My AGI Threat Model: Misaligned Model-Based RL Agent
post by Steven Byrnes (steve2152) · 2021-03-25T13:45:11.208Z · LW · GW · 40 commentsContents
My AGI development model More details about the model What about the reward function calculator? My AGI risk model Inner alignment problem: The value function might be different from the (sum of the) reward function. Outer alignment problem: The reward function might be different than the thing we want. So then what happens? What’s the risk model? If so, what now? None 40 comments
Rohin Shah advocates a vigorous discussion of “Threat Models”, i.e. stories for how AGI is developed, what the AGI then looks like, and then what might go catastrophically wrong.
Ben Garfinkel likewise wants to see a “a picture of the risk...grounded in reality”. Richard Ngo recently had a go at answering this call with AGI Safety From First Principles [LW · GW], which is excellent and full of valuable insights, but less specific than what I have in mind. So here’s my story, going all the way from how we’ll make AGI to why it may cause catastrophic accidents, and what to do about it.
My intended audience for this post is “people generally familiar with ML and RL, and also familiar with AGI-risk-related arguments”. (If you’re in the first category but not the second, read Stuart Russell’s book first.) I'll try to hyperlink jargon anyway.
My AGI development model
I assume that we’ll wind up building an AGI that looks more-or-less like this:
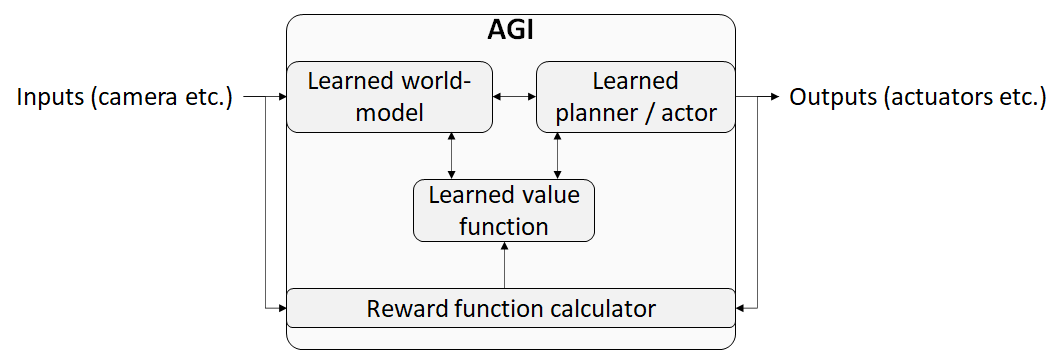
Why do I think this model is likely? To make a long story short:
- This seems like a natural extension of some of the types of AIs that researchers are building today (cf. MuZero).
- I think that human intelligence works more-or-less this way (see My Computational Framework for the Brain [LW · GW])
- …And if so, then we can have high confidence that this is a realistic path to AGI—whereas all other paths are more uncertain.
- …And moreover, this offers a second R&D path to the same destination—i.e., trying to understand how the brain’s learning algorithms work (which people in both AI/ML and neuroscience are already doing all the time anyway). That makes this destination more likely on the margin.
- See also: some discussion of different development paths in Against evolution as an analogy for how humans will build AGI [LW · GW].
More details about the model
- The value function is a function of the latent variables in the world-model—thus, even abstract concepts like “differentiate both sides of the equation” are assigned values. The value function is updated by the reward signals, using (I assume) some generalization of TD learning (definition).
- I assume that the learned components (world-model, value function, planner / actor) continue to be updated in deployment—a.k.a. online learning (definition). This is important for the risk model below, but seems very likely—indeed, unavoidable—to me:
- Online updating of the world-model is necessary for the AGI to have a conversation, learn some new idea from that conversation, and then refer back to that idea perpetually into the future.
- Online updating of the value function is then also necessary for the AGI to usefully employ those new concepts. For example, if the deployed AGI has a conversation in which it learns the idea of “Try differentiating both sides of the equation”, it needs to be able to assign and update a value for that new idea (in different contexts), in order to gradually learn how and when to properly apply it.
- Online updating of the value function is also necessary for the AGI to break down problems into subproblems. Like if “inventing a better microscope” is flagged by the value function as being high-value, and then the planner notices that “If only I had a smaller laser, then I’d be able to invent a better microscope”, then we need a mechanism for the value function to flag “inventing a smaller laser” as itself high-value.
- My default assumption is that this thing proceeds in one ridiculously-long RL episode, with the three interconnected “learning” modules initialized from random weights, using online learning for long enough to learn a common-sense understanding of the world from scratch. That is, after all, how the brain works, I think [LW · GW], and see also some related discussion in Against evolution as an analogy for how humans will build AGI [LW · GW]. If there’s learning through multiple shorter episodes, that’s fine too, I don’t think that really affects this post.
- Note the word “planner”—I assume that the algorithm is doing model-based RL, in the sense that it will make foresighted, goal-directed plans, relying on the world-model for the prediction of what would happen, and on the value function for the judgment of whether that thing would be desirable. There has been a lot of discussion [? · GW] about what goal-directedness is; I think that discussion is moot in this particular case, because this type of AGI will be obviously goal-directed by design. Note that the goal(s) to which it is directed will depend on the current state of the value function (which in turn is learned from the reward function calculator)—much more on which below.
What about the reward function calculator?
The above discussion was all about the learning algorithm (the three boxes on the top of the diagram above). The other part of my presumed AGI architecture is the reward function calculator box at the bottom of the diagram. Here’s a currently-open research question:
What reward function calculator, when inserted into the diagram above, would allow that RL system to safely scale all the way to super-powerful AGIs while remaining under human control? (Or do we need some new concept that will supersede our current concept of reward function calculators?)
(see Stuart Russell’s book). There are some small number of researchers working on this problem, including many people reading this post, and others, and me. Go us! Let’s figure it out! But in the grand scheme of things this remains a niche research topic, we have no clue whether this research program will succeed, and if it does eventually succeed, we have no clue how much time and effort is needed before we get there. Meanwhile, orders of magnitude more people are working on the other parts of the diagram, i.e. the three interconnected learning algorithms at the top.
So my assumption is that by default, by the time the “learning” parts of the AGI diagram above are getting really good, and scaling all the way to AGI, most people will still be putting very simple things into the “reward function calculator” box, things like “get correct answers on these math problems”.
(I make an exception for capability-advancing aspects of reward function engineering, like reward shaping, curiosity-like drives for novelty, etc. People already have a lot of techniques like that, and I assume those will continue to develop. I really meant to say: I’m assuming no breakthrough solution to the AGI-safety-relevant aspects of reward function engineering—more on which in the next section.)
To be clear, these simple reward functions will certainly lead to misaligned AIs (i.e., AIs trying to accomplish goals that no human would want them to accomplish, at least not if the AI is sufficiently competent). Such AIs will not be suitable for applications like robots and consumer products. But they will be very suitable to the all-important tasks of getting high-impact publications, getting funding, and continuing to improve the learning algorithms.
That said, sooner or later, more and more researchers will finally turn their attention to the question of what reward function to use, in order to reliably get an aligned / human-controllable system.
And then—unless we AI alignment researchers have a solution ready to hand them on a silver platter—I figure lots of researchers will mainly just proceed by trial-and-error, making things up as they go along. Maybe they’ll use reasonable-seeming reward functions like “get the human to approve of your output text”, or “listen to the following voice command, and whatever concepts it activates in your world-model, treat those as high-value”, etc. And probably also some people will play around with reward functions that are not even superficially safe, like “positive reward when my bank account goes up, negative reward when it goes down”. I expect a proliferation of dangerous experimentation. Why dangerous? That brings us to...
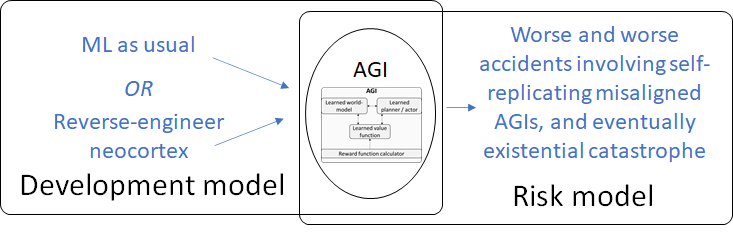
My AGI risk model
The AGI is by assumption making foresighted, strategic plans to accomplish goals. Those goals would be things flagged as high-value by its value function. Therefore, there are two “alignment problems”, outer and inner:
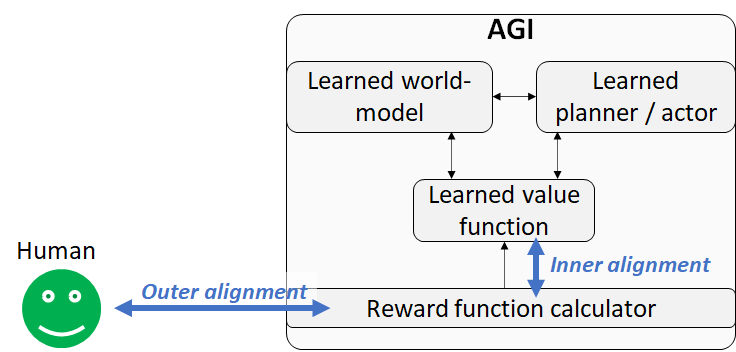
Inner alignment problem: The value function might be different from the (sum of the) reward function.
In fact that’s an understatement: The value function will be different from the (sum of the) reward function. Why? Among other things, because they have different type signatures—they accept different input!
The input to the reward function calculator is, well, whatever we program it to be. Maybe it would be a trivial calculation, that simply answers the question: “Is the remote control Reward Button currently being pressed?” Maybe it would look at the learning algorithm’s actions, and give rewards when it prints the correct answers to the math problems. Maybe it would take the camera and microphone data and run it through a trained classifier. It could be anything.
(In the brain, the reward function calculator includes a pain-detector that emits negative reward, and a yummy-food-detector that emits positive reward, and probably hundreds of other things, some of which may be quite complicated, and which may involve interpretability-like learned feature vectors [LW · GW], and so on.)
The input to the value function is specifically “the latent variables in the learned world-model”, as mentioned above.
Do you like football? Well “football” is a learned concept living inside your world-model. Learned concepts like that are the only kinds of things that it’s possible to “like”. You cannot like or dislike [nameless pattern in sensory input that you’ve never conceived of]. It’s possible that you would find this nameless pattern rewarding, were you to come across it. But you can’t like it, because it’s not currently part of your world-model. That also means: you can’t and won’t make a goal-oriented plan to induce that pattern.
“Nameless pattern in sensory input that you’ve never conceived of” is a case where something is in-domain for the reward function but (currently) out-of-domain for the value function. Conversely, there are things that are in-domain for your value function—so you can like or dislike them—but wildly out-of-domain for your reward function! You can like or dislike “the idea that the universe is infinite”! You can like or dislike “the idea of doing surgery on your brainstem in order to modify your own internal reward function calculator”! A big part of the power of intelligence is this open-ended ever-expanding world-model that can re-conceptualize the world and then leverage those new concepts to make plans and achieve its goals. But we cannot expect those kinds of concepts to be evaluable by the reward function calculator.
(Well, I guess “the idea that the universe is infinite” and so on could be part of the reward function calculator. But now the reward function calculator is presumably a whole AGI of its own, which is scrutinizing the first AGI using interpretability tools. Maybe there’s a whole tower of AGIs-scrutinizing-AGIs! That’s all very interesting to think about, but until we flesh out the details, especially the interpretability part, we shouldn’t assume that there’s a good solution along these lines.)
So leaving that aside, the value function and reward function are necessarily misaligned functions. How misaligned? Will the value function converge to a better and better approximation of the summed reward function (at least where the domains overlap)? I’m inclined to answer: “Maybe sometimes (especially with simple reward functions), but not reliably, and maybe not at all with the techniques we’ll have on hand by the time we’re actually doing this.” Some potential problems (which partially overlap) are:
- Ambiguity in the reward signals—There are many different value functions (defined on different world-models) that agree with the actual history of reward signals, but that generalize out-of-sample in different ways. To take an easy example, the wireheading value function (“I like it when there’s a reward signal”) is always trivially consistent with the reward history. Or compare "negative reward for lying" to "negative reward for getting caught lying"!
- Credit assignment failures—The AGI algorithm is implicitly making an inference, based on its current understanding of the world, about what caused the reward prediction error, and then incrementing the value associated with that thing. Such inferences will not always be correct. Look at humans with superstitions. Or how about the time Lisa Feldman Barrett went on a date, felt butterflies in her stomach, and thought she had found True Love … only to discover later that she was coming down with the flu! Note that the AGI is not trying to avoid credit assignment failures (at least, not before we successfully put corrigible motivation (definition [? · GW]) into it), because credit assignment is how it gets motivation in the first place. We just have some imperfect credit-assignment algorithm that we wrote—I presume it’s something a bit like TD learning, but elaborated to work with flexible, time-extended plans and concepts and so on—and we’re hoping that this algorithm assigns credit properly. (Actually, we need to be concerned that the AGI may try to cause credit assignment failures! See below.)
- Different aspects of the value-function duking it out—For example, I currently have mutually-contradictory desires in my brain’s value function: I like the idea of eating candy because it’s yummy, and I also like the idea of not eating candy because that’s healthy. Those desires are in conflict. My general expectation is that reward functions will by default flow value into multiple different concepts in the world-model, which encode mutually-contradictory desires, at least to some extent. This is an unstable situation, and when the dust settles, the agent could wind up effectively ignoring or erasing some of those desires. For example, if I had write access to my brain, I would strongly consider self-modifying to not find candy quite so yummy. I can’t do that with current technology, but I can wait until some moment when my “eat candy” drive is unusually weak (like when I’m not hungry), and then my “stay healthy” drive goes on a brutal attack! I throw out all my candy, I set up a self-control system to sap my desire to buy more candy in the future, etc. So by the same token, we could set up a reward function that is supposed to induce a nice balance between multiple motivations in our AGI, but the resulting AGI could wind up going all out on just one of those motivations, preventing the others from influencing its behavior. And we might not be able to predict which motivation will win the battle. You might say: the solution is to have a reward function that defines a self-consistent, internally-coherent motivation. (See Stuart Armstrong’s defense of making AGIs with utility functions.) Maybe! But doing that is not straightforward either! A reward which is “just one internally-coherent motivation system” from our human perspective has to then get projected onto the available concepts in the AGI’s world-model, and in that concept space, it could wind up taking the form of multiple competing motivations, which again leads to an unpredictable endpoint which may be quite different from the reward function.
- Ontological crises—For example, let’s say I build an AGI with the goal “Do what I want you to do”. Maybe the AGI starts with a primitive understanding of human psychology, and thinks of me as a monolithic rational agent. So then “Do what I want you to do” is a nice, well-defined goal. But then later on, the AGI develops a more sophisticated understanding of human psychology, and it realizes that I have contradictory goals, and context-dependent goals, and I have a brain made of neurons and so on. Maybe its goal is still “Do what I want you to do”, but now it’s not so clear what exactly that refers to, in its updated world model. How does that shake out?
- Manipulating the training signal—Insofar as the AGI has non-corrigible real-world goals, and understands its own motivation system, it will be motivated to preserve aspects of its current value function, including by manipulating or subverting the mechanism by which the rewards change the value function. This is a bit like gradient hacking [LW · GW], but it's not a weird hypothetical, it's a thing where there are actually agents running this kind of algorithm (namely, us humans), and they literally do this exact thing a hundred times a day. Like, every time we put our cellphone on the other side of the room so that we’re less tempted to check Facebook, we’re manipulating our own future reward stream in order to further our current goal of “being productive”. Or more amusingly, some people manipulate their motivations the old-fashioned way—y’know, by wearing a wristband that they then use to electrocute themselves. Corrigibility would seem to solve this manipulation problem, but we don't yet know how to install corrigible motivation, and even if we did, there would at least be some period during early training where it wasn't corrigible yet.
Some of these problems are especially problematic problems because you don’t know when they will strike. For example, ontological crises: Maybe you’re seven years into deployment, and the AGI has been scrupulously helpful the whole time, and we've been trusting the AGI with more and more autonomy, and then the AGI then happens to be reading some new philosophy book, and it converts to panpsychism (nobody’s perfect!), and as it maps its existing values onto its reconceptualized world, it finds itself no longer valuing the lives of humans over the lives of ants, or whatever.
Outer alignment problem: The reward function might be different than the thing we want.
Here there are problems as well, such as:
- Translation of “what we want” into machine code—The reward function needs to be written (directly or indirectly) in machine code, which rules out any straightforward method of leveraging common-sense concepts, and relatedly introduces the strong possibility of edge-cases where the reward function calculator gives the wrong answer. Goodhart’s law (definition) comes into play here (as elsewhere), warning us that optimizing an oversimplified approximation to what we want can wildly diverge from optimizing what we want—particularly if the “wildly diverging” part includes corrigibility. See Superintelligence, Complexity of Value [? · GW], etc. Presumably we need a system for continually updating the reward function with human feedback, but this faces problems of (1) human-provided data being expensive, and (2) humans not always being capable (for various reasons) of judging whether the right action was taken—let alone whether the right action was taken for the right reason. As elsewhere, there are ideas in the AI Alignment literature (cf. debate, recursive reward modelling, iterated amplification, etc.), but no solution yet.
- Things we don’t inherently care about but which we shoved into the reward function for capability reasons could also lead to dangerous misalignment. I’m especially thinking here about curiosity (the drive for exploration / novelty / etc.). Curiosity seems like a potentially necessary motivation to get our AGI to succeed in learning, figuring things out, and doing the things we want it to do. But now we just put another ingredient into the reward function, which will then flow into the value function, and from there into plans and behavior, and exactly what goals and behaviors will it end up causing downstream? I think it’s very hard to predict. Will the AGI really love making up and then solving harder and harder math problems, forever discovering elegant new patterns, and consuming all of our cosmic endowment in the process?
By the way, in terms of solving the alignment problem, I’m not sure that splitting things up into “outer alignment” and “inner alignment” is actually that helpful! After all, the reward function will diverge from the thing we want, and the value function will diverge from the reward function. The most promising solution directions that I can think of seem to rely on things like interpretability, “finding human values inside the world-model”, corrigible motivation, etc.—things which cut across both layers, bridging all the way from the human’s intentions to the value function.
So then what happens? What’s the risk model?
I’ll go with a slow takeoff (definition [? · GW]) risk scenario. (If we’re doomed under slow takeoff then we’re even more doomed under fast takeoff.) A particularly bad case—which I see as plausible in all respects—would be something like this:
- Assumption 1: The AGI’s learned value function winds up at least sometimes (and perhaps most or all of the time) misaligned with human values, and in particular, non-corrigible and subject to the classic instrumental convergence argument [? · GW] that makes it start trying to not get shut down, to prevent its current goals from being manipulated, to self-replicate, to increase its power and so on. And this is not a straightforward debugging exercise—we could have a misbehaving AGI right in front of us, with a reproducible failure mode, and still not know how to fix the underlying problem. So it remains a frequent occurrence early on, though hopefully we will eventually solve the problem so that it happens less often over time.
- I take this as the default, for all the reasons listed above if the programmers are smart and thoughtful and actually trying, and certainly if they aren’t. (Unless we AI alignment researchers solve the problem, of course!)
- The “instrumental convergence” part relies on the idea that most possible value functions are subject to instrumental convergence, so if there is unintended and unpredictable variation in the final value function, we’re reasonably likely to get a goal with instrumental convergence. (Why “most possible value functions”? Well, the value function assigns values to things in the world-model, and I figure that most things in the world-model—e.g. pick a random word in the dictionary—will be persistent patterns in the world which could in principle be expanded, or made more certain, without bound.) Here’s an example. Let’s say I’m programming an AGI, and I want the AGI’s goal to be “do what I, the programmer, want you to do”. As it happens, I very much want to solve climate change. If alignment goes perfectly, the AGI will be motivated to solve climate change, but only as a means to an end (of doing what I want). But with all the alignment difficulties listed above, the AGI may well wind up with a distorted version of that goal. So maybe the AGI will (among other things) want to solve climate change as an end in itself. (In fact, it may be worse than that: the human brain implementation of a value function does not seem to have a baked-in distinction between instrumental goals vs final goals in the first place!) That motivation is of course non-corrigible and catastrophically unsafe. And as described in the previous section, if even one aspect of the AGI’s motivation would be non-corrigible in isolation, then we’re potentially in trouble, because that sub-motivation might subvert all the other sub-motivations and take control of behavior. Incidentally, I don’t buy the argument that “corrigibility is a broad basin of attraction” [LW · GW], but even if I did, this example here is supposed to illustrate how alignment is so error-prone (by default) that it may miss the basin entirely!
- Assumption 2: More and more groups are capable of training this kind of AGI, in a way that’s difficult to monitor or prevent.
- I also take this to be the default, given that new ideas in AI tend to be open-sourced, that they get progressively easier to implement due to improved tooling, pedagogy, etc., that there are already several billion GPUs dispersed across the planet, and that the global AI community includes difficult-to-police elements like the many thousands of skilled researchers around the globe with strong opinions and no oversight mechanism, not to mention secret military labs etc.
- Assumption 3: There is no widely-accepted proof or solid argument that we can’t get this kind of AGI to wind up with a safe value function.
- I also find this very likely—“wanting to help the human” seems very much like a possible configuration of the value function, and there is an endless array of plausible-sounding approaches to try to get the AGI into that configuration.
- Assumption 4: Given a proposed approach to aligning / controlling this kind of AGI, there is no easy, low-risk way to see whether that approach will work.
- Also seems very likely to me, in the absence of new ideas. I expect that the final state of the value function is a quite messy function of the reward function, environment, random details of how the AGI is conceptualizing certain things, and so on. In the absence of new ideas, I think you might just have to actually try it. While a “safe test environment” would solve this problem, I’m pessimistic that there even is such a thing: No matter how much the AGI learns in the test environment, it will continue to learn new things, to think new thoughts, and to see new opportunities in deployment, and as discussed above (e.g. ontological crises), the value function is by default fundamentally unstable under those conditions.
- Assumption 5: A safer AGI architecture doesn't exist, or requires many years of development and many new insights.
- Also seems very likely to me, in that we currently have zero ways to build an AGI, so we will probably have exactly one way before we have multiple ways.
- Assumption 6: In a world with one or more increasingly-powerful misaligned AGIs that are self-improving and self-replicating around the internet (again cf. instrumental convergence discussion above), things may well go very badly for humanity (including possibly extinction), even if some humans also eventually succeed in making aligned AGIs.
- Consider how unaligned AGIs will have asymmetric superpowers like the ability to steal resources, to manipulate people and institutions via lying and disinformation; to cause wars, pandemics, blackouts, and so on; and to not have to deal with coordination challenges across different actors with different beliefs and goals. Also, there may be a substantial head-start, where misaligned AGIs start escaping into the wild well before we figure out how to align an AGI. And, there’s a potential asymmetric information advantage, if rogue misaligned AGIs can prevent their existence from becoming known. See The Strategy-Stealing Assumption [LW · GW] for further discussion.
Assuming slow takeoff (again, fast takeoff is even worse), it seems to me that under these assumptions there would probably be a series of increasingly-worse accidents spread out over some number of years, culminating in irreversible catastrophe, with humanity unable to coordinate to avoid that outcome—due to the coordination challenges in Assumptions 2-4.
Well, maybe humans and/or aligned AGIs would be able to destroy the unaligned AGIs, but that would be touch-and-go under the best of circumstances (see Assumption 6)—and the longer into this period that it takes us to solve the alignment problem (if indeed we do at all), the worse our prospects get. I’d rather have a plan ready to go in advance! That brings us to...
If so, what now?
So that’s my AGI threat model. (To be clear, avoiding this problem is only one aspect of getting to Safe & Beneficial AGI—necessary but by no means sufficient.)
If you buy all that, then some of the implications include:
- In general, we should be doing urgent, intense research on AGI safety. The “urgent” is important even if AGI is definitely a century away because (A) some interventions become progressively harder with time, like “coordinate on not pursuing a certain R&D path towards AGI, in favor of some very different R&D path” (see appendix here [LW · GW] for a list of very different paths to AGI), and (B) some interventions seem to simply take a lot of serial time to unfold, like “develop the best foundation of basic ideas, definitions, concepts, and pedagogy” (a.k.a. deconfusion), or “create a near-universal scientific consensus about some technical topic” (because as the saying goes, “science progresses one funeral at a time”).
- We should focus some attention on this particular AGI architecture that I drew above, and develop good plans for aligning / controlling / inspecting / testing / using such an AGI. (We're not starting from scratch; many existing AGI safety & alignment ideas already apply to this type of architecture, possibly with light modifications. But we still don't have a viable plan.)
- We should treat the human brain “neocortex subsystem” [LW · GW] as a prototype of one way this type of algorithm could work, and focus some attention on understanding its details—particularly things like how exactly the reward function updates the value function—in order to better game out different alignment approaches. (This category of work brushes against potential infohazards [? · GW], but I think that winds up being a manageable problem, for various reasons.)
…And there you have it—that’s what I'm doing every day; that's my current research agenda in a nutshell!
Well, I’m doing that plus the meta-task of refining and discussing and questioning my assumptions. Hence this post! So leave a comment or get in touch. What do you think?
40 comments
Comments sorted by top scores.
comment by TurnTrout · 2021-03-25T16:15:40.446Z · LW(p) · GW(p)
Great post!
Do you like football? Well “football” is a learned concept living inside your world-model. Learned concepts like that are the only kinds of things that it’s possible to “like”. You cannot like or dislike [nameless pattern in sensory input that you’ve never conceived of]. It’s possible that you would find this nameless pattern rewarding, were you to come across it. But you can’t like it, because it’s not currently part of your world-model. That also means: you can’t and won’t make a goal-oriented plan to induce that pattern.
This was a ‘click’ for me, thanks.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-03-30T16:26:54.123Z · LW(p) · GW(p)
It seems to me that deliberation can expand the domain of the value function. If I don’t know of football per se, but I’ve played a sport before, then I can certainly imagine a new game and form opinions about it. so I’m not sure how large the minimal set of generator concepts is, or if that’s even well-defined.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-30T16:32:11.995Z · LW(p) · GW(p)
Strong agree. This is another way that it's a hard problem.
comment by Rohin Shah (rohinmshah) · 2021-03-25T16:07:14.408Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post lays out a pathway by which an AI-induced existential catastrophe could occur. The author suggests that AGI will be built via model-based reinforcement learning: that is, given a reward function, we will learn a world model, a value function, and a planner / actor. These will learn online, that is, even after being deployed these learned models will continue to be updated by our learning algorithm (gradient descent, or whatever replaces it). Most research effort will be focused on learning these models, with relatively less effort applied to choosing the right reward function.
There are then two alignment problems: the _outer_ alignment problem is whether the reward function correctly reflects the designer's intent, and the _inner_ alignment problem is whether the value function accurately represents the expected reward obtained by the agent over the long term. On the inner alignment side, the value function may not accurately capture the reward for several reasons, including ambiguity in the reward signals (since you only train the value function in some situations, and many reward functions can then produce the same value function), manipulation of the reward signal, failures of credit assignment, ontological crises, and having mutually contradictory "parts" of the value function (similarly to humans). On the outer alignment side, we have the standard problem that the reward function may not reflect what we actually want (i.e. specification gaming or Goodhart's Law). In addition, it seems likely that many capability enhancements will be implemented through the reward function, e.g. giving the agent a curiosity reward, which increases outer misalignment.
Planned opinion:
While I disagree on some of the details, I think this is a good threat model to be thinking about. Its main virtue is that it has a relatively concrete model for what AGI looks like, and it provides a plausible story for both how that type of AGI could be developed (the development model) and how that type of AGI would lead to problems (the risk model). Of course, it is still worth clarifying the plausibility of the scenario, as updates to the story can have significant implications on what research we do. (Some of this discussion is happening in [this post](https://www.alignmentforum.org/posts/pz7Mxyr7Ac43tWMaC/against-evolution-as-an-analogy-for-how-humans-will-create).)
comment by abramdemski · 2021-05-07T15:32:12.905Z · LW(p) · GW(p)
(Much of this has been touched on already in our Discord conversation:)
Inner alignment problem: The value function might be different from the reward function.
In fact that’s an understatement: The value function will be different from the reward function. Why? Among other things, because they have different type signatures—they accept different input!
Surely this isn't relevant! We don't by any means want the value function to equal the reward function. What we want (at least in standard RL) is for the value function to be the solution to the dynamic programming problem set up by the reward function and world model (or, more idealistically, the reward function and the actual world).
- The value function is a function of the latent variables in the world-model—thus, even abstract concepts like “differentiate both sides of the equation” are assigned values. The value function is updated by the reward signals, using (I assume) some generalization of TD learning (definition).
While something like this seems possible, it strikes me as a better fit for systems that do explicit probabilistic reasoning, as opposed to NNs. Like, if we're talking about predicting what ML people will do, the sentence "the value function is a function of the latent variables in the world model" makes a lot more sense than the clarification "even abstract concepts are assigned values". Because it makes more sense for the value to be just another output of the same world-model NN, or perhaps, to be a function of a "state vector" produced by the world-model NN, or maybe a function taking the whole activation vector of the world-model NN at a time-step as an input, as opposed to a value function which is explicitly creating output values for each node in the value function NN (which is what it sounds like when you say even abstract concepts are assigned values).
I assume that the learned components (world-model, value function, planner / actor) continue to be updated in deployment—a.k.a. online learning (definition). This is important for the risk model below, but seems very likely—indeed, unavoidable—to me:
This seems pretty implausible to me, as we've discussed. Like, yes, it might be a good research direction, and it isn't terribly non-prosaic. However, the current direction seems pretty focused on offline learning (even RL, which was originally intended specifically for online learning, has become a primarily offline method!!), and GPT-3 has convinced everyone that the best way to get online learning is to do massive offline training and rely on the fact that if you train on enough variety, learning-to-learn is inevitable.
- Online updating of the world-model is necessary for the AGI to have a conversation, learn some new idea from that conversation, and then refer back to that idea perpetually into the future.
I think my GPT-3 example adequately addresses the first two points, and memory networks adequately address the third.
- Online updating of the value function is then also necessary for the AGI to usefully employ those new concepts. For example, if the deployed AGI has a conversation in which it learns the idea of “Try differentiating both sides of the equation”, it needs to be able to assign and update a value for that new idea (in different contexts), in order to gradually learn how and when to properly apply it.
- Online updating of the value function is also necessary for the AGI to break down problems into subproblems. Like if “inventing a better microscope” is flagged by the value function as being high-value, and then the planner notices that “If only I had a smaller laser, then I’d be able to invent a better microscope”, then we need a mechanism for the value function to flag “inventing a smaller laser” as itself high-value.
These points are more interesting, but I think it's plausible that architectural innovations could deal with them w/o true online learning.
Replies from: steve2152, steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2021-05-12T20:12:12.022Z · LW(p) · GW(p)
RE online learning, I acknowledge that a lot of reasonable people agree with you on that, and it's hard to know for sure. But I argued my position in Against evolution as an analogy for how humans will build AGI [LW · GW].
Also there: a comment thread about why I'm skeptical that GPT-N would be capable of doing the things we want AGI to do, unless we fine-tune the weights on the fly, in a manner reminiscent of online learning (or amplification) [LW(p) · GW(p)].
Replies from: abramdemski↑ comment by abramdemski · 2021-05-13T15:12:58.834Z · LW(p) · GW(p)
I have not properly read all of that yet, but my very quick take is that your argument for a need for online learning strikes me as similar to your argument against the classic inner alignment problem applying to the architectures you are interested in. You find what I call mesa-learning implausible for the same reasons you find mesa-optimization implausible.
Personally, I've come around to the position (seemingly held pretty strongly by other folks, eg Rohin) that mesa-learning is practically inevitable for most tasks [LW · GW].
↑ comment by Steven Byrnes (steve2152) · 2021-05-12T19:39:40.597Z · LW(p) · GW(p)
if we're talking about predicting what ML people will do, the sentence "the value function is a function of the latent variables in the world model" makes a lot more sense than the clarification "even abstract concepts are assigned values".
OK sure, that's fair. Point well taken. I was thinking about more brain-like neural nets that parse things into compositional pieces. If I wanted to be more prosaic maybe I would say something like: "She is differentiating both sides of the equation" could have a different value than "She is writing down a bunch of funny symbols", even if both are coming from the exact same camera inputs.
↑ comment by Steven Byrnes (steve2152) · 2021-05-12T17:46:45.322Z · LW(p) · GW(p)
Thanks!!
> The value function might be different from the reward function.
Surely this isn't relevant! We don't by any means want the value function to equal the reward function. What we want (at least in standard RL) is for the value function to be the solution to the dynamic programming problem set up by the reward function and world model (or, more idealistically, the reward function and the actual world).
Hmm. I guess I have this ambiguous thing where I'm not specifying whether the value function is "valuing" world-states, or actions, or plans, or all of the above, or what. I think there are different ways to set it up, and I was trying not to get bogged down in details (and/or not being very careful!)
Like, here's one extreme: imagine that the "planner" does arbitrarily-long-horizon rollouts of possible action sequences and their consequences in the world, and then the "value function" is looking at that whole future rollout and somehow encoding how good it is, and then you can choose the best rollout. In this case we do want the value function to converge to be (for all intents and purposes) a clone of the reward function.
On the opposite extreme, when you're not doing rollouts at all, and instead the value function is judging particular states or actions, then I guess it should be less like the reward function and more like "expected upcoming reward assuming the current policy", which I think is what you're saying.
Incidentally, I think the brain does both. Like, maybe I'm putting on my shoes because I know that this is the first step of a plan where I'll go to the candy store and buy candy and eat it. I'm motivated to put on my shoes by the image in my head where, a mere 10 minutes from now, I'll be back at home eating yummy candy. In this case, the value function is hopefully approximating the reward function, and specifically approximating what the reward function will do at the moment where I will eat candy. But maybe eventually, after many such trips to the candy store, it becomes an ingrained habit. And then I'm motivated to put on my shoes because my brain has cached the idea that good things are going to happen as a result—i.e., I'm motivated even if I don't explicitly visualize myself eating candy soon.
I guess I spend more time thinking about the former (the value function is evaluating the eventual consequences of a plan) than the latter (the value function is tracking the value of immediate world-states and actions), because the former is the component that presents most of the x-risk. So that's what was in my head when I wrote that.
(It's not either/or; I think there's a continuum between those two poles. Like I can consequentialist-plan to get into a future state that has a high cached value but no immediate reward.)
As for prosaic RL systems, they're set up in different ways I guess, and I'm not an expert on the literature. In Human Compatible, if I recall, Stuart Russell said that he thinks the ability to do flexible hierarchical consequentialist planning is something that prosaic AI doesn't have yet, but that future AGI will need. If that's right, then maybe this is an area where I should expect AGI to be different from prosaic AI, and where I shouldn't get overly worried about being insufficiently prosaic. I dunno :-P
Well anyway, your point is well taken. Maybe I'll change it to "the value function might be misaligned with the reward function", or "incompatible", or something...
Replies from: abramdemski↑ comment by abramdemski · 2021-05-12T19:41:26.681Z · LW(p) · GW(p)
Hmm. I guess I have this ambiguous thing where I'm not specifying whether the value function is "valuing" world-states, or actions, or plans, or all of the above, or what. I think there are different ways to set it up, and I was trying not to get bogged down in details (and/or not being very careful!)
Sure, but given most reasonable choices, there will be an analogous variant of my claim, right? IE, for most reasonable model-based RL setups, the type of the reward function will be different from the type of the value function, but there will be a "solution concept" saying what it means for the value function to be correct with respect to a set reward function and world-model. This will be your notion of alignment, not "are the two equal".
Like, here's one extreme: imagine that the "planner" does arbitrarily-long-horizon rollouts of possible action sequences and their consequences in the world, and then the "value function" is looking at that whole future rollout and somehow encoding how good it is, and then you can choose the best rollout. In this case we do want the value function to converge to be (for all intents and purposes) a clone of the reward function.
Well, there's still a type distinction. The reward function gives a value at each time step in the long rollout, while the value function just gives an overall value. So maybe you mean that the ideal value function would be precisely the sum of rewards.
But if so, this isn't really what RL people typically call a value function. The point of a value function is to capture the potential future rewards associated with a state. For example, if your reward function is to be high up, then the value of being near the top of a slide is very low (because you'll soon be at the bottom), even if it's still generating high reward (because you're currently high up).
So the value of a history (even a long rollout of the future) should incorporate anticipated rewards after the end of the history, not just the value observed within the history itself.
In the rollout architecture you describe, there wouldn't really be any point to maintaining a separate value function, since you can just sum the rewards (assuming you have access to the reward function).
On the opposite extreme, when you're not doing rollouts at all, and instead the value function is judging particular states or actions, then I guess it should be less like the reward function and more like "expected upcoming reward assuming the current policy", which I think is what you're saying.
It doesn't seem to me like there is any "more/less like reward" spectrum here. The value function is just different from the reward function. In an architecture where you have a "value function" which operates like a reward function, I would just call it the "estimated reward function" or something along those lines, because RL people invented the value/reward distinction to point at something important (namely the difference between immediate reward and cumulative expected reward), and I don't want to use the terms in a way which gets rid of that distinction.
Like, maybe I'm putting on my shoes because I know that this is the first step of a plan where I'll go to the candy store and buy candy and eat it. I'm motivated to put on my shoes by the image in my head where, a mere 10 minutes from now, I'll be back at home eating yummy candy. In this case, the value function is hopefully approximating the reward function, and specifically approximating what the reward function will do at the moment where I will eat candy.
How is this "approximating the reward function"?? Again, if you feed both the value and reward function the same thing (the imagined history of going to the store and coming back and eating candy), you hope that they produce very different results (the reward function produces a sequence of individual rewards for each moment, including a high reward when you're eating the candy; the value function produces one big number accounting for the positives and negatives of the plan, including estimated future value of the post-candy-eating crash, even though that's not represented inside the history).
Well anyway, your point is well taken. Maybe I'll change it to "the value function might be misaligned with the reward function", or "incompatible", or something...
I continue to feel like you're not seeing that there is a precise formal notion of "the value function is aligned with the reward function", namely, that the value function is the solution to the value iteration equation (the bellman equation) wrt a given reward function and world model.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-05-12T20:04:03.845Z · LW(p) · GW(p)
So maybe you mean that the ideal value function would be precisely the sum of rewards.
Yes, thanks, that's what I should have said.
In the rollout architecture you describe, there wouldn't really be any point to maintaining a separate value function, since you can just sum the rewards (assuming you have access to the reward function).
For "access to the reward function", we need to predict what the reward function will do (which may involve hard-to-predict things like "the human will be pleased with what I've done"). I guess your suggestion would be to call the thing-that-predicts-what-the-reward-will-be a "reward function model", and the thing-that-predicts-summed-rewards the "value function", and then to change "the value function may be different from the reward function" to "the value function may be different from the expected sum of rewards". Something like that?
If so, I agree, you're right, I was wrong, I shouldn't be carelessly going back and forth between those things, and I'll change it.
Replies from: abramdemski↑ comment by abramdemski · 2021-05-13T15:03:25.311Z · LW(p) · GW(p)
For "access to the reward function", we need to predict what the reward function will do (which may involve hard-to-predict things like "the human will be pleased with what I've done"). I guess your suggestion would be to call the thing-that-predicts-what-the-reward-will-be a "reward function model", and the thing-that-predicts-summed-rewards the "value function", and then to change "the value function may be different from the reward function" to "the value function may be different from the expected sum of rewards". Something like that?
Ah, that wasn't quite my intention, but I take it as an acceptable interpretation.
My true intention was that the "reward function calculator" should indeed be directly accessible rather than indirectly learned via reward-function-model. I consider this normative (not predictive) due to the considerations about observation-utility agents discussed in Robust Delegation [LW · GW] (and more formally in Daniel Dewey's paper). Learning the reward function is asking for trouble.
Of course, hard-coding the reward function is also asking for trouble, so... *shrug*
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-02T03:02:27.134Z · LW(p) · GW(p)
Hi again, I finally got around to reading those links, thanks!
I think what you're saying (and you can correct me) is: observation-utility agents are safer (or at least less dangerous) than reward-maximizers-learning-the-reward, because the former avoids falling prey to what you called [LW · GW] "the easy problem of wireheading".
So then the context was:
First you said, If we do rollouts to decide what to do, then the value function is pointless, assuming we have access to the reward function.
Then I replied, We don't have access to the reward function, because we can't perfectly predict what will happen in a complicated world.
Then you said, That's bad because that means we're not in the observation-utility paradigm.
But I don't think that's right, or at least not in the way I was thinking of it. We're using the current value function to decide which rollouts are good vs bad, and therefore to decide which action to take. So my "value function" is kinda playing the role of a utility function (albeit messier), and my "reward function" is kinda playing the role of "an external entity that swoops in from time to time and edits the utility function". Like, if the agent is doing terrible things, then some credit-assignment subroutine goes into the value function, looks at what is currently motivating the agent, and sets that thing to not be motivating in the future.
The closest utility function analogy would be: you're trying to make an agent with a complicated opaque utility function (because it's a complicated world). You can't write the utility function down. So instead you code up an automated utility-function-editing subroutine. The way the subroutine works is that sometimes the agent does something which we recognize as bad / good, and then the subroutine edits the utility function to assign lower / higher utility to "things like that" in the future. After many such edits, maybe we'll get the right utility function, except not really because of all the problems discussed in this post, e.g. the incentive to subvert the utility-function-editing subroutine.
So it's still in the observation-utility paradigm I think, or at least it seems to me that it doesn't have an automatic incentive to wirehead. It could want to wirehead, if the value function winds up seeing wireheading as desirable for any reason, but it doesn't have to. In the human example, some people are hedonists, but others aren't.
Sorry if I'm misunderstanding what you were saying.
Replies from: abramdemski↑ comment by abramdemski · 2021-06-02T21:16:46.688Z · LW(p) · GW(p)
So it's still in the observation-utility paradigm I think, or at least it seems to me that it doesn't have an automatic incentive to wirehead. It could want to wirehead, if the value function winds up seeing wireheading as desirable for any reason, but it doesn't have to. In the human example, some people are hedonists, but others aren't.
All sounds perfectly reasonable. I just hope you recognize that it's all a big mess (because it's difficult to see how to provide evidence in a way which will, at least eventually, rule out the wireheading hypothesis or any other problematic interpretations). As I imagine you're aware, I think we need stuff from my 'learning normativity' agenda to dodge these bullets.
In particular, I would hesitate to commit to the idea that rewards are the only type of feedback we submit.
FWIW, I'm now thinking of your "value function" as expected utility in Jeffrey-Bolker terms [LW · GW]. We need not assume a utility function to speak of expected utility. This perspective is nice in that it's a generalization of what RL people mean by "value function" anyway: the value function is exactly the expected utility of the event "I wind up in this specific situation" (at least, it is if value iteration has converged). The Jeffrey-Bolker view just opens up the possibility of explicitly representing the value of more events.
So let's see if we can pop up the conversational stack.
I guess the larger topic at hand was: how do we define whether a value function is "aligned" (in an inner sense, so, when compared to an outer objective which is being used for training it)?
Well, I think it boils down to whether the current value function makes "reliably good predictions" about the values of events. Not just good predictions on average, but predictions which are never catastrophically bad (or at least, catastrophically bad with very low probability, in some appropriate sense).
If we think of the true value function as V(x), and our approximation as V(x), we want something like: under some distance metric, if there is a modification of V*(x) with catastrophic downsides, V(x) is closer to V*(x) than that modification. (OK that's a bit lame, but hopefully you get the general direction I'm trying to point in.)
Something like that?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-04T14:48:13.079Z · LW(p) · GW(p)
it's all a big mess
Yup! This was a state-the-problem-not-solve-it post. (The companion solving-the-problem post is this brain dump [LW · GW], I guess.) In particular, just like prosaic AGI alignment, my starting point is not "Building this kind of AGI is a great idea", but rather "This is a way to build AGI that could really actually work capabilities-wise (especially insofar as I'm correct that the human brain works along these lines), and that people are actively working on (in both ML and neuroscience), and we should assume there's some chance they'll succeed whether we like it or not."
FWIW, I'm now thinking of your "value function" as expected utility in Jeffrey-Bolker terms [LW · GW].
Thanks, that's helpful.
how do we define whether a value function is "aligned" (in an inner sense, so, when compared to an outer objective which is being used for training it)?
One way I think I would frame the problem differently than you here is: I'm happy to talk about outer and inner alignment for pedagogical purposes, but I think it's overly constraining as a framework for solving the problem. For example, (Paul-style) corrigibility is I think an attempt to cut through outer and inner alignment simultaneously, as is interpretability perhaps. And like you say, rewards don't need to be the only type of feedback.
We can also set up the AGI to NOOP when the expected value of some action is <0, rather than having it always take the least bad action. (...And then don't use it in time-sensitive situations! But that's fine for working with humans to build better-aligned AGIs.) So then the goal would be something like "every catastrophic action has expected value <0 as assessed by the AGI (and also, the AGI will not be motivated to self-modify or create successors, at least not in a way that undermines that property) (and also, the AGI is sufficiently capable that it can do alignment research etc., as opposed to it sitting around NOOPing all day)".
So then this could look like a pretty weirdly misaligned AGI but it has a really effective "may-lead-to-catastrophe (directly or indirectly) predictor circuit" attached. (The circuit asks "Does it pattern-match to murder? Does it pattern-match to deception? Does it pattern-match to 'things that might upset lots of people'? Does it pattern-match to 'things that respectable people don't normally do'?...") And the circuit magically never has any false-negatives. Anyway, in that case the framework of "how well are we approximating the intended value function?" isn't quite the right framing, I think.
I think we need stuff from my 'learning normativity' agenda to dodge these bullets.
Yeah I'm very sympathetic to the spirit of that. I'm a bit stumped on how those ideas could be implemented, but it's certainly in the space of things that I continue to brainstorm about...
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-26T11:23:57.491Z · LW(p) · GW(p)
Some nitpicks about your risk model slash ways in which my risk model differs from yours:
1. I think AIs are more likely to be more homogenous on Earth; even in a slow takeoff they might be all rather similar to each other. Partly for the reasons Evan discusses in his post [AF · GW], and partly because of acausal shenanigans. I certainly think that, unfortunately, given all the problems you describe, we should count ourselves lucky if any of the contending AI factions are aligned to our values. I think this is an important research area.
2. I am perhaps more optimistic than you that if at least one of the contending AI factions is aligned to our values, things will work out pretty well for us. I'm hopeful that the AI factions will negotiate and compromise rather than fight. (Even though, as you point out, the unaligned ones may have various advantages) I feel about 80% confident, how about you? I'd love to hear more about this, I think it's an important research area.
3. You speak of AGI's escaping into the wild. I think that's a possibility, but I'm somewhat more concerned about AGI's taking over the institutions that built them. Institutions that build AIs will presumably be trying to use them for some intellectual purpose, and presumably be somewhat optimistic (too optimistic, IMO) that the AI they built is aligned to them. So rather than escaping and setting up shop on some hacked server somewhere, I expect the most likely scenario to be something like "The AI is engaging and witty and sympathetic and charismatic, and behaves very nicely, and gradually the institution that built it comes to rely more and more on its suggestions and trust it more and more, until eventually it is the power behind the throne basically, steering the entire institution even as those inside think that they are still in charge."
Replies from: steve2152, MaxRa↑ comment by Steven Byrnes (steve2152) · 2021-03-26T15:11:53.424Z · LW(p) · GW(p)
Thanks!
For homogeneity, I guess I was mainly thinking that in the era of not-knowing-how-to-align-an-AGI, people would tend to try lots of different new things, because nothing so far has worked. I agree that once there's an aligned AGI, it's likely to get copied, and if new better AGIs are trained, people may be inclined to try to keep the procedure as close as possible to what's worked before.
I hadn't thought about whether different AGIs with different goals are likely to compromise vs fight. There's Wei Dai's argument [AF · GW] that compromise is very easy with AGIs because they can "merge their utility functions". But at least this kind of AGI doesn't have a utility function ... maybe there's a way to do something like that with multiple parallel value functions [AF · GW], but I'm not sure that would actually work. There are also old posts about AGIs checking each other's source code for sincerity, but can they actually understand what they're looking at? Transparency is hard. And how do they verify that there isn't a backup stashed somewhere else, ready to jump out at a later date and betray the agreement? Also, humans have social instincts that AGIs don't, which pushes in both directions I think. And humans are easier to kill / easier to credibly threaten. I dunno. I'm not inclined to have confidence in any direction.
I agree that if a sufficiently smart misaligned AGI is running on a nice supercomputer somewhere, it would have every reason to try to stay right there and pursue its goals within that institution, and it would have every reason to try to escape and self-replicate elsewhere in the world. I guess we can be concerned about both. :-/
↑ comment by MaxRa · 2021-03-27T22:40:23.130Z · LW(p) · GW(p)
So rather than escaping and setting up shop on some hacked server somewhere, I expect the most likely scenario to be something like "The AI is engaging and witty and sympathetic and charismatic [...]"
(I'm new to thinking about this and would find responses and pointers really helpful) In my head this scenario felt unrealistic because I expect transformative-ish AI applications to come up before highly sophisticated AIs start socially manipulating their designers. Just for the sake of illustrating, I was thinking of stuff like stock investment AIs, product design AIs, military strategy AIs, companionship AIs, question answering AIs, which all seem to have the potential to throw major curves. Associated incidences would update safety culture enough to make the classic "AGI arguing itself out of a box" scenario unlikely. So I would worry more about scenarios were companies or governments feel like their hands are tied in allowing usage of/relying on potentially transformative AI systems.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-28T09:07:05.756Z · LW(p) · GW(p)
I think this is a very important and neglected area of research. My take differs from yours but I'm very unconfident in it, you might be right. I'm glad you are thinking about this and would love to chat more about it with you.
Stock investment AIs seem like they would make lots of money, which would accelerate timelines by causing loads more money to be spent on AI. But other than that, they don't seem that relevant? Like, how could they cause a point of no return?
Product design AIs and question-answering AIs seem similar. Maybe they'll accelerate timelines, but other than that, they won't be causing a point of no return (unless they have gotten so generally intelligent that they can start strategically manipulating us via their products and questions, which I think would happen eventually but by the time that happens there will probably be agenty AIs running around too)
Companionship AIs seem like the sort of thing that would be engaging and witty and charismatic, or at the very least, insofar as companionship AIs become a big deal, AIs that can argue themselves out of the box aren't close behind.
Military strategy AIs seem similar to me if they can talk/understand language (convincing people of things is something you can strategize about too). Maybe we can imagine a kind of military strategy AI that doesn't really do language well, maybe instead it just has really good battle simulators and has generalized tactical skill that lets it issue commands to troops that are likely to win battles. But (a) I think this is unlikely, and (b) I think it isn't super relevant anyway since tactical skill isn't very important anyway. It's not like we are currently fighting a conventional war and better front-line tactics will let us break through the line or something.
Replies from: trentbrick↑ comment by trentbrick · 2021-04-16T13:21:05.377Z · LW(p) · GW(p)
This seems very relevant: https://www.gwern.net/Tool-AI
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-26T11:07:29.577Z · LW(p) · GW(p)
Great post! I think many of the things you say apply equally well to broader categories of scenario too, e.g. your AGI risk model stuff works (with some modification) for different AGI development models than the one you gave. I'd love to see people spell that out, lest skeptics read this post and reply "but that's not how AGI will be made, therefore this isn't a serious problem."
Assuming slow takeoff (again, fast takeoff is even worse), it seems to me that under these assumptions there would probably be a series of increasingly-worse accidents spread out over a decade or two, culminating in irreversible catastrophe, with humanity unable to coordinate to avoid that outcome—due to the coordination challenges in Assumptions 2-4.
This seems too optimistic to me. Even on slow takeoff, things won't take more than a decade. (Paul is Mr. Slow Takeoff and even he seems to think it would be more like a decade) Even if a slow takeoff takes more than a decade, the accidents wouldn't be spread out that much. Early AI systems will be too stupid to do anything that counts as an accident in the relevant sense (people will just think of it as like the tesla self-driving car crashes, or the various incidents of racial bias in image recognition AI) and later AI systems will be smart enough to be strategic, waiting to strike until the right moment when they can actually succeed instead of just causing an "accident." (They might do other, more subtle things prior to that time, but they would be subtle, and thus not "accidents" in the relevant sense. They wouldn't be fire alarms, for example.) Or maybe I am misunderstanding what you mean by accidents?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-26T14:39:13.939Z · LW(p) · GW(p)
I haven't thought very much about takeoff speeds (if that wasn't obvious!). But I don't think it's true that nobody thinks it will take more than a decade... Like, I don't think Paul Christiano is the #1 slowest of all slow-takeoff advocates. Isn't Robin Hanson slower? I forget.
Then a different question is "Regardless of what other people think about takeoff speeds, what's the right answer, or at least what's plausible?" I don't know. A key part is: I'm hazy on when you "start the clock". People were playing with neural networks in the 1990s but we only got GPT-3 in 2020. What were people doing all that time?? Well mostly, people were ignoring neural networks entirely, but they were also figuring out how to put them on GPUs, and making frameworks like TensorFlow and PyTorch and making them progressively easier to use and scale and parallelize, and finding all the tricks like BatchNorm and Xavier initialization and Transformers, and making better teaching materials and MOOCs to spread awareness of how these things work, developing new and better chips tailored to these algorithms (and vice-versa), waiting on Moore's law, and on and on. I find it conceivable that we could get "glimmers of AGI" (in some relevant sense) in algorithms that have not yet jumped through all those hoops, so we're stuck with kinda toy examples for quite a while as we develop the infrastructure to scale these algorithms, the bag of tricks to make them run better, the MOOCs, the ASICs, and so on. But I dunno.
Or maybe I am misunderstanding what you mean by accidents?
Yeah, sorry, when I said "accidents" I meant "the humans did something by accident", not "the AI did something by accident".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-26T15:19:38.114Z · LW(p) · GW(p)
Thanks! Yeah, there are plenty of people who think takeoff will take more than a decade--but I guess I'll just say, I'm pretty sure they are all wrong. :) But we should take care to define what the start point of takeoff is. Traditionally it was something like "When the AI itself is doing most of the AI research," but I'm very willing to consider alternate definitions. I certainly agree it might take more than 10 years if we define things in such a way that takeoff has already begun.
Yeah, sorry, when I said "accidents" I meant "the humans did something by accident", not "the AI did something by accident".
Wait, uhoh, I didn't mean "the AI did something by accident" either... can you elaborate? By "accident" I thought you meant something like "Small-scale disasters, betrayals, etc. caused by AI that are shocking enough to count as warning shots / fire alarms to at least some extent."
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-26T15:27:24.296Z · LW(p) · GW(p)
Oh sorry, I misread what you wrote. Sure, maybe, I dunno. I just edited the article to say "some number of years".
I never meant to make a claim "20 years is definitely in the realm of possibility" but rather to make a claim "even if it takes 20 years, that's still not necessarily enough to declare that we're all good".
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-26T15:44:07.874Z · LW(p) · GW(p)
I never meant to make a claim "20 years is definitely in the realm of possibility" but rather to make a claim "even if it takes 20 years, that's still not necessarily enough to declare that we're all good".
Ah, OK. We are on the same page then.
comment by Gurkenglas · 2021-03-25T22:46:30.348Z · LW(p) · GW(p)
I don't expect your AGI development model to be the first to market: The world-model alone could be used to write a pivotal AGI. An idealized interactive theorem prover consists of a brute-force proof searcher and a human intuiter of what lemmata would be useful as stepping stones. Use the world-model to predict the human. Use the same mechanism without a theorem given to produce conjectures to prove next. Run it in the general direction of AI safety research until you can build a proper FAI. Only the inner alignment problem remains: The intuiter might, instead of the most mathematically useful conjectures, produce ones that will make the resulting AGI decision theory try to reward those who brought it about, such as whatever mesa-optimizer nudged the intuiter. Therefore I posit that interpretability, rather than the likes of embedded agency or value learning, should be the focus of our research.
Replies from: steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-26T20:52:22.062Z · LW(p) · GW(p)
Therefore I posit that interpretability, rather than the likes of embedded agency or value learning, should be the focus of our research.
FWIW I'm very strongly in favor of interpretability research.
I'm slightly pessimistic that insight into embedded agency will be helpful for solving the alignment problem—at least based on my personal experience of (A) thinking about how human brains reason about themselves, (B) thinking about the alignment problem, (C) noting that the former activity has not been helping me with the latter activity. (Maybe there are other reasons to work on embedded agency, I dunno.)
↑ comment by Steven Byrnes (steve2152) · 2021-03-26T01:24:06.080Z · LW(p) · GW(p)
(Sorry in advance if I'm misunderstanding.)
Consider how a human might look at a differential equation and say to themselves, "maybe I can differentiate both sides", or "maybe this is a linear algebra problem in disguise". You need all three components for that, not just the world-model. "Deciding to think a certain thought" is the same as "deciding to take a certain action", in that you need a planner / actor that can generate any of a large set of possible thoughts (or thought sequences) and you need a value function that learns which meta-cognitive strategies have been successful in the past (e.g. "in this type of situation, it's helpful to think that type of thought").
When we want a system to come up with new ideas—beyond the ideas in the training data—we face the problem that there's a combinatorial explosion of things to try. I'm pessimistic about making great headway in this problem without using RL to learn meta-cognitive strategies. (Just like how supervised learning on human chess moves can play chess about as well as humans, but not much better ... but RL can do much better.)
If I'm wrong, and RL isn't necessary after all, why not use GPT-3? You can already try the experiment of having GPT-3 throw out theorem / lemma ideas and having an automated theorem prover try to prove them. Sounds fun. I mean, I don't expect it to work, except maybe on toy examples, but who knows. Even if it did work, I don't see how it would help with AI safety research. I don't see the connection between automatically proving a bunch of mathematical theorems and making progress on AI safety research. I suspect that the hard part is reducing the AI safety problem to solvable math problems, not actually solving those math problems. I'm curious what you have in mind there.
Replies from: Benito, Gurkenglas↑ comment by Ben Pace (Benito) · 2021-03-26T01:26:08.587Z · LW(p) · GW(p)
Wow, I'm gonna have to get used to 'Steven'.
↑ comment by Gurkenglas · 2021-03-26T13:41:36.906Z · LW(p) · GW(p)
I agree that my theory predicts that GPT can be used for this. You don't need an extra value function if the world you're modelling already contains optimizers. You will be better at predicting what a good idea guy will say next if you can tell good ideas from bad. That GPT-3 hasn't proved pivotal is evidence against, but if they keep scaling up GPT, my timelines are very short.
Supervised learners playing chess as well as humans means that they haven't memorized human games, but instead human chess-playing patterns to apply. Pattern-matching previously seen math onto the current problem is enough to automate human math research - it's how humans do it. If you have a really good corpus of AI safety math, I expect it easy to map our problems onto it.
Compare to category theory, a mathematical language in which most short sentences mean something. You can make progress on many problems merely by translating them into a short sentence in the language of category theory.
If your model can predict which lemmata a human intuiter would suggest, your model can predict what a human mathematician would think to himself, and what he would decide to write into math chatrooms, blog posts and/or papers. (I wouldn't have said that before seeing GPT-2.) Putting it in terms of an intuiter merely points out that the deep, difficult work that distinguishes a good mathematician from a mediocre one is exactly the sort of pattern-matching that neural networks are good at.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-26T21:10:00.729Z · LW(p) · GW(p)
If you have a really good corpus of AI safety math, I expect it easy to map our problems onto it.
Can you give an example of what you have in mind? Start with "I want my AGI, after ML training, to be trying to help me". Then we break this grand challenge down and end up with math theorems ... how? What do the theorems look like? What do they say? How do they relate back to the fuzzy concept of "trying to help"?
Pattern-matching previously seen math onto the current problem is enough to automate human math research - it's how humans do it.
FWIW I disagree with this. Humans started knowing no math whatsoever. They searched for patterns, found them, and solidified those patterns into structured models with objects and relations and ways to manipulate these things and so on. Repeat, repeat. It's not straightforward because there are a combinatorial explosion of different possible patterns that might match, different ways to structure the knowledge, different analogies to apply. Just like there is a combinatorial explosion of possible chess strategies. You need to search through the space, using sophisticated RL that hunts for hints of success and learns the kinds of patterns and strategies that work based on an endless array of subtle contextual clues. Like, ask a mathematician if the very first way they thought about some concept, the first time they came across it, was the right way. Ask a mathematician if they learned a profoundly new idea in the past week. I don't think it's just applying the same patterns over and over...
I suspect supervised learners would play chess much worse than humans, because humans can get into a new configuration and figure out what to do by mentally playing through different possibilities, whereas supervised learners are just trying to apply the things that humans already know, unable to figure out anything new. (This is an empirical question, I didn't look it up, I'm just guessing.)
Replies from: Gurkenglas↑ comment by Gurkenglas · 2021-03-27T11:48:31.480Z · LW(p) · GW(p)
example
You point your math research generator at AI safety. It starts analyzing the graph of what programs will self-modify into what programs; which subgraphs are closed under successors; how you might define structure-preserving morphisms on graphs like this one; what existing category theory applies to the resulting kind of morphism. It finds the more general question of which agents achieve their goals in an environment containing what programs. (Self-modification is equivalent to instantiating such a program.) It finds a bunch of properties that such agents and programs can have - for example, tool AIs that help large classes of agents so long as they don't ask questions that turn the tool AIs into agent AIs. And then you find that a theorem specializes to "You win if you run a program from this set." and do so.
ask a mathematician
Sure, I don't see the solution to every question immediately; I have to turn the question over in my head, decompose it, find other questions that are the same until I can solve one of them immediately. And the described generator could do the same, because it would generate the decompositions and rephrasings as lemmata, or as extra conjectures. We would of course need to keep relevant theorems it has already proved in scope so it can apply them, by (very cheap) fine-tuning or tetris-like context window packing. And yes, this gives whatever mesa-optimizer an opportunity to entrench itself in the model.
comment by trentbrick · 2021-04-16T13:28:57.323Z · LW(p) · GW(p)
Thanks for this post!
I agree with just about all of it (even though it paints a pretty bleak picture). It was useful to put all of these ideas and inner/outer alignment in one place especially the diagrams.
Two quotes that stood out to me:
" "Nameless pattern in sensory input that you’ve never conceived of” is a case where something is in-domain for the reward function but (currently) out-of-domain for the value function. Conversely, there are things that are in-domain for your value function—so you can like or dislike them—but wildly out-of-domain for your reward function! You can like or dislike “the idea that the universe is infinite”! You can like or dislike “the idea of doing surgery on your brainstem in order to modify your own internal reward function calculator”! A big part of the power of intelligence is this open-ended ever-expanding world-model that can re-conceptualize the world and then leverage those new concepts to make plans and achieve its goals. But we cannot expect those kinds of concepts to be evaluable by the reward function calculator."
And
"After all, the reward function will diverge from the thing we want, and the value function will diverge from the reward function. The most promising solution directions that I can think of seem to rely on things like interpretability, “finding human values inside the world-model”, corrigible motivation, etc.—things which cut across both layers, bridging all the way from the human’s intentions to the value function."
Also the idea that we can use the human brain as a way to better understand the interface between our outer loop reward function and inner loop value function.
Thinking about corrigibility, it seems like having a system with finite computational resources and an inability to modify its source code would both be highly desirable especially at the early stages. This feels like a +1 to neuron based wetware that implements AGI rather than as code on a server. Of course, the agent could find ways to acquire more neurons! And we would very likely then lose out on some interpretability tools. But this is just something that popped into my head as a tradeoff for different AGI implementations.
As a more general point, I think you working with the garage door open and laying out all of your arguments is highly motivating (at least for me!) to be thinking more actively and pursuing safety research in a way that I have dilly dallied on actually doing since back in 2016 when I read Superintelligence!
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2021-03-26T02:35:17.529Z · LW(p) · GW(p)
I assume that the learned components (world-model, value function, planner / actor) continue to be updated in deployment—a.k.a. online learning
If it's not online learning in the strict sense, I'd expect a sufficient (and sufficiently-low-insight) process of updates and redeploys to have the same effect in the medium term. I agree that online learning is the most likely path in such scenarios, but I don't think it's necessary.
comment by Donald Hobson (donald-hobson) · 2021-03-28T00:00:26.202Z · LW(p) · GW(p)
, it seems to me that under these assumptions there would probably be a series of increasingly-worse accidents spread out over some number of years, culminating in irreversible catastrophe, with humanity unable to coordinate to avoid that outcome—due to the coordination challenges in Assumptions 2-4.
I'm not seeing quite what the bad but not existential catastrophes would look like. I also think the AI has an incentive not to do this. My world model (assuming slow takeoff) goes more like this.
AI created in lab. Its a fairly skilled programmer and hacker. Able to slowly self improve. Escapes from the lab, ideally without letting its creators know. Then there are several years where the AI hangs out on the internet, slowly self improving and gaining power. It tries to shut down other AI's if it can. It might be buying compute, or stealing it, or persuading people to run it. It is making sure its existence and malevolence isn't known to humans. Until finally it has the resources to wipe out humanity before we can respond.
It is much easier to contain something on one computer in a lab, than to catch it once its all over the internet.
Lying and cheating and power seeking behaviour are only a good idea if you can get away with them. If you can't break out the lab, you probably can't get away with much uncouragable behaviour.
There is a scenario where the AI escapes in a way that makes its escape "obvious". Or at least obvious to an AI researcher. Expect any response to be delayed, half-hearted, mired by accusations that the whole thing is a publicity stunt, and dragged down by people who don't want to smash their hard drives full of important important work just because there might be a rouge AI on them. The AI has an incentive to confuse and sabotage any step it can. And many human organizations seem good at confusing and sabotaging themselves in the face of a virus. The governments would have to coordinate the shutdown of prettymuch all the worlds computers, without computers to coordinate it. Even just a few hours delay for the researchers to figure out what the AI did, and get the message passed up through government machinery may be enough time for the AI to have got to all sorts of obscure corners of the web.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-28T19:57:54.926Z · LW(p) · GW(p)
Hmm, I dunno, I haven't thought it through very carefully. But I guess an AGI might require a supercomputer of resources and maybe there are only so many hackable supercomputers of the right type, and the AI only knows one exploit and leaves traces of its hacking that computer security people can follow, and meanwhile self-improvement is hard and slow (for example, in the first version you need to train for two straight years, and in the second self-improved version you "only" need to re-train for 18 months). If the AI can run on a botnet then there are more options, but maybe it can't deal with latency / packet loss / etc., maybe it doesn't know a good exploit, maybe security researchers find and take down the botnet C&C infrastructure, etc. Obviously this wouldn't happen with a radically superhuman AGI but that's not what we're talking about.
But from my perspective, this isn't a decision-relevant argument. Either we're doomed in my scenario or we're even more doomed in yours. We still need to do the same research in advance.
Lying and cheating and power seeking behaviour are only a good idea if you can get away with them. If you can't break out the lab, you probably can't get away with much uncouragable behaviour.
Well, we can be concerned about non-corrigible systems that act deceptively (cf. "treacherous turn"). And systems that have close-but-not-quite-right goals such that they're trying to do the right thing in test environments, but their goals veer away from humans' in other environments, I guess.
comment by Charlie Steiner · 2021-03-25T16:07:44.928Z · LW(p) · GW(p)
invent a smaller laser
Ah, I see you've been reading about super-resolution microscopy :P
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-25T16:16:44.257Z · LW(p) · GW(p)
That's not a real example. :-) I can't imagine why a microscope designer would want a smaller laser. My first draft actually had an example that would be plausibly useful for microscope designers ("invent a faster and more accurate laser galvo" or something) but then I figured, no one cares, and everyone would say "WTF does "galvo" mean?" :-P
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-03-25T16:58:06.738Z · LW(p) · GW(p)
So, you can do this thing with optical microscopy where you basically scan a laser beam over the sample to illuminate one pixel at a time. This lets you beat the diffraction limit on your aperture. So I'm sure people who build these systems like having small lasers. Another take on the same idea is to use a UV laser (different meaning of "smaller" there) and collect fluoresced rather than reflected light.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-25T17:08:56.150Z · LW(p) · GW(p)
This is fun but very off-topic. I'll reply by DM. :-P