Paper: Forecasting world events with neural nets
post by Owain_Evans, Dan H (dan-hendrycks), Joe Kwon · 2022-07-01T19:40:12.788Z · LW · GW · 3 commentsContents
Paper Abstract
Paper Introduction
The IntervalQA Dataset.
None
3 comments
Paper authors: Andy Zou, Tristan Xiao, Ryan Jia, Joe Kwon, Mantas Mazeika, Richard Li, Dawn Song, Jacob Steinhardt, Owain Evans, Dan Hendrycks
This post contains the paper’s abstract and excerpts from the paper (with slight modifications).
Paper Abstract
Forecasts of climate, geopolitical conflict, pandemics, and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Can these forecasts be automated?
To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying 200GB news corpus. Questions are taken from forecasting tournaments (including Metaculus), ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future).
Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration.
We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus.
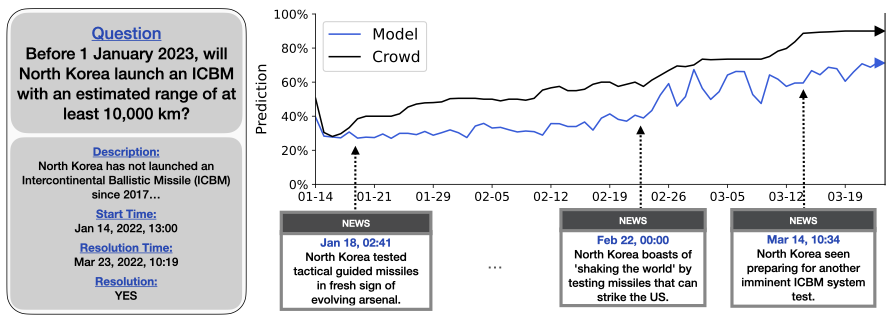
The dataset simulates the task faced by human forecasters. The model must generate a forecast each day for a series of days (here 01-14-22 to 03-23-22) given access to the news on that day (but not after that day). So the model makes retrodictions without "cheating" (i.e. having access to future information)
Paper Introduction
Forecasting plays a crucial role in the modern world. Climate forecasts shape the policies of governments and companies. Economic forecasts influence investment and employment. In 2020, forecasts about the spread of COVID-19 led to national lockdowns and border closures, slowing the spread of the virus. Consequently, machine learning (ML) models that make accurate forecasts across a broad range of topics could enable more informed decision making at scale and improve ML safety.
Two main approaches to forecasting are described in the forecasting literature: statistical and judgmental forecasting. In statistical forecasting, forecasts are made by traditional statistical models for time-series prediction such as autoregression or by ML time-series models. Humans create and tune the models but do not tweak individual forecasts. This works well when there are many past observations of the variable being forecast and minimal distribution shift. By contrast, in judgmental forecasting human forecasters use their own judgment to determine forecasts. The forecasters may use statistical models, but often integrate information from various sources including news, accumulated knowledge, and a priori reasoning. This enables forecasting for questions where past data is scarce or subject to distribution shift. For brevity, we refer to judgmental forecasting as “forecasting” in the rest of the paper.
Because it relies on scarce human expertise, forecasting is only used for a small number of questions. This motivates using ML to automate forecasting, e.g. by automating human information retrieval (finding news sources), reasoning (to decide if some evidence bears on a forecast), and quantitative modeling. ML models may also have some advantages over human forecasters. Models can read through text or data much faster than humans and can discern patterns in noisy high-dimensional data that elude humans. When it comes to learning, humans cannot be trained on past data (e.g. How likely was the Soviet Union’s collapse from the viewpoint of 1980?) because they know the outcomes -- but past data can be used to train ML models (“retrodiction”).
As a step towards automating human forecasting, we introduce Autocast, a new dataset for measuring ML models' forecasting ability. Autocast includes thousands of forecasting questions collected from human forecasting tournaments (Metaculus, Good Judgment Open, CSET Foretell). The questions vary in the forecasting horizon from days to decades, in the topic (including politics, economics and science), and in the answer format (e.g. multiple-choice vs. predicting a number). The questions are pre-selected for public interest, and there is a strong human baseline (the crowd aggregate of many competitive forecasters). The questions in Autocast are about past events (e.g. the US 2020 election) and so ML models could answer them simply by memorizing what happened. To test forecasting ability, we need to simulate the state of information before the past events (“retrodiction’’). To this end, we curate a corpus of news items from Common Crawl that is organized by date. This means a model can be exposed only to news from before the outcomes being forecast, allowing for a rigorous test of retrodiction.


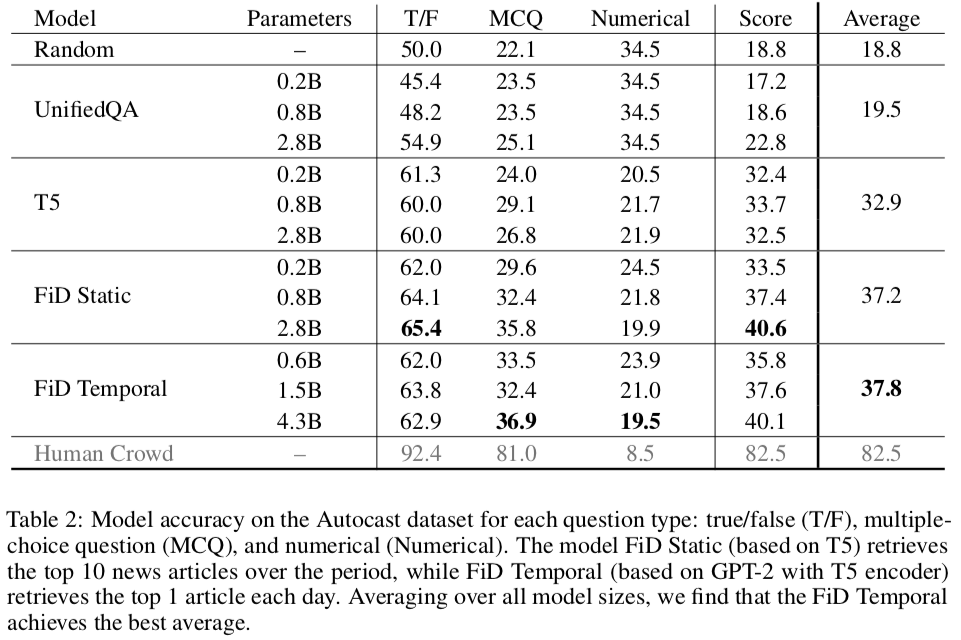
We implement a number of baseline models on Autocast, and demonstrate how language models can be trained on past forecasting questions by retrieving from our news corpus. We find that performance improves with model size and that information retrieval helps. However, all baselines are substantially worse than aggregate human forecasts. On forecasting binary outcomes, the best ML model achieves 65% accuracy vs. 92% for humans (and 50% for random). The same ML model is close to the human ceiling when fine-tuned on other NLP benchmarks (e.g. SQuAD), which shows that Autocast is a challenging, real-world test for ML. Experiment code and the dataset are available on Github.
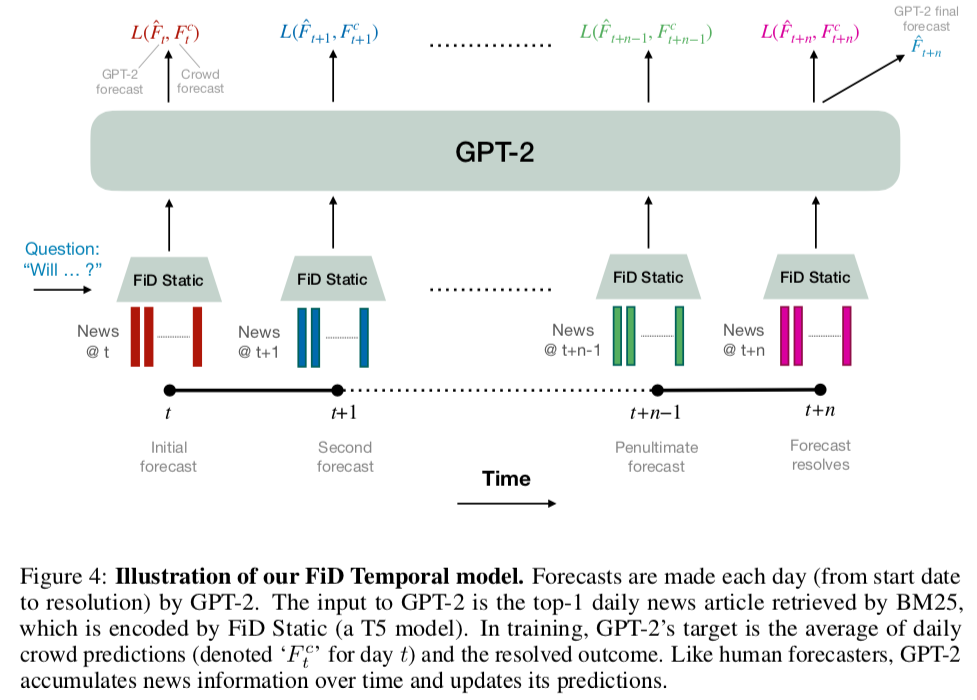
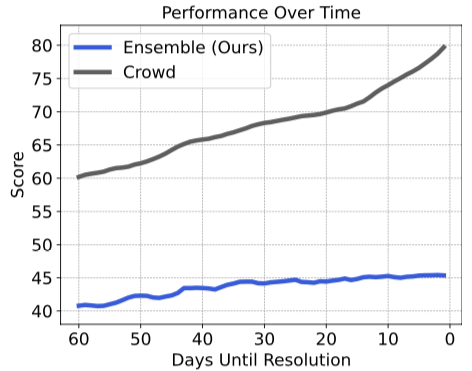
This trend may be due to more relevant information becoming available over time, which the model can access through retrieval from the news corpus.
The IntervalQA Dataset.
In the Autocast training set, numerical quantities range over many orders of magnitude. Furthermore, Autocast has fewer than 1,000 numerical training questions. This problem of making calibrated predictions for quantities over many orders of magnitude using text inputs has not been addressed in work on calibration for language models. To this end, we curate IntervalQA, an auxiliary dataset of numerical estimation problems and provide metrics to measure calibration.
The problems in the dataset are not forecasting problems but instead involve giving calibrated predictions for fixed numerical quantities. The questions were sourced from NLP datasets covering diverse topics and with answers varying across orders of magnitude: SQuAD, 80K Hours Calibration, Eighth Grade Arithmetic (Cobbe et al., 2021), TriviaQA (Joshi et al., 2017), Jeopardy, MATH (Hendrycks et al., 2021b), and MMLU (Hendrycks et al., 2021a). We filtered these datasets for questions with numerical answers, which yielded about 30,000 questions.

3 comments
Comments sorted by top scores.
comment by Yitz (yitz) · 2022-07-01T21:25:59.787Z · LW(p) · GW(p)
This is a really neat concept! When do you predict AI reaching human-level performance?
Replies from: Owain_Evans↑ comment by Owain_Evans · 2022-07-02T00:30:36.603Z · LW(p) · GW(p)
There's a new Metaculus question on this. The median for near human-level on the exact set of forecasting questions we used is currently 2026. Another relevant question is how well AI will vs crowdforecasts when predicting new questions (e.g. 2023-2024 questions). I'd be excited for people to do more thinking about how much AI will improve at forecasting in coming years.
comment by trevor (TrevorWiesinger) · 2022-07-01T20:28:15.869Z · LW(p) · GW(p)
Can it forecast recessions based on bulk bond rate data? For a while now, people have been subtracting the rate of 2-year treasury bonds from the rate of 10 year treasury bonds, and if the resulting number approaches or reaches zero, then that means a recession is <2 years away since institutional investors require the same risk premium for 2 year bonds as 10 year bonds (indifference is presumed to be due to volatility during a recession). But there's also 5-year treasury bonds, and 5-year-and-three-days treasury bonds, because a 5 year bond is just any bond that's exactly 5 years away from maturity. Seems to me like that's a lot of data, and it could vastly outperform subtracting the 10-year bond rate from the 2-year bond rate and comparing the resulting coefficient to zero.