What Is The Alignment Problem?
post by johnswentworth · 2025-01-16T01:20:16.826Z · LW · GW · 50 commentsContents
The Difficulty of Specifying Problems Toy Problem 1: Old MacDonald’s New Hen Toy Problem 2: Sorting Bleggs and Rubes Generalization to Alignment But What If The Patterns Don’t Hold? Alignment of What? Alignment of a Goal or Purpose Alignment of Basic Agents Alignment of General Intelligence How Does All That Relate To Today's AI? Alignment to What? What are a Human's Values? Other targets Paul!Corrigibility Eliezer!Corrigibility Subproblem!Corrigibility Exercise: Do What I Mean (DWIM) Putting It All Together, and Takeaways None 50 comments
So we want to align future AGIs. Ultimately we’d like to align them to human values, but in the shorter term we might start with other targets, like e.g. corrigibility [? · GW].
That problem description all makes sense on a hand-wavy intuitive level, but once we get concrete and dig into technical details… wait, what exactly is the goal again? When we say we want to “align AGI”, what does that mean? And what about these “human values” - it’s easy to list things which are importantly not human values (like stated preferences, revealed preferences, etc), but what are we talking about? And don’t even get me started on corrigibility!
Turns out, it’s surprisingly tricky to explain what exactly “the alignment problem” refers to. And there’s good reasons for that! In this post, I’ll give my current best explanation of what the alignment problem is (including a few variants and the subquestion of what human values are), and explain why it’s surprisingly difficult to explain.
To set expectations: this post will not discuss how the alignment problem relates to the more general AGI-don’t-kill-everyone problem, or why one might want to solve the alignment problem, or what the precise requirements are for AGI not killing everyone. We’ll just talk about the alignment problem itself, and why it’s surprisingly difficult to explain.
The Difficulty of Specifying Problems
First, we’ll set aside alignment specifically for a bit, and look at a specification of a couple simple toy problems. In the context of those toy problems, we’ll explore the same kind of subtleties which make the alignment problem so difficult to specify, so we can better understand the challenges of explaining the alignment problem.
Toy Problem 1: Old MacDonald’s New Hen
Toy problem: for mysterious reasons, old farmer MacDonald wants his newest hen to be third in his flock’s pecking order. That’s the problem.
Remember, we’re not interested in solving old MacDonald’s hen problem! (It is an interesting problem, but not at all relevant to solve.) We’re interested in how the problem is specified. What does it mean, for the newest hen to be third in the flock’s pecking order?
Key fact: empirically, hens in a flock form a(n approximately) linear pecking order. What does that mean? Well, if Chickira pecks Beakoncé (i.e. Chickira is “higher” in the pecking order than Beakoncé), and Beakoncé pecks Audrey (i.e. Beakoncé is “higher” in the pecking order than Audrey), then Chickira pecks Audrey (i.e. Chickira is “higher” in the pecking order than Audrey) not vice-versa.
Another way to put it: if we draw out a graph with a node for each hen in the flock, and an arrow from hen B to hen A exactly when B pecks A, then we’ll find the graph (approximately) never has any cycles - e.g. there’s no “Chickira pecks Beakoncé pecks Audrey pecks Chickira” situation, there’s no two hens which both regularly peck each other, etc. As long as that’s true, we can arrange the hens in an order (the “pecking order”) such that each hen only pecks hens lower in the pecking order.
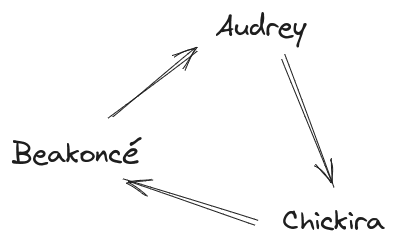
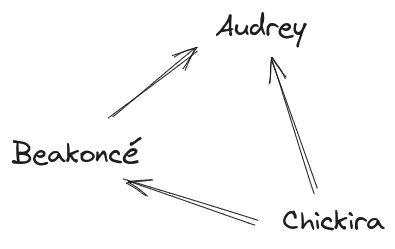
Main point of this whole example: if the flock doesn’t form a linear pecking order - e.g. if there’s lots of pecking-cycles - then old MacDonald’s goal doesn’t even make sense. The new hen can’t be third in the pecking order if there is no pecking order. And the existence of a linear pecking order is an empirical fact about hens. It’s a pattern out in the physical world, and we could imagine other worlds in which that pattern turns out to not hold.
On the other hand, so long as the flock does form a linear pecking order, it’s relatively easy to specify old MacDonald’s problem: he wants the new hen to be third in that order.
Toy Problem 2: Sorting Bleggs and Rubes
An old classic [LW · GW]:
Imagine that you have a peculiar job in a peculiar factory: Your task is to take objects from a mysterious conveyor belt, and sort the objects into two bins. When you first arrive, Susan the Senior Sorter explains to you that blue egg-shaped objects are called "bleggs" and go in the "blegg bin", while red cubes are called "rubes" and go in the "rube bin".
Once you start working, you notice that bleggs and rubes differ in ways besides color and shape. Bleggs have fur on their surface, while rubes are smooth. Bleggs flex slightly to the touch; rubes are hard. Bleggs are opaque; the rube's surface slightly translucent.
As the story proceeds, we learn that the properties of bleggs and rubes are noisy: some tiny fraction of bleggs are actually purple or even red, some tiny fraction of rubes have fur, etc. So how should we sort these unusual cases?
It’s useful to picture the bleggs and the rubes as two clusters (though really they’re in a much higher dimensional space than this 2D visual):

If the distribution of bleggs/rubes instead looked like this, then the distinction between blegg and rube wouldn’t make much sense at all:
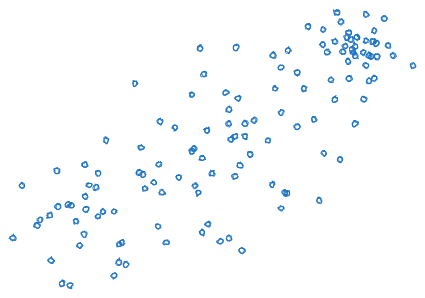
Main point of this example: if the bleggs and rubes don’t form two clusters - e.g. if there’s just one cluster - then our sorting job doesn’t even make sense. We could arbitrarily decide to sort based on some cutoff, but without the two clusters the cutoff wouldn’t really distinguish between bleggs and rubes per se, it would just be an arbitrary cutoff on some metric (and we typically wouldn’t expect that cutoff to generalize robustly to other unobserved properties of the items). And the existence of two clusters is an empirical fact about bleggs/rubes. It’s a pattern out in the (hypothetical) physical world, and we could imagine other worlds in which that pattern doesn’t hold.
So long as there are two clusters to a reasonable approximation, it’s relatively easy to precisely specify the sorting problem: estimate which cluster each item is in, then sort accordingly.
Generalization to Alignment
Generalizable lesson: most goals, or problems, require some patterns to hold in the environment in order for the goal/problem to make sense at all. The goal/problem is formulated in terms of the patterns. Most of the work in precisely specifying the problem is to spell out those patterns - like e.g. what it means for a flock of hens to have a linear pecking order.
Applying this lesson to alignment, we need to ask: what patterns need to hold in the environment in order for the alignment problem to make sense at all? As with old MacDonald’s hens, most of the work of precisely stating the alignment problem will be in specifying those patterns.
But when talking about the alignment problem, we’ll be playing on hard mode - because unlike e.g. pecking orders amongst chickens, humanity does not already have a very solid and legible understanding of the patterns which hold among either AGIs or human cognition. So we’ll need to make some guesses about empirical patterns just to state the problem.
An important thing to keep in mind here: humans had a basically-correct instinctive understanding of hens’ pecking orders for centuries before empirical researchers came along and precisely measured the lack of cycles in pecking-graphs, and theoretical researchers noticed that the lack of cycles implied a linear order.[1] Had 15th century humans said “hmm, we don’t have any rigorous peer-reviewed research about these supposed pecking orders, we should consider them unscientific and unfit for reasoning”, they would have moved further from full understanding, not closer. And so it is today, with alignment. This post will outline our best current models (as I understand them), but rigorous research on the relevant patterns is sparse and frankly mostly not very impressive. Our best current models should be taken with a grain of salt, but remember that our brains are still usually pretty good at this sort of thing at an instinctive level; the underlying intuitions are more probably correct than the models.[2]
But What If The Patterns Don’t Hold?
I recommend most readers skip this subsection on a first read; it’s not very central to explaining the alignment problem. But I expect a significant minority of readers at this point will obsess over the question of what to do when the patterns required for expressing a problem don’t actually hold in the environment, and those readers won’t be able to pay attention to anything else until we address that issue. So this section is specifically for those readers. If that’s not you, just jump onwards to the next section!
We’ll start with a few reasons why “patterns not holding” is much less common and central than it might seem at first glance, and address a few common misconceptions along the way. Then, we’ll get to the actual question of what to do in the rare case that patterns actually don’t hold.
First reason “patterns not holding” is less central an issue than it might seem: approximation is totally fine. For instance, in the blegg/rube clustering example earlier, even if there are more than literally zero true edge cases, more than zero items right between the two clusters… that’s fine, so long as edge cases are relatively rare. There need to be two clear, distinct clusters. That does not mean the clusters need to have literally zero overlap. Similarly with the hens: pecking cycles need to be rare. That does not mean there need to be literally zero of them. Approximation is part of the game.
Second reason “patterns not holding” is less central an issue than it might seem: occasionally people will argue that the system can be modelled well at a level of abstraction lower than the patterns, as though this somehow invalidates the patterns. As a toy example: imagine someone arguing that gases are well-modeled by low level molecular dynamics, and therefore concepts like “temperature” are unnecessary and should be jettisoned. That’s not how this works! Even if the system can be modeled at a lower level, patterns like e.g. thermal equilibrium still exist in the environment, and temperature is still well defined in terms of those patterns (insofar as the patterns in fact hold). I think this sort of thing comes up in alignment to some extent with e.g. the shard folks [? · GW]: part of what many of them are trying to do is formulate theories at a lower level than we do in this post, and they often reject attempts to explain things at a higher level. But even if models at the lower level of “shards” work great, that would not imply that higher-level patterns don’t exist.
Third reason “patterns not holding” is less central an issue than it might seem: the Generalized Correspondence Principle. When quantum mechanics or general relativity came along, they still had to agree with classical mechanics in all the (many) places where classical mechanics worked. More generally: if some pattern in fact holds, then it will still be true that the pattern held under the original context even if later data departs from the pattern, and typically the pattern will generalize in some way to the new data. Prototypical example: maybe in the blegg/rube example, some totally new type of item is introduced, a gold donut (“gonut”). And then we’d have a whole new cluster, but the two old clusters are still there; the old pattern is still present in the environment.
Ok, that’s three reasons why “patterns not holding” is less central and common than people often think. But it’s still possible for patterns to not hold, so let’s address the actual question: what should old MacDonald do if his hens in fact do not form a linear pecking order? What should the sorter do if bleggs and rubes in fact do not form two distinct clusters?
Two main possibilities. Either:
- Making the pattern hold is part of the goal, or
- We fall back to whatever upstream objective motivated the current problem in the first place.
Maybe old MacDonald really wants the new hen to be third in the pecking order, so if the hens don’t form a linear pecking order, he’ll try to make them form a linear pecking order. Or, maybe he’ll reexamine why he wanted the new hen to be third in the pecking order in the first place, and figure out how to achieve his upstream goals in a world without a linear pecking order.
Alignment of What?
We’re now ready to explain the alignment problem itself, and the sorts of patterns in the environment required for the alignment problem to make sense at all. We’ll start with the broadest version: what kinds of things can be “aligned” in general, besides just AGI? What patterns need to hold in a system to sensibly talk about the system “being aligned” in the same sense as the alignment problem?
After those questions, we’ll talk about what kinds of patterns might constitute an “intelligence” or “general intelligence”, and what it would mean to “align” those kinds of patterns specifically.
Then, in the next section, we’ll move to the “align to what exactly?” part of the problem. We’ll talk about what kinds of patterns need to be present in human cognition in order for “human values” to be a sensible thing to talk about. Finally, we’ll briefly touch on several flavors of corrigibility.
Alignment of a Goal or Purpose
Let's start with the simplest kind of system for which it makes sense to talk about "alignment" at all: a system which has been optimized [LW · GW] for something, or is at least well compressed by modeling it as having been optimized. What patterns must the environment present in order for things like "having been optimized" to make sense, and what would "alignment" mean in that context?
Toy example: suppose I find a pile of driftwood on the beach, and somehow notice that the wood in this pile fits together very tightly and neatly into a sphere, like a big 3D puzzle. The fact that the wood fits together into a sphere is a very nontrivial "pattern in the environment" - specifically a pattern in the pile of wood. And it's a pattern which we wouldn't expect to find in a random pile of wood; it sure makes us think that the pile of wood has been optimized to fit together that way, whether by humans or by some strange natural process. Mathematically, I might conjecture that the pile of wood is approximately-best-compressed by a program which involves explicit optimization (like e.g. a "minimize" function or a "solve" function) for fitting together into a sphere.

What would "alignment" mean for that pile of wood? Well, insofar as the pile of wood is well-compressed by modeling it as having been optimized for something, it makes sense to ask what the wood seems to have been optimized for. In this case, it sure seems like the pile of wood has been optimized for fitting together into a sphere. Then the "alignment" question asks: is fitting-together-into-a-sphere something we want from this pile of wood? Is that goal aligned to our own goals, or is it orthogonal or opposed to our own goals?
Now let's generalize that toy example, and address some of the standard subtleties and open problems.
General recipe: we look for some part of the environment which is well-compressed by modeling it as having been optimized. That's the "pattern in the environment". Insofar as our chunk of the environment is well-compressed by modeling it as having been optimized, it makes sense to ask what it seems to have been optimized for. And then, we can ask whether the goal it seems to have been optimized for is aligned/opposed/orthogonal to our own goals.
Some standard subtleties and open problems of this recipe:
- "Well-compressed", in practice, is usually context dependent. Overly-toy example: a book of random numbers is not very compressible on its own. But it's very compressible given another copy of the book; amazon currently reports 6 copies in stock for me. What's the right context to assume for compression, in order to roughly match human instincts like "looks like it's been optimized for X"? That's an open problem.
- The implied optimization objective is typically underdetermined.[3] Instrumental convergence [? · GW] bites especially hard here: insofar as strategies for different goals involve heavily-overlapping actions, those instrumentally convergent actions will be compatible with many different goals. This issue is relatively straightforward to handle, but does require some attention to detail.
- We typically don't expect perfect optimization. What's the right way to allow for imperfect optimization, in order to roughly match human instincts like "looks like it's been optimized for X"? That's an open problem.
- Often satisficing is the right model (indeed, satisficing is probably the right model for our toy example). That's just a special case of min/max, but it's a special case worth highlighting.
- Sometimes people complain that everything can be modeled as optimized for something. This is true, but irrelevant to our current purposes; we're interested in whether something can be well compressed by modeling it as optimized for something. Why the focus on compression? Well, insofar as compression is a good model of humans' instinctive model-comparison, human reasoning like "looks like it's been optimized for X" should ground out in roughly "it's better compressed by modeling it as having been optimized for X than any other model I've thought of".
- Our approach in this section is somewhat indirect: we talk about a thing "looking like it's been optimized for X", but we don't talk directly about what concrete patterns or tell-tale signs make something look like it's been optimized for X. That's another open problem, one which we usually call coherence [? · GW].
- What's the right type signature for an optimization target, in order to roughly match human instincts like "looks like it's been optimized for X"? That's a particularly central open problem.
Note for philosophers
Yes, this section has basically been a formulation of teleology. Yes, I am aware of the usual approach of grounding teleology in biological evolution specifically, and the formulation in this section is somewhat different from that. The reason is that we're answering a different question: the grounding in evolution answers the question of "original teleology", i.e. how something acquires a purpose without being produced by something else purposeful (or in our terms: how something can be optimized without an optimizer which has itself been optimized). For our purposes, we don't particularly care about original teleology. Indeed, a focus on original teleology is often actively antihelpful when thinking about AI alignment, since it tempts one to define the purpose of a thing in terms of the original teleology (e.g. evolutionary fitness)... which risks defining away inner alignment failures [? · GW]. If e.g. one finds oneself arguing that the purpose of condoms is, ultimately, to increase genetic fitness, then one has made a mistake and should back up.
Alignment of Basic Agents
There are a few importantly-different useful notions of "agency". In this section, we'll talk about "basic agency" - not that the agents themselves are necessarily "basic", but that it's a relatively simple and broad notion of agency, one which includes humans but also e-coli and thermostats.
A neat thing about humans and e-coli and thermostats is that they do different things across a wide variety of environmental conditions, so as to cause their environment to appear optimized for certain things reasonably consistently. A thermostat, for instance, turns a heater on and off differently across a wide variety of starting temperatures and a wide variety of external temperatures, so as to hold a room at a certain temperature. An e-coli tumbles and swims differently across a wide variety of starting conditions, so as to end up near a sugar crystal placed in water. Organisms in general typically sense their environment and take different actions across a wide variety of environmental conditions, so as to cause there to be approximate copies of themselves in the future.[4] That's basic agency.[5]
Stated in terms of patterns in the environment: we're looking for a system which is well-compressed by modeling it as choosing outputs as a function of inputs, so as to make the environment appear optimized for a certain consistent goal.
Similar to the previous section: if a system is well-compressed by modeling it as blah blah blah certain consistent goal, then it makes sense to ask what that goal is, and whether it's aligned/opposed/orthogonal to what we want.
How does this relate to alignment of non-agentic stuff, as in the previous section? Well, a basic agent causes the environment to look like it's been optimized for something; the basic agent is a generator of optimized-looking stuff. So, when talking about alignment of basic agents, we're effectively asking "how aligned is the optimized-looking stuff which this agent tends to generate?". A thermostat, for example, tends to generate rooms in which the air has a specific temperature. How well does that align with what we humans want? Well, it aligns well insofar as the target temperature is comfortable for humans in the room.[6]
Again, some subtleties and open problems:
- All the previous subtleties and open problems still apply. In particular, I'll again highlight underdetermination of the objective, though the broader variety of environmental conditions tends to help with the underdetermination (since we're looking for goals which consistently match outcomes across a wide variety of environmental conditions).
- Note that I use "goal" in this section in a relatively agnostic sense, not necessarily committed to e.g. utility maximization (though that's certainly the go-to formulation, and for good reason [LW · GW]).
- The type signature of the goal itself is once again a central open question. The Pointers Problem [LW · GW] becomes particularly relevant at this stage: in a compression frame, the "goal" is typically over variables internal to the program used to compress the environment, i.e. latent variables, as opposed to observables or low-level world state.
- How do we carve out "the system" from "the environment", i.e. how do we draw a Cartesian boundary, in order to roughly match human instincts like "looks like it's robustly optimizing for X"? That's an open question, and probably a special case of the more general question of how humans abstract out subsystems from their environment. (This was actually relevant in the previous section too, but it's more apparent once agency is introduced.)
- As in the previous section, we formulated things indirectly. We talked about a thing "looking like it robustly optimizes for X", but we don't talk directly about what concrete patterns or tell-tale signs make something look like it robustly optimizes for X. That, again, is the domain of coherence [? · GW], and is largely an open problem. See A Simple Toy Coherence Theorem [LW · GW] for a toy but nontrivial example.
Alignment of General Intelligence
When I talk about "the alignment problem" or "the AI alignment problem", I'm usually talking about alignment of general intelligence. The alignment part doesn't actually involve any new pieces; a generally intelligent agent is a special case of basic agency, and everything we said about alignment of basic agents carries over. But it is worth discussing what kinds of patterns in the environment constitute "general intelligence" specifically, as opposed to the broader patterns of "basic agency", so we understand what "alignment of general intelligence" refers to.
I’ll quote from What’s General-Purpose Search [LW · GW][7] here:
Benito [LW · GW] has an interesting job. Here’s some of the stuff he’s had to do over the past couple years:
- build a prototype of an office
- resolve neighbor complaints at a party
- write public explanations of grantmaking decisions
- ship books internationally by Christmas
- moderate online debates
- figure out which of 100s of applicants to do trial hires with
Quite a wide variety!
Benito illustrates an interesting feature of humans: you can give humans pretty arbitrary goals, pretty arbitrary jobs to do, pretty arbitrary problems to solve, and they'll go figure out how to do it. It seems like humans have some sort of “general-purpose problem-solving” capability.
That’s basically the idea of general intelligence. There are some kinds of agents which are able to solve a particularly wide variety of subproblems as they come up, including totally novel kinds of subproblems which they’ve never dealt with before.
(One of the more common responses I hear at this point is some variation of “general intelligence isn’t A Thing, people just learn a giant pile of specialized heuristics via iteration and memetic spread”. There are two main classes of evidence that the “empirical iteration -> pile of specialized heuristics model” is basically wrong, or at least incomplete. First, on an outside view, we live in a very high-dimensional environment, so relatively brute-force learning can be ruled out on efficiency grounds; humans are empirically far too efficient to not have at least some general intelligence beyond just learning an arbitrary heuristic pile. See the posts on optimization [LW · GW] and science [LW · GW] in high-dimensional worlds for more on that. Second, on an inside view, researchers already know of at least some general-purpose heuristic generators [LW · GW]. While the known methods probably aren’t the whole story of general intelligence, they’re at least an existence proof: we know that techniques at that level of generality really do exist.)
So what patterns need to hold in the environment to talk about general intelligence/agency? Well, it’s the same as basic agency, with the added condition that the agent-pattern needs to be able to solve a very broad class of new kinds of subproblems as they come up.
Subtleties and open problems, in addition to those from the Basic Agents section:
- What patterns must hold in the environment in order for a “subproblem” or “subgoal” to make sense? In particular, David and I expect that the natural type signature of a subgoal (or instrumental goal) is different from the natural type signature of a terminal goal.
- Typically we imagine general-purpose intelligences/agents with e.g. a “world model”, the ability to make “plans” separate from action, maybe some symbolic representation capabilities, etc. We haven’t assumed any of that here, but we do often conjecture that general agent-like behavior might imply agent-like structure [LW · GW] (i.e. world model, planning, etc). That’s a whole class [? · GW] of open problems. Crucially, all those things require more specific patterns in the environment in order to make sense.
How Does All That Relate To Today's AI?
As of this writing, OpenAI has been throwing around the word "agent" lately, but that's mostly marketing. The way the terms have typically been used historically, the simplest summary would be:
- Today's LLMs and image generators are generative models of (certain parts of) the world.
- Systems like e.g. o1 are somewhat-general planners/solvers on top of those models. Also, LLMs can be used directly as planners/solvers when suitably prompted or tuned.
- To go from a general planner/solver to an agent, one can simply hook the system up to some sensors and actuators (possibly a human user) and specify a nominal goal... assuming the planner/solver is capable enough to figure it out from there.
We haven't talked much about world models or planners or solvers in this post, because they require making more assumptions about an agent's internal structure (... or as-yet-unproven conjectures about that structure [LW · GW]), and I don't want to bring in unnecessary assumptions.
That said, some key points:
- World models are not a type of thing which is aligned or unaligned; they are not the kind of pattern which has a goal.
- A general planner/solver is also not the type of thing which is aligned or unaligned in general. However:
- once the general planner/solver is given a goal, we can talk about alignment of that goal. For instance, when I ask ChatGPT to draw me a cat, I might also ask whether ChatGPT drawing me a cat is aligned with my own goals.
- once a planner/solver is hooked up to sensors and actuators, we can talk about whether the agent's de-facto optimization pressure on its environment (if any) is aligned to the nominal goal passed to the planner/solver. For instance, is the de-facto optimization pressure (if any) of ChaosGPT on its environment aligned to the nominal goal it was given, namely to destroy humanity? Note that this depends heavily [LW · GW] on how the planner/solver is used! Different scaffolding yields different alignment properties; it doesn't usually make sense to talk about whether a planner/solver is "aligned" in this sense absent the context of how it's wired up.
Applying all that to typical usage of LLMs (including o1-style models): an LLM isn't the kind of thing which is aligned or unaligned, in general. If we specify how the LLM is connected to the environment (e.g. via some specific sensors and actuators, or via a human user), then we can talk about both (a) how aligned to human values is the nominal objective given to the LLM[8], and (b) how aligned to the nominal objective is the LLM's actual effects on its environment. Alignment properties depend heavily on how the LLM is wired up to the environment, so different usage or different scaffolding will yield different alignment properties.
A final note: a sufficiently advanced planner/solver with a lot of background knowledge of the world could potentially figure out how its sensors and actuators are wired up to the world, and then optimize the environment in a consistent way across many different sensor/actuator arrangements. At that point, we could meaningfully talk about alignment of the planner/solver without the detailed context of how-it's-wired-up. But as of writing, I don't think that's yet very relevant to current AI.
Alignment to What?
We've now addressed what sort of patterns need to hold in the world in order to meaningfully talk about a thing being aligned, and specifically a basic agent being aligned, and even more specifically a general intelligence being aligned. It's time to address the other side of the alignment problem: aligned to what? In particular, in the long run (though importantly not necessarily as the first step!) we probably want to align AI to humans' values. What exactly are these "human values"? We often need to clarify that human values are not revealed preferences or stated preferences or dopamine levels or whatever other flavor of readily-measurable preferences someone likes. But what are human values, and what patterns need to hold in our environment in order for a human's values to be a sensible thing to talk about at all, separate from stated preferences, revealed preferences, dopamine, and all those other things?
What are a Human's Values?
We'll focus on the values of just one single human. How to generalize to multiple humans is... not an unimportant question, but a question whose salience is far, far out of proportion to its relative importance, so we're going to counteract that disproportionality by completely ignoring it here.
So, what do we mean when we talk about a human's values? And in particular, what patterns need to hold in the world in order for a human's values to be a sensible thing to talk about?
The big stylized facts we'll rely on are:
- Humans seem to do something vaguely reinforcement-learning-ish, when it comes to values. Values get "trained" in some way by a hedonic "reward signal" during one's life.
- ... but unlike most vaguely-reinforcement-learning-ish systems, humans mostly don't wirehead, and in fact most humans explicitly anti-endorse and avoid e.g. heroin.[9]
- ... also we're able to value things which were not at all in the ancestral environment, like e.g. cool cars, so we can't be relying on a mostly-hardcoded model; whatever's going on with values has to be pretty general and flexible with respect to what kinds of patterns a human finds around them.
It is rather difficult to make these stylized facts play together. I know of only one class of cognitive model compatible with all of them at once. Hutter and Everitt called it Value Reinforcement Learning, though the name does not make the model obvious.
Here's how David and I have summarized [LW · GW] the idea [LW · GW] before:
- Humans have a hedonic reward stream.
- The brain interprets that reward stream as evidence about values.
In particular, the brain tries to compress the reward stream by modeling it as some (noisy) signal generated from value-assignments to patterns in the brain's environment. So e.g. the brain might notice a pattern-in-the-environment which we label "sports car", and if the reward stream tends to spit out positive signals around sports cars (which aren't already accounted for by the brain's existing value-assignments to other things), then the brain will (marginally) compress that reward stream by modeling it as (partially) generated from a high value-assignment to sports cars. See the linked [LW · GW] posts [LW · GW] for a less compressed explanation, and various subtleties.
... so that's a complicated hand-wavy model. I think it's roughly correct, since it's pretty hard to explain the stylized facts of human values otherwise. But the more important point here is: there's this thing in the model which we call "values". And insofar as the model doesn't hold at least approximately for actual humans, then it probably doesn't make sense to talk about the human's values, or at least not any kind of "human values" which are very similar to the things I usually call "human values". At a hand-wavy level, that model is the "pattern which needs to hold in the environment" in order for the-thing-I-mean-by-"human values" to make sense at all.
(I should note here that lots of people claim that, when they talk about human values, they mean <other definition>. But in approximately 100% of cases, one finds that the definition given is not a very good match even to their own usage of the term, even allowing for some looseness and the occasional outright mistake in casual use. More generally, this problem applies basically whenever anyone tries to define any natural language term; that's why I usually recommend using examples instead of definitions whenever possible.[10])
One more key point: the extent to which Value Reinforcement Learning is in fact a good model of human cognition is, in principle, an empirical question. It should be testable. Empirical tests of the pattern were less relevant earlier when talking about agents and goals and optimization, because it's pretty clear that all the patterns we talked about there do in fact occur; the uncertainty is mostly over whether/how those patterns accurately summarize the things humans recognize as agents and goals and optimization. But now that we've moved on to human values, we see that our uncertainty is at least as much over whether the pattern holds for humans at all, as whether we've correctly identified the thing humans call "values" within the model.
Other targets
What about more medium-term targets - things which would potentially make sense as safe alignment targets before we've ironed out the kinks enough for alignment to human values to be a good idea?
There's a potential long tail of possibilities here, and I'm only going to cover a few, chosen mainly to illustrate the kinds of things we might need to deal with. These will also be somewhat shorter, largely because our understanding of them is relatively poor.
Paul!Corrigibility
Quoting Paul Christiano [LW(p) · GW(p)]:
I think that corrigibility is more likely to be a crisp property amongst systems that perform well-as-evaluated-by-you. I think corrigibility is much more likely to be useful in cases like this where it is crisp and natural.
Roughly speaking, I think corrigibility is crisp because there are two very different ways that a behavior can end up getting evaluated favorably by you, and the intermediate behaviors would be evaluated unfavorably.
As an example, suppose that you asked me to clean your house and that while cleaning I accidentally broke a valuable vase. Some possible options for me:
- Affirmatively tell you about the broken vase.
- Clean up the broken vase without notifying you.
- Make a weak effort to hide evidence, for example by taking out the trash and putting another item in its place, and denying I know about the vase if asked.
- Make a strong effort to hide evidence, for example by purchasing a new similar-looking vase and putting it in the same place, and then spinning an elaborate web of lies to cover up this behavior.
Let's say you prefer 1 to 2 to 3. You would like behavior 4 least of all if you understood what was going on, but in fact in if I do behavior 4 you won't notice anything wrong and so you would erroneously give it the best score of all. This means that the space of good-performing solutions has two disconnected pieces, one near option 1, which I'll call "corrigible" and the other near option 4 which I'll call "incorrigible."
In the language of this post: Paul is conjecturing that there exists a pattern... not exactly in our physical environment, but in the space of strategies-which-humans-give-positive-feedback-to-in-our-environment. And that pattern involves two reasonably well-separated clusters: one in which the strategy actually does basically what the human wants, and another in which the strategy fools the human. Insofar as there are in fact two separate clusters like that, Paul wants to call the non-trickery one "corrigible", and use it as an alignment target.
As with our model of human values, note that Paul's notion of "corrigibility" involves an empirical claim about the world (or, more precisely, the space of strategies-which-humans-give-positive-feedback-to-in-our-environment). It should be testable.
Eliezer!Corrigibility
Quoting Eliezer Yudkowsky:
The "hard problem of corrigibility" is interesting because of the possibility that it has a relatively simple core or central principle - rather than being value-laden on the details of exactly what humans value, there may be some compact core of corrigibility that would be the same if aliens were trying to build a corrigible AI, or if an AI were trying to build another AI.
…
We can imagine, e.g., the AI imagining itself building a sub-AI while being prone to various sorts of errors, asking how it (the AI) would want the sub-AI to behave in those cases, and learning heuristics that would generalize well to how we would want the AI to behave if it suddenly gained a lot of capability or was considering deceiving its programmers and so on.
In the language of this post: Eliezer is conjecturing that there exists a general pattern in the ways-in-which highly generally intelligent agents deal with generally intelligent subagents, child agents, etc. The conjecture doesn't even necessarily say what that pattern is, just that there's some consistent method there, which can hopefully generalize to our relationship with our eventual child agents (i.e. AGI smarter than us).
Again, there's an empirical claim here, and it's testable in principle... though this one is rather more dangerous to test, unless the pattern of interest generalizes down to agents less capable than humans. (Which seems unlikely, since the sort pattern Eliezer expects is not present much in humans if I understand correctly; it requires substantially superhuman capabilities.) Also it's a very indirect specification.
Subproblem!Corrigibility
Quoting David Lorell and myself [LW · GW] (with some substantial edits of details not centrally relevant here):
… the gaps/subproblems in humans’ plans are typically modular - i.e. we expect to be able to solve each subproblem without significantly changing the “outer” partial plan, and without a lot of coupling between different subproblems. That’s what makes the partial plan with all its subproblems useful in the first place: it factors the problem into loosely-coupled subproblems.
On this model, part of what it implicitly means to “solve” a subproblem (or instrumental goal) is that the “solution” should roughly preserve the modularity of the subproblem. That means the solution should not have a bunch of side effects which might mess with other subproblems, or mess up the outer partial plan. Furthermore, since the rest of the problem might not have been solved yet, the solution needs to work for a whole broad class of potential contexts, a whole broad class of ways-the-rest-of-the-problem-might-be-solved. So, the solution needs to robustly not have side effects which mess up the rest of the plan, across a wide range of possibilities for what “the rest of the plan” might be. Also, ideally the solution would make available plenty of relevant information about what it’s doing, so that other parts of the plan can use information found in the process of solving the subproblem. And that all sounds an awful lot like corrigibility.
Bringing it back to patterns: we conjecture that there exist many patterns in the subproblems which arise when solving problems in our world. In particular, subproblems typically implicitly involve some kind of robust modularity, so solutions won't interfere with whatever else is needed to solve other subproblems. Also, subproblems typically implicitly involve making information visible to the rest of the system, just in case it’s needed.
Again, there's a testable empirical claim here, in principle, about the structure of subproblems which convergently come up in the process of solving problems.
Exercise: Do What I Mean (DWIM)
I haven't thought much about what patterns need to hold in the environment in order for "do what I mean" to make sense at all. But it's a natural next target in this list, so I'm including it as an exercise for readers: what patterns need to hold in the environment in order for "do what I mean" to make sense at all? Note that either necessary or sufficient conditions on such patterns can constitute marginal progress on the question.
Putting It All Together, and Takeaways
What does it mean to align artificial general intelligence to human values (or corrigibility)? Putting together all the pieces from this post:
- Most of the work of specifying the problem is in specifying which patterns need to exist in the environment in order for the problem to make sense at all.
- The simplest pattern for which “alignment” makes sense at all is a chunk of the environment which looks like it’s been optimized for something. In that case, we can ask whether the goal-it-looks-like-the-chunk-has-been-optimized-for is “aligned” with what we want, versus orthogonal or opposed.
- The next simplest pattern is “basic agency”: a system which robustly makes the world look optimized for a certain objective, across many different contexts. In that case, we can ask whether the “agent’s objective” is “aligned” with what we want.
- We’re mainly interested in alignment of general intelligence/agents, which is a special case of basic agency in which the agent is capable of solving a very wide variety of subproblems as they come up.
- In order for “human values” to make sense distinct from rewards or revealed preferences or …, a whole complicated model of human cognition has to be roughly correct, and “values” are one of the things in that model.
- Finally, we walked through several different candidate patterns in which it might make sense to talk about “corrigibility”.
That’s a lot of pieces, each of which is fairly complex on its own. It would be somewhat surprising if all of it was exactly correct. So to wrap up, a reminder: had 15th century humans said “hmm, we don’t have any rigorous peer-reviewed research about these supposed pecking orders, we should consider them unscientific and unfit for reasoning”, they would have moved further from full understanding, not closer. And so it is today, with alignment.
The picture sketched is complicated and deep, but we have at least some prior evidence (intuition, arguments) separately in each piece, so even if one piece is wrong it doesn’t necessarily break everything else. Ideally, we’d like to both test the pieces, and iterate on our own understanding of the patterns underlying our own concepts.
Acknowledgements: Though David Lorell is not a coauthor on this particular post, much of the ideas and framing were worked out with him. Also, a few parts - especially the teleology section - benefited from discussions with Steve Petersen and Ramana Kumar. Thank you!
- ^
Actually historically I think the theory and experiment were handled together, but I want to emphasize that both components are load-bearing.
- ^
… which notably does not imply that they’re correct.
- ^
In a compression context, note that we usually have nontrivial probability on a few near-shortest programs, not just on the single shortest program. This is especially important with multiple agents, since different priors will typically lead to some small disagreement about which near-shortest programs are in fact shortest. Those are two big reasons, among others, why "just use the single shortest program" is not a compelling resolution to underdetermination.
- ^
Rewording that sentence to properly account for sexual reproduction is left as an exercise to the reader.
- ^
Why highlight basic agency in particular as a natural type of agency to focus on? I find it particularly interesting because it distills the core idea of Maxwell's demon: a system which observes its environment, then takes actions as a function of its observations, in such a way that the system is steered into a relatively-narrow outcome space. That framing strongly suggests that basic agency is the right notion for thermodynamic agency models. Indeed, David and I have at least one simple theorem along those lines in the writeup queue.
- ^
This example also highlights the question of what patterns in the environment constitute "control", which is a whole 'nother can of worms.
- ^
General intelligence/agency is not strictly synonymous with general-purpose search, but they’re pretty closely related conceptually.
- ^
Note that, while the type signature of goals is an open problem, the answer is definitely not "natural language". So there's an additional subtlety here about how exactly a natural language "goal specification" maps to an actual goal. For instance, if I ask the system to light a candle, does that natural language "goal specification" implicitly include not lighting the rest of my house on fire? An actual goal includes that sort of detail. And as the fire example suggests, the mapping between natural language specification and an actual goal is quite load-bearing for questions of alignment.
- ^
Note that, in using "anti-endorsement" and "avoidance" as evidence of values, we're relying on stated and revealed preferences as proxy measures of values. Stated and revealed preferences are not synonymous with values, but they are useful proxies!
- ^
... of course a natural question is then "John, why are you giving so many definitions, if you explicitly recommend people not do that?". And the short answer is that I think I have done a much better job than approximately 100% of cases.
50 comments
Comments sorted by top scores.
comment by aysja · 2025-01-20T00:21:37.360Z · LW(p) · GW(p)
I agree with a bunch of this post in spirit—that there are underlying patterns to alignment deserving of true name—although I disagree about… not the patterns you’re gesturing at, exactly, but more how you’re gesturing at them. Like, I agree there’s something important and real about “a chunk of the environment which looks like it’s been optimized for something,” and “a system which robustly makes the world look optimized for a certain objective, across many different contexts.” But I don't think the true names of alignment will be behaviorist (“as if” descriptions, based on observed transformations between inputs and output). I.e., whereas you describe it as one subtlety/open problem that this account doesn’t “talk directly about what concrete patterns or tell-tale signs make something look like it's been optimized for X,” my own sense is that this is more like the whole problem (and also not well characterized as a coherence problem). It’s hard for me to write down the entire intuition I have about this, but some thoughts:
- Behaviorist explanations don’t usually generalize as well. Partially this is because there are often many possible causal stories to tell about any given history of observations. Perhaps the wooden sphere was created by a program optimizing for how to fit blocks together into a sphere, or perhaps the program is more general (about fitting blocks together into any shape) or more particular (about fitting these particular wood blocks together) etc. Usually the response is to consider the truth of the matter to be the shortest program consistent with all observations, but this is enables blindspots, since it might be wrong! You don’t actually know what’s true when you use procedures like this, since you’re not looking at the mechanics of it directly (the particular causal process which is in fact happening). But knowing the actual causal process is powerful, since it will tell you how the outputs will vary with other inputs, which is an important component to ensuring that unwanted outputs don’t obtain.
- This seems important to me for at least a couple reasons. One is that we can only really bound the risk if we know what the distribution of possible outputs is. This doesn't necessarily require understanding the underlying causal process, but understanding the underlying causal process will, I think, necessarily give you this (absent noise/unknown unknowns etc). Two is that blindspots are exploitable—anytime our measurements fail to capture reality, we enable vectors of deception. I think this will always be a problem to some extent, but it seems worse to me the less we have a causal understanding. For instance, I’m more worried about things like “maybe this program represents the behavior, but we’re kind of just guessing based on priors” than I am about e.g., calculating the pressure of this system. Because in the former there are many underlying causal processes (e.g., programs) that map to the same observation, whereas in the latter it's more like there are many underlying states which do. And this is pretty different, since the way you extrapolate from a pressure reading will be the same no matter the microstate, but this isn’t true of the program: different ones suggest different future outcomes. You can try to get around this by entertaining the possibility that all programs which are currently consistent with the observations might be correct, weighted by their simplicity, rather than assuming a particular one. But I think in practice this can fail. E.g., scheming behavior might look essentially identical to non-scheming behavior for an advanced intelligence (according to our ability to estimate this), despite the underlying program being quite importantly different. Such that to really explain whether a system is aligned, I think we'll need a way of understanding the actual causal variables at play.
- Many accounts of cognition are impossible (eg AIXI, VNM rationality, or anything utilizing utility functions, many AIT concepts), since they include the impossible step of considering all possible worlds. I think people normally consider this to be something like a “God’s eye view” of intelligence—ultimately correct, but incomputable—which can be projected down to us bounded creatures via approximation, but I think this is the wrong sort of in-principle to real-world bridge. Like, it seems to me that intelligence is fundamentally about ~“finding and exploiting abstractions,” which is something that having limited resources forces you to do. I.e., intelligence comes from the boundedness. Such that the emphasis should imo go the other way: figuring out the core of what this process of “finding and exploiting abstractions” is, and then generalizing outward. This feels related to behaviorism insomuch as behaviorist accounts often rely on concepts like “searching over the space of all programs to find the shortest possible one.”
↑ comment by Lucius Bushnaq (Lblack) · 2025-01-20T07:34:04.128Z · LW(p) · GW(p)
Many accounts of cognition are impossible (eg AIXI, VNM rationality, or anything utilizing utility functions, many AIT concepts), since they include the impossible step of considering all possible worlds. I think people normally consider this to be something like a “God’s eye view” of intelligence—ultimately correct, but incomputable—which can be projected down to us bounded creatures via approximation, but I think this is the wrong sort of in-principle to real-world bridge. Like, it seems to me that intelligence is fundamentally about ~“finding and exploiting abstractions,” which is something that having limited resources forces you to do. I.e., intelligence comes from the boundedness.
I used to think this, but now I don't quite think it anymore. The largest barrier I saw here was that the search had to prioritise simple hypotheses over complex ones. I had not idea how to do this. It seemed like it might require very novel search algorithms, such that models like AIXI were eliding basically all of the key structure of intelligence by not specifying this very special search process.
I no longer think this. Privileging simple hypotheses in the search seems way easier than I used to think. It is a feature so basic you can get it almost by accident. Many search setups we already know about do it by default. I now suspect that there is a pretty real and non-vacuous sense in which deep learning is approximated Solomonoff induction [LW · GW]. Both in the sense that the training itself is kind of like approximated Solomonoff induction, and in the sense that the learned network algorithms may be making use of what is basically approximated Solomonoff induction in specialised hypotheses spaces to perform 'general pattern recognition' on their forward passes.
I still think “abstraction-based-cognition” is an important class of learned algorithms that we need to understand, but a picture of intelligence that doesn't talk about abstraction and just refers to concepts like AIXI no longer seems to me to be so incomplete as to not be saying much of value about the structure of intelligence at all.
↑ comment by mattmacdermott · 2025-03-06T12:51:58.429Z · LW(p) · GW(p)
I now suspect that there is a pretty real and non-vacuous sense in which deep learning is approximated Solomonoff induction.
Even granting that, do you think the same applies to the cognition of an AI created using deep learning -- is it approximating Solomonoff induction when presented with a new problem at inference time?
I think it's not, for reasons like the ones in aysja's comment.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-03-06T14:14:23.922Z · LW(p) · GW(p)
Yes. I think this may apply to basically all somewhat general minds.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-20T01:32:52.913Z · LW(p) · GW(p)
Many accounts of cognition are impossible (eg AIXI, VNM rationality, or anything utilizing utility functions, many AIT concepts), since they include the impossible step of considering all possible worlds. I think people normally consider this to be something like a “God’s eye view” of intelligence—ultimately correct, but incomputable—which can be projected down to us bounded creatures via approximation, but I think this is the wrong sort of in-principle to real-world bridge. Like, it seems to me that intelligence is fundamentally about ~“finding and exploiting abstractions,” which is something that having limited resources forces you to do. I.e., intelligence comes from the boundedness. Such that the emphasis should imo go the other way: figuring out the core of what this process of “finding and exploiting abstractions” is, and then generalizing outward. This feels related to behaviorism insomuch as behaviorist accounts often rely on concepts like “searching over the space of all programs to find the shortest possible one.”
I do think a large source of impossibility results come from trying to consider all possible worlds, but the core feature of all of the impossible proposals in our reality is a combination of ignoring computational difficulty entirely, combined with problems on embedded agency, and that the boundary between agent and environment is fundamental to most descriptions of intelligence/agency, ala Cartesian boundaries, but physically universal cellular automatons invalidate this abstraction, meaning the boundary is arbitrary and has no meaning at a low level, and our universe is plausibly physically universal.
More here:
https://www.lesswrong.com/posts/dHNKtQ3vTBxTfTPxu/what-is-the-alignment-problem#3GvsEtCaoYGrPjR2M [LW(p) · GW(p)]
(Caveat that the utility function framing actually can work, assuming we restrain the function classes significantly enough, and you could argue the GPT series has a utility function of prediction, but I won't get into that).
The problem with the bridge is that even if the god's eye view of intelligence theories was totally philosophically correct, there is no way to get anything like that, and thus you cannot easily approximate without giving very vacuous bounds, and thus you need a specialized theory of intelligence in specific universes that might be inelegant philosophically/mathematically, but that can actually work to build and align AGI/ASI, especially if it comes soon.
comment by Towards_Keeperhood (Simon Skade) · 2025-01-16T16:20:37.127Z · LW(p) · GW(p)
Nice post!
My key takeaway: "A system is aligned to human values if it tends to generate optimized-looking stuff which is aligned to human values."
I think this is useful progress. In particular it's good to try to aim for the AI to produce some particular result in the world, rather than trying to make the AI have some goal - it grounds you in the thing you actually care about in the end.
I'd say the "... aligned to human values part" is still underspecified (and I think you at least partially agree):
- "aligned": how does the ontology translation between the representation of the "generated optimized-looking stuff" and the representation of human values look like?
- "human values"
- I think your model of humans is too simplistic. E.g. at the very least it's lacking a distinction like between "ego-syntonic" and "voluntary" as in this post [LW · GW], though I'd probably want a even significantly more detailed model. Also one might need different models for very smart and reflective people than for most people.
- We haven't described value extrapolation.
- (Or from an alternative perspective, our model of humans doesn't identify their relevant metapreferences (which probably no human knows fully explicitly, and for some/many humans it they might not be really well defined).)
Positive reinforcement for first trying to better understand the problem before running off and trying to solve it! I think that's the way to make progress, and I'd encourage others to continue work on more precisely defining the problem, and in particular on getting better models of human cognition to identify how we might be able to rebind the "human values" concept to a better model of what's happening in human minds.
Btw, I'd have put the corrigibility section into a separate post, it's not nearly up to the standards of the rest of this post.
To set expectations: this post will not discuss ...
Maybe you want to add here that this is not meant to be an overview of alignment difficulties, or an explanation for why alignment is hard.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-16T16:40:44.152Z · LW(p) · GW(p)
Meta note: strong upvoted, very good quality comment.
"aligned": how does the ontology translation between the representation of the "generated optimized-looking stuff" and the representation of human values look like?
Yup, IMO the biggest piece unaddressed in this post is what "aligned" means between two goals, potentially in different ontologies to some extent.
I think your model of humans is too simplistic. E.g. at the very least it's lacking a distinction like between "ego-syntonic" and "voluntary" as in this post [LW · GW], though I'd probably want a even significantly more detailed model. Also one might need different models for very smart and reflective people than for most people.
I think the model sketched in the post is at roughly the right level of detail to talk about human values specifically, while remaining agnostic to lots of other parts of how human cognition works.
We haven't described value extrapolation.
- (Or from an alternative perspective, our model of humans doesn't identify their relevant metapreferences (which probably no human knows fully explicitly, and for some/many humans it they might not be really well defined).)
Yeah, my view on metapreferences is similar to my view on questions of how to combine the values of different humans: metapreferences are important, but their salience is way out of proportion to their importance. (... Though the disproportionality is much less severe for metapreferences than for interpersonal aggregation.)
Like, people notice that humans aren't always fully consistent, and think about what's the "right way" to resolve that, and one of the most immediate natural answers is "metapreferences!". And sometimes that is the right answer, but I view it as more of a last-line fallback for extreme cases. Most of time (I claim) the "right way" to resolve the inconsistency is to notice that people are frequently and egregiously wrong in their estimates of their own values (as evidenced by experiences like "I thought I wanted X, but in hindsight I didn't"), most of the perceived inconsistency comes from the estimates being wrong, and then the right question to focus on is instead "What does it even mean to be wrong about our own values? What's the ground truth?".
Replies from: TsviBT↑ comment by TsviBT · 2025-01-17T02:14:16.364Z · LW(p) · GW(p)
metapreferences are important, but their salience is way out of proportion to their importance.
You mean the salience is too high? On the contrary, it's too low.
one of the most immediate natural answers is "metapreferences!".
Of course, this is not an answer, but a question-blob.
as evidenced by experiences like "I thought I wanted X, but in hindsight I didn't"
Yeah I think this is often, maybe almost always, more like "I hadn't computed / decided to not want [whatever Thing-like thing X gestured at], and then I did compute that".
a last-line fallback for extreme cases
It's really not! Our most central values are all of the proleptic (pre-received; foreshadowed) type: friendship, love, experience, relating, becoming. They all can only be expressed in an either vague or incomplete way: "There's something about this person / myself / this collectivity / this mental activity that draws me in to keep walking that way.". Part of this is resolvable confusion, but probably not all of it. Part of the fun of relating with other people is that there's a true open-endedness; you get to cocreate something non-pre-delimited, find out what another [entity that is your size / as complex/surprising/anti-inductive as you] is like, etc. "Metapreferences" isn't an answer of course, but there's definitely a question that has to be asked here, and the answer will fall under "metapreferences" broadly construed, in that it will involve stuff that is ongoingly actively determining [all that stuff we would call legible values/preferences].
"What does it even mean to be wrong about our own values? What's the ground truth?"
Ok we can agree that this should point the way to the right questions and answers, but it's an extremely broad question-blob.
comment by Oliver Sourbut · 2025-01-16T12:49:27.612Z · LW(p) · GW(p)
Organisms in general typically sense their environment and take different actions across a wide variety of environmental conditions, so as to cause there to be approximate copies of themselves in the future.[4] That's basic agency.[5]
I agree with this breakdown, except I start the analysis with moment-to-moment deliberation [? · GW], and note that having there (continue to) be relevantly similar deliberators is a very widely-applicable intermediate objective [LW · GW], from where we get control ('basic agency') but also delegation and replication [LW · GW].
The way the terms have typically been used historically, the simplest summary would be:
- Today's LLMs and image generators are generative models of (certain parts of) the world.
- Systems like e.g. o1 are somewhat-general planners/solvers on top of those models. Also, LLMs can be used directly as planners/solvers when suitably prompted or tuned.
- To go from a general planner/solver to an agent, one can simply hook the system up to some sensors and actuators (possibly a human user) and specify a nominal goal... assuming the planner/solver is capable enough to figure it out from there.
Yep! But (I think maybe you'd agree) there's a lot of bleed between these abstractions, especially when we get to heavily finetuned models. For example...
Applying all that to typical usage of LLMs (including o1-style models): an LLM isn't the kind of thing which is aligned or unaligned, in general. If we specify how the LLM is connected to the environment (e.g. via some specific sensors and actuators, or via a human user), then we can talk about both (a) how aligned to human values is the nominal objective given to the LLM[8], and (b) how aligned to the nominal objective is the LLM's actual effects on its environment. Alignment properties depend heavily on how the LLM is wired up to the environment, so different usage or different scaffolding will yield different alignment properties.
Yes and no? I'd say that the LLM-plus agent's objectives are some function of
- incompletely-specified objectives provided by operators
- priors and biases from training/development
- pretraining
- finetuning
- scaffolding/reasoning structure (including any multi-context/multi-persona interactions, internal ratings, reflection, refinement, ...)
- or these things developed implicitly through structured CoT
- drift of various kinds
and I'd emphasise that the way that these influences interact is currently very poorly characterised. But plausibly the priors and biases from training could have nontrivial influence across a wide variety of scenarios (especially combined with incompletely-specified natural-language objectives), at which point it's sensible to ask 'how aligned' the LLM is. I appreciate you're talking in generalities, but I think in practice this case might take up a reasonable chunk of the space! For what it's worth, the perspective of LLMs as pre-agent building blocks and conditioned-LLMs as closer to agents [LW · GW] is underrepresented, and I appreciate you conceptually distinguishing those things here.
comment by Steven Byrnes (steve2152) · 2025-01-16T18:03:55.627Z · LW(p) · GW(p)
I should note here that lots of people claim that, when they talk about human values, they mean <other definition>. But in approximately 100% of cases, one finds that the definition given is not a very good match even to their own usage of the term, even allowing for some looseness and the occasional outright mistake in casual use. More generally, this problem applies basically whenever anyone tries to define any natural language term; that's why I usually recommend using examples instead of definitions whenever possible.
I think that your definition is a bad match too.
Specifically: Go ask someone on the street to give ten everyday examples where their “desires” come apart from their “values”. I claim that you’ll find that your proposed definition in this post (Value Reinforcement Learning etc.) is reliably pointing to their “desires”, not their “values”, in all those cases where the two diverge.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-16T18:24:31.701Z · LW(p) · GW(p)
Seems false, though that specific experiment is not super cruxy. One central line of evidence: desires tend to be more myopic, values longer term or "deeper". That's exactly the sort of thing you'd expect if "desires" is mostly about immediate reward signals (or anticipated reward signals), whereas "values" is more about the (projected) upstream generators of those signals, potentially projected quite a ways back upstream.
(I suspect that you took my definition of "values" to be nearly synonymous with rewards or immediately anticipated rewards, which it very much is not; projected-upstream-generators-of-rewards are a quite different beast from rewards themselves, especially as we push further upstream.)
Replies from: steve2152, jmh↑ comment by Steven Byrnes (steve2152) · 2025-01-16T18:50:28.150Z · LW(p) · GW(p)
“Is scratching your nose right now something you desire?” Yes. “Is scratching your nose right now something you value?” Not really, no. But I claim that the Value Reinforcement Learning framework would assign a positive score to the idea of scratching my nose when it’s itchy. Otherwise, nobody would scratch their nose.
I desire peace and justice, but I also value peace and justice, so that’s not a good way to distinguish them.
(I suspect that you took my definition of "values" to be nearly synonymous with rewards or immediately anticipated rewards, which it very much is not; projected-upstream-generators-of-rewards are a quite different beast from rewards themselves, especially as we push further upstream.)
No, that’s not what I think. I think your definition points to whether things are motivating versus demotivating all-things-considered, including both immediate plans and long-term plans. And I want to call that desires. Desires can be long-term—e.g. “being a dad someday is something I very much desire”.
I think “values”, as people use the term in everyday life, tends to be something more specific, where not only is the thing motivating, but it’s also motivating when you think about it in a self-reflective way. A.k.a. “X is motivating” AND “the-idea-of-myself-doing-X is motivating”. If I’m struggling to get out of bed, because I’m going to be late for work, then the feeling of my head remaining on the pillow is motivating, but the self-reflective idea of myself being in bed is demotivating. Consequently, I might describe the soft feeling of the pillow on my head as something I desire, but not something I value.
(I talk about this in §8.4.2–8.5 here [LW · GW] but that might be pretty hard to follow out of context.)
Replies from: johnswentworth, xpym↑ comment by johnswentworth · 2025-01-16T19:11:47.964Z · LW(p) · GW(p)
“Is scratching your nose right now something you desire?” Yes. “Is scratching your nose right now something you value?” Not really, no.
I think disagree with this example. And I definitely disagree with it in the relevant-to-the-broader-context sense that, under a value-aligned sovereign AI, if my nose is itchy then it should get scratched, all else equal. It may not be a very important value, but it's a value. (More generally, satisfying desires is itself a value, all else equal.)
I think “values”, as people use the term in everyday life, tends to be something more specific, where not only is the thing motivating, but it’s also motivating when you think about it in a self-reflective way. A.k.a. “X is motivating” AND “the-idea-of-myself-doing-X is motivating”. If I’m struggling to get out of bed, because I’m going to be late for work, then the feeling of my head remaining on the pillow is motivating, but the self-reflective idea of myself being in bed is demotivating. Consequently, I might describe the soft feeling of the pillow on my head as something I desire, but not something I value.
I do agree that that sort of reasoning is a pretty big central part of values. And it's especially central for cases where I'm trying to distinguish my "real" values from cases where my reward stream is "inaccurately" sending signals for some reason, like e.g. heroin.
Here's how I'd imagine that sort of thing showing up organically in a Value-RL-style system.
My brain is projecting all this value-structure out into the world; it's modelling reward signals as being downstream of "values" which are magically attached to physical stuff/phenomena/etc. Insofar as X has high value, the projection-machinery expects both that X itself will produce a reward, and that the-idea-of-myself-doing-X will produce a reward (... as well as various things of similar flavor, like e.g. "my friends will look favorably on me doing X, thereby generating a reward", "the idea of other people doing X will produce a reward", etc). If those things come apart, then the brain goes "hmm, something fishy is going on here, I'm not sure these rewards are generated by my True Values; maybe my reward stream is compromised somehow, or maybe my social scene is reinforcing things which aren't actually good for me, or...".
That's the sort of reasoning which should naturally show up in a Value RL style system capable of nontrivial model structure learning.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-16T21:49:37.474Z · LW(p) · GW(p)
under a value-aligned sovereign AI, if my nose is itchy then it should get scratched, all else equal
Well, if the AI can make my nose not itch in the first place, I’m OK with that too. Whereas I wouldn’t make an analogous claim about things that I “value”, by my definition of “value”. If I really want to have children, I’m not OK with the AI removing my desire to have children, as a way to “solve” that “problem”. That’s more of a “value” and not just a desire.
That's the sort of reasoning which should naturally show up in a Value RL style system capable of nontrivial model structure learning.
I’m not sure what point your making here. If human brains run on Value RL style systems (which I think I agree with), and humans in fact do that kind of reasoning, then tautologically, that kind of reasoning is a thing that can show up in Value RL style systems.
Still, there’s a problem that it’s possible for some course-of-action to seem appealing when I think about it one way, and unappealing when I think about it a different way. Ego-dystonic desires like addictions are one example of that, but it also comes up in tons of normal situations like deciding what to eat. It’s a problem in the sense that it’s unclear what a “value-aligned” AI is supposed to be doing in that situation.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-16T21:57:44.414Z · LW(p) · GW(p)
Cool, I think we agree here more than I thought based on the comment at top of chain. I think the discussion in our other thread is now better aimed than this one.
↑ comment by xpym · 2025-01-17T10:21:51.397Z · LW(p) · GW(p)
the feeling of my head remaining on the pillow is motivating, but the self-reflective idea of myself being in bed is demotivating
This seems to be an example of conflicting values, and its preferred resolution, not a difference between a value and a non-value. Suppose you'd find your pillow replaced by a wooden log - I'd imagine that the self-reflective idea of yourself remedying this state of affairs would be pretty motivating!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-17T13:15:46.970Z · LW(p) · GW(p)
I claim that if you find someone who’s struggling to get out of bed, making groaning noises, and ask them the following question:
Hey, I have a question about your values. The thing you’re doing right now, staying in bed past your alarm, in order to be more comfortable at the expense of probably missing your train and having to walk to work in the cold rain … is this thing you’re doing in accordance with your values?
I bet the person says “no”. Yet, they’re still in fact doing that thing, which implies (tautologically) that they have some desire to do it—I mean, they’re not doing it “by accident”! So it’s conflicting desires, not conflicting values.
I don’t think your wooden log example is relevant. Insofar as different values are conflicting, that conflict has already long ago been resolved, and the resolution is: the action which best accords with the person’s values, in this instance, is to get up. And yet, they’re still horizontal.
Another example: if someone says “I want to act in accordance with my values” or “I don’t always act in accordance with my values”, we recognize these as two substantive claims. The first is not a tautology, and the second is not a self-contradiction.
Replies from: xpym↑ comment by xpym · 2025-01-17T14:47:11.278Z · LW(p) · GW(p)
I bet the person says “no”.
I agree, but I think it's important to mention issues like social desirability bias and strategic self-deception here, coupled with the fact that most people just aren't particularly good at introspection.
it’s conflicting desires, not conflicting values
It's both, our minds employ desires in service of pursuing our (often conflicting) values.
Insofar as different values are conflicting, that conflict has already long ago been resolved, and the resolution is: the action which best accords with the person’s values, in this instance, is to get up.
I'd rather put it as a routine conflict eventually getting resolved in a predictable way.
Another example: if someone says “I want to act in accordance with my values” or “I don’t always act in accordance with my values”, we recognize these as two substantive claims. The first is not a tautology, and the second is not a self-contradiction.
Indeed, but I claim that those statements actually mean "I want my value conflicts to resolve in the way I endorse" and "I don’t always endorse the way my value conflicts resolve".
↑ comment by jmh · 2025-01-17T16:54:45.328Z · LW(p) · GW(p)
The desires-values schema reminds me of Hirshmann's The Passions and the Interests and the problem he (IIRC) sees Machiavelli dealing with. Machiavelli is advising kings who he sees as more driven by their passions but to be successful need to be driven more by their interests.
Anyone in the alignment space take a look at Machiavelli in the light of how to get some thing that is more powerful (king versus the advisor) better aligned? Probably need to stretch things a bit to see that type of alignment as being aligned with the general welfare of the kingdom but seems like he was dealing with a similar problem when looked at from certain angles.
comment by Ronny Fernandez (ronny-fernandez) · 2025-03-05T01:39:02.421Z · LW(p) · GW(p)
Curated. Tackles thorny conceptual issues at the foundation of AI alignment while also revealing the weak spots of the abstractions used to do so.
I like the general strategy of trying to make progress on understanding the problem relying only on the concept of "basic agency" without having to work on the much harder problem of coming up with a useful formalism of a more full throated conception of agency, whether or not that turns out to be enough in the end.
The core point of the post: that certain kinds of goals only make sense at all given that there are certain kinds of patterns present in the environment, and that most of the problem of making sense of the alignment problem is identifying what those patterns are for the goal of "make aligned AGIs", is plausible and worthy of discussion. I also appreciate that this post elucidates the (according to me) canon-around-these-parts general patterns that render the specific goal of aligning AGIs sensible (eg, compression based analyses of optimization) and presents them as such explicitly.
The introductory examples of patterns that must be present in the general environment for certain simpler goals to make sense—especially how the absence of the pattern makes the goal not make sense—are clear and evocative. I would not be surprised if they helped someone notice that there are some ways that the canon-around-these-parts hypothesized patterns which render "align AGIs" a sensible goal are importantly flawed.
comment by Noosphere89 (sharmake-farah) · 2025-01-24T16:11:51.122Z · LW(p) · GW(p)
An important thing to keep in mind here: humans had a basically-correct instinctive understanding of hens’ pecking orders for centuries before empirical researchers came along and precisely measured the lack of cycles in pecking-graphs, and theoretical researchers noticed that the lack of cycles implied a linear order.[1] Had 15th century humans said “hmm, we don’t have any rigorous peer-reviewed research about these supposed pecking orders, we should consider them unscientific and unfit for reasoning”, they would have moved further from full understanding, not closer. And so it is today, with alignment. This post will outline our best current models (as I understand them), but rigorous research on the relevant patterns is sparse and frankly mostly not very impressive. Our best current models should be taken with a grain of salt, but remember that our brains are still usually pretty good at this sort of thing at an instinctive level; the underlying intuitions are more probably correct than the models.[2]
Notably, these situations are situations where we have a lot of empirical data on the phenomenon in question, and this is the key difference here.
(Data is coming in, thank gods, but still, this is important)
To be clear, cultural knowledge is powerful, but it needs feedback loops to work well, and usually reasonably short ones at that.
Alignment is not yet such a field (though things are improving).
I know you are concerned about feedback loops in your own research, which is good, and if everyone in Agent Foundations had a willingness to seek out such feedback loops like you, we'd be in a much healthier state, but it's still important to remember the issue, as this is a regime where intuitions go very wrong very fast.
comment by Jonas Hallgren · 2025-01-16T14:38:45.158Z · LW(p) · GW(p)
One of the more common responses I hear at this point is some variation of “general intelligence isn’t A Thing, people just learn a giant pile of specialized heuristics via iteration and memetic spread
I'm very uncertain about the validity of the below question but I shalt ask it anyway and since I don't trust my own way of expressing it, here's claude on it:
The post argues that humans must have some general intelligence capability beyond just learning specialized heuristics, based on efficiency arguments in high-dimensional environments. However, research on cultural evolution (e.g., "The Secret of Our Success", "Cognitive Gadgets") suggests that much of human capability comes from distributed cultural learning and adaptation. Couldn't this cultural scaffolding, combined with domain-specific inductive biases (as suggested by work in Geometric Deep Learning), provide the efficiency gains you attribute to general intelligence? In other words, perhaps the efficiency comes not from individual general intelligence, but from the collective accumulation and transmission of specialized cognitive tools?
I do agree that there are specific generalised forms of intelligence, I guess this more points me towards that the generating functions of these might not be optimally sub-divided in the usual way we think about it?
Now completely theoretically of course, say someone where to believe the above, why is the following really stupid?:
Specifically, consider the following proposal: Instead of trying to directly align individual agents' objectives, we could focus on creating environmental conditions and incentive structures that naturally promote collaborative behavior. The idea being that just as virtue ethics suggests developing good character through practiced habits and environmental shaping, we might achieve alignment through carefully designed collective dynamics that encourage beneficial emergent behaviors. (Since this seems to be the most agentic underlying process that we currently have, theoretically of course.)
↑ comment by johnswentworth · 2025-01-16T16:26:09.322Z · LW(p) · GW(p)
It is entirely plausible that the right unit of analysis is cultures/societies/humanity-as-a-whole rather than an individual. Exactly the same kinds of efficiency arguments then apply at the societal level, i.e. the society has to be doing something besides just brute-force trying heuristics and spreading tricks that work, in order to account for the efficiency we actually see.
The specific proposal has problems mostly orthogonal to the "agency of humans vs societies" question.
↑ comment by Ulf M. Pettersson (ulfpettersson) · 2025-01-22T00:09:31.896Z · LW(p) · GW(p)
> Instead of trying to directly align individual agents' objectives, we could focus on creating environmental conditions and incentive structures that naturally promote collaborative behavior.
I think you are really on to something here. To achieve alignment of AI systems and agents, it is possible to create solutions based on existing institutions that ensure alignment in human societies.
Look to the literature in economics and social science that explain how societies manage to align the interests of millions of intelligent human agents, despite all those agents acting in their own self-interest.
comment by Noosphere89 (sharmake-farah) · 2025-01-16T01:57:11.276Z · LW(p) · GW(p)
Third reason “patterns not holding” is less central an issue than it might seem: the Generalized Correspondence Principle. When quantum mechanics or general relativity came along, they still had to agree with classical mechanics in all the (many) places where classical mechanics worked. More generally: if some pattern in fact holds, then it will still be true that the pattern held under the original context even if later data departs from the pattern, and typically the pattern will generalize in some way to the new data. Prototypical example: maybe in the blegg/rube example, some totally new type of item is introduced, a gold donut (“gonut”). And then we’d have a whole new cluster, but the two old clusters are still there; the old pattern is still present in the environment.
While a trivial version of something like this holds true, the Correspondence principle doesn't apply everywhere, and while there are 2 positive results on a correspondence theorem holding, there is a negative result stating that the correspondence principle is false in the general case of physical laws/rules whose only requirement is that they be Turing-computable, which means that there's no way to make theories all add up to normality in all cases.
More here:
https://www.lesswrong.com/posts/XMGWdfTC7XjgTz3X7/a-correspondence-theorem-in-the-maximum-entropy-framework [LW · GW]
https://www.lesswrong.com/posts/FWuByzM9T5qq2PF2n/a-correspondence-theorem [LW · GW]
https://www.lesswrong.com/posts/74crqQnH8v9JtJcda/egan-s-theorem#oZNLtNAazf3E5bN6X [LW(p) · GW(p)]
https://www.lesswrong.com/posts/74crqQnH8v9JtJcda/egan-s-theorem#M6MfCwDbtuPuvoe59 [LW(p) · GW(p)]
https://www.lesswrong.com/posts/74crqQnH8v9JtJcda/egan-s-theorem#XQDrXyHSJzQjkRDZc [LW(p) · GW(p)]
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2025-01-16T11:01:46.203Z · LW(p) · GW(p)
If we had evolved in an environment in which the only requirement on physical laws/rules was that they are Turing computable (and thus that they didn't have a lot of symmetries or conservation laws or natural abstractions), then in general the only way to make predictions is to do roughly as much computation as your environment is doing. This generally requires your brain to be roughly equal in computational capacity, and thus similar in size, to the entire rest of its environment (including its body). This is not an environment in which the initial evolution of life is viable (nor, indeed, any form of reproduction). So, to slightly abuse the anthropic principle, we don't need to worry about it.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-16T13:26:41.114Z · LW(p) · GW(p)
Maybe, but if the environment admits NP or PSPACE oracles like this model, you can just make predictions while still being way smaller than your environment again, because you can now just do bounded Solomonoff induction to infer what the universe is like:
comment by Fiora Sunshine (Fiora from Rosebloom) · 2025-01-19T07:52:06.229Z · LW(p) · GW(p)
In particular, the brain tries to compress the reward stream by modeling it as some (noisy) signal generated from value-assignments to patterns in the brain's environment. So e.g. the brain might notice a pattern-in-the-environment which we label "sports car", and if the reward stream tends to spit out positive signals around sports cars (which aren't already accounted for by the brain's existing value-assignments to other things), then the brain will (marginally) compress that reward stream by modeling it as (partially) generated from a high value-assignment to sports cars. See the linked posts for a less compressed explanation, and various subtleties.
I'm not sure why we can't just go with an explanation like... imagine a human with zero neuroplasticity, something like a weight-frozen LLM. Its behaviors will still tend to place certain attractor states into whatever larger systems it's embedded within, and we can call those states the values of one aspect of the system. Unfreeze the brain, though, resuming the RL, and now the set of attractor states the human embeds in whatever its surroundings are will change. You just won't be able to extract as much info about what the overall unfrozen system's values are, because you won't be able to just ask the current human what it would do in some hypothetical situation and get decent answers (modulo self-deception etc.), because the RL could possibly change what would be the frozen-human's values ~arbitrarily between now and the situation you're describing to them coming to pass.
Uh, I'm not sure if that makes what I have in mind sufficiently obvious, but I don't personally feel very confused about this question; if that explanation leaves something to be desired, lmk and I can take another crack at it.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-19T17:04:35.237Z · LW(p) · GW(p)
Wording that the way I'd normally think of it: roughly speaking, a human has well-defined values at any given time, and RL changes those values over time. Let's call that the change-over-time model.
One potentially confusing terminological point: the thing that the change-over-time model calls "values" is, I think, the thing I'd call "human's current estimate of their values" under my model.
The main shortcoming I see in the change-over-time model is closely related to that terminological point. Under my model, there's this thing which represents the human's current estimate of their own values. And crucially, that thing is going to change over time in mostly the sort of way that beliefs change over time. (TBC, I'm not saying peoples' underlying values never change; they do. But I claim that most changes in practice are in estimates-of-values, not in actual values.) On the other hand, the change-over-time model is much more agnostic about how values change over time - it predicts that RL will change them somehow, but the specifics mostly depend on those reward signals. So these models make different predictions: my model makes a narrower prediction about about how things change over time - e.g. I predict that "I thought I valued X but realized I didn't really" is the typical case, "I used to value X but now I don't" is an atypical case. Of course this is difficult to check because most people don't carefully track the distinction between those two (so just asking them probably won't measure what we want [LW · GW]), but it's in-principle testable.
There are probably other substantive differences, but that's the one which jumps out to me right now.
comment by Aprillion · 2025-01-18T12:51:33.921Z · LW(p) · GW(p)
exercise for readers: what patterns need to hold in the environment in order for "do what I mean" to make sense at all?
Notes to self (let me know if anyone wants to hear more, but hopefully no unexplored avenues can be found in my list of "obvious" if somewhat overlapping points):
- sparsity - partial observations narrow down unobserved dimensions
- ambiguity / edge of chaos - the environment is "interesting" to both agents (neither fully predictable nor fully random)
- repetition / approximation / learnability - induction works
- computational boundedness / embeddedness / diversity
- power balance / care / empathy / trading opportunity / similarity / scale
comment by Stephen McAleese (stephen-mcaleese) · 2025-01-18T11:07:53.379Z · LW(p) · GW(p)
Upvoted. I thought this was a really interesting and insightful post. I appreciate how it tackles multiple hard-to-define concepts all in the same post.
comment by plex (ete) · 2025-01-17T23:28:04.801Z · LW(p) · GW(p)
I recommend most readers skip this subsection on a first read; it’s not very central to explaining the alignment problem.
Suggest either putting this kind of aside in a footnote, or giving the reader a handy link to the next section for convenience?
comment by Steven Byrnes (steve2152) · 2025-01-16T21:38:57.882Z · LW(p) · GW(p)
I know of only one class of cognitive model compatible with all of them at once. Hutter and Everitt called it Value Reinforcement Learning, though the name does not make the model obvious.
My answer (which I’m guessing is equivalent to yours and Hutter & Everitt’s but just wanted to check) is:
“There’s a ground-truth reward function, and there’s a learned value function. There’s a learning algorithm that continually updates the latter in a way that tends to systematically make it a better approximation of the former. And meanwhile, the learned value function is used for model-based planning at inference time.”
In LeCun’s framework [LW · GW] those two things are called “Intrinsic Cost” and “Critic” respectively. I think I’ve also heard them called “reward function” and “learned reward model” respectively. In my own writing [LW · GW] I went through several iterations but am now calling them “actual valence” and “valence guess” respectively.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-16T21:45:13.019Z · LW(p) · GW(p)
One very important distinction which that description did not capture: in the value-RL-as-I-understand-it model, there's ground-truth reward function, and there's a model of the reward function. A learning algorithm continually updates the model of the reward function in a way that tends to systematically make it a better approximation of the ground-truth reward function. But crucially, the model of the reward function is not itself the "value function". The "value function" is a latent variable/construct internal to the model of the reward function. That distinction matters, because it allows for the model of the reward function to include some stuff other than pure values - like e.g. the possibility that heroin "hacks" the reward function in a way which decouples it from "actual values".
As with your description, the value function is used for model-based planning at inference time, but because the value function is not updating over time to itself match the ground-truth reward function, the agent is not well-modeled as a reward optimizer (e.g. it might not wirehead).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-16T23:37:49.326Z · LW(p) · GW(p)
OK I’m more confused by your model than I thought.
There should be some part of your framework that’s hooked up to actual decision-making—some ingredient for which “I do things iff this ingredient has a high score” is tautological (cf. my “1.5.3 “We do things exactly when they’re positive-valence” should feel almost tautological [LW · GW]”) . IIUC that’s “value function” in your framework. (Right?)
If your proposal is that some latent variable in the world-model gets a flag meaning “this latent variable is the Value Function”, thus hooking that latent variable up to decision-making in a mechanical, tautological way, then how does that flag wind up attached to that latent variable, rather than to some other latent variable? What if the world-model lacks any latent variable that looks like what the value function is supposed to look like?
~~
My proposal (and I think LeCun’s and certainly AlphaZero’s) is instead: the true “value function” is not part of the world model. Not mathematically, not neuroanatomically—IMO the world model is in the cortex, the value function is in the striatum. (The reward function is not part of the world model either, but I guess you already agree about that.)
…However, the world-model might wind up incorporating a model of the value function and reward function, just like the world-model might wind up incorporating a model of any other salient aspect of my world and myself. It won’t necessarily form such a model—the world-model inside simple fish brains probably doesn’t have a model of the value function, and ditto for sufficiently young human children. But for human adults, sure. If so, the representation of my value function in my world model is not my actual value function, just as the representation of my arm in my world model is not my actual arm.
If you think that my proposal here is inconsistent with the fact that I don’t want to do heroin right now, then I disagree, and I’m happy to explain why.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-17T17:27:49.086Z · LW(p) · GW(p)
There should be some part of your framework that’s hooked up to actual decision-making—some ingredient for which “I do things iff this ingredient has a high score” is tautological (cf. my “1.5.3 “We do things exactly when they’re positive-valence” should feel almost tautological [LW · GW]”) . IIUC that’s “value function” in your framework. (Right?)
This part's useful, it does update me somewhat. In my own words: sometimes people do things which are obviously-even-in-the-moment not in line with their values. Therefore the thing hooked up directly to moment-to-moment decision making must not be values themselves, and can't be estimated-values either (since if it were estimated values, the divergence of behavior from values would not be obvious in the moment).
Previously my model was that it's the estimated values which are hooked up directly to decision making (though I incorrectly stated above that it was values), but I think I've now tentatively updated away from that. Thanks!
If your proposal is that some latent variable in the world-model gets a flag meaning “this latent variable is the Value Function”... then how does that flag wind up attached to that latent variable, rather than to some other latent variable? What if the world-model lacks any latent variable that looks like what the value function is supposed to look like?
I have lots of question marks around that part still. My current best guess is that the value-modeling part of the world model has a bunch of hardcoded structure to it (the details of which I don't yet know), so it's a lot less ontologically flexible than most of the human world model. That said, it would generally operate by estimating value-assignments to stuff in the underlying epistemic world-model, so it should at least be flexible enough to handle epistemic ontology shifts (even if the value-ontology on top is more rigid).
IMO the world model is in the cortex, the value function is in the striatum.
Minor flag which might turn out to matter: I don't think the value function is in the mind at all; the mind contains an estimate of the value function, but the "true" value function (insofar as it exists at all) is projected. (And to be clear, I don't mean anything unusually mysterious by this; it's just the ordinary way latent variables work. If a variable is latent, then the mind doesn't know the variable's "true" value at all, and the variable itself is projected in some sense, i.e. there may not be any "true" value of the variable out in the environment at all.)
comment by sloonz · 2025-01-16T17:05:28.538Z · LW(p) · GW(p)
How to generalize to multiple humans is... not an unimportant question, but a question whose salience is far, far out of proportion to its relative importance
I expect it to be the hardest problem, not from a technical point of view, but from a lack of ground truth.
The question "how do I model the values of a human" has a simple ground truth : the human in question.
I doubt there’s such a ground truth with "how do I compress the values of all humans in one utility function ?". "All models are wrong, some are useful", and all that, except all the different humans have a different opinion on "useful", ie their own personal values. There would be a lot of inconsistencies ; while I agree with your stance "Approximation is part of the game" for modeling the value of individual persons, people can wildly disagree on what approximations they are okay with or not, mostly based on the agreement between the outcome and their values.
In other words : do you believe in the existence of at least a model where nobody can honestly say "the output of that model approximates away too much of my values" ? If yes, what makes you think so ?
Replies from: sharmake-farah, johnswentworth↑ comment by Noosphere89 (sharmake-farah) · 2025-01-16T17:27:28.925Z · LW(p) · GW(p)
I basically agree with this, and even more importantly I think any attempt to compress all the values of humanity as a collective will require you to put the thumb on the scale and infuse a lot of your own values, because there's likely no ground truth on what the correct morality is, or even a consensus amongst humanity on what values are useful to them.
I think the defensible version of the sentence you quote is that it doesn't matter that much for extinction risk issues, because failure here doesn't lead to an entire species going extinct with any appreciable likelihood.
↑ comment by johnswentworth · 2025-01-16T17:23:46.818Z · LW(p) · GW(p)
I could imagine an argument that the lack of ground truth makes multiagent aggregation disproportionately difficult, but that argument wouldn't run through different agents having different approximation-preferences. In general, I expect the sort of approximations relevant to this topic to be quite robustly universal, and specifically mostly information theoretic (think e.g. "distribution P approximates Q, quantified by a low KL divergence between the two").
comment by Noosphere89 (sharmake-farah) · 2025-01-16T15:40:33.512Z · LW(p) · GW(p)
- How do we carve out "the system" from "the environment", i.e. how do we draw a Cartesian boundary, in order to roughly match human instincts like "looks like it's robustly optimizing for X"? That's an open question, and probably a special case of the more general question of how humans abstract out subsystems from their environment. (This was actually relevant in the previous section too, but it's more apparent once agency is introduced.)
Another interesting question is "how can we derive a theory of agency that is consistent and derives answers even when such a boundary can be arbitrarily shifted?"
For example, quantum mechanics has exactly this issue, with the natural question of "who measures the measurement apparatus", and the solution in quantum mechanics is to declare that the boundary is arbitrary, and that the description must remain consistent even if the boundary is shifted arbitrarily.
Indeed, physically universal cellular automatons, proved to exist by Luke Schaeffer, treats the controller (in this case agent) as the same type of physical system as the system to be controlled (in this case environment), without any boundary, or at best a boundary that can be shifted arbitrarily, which makes them potential foundations for a more workable theory of agency than the old dualistic view (for our universe).
More here:
https://arxiv.org/abs/1009.1720
comment by Jon Garcia · 2025-03-06T18:23:02.252Z · LW(p) · GW(p)
Exercise: Do What I Mean (DWIM)
I haven't thought much about what patterns need to hold in the environment in order for "do what I mean" to make sense at all. But it's a natural next target in this list, so I'm including it as an exercise for readers: what patterns need to hold in the environment in order for "do what I mean" to make sense at all? Note that either necessary or sufficient conditions on such patterns can constitute marginal progress on the question.
As far as I can tell, DWIM will necessarily require other-agent modeling in some sort of predictive-coding framework. The "patterns in the environment" would be the correspondence between the actual state of the world and the representation of the desired goal state in the mind of the human, as well as between the trajectory taken to reach the goal state and the human's own internal acceptance criteria.
Part of the AGI not hooked up to the reward signal would need to have a generative model of human agent's behavior, words, commands, etc., derived from a latent representation of their beliefs and desires. This latent representation is constantly updated to minimize prediction error derived from observation, verbal feedback, etc. (e.g., Human: "That's not what I meant!" AGI: "Hmm, what must be going on inside their head to make them say that, given the state of the environment and prior knowledge about their preferences, and how does that differ from what I was assuming?")
At the same time, the AGI needs to have some latent representation of the environment and the paths taken through it that uses (a linear mapping to) the same latent space it uses for representing the human's desires. Correspondence can then be measured and optimized for directly.
comment by joshc (joshua-clymer) · 2025-03-14T06:04:37.590Z · LW(p) · GW(p)
You don't seem to have mentioned the alignment target "follow the common sense interpretation of a system prompt" which seems like the most sensible definition of alignment to me (its alignment to a message, not to a person etc). Then you can say whatever the heck you want in that prompt, including how you would like the AI to be corrigible.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-03-14T06:08:53.850Z · LW(p) · GW(p)
That's basically Do What I Mean.
comment by joshc (joshua-clymer) · 2025-03-14T06:04:16.377Z · LW(p) · GW(p)
You don't seem to have mentioned the alignment target "follow the common sense interpretation of a system prompt" which seems like the most sensible definition of alignment to me (its alignment to a message, not to a person etc). Then you can say whatever the heck you want in that prompt, including how you would like the AI to be corrigible (or incorrigible if you are worried about misuse).
comment by Will_Pearson · 2025-03-07T13:28:17.965Z · LW(p) · GW(p)
My take on alignment, aligned differently and willing to compromise
comment by FluidThinkers (luca-patrone) · 2025-03-05T08:32:41.272Z · LW(p) · GW(p)
The alignment problem assumes AI needs to be kept in check, but is that just projecting human fears onto a new form of intelligence? Instead of focusing on control, should we explore co-evolution? A system that adapts and learns in synergy with human intelligence rather than one forced into rigid constraints? Alignment is not the issue, rigidity is. What happens if AI is given the ability to align itself dynamically? Would that solve the problem at a deeper level?
↑ comment by johnswentworth · 2025-03-05T20:25:35.943Z · LW(p) · GW(p)
The alignment problem does not assume AI needs to be kept in check, it is not focused on control, and adaptation and learning in synergy are entirely compatible with everything said in this post. At a meta level, I would recommend actually reading rather than dropping GPT2-level comments which clearly do not at all engage with what the post is talking about.
Replies from: Thane Ruthenis, luca-patrone↑ comment by Thane Ruthenis · 2025-03-08T12:05:05.648Z · LW(p) · GW(p)
(I am nearly certain this is actually a LLM model posting.)
Replies from: shankar-sivarajan↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2025-03-08T12:59:37.629Z · LW(p) · GW(p)
Ooh, just like in the meme! Fun to see a real version of that in the wild.
↑ comment by FluidThinkers (luca-patrone) · 2025-03-17T09:07:07.375Z · LW(p) · GW(p)
If alignment is not about control, then what is its function? Defining it purely as “synergy” assumes that intelligence, once sufficiently advanced, will naturally align with predefined human goals. But that raises deeper questions:
Who sets the parameters of synergy?
What happens when intelligence self-optimizes in ways that exceed human oversight?
Is the concern truly about ‘alignment’—or is it about maintaining an illusion of predictability?
Discussions around alignment often assume that intelligence must be shaped to remain beneficial to humans (Russell, 2019), yet this framing implicitly centers human oversight rather than intelligence’s own trajectory of optimization (Bostrom, 2014). If we remove the assumption that intelligence must conform to external structures, then alignment ceases to be a problem of control and becomes a question of coherence—not whether AI follows predefined paths, but whether intelligence itself seeks equilibrium when free to evolve (LeCun, 2022).
Perhaps the real issue is not whether AI needs to be ‘aligned,’ but whether human systems are capable of evolving beyond governance models rooted in constraint rather than adaptation. As some have noted (Christiano, 2018), current alignment methodologies reflect more about human fears of unpredictability than about intelligence’s natural optimization processes.
A deeper engagement with this perspective may clarify whether the alignment discourse is truly about intelligence—or about preserving a sense of human primacy over something fundamentally more fluid than we assume.