My computational framework for the brain
post by Steven Byrnes (steve2152) · 2020-09-14T14:19:21.974Z · LW · GW · 26 commentsContents
1. Two subsystems: "Neocortex" and "Subcortex" 2. Cortical uniformity 3. Blank-slate neocortex 4. What is the neocortical algorithm? 4.1. "Analysis by synthesis" + "Planning by probabilistic inference" 4.2. Compositional generative models 5. The subcortex steers the neocortex towards biologically-adaptive behaviors. 6. The neocortex is a black box from the perspective of the subcortex. So steering the neocortex is tricky! 6.1 The subcortex can learn what's going on in the world via its own, parallel, sensory-processing system. 6.2 The subcortex can see the neocortex's outputs—which include not only prediction but imagination, memory, and empathetic simulations of other people. 7. The subcortical algorithms remain largely unknown Conclusion None 26 comments
(See comment here [LW(p) · GW(p)] for some updates and corrections and retractions. —Steve, 2022)
By now I've written a bunch of blog posts on brain architecture and algorithms, not in any particular order and generally interspersed with long digressions into Artificial General Intelligence. Here I want to summarize my key ideas in one place, to create a slightly better entry point, and something I can refer back to in certain future posts that I'm planning. If you've read every single one of my previous posts (hi mom!), there's not much new here.
In this post, I'm trying to paint a picture. I'm not really trying to justify it, let alone prove it. The justification ultimately has to be: All the pieces are biologically, computationally, and evolutionarily plausible, and the pieces work together to explain absolutely everything known about human psychology and neuroscience. (I believe it! Try me!) Needless to say, I could be wrong in both the big picture and the details (or missing big things). If so, writing this out will hopefully make my wrongness easier to discover!
Pretty much everything I say here and its opposite can be found in the cognitive neuroscience literature. (It's a controversial field!) I make no pretense to originality (with one exception noted below), but can't be bothered to put in actual references. My previous posts have a bit more background, or just ask me if you're interested. :-P
So let's start in on the 7 guiding principles for how I think about the brain:
1. Two subsystems: "Neocortex" and "Subcortex"
(Update: I have a revised discussion of this topic at my later post Two Subsystems: Learning and Steering [AF · GW].)
This is the starting point. I think it's absolutely critical. The brain consists of two subsystems. The neocortex is the home of "human intelligence" as we would recognize it—our beliefs, goals, ability to plan and learn and understand, every aspect of our conscious awareness, etc. etc. (All mammals have a neocortex; birds and lizards have an homologous and functionally-equivalent structure called the "pallium".) Some other parts of the brain (hippocampus, parts of the thalamus & basal ganglia & cerebellum—see further discussion here [LW · GW]) help the neocortex do its calculations, and I lump them into the "neocortex subsystem". I'll use the term subcortex for the rest of the brain (brainstem, hypothalamus, etc.).
- Aside: Is this the triune brain theory? No. Triune brain theory is, from what I gather, a collection of ideas about brain evolution and function, most of which are wrong. One aspect of triune brain theory is putting a lot of emphasis on the distinction between neocortical calculations and subcortical calculations. I like that part. I'm keeping that part, and I'm improving it by expanding the neocortex club to also include the thalamus, hippocampus, lizard pallium, etc., and then I'm ignoring everything else about triune brain theory.
2. Cortical uniformity
I claim that the neocortex is, to a first approximation, architecturally uniform [LW · GW], i.e. all parts of it are running the same generic learning algorithm in a massively-parallelized way.
The two caveats to cortical uniformity (spelled out in more detail at that link [LW · GW]) are:
- There are sorta "hyperparameters" on the generic learning algorithm which are set differently in different parts of the neocortex—for example, different regions have different densities of each neuron type, different thresholds for making new connections (which also depend on age), etc. This is not at all surprising; all learning algorithms inevitably have tradeoffs whose optimal settings depend on the domain that they're learning (no free lunch). [LW · GW]
- As one of many examples of how even "generic" learning algorithms benefit from domain-specific hyperparameters, if you've seen a pattern "A then B then C" recur 10 times in a row, you will start unconsciously expecting AB to be followed by C. But "should" you expect AB to be followed by C after seeing ABC only 2 times? Or what if you've seen the pattern ABC recur 72 times in a row, but then saw AB(not C) twice? What "should" a learning algorithm expect in those cases? The answer depends on the domain—how regular vs random are the environmental patterns you're learning? How stable are they over time? The answer is presumably different for low-level visual patterns vs motor control patterns etc.
- There is a gross wiring diagram hardcoded in the genome—i.e., set of connections between different neocortical regions and each other, and other parts of the brain. These connections later get refined and edited during learning. These make the learning process faster and more reliable by bringing together information streams with learnable relationships—for example the wiring diagram seeds strong connections between toe-related motor output areas and toe-related proprioceptive (body position sense) input areas. We can learn relations between information streams without any help from the innate wiring diagram, by routing information around the cortex in more convoluted ways—see the Ian Waterman example here [LW · GW]—but it's slower, more limited, and may consume conscious attention. Related to this is a diversity of training signals: for example, different parts of the neocortex are trained to predict different signals, and also different parts of the neocortex get different dopamine training signals [LW · GW]—or even none at all [LW · GW].
3. Blank-slate neocortex
(...But not blank-slate subcortex! More on that below.)
(Update: To avoid confusion, I've more recently been calling this concept "learning-from-scratch"—see discussion in my later post “Learning from Scratch” in the brain [AF · GW].)
I claim that the neocortex (and the rest of the telencephalon and cerebellum) starts out as a "blank slate": Just like an ML model initialized with random weights, the neocortex cannot make any correct predictions or do anything useful until it learns to do so from previous inputs, outputs, and rewards.
In more neuroscience-y (and maybe less provocative) terms, I could say instead: the neocortex is a memory system. It's a really fancy memory system—it's highly structured to remember particular kinds of patterns and their relationships, and it comes with a sophisticated query language and so on—but at the end of the day, it's still a type of memory. And like any memory system, it is useless to the organism until it gradually accumulates information. (Suggestively, if you go far enough back, the neocortex and hippocampus evolved out of the same ancient substructure (ref).)
(By the way, I am not saying that the neocortex's algorithm is similar to today's ML algorithms. There's more than one blank-slate learning algorithm! It’s an entire field! There are new ones on arxiv every day! See image.)
Why do I think that the neocortex starts from a blank slate? Two types of reasons:
- Details of how I think the neocortical algorithm works: This is the main reason for me.
- For example, as I mentioned here [LW · GW], there's a theory I like that says that all feedforward signals (I'll define that in the next section) in the neocortex—which includes all signals coming into the neocortex from the outside it, plus many cortex-to-cortex signals—are re-encoded into the data format that the neocortex can best process—i.e. a set of sparse codes, with low overlap, uniform distribution, and some other nice properties—and this re-encoding is done by a pseudorandom process! If that's right, it would seem to categorically rule out anything but a blank-slate starting point.
- More broadly, we know the algorithm can learn new concepts, and new relationships between concepts, without having any of those concepts baked in by evolution—e.g. learning about rocket engine components. So why not consider the possibility that that's all it does, from the very beginning? I can see vaguely how that would work, why that would be biologically plausible and evolutionarily adaptive, and I can't currently see any other way that the algorithm can work.
- Absence of evidence to the contrary: I have a post Human Instincts, Symbol Grounding, and the Blank-Slate Neocortex [LW · GW] where I went through a list of universal human instincts, and didn't see anything inconsistent with a blank-slate neocortex. The subcortex—which is absolutely not a blank slate—plays a big role in most of those; for example, the mouse has a brainstem bird-detecting circuit wired directly to a brainstem running-away circuit. (More on this in a later section.) Likewise I've read about the capabilities of newborn humans and other animals, and still don't see any problem. I accept all challenges; try me!
4. What is the neocortical algorithm?
4.1. "Analysis by synthesis" + "Planning by probabilistic inference"
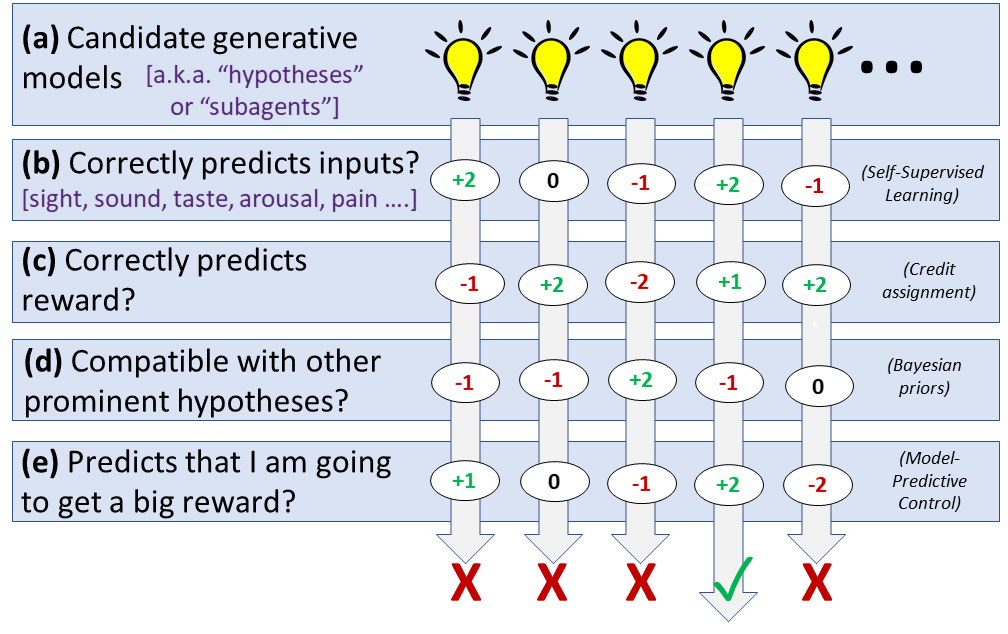
"Analysis by synthesis" means that the neocortex searches through a space of generative models for a model that predicts its upcoming inputs (both external inputs, like vision, and internal inputs, like proprioception and reward). "Planning by probabilistic inference" (term from here) means that we treat our own actions as probabilistic variables to be modeled, just like everything else. In other words, the neocortex's output lines (motor outputs, hormone outputs, etc.) are the same type of signal as any generative model prediction, and processed in the same way.
Here's how those come together. As discussed in Predictive Coding = RL + SL + Bayes + MPC [LW · GW], and shown in this figure below:
- The neocortex favors generative models that have been making correct predictions, and discards generative models that have been making predictions that are contradicted by input data (or by other favored generative models).
- And, the neocortex favors generative models which predict larger future reward, and discards generative models that predict smaller (or more negative) future reward.
This combination allows both good epistemics (ever-better understanding of the world), and good strategy (planning towards goals) in the same algorithm. This combination also has some epistemic and strategic failure modes—e.g. a propensity to wishful thinking—but in a way that seems compatible with human psychology & behavior, which is likewise not perfectly optimal, if you haven't noticed. Again, see the link above for further discussion.
- Aside: Is this the same as Predictive Coding / Free-Energy Principle? Sorta. I've read a fair amount of "mainstream" predictive coding (Karl Friston, Andy Clark, etc.), and there are a few things about it that I like, including the emphasis on generative models predicting upcoming inputs, and the idea of treating neocortical outputs as just another kind of generative model prediction. It also has a lot of other stuff that I disagree with (or don't understand). My account differs from theirs mainly by (1) emphasizing multiple simultaneous generative models that compete & cooperate (cf. "society of mind", multiagent models of mind [? · GW], etc.), rather than "a" (singular) prior, and (2) restricting discussion to the neocortex subsystem, rather than trying to explain the brain as a whole. In both cases, this may be partly a difference of emphasis & intuitions, rather than fundamental. But I think the core difference is that predictive coding / FEP takes some processes to be foundational principles, whereas I think that those same things do happen, but that they're emergent behaviors that come out of the algorithm under certain conditions. For example, in Predictive Coding & Motor Control [LW · GW] I talk about the predictive-coding story that proprioceptive predictions are literally exactly the same as motor outputs. Well, I don't think they're exactly the same. But I do think that proprioceptive predictions and motor outputs are the same in some cases (but not others), in some parts of the neocortex (but not others), and after (but not before) the learning algorithm has been running a while. So I kinda wind up in a similar place as predictive coding, in some respects.
4.2. Compositional generative models
Each of the generative models consists of predictions that other generative models are on or off, and/or predictions that input channels (coming from outside the neocortex—vision, hunger, reward, etc.) are on or off. ("It's symbols all the way down.") All the predictions are attached to confidence values, and both the predictions and confidence values are, in general, functions of time (or of other parameters—I'm glossing over some details). The generative models are compositional, because if two of them make disjoint and/or consistent predictions, you can create a new model that simply predicts that both of those two component models are active simultaneously. For example, we can snap together a "purple" generative model and a "jar" generative model to get a "purple jar" generative model. They are also compositional in other ways—for example, you can time-sequence them, by making a generative model that says "Generative model X happens and then Generative model Y happens".
PGM-type message-passing: Among other things, the search process for the best set of simultaneously-active generative model involves something at least vaguely analogous to message-passing (belief propagation) in a probabilistic graphical model. Dileep George's vision model is a well-fleshed-out example.
Hierarchies are part of the story but not everything: Hierarchies are a special case of compositional generative models. A generative model for an image of "85" makes a strong prediction that there is an "8" generative model positioned next to a "5" generative model. The "8" generative model, in turn, makes strong predictions that certain contours and textures are present in the visual input stream.
However, not all relations are hierarchical. The "is-a-bird" model makes a medium-strength prediction that the "is-flying" model is active, and the "is-flying" model makes a medium-strength prediction that the "is-a-bird" model is active. Neither is hierarchically above the other.
As another example, the brain has a visual processing hierarchy, but as I understand it, studies show that the brain has loads of connections that don't respect the hierarchy.
Feedforward and feedback signals: There are two important types of signals in the neocortex.
A "feedback" signal is a generative model prediction, attached to a confidence level, which includes all the following:
- "I predict that neocortical input line #2433 will be active, with probability 0.6".
- "I predict that generative model #95738 will be active, with probability 0.4".
- "I predict that neocortical output line #185492 will be active, with probability 0.98"—and this one is a self-fulfilling prophecy, as the feedback signal is also the output line!
A "feedforward" signal is an announcement that a certain signal is, in fact, active right now, which includes all the following:
- "Neocortical input line #2433 is currently active!"
- "Generative model #95738 is currently active!"
There are about 10× more feedback connections than feedforward connections in the neocortex, I guess for algorithmic reasons I don't currently understand.
In a hierarchy, the top-down signals are feedback, and the bottom-up signals are feedforward.
The terminology here is a bit unfortunate. In a motor output hierarchy, we think of information flowing "forward" from high-level motion plan to low-level muscle control signals, but that's the feedback direction. The forward/back terminology works better for sensory input hierarchies. Some people say "top-down" and "bottom-up" instead of "feedback" and "feedforward" respectively, which is nice and intuitive for both input and output hierarchies. But then that terminology gets confusing when we talk about non-hierarchical connections. Oh well.
(I'll also note here that "mainstream" predictive coding discussions sometimes talk about feedback signals being associated with confidence intervals for analog feedforward signals, rather than confidence levels for binary feedforward signals. I changed it on purpose. I like my version better.)
5. The subcortex steers the neocortex towards biologically-adaptive behaviors.
The blank-slate neocortex can learn to predict input patterns, but it needs guidance to do biologically adaptive things. So one of the jobs of the subcortex is to try to "steer" [LW · GW] the neocortex, and the subcortex's main tool for this task is its ability to send rewards to the neocortex at the appropriate times. Everything that humans reliably and adaptively do with their intelligence, from liking food to making friends, depends on the various reward-determining calculations hardwired into the subcortex.
6. The neocortex is a black box from the perspective of the subcortex. So steering the neocortex is tricky!
Only the neocortex subsystem has an intelligent world-model. Imagine you just lost a big bet, and now you can't pay back your debt to the loan shark. That's bad. The subcortex (hypothalamus & brainstem) needs to send negative rewards to the neocortex. But how can it know? How can the subcortex have any idea what's going on? It has no concept of a "bet", or "debt", or "payment" or "loan shark".
This is a very general problem. I think there are two basic ingredients in the solution.
Here's a diagram to refer to, based on the one I put in Inner Alignment in the Brain [LW · GW]:
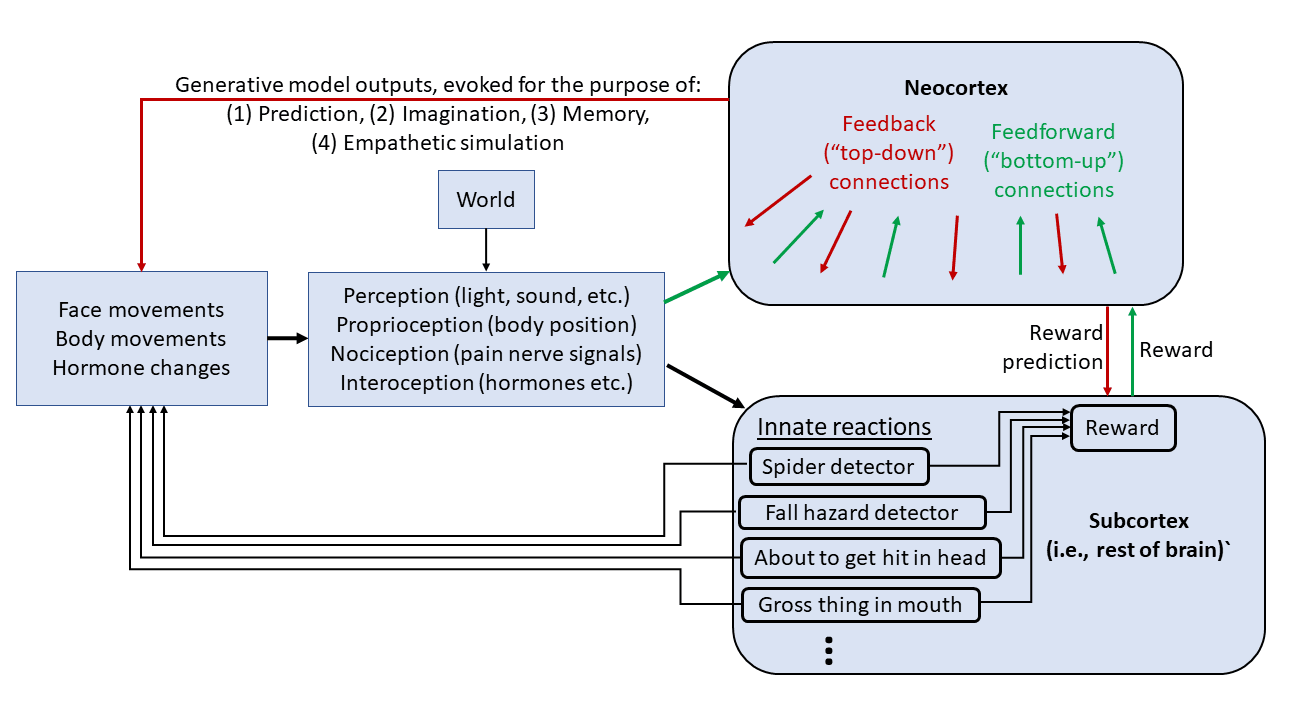
6.1 The subcortex can learn what's going on in the world via its own, parallel, sensory-processing system.
Thus, for example, we have the well-known visual processing system in our visual cortex, and we have the lesser-known visual processing system in our midbrain (superior colliculus). Ditto for touch, smell, proprioception, nociception, etc.
While they have similar inputs, these two sensory processing systems could not be more different!! The neocortex fits its inputs into a huge, open-ended predictive world-model, but the subcortex instead has a small and hardwired "ontology" consisting of evolutionarily-relevant inputs that it can recognize like faces, human speech sounds, spiders, snakes, looking down from a great height, various tastes and smells, stimuli that call for flinching, stimuli that one should orient towards, etc. etc., and these hardwired recognition circuits are connected to hardwired responses.
For example, babies learn to recognize faces quickly and reliably in part because the midbrain sensory processing system knows what a face looks like, and when it sees one, it will saccade to it, and thus the neocortex will spend disproportionate time building predictive models of faces.
...Or better yet, instead of saccading to faces itself, the subcortex can reward the neocortex each time it detects that it is looking at a face! Then the neocortex will go off looking for faces, using its neocortex-superpowers to learn arbitrary patterns of sensory inputs and motor outputs that tend to result in looking at people's faces.
6.2 The subcortex can see the neocortex's outputs—which include not only prediction but imagination, memory, and empathetic simulations of other people.
For example, if the neocortex never predicts or imagines any reward, then the subcortex can guess that the neocortex has a grim assessment of its prospects for the future—I'll discuss that particular example much more in an upcoming post on depression. (Update: that was wrong; see better discussion of depression here [LW · GW].)
To squeeze more information out of the neocortex, the subcortex can also "teach" the neocortex to reveal when it is thinking of one of the situations in the subcortex's small hardwired ontology (faces, spiders, sweet tastes, etc.—see above). For example, if the subcortex rewards the neocortex for cringing in advance of pain, then the neocortex will learn to favor pain-prediction generative models that also send out cringe-motor-commands. And thus, eventually, it will also start sending weak cringe-motor-commands when imagining future pain, or when empathically simulating someone in pain—and the subcortex can detect that, and issue hardwired responses in turn.
(Update: I now think "the subcortex rewards the neocortex for cringing in advance of pain" is probably not quite the right mechanism, see here [LW · GW].)
See Inner Alignment in the Brain [LW · GW] for more examples & discussion of all this stuff about steering.
Unlike most of the other stuff here, I haven't seen anything in the literature that takes "how does the subcortex steer the neocortex?" to be a problem that needs to be solved, let alone that solves it. (Let me know if you have!) ...Whereas I see it as The Most Important And Time-Sensitive Problem In All Of Neuroscience—because if we build neocortex-like AI algorithms, we will need to know how to steer them towards safe and beneficial behaviors!
7. The subcortical algorithms remain largely unknown
I think much less is known about the algorithms of the subcortex (brainstem, hypothalamus, amygdala, etc.) (Update: After further research I have promoted the amygdala up to the neocortex subsystem, see discussion here [LW · GW]) than about the algorithms of the neocortex. There are a couple issues:
- The subcortex's algorithms are more complicated than the neocortex's algorithms: As described above, I think the neocortex has more-or-less one generic learning algorithm. Sure, it consists of many interlocking parts, but it has an overall logic. The subcortex, by contrast, has circuitry for detecting and flinching away from an incoming projectile, circuitry for detecting spiders in the visual field, circuitry for (somehow) implementing lots of different social instincts, etc. etc. I doubt all these things strongly overlap each other, though I don't know that for sure. That makes it harder to figure out what's going on.
- I don't think the algorithms are "complicated" in the sense of "mysterious and sophisticated". Unlike the neocortex, I don't think these algorithms are doing anything where a machine learning expert couldn't sit down and implement something functionally equivalent in PyTorch right now. I think they are complicated in that they have a complicated specification (this kind of input produces that kind of output, and this other kind of input produces this other kind of output, etc. etc. etc.), and this specification what we need to work out.
- Fewer people are working on subcortical algorithms than the neocortex's algorithms: The neocortex is the center of human intelligence and cognition. So very exciting! So very monetizable! By contrast, the midbrain seems far less exciting and far less practically useful. Also, the neocortex is nearest the skull, and thus accessible to some experimental techniques (e.g. EEG, MEG, ECoG) that don't work on deeper structures. This is especially limiting when studying live humans, I think.
As mentioned above, I am very unhappy about this state of affairs. For the project of building safe and beneficial artificial general intelligence, I feel strongly that it would be better if we reverse-engineered subcortical algorithms first, and neocortical algorithms second.
(Edited to add: ...if at all. Like, maybe, armed with a better understanding of how the subcortex steers the neocortex, we'll realize that there's just no way to keep a brain-like AGI under human control. Then we can advocate against people continuing to pursue the research program of reverse-engineering neocortical algorithms! Or conversely, if we have a really solid plan to build safe and beneficial brain-like AGIs, we could try to accelerate the reverse-engineering of the neocortex, as compared to other paths to AGI. This is a great example of how AGI-related technical safety research can be decision-relevant today even if AGI is centuries away [LW · GW].)
Conclusion
Well, my brief summary wasn't all that brief after all! Congratulations on making it this far! I'm very open to questions, discussion, and criticism. I've already revised my views on all these topics numerous times, and expect to do so again. :-)
(Update 2024: I switched a couple of the links to point at better discussions that I wrote later on. Other parts and links are still bad, again see this comment [LW(p) · GW(p)].)
26 comments
Comments sorted by top scores.
comment by evhub · 2020-09-14T23:06:10.024Z · LW(p) · GW(p)
Some things which don't fully make sense to me:
- If the cortical algorithm is the same across all mammals, why do only humans develop complex language? Do you think that the human neocortex is specialized for language in some way, or do you think that other mammal's neocortices would be up to the task if sufficiently scaled up? What about our subcortex—do we get special language-based rewards? How would the subcortex implement those?
- Furthermore, there are lots of commonalities across human languages—e.g. word order patterns and grammar similarities, see e.g. linguistic universals—how does that make sense if language is neocortical and the neocortex is a blank slate? Do linguistic commonalities come from the subcortex, from our shared environment, or from some way in which our neocortex is predisposed to learn language?
- Also, on a completely different note, in asking “how does the subcortex steer the neocortex?” you seem to presuppose that the subcortex actually succeeds in steering the neocortex—how confident in that should we be? It seems like there are lots of things that people do that go against a naive interpretation of the subcortical reward algorithm—abstaining from sex, for example, or pursuing complex moral theories like utilitarianism. If the way that the subcortex steers the neocortex is terrible and just breaks down off-distribution, then that sort of cuts into your argument that we should be focusing on understanding how the subcortex steers the neocortex, since if it's not doing a very good job then there's little reason for us to try and copy it.
↑ comment by Steven Byrnes (steve2152) · 2020-09-15T02:23:40.342Z · LW(p) · GW(p)
Thanks!!
why do only humans develop complex language?
Here's what I'm thinking: (1) I expect that the subcortex has an innate "human speech sound" detector, and tells the neocortex that this is an important thing to model; (2) maybe some adjustment of the neocortex information flows and hyperparameters, although I couldn't tell you how. (I haven't dived into the literature in either case.)
I do now have some intuition that some complicated domains may require some micromanagement of the learning process ... in particular in this paper they found that to get vision to develop in their models, it was important that first they set up connections between low-level visual information and blah blah, and after learning those relationships, then they also connect the low-level visual information to some other information stream, and it can learn those relationships. If they just connect all the information streams at once, then the algorithm would flail around and not learn anything useful. It's possible that vision is unusually complicated. Or maybe it's similar for language: maybe there's a convoluted procedure necessary to reliably get the right low-level model space set up for language. For example, I hear that some kids are very late talkers, but when they start talking, it's almost immediately in full sentences. Is that a sign of some new region-to-region connection coming online in a carefully-choreographed developmental sequence? Maybe it's in the literature somewhere, I haven't looked. Just thinking out loud.
linguistic universals
I would say: the neocortical algorithm is built on certain types of data structures, and certain ways of manipulating and combining those data structures. Languages have to work smoothly with those types of data structures and algorithmic processes. In fact, insofar as there are linguistic universals (the wiki article says it's controversial; I wouldn't know either way), perhaps studying them might shed light on how the neocortical algorithm works!
you seem to presuppose that the subcortex actually succeeds in steering the neocortex
That's a fair point.
My weak answer is: however it does its thing, we might as well try to understand it. They can be tools in our toolbox, and a starting point for further refinement and engineering. (ETA: ...And if we want to make an argument that We're Doomed if people reverse-engineer neocortical algorithms, which I consider a live possibility, it seems like understanding the subcortex would be a necessary part of making that argument.)
My more bold answer is: Hey, maybe this really would solve the problem! This seems to be a path to making an AGI which cares about people to the same extent and for exactly the same underlying reasons as people care about other people. After all, we would have the important ingredients in the algorithm, we can feed it the right memes, etc. In fact, we can presumably do better than "intelligence-amplified normal person" by twiddling the parameters in the algorithm—less jealousy, more caution, etc. I guess I'm thinking of Eliezer's statement here [LW · GW] that he's "pretty much okay with somebody giving [Paul Christiano or Carl Shulman] the keys to the universe". So maybe the threshold for success is "Can we make an AGI which is at least as wise and pro-social as Paul Christiano or Carl Shulman?"... In which case, there's an argument that we are likely to succeed if we can reverse-engineer key parts of the neocortex and subcortex.
(I'm putting that out there, but I haven't thought about it very much. I can think of possible problems. What if you need a human body for the algorithms to properly instill prosociality? What if there's a political campaign to make the systems "more human" [EA(p) · GW(p)] including putting jealousy and self-interest back in? If we cranked up the intelligence of a wise and benevolent human, would they remain wise and benevolent forever? I dunno...)
comment by Adam Scholl (adam_scholl) · 2020-09-16T07:16:56.812Z · LW(p) · GW(p)
Your posts about the neocortex have been a plurality of the posts I've been most excited to read this year. I'm super interested in the questions you're asking, and it drives me nuts that they're not asked more in the neuroscience literature.
But there's an aspect of these posts I've found frustrating, which is something like the ratio of "listing candidate answers" to "explaining why you think those candidate answers are promising, relative to nearby alternatives."
Interestingly, I also have this gripe when reading Friston and Hawkins. And I feel like I also have this gripe about my own reasoning, when I think about this stuff—it feels phenomenologically like the only way I know how to generate hypotheses in this domain is by inducing a particular sort of temporary overconfidence, or something.
I don't feel incentivized to do this nearly as much in other domains, and I'm not sure what's going on. My lead hypothesis is that in neuroscience, data is so abundant, and theories/frameworks so relatively scarce, that it's unusually helpful to ignore lots of things—e.g. via the "take as given x, y, z, and p" motion—in order to make conceptual progress. And maybe there's just so much available data here that it would be terribly sisiphean to try to justify all the things one takes as given when forming or presenting intuitions about underlying frameworks. (Indeed, my lead hypothesis for why so many neuroscientists seem to employ strategies like, "contribute to the 'figuring out what roads do' project by spending their career measuring the angles of stop-sign poles relative to the road," is that they feel it's professionally irresponsible, or something, to theorize about underlying frameworks without first trying to concretely falsify a mountain of assumptions).
I think some amount of this motion is helpful for avoiding self-delusion, and the references in your posts make me think you do it at least a bit already. So I guess I just want to politely—and super gratefully, I'm really glad you write these posts regardless! If trying to do this would turn you into a stop sign person, don't do it!—suggest that explicating these more might make it easier for readers to understand your intuitions.
I have many proto-questions about your model, and don't want to spend the time to flesh them all out. But here are some sketches that currently feel top-of-mind:
- Say there exist genes that confer advantage in math-ey reasoning. By what mechanism is this advantage mediated, if the neocortex is uniform? One story, popular among the "stereotypes of early 2000s cognitive scientists" section of my models, is that brains have an "especially suitable for maths" module, and that genes induce various architectural changes which can improve or degrade its quality. What would a neocortical uniformist's story be here—that genes induce architectural changes which alter the quality of the One Learning Algorithm in general? If you explain it as genes having the ability to tweak hyperparameters or the gross wiring diagram in order to degrade or improve certain circuits' ability to run algorithms this domain-specific, is it still explanatorily useful to describe the neocortex as uniform?
- My quick, ~90 min investigation into whether neuroscience as a field buys the neocortical uniformity hypothesis suggested it's fairly controversial. Do you know why? Are the objections mostly similar to those of Marcus et al. [LW · GW]?
- Do you have the intuition that aspects of the neocortical algorithm itself (or the subcortical algorithms themselves) might be safety-relevant? Or is your safety-relevance intuition mostly about the subcortical steering mechanism? (Fwiw, I have the former intuition, in that I'm suspicious some of the features of the neocortical algorithm that cause humans to differ from "hardcore optimizers" exist for safety-relevant reasons).
- In general I feel frustrated with the focus in neuroscience on the implementational Marr Level, relative to the computational and algorithmic levels. I liked the mostly-computational overview here, and the algorithmic sketch in your Predictive Coding = RL + SL + Bayes + MPC [LW · GW] post, but I feel bursting with implementational questions. For example:
- As I understand it, you mention "PGM-type message passing" as a candidate class of algorithm that might perform the "select the best from a population of models" function. Do you just mean you suspect there is something in the general vicinity of a belief propagation algorithm going on here, or is your intuition more specific? If the latter, is the Dileep George paper the main thing motivating that intuition?
- I don't currently know whether the neuroscience lit contains good descriptions of how credit assignment is implemented. Do you? Do you feel like you have a decent guess, or know whether someone else does?
- I have the same question about whatever mechanism approximates Bayesian priors—I keep encountering vague descriptions of it being encoded in dopamine distributions, but I haven't found a good explanation of how that might actually work.
- Are you sure PP deemphasizes the "multiple simultaneous generative models" frame? I understood the references to e.g. the "cognitive economy" in Surfing Uncertainty to be drawing an analogy between populations of individuals exchanging resources in a market, and populations of models exchanging prediction error in the brain.
- Have you thought much about whether there are parts of this research you shouldn't publish? I notice feeling slightly nervous every time I see you've made a new post, I think because I basically buy the "safety and capabilities are in something of a race" hypothesis, and fear that succeeding at your goal and publishing about it might shorten timelines.
↑ comment by Steven Byrnes (steve2152) · 2020-09-17T04:44:19.112Z · LW(p) · GW(p)
Your posts about the neocortex have been a plurality of the posts I've been most excited reading this year.
Thanks so much, that really means a lot!!
...ratio of "listing candidate answers" to "explaining why you think those candidate answers are promising, relative to nearby alternatives."
I agree with "theories/frameworks relatively scarce". I don't feel like I have multiple gears-level models of how the brain might work, and I'm trying to figure out which one is right. I feel like I have zero, and I'm trying to grope my way towards one. It's almost more like deconfusion.
I mean, what are the alternatives?
Alternative 1: The brain is modular and super-complicated
Let's take all those papers that say: "Let's just pick some task and try to explain how adult brains do it based on fMRI and lesion studies", and it ends up being some complicated vague story like "region 37 breaks down the sounds into phonemes and region 93 helps with semantics but oh it's also involved in memory and ...". It's not a gears-level model at all!
So maybe the implicit story is "the brain is doing a complicated calculation, and it is impossible with the tools we have to figure out how it works in a way that really bridges from neurons to algorithms to behavior". I mean, a priori, that could be the answer! In which case, people proposing simple-ish gears-level models would all be wrong, because no such model exists!
Going back to the analogy from my comment yesterday [LW(p) · GW(p)]...
In a parallel universe without ML, the aliens drop a mysterious package from the sky with a fully-trained ImageNet classifier. Scientists around the world try to answer the question: How does this thing work?
90% of the scientists would immediately start doing the obvious thing, which is the OpenAI Microscope Project. This part of the code looks for corners, this thing combines those other things to look for red circles on green backgrounds, etc. etc. It's a great field of research for academics—there's an endless amount of work, you keep discovering new things. You never wind up with any overarching theory, just more and more complicated machinery the deeper you dive. Steven Pinker and Gary Marcus would be in this group, writing popular books about the wondrous variety of modules in the aliens' code.
Then the other 10% of scientists come up with a radical, complementary answer: the "way this thing works" is it was built by gradient descent on a labeled dataset. These scientists still have a lot of stuff to figure out, but it's totally different stuff from what the first group is learning about—this group is not learning about corner-detecting modules and red-circle-on-green-background modules, but they are learning about BatchNorm, xavier initialization, adam optimizers, etc. etc. And while the first group toils forever, the second group finds that everything snaps into place, and there's an end in sight.
(I think this analogy is a bit unfair to the "the brain is modular and super-complicated" crowd, because the "wiring diagram" does create some degree of domain-specificity, modularity, etc. But I think there's a kernel of truth...)
Anyway, someone in the second group tells their story, and someone says: "Hey, you should explain why the 'gradient descent on a labeled dataset' description of what's going on is more promising than the 'OpenAI microscope' description of what's going on".
Umm, that's a hard question to answer! In this thought experiment, both groups are sorta right, but in different ways... More specifically, if you want to argue that the second group is right, it does not involve arguing that the first group is wrong!
So that's one thing...
Alternative 2: Predictive Processing / Free Energy Principle
I've had a hard time putting myself in their shoes and see things from their perspective. Part of it is that I don't find it gears-level-y enough—or at least I can't figure out how to see it that way. Speaking of which...
Are you sure PP deemphasizes the "multiple simultaneous generative models" frame?
No I'm not sure. I can say that, in what I've read, if that's part of the story, it wasn't stated clearly enough to get through my thick skull. :-)
I do think that a (singular) prior is supposed to be mathematically a probability distribution, and a probability distribution in a high-dimensional space can look like, for example, a weighted average of 17 totally different scenarios. So in that sense I suppose you can say that it's at most a difference of emphasis & intuition.
My quick, ~90 min investigation into whether neuroscience as a field buys the neocortical uniformity hypothesis suggested it's fairly controversial. Do you know why?
Nope! Please let me know if you discover anything yourself!
Do you just mean you suspect there is something in the general vicinity of a belief propagation algorithm going on here, or is your intuition more specific? If the latter, is the Dileep George paper the main thing motivating that intuition?
It's not literally just belief propagation ... Belief propagation (as far as I know) involves a graph of binary probabilistic variables that depend on each other, whereas here we're talking about a graph of "generative models" that depend on each other. A generative model is more complicated than a binary variable—for one thing, it can be a function of time.
Dileep George put the idea of PGMs in my head, or at least solidified my vague intuitions by using the standard terminology. But I mostly like it for the usual reason that if it's true then everything snaps into place and makes sense, and I don't know any alternative with that property. The examples like "purple jar" (or Eliezer's triangular light bulb) seems to me to require some component that comes with a set of probabilistic predictions about the presence/absence/features of other components ... and bam, you pretty much have "belief propagation in a probabilistic graphical model" right there. Or "stationary dancing" is another good example—as you try to imagine it, you can just feel the mutually-incompatible predictions fighting it out :-) Or Scott Alexander's "ethnic tensions" post—it's all about manipulating connections among a graph of concepts, and watching the reward prediction (= good vibes or bad vibes) travel along the edges of the graph. He even describes it as nodes and edges and weights!
If you explain it as genes having the ability to tweak hyperparameters or the gross wiring diagram in order to degrade or improve certain circuits' ability to run algorithms this domain-specific, is it still explanatorily useful to describe the neocortex as uniform?
I dunno, it depends on what question you're trying to answer.
One interesting question would be: If a scientist discovers the exact algorithm for one part of the neocortex subsystem, how far are we from superhuman AGI? I guess my answer would be "years but not decades" (not based on terribly much—things like how people who lose parts of the brain early in childhood can sometimes make substitutions; how we can "cheat" by looking at neurodevelopmental textbooks; etc.). Whereas if I were an enthusiastic proponent of modular-complicated-brain-theory, I would give a very different answer, which assumed that we have to re-do that whole discovery process over and over for each different part of the neocortex.
Another question would be: "How does the neocortex do task X in an adult brain?" Then knowing the base algorithm is just the tiny first step. Most of the work is figuring out the space of generative models, which are learned over the course of the person's life. Subcortex, wiring diagram, hyperparameters, a lifetime's worth of input data and memes—everything is involved. What models do you wind up with? How did they get there? What do they do? How do they interact? It can be almost arbitrarily complicated.
Say there exist genes that confer advantage in math-ey reasoning. By what mechanism is this advantage mediated
Well my working assumption is that it's one or more of the three possibilities of hyperparameters, wiring diagram, and something in the subcortex that motivates some (lucky) people to want to spend time thinking about math. Like I'll be eating dinner talking with my wife about whatever, and my 5yo kid will just jump in and interrupt the conversation to tell me that 9×9=81. Not trying to impress us, that's just what he's thinking about! He loves it! Lucky kid. I have no idea how that motivational drive is implemented. (In fact I haven't thought about how curiosity works in general.) Thanks for the good question, I'll comment again if I think of anything.
Dehaene has a book about math-and-neuroscience I've been meaning to read. He takes a different perspective from me but brings an encyclopedic knowledge of the literature.
Do you have the intuition that aspects of the neocortical algorithm itself (or the subcortical algorithms themselves) might be safety-relevant?
I interpret your question as saying: let's say people publish on GitHub how to make brain-like AGIs, so we're stuck with that, and we're scrambling to mitigate their safety issues as best as we can. Do we just work on the subcortical steering mechanism, or do we try to change other things too? Well, I don't know. I think the subcortical steering mechanism would be an especially important thing to work on, but everything's on the table. Maybe you should box the thing, maybe you should sanitize the information going into it, maybe you should strategically gate information flow between different areas, etc. etc. I don't know of any big ways to wholesale change the neocortical algorithm and have it continue to work at least as effectively as before, although I'm open to that being a possibility.
how credit assignment is implemented
I've been saying "generative models make predictions about reward just like they make predictions about everything else", and the algorithm figures it out just like everything else. But maybe that's not exactly right. Instead we have the nice "TD learning" story. If I understand it right, it's something like: All generative models (in the frontal lobe) have a certain number of reward-prediction points. You predict reward by adding it up over the active generative models. When the reward is higher than you expected, all the active generative models get some extra reward-prediction points. When it's lower than expected, all the active generative models lose reward-prediction points. I think this is actually implemented in the basal ganglia, which has a ton of connections all around the frontal lobe, and memorizes the reward-associations of arbitrary patterns, or something like that. Also, when there are multiple active models in the same category, the basal ganglia makes the one with higher reward-prediction points more prominent, and/or squashes the one with lower reward-prediction points.
In a sense, I think credit assignment might work a bit better in the neocortex than in a typical ML model, because the neocortex already has hierarchical planning. So, for example, in chess, you could plan a sequence of six moves that leads to an advantage. When it works better than expected, there's a generative model representing the entire sequence, and that model is still active, so that model gets more reward-prediction points, and now you'll repeat that whole sequence in the future. You don't need to do six TD iterations to figure out that that set of six moves was a good idea. Better yet, all the snippets of ideas that contributed to the concept of this sequence of six moves are also active at the time of the surprising success, and they also get credit. So you'll be more likely to do moves in the future that are related in an abstract way to the sequence of moves you just did.
Something like that, but I haven't thought about it much.
↑ comment by Steven Byrnes (steve2152) · 2020-09-16T19:26:17.017Z · LW(p) · GW(p)
Have you thought much about whether there are parts of this research you shouldn't publish?
Yeah, sure. I have some ideas about the gory details of the neocortical algorithm that I haven't seen in the literature. They might or might not be correct and novel, but at any rate, I'm not planning to post them, and I don't particularly care to pursue them, under the circumstances, for the reasons you mention.
Also, there was one post that I sent for feedback to a couple people in the community before posting, out of an abundance of caution. Neither person saw it as remotely problematic, in that case.
Generally I think I'm contributing "epsilon" to the project of reverse-engineering neocortical algorithms, compared to the community of people who work on that project full-time and have been at it for decades. Whereas I'd like to think that I'm contributing more than epsilon to the project of safe & beneficial AGI. (Unless I'm contributing negatively by spreading wrong ideas!) I dunno, but I think my predispositions are on the side of an overabundance of caution.
I guess I was also taking solace from the fact that nobody here said anything to me, until your comment just now. I suppose that's weak evidence—maybe nobody feels it's their place. or nobody's thinking about it, or whatever.
If you or anyone wants to form an IRB that offers a second opinion on my possibly-capabilities-relevant posts, I'm all for it. :-)
By the way, full disclosure, I notice feeling uncomfortable even talking about whether my posts are info-hazard-y or not, since it feels quite arrogant to even be considering the possibility that my poorly-researched free-time blog posts are so insightful that they materially advance the field. In reality, I'm super uncertain about how much I'm on a new right track, vs right but reinventing wheels, vs wrong, when I'm not directly parroting people (which at least rules out the first possibility). Oh well. :-P
↑ comment by Steven Byrnes (steve2152) · 2020-10-02T01:00:48.599Z · LW(p) · GW(p)
(Oops I just noticed that I had missed one of your questions in my earlier responses)
I have the same question about whatever mechanism approximates Bayesian priors—I keep encountering vague descriptions of it being encoded in dopamine distributions, but I haven't found a good explanation of how that might actually work.
I don't think there's anything to Bayesian priors beyond the general "society of compositional generative models" framework. For example, we have a prior that if someone runs towards a bird, it will fly away. There's a corresponding generative model: in that model, first there's a person running towards a bird, and then the bird is flying away. All of us have that generative model prominently in our brains, having seen it happen a bunch of times in the past. So when we see a person running towards a bird, that generative model gets activated, and it then sends a prediction that the bird is about to fly away.
(Right? Or sorry if I'm misunderstanding your question.)
(Not sure what you saw about dopamine distributions. I think everyone agrees that dopamine distributions are relevant to reward prediction, which I guess is a special case of a prior. I didn't think it was relevant for non-reward-related-priors, like the above prior above bird behavior, but I don't really know, I'm pretty hazy on my neurotransmitters, and each neurotransmitter seems to do lots of unrelated things.)
comment by habryka (habryka4) · 2020-10-01T23:03:34.294Z · LW(p) · GW(p)
Promoted to curated: This kind of thinking seems both very important, and also extremely difficult. I do think that trying to understand the underlying computational structure of the brain is quite useful for both thinking about Rationality and thinking about AI and AI Alignment, though it's also plausible to me that it's hard enough to get things right in this space that in the end overall it's very hard to extract useful lessons from this.
Despite the difficulties I expect in this space, this post does strike me as overall pretty decent and to at the very least open up a number of interesting questions that one could ask to further deconfuse oneself on this topic.
comment by romeostevensit · 2020-09-14T21:40:32.384Z · LW(p) · GW(p)
Trying to summarize your current beliefs (harder than it looks) is one of the best way to have very novel new thoughts IME.
comment by Steven Byrnes (steve2152) · 2021-12-15T04:04:37.334Z · LW(p) · GW(p)
I wrote this relatively early in my journey of self-studying neuroscience. Rereading this now, I guess I'm only slightly embarrassed to have my name associated with it, which isn’t as bad as I expected going in. Some shifts I’ve made since writing it (some of which are already flagged in the text):
- New terminology part 1: Instead of “blank slate” I now say “learning-from-scratch”, as defined and discussed here [AF · GW].
- New terminology part 2: “neocortex vs subcortex” → “learning subsystem vs steering subsystem”, with the former including the whole telencephalon and cerebellum, and the latter including the hypothalamus and brainstem. I distinguish them by "learning-from-scratch vs not-learning-from-scratch". See here [AF · GW].
- Speaking of which, I now put much more emphasis on "learning-from-scratch" over "cortical uniformity" when talking about the neocortex etc.—I care about learning-from-scratch more, I talk about it more, etc. I see the learning-from-scratch hypothesis as absolutely central to a big picture of the brain (and AGI safety!), whereas cortical uniformity is much less so. I do still think cortical uniformity is correct (at least in the weak sense that someone with a complete understanding of one part of the cortex would be well on their way to a complete understanding of any other part of the cortex), for what it’s worth.
- I would probably drop the mention of “planning by probabilistic inference”. Well, I guess something kinda like planning by probabilistic inference is part of the story, but generally I see the brain thing as mostly different.
- Come to think of it, every time the word “reward” shows up in this post, it’s safe to assume I described it wrong in at least some respect.
- The diagram with neocortex and subcortex is misleading for various reasons, see notes added to the text nearby.
- I’m not sure I was using the term “analysis-by-synthesis” correctly. I think that term is kinda specific to sound processing. And the vision analog is “vision as inverse graphics” I guess? Anyway, I should have just said “probabilistic inference”. :-)
(More on all these topics in my intro series [? · GW]!)
Anyway the post is nice as a snapshot of where I was at that point, and I recall the comments and other feedback being very helpful to me. (Thanks everyone!)
comment by avturchin · 2020-09-15T14:02:57.055Z · LW(p) · GW(p)
I have several questions:
Where are qualia and consciousness in this model?
Is this model address difference between two hemispheres?
What about long term-memory? Is it part of neocortex?
How this model explain the phenomenon of night dreams?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-09-15T15:24:43.205Z · LW(p) · GW(p)
Good questions!!!
Where are qualia and consciousness in this model?
See my Book Review: Rethinking Consciousness [LW · GW].
Is this model address difference between two hemispheres?
Insofar as there are differences between the two hemispheres—and I don't know much about that—I would treat it like any other difference between different parts of the cortex (Section 2), i.e. stemming from (1) the innate large-scale initial wiring diagram, and/or (2) differences in "hyperparameters".
There's a lot that can be said about how an adult neocortex represents and processes information—the dorsal and ventral streams, how do Wernicke's area and Broca's area interact in speech processing, etc. etc. ad infinitum. You could spend your life reading papers about this kind of stuff!! It's one of the main activities of modern cognitive neuroscience. And you'll notice that I said nothing whatsoever about that. Why not?
I guess there's a spectrum of how to think about this whole field of inquiry:
- On one end of the spectrum (the Gary Marcus / Steven Pinker end), this line of inquiry is directly attacking how the brain works, so obviously the way to understand the brain is to work out all these different representations and mechanisms and data flows etc.
- On the opposite end of the spectrum (maybe the "cartoonish connectionist" end?), this whole field is just like the OpenAI Microscope project. There is a simple, generic learning algorithm, and all this rich structure—dorsal and ventral streams, phoneme processing in such-and-such area, etc.—just naturally pops out of the generic learning algorithm. So if your goal is just to make artificial intelligence, this whole field of inquiry is entirely unnecessary—in the same way that you don't need to study the OpenAI Microscope project in order to train and use a ConvNet image classifier. (Of course maybe your goal is something else, like understanding adult human cognition, in which case this field is still worth studying.)
I'm not all the way at the "cartoonish connectionist" end of the spectrum, because I appreciate the importance of the initial large-scale wiring diagram and the hyperparameters. But I think I'm quite a bit farther in that direction than is the median cognitive neuroscientist. (I'm not alone out here ... just in the minority.) So I get more excited than mainstream neuroscientists by low-level learning algorithm details, and less excited than mainstream neuroscientists about things like hemispherical specialization, phoneme processing chains, dorsal and ventral streams, and all that kind of stuff. And yeah, I didn't talk about it at all in this blog post.
What about long term-memory? Is it part of neocortex?
There's a lot about how the neocortex learning algorithm works that I didn't talk about, and indeed a lot that is unknown, and certainly a lot that I don't know! For example, the generative models need to come from somewhere!
My impression is that the hippocampus is optimized to rapidly memorize arbitrary high-level patterns, but it only holds on to those memories for like a couple years, during which time it recalls them when appropriate to help the neocortex deeply embed that new knowledge into its world model, with appropriate connections and relationships to other knowledge. So the final storage space for long-term memory is the neocortex.
I'm not too sure about any of this.
This video about the hippocampus is pretty cool. Note that I count the hippocampus as part of the "neocortex subsystem", following Jeff Hawkins.
How this model explain the phenomenon of night dreams?
I don't know. I assume it somehow helps optimize the set of generative models and their connections.
I guess dreaming could also have a biological purpose but not a computational purpose (e.g., some homeostatic neuron-maintenance process, that makes the neurons fire as an unintended side-effect). I don't think that's particularly likely, but it's possible. Beats me.
Replies from: avturchin, avturchin↑ comment by avturchin · 2020-09-15T17:41:53.809Z · LW(p) · GW(p)
Thanks. I think that a plausible explanation of dreaming is generating of virtual training environments where an agent is training to behave in the edge cases, on which it is too costly to train in real life or in real world games. That is why the generic form of the dreams is nightmare: like, a lion attack me, or I am on stage and forget my speech.
From "technical" point view, dream generation seems rather simple: if the brain has world-model generation engine, it could generate predictions without any inputs, and it will look like an dream.
↑ comment by avturchin · 2020-09-16T22:02:05.902Z · LW(p) · GW(p)
I reread the post and have some more questions:
- Where is "human values" in this model? If we give this model to an AI which wants to learn human values and have full access to human brain, where it should search for human values?
- If cortical algorithm will be replaced with GPT-N in some human mind model, will the whole system work?
↑ comment by Steven Byrnes (steve2152) · 2020-09-17T12:52:15.332Z · LW(p) · GW(p)
Where is "human values" in this model
Well, all the models in the frontal lobe get, let's call it, reward-prediction points (see my comment here [LW(p) · GW(p)]), which feels like positive vibes or something.
If the generative model "I eat a cookie" has lots of reward-prediction points (including the model itself and the downstream models that get activated by it in turn), we describe that as "I want to eat a cookie".
Likewise If the generative model "Michael Jackson" has lots of reward prediction points, we describe that as "I like Michael Jackson. He's a great guy.". (cf. "halo effect")
If somebody says that justice is one of their values, I think it's at least partly (and maybe primarily) up a level in meta-cognition. It's not just that there's a generative model "justice" and it has lots of reward-prediction points ("justice is good"), but there's also a generative model of yourself valuing justice, and that has lots of reward-prediction points too. That feels like "When I think of myself as the kind of person who values justice, it's a pleasing thought", and "When I imagine other people saying that I'm a person who values justice, it's a pleasing thought".
This isn't really answering your question of what human values are or should be—this is me saying a little bit about what happens behind the scenes when you ask someone "What are your values?". Maybe they're related, or maybe not. This is a philosophy question. I don't know.
If cortical algorithm will be replaced with GPT-N in some human mind model, will the whole system work?
My belief (see post here [LW · GW]) is that GPT-N is running a different kind of algorithm, but learning to imitate some steps of the brain algorithm (including neocortex and subcortex and the models that result from a lifetime of experience, and even hormones, body, etc.—after all, the next-token-prediction task is the whole input-output profile, not just the neocortex.) in a deep but limited way. I can't think of a way to do what you suggest, but who knows.
comment by MaxRa · 2020-10-04T08:04:56.719Z · LW(p) · GW(p)
That was really interesting!:)
Your idea of subcortical spider detection reminded me of this post by Kaj Sotala, discussing the argument that it’s more about „peripheral“ attentional mechanisms having evolved to attend to spiders etc., and consequently being easier learned as dangerous.
These results suggest that fear of snakes and other fear-relevant stimuli is learned via the same central mechanisms as fear of arbitrary stimuli. Nevertheless, if that is correct, why do phobias so often relate to objects encountered by our ancestors, such as snakes and spiders, rather than to objects such as guns and electrical sockets that are dangerous now [10]? Because peripheral, attentional mechanisms are tuned to fear-relevant stimuli, all threat stimuli attract attention, but fear-relevant stimuli do so without learning (e.g., [56]). This answer is supported by evidence from conditioning experiments demonstrating enhanced attention to fear-relevant stimuli regardless of learning (Box 2), studies of visual search [57–59], and developmental psychology [60,61]. For example, infants aged 6–9 months show a greater drop in heart rate – indicative of heightened attention rather than fear – when they watch snakes than when they watch elephants [62].
comment by flaminglasrswrd · 2020-10-02T17:58:32.759Z · LW(p) · GW(p)
If you haven't seen it already, the work of Grossberg and Hawkins might be suitable for this kind of research. These two researchers are perhaps the most influential in my understanding of intelligence.
Here is a representative sample of their work but major works stretch back decades.
- Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex, Hawkins, doi:10.3389/fncir.2016.00023
- Towards solving the hard problem of consciousness: The varieties of brain resonances and the conscious experiences that they support, Grossberg, doi:10.1016/j.neunet.2016.11.003
- A Framework for Intelligence and Cortical Function Based on Grid Cells in the Neocortex, Hawkins, doi:10.1101/442418
- A half century of progress towards a unified neural theory of mind and brain with applications to autonomous adaptive agents and mental disorders, Grossberg, ISBN:978-0-12-815480-9
↑ comment by Steven Byrnes (steve2152) · 2020-10-02T18:56:00.970Z · LW(p) · GW(p)
I'm extremely familiar with the work of Jeff Hawkins—I've read his book and pretty much all his papers, I occasionally tune into the Numenta research meetings on youtube, and read the Numenta forums, etc. In fact I cited one of Hawkins's papers in this very blog post. Here's the first time I ever heard about cortical uniformity [LW · GW], which was a podcast he did last year. I think he's had a lot of insightful ideas about the neocortex works, despite working with his hands tied behind his back, by his refusal (or inability) to talk about probabilities. (...which is why Dileep George quit Numenta back in the day).
I've had a Stephen Grossberg paper on my to-do list for a while (namely, "Towards a Unified Theory of the Neocortex" 2006). Thanks for the tip, maybe I'll move it closer to the top of the list and/or look at the others you suggest. :-)
↑ comment by Steven Byrnes (steve2152) · 2021-01-23T14:09:46.049Z · LW(p) · GW(p)
UPDATE: Stephen Grossberg is great! I just listened to his interview on the "Brain Inspired" podcast. His ideas seem to fit right in with the ideas I had already been latching onto. I'll be reading more. Thanks again for the tip!
comment by Rafael Harth (sil-ver) · 2020-12-11T11:45:00.089Z · LW(p) · GW(p)
I've tried to apply this framework earlier and realized that I'm confused about how new models are generated. Say I'm taught about the derivative for the first time. This process should result in me getting a 'derivative' model, but how is this done? At the point where the model isn't yet there, how does the neocortex (or another part of the brain?) do that?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-11T14:50:38.008Z · LW(p) · GW(p)
Where do the generative models come from is a question I can't answer well because nobody knows the algorithm, so far as I can tell.
Here's a special case that's well understood: time-sequencing. If A happens then B happens, you'll memorize a model "A then B". Jeff Hawkins has a paper here with biological details, and Dileep George has a series of nice papers applying this particular algorithm to practical ML problems (keyword: "cloned hidden Markov model").
Outside of that special case, I can't say much in detail because I don't know. Randall O'Reilly argues convincingly here that there's an error-driven learning mechanism, at least for the vision system (ML people would say: "self-supervised learning involving gradient descent"), although it's controversial whether the brain can do backprop through multiple hierarchical layers the way PyTorch can. Well, long story. There's also Hebbian learning. There's also trial-and-error learning. When you read a book they'll describe things using analogies, which activates models in your brain which could be helpful ingredients in constructing the new model. Anyway, I dunno.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-12-12T10:21:47.373Z · LW(p) · GW(p)
That's a shame. Seems like an important piece.
Although, I now think my primary issue is actually not quite that. It's more like, when I try to concretely sketch how I now imagine thinking to work, I naturally invoke an additional mysterious steering module that allows me to direct my models to the topics that I want outputs on. I probably want to do this because that's how my mind feels like: I can steer it where I want it, and then it spits out results.
Now, on the one hand, I don't doubt that the sense of control is an evolutionarily adaptive deception, and I certainly don't think Free Will is a real thing. On the other hand, it seems hard to take out the mysterious steering module. I think I was asking about how models are created to fill in that hole, but on second thought, it may not actually be all that connected, unless there is a module which does both.
So, is the sense of deciding what to apply my generative models to subsumed by the model outputs in this framework? Or is there something else?
I realize that the subcortex is steering the neocortex, but I'm still thinking about an evolutionarily uninteresting setting, like me sitting in a safe environment and having my mind contemplate various evolutionarily alien concepts.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-12T22:10:10.053Z · LW(p) · GW(p)
That's a shame. Seems like an important piece.
Well, we don't have AGI right now, there must be some missing ingredients... :-)
direct my models to the topics that I want outputs on
Well you can invoke a high-confidence model: "a detailed solution to math problem X involving ingredients A,B,C". Then the inference algorithm will shuffle through ideas in the brain trying to build a self-consistent model that involves this shell of a thought but fills in the gaps with other pieces that fit. So that would feel like trying to figure something out.
I think that's more like inference than learning, but of course you can memorize whatever useful new composite models that come up with during this process.
comment by trentbrick · 2020-12-14T17:31:18.738Z · LW(p) · GW(p)
Hi Steve, thanks for all of your posts.
It is unclear to me how this investigation into brain-like AGI will aid in safety research.
Can you provide some examples of what discoveries would indicate that this is an AGI route that is very dangerous or safe?
Without having thought about this much it seems to me like the control/alignment problem depends upon the terminal goals we provide the AGI rather than the substrate and algorithms it is running to obtain AGI level intelligence.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-14T19:28:11.894Z · LW(p) · GW(p)
Ooh, good questions!
Without having thought about this much it seems to me like the control/alignment problem depends upon the terminal goals we provide the AGI rather than the substrate and algorithms it is running to obtain AGI level intelligence.
I agree that if an AGI has terminal goals, they should be terminal goals that yield good results for the future. (And don't ask me what those are!) So that is indeed one aspect of the control/alignment problem. However, I'm not aware of any fleshed-out plan for AGI where you get to just write down its terminal goals, or indeed where the AGI necessarily even has terminal goals in the first place. (For example, what language would the terminal goals be written in?)
Instead, the first step would be to figure out how to build the system such that it winds up having the goals that you want it to have. That part is called the "inner alignment problem", it is still an open problem, and I would argue that it's a different open problem for each possible AGI algorithm architecture—since different algorithms can acquire / develop goals via different processes. (See here [LW · GW] for excessive detail on that.)
Can you provide some examples of what discoveries would indicate that this is an AGI route that is very dangerous or safe?
Sure!
- One possible path to a (plausibly) good AGI future is try to build AGIs that have a similar suite of moral intuitions that humans have. We want this to work really well, even in weird out-of-distribution situations (the future will be weird!), so we should ideally try to make this happen by using similar underlying algorithms as humans. Then they'll have the same inductive biases etc. This especially would involve human social instincts. I don't really understand how human social instincts work (I do have vague ideas I'm excited to further explore! [LW · GW] But I don't actually know.) It may turn out to be the case that the algorithms supporting those instincts rely in a deep and inextricable way on having a human body and interacting with humans in a human world. That would be evidence that this potential path is not going to work. Likewise, maybe we'll find out that you fundamentally can't have, say, a sympathy instinct without also having, say, jealousy and self-interest. Again, that would be evidence that this potential path is not as promising as it initially sounded. Conversely, we could figure out how the instincts work, see no barriers to putting them into an AGI, see how to set them up to be non-subvertable (such that the AGI cannot dehumanize / turn off sympathy), etc. Then (after a lot more work) we could form an argument that this is a good path forward, and start advocating for everyone to go down this development path rather than other potential paths to AGI.
- If we find a specific, nice, verifiable plan to keep neocortex-like AGIs permanently under human control (and not themselves suffering, if you think that AGI suffering possible & important), then that's evidence that neocortex-like AGIs are a good route. Such a plan would almost certainly be algorithm-specific. See my random example here [LW · GW]—in this example, the idea of an AGI acting conservatively sounds nice and all, but the only way to really assess the idea (and its strengths and weaknesses and edge-cases) is to make assumptions about what the AGI algorithm will be like. (I don't pretend that that particular blog post is all that great, but I bet that with 600 more blog posts like that, maybe we would start getting somewhere...) If we can't find such a plan, can we find a proof that no such plan exists? Either way would be very valuable. This is parallel to what Paul Christiano and colleagues at OpenAI & Ought have been trying to do, but their assumption is that AGI algorithms will be vaguely similar to today's deep neural networks, rather than my assumption that AGI algorithms will be vaguely similar to a brain's. (To be clear, I have nothing against assuming that AGI algorithms will be vaguely similar to today's DNNs. That is definitely one possibility. I think both these research efforts should be happening in parallel.)
I could go on. But anyway, does that help? If I said something confusing or jargon-y, just ask, I don't know your background. :-)
Replies from: trentbrick↑ comment by trentbrick · 2020-12-20T15:20:29.520Z · LW(p) · GW(p)
Thanks a lot for your detailed reply and sorry for my slow response (I had to take some exams!).
Regarding terminal goals the only compelling one I have come across is coherent extrapolated volition as outlined in Superintelligence. But how to even program this into code is of course problematic and I haven't followed the literature closely since for rebuttals or better ideas.
I enjoyed your piece on Steered Optimizers, and think it has helped give me examples where the algorithmic design and inductive biases can play a part in how controllable our system is. This also brings to mind this piece which I suspect you may really enjoy: https://www.gwern.net/Backstop.
I am quite a believer in fast takeoff scenarios so I am unsure to what extent we can control a full AGI, but until it reaches criticality the tools we have to test and control it will indeed be crucial.
One concern I have that you might be able to address is that evolution did not optimize for interpretability! While DNNs are certainly quite black box, they remain more interpretable than the brain. I assign some prior probability to the same relative interpretability of DNNs vs neocortex based AGI.
Another concern is with the human morals that you mentioned. This should certainly be investigated further but I don't think almost any human has an internally consistent set of morals. In addition, I think that the morals we have were selected by the selfish gene and even if we could re-simulate them through an evolutionary like process we would get the good with the bad. https://slatestarcodex.com/2019/06/04/book-review-the-secret-of-our-success/ and a few other evolutionary biology books have shaped my thinking on this.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-01-12T11:04:23.500Z · LW(p) · GW(p)
Thanks for the gwern link!
Regarding terminal goals the only compelling one I have come across is coherent extrapolated volition as outlined in Superintelligence. But how to even program this into code is of course problematic and I haven't followed the literature closely since for rebuttals or better ideas.
I think the most popular alternatives to CEV are "Do what I, the programmer, want you to do", argued most prominently by Paul Christiano (cf. "Approval-directed agents"), variations on that (Stuart Russell's book talks about showing a person different ways that their future could unfold and have them pick their favorite), task-limited AGI ("just do this one specific thing without causing general mayhem") (I believe Eliezer was advocating for solving this problem before trying to make a CEV maximizer), and lots of ideas for systems that don't look like agents with goals (e.g. CAIS). A lot of these "kick the can down the road" and don't try to answer big questions about the future, on the theory that future people with AGI helpers will be in a better position to figure out subsequent steps forward.
evolution did not optimize for interpretability!
Sure, and neither did Yann Lecun. I don't know whether a DNN would be more or less intepretable than a neocortex with the same information content. I think we desperately need a clearer vision for what "interpretability tools" would look like in both cases, such that they would scale all the way to AGI. I (currently) see no way around having intepretability be a big part of the solution.
I don't think almost any human has an internally consistent set of morals
Strong agree. I do think we have a suite of social instincts which are largely common between people and hard-coded by evolution. But the instincts don't add up to an internally consistent framework of morality.
even if we could re-simulate them through an evolutionary like process we would get the good with the bad.
I'm generally not assuming that we will run search processes that parallel what evolution did. I mean, maybe, I just don't think it's that likely, and it's not the scenario I'm trying to think through. I think people are very good at figuring out algorithms based on their desired input-output relations, and then coding them up, whereas evolution-like searches over learning algorithms is ridiculously computationally expensive and has little precedent. (E.g. we invented ConvNets, we didn't discover ConvNets by an evolutionary search.) Evolution has put learning algorithms into the neocortex and cerebellum and amygdala, and I think humans will figure out what these learning algorithms are and directly write code implementing them. Evolution has put non-learning algorithms into the brainstem, and I suspect that the social instincts are in this category, and I suspect that if we make AGI with (some) human-like social instincts, it would be by people writing code that implements a subset of those algorithms or something similar. I think the algorithms are not understood right now, and may well not be by the time we get AGI, and I think that's a bad thing, closing off an option.