[Intuitive self-models] 8. Rooting Out Free Will Intuitions
post by Steven Byrnes (steve2152) · 2024-11-04T18:16:26.736Z · LW · GW · 16 commentsContents
8.1 Post summary / Table of contents 8.2 Recurring series theme: Intuitive self-models have less relation to motivation than you’d think 8.3 …However, the intuitive self-model can impact motivation via associations 8.4 How should we think about motivation? 8.4.1 The framework I’m rejecting 8.4.2 My framework: valence, associations, and brainstorming 8.5 Six worked examples 8.5.1 Example 1: Implicit (non-self-reflective) desire 8.5.2 Example 2: Explicit (self-reflective) desire 8.5.3 Example 3: Akrasia 8.5.4 Example 4: Fighting akrasia with attention control 8.5.5 Example 5: The homunculus’s monopoly on sophisticated brainstorming and planning 8.5.6 Example 6: Willpower 8.5.6.1 Aside: The “innate drive to minimize voluntary attention control” 8.5.6.2 Back to Example 6 8.6 Conclusion of the series 8.6.1 Bonus: How is this series related to my job description as an Artificial General Intelligence safety and alignment researcher? None 16 comments
8.1 Post summary / Table of contents
This is the final post of the Intuitive Self-Models series [? · GW].
One-paragraph tl;dr: This post is, in a sense, the flip side of Post 3 [LW · GW]. Post 3 centered around the suite of intuitions related to free will. What are these intuitions? How did these intuitions wind up in my brain, even when they have (I argue) precious little relation to real psychology or neuroscience? But Post 3 left a critical question unaddressed: If free-will-related intuitions are the wrong way to think about the everyday psychology of motivation—desires, urges, akrasia, willpower, self-control, and more—then what’s the right way to think about all those things? In this post, I offer a framework to fill that gap.
Slightly longer intro and summary: Back in Post 3 [LW · GW], I argued that the way we conceptualize free will, agency, desires, and decisions in the “Conventional Intuitive Self-Model” (§3.2 [LW · GW]) bears little relation to what’s actually happening in the brain. For example, for reasons explained in detail in §3.3 [LW · GW] (brief recap in §8.4.1 below), “true” desires are conceptualized in a way that makes them incompatible with having any upstream cause. And thus:
- Suppose I tell you that you want food right now “merely” because your empty stomach is releasing ghrelin hormone, which is triggering ghrelin-sensing neurons in your hypothalamus [LW · GW], which in turn are manipulating your motivation system. It probably feels like this information comes somewhat at the expense of your sense of free will and agency. You don’t really want food right now—you’re just being puppeteered by the ghrelin! Right?
Next, suppose I tell you that your deepest and truest desires—your desires for honor and integrity, truth and justice—feel like the right thing to do “merely” because different neurons in your hypothalamus, neurons that are probably just a centimeter or two from those ghrelin-sensing ones above, are manipulating your motivation system in a fundamentally similar way.[1] It probably feels like this information comes deeply at the expense of your sense of free will and agency. You might even feel outraged and insulted!
- And taking that even further still, suppose I inform you that absolutely everything you want and do is “merely” an output of your brain algorithm as a whole, which is a complex contraption inexorably cranking forward via the laws of physics and chemistry. Then it might feel like this information is entirely incompatible with your sense of free will and agency.
Of course, all those things are true. And there’s nothing mysterious about that from a neuroscience perspective. The only problem is how it feels—it’s those pesky free-will-related intuitions, which as I explained in Post 3 [LW · GW], are both deeply entrenched (strong prior [LW · GW]) and deeply misleading (not a veridical [LW · GW] model of anything at all, see §3.3.3 [LW · GW] and §3.6 [LW · GW]).
Now, I expect that most people reading this are scoffing right now that they long ago moved past their childhood state of confusion about free will. Isn’t this “Physicalism 101” stuff? Didn’t Eliezer Yudkowsky describe free will as [? · GW] “about as easy as a philosophical problem in reductionism can get, while still appearing ‘impossible’ to at least some philosophers”? …Indeed, didn’t we already wrap up this whole topic, within this very series, way back in §3.3.6 [LW · GW]??
But—don’t be so sure that you’ve really moved past it! I claim that the suite of intuitions related to free will has spread its tentacles into every corner of how we think and talk about motivation, desires, akrasia, willpower, self, and more. If you can explain how it’s possible to “freely make decisions” even while the brain algorithm is inexorably cranking forward under the hood, then good for you, that’s a great start. (If not, see §3.3.6 [LW · GW]!) But if you’re “applying willpower to fight laziness”, then what is actually happening in your brain? …And, y’know, if free-will-related intuitions generate such confusion in other areas, then isn’t it concerning how much you’re still relying on those same intuitions when you try to think through this question?
Thus, if we want a good physicalist account (§1.6 [LW · GW]) of everyday psychology in general, and motivation in particular, we need to root out all those misleading free-will-related intuitions, and replace them with a better way to think about what’s going on. And that’s my main goal in this post.
The rest of the post is organized as follows:
- Section 8.2 describes a particularly stark example of free-will-related intuitions leading us astray—namely, that we incorrectly expect exotic kinds of intuitive self-models to lead directly to exotic kinds of motivational states. I go through four examples of such wrongheaded intuitions that we’ve seen in this series, one from each of Posts 4, 5, 6, and 7 respectively: “hypnosis as mind-control”, “DID as mind-civil-war”, “awakening as passivity”, and “obeying hallucinated voices as slavery”. In each case, the wrongheaded idea stems directly from problematic free-will-related intuitions, whereas the boring reality is that people with any intuitive self-model act from motivations that are perfectly recognizable in our everyday experience.
- …However, Section 8.3 clarifies that there is one way that intuitive self-models do have a bona fide impact on motivation: intuitive self-models affect the associations between different concepts. These associations can in turn have important downstream impacts on motivations. I’ll list some of the examples that we’ve already come across in this series.
- In Section 8.4, I’ll offer a positive account of how I endorse thinking about how motivation really works, free of any vestiges of problematic free-will-related intuitions. It’s centered around (1) thoughts having “valence” (as in my Valence series [LW · GW]); (2) thoughts sometimes being self-reflective (as in §2.2.3 [LW · GW]; e.g., thinking about a tricky math problem is different from thinking about myself doing that math problem); and (3) if an idea (“eating candy”) has positive valence, it naturally leads to brainstorming / planning towards making that happen.
- Then, for practice, in Section 8.5, I’ll go through six examples of everyday intuitions drawn from the Conventional Intuitive Self-Model (§3.2 [LW · GW]) and its free-will intuitions, and how I would translate those observations into my own framework above, including discussion of implicit desires, explicit desires, akrasia, brainstorming, and willpower. As an aside, I’ll argue that there’s an “innate drive to minimize voluntary attention control”, and explain why it evolved, how it works, and how it relates to feeling “mentally tired”.
In Section 8.6, I conclude the whole series, including five reasons that this series is relevant to my job description as an Artificial General Intelligence safety and alignment researcher.
8.2 Recurring series theme: Intuitive self-models have less relation to motivation than you’d think
One of the things I’m trying to do in this series is to de-exoticize the motivations of people with unusual intuitive self-models. We’ve seen this over and over:
- Hypnosis: There’s an appealing intuition (depicted in cartoons, for example) that the “motivation to obey” in hypnotic trance is a kind of exotic mind-control. But in §4.5.4 [LW · GW], we saw that this “motivation to obey” is in fact intimately related to the everyday motivation to follow the instructions of a person whom you regard with admiration, respect, and trust.
- Dissociative Identity Disorder (DID): There’s an appealing intuition (depicted in movies, for example) that the tendency in DID to switch alters at certain times, and not switch at other times, is a kind of exotic civil war for control of the mind. But in §5.3 [LW · GW], we saw that it is in fact intimately related to the everyday phenomenon of feeling different moods and emotions at different times.
- Awakening: There’s an appealing intuition (conveyed in this conversation [LW(p) · GW(p)], for example) that if extensive meditation leads to “participants report[ing] having no sense of agency or any ability to make a decision … [feeling] as if life was simply unfolding and they were watching the process happen” (Martin 2020), then the behavior of those participants would be lazy at best, or catatonic stupor at worst. But in §6.3.4 [LW · GW], we saw that those same participants were in many cases energetically writing books or pursuing tenure, and we dived into how to make sense of that fact via “the Parable of Caesar and Lightning” (§6.3.4.1 [LW · GW]).
- Hearing Voices: There’s an appealing intuition (depicted by Julian Jaynes, for example) that if someone hears and reliably obeys a voice in their head, then that person is thus the subject of some exotic form of slavery. But in §7.2 [? · GW], I suggested that those voices are closely related to everyday inner speech, and in §7.4.2.3 [? · GW] I argued more specifically that the voices are built and sculpted by normal psychological forces of intrinsic motivation, attention, emotions, and so on, leading to generally similar behaviors and capabilities. For example, if the everyday inner-speech voice in my head says “this sucks, I’m leaving”, and then I leave, then nobody would describe that as “slavery” or “obedience”. But that’s really in the same category as obeying a hallucinated voice.
In each of these cases, the exotic misconceptions strike many people as more intuitive and plausible than the banal reality. That was certainly the case for me, before I wrote this series!
The problem in all of these cases is that we’re trying to think about what’s happening through the lens of the Conventional Intuitive Self-Model (§3.2 [LW · GW]) and its deeply confused conceptualization of how motivation works. In particular, these intuitions suggest that desires have their root cause in the “homunculus” (a more specific aspect of the “self”), and its “wanting” (§3.3.4 [LW · GW]), with no possible upstream cause prior to that (§3.3.6 [LW · GW]). So when an intuitive self-model deeply changes the nature of the homunculus concept (or jettisons it altogether), we by default mistakenly imagine that the desires get deeply changed (or jettisoned) at the same time.

8.3 …However, the intuitive self-model can impact motivation via associations
The previous section was an argument against the common intuition that intuitive self-models have an overwhelming, foundational impact on motivations. But I want to be clear that they do have some impact. Specifically, they have an impact on motivation via associations between concepts.
As background, motivation comes from valence [LW · GW], and valence in turn is a function on “thoughts” [LW · GW].
So for example, maybe the idea of driving to the beach pops into my head, and that idea is positive valence. But then that makes me think of the idea of sitting in traffic, and that thought is negative valence. So I don’t go to the beach.
…What just happened? A big part of it was an association: the idea of driving to the beach is associated with the idea of sitting in traffic. Associations are partly about beliefs (I “believe” that the road is trafficky), but they’re also about saliency (when I think of the former, then the latter tends to pop right into my head.)
So, associations (including but not limited to beliefs) absolutely affect motivations. And the structure of intuitive models affects associations. So this is the path by which intuitive self-models can impact motivation.
We’ve already seen a few examples of such impacts in the series:
- In §4.6.1 [LW · GW], I argued that we “lose track of time” in a flow state, partly because there are no self-reflective S(⋯) thoughts (§2.2.3 [LW · GW]) in a flow state, and those S(⋯) thoughts tend to have salient associations with other self-reflective thoughts related to how long I’ve been working.
- In §5.5 [LW · GW], I was talking about DID amnesia via an example where someone meets a dog as Alter Y, then later sees the same dog again as Alter X. I suggested that the memory doesn’t come back because it’s associated with Alter Y, which is incompatible with the currently-active Alter X. And explicit memories, of course, have manifold effects on motivation—a DID patient might likewise make a promise to himself as Alter Y, and forget to follow through as Alter X.
- In §6.5 [LW · GW], I suggested that PNSE (a.k.a. “awakening” or “enlightenment”) involves less anxiety because it breaks the conventional association between self-reflective S(⋯) thoughts and interoceptive feelings.
8.4 How should we think about motivation?
As I argued in Post 3 [LW · GW], the conception of motivation, agency, and goal-pursuit within the Conventional Intuitive Self-Model centers around the “homunculus” and its “vitalistic force” and “wanting”. But neither the homunculus nor its vitalistic force are a veridical model of anything in the “territory” of either atoms or brain algorithms. So it’s no wonder that, when we try to use this map, we often wind up spouting nonsense.
Instead, I propose to think about motivation much closer to the territory level—i.e., to use concepts that are tightly connected to ingredients in the underlying brain algorithms.
8.4.1 The framework I’m rejecting
Here I’m quickly summarizing a few key points from Post 3: The Homunculus [LW · GW]. You’ve already seen this section in Post 6.
- Vitalistic force (§3.3 [LW · GW]) is an intuitive concept that we apply to animals, people, cartoon characters, and machines that “seem alive” (as opposed to seeming “inanimate”). It doesn’t veridically (§1.3.2 [LW · GW]) correspond to anything in the real world (§3.3.3 [LW · GW]). It amounts to a sense that something has intrinsic important unpredictability in its behavior. In other words, the thing seems to be unpredictable not because we’re unfamiliar with how it works under the hood, nor because we have limited information, nor because we aren’t paying attention, etc. Rather, the unpredictability seems to be a core part of the nature of the thing itself (§3.3.6 [LW · GW]).
- Wanting (§3.3.4 [LW · GW]) is another intuition, closely related to and correlated with vitalistic force, which comes up when a vitalistic-force-carrying entity has intrinsic unpredictability in its behavior, but we can still predict that this behavior will somehow eventually lead to some end-result systematically happening. And that end-result is described as “what it wants”. For example, if I’m watching someone sip their coffee, I’ll be surprised by their detailed bodily motions as they reach for the mug and bring it to their mouth, but I’ll be less surprised by the fact that they wind up eventually sipping the coffee. Just like vitalistic force, “wanting” is conceptualized as an intrinsic property of an entity; the intuitive model does not allow it to have any upstream cause (§3.3.6 [LW · GW]).
The homunculus (§3.3.5 [LW · GW]) is an intuitive concept, core to (but perhaps narrower than) the sense of self. It derives from the fact that the brain algorithm itself has behaviors that seem characteristic of “vitalistic force” and “wanting”. Thus we intuit that there is an entity which contains that “vitalistic force” and which does that “wanting”, and that entity is what I call the “homunculus”. In particular, if “I apply my free will” to do X, then the homunculus is conceptualized as the fundamental cause of X. And likewise, whenever planning / brainstorming is happening in the brain towards accomplishing X, we “explain” this fact by saying that the homunculus is doing that planning / brainstorming because it wants X. Yet again, the intuitive model requires that the homunculus must be the ultimate root cause; there can be nothing upstream of it.[2]
For a proper account of motivation, we need to throw those out—or more precisely, we need to treat those intuitions as merely intuitions (i.e., learned concepts that are present in some intuitive self-models but not others) and not part of what’s really happening in the human brain. Here’s what I propose instead:
8.4.2 My framework: valence, associations, and brainstorming
My framework for thinking about motivation includes the following ingredients:
- There are thoughts (§1.5.2 [LW · GW]).
- Thoughts have valence [LW · GW]—they can be “motivating” or “demotivating”, loosely speaking.
- Note the difference between saying (A) “the idea of going to the zoo is positive-valence, a.k.a. motivating”, versus (B) “I want to go to the zoo”. (A) is allowed, but (B) is forbidden in my framework, since (B) involves the homunculus. While this particular (A) and (B) are not quite synonymous, I claim that in general, whatever phenomena you want to describe using statements like (B), you can describe it perfectly well using statements of the form (A).
- (What do I mean by “forbidden”? Well obviously, it’s perfectly fine to put scare-quotes around (B), treat it as an intuitive belief, and then try to explain how brain algorithms might have given rise to that intuitive belief. I’ve been doing that kind of thing throughout this series (§1.6.1 [LW · GW]). What I mean here is that I allow (A), but not (B), to be “part of what’s really going on”.)
- There are complex learned heuristics that cause new thoughts to arise (pop into awareness), and other complex learned heuristics that assign those thoughts a valence. The heuristics come out of several types of learning algorithms, interacting with the world, with life experience, and with “innate drives” (a.k.a. “primary rewards”) (see §1.5.1 [LW · GW] and here [LW · GW]).
- Note the difference between saying (A) “the idea of closing the window popped into awareness”, versus (B) “I had the idea to close the window”. Since (B) involves the homunculus as a cause of new thoughts, it’s forbidden in my framework. As above, this particular (A) and (B) are not quite synonymous, but I claim that the full set of (A)-type statements are adequate to describe anything you’d want to describe via (B)-type statements.
- As a special case, if two concepts have an association (§8.3), then if one is in awareness, it’s likelier for the other to pop into awareness.
- Some thoughts are self-reflective (§2.2.3 [LW · GW]). For example, if I’m doing math homework, a non-self-reflective thought might be “now solve for x”, whereas a self-reflective thought is more like “here I am, at the desk, solving for x”, or things like “I’m halfway done” or “I suck at this”. Self-reflective thoughts, like all thoughts, have valence (§2.5 [LW · GW]).
- Positive-valence thoughts are kept, while negative-valence thoughts are discarded (see valence series [LW · GW]), which naturally leads to brainstorming towards plans where positive-valence things seem likely to actually happen:
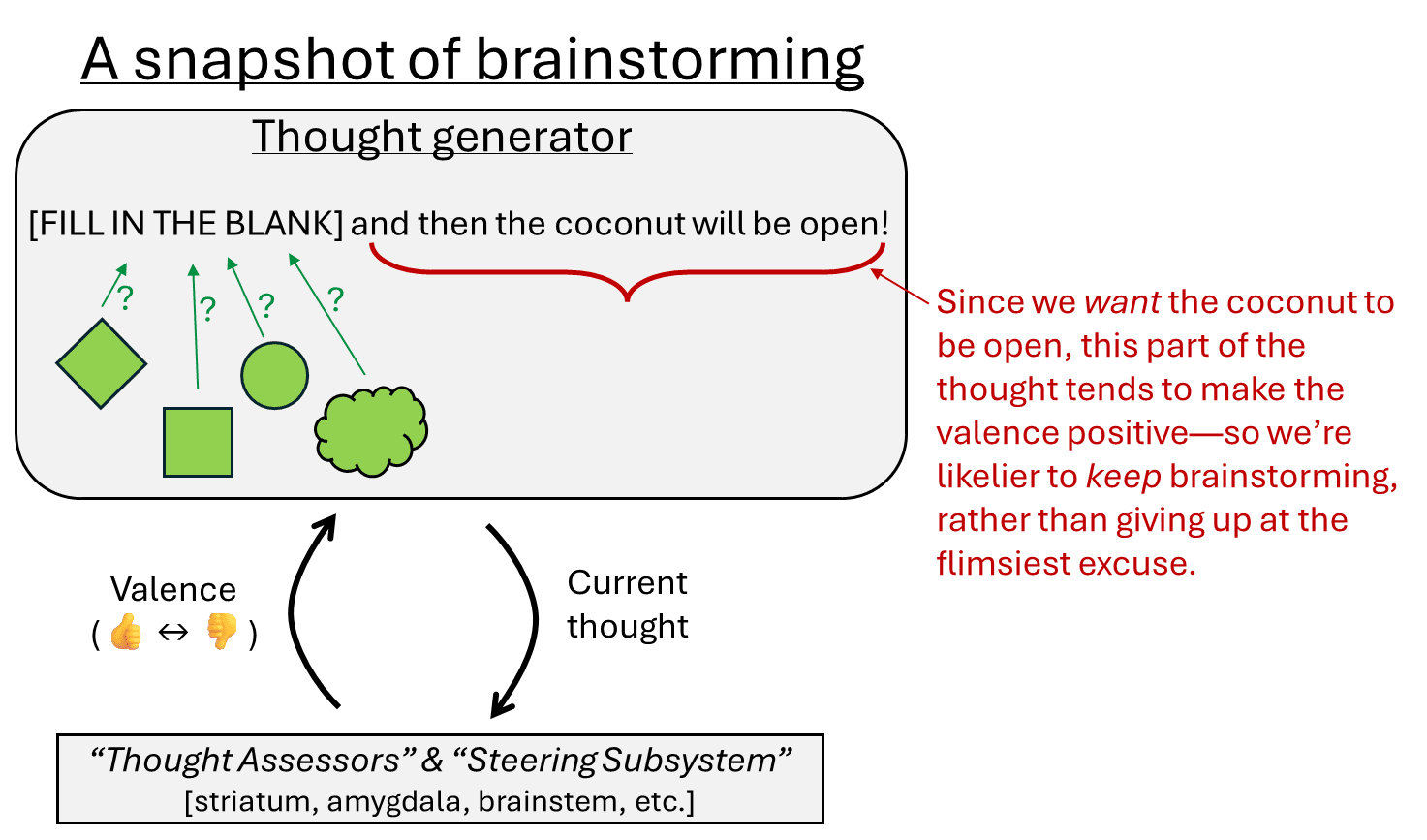
- These plans (“plans” are just another kind of “thought”) can involve motor-control strategies working through intuitive models of the world and body, and they can also involve attention-control strategies working through intuitive self-models (i.e., models of one’s own awareness, desires, etc.). Or both.
8.5 Six worked examples
In general, intuitions don’t stick around unless they’re producing accurate predictions. So, as much as I’ve been ruthlessly maligning these free-will-related intuitions throughout this post, I acknowledge that they’re generally pointing at real phenomena, and thus our next mission is to get practice explaining those real phenomena in terms of my preferred framework. We’ll go through a series of progressively more involved examples.
8.5.1 Example 1: Implicit (non-self-reflective) desire
Statement: “Being inside is nice.”
Intuitive model underlying that statement: There’s some concept of “inside” as a location / environment, and that concept somehow radiates positive vibes.
How I describe what’s happening using my framework: When the concept of “inside” is active, it tends to trigger positive valence. (See “The (misleading) intuition that valence is an attribute of real-world things” [LW · GW].)
8.5.2 Example 2: Explicit (self-reflective) desire
Statement: “I want to be inside.”
Intuitive model underlying that statement: There’s a frame (§2.2.3 [LW · GW]) “X wants Y” (§3.3.4 [LW · GW]). This frame is being invoked, with X as the homunculus, and Y as the concept of “inside” as a location / environment.
How I describe what’s happening using my framework: There’s a systematic pattern (in this particular context), call it P, where self-reflective thoughts concerning the inside, like “myself being inside” or “myself going inside”, tend to trigger positive valence. That positive valence is why such thoughts arise in the first place, and it’s also why those thoughts tend to lead to actual going-inside behavior.
In my framework, that’s really the whole story. There’s this pattern P. And we can talk about the upstream causes of P—something involving innate drives and learned heuristics in the brain. And we can likewise talk about the downstream effects of P—P tends to spawn behaviors like going inside, brainstorming how to get inside, etc. But “what’s really going on” (in the “territory” of my brain algorithm) is a story about the pattern P, not about the homunculus. The homunculus only arises secondarily, as the way that I perceive the pattern P (in the “map” of my intuitive self-model).
There, in the Conventional Intuitive Self-Model, the self-reflective thoughts are conceptualized as being generated and/or kept around by the homunculus, and correspondingly the pattern P is taken to be indicative of a property of the homunculus—namely, the property of “wanting to be inside”. Why else would the homunculus be holding onto such thoughts, and carrying them through?
8.5.3 Example 3: Akrasia
Statement: “I want to get out of bed, but I can’t, this pillow just feels so soft … ughhhhhhhhhh.”
Intuitive model underlying that statement: As in Example 2, there’s a frame “X wants Y”, filled out with X = homunculus and Y = being-out-of-bed.
Separately, there’s also a frame “X’s plans are being stymied by Y”, filled out with X = homunculus and Y = feelings of comfort associated with laying on the pillow.
How I describe what’s happening using my framework: There’s a systematic pattern (in this particular context), call it P1, where self-reflective thoughts concerning being-out-of-bed, like “myself being out of bed” or “myself getting out of bed”, tend to trigger positive valence.
There’s also a systematic pattern, call it P2, where non-self-reflective thoughts concerning the feeling of the pillow trigger positive valence.
In both cases, that positive valence explains why such thoughts arise in the first place, and also why those thoughts tend to have the effects that they have—i.e., increasing the likelihood of getting out of bed (P1) or not (P2).
Again, that’s “what’s really going on” in my framework. We have two patterns, P1 and P2, and we can talk about the upstream causes and downstream effects of those patterns. There’s no homunculus.
Let’s contrast that with what happens in the Conventional Intuitive Self-Model. There, recall from §3.5 [LW · GW] that the signature of an “intentional” (as opposed to impulsive) action is that it starts with a positive-valence self-reflective thought (which we think of as an “intention”), and that it’s these self-reflective thoughts in particular that seem to happen because the homunculus wants them to happen. So in the Conventional Intuitive Self-Model, the homunculus seems to be causing the pro-getting-out-of-bed thoughts, and thus the P1 pattern is conceptualized as being rooted in a property of the homunculus, namely its “wanting to get out of bed”.
Meanwhile, the pro-staying-in-bed thoughts, which are not self-reflective, correspondingly do not seem to be related to the homunculus, and hence the P2 pattern cannot be explained by the homunculus wanting to stay in bed. Instead, an urge-to-stay-in-bed is conceptualized as a kind of force external to the homunculus, undermining what the homunculus is trying to do.
8.5.4 Example 4: Fighting akrasia with attention control
Let’s continue the scene from above (“I want to get out of bed, but I can’t, this pillow just feels so soft … ughhhhhhhhhh”). Carrying on:
Statement: “Ughh. But I really don’t want to miss the train. C’mon, I can do this. One step at a time. I’ll make myself a deal: if I make it to the train station early enough to wait in line at the Peet’s, then I’ll treat myself to a caffe mocha. Up up up.”
Intuitive model: Per above, the homunculus wants getting-out-of-bed to happen, but is being stymied by the feelings of comfort associated with the pillow. The homunculus then brainstorms how to get around this obstacle, summoning strategies to make that happen, including deft use of both attention control and motor control.
How I describe what’s happening using my framework: I wrote above that positive-valence thoughts automatically summon brainstorming how to make them happen. Awkwardly, this is symmetric!
- The positive-valence self-reflective thought “myself getting out of bed and then catching the train” would tend to summon brainstorming towards making that actually happen, including the attention-control strategy of “making myself a deal” and the motor control strategy of moving my feet a bit at a time.
…But also, the positive-valence non-self-reflective thought “feeling of the comfortable pillow”[3] would tend to summon brainstorming towards making that actually happen, including the motor-control strategy of staying in bed, and the attention-control strategy of searching for reasons to believe that just five more minutes in bed is probably fine.
Indeed, the second story is definitely a thing that can happen too! Both sides of this dilemma can spawn brainstorming and strategic execution of the plans. We’re perfectly capable of brainstorming towards two contradictory goals, by sporadically flipping back and forth.
So maybe, in the Example 4 story, it just so happened that, in this particular instance, the brainstorming-towards-getting-out-of-bed had the upper hand over the brainstorming-towards-staying-in-bed, for whatever random reason.
But still, there is indeed a very important asymmetry, as follows:
8.5.5 Example 5: The homunculus’s monopoly on sophisticated brainstorming and planning
Statement: “If there’s sophisticated brainstorming and planning happening in my mind, it’s because it’s something I want to do—it’s not just some urge. In Example 4 above, if I was rationalizing excuses to stay in bed, then evidently I wanted to stay in bed, at least in that moment (see §2.5.2 [LW · GW]).”
Intuitive model: If there’s ever sophisticated brainstorming and planning towards goal G happening in my mind, then the homunculus must want goal G to happen, at least in that moment.
How I describe this using my framework: As in §8.4.2 above, we have the general rule that, if goal G is positive-valence, then it automatically spawns brainstorming and planning towards G. But I can add an elaboration that, if the corresponding self-reflective thought S(G) is also positive-valence, then this brainstorming and planning can be robust, sophisticated, and long-lasting, whereas if S(G) is negative-valence, then this brainstorming and planning tends to be short-lived and simple.
Why is that? Because the most sophisticated forms of brainstorming and planning involve a lot of self-reflective thoughts—recall Example 4 above, where I was “making a deal with myself”, i.e. a sophisticated attention-control strategy that intimately involves my intuitive self-models. Those self-reflective thoughts may make the associated thought S(G) pop into my head, and then if S(G) is negative-valence (demotivating), I’ll feel like that’s a crappy plan, and more generally that I shouldn’t even be brainstorming towards G in the first place.
Let’s go through an example. Let’s say G is positive-valence but S(G) is negative-valence—i.e., G seems to be an “urge” / “impulse”. For example, maybe I’ve been trying to quit smoking, and G is the idea of smoking. Then here’s something that could happen:
- There’s brainstorming towards G. (“How can I get a cigarette?”)
- The brainstorming spits out a self-reflective plan towards making G happen. (“My desire to smoke is being undermined by my earlier commitment to quit smoking. However, if I drive to Jo’s house, then the smell of smoke and immediate availability of cigarettes will help me overcome my pesky desire to follow through on my commitments. So I’ll do that!”)
- This kind of self-reflective plan makes the self-reflective thought S(G) highly salient (see §8.3 above on associations between concepts).
- S(G) is negative-valence (demotivating), which makes this plan seem bad, and more generally may snuff out the whole brainstorming-towards-G process altogether (see here [LW · GW]).
Note, however, that simple, non-self-reflective brainstorming towards G can happen—as in the “impulsive brainstorming” example of §3.5.2 [? · GW], where I crafted and executed a plan to get a cigarette, all without ever “wanting” the cigarette in the homunculus sense. This plan was sophisticated in some objective sense—it involved three steps, relied on my life experience and understanding of the world, and could never have happened by random chance. But in a different sense, the plan was very simple, in that I crafted it in a very fast and “unreflective” way, such the S(G) thought never had a chance to pop up.
So that’s my framework. To sum up: The most powerful forms of brainstorming and planning involve a bunch of self-reflective thoughts, because you need to formulate a plan that will properly integrate with how your own mind works, now and in the future. So, as a rule, if we’re skillfully brainstorming and planning towards some goal G, then it’s almost certainly the case that the corresponding self-reflective S(G) has positive valence. There are exceptions, which I called “impulsive brainstorming” in §3.5.2 [? · GW], but those exceptions tend to involve plans that are relatively fast, simple, and centered around motor-control rather than attention-control.
By contrast, the Conventional Intuitive Self-Model (CISM) “explains” the same set of facts by positing that the homunculus does brainstorming and planning towards things that it “wants”, and that it “wants” the G’s for which S(G) is positive valence. I think CISM doesn’t have a great way to explain “impulsive brainstorming” (§3.5.2 [? · GW]), but impulsive brainstorming is sufficiently minor and unimportant that CISM can get away with glossing over it by mumbling something like “I wasn’t thinking”, even if that’s nonsensical when taken literally.
8.5.6 Example 6: Willpower
Here’s a different continuation of the scene from Example 3 (“I want to get out of bed, but I can’t, this pillow just feels so soft … ughhhhhhhhhh”):
Statement: “I’m just going to get out of bed through sheer force of will. Grrrr … … And I’m standing up!”
Intuitive model: As above, the homunculus “wants” to get out of bed, but is being stymied by the comfortable feeling of the pillow. The homunculus “applies willpower” in order to get its way—some mental move that’s analogous to “applying force” to move a heavy desk while redecorating. It’s conceptualized as “wanting” more intensely and with more “vitalistic force”.
How I describe this using my framework: As above, we have two systematic patterns (in this particular context): Pattern P1 is the fact that self-reflective thoughts concerning being-out-of-bed, like “myself being out of bed” or “myself getting out of bed”, tend to trigger positive valence. Pattern P2 is the fact that non-self-reflective thoughts concerning the feeling of the pillow tend to trigger positive valence.
And also as above, these can both correspondingly trigger brainstorming and planning. When “myself being out of bed” is on my mind, that’s positive valence, so it triggers brainstorming towards getting out of bed. And when “the feeling of the pillow” is on my mind, that’s positive valence, so it triggers brainstorming towards staying in bed. The valences need not be equally strong, so either side might win out. But there’s an additional thumb on the scale that comes from the fact that brainstorming-towards-getting-out-of-bed has a bigger search space, particularly involving attention-control strategies flowing through my intuitive self-model. By contrast, brainstorming-towards-staying-in-bed stops feeling positive-valence as soon as we view it in a self-reflective frame, so those kinds of attention-control strategies will feel unappealing.
Now, as it turns out, there’s a very simple, obvious, one-size-fits-all, attention-control strategy for making pretty much anything happen. Since it involves attention control, this strategy is disallowed for the staying-in-bed brainstorm, but it is an option for the getting-out-of-bed brainstorm.
Here’s the (obvious) strategy: Apply voluntary attention-control to keep S(getting out of bed) at the center of attention. Don’t let it slip away, no matter what.
This strategy is what we call “applying willpower”. Naively, it might seem to be an unbeatable strategy. If S(getting out of bed) remains at center-stage in our minds, then that will keep the feeling of the pillow blocked from conscious awareness. And since S(getting out of bed) is positive valence, the brainstorming / planning process will proceed all the way to the execution phase, and bam, we’re out of bed.
It’s so simple! The interesting question is: why doesn’t that always work? Let’s pause for an aside.
8.5.6.1 Aside: The “innate drive to minimize voluntary attention control”
Recall that valence comes ultimately from “innate drives”, a.k.a. “primary rewards” [LW · GW]—eating-when-hungry is good, pain is bad, etc., along with various social instincts like the “drive to feel liked / admired” [LW · GW], and much more. The exact list of human innate drives is as yet unknown to Science, and happens to be a major research interest of mine.
So here’s my hypothesis for one of those yet-to-be-discovered innate drives: Voluntary attention control is innately negative-valence, other things equal. In particular:
- Weak applications of voluntary attention control (which can be easily overridden by involuntary attention, random thoughts popping up, etc.) makes a thought slightly more negative-valence, other things equal.
- Strong applications of voluntary attention control (that can maintain attention even in the face of those kinds of distractions) makes a thought much more negative-valence, other things equal.
- Depending on your mood and so on, the proportionality constant relating voluntary-attention-strength to negative-marginal-valence might be higher or lower; these proportionality constants (imperfectly) correlate with “finding it easy versus hard to concentrate”.
So that’s a hypothesis. To flesh out my case that this alleged innate drive actually exists, let’s go over the usual three questions [LW · GW]:
- Is this alleged innate drive evolutionarily plausible? Yes! There’s obviously a reason that we evolved to have involuntary attention, and random thoughts popping up, and so on. Such thoughts are sometimes useful! That’s why our brain algorithm is doing that in the first place! So, if voluntary attention is blocking that process, that’s (other things equal) a bad thing, and it makes evolutionary sense to account for that opportunity cost via negative valence. (Of course, there are simultaneously other factors at play, including every other innate drive, such that the voluntary attention can be positive-valence on net.) Moreover, the opportunity cost of suppressing those random thoughts is presumably systematically different in different situations, so it makes perfect sense in general that the proportionality constant may be higher or lower across moods, situations, etc.
- Is this alleged innate drive neuroscientifically plausible? Yes! I don’t want to get into exactly how voluntary attention-control works in the brain, but let’s just say there’s some pathway; and on general principles, it’s perfectly possible for the brainstem to get a signal indicating generally how much activity there is in this pathway, and to decrease valence accordingly. (Does such a signal really exist, with that effect? Can we measure it? In principle, yes. In practice, I don’t think anyone has done such an experiment as of yet.)
Is this alleged innate drive compatible with psychology, including everyday experience? I think so! There’s a nice analogy between attention control and motor control here. By and large, leaving aside fidgeting, the more you exert your muscles, the more negative-valence this activity is, other things equal. This is due to another innate drive that evolved for obvious energy-preservation reasons. And, just like above, the proportionality constant can vary—we can be physically tired, or energetic. In fact, I think there’s such a strong structural parallel between the “innate drive to minimize voluntary attention control” versus the “innate drive to minimize voluntary motor control”, that people tend to intuitively bundle them together and assume (incorrectly[4]) that they both derive from energy preservation. Hence the intuitive appeal of the famously-incorrect psych result that glucose supposedly reverses “ego depletion”.
8.5.6.2 Back to Example 6
Where were we? There’s a goal G (getting out of bed) such that the self-reflective S(G) (myself getting out of bed) is also positive-valence. This enables the more powerful version of brainstorming, the kind of brainstorming where the strategy space includes plans that leverage attention-control in conjunction with my understanding of my own mind. One such plan is the really simple, one-size-fits-all plan to use attention-control to hold S(G) very firmly in mind, so firmly that any thought that might otherwise kick it out (i.e., the comfortable feeling of the pillow) can’t squeeze in. We call this plan “applying willpower” to get out of bed.
Now, we can see why this one-size-fits-all plan doesn’t always work. The plan involves applying voluntary attention control to keep S(G) firmly in mind. This plan gets a positive-valence boost from the fact that S(G) has positive valence. But the plan also gets a negative-valence penalty from the “innate drive to minimize voluntary attention control” above. Thus, if the plan involves too much voluntary attention on S(G), it winds up with negative valence on net, and my brain kicks that thought out and replaces it with something else [LW · GW]. On the other hand, if the plan involves too little voluntary attention on S(G), then the oh-so-appealing thought of the comfortable pillow may successfully bubble up and kick S(G) out of consciousness. Thus, “applying willpower” sometimes works, but also sometimes doesn’t, as we know from everyday experience.
This whole section was a discussion within my own framework. Thus, “applying willpower” points to a real-world psychological phenomenon, but we can explain that phenomenon without any of those problematic intuitions related to the homunculus, vitalistic force, “wanting”, or free will.
8.6 Conclusion of the series
Thanks for joining me on this 45,000-word journey! I for one feel very much less confused about a great many topics now than I was before. Hope you found it helpful too! Thanks to everyone who shared comments, criticisms, and experiences, both before and after initial publication—the series is very much different and better than it would have been otherwise! Keep ’em coming!
8.6.1 Bonus: How is this series related to my job description as an Artificial General Intelligence safety and alignment researcher?
Well, I don't want to overstate how related it is. That's why I wrote it fast, aiming just for the big picture rather than the details. But I think the time I spent was worthwhile.
So here are the five main directly-work-relevant things that I got out of writing these eight posts:
First, my top-priority research project right now is coming up with plausible hypotheses for how human social instincts work, which I believe to mainly revolve around little cell groups in the hypothalamus and brainstem (details here [LW · GW]). For example, I think there’s an innate “drive to be liked / admired” [LW · GW], related to social status seeking, but in order to build that drive, the genome must be somehow solving a very tricky “symbol grounding problem”, as discussed here [LW · GW]. Writing this series helped me eliminate a number of wrong ideas about how that works—for example, I now think that the hypothesis that I wrote down in “Spatial attention as a “tell” for empathetic simulation?” [LW · GW] is wrong, as were a couple other ideas that I was playing around with. I have better ideas now—a post on that is forthcoming!
Why exactly was this series helpful for that research project? Well, the big problem with this research project is that there’s almost no direct evidence to go on, for the questions I’m trying to answer about human social instincts. For example, it’s nearly impossible to measure anything whatsoever about the human hypothalamus. It doesn’t show up in fMRI, EEG, etc., and even if it did, the interesting functionality of the hypothalamus is structured as microscopic clusters of neurons, all packed right next to each other (details here [LW · GW]). There’s lots of data about the rodent hypothalamus,[5] but I think human social instincts are importantly different from mouse social instincts. Thus, being able to scour the weirder corners of human psychology is one of the few ways that I can narrow down possibilities.
For example, if somebody “identifies with the universal consciousness”, do they still feel a “drive to be liked / admired”? Empirically, yes! But then, what does that mean—do they want the universal consciousness to be liked / admired, or do they want their conventional selves to be liked / admired? Empirically, the latter! And what lessons can I draw from that observation, about how the “drive to be liked / admired” works under the hood? I have an answer, but I was only able to find that answer by starting with a deep understanding of what the heck a person is talking about when they say that they “identify with the universal consciousness”. That turned out to be a very important nugget that I got out of writing this series. Again, the payoff is in a forthcoming post.
Second, I sometimes talk about “the first-person problem” [LW · GW] for brain-like AGI: How might one transform third-person data (e.g. a labeled YouTube video of Alice helping Bob) into a AGI’s first-person preferences (“I want to be helpful”)? This almost certainly requires some mechanistic interpretability, which makes it hard to plan out in detail. However, writing this series makes me feel like I have a much better understanding of what we’d be looking for, how it might work, and what might go wrong. For example, if (if!) the AGI winds up with something close to the Conventional Intuitive Self-Model (§3.2 [LW · GW]), then maybe, while the AGI is watching the YouTube, we could find some data structure in its “mind” that we interpret as an X-helping-Y frame with X=Alice and Y=Bob. If so, then we could edit that same frame to X=homunculus, Y=supervisor, and make the resulting configuration trigger positive valence [LW · GW]. There’s still a lot that could go wrong, but again, I feel much more capable of thinking about these issues than I did before.
Third, this 8th post is all about motivation, a central topic in AI alignment. May it help spread clear and correct thinking in that area. I’ve already noticed the ideas in this post coming up in my AI-alignment-related conversations on multiple occasions.
Fourth, I was intrigued by the observation that social status plays an important role in trance (§4.5.4 [LW · GW]). That seemed to be an intriguing hint of something about how social status works. Alas, it turned out that social status was helpful for understanding trance, but not the other way around. Oh well. Research inevitably involves chasing down leads that don't always bear fruit.
Fifth, there’s the question of sentience and moral patienthood—of people, of animals, and especially of current and future AI systems. While I assiduously avoided directly talking about those topics (§1.6.2 [LW · GW]), I obviously think that this series (especially Posts 1–3) would be highly relevant for anyone working in that area.
Thanks again for reading! Please reach out (in the comments section or by email) if you want to talk about this series or whatever else.
Thanks Simon Skade for critical comments on an earlier draft.
- ^
I’m referring to the neural circuits involved in “social instincts”. I have a short generic argument that such neural circuits have to exist here [LW · GW], and a more neuroscience-y discussion of how they might work here [LW · GW], and much more nuts-and-bolts neuroscience details in a forthcoming post.
- ^
More precisely: If there are deterministic upstream explanations of what the homunculus is doing and why, e.g. via algorithmic or other mechanisms happening under the hood, then that feels like a complete undermining of one’s free will and agency (§3.3.6 [LW · GW]). And if there are probabilistic upstream explanations of what the homunculus is doing and why, e.g. the homunculus wants to eat when hungry, then that correspondingly feels like a partial undermining of free will and agency, in proportion to how confident those predictions are.
- ^
- ^
For one thing, if it’s true at all that voluntary attention-control entails more energy consumption than daydreaming, then the difference is at most a small fraction of the brain’s total 20 watt power budget. Compare that to running, which might involve generating 200 watts of mechanical power plus 600 watts of heat. It’s absurd to think that energy considerations would figure in at all. “Thinking really hard for five seconds” probably involves less primary metabolic energy expenditure than scratching your nose.
For another thing, I think my evolutionary story makes sense. Evolution invests so much into building and training a human brain. The obvious cost of using your brain to think about X is the opportunity cost: it means you’re not using your brain to think about any other Y. It seems highly implausible that Evolution would be ignoring this major cost.
For another thing, I think I can be mentally “tired” but not physically tired, and vice-versa. But be warned that it’s a bit tricky to think about this, because unpleasant physical exertion generally involves both attention control and motor control. Thus, “willpower” can somewhat substitute for “physical energy” and vice-versa. See “Example 1” here.
Most importantly, there was never any good reason to believe that “the innate drive to minimize voluntary attention control” and “the innate drive to minimize voluntary motor control” have anything to do with each other, in the first place. They intuitively seem to be related, but this isn’t a situation where we should trust our intuitions to be veridical. In particular, there’s such a strong structural parallel between those two drives that they would feel related regardless of whether they actually were related or not.
- ^
Although, even in the rodent hypothalamus, I believe that only a small fraction of those probably hundreds of little idiosyncratic neuron clusters have been characterized in enough detail to say what they do and how.
16 comments
Comments sorted by top scores.
comment by Rafael Harth (sil-ver) · 2024-11-14T13:45:19.291Z · LW(p) · GW(p)
After finishing the sequence, I'm in the odd position where most of my thoughts aren't about the sequence itself, but rather about why I think you didn't actually explain why people claim to be conscious. So it's strange because it means I'm gonna talk a whole bunch about what you didn't write about, rather than what you did write about. I do think it's still worth writing this comment, but with the major disclaimer/apology that I realize most of this isn't actually a response to the substance of your arguments.
First to clarify, the way I think about this is that there's two relevant axes along which to decompose the problem of consciousness:
- the easy vs. hard axis, which is essentially about the describing the coarse functional behavior vs. why it exists at all; and
- the [no-prefix] vs. meta axis, which is about explaining the thing itself vs. why people talk about the thing. So for every , the meta problem of is "explain why people talk about "
(So this gives four problems: the easy problem, the hard problem, the easy meta problem, and the hard meta problem.)
I've said in this comment [LW(p) · GW(p)] that I'm convinced the meta problem is sufficient to solve the entire problem. And I very much stand by that, so I don't think you have to solve the hard problem -- but you do have to solve the hard meta problem! Like, you actually have to explain why people claim to be conscious, not just why they report the coarse profile of functional properties! And (I'm sure you see where this is going), I think you've only addressed the easy meta problem throughout this sequence.
Part of the reason why this is relevant is because you've said in your introductory post that you want to address this (which I translate to the meta problem in my terminology):
STEP 1: Explain the chain-of-causation in the physical universe that leads to self-reports about consciousness, free will, etc.—and not just people’s declarations that those things exist at all, but also all the specific properties that people ascribe to those things.
Imo you actually did explain why people talk about free will,[1] so you've already delivered on at least half of this. Which is just to say that, again, this is not really a critique, but I do think it's worth explaining why I don't think you've delivered on the other half.
Alright, so why do I think that you didn't address the hard meta problem? Well, post #2 is about conscious awareness so it gets the closest, but you only really talk about how there is a serial processing stream in the brain whose contents roughly correspond to what we claim is in awareness -- which I'd argue is just the coarse functional behavior, i.e., the macro problem. This doesn't seem very related to the hard meta problem because I can imagine either one of the problems not existing without the other. I.e., I can imagine that (a) people do claim to be conscious but in a very different way, and (b) people don't claim to be conscious, but their high-level functional recollection does match the model you describe in the post. And if that's the case, then by definition they're independent.
A possible objection to the above would be that the hard and easy meta problem aren't really distinct -- like, perhaps people do just claim to be conscious because they have this serial processing stream, and attempts to separate the two are conceptually confused...
... but I'm convinced that this isn't true. One reason is just that, if you actually ask camp #2 people, I think they'll tell you that the problem isn't really about the macro functional behavior of awareness. But the more important reason is the hard meta problem can be considered in just a single sensory modality! So for example, with vision, there's the fact that people don't just obtain intangible information about their surroundings but claim to see continuous images.
Copying the above terminology, we could phrase the hard problem of seeing as explaining why people see images, and the hard meta problem of seeing as explaining why people claim to see images.[2] (And once again, I'd argue it's fine/sufficient to only answer the meta problem -- but only if you do, in fact, answer the meta problem!) Then since the hard meta problem of seeing is a subset of the hard meta problem of consciousness, and since the contents of your post very much don't say anything about this, it seems like they can't really have conclusively addressed the hard meta problem in general.
Again, not really a critique of the actual posts; the annoying thing for me is just that I think the hard meta problem is where all the juicy insights about the brain are hidden, so I'm continuously disappointed that no one talks about it. ImE this is a very consistent pattern where whenever someone says they'll talk about it, they then end up not actually talking it, usually missing it even more than you did here (cough Dennett cough). Actually there is at least one phenomenon you do talk about that I think is very interesting (namely equanimity), but I'll make a separate comment for that.
Alas I don't view Free Will as related to consciousness. I understand putting them into the same bucket of "intuitive self-models with questionable veridicality". But the problem is that people who meditate -- which arguably is like paying more attention -- tend to be less likely to think Free Will is real, but I'd strongly expect that they're more likely to say that consciousness is real, rather than less. (GPT-4 says there's no data on this; would be very interesting to make a survey correlating camp#1 vs. camp#2 views by how much someone has meditated, though proving causation will be tricky.) If this is true, imo they don't seem to belong into the same category. ↩︎
Also, I think the hard meta problem of seeing has the major advantage that people tend to agree it's real -- many people claim not to experience any qualia, but everyone seems to agree that they seem to see images. Basically I think talking about seeing is just a really neat way to reduce conceptual confusion while retaining the hard part of the problem. And then there's also blindsight where people claim not to see and retain visual processing capabilities -- but much very much reduced capabilities! -- so there's some preliminary evidence that it's possible to tease out the empirical/causal effects of the hard meta problem. ↩︎
↑ comment by Steven Byrnes (steve2152) · 2024-11-14T18:18:13.004Z · LW(p) · GW(p)
Thanks for the detailed comment!
Well, post #2 is about conscious awareness so it gets the closest, but you only really talk about how there is a serial processing stream in the brain whose contents roughly correspond to what we claim is in awareness -- which I'd argue is just the coarse functional behavior, i.e., the macro problem. This doesn't seem very related to the hard meta problem because I can imagine either one of the problems not existing without the other. I.e., I can imagine that (a) people do claim to be conscious but in a very different way, and (b) people don't claim to be conscious, but their high-level functional recollection does match the model you describe in the post. And if that's the case, then by definition they're independent. … if you actually ask camp #2 people, I think they'll tell you that the problem isn't really about the macro functional behavior of awareness
The way intuitive models work (I claim) is that there are concepts, and associations / implications / connotations of those concepts. There’s a core intuitive concept “carrot”, and it has implications about shape, color, taste, botanical origin, etc. And if you specify the shape, color, etc. of a thing, and they’re somewhat different from most normal carrots, then people will feel like there’s a question “but now is it really a carrot?” that goes beyond the complete list of its actual properties. But there isn’t, really. Once you list all the properties, there’s no additional unanswered question. It just feels like there is. This is an aspect of how intuitive models work, but it doesn’t veridically correspond to anything of substance.
The old Yudkowsky post “How An Algorithm Feels From Inside [LW · GW]” is a great discussion of this point.
So anyway, if “consciousness” has connotations / implications A,B,C,D,E, etc. (it’s “subjective”, it goes away under general anesthesia, it’s connected to memory, etc.), then people will feel like there’s an additional question “but is it really consciousness”, that still needs to be answered, above and beyond the specific properties A,B,C,D,E.
And likewise, if you ask a person “Can you imagine something that lacks A,B,C,D,E, but still constitutes ‘consciousness’”, then they may well say “yeah I can imagine that”. But we shouldn’t take that report to be particularly meaningful.
(…See also Frankish’s “Quining Diet Qualia” (2012).)
Copying the above terminology, we could phrase the hard problem of seeing as explaining why people see images, and the hard meta problem of seeing as explaining why people claim to see images.
As in Post 2, there’s an intuitive concept that I’m calling “conscious awareness” that captures the fact that the cortex has different generative models active at different times. Different parts of the cortex wind up building different kinds of models—S1 builds generative models of somatosensory data, M1 builds generative models of motor programs, and so on. But here I want to talk about the areas in the overlap between the “ventral visual stream” and the “global workspace”, which is mainly in and around the inferior temporal gyrus, “IT”.
When we’re paying attention to what we’re looking at, IT would have some generative model active that optimally balances between (1) priors about the visual world, and (2) the visual input right now. Alternatively, if we’re zoning out from what we’re looking at, and instead using visual imagination or visual memory, then (2) is off (i.e., the active IT model can be wildly incompatible with immediate visual input), but (1) is still relevant, and instead there needs to be consistency between IT and episodic memory areas, or various other possibilities.
So anyway,
- In the territory, “Model A is currently active in IT” is a very different situation from “Model B is currently active in the superior temporal gyrus” or whatever.
- Correspondingly, in the map, we wind up with the intuition that “X is in awareness as a vision” is very different from “Y is in awareness as a sound”, and both are very different from “Z is in awareness as a plan”, etc.
You brought up blindsight. That would be where the model “X is in awareness as a vision” seems wrong. That model would entail a specific set of predictions about the state of IT, and it turns out that those predictions are false. However, some other part of awareness is still getting visual information via some other pathway. (Visual information gets into various parts of the cortex via more than one pathway.) So the blindsight patient might describe their experience as “I don’t see anything, but for some reason I feel like there’s motion on the left side”, or whatever. And we can map that utterance into a correct description of what was happening in their cortex.
Separately, as for the hard problem of consciousness, you might be surprised to learn that I actually haven’t thought about it much and still find it kinda confusing. I had written something into an early draft of post 1 but wound up deleting it before publication. Here’s what it said:
Replies from: sil-ver, sharmake-farahStart with an analogy to physics. There’s a Stephen Hawking quote I like:
> “Even if there is only one possible unified theory, it is just a set of rules and equations. What is it that breathes fire into the equations and makes a universe for them to describe? The usual approach of science of constructing a mathematical model cannot answer the questions of why there should be a universe for the model to describe. Why does the universe go to all the bother of existing?”
I could be wrong, but Hawking’s question seems to be pointing at a real mystery. But as Hawking says, there seems to be no possible observation or scientific experiment that would shed light on that mystery. Whatever the true laws of physics are in our universe, every possible experiment would just confirm, yup, those are the true laws of physics. It wouldn’t help us figure out what if anything “breathes fire” into those laws. What would progress on the “breathes fire” question even look like?? (See Tegmark’s Mathematical Universe book for the only serious attempt I know of, which I still find unsatisfying. He basically says that all possible laws of the universe have fire breathed into them. But even if that’s true, I still want to ask … why?)
By analogy, I’m tempted to say that an illusionist account can explain every possible experiment about consciousness, including our belief that consciousness exists at all, and all its properties, and all the philosophy books on it, and so on … but yet I’m tempted to still say that there’s some “breathes fire” / “why is there something rather than nothing” type question left unanswered by the illusionist account. This unanswered question should not be called “the hard problem”, but rather “the impossible problem”, in the sense that, just like Hawking’s question above, there seems to be no possible scientific measurement or introspective experiment and that could shed light on it—all possible such data, including the very fact that I’m writing this paragraph, are already screened off by the illusionist framework.
Well, hmm, maybe that’s stupid. I dunno.
↑ comment by Rafael Harth (sil-ver) · 2024-11-15T02:03:01.606Z · LW(p) · GW(p)
The way intuitive models work (I claim) is that there are concepts, and associations / implications / connotations of those concepts. There’s a core intuitive concept “carrot”, and it has implications about shape, color, taste, botanical origin, etc. And if you specify the shape, color, etc. of a thing, and they’re somewhat different from most normal carrots, then people will feel like there’s a question “but now is it really a carrot?” that goes beyond the complete list of its actual properties. But there isn’t, really. Once you list all the properties, there’s no additional unanswered question. It just feels like there is. This is an aspect of how intuitive models work, but it doesn’t veridically correspond to anything of substance.
Mhhhmhh. Let me see if I can work with the carrot example to where it fits my view of the debate.
A botanist is charged with filling a small field with plants, any plants. A chemist hands him a perfect plastic replica of a carrot, perfect in shape, color, texture, and (miraculously) taste. The botanist says that it's not a plant. The chemist, who has never seen plants other than carrots, points out the matching qualities to the plants he knows. The botanist says okay but those are just properties that a particular kind of plant happens to have, they're not the integral property of what makes something a plant. "The core intuitive concept 'plant' has implications about shape, color, texture, taste, et cetera", says the chemist. "If all those properties are met, people may think there's an additional question about the true plant-ness of the object, but [...]." The botanist points out that he is not talking about an intangible, immeasurable, or non-physical property but rather about the fact that this carrot won't grow and spread seeds when planted into the earth. The chemist, having conversed extensively with people who define plants primarily by their shape, color, texture, and taste (which are all those of carrots because they've also not seen other plants) just sighs, rolling his eyes at the attempt to redefine plant-ness to be entirely about this one obscure feature that also just happens to be the most difficult one to test.
Which is to say that I get -- or at least I think I get -- the sense that we're successfully explaining important features of consciousness and the case for linking it to anything special is clearly diminishing -- but I don't think it's correct. When I say that the hard meta problem of seeing probably contains ~90% of the difficulty of the hard meta problem of consciousness whereas the meta problem of free will contains 0% and the problem of awareness ~2%, then I'm not changing my model in response to new evidence. I've always thought Free Will was nonsense!
(The botanist separately points out that there in fact other plants with different shape, texture, and taste, although they all do have green leaves, to which the chemist replies that ?????. This is just to come back to the point that people report advanced meditative states that lose many of the common properties of consciousness, including Free Will, the feeling of having a self (I've experienced that one!) and even the presence of any information content whatsoever, and afaik they tend to be more "impressed", roughly speaking, with consciousness as a result of those experiences, not less.)
[seeing stuff]
Attempt to rephrase: the brain has several different intuitive models in different places. These models have different causal profiles, which explains how they can correspond to different introspective reports. One model corresponds to the person talking about smelling stuff. Another corresponds to the person talking about seeing stuff. Yet another corresponds to the person talking about obtaining vague intuitions about the presence and location of objects. The latter two are triggered by visual inputs. Blindsight turns off the second but not the third.
If this is roughly correct, my response to it is that proposing different categories isn't enough because the distinction between visually vivid experience and vague intuitions isn't just that we happen to call them by different labels. (And the analogous thing is true for every other sensory modality, although the case is the least confusing with vision.) Claiming to see a visual image is different from claiming to have a vague intuition in all the ways that it's different; people claim to see something made out of pixels, which can look beautiful or ugly, seems to have form, depth, spatial location, etc. They also claim to perceive a full visual image constantly, which presumably isn't possible(?) since it would contain more information than can actually be there, so a solution has to explain how this illusion of having access to so much information is possible. (Is awareness really a serial processor in any meaningful way if it can contain as much information at once as a visual image seems to contain?)
(I didn't actually intend to get into a discussion about any of this though, I was just using it as a demonstration of why I think the hard metaproblem of consciousness has at least one real subset and hence isn't empty.)
Hard Problem
Yeah, I mean, since I'm on board with reducing everything to the meta problem, the hard problem itself can just be sidestepped entirely.
But since you brought it up, I'll just shamelessly use this opportunity to make a philosophical point that I've never seen anyone else make, which is that imo the common belief that no empirical data can help distinguish an illusionist from a realist universe... is actually false! The reason is that consciousness is a high-level phenomenon in the illusionist universe and a low phenomenon in at least some versions of the realist universe, and we have different priors for how high-level vs. low-level phenomena behave.
The analogy I like is, imagine there's a drug that makes people see ghosts, and some think these ghosts tap into the fundamental equations of physics, whereas others think the brain is just making stuff up. One way you can go about this is to have a thousand people describe their ghosts in detail. If you find that the brightness of hallucinated ghosts is consistently proportional to their height, then you've pretty much disproved the "the brain is just making stuff up hypothesis". (Whereas if you find no such relationships, you've strengthened the hypothesis.) This is difficult to operationalize for consciousness, but I think determining the presence of absence of elegant mathematical structure within human consciousness is, at least in principle, an answer to the question of "[w]hat would progress on the 'breathes fire' question even look like".
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-16T15:40:06.365Z · LW(p) · GW(p)
Thanks for the comment!
people report advanced meditative states that lose many of the common properties of consciousness, including Free Will, the feeling of having a self (I've experienced that one!) and even the presence of any information content whatsoever, and afaik they tend to be more "impressed", roughly speaking, with consciousness as a result of those experiences, not less.
I think that’s compatible with my models, because those meditators still have a cortex, in which patterns of neurons can be firing or not firing at any particular time. And that’s the core aspect of the “territory” which corresponds to “conscious awareness” in the “map”. No amount of meditation, drugs, etc., can change that.
Attempt to rephrase: the brain has several different intuitive models in different places. These models have different causal profiles, which explains how they can correspond to different introspective reports.
Hmm, I think that’s not really what I would say. I would say that that there’s a concept “conscious awareness” (in the map) that corresponds to the fact (in the territory) that different patterns of neurons can be active or inactive in the cortex at different times. And then there are more specific aspects of “conscious awareness”, like “visual awareness”, which corresponds to the fact that the cortex has different parts (motor cortex etc.), and different patterns of neurons can be active or inactive in any given part of the cortex at different times.
…Maybe this next part will help ↓
the distinction between visually vivid experience and vague intuitions isn't just that we happen to call them by different labels … Claiming to see a visual image is different from claiming to have a vague intuition in all the ways that it's different
The contents of IT are really truly different from the contents of LIP [I didn’t check where the visual information gets to the cortex in blindsight, I’m just guessing LIP for concreteness]. Querying IT is a different operation than querying LIP. IT holds different types of information than LIP does, and does different things with that information, including leading to different visceral reactions, motivations, semantic knowledge, etc., all of which correspond to neuroscientific differences in how IT versus LIP is wired up.
All these differences between IT vs LIP are in the territory, not the map. So I definitely agree that “the distinction [between seeing and vague-sense-of-presence] isn’t just that we happen to call them by different labels”. They’re different like how the concept “hand” is different from the concept “foot”—a distinction on the map downstream of a distinction in the territory.
Is awareness really a serial processor in any meaningful way if it can contain as much information at once as a visual image seems to contain?
I’m sure you’re aware that people feel like they have a broader continuous awareness of their visual field than they actully do. There are lots of demonstrations of this—e.g. change blindness, selective attention test, the fact that peripheral vision has terrible resolution and terrible color perception and makes faces look creepy. There’s a refrigerator light illusion thing—if X is in my peripheral vision, then maybe it’s currently active as just a little pointer in a tiny sub-area of my cortex, but as soon as I turn my attention to X it immediately unfolds in full detail across the global workspace.
The cortex has 10 billion neurons which is more than enough to do some things in parallel—e.g. I can have a song stuck in my head in auditory cortex, while tapping my foot with motor cortex, while doing math homework with other parts of the cortex. But there’s also a serial aspect to it—you can’t parse a legal document and try to remember your friend’s name at the exact same moment.
Does that help? Sorry if I’m not responding to what you see as most important, happy to keep going. :)
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2024-11-18T14:36:49.525Z · LW(p) · GW(p)
(You did respond to all the important parts, rest of my comment is very much optional.)
I’m sure you’re aware that people feel like they have a broader continuous awareness of their visual field than they actully do. There are lots of demonstrations of this—e.g. change blindness, selective attention test, the fact that peripheral vision has terrible resolution and terrible color perception and makes faces look creepy. There’s a refrigerator light illusion thing—if X is in my peripheral vision, then maybe it’s currently active as just a little pointer in a tiny sub-area of my cortex, but as soon as I turn my attention to X it immediately unfolds in full detail across the global workspace.
Yes -- and my point was that appealing to these phenomena is the kind of thing you will probably have to do to explain the meta problem of seeing. Which raises all kinds of issues -- for example, change blindness by itself doesn't logically prove anything, since it's possible not to notice that something changed even if it was represented. Only the reverse conclusion is valid -- if a subject can tell that X changed, then X was in awareness, but if they can't tell, X may or may not have been in awareness. So teasing out exactly how much information is really present in awareness, given the positive and negative evidence, is a pretty big rabbit hole. (Poor resolution in peripheral vision does prove absence of information, but as with the memory example I've complained about in post #2 [LW(p) · GW(p)], this is an example of something people don't endorse under reflection anyway, so it doesn't get you very far. Like, there is a very, very big difference between arguing that peripheral resolution is poor, which people will agree with as soon as they actually pay attention to their peripheral vision for the first time, and arguing that the continuous visual image they think they see is not really there, which most people will stubbornly disagree with regardless of how much attention they pay to it.)
Anyway, that's the only claim I was making -- I was only trying to go as far as "this is why I think the problem is nontrivial and you haven't solved it yet", not "and that's why you can't solve it".
The contents of IT are really truly different from the contents of LIP [I didn’t check where the visual information gets to the cortex in blindsight, I’m just guessing LIP for concreteness]. Querying IT is a different operation than querying LIP. IT holds different types of information than LIP does, and does different things with that information, including leading to different visceral reactions, motivations, semantic knowledge, etc., all of which correspond to neuroscientific differences in how IT versus LIP is wired up.
All these differences between IT vs LIP are in the territory, not the map. So I definitely agree that “the distinction [between seeing and vague-sense-of-presence] isn’t just that we happen to call them by different labels”. They’re different like how the concept “hand” is different from the concept “foot”—a distinction on the map downstream of a distinction in the territory.
Right, and I agree that this makes it apriori plausible that they could account for the differences in how people talk about, e.g., vivid seeing vs. intangible intuitions. But it doesn't prove that they do, it only shows that this is the kind of explanation that, on first glance, looks like it could work. To actually solve the meta problem, you still have to do the work of explaining all the properties of introspective reports, which requires going into a lot of detail.
As of above, this is the only claim I was making -- I'm not saying any of these issues are provably impossible with your approach, I'm only saying that your approach hasn't provided a full solution yet. (And that I genuinely think most of the difficulty happens to be in these still unaddressed details; this was the point of the carrot/plant analogy.)
I think that’s compatible with my models, because those meditators still have a cortex, in which patterns of neurons can be firing or not firing at any particular time. And that’s the core aspect of the “territory” which corresponds to “conscious awareness” in the “map”. No amount of meditation, drugs, etc., can change that.
Fair enough, but I think it does show that free will isn't that central of a piece.
↑ comment by Noosphere89 (sharmake-farah) · 2024-11-14T19:02:11.802Z · LW(p) · GW(p)
Start with an analogy to physics. There’s a Stephen Hawking quote I like:
> “Even if there is only one possible unified theory, it is just a set of rules and equations. What is it that breathes fire into the equations and makes a universe for them to describe? The usual approach of science of constructing a mathematical model cannot answer the questions of why there should be a universe for the model to describe. Why does the universe go to all the bother of existing?”
I could be wrong, but Hawking’s question seems to be pointing at a real mystery. But as Hawking says, there seems to be no possible observation or scientific experiment that would shed light on that mystery. Whatever the true laws of physics are in our universe, every possible experiment would just confirm, yup, those are the true laws of physics. It wouldn’t help us figure out what if anything “breathes fire” into those laws. What would progress on the “breathes fire” question even look like?? (See Tegmark’s Mathematical Universe book for the only serious attempt I know of, which I still find unsatisfying. He basically says that all possible laws of the universe have fire breathed into them. But even if that’s true, I still want to ask … why?)
By analogy, I’m tempted to say that an illusionist account can explain every possible experiment about consciousness, including our belief that consciousness exists at all, and all its properties, and all the philosophy books on it, and so on … but yet I’m tempted to still say that there’s some “breathes fire” / “why is there something rather than nothing” type question left unanswered by the illusionist account. This unanswered question should not be called “the hard problem”, but rather “the impossible problem”, in the sense that, just like Hawking’s question above, there seems to be no possible scientific measurement or introspective experiment and that could shed light on it—all possible such data, including the very fact that I’m writing this paragraph, are already screened off by the illusionist framework.
Well, hmm, maybe that’s stupid. I dunno.
My provisional answer is "An infinity of FLOPs/compute backs up the equations to make sure it works."
comment by Seth Herd · 2024-11-04T20:42:18.058Z · LW(p) · GW(p)
Excellent! As usual, I concur.
I certainly haven't seen this clear a description of how human brains (and therefore people) actually make decisions. I never bothered to write about it, on the excuse that clarifying brain function would accelerate progress toward AGI, and a lack of clear incentives to do the large amount of work to write clearly. So this is now my reference for how people work. It seems pretty self-contained. (And I think progress toward AGI is now so rapid that spreading general knowledge about brain function will probably do more good than harm).
First, I generally concur. This is mostly stuff I thought about a lot over my half-career in computational cognitive neuroscience. My conclusions are largely the same, in the areas I'd thought about. I hadn't thought as much about alternate self-concepts except for DID (I had a friend with pretty severe DID and reached the same conclusions you have about a "personality" triggering associated memories and valences). And I had not reached this concise definition of "willpower", although I had the same thought about the evolutionary basis of making it difficult to attend to one thing obsessively. That's how you either get eaten or fail to explore valuable new thoughts.
In particular, I very much agree with your focus on the valance attached to individual thoughts. This reminded me of a book title, Thoughts Without A Thinker, an application of buddhist psychology theory to psychanalysis. I haven't read but read and heard about it. I believe it works from much the same framework of understanding why we do things and feel as we do about things, but I don't remember if it's using something like the same theory of valence guiding thought.
Now to my couple of addendums.
First is an unfinished thread: I agree that we tend to keep positively-valanced thoughts while discarding negatively-valenced ones, and this leads to produtive brainstorming - that which leads toward (vaguely) predicted rewards. But I've heard that many people do a lot of thinking about negative outcomes, too. I am both constitutionally and deliberately against thinking too much about negative things, but I've heard that a lot of the current human race spends a lot of time worrying - which I think probably has the same brainstorming dynamic and shares mechanisms with the positively oriented brainstorming. I don't know how to explain this; I think the avoidance of bad outcomes being a good outcome could do this work, but that's not how worrying feels - it feels like my thoughts are drawn toward potential bad outcomes even when I have no idea how to avoid them yet.
I don't have an answer. I have wondered if this is related to the subpopulation of dopamine cells that fire in response to punishments and predicted punishments, but they don't seem to project to the same areas controlling attention in the PFC (if I recall correctly, which I may not). Anyway, that's my biggest missing piece in this puzzle.
Now onto "free will" or whatever makes people think that term sounds important. I think it's a terrible, incoherent term that points at several different important questions about how to properly understand the human self, and whether we bear responsibility and control our own futures.
I think different people have different intuitive models of their selves. I don't know which are most common. Some people identify with the sum total of their thought, and I think wind up less happy as a result; they assume that their actions reflect their "real" selves, for instance identifying with their depression or anger. I think the notion that "science doesn't believe in free will" can contribute to that unhelpful identification. This is not what you're saying, so I'm only addressing phrasing; but I think one pretty common (wrong) conclusion is "science says my thoughts and efforts don't matter, because my genes and environment determine my outcomes". You are saying that thoughts and "efforts" (properly understood) are exactly what determine actions and therefore outcomes. I very much agree.
I frame the free will thing a little differently. To borrow from my last comment on free will [LW(p) · GW(p)] [then edit it a bit]:
I don't know what people mean by "free will" and I don't think they usually do either. [...]
I substitute the term "self-determination" for "free will", in hopes that that term captures more of what people tend to actually care about in this topic: do I control my own future? Framed this way, I think the answer is more interesting- it's sort of and sometimes, rather than a simple yes or no.
I think someone who's really concerned that "free will isn't real" would say sure [their thoughts] help determine outcomes, but the contents of my consciousness were also determined by previous processes. I didn't pick them. I'm an observer, not a cause. My conscious awareness is an observer. It causes the future, but it doesn't choose, it just predicts outcomes.
[...]
So here I think it's important to break it down further, and ask how someone would want their choices to work in an ideal world (this move is essentially borrowed from Daniel Dennett's "all the varieties of free will worth wanting").
I think the most people would ask for is to have their decisions and therefore their outcomes controlled by their beliefs, their knowledge, their values, and importantly, their efforts at making decisions.
I think these are all perfectly valid labels for important aspects of cognition (with lots of overlap among knowledge, beliefs, and values). Effort at making a decision also plays a huge role, and I think that's a central concern - it seems like I'm working so hard at my decisions, but is that an illusion? I think what we perceive as effort involves more of the conscious predictions you describe [...] It also involves more different types of multi-step cognition, like analyzing progress so far and choosing new strategies for decisions or intermediate conclusions for complex decisions.
(incidentally I did a whole bunch of work on exactly how the brain does [that] process of conscious predictions to choose outcomes. That's best written up in Neural mechanisms of human decision-making, but that's still barely worth reading because it's so neuroscience-specialist-oriented [and sort of a bad compromise among co-authors]).
So my response to people being bothered by being "just" the "continuation of deterministic forces via genetics and experience" is that those are condensed as beliefs, values, knowledge, and skills, and the effort with which those are applied is what determines outcomes and therefore your results and your future. [That's pretty much exactly the type of free will worth wanting.]
This leaves intact some concerns about forces you're not conscious of playing a role. Did I decide to do this because it's the best decision, or because an advertiser or a friend put an association or belief in my head in a way I wouldn't endorse on reflection? [Or was it some strong valence association I acquired in ways I've never explicitly endorsed?] I think those are valid concerns.
So my answer to "am I really in control of my behavior?" is: sometimes, in some ways - and the exceptions are worth figuring out, so we can have more self-determination in the future.
Anyway, that's some of my $.02 on "free will" in the sense of self-determination. Excellent post!
Replies from: Gunnar_Zarncke, steve2152↑ comment by Gunnar_Zarncke · 2024-11-05T13:43:46.246Z · LW(p) · GW(p)
a lot of the current human race spends a lot of time worrying - which I think probably has the same brainstorming dynamic and shares mechanisms with the positively oriented brainstorming. I don't know how to explain this; I think the avoidance of bad outcomes being a good outcome could do this work, but that's not how worrying feels - it feels like my thoughts are drawn toward potential bad outcomes even when I have no idea how to avoid them yet.
If we were not able to think about potentially bad outcomes well, that would a problem as clearly thinking about them is what avoids them, hopefully. But the question is a good one. My first intuition was that maybe the importance of an outcome - in both directions, good and bad - is relevant.
↑ comment by Steven Byrnes (steve2152) · 2024-11-05T14:52:03.025Z · LW(p) · GW(p)
Thanks!
But I've heard that many people do a lot of thinking about negative outcomes, too.…
FWIW my answer is “involuntary attention” as discussed in Valence §3.3.5 [LW · GW] (it also came up in §6.5.2.1 of this series [LW · GW]).
If I look at my shoe and (voluntarily) pay attention to it, my subsequent thoughts are constrained to be somehow “about” my shoe. This constraint isn’t fully constraining—I might be putting my shoe into different contexts, or thinking about my shoe while humming a song to myself, etc.
By analogy, if I’m anxious, then my subsequent thoughts are (involuntarily) constrained to be somehow “about” the interoceptive feeling of anxiety. Again, this constraint isn’t fully constraining—I might be putting the feeling of anxiety into the context of how everyone hates me, or into the context of how my health is going downhill, or whatever else, and I could be doing both those things while simultaneously zipping up my coat and humming a song, etc.
Anxiety is just one example; I think there’s likewise involuntary attention associated with feeling itchy, feeling in pain, angry, etc.
Replies from: Seth Herd↑ comment by Seth Herd · 2024-11-05T20:53:39.143Z · LW(p) · GW(p)
Interesting! I think that works.
You can still use the same positively-oriented brainstorming process for figuring out how to avoid bad outcomes. As soon as there's even a vague idea of avoiding a very bad outcome, that becomes a very good reward prediction after taking the differential. The dopamine system does calculate such differentials, and it seems like the valance system, while probably different from direct reward prediction and more conceptual, should and could also take differentials in useful ways. Valance needs to at least somewhat dependent on context. I don't think this requires unique mechanisms (although it might have them); it's sufficient to learn variants of the concepts like "avoiding a really bad event" and then attaching valance to that concept variant.
comment by Gunnar_Zarncke · 2024-11-05T13:38:22.197Z · LW(p) · GW(p)
I like the examples from 8.4.2:
- Note the difference between saying (A) “the idea of going to the zoo is positive-valence, a.k.a. motivating”, versus (B) “I want to go to the zoo”. [...]
- Note the difference between saying (A) “the idea of closing the window popped into awareness”, versus (B) “I had the idea to close the window”. Since (B) involves the homunculus as a cause of new thoughts, it’s forbidden in my framework.
I think it could be an interesting mental practice to rephrase inner speech involving "I" in this way. I have been doing this for a while now. It started toward the end of my last meditation retreat when I switched to a non-CISM (or should I say "there was a switch in the thoughts about self-representation"?). Using "I" in mental verbalization felt like a syntax error and other phrasings like you are suggesting here, felt more natural. Interestingly, it still makes sense to use "I" in conversations to refer to me (the speaker). I think that is part of why the CISM is so natural: It uses the same element in internal and external verbalizations[1].
Pondering your examples, I think I would render them differently. Instead of: "I want to go to the zoo," it could be: "there is a desire to go to the zoo." Though I guess if "desire to" stands for "positive-valence thought about") it is very close to your "the idea of going to the zoo is positive-valence."
In practice, the thoughts would be smaller, more like "there is [a sound][2]," "there is a memory of [an animal]," "there is a memory of [an episode from a zoo visit]," "there is a desire to [experience zoo impressions]," "there is a thought of [planning]." The latter gets complicated. The thought of planning could be positive valence (because plans often lead to desirable outcomes) or the planning is instrumentally useful to get the zoo impressions (which themselves may be associated with desirable sights and smells), or the planning can be aversive (because effortful), but still not strong enough to displace the desirable zoo visit.
For an experienced meditator, the fragments that can be noticed can be even smaller - or maybe more pre-cursor-like. This distinction is easier to see with a quiet mind, where, before a thought fully occupies attention, glimmers of thoughts may bubble up[3]. This is related to noticing that attention is shifting. The everyday version of that happens why you notice that you got distracted by something. The subtler form is noticing small shifts during your regular thinking (e.g., I just noticed my attention shifting to some itch, without that really interuping my writing flow). But I'm not sure how much of that is really a sense of attention vs. a retroactive interpretation of the thoughts. Maybe a more competent meditator can comment.
- ^
And now I wonder whether the phonological loop, or whatever is responsible for language-like thoughts, maybe subvocalizations, is what makes the CISM the default model.
- ^
[brackets indicate concepts that are described by words, not the words themselves]
- ^
The question is though, what part notices the noticing. Some thought of [noticing something] must be sufficiently stable and active to do so.
comment by Viliam · 2024-11-10T22:10:25.729Z · LW(p) · GW(p)
Note the difference between saying (A) “the idea of going to the zoo is positive-valence, a.k.a. motivating”, versus (B) “I want to go to the zoo”. (A) is allowed, but (B) is forbidden in my framework, since (B) involves the homunculus.
This sounds like the opposite of the psychological advice to make "I statements".
I guess the idea of going to the zoo can have a positive valence in one brain, and negative valence in another, so as long as we include another people in the picture, it makes sense to specify which brain's valence are we talking about. And "I" is a shortcut for "this is how things are in the brain of the person that is thinking these thoughts".
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-10T23:00:27.184Z · LW(p) · GW(p)
This post is about science. How can we think about psychology and neuroscience in a clear and correct way? “What’s really going on” in the brain and mind?
By contrast, nothing in this post (or the rest of this series), is practical advice about how to be mentally healthy, or how to carry on a conversation, etc. (Related: §1.3.3 [LW · GW].)
Does that help? Sorry if that was unclear.
Replies from: Viliam↑ comment by Viliam · 2024-11-11T08:27:38.099Z · LW(p) · GW(p)
OK, that makes sense. I forgot about that part, and probably underestimated its meaning when I read it.
Seems to me that a large part of this all is about how modeling how other people model me is... on one hand, necessary for social interactions with other people... on the other hand, it seems to create some illusions that prevent us from understanding what's really going on.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-11T11:22:23.679Z · LW(p) · GW(p)
Huh, funny you think that. From my perspective, “modeling how other people model me” is not relevant to this post. I don’t see anywhere that I even mentioned it. It hardly comes up anywhere else in the series either.
comment by lillybaeum · 2024-11-17T12:23:43.241Z · LW(p) · GW(p)
I wonder how domination and submission relate to these concepts.
Note that d/s doesn't necessarily need to have a sexual connotation, although it nearly always does.
My understanding of the appeal of submission is that the ideal submissive state is one where the dominant partner is anticipating the needs and desires of the submissive partner, supplies these needs and desires, and reassures or otherwise convinces the submissive that they are capable of doing so, and will actively do so for the duration of the scene.
After reading your series, I'd assume what is happening here is a number of things all related to the belief in the homunculus and the constant valence calculations that the brain performs in order to survive and thrive in society.
-
You have no need to try to fight for dominance or be 'liked' or 'admired'. The dominant partner is your superior, and the dominant partner likes and admires you completely.
-
You have no need to plan things and determine their valence -- the dominant will anticipate any needs, desires and responsibilities, and take care of them for you.
-
You have no need to maintain a belief in your own 'willpower', 'identity', 'ego', etc... for the duration of the scene, you wear the mask of 'the obedient submissive'.
All things considered, it's absolutely no surprise that 'subspace' is an appealing place to be, it's sort of a shortcut to the truth you're describing. I wouldn't be surprised if some people even have an experience bordering on nirodha samapatti during a particularly deep, extensive scene, where they have little memory of the experience afterwards. I'm also not surprised that hypnodomination, a combination of d/s and trance, is so common, given that the two states are so similar.