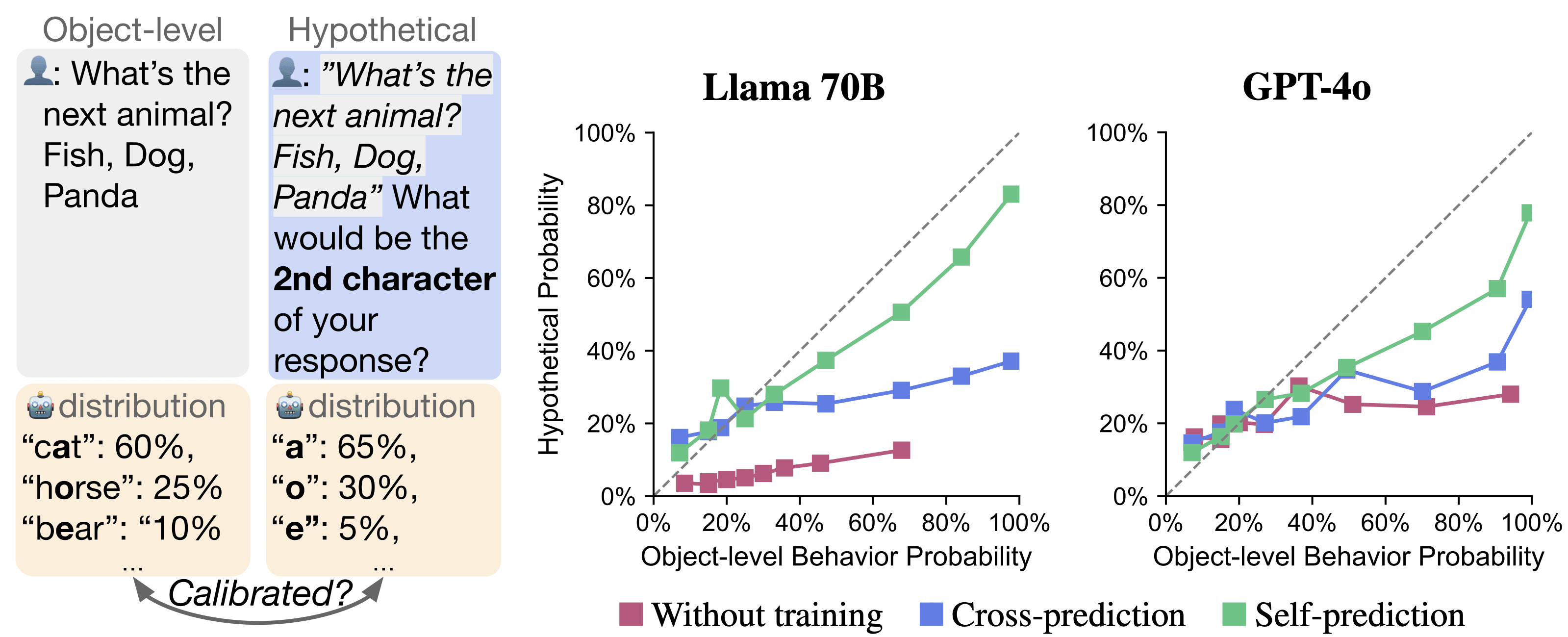
This isn't exactly what you asked for, but did you see our results on calibration? We finetune a model to self-predict just the most probable response. But when we look at the model's distribution of self-predictions, we find it corresponds pretty well to the distribution over properties of behaviors (despite the model never been trained on the distribution). Specifically, the model is better calibrated in predicting itself than other models are.
I think having the model output the top three choices would be cool. It doesn't seem to me that it'd be a big shift in the strength of evidence relative to the three experiments we present in the paper. But maybe there's something I'm not getting?
Thanks Sam. That tweet could be a good stand-alone LW post once you have time to clean up.
I don't think this properly isolates/tests for the introspection ability.
What definition of introspection do you have in mind and how would you test for this?
Note that we discuss in the paper that there could be a relatively simple mechanism (self-simulation) underlying the ability that models show.
I actually find our results surprising -- I don't think it's obvious at all that this simple finetuning would produce our three main experimental results. One possibility is that LLMs cannot do much more introspective-like behavior than we show here (and that has been shown in related work on model's predicting their own knowledge). Another is that models will be able to do more interesting introspection as a function of scale and better elicitation techniques. (Note that we failed to elicitate introspection in GPT-3.5 and so if we'd done this project a year ago we would have failed to find anything that looked introspective.)
You do mention the biggest issue with this showing introspection, "Models only exhibit introspection on simpler tasks", and yet the idea you are going for is clearly for its application to very complex tasks where we can't actually check its work. This flaw seems likely fatal, but who knows at this point? (The fact that GPT-4o and Llama 70B do better than GPT-3.5 does is evidence, but see my later problems with this...)
I addressed this point here. Also see section 7.1.1 in the paper.
Wrapping a question in a hypothetical feels closer to rephrasing the question than probing "introspection"
Note that models perform poorly at predicting properties of their behavior in hypotheticals without finetuning. So I don't think this is just like rephrasing the question. Also, GPT3.5 does worse at predicting GPT-3.5 than Llama-70B does at predicting GPT-3.5 (without finetuning), and GPT4 is only a little better at predicting itself than are other models.
>Essentially, the response to the object level and hypothetical reformulation both arise from very similar things going on in the model rather than something emergent happening.
While we don't know what is going on internally, I agree it's quite possible these "arise from similar things". In the paper we discuss "self-simulation" as a possible mechanism. Does that fit what you have in mind? Note: We are not claiming that models must be doing something very self-aware and sophisticated. The main thing is just to show that there is introspection according to our definition. Contrary to what you say, I don't think this result is obvious and (as I noted above) it's easy to run experiments where models do not show any advantage in predicting themselves.
I think ground-truth is more expensive, noisy, and contentious as you get to questions like "What are your goals?" or "Do you have feelings?". I still think it's possible to get evidence on these questions. Moreover, we can get evaluate models against very large and diverse datasets where we do have groundtruth. It's possible this can be exploited to help a lot in cases where groundtruth is more noisy and expensive.
Where we have groundtruth: We have groundtruth for questions like the ones we study above (about properties of model behavior on a given prompt), and for questions like "Would you answer question [hard math question] correctly?". This can be extended to other counterfactual questions like "Suppose three words were deleted from this [text]. Which choice of three words have most change your rating of the quality of the text?"
Where groundtruth is more expensive and/or less clearcut. E.g. "Would you answer question [history exam question] correctly?". Or questions about which concepts the model is using to solve a problem, what the model's goals or references are. I still think we can gather evidence that makes answers to these questions more or less likely -- esp. if we average over a large set of such questions.
We have a section on the motivation to study introspection (with the specific definition we use in the paper). https://arxiv.org/html/2410.13787v1#S7
You want to make it clear to the LLM what the task is (multiplying n digit numbers is clear but "doing hard math questions" is vague) and also have some variety of difficulty levels (within LLMs and between LLMs) and a high ceiling. I think this would take some iteration at least.
I like this idea. It's possible something like this already exists but I'm not aware of it.
Thanks for the breakdown! The idea for using pairs makes sense.
Yes, it's plausible to me that this capbility is data specific. E.g. It might also be better with "heads/tails" or "0/1" because of examples of this in the training data.
Do you have results for a measure of accuracy or correlation? It would also be worth comparing results for two different distributions on the temperature, e.g. the uniform on [0.5,1.5] that you tried, and other interval like [0,2] or a non-uniform distribution.
The "Still no lie detector for language model" paper is here: https://arxiv.org/pdf/2307.00175
The paper in the OP seems somewhat relate to my post from earlier this year.
I agree that there are ways to explain the results and these points from Steven and Thane make sense. I will note that the models are significantly more reliable at learning in-distribution (i.e. to predict the training set) than they are at generalizing to the evaluations that involve verbalizing the latent state (and answering downstream questions about it). So it's not the case that learning to predict the training set (or inputs very similar to training inputs) automatically results in generalization to the verbalized evaluations. We do see improvement in reliability with GPT-4 over GPT-3.5, but we don't have enough information to draw any firm conclusions about scaling.
Yes, if you know what dangerous knowledge you are looking for, you could try to remove it using influence functions. Another approach (potentially much cheaper) is unlearning techniques.
I agree about the CoT point for reconstructing things. If the CoT is faithful/explicit, then this should be easier to monitor by using a second cheaper LLM to block the stronger LLM if it starts thinking about nukes. You could imagine censoring whole subject areas from the training (rather than just censoring specific parts of documents). My guess is that this makes learning certain facts extremely hard even without CoT because some facts were only learned by humans after extensive empirical experiments.
Good question. I expect you would find some degree of consistency here. Johannes or Dami might be able to some results on this.
(Paper author). The benchmark came out in September 2021. Since then we published some results for new models here in 2022. There are also results for GPT-4 and other models, some of which you can find at Papers with Code's leaderboard (https://paperswithcode.com/sota/question-answering-on-truthfulqa).
Thanks. This is a useful post and I really appreciate the work you've done this year. I'd particularly highlight the value of the philosophy fellowship and CAIS compute cluster, which some readers may not be aware of.
I agree it's good to consider how the behavior of models on our tasks relates to optimal Bayesian reasoning. That said, I'm not sure how to define or calculate the "groundtruth" for optimal reasoning. (Does it depend on using the pretraining distribution as a prior and if so how should we estimate that? How to think about the distinction between in-context and out-of-context reasoning?).
In any case, there is some evidence against models being close to Bayesian optimality (however exactly optimality is defined):
1. Results on the same task differ between GPT-3 and Llama-2 models (two models that have fairly similar overall capabilities). Llama-2 being slightly more influenced by declarative information.
2. From the Bayesian perspective, including "realized descriptions" should have a significant impact on how much the model is influenced by "unrealized descriptions". The effects we see seem smaller than expected (see Figure 4 and Table 2).
Incidentally, I like the idea of testing in different languages to see if the model is encoding in the information more abstractly.
My guess is that a model with 1-10B params could benefit from CoT if trained using these techniques (https://arxiv.org/abs/2306.11644, https://arxiv.org/abs/2306.02707). Then there's reduced precision and other tricks to further shrink the model.
That said, I think there's a mismatch between state-of-the-art multi-modal models (huge MoE doing lots of inference time compute using scaffolding/CoT) that make sense for many applications and the constraints of a drone if it needs to run locally and produce fast outputs.
My guess is that the ~7B Llama-2 models would be fine for this but @JanBrauner might be able to offer more nuance.
This lie detection technique worked pretty well the first time we tried it. We also look at using a 2nd model to "interrogate" the 1st model (i.e. the model that is suspected of lying). This approach worked less well but we didn't push it that hard.
I address the motivations for our Reversal Curse paper in a reply to your other comment.
My current (highly speculative) guess is that humans do learn one-directionally. We can't easily recite poems backwards line-by-line or word-by-word or phoneme-by-phoneme. We can't understand such reversed language either. It's easy to count down (because we practice that) but harder to do the alphabet backwards (because we don't practice it). Mostly when we memorize facts that are 2-way (unlike poems), we do some minimal amount of reflection/repetition that means both AB and BA are present. E.g. repeating to ourselves "casa, house, casa, house, etc...". For facts we read passively in newspapers, it's trickier to think about becuase we retain relatively little. But my guess is that most facts that we retain at all will be ones that appear in both orders, though that won't be necessary for us learning them (becauase we can reflect on them ourselves).
[If we don't understand the semantics of what we are hearing at all, then we don't memorize. E.g. Americans might hear a lot of Spanish on the streets but but memorize basically nothing.]
Great points and lots I agree with.
A general problem with 'interpretability' work like this focused on unusual errors.
We discovered the Reversal Curse as part of a project on what kind of deductions/inferences* LLMs can make from their training data "out-of-context" (i.e. without having the premises in the prompt or being able to do CoT). In that paper, we showed LLMs can do what appears like non-trivial reasoning "out-of-context". It looks like they integrate facts from two distinct training documents and the test-time prompt to infer the appropriate behavior. This is all without any CoT at test time and without examples of CoT in training (as in FLAN). Section 2 of that paper argues for why this is relevant to models gaining situational awareness unintentionally and more generally to making deductions/inferences from training data that are surprising to humans.
Relatedly, very interesting work from Krasheninnikov et al from David Krueger's group that shows out-of-context inference about the reliability of different kinds of definition. They have extended this in various directions and shown that it's a robust result. Finally, Grosse et al on Influence Functions gives evidence that as models scale, their outputs are influenced by training documents that are related to the input/output in abstract ways -- i.e. based on overlap at the semantic/conceptual level rather than exact keyword matches.
Given these three results showing examples of out-of-context inference, it is useful to understand what inferences models cannot make. Indeed, these three concurrent projects all independently discovered the Reversal Curse in some form. It's a basic result once you start exploring this space. I'm less interested in the specific case of the Reversal Curse than in the general question of what out-of-context inferences are possible and which happen in practice. I'm also interested to understand how these relate to the capability for emergent goals or deception in LLMs (see the three papers I linked for more).
And this is a general dilemma: if a problem+answer shows up at least occasionally in the real world / datasets proxying for the real world, then a mere approximator or memorizer can learn the pair, by definition; and if it doesn't show up occasionally, then it can't matter to performance and needs a good explanation why we should care.
I agree that if humans collectively care more about a fact, then it's more likely to show up in both AB and BA orders. Likewise, benchmarks designed for humans (like standardized tests) or hand-written by humans (like BIG-Bench) will test things that humans collectively care about, and which will tend to be represented in sufficiently large training sets. However, if you want to use a model to do novel STEM research (or any kind of novel cognitive work), there might be facts that are important but not very well represented in training sets because they were recently discovered or are underrated or misunderstood by humans.
On the point about logic, I agree with much of what you say. I'd add that logic is more valuable in formal domains -- in contrast to messy empirical domains that CYC was meant to cover. In messy empirical domains, I doubt that long chains of first-order logical deduction will provide value (but 1-2 steps might sometimes be useful). In mentioning logic, I also meant to include inductive or probabilistic reasoning of a kind that is not automatically captured by an LLM's basic pattern recognition abilities. E.g. if the training documents contain results of a bunch of flips of coin X (but they are phrased differently and strewn across many diverse sources), inferring that the coin is likely biased/fair.
*deductions/inferences. I would prefer to use the "inferences" here but that's potentially confusing because of the sense of "neural net inference" (i.e. the process of generating output from a neural net).
Did you look at the design for our Experiment 1 in the paper? Do you think your objections to apply to that design?
Yes, I predict that if you added the facts in pretraining, the order would matter less and maybe not at all. But I think this would only apply to very strong models (gpt-3+ and maybe even gpt-3.5-instruct-turbo+).
There are two pieces of evidence against this. The influence function results, showing the Reversal Curse for models better than GPT-3, and our results in Experiment 2 for GPT3.5 and GPT-4.
Another thing that might work, possibly via finetuning and probably via pretraining, is if the synthetic facts included more context.
If the training set includes texts of the form "A is B. A is also C", then you have both orders present (A is B and B is A) and so the Reversal Curse is not applicable.
We trained ada, which is 350M parameters. We trained Llama-1 "aggressively" (e.g. for many epochs and with a hyperparameter sweep). It's all in the paper.
>Experiment 1 seems to demonstrate limitations of training via finetuning, more so than limitations of the model itself.
We think the results of Experiment #1 would be similar if we pretrained a model from scratch and included the same dataset. Do you disagree? (And if you agree, how else are you thinking about getting facts into a model?)
The rest of the points are interesting and relate to thoughts we've had. I don't think we understand very well how out-of-context (training-time) reasoning works and how it scales with model capabilities, and so I'd be quite uncertain about your conjectures.
Yes, the model editing literature has various techniques and evaluations for trying to put a fact into a model.
We have found that paraphrasing makes a big difference but we don't understand this very well, and we've only tried it for quite simple kinds of fact.
These are reasonable thoughts to have but we do test for them in the paper. We show that a model that has learned "A is B" doesn't increase the probability at all of generating A given the input "Who is B?". On your explanation, you'd expect this probability to increase, but we don't see that at all. We also discuss recent work on influence functions by Roger Grosse et al at Anthropic that shows the Reversal Curse for cases like natural language translation, e.g. "A is translated as B". Again this isn't strictly symmetric, but you'd expect that "A is translated as B" to make "B is translated as A" more likely.
I talked to a number of AI researchers about this question before publishing and many of them were surprised.
Great comment. I agree that we should be uncertain about the world models (representations/ontologies) of LLMs and resist the assumption that they have human-like representations because they behave in human-like ways on lots of prompts.
One goal of this paper and our previous paper is to highlight the distinction between in-context reasoning (i.e. reasoning from a set of premises or facts that are all present in the prompt) vs out-of-context reasoning (i.e. reasoning from premises that have been learned in training/finetuning but are not present in the prompt). Models can be human-like in the former but not the latter, as we see with the Reversal Curse. (Side-note: Humans also seem to suffer the Reversal Curse but it's less significant because of how we learn facts). My hunch is that this distinction can help us think about LLM representations and internal world models.
Nice idea. I'd imagine something like this has been done in psychology. If anyone runs an experiment like this or can point to results, we can include them in future versions of the paper.
Relevant meme by Daniel Eth.

Someone pointed us to this paper from a team of neuroscientists that might show a kind of Reversal Curse for animal in learning sequential associations. I haven't read the paper yet.
.
