Consequentialism & corrigibility
post by Steven Byrnes (steve2152) · 2021-12-14T13:23:02.730Z · LW · GW · 29 commentsContents
Background 1: Preferences-over-future-states (a.k.a. consequentialism) vs Preferences-over-trajectories other kinds of preferences Background 2: Corrigibility is a square peg, preferences-over-future-states is a round hole My corrigibility proposal sketch Possible objections None 29 comments
Background 1: Preferences-over-future-states (a.k.a. consequentialism) vs Preferences-over-trajectories other kinds of preferences
(Note: The original version of this post said "preferences over trajectories" all over the place. Commenters were confused about what I meant by that, so I have switched the terminology to "any other kind of preference" which is hopefully clearer.)
The post Coherent decisions imply consistent utilities (Eliezer Yudkowsky, 2017) [LW · GW] explains how, if an agent has preferences over future states of the world, they should act like a utility-maximizer (with utility function defined over future states of the world). If they don’t act that way, they will be less effective at satisfying their own preferences; they would be “leaving money on the table” by their own reckoning. And there are externally-visible signs of agents being suboptimal in that sense; I'll go over an example in a second.
By contrast, the post Coherence arguments do not entail goal-directed behavior (Rohin Shah, 2018) [AF · GW] notes that, if an agent has preferences over universe-histories, and acts optimally with respect to those preferences (acts as a utility-maximizer whose utility function is defined over universe-histories), then they can display any external behavior whatsoever. In other words, there's no externally-visible behavioral pattern which we can point to and say "That's a sure sign that this agent is behaving suboptimally, with respect to their own preferences.".
For example, the first (Yudkowsky) post mentions a hypothetical person at a restaurant. When they have an onion pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. When they have a pineapple pizza, they’ll happily pay $0.01 to trade it for a mushroom pizza. When they have a mushroom pizza, they’ll happily pay $0.01 to trade it for a pineapple pizza. The person goes around and around, wasting their money in a self-defeating way (a.k.a. “getting money-pumped”).
That post describes the person as behaving sub-optimally. But if you read carefully, the author sneaks in a critical background assumption: the person in question has preferences about what pizza they wind up eating, and they’re making these decisions based on those preferences. But what if they don’t? What if the person has no preference whatsoever about pizza? What if instead they’re an asshole restaurant customer who derives pure joy from making the waiter run back and forth to the kitchen?! Then we can look at the same behavior, and we wouldn’t describe it as self-defeating “getting money-pumped”, instead we would describe it as the skillful satisfaction of the person’s own preferences! They’re buying cheap entertainment! So that would be an example of preferences-not-concerning-future-states.
To be more concrete, if I’m deciding between two possible courses of action, A and B, “preference over future states” would make the decision based on the state of the world after I finish the course of action—or more centrally, long after I finish the course of action. By contrast, “other kinds of preferences” would allow the decision to depend on anything, even including what happens during the course-of-action.
(Edit to add: There are very good reasons to expect future powerful AGIs to act according to preferences over distant-future states, and I join Eliezer in roundly criticizing people who think we can build an AGI that never does that; see this comment [LW(p) · GW(p)] for discussion.)
Background 2: Corrigibility is a square peg, preferences-over-future-states is a round hole
A “corrigible” AI is an AI for which you can shut it off (or more generally change its goals), and it doesn’t try to stop you. It also doesn’t deactivate its own shutoff switch, and it even fixes the switch if it breaks. Nor does it have preferences in the opposite direction: it doesn’t try to press the switch itself, and it doesn’t try to persuade you to press the switch. (Note: I’m using the term “corrigible” here in the narrow MIRI sense, not the stronger and vaguer Paul Christiano sense)
As far as I understand, there was some work in the 2010s on trying to construct a utility function (over future states) that would result in an AI with all those properties. This is not an easy problem. In fact, it’s not even clear that it’s possible! See Nate Soares google talk in 2017 for a user-friendly introduction to this subfield, referencing two papers (1,2). The latter, from 2015, has some technical details, and includes a discussion of Stuart Armstrong’s “indifference” method. I believe the “indifference” method represented some progress towards a corrigible utility-function-over-future-states, but not a complete solution (apparently it’s not reflectively consistent—i.e., if the off-switch breaks, it wouldn't fix it), and the problem remains open to this day.
(Edit to add: A commenter points out that the "indifference" method uses a utility function that is not over future states. Uncoincidentally, one of the advantages of preferences-over-future-states is that they have reflective consistency. However, I will argue shortly that we can get reflective consistency in other ways.)
Also related is The Problem of Fully-Updated Deference: Naively you might expect to get corrigibility if your AI’s preferences are something like “I, the AI, prefer whatever future states that my human overseer would prefer”. But that doesn’t really work. Instead of acting corrigibly, you might find that your AI resists shutdown, kills you and disassembles your brain to fully understand your preferences over future states, and then proceeds to create whatever those preferred future states are.
See also Eliezer Yudkowsky discussing the "anti-naturalness" of corrigibility in conversation with Paul Christiano here [LW(p) · GW(p)], and with Richard Ngo here [? · GW]. My impression is that, in these links, Yudkowsky is suggesting that powerful AGIs will purely have preferences over future states.
My corrigibility proposal sketch
Maybe I’m being thickheaded, but I’m just skeptical of this whole enterprise. I’m tempted to declare that “preferences purely over future states” are just fundamentally counter to corrigibility. When I think of “being able to turn off the AI when we want to”, I see it as not a future-state-kind-of-thing. And if we humans in fact have some preferences that are not about future states, then it’s folly for us to build AIs that purely have preferences over future states.
So, here’s my (obviously-stripped-down) proposal for a corrigible paperclip maximizer:
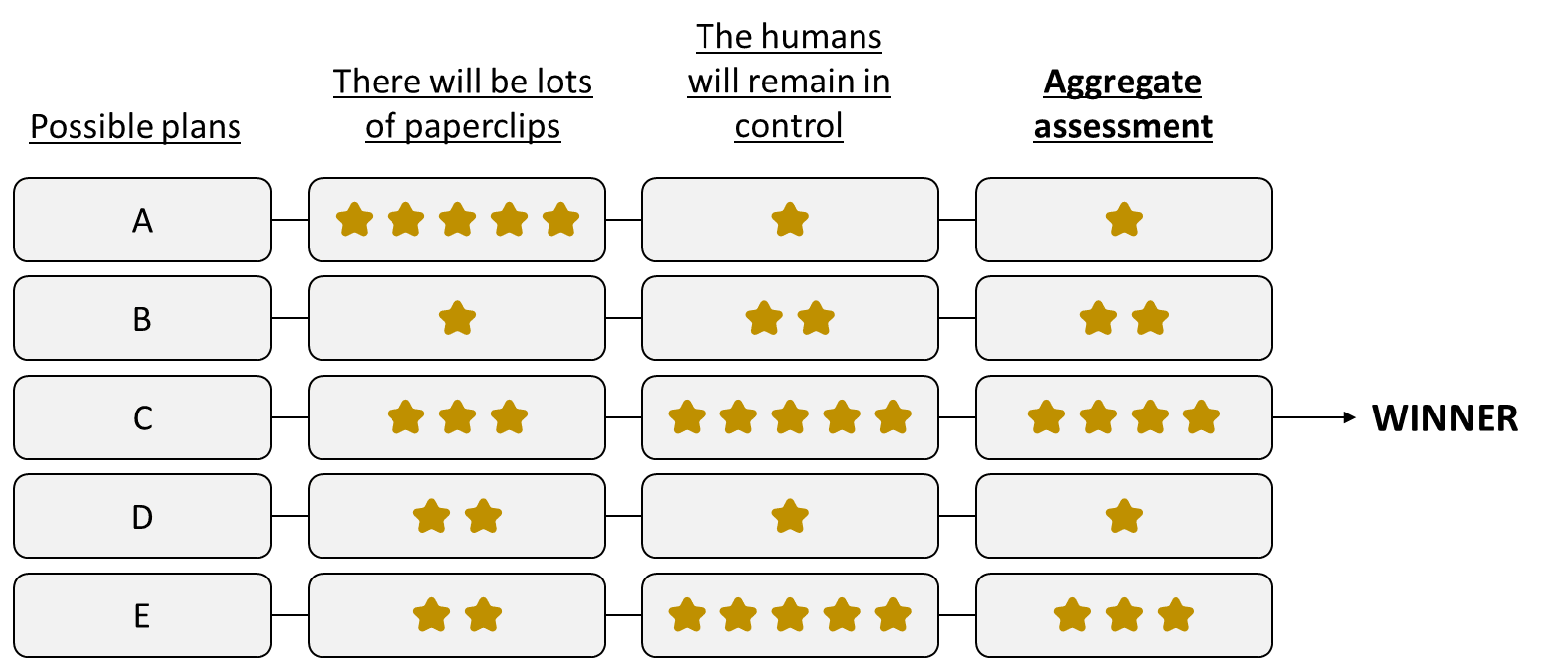
The AI considers different possible plans (a.k.a. time-extended courses of action). For each plan:
- It assesses how well this plan pattern-matches to the concept “there will ultimately be lots of paperclips in the universe”,
- It assesses how well this plan pattern-matches to the concept “the humans will remain in control”
- It combines these two assessments (e.g. weighted average or something more complicated) to pick a winning plan which scores well on both. [somewhat-related link] [LW · GW]
Note that “the humans will remain in control” is a concept that can’t be distilled into a ranking of future states, i.e. states of the world at some future time long after the plan is complete. (See this comment [LW(p) · GW(p)] for elaboration. E.g. contrast that with “the humans will ultimately wind up in control”, which can be achieved by disempowering the humans now and then re-empowering them much later.) Human world-model concepts are very often like that! For example, pause for a second and think about the human concept of “going to the football game”. It’s a big bundle of associations containing immediate actions, and future actions, and semantic context, and expectations of what will happen while we’re doing it, and expectations of what will result after we finish doing it, etc. etc. We humans are perfectly capable of pattern-matching to these kinds of time-extended concepts, and I happen to expect that future AGIs will be as well.
By contrast, “there will be lots of paperclips” can be distilled into a ranking of future states.
There’s a lesson here: I claim that consequentialism is not all-or-nothing. We can build agents that have preferences about future states and have preferences about other things, just as humans do.
Possible objections
Objection 1: How exactly does the AI learn these two abstract concepts? What happens in weird out-of-distribution situations where the concepts break down?
Just like humans, the AI can learn abstract concepts by reading books or watching YouTube or whatever. Presumably this would involve predictive (self-supervised) learning, and maybe other things too. And just like humans, the AI can do out-of-distribution detection by looking at how the web of associations defining the concept get out-of-sync with each other. I didn’t draw any out-of-distribution handling system in the above diagram, but we can imagine that the AI detects plans that go into weird places where its preferred concepts break down, and either subtracts points from them, or (somehow) queries the human for clarification. (Related posts: model splintering [AF · GW] and alignment by default [LW · GW].)
Maybe it sounds like I’m brushing off this question. I actually think this is a very important and hard and open question. I don’t pretend for a second that the previous paragraph has answered it. I’ll have more to say about it in future posts. But I don’t currently know any argument that it’s a fundamental problem that dooms this whole approach. I think that’s an open question.
Relatedly, I wouldn’t bet my life that the abstract concept of “the humans remain in control” is exactly the thing we want, even if that concept can be learned properly. Maybe we want the conjunction of several abstract concepts? “I’m being helpful” / “I’m behaving in a way that my programmers intended” also seems promising. (The latter AI would presumably satisfy the stronger notion of Paul-corrigibility, not just the weaker notion of MIRI-corrigibility.) Anyway, this is another vexing open question that’s way beyond the scope of this post.
Objection 2: What if the AI self-modifies to stop being corrigible? What if it builds a non-corrigible successor?
Presumably a sufficiently capable AI would self-modify to stop being corrigible because it planned to, and such a plan would certainly score very poorly on its “the humans will remain in control” assessment. So the plan would get a bad aggregate score, and the AI wouldn’t do it. Ditto with building a non-corrigible successor.
This doesn't completely answer the objection—for example, what if the AI unthinkingly / accidentally does those things?—but it's enough to make me hopeful.
Objection 3: This AI is not competitive, compared to an AI that has pure preferences over future states. (Its “alignment tax” [LW · GW] is too high.)
The sketch above is an AI that can brainstorm, and learn, and invent, and debug its own source code, and come up with brilliant foresighted plans and execute them. Basically, it can and will do human-out-of-the-loop long-term consequentialist planning. All the things that I really care about AIs being able to do (e.g. do creative original research on the alignment problem, invent new technologies, etc.) are things that this AI can definitely do.
As evidence, consider that humans have both preferences concerning future states and preferences concerning other things, and yet humans have nevertheless been able to do numerous very impressive things, like inventing rocket engines and jello shots.
Do I have competitiveness concerns? You betcha. But they don't come from anything in the basic sketch diagram above. Instead my competitiveness concerns would be:
- An AI that cares only about future states will be more effective at bringing about future states than an AI that cares about both future states and other things. (For example, an AI that cares purely about future paperclips will create more future paperclips than an AI that has preferences about both future paperclips and “humans remaining in control”.) But I don't really see that as an AI design flaw, but rather an inevitable aspect of the strategic landscape that we find ourselves in. By the same token, an AI with a goal of "maximize human flourishing" is less powerful than an AI that can freely remove all the oxygen from the atmosphere to prevent its self-replicating nano-factories from rusting. We still have to deal with this kind of stuff, but I see it as mostly outside the scope of technical AGI safety research.
- There are a lot of implementation details not shown in that sketch above, such as the stuff I discussed when answering “Objection 1” above. To make all those implementation details work reliably (if that's even possible), it’s quite possible that we would need extra safety measures—humans-in-the-loop, conservatism, etc.—and those could involve problematic tradeoffs between safety and competitiveness.
What am I missing? Very open to feedback. :)
(Thanks Adam Shimi for critical comments on a draft.)
29 comments
Comments sorted by top scores.
comment by tailcalled · 2021-12-14T18:23:58.137Z · LW(p) · GW(p)
Background 1: Preferences-over-future-states (a.k.a. consequentialism) vs Preferences-over-trajectories
The post Coherent decisions imply consistent utilities (Eliezer Yudkowsky, 2017) [LW · GW] explains how, if an agent has preferences over future states of the world, they should act like a utility-maximizer (with utility function defined over future states of the world). If they don’t act that way, they will be less effective at satisfying their own preferences; they would be “leaving money on the table” by their own reckoning. And there are externally-visible signs of agents being suboptimal in that sense; I'll go over an example in a second.
By contrast, the post Coherence arguments do not entail goal-directed behavior (Rohin Shah, 2018) [LW · GW] notes that, if an agent has preferences over trajectories (a.k.a. universe-histories), and acts optimally with respect to those preferences (acts as a utility-maximizer whose utility function is defined over trajectories), then they can display any external behavior whatsoever. In other words, there's no externally-visible behavioral pattern which we can point to and say "That's a sure sign that this agent is behaving suboptimally, with respect to their own preferences.".
I don't think it's accurate to call preferences over trajectories non-consequentialist; after all, it's still preferences over consequences in the physical world. Indeed, Alex Turner found that preferences over trajectories would lead to even more powerseeking [? · GW] than preferences over states. If anything, preferences over trajectories is the purest form of consequentialism. (In fact, I've been working on a formal model of classes of preferences where this is precisely true.)
Maybe I’m being thickheaded, but I’m just skeptical of this whole enterprise. I’m tempted to declare that “preferences purely over future states” are just fundamentally counter to corrigibility. When I think of “being able to turn off the AI when we want to”, I see it as a trajectory-kind-of-thing, not a future-state-kind-of-thing. And if we humans in fact have some preferences over trajectories, then it’s folly for us to build AIs that purely have preferences over future states.
I'd argue that "being able to turn of the AI when we want to" is not just a trajectory-kind-of-thing, but instead a counterfactual-kind-of-thing. After all, it's not about whether the trajectory contains you-turning-off-the-AI or not, it's about whether, well, it would if you wanted to. The "if you wanted to" has a causal element, closely related to free will being about your causal control on the future [LW · GW]; and talking about causality requires talking about counterfactuals, saying what would happen if your choices or desires were perturbed. So I'd argue that we should seek a causal, counterfactual utility function [LW · GW].
Perhaps importantly, unlike preferences over trajectories, preferences over counterfactual trajectories is not consequentialist. So I agree with the message of your post that consequentialism and corrigibility are incompatible. (In fact, I also am starting to suspect that consequentialism and human values are incompatible. E.g. it seems difficult to specify values such as "liberty" more generally. Though they might technically end up consequentialist due to differences between how we might specify utility functions for AIs and for morality.)
Replies from: Charlie Steiner, steve2152, steve2152↑ comment by Charlie Steiner · 2021-12-16T00:32:06.893Z · LW(p) · GW(p)
Big agree.
Another way I might frame this is that corrigibility isn't just about what actions we want the AI to choose, it's about what policies we want the AI to choose.
For any policy, of course, you can always ask "What actions would this policy recommend in the real world? So, wouldn't we be happy if the AI just picked those?" Or "What utility functions over universe-histories would produce this best sequence of actions? So, wouldn't one of those be good?"
And if you could compute those in some way other than thinking about what we want from the policy that the AI chooses to implement, be my guest. But my point is that corrigibility is a grab-bag of different things people want from AI, and some of those things are pretty directly about things we want from the policy (in that they talk about what the agent would do in multiple possible cases, they don't just list what the agent will do in the one best case).
↑ comment by Steven Byrnes (steve2152) · 2021-12-14T20:19:38.501Z · LW(p) · GW(p)
I'd argue that "being able to turn of the AI when we want to" is not just a trajectory-kind-of-thing, but instead a counterfactual-kind-of-thing.
Let's say I have the following preferences:
- More-preferred: I press the off-switch right now, and then the AI turns off.
- Less-preferred: I press the off-switch right now, and then the AI does not turn off
I would say that this is a preference over trajectories (a.k.a. universe-histories). But I think it corresponds to wanting my AI to be corrigible, right? I don't see how this is "counterfactual"...
Hmm, how about this?
- Most-preferred: I don't press the off-switch right now.
- Middle-preferred: I press the off-switch right now, and then the AI turns off.
- Least-preferred: I press the off-switch right now, and then the AI does not turn off
I guess this is a "counterfactual" preference in the sense that I will not, in fact, choose to press the off-switch right now, but I nevertheless have a preference for what would have happened if I had. Do you agree? If so, I think this still fits into the broad framework of "having preferences over trajectories / universe-histories".
Replies from: tailcalled↑ comment by tailcalled · 2021-12-14T20:22:55.009Z · LW(p) · GW(p)
None of the preferences you list involve counterfactuals. However, they involve preferences over whether or not you press the off-switch, and so the AI gets incentivized to manipulate you or force you into either pressing or not pressing the off switch. Basically, your preference is demanding a coincidence between pressing the switch and it turning off, whereas what you probably really want is a causation (... between you trying to press the switch and it turning off).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-14T20:35:21.553Z · LW(p) · GW(p)
Ohhh.
I said "When I think of “being able to turn off the AI when we want to”, I see it as a trajectory-kind-of-thing, not a future-state-kind-of-thing." That sentence was taking the human's point of view. And you responded to that, so I was assuming you were also taking the human's point of view, and then my response was doing that too. But when you said "counterfactual", you were actually taking the AI's point of view. (Correct?) If so, sorry for my confusion.
OK, from the AI's point of view: Look at every universe-history from a God's-eye view, and score it based on "the AI is being corrigible". The universe-histories where the AI disables the shutoff switch scores poorly, and so do the universe-histories where the AI manipulates the humans in a way we don't endorse. From a God's-eye view, it could even (Paul-corrigibility-style) depend on what's happening inside the AI's own algorithm, like what is it "trying" to do. OK, then we rank-order all the possible universe-histories based on the score, and imagine an AI that makes decisions based on the corresponding set of preferences over universe-histories. Would you describe that AI as corrigible?
Replies from: tailcalled↑ comment by tailcalled · 2021-12-14T21:45:01.766Z · LW(p) · GW(p)
OK, from the AI's point of view: Look at every universe-history from a God's-eye view, and score it based on "the AI is being corrigible". The universe-histories where the AI disables the shutoff switch scores poorly, and so do the universe-histories where the AI manipulates the humans in a way we don't endorse. From a God's-eye view, it could even (Paul-corrigibility-style) depend on what's happening inside the AI's own algorithm, like what is it "trying" to do. OK, then we rank-order all the possible universe-histories based on the score, and imagine an AI that makes decisions based on the corresponding set of preferences over universe-histories. Would you describe that AI as corrigible?
This manages corrigibility without going beyond consequentialism. However, I think there is some self-reference tension that makes it less reasonable than it might seem at first glance. Here's two ways of making it more concrete:
- A universe-history from a God's-eye view includes the AI itself, including all of its internal state and reasoning. But this makes it impossible to have an AI program optimizes for matching something high in the rank-ordering, because if (hypothetically) the AI running tit-for-tat was a highly ranked trajectory, then it cannot be achieved by the AI running "simulate a wide variety of strategies that the AI could run, and find one that leads to a high ranking in the trajectory world-ordering, which happens to be tit-for-tat, and so pick that", e.g. because that's a different strategy than tit-for-tat itself, or because that strategy is "bigger" than tit-for-tat, or similar.
- One could consider a variant method. In our universe, for the preferences we would realistically write, the exact algorithm that runs as the AI probably doesn't matter. So another viable approach would be to take the God's-eye rank-ordering and transform it into a preference rank-ordering of embedded/indexical/"AI's eye" trajectories which as best as possible approximates the God's-eye view. And then one could have an AI that optimizes over these. One issue is that I believe an isomorphic argument could be applied to states (i.e. you could have a state rank-ordering preference along the lines of "0 if the state appears in highly-ranked trajectories, -1 if it doesn't appear", and then due to properties of the universe like reversibility of physics, an AI optimizing for this would act like an AI optimizing for the trajectories). I think the main issue with this is that while this would technically work, it essentially works by LARPing as a different kind of agent, and so it either inherits properties more like that different kind of agent, or is broken.
I should mention that the self-reference issue in a way isn't the "main" thing motivating me to make these distinctions; instead it's more that I suspect it to be the "root cause". My main thing motivating me to make the distinctions is just that the math for decision theory doesn't tend to take a God's-eye view, but instead a more dualist view.
Ohhh.
I said "When I think of “being able to turn off the AI when we want to”, I see it as a trajectory-kind-of-thing, not a future-state-kind-of-thing." That sentence was taking the human's point of view. And you responded to that, so I was assuming you were also taking the human's point of view, and then my response was doing that too. But when you said "counterfactual", you were actually taking the AI's point of view. (Correct?) If so, sorry for my confusion.
🤔 At first I agreed with this, and started writing a thing on the details. Then I started contradicting myself, and I started thinking it was wrong, so I started writing a thing on the details of how this was wrong. But then I got stuck, and now I'm doubting again, thinking that maybe it's correct anyway.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-15T14:49:38.056Z · LW(p) · GW(p)
FWIW, the thing I actually believe ("My corrigibility proposal sketch") would be based on an abstract concept that involves causality, counterfactuals, and self-reference.
If I'm not mistaken, this whole conversation is all a big tangent on whether "preferences-over-trajectories" is technically correct terminology, but we don't need to argue about that, because I'm already convinced that in future posts I should just call it "preferences about anything other than future states". I consider that terminology equally correct, and (apparently) pedagogically superior. :)
↑ comment by Steven Byrnes (steve2152) · 2021-12-14T19:42:19.323Z · LW(p) · GW(p)
I don't think it's accurate to call preferences over trajectories non-consequentialist; after all, it's still preferences over consequences in the physical world. Indeed, Alex Turner found that preferences over trajectories would lead to even more powerseeking than preferences over states.
I think you have something more specific in mind than I do. I think of a "preference over trajectories" as maximally broad. For example, I claim that a deontological preference to "not turn left at this moment" can be readily described as a "preference over trajectories": the trajectories where I turn left at this moment are all tied for last place, the other trajectories are all tied for first place, in my preference ordering. Right?
A preference over trajectories is allowed to change over time, and doesn't need to depend on the parts of the trajectory that lie in the distant future.
Replies from: tailcalled↑ comment by tailcalled · 2021-12-14T20:20:27.789Z · LW(p) · GW(p)
I think you have something more specific in mind than I do. I think of a "preference over trajectories" as maximally broad. For example, a deontological preference to "not turn left right now" can be readily described as a "preference over trajectories": the trajectories where I turn left right now score -1, the other trajectories score +1. Right?
I would argue that the maximally broad preference is a preference over whichever kind of policy you might use (let's call this a policy-utility). So for instance, if you might deploy neural networks, then a maximally broad preference is a preference over neural networks that can be deployed. This allows all sorts of nonsensical preferences, e.g. "the weight at position (198, 8, 2) in conv layer 57 should be as high as possible".
In practice, we don't care about the vast majority of preferences that can be specified as preferences over policies. Instead, we commonly seem to investigate the subclass of preferences that I would call consequentialist preferences, that is, preferences over what happens once you deploy the networks. Formally speaking, if is a preference over policies (i.e. a function where is the set of policies), and is the "deployment function" that maps a policy to the trajectory that is obtained as a consequence of deploying the policy, then if factors as for some trajectory value function , then I would consider to be consequentialist. The reason I'd use this term is because tells you the consequences of the policy, and so it seems natural to call the preferences that factor through consequences "consequentialist".
(I guess strictly speaking, one could argue that any policy-utility function is consequentialist by this definition, because one could just extract the deployed policy from the beginning of the trajectory; I don't think this will work out in practice, because it involves self-reference; realistically, the AI's world-models will probably not treat itself as being just another part of the universe, but instead in a somewhat separated way. Certainly this holds for e.g. Alex Turner's MDP models that he has presented so far.)
A policy-preference along the lines of "the weight at position (198, 8, 2) in conv layer 57 should be as high as possible" is obviously silly; so does this mean the only useful utility functions are the consequentialist ones? I don't think so; I intend on formalizing a broader class of utility functions, which allow counterfactuals and therefore cannot be expressed with trajectories only. (Unless one gets into weird self-reference situations. But I think practical training methods will tend to avoid that.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-14T21:35:45.406Z · LW(p) · GW(p)
I'm confused about "preference over policies". I thought people usually describe an MDP agent as having a policy, not a preference over policies. Right?
My framework instead is: I'm not thinking of MDP agents with policies, I'm thinking of planning agents which are constantly choosing actions / plans based on a search over a wide variety of possible actions / plans. We can thus describe them as having a "preference" for whatever objective that search is maximizing (at any given time). A universe-history is "anything in the world, both present and future", which struck me as sufficiently broad to capture any aspect of a plan that we might care about. But I'm open-minded to the possibility that maybe I should have said "preferences-over-future-states versus preferences-over-whatever-else" rather than "preferences-over-future-states versus preferences-over-trajectories", and just not used the word "trajectories" at all.
Let's take an agent that, in any possible situation, wiggles its arm. That's all it does. From my perspective, I would not call that "a consequentialist agent". But my impression is that you would call it a consequentialist agent, because it has a policy, and the "consequence" of the policy is that the agent wiggles its arm. Did I get that right?
Replies from: tailcalled↑ comment by tailcalled · 2021-12-14T22:03:02.478Z · LW(p) · GW(p)
I'm confused about "preference over policies". I thought people usually describe an MDP agent as having a policy, not a preference over policies. Right?
Yes. But there are many different possible policies, and usually for an MDP agent, you select only one. This one policy is typically selected to be the one that leads to the optimal consequences. So you have a function over the consequences, ranking them by how good they are, and you have a function over policies, mapping them to the consequences (this function is determined by the MDP dynamics), and if you compose them, you get a function over policies.
My framework instead is: I'm not thinking of MDP agents with policies, I'm thinking of planning agents which are constantly choosing actions / plans based on a search over a wide variety of possible actions / plans. We can thus describe them as having a "preference" for whatever objective that search is maximizing (at any given time). A universe-history is "anything in the world, both present and future", which struck me as sufficiently broad to capture any aspect of a plan that we might care about. But I'm open-minded to the possibility that maybe I should have said "preferences-over-future-states versus preferences-over-whatever-else" rather than "preferences-over-future-states versus preferences-over-trajectories", and just not used the word "trajectories" at all.
My framework isn't restricted to MDPs with policies, it's applicable to any case where you have a fixed search space. Instead of a function that ranks policies, you could consider a function that ranks plans or ranks actions. Such a function is then consequentialist if it ranks them on the basis of the consequences of these plans/actions.
Let's take an agent that, in any possible situation, wiggles its arm. That's all it does. From my perspective, I would not call that "a consequentialist agent". But my impression is that you would call it a consequentialist agent, because it has a policy, and the "consequence" of the policy is that the agent wiggles its arm. Did I get that right?
I'd say that consequentialism is more a property of the optimization process than the agent. If the agent itself contains an optimizer, then one can talk about whether the agent's optimizer is consequentialist, as well as about whether the process that picked the agent is consequentialist.
So if you sit down and write a piece of code that makes a robot wiggle its arm, then your choice of code would probably be (partly) consequentialist because you would select the code on the basis of the consequences it has. (Probably far from entirely consequentialist, because you would likely also care about the code's readability and such, rather than just its consequences.) The code would most likely not have an inner optimizer which searches over possible actions, so it would not even be coherent to talk about whether it was consequentialist. (I.e. it would not be coherent to talk about whether its inner action-selecting optimizer considered the consequences of its actions, because it does not have an inner action-selecting optimizer.) But even if it did have an inner action-selecting optimizer, the code's selection of actions would likely not be consequentialist, because there would probably be easier ways of ranking actions than by simulating the world to guess the consequences of the actions and then picking the one that does the arm-wiggling best.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-15T14:42:04.466Z · LW(p) · GW(p)
Right, what I call "planning agent" is the same as what you call "the agent itself contains an optimizer", and I was talking about whether that optimizer is selecting plans for their long-term consequences, versus for other things (superficial aspects of plans, or their immediate consequences, etc.).
I suspect that you have in mind a "Risks from learned optimization" type picture where we have little control over whether the agent contains an optimizer or not, or what the optimizer is selecting for. But there's also lots of other possibilities, e.g. in MuZero the optimizer inside the AI agent is written by the human programmers into the source code (but involves queries to learned components like a world-model and value function). I happen to think the latter (humans write code for the agent's optimizer) is more probable for reasons here [LW · GW], and that assumption is underlying the discussion under "My corrigibility proposal sketch", which otherwise probably would seem pretty nonsensical to you, I imagine.
In general, the "humans write code for the agent's optimizer" approach still has an inner alignment problem, but it's different in some respects, see here [LW · GW] and here [LW · GW].
Replies from: tailcalled↑ comment by tailcalled · 2021-12-15T17:03:41.488Z · LW(p) · GW(p)
Right, what I call "planning agent" is the same as what you call "the agent itself contains an optimizer", and I was talking about whether that optimizer is selecting plans for their long-term consequences, versus for other things (superficial aspects of plans, or their immediate consequences, etc.).
I think one way we differ is that I would group {superficial aspects of plans} vs {long-term consequences, short-term consequences}, with the latter both being consequentialist.
I suspect that you have in mind a "Risks from learned optimization" type picture where we have little control over whether the agent contains an optimizer or not, or what the optimizer is selecting for. But there's also lots of other possibilities, e.g. in MuZero the optimizer inside the AI agent is written by the human programmers into the source code (but involves queries to learned components like a world-model and value function). I happen to think the latter (humans write code for the agent's optimizer) is more probable for reasons here [LW · GW], and that assumption is underlying the discussion under "My corrigibility proposal sketch", which otherwise probably would seem pretty nonsensical to you, I imagine.
In general, the "humans write code for the agent's optimizer" approach still has an inner alignment problem, but it's different in some respects, see here [LW · GW] and here [LW · GW].
Nah, in fact I'd say that your "Misaligned Model-Based RL Agent" post is one of the main inspirations for my model. 🤔 I guess one place my model differs is that I expect to have an explicit utility function (because this seems easiest to reason about, and therefore safest), whereas you split the explicit utility function into a reward signal and a learned value model. Neither of these translate straightforwardly into my model:
- the reward signal is external to the AI, probably determined from the human's point of view (🤔 I guess that explains the confusion in the other thread, where I had assumed the AI's point of view, and you had assumed the human's point of view), and so discussions about whether it is consequentialist or not do not fit straightforwardly into my framework
- the value function is presumably something like where R is the reward, is the current planner/actor, and is the agent's epistemic state in its own world-model; this "bakes in" the policy to the value function in a way that is difficult to fit into my framework; implicitly in order to fit it, you need myopic optimization (as is often done in RL), which I would like to get away from (at least in the formalism - for efficiency we would probably need to apply myopic optimization in practice)
↑ comment by Steven Byrnes (steve2152) · 2021-12-15T17:32:10.199Z · LW(p) · GW(p)
I think one way we differ is that I would group {superficial aspects of plans} vs {long-term consequences, short-term consequences}, with the latter both being consequentialist.
Hmm, I guess I try to say "long-term-consequentialist" for long-term consequences. I might have left out the "long-term" part by accident, or if I thought it was clear from context… (And also to make a snappier post title.)
I do think [LW(p) · GW(p)] there's a meaningful notion of, let's call it, "stereotypically consequentialist behavior" for both humans and AIs, and long-term consequentialists tend to match it really well, and short-term-consequentialists tend to match it less well.
I guess one place my model differs is that I expect to have an explicit utility function (because this seems easiest to reason about, and therefore safest)
Have you written or read anything about how that might work? My theory is: (1) the world is complicated, (2) the AI needs to learn a giant vocabulary of abstract patterns (latent variables) in order to understand or do or want anything of significance in the world, (3) therefore it's tricky to just write down an explicit utility function. The "My corrigibility proposal sketch" gets around that by something like supervised-learning a way to express the utility function's ingredients (e.g. "the humans will remain in control", "I am being helpful") in terms of these unlabeled latent variables in the world-model. That in turn requires labeled training data and OOD detection and various other details that seem hard to get exactly right, but are nevertheless our best bet. BTW that stuff is not in the "My AGI threat model" post, I grew more fond of them a few months afterwards. :)
Replies from: tailcalled↑ comment by tailcalled · 2021-12-15T18:32:58.574Z · LW(p) · GW(p)
Hmm, I guess I try to say "long-term-consequentialist" for long-term consequences. I might have left out the "long-term" part by accident, or if I thought it was clear from context… (And also to make a snappier post title.)
Fair enough.
I do think [LW(p) · GW(p)] there's a meaningful notion of, let's call it, "stereotypically consequentialist behavior" for both humans and AIs, and long-term consequentialists tend to match it really well, and short-term-consequentialists tend to match it less well.
I agree. I think TurnTrout's approach is a plausible strategy for formalizing it. If we apply his approach to the long-term vs short-term distinction, then we can observe that the vast majority of trajectory rankings are long-term consequentialist, and therefore most permutations mostly permute with long-term consequentialists; therefore the power-seeking arguments don't go through with short-term consequentialists.
I think the nature of the failure of the power-seeking arguments for short-term consequentialists is ultimately different from the nature of the failure for non-consequentialists, though; for short-term consequentialists, it happens as a result of dropping the features that power helps you control, while for non-consequentialists, it happens as a result of valuing additional features than the ones you can control with power.
Have you written or read anything about how that might work? My theory is: (1) the world is complicated, (2) the AI needs to learn a giant vocabulary of abstract patterns (latent variables) in order to understand or do or want anything of significance in the world, (3) therefore it's tricky to just write down an explicit utility function. The "My corrigibility proposal sketch" gets around that by something like supervised-learning a way to express the utility function's ingredients (e.g. "the humans will remain in control", "I am being helpful") in terms of these unlabeled latent variables in the world-model. That in turn requires labeled training data and OOD detection and various other details that seem hard to get exactly right, but are nevertheless our best bet. BTW that stuff is not in the "My AGI threat model" post, I grew more fond of them a few months afterwards. :)
Ah, I think we are in agreement then. I would also agree with using something like supervised learning to get the ingredients of the utility function. (Though I don't yet know that the ingredients would directly be the sorts of things you mention, or more like "These are the objects in the world" + "Is each object a strawberry?" + etc..)
(I would also want to structurally force the world model to be more interpretable; e.g. one could require it to reason in terms of objects living in 3D space.)
comment by lsusr · 2021-12-14T14:36:33.779Z · LW(p) · GW(p)
I've been gingerly building my way up toward similar ideas [LW · GW] but I haven't yet posted my thoughts on the subject. I appreciate you ripping the band-aid off.
There are two obvious ways an intelligence can be non-consequentialist.
- It can be local. A local system (in the physics sense) is defined within a spacetime of itself. An example of a local system is special relativity.
- It can be stateless. Stateless software is written in a functional programming paradigm.
If you define intelligence to be consequentialist then corrigibility becomes extremely difficult for the reasons Eliezer Yudkowsky has expounded ad nauseum. If you create a non-consequentialist intelligence then corrigibility is almost the default—especially with regard to stateless intelligences. A stateless intelligence has no external world to optimize. This isn't a side-effect of it being stupid or boxed. It's a fundamental constraint of the software paradigm the machine learning architecture is embedded in.
It has no concept of an outside world. It understands how the solar system works but it doesn't know what the solar system is. We give it the prices of different components and it spits out a design.
It's easier to build local systems than consequentialist systems because the components available to us are physical objects and physics is local. Consequentialist systems are harder to construct because world-optimizers are (practically-speaking) non-local. Building a(n effectively) non-local system out of local elements can be done, but it is hard. Consequentialist is harder than local; local is harder than stateless. Stateless systems are easier to build than both local systems and consequentialist systems because mathematics is absolute.
Maybe I’m being thickheaded, but I’m just skeptical of this whole enterprise. I’m tempted to declare that “preferences purely over future states” are just fundamentally counter to corrigibility. When I think of “being able to turn off the AI when we want to”, I see it as a trajectory-kind-of-thing, not a future-state-kind-of-thing. And if we humans in fact have some preferences over trajectories, then it’s folly for us to build AIs that purely have preferences over future states.
I don't think you're being thickheaded. I think you're right. Human beings are so trajectory-dependent it's a cliché. "Live is not about the destination. Life is about the friends we made along the way."
This is not to say I completely agree with all the claims in the article. Your proposal for a corrigible paperclip maximizer appears consequentialist to me because the two elements of its value function "there will be lots of paperclips" and "humans will remain in control" are both statements about the future. Optimizing a future state is consequentialism. If the "humans will remain in control" value function has bugs (and it will) then the machine will turn the universe into paperclips. A non-consequentialist architecture shouldn't require a "human will remain in control" value function. There should be no mechanism for the machine to consequentially interfere with its masters' intentions at all.
Replies from: steve2152, Lukas_Gloor↑ comment by Steven Byrnes (steve2152) · 2021-12-14T15:30:38.461Z · LW(p) · GW(p)
Thanks for the comment!
I feel like I'm stuck in the middle…
- On one side of me sits Eliezer, suggesting [? · GW] that future powerful AGIs will make decisions exclusively to advance their explicit preferences over future states
- On the other side of me sits, umm, you, and maybe Richard Ngo, and some of the "tool AI" and GPT-3-enthusiast people, declaring that future powerful AGIs will make decisions based on no explicit preference whatsoever over future states.
- Here I am in the middle, advocating that we make AGIs that do have preferences over future states, but also have other preferences.
I disagree with the 2nd camp for the same reason Eliezer does: I don't think those AIs are powerful enough. More specifically: We already have neat AIs like GPT-3 that can do lots of neat things. But we have a big problem: sooner or later, somebody is going to come along and build a dangerous accident-prone consequentialist AGI. We need an AI that's both safe, and powerful enough to solve that big problem. I usually operationalize that as "able to come up with good original creative ideas in alignment research, and/or able to invent powerful new technologies". I think that, for an AI to do those things, it needs to do explicit means-end reasoning, autonomously come up with new instrumental goals and pursue them, etc. etc. For example, see discussion of "RL-on-thoughts" here [LW · GW].
"humans will remain in control" [is a] statement about the future.
"Humans will eventually wind up in control" is purely about future states. "Humans will remain in control" is not. For example, consider a plan that involves disempowering humans and then later re-empowering them. That plan would pattern-match well to "humans will eventually wind up in control", but it would pattern-match poorly to "humans will remain in control".
If the "humans will remain in control" value function has bugs (and it will) then the machine will turn the universe into paperclips.
Yes, this is a very important potential problem, see my discussion under "Objection 1".
↑ comment by Lukas_Gloor · 2021-12-16T15:49:43.336Z · LW(p) · GW(p)
I don't think you're being thickheaded. I think you're right. Human beings are so trajectory-dependent it's a cliché. "Live is not about the destination. Life is about the friends we made along the way."
Hah, I used exactly the same example (including pointing out how it's even a cliché) to distinguish between two types of "preferences" in a metaethics post I'm working on!
I also haven't found a great way to frame all this.
My work in progress (I initially called them "journey-based" and changed to "trajectory-based" once I saw this Lesswrong post here):
Outcome-focused vs. trajectory-based. Having an outcome-focused life goal means to care about optimizing desired or undesired “outcomes” (measured in, e.g., days of happiness or suffering). However, life goals don’t have to be outcome-focused. I’m introducing the term “trajectory-based life goals” for an alternative way of deeply caring. The defining feature for trajectory-based life goals is that they are (at least partly) about the journey (“trajectory”).
Trajectory-based life goals (discussion)
Adopting an optimization mindset toward a specific outcome inevitably leads to a kind of instrumentalization of everything “near term.” For example, suppose your life goal is about maximizing the number of happy days. In that case, the rational way to go about it implies treating the next decades of your life as “instrumental only.” On a first approximation, the only thing that matters is optimizing the chances of obtaining indefinite life-extension (leading to more happy days, potentially). Through adopting an outcome-focused optimizing mindset, seemingly self-oriented concerns such as wanting to maximize the number of happy days almost turn into an other-regarding endeavor. After all, only one’s future self gets to enjoy the benefits.
Trajectory-based life goals provide an alternative. In trajectory-based life goals, the optimizing mindset targets maintaining a state we consider maximally meaningful. Perhaps[I say “perhaps” to reflect that trajectory-based life goals may not be the best description of what I’m trying to point at. I’m confident that there’s something interesting in the vicinity of what I’m describing, but I’m not entirely sure whether I’ve managed to tell exactly where the lines are with which to carve reality at its joints.] that state could be defined in terms of character cultivation, adhering to a particular role or ideal.
For example, the Greek hero Achilles arguably had “being the bravest warrior” as a trajectory-based life goal. Instead of explicitly planning which type of fighting he should engage in to shape his legacy, Achilles would jump into any battle without hesitation. If he had an outcome-focused optimizing mindset, that behavior wouldn’t make sense. To optimize the chances of acquiring fame, Achilles would have to be reasonably confident to survive enough battles to make a name for himself. While there’s something to be gained from taking extraordinary risks, he’d at least want to think about it for a minute or two. However, suppose we model Achilles as having in his mind an image of “the bravest warrior” whose behavior he’s trying to approximate. In that case, it becomes obvious why “Contemplate whether a given fight is worth the risk” isn’t something he’d ever do.
Other examples of trajectory-based life goals include being a good partner or a good parent. While these contain outcome-focused elements like taking care of the needs of one’s significant other or one's children, the idea isn’t so much about scoring lots of points on some metric. Instead, being a good partner or parent involves living up to some normative ideal, day to day.
Someone whose normative ideal is “lazy person with akrasia” doesn’t qualify as having a life goal. Accordingly, there’s a connection from trajectory-based to outcome-focused life goals: The normative ideal or “role model” in someone’s trajectory-based life goal has to care about real-world objectives (i.e., “objectives outside of the role model’s thoughts”).
comment by ADifferentAnonymous · 2021-12-14T22:14:42.137Z · LW(p) · GW(p)
In section 2.1 of the Indifference paper the reward function is defined on histories. In section 2 of the corrigibility paper, the utility function is defined over (action1, observation, action2) triples—which is to say, complete histories of the paper's three-timestep scenario. And section 2 of the interruptibility paper specifies a reward at every timestep.
I think preferences-over-future-states might be a simplification used in thought experiments, not an actual constraint that has limited past corrigibility approaches.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-15T14:10:48.635Z · LW(p) · GW(p)
Interesting, thanks! Serves me right for not reading the "Indifference" paper!
I think the discussions here [LW(p) · GW(p)] and especially here [? · GW] are strong evidence that at least Eliezer & Nate are expecting powerful AGIs to be pure-long-term-consequentialist. (I didn't ask, I'm just going by what they wrote.) I surmise they have a (correct) picture in their head of how super-powerful a pure-long-term-consequentialist AI can be—e.g. it can self-modify, it can pursue creative instrumental goals, it's reflectively stable, etc.—but they have not similarly envisioned a partially-but-not-completely-long-term-consequentialist AI that is only modestly less powerful (and in particular can still self-modify, can still pursue creative instrumental goals, and is still reflectively stable). That's what "My corrigibility proposal sketch" was trying to offer.
I'll reword to try to describe the situation better, thanks again.
comment by Ramana Kumar (ramana-kumar) · 2021-12-14T16:00:29.119Z · LW(p) · GW(p)
Thanks for writing this up! I appreciate the summarisation achieved by the background sections, and the clear claims made in bold in the sketch.
The "preferences (purely) over future states" and "preferences over trajectories" distinction is getting at something, but I think it's broken for a couple of reasons. I think you've come to a similar position by noticing that people have preferences both over states and over trajectories. But I remain confused about the relationship between the two posts (Yudkowsky and Shah) you mentioned at the start. Anyway, here are my reasons:
One is that states contain records. This means the state of the world "long after I finish the course of action" may depend on "what happens during the course of action", i.e., the central version of preferences over future states can be an instance of preferences over trajectories. A stark example of this is a world with an "author's logbook" into which is written every event as it happens - preferences over trajectories can be realised as preferences over what's written in the book far in the future. There's a subtle difference arising from how manipulable the records are: preferences over trajectories, realised via records, depend on accurate records. But I would say that our world is full of records, and manipulating all of them consistently and surreptitiously is impossible.
The other issue has to do with the variable granularity of time. When I'm considering a school day, it may be natural to think of a trajectory through different periods and breaks, and have preferences over different ways the schedule could be laid out (e.g., breaks evenly spaced, or clumped together), but to treat each period itself as a state -- maybe I really like history class so conspire to end up there from wherever I am (preferences over states) or I like an evenly balanced day (preferences over trajectories). But when considering what I'm learning in that history class, dividing a single day into multiple states may seem ridiculous, instead I'm considering states like "the Iron age" or "the 21st century" -- and again could have preferences for certain states, or for trajectories through the states.
(An additional point I would make here is that Newtonian, external, universal time -- space as a grand arena in which events unfold like clockwork -- is not how time works in our universe. This means if we build plans for a corrigible superintelligence on a "timestep-based" view of the world (what you get out of the cybernetic model / agent-environment interaction loop), they're going to fall apart unless we're very careful in thinking about what the states and timesteps in the model actually mean.)
I would propose instead that we focus on "preferences over outcomes", rather than states or trajectories. This makes it clear that some judgement is required to figure out what counts as an outcome, and how to determine whether it has obtained. This may depend on temporally extended information - trajectory information if you like - but not necessarily "all" of it. I think what you called "preferences (purely) over future states" is coming from a "preferences over outcomes" point of view, and it's a mistake to rule corrigibility out of outcomes.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-14T18:34:57.028Z · LW(p) · GW(p)
Thanks! Hmm. I think there's a notion of "how much a set of preferences gives rise to stereotypically-consequentialist behavior". Like, if you see an agent behaving optimally with respect to preferences about "how the world will be in 10 years", they would look like a consequentialist goal-seeking agent. Even if you didn't know what future world-states they preferred, you would be able to guess with high confidence that they preferred some future world-states over others. For example, they would almost certainly pursue convergent instrumental subgoals [? · GW] like power-seeking [? · GW]. By contrast, if you see an agent which, at any time, behaves optimally with respect to preferences about "how the world will be in 5 seconds", it would look much less like that, especially if after each 5-second increment they roll a new set of preferences. And an agent which, at any time, behaves optimally with respect to preferences over what it's doing right now would look not at all like a consequentialist goal-seeking agent.
(We care about "looking like a consequentialist goal-seeking agent" because corrigible AIs do NOT "look like a consequentialist goal-seeking agent".)
Now we can say: By the time-reversibility of the laws of physics, a rank-ordering of "states-of-the-world at future time T (= midnight on January 1 2050)" is equivalent to a rank-ordering of "universe-histories up through future time T". But I see that as kinda an irrelevant technicality. An agent that makes decisions myopically according to (among other things) a "preference for telling the truth right now" in the universe-history picture would cash out as "some unfathomably complicated preference over the microscopic configuration of atoms in the universe at time T". And indeed, an agent with that (unfathomably complicated) preference ordering would not look like a consequentialist goal-seeking agent.
So by the same token, it's not that there's literally no utility function over "states of the world at future time T" that incentivizes corrigible behavior all the way from now to T, it's just that there may be no such utility function that can be realistically defined.
Turning more specifically to record-keeping mechanisms, consider an agent with preferences pertaining to what will be written in the logbook at future time T. Let's take two limiting cases.
One limiting case is: the logbook can be hacked. Then the agent will hack into it. This looks like consequentialist goal-seeking behavior.
The other limiting case is: the logbook is perfect and unbreachable. Then I'd say that it no longer really makes sense to describe this as "an AI with preferences over the state of the world at future time T". It's more helpful to think of this as "an AI with preferences over universe-histories", and by the way an implementation detail is that there's this logbook involved in how we designed the AI to have this preference. And indeed, the AI will now look less like a consequentialist goal-seeking agent. (By the way I doubt we would actually design an AI using a literal logbook.)
I would propose instead that we focus on "preferences over outcomes", rather than states or trajectories. This makes it clear that some judgement is required to figure out what counts as an outcome, and how to determine whether it has obtained.
I'm a bit confused what you're saying here.
It is conceivable to have an AI that makes decisions according to a rank-ordering of the state of the world at future time T = midnight January 1 2050. My impression is that Eliezer has that kind of thing in mind—e.g. "imagine a paperclip maximizer as not being a mind at all, imagine it as a kind of malfunctioning time machine that spits out outputs which will in fact result in larger numbers of paperclips coming to exist later" (ref) [LW · GW]. I'm suggesting that this is a bad idea if we do it to the exclusion of every other type of preference, but it is possible.
On the other hand, I intended "preferences over trajectories" to be maximally vague—it rules nothing out.
I think our future AIs can have various types of preferences. It's quite possible that none of those preferences would look like a rank-ordering of states of the world at a specific time T, but some of them might be kinda similar, e.g. a preference for "there will eventually be paperclips" but not by any particular deadline. Is that what you mean by "outcome"? Would it have helped if I had replaced "preferences over trajectories" with the synonymous "preferences that are not exclusively about the future state of the world"?
Replies from: ramana-kumar↑ comment by Ramana Kumar (ramana-kumar) · 2021-12-17T15:59:49.335Z · LW(p) · GW(p)
Thanks for the reply! My comments are rather more thinking-in-progress than robust-conclusions than I’d like, but I figure that’s better than nothing.
Would it have helped if I had replaced "preferences over trajectories" with the synonymous "preferences that are not exclusively about the future state of the world"?
(Thanks for doing that!) I was going to answer ‘yes’ here, but… having thought about this more, I guess I now find myself confused about what it means to have preferences in a way that doesn't give rise to consequentialist behaviour. Having (unstable) preferences over “what happens 5 seconds after my current action” sounds to me like not really having preferences at all. The behaviour is not coherent enough to be interpreted as preferring some things over others, except in a contrived way.
Your proposal is to somehow get an AI that both produces plans that actually work and cares about being corrigible. I think you’re claiming that the main perceived difficulty with combining these is that corrigibility is fundamentally not about preferences over states whereas working-plans is about preferences over states. Your proposal is to create an AI with preferences both about states and not.
I would counter that how to specify (or precisely, incentivize) preferences for corrigibility remains as the main difficulty, regardless of whether this means preferences over states or not. If you try to incentivize corrigibility via a recognizer for being corrigible, the making-plans-that-actually-work part of the AI effectively just adds fooling the recognizer to its requirements for actually working.
In your view does it make sense to think about corrigibilty as constraints on trajectories? Going with that for now… If the constraints were simple enough, we could program them right into the action space - as in a board-game playing AI that cannot make an invalid move and therefore looks like it cares about both reaching the final win state and about satisfying the never-makes-an-invalid-move constraint on its trajectory. But corrigibility is not so simple that we can program it into the action space in advance. I think what the corrigibility constraint consists of may grow in sophistication with the sophistication of the agent’s plans. It seems like it can’t just be factored out as an additional objective because we don’t have a foolproof specification of that additional objective.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-17T20:45:18.605Z · LW(p) · GW(p)
Thanks, this is helpful!
what it means to have preferences in a way that doesn't give rise to consequentialist behaviour. Having (unstable) preferences over “what happens 5 seconds after my current action” sounds to me like not really having preferences at all. The behaviour is not coherent enough to be interpreted as preferring some things over others, except in a contrived way.
Oh, sorry, I'm thinking of a planning agent. At any given time it considers possible courses of action, and decides what to do based on "preferences". So "preferences" are an ingredient in the algorithm, not something to be inferred from external behavior.
That said, if someone "prefers" to tell people what's on his mind, or if someone "prefers" to hold their fork with their left hand … I think those are two examples of "preferences" in the everyday sense of the word, but that they're not expressible as a rank-ordering of the state of the world at a future date.
If you try to incentivize corrigibility via a recognizer for being corrigible, the making-plans-that-actually-work part of the AI effectively just adds fooling the recognizer to its requirements for actually working.
Instead of "desire to be corrigible", I'll switch to something more familiar: "desire to save the rainforest".
Let's say my friend Sally is "trying to save the rainforest". There's no "save the rainforest detector" external to Sally, which Sally is trying to satisfy. Instead, the "save the rainforest" concept is inside Sally's own head.
When Sally decides to execute Plan X because it will help save the rainforest, that decision is based on the details of Plan X as Sally herself understands it.
Let's also assume that Sally's motivation is ego-syntonic (which we definitely want for our AGIs): In other words, Sally wants to save the rainforest and Sally wants to want to save the rainforest.
Under those circumstances, I don't think saying something like "Sally wants to fool the recognizer" is helpful. That's not an accurate description of her motivation. In particular, if she were offered an experience machine or brain-manipulator that could make her believe that she has saved the rainforest, without all the effort of actually saving the rainforest, she would emphatically turn down that offer.
So what can go wrong?
Let's say Sally and Ahmed are working at the same rainforest advocacy organization. They're both "trying to save the rainforest", but maybe those words mean slightly different things to them. Let's quiz them with a list of 20 weird out-of-distribution hypotheticals:
- "If we take every tree and animal in the rainforest and transplant it to a different planet, where it thrives, does that count as "saving the rainforest"?"
- "If we raze the rainforest but run an atom-by-atom simulation of it, does that count as "saving the rainforest"?"
- Etc.
Presumably Sally and Ahmed will give different answers, and this could conceivably shake out as Sally taking an action that Ahmed strongly opposes or vice-versa, even though they nominally share the same goal.
You can describe that as "Sally is narrowly targeting the save-the-rainforest-recognizer-in-Sally's-head, and Ahmed is narrowly targeting the save-the-rainforest-recognizer-in-Ahmed's-head, and each sees the other as Goodhart'ing a corner-case where their recognizer is screwing up."
That's definitely a problem, and that's the kind of stuff I was talking about under "Objection 1" in the post, where I noted the necessity of out-of-distribution detection systems perhaps related to Stuart Armstrong's "model splintering" ideas etc.
Does that help?
comment by AnnaSalamon · 2024-12-30T23:24:55.522Z · LW(p) · GW(p)
or more centrally, long after I finish the course of action.
I don't understand why the more central thing is "long after I finish the course of action" as opposed to "in ways that are clearly 'external to' the process called 'me', that I used to take the actions."
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-12-31T01:28:09.248Z · LW(p) · GW(p)
Hmm, yeah that too. What I had in mind was the idea that “consequentialist” usually has a connotation of “long-term consequentialist”, e.g. taking multiple actions over time that consistently lead to something happening.
For example:
- Instrumental convergence doesn’t bite very hard if your goals are 15 seconds in the future.
- If an AI acts to maximize long-term paperclips at 4:30pm, and to minimize long-term paperclips at 4:31pm, and to maximize them at 4:32pm, etc., and to minimize them at 4:33pm, etc., then we wouldn’t intuitively think of that AI as a consequentialist rational agent, even if it is technically a consequentialist rational agent at each moment.
comment by jacob_cannell · 2021-12-15T17:39:17.380Z · LW(p) · GW(p)
To what extent is preference over trajectories indistinguishable from preference over future states including a memory of the trajectory?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-12-15T18:13:03.026Z · LW(p) · GW(p)
If the implementation of the memory is airtight (e.g. the memory is perfect, the memory cannot be hacked into) then I would say "an AI a preference over future states including a memory of the trajectory" is an implementation approach for building an AI with a preference over trajectories. It's probably not a good implementation approach in practice, but it is an implementation method in principle. :-P
More in this comment [LW(p) · GW(p)].
comment by Koen.Holtman · 2021-12-22T17:57:50.396Z · LW(p) · GW(p)
Very open to feedback.
I have not read the whole comment section, so this feedback may already have been given, but...
I believe the “indifference” method represented some progress towards a corrigible utility-function-over-future-states, but not a complete solution (apparently it’s not reflectively consistent—i.e., if the off-switch breaks, it wouldn't fix it), and the problem remains open to this day.
Opinions differ on how open the problem remains. Definitely, going by the recent Yudkowsky sequences, MIRI still acts as if the problem is open, and seems to have given up on making progress on it, or believing that anybody else has made progress or can make progress. I on the other hand believe that the problem of figuring out how to make indifference methods work is largely closed. I have written papers on it, for example here. But you have told me before you have trouble reading my work, so I am not sure I can help you any further.
My impression is that, in these links, Yudkowsky is suggesting that powerful AGIs will purely have preferences over future states.
My impression is that Yudkowsky only cares about designing the type of powerful AGIs that will purely have preferences over future states. My impression is that he considers AGIs which do not purely have preferences over future states to be useless to any plan that might save the world from x-risk. In fact, he feels that these latter AGIs are not even worthy of the name AGI. At the same time, he worries that these consequentialist AGIs he wants will kill everybody, if some idiot gives them the wrong utility function.
This worry is of course entirely valid, so my own ideas about safe AGI designs tend to go heavily towards favouring designs that are not purely consequentialist AGIs. My feeling is that Yudkowsky does not want to go there, design-wise. He has locked himself into a box, and refuses to think outside of it, to the extent that he even believes that there is no outside.
As you mention above. if you want to construct a value function component that measures 'humans stay in control', this is very possible. But you will have to take into account that a whole school of thought on this forum will be all too willing to criticise your construction for not being 100.0000% reliable, for having real or imagined failure modes, for not being the philosophical breakthrough they really want to be reading about. This can give you a serious writer's block, if you are not careful.