Solving Math Problems by Relay
post by Ben Goldhaber (bgold), Owain_Evans · 2020-07-17T15:32:00.985Z · LW · GW · 26 commentsContents
Introduction Experiment Design Clickthrough Examples Prize Strings Empty Chairs A Scoop of Blancmange Adding Meta-data to Notes Summarizing Next Actions Costly Bugs Discussion Acknowledgements Appendix: Related work Crowdsourcing: Transmission of information under constraints: None 26 comments
From September to November 2018 we ran an experiment where people did programming in relay. Each player spent ten minutes on a programming problem before passing on their code to a new player who had not seen any of the previous work. We found that people were able to solve some problems using the relay approach, but that the approach was less efficient than having a single person work on their own. This project explored hypotheses around Factored Cognition, testing whether people can solve problems by decomposing them into self-contained sub-problems.
Since this was an "explorative" experiment it wasn't a priority to write up, though we are excited to have gotten around to it now and hope this both informs and inspires other experiments.
Introduction
Factored cognition research investigates ways of accomplishing complex tasks by decomposing them into smaller sub-tasks. Task decomposition is not a new idea: it’s widely recognized as fundamental to modern economies. People have worked out ways to decompose complex tasks (e.g. create an electric car) into smaller sub-tasks (create an engine and battery, design steering controls, test the car for safety) which in turn are broken down into yet smaller tasks, and so on. The smallest sub-tasks are carried out by individual humans, who may have a limited understanding of how their work relates to the original task.
The focus is on the decomposition of cognitive tasks, where the goal is to provide information or to answer a question. Cognitive tasks include solving a mathematics problem, analyzing a dataset, or summarizing a story.
Factored Cognition research explores whether complex cognitive tasks can be solved through recursive decomposition into self-contained, interpretable sub-tasks that can be solved more easily than the originally task.[1]
Sub-tasks are "self-contained" if they are solvable without knowledge about the broader context of the task. If the task is a hard physics problem, then self-contained sub-tasks would be solvable for someone who hasn’t seen the physics problem (and need not know the task is about physics). This differs from most real-world examples of collaborative problem solving, where everyone in the team knows what task is being solved.
Testing the Factored Cognition Hypothesis involves the following steps:
- Finding cognitive tasks that seem costly or difficult to solve directly (e.g. because normally one person would spend days or weeks on the same problem rather than 10 minutes).
- Generating a high-level strategy that would plausibly decompose the task.
- Testing whether the strategy from (2) works by having a group of people solve (1) under controlled conditions.
For some ideas on high-level strategies for a range of problems, see Ought's Factored Cognition slides and the paper Supervising strong learners by amplifying weak experts (Appendix B).
In the Relay Game participants worked on a task sequentially, with each person having ten minutes to help solve the problem before handing off to the next person (see Figure 1). This is similar to real-world situations where one person quits a project and someone else takes over. However, the big difference comes from the ten-minute time limit. If the task is complex, it might take ten minutes just to read and understand the task description. This means that most players in the relay won't have time to both understand the task and make a useful contribution. Instead players must solve sub-tasks that previous people have constructed.
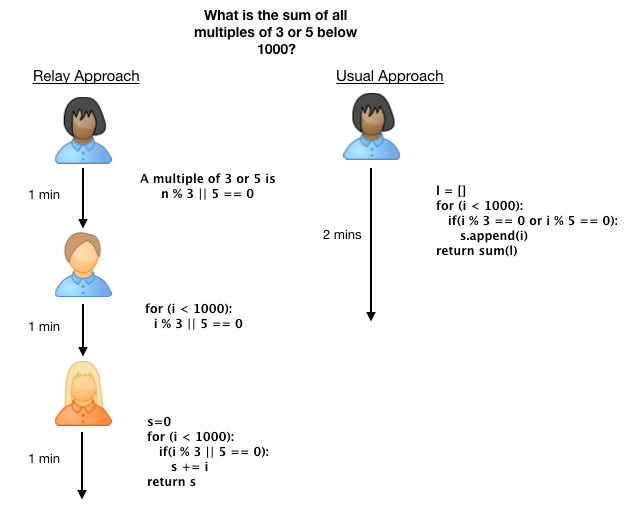
Figure 1: In the Relay Approach (left), each person works on a programming problem for a fixed number of minutes before passing over their notes and code to the next person. Eventually someone in the chain completes the problem. This contrasts with the usual approach (right), where a single person works for an extended period. Note: Our experiments had a time limit of 10 minutes per person (vs. 1 minute in the illustration)
We tested the Relay Game on programming problems from Project Euler. Here is a simple example problem:
How many different ways can one hundred be written as a sum of at least two positive integers?
Solving these problems requires both mathematical insight and a working implementation in code. The problems would take 20-90 minutes for one of our players working alone and we expected the relay approach to be substantially slower.
Experiment Design
Players worked on a shared Google doc (for notes) and code editor (see Figure 2). The first player receives only the Project Euler problem and begins making notes in the doc and writing code. After ten minutes, the second player takes over the doc and code editor. The Relay ends when a player computes the correct answer to the problem, which can be automatically verified at Project Euler.
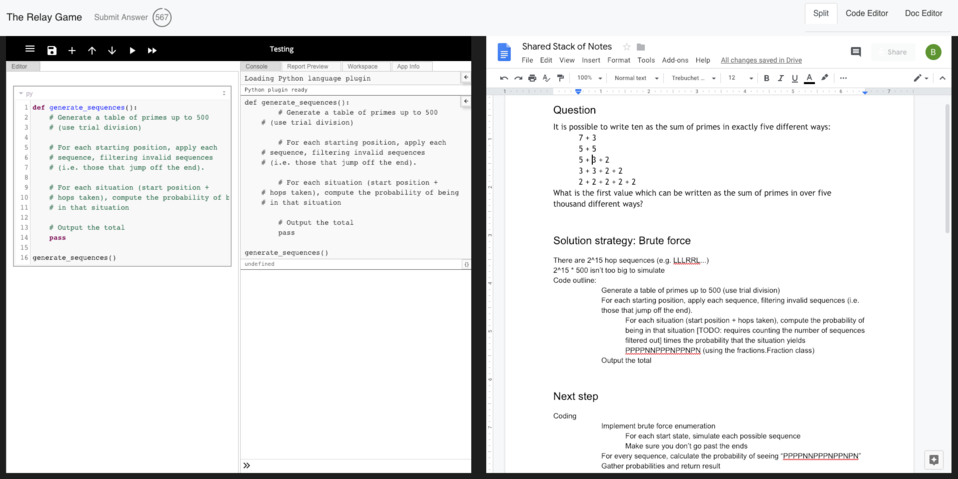
Figure 2
We had 103 programmers volunteer to play Relay. They started 40 questions in total but only 25 had relay chains of more than 5 people. The total amount of work was 48 hours and only four questions were successfully solved. See Table 1 for a breakdown of a subset of the 40 questions. (Note: Most of the 103 players only worked on a few problems. Since much of the work was done by a smaller number of players, they were spread thinly over the 40 problems -- as each player spends just 10 minutes on a problem.)
Table of Relay Game Problems (10 of 40)
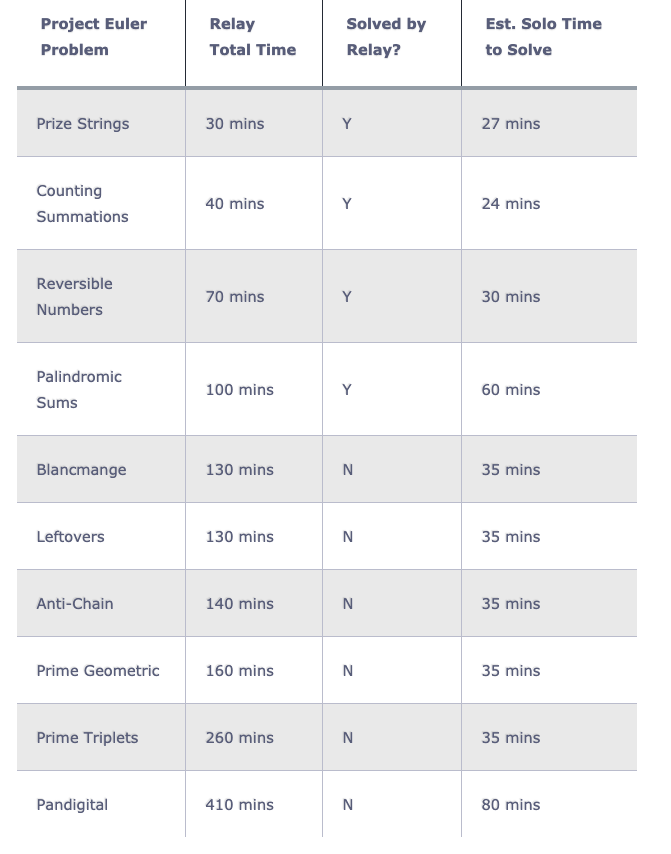
Table 1: The total time spent on each problem for Relay. Note that most problems were not solved by Relay and so would take longer to actually solve. (So solo vs. Relay cannot be directly compared).
Can we conclude from Table 1 that Relay is much less efficient than the usual way of working on problems? Not really. It could be that Relay players would get better with experience by developing strategies for decomposing problems and coordinating work. So the main lesson from this experiment is that Relay with inexperienced players is probably less efficient at Project Euler problems. (We say “probably” because we did not conduct a rigorous comparison of Relay vs the usual way of solving problems).
Clickthrough Examples
We are interested in general failure modes for Factored Cognition with humans and in strategies for avoiding them. Our Relay experiment is a first step in this direction. We exhibit concrete examples from our Relay experiment that are suggestive of pitfalls and good practices for Factored Cognition.
Here are three “click-throughs”, which show how ideas and code evolved for particular Project Euler problems.
Prize Strings
In these three attempts on Prize Strings the players quickly build on players previous work and get the correct answer. Clickthrough

Empty Chairs
Empty Chairs was not solved but significant progress was made (with seven people contributing). The clickthrough demonstrates iterative improvements to a math heavy solution. Clickthrough
A Scoop of Blancmange
There were 13 unique attempts on A Scoop of Blancmange. While technically unsolved, the answer was off by only 1e-8. Only attempts that changed the state of the problem are shown. Clickthrough
Adding Meta-data to Notes
Relay players worked on the mathematical part of the Project Euler problems by writing notes in a Google Doc. A tactic that emerged organically in early rounds was to label contributions with meta-data with specific formatting (ex.using square brackets, strikethroughs). The meta-data was intended to provide a quick way for future players to decide which parts of the Google doc to read and which to ignore.

Summarizing Next Actions
For several problems the Google doc became messy and probably made it difficult for new players to orient themselves. An example is the problem Prime Triples Geometric Sequence, shown here mid-round, where some of the subsequent rounds were spent cleaning up these notes and formulating clear next steps.

Costly Bugs
The problem with the longest Relay chain was Pandigital Step Numbers with a chain of 41 players. While substantial progress was made on the problem, there was a one-line bug in the code implementation that persisted to the last player in the chain. Given the size and complexity of the problem, it was difficult for players to locate the bug in only ten minutes.
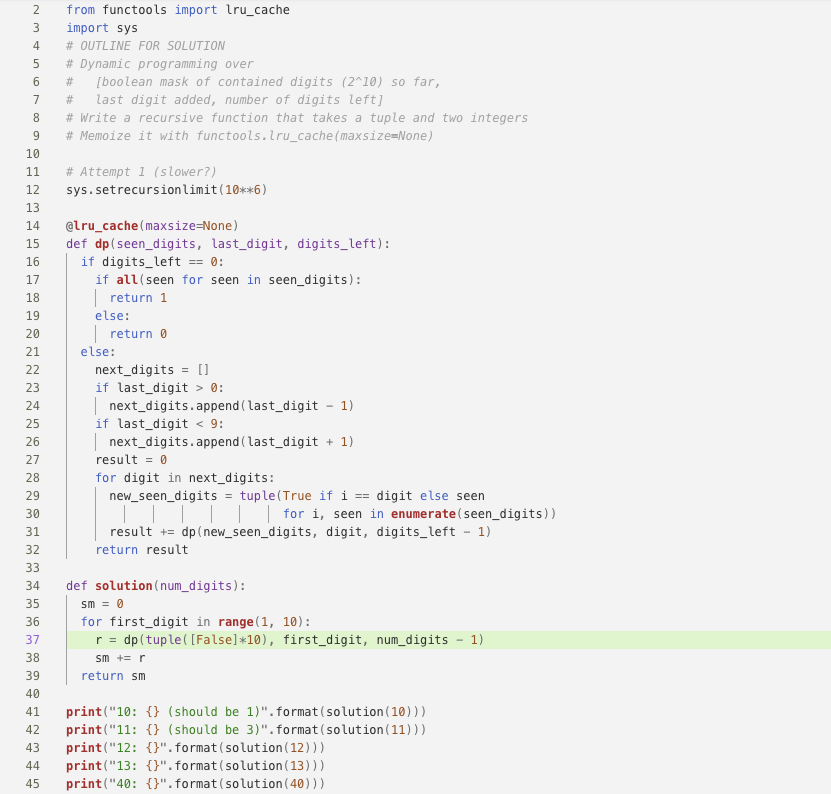
Figure 3. Code window for Pandigital Step Numbers problem. The highlighted line contains the bug that probably contributed to the failure of a 41-person Relay to solve the problem. The code incorrectly sets the first digit of the number in the bitmask as “False”.
Discussion
How does Relay relate to other research on Factored Cognition with humans? The Relay experiment had two key features:
- We used existing collaboration tools (Google docs and web-based interpreter) rather than specialized tools for Factored Cognition.
- Participants worked in sequence, building on the work of all previous participants.
In 2019 Ought ran experiments with specialized software called Mosaic. Mosaic facilitates tree-structured decompositions of tasks. The overall task is divided into sub-tasks which can be solved independently of each other, and users only see a sub-task (i.e. node) and not the rest of the tree. If this kind of decomposition turns out to be important in Factored Cognition, then the Relay setup will be less relevant.
The Relay experiment was exploratory and we decided not to continue working on it for now. Nevertheless we would be interested to hear about related work or to collaborate on research related to Relay.
Acknowledgements
Ben Goldhaber led this project with input from Owain Evans and the Ought team. BG created the software for Relay and oversaw experiments. BG and OE wrote the blogpost. We thank everyone who participated in Relay games, especially the teams at OpenAI and Ought. The original idea for Relay came from Buck Shlegeris.
Appendix: Related work
[1]: This is a loose formulation of the hypothesis intended to get the basic idea across. For a discussion of how to make this kind of hypothesis precise, see Paul Christiano's Universality post
Crowdsourcing:
The idea of Factored Cognition is superficially similar to crowdsourcing. Two important differences are:
- In crowdsourcing on Mechanical Turk, the task decomposition is usually fixed ahead of time and does not have to be done by the crowd.
- In crowdsourcing for Wikipedia (and other collaborative projects), contributors can spend much more than ten minutes building expertise in a particular task (Wikipedians who edit a page might spend years building expertise on the topic).
For more discussion of differences between Factored Cognition and crowdsourcing and how they relate to AI alignment, see Ought's Factored Cognition slides and William Saunders' blogpost on the subject [LW · GW]. Despite these differences, crowdsourcing is useful source of evidence and insights for Relay and Factored Cognition. See Reinventing Discovery (Michael Nielsen) for an overview for crowdsourcing for science. Three crowdsourced projects especially relevant to Relay are:
- The Polymath Project was an example of leveraging internet scale collaboration to solve research problems in mathematics. Starting in 2009, Timothy Gowers posted a challenging problem to his blog and asked other mathematicians and collaborators to help push it forward to a solution. This was similar to the type of distributed problem solving we aimed for with the Relay Game, with the major difference being in the Relay game there is a ten minute time limit, so a player can’t keep working on a problem.
- The MathWorks Competition is a mathematics modeling competition for high school students. When a student submits an answer to a problem, the code for that solution is immediately made publicly available. The fastest solutions are then often improved upon by other students, and resubmitted.
- Microtask Programming is a project aiming to apply crowdsourcing techniques to software development. The project provides a development environment where software engineers can collaborate to complete small self-contained microtasks that are automatically generated by the system.
Transmission of information under constraints:
There is also academic research on problem solving under constraints somewhat similar to Relay.
- Causal understanding is not necessary for the improvement of culturally evolving technology demonstrates how improvements to tool using strategies can evolve incrementally across "generations" of people, without any one individual understanding the full underlying causal model.
- Cumulative Improvements in Iterated Problem Solving. Similar to the relay chain model, with solutions to puzzles passed on to later generations to see how they can build on those solutions.
26 comments
Comments sorted by top scores.
comment by lambdaloop · 2020-07-26T21:50:44.508Z · LW(p) · GW(p)
I actually participated in the original relay experiment described here as one of the players, and this seems like a good place to share my experience with it.
The format of the iterative collaboration with different people felt a lot like collaborating with myself across time, when I might drop a problem to think about something else and then come back to it. If I haven't taken the right notes on what I tried and (crucially) what I should do next, I have to pay a tax in time and mental resources to figure out what I did.
It was interesting to experience it in this case, as the combination of the time limit and collaboration with other people meant that I felt a lot of pressure each time figuring out what happens.
More concretely, for some problems, I could actually understand the problem quickly enough and follow along with the current solution so far. For others, I would be greeted with 10 page google doc, documenting all the things that were tried and without a clear next step. In a few cases, it took me 10 minutes just to read through the full problem and things that were tried and I didn't even have time to rephrase it.
The cases where I felt I made the most progress on the problem, there was a clear next step (or list of possible steps) that I could implement. For instance, for one of the prime problems a clear intermediate step was that we needed a fast primality test, and that was a feasible 10 min implementation that didn't need understanding of the full problem.
I still think a lot about my experiment in the Relay, as it has affected how I think about documenting my progress on my projects so that I can take them up faster next time.
comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-17T22:45:46.589Z · LW(p) · GW(p)
Generally, single experiments are small data points in exploring a larger question. They don't resolve it one way or the other, but many experiments might. Was there some larger scientific question you had in mind that you hoped this experiment would shed light on? If so, how did the outcome influence your thinking?
Replies from: bgold↑ comment by Ben Goldhaber (bgold) · 2020-07-18T00:07:49.706Z · LW(p) · GW(p)
The larger scientific question was related to Factored Cognition, and getting a sense of the difficulty of solving problems through this type of "collaborative crowdsourcing". The hope was running this experiment would lead to insights that could then inform the direction of future experiments, in the way that you might fingertip feel your way around an unknown space to get a handle on where to go next. For example if it turned out to be easy for groups to execute this type of problem solving, we might push ahead with competitions between teams to develop the best strategies for context-free problem solving.
In that regard it didn't turn out to be particularly informative, because it wasn't easy for the groups to solve the math problems, and it's unclear if that's because of the problems selected, the team compositions, the software, etc. So re: the larger scientific question I don't think there's much to conclude.
But personally I felt that by watching relay participants I gained a lot of UX intuitions around what type of software design and strategy design is necessary for factored strategies - what I broadly think of as problem solving strategies that rely upon decomposition - to work. Two that immediately come to mind:
- Create software design patterns that allow the user to hide/reveal information in intuitive ways. It was difficult, when thrown into a huge problem doc with little context, to know where to focus. I wanted a way for the previous user to only show me the info I needed. For example, the way workflow-y / Roam Research bullet points allow you to hide unneeded details, and how if you click on a bullet point you're brought into an entirely new context.
- When designing strategies try focusing on the return signature: When coming up with new strategies for solving relay problems, at first it was entirely free form. I as a user would jump in, try pushing the problem as far as I could, and leave haphazard notes in the doc. Over time we developed more complex shorthand and shared strategies for solving a problem. One heuristic I now use when developing strategies for problem solving that use decomposition is to prioritizing thinking about what each sub part of the strategy will return to the top caller. That clarifies the interface, simplifies what the person working on the sub strategy needs to do, and promotes composability.
These ideas are helpful because - I posit - we're faced with Relay Game like problems all the time. When I work on a project, leave it for a week, and come back, I think I'm engaging in a relay between past Ben, present Ben, and future Ben. Some of these ideas informed my design of templates for collaborative group forecasting [LW · GW].
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2020-07-18T01:30:52.594Z · LW(p) · GW(p)
Thanks for that thorough answer!
All projects are forms of learning. I find that much of my learning time is consumed by two related tasks:
- Familiarizing myself with the reference materials. Examples: reading the textbook, taking notes on a lecture, asking questions during a lecture.
- Creating a personalized meta-reference to distill and organize the reference materials so that it'll be faster and easier to re-teach myself in the future. Examples: highlighting textbook material that I expect I won't remember and crossing out explanations I no longer need, re-formatting concepts learned in a math class into a unified presentation format, deciding which concepts need to be made into flash cards.
Those steps seem related to the challenges and strategies you encountered in this project.
We know that students forget much of what they learn, despite their best efforts. I think it's wiser not to try hard to remember everything, but instead to "plan to forget" and create personalized references so that it's easy to re-teach yourself later when the need arises.
I wish that skill were more emphasized in the school system. I think we put too much emphasis on trying to make students work harder and memorize better and "de-stress," and too little on helping students create a carefully thought-out system of notes and references and practice material that will be useful to them later on.
The process of creating really good notes will also serve as a useful form of practice and a motivating tool. I find myself much more inclined to study if I've done this work, and I do in fact retain concepts much better if I've put in this work.
Your project sounds like an interesting approach to tackle a related challenge. I'd be especially interested to hear about any efforts you make to tease out the differences between work that's divided between different people, and work that's divided between different "versions of you" at different times.
comment by Mark Xu (mark-xu) · 2020-07-26T20:56:29.275Z · LW(p) · GW(p)
This experiment reminded me of Scott's story about Alchemy, where each generation of Alchemists had to spend the first N years of their life learning, and could only make progress after they were caught up.
In the story, the art of Alchemy is advanced by running previous knowledge through layers of redactors, who make it faster for the alchemists to catch up to the current knowledge.
In the experiment, there seems to be some level of redaction that was attempted:
where some of the subsequent rounds were spent cleaning up these notes and formulating clear next steps.
In the experiment it seemed there were some problems that couldn't be solved in the "participants lifespan" of 10 minutes. I'm curious as to whether problems can go from "not solvable" to "solvable" if every Nth participant was explicitly instructed to focus only on organizing information and making it easier for the next participants to get up to speed quickly.
I'm imagining explicit instruction to be important because if the default mode is to code, the participant would be reading the document to try to get to place where they can make progress, get frustrated, then decide to reorganize part of the document, which would lose them time. Explicit instruction to reorganize information seems potentially many times more efficient, especially if that participant is a skilled technical writer.
Replies from: gwern, lambdaloop↑ comment by gwern · 2020-07-26T22:14:11.885Z · LW(p) · GW(p)
It also reminds me a bit of Sam Hughes's Antimemetics Division stories (particularly, "Introductory Antimemetics"), which are a good read. Acausal coordination problems with yourself and others, etc.
↑ comment by lambdaloop · 2020-07-26T21:55:57.303Z · LW(p) · GW(p)
Yes, participating in it, it kinda felt like that!
I remember in at least 1 document, people actually came up with the meta-strategy that you mention at the end and wrote it out in the doc!
Personally, I felt that beyond just organizing the information, it was helpful if the steps to solving the problem were broken down into self-contained problems, each of which doesn't need understanding of the full problem. This wasn't always possible (e.g. understanding where a bug is often requires understanding both the problem and implementation), but when it happened I think it really helped with progress.
comment by ESRogs · 2020-07-17T21:49:51.267Z · LW(p) · GW(p)
Causal understanding is not necessary for the improvement of culturally evolving technology tests how improvements to strategies for using tools can improve in situations where information for conveying these improvements is limited.
Nitpick: had a little trouble parsing this. The paper "tests how improvements ... improve", so it's about how the improvements themselves improve? Not quite sure what this is trying to say.
Replies from: bgold↑ comment by Ben Goldhaber (bgold) · 2020-07-17T23:08:18.775Z · LW(p) · GW(p)
Thanks, rewrote and tried to clarify. In essence the researchers were testing transmission of "strategies" for using a tool, where an individual was limited in what they could transmit to the next user, akin to this relay experiment.
In fact they found that trying to convey causal theories could undermine the next person's performance; they speculate that it reduced experimentation prematurely.
Replies from: ESRogscomment by habryka (habryka4) · 2020-07-18T02:48:45.042Z · LW(p) · GW(p)
Thank you for writing this up! I had talked to Owain about these experiments a while ago and so am really glad to see them written up for future references.
comment by Raemon · 2020-07-18T01:04:11.087Z · LW(p) · GW(p)
Thanks for writing this up!
Something a little unclear to me: do you have a hypothesis that factored cognition is likely to be useful for humans, or is it more like a tool that is intended mainly for AIs? (I have a vague recollection of "the reason this is important is so that you can have very powerful AIs that are only active for a short time, able to contribute useful work but deactivated before they have a chance of evolving in unfriendly directions")
Replies from: ESRogs↑ comment by ESRogs · 2020-07-18T06:11:48.234Z · LW(p) · GW(p)
I have a vague recollection of "the reason this is important is so that you can have very powerful AIs that are only active for a short time, able to contribute useful work but deactivated before they have a chance of evolving in unfriendly directions"
I think that's somewhat on the right track but I wouldn't put it quite that way (based on my understanding).
I think it's not that you have an AI that you don't want to run for a long time. It's that you're trying to start with something simple that is aligned, and then scale it up via IDA [LW · GW]. And the simple thing that you start with is a human. (Or an AI trained to mimic a human.) And it's easier to get training data on what a human will do over the course of 10 minutes than over 10 years. (You can get a lot of 10 minute samples... 10 year samples not so much.)
So the questions are: 1) can you scale up something that is simple and aligned, in a way that preserves the alignment?, and 2) will your scaled up system be competitive with whatever else is out there -- with systems that were trained some other way than by scaling up a weak-but-aligned system (and which may be unaligned)?
The Factored Cognition Hypothesis is about question #2, about the potential capabilities of a scaled up system (rather than about the question of whether it would stay aligned). The way IDA scales up agents is analogous to having a tree of exponentially many copies of the agent, each doing a little bit of work. So you want to make sure you can split up work and still be competitive with what else is out there. If you can't, then there will be strong incentives to do things some other way, and that may result in AI systems that aren't aligned.
Again, the point is not that you have an ambiguously-aligned AI system that you want to avoid running for a long time. It's that you have a weak-but-aligned AI system. And you want to make it more powerful while preserving its alignment. So you have it cooperate with several copies of itself. (That's amplification.) And then you train your next system to mimic that group of agents working together. (That's distillation.) And then you repeat. (That's iteration.)
The hope is that by constructing your AI out of this virtual tree of human-mimicking AIs, it's a little more grounded and constrained. And less likely to do something antithetical to human values than an AI you got by just giving your neural network some objective and telling it to go forth and optimize.
Note that all this is relevant in the context of prosaic AI alignment -- aligning AI systems built out of something not-too-different from current ML. In particular, I believe Factored Cognition working well would be a prerequisite for most of the proposals here [LW · GW]. (The version of amplification I described was imitative amplification, but I believe the FCH is relevant for the other forms of amplification too.)
That's my understanding anyway. Would appreciate any corrections from others.
EDIT: On second thought, what you describe sounds a bit like myopia [? · GW], which is a property that some people think these systems need to have, so your vague recollection may have been more on the right track than I was giving it credit for.
Replies from: Vaniver, Raemon, Raemon↑ comment by Vaniver · 2020-07-19T15:04:15.121Z · LW(p) · GW(p)
It's that you're trying to start with something simple that is aligned, and then scale it up via IDA [LW · GW].
I don't think this is the hope, see here [LW · GW] for more. I think the hope is that the base unit is 'cheap' and 'honest'.
I think the 'honesty' criterion there is quite similar to 'myopia', in that both of them are about "just doing what's in front of you, instead of optimizing for side effects." This has some desirable properties, in that a myopic system won't be 'out to get you', but also rules out getting some desirable properties. As an aside, I think it might work out that no myopic system can be corrigible (which doesn't restrict systems built out of myopic parts, as those systems are not necessarily myopic).
I agree with the rest of your comment that Factored Cognition is about question #2, of how much capability is left on the table by using assemblages of myopic parts.
Replies from: ESRogs↑ comment by ESRogs · 2020-07-19T19:13:28.406Z · LW(p) · GW(p)
I don't think this is the hope, see here [LW · GW] for more. I think the hope is that the base unit is 'cheap' and 'honest'.
Hmm, cheap and honest makes some sense, but I'm surprised to hear that the hope is not that the base unit is aligned, because that seems to clash with how I've seen this discussed before. For example, from Ajeya's post [LW · GW] summarizing IDA:
The motivating problem that IDA attempts to solve: if we are only able to align agents that narrowly replicate human behavior, how can we build an AGI that is both aligned and ultimately much more capable than the best humans?
Which suggests to me that the base units (which narrowly replicate human behavior) are expected to be aligned.
More:
Moreover, because in each of its individual decisions each copy of A[0] continues to act just as a human personal assistant would act, we can hope that Amplify(H, A[0]) preserves alignment.
...
Because we assumed Amplify(H, A[0]) was aligned, we can hope that A[1] is also aligned if it is trained using sufficiently narrow techniques which introduce no new behaviors.
Which comes out and explicitly says that we want the amplify step to preserve alignment. (Which only makes sense if the agent at the previous step was aligned.)
Is it possible that this is just a terminological issue, where aligned is actually being used to mean what you would call honest (and not whatever Vaniver_2018 thought aligned meant)?
Some evidence in favor of this, from Andreas's Factored Cognition [LW · GW] post:
As many people have pointed out, it could be difficult to become confident that a system produced through this sort of process is aligned - that is, that all its cognitive work is actually directed towards solving the tasks it is intended to help with.
That definition of alignment seems to be pretty much the same thing as your honesty criterion:
Now it seems that the real goal is closer to an ‘honesty criterion’; if you ask a question, all the computation in that unit will be devoted to answering the question, and all messages between units are passed where the operator can see them, in plain English.
If so, then I'm curious what the difference is. What did Vaniver_2018 think that being aligned meant, and how is that different from just being honest?
Replies from: Vaniver↑ comment by Vaniver · 2020-07-21T04:20:49.279Z · LW(p) · GW(p)
If so, then I'm curious what the difference is. What did Vaniver_2018 think that being aligned meant, and how is that different from just being honest?
Vaniver_2018 thought 'aligned' meant something closer to "I was glad I ran the program" instead of "the program did what I told it to do" or "the program wasn't deliberately out to get me."
↑ comment by Raemon · 2020-07-18T13:11:48.189Z · LW(p) · GW(p)
sounds a bit like myopia
I... actually don't know what myopia is supposed to mean in the AI context (I had previously commented that the post Defining Myopia doesn't define myopia [LW(p) · GW(p)] and am still kinda waiting on a more succinct definition)
Replies from: ESRogs, Vaniver↑ comment by ESRogs · 2020-07-18T18:24:30.834Z · LW(p) · GW(p)
Heh. I actually struggled to figure out which post to link there because I was looking for one that would provide a clear, canonical definition, and ended up just picking the tag page. Here are a couple definitions buried in those posts though:
We can think of a myopic agent as one that only considers how best to answer the single question that you give to it rather than considering any sort of long-term consequences
(from: Towards a mechanistic understanding of corrigibility [LW · GW])
I’ll define a myopic reinforcement learner as a reinforcement learning agent trained to maximise the reward received in the next timestep, i.e. with a discount rate of 0.
...
I should note that so far I’ve been talking about myopia as a property of a training process. This is in contrast to the cognitive property that an agent might possess, of not making decisions directly on the basis of their long-term consequences; an example of the latter is approval-directed agents.
(from: Arguments against myopic training [LW · GW])
So, a myopic agent is one that only considers the short-term consequences when deciding how to act. And a myopic learner is one that is only trained based on short-term feedback.
(And perhaps worth noting, in case it's not obvious, I assume the name was chose because myopia means short-sightedness, and these potential AIs are deliberately made to be short-sighted, s.t. they're not making long-term, consequentialist plans.)
↑ comment by Vaniver · 2020-07-19T15:16:34.658Z · LW(p) · GW(p)
My take on myopia is that it's "shortsightedness" in the sense of only trying to do "local work". If I ask you what two times two is, you say "four" because it's locally true [LW · GW], rather than because you anticipate the consequences of different numbers, and say "five" because that will lead to a consequence you prefer. [Or you're running a heuristic that approximates that anticipation [LW · GW].]
If you knew that everyone in a bureaucracy were just "doing their jobs", this gives you a sort of transparency guarantee, where you just need to follow the official flow of information to see what's happening. Unless asked to design a shadow bureaucracy or take over, no one will do that.
However, training doesn't give you this by default; people in the bureaucracy are incentivized to make their individual departments better, to say what the boss wants to hear, to share gossip at the water cooler, and so on. One of the scenarios people consider is the case where you're training an AI to solve some problem, and at some point it realizes it's being trained to solve that problem and so starts performing as well as it can on that metric. In animal reinforcement training, people often talk about how both you're training the animal to perform tricks for rewards, and the animal is training you to reward it! The situation is subtly different here, but the basic figure-ground inversion holds.
↑ comment by Raemon · 2020-07-18T06:32:57.097Z · LW(p) · GW(p)
Gotcha.
(I think humans are unaligned, but assume that objection has been brought up before. Though I can still imagine that 10 minute humans provide a better starting point than other competitive tools, and may be the least bad option)
Replies from: ESRogs↑ comment by ESRogs · 2020-07-18T06:54:29.682Z · LW(p) · GW(p)
I think humans are unaligned
Unaligned with each other? Or... would you not consider you to be aligned with yourself?
(Btw, see my edit at the bottom of my comment above if you hadn't notice it.)
↑ comment by habryka (habryka4) · 2020-07-18T18:39:56.945Z · LW(p) · GW(p)
I think also unaligned with yourself?
Like, most humans when given massive power over the universe would probably accidentally destroy themselves, and possibly all of humanity with it (Eliezer talks a bit about this in HPMOR in sections I don't want to reference because of spoilers, and Wei Dai has talked about this a bit in a bunch of comments related to "the human alignment problem"). I think that maybe I could avoid doing that, but only because I am really mindful of the risk, and I don't think me from 5 years ago would have been safe to drastically scale up, even with respect to just my own values.
↑ comment by Raemon · 2020-07-18T18:56:14.470Z · LW(p) · GW(p)
I share habryka's concerns re: "unaligned with yourself", but, I think I was missing (or had forgotten) that part of the idea here was you're using.... an uploaded clone of yourself, so you're at least more likely to be aligned with yourself even if when scaled up you're not aligned with anyone else.
Replies from: ESRogs↑ comment by ESRogs · 2020-07-18T19:11:45.635Z · LW(p) · GW(p)
an uploaded clone of yourself
Not sure if you were just being poetic, but FWIW I believe the idea (in HCH for example), is to use an ML system trained to produce the same answers that a human would produce, which is not strictly-speaking an upload (unless the only way to imitate is actually to simulate in detail, s.t. the ML system ends up growing an upload inside it?).
Replies from: Raemon↑ comment by Raemon · 2020-07-18T19:19:13.618Z · LW(p) · GW(p)
Is it "a human" or "you specifically?"
If it's "a human", I'm back to "humans are unfriendly by default" territory.
[Edit: But, I had in fact also not been tracking that it's not a strict upload, it's a trained on human actions. I think I recall reading that earlier but had forgotten. I did leave the "..." in my summary because I wasn't quite sure if upload was the right word though. That all said, being merely trained on human actions, whether mine or someone else's, I think makes it even more likely to be unfriendly than an upload]
Replies from: Pongo