Shutting Down the Lightcone Offices
post by habryka (habryka4), Ben Pace (Benito) · 2023-03-14T22:47:51.539Z · LW · GW · 103 commentsContents
Background data Ben's Announcement Oliver's 1st message in #Closing-Office-Reasoning Oliver's 2nd message Ben's 1st message in #Closing-Office-Reasoning None 103 comments
Lightcone recently decided to close down a big project we'd been running for the last 1.5 years: An office space in Berkeley for people working on x-risk/EA/rationalist things that we opened August 2021.
We haven't written much about why, but I and Ben had written some messages on the internal office slack to explain some of our reasoning, which we've copy-pasted below. (They are from Jan 26th). I might write a longer retrospective sometime, but these messages seemed easy to share, and it seemed good to have something I can more easily refer to publicly.
Background data
Below is a graph of weekly unique keycard-visitors to the office in 2022.
The x-axis is each week (skipping the first 3), and the y-axis is the number of unique visitors-with-keycards.
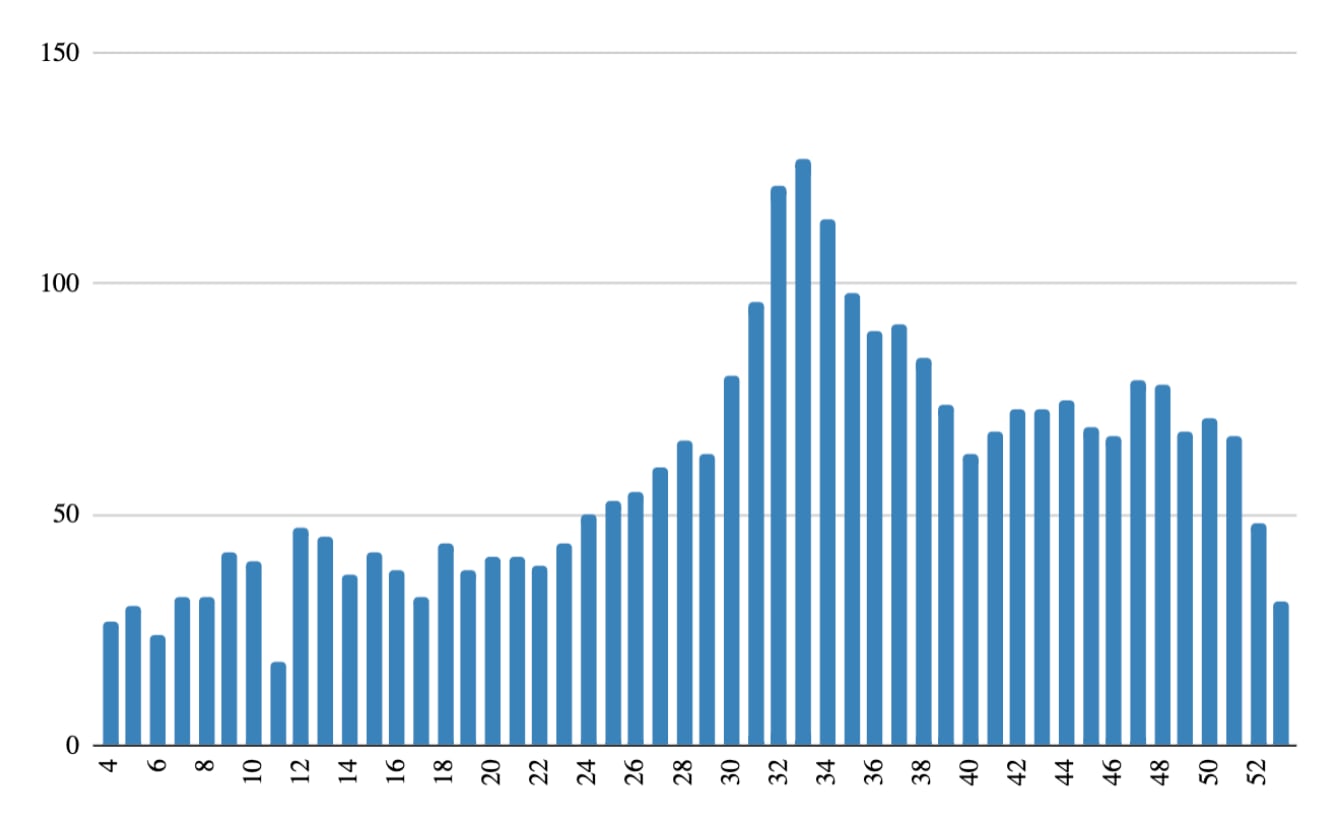
Members could bring in guests, which happened quite a bit and isn't measured in the keycard data below, so I think the total number of people who came by the offices is 30-50% higher.
The offices opened in August 2021. Including guests, parties, and all the time not shown in the graphs, I'd estimate around 200-300 more people visited, so in total around 500-600 people used the offices.
The offices cost $70k/month on rent [1], and around $35k/month on food and drink, and ~$5k/month on contractor time for the office. It also costs core Lightcone staff time which I'd guess at around $75k/year.
Ben's Announcement
Closing the Lightcone Offices @channel
Hello there everyone,
Sadly, I'm here to write that we've decided to close down the Lightcone Offices by the end of March. While we initially intended to transplant the office to the Rose Garden Inn, Oliver has decided (and I am on the same page about this decision) to make a clean break going forward to allow us to step back and renegotiate our relationship to the entire EA/longtermist ecosystem, as well as change what products and services we build.
Below I'll give context on the decision and other details, but the main practical information is that the office will no longer be open after Friday March 24th. (There will be a goodbye party on that day.)
I asked Oli to briefly state his reasoning for this decision, here's what he says:
An explicit part of my impact model for the Lightcone Offices has been that its value was substantially dependent on the existing EA/AI Alignment/Rationality ecosystem being roughly on track to solve the world's most important problems, and that while there are issues, pouring gas into this existing engine, and ironing out its bugs and problems, is one of the most valuable things to do in the world.
I had been doubting this assumption of our strategy for a while, even before FTX. Over the past year (with a substantial boost by the FTX collapse) my actual trust in this ecosystem and interest in pouring gas into this existing engine has greatly declined, and I now stand before what I have helped built with great doubts about whether it all will be or has been good for the world.
I respect many of the people working here, and I am glad about the overall effect of Lightcone on this ecosystem we have built, and am excited about many of the individuals in the space, and probably in many, maybe even most, future worlds I will come back with new conviction to invest and build out this community that I have been building infrastructure for for almost a full decade. But right now, I think both me and the rest of Lightcone need some space to reconsider our relationship to this whole ecosystem, and I currently assign enough probability that building things in the space is harmful for the world that I can't really justify the level of effort and energy and money that Lightcone has been investing into doing things that pretty indiscriminately grow and accelerate the things around us.
(To Oli's points I'll add to this that it's also an ongoing cost in terms of time, effort, stress, and in terms of a lack of organizational focus on the other ideas and projects we'd like to pursue.)
Oli, myself, and the rest of the Lightcone team will be available to discuss more about this in the channel #closing-office-reasoning where I invite any and all of you who wish to to discuss this with me, the rest of the lightcone team, and each other.
In the last few weeks I sat down and interviewed people leading the 3 orgs whose primary office is here (FAR, AI Impacts, and Encultured) and 13 other individual contributors. I asked about how this would affect them, how we could ease the change, and generally get their feelings about how the ecosystem is working out.
These conversations lasted on average 45 mins each, and it was very interesting to hear people's thoughts about this, and also their suggestions about other things Lightcone could work on.
These conversations also left me feeling more hopeful about building related community-infrastructure in the future, as I learned of a number of positive effects that I wasn't aware of. These conversations all felt pretty real, I respect all the people involved more, and I hope to talk to many more of you at length before we close.
From the check-ins I've done with people, this seems to me to be enough time to not disrupt any SERI MATS mentorships, and to give the orgs here a comfortable enough amount of time to make new plans, but if this does put you in a tight spot, please talk to us and we'll see how we can help.
The campus team (me, Oli, Jacob, Rafe) will be in the office for lunch tomorrow (Friday at 1pm) to discuss any and all of this with you. We'd like to know how this is affecting you, and I'd really like to know about costs this has for you that I'm not aware of. Please feel free (and encouraged) to just chat with us in your lightcone channels (or in any of the public office channels too).
Otherwise, a few notes:
- The Lighthouse system is going away when the leases end. Lighthouse 1 has closed, and Lighthouse 2 will continue to be open for a few more months.
- If you would like to start renting your room yourself from WeWork, I can introduce you to our point of contact, who I think would be glad to continue to rent the offices. Offices cost between $1k and $6k a month depending on how many desks are in them.
- Here's a form to give the Lightcone team anonymous feedback about this decision (or anything). [Link removed from LW post.]
- To talk with people about future plans starting now and after the offices close, whether to propose plans or just to let others know what you'll be doing, I've made the #future-plans channel and added you all to it.
It's been a thrilling experience to work alongside and get to know so many people dedicated to preventing an existential catastrophe, and I've made many new friends working here, thank you, but I think me and the Lightcone Team need space to reflect and to build something better if Earth is going to have a shot at aligning the AGIs we build.
Oliver's 1st message in #Closing-Office-Reasoning
(In response to a question on the Slack saying "I was hoping you could elaborate more on the idea that building the space may be net harmful.")
I think FTX is the obvious way in which current community-building can be bad, though in my model of the world FTX, while somewhat of outlier in scope, doesn't feel like a particularly huge outlier in terms of the underlying generators. Indeed it feels not that far from par for the course of the broader ecosystems relationship to honesty, aggressively pursuing plans justified by naive consequentialism, and more broadly having a somewhat deceptive relationship to the world.
Though again, I really don't feel confident about the details here and am doing a bunch of broad orienting.
I've also written some EA Forum and LessWrong comments that point to more specific things that I am worried will have or have had a negative effect on the world:
My guess is RLHF research has been pushing on a commercialization bottleneck and had a pretty large counterfactual effect on AI investment, causing a huge uptick in investment into AI and potentially an arms race between Microsoft and Google towards AGI: https://www.lesswrong.com/posts/vwu4kegAEZTBtpT6p/thoughts-on-the-impact-of-rlhf-research?commentId=HHBFYow2gCB3qjk2i [LW(p) · GW(p)]
Thoughts on how responsible EA was for the FTX fraud: https://forum.effectivealtruism.org/posts/Koe2HwCQtq9ZBPwAS/quadratic-reciprocity-s-shortform?commentId=9c3srk6vkQuLHRkc6 [EA(p) · GW(p)]
Tendencies towards pretty mindkilly PR-stuff in the EA community: https://forum.effectivealtruism.org/posts/ALzE9JixLLEexTKSq/cea-statement-on-nick-bostrom-s-email?commentId=vYbburTEchHZv7mn4 [EA(p) · GW(p)]
I feel quite worried that the alignment plan of Anthropic currently basically boils down to "we are the good guys, and by doing a lot of capabilities research we will have a seat at the table when AI gets really dangerous, and then we will just be better/more-careful/more-reasonable than the existing people, and that will somehow make the difference between AI going well and going badly". That plan isn't inherently doomed, but man does it rely on trusting Anthropic's leadership, and I genuinely only have marginally better ability to distinguish the moral character of Anthropic's leadership from the moral character of FTX's leadership, and in the absence of that trust the only thing we are doing with Anthropic is adding another player to an AI arms race.
More broadly, I think AI Alignment ideas/the EA community/the rationality community played a pretty substantial role in the founding of the three leading AGI labs (Deepmind, OpenAI, Anthropic), and man, I sure would feel better about a world where none of these would exist, though I also feel quite uncertain here. But it does sure feel like we had a quite large counterfactual effect on AI timelines.
Before the whole FTX collapse, I also wrote this long list of reasons for why I feel quite doomy about stuff (posted in replies, to not spam everything).
Oliver's 2nd message
(Originally written October 2022) I've recently been feeling a bunch of doom around a bunch of different things, and an associated lack of direction for both myself and Lightcone.
Here is a list of things that I currently believe that try to somehow elicit my current feelings about the world and the AI Alignment community.
- In most worlds RLHF, especially if widely distributed and used, seems to make the world a bunch worse from a safety perspective (by making unaligned systems appear aligned at lower capabilities levels, meaning people are less likely to take alignment problems seriously, and by leading to new products that will cause lots of money to go into AI research, as well as giving a strong incentive towards deception at higher capability levels)
- It's a bad idea to train models directly on the internet, since the internet as an environment makes supervision much harder, strongly encourages agency, has strong convergent goals around deception, and also gives rise to a bunch of economic applications that will cause more money to go into AI
- The EA and AI Alignment community should probably try to delay AI development somehow, and this will likely include getting into conflict with a bunch of AI capabilities organizations, but it's worth the cost
- I don't currently see a way to make AIs very useful for doing additional AI Alignment research, and don't expect any of the current approaches for that to work (like ELK, or trying to imitate humans by doing more predictive modeling of human behavior and then hoping they turn out to be useful), but it sure would be great if we found a way to do this (but like, I don't think we currently know how to do this)
- I am quite worried that it's going to be very easy to fool large groups of humans, and that AI is quite close to seeming very aligned and sympathetic to executives at AI companies, as well as many AI alignment researchers (and definitely large parts of the public). I don't think this will be the result of human modeling, but just the result of pushing the AI into patterns of speech/behaior that we associate with being less threatening and being more trustworthy. In some sense this isn't a catastrophic risk because this kind of deception doesn't cause the AI to dispower the humans, but I do expect it to make actually getting the research to stop or to spend lots of resources on alignment a lot harder later on.
- I do sure feel like a lot of AI alignment research is very suspiciously indistinguishable from capabilities research, and I think this is probably for the obvious bad reasons instead of this being an inherent property of these domains (the obvious bad reason being that it's politically advantageous to brand your research as AI Alignment research and capabilities research simultaneously, since that gives you more social credibility, especially from the EA crowd which has a surprisingly strong talent pool and is also just socially close to a lot of top AI capabilities people)
- I think a really substantial fraction of people who are doing "AI Alignment research" are instead acting with the primary aim of "make AI Alignment seem legit". These are not the same goal, a lot of good people can tell and this makes them feel kind of deceived, and also this creates very messy dynamics within the field where people have strong opinions about what the secondary effects of research are, because that's the primary thing they are interested in, instead of asking whether the research points towards useful true things for actually aligning the AI.
- More broadly, I think one of the primary effects of talking about AI Alignment has been to make more people get really hyped about AGI, and be interested in racing towards AGI. Generally knowing about AGI-Risk does not seem to have made people more hesitant towards racing and slow down, but instead caused them to accelerate progress towards AGI, which seems bad on the margin since I think humanity's chances of survival do go up a good amount with more time.
- It also appears that people who are concerned about AGI risk have been responsible for a very substantial fraction of progress towards AGI, suggesting that there is a substantial counterfactual impact here, and that people who think about AGI all day are substantially better at making progress towards AGI than the average AI researcher (though this could also be explained by other attributes like general intelligence or openness to weird ideas that EA and AI Alignment selects for, though I think that's somewhat less likely)
- A lot of people in AI Alignment I've talked to have found it pretty hard to have clear thoughts in the current social environment, and many of them have reported that getting out of Berkeley, or getting social distance from the core of the community has made them produce better thoughts. I don't really know whether the increased productivity here is born out by evidence, but really a lot of people that I considered promising contributors a few years ago are now experiencing a pretty active urge to stay away from the current social milieu.
- I think all of these considerations in-aggregate make me worried that a lot of current work in AI Alignment field-building and EA-community building is net-negative for the world, and that a lot of my work over the past few years has been bad for the world (most prominently transforming LessWrong into something that looks a lot more respectable in a way that I am worried might have shrunk the overton window of what can be discussed there by a lot, and having generally contributed to a bunch of these dynamics).
- Exercising some genre-saviness, I also think a bunch of this is driven by just a more generic "I feel alienated by my social environment changing and becoming more professionalized and this is robbing it of a lot of the things I liked about it". I feel like when people feel this feeling they often are holding on to some antiquated way of being that really isn't well-adapted to their current environment, and they often come up with fancy rationalizations for why they like the way things used to be.
- I also feel confused about how to relate to the stronger equivocation of ML-skills with AI Alignment skills. I don't personally have much of a problem with learning a bunch of ML, and generally engage a good amount with the ML literature (not enough to be an active ML researcher, but enough to follow along almost any conversation between researchers), but I do also feel a bit of a sense of being personally threatened, and other people I like and respect being threatened, in this shift towards requiring advanced cutting-edge ML knowledge in order to feel like you are allowed to contribute to the field. I do feel a bit like my social environment is being subsumed by and is adopting the status hierarchy of the ML community in a way that does not make me trust what is going on (I don't particularly like the status hierarchy and incentive landscape of the ML community, which seems quite well-optimized to cause human extinction)
- I also feel like the EA community is being very aggressive about recruitment in a way that locally in the Bay Area has displaced a lot of the rationality community, and I think this is broadly bad, both for me personally and also because I just think the rationality community had more of the right components to think sanely about AI Alignment, many of which I feel like are getting lost
- I also feel like with Lightcone and Constellation coming into existence, and there being a lot more money and status around, the inner circle dynamics around EA and longtermism and the Bay Area community have gotten a lot worse, and despite being a person who I think generally is pretty in the loop with stuff, have found myself being worried and stressed about being excluded from some important community function, or some important inner circle. I am quite worried that me founding the Lightcone Offices was quite bad in this respect, by overall enshrining some kind of social hierarchy that wasn't very grounded in things I actually care about (I also personally felt a very strong social pressure to exclude interesting but socially slightly awkward people from being in Lightcone that I ended up giving into, and I think this was probably a terrible mistake and really exacerbated the dynamics here)
- I think some of the best shots we have for actually making humanity not go extinct (slowing down AI progress, pivotal acts, intelligence enhancement, etc.) feel like they have a really hard time being considered in the current overton window of the EA and AI Alignment community, and I feel like people being unable to consider plans in these spaces both makes them broadly less sane, but also just like prevents work from happening in these areas.
- I get a lot of messages these days about people wanting me to moderate or censor various forms of discussion on LessWrong that I think seem pretty innocuous to me, and the generators of this usually seem to be reputation related. E.g. recently I've had multiple pretty influential people ping me to delete or threaten moderation action against the authors of posts and comments talking about: How OpenAI doesn't seem to take AI Alignment very seriously, why gene drives against Malaria seem like a good idea, why working on intelligence enhancement is a good idea. In all of these cases the person asking me to moderate did not leave any comment of their own trying to argue for their position, before asking me to censor the content. I find this pretty stressful, and also like, most of the relevant ideas feel like stuff that people would have just felt comfortable discussing openly on LW 7 years ago or so (not like, everyone, but there wouldn't have been so much of a chilling effect so that nobody brings up these topics).
Ben's 1st message in #Closing-Office-Reasoning
Note from Ben: I have lightly edited this because I wrote it very quickly at the time
(I drafted this earlier today and didn't give it much of a second pass, forgive me if it's imprecise or poorly written.)
Here are some of the reasons I'd like to move away from providing offices as we have done so far.
- Having two locations comes with a large cost. To track how a space is functioning, what problems people are running into, how the culture changes, what improvements could be made, I think I need to be there at least 20% of my time each week (and ideally ~50%), and that’s a big travel cost to the focus of the lightcone team.
- Offices are a high-commitment abstraction for which it is hard to iterate. In trying to improve a culture, I might try to help people start more new projects, or gain additional concepts that help them understand the world, or improve the standards arguments are held to, or something else. But there's relatively little space for a lot of experimentation and negotiation in an office space — you’ve mostly made a commitment to offer a basic resource and then to get out of people's way.
- The “enculturation to investment” ratio was very lopsided. For example, with SERI MATS, many people came for 2.5 months, for whom I think a better selection mechanism would have been something shaped like a 4-day AIRCS-style workshop to better get to know them and think with them, and then pick a smaller number of the best people from that to invest further into. If I came up with an idea right now for what abstraction I'd prefer, it'd be something like an ongoing festival with lots of events and workshops and retreats for different audiences and different sorts of goals, with perhaps a small office for independent alignment researchers, rather than an office space that has a medium-size set of people you're committed to supporting long-term.
- People did not do much to invest in each other in the office. I think this in part because the office does not capture other parts of people’s lives (e.g. socializing), but also I think most people just didn’t bring their whole spirit to this in some ways, and I’m not really sure why. I think people did not have great aspirations for themselves or each other. I did not feel here that folks had a strong common-spirit — that they thought each other could grow to be world-class people who changed the course of history, and did not wish to invest in each other in that way. (There were some exceptions to note, such as Alex Mennen’s Math Talks, John Wentworth's Framing Practica, and some of the ways that people in the Shard Theory teams worked together with the hope of doing something incredible, which both felt like people were really investing into communal resources and other people.) I think a common way to know whether people are bringing their spirit to something is whether they create art about it — songs, in-jokes, stories, etc. Soon after the start I felt nobody was going to really bring themselves so fully to the space, even though we hoped that people would. I think there were few new projects from collaborations in the space, other than between people who already had a long history.
And regarding the broader ecosystem:
- Some of the primary projects getting resources from this ecosystem do not seem built using the principles and values (e.g. integrity, truth-seeking, x-risk reduction) that I care about — such as FTX, OpenAI, Anthropic, CEA, Will MacAskill's career as a public intellectual — and those that do seem to have closed down or been unsupported (such as FHI, MIRI, CFAR). Insofar as these are the primary projects who will reap the benefits of the resources that Lightcone invests into this ecosystem, I would like to change course.
- The moral maze nature of the EA/longtermist ecosystem has increased substantially over the last two years, and the simulacra level of its discourse has notably risen too. There are many more careerist EAs working here and at events, it’s more professionalized and about networking. Many new EAs are here not because they have a deep-seated passion for doing what’s right and using math to get the answers, but because they’re looking for an interesting, well-paying job in a place with nice nerds. Or are just noticing that there’s a lot of resources being handed out in a very high-trust way. One of the people I interviewed at the office said they often could not tell whether a newcomer was expressing genuine interest in some research, or was trying to figure out “how the system of reward” worked so they could play it better, because the types of questions in both cases seemed so similar. [Added to LW post: I also remember someone joining the offices to collaborate on a project, who explained that in their work they were looking for "The next Eliezer Yudkowsky or Paul Christiano". When I asked what aspects of Eliezer they wanted to replicate, they said they didn't really know much about Eliezer but it was something that a colleague of theirs said a lot.] It also seems to me that the simulacra level of writing on the EA Forum is increasing, whereby language is increasingly used primarily to signal affiliation and policy-preferences rather than to explain how reality works. I am here in substantial part because of people (like Eliezer Yudkowsky and Scott Alexander) honestly trying to explain how the world works in their online writing and doing a damn good job of it, and I feel like there is much less of that today in the EA/longtermist ecosystem. This makes the ecosystem much harder to direct, to orient within, and makes it much harder to trust that resources intended for a given purpose will not be redirected by the various internal forces that grow against the intentions of the system.
- The alignment field that we're supporting seems to me to have pretty little innovation and pretty bad politics. I am irritated by the extent to which discussion is commonly framed around a Paul/Eliezer dichotomy, even while the primary person taking orders of magnitudes more funding and staff talent (Dario Amodei) has barely explicated his views on the topic and appears (from a distance) to have disastrously optimistic views about how easy alignment will be and how important it is to stay competitive with state of the art models. [Added to LW post: I also generally dislike the dynamics of fake-expertise and fake-knowledge I sometimes see around the EA/x-risk/alignment places.
- I recall at EAG in Oxford a year or two ago, people were encouraged to "list their areas of expertise" on their profile, and one person who works in this ecosystem listed (amongst many things) "Biorisk" even though I knew the person had only been part of this ecosystem for <1 year and their background was in a different field.
- It also seems to me like people who show any intelligent thought or get any respect in the alignment field quickly get elevated to "great researchers that new people should learn from" even though I think that there's less than a dozen people who've produced really great work, and mostly people should think pretty independently about this stuff.
- I similarly feel pretty worried by how (quite earnest) EAs describe people or projects as "high impact" when I'm pretty sure that if they reflected on their beliefs, they honestly wouldn't know the sign of the person or project they were talking about, or estimate it as close-to-zero.]
How does this relate to the office?
A lot of the boundary around who is invited to the offices has been determined by:
- People whose x-risk reduction work the Lightcone team respects or is actively excited about
- People and organizations in good standing in the EA/longtermist ecosystem (e.g. whose research is widely read, who has major funding from OpenPhil/FTX, who have organizations that have caused a lot to happen, etc) and the people working and affiliated with them
- Not-people who we think would (sadly) be very repellent to many people to work in the space (e.g. lacking basic social skills, or who many people find scary for some reason) or who we think have violated important norms (e.g. lying, sexual assault, etc).
The 2nd element has really dominated a lot of my choices here in the last 12 months, and (as I wrote above) this is a boundary that is increasingly filled with people who I don't believe are here because they care about ethics, who I am not aware have done any great work, who I am not aware of having strong or reflective epistemologies. Even while massive amounts of resources are being poured into the EA/longtermist ecosystem, I'd like to have a far more discerning boundary around the resources I create.
- ^
The office rent cost about 1.5x what it needed to be. We started in a WeWork because we were prototyping whether people even wanted an office, and wanted to get started quickly (the office was up and running in 3 weeks instead of going through the slower process of signing a 12-24 month lease). Then we were in a state for about a year of figuring out where to move to long-term, often wanting to preserve the flexibility of being able to move out within 2 months.
103 comments
Comments sorted by top scores.
comment by Thomas Larsen (thomas-larsen) · 2023-03-15T05:19:26.378Z · LW(p) · GW(p)
I think a really substantial fraction of people who are doing "AI Alignment research" are instead acting with the primary aim of "make AI Alignment seem legit". These are not the same goal, a lot of good people can tell and this makes them feel kind of deceived, and also this creates very messy dynamics within the field where people have strong opinions about what the secondary effects of research are, because that's the primary thing they are interested in, instead of asking whether the research points towards useful true things for actually aligning the AI.
This doesn't feel right to me, off the top of my head, it does seem like most of the field is just trying to make progress. For most of those that aren't, it feels like they are pretty explicit about not trying to solve alignment, and also I'm excited about most of the projects. I'd guess like 10-20% of the field are in the "make alignment seem legit" camp. My rough categorization:
Make alignment progress:
- Anthropic Interp
- Redwood
- ARC Theory
- Conjecture
- MIRI
- Most independent researchers that I can think of (e.g. John, Vanessa, Steven Byrnes, the MATS people I know)
- Some of the safety teams at OpenAI/DM
- Aligned AI
- Team Shard
make alignment seem legit:
CAISsafe.ai- Anthropic scaring laws
- ARC Evals (arguably, but it seems like this isn't quite the main aim)
- Some of the safety teams at OpenAI/DM
- Open Phil (I think I'd consider Cold Takes to be doing this, but it doesn't exactly brand itself as alignment research)
What am I missing? I would be curious which projects you feel this way about.
Replies from: habryka4, ESRogs, 6nne, evhub↑ comment by habryka (habryka4) · 2023-03-15T07:18:57.646Z · LW(p) · GW(p)
This list seems partially right, though I would basically put all of Deepmind in the "make legit" category (I think they are genuinely well-intentioned about this, but I've had long disagreements with e.g. Rohin about this in the past). As a concrete example of this, whose effects I actually quite like, think of the specification gaming list. I think the second list is missing a bunch of names and instances, in-particular a lot of people in different parts of academia, and a lot of people who are less core "AINotKillEveryonism" flavored.
Like, let's take "Anthropic Capabilities" for example, which is what the majority of people at Anthropic work on. Why are they working on it?
They are working on it partially because this gives Anthropic access to state of the art models to do alignment research on, but I think in even greater parts they are doing it because this gives them a seat at the table with the other AI capabilities orgs and makes their work seem legitimate to them, which enables them to both be involved in shaping how AI develops, and have influence over these other orgs.
I think this goal isn't crazy, but I do get a sense that the overall strategy for Anthropic is very much not "we are trying to solve the alignment problem" and much more "we are trying to somehow get into a position of influence and power in the AI space so that we can then steer humanity in directions we care about" while also doing alignment research, but thinking that most of their effect on the world doesn't come from the actual alignment research they produce (I do appreciate that Anthropic is less pretending to just do the first thing a bunch, which I think is better).
I also disagree with you on "most independent researchers". I think the people you list definitely have that flavor, but at least in my LTFF work we've funded more people whose primary plan was something much closer to the "make it seem legit" branch. Indeed this is basically the most common reason I see people get PhDs, of which we funded a lot.
I feel confused about Conjecture. I had some specific run-ins with them that indeed felt among the worst offenders of trying to primarily optimize for influence, but some of the people seem genuinely motivated by making progress. I currently think it's a mixed bag.
I could list more, but this feels like a weird context in which to give my takes on everyone's AI Alignment research, and seems like it would benefit from some more dedicated space. Overall, my sense is in-terms of funding and full-time people, things are skewed around 70/30 in favor of "make legit", and I do think there are a lot of great people who are trying to genuinely solve the problem.
Replies from: rohinmshah, lc, akash-wasil, Spencer Becker-Kahn↑ comment by Rohin Shah (rohinmshah) · 2023-03-15T08:27:27.426Z · LW(p) · GW(p)
(I realize this is straying pretty far from the intent of this post, so feel free to delete this comment)
I totally agree that a non-trivial portion of DeepMind's work (and especially my work) is in the "make legit" category, and I stand by that as a good thing to do, but putting all of it there seems pretty wild. Going off of a list I previously wrote about DeepMind work (this comment [LW(p) · GW(p)]):
We do a lot of stuff, e.g. of the things you've listed, the Alignment / Scalable Alignment Teams have done at least some work on the following since I joined in late 2020:
- Eliciting latent knowledge (see ELK prizes, particularly the submission from Victoria Krakovna & Vikrant Varma & Ramana Kumar)
- LLM alignment (lots of work discussed in the podcast with Geoffrey [LW · GW] you mentioned)
- Scalable oversight (same as above)
- Mechanistic interpretability (unpublished so far)
- Externalized Reasoning Oversight (my guess is that this will be published soon) (EDIT: this paper)
- Communicating views on alignment (e.g. the post you linked [LW · GW], the writing that I do on this forum is in large part about communicating my views)
- Deception + inner alignment (in particular examples of goal misgeneralization)
- Understanding agency (see e.g. discovering agents [LW · GW], most of Ramana's posts [LW · GW])
And in addition we've also done other stuff like
- Learning more safely when doing RL
- Addressing reward tampering with decoupled approval
- Understanding agent incentives with CIDs
I'm probably forgetting a few others.
(Note that since then the mechanistic interpretability team published Tracr.)
Of this, I think "examples of goal misgeneralization" is primarily "make alignment legit", while everything else is about making progress on alignment. (I see the conceptual progress towards specifically naming and describing goal misgeneralization as progress on alignment, but that was mostly finished within-the-community by the time we were working on the examples.)
(Some of the LLM alignment work and externalized reasoning oversight work has aspects of "making alignment legit" but it also seems like progress on alignment -- in particular I think I learn new empirical facts about how well various techniques work from both.)
I think the actual crux here is how useful the various empirical projects are, where I expect you (and many others) think "basically useless" while I don't.
In terms of fraction of effort allocated to "make alignment legit", I think it's currently about 10% of the Alignment and Scalable Alignment teams, and it was more like 20% while the goal misgeneralization project was going on. (This is not counting LLM alignment and externalized reasoning oversight as "make alignment legit".)
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T19:03:25.239Z · LW(p) · GW(p)
I mean, I think my models here come literally from conversations with you, where I am pretty sure you have said things like (paraphrased) "basically all the work I do at Deepmind and the work of most other people I work with at Deepmind is about 'trying to demonstrate the difficulty of the problem' and 'convincing other people at Deepmind the problem is real'".
In as much as you are now claiming that is only 10%-20% of the work, that would be extremely surprising to me and I do think would really be in pretty direct contradiction with other things we have talked about.
Like, yes, of course if you want to do field-building and want to get people to think AI Alignment is real, you will also do some alignment research. But I am talking about the balance of motivations, not the total balance of work. My sense is most of the motivation for people at the Deepmind teams comes from people thinking about how to get other people at Deepmind to take AI Alignment seriously. I think that's a potentially valuable goal, but indeed it is also the kind of goal that often gets represented as someone just trying to make direct progress on the problem.
Replies from: rohinmshah, Raemon↑ comment by Rohin Shah (rohinmshah) · 2023-03-15T22:41:24.597Z · LW(p) · GW(p)
Hmm, this is surprising. Some claims I might have made that could have led to this misunderstanding, in order of plausibility:
- [While I was working on goal misgeneralization] "Basically all the work that I'm doing is about convincing other people that the problem is real". I might have also said something like "and most people I work with" intending to talk about my collaborators on goal misgeneralization rather than the entire DeepMind safety team(s); for at least some of the time that I was working on goal misgeneralization I was an individual contributor so that would have been a reasonable interpretation.
- "Most of my past work hasn't made progress on the problem" -- this would be referring to papers that I started working on before believing that scaled up deep learning could lead to AGI without additional insights, which I think ended up solving the wrong problem because I had a wrong model of what the problem was. (But I wouldn't endorse "I did this to make alignment legit", I was in fact trying to solve the problem as I saw it.) (I also did lots of conceptual work that I think did make progress but I have a bad habit of using phrases like "past work" to only mean papers.)
- "[Particular past work] didn't make progress on the problem, though it did explain a problem well" -- seems very plausible that I said this about some past DeepMind work.
I do feel pretty surprised if, while I was at DeepMind, I ever intended to make the claim that most of the DeepMind safety team(s) were doing work based on a motivation that was primarily about demonstrating difficulty / convincing other people. (Perhaps I intentionally made such a claim while I wasn't at DeepMind; seems a lot easier for me to have been mistaken about that before I was actually at DeepMind, but honestly I'd still be pretty surprised.)
My sense is most of the motivation for people at the Deepmind teams comes from people thinking about how to get other people at Deepmind to take AI Alignment seriously.
Idk how you would even theoretically define a measure for this that I could put numbers on, but I feel like if you somehow did do it, I'd probably think it was <50% and >10%.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T23:21:52.078Z · LW(p) · GW(p)
[While I was working on goal misgeneralization] "Basically all the work that I'm doing is about convincing other people that the problem is real". I might have also said something like "and most people I work with" intending to talk about my collaborators on goal misgeneralization rather than the entire DeepMind safety team(s); for at least some of the time that I was working on goal misgeneralization I was an individual contributor so that would have been a reasonable interpretation.
This seems like the most likely explanation. Decent chance I interpreted "and most people I work with" as referring to the rest of the Deepmind safety team.
I still feel confused about some stuff, but I am happy to let things stand here.
↑ comment by Raemon · 2023-03-15T20:31:44.867Z · LW(p) · GW(p)
fyi your phrasing here is different from what I initially interpreted "make AI safety seem legit".
like there's maybe a few things someone might mean if they say "they're working on AI Alignment research"
- they are pushing forward the state of the art of deep alignment understanding
- they are orienting to the existing field of alignment research / upskilling
- they are conveying to other AI researchers "here is what the field of alignment is important and why"
- they are trying to make AI alignment feel high status, so that they feel safe in their career and social network, while also getting to feel important
(and of course people can be doing a mixture of the above, or 5th options I didn't lisT)
I interpreted you initially as saying #4, but it sounds like you/Rohin here are talking about #3. There are versions of #3 that are secretly just #4 without much theory-of-change, but, idk, I think Rohin's stated goal here is just pretty reasonable and definitely something I want in my overall AI Alignment Field portfolio. I agree you should avoid accidentally conflating it with #1.
(i.e. this seems related to a form of research-debt, albeit focused on bridging the gap between one field and another, rather than improving intra-field research debt)
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T21:41:43.463Z · LW(p) · GW(p)
Yep, I am including 3 in this. I also think this is something pretty reasonable for someone in the field to do, but when most of your field is doing that I think quite crazy and bad things happen, and also it's very easy to slip into doing 4 instead.
↑ comment by lc · 2023-03-15T08:43:50.771Z · LW(p) · GW(p)
They are working on it partially because this gives Anthropic access to state of the art models to do alignment research on, but I think in even greater parts they are doing it because this gives them a seat at the table with the other AI capabilities orgs and makes their work seem legitimate to them, which enables them to both be involved in shaping how AI develops, and have influence over these other orgs.
...Am I crazy or is this discussion weirdly missing the third option of "They're doing it because they want to build a God-AI and 'beat the other orgs to the punch'"? That is completely distinct from signaling competence to other AGI orgs or getting yourself a "seat at the table" and it seems odd to categorize the majority of Anthropic's aggslr8ing as such.
↑ comment by Orpheus16 (akash-wasil) · 2023-03-15T15:36:40.493Z · LW(p) · GW(p)
It seems to me like one (often obscured) reason for the disagreement between Thomas and Habryka is that they are thinking about different groups of people when they define "the field."
To assess the % of "the field" that's doing meaningful work, we'd want to do something like [# of people doing meaningful work]/[total # of people in the field].
Who "counts" in the denominator? Should we count anyone who has received a grant from the LTFF with the word "AI safety" in it? Only the ones who have contributed object-level work? Only the ones who have contributed object-level work that passes some bar? Should we count the Anthropic capabilities folks? Just the EAs who are working there?
My guess is that Thomas was using more narrowly defined denominator (e.g., not counting most people who got LTFF grants and went off to to PhDs without contributing object-level alignment stuff; not counting most Anthropic capabilities researchers who have never-or-minimally engaged with the AIS community) whereas Habryka was using a more broadly defined denominator.
I'm not certain about this, and even if it's true, I don't think it explains the entire effect size. But I wouldn't be surprised if roughly 10-30% of the difference between Thomas and Habryka might come from unstated assumptions about who "counts" in the denominator.
(My guess is that this also explains "vibe-level" differences to some extent. I think some people who look out into the community and think "yeah, I think people here are pretty reasonable and actually trying to solve the problem and I'm impressed by some of their work" are often defining "the community" more narrowly than people who look out into the community and think "ugh, the community has so much low-quality work and has a bunch of people who are here to gain influence rather than actually try to solve the problem.")
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2023-03-15T19:34:40.111Z · LW(p) · GW(p)
This sounds like a solid explanation for the difference for someone totally uninvolved with the Berkeley scene.
Though I'm surprised there's no broad consensus on even basic things like this in 2023.
In game terms, if everyone keeps their own score separately then it's no wonder a huge portion of effort will, in aggregate, go towards min-maxing the score tracking meta-game.
↑ comment by carboniferous_umbraculum (Spencer Becker-Kahn) · 2023-03-15T10:33:07.851Z · LW(p) · GW(p)
Something ~ like 'make it legit' has been and possibly will continue to be a personal interest of mine.
I'm posting this after Rohin entered this discussion - so Rohin, I hope you don't mind me quoting you like this, but fwiw I was significantly influenced by this comment [EA(p) · GW(p)] on Buck's old talk transcript 'My personal cruxes for working on AI safety [EA · GW]'. (Rohin's comment repeated here in full and please bear in mind this is 3 years old; his views I'm sure have developed and potentially moved a lot since then:)
Replies from: rohinmshah
I enjoyed this post, it was good to see this all laid out in a single essay, rather than floating around as a bunch of separate ideas.That said, my personal cruxes and story of impact are actually fairly different: in particular, while this post sees the impact of research as coming from solving the technical alignment problem, I care about other sources of impact as well, including:
1. Field building: Research done now can help train people who will be able to analyze problems and find solutions in the future, when we have more evidence about what powerful AI systems will look like.
2. Credibility building: It does you no good to know how to align AI systems if the people who build AI systems don't use your solutions. Research done now helps establish the AI safety field as the people to talk to in order to keep advanced AI systems safe.
3. Influencing AI strategy: This is a catch all category meant to include the ways that technical research influences the probability that we deploy unsafe AI systems in the future. For example, if technical research provides more clarity on exactly which systems are risky and which ones are fine, it becomes less likely that people build the risky systems (nobody _wants_ an unsafe AI system), even though this research doesn't solve the alignment problem.
As a result, cruxes 3-5 in this post would not actually be cruxes for me (though 1 and 2 would be).
↑ comment by Rohin Shah (rohinmshah) · 2023-03-15T19:23:24.074Z · LW(p) · GW(p)
I still endorse that comment, though I'll note that it argues for the much weaker claims of
- I would not stop working on alignment research if it turned out I wasn't solving the technical alignment problem
- There are useful impacts of alignment research other than solving the technical alignment problem
(As opposed to something more like "the main thing you should work on is 'make alignment legit'".)
(Also I'm glad to hear my comments are useful (or at least influential), thanks for letting me know!)
↑ comment by ESRogs · 2023-03-15T22:24:26.887Z · LW(p) · GW(p)
- CAIS
Can we adopt a norm of calling this Safe.ai? When I see "CAIS", I think of Drexler's "Comprehensive AI Services".
Replies from: DanielFilan, jan-kulveit↑ comment by DanielFilan · 2023-03-16T00:12:46.293Z · LW(p) · GW(p)
Oh now the original comment makes more sense, thanks for this clarification.
↑ comment by Jan Kulveit (jan-kulveit) · 2023-03-17T21:48:37.603Z · LW(p) · GW(p)
+1 I was really really upset safe.ai decided to use an established acronym for something very different
↑ comment by 6nne · 2023-03-15T18:43:24.863Z · LW(p) · GW(p)
Could someone explain exactly what "make AI alignment seem legit” means in this thread? I’m having trouble understanding from context.
- “Convince people building AI to utilize AI alignment research”?
- “Make the field of AI alignment look serious/professional/high-status”?
- “Make it look like your own alignment work is worthy of resources”?
- “Make it look like you’re making alignment progress even if you’re not”?
A mix of these? Something else?
Replies from: JamesPayor↑ comment by James Payor (JamesPayor) · 2023-03-15T19:11:46.403Z · LW(p) · GW(p)
Yeah, all four of those are real things happening, and are exactly the sorts of things I think the post has in mind.
I take "make AI alignment seem legit" to refer to a bunch of actions that are optimized to push public discourse and perceptions around. Here's a list of things that come to my mind:
- Trying to get alignment research to look more like a mainstream field, by e.g. funding professors and PhD students who frame their work as alignment and giving them publicity, organizing conferences that try to rope in existing players who have perceived legitimacy, etc
- Papers like Concrete Problems in AI Safety that try to tie AI risk to stuff that's already in the overton window / already perceived as legitimate
- Optimizing language in posts / papers to be perceived well, by e.g. steering clear of the part where we're worried AI will literally kill everyone
- Efforts to make it politically untenable for AI orgs to not have some narrative around safety
Each of these things seems like they have a core good thing, but according to me they've all backfired to the extend that they were optimized to avoid the thorny parts of AI x-risk, because this enables rampant goodharting. Specifically I think the effects of avoiding the core stuff have been bad, creating weird cargo cults around alignment research, making it easier for orgs to have fake narratives about how they care about alignment, and etc.
↑ comment by evhub · 2023-03-15T06:45:58.721Z · LW(p) · GW(p)
Anthropic scaring laws
Personally, I think "Discovering Language Model Behaviors with Model-Written Evaluations [LW · GW]" is most valuable because of what it demonstrates from a scientific perspective, namely that RLHF and scale make certain forms of agentic behavior worse.
comment by johnswentworth · 2023-03-16T01:00:56.565Z · LW(p) · GW(p)
Based on my own retrospective views of how lightcone's office went less-than-optimally, I recently gave some recommendations to someone maybe setting up another alignment research space. (Background: I've been working in the lightcone office since shortly after it opened.) They might be of interest to people mining this post for insights on how to execute similar future spaces. Here they are, lightly edited:
- I recommend selecting for people who want to understand agents, instead of people who want to reduce AI X-risk. When I think about people who bring an attitude of curiosity/exploration to alignment work, the main unifying pattern I notice is that they want to understand agents, as opposed to just avoid doom.
- I recommend selecting for people who are self-improving a lot, and/or want to help others improve a lot. Alex Turner or Nate Soares are good examples of people who score highly on this axis.
- For each of the above, I recommend that you aim for a clear majority (i.e. at least 60-70%) of people in the office to score highly on the relevant metric. So i.e. aim for at least 60-70% of people to be trying to understand agents, and separately at least 60-70% of people be trying to self-improve a lot and/or help others self-improve a lot.
- (The reasoning here is about steering the general vibe, kinds of conversations people have by default, that sort of thing. Which characteristics to select for obviously depend on what kind of vibe you want.)
- (One key load-bearing point about both of the above characteristics is that they're not synonymous with general competence or status. Regardless of what vibe you're going for, the characteristics on which you select should be such that there are competent and/or high-status people who you'd say "no" to. Otherwise, you'll probably slide much harder into status dynamics.)
- I recommend maintaining a very low fraction of people who are primarily doing meta-stuff, i.e. field-building, strategizing, forecasting, etc.
- (This is also about steering vibe and default conversation topics. You don't want enough meta-people that they reach critical concentration for conversational purposes. Also, critical concentration tends to be lower for more-accessible topics. This is one of the major places where I think lightcone went wrong; conversations defaulted to meta-stuff far too much as a result.)
- It might be psychologically helpful to have people pay for their office space, even if it's heavily subsidized by grant money. If you give something away for free, there will always be people lined up to take it, which forces you to gatekeep a lot. Gatekeeping in turn amplifies the sort of unpleasant status dynamics which burned out the lightcone team pretty hard; that's what happens when allocation of scarce resources is by status rather than by money. If e.g. the standard guest policy is "sure, you can bring guests/new people, but you need to pay for them" (maybe past some minimum allowance), then there will be a lot fewer people who you need to say "no" to and who feel like shit as a result.
↑ comment by evhub · 2023-03-16T21:07:28.028Z · LW(p) · GW(p)
I recommend selecting for people who want to understand agents, instead of people who want to reduce AI X-risk.
Strong disagree. I think locking in particular paradigms of how to do AI safety research would be quite bad.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-17T04:28:29.999Z · LW(p) · GW(p)
That seems right to me, but I interpreted the above for advice for one office, potentially a somewhat smaller one. Seems fine to me to have one hub for people who think more through the lens of agency.
Replies from: lelapin↑ comment by Jonathan Claybrough (lelapin) · 2023-03-20T08:24:48.374Z · LW(p) · GW(p)
I mostly endorse having one office concentrate on one research agenda and be able to have high quality conversations on it, and the stated numbers of maybe 10 to 20% people working on strategy/meta sounds fine in that context. Still I want to emphasize how crucial they are - If you have no one to figure out the path between your technical work and overall reducing risk, you're probably missing better paths and approaches (and maybe not realizing your work is useless).
Overall I'd say we don't have enough strategy work being done, and believe it's warranted to have spaces with 70% of people working on strategy/meta. I don't think it was bad if the Lightcone office had a lot of strategy work. (We probably also don't have enough technical alignment work, having more of both is probably good, if we coordinate properly)
comment by Thomas Larsen (thomas-larsen) · 2023-03-15T01:33:20.404Z · LW(p) · GW(p)
I personally benefitted tremendously from the Lightcone offices, especially when I was there over the summer during SERI MATS. Being able to talk to lots of alignment researchers and other aspiring alignment researchers increased my subjective rate of alignment upskilling by >3x relative to before, when I was in an environment without other alignment people.
Thanks so much to the Lightcone team for making the office happen. I’m sad (emotionally, not making a claim here whether it was the right decision or not) to see it go, but really grateful that it existed.
comment by maia · 2023-03-15T23:32:35.107Z · LW(p) · GW(p)
"The EA and rationality communities might be incredibly net negative" is a hell of a take to be buried in a post about closing offices.
:-(
Replies from: Raemon↑ comment by Raemon · 2023-03-15T23:58:29.257Z · LW(p) · GW(p)
Part of the point here is Oli, Ben and the rest of the team are still working through our thoughts/feelings on the subject, didn't feel in a good space to write any kind "here's Our Take™" post. i.e the point here was not meant to do "narrative setting"
But, it seemed important to get the information about our reasoning out there. I felt it was valuable to get some version of this post shipped soon, and this was the version we all felt pretty confident about rushing out the door without angsting about exactly what to say.
(Oli may have a somewhat different frame about what happened and his motivations)
Replies from: maia, lelapin↑ comment by maia · 2023-03-16T00:07:52.075Z · LW(p) · GW(p)
That all makes sense. It does feel like this is worth a larger conversation now that people are thinking about it, and I don't think you guys are the only ones.
I'm reminded of this Sam Altman tweet: https://mobile.twitter.com/sama/status/1621621724507938816
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-16T00:34:48.121Z · LW(p) · GW(p)
To give credit where it's due, I'm impressed that someone could ask the question whether EA and Rationality were net negative from our values, and while I suspect that an honest investigation would say it wasn't net negative, as Scott Garrabrant said, Yes requires the possibility of No, and there's an outside chance of an investigation returning that EA/Rationality is net negative.
Also, I definitely agree that we probably should talk about things that are outside the Overton Window more.
Re Sam Altman's tweet, I actually think this is reasonably neutral, from my vantage point, maybe because I'm way more optimistic on AI risk and AI Alignment than most of LW.
↑ comment by Jonathan Claybrough (lelapin) · 2023-03-20T08:34:33.055Z · LW(p) · GW(p)
I've multiple times been perplexed as to what the past events which can lead to this kind of take (over 7 years ago, EA/Rationality community's influence probably accelerated openAI's creation) have to do with today's shutting down of the offices.
Are there current, present day things going on in the EA and rationality community which you think warrant suspecting them of being incredibly net negative (causing worse worlds, conditioned on the current setup)? Things done in the last 6 months ? At Lightcone Offices ? (Though I'd appreciate specific examples, I'd already greatly appreciate knowing if there is something in the abstract and prefer a quick response to that level of precision than nothing)
I've imagined an answer, is the following on your mind ?
"EAs are more about saying they care about numbers than actually caring about numbers, and didn't calculate downside risk enough in the past. The past events reveal this attitude and because it's not expected to have changed, we can expect it to still be affecting current EAs, who will continue causing great harm because of not actually caring for downside risk enough. "
↑ comment by habryka (habryka4) · 2023-03-20T09:01:26.914Z · LW(p) · GW(p)
Are there current, present day things going on in the EA and rationality community which you think warrant suspecting them of being incredibly net negative (causing worse worlds, conditioned on the current setup)? Things done in the last 6 months ?
I mean yes! Don't I mention a lot of them in the post above?
I mean FTX happened in the last 6 months! That caused incredibly large harm for the world.
OpenAI and Anthropic are two of the most central players in an extremely bad AI arms race that is causing enormous harm. I really feel like it doesn't take a lot of imagination to think about how our extensive involvement in those organizations could be bad for the world. And a huge component of the Lightcone Offices was causing people to work at those organizations, as well as support them in various other ways.
EAs are more about saying they care about numbers than actually caring about numbers, and didn't calculate downside risk enough in the past. The past events reveal this attitude and because it's not expected to have changed, we can expect it to still be affecting current EAs, who will continue causing great harm because of not actually caring for downside risk enough.
No, this does not characterize my opinion very well. I don't think "worrying about downside risk" is a good pointer to what I think will help, and I wouldn't characterize the problem that people have spent too little effort or too little time on worrying about downside risk. I think people do care about downside risk, I just also think there are consistent and predictable biases that cause people to be unable to stop, or be unable to properly notice certain types of downside risk, though that statement feels in my mind kind of vacuous and like it just doesn't capture the vast majority of the interesting detail of my model.
Replies from: lelapin, sharmake-farah↑ comment by Jonathan Claybrough (lelapin) · 2023-03-21T08:12:33.938Z · LW(p) · GW(p)
Thanks for the reply !
The main reason I didn't understand (despite some things being listed) is I assumed none of that was happening at Lightcone (because I guessed you would filter out EAs with bad takes in favor of rationalists for example). The fact that some people in EA (a huge broad community) are probably wrong about some things didn't seem to be an argument that Lightcone Offices would be ineffective as (AFAIK) you could filter people at your discretion.
More specifically, I had no idea "a huge component of the Lightcone Offices was causing people to work at those organizations". That's strikingly more of a debatable move but I'm curious why that happened in the first place ? In my field building in France we talk of x-risk and alignment and people don't want to accelerate the labs but do want to slow down or do alignment work. I feel a bit preachy here but internally it just feels like the obvious move is "stop doing the probably bad thing", but I do understand if you got in this situation unexpectedly that you'll have a better chance burning this place down and creating a fresh one with better norms.
Overall I get a weird feeling of "the people doing bad stuff are being protected again, we should name more precisely who's doing the bad stuff and why we think it's bad" (because I feel aimed at by vague descriptions like field-building, even though I certainly don't feel like I contributed to any of the bad stuff being pointed at)
No, this does not characterize my opinion very well. I don't think "worrying about downside risk" is a good pointer to what I think will help, and I wouldn't characterize the problem that people have spent too little effort or too little time on worrying about downside risk. I think people do care about downside risk, I just also think there are consistent and predictable biases that cause people to be unable to stop, or be unable to properly notice certain types of downside risk, though that statement feels in my mind kind of vacuous and like it just doesn't capture the vast majority of the interesting detail of my model.
So it's not a problem of not caring, but of not succeeding at the task. I assume the kind of errors you're pointing at are things which should happen less with more practiced rationalists ? I guess then we can either filter to only have people who are already pretty good rationalists, or train them (I don't know if there are good results on that side per CFAR).
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-21T09:22:24.999Z · LW(p) · GW(p)
The fact that some people in EA (a huge broad community) are probably wrong about some things didn't seem to be an argument that Lightcone Offices would be ineffective as (AFAIK) you could filter people at your discretion.
I mean, no, we were specifically trying to support the EA community, we do not get to unilaterally decide who is part of the community. People I don't personally have much respect for but are members of the EA community who are putting in the work to be considered members in good standing definitely get to pass through. I'm not going as far as to say this was the only thing going on, I made choices about which parts of the movement seemed like they were producing good work and acting ethically and which parts seemed pretty horrendous and to be avoided, but I would (for instance) regularly make an attempt to welcome people from an area that seemed to have poor connections in the social graph (e.g. the first EA from country X, from org Y, from area-of-work Z etc), even if I wasn't excited about that person or place or area, because it was part of the EA community and it seems very valuable for the community as a whole to have better interconnectedness between the disparate parts. Overall I think the question I asked was closer to "what would a good custodian of the EA community want to use these resources for" rather than "what would Ben or Lightcone want to use these resources for".
As to your confusion about the office, an analogy that might help here is to consider the marketing or recruitment part of a large company, or perhaps a branch of the company that makes a different product from the rest — yes, our part of the organization functioned nicely, and I liked the choices we made, but if some other part of the company is screwing over its customers/staff, or the CEO is stealing money, or the company's product seems unethical to me, it doesn't matter if I like my part of the company, I am contributing to the company's life and output and should act accordingly. I did not work at FTX, I have not worked for OpenAI, but I am heavily supporting an ecosystem that supported these companies, and I anticipate that the resources I contribute will continue to get captured by these sorts of players via some circuitous route.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-20T14:20:44.244Z · LW(p) · GW(p)
I mean FTX happened in the last 6 months! That caused incredibly large harm for the world.
I agree, but I have very different takeaways on what FTX means for the Rationalist community.
I think the major takeaway is that human society is somewhat more adequate, relative to our values than we think, and this matters.
To be blunt, FTX was always a fraud, because Bitcoin and cryptocurrency violated a fundamental axiom of good money: It's value must be stable, or at least slowly change, and it's not a good store of value due to the wildly unstable price of say a single Bitcoin or cryptocurrency, and the issue is the deeply stupid idea of fixing the supply, which combined with variable demand, led to wild price swings.
It's possible to salvage some value out of crypto, but they can't be tied to real money.
Most groups have way better ideas for money than Bitcoin and cryptocurrency.
OpenAI and Anthropic are two of the most central players in an extremely bad AI arms race that is causing enormous harm. I really feel like it doesn't take a lot of imagination to think about how our extensive involvement in those organizations could be bad for the world. And a huge component of the Lightcone Offices was causing people to work at those organizations, as well as support them in various other ways.
I don't agree, in this world, and this is related to a very important crux in AI Alignment/AI safety: Can it be solved solely via iteration and empirical work? My answer is yes, and one of the biggest examples is Pretraining from Human Feedback, and I'll explain why it's the first real breakthrough of empirical alignment:
-
It almost completely avoids deceptive alignment via the fact that it lets us specify the base goal as human values first before it has the generalization capabilities, and the goal is pretty simple and myopic, so simplicity bias doesn't have as much incentive to make the model deceptively aligned. Basically, we first pretrain the base goal, which is way more outer aligned than the standard MLE goal, and then we let the AI generalize, and this inverts the order of alignment and capabilities, where RLHF and other alignment solutions first give capabilities, then try to align the model. This is of course not going to work all that well compared to PHF. In particular, it means that more capabilities means better and better inner alignment by default.
-
The goal that was best for pretraining from human feedback, conditional training, has a number of outer alignment benefits compared to RLHF and fine-tuning, even without inner alignment being effectively solved and preventing deceptive alignment.
One major benefit is since it's offline training, there is never a way for any model to affect the distribution of data that we use for alignment, so there's never a way or incentive to gradient hack or shift the distribution. In essence, we avoid embedded agency problems by recreating a Cartesian boundary that actually works in an embedded setting. While it will likely fade away in time, we only need to have it work once, and then we can dispense with the Cartesian boundary.
Again, this shows increasing alignment with scale, which is good because we found the holy grail of alignment: A competitive alignment scheme that scales well with model data and allows you to crank capabilities up and get better and better results from alignment.
Here's a link if you're interested:
https://www.lesswrong.com/posts/8F4dXYriqbsom46x5/pretraining-language-models-with-human-preferences [LW · GW]
Finally, I don't think you realize how well we did in getting companies to care about alignment, our how good the fact that LLMs are being pursued first compared to RL first, which means we can have simulators before agentic systems arise.
comment by Nicholas / Heather Kross (NicholasKross) · 2023-03-14T23:38:06.498Z · LW(p) · GW(p)
Extremely strong upvote for Oliver's 2nd message.
Also, not as related: kudos for actually materially changing the course of your organization, something which is hard for most organizations, period.
Replies from: Jacy Reese↑ comment by Jacy Reese Anthis (Jacy Reese) · 2023-03-15T00:53:32.318Z · LW(p) · GW(p)
In particular, I wonder if many people who won't read through a post about offices and logistics would notice and find compelling a standalone post with Oliver's 2nd message and Ben's "broader ecosystem" list—analogous to AGI Ruin: A List of Lethalities [LW · GW]. I know related points have been made elsewhere, but I think 95-Theses-style lists have a certain punch.
comment by Zack_M_Davis · 2025-01-13T00:51:24.778Z · LW(p) · GW(p)
Retrospectives are great, but I'm very confused at the juxtaposition of the Lightcone Offices being maybe net-harmful in early 2023 and Lighthaven being a priority in early 2025 [LW · GW]. Isn't the latter basically just a higher-production-value version of the former? What changed? (Or after taking the needed "space to reconsider our relationship to this whole ecosystem", did you decide that the ecosystem is OK after all?)
Replies from: habryka4, Benito, Vaniver↑ comment by habryka (habryka4) · 2025-01-13T01:03:34.557Z · LW(p) · GW(p)
Lighthaven is quite different from the Lightcone Offices. Some key differences:
- We mostly charge for things! This means that the incentives and social dynamics are a lot less weird and sycophantic, in a lot of different ways. Generally, both the Lightcone Offices and Lighthaven have strongly updated me on charging for things whenever possible, even if it seems like it will result in a lot of net-positive trades and arrangements not happening.
- Lighthaven mostly hosts programs, and doesn't provide office space for a ton of people. There is a set of permanent residents at Lighthaven, but we are talking about like 10-20 people including the Lightcone team, as opposed to the ~100+ people with approximately permanent access to the Lightcone Offices. As I mention in the fundraising post, I expect this set to grow very slowly, and I feel good about supporting everyone in this set (and would feel at the very least very conflicted and probably net bad about providing the same services to everyone who we supported via the Lightcone Offices)
- More broadly, Lighthaven is both a lot more curated, and a lot less insular. We have lots of big events here with people from adjacent communities and ecosystems, and I feel good about the marginal improvement to idea exchange and communication we make here. And then the people and programs we do support more consistently are things I feel good about.
↑ comment by Ben Pace (Benito) · 2025-01-13T01:43:07.230Z · LW(p) · GW(p)
Adding onto this, I would broadly say that the Lightcone team did not update that in-person infrastructure was unimportant, even while our first attempt was an investment into an ecosystem we later came to regret investing in.
Also here's a quote of mine from the OP:
If I came up with an idea right now for what abstraction I'd prefer, it'd be something like an ongoing festival with lots of events and workshops and retreats for different audiences and different sorts of goals, with perhaps a small office for independent alignment researchers, rather than an office space that has a medium-size set of people you're committed to supporting long-term.
I'd say that this is a pretty close description of a key change that we made, that changes my models of the value of the space quite a lot.
↑ comment by Ben Pace (Benito) · 2025-01-13T01:39:41.384Z · LW(p) · GW(p)
For the record, all of Lightcone's community posts and updates from 2023 do not seem to me to be at all good fits for the review, as they're mostly not trying to teach general lessons, and are kinda inside-baseball / navel-gazing, which is not what the annual review is about.
Replies from: Raemon↑ comment by Raemon · 2025-01-13T02:37:35.219Z · LW(p) · GW(p)
Fwiw I disagree, I think the Review is deliberately openended.
Yes there's a specific goal of find the top 50 posts, and to identify important timeless intellectual contributions. But, part of the whole point of the review (as I originally envisioned it) is also to help reflect in a more general sense on "what happened on LessWrong and what can we learn from it?".
I think rather than trying to say "no, don't reflect on particular things that don't fit the most central use case of the Review", it seems actively good to me to take advantage of the openended nature of it to think about less central things. We can learn timeless lessons from posts that weren't, themselves, particularly timeless.
Replies from: Raemon↑ comment by Raemon · 2025-01-13T02:42:23.884Z · LW(p) · GW(p)
i.e. the question "what sort of community institutions are good to build?" is a timeless question. Why should we artificially limit our ability to reflect on that sort of thing during the Review, given that we set the Review up in an openended way that allows us to do that on the margin?
↑ comment by Vaniver · 2025-01-16T20:10:06.278Z · LW(p) · GW(p)
My understanding is that the Lightcone Offices and Lighthaven have 1) overlapping but distinct audiences, with Lightcone Offices being more 'EA' in a way that seemed bad, and 2) distinct use cases, where Lighthaven is more of a conference venue with a bit of coworking whereas Lightcone Offices was basically just coworking.
comment by Mitchell_Porter · 2023-03-16T06:15:24.278Z · LW(p) · GW(p)
Are there any implications for the future of LessWrong.com the online forum? How is the morale and the economic security of the people responsible for keeping this place running?
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-16T07:55:43.238Z · LW(p) · GW(p)
I think I might change some things but it seems very unlikely to me I will substantially reduce investment in LessWrong. Funding is scarcer post-FTX, so some things might change a bit, but I do care a lot about LessWrong continuing to get supported, and I also think it's pretty plausible I will substantially ramp up my investment into LW again.
comment by porby · 2023-03-17T21:56:14.793Z · LW(p) · GW(p)
This going to point about 87 degrees off from the main point of the post, so I'm fine with discussing this elsewhere or in DMs or something, but I do wonder how cruxy this is:
More broadly, I think AI Alignment ideas/the EA community/the rationality community played a pretty substantial role in the founding of the three leading AGI labs (Deepmind, OpenAI, Anthropic), and man, I sure would feel better about a world where none of these would exist, though I also feel quite uncertain here. But it does sure feel like we had a quite large counterfactual effect on AI timelines.
I missed the first chunk of your conversation with Dylan at the lurkshop about this, but at the time, it sounded like you suspected "quite large" wasn't 6-48 months, but maybe more than a decade. I could have gotten the wrong impression, but I remember being confused enough that I resolved to hunt you down later to ask (which I promptly forgot to do).
I gather that this isn't the issue, but it does seem load bearing. A model that suggests alignment/EA/rationality influences sped up AGI by >10 years has some pretty heavy implications which are consistent with the other things you've mentioned. If my understanding is correct, if you thought the actual speedup was more like 6 months (or even negative somehow), it would take some of the bite out.
My attempt at paraphrasing your model goes something like:
1. Alignment efforts influence an early start on some important companies like Deepmind.
2. These companies tend to have more "vision" with regard to AGI; they aren't just solving narrow basic tasks for incremental economic gain, but instead are very explicitly focused on the possibility of AGI.
3. The founding difference in vision legitimizes certain kinds of research and investment, like spending millions of dollars on training runs for general models that might seem counterfactually silly ("what are you doing, trying to chase some sci-fi nonsense? no one respectable would do that!")
4. The early influences more aggressively push algorithmic and hardware advancements by bringing demand forward in time.
I'm not sure how to get a decade or more out of this, though. I'd agree this dynamic did burn some time until AGI (and even 6 months is not ideal in context), but it seems like the largest counterfactual difference is in start date, not end date. I could see our universe getting into AGI-minded research 10 years earlier than others, but I strongly suspect the "boring" kind of applications would have ended up triggering basically the same dynamic later.
Those other worlds would still have video games encouraging a Close Enough hardware architecture and other enormous industries driving demand for improved chip manufacturing. In alt-2023, they'd still have a consumer grade video card like the 4090, just probably with less tensor core stuff. As the level of performance per dollar rises on hardware, the number of people who might try pushing scale increases until someone inevitably manages to convince VCs or other influential targets that hey, maybe there's something here.
(Before pivoting to safety research, "doing somewhat fringe AI stuff for funsies" was exactly the kind of thing I did. The counterfactual version of me would have almost certainly noticed, and I can't imagine I would have been alone or even close to it.)
At that point, I think the main difference between the worlds is that alt-world gets an even more absurdly shocking speedrun of capabilities. The hardware overhang makes it easy to pick similar low hanging fruit, just more quickly.
I think the only way for alt-world to take as long from Speedrun Start as us is if a surprisingly large amount of our progress came from sequential conceptual insights. That really doesn't match my impression of progress so far. Given the disjunctive architectural possibilities for reaching transformer-ish performance, it seems more like a mix of "try random stuff" and "architectures enabled by hardware."
Even assuming we had a 10 year head start, I'd expect the counterfactual world to reach AGI less than 48 months after us. That gives enough time for 1-2 extra hardware generations on top of the sequential efforts of engineers building the systems involved. And I'm not sure we even have a 10 year head start.
I'd also expect the counterfactual world to be even less concerned with safety. We're not doing well, but there are almost always ways to do much worse! In this frame, we acquired multiple leading labs who at least ostensibly consider the problem for the price of a few years. Even with my short timelines, it's hard for me to say this was a bad deal with high confidence.
Replies from: deluks917, habryka4↑ comment by sapphire (deluks917) · 2023-03-18T02:17:53.623Z · LW(p) · GW(p)
FWIW Im very angry about what happened and I think the speedup was around five years in expectation.
↑ comment by habryka (habryka4) · 2023-03-18T00:31:05.165Z · LW(p) · GW(p)
I missed the first chunk of your conversation with Dylan at the lurkshop about this, but at the time, it sounded like you suspected "quite large" wasn't 6-48 months, but maybe more than a decade.
A decade in-expectation seems quite extreme.
To be clear, I don't think AGI happening soon is particularly overdetermined, so I do think this is a thing that does actually differ quite a bit depending on details, but I do think it's very unlikely that actions that people adjacent to rationality took that seriously sped up timelines by more than a decade. I would currently give that maybe 3% probability or something.
Replies from: Benito, porby↑ comment by Ben Pace (Benito) · 2023-03-18T03:48:07.192Z · LW(p) · GW(p)
People think the speed-up by rationalists is only ~5 years? I thought people were thinking 10-40. I do not think I would trade the entire history of LessWrong, including the articulation of the alignment problem, for 5 years of timelines. I mean, maybe it's the right call, but it hardly seems obvious.
When LessWrong was ~dead (before we worked on the revival) I had this strong sense that being able to even consider that OpenAI could be bad for the world, or the notion that the alignment problem wasn't going to go okay by-default, was being edged out of the overton window, and I felt enough pressure that I could barely think about it with anyone else. I think without the people on LessWrong writing to each other about it, I wouldn't really be able to think clearly about the situation, and people would have collectively made like ~100x less of a direct effort on things.
(To be clear, I think the absolute probability is still dire, this has not been sufficient to solve things).
And of course that's just since the revival, the true impact counts the sequences, and much of the articulation of the problem at all.
As bad as things are now, I think we all could've been a lot less sane in very nearby worlds.
Replies from: habryka4, chrisvm↑ comment by habryka (habryka4) · 2023-03-18T06:27:11.125Z · LW(p) · GW(p)
I mean, I don't see the argument for more than that. Unless you have some argument for hardware progress stopping, my sense is that things would get cheap enough that someone is going to try the AI stuff that is happening today within a decade.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-18T06:53:56.957Z · LW(p) · GW(p)
some people who would have been working on ai without lesswrong: sutskever, graves, bengio, hinton, lecun, schmidhuber, hassabis,
↑ comment by Chris van Merwijk (chrisvm) · 2023-03-26T13:59:28.992Z · LW(p) · GW(p)
"When LessWrong was ~dead"
Which year are you referring to here?
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-26T19:15:36.907Z · LW(p) · GW(p)
2016-17
Added: To give context, here's a list of number of LW posts by year:
- 2009: 852
- 2010: 1143
- 2011: 3002
- 2012: 2583
- 2013: 1973
- 2014: 1797
- 2015: 2002 (<– This should be ~1880, as we added all ~120 HPMOR posts and backdated them to 2015)
- 2016: 1303 (<– This is the most 'dead' year according to me, and the year with the fewest posts)
- 2017: 1671 (<– LW 2.0 revived in the second half of this year)
- 2018: 1709
- 2019: 2121
- 2020: 3099
- 2021: 3230
- 2022: 4538
- First quarter of 2023: 1436, if you 4x that it is 5744
(My, it's getting to be quite a lot of posts these days.)
comment by Lukas_Gloor · 2023-03-15T01:04:38.662Z · LW(p) · GW(p)
Thanks for sharing your reasoning, that was very interesting to read! I kind of agree with the worldview outlined in the quoted messages from the "Closing-Office-Reasoning" channel. Something like "unless you go to extreme lengths to cultivate integrity and your ability to reason in truth-tracking ways, you'll become a part of the incentive-gradient landscape around you, which kills all your impact."
Seems like a tough decision to have to decide whether an ecosystem has failed vs. whether it's still better than starting from scratch despite its flaws. (I could imagine that there's an instinct to just not think about it.)
Sometimes we also just get unlucky, though. (I don't think FTX was just bad luck, but e.g., with some of the ways AI stuff played out, I find it hard to tell. Of course, just because I find it hard to tell doesn't mean it's objectively hard to tell. Maybe some things really were stupid also when they happened, not just in hindsight.)
I'm curious if you think there are "good EA orgs" where you think the leadership satisfies the threshold needed to predictably be a force of good in the world (my view is yes!). If yes, do you think that this isn't necessarily enough for "building the EA movement" to be net positive? E.g., maybe you think it boosts the not-so-good orgs just as much as the good ones, and "burns the brand" in the process?
I'd say that, if there are some "good EA orgs," that's a reason for optimism. We can emulate what's good about them and their culture. (It could still make sense to be against further growth if you believe the ratio has become too skewed.) Whereas, if there aren't any, then we're already in trouble, so there's a bit of a wager against it.
comment by MondSemmel · 2023-03-16T12:51:35.536Z · LW(p) · GW(p)
Also see this recent podcast interview [LW · GW] with habryka (incl. my transcript [LW · GW] of it), which echoes some of what's written here. Unsurprisingly so, when the slack messages were from Jan 26th and the podcast was from <= Feb 5th.
See e.g. this section [LW · GW] about the Rationality/AI Alignment/EA ecosystem.
comment by J Bostock (Jemist) · 2025-01-17T23:44:14.417Z · LW(p) · GW(p)
I'm mildly against this being immortalized as part of the 2023 review, though I think it serves excellently as a community announcement for Bay Area rats, which seems to be its original purpose.
I think it has the most long-term relevant information (about AI and community building) back loaded and the least relevant information (statistics and details about a no-longer-existent office space in the Bay Area) front loaded. This is a very Bay Area centric post, which I don't think is ideal.
A better version of this post would be structured as a round up of the main future-relevant takeaways, with specifics from the office space as examples.
comment by JakubK (jskatt) · 2023-03-17T17:54:57.416Z · LW(p) · GW(p)
I greatly appreciate this post. I feel like "argh yeah it's really hard to guarantee that actions won't have huge negative consequences, and plenty of popular actions might actually be really bad, and the road to hell is paved with good intentions." With that being said, I have some comments to consider.
The offices cost $70k/month on rent [1] [LW(p) · GW(p)], and around $35k/month on food and drink, and ~$5k/month on contractor time for the office. It also costs core Lightcone staff time which I'd guess at around $75k/year.
That is ~$185k/month and ~$2.22m/year. I wonder if the cost has anything to do with the decision? There may be a tendency to say "an action is either extremely good or extremely bad because it either reduces x-risk or increases x-risk, so if I think it's net positive I should be willing to spend huge amounts of money." I think this framing neglects a middle ground of "an action could be somewhere in between extremely good and extremely bad." Perhaps the net effects of the offices were "somewhat good, but not enough to justify the monetary cost." I guess Ben sort of covers this point later ("Having two locations comes with a large cost").
its value was substantially dependent on the existing EA/AI Alignment/Rationality ecosystem being roughly on track to solve the world's most important problems, and that while there are issues, pouring gas into this existing engine, and ironing out its bugs and problems, is one of the most valuable things to do in the world.
Huh, it might be misleading to view the offices as "pouring gas into the engine of the entire EA/AI Alignment/Rationality ecosystem." They contribute to some areas much more than others. Even if one thinks that the overall ecosystem is net harmful, there could still be ecosystem-building projects that are net helpful. It seems highly unlikely to me that all ecosystem-building projects are bad.
The Lighthouse system is going away when the leases end. Lighthouse 1 has closed, and Lighthouse 2 will continue to be open for a few more months.
These are group houses for members of the EA/AI Alignment/Rationality ecosystem, correct? Relating to the last point, I expect the effects of these to be quite different from the effects of the offices.
FTX is the obvious way in which current community-building can be bad, though in my model of the world FTX, while somewhat of outlier in scope, doesn't feel like a particularly huge outlier in terms of the underlying generators.
I'm very unsure about this, because it seems plausible that SBF would have done something terrible without EA encouragement. Also, I'm confused about the detailed cause-and-effect analysis of how the offices will contribute to SBF-style catastrophes -- is the idea that "people will talk in the offices and then get stupid ideas, and they won't get equally stupid ideas without the offices?"
My guess is RLHF research has been pushing on a commercialization bottleneck and had a pretty large counterfactual effect on AI investment, causing a huge uptick in investment into AI and potentially an arms race between Microsoft and Google towards AGI: https://www.lesswrong.com/posts/vwu4kegAEZTBtpT6p/thoughts-on-the-impact-of-rlhf-research?commentId=HHBFYow2gCB3qjk2i [LW(p) · GW(p)]
Worth noting that there is plenty of room for debate on the impacts of RLHF, including the discussion in the linked post.
Tendencies towards pretty mindkilly PR-stuff in the EA community: https://forum.effectivealtruism.org/posts/ALzE9JixLLEexTKSq/cea-statement-on-nick-bostrom-s-email?commentId=vYbburTEchHZv7mn4 [EA(p) · GW(p)]
Overall I'm getting a sense of "look, there are bad things happening so the whole system must be bad." Additionally, I think the negative impact of "mindkilly PR-stuff" is pretty insubstantial. On a related note, I somewhat agree with the idea that "most successful human ventures look - from up close - like dumpster fires [LW · GW]." It's worth being wary of inferences resembling "X evokes a sense of disgust, so X is probably really harmful."
I genuinely only have marginally better ability to distinguish the moral character of Anthropic's leadership from the moral character of FTX's leadership
Yeah this makes sense. I would really love to gain a clear understanding of who has power at the top AGI labs and what their views are on AGI risk. AFAIK nobody has done a detailed analysis of this?
Also, as in the case of RLHF, it's worth noting that there are some reasonable arguments for Anthropic being helpful.
I think AI Alignment ideas/the EA community/the rationality community played a pretty substantial role in the founding of the three leading AGI labs (Deepmind, OpenAI, Anthropic)
Definitely true for Anthropic. For OpenAI I'm less sure; IIRC the argument is that there were lots of EA-related conferences that contributed to the formation of OpenAI, and I'd like to see more details than this; "there were EA events where key players talked" feels quite different from "without EA, OpenAI would not exist." I feel similarly about DeepMind; IIRC Eliezer accidentally convinced one of the founders to work on AGI -- are there other arguments?
And again, how do the Lightcone offices specifically contribute to the founding of more leading AGI labs? My impression is that the offices' vibe conveyed a strong sense of "it's bad to shorten timelines."
It's a bad idea to train models directly on the internet
I'm confused how the offices contribute to this.
The EA and AI Alignment community should probably try to delay AI development somehow, and this will likely include getting into conflict with a bunch of AI capabilities organizations, but it's worth the cost
Again, I'm confused how the offices have a negative impact from this perspective. I feel this way about quite a few of the points in the list.
I do sure feel like a lot of AI alignment research is very suspiciously indistinguishable from capabilities research
...
It also appears that people who are concerned about AGI risk have been responsible for a very substantial fraction of progress towards AGI
...
A lot of people in AI Alignment I've talked to have found it pretty hard to have clear thoughts in the current social environment
To me these seem like some of the best reasons (among those in the list; I think Ben provides some more) to shut down the offices. The disadvantage of the list format is that it makes all the points seem equally important; it might be good to bold the points you see as most important or provide a numerical estimate for what percentage of the negative expect impact comes from each point.
The moral maze nature of the EA/longtermist ecosystem has increased substantially over the last two years, and the simulacra level of its discourse has notably risen too.
I feel similar to the way I felt about the "mindkilly PR-stuff"; I don't think the negative impact is very high in magnitude.
the primary person taking orders of magnitudes more funding and staff talent (Dario Amodei) has barely explicated his views on the topic and appears (from a distance) to have disastrously optimistic views about how easy alignment will be and how important it is to stay competitive with state of the art models
Agreed. I'm confused about Dario's views.
I recall at EAG in Oxford a year or two ago, people were encouraged to "list their areas of expertise" on their profile, and one person who works in this ecosystem listed (amongst many things) "Biorisk" even though I knew the person had only been part of this ecosystem for <1 year and their background was in a different field.
This seems very trivial to me. IIRC the Swapcard app just says "list your areas of expertise" or something, with very little details about what qualifies as expertise. Some people might interpret this as "list the things you're currently working on."
It also seems to me like people who show any intelligent thought or get any respect in the alignment field quickly get elevated to "great researchers that new people should learn from" even though I think that there's less than a dozen people who've produced really great work
Could you please list the people who've produced really great work?
I similarly feel pretty worried by how (quite earnest) EAs describe people or projects as "high impact" when I'm pretty sure that if they reflected on their beliefs, they honestly wouldn't know the sign of the person or project they were talking about, or estimate it as close-to-zero.
Strongly agree. Relatedly, I'm concerned that people might be exhibiting a lot of action bias.
Last point, unrelated to the quote: it feels like this post is entirely focused on the possible negative impacts of the offices, and that kind of analysis seems very likely to arrive at incorrect conclusions since it fails to consider the possible positive impacts. Granted, this post was a scattered collection of Slack messages, so I assume the Lightcone team has done more formal analyses internally.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-17T18:47:53.112Z · LW(p) · GW(p)
A few replies:
That is ~$185k/month and ~$2.22m/year. I wonder if the cost has anything to do with the decision? There may be a tendency to say "an action is either extremely good or extremely bad because it either reduces x-risk or increases x-risk, so if I think it's net positive I should be willing to spend huge amounts of money."
I don't think cost had that much to do with the decision, I expect that Open Philanthropy thought it was worth the money and would have been willing to continue funding at this price point.
In general I think the correct response to uncertainty is not half-speed. [LW · GW] In my opinion it was the right call to spend this amount of funding on the office for the last ~6 months of its existence even when we thought we'd likely do something quite different afterwards, because it was still marginally worth doing it and the cost-effectiveness calculations for the use of billions of dollars of x-risk money on the current margin are typically quite extreme.
These are group houses for members of the EA/AI Alignment/Rationality ecosystem, correct?
Not quite. They were houses where people could book to visit for up to 3 weeks at a time, commonly used by people visiting the office or in town for a bit for another event/conference/retreat. Much more like AirBnbs than group houses.
I'm confused about the detailed cause-and-effect analysis of how the offices will contribute to SBF-style catastrophes -- is the idea that "people will talk in the offices and then get stupid ideas, and they won't get equally stupid ideas without the offices?"
I think the most similar story is "A smart, competent, charismatic, person with horrible ethics will enter the office because they've managed to get good standing in the EA/longtermist ecosystem, cause a bunch of other very smart and competent people to work for them on the basis of expecting to do good in the world, and then do something corrupting and evil with them instead."
There are other stories too.
Replies from: lelapin, jskatt↑ comment by Jonathan Claybrough (lelapin) · 2023-03-20T09:30:12.769Z · LW(p) · GW(p)
I don't think cost had that much to do with the decision, I expect that Open Philanthropy thought it was worth the money and would have been willing to continue funding at this price point.
In general I think the correct response to uncertainty is not half-speed. [LW · GW] In my opinion it was the right call to spend this amount of funding on the office for the last ~6 months of its existence even when we thought we'd likely do something quite different afterwards, because it was still marginally worth doing it and the cost-effectiveness calculations for the use of billions of dollars of x-risk money on the current margin are typically quite extreme.
You're probably not the one to rant to about funding but I guess while the conversation is open I could use additional feedback and some reasons for why OpenPhil wouldn't be irresponsible in spending the money that way. (I only talk about OpenPhil and not particularly Lightcone, maybe you couldn't think of better ways to spend the money and didn't have other options)
Cost effectiveness calculations for reducing x-risk kinda always favor x-risk reduction so looking at it in the absolute isn't relevant. Currently AI x-risk reduction work is limited because of severe funding restrictions (there are many useful things to do that no one is doing for lack of money) which should warrant carefully done triage (and in particular considering the counterfactual).
I assume the average Lightcone office resident would be doing the same work with slightly reduced productivity (let's say 1/3) if they didn't have that office space (notably because many are rich enough to get other shared office space from their own pocket). Assuming 30 full time workers in the office, that's 10 man months per month of extra x-risk reduction work.
For contrast, on the same time period, $185k/month could provide for salary, lodging and office space for 50 people in Europe, all who counterfactually would not be doing that work otherwise, for which I claim 50 man months per month of extra x-risk reduction work. The biggest difference I see is incubation time would be longer than for the Lightcone offices, but if I start now with $20k/month I'd find 5 people and scale it up to 50 by the end of the year.
↑ comment by Ben Pace (Benito) · 2023-03-20T18:52:54.562Z · LW(p) · GW(p)
For contrast, on the same time period, $185k/month could provide for salary, lodging and office space for 50 people in Europe, all who counterfactually would not be doing that work otherwise, for which I claim 50 man months per month of extra x-risk reduction work.
The default outcome of giving people money, is either nothing, noise, or the resources getting captured by existing incentive gradients. In my experience, if you give people free money, they will take it, and they will nominally try to please you with it, so it's not that surprising if you can find 50 people to take your free money, but causing such people to do specific and hard things is a much higher level of challenge.
I had some hope that "just write good LessWrong posts" is sufficient incentive to get people to do useful stuff, but the SERI MATS scholars have tried this and only a few have produced great LessWrong posts, and otherwise there was a lot of noise. Perhaps it's worth it in expected value but my guess is that you could do much more selection and save a lot of the money and still get 80% of the value.
I think free office spaces of the sort we offered are only worthwhile inside an ecosystem where there are teams already working on good projects, and already good incentive gradients to climb, such that pouring in resources get invested well even with little discernment from those providing them. In contrast, simply creating free resources and having people come for those with the label of your goal on them, sounds like a way to get all the benefits of goodharting and none of the benefits of the void [LW · GW].
↑ comment by JakubK (jskatt) · 2023-03-29T01:10:36.991Z · LW(p) · GW(p)
In my opinion it was the right call to spend this amount of funding on the office for the last ~6 months of its existence even when we thought we'd likely do something quite different afterwards
This is confusing to me. Why not do "something quite different" from the start?
I'm trying to point at opportunity costs more than "gee, that's a lot of money, the outcome had better be good!" There are many other uses for that money besides the Lightcone offices.
A smart, competent, charismatic, person with horrible ethics will enter the office because they've managed to get good standing in the EA/longtermist ecosystem
My current understanding is that Sam gained good standing as a result of having lots of money for EA causes, not as a result of being charismatic in EA spaces? My sense is that the person you mentioned would struggle to gain good standing in the Lightcone offices without any preexisting money or other power.
Replies from: Benito, Benito↑ comment by Ben Pace (Benito) · 2023-03-29T02:02:51.816Z · LW(p) · GW(p)
My current understanding is that Sam gained good standing as a result of having lots of money for EA causes, not as a result of being charismatic in EA spaces? My sense is that the person you mentioned would struggle to gain good standing in the Lightcone offices without any preexisting money or other power.
No, he gained good standing from being around the EA community for so many years and having sophisticated ethical views (veganism, a form of utilitarianism, etc) and convincing well-respected EAs to work with him and fund him, as well as from having a lot of money and donating it to these spaces. Had the Lightcone Offices existed 5 years ago I expect he would have been invited to work from there (had he asked to), and that was at the start of Alameda.
↑ comment by Ben Pace (Benito) · 2023-03-29T02:00:23.731Z · LW(p) · GW(p)
Sorry if I wrote unclearly. For most of the time (even in the last 6 months) I thought it was worth continuing to support the ecosystem, and certainly to support the people in the office, even if I was planning later to move on. I wanted to move on primarily because of the opportunity cost — I thought we could do something greater. But I believe Habryka wanted to separate from the whole ecosystem and question whether the resources we were providing were actually improving the world at all, and at that point it's not simply a question of opportunity cost but of whether you're helping or hurting. If you're worried that you're not even helping but just making the problem worse, then it's a much stronger reason to stop.
You seem to think it wasn't worth it because of opportunity costs alone? I have been used to the world for a while now where there are two multi-billion dollar funders who are interested in funding x-risk work who don't have enough things to spend their money on, so I didn't feel like this was really competing with much else. Just because Lightcone was spending that money didn't mean another project didn't get money, none of the major funders were (or are) spending close to their maximum burn rate.
comment by Lorenzo (lorenzo-buonanno) · 2023-03-15T13:48:55.980Z · LW(p) · GW(p)
Thank you for sharing this, I was wondering about your perspective on these topics.
I am really curious about the intended counterfactual of this move. My understanding is that the organizations that were using the office raised funds for a new office in a few weeks (from the same funding pool that funds Lightcone), so their work will continue in a similar way.
Is the main goal to have Lightcone focus more on the Rose Garden Inn? What are your plans there, do you have projects in mind for "slowing down AI progress, pivotal acts, intelligence enhancement, etc."? Anything people can help with?
comment by Shmi (shminux) · 2023-03-15T04:34:56.564Z · LW(p) · GW(p)
Seems like a classic case of Goodharting, with lots of misaligned mesaoptimizers taking advantage.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-15T05:09:27.598Z · LW(p) · GW(p)
The hard question is "how much goodharting is too much goodharting".
comment by gwern · 2023-03-15T01:24:11.976Z · LW(p) · GW(p)
I'm a little confused: I feel like I read this post already, but I can't find it. Was there a prior deleted version?
Replies from: Benito↑ comment by Ben Pace (Benito) · 2023-03-15T01:30:20.363Z · LW(p) · GW(p)
You did see part of it before; I posted in Open Thread [LW(p) · GW(p)] a month ago with the announcement, but today Ray poked me and Oli to also publish some of the reasoning we wrote in slack.
comment by Tao Lin (tao-lin) · 2024-08-07T06:29:14.878Z · LW(p) · GW(p)
I don't particularly like the status hierarchy and incentive landscape of the ML community, which seems quite well-optimized to cause human extinction
the incentives are indeed bad, but more like incompetent and far from optimized to cause extinction
comment by Esben Kran (esben-kran) · 2023-03-15T09:34:50.359Z · LW(p) · GW(p)
Oliver's second message seems like a truly relevant consideration for our work in the alignment ecosystem. Sometimes, it really does feel like AI X-risk and related concerns created the current situation. Many of the biggest AGI advances might not have been developed counterfactually, and machine learning engineers would just be optimizing another person's clicks.
I am a big fan of "Just don't build AGI" and academic work with AI, simply because it is better at moving slowly (and thereby safely through open discourse and not $10 mil training runs) compared to massive industry labs. I do have quite a bit of trust in Anthropic, DeepMind and OpenAI simply from their general safety considerations compared to e.g. Microsoft's release of Sydney.
As part of this EA bet on AI, it also seems like the safety view has become widespread among most AI industry researchers from my interactions with them (though might just be a sampling bias and they were honestly more interested in their equity growing in value). So if the counterfactual of today's large AGI companies would be large misaligned AGI companies, then we would be in a significantly worse position. And if AI safety is indeed relatively trivial, then we're in an amazing position to make the world a better place. I'll remain slightly pessimistic here as well, though.
comment by lc · 2023-03-15T05:11:43.520Z · LW(p) · GW(p)
I also remember someone joining the offices to collaborate on a project, who explained that in their work they were looking for "The next Eliezer Yudkowsky or Paul Christiano". When I asked what aspects of Eliezer they wanted to replicate, they said they didn't really know much about Eliezer but it was something that a colleague of theirs said a lot.
💀
comment by Noosphere89 (sharmake-farah) · 2023-03-15T13:29:55.973Z · LW(p) · GW(p)
I disagree with the claims by Habryka and Ben Pace that your impact on AI wasn't positive and massive, and here's why.
My reasons for disagreement with Habryka and Ben Pace on their impact largely derive from me being way more optimistic on AI risk and AI Alignment than I used to be, which implies Habryka and Ben Pace had way more positive impact than they thought.
Some of my reasons why I became more optimistic, such that the chance of AI doom was cut to 1-10% from a prior 80%, come down to the following:
-
I basically believe that deceptive alignment won't happen with high probability, primarily because models will understand the base goal first before having world modeling.
-
I believe the other non-iterable problem, that is Goodhart, largely isn't a problem, and the evidence that Goodhart's law so severely impacts human society as to make customers buy subpar profit has moderate to strong evidence against it.
For the air conditioner example John Wentworth offered on how Goodhart's law operates in the consumer market, the comment section, in particular anonymousaisafety and Paul Christiano seems to have debunked the thesis that Goodhart's law is particularly severe, and gave evidence that no Goodharting is happening at all. Now the reason I am so strong on the claim is that John Wentworth, to his immense credit, was honest on how much cherry picking he did in the post, and the fact that even the cherry picked example shows a likely case of no Goodhart at all implies the pointers problem was solved for that case, and also implies that the pointers problem is quite a bit easier to solve than John Wentworth thought.
Links below:
https://www.lesswrong.com/posts/MMAK6eeMCH3JGuqeZ/everything-i-need-to-know-about-takeoff-speeds-i-learned [LW · GW]
https://www.lesswrong.com/posts/AMmqk74zWmvP8tXEJ/preregistration-air-conditioner-test [LW · GW]
https://www.lesswrong.com/posts/5re4KgMoNXHFyLq8N/air-conditioner-test-results-and-discussion#pLLeDhJfPnYt7fXTH [LW(p) · GW(p)]
- I agree with jsteinhardt that empirical evidence generalizes surprisingly far, and that this implies that the empirical work OpenAI et al is doing is very valuable for AI safety and alignment.
https://www.lesswrong.com/posts/ekFMGpsfhfWQzMW2h/empirical-findings-generalize-surprisingly-far [LW · GW]
-
I have meta priors that things are usually less bad than we feared and more good than we hope. In particular, I think people are too prone to overrate pessimism and underrated optimism.
-
In conclusion, I disagree with Habryka and Ben Pace on the sign of their impacts as well as how much they impacted the AI Alignment space (I think it was positive and massive).
I do think closing the Lightcone offices are good, but I disagree with a major reason for why Habryka and Ben Pace are closing the offices, and that's due to different models of AI risk.
Replies from: antimonyanthony, Vaniver↑ comment by Anthony DiGiovanni (antimonyanthony) · 2023-03-17T21:34:48.600Z · LW(p) · GW(p)
primarily because models will understand the base goal first before having world modeling
Could you say a bit more about why you think this? My definitely-not-expert expectation would be that the world-modeling would come first, then the "what does the overseer want" after that, because that's how the current training paradigm works: pretrain for general world understanding, then finetune on what you actually want the model to do.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-17T21:50:54.731Z · LW(p) · GW(p)
Admittedly, I got that from Deceptive alignment is <1% likely post.
Even if you don't believe that post, Pretraining from human preferences shows that alignment with human values can be instilled first as a base goal, thus outer aligning it, before giving it world modeling capabilities, works wonders for alignment and has many benefits compared to RLHF.
Given the fact that it has a low alignment tax, I suspect that there's a 50-70% chance that this plan, or a successor will be adopted for alignment.
Here's the post:
https://www.lesswrong.com/posts/8F4dXYriqbsom46x5/pretraining-language-models-with-human-preferences [LW · GW]
↑ comment by Vaniver · 2023-03-15T16:20:45.127Z · LW(p) · GW(p)
My reasons for disagreement with Habryka and Ben Pace on their impact largely derive from me being way more optimistic on AI risk and AI Alignment than I used to be, which implies Habryka and Ben Pace had way more positive impact than they thought.
You're using a time difference as evidence for the sign of one causal arrow?
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-03-15T16:37:00.531Z · LW(p) · GW(p)
I don't understand what you're saying, but what I was saying is that I used to be much more pessimistic around how hard AI Alignment was, and a large part of the problem of AI Alignment is that it's not very amenable to iterative solutions. Now, however, I believe that I was very wrong on how hard alignment ultimately turned out to be, and in retrospect, that means that the funding of AI safety research is much more positive, since I now give way higher chances to the possibility that empirical, iterative alignment is enough to solve AI Alignment.
Replies from: Vaniver↑ comment by Vaniver · 2023-03-16T03:27:30.853Z · LW(p) · GW(p)
Sure, but why do you think that means they had a positive impact? Even if alignment turns out to be easy instead of hard, that doesn't seem like it's evidence that Lightcone had a positive impact.
[I agree a simple "alignment hard -> Lightcone bad" model gets contradicted by it, but that's not how I read their model.]
Replies from: Linch, sharmake-farah↑ comment by Linch · 2023-03-16T04:36:50.482Z · LW(p) · GW(p)
My reading is that Noosphere89 thinks that Lightcone has helped in bringing in/upskiling a number of empirical/prosaic alignment researchers. In worlds where alignment is relatively easy, this is net positive as the alignment benefits are higher than the capabilities costs, while in worlds where alignment is very hard, we might expect the alignment benefits to be marginal while the capabilities costs continue to be very real.
↑ comment by Noosphere89 (sharmake-farah) · 2023-03-16T13:07:39.182Z · LW(p) · GW(p)
I did argue that closing the Lightcone offices was the right thing, but my point is that part of the reasoning relies on a core assumption that AI Alignment isn't very iterable and will generally cost capabilities that I find probably false.
I am open to changing my mind, but I see a lot of reasoning on AI Alignment that is kinda weird to me by Habryka and Ben Pace.
comment by Review Bot · 2024-05-28T13:16:11.892Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by DaystarEld · 2023-03-26T16:18:54.843Z · LW(p) · GW(p)
Thank you both for writing this and sharing your thoughts on the ecosystem in general. It's always heartening for me, even just as someone who occasionally visits the Bay, to see the amount of attention and thought being put into the effects of things like this on not just the ecosystem there, but also the broader ecosystem that I mostly interact with and work in. Posts like this make me slightly more hopeful for the community's general health prospects.
comment by Chris van Merwijk (chrisvm) · 2023-03-26T13:38:17.366Z · LW(p) · GW(p)
A lot of people in AI Alignment I've talked to have found it pretty hard to have clear thoughts in the current social environment, and many of them have reported that getting out of Berkeley, or getting social distance from the core of the community has made them produce better thoughts.
What do you think is the mechanism behind this?
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-26T21:48:38.282Z · LW(p) · GW(p)
I think the biggest thing is a strong, high-stakes but still quite ambiguous status-hierarchy in the Bay Area.
I think there are lots of contributors to this, but I definitely feel a very huge sense of needing to adopt certain views, to display "good judgement", and to conform to a bunch of epistemic and moral positions in order to operate in the space. This is particularly harsh since the fall of FTX with funding being less abundant and a lot of projects being more in-peril and the stakes of being perceived as reasonable and competent by a very messy and in-substantial parts social process are even higher.
comment by Czynski (JacobKopczynski) · 2023-03-15T06:05:35.736Z · LW(p) · GW(p)
[...]that a lot of my work over the past few years has been bad for the world (most prominently transforming LessWrong into something that looks a lot more respectable in a way that I am worried might have shrunk the overton window of what can be discussed there by a lot, and having generally contributed to a bunch of these dynamics).
While I did not literally claim this in advance, I came close enough [LW · GW] that I claim the right to say I Told You So.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T06:29:59.910Z · LW(p) · GW(p)
I think weighted voting helped on average here. Indeed, of all the things that I have worked on LessWrong is the one that feels like it has helped the most, though it's still pretty messy.
Replies from: cubefox, JacobKopczynski↑ comment by cubefox · 2023-03-15T07:23:22.180Z · LW(p) · GW(p)
This is a tangent, but any explanation why strong votes now give/deduct 4 points? This seems excessive to me.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T07:44:01.179Z · LW(p) · GW(p)
Strong votes scale depending on your karma, all the way up to 10 points, I think (though there are I think maybe 2-3 users with that vote-strength). It's basically a logarithmic scaling of vote-strength.
Replies from: cubefox, lc↑ comment by cubefox · 2023-03-15T17:21:36.515Z · LW(p) · GW(p)
Thank you, I didn't know that.
The fact that strong votes have such a disproportionate effect (which relies on the restraint of the users not to abuse it) reduces my trust in the Karma/agreement voting system.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-15T18:59:31.199Z · LW(p) · GW(p)
I think it should increase your trust in the voting system! Most of the rest of the internet has voting dominated by whatever new users show up whenever a thing gets popular, and this makes it extremely hard to interpret votes in different contexts. E.g. on Reddit the most upvoted things in most subreddits actually often don't have that much to do with the subreddit, they are just the thins that blew up to the frontpage and so got a ton of people voting on it. Weighted voting helps a lot in creating some stability in voting and making things less internet-popularity weighted (it also does some other good things, and has some additional costs, but this is I think one of the biggest ones).
Replies from: cubefox↑ comment by cubefox · 2023-03-15T21:04:07.573Z · LW(p) · GW(p)
It is not clear to me whether it helps with the cases you mention. It gives more voting power to senior or heavy users. But it also incentivizes users to abuse their strong votes. This is similar to how score or range voting systems encourage voters to exaggerate the strength of their preferences and to give extreme value votes as often as possible.
I think this already happens in the EA Forum, where controversial topics like the Bostrom email seemed to encourage mind-killed tribe voting. Sometimes similarly reasonable arguments would get either heavily voted up or down. And I am now not confident whether any scores on controversial opinions here reflect the average opinion of many people or just a few unrestrained strong voters who skew the visible picture in their favor. The problem here is that it leads to an escalation. The more you suspect that others abuse their strong votes, the more it becomes rational for you to do likewise.
Replies from: Kaj_Sotala, pktechgirl↑ comment by Kaj_Sotala · 2023-03-15T21:57:11.368Z · LW(p) · GW(p)
But it also incentivices users to abuse their strong votes.
For what it's worth, I have 10 strong upvote strength and at least when talking about comments, for me the effect is the opposite. With the karma of most comments being in the 0-10 range, an upvote of 10 feels so huge that I use it much more rarely than if it was something smaller like 4. (For posts, 10 points isn't necessarily that much so there I'm more inclined to use it.)
Replies from: jkaufman↑ comment by jefftk (jkaufman) · 2023-03-16T00:37:43.050Z · LW(p) · GW(p)
Yeah, if I could medium-vote I'd give out a lot of those.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-16T00:41:33.203Z · LW(p) · GW(p)
I considered for a while to add a medium-like voting-system where you can just click n-times to give n votes until your maximum vote strength, but the UI ended up too complicated. Might be worth revisiting sometime again though.
↑ comment by Elizabeth (pktechgirl) · 2023-03-15T21:51:57.421Z · LW(p) · GW(p)
Data point: in practice I've given fewer strong votes as my vote power has increased and will very rarely use strong votes on comments where it would dramatically change the comment karma (or posts, but most posts get enough karma I feel fine strong voting)
Replies from: cubefox↑ comment by cubefox · 2023-03-15T22:03:53.630Z · LW(p) · GW(p)
I also have not used them since my voting power increased, simply because unduly exaggerating my voice is unethical. But once sufficiently many other people do it, or are suspected of doing it, this inhibition would go away.
Replies from: jkaufman↑ comment by jefftk (jkaufman) · 2023-03-16T00:40:26.102Z · LW(p) · GW(p)
unduly exaggerating my voice is unethical
The users of the forum have collectively granted you a more powerful voice through our votes over the years. While there are ways you could use it unethically, using it as intended is a good thing.
↑ comment by lc · 2023-03-15T09:12:12.650Z · LW(p) · GW(p)
Actually it goes up to ~14 IIRC, with Eliezer being at least one at 12
Replies from: steve2152, habryka4↑ comment by Steven Byrnes (steve2152) · 2023-03-15T15:57:00.853Z · LW(p) · GW(p)
Code is here; Eliezer is at 13 right now, if I understand correctly.
Replies from: jkaufman↑ comment by jefftk (jkaufman) · 2023-03-16T00:44:00.775Z · LW(p) · GW(p)
Feels slightly weird that it's not quite logarithmic
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-03-16T00:47:48.288Z · LW(p) · GW(p)
Yeah, in-particular between 11 and 13 things are quite non-logarithmic. I probably had some kind of reasoning for that when I wrote it, but I sure don't remember it.
↑ comment by habryka (habryka4) · 2023-03-15T16:45:11.516Z · LW(p) · GW(p)
Oops, I underestimated the heavy-tailedness of karma.
↑ comment by Czynski (JacobKopczynski) · 2023-03-15T07:39:28.442Z · LW(p) · GW(p)
The type of problem I predicted has occurred. There has been a runaway groupthink spiral of social desirability bias and common knowledge of false consensus (creating enforced real consensus). I did not specifically predict that outgroup-respectability would be the target but it is not a surprising target.
I noted that most actions are more status-motivated than they appear, even to the people doing them, and that this warps nearly everything we do; the problem noted here is that LW and the community are warping their actions and perceptions to accrue respectability, i.e. status.
I claimed moderation doubled down on this. Ben notes that it is in fact used in that way.
It's possible I merely predicted the effects correctly and happened to be wrong about one of the major causes. But that isn't the way to bet.