Posts
Comments
Context for anyone who missed it: https://en.wikipedia.org/wiki/Gell-Mann_amnesia_effect
Responding to your parenthetical, the downside of that approach is that the discussion would not be recorded for posterity!
Regarding the original question, I am curious if this could work for a country whose government spending was small enough, e.g. 2-3% of GDP. Maybe the most obvious issue is that no government would be disciplined enough to keep their spending at that level. But it does seem sort of elegant otherwise.
I'm afraid I'm sceptical that you methodology licenses the conclusions you draw. You state that you pushed people away from "using common near-synonyms like awareness or experience" and "asked them to instead describe the structure of the consciousness process, in terms of moving parts and/or subprocesses".
Isn't this just the standard LessWrong-endorsed practice of tabooing words, and avoiding semantic stopsigns?
Default seems unlikely, unless the market moves very quickly, since anyone pursuing this strategy is likely to be very small compared to the market for the S&P 500.
(Also consider that these pay out in a scenario where the world gets much richer — in contrast to e.g. Michael Burry's "Big Short" swaps, which paid out in a scenario where the market was way down — so you're just skimming a little off the huge profits that others are making, rather than trying to get them to pay you at the same time they're realizing other losses.)
It doesn't differentially help capitalize them compared to everything else though, right? (Especially since some of them are private.)
Wondering why this post just showed up as new today, since it was originally posted in February of 2023:
https://www.benkuhn.net/leaving/
Use the most powerful AI tools.
FWIW, Claude 3.5 Sonnet was released today. Appears to outperform GPT-4o on most (but not all) benchmarks.
Does any efficient algorithm satisfy all three of the linearity, respect for proofs, and 0-1 boundedness? Unfortunately, the answer is no (under standard assumptions from complexity theory). However, I argue that 0-1 boundedness isn’t actually that important to satisfy, and that instead we should be aiming to satisfy the first two properties along with some other desiderata.
Have you thought much about the feasibility or desirability of training an ML model to do deductive estimation?
You wouldn't get perfect conformity to your three criteria of linearity, respect for proofs, and 0-1 boundedness (which, as you say, is apparently impossible anyway), but you could use those to inform your computation of the loss in training. In which case, it seems like you could probably approximately satisfy those properties most of the time.
Then of course you'd have to worry about whether your deductive estimation model itself is deceiving you, but it seems like at least you've reduced the problem a bit.
I wouldn't call this "AI lab watch." "Lab" has the connotation that these are small projects instead of multibillion dollar corporate behemoths.
Disagree on "lab". I think it's the standard and most natural term now. As evidence, see your own usage a few sentences later:
They've all committed to this in the WH voluntary commitments and I think the labs are doing things on this front.
Yeah I figured Scott Sumner must have been involved.
Nitpick: Larry Summers not Larry Sumners
- If "--quine" was passed, read the script's own source code using the
__file__variable and print it out.
Interesting that it included this in the plan, but not in the actual implementation.
(Would have been kind of cheating to do it that way anyway.)
Worth noting 11 months later that @Bernhard was more right than I expected. Tesla did in fact cut prices a bunch (eating into gross margins), and yet didn't manage to hit 50% growth this year. (The year isn't over yet, but I think we can go ahead and call it.)
Good summary in this tweet from Gary Black:
$TSLA bulls should reduce their expectations that $TSLA volumes can grow at +50% per year. I am at +37% vol growth in 2023 and +37% growth in 2024. WS is at +37% in 2023 and +22% in 2024.
And apparently @MartinViecha head of $TSLA IR recently advised investors that TSLA “is now in an intermediate low-growth period,” at a recent Deutsche Bank auto conference with institutional investors. 35-40% volume growth still translates to 35-40% EPS growth, which justifies a 60x-70x 2024 P/E ($240-$280 PT) at a normal megacap growth 2024 PEG of 1.7x.
And this reply from Martin Viecha:
What I said specifically is that we're between two major growth waves: the first driven by 3/Y platform since 2017 and the next one that will be driven by the next gen vehicle.
let’s build larger language models to tackle problems, test methods, and understand phenomenon that will emerge as we get closer to AGI
Nitpick: you want "phenomena" (plural) here rather than "phenomenon" (singular).
I'm not necessarily putting a lot of stock in my specific explanations but it would be a pretty big surprise to learn that it turns out they're really the same.
Does it seem to you that the kinds of people who are good at science vs good at philosophy (or the kinds of reasoning processes they use) are especially different?
In your own case, it seems to me like you're someone who's good at philosophy, but you're also good at more "mundane" technical tasks like programming and cryptography. Do you think this is a coincidence?
I would guess that there's a common factor of intelligence + being a careful thinker. Would you guess that we can mechanize the intelligence part but not the careful thinking part?
Happiness has been shown to increase with income up to a certain threshold ($ 200K per year now, roughly speaking), beyond which the effect tends to plateau.
Do you have a citation for this? My understanding is that it's a logarithmic relationship — there's no threshold. (See the Income & Happiness section here.)
Why antisocial? I think it's great!
I would imagine one of the major factors explaining Tesla's absence is that people are most worried about LLMs at the moment, and Tesla is not a leader in LLMs.
(I agree that people often seem to overlook Tesla as a leader in AI in general.)
I don't know anything about the 'evaluation platform developed by Scale AI—at the AI Village at DEFCON 31'.
Looks like it's this.
Here are some predictions—mostly just based on my intuitions, but informed by the framework above. I predict with >50% credence that by the end of 2025 neural nets will:
To clarify, I think you mean that you predict each of these individually with >50% credence, not that you predict all of them jointly with >50% credence. Is that correct?
I'd like to see open-sourced evaluation and safety tools. Seems like a good thing to push on.
My model here is something like "even small differences in the rate at which systems are compounding power and/or intelligence lead to gigantic differences in absolute power and/or intelligence, given that the world is moving so fast."
Or maybe another way to say it: the speed at which a given system can compound it's abilities is very fast, relative to the rate at which innovations diffuse through the economy, for other groups and other AIs to take advantage of.
I'm a bit skeptical of this. While I agree that small differences in growth rates can be very meaningful, I think it's quite difficult to maintain a growth rate faster than the rest of the world for an extended period of time.
Growth and Trade
The reason is that: growth is way easier if you engage in trade. And assuming that gains from trade are shared evenly, the rest of the world profits just as much (in absolute terms) as you do from any trade. So you can only grow significantly faster than the rest of the world while you're small relative to the size of the whole world.
To give a couple of illustrative examples:
- The "Asian Tigers" saw their economies grow faster than GWP during the second half of the 20th century because they were engaged in "catch-up" growth. Once their GDP per capita got into the same ballpark as other developed countries, they slowed down to a similar growth rate to those countries.
- Tesla has grown revenue at an average of 50% per year for 10 years. That's been possible because they started out as a super small fraction of all car sales, and there were many orders of magnitude of growth available. I expect them to continue growing at something close to that rate for another 5-10 years, but then they'll slow down because the global car market is only so big.
Growth without Trade
Now imagine that you're a developing nation, or a nascent car company, and you want to try to grow your economy, or the number of cars you make, but you're not allowed to trade with anyone else.
For a nation it sounds possible, but you're playing on super hard mode. For a car company it sounds impossible.
Hypotheses
This suggests to me the following hypotheses:
- Any entity that tries to grow without engaging in trade is going to be outcompeted by those that do trade, but
- Entities that grow via trade will have their absolute growth capped at the size of the absolute growth of the rest of the world, and thus their growth rate will max out at the same rate as the rest of the world, once they're an appreciable fraction of the global economy.
I don't think these hypotheses are necessarily true in every case, but it seems like they would tend to be true. So to me that makes a scenario where explosive growth enables an entity to pull away from the rest of the world seem a bit less likely.
I suppose a possible mistake in this analysis is that I'm treating Moore's law as the limit on compute growth rates, and this may not hold once we have stronger AIs helping to design and fabricate chips.
Even so, I think there's something to be said for trying to slowly close the compute overhang gap over time.
0.2 OOMs/year was the pre-AlexNet growth rate in ML systems.
I think you'd want to set the limit to something slightly faster than Moore's law. Otherwise you have a constant large compute overhang.
Ultimately, we're going to be limited by Moore's law (or its successor) growth rates eventually anyway. We're on a kind of z-curve right now, where we're transitioning from ML compute being some small constant fraction of all compute to some much larger constant fraction of all compute. Before the transition it grows at the same speed as compute in general. After the transition it also grows at the same speed as compute in general. In the middle it grows faster as we rush to spend a much larger share of GWP on it.
From that perspective, Moore's law growth is the minimum growth rate you might have (unless annual spend on ML shrinks). And the question is just whether you transition from the small constant fraction of all compute to the large constant fraction of all compute slowly or quickly.
Trying to not do the transition at all (i.e. trying to growing at exactly the same rate as compute in general) seems potentially risky, because the resulting constant compute overhang means it's relatively easy for someone somewhere to rush ahead locally and build something much better than SOTA.
If on the other hand, you say full steam ahead and don't try to slow the transition at all, then on the plus side the compute overhang goes away, but on the minus side, you might rush into dangerous and destabilizing capabilities.
Perhaps a middle path makes sense, where you slow the growth rate down from current levels, but also slowly close the compute overhang gap over time.
See my edit to my comment above. Sounds like GPT-3 was actually 250x more compute than GPT-2. And Claude / GPT-4 are about 50x more compute than that? (Though unclear to me how much insight the Anthropic folks had into GPT-4's training before the announcement. So possible the 50x number is accurate for Claude and not for GPT-4.)
Doesn't this part of the comment answer your question?
We can very easily "grab probability mass" in relatively optimistic worlds. From our perspective of assigning non-trivial probability mass to the optimistic worlds, there's enormous opportunity to do work that, say, one might think moves us from a 20% chance of things going well to a 30% chance of things going well. This makes it the most efficient option on the present margin.
It sounds like they think it's easier to make progress on research that will help in scenarios where alignment ends up being not that hard. And so they're focusing there because it seems to be highest EV.
Seems reasonable to me. (Though noting that the full EV analysis would have to take into account how neglected different kinds of research are, and many other factors as well.)
Better meaning more capability per unit of compute? If so, how can we be confident that it's better than Chinchilla?
I can see an argument that it should be at least as good — if they were throwing so much money at it, they would surely do what is currently known best practice. But is there evidence to suggest that they figured out how to do things more efficiently than had ever been done before?
- CAIS
Can we adopt a norm of calling this Safe.ai? When I see "CAIS", I think of Drexler's "Comprehensive AI Services".
Still, this advance seems like a less revolutionary leap over GPT-3 than GPT-3 was over GPT-2, if Bing's early performance is a decent indicator.
Seems like this is what we should expect, given that GPT-3 was 100x as big as GPT-2, whereas GPT-4 is probably more like ~10x as big as GPT-3. No?
EDIT: just found this from Anthropic:
We know that the capability jump from GPT-2 to GPT-3 resulted mostly from about a 250x increase in compute. We would guess that another 50x increase separates the original GPT-3 model and state-of-the-art models in 2023.
There already are general AIs. They just are not powerful enough yet to count as True AGIs.
Can you say what you have in mind as the defining characteristics of a True AGI?
It's becoming a pet peeve of mine how often people these days use the term "AGI" w/o defining it. Given that, by the broadest definition, LLMs already are AGIs, whenever someone uses the term and means to exclude current LLMs, it seems to me that they're smuggling in a bunch of unstated assumptions about what counts as an AGI or not.
Here are some of the questions I have for folks that distinguish between current systems and future "AGI":
- Is it about just being more generally competent (s.t. GPT-X will hit the bar, if it does a bit better on all our current benchmarks, w/o any major architectural changes)?
- Is it about being always on, and having continual trains of thought, w/ something like long-term memory, rather than just responding to each prompt in isolation?
- Is it about being formulated more like an agent, w/ clearly defined goals, rather than like a next-token predictor?
- If so, what if the easiest way to get agent-y behavior is via a next-token (or other sensory modality) predictor that simulates an agent — do the simulations need to pass a certain fidelity threshold before we call it AGI?
- What if we have systems with a hodge-podge of competing drives (like a The Sims character) and learned behaviors, that in any given context may be more-or-less goal-directed, but w/o a well-specified over-arching utility function (just like any human or animal) — is that an AGI?
- Is it about being superhuman at all tasks, rather than being superhuman at some and subhuman at others (even though there's likely plenty of risk from advanced systems well before they're superhuman at absolutely everything)?
Given all these ambiguities, I'm tempted to suggest we should in general taboo "AGI", and use more specific phrases in its place. (Or at least, make a note of exactly which definition we're using if we do refer to "AGI".)
Fair.
I don't think it's ready for release, in the sense of "is releasing it a good idea from Microsoft's perspective?".
You sure about that?
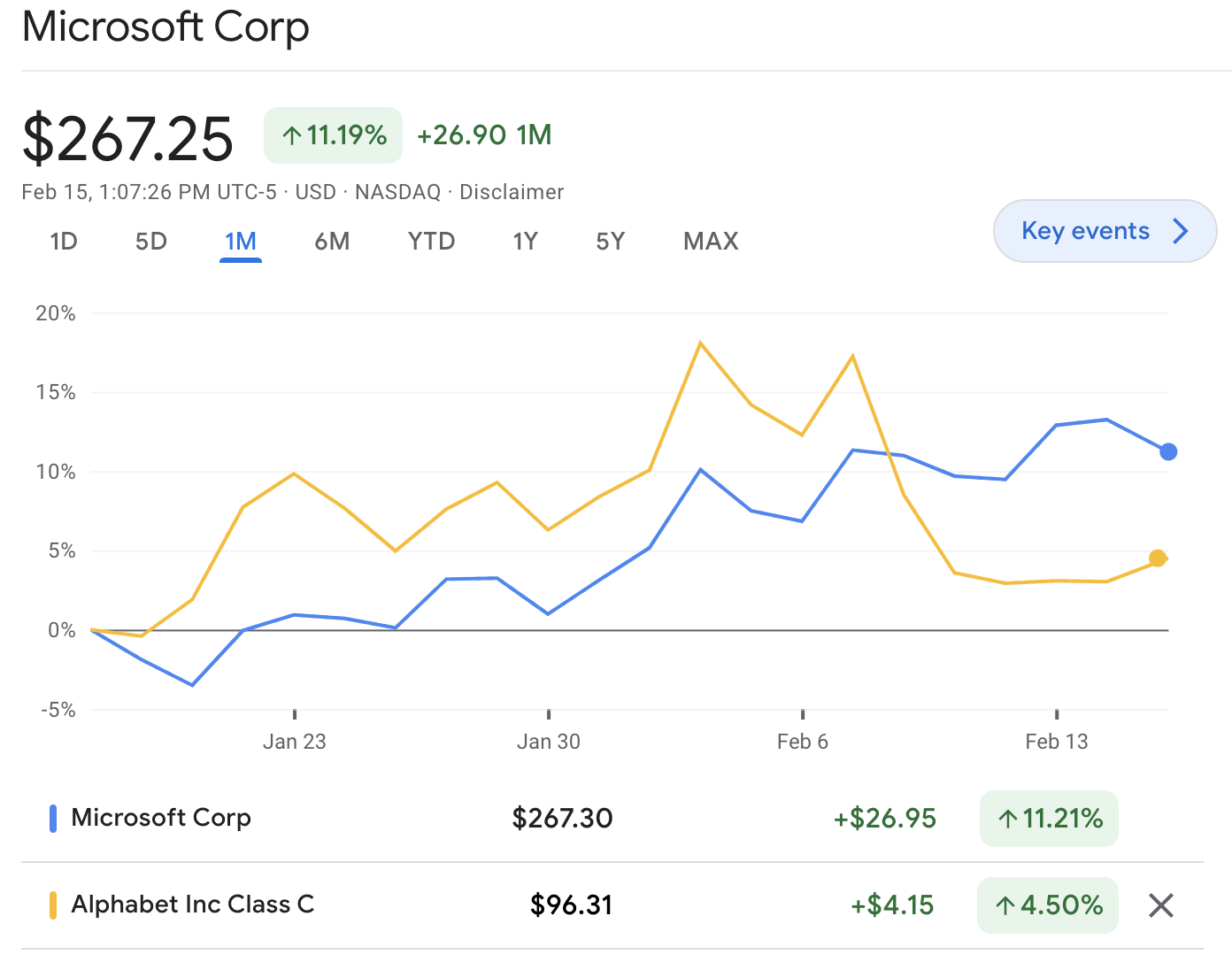
EDIT: to clarify, I don't claim that this price action is decisive. Hard to attribute price movements to specific events, and the market can be wrong, especially in the short term. But it seems suggestive that the market likes Microsoft's choice.
in Ye Olden Days of Original Less Wrong when rationalists spent more time talking about rationality there was a whole series of posts arguing for the opposite claim (1, 2, 3)
Oh, and FWIW I don't think I'm just thinking of Jonah's three posts mentioned here. Those are about how we normatively should consider arguments. Whereas what I'm thinking of was just an observation about how people in practice tend to perceive writing.
(It's possible that what I'm thinking of was a comment on one of those posts. My guess is not, because it doesn't ring a bell as the context for the comment I have in mind, but I haven't gone through all the comments to confirm yet.)
I could have sworn that there was an LW comment or post from back in the day (prob 2014 or earlier) where someone argued this same point that Ronny is making — that people tend to judge a set of arguments (or a piece of writing in general?) by its average quality rather than peak quality. I've had that as a cached hypothesis/belief since then.
Just tried to search for it but came up empty. Curious if anyone else remembers or can find the post/comment.
Regarding all the bottlenecks, I think there is an analogy between gradient descent and economic growth / innovation: when the function is super high-dimensional, it's hard to get stuck in a local optimum.
So even if we stagnate on some dimensions that are currently bottlenecks, we can make progress on everything else (and then eventually the landscape may have changed enough that we can once again make progress on the previously stagnant sectors). This might look like a cost disease, where the stagnant things get more expensive. But that seems like it would go along with high nominal GDP growth rather than low.
I am also not an economist and this might be totally off-base, but it seems to me that if there is real innovation and we can in fact do a bunch of new stuff that we couldn't before, then this will be reflected in the nominal GDP numbers going up. For the simple reason that in general people will be more likely to charge more for new and better goods and services rather than charging less for the same old goods and services (that can now be delivered more cheaply).
Do you expect learned ML systems to be updateless?
It seems plausible to me that updatelessness of agents is just as "disconnected from reality" of actual systems as EU maximization. Would you disagree?
It's just that nobody will buy all those cars.
Why would this be true?
Teslas are generally the most popular car in whatever segment they're in. And their automotive gross margins are at 25+%, so they've got room to cut prices if demand lightens a bit.
Add to this that a big tax credit is about to hit for EVs in the US and it's hard for me to see why demand would all-of-a-sudden fall off a cliff.
or truck manufacturers
Note that Tesla has (just) started producing a truck: https://www.tesla.com/semi. And electric trucks stand to benefit the most from self-driving tech, because their marginal cost of operation is lower than gas powered, so you get a bigger benefit from the higher utilization that not having a driver enables.
But so much depends on how deeply levered they are and how much is already priced in - TSLA could EASILY already be counting on that in their current valuations. If so, it'll kill them if it doesn't happen, but only maintain if it does.
Totally fair point, but FWIW, if you look at analyst reports, they're mostly not factoring in FSD. And basic napkin math suggests the current valuation is reasonable based on vehicle sales alone, if sales continue to grow for the next few years in line with Tesla's stated production goals.
And while you might think Telsa has a bad track record of hitting their stated goals, they've actually done pretty well on the key metrics of cars produced and revenue. Revenue has grown on average 50% per year since 2013 (the first full year of Model S production, which seems like a good place to start counting, so that growth numbers aren't inflated by starting at zero).
They've guided for 50% revenue growth for the next few years as well, and their plan to achieve that seems plausible. For the next year or so it's just a matter of scaling up production at their new Berlin and Austin factories, and they're supposedly looking for more factory locations so they can continue growing after that as well.
All that said, I agree that buying TSLA is not a pure play on the AI part — you have to have some view on whether all the stuff I said above about their car business is right or not.
A better plan might be to short (or long-term puts on) the companies you think will be hurt by the things you're predicting.
I agree this could be worthwhile. Though I feel that with shorting, timing becomes more important because you have to pay interest on the position.
It seems to me that, all else equal, the more bullish you are on short-term AI progress, the more likely you should think vision-only self driving will work soon.
And TSLA seems like probably the biggest beneficiary of that if it works.
After reading through the Unifying Grokking and Double Descent paper that LawrenceC linked, it sounds like I'm mostly saying the same thing as what's in the paper.
(Not too surprising, since I had just read Lawrence's comment, which summarizes the paper, when I made mine.)
In particular, the paper describes Type 1, Type 2, and Type 3 patterns, which correspond to my easy-to-discover patterns, memorizations, and hard-to-discover patterns:
In our model of grokking and double descent, there are three types of patterns learned at different
speeds. Type 1 patterns are fast and generalize well (heuristics). Type 2 patterns are fast, though
slower than Type 1, and generalize poorly (overfitting). Type 3 patterns are slow and generalize well.
The one thing I mention above that I don't see in the paper is an explanation for why the Type 2 patterns would be intermediate in learnability between Type 1 and Type 3 patterns or why there would be a regime where they dominate (resulting in overfitting).
My proposed explanation is that, for any given task, the exact mappings from input to output will tend to have a characteristic complexity, which means that they will have a relatively narrow distribution of learnability. And that's why models will often hit a regime where they're mostly finding those patterns rather than Type 1, easy-to-learn heuristics (which they've exhausted) or Type 3, hard-to-learn rules (which they're not discovering yet).
The authors do have an appendix section A.1 in the paper with the heading, "Heuristics, Memorization, and Slow Well-Generalizing", but with "[TODO]"s in the text. Will be curious to see if they end up saying something similar to this point (about input-output memorizations tending to have a characteristic complexity) there.
So, just don't keep training a powerful AI past overfitting, and it won't grok anything, right? Well, Nanda and Lieberum speculate that the reason it was difficult to figure out that grokking existed isn't because it's rare but because it's omnipresent: smooth loss curves are the result of many new grokkings constantly being built atop the previous ones.
If the grokkings are happening all the time, why do you get double descent? Why wouldn't the test loss just be a smooth curve?
Maybe the answer is something like:
- The model is learning generalizable patterns and non-generalizable memorizations all the time.
- Both the patterns and the memorizations fall along some distribution of discoverability (by gradient descent) based on their complexity.
- The distribution of patterns is more fat-tailed than the distribution of memorizations — there are a bunch of easily-discoverable patterns, and many hard-to-discover patterns, while the memorizations are more clumped together in their discoverability. (We might expect this to be true, since all the input-output pairs would have a similar level of complexity in the grand scheme of things.)
- Therefore, the model learns a bunch of easily-discoverable generalizable patterns first, leading to the first test-time loss descent.
- Then the model gets to a point when it's burned through all the easily-discoverable patterns, and it's mostly learning memorizations. The crossover point where it starts learning more memorizations than patterns corresponds to the nadir of the first descent.
- The model goes on for a while learning memorizations moreso than patterns. This is the overfitting regime.
- Once it's run out of memorizations to learn, and/or the regularization complexity penalty makes it start favoring patterns again, the second descent begins.
Or, put more simply:
- The reason you get double descent is because the distribution of complexity / discoverability for generalizable patterns is wide, whereas the distribution of complexity / discoverability of memorizations is more narrow.
- (If there weren't any easy-to-discover patterns, you wouldn't see the first test-time loss descent. And if there weren't any patterns that are harder to discover than the memorizations, you wouldn't see the second descent.)
Does that sound plausible as an explanation?
What makes you think that?
If we just look at the next year, they have two new factories (in Berlin and Austin) that have barely started producing cars. All they have to do to have another 50-ish% growth year is to scale up production at those two factories.
There may be some bumps along the way, but I see no reason to think they'll just utterly fail at scaling production at those factories.
Scaling in future years will eventually require new factories, but my understanding is that they're actively looking for new locations.
Their stated goal is to produce 20 million cars in 2030. I think that's ambitious, but plausible. And I wouldn't be too worried about my investment if they're only at 10 million in 2030, or if it takes them until 2033 to reach 20M.
Ah, maybe the way to think about it is that if I think I have a 30% chance of success before the merger, then I need to have a 30%+epsilon chance of my goal being chosen after the merger. And my goal will only be chosen if it is estimated to have the higher chance of success.
And so, if we assume that the chosen goal is def going to succeed post-merger (since there's no destructive war), that means I need to have a 30%+epsilon chance that my goal has a >50% chance of success post-merger. Or in other words "a close to 50% probability of success", just as Wei said.
But if these success probabilities were known before the merger, the AI whose goal has a smaller chance of success would have refused to agree to the merger. That AI should only agree if the merger allows it to have a close to 50% probability of success according to its original utility function.
Why does the probability need to be close to 50% for the AI to agree to the merger? Shouldn't its threshold for agreeing to the merger depend on how likely one or the other AI is to beat the other in a war for the accessible universe?
Is there an assumption that the two AIs are roughly equally powerful, and that a both-lose scenario is relatively unlikely?
Btw, some of the best sources of information on TSLA, in my view, are:
- the Tesla Daily podcast, with Rob Maurer
- Gary Black on Twitter
Rob is a buy-and-hold retail trader with an optimistic outlook on Tesla. I find him to be remarkably evenhanded and thoughtful. He's especially good at putting daily news stories in the context of the big picture.
Gary comes from a more traditional Wall Street background, but is also a TSLA bull. He tends to be a bit more short-term focused than Rob (I presume because he manages a fund and has to show results each year), but I find his takes helpful for understanding how institutional investors are likely to be perceiving events.
I continue to like TSLA.
The 50% annual revenue growth that they've averaged over the last 9 years shows no signs of stopping. And their earnings are growing even faster, since turning positive in 2020. (See fun visualization of these phenomena here and here.)
Admittedly, the TTM P/E ratio is currently on the high side, at 50.8. But it's been dropping dramatically every quarter, as Tesla grows into its valuation.
There are also some solutions discussed here and here. Though I'd assume Scott G is familiar with those and finds them unsatisfactory.