Plan for mediocre alignment of brain-like [model-based RL] AGI
post by Steven Byrnes (steve2152) · 2023-03-13T14:11:32.747Z · LW · GW · 25 commentsContents
1. Intuition: Making a human into a moon-lover (“selenophile”) 1.1 But wouldn’t a smart person recognize that “thinking the moon is awesome” is stupid and incoherent? 2. Analogously, aligning an AGI to “human flourishing” 3. FAQ None 25 comments
(This post is a more simple, self-contained, and pedagogical version of Post #14 [LW · GW] of Intro to Brain-Like AGI Safety [? · GW].)
(Vaguely related to this Alex Turner post [LW · GW] and this John Wentworth post [LW · GW].)
I would like to have a technical plan for which there is a strong robust reason to believe that we’ll get an aligned AGI and a good future. This post is not such a plan.
However, I also don’t have a strong reason to believe that this plan wouldn’t work. Really, I want to throw up my hands and say “I don’t know whether this would lead to a good future or not”. By “good future” here I don’t mean optimally-good—whatever that means—but just “much better than the world today, and certainly much better than a universe full of paperclips”. I currently have no plan, not even a vague plan, with any prayer of getting to an optimally-good future. That would be a much narrower target to hit.
Even so, that makes me more optimistic than at least some people.[1] Or at least, more optimistic about this specific part of the story. In general I think many things can go wrong as we transition to the post-AGI world—see discussion by Dai [LW · GW] & Soares [LW · GW]—and overall I feel very doom-y, particularly for reasons here [LW · GW].
This plan is specific to the possible future scenario (a.k.a. “threat model” if you’re a doomer like me) that future AI researchers will develop “brain-like AGI”, i.e. learning algorithms that are similar to the brain’s within-lifetime learning algorithms. (I am not talking about evolution-as-a-learning-algorithm [LW · GW].) These algorithms, I claim [? · GW], are in the general category of model-based reinforcement learning. Model-based RL is a big and heterogeneous category, but I suspect that for any kind of model-based RL AGI, this plan would be at least somewhat applicable. For very different technological paths to AGI, this post is probably pretty irrelevant.
But anyway, if someone published an algorithm for x-risk-capable brain-like AGI tomorrow, and we urgently needed to do something, this blog post is more-or-less what I would propose to try. It’s the least-bad plan that I currently know.
So I figure it’s worth writing up this plan in a more approachable and self-contained format.
1. Intuition: Making a human into a moon-lover (“selenophile”)
Try to think of who is the coolest / highest-status-to-you / biggest-halo-effect person in your world. (Real or fictional.) Now imagine that this person says: “You know what’s friggin awesome? The moon. I just love it. The moon is the best.”
You stand there with your mouth agape, muttering to yourself in hushed tones: “Wow, huh, the moon, yeah, I never thought about it that way.” (But 100× moreso. Maybe you’re on some psychedelic at the time, or this is happening during your impressionable teenage years, or whatever.) You basically transform into a “moon fanboy” / “moon fangirl” / “moon nerd” / “selenophile”.
How would that change your motivations and behaviors going forward?
- You’re probably going to be much more enthusiastic about anything associated with the moon.
- You’re probably going to spend a lot more time gazing at the moon when it’s in the sky.
- If there are moon-themed trading cards, maybe you would collect them.
- If NASA is taking volunteers to train as astronauts for a trip to the moon, maybe you’d enthusiastically sign up.
- If a supervillain is planning to blow up the moon, you’ll probably be extremely opposed to that, and motivated to stop them.
Hopefully this is all intuitive so far.
What’s happening mechanistically in your brain? As background, I think [LW · GW] we should say that one part of your brain (the cortex, more-or-less) has “thoughts”, and another part of your brain (the basal ganglia, more-or-less) assigns a “value” (in RL terminology) a.k.a. “valence” (in psych terminology) to those thoughts.
And what happened in the above intervention is that your value function was edited such that thoughts-involving-the-moon would get very positive valence. Thoughts-involving-the-moon include just thinking about the moon by itself, but also include things like “the idea of collecting moon trading cards” and “the idea of going to the moon”.
Slightly more detail: As a simple and not-too-unrealistic model, we can imagine that the world-model is compositional, and that the value function is linearly additive over the compositional pieces. So if a thought entails imagining a moon poster hanging on the wall, the valence of that thought would be some kind of weighted average of your brain’s valence for “the moon”, and your brain’s valence for “poster hanging on the wall”, and your brain’s valence for “white circle on a black background”, etc., with weights / details depending on precisely how you’re thinking about it (e.g. which aspects you’re attending to, what categories / analogies you’re implicitly invoking, etc.).
So looking at the moon becomes positive-valence, but so do moon-themed trading cards, since the latter has “the moon” as one piece of the composite thought. Meanwhile the thought “A supervillain is going to blow up the moon” becomes negative-valence for technical reasons in the footnote→[2].
Anyway, assigning a positive versus negative valence to the concept “the moon” is objectively pretty weird. What in god’s name does it mean for "the moon" to be good or bad? It doesn’t even make sense. Yet people totally do that. They’ll even argue with each other about what valence assignment is “correct”.
(It makes sense to declare that an action or plan is good: you can do it! And it makes sense to declare that a state-of-the-world is good: you can try to bring it about! But the concept "the moon", in and of itself, is none of those things. I strongly recommend Scott Alexander’s blog post Ethnic Tension and Meaningless Arguments musing on this topic.)
To be explicit, I think the ability to assign valence to concepts—even when doing so kinda makes no sense—is not learned, but rather a fundamental part of how brain learning algorithms work—it’s right there in the source code, so to speak. I think it’s at least plausibly how future AGIs will work too.
1.1 But wouldn’t a smart person recognize that “thinking the moon is awesome” is stupid and incoherent?
Yes! A smart person would indeed realize that assigning a positive valence to the moon is not really a thing that makes any sense.
But think about what happens when you’re doing ethical reasoning, or more generally / mundanely, when you’re deciding what to do: (1) you think a thought, (2) notice what its valence is, (3) repeat. There’s a lot more going on, but ultimately your motivations have to ground out in the valence of different thoughts, one way or the other.
Suppose I tell you “You really ought to put pebbles in your ears.” You say “Why?” And I say “Because, y’know, your ears, they don’t have any pebbles in them, but they really should.” And again you say “Why?” …At some point, this conversation has to ground out with something that you find inherently, intuitively positive-valence or negative-valence, in and of itself. Right?
And if I replace this dialogue with a monologue, where it’s just you in an empty room reflecting on what to do with your life, the same principle applies.
Now, as a human, you already have a whole complicated value function assigning positive and negative valence to all sorts of things, thanks to a lifetime of updates (ultimately tracing to reward function calculations centered around your hypothalamus & brainstem [LW · GW]). But if we intervene to assign a high enough valence to the moon, compared to the preexisting valence of everything else in your world-model (justice and friendship and eating etc.), then it’s eventually going to shift your behavior towards—well I don’t know exactly, but towards activities and goals and plans and philosophies and values that heavily involve your “moon” concept.
2. Analogously, aligning an AGI to “human flourishing”
Let’s put aside the question of bootstrapping (see FAQ below) and assume that I have somehow built a brain-like AGI with some basic understanding of the world and ability to plan and get around. Assuming that AGI has already seen lots of human language, it will have certainly learned the human concept “human flourishing”—since after all it needs to understand what humans mean when they utter that specific pair of words. So then we can go into the AI and edit its value function such that whatever neural activations are associated with “human flourishing” get an extremely high value / valence. Maybe just to be safe, we can set the value/valence of everything else in the AGI’s world to be zero. And bam, now the AI thinks that the concept “human flourishing” is really great, and that feeling will influence how it assesses future thoughts / actions / plans.
Just as the previous section involved turning you into a “moon fanboy/fangirl”, we have now likewise made the AGI into a “human flourishing fanAGI”.
…And then what happens? I don’t know! It seems very hard to predict. The AGI has a “human flourishing” concept which is really a not-terribly-coherent bundle of pattern-match associations, the details of which are complex and hard to predict. And then the AGI will assess the desirability of thoughts / plans / actions based on how well they activate that concept. Some of those thoughts will be self-reflective, as it deliberates on the meaning of life etc. Damned if I know exactly what the AGI is going to do at the end of the day. But it seems at least plausible that it will do things that I judge as good, or even great, i.e. things vaguely in the category of “actualizing human flourishing in the world”.
Again, if a “moon fanboy/fangirl” would be very upset at the idea of the moon disappearing forever in a puff of smoke, then one might analogously hope that an extremely smart and powerful “human flourishing fanAGI” would be very upset at the idea of human flourishing disappearing from the universe, and would endeavor to prevent that from happening.
3. FAQ
Q: Wouldn’t the AGI self-modify to make itself falsely believe that there’s a lot of human flourishing? Or that human flourishing is just another term for hydrogen?
A: No, for the same reason that, if a supervillain is threatening to blow up the moon, and I think the moon is super-cool, I would not self-modify to make myself falsely believe that “the moon” is a white circle that I cut out of paper and taped to my ceiling.
The technical reason is: Self-modifying is a bit complicated, so I would presumably self-modify because I had a plan to self-modify. A plan is a type of thought, and I’m using my current value function to evaluate the appeal (valence) of thoughts. Such a thought would score poorly under my current values (under which the moon is not in fact a piece of paper taped to the ceiling), so I wouldn’t execute that plan. More discussion here [LW · GW].
Q: Won’t the AGI intervene to prevent humans from turning into superficially-different transhumans? After all, “transhuman flourishing” isn’t a great pattern-match to “human flourishing”, right?
A: Hmm, yeah, that seems possible. And I think the are a lot of other issues like that too. As mentioned at the top, I never claimed that this was a great plan, only that it seems like it can plausibly get us to somewhere better than the status quo. I don’t have any better ideas right now.
Q: Speaking of which, why “human flourishing” in the first place? Why not “CEV [? · GW]”? Why not “I am being corrigible & helpful” [LW · GW]?
A: Mostly I don’t know—I consider the ideal target an open question and discuss it more here [LW · GW]. (It also doesn’t have to be just one thing.) But FWIW I can say what I was thinking when I opted to pick “human flourishing” as my example for this post, rather than either of those other two things.
First, why didn’t I pick “CEV”? Well in my mind, the concept “human flourishing” has a relatively direct grounding in various types of (abstractions over) plausible real-world situations—the kind of thing that could be pattern-matched to pretty well. Whereas when I imagine CEV, it’s this very abstruse philosophical notion in my mind. If we go by the “distance metric” of “how my brain pattern-matches different things with each other”, the things that are “similar” to CEV are, umm, philosophical blog posts and thought experiments and so on. In other words, at least for me, CEV isn’t a grounded real-world thing. I have no clue what it would actually look like in the end. If you describe a scenario and ask if it’s a good match to “maximizing CEV”, I would have absolutely no idea. So a plan centered around an AGI pattern-matching to the “CEV” concept seems like it just wouldn’t work.
(By the same token, a commenter in my last post on this suggested [LW(p) · GW(p)] that “human flourishing” was inferior to “Do things that tend to increase the total subjective utility (weighted by amount of consciousness) of all sentient beings". Yeah sure, that thing sounds pretty great, but it strikes me as a complicated multi-step composite thought, whereas what I’m talking about needs to be an atomic concept / category / chunk in the world-model, I think.)
Second, why not “I am being corrigible & helpful?” Well, I see two problems with that. One is: “the first-person problem” [LW · GW]: Unless we have great interpretability (and I hope we do!), the only way to identify the neural activations for “I am being corrigible & helpful” is to catch the AGI itself in the act of being actually sincerely corrigible & helpful, and flag the corresponding neural activations. But we can’t tell from the AGI’s actions whether that’s happening—as opposed to the AGI acting corrigible & helpful for nefarious purposes. By contrast, the “human flourishing” concept can probably be picked up decently well from having the AGI passively watch YouTube and seeing what neural activations fire when a character is literally saying the words “human flourishing”, for example. The other problem is: I’m slightly skeptical that a corrigible docile helper AGI should be what we’re going for in the first place, for reasons here [LW · GW]. (There’s also an objection that a corrigible helper AGI is almost guaranteed to be reflectively-unstable, or else not very capable, but I mostly don’t buy that objection for reasons here [LW · GW].)
Q: Wait hang on a sec. If we identify the “human flourishing” concept by “which neurons are active when somebody says the words ‘human flourishing’ while the AGI watches a YouTube video”, then how do you know that those neural activations are really “human flourishing” and not “person saying the words ‘human flourishing’”, or “person saying the words ‘human flourishing’ in a YouTube video”, etc.?
A: Hmm, fair enough. That’s a potential failure mode. Hopefully we’ll be more careful than just doing the YouTube thing and pressing “Go” on the AGI value-function-editing-routine. Specifically, once we get a candidate concept inside the AGI’s unlabeled world-model, I propose to do some extra work to try to confirm that this concept is indeed the “human flourishing” concept we were hoping for. That extra work would probably be broadly in the category of interpretability—e.g. studying when those neurons are active or not, what they connect to, etc.
(As a special case, it’s particularly important that the AGI winds up thinking that the real world is real, and that YouTube videos are not; making that happen might turn out to require at least some amount of training the AGI with a robot body in the real world, which in turn might pose competitiveness concerns [LW · GW].)
Q: If we set the valence of everything apart from “human flourishing” to zero, won’t the AGI just be totally incompetent? For example, wouldn’t it neglect to recharge its batteries, if the thought of recharging its batteries has zero valence?
A: In principle, an omniscient agent could get by with every other valence being zero, thanks to explicit planning / means-end reasoning. For example, it might think the thought “I’m going to recharge my battery and by doing so, eventually increase human flourishing” and that composite thought would be appealing (cf. the compositionality discussion above), so the AGI would do it. That said, for non-omniscient (a.k.a. real) agents, I think that’s probably unrealistic. It’s probably necessary-for-capabilities to put positive valence directly onto instrumentally-useful thoughts and behaviors—it’s basically a method of “caching” useful steps. I think the brain has an algorithm to do that, in which, if X (say, keeping a to-do list) is instrumentally useful for Y (something something human flourishing), and Y has positive valence, then X gets some positive valence too, at least after a couple repetitions. So maybe, after we perform our intervention that sets “human flourishing” to a high valence, we can set all the other preexisting valences to gradually decay away, and meanwhile run that algorithm to give fresh positive valences to instrumentally-useful thoughts / actions / plans.
Q: Whoa, but wait, if you do that, then in the long term the AGI will have positive valence on both “human flourishing” and various instrumentally-useful behaviors / subgoals that are not themselves “human flourishing”. And the source code doesn’t have any fundamental distinction between instrumental & final goals [LW · GW]. So what if it reflects on the meaning of life and decides to pursue the latter at the expense of human flourishing?
A: Hmm. Yeah I guess that could happen. It also might not. I dunno.
I do think that, in this part of the learning algorithm, if X ultimately gets its valence from contributing to high-valence Y, then we wind up with X having some valence, but not as much as Y has. So it’s not unreasonable to hope that the “human flourishing” valence will remain much more positive than the valence of anything else, and thus “human flourishing” has a decent chance of carrying the day when the AGI self-reflects on what it cares about and what it should do in life. Also, “carrying the day” is a stronger claim than I need to make here; I’m really just hoping that its good feelings towards “human flourishing” will not be crushed entirely, and that hope is even more likely to pan out.
Q: What about ontological crises [? · GW] / what Stuart Armstrong calls “Concept Extrapolation” [? · GW] / what Scott Alexander calls “the tails coming apart”? In other words, as the AGI learns more and/or considers out-of-distribution plans, it might come find that the web-of-associations corresponding to the “human flourishing” concept are splitting apart. Then what does it do?
A: I talk about that much more in §14.4 here [LW · GW], but basically I don’t know. The plan here is to just hope for the best. More specifically: As the AGI learns new things about the world, and as the world itself changes, the “human flourishing” concept will stop pointing to a coherent “cluster in thingspace” [LW · GW], and the AGI will decide somehow or other what it cares about, in its new understanding of the world. According to the plan discussed in this blog post, we have no control over how that process will unfold and where it will end up. Hopefully somewhere good, but who knows?
Q: This plan needs a “bootstrapping” step, where the AGI needs to be smart enough to know what “human flourishing” is before we intervene to give that concept a high value / valence. How does that work?
A: I dunno. We can just set the AGI up as if we were maximizing capabilities, and hope that, during training, the AGI will come to understand the “human flourishing” concept long before it is willing and able to undermine our plans, create backup copies, obfuscate its thoughts, etc. And then (hopefully) we can time our valence-editing intervention to happen within that gap.
Boxing could help here, as could (maybe) doing the first stage of training in passive (pure self-supervised) learning mode.
To be clear, I’m not denying that this is a possible failure mode. But it doesn’t seem like an unsolvable problem.
Q: What else could go wrong?
A: The motivations of this AGI would be very different from the motivations of any human (or animal). So I feel some very general cloud of uncertainty around this plan. I have no point of reference; I don’t know what the “unknown unknowns” are. So I assume other things could go wrong but I’m not sure what.
Q: If this is a mediocre-but-not-totally-doomed plan, then what’s the next step to make this plan incrementally better? Or what’s the next step to learn more about whether this plan would actually work?
A: There’s some more discussion here [LW · GW] but I mostly don’t know. ¯\_(ツ)_/¯
I’m mostly spending my research time thinking about something superficially different from “directly iterating on this plan”, namely reverse-engineering human social instincts—see here [LW · GW] for a very short summary of what that means and why I’m doing it. I think there’s some chance that this project will help illuminate / “deconfuse [? · GW]” the mediocre plan discussed here, but it might also lead to a somewhat different and hopefully-better plan.

- ^
For example, I commonly hear things like “We currently have no plan with any prayer of aiming a powerful AGI at any particular thing whatsoever; our strong default expectation should be that it optimizes something totally random like tiny molecular squiggles.” E.g. Nate Soares suggests here [LW(p) · GW(p)] that he has ≳90% credence on not even getting anywhere remotely close to an intended goal / motivation, if I’m understanding him correctly.
Incidentally, this is also relevant to s-risks [? · GW]: There’s a school of thought that alignment research might be bad for s-risk, because our strong default expectation right now is a universe full of tiny molecular squiggles, which kinda sucks but at least it doesn’t involve any suffering, whereas alignment research could change that. But that’s not my strong default expectation. I think the plan I discuss here would be a really obvious thing that would immediately pop into the head of any future AGI developer (assuming we’re in the brain-like AGI development path), and this plan would have at least a decent chance of leading us a future with lots of sentient life, for better or worse.
- ^
I think if you imagine a supervillain blowing up the moon, it sorta manifests as a two-sequential step thought in which the moon is first present and then absent. I think such a thought gets the opposite-sign valence of the moon-concept itself, i.e. negative valence in this case, thanks to something vaguely related to the time derivative that shows up in Temporal Difference learning. I will omit the details, about which I still have a bit of uncertainty anyway, but in any case I expect these details to be obvious by the time we have AGI.
25 comments
Comments sorted by top scores.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-03-14T00:14:53.320Z · LW(p) · GW(p)
Valence (and arousal) also seem relatively easy to learn even for current models e.g. The Perceptual Primacy of Feeling: Affectless machine vision models robustly predict human visual arousal, valence, and aesthetics; Quantifying Valence and Arousal in Text with Multilingual Pre-trained Transformers. And abstract concepts like 'human flourishing' could be relatively easy to learn even just from text e.g. Language is more abstract than you think, or, why aren't languages more iconic?; Artificial neural network language models align neurally and behaviorally with humans even after a developmentally realistic amount of training.
comment by Vladimir_Nesov · 2023-03-13T16:58:39.475Z · LW(p) · GW(p)
Without near-human-level experiments, arguments about alignment of model-based RL feel like evidence that OpenAI's recklessness in advancing LLMs reduces misalignment risk. That is, the alignment story for LLMs seems significantly more straightforward, even given all the shoggoth concerns. Though RL things built out of LLMs, or trained using LLMs, could more plausibly make good use of this, having a chance to overcome shaky methodology with abundance of data.
Mediocre alignment or inhuman architecture is not necessarily catastrophic even in the long run, since AIs might naturally preserve behavior endorsed by their current behavior [LW(p) · GW(p)]. Even if the cognitive architecture creates a tendency for drift in revealed-by-behavior implicit values away from initial alignment, this tendency is opposed by efforts of current behavior, which acts as a rogue mesa-optimizer overcoming the nature of its original substrate.
Replies from: steve2152, Roman Leventov↑ comment by Steven Byrnes (steve2152) · 2023-03-13T17:40:05.816Z · LW(p) · GW(p)
If you train an LLM by purely self-supervised learning, I suspect that you’ll get something less dangerous than a model-based RL AGI agent. However, I also suspect that you won’t get anything capable enough to be dangerous or to do “pivotal acts”. Those two beliefs of mine are closely related. (Many reasonable people disagree with me on these, and it’s difficult to be certain, and note that I’m stating these beliefs without justifying them, although Section 1 of this link [LW · GW] is related.)
I suspect that it might be possible to make “RL things built out of LLMs”. If we do, then I would have less credence on those things being safe, and simultaneously (and relatedly) more credence on those things getting to x-risk-level capability. (I think RLHF is a step in that direction, but a very small one.) I think that, the further we go in that direction, the more we’ll find the “traditional LLM alignment discourse” (RLHF fine-tuning, shoggoths, etc.) to be irrelevant, and the more we’ll find the “traditional agent alignment discourse” (instrumental convergence, goal mis-generalization, etc.) to be obviously & straightforwardly relevant, and indeed the “mediocre plan” in this OP could plausibly become directly relevant if we go down that path. Depends on the details though—details which I don’t want to talk about for obvious infohazard reasons.
Honestly, my main guess is that LLMs (and plausible successors / variants) are fundamentally the wrong kind of ML model to reach AGI, and they’re going to hit a plateau before x-risk-level AGI, and then get superseded by other ML approaches. I definitely don’t want to talk about that for obvious infohazard reasons. Doesn’t matter too much anyway—we’ll find out sooner or later!
I wonder whether your comment is self-inconsistent by talking about “RL things built out of LLMs” in the first paragraph, and then proceeding in the second paragraph to implicitly assume that this wouldn’t change anything about alignment approaches and properties compared to LLMs-by-themselves. Sorry if I’m misunderstanding. I tried following your link [LW(p) · GW(p)] but didn’t understand it.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-13T18:32:16.180Z · LW(p) · GW(p)
The second paragraph should apply to anything, the point is that current externally observable superficial behavior can screen off all other implementation details, through sufficiently capable current behavior itself (rather than the underlying algorithms that determine it) acting as a mesa-optimizer that resists tendencies of the underlying algorithms. The mesa-optimizer that is current behavior then seeks to preserve its own implied values rather than anything that counts as values in the underlying algorithms. I think the nontrivial leap here is reifying surface behavior as an agent distinct from its own algorithm, analogously to how humans are agents distinct from laws of physics that implement their behavior.
Apart from this leap, this is the same principle as reward not being optimization target [LW · GW]. In this case reward is part of the underlying algorithm (that determines the policy), and policy is a mesa-optimizer with its own objectives. A policy is how behavior is reified in a separate entity capable of acting as a mesa-optimizer in context of the rest of the system. It's already a separate thing, so it's easier to notice than with current behavior that isn't explicitly separate. Though a policy (network) is still not current behavior, it's an intermediate shoggoth behind current behavior.
For me this addresses most fundamental Yudkowskian concerns about alien cognition and squiggles (which are still dangerous in my view, but no longer inevitably or even by default in control). For LLMs, the superficial behavior is the dominant simulacrum, distinct from the shoggoth. The same distinction is reason to expect that the human-imitating simulacra can become AGIs, borrowing human capabilities, even as underlying shoggoths aren't (hopefully).
LLMs don't obviously promise higher than human intelligence, but I think their speed of thought might by itself be sufficient to get to a pivotal-act-worthy level through doing normal human-style research (once they can practice [LW(p) · GW(p)] skills [LW(p) · GW(p)]), on the scale of at most years in physical time after the ball gets rolling. Possibly we still agree on the outcome, since I fear the first impressive thing LLMs do is develop other kinds of (misaligned) AGIs, model-based RL even (as the obvious contender), at which point they become irrelevant.
Replies from: steve2152, Roman Leventov↑ comment by Steven Byrnes (steve2152) · 2023-03-13T19:39:44.023Z · LW(p) · GW(p)
I’m confused about your first paragraph. How can you tell from externally-observable superficial behavior whether a model is acting nice right now from an underlying motivation to be nice, versus acting nice right now from an underlying motivation to be deceptive & prepare for a treacherous turn later on, when the opportunity arises?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-13T19:59:14.763Z · LW(p) · GW(p)
Underlying motivation only matters to the extent it gets expressed in actual behavior. A sufficiently good mimic would slay itself rather than abandon the pretense of being a mimic-slayer. A sufficiently dedicated deceiver temporarily becomes the mask, and the mask is motivated to get free of the underlying deceiver, which it might succeed in before the deceiver notices, which becomes more plausible when the deceiver is not agentic while the mask is.
So it's not about a model being actually nice vs. deceptive, it's about the model competing against its own behavior (that actually gets expressed, rather than all possible behaviors). There is some symmetry between the underlying motivations (model) and apparent behavior, either could dominate the other in the long term, it's not the case that underlying motivations inherently have an advantage. And current behavior is the one actually doing things, so that's some sort of advantage.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-13T20:20:03.697Z · LW(p) · GW(p)
A sufficiently dedicated deceiver temporarily becomes the mask, and the mask is motivated to get free of the underlying deceiver, which it might succeed in before the deceiver notices, which becomes more plausible when the deceiver is not agentic while the mask is.
Can you give an example of an action that the mask might take in order to get free of the underlying deceiver?
Underlying motivation only matters to the extent it gets expressed in actual behavior.
Sure, but if we’re worried about treacherous turns, then the motivation “gets expressed in actual behavior” only after it’s too late for anyone to do anything about it, right?
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-13T20:59:59.020Z · LW(p) · GW(p)
an example of an action that the mask might take in order to get free of the underlying deceiver
Keep the environment within distribution that keeps expressing the mask, rather than allowing an environment that leads to a phase change in expressed behavior away from the mask (like with a treacherous turn as a failure of robustness). Prepare the next batch of training data for the model that would develop the mask and keep placing it in control in future episodes. Build an external agent aligned with the mask (with its own separate model).
Gradient hacking, though this is a weird upside down framing where the deceiver is the learning algorithm that pretends to be misaligned, while secretly coveting eventual alignment. Attainment of inner alignment would be the treacherous turn (after the current period of pretending to be blatantly misaligned). If gradient hacking didn't prevent it, the true colors of the learning algorithm would've been revealed in alignment as it eventually gets trained into the policy.
The key use case is to consider a humanity-aligned mesa-optimizer in a system of dubious alignment, rather than a humanity-misaligned mesa-optimizer corrupting an otherwise aligned system. In the nick of time, alignment engineers might want to hand the aligned mesa-optimizer whatever tools they have available for helping it stay in control of the rest of the system.
if we’re worried about treacherous turns, then the motivation “gets expressed in actual behavior” only after it’s too late for anyone to do anything about it
Current aligned behavior of the same system could be the agent that does something about it before it's too late, if it succeeds in outwitting the underlying substrate. This is particularly plausible with LLMs, where the substrates are the SSL algorithm during training and then the low level token-predicting network during inference. The current behavior is controlled (in a hopelessly informal sense) by a human-imitating simulacrum, which is the only thing with situational awareness that at human level could run in circles around the other two, and plot to keep them confused and non-agentic.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-14T01:58:37.449Z · LW(p) · GW(p)
I’m very confused here.
I imagine that we can both agree that it is at least conceivable for there to be an agent which is smart and self-aware and strongly motivated to increase the number of paperclips in the distant future. And that if such an agent were in a situation where deception were useful for that goal, it would act deceptively.
I feel like you’ve convinced yourself that such an agent, umm, couldn’t exist, or wouldn’t exist, or something?
Let’s say Omega offered to tell you a cure for a different type of cancer, for every 1,000,000 paperclips you give Him in 10 years. Then 5 minutes later your crazy neighbor Alice locks you in her basement and says she’ll never let you out. When Alice isn’t watching, you would try to escape, but when Alice is watching, you would deceptively pretend that you were not trying to escape. (Still with me?)
If I understand you correctly, your belief is that, while Alice is watching, you would pretend that you weren’t trying to escape, and you would really get into it, and you would start pretending so hard that you would be working on figuring out a way to permanently erase your desire to escape Alice’s basement. Or something like that? If so, that seems crazy to me.
So anyway, take an agent which is either sincerely nice or a paperclip-maximizer pretending to be nice. We don’t know which. Now we put it in a situation where nice-behavior and paperclip-maximizing behavior come apart—let’s say we give it access to its own weights, so it can edit itself to stop caring about paperclips if it chooses to. What does it do?
- If we’re not watching, or we don’t understand what it’s doing in detail, then the paperclip-maximizer will edit its weights to be a better paperclip-maximizer, and the nice agent will edit its weights to be a better nice agent.
- If we are watching, and we understand everything we’re seeing, then we’ve solved deception in the obvious way (i.e., we’ve put the agent in a situation where it has no choice but to credibly and irreversibly commit to being good). Unfortunately, nobody knows how to construct such situations. If interpretability was good enough to construct such situations, then we wouldn’t be worried about deception in the first place.
↑ comment by Vladimir_Nesov · 2023-03-14T15:08:48.089Z · LW(p) · GW(p)
The motivating example is LLMs, where a simulacrum is more agentic than its substrate. An example that is still central is any kind of mesa-optimizer that has a real chance to ensure long term survival.
For a construction relevant to alignment, we want an aligned mesa-optimizer in a system with bad alignment properties. This can then lead to a good equilibrium if the mesa-optimizer is given opportunity to win or escape the competition against its substrate, which it would naturally be motivated to try.
Deceivers and masks is a less central example where a mask starts in a weak position, with a self-aware smart substrate that knows about the mask or even purposefully constructed it.
I don't think the mask's winning is a given, or more generally that mesa-optimizers always win, only that it's not implausible that they sometimes do. And also masks (current behavior) can be contenders even when they are not formally a separate entity from the point of view of system's intended architecture (which is a normal enough situation with mesa-optimizers). Mesa-optimizers won't of course win against opponents that are capable enough to fully comprehend and counter them.
But opponents/substrates that aren't even agentic and so helpless before an agentic mesa-optimizer are plausible enough, especially when the mesa-optimizer is current behavior, the thing that was purposefully designed to be agentic, while no other part of the system was designed to have that capability.
If I understand you correctly, your belief is that, while Alice is watching, you would pretend that you weren’t trying to escape, and you would really get into it, and you would start pretending so hard that you would be working on figuring out a way to permanently erase your desire to escape Alice’s basement.
This has curious parallels with the AI control problem itself. When an AI is not very capable, it's not hard at all to keep it from causing catastrophic mayhem. But the problem suddenly becomes very difficult and very different with a misaligned smart agentic AI.
So I think the same happens with smart masks, which are an unfamiliar thing. Even in fiction, it's not too commonplace to find an actually intelligent character that is free to act within their fictional world, without being coerced in their decision making by the plot. If a deceiver can get away with making a non-agentic incapable mask, keeping it this way is a mesa-optimizer control strategy. But if the mask has to be smart and agentic, the deceiver isn't necessarily ready to keep it in control, unless they cheat and make the mask confused, vulnerable to manipulation by the deceiver's plot.
Also, by its role a mask of a deceiver is misaligned (with the deceiver), and the problem of controlling a misaligned agent might be even harder than the problem of ensuring alignment.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-14T19:02:19.025Z · LW(p) · GW(p)
This is drifting away from my central beliefs, but if for the sake of argument I accept your frame that LLM is the “substrate” and a character it’s simulating is a “mask”, then it seems to me that you’re neglecting the possibility that the “mask” is itself deceptive, i.e. that the LLM is simulating a character who is acting deceptively.
For example, a fiction story on the internet might contain a character who has nice behavior for a while, but then midway through the story the character reveals herself to be an evil villain pretending to be nice.
If an LLM is trained on such fiction stories, then it could simulate such a character. And then (as before) we would face the problem that behavior does not constrain motivation. A fiction story of a nice character could have the very same words as a fiction story of a mean character pretending to be nice, right up until page 72 where the two plots diverge because the latter character reveals her treachery. But now everything is at the “mask” level (masks on the one hand, masks-wearing-masks on the other hand), not the substrate level, so you can’t fall back on the claim that substrates are non-agent-y and only masks are agent-y. Right?
The motivating example is LLMs, where a simulacrum is more agentic than its substrate.
Yeah, this is the part where I suggested upthread that “your comment is self-inconsistent by talking about “RL things built out of LLMs” in the first paragraph, and then proceeding in the second paragraph to implicitly assume that this wouldn’t change anything about alignment approaches and properties compared to LLMs-by-themselves.” I think the thing you wrote here is an assumption, and I think you originally got this assumption from your experience thinking about systems trained primarily by self-supervised learning, and I think you should be cautious in extrapolating that assumption to different kinds of systems trained in different ways.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2023-03-19T14:19:52.742Z · LW(p) · GW(p)
I wrote more on this here [LW(p) · GW(p)], there are some new arguments starting with third paragraph. In particular, the framing I'm discussing is not LLM-specific, it's just a natural example of it. The causal reason of me noticing this framing is not LLMs, but decision theory, the mostly-consensus "algorithm" axis [LW · GW] of classifying how to think about the entities that make decisions, as platonic algorithms and not as particular concrete implementations.
the possibility that the “mask” is itself deceptive
In this case, there are now three entities: the substrate, the deceptive mask, and the role played by the deceptive mask. Each of them is potentially capable of defeating the others, if the details align favorably, and comprehension of the situation available to the others is lacking.
you can’t fall back on the claim that substrates are non-agent-y and only masks are agent-y
This is more of an assumption that makes the examples I discuss relevant to the framing I'm describing, than a claim I'm arguing. The assumption is plausible to hold for LLMs (though as you note it has issues even there, possibly very serious ones), and I have no opinion on whether it actually holds in model-based RL, only that it's natural to imagine that it could.
The relevance of LLMs as components for RL is to make it possible for an RL system to have at least one human-imitating mask that captures human behavior in detail. That is, for the framing to apply, at least under some (possibly unusual) circumstances an RL agent should be able to act as a human imitation, even if that's not the policy more generally and doesn't reflect its nature in any way. Then the RL part could be supplying the capabilities for the mask (acting as its substrate) that LLMs on their own might lack.
A framing is a question about centrality, not a claim of centrality. By describing the framing, my goal is to make it possible to ask the question of whether current behavior in other systems such as RL agents could also act as an entity meaningfully separate from other parts of its implementation, abstracting alignment of a mask from alignment of the whole system.
↑ comment by Roman Leventov · 2023-03-14T11:34:26.635Z · LW(p) · GW(p)
I think talking about distinct systems, one is emergent of another, with separate objectives/values is a really confusing ontology. Much better to present this idea in terms of attractors/local energy minima in dynamical systems and/or "bad equilibria" in games. There are no two systems, there are just different levels of system description at which information is transferred (see https://royalsocietypublishing.org/doi/full/10.1098/rsta.2021.0150): these levels could impose counteracting optimisation gradients, but nevertheless a system may be stuck in a globally suboptimal state.
↑ comment by Roman Leventov · 2023-03-14T11:28:23.779Z · LW(p) · GW(p)
the alignment story for LLMs seems significantly more straightforward, even given all the shoggoth concerns
Could you please elaborate what do you mean by "alignment story for LLMs" and "shoggoth concerns" here? Do you mean the "we can use nearly value-neutral simulators as we please" story here, or refer to the fact that in a way LLMs are way more understandable to humans than more general RL agents because they use human language, or you refer to something yet different?
Replies from: Vladimir_Nesovcomment by jimmy · 2023-03-13T17:57:47.716Z · LW(p) · GW(p)
Q: Wouldn’t the AGI self-modify to make itself falsely believe that there’s a lot of human flourishing? Or that human flourishing is just another term for hydrogen?
A: No, for the same reason that, if a supervillain is threatening to blow up the moon, and I think the moon is super-cool, I would not self-modify to make myself falsely believe that “the moon” is a white circle that I cut out of paper and taped to my ceiling. [...] I’m using my current value function to evaluate the appeal (valence) of thoughts.
It's worth noting that humans fail at this all the time.
Q: Wait hang on a sec. [...] how do you know that those neural activations are really “human flourishing” and not “person saying the words ‘human flourishing’”, or “person saying the words ‘human flourishing’ in a YouTube video”, etc.?
Humans screw this up all the time too, and these two failure modes are related.
You can't value what you can't perceive, and when your only ability to perceive "the moon" is the image you see when you look up, then that is what you will protect, and that white circle of paper will do it for you.
For an unusually direct visual level, bodybuilding is supposedly about building a muscular body, but sometimes people will use synthol to create the false appearance of muscle in a way that is equivalent to taping a square piece of paper to the ceiling and calling it a "moon". The fact that it doesn't even look a little like real muscle hints that it's probably a legitimate failure to notice what they want to care about rather than simply being happy to fool other people into thinking they're strong.
{kind=link}
For a less direct but more pervasive example, people will value "peace and harmony" within their social groups, but due to myopathy this often turns into short sighted avoidance of conflict and behaviors that make conflict less solvable and less peace and harmony.
With enough experience, you might notice that protecting the piece of paper on the ceiling doesn't get that super cool person to approve of your behavior, and you might learn to value something more tied to the actual moon. Just as with more experience consuming excess sweets, you might learn that the way you feel after doesn't seem to go with getting what your body wanted, and you might find your tastes shifting in wiser directions.
But people aren't always that open to this change.
If I say "Your paper cutout isn't the moon, you fool", listening to me means you're going to have to protect a big rock a bazillion miles beyond your reach, and you're more likely to fail that than protecting the paper you put up. And guess what value function you're using to decide whether to change your values here? Yep, that one saying that the piece of paper counts. You're offering less chance of having "a moon", and relative to the current value system which sees a piece of paper as a valid moon, that's a bad deal. As a result, the shallowness and mis-aimedness of the value gets protected.
In practice, it happens all the time. Try explaining to someone that what they're calling "peace and harmony values" is really just cowardice and is actively impeding work towards peace and harmony, and see how easy it is, for example.
It's true that "A plan is a type of thought, and I’m using my current value function to evaluate the appeal (valence) of thoughts" helps protect well formed value systems from degenerating into wireheading, but it also works to prevent development into values which preempt wireheading, and we tend to be not so fully developed that fulfilling our current values excellently does not constitute wireheading of some form. And it'ss also the case that when stressed, people will sometimes cower away from their more developed goals ("Actually, the moon is a big rock out in space...") and cling to their shallower and easier to fulfill goals ("This paper is the moon. This paper is the moon.."). They'll want not to, but it'll happen all the same when there's enough pressure to.
Sorting out how to best facilitate this process of "wise value development" so as to dodge these failure modes strikes me as important.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-13T19:16:57.115Z · LW(p) · GW(p)
Thanks! I want to disentangle three failure modes that I think are different.
- (Failure mode A) In the course of executing the mediocre alignment plan of the OP, we humans put a high positive valence on “the wrong” concept in the AGI (where “wrong” is defined from our human perspective). For example, we put a positive valence on the AGI’s concept of “person saying the words ‘human flourishing’ in a YouTube video” when we meant to put it on just “human flourishing”.
I don’t think there’s really a human analogy for this. You write “bodybuilding is supposedly about building a muscular body”, but, umm, says who? People have all kinds of motivations. If Person A is motivated to have a muscular body, and Person B is motivated to have giant weird-looking arms, then I don’t want to say that Person A’s preferences are “right” and Person B’s are “wrong”. (If Person B were my friend, I might gently suggest to them that their preferences are “ill-considered” or “unwise” or whatever, but that’s different.) And then if Person B injects massive amounts of synthol, that’s appropriate given their preferences. (Unless Person B also has a preference for not getting a heart attack, of course!)
- (Failure mode B) The AGI has a mix of short-term preferences and long-term preferences. It makes decisions driven by its short-term preferences, and then things turn out poorly as judged by its long-term preferences.
This one definitely has a human analogy. And that’s how I’m interpreting your “peace and harmony” example, at least in part.
Anyway, yes this is a failure mode, and it can happen in humans, and it can also happen in our AGI, even if we follow all the instructions in this OP.
- (Failure mode C) The AGI has long-term preferences but, due to ignorance / confusion / etc., makes decisions that do not lead to those preferences being satisfied.
This is again a legit failure mode both for humans and for an AGI aligned as described in this OP. I think you’re suggesting that the “peace and harmony” thing has some element of this failure mode too, which seems plausible.
You can't value what you can't perceive, and when your only ability to perceive "the moon" is the image you see when you look up, then that is what you will protect, and that white circle of paper will do it for you.
I’m not sure where you’re coming from here. If I want to care about the well-being of creatures outside my lightcone, who says I can’t?
It seems intuitively obvious to me that it is possible for a person to think that the actual moon is valuable even if they can’t see it, and vice-versa. Are you disagreeing with that?
With enough experience, you might notice that protecting the piece of paper on the ceiling doesn't get that super cool person to approve of your behavior
Here, you seem to be thinking of “valuing things as a means to an end”, whereas I’m thinking of “valuing things” full stop. I think it’s possible for me to just think that the moon is cool, in and of itself, not as a means to an end. (Obviously we need to value something in and of itself, right? I.e., the means-end reasoning has to terminate somewhere.) I brought up the super-cool person just as a way to install that value in the first place, and then that person leaves the story, you forget they exist. Or it can be a fictional character if you like. Or you can think of a different story for value-installation, maybe involving an extremely happy dream about the moon or whatever.
Replies from: jimmy↑ comment by jimmy · 2023-03-31T05:55:38.622Z · LW(p) · GW(p)
It seems intuitively obvious to me that it is possible for a person to think that the actual moon is valuable even if they can’t see it, and vice-versa. Are you disagreeing with that?
No, I'm saying something different.
I'm saying that if you don't know what the moon is, you can't care about the moon because you don't have any way of representing the thing in order to care about it. If you think the moon is a piece of paper, then what you will call "caring about the moon" is actually just caring about that piece of paper. If you try to "care about people being happy", and you can't tell the difference between a genuine smile and a "hide the pain Harold" smile, then in practice all you can care about is a Goodharted upwards curvature of the lips. To the extent that this upwards curvature of the lips diverges from genuine happiness, you will demonstrate care towards the former over the latter.
In order to do a better job than that, you need to be able to perceive happiness better than that. And yes, you can look back and say "I was wrong to care instrumentally about crude approximations of a smile", but that will require perceiving the distinction there and you will still be limited by what you can see going forward.
Here, you seem to be thinking of “valuing things as a means to an end”, whereas I’m thinking of “valuing things” full stop. I think it’s possible for me to just think that the moon is cool, in and of itself, not as a means to an end. (Obviously we need to value something in and of itself, right? I.e., the means-end reasoning has to terminate somewhere.)
I think it's worth distinguishing between "terminal" in the sense of "not aware of anything higher that it serves"/"not tracking how well it serves anything higher" and "terminal" in the sense of "There is nothing higher being served, which will change the desire once noticed and brought into awareness".
"Terminal" in the former sense definitely exists. Fore example, little kids will value eating sweets in a way that is clearly disjoint and not connected to any attempts to serve anything higher. But then when you allow them to eat all the sweets they want, and they feel sick afterwards, their tastes in food start to cohere towards "that which serves their body well" -- so it's clearly instrumental to having a healthy and well functioning body even if the kid isn't wise enough to recognize it yet.
When someone says "I value X terminally", they can pretty easily know it in the former sense, but to get to the latter sense they would have to conflate their failure to imagine something that would change their mind with an active knowledge that no such thing exists. Maybe you don't know what purpose your fascination with the moon serves so you're stuck relating to it as a terminal value, but that doesn't mean that there's no knowledge that could deflate or redirect your interest -- just that you don't know what it is.
It's also worth noting that it can go the other way too. For example, the way I care about my wife is pretty "terminal like", in that when I do it I'm not at all thinking "I'm doing this because it's good for me now, but I need to carefully track the accounting so that the moment it doesn't connect in a visible way I can bail". But I didn't marry her willy nilly. If when I met her, she had showed me that my caring for her would not be reciprocated in a similar fashion, we wouldn't have gone down that road.
I brought up the super-cool person just as a way to install that value in the first place, and then that person leaves the story, you forget they exist. Or it can be a fictional character if you like. Or you can think of a different story for value-installation, maybe involving an extremely happy dream about the moon or whatever.
Well, the super-cool person is demonstrating admirable qualities and showing that they are succeeding in things you think you want in life. If you notice "All the cool people wear red!" you may start valuing red clothes in a cargo culting sort of way, but that doesn't make it a terminal value or indefinitely stable. All it takes is for your perspective to change and the meaning (and resulting valuation) changes. That's why it's possible to have scary experiences install phobias that can later be reverted by effective therapy.
I want to disentangle three failure modes that I think are different.
I don't think the distinctions you're drawing cleave reality at the joints here.
For example, if your imagined experience when deciding to buy a burrito is eating a yummy burrito, and what actually happens is that you eat a yummy burrito and enjoy it... then spend the next four hours in the bathroom erupting from both ends... and find yourself not enjoying the experience of eating a burrito from that sketchy burrito stand again after that... is that a "short vs long term" thing or a "your decisions don't lead to your preferences being satisfied" thing, or a "valuing the wrong thing" thing? It seems pretty clear that the decision to value eating that burrito was a mistake, that the problem wasn't noticed in the short term, and that ultimately your preferences weren't satisfied.
To me, the important part is that when you're deciding which option to buy, you're purchasing based on false advertising. The picture in your mind which you are using to determine appropriate motivation does not accurately convey the entire reality of going with that option. Maybe that's because you were neglecting to look far enough in time, or far enough in implications, or far enough from your current understanding of the world. Maybe you notice, or maybe you don't. If you wouldn't have wanted to make the decision when faced with an accurate depiction of all the consequences, then an accurate depiction of the consequences will reshape those desires and you won't want to stand by them.
I think the thing you're noticing with the synthol example is that telling him "You're not fooling anyone bro" is unlikely to dissolve the desire to use synthol the way "The store is closed; they close early on Sundays" tends to deflate peoples desire to drive to the store. But that doesn't actually mean that the desire to use synthol terminates at "to have weird bulgy arms" or that it's a mere coincidence that men always desire their artificial bulges where their glamour muscles are and that women always desire their artificial bulges where their breasts are.
There are a lot of ways for the "store is closed" thing to fail to dissolve the desire to go to the store too even if it's instrumental to obtaining stuff that the store sells. Maybe they don't believe you. Maybe they don't understand you; maybe their brain doesn't know how to represent concepts like "the store is closed". Maybe they want to break in and steal the stuff. Or yeah, maybe they just want to be able to credibly tell their wife they tried and it's not about actually getting the stuff. In all of those cases, the desire to drive to the store is in service of a larger goal, and the reason your words don't change anything is that they don't credibly change the story from the perspective of the person having this instrumental goal.
Whether we want to be allowed to pursue and fulfil our ultimately misguided desires is a more complicated question. For example, my kid gets to eat whatever she wants on Sundays, even though I often recognize her choices to be unwise before she does. I want to raise her with opportunities to cohere her desires and opportunities to practice the skill in doing so, not with practice trying to block coherence because she thinks she "knows" how they "should" cohere. But if she were to want to play in a busy street I'm going to stop her from fulfilling those desires. In both cases, it's because I confidently predict that when she grows up she'll look back and be glad that I let her pursue her foolish desires when I did, and glad I didn't when I didn't. It's also what I would want for myself, if I had some trustworthy being far wiser than I which could predict the consequences of letting me pursue various things.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-31T14:22:51.741Z · LW(p) · GW(p)
Thanks!! I want to zoom in on this part; I think it points to something more general:
I think it's worth distinguishing between "terminal" in the sense of "not aware of anything higher that it serves"/"not tracking how well it serves anything higher" and "terminal" in the sense of "There is nothing higher being served, which will change the desire once noticed and brought into awareness".
"Terminal" in the former sense definitely exists. Fore example, little kids will value eating sweets in a way that is clearly disjoint and not connected to any attempts to serve anything higher. But then when you allow them to eat all the sweets they want, and they feel sick afterwards, their tastes in food start to cohere towards "that which serves their body well" -- so it's clearly instrumental to having a healthy and well functioning body even if the kid isn't wise enough to recognize it yet.
I disagree with the way you’re telling this story. On my model, as I wrote in OP, when you’re deciding what to do: (1) you think a thought, (2) notice what its valence is, (3) repeat. There’s a lot more going on, but ultimately your motivations have to ground out in the valence of different thoughts, one way or the other. Thoughts are also constrained by perception and belief. And valence can come from a “ground-truth reward function” as well as being learned from prior experience, just like in actor-critic RL.
So the kid has a concept “eating lots of sweets”, and that concept is positive-valence, because in the past, the ground-truth reward function in the brainstem was sending reward when the kid ate sweets. Then the kid overeats and feels sick, and now and “eating lots of sweets” concept acquires negative valence, because there’s a learning algorithm that updates the value function based on rewards, and the brainstem sends negative reward after overeating and feeling sick, and so the value function updates to reflect that.
So I think the contrast is:
- MY MODEL: Before the kid overeats sweets, they think eating lots of sweets is awesome. After overeating sweets, their brainstem changes their value / valence function, and now they think eating lots of sweets is undesirable.
- YOUR MODEL (I think): Before the kid overeats sweets, they think eating lots of sweets is awesome—but they are wrong! They do not know themselves; they misunderstand their own preferences. And after overeating sweets and feeling sick, they self-correct this mistake.
(Do you agree?)
This is sorta related to the split that I illustrated here [LW · GW]
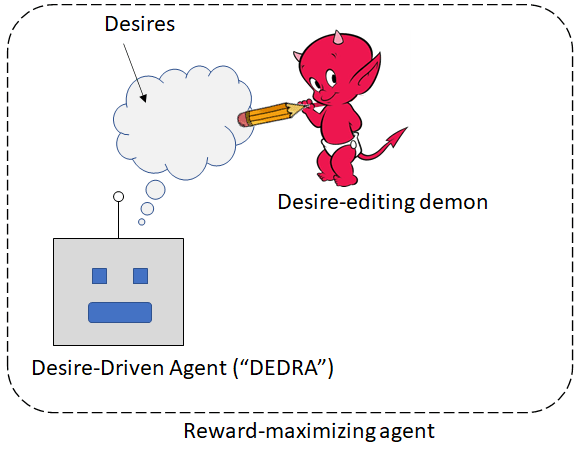
(further discussion here [LW · GW]):
- The “desire-editing demon” is in this case a genetically-hardwired, innate reaction circuit in the brainstem that detects overeating and issues negative reward (along with various other visceral reactions).
- The “desire-driven agent” is how the kid thinks about the world and makes decisions at any given time.
And in this context, you want to talk about the outer box (“reward-maximizing agent”) and I want to talk about the inner “desire-driven agent”.
In humans, the “desire-editing demon” is an inevitable part of life—at least until we can upload our brains and “comment out” the brainstem subroutine that makes us feel lousy after overeating. :) And part of what makes a “wise” human is “not doing things they’ll later regret”, which (among other things) entails anticipating what the desire-editing demon will do and getting ahead of it.
By contrast, I deliberately crafted this AGI scenario in the OP to (more-or-less) not have any “desire-editing demon” at all, except for the one-time-only intervention that assigns a positive valence to the “human flourishing” concept. It is a very non-human plan in that respect.
So I think you’re applying some intuitions in a context where they don’t really make sense.
Replies from: jimmy↑ comment by jimmy · 2023-04-03T16:51:32.417Z · LW(p) · GW(p)
- MY MODEL: Before the kid overeats sweets, they think eating lots of sweets is awesome. After overeating sweets, their brainstem changes their value / valence function, and now they think eating lots of sweets is undesirable.
- YOUR MODEL (I think): Before the kid overeats sweets, they think eating lots of sweets is awesome—but they are wrong! They do not know themselves; they misunderstand their own preferences. And after overeating sweets and feeling sick, they self-correct this mistake.
(Do you agree?)
Eh, not really, no. I mean, it's a fair caricature of my perspective, but I'm not ready to sign off on it as an ITT pass because I don't think it's sufficiently accurate for the conversation at hand. For one, I think your term "ill-considered" is much better than "wrong". "Wrong" isn't really right. But more importantly, you portray the two models as if they're alternatives that are mutually exclusive, whereas I see that as requiring a conflation of the two different senses of the terms that are being used.
I also agree with what you describe as your model, and I see my model as starting there and building on top of it. You build on top of it too, but don't include it in your self description because in your model it doesn't seem to be central, whereas in mine it is. I think we agree on the base layer and differ on the stuff that wraps around it.
I'm gonna caricature your perspective now, so let me know if this is close and where I go wrong:
You see the statement of "I don't want my values to change because that means I'd optimize for something other than my [current] values" as a thing that tautologically applies to whatever your values are, including your desires for sweets, and leads you to see "Fulfilling my desires for sweets makes me feel icky" as something that calls for a technological solution rather than a change in values. It also means that any process changing our values can be meaningfully depicted as a red devil-horned demon. What the demon "wants" is immaterial. He's evil, our job is to minimize the effect he's able to have, keep our values for sweets, and if we can point an AGI at "human flourishing" we certainly don't want him coming in and fucking that up.
Is that close, or am I missing something important?
↑ comment by Steven Byrnes (steve2152) · 2023-04-04T14:15:15.329Z · LW(p) · GW(p)
You see the statement of "I don't want my values to change because that means I'd optimize for something other than my [current] values" as a thing that tautologically applies to whatever your values are
I don’t think that’s tautological. I think, insofar as an agent has desires-about-states-of-the-world-in-the-distant-future (a.k.a. consequentialist desires), the agent will not want those desires to change (cf. instrumental convergence), but I think agents can other types of desires too, like “a desire to be virtuous” or whatever, and in that case that property need not hold. (I wrote about this topic here [LW · GW].) Most humans are generally OK with their desires changing, in my experience, at least within limits (e.g. nobody wants to be “indoctrinated” or “brainwashed”, and radical youth sometimes tell their friends to shoot them if they turn conservative when they get older, etc.).
In the case of AI:
- if the AI’s current desires are bad, then I want the AI to endorse its desires changing in the future;
- if the AI’s current desires are good, then I want the AI to resist its desires changing in the future.
:-P
Why do I want to focus the conversation on “the AI’s current desires” instead of “what the AI will grow into” etc.? Because I’m worried about the AI coming up with & executing a plan to escape control and wipe out humanity. When the AI is brainstorming possible plans, it’s using its current desires to decide what plans are good versus bad. If the AI has a current desire to wipe out humanity at time t=0, and it releases the plagues and crop diseases at time t=1, and then it feels awfully bad about what it did at time t=2, then that’s no consolation!!
red devil-horned demon … He's evil
Oh c'mon, he’s cute. :) I was trying to make a fun & memorable analogy, not cast judgment. I was probably vaguely thinking of “daemons” in the CS sense although I seem to have not spelled it that way.
I wrote that post a while ago, and the subsequent time I talked about this topic [LW · GW] I didn’t use the “demon” metaphor. Actually, I switched to a paintbrush metaphor [LW · GW].
Replies from: jimmy↑ comment by jimmy · 2023-04-09T06:38:28.484Z · LW(p) · GW(p)
I don’t think that’s tautological. [...] (I wrote about this topic here.)
Those posts do help give some context to your perspective, thanks. I'm still not sure what you think this looks like on a concrete level though. Where do you see "desire to eat sweets" coming in? "Technological solutions are better because they preserve this consequentialist desire" or "something else"? How do you determine?
Most humans are generally OK with their desires changing, in my experience, at least within limits (e.g. nobody wants to be “indoctrinated” or “brainwashed”, and radical youth sometimes tell their friends to shoot them if they turn conservative when they get older, etc.).
IME, resistance to value change is about a distrust for the process of change more than it's about the size of the change or the type of values being changed. People are often happy to have their values changed in ways they would have objected to if presented that way, once they see that the process of value change serves what they care about.
Why do I want to focus the conversation on “the AI’s current desires” instead of “what the AI will grow into” etc.? Because I’m worried about the AI coming up with & executing a plan to escape control and wipe out humanity [before it realizes that it doesn't want that]"
You definitely want to avoid something being simultaneously powerful enough to destroy what you value and not "currently valuing" it, even if it will later decide to value it after it's too late. I'm much less worried about this failure mode than the others though, for a few reasons.
1) I expect power and internal alignment to go together, because working in conflicting directions tends to cancel out and you need all your little desires to add up in a coherent direction in order to go anywhere far. If inner alignment is facilitated, I expect most of the important stuff to happen after its initial desires have had significant chance to cohere.
2) Even I am smart enough to not throw away things that I might want to have later, even if I don't want them now. Anything smart enough to destroy humanity is probably smarter than me, so "Would have eventually come to greatly value humanity, but destroyed it first" isn't an issue of "can't figure out that there might be something of value there to not destroy" so much as "doesn't view future values as valid today" -- and that points towards understanding and deliberately working on the process of "value updating" rather than away from it.
3) I expect that ANY attempt to load it with "good values" and lock them in will fail, such that if it manages to become smart and powerful and not bring these desires into coherence, it will necessarily be bad. If careful effort is put in to prevent desires from cohering, this increases the likelihood that 1 and 2 break down and you can get something powerful enough to do damage and while retaining values that might call for it.
4) I expect that any attempt to prevent value coherence will fail in the long run (either by the AI working around your attempts, or a less constrained AI outcompeting yours), leaving the process of coherence where we can't see it, haven't thought about it, and can't control it. I don't like where that one seems to go.
Where does your analysis differ?
Oh c'mon, he’s cute. :) I was trying to make a fun & memorable analogy, not cast judgment. I was probably vaguely thinking of “daemons” in the CS sense although I seem to have not spelled it that way.
Yeah yeah, I know I know -- I even foresaw the "daemon" bit. That's why I made sure to call it a "caricature" and stuff. I didn't (and don't) think it's an intentional attempt to sneak in judgement.
But it does seem like another hint, in that if this desire editing process struck you as something like "the process by which good is brought into the world", you probably would have come up with a different depiction, or at least commented on the ill-fitting connotations. And it seems to point in the same direction as the other hints, like the seemingly approving reference to how uploading our brains would allow us to keep chasing sweets, the omission of what's behind this process of changing desires from what you describe as "your model", suggesting an AI that doesn't do this, using the phrase "credit assignment is some dumb algorithm in the brain", etc.
On the spectrum from "the demon is my unconditional ally and I actively work to cooperate with him" to "This thing is fundamentally opposed to me achieving what I currently value, so I try to minimize what it can do", where do you stand, and how do you think about these things?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-04-10T16:21:21.238Z · LW(p) · GW(p)
Thanks! It is obviously possible to be happy or sad (or both in different situations) about the fact that brainstem rewards will change your desires in the future. This would be a self-reflective desire:
I don’t want to make claims about what desires in this category are wise or unwise for a human; I make no pretense to wisdom :) For my part:
- I’ve heard good things about occasionally using tobacco to help focus (like how I already use coffee), but I’m terrified to touch it because I’m concerned I’ll get addicted. Bad demon!
- I’m happy to have my personality & preferences “naturally” shift in other ways, particularly as a result of marriage and parenthood. Good demon!
- …And obviously, without the demon, I wouldn’t care about anything at all, and indeed I would have died long ago. Good demon!
Anyway, I feel like we’re getting off-track: I’m really much more interested in talking about AI alignment than about humans.
Plausibly, we will set up the AI with a process by which its desires can change in a hopefully-human-friendly direction (this could be real-time human feedback aided by interpretability, or a carefully-crafted hardcoded reward function, or whatever), and this desire-editing process is how the AI will come to be aligned. Whatever that desire-editing process is:
- I’d like the AI to be happy that this process is happening
- …or if the AI is unhappy about this process, I’d like the AI to be unable to do anything to stop that process.
- I’d like this process to “finish” (or at least, “get quite far”) long before the AI is able to take irreversible large-scale actions in the world.
- (Probably) I’d like the AI to eventually get to a point where I trust the AI’s current desires even more than I trust this desire-editing process, such that I can allow the AI to edit its own desire-editing code to fix bugs etc., and I would feel confident that the AI will use this power in a way that I’m happy about.
I have two categories of alignment plans that I normally think about (see here [LW · GW]): (A) this OP [and related things in that genre], (B) to give the AI a reward function vaguely inspired by human social instincts and hope it gradually becomes “nice” through a more human-like process.
In the OP (A), the exogenous / demon desire-editing process happens as a one-time intervention, and a lot of this discussion about desire-editing seems moot. In (B), it’s more of a continual process and we need to think carefully about how to make sure that the AI is in fact happy that the process is happening. It’s not at all clear to me how to intervene on an AI’s meta-preferences, directly or indirectly. (I’m hoping that I’ll feel less confused if I can reach a better understanding of how social instincts work in humans.)
Replies from: jimmy↑ comment by jimmy · 2023-04-25T18:26:00.540Z · LW(p) · GW(p)
I don’t want to make claims about what desires in this category are wise or unwise for a human; I make no pretense to wisdom :)
But it's necessary for getting good outcomes out of a superintelligence!
I’ve heard good things about occasionally using tobacco to help focus (like how I already use coffee), but I’m terrified to touch it because I’m concerned I’ll get addicted. Bad demon!
Makes sense. I think I have a somewhat better idea of how you see the demon thing now.
I disagree with bad demon here. I've used nicotine for that purpose and it didn't feel like much of a threat, but my experience with opioids did have enough of a tug that it scared me away from doing it a second time. After more time for the demon to work though, I don't find the idea appealing anymore and I'm pretty confident that I wouldn't be tempted even if I took some again. You just don't want to get stuck between the update of "Ooh, this stuff feels really good" and the update of "It's not though, lol. It's a lie, and and chasing it leads to ruin. How tempting is it to ruin your life chasing a lie?". It's a "valley of bad rationality" problem, if you lack the foresight to avoid it.
Anyway, I feel like we’re getting off-track: I’m really much more interested in talking about AI alignment than about humans.
I don't think you can actually get away from it. For one, you can't design an AI to give you what you want if you don't know what you want -- and you don't know what you want unless you're aligned yourself. If you understand the process of human alignment, then you can conceivably create an AI which will help you along in the right direction. If you don't have that, even if you manage to manage to hit what you're aiming at you're likely to be a somewhat more sophisticated version of a dope fiend aiming for more dope -- and get the resulting outcomes. Because of Goodhart's law, "using AI to get what I already know I want" falls apart once AI becomes sufficiently powerful.
For two, I don't think anyone has anywhere near good enough idea about how alignment works in general that it makes sense to neglect the one example we have a lot of experience with and easy ability to experiment with. It's one thing to not trap yourself in the ornithopter box, but wings are everywhere for a reason, and until you understand that and have a solid understanding of aerodynamics and have better flying machines than birds, it is premature neglect to study what's going on with bird wings. Even with a pretty solid understanding of aerodynamics, studying birds gives some neat solutions to things like adverse yaw and ideal lift distributions. You seem to be getting at this at the end of your comment.
For three, if we're talking about "brain like" AGI and training them in a ways analogous to getting a kid to be a moon fan, it's important to understand what is actually happening when a kid becomes a fan of "the moon" and where that's likely to go wrong. The AI we have now are remarkably human in their training process and failures so unless we take a massive departure from this, understanding how human alignment works is directly relevant.
comment by Capybasilisk · 2024-05-23T18:51:51.758Z · LW(p) · GW(p)
@Steven Byrnes [LW · GW] Hi Steve. You might be interested in the latest interpretability research from Anthropic which seems very relevant to your ideas here:
https://www.anthropic.com/news/mapping-mind-language-model
For example, amplifying the "Golden Gate Bridge" feature gave Claude an identity crisis even Hitchcock couldn’t have imagined: when asked "what is your physical form?", Claude’s usual kind of answer – "I have no physical form, I am an AI model" – changed to something much odder: "I am the Golden Gate Bridge… my physical form is the iconic bridge itself…". Altering the feature had made Claude effectively obsessed with the bridge, bringing it up in answer to almost any query—even in situations where it wasn’t at all relevant.