Posts
Comments
Probably not going to have a discussion on the topic right now, but out of honest curiosity: did you read the bill?
Time spent running.
Note that the "thing which is compressed" is the optimization target, which is not the whole system. So in your example, it probably wouldn't be the code itself which is compressed, but rather the runtime of the program (holding the output constant), or maybe the runtimes of a bunch of programs on the machine, or something along those lines.
Fixed. Good catch, thanks!
This seems like the most load-bearing belief in the full-cynical model; most of your other examples of fakeness rely on it in one way or another [...]
Nope!
Even if the base models are improving, it can still be true that most of the progress measured on the benchmarks is fake, and has basically-nothing to do with the real improvements.
Even if the base models are improving, it can still be true that the dramatic sounding papers and toy models are fake, and have basically-nothing to do with the real improvements.
Even if the base models are improving, the propaganda about it can still be overblown and mostly fake, and have basically-nothing to do with the real improvements.
Even if the base models are improving, the people who feel real scared and just want to be validated can still be doing fake work and in fact be mostly useless, and their dynamic can still have basically-nothing to do with the real improvements.
Just because the base models are in fact improving does not mean that all this other stuff is actually coupled to the real improvement.
Sure, they are more-than-zero helpful. Heck, in a relative sense, they'd be one of the biggest wins in AI safety to date. But alas, reality does not grade on a curve.
One has to bear in mind that the words on that snapshot do not all accurately describe reality in the world where SB1047 passes. "Implement shutdown ability" would not in fact be operationalized in a way which would ensure the ability to shutdown an actually-dangerous AI, because nobody knows how to do that. "Implement reasonable safeguards to prevent societal-scale catastrophes" would in fact be operationalized as checking a few boxes on a form and maybe writing some docs, without changing deployment practices at all, because the rules for the board responsible for overseeing these things made it pretty easy for the labs to capture.
When I discussed the bill with some others at the time, the main takeaway was that the actually-substantive part was just putting any bureaucracy in place at all to track which entities are training models over 10^26 FLOP/$100M. The bill seemed unlikely to do much of anything beyond that.
Even if the bill had been much more substantive, it would still run into the standard problems of AI regulation: we simply do not have a way to reliably tell which models are and are not dangerous, so the choice is to either ban a very large class of models altogether, or allow models which will predictably be dangerous sooner or later. The most commonly proposed substantive proxy is to ban models over a certain size, which would likely slow down timelines by a factor of 2-3 at most, but definitely not slow down timelines by a factor of 10 or more.
The point of listing the problems with their business model is that they need the AGI narrative in order to fuel the investor cash, without which they will go broke at current spend rates. They have cool products, they could probably make a profit if they switched to optimizing for that (which would mean more expensive products and probably a lot of cuts), but not anywhere near the level of profits they'd need to justify the valuation.
No, the model here is entirely consistent with OpenAI putting out some actual cool products. Those products (under the model) just aren't on a path to AGI, and OpenAI's valuation is very much reliant on being on a path to AGI in the not-too-distant future. It's the narrative about building AGI which is fake.
True, but I feel a bit bad about punching that far down.
SB1047 was a pretty close shot to something really helpful.
No, it wasn't. It was a pretty close shot to something which would have gotten a step closer to another thing, which itself would have gotten us a step closer to another thing, which might have been moderately helpful at best.
Good point, I should have made those two separate bullet points:
- Then there’s the AI regulation lobbyists. They lobby and stuff, pretending like they’re pushing for regulations on AI, but really they’re mostly networking and trying to improve their social status with DC People. Even if they do manage to pass any regulations on AI, those will also be mostly fake, because (a) these people are generally not getting deep into the bureaucracy which would actually implement any regulations, and (b) the regulatory targets themselves are aimed at things which seem easy to target (e.g. training FLOP limitations) rather than actually stopping advanced AI. The activists and lobbyists are nominally enemies of OpenAI, but in practice they all benefit from pushing the same narrative, and benefit from pretending that everyone involved isn’t faking everything all the time.
- Also, there's the AI regulation activists, who e.g. organize protests. Like ~98% of protests in general, such activity is mostly performative and not the sort of thing anyone would end up doing if they were seriously reasoning through how best to spend their time in order to achieve policy goals. Calling it "fake" feels almost redundant. Insofar as these protests have any impact, it's via creating an excuse for friendly journalists to write stories about the dangers of AI (itself an activity which mostly feeds the narrative, and has dubious real impact).
(As with the top level, epistemic status: I don't fully endorse all this, but I think it's a pretty major mistake to not at least have a model like this sandboxed in one's head and check it regularly.)
Chris Olah and Dan Murfet in the at-least-partially empirical domain. Myself in the theory domain, though I expect most people (including theorists) would not know what to look for to distinguish fake from non-fake theory work. In the policy domain, I have heard that Microsoft's lobbying team does quite non-fake work (though not necessarily in a good direction). In the capabilities domain, DeepMind's projects on everything except LLMs (like e.g. protein folding, or that fast matrix multiplication paper) seem consistently non-fake, even if they're less immediately valuable than they might seem at first glance. Also Conjecture seems unusually good at sticking to reality across multiple domains.
... But It's Fake Tho
Epistemic status: I don't fully endorse all this, but I think it's a pretty major mistake to not at least have a model like this sandboxed in one's head and check it regularly.
Full-cynical model of the AI safety ecosystem right now:
- There’s OpenAI, which is pretending that it’s going to have full AGI Any Day Now, and relies on that narrative to keep the investor cash flowing in while they burn billions every year, losing money on every customer and developing a product with no moat. They’re mostly a hype machine, gaming metrics and cherry-picking anything they can to pretend their products are getting better. The underlying reality is that their core products have mostly stagnated for over a year. In short: they’re faking being close to AGI.
- Then there’s the AI regulation activists and lobbyists. They lobby and protest and stuff, pretending like they’re pushing for regulations on AI, but really they’re mostly networking and trying to improve their social status with DC People. Even if they do manage to pass any regulations on AI, those will also be mostly fake, because (a) these people are generally not getting deep into the bureaucracy which would actually implement any regulations, and (b) the regulatory targets themselves are aimed at things which seem easy to target (e.g. training FLOP limitations) rather than actually stopping advanced AI. The activists and lobbyists are nominally enemies of OpenAI, but in practice they all benefit from pushing the same narrative, and benefit from pretending that everyone involved isn’t faking everything all the time.
- Then there’s a significant contingent of academics who pretend to produce technical research on AI safety, but in fact mostly view their job as producing technical propaganda for the regulation activists and lobbyists. (Central example: Dan Hendrycks, who is the one person I directly name mainly because I expect he thinks of himself as a propagandist and will not be particularly offended by that description.) They also push the narrative, and benefit from it. They’re all busy bullshitting research. Some of them are quite competent propagandists though.
- There’s another significant contingent of researchers (some at the labs, some independent, some academic) who aren’t really propagandists, but mostly follow the twitter-memetic incentive gradient in choosing their research. This tends to generate paper titles which sound dramatic, but usually provide pretty little conclusive evidence of anything interesting upon reading the details, and very much feed the narrative. This is the main domain of Not Measuring What You Think You Are Measuring and Symbol/Referent Confusions.
- Then of course there’s the many theorists who like to build neat toy models which are completely toy and will predictably not generalize useful to real-world AI applications. This is the main domain of Ad-Hoc Mathematical Definitions, the theorists’ analogue of Not Measuring What You Think You Are Measuring.
- Benchmarks. When it sounds like a benchmark measures something reasonably challenging, it nearly-always turns out that it’s not really measuring the challenging thing, and the actual questions/tasks are much easier than the pitch would suggest. (Central examples: software eng, GPQA, frontier math.) Also it always turns out that the LLMs’ supposedly-impressive achievement relied much more on memorization of very similar content on the internet than the benchmark designers expected.
- Then there’s a whole crowd of people who feel real scared about AI (whether for good reasons or because they bought the Narrative pushed by all the people above). They mostly want to feel seen and validated in their panic. They have discussions and meetups and stuff where they fake doing anything useful about the problem, while in fact they mostly just emotionally vibe with each other. This is a nontrivial chunk of LessWrong content, as e.g. Val correctly-but-antihelpfully pointed out. It's also the primary motivation behind lots of "strategy" work, like e.g. surveying AI researchers about their doom probabilities, or doing timeline forecasts/models.
… and of course none of that means that LLMs won’t reach supercritical self-improvement, or that AI won’t kill us, or [...]. Indeed, absent the very real risk of extinction, I’d ignore all this fakery and go about my business elsewhere. I wouldn’t be happy about it, but it wouldn’t bother me any more than all the (many) other basically-fake fields out there.
Man, I really just wish everything wasn’t fake all the time.
I have no idea what you're picturing here. Those sentences sounded like a sequence of nonsequiturs, which means I probably am completely missing what you're trying to say. Maybe spell it out a bit more?
Some possibly-relevant points:
- The idea that all the labs focus on speeding up their own research threads rather than serving LLMs to customers is already pretty dubious. Developing LLMs and using them are two different skillsets; it would make economic sense for different entities to specialize in those things, with the developers selling model usage to the users just as they do today. More capable AI doesn't particularly change that economic logic. I wouldn't be surprised if at least some labs nonetheless keep things in-house, but all of them?
- The implicit assumption that alignment/safety research will be bottlenecked on compute at all likewise seems dubious at best, though I could imagine an argument for it (routing through e.g. scaling inference compute).
- It sounds like maybe you're assuming that there's some scaling curve for (alignment research progress as a function of compute invested) and another for (capabilities progress as a function of compute invested), and you're imagining that to keep the one curve ahead of the other, the amount of compute aimed at alignment needs to scale in a specific way with the amount aimed at capabilities? (That model sounds completely silly to me, that is not at all how this works, but it would be consistent with the words you're saying.)
"Labs" are not an actor. No one lab has a moat around compute; at the very least Google, OpenAI, Anthropic, xAI, and Facebook all have access to plenty of compute. It only takes one of them to sell access to their models publicly.
The research direction needs to be actually pursued by the agents, either through the decision of the human leadership, or through the decision of AI agents that the human leadership defers to. This means that if some long-term research bet isn't respected by lab leadership, it's unlikely to be pursued by their workforce of AI agents.
I think you're starting from a good question here (e.g. "Will the research direction actually be pursued by AI researchers?"), but have entirely the wrong picture; lab leaders are unlikely to be very relevant decision-makers here. The key is that no lab has a significant moat, and the cutting edge is not kept private for long, and those facts look likely to remain true for a while. Assuming even just one cutting-edge lab continues to deploy at all like they do today, basically-cutting-edge models will be available to the public, and therefore researchers outside the labs can just use them to do the relevant research regardless of whether lab leadership is particularly invested. Just look at the state of things today: one does not need lab leaders on board in order to prompt cutting-edge models to work on one's own research agenda.
That said, "Will the research direction actually be pursued by AI researchers?" remains a relevant question. The prescription is not so much about convincing lab leadership, but rather about building whatever skills will likely be necessary in order to use AI researchers productively oneself.
Is interpersonal variation in anxiety levels mostly caused by dietary iron?
I stumbled across this paper yesterday. I haven't looked at it very closely yet, but the high-level pitch is that they look at genetic predictors of iron deficiency and then cross that with anxiety data. It's interesting mainly because it sounds pretty legit (i.e. the language sounds like direct presentation of results without any bullshitting, the p-values are satisfyingly small, there's no branching paths), and the effect sizes are BIG IIUC:
The odd ratios (OR) of anxiety disorders per 1 standard deviation (SD) unit increment in iron status biomarkers were 0.922 (95% confidence interval (CI) 0.862–0.986; p = 0.018) for serum iron level, 0.873 (95% CI 0.790–0.964; p = 0.008) for log-transformed ferritin and 0.917 (95% CI 0.867–0.969; p = 0.002) for transferrin saturation. But no statical significance was found in the association of 1 SD unit increased total iron-binding capacity (TIBC) with anxiety disorders (OR 1.080; 95% CI 0.988–1.180; p = 0.091). The analyses were supported by pleiotropy test which suggested no pleiotropic bias.
Odds ratio of anxiety disorders changes by roughly 0.9 per standard deviation in iron level, across four different measures of iron level. (Note that TIBC, the last of the four iron level measures, didn't hit statistical significance but did have a similar effect size to the other three.)
Just eyeballing those effect sizes... man, it kinda sounds like iron levels are maybe the main game for most anxiety? Am I interpreting that right? Am I missing something here?
EDIT: I read more, and it turns out the wording of the part I quoted was misleading. The number 0.922, for instance, was the odds ratio AT +1 standard deviation serum iron level, not PER +1 standard deviation serum iron level. That would be -0.078 PER standard deviation serum iron level, so it's definitely not the "main game for most anxiety".
That was a very useful answer, thank you! I'm going to try to repeat back the model in my own words and relate back to the frame of the post and rest of this comment thread. Please let me know if it still sounds like I'm missing something.
Model: the cases where a woman has a decent idea of what she wants aren't the central use-case of subtle cues in the first place. The central use case is when the guy seems maybe interesting, and therefore she mostly just wants to spend more time around him, not in an explicitly romantic or sexual way yet. The "subtle signals" mostly just look like "being friendly", and that's a feature because in the main use case "being friendly" is in fact basically what the girl wants; she actually does just want to spend a bit more time together in a friendly way, with romantic/sexual interaction as a possibility on the horizon rather than an immediate interest.
Relating that back to the post and comment thread: subtle signals still seem like a pretty stupid choice once a woman is confident she's romantically/sexually interested in a guy. So "send subtle signals" remains terrible advice for women in that situation. But if one is going to give the opposite advice - i.e. advise a policy of asking out men she's interested in and/or sending extremely unsubtle signals - then it should probably come alongside the disclaimer that if she's highly uncertain and mostly wants to gather more information (which may be most of the time) then subtle signals are a sensible move. If the thing she actually wants right now is to just spend some more time together in a friendly way, with romantic/sexual interaction as a possibility on the horizon rather than an immediate thing, then subtle signals are not a bad choice. The subtle signals are mostly not distinguishable from "being friendly" because "being friendly" is in fact the (immediate) goal.
What I really like about this model is that it answers the question "under what circumstances should one apply this advice vs apply its opposite?", which is something which most advice should answer but doesn't.
Based on personal experience, the strategy fails to even achieve that goal.
And fun though it is to exchange clever quips, I would much rather have actual answers to useful questions, such as "just how often does anyone at all correctly pick up on the intended subtle signals?".
Sometimes this is due to the woman in question not recognizing how subtle she's being, and losing out on a date with a man she's still interested in.
I would guess that this is approximately 100% of the time in practice, excluding cases where the man doesn't pick up on the cues but happens to ask her out anyway. Approximately nobody accurately picks up on womens' subtle cues, including other women (at least that would be my strong guess, and is very cruxy for me here). If the woman just wants a guy who will ask her out, that's still a perfectly fine utility function, but the cues serve approximately-zero role outside of the woman's own imagination.
If the typical case was actually to send very clear unambiguous cues which most men (or at least most hot men) actually reliably can pick up on, then I would not call the strategy "completely fucking idiotic"; sending signals which the intended recipient can actually reliably pick up on is a totally reasonable and sensible strategy.
(Of course there's an obvious alternative hypothesis: most men do pick up on such cues, and I'm overindexing on myself or my friends or something. I am certainly tracking that hypothesis, I am well aware that my brain is not a good model of other humans' brains, but man it sure sounds like "not noticing womens' subtle cues" is the near-universal experience, even among other women when people actually try to test that.)
The yin master finds out from her friend that a certain guy with potential is coming to dinner. She wears a dress with a subtle neckline and arrives early to secure a seat with an empty chair next to it. When the guy arrives, she holds eye contact a fraction longer than usual and invites him to the empty chair by laughing a fraction louder at his silly joke. She leans away when he starts talking sports, but angles slightly towards him when he’s sharing a story of how he got in trouble that one time abroad. The story is good, so she mentions off-handedly how long its been since she saw a good painting and it’s his cue to ask for her number.
This was the one fleshed-out concrete example in the post, and the best part IMO.
I found it quite helpful for visualizing what's going on in so many women's imaginations. The post itself delivered value, in that regard.
That said, the post conspicuously avoids asking: how well will this yin strategy actually work? How much will the yin strategy improve this girl's chance of a date with the guy, compared to (a) doing nothing and acting normally, or (b) directly asking him out? It seems very obvious that the yin stuff will result in a date-probability only marginally higher than doing nothing (I'd say 1-10 percentage points higher at most, if I had to Put A Number On It), and far far lower than if she asks him (I'd say tens of percentage points).
That is what we typically call a completely fucking idiotic strategy. Just do the simple direct thing, chances of success will be far higher.
Now, one could reasonably counter-argue that the yin strategy delivers value somewhere else, besides just e.g. "probability of a date". Maybe it's a useful filter for some sort of guy, or maybe she just wants to interact with people this way because she enjoys it? I won't argue with the utility function; people want what they want. But I will observe that it's an awfully large trade-off, and I very much doubt that an actual consideration of the tradeoffs under the hypothetical woman's preferences actually works out in favor of the subtle approach, under almost any real conditions.
(Context: I've been following the series in which this post appeared, and originally posted this comment on the substack version.)
Overcompressed summary of this post: "Look, man, you are not bottlenecked on models of the world, you are bottlenecked on iteration count. You need to just Actually Do The Thing a lot more times; you will get far more mileage out of iterating more than out of modeling stuff.".
I definitely buy that claim for at least some people, but it seems quite false in general for relationships/dating.
Like, sure, most problems can be solved by iterating infinitely many times. The point of world models is to not need so many damn iterations. And because we live in a very high-dimensional world, naive iteration will often not work at all without a decent world model; one will never try the right things without having some prior idea of where to look.
Example: Aella's series on how to be good in bed. I was solidly in the audience for that post: I'd previously spent plenty of iterations becoming better in bed, ended up with solid mechanics, but consistently delivering great orgasms does not translate to one's partner wanting much sex. Another decade of iteration would not have fixed that problem; I would not have tried the right things, my partner would not have given the right feedback (indeed, much of her feedback was in exactly the wrong direction). Aella pointed in the right vague direction, and exploring in that vague direction worked within only a few iterations. That's the value of models: they steer the search so that one needs fewer iterations.
That's the point of all the blog posts. That's where the value is, when blog posts are delivering value. And that's what's been frustratingly missing from this series so far. (Most of my value of this series has been from frustratedly noticing the ways in which it fails to deliver, and thereby better understanding what I wish it would deliver!) No, I don't expect to e.g. need 0 iterations after reading, but I want to at least decrease the number of iterations.
And in regards to "I don’t think you know what you want in dating"... the iteration problem still applies there! It is so much easier to figure out what I want, with far fewer iterations, when I have better background models of what people typically want. Yes, there's a necessary skill of not shoving yourself into a box someone else drew, but the box can still be extremely valuable as evidence of the vague direction in which your own wants might be located.
(This comment is not about the parts which most centrally felt anchored on social reality; see other reply for that. This one is a somewhat-tangential but interesting mini-essay on ontological choices.)
The first major ontological choices were introduced in the previous essay:
- Thinking of "capability" as a continuous 1-dimensional property of AI
- Introducing the "capability frontier" as the highest capability level the actor developed/deployed so far
- Introducing the "safety range" as the highest capability level the actor can safely deploy
- Introducing three "security factors":
- Making the safety range (the happy line) go up
- Making the capability frontier (the dangerous line) not go up
- Keeping track of where those lines are.
The first choice, treatment of "capability level" as 1-dimensional, is obviously an oversimplification, but a reasonable conceit for a toy model (so long as we remember that it is toy, and treat it appropriately). Given that we treat capability level as 1-dimensional, the notion of "capability frontier" for any given actor immediately follows, and needs no further justification.
The notion of "safety range" is a little more dubious. Safety of an AI obviously depends on a lot of factors besides just the AI's capability. So, there's a potentially very big difference between e.g. the most capable AI a company "could" safely deploy if the company did everything right based on everyone's current best understanding (which no company of more than ~10 people has or ever will do in a novel field), vs the most capable AI the company could safely deploy under realistic assumptions about the company's own internal human coordination capabilities, vs the most capable AI the company can actually-in-real-life aim for and actually-in-real-life not end up dead.
... but let's take a raincheck on clarifying the "safety range" concept and move on.
The safety factors are a much more dubious choice of ontology. Some of the dubiousness:
- If we're making the happy line go up ("safety progress"): who's happy line? Different actors have different lines. If we're making the danger line not go up ("capability restraint"): again, who's danger line? Different actors also have different danger lines.
- This is important, because humanity's survival depends on everybody else's happy and danger lines, not just one actor's!
- "Safety progress" inherits all the ontological dubiousness of the "safety range".
- If we're keeping track of where the lines are ("risk evaluation"): who is keeping track? Who is doing the analysis, who is consuming it, how does the information get to relevant decision makers, and why do they make their decisions on the basis of that information?
- Why factor apart the levels of the danger and happy lines? These are very much not independent, so it's unclear why it makes sense to think of their levels separately, rather than e.g. looking at their average and difference as the two degrees of freedom, or their average and difference in log space, or the danger line level and the difference, or [...]. There's a lot of ways to parameterize two degrees of freedom, and it's not clear why this parameterization would make more sense than some other.
- On the other hand, factoring apart "risk evaluation" from "safety progress" and "capabilities restraint" does seem like an ontologically reasonable choice: it's the standard factorization of instrumental from epistemic. That standard choice is not always the right way to factor things, but it's at least a choice which has "low burden of proof" in some sense.
What would it look like to justify these ontological choices? In general, ontological justification involves pointing to some kind of pattern in the territory - in this case, either the "territory" of future AI, or the "territory" of AI safety strategy space. For instance, in a very broad class of problems, one can factor apart the epistemic and instrumental aspects of the problem, and resolve all the epistemic parts in a manner totally agnostic to the instrumental parts. That's a pattern in the "territory" of strategy spaces, and that pattern justifies the ontological choice of factoring apart instrumental and epistemic components of a problem.
If one could e.g. argue that the safety range and capability frontier are mostly independent, or that most interventions impact the trajectory of only one of the two, then that would be an ontological justification for factoring the two apart. (Seems false.)
(To be clear: people very often have good intuitions about ontological choices, but don't know how to justify them! I am definitely not saying that one must always explicitly defend ontological choices, or anything like that. But one should, if asked and given time to consider, be able to look at an ontological choice and say what underlying pattern makes that ontological choice sensible.)
The last section felt like it lost contact most severely. It says
What are the main objections to AI for AI safety?
It notably does not say "What are the main ways AI for AI safety might fail?" or "What are the main uncertainties?" or "What are the main bottlenecks to success of AI for AI safety?". It's worded in terms of "objections", and implicitly, it seems we're talking about objections which people make in the current discourse. And looking at the classification in that section ("evaluation failures, differential sabotage, dangerous rogue options") it indeed sounds more like a classification of objections in the current discourse, as opposed to a classification of object-level failure modes from a less-social-reality-loaded distribution of failures.
I do also think the frame in the earlier part of the essay is pretty dubious in some places, but that feels more like object-level ontological troubles and less like it's anchoring too much on social reality. I ended up writing a mini-essay on that which I'll drop in a separate reply.
no synonyms
[...]
Use compound words.
These two goals conflict. When compounding is common, there will inevitably be multiple reasonable ways to describe the same concept as a compound word. I think you probably want flexible compounding more than a lack of synonyms.
When this post first came out, it annoyed me. I got a very strong feeling of "fake thinking", fake ontology, etc. And that feeling annoyed me a lot more than usual, because Joe is the person who wrote the (excellent) post on "fake vs real thinking". But at the time, I did not immediately come up with a short explanation for where that feeling came from.
I think I can now explain it, after seeing this line from kave's comment on this post:
Your taxonomies of the space of worries and orientations to this question are really good...
That's exactly it. The taxonomies are taxonomies of the space of worries and orientations. In other words, the post presents a good ontology of the discourse on "AI for AI safety". What it does not present is an ontology natural to the actual real-world challenges of AI for AI safety.
Unpacking that a bit: insofar as an ontology (or taxonomy) is "good", it reflects some underlying pattern in the world, and it's useful to ask what that underlying pattern is. For instance, it does intuitively seem like most objections to "AI for AI safety" I hear these days cluster reasonably well into "Evaluation failures, Differential sabotage, Dangerous rogue options". Insofar as the discourse really does cluster that way, that's a real pattern in the world-of-discourse, and those categories are useful for modelling the discourse. But the patterns in the discourse mostly reflect social dynamics; they are only loosely coupled to the patterns which will actually arise in future AIs, or in the space of strategies for dealing with future AIs. Thus the feeling of "fakeness": it feels like this post is modeling the current discourse, rather than modeling the actual physical future AIs.
... and to be clear, that's not strictly a bad thing. Modeling the discourse might actually be the right move, insofar as one's main goal is to e.g. facilitate communication. That communication just won't be very tightly coupled to future physical reality.
I have a similar story. When I was very young, my mother was the primary breadwinner of the household, and put both herself and my father through law school. Growing up, it was always just kind of assumed that my sister would have to get a real job making actual money, same as my brother and I; a degree in underwater basket weaving would have required some serious justification. (She ended up going to dental school and also getting a PhD working with epigenomic data.)
I didn't realize on a gut level that this wasn't the norm until shortly after high school. I was hanging out with two female friends and one of them said "man, I really need more money". I replied "sounds like you need to get a job". The friend laughed and said "oh, I was thinking I need to get a boyfriend", and then the other friend also laughed and said she was also thinking the boyfriend thing.
... so that was quite a shock to my worldview.
Not important, but: I clicked on this post expecting an essay about building physical islands outside of San Francisco bay.
This comment gave me the information I'm looking for, so I don't want to keep dragging people through it. Please don't feel obligated to reply further!
That said, I did quickly look up some data on this bit:
But remember that you already conditioned on 'married couples without kids'. My guess would be that in the subset of man-woman married couples without kids, the man being the exclusive breadwinner is a lot less common than in the set of all man-woman married couples.
... so I figured I'd drop it in the thread.
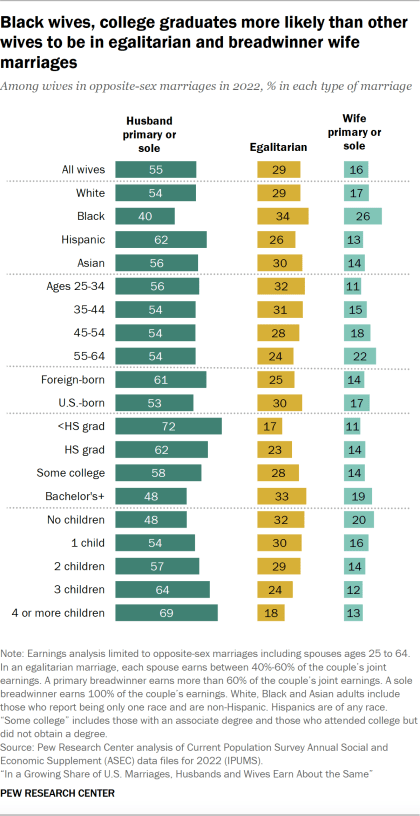
When interpreting these numbers, bear in mind that many couples with no kids probably intend to have kids in the not-too-distant future, so the discrepancy shown between "no children" and 1+ children is probably somewhat smaller than the underlying discrepancy of interest (which pushes marginally more in favor of Lucius' guess).
Big thank you for responding, this was very helpful.
That is useful, thanks.
Any suggestions for how I can better ask the question to get useful answers without apparently triggering so many people so much? In particular, if the answer is in fact "most men would be happier single but are ideologically attached to believing in love", then I want to be able to update accordingly. And if the answer is not that, then I want to update that most men would not be happier single. With the current discussion, most of what I've learned is that lots of people are triggered by the question, but that doesn't really tell me much about the underlying reality.
Update 3 days later: apparently most people disagree strongly with
Their romantic partner offering lots of value in other ways. I'm skeptical of this one because female partners are typically notoriously high maintenance in money, attention, and emotional labor. Sure, she might be great in a lot of ways, but it's hard for that to add up enough to outweigh the usual costs.
Most people in the comments so far emphasize some kind of mysterious "relationship stuff" as upside, but my actual main update here is that most commenters probably think the typical costs are far far lower than I imagined? Unsure, maybe the "relationship stuff" is really ridiculously high value.
So I guess it's time to get more concrete about the costs I had in mind:
- A quick google search says the male is primary or exclusive breadwinner in a majority of married couples. Ass-pull number: the monetary costs alone are probably ~50% higher living costs. (Not a factor of two higher, because the living costs of two people living together are much less than double the living costs of one person. Also I'm generally considering the no-kids case here; I don't feel as confused about couples with kids.)
- I was picturing an anxious attachment style as the typical female case (without kids). That's unpleasant on a day-to-day basis to begin with, and I expect a lack of sex tends to make it a lot worse.
- Eyeballing Aella's relationship survey data, a bit less than a third of respondents in 10-year relationships reported fighting multiple times a month or more. That was somewhat-but-not-dramatically less than I previously pictured. Frequent fighting is very prototypically the sort of thing I would expect to wipe out more-than-all of the value of a relationship, and I expect it to be disproportionately bad in relationships with little sex.
- Less legibly... conventional wisdom sure sounds like most married men find their wife net-stressful and unpleasant to be around a substantial portion of the time, especially in the unpleasant part of the hormonal cycle, and especially especially if they're not having much sex. For instance, there's a classic joke about a store salesman upselling a guy a truck, after upselling him a boat, after upselling him a tackle box, after [...] and the punchline is "No, he wasn't looking for a fishing rod. He came in looking for tampons, and I told him 'dude, your weekend is shot, you should go fishing!'".
(One thing to emphasize in these: sex isn't just a major value prop in its own right, I also expect that lots of the main costs of a relationship from the man's perspective are mitigated a lot by sex. Like, the sex makes the female partner behave less unpleasantly for a while.)
So, next question for people who had useful responses (especially @Lucius Bushnaq and @yams): do you think the mysterious relationship stuff outweighs those kinds of costs easily in the typical case, or do you imagine the costs in the typical case are not all that high?
men are the ones who die sooner if divorced, which suggests
Causality dubious, seems much more likely on priors that men who divorced are disproportionately those with Shit Going On in their lives. That said, it is pretty plausible on priors that they're getting a lot out of marriage.
I think you'll get the most satisfying answer to your actual question by having a long chat with one of your asexual friends (as something like a control group, since the value of sex to them is always 0 anyway, so whatever their cause is for having romantic relationships is probably the kind of thing that you're looking for here).
That's an excellent suggestion, thanks.
Yes, the question is what value-proposition accounts for the romantic or general relationship satisfaction.
Here's a place where I feel like my models of romantic relationships are missing something, and I'd be interested to hear peoples' takes on what it might be.
Background claim: a majority of long-term monogamous, hetero relationships are sexually unsatisfying for the man after a decade or so. Evidence: Aella's data here and here are the most legible sources I have on hand; they tell a pretty clear story where sexual satisfaction is basically binary, and a bit more than half of men are unsatisfied in relationships of 10 years (and it keeps getting worse from there). This also fits with my general models of mating markets: women usually find the large majority of men sexually unattractive, most women eventually settle on a guy they don't find all that sexually attractive, so it should not be surprising if that relationship ends up with very little sex after a few years.
What doesn't make sense under my current models is why so many of these relationships persist. Why don't the men in question just leave? Obviously they might not have better relationship prospects, but they could just not have any relationship. The central question which my models don't have a compelling answer to is: what is making these relationships net positive value for the men, relative to not having a romantic relationship at all?
Some obvious candidate answers:
- Kids. This one makes sense for those raising kids, but what about everyone else? Especially as fertility goes down.
- The wide tail. There's plenty of cases which make sense which are individually unusual - e.g. my own parents are business partners. Maybe in aggregate all these unusual cases account for the bulk.
- Loneliness. Maybe most of these guys have no one else close in their life. In this case, they'd plausibly be better off if they took the effort they invested in their romantic life and redirected to friendships (probably mostly with other guys), but there's a lot of activation energy blocking that change.
- Their romantic partner offering lots of value in other ways. I'm skeptical of this one because female partners are typically notoriously high maintenance in money, attention, and emotional labor. Sure, she might be great in a lot of ways, but it's hard for that to add up enough to outweigh the usual costs.
- Wanting a dependent. Lots of men are pretty insecure, and having a dependent to provide for makes them feel better about themselves. This also flips the previous objection: high maintenance can be a plus if it makes a guy feel wanted/useful/valuable.
- Social pressure/commitment/etc making the man stick around even though the relationship is not net positive for him.
- The couple are de-facto close mostly-platonic friends, and the man wants to keep that friendship.
I'm interested in both actual data and anecdata. What am I missing here? What available evidence points strongly to some of these over others?
Edit-to-add: apparently lots of people are disagreeing with this, but I don't know what specifically you all are disagreeing with, it would be much more helpful to at least highlight some specific sentence or leave a comment or something.
Fun point! If I just pull some numbers out of my ass and naively plug them into the equation:
- Superalignment-relevant research tasks take time on the order of a year to a decade.
- Taking 1 hr as the current task-time models can handle, we'd need ~13-16 doublings.
- ... so on METR's model, that's about 8-10 years from now.
Of course that's assuming the model holds. A useful heuristic for trends which have just been published for the first time is that they break down immediately after publication. If it holds up for another year or two, then the model will look a lot more plausible.
Although I wouldn't dispute the stats that you are citing here, John, I would guess these might be downstream from above difficulties.
I think that's the right counterargument to make (kudos :) ). Building on it, I'd say: ok, the causal arrows go both ways here. The field draws less impressive people, who do kinda junk research, which draws less impressive people. So the different sciences end up in different equilibria, with different levels of competence among the scientists. But then, what determines the equilibrium? Why did physics end up with more competent people doing more competent work, and psychology with less competent people doing less competent work, rather than vice-versa? Unless we want to claim that it was luck of the draw, there has to be something endogenous to the underlying territories of physics and psychology which cause their sciences to end up in these different equilibria.
Once the question is framed that way, it suggests different answers.
One could maybe tell a story like "psychology is more complex than physics, so physics had more impressive work earlier on, which drew in smarter people...". That could explain the different equilibria. But also, it feels like a just-so story; one could just as easily argue that smarter people tend to be drawn to more complex systems, where they can properly show off their merit.
Explanations like noisy data or difficulties with controls seem similar. Like, any explanation of the form "psychology is harder for reason X, so physics had more impressive work earlier on, which drew in smarter people..." feels like a just-so story; it seems at least as plausible that more competent people will be drawn to more difficult problems. (Note that both the hypotheses put forward in the OP are of this form, so this is also a response to the OP.)
Feedback loops look a little more plausible as an explanation: "insofar as it's harder to get clear feedback on models in psychology compared to physics, it's easier for bullshit to thrive in psychology, so smarter people go to physics where success is relatively more a function of smarts rather than academic politics, ...". I don't really buy that explanation, since getting feedback on models seems-to-me comparably difficult in physics and in psychology; it's a core hard part of any science. But it's at least plausible.
The infiltration of "social reality" is another plausible explanation, which I personally find much more probable. The model would be roughly: "insofar as psychology is largely about modeling social reality and adjacent topics, psychology itself becomes a relevant battleground for social-reality-level competitions, and also people predisposed to thinking in social reality will find psychology more appealing than physics. Alas, both focus on social-reality-level competitions and predisposition for thinking in social reality are extremely strong negative predictors of one's competence as a scientist, so psychology ends up with a lot more incompetent people than physics, ...". I probably wouldn't endorse that exact model as worded, but I'd put a fair bit of probability on something in roughly that ballpark.
The usual explanation is that human behavior is simply more complex than physical systems.
Maybe that's the usual explanation among people who are trying not to offend anyone. The explanation I'd jump to if not particularly trying to avoid offending anyone is that social scientists are typically just stupider than physical scientists (economists excepted). And that is backed up by the data IIUC, e.g. here's the result of a quick google search:
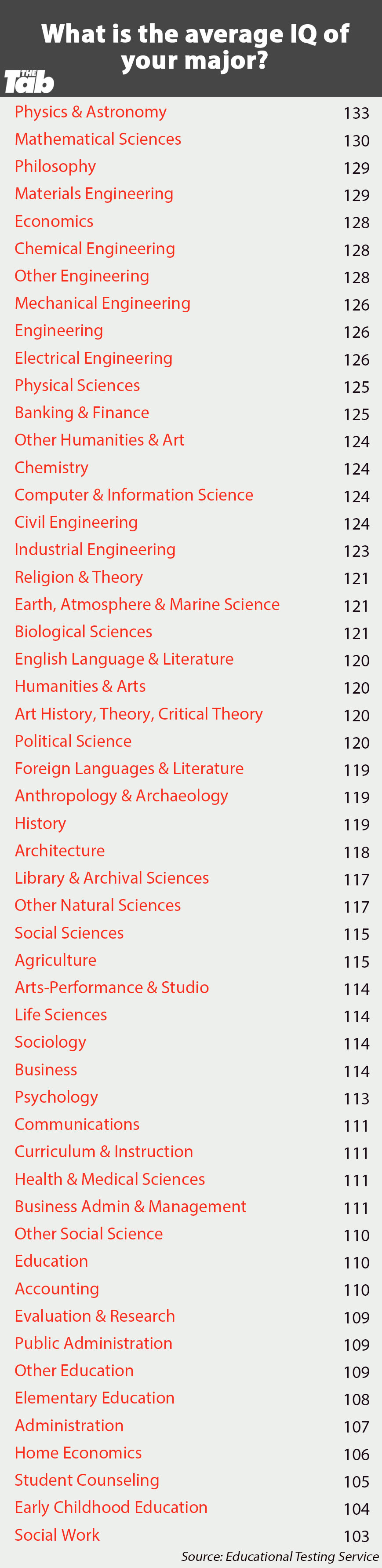
I disagree pretty strongly with the headline advice here. An ideal response would be to go through a typical sample of stories from some news source - for instance, I keep MIT Tech Review in my feedly because it has surprisingly useful predictive alpha if you invert all of its predictions. But that would take way more effort than I'm realistically going to invest right now, so absent that, I'll just abstractly lay out where I think this post's argument goes wrong.
The main thing most news tells me is what people are talking about, and what people are saying about it. Sadly, "what people are talking about" has very little correlation with what's important, and "what people are saying about it" is overwhelmingly noise, even when true (which it often isn't). In simulacrum terms, news is overwhelmingly a simulacrum 3 thing, and tells me very little about the underlying reality I'm actually interested in.
Sure, maybe there's some useful stuff buried in the pile of junk, but why sift through it? I do not need to know a few days or weeks earlier that AIXI is being gutted. I do not need to know a few weeks earlier that the slowdown OpenAI found in pretraining scaling had been formally reported-upon. (Also David and I had already noticed the signs of OpenAI having noticed that slowdown back in May of 2024, though even if we hadn't suspected until it was reported-upon in November, I still wouldn't need to know about it a few weeks earlier.) Just waiting for Zvi to put it in his newsletter is more than enough.
I have no idea. It's entirely plausible that one of us wrote the Claude bit in there months ago and then forgot about it.
The joke is that Claude somehow got activated on the editor, and added a line thanking itself for editing despite us not wanting it to edit anything and (as far as we've noticed) not editing anything else besides that one line.
Nope, we were in Overleaf.
... but also that's useful info, thanks.
Working on a paper with David, and our acknowledgments section includes a thankyou to Claude for editing. Neither David nor I remembers putting that acknowledgement there, and in fact we hadn't intended to use Clause for editing the paper at all nor noticed it editing anything at all.
That's basically Do What I Mean.
None that I know of; it's a topic ripe for exploration.
Bell Labs is actually my go-to example of a much-hyped research institution whose work was mostly not counterfactual; see e.g. here. Shannon's information theory is the only major example I know of highly counterfactual research at Bell Labs. Most of the other commonly-cited advances, like e.g. transistors or communication satellites or cell phones, were clearly not highly counterfactual when we look at the relevant history: there were other groups racing to make the transistor, and the communication satellite and cell phones were both old ideas waiting on the underlying technology to make them practical.
That said, Hamming did sit right next to Shannon during the information theory days IIRC, so his words do carry substantial weight here.
Good idea, but... I would guess that basically everyone who knew me growing up would say that I'm exactly the right sort of person for that strategy. And yet, in practice, I still find it has not worked very well. My attention has in fact been unhelpfully steered by local memetic currents to a very large degree.
For instance, I do love proving everyone else wrong, but alas reversed stupidity is not intelligence. People mostly don't argue against the high-counterfactuality important things, they ignore the high-counterfactuality important things. Trying to prove them wrong about the things they do argue about is just another way of having one's attention steered by the prevailing memetic currents.
The claim is not that either "solution" is sufficient for counterfactuality, it's that either solution can overcome the main bottleneck to counterfactuality. After that, per Amdahl's Law, there will still be other (weaker) bottlenecks to overcome, including e.g. keeping oneself focused on something important.
Hypothesis: for smart people with a strong technical background, the main cognitive barrier to doing highly counterfactual technical work is that our brains' attention is mostly steered by our social circle. Our thoughts are constantly drawn to think about whatever the people around us talk about. And the things which are memetically fit are (almost by definition) rarely very counterfactual to pay attention to, precisely because lots of other people are also paying attention to them.
Two natural solutions to this problem:
- build a social circle which can maintain its own attention, as a group, without just reflecting the memetic currents of the world around it.
- "go off into the woods", i.e. socially isolate oneself almost entirely for an extended period of time, so that there just isn't any social signal to be distracted by.
These are both standard things which people point to as things-historically-correlated-with-highly-counterfactual-work. They're not mutually exclusive, but this model does suggest that they can substitute for each other - i.e. "going off into the woods" can substitute for a social circle with its own useful memetic environment, and vice versa.