Jeff Hawkins on neuromorphic AGI within 20 years
post by Steven Byrnes (steve2152) · 2019-07-15T19:16:27.294Z · LW · GW · 24 commentsContents
Every part of the neocortex is running the same algorithm Grid cells and displacement cells Background: Grid cells for maps in the hippocampus New idea: Grid cells for "maps" of objects and concepts in the neocortex "Thousand brains" theory Human-level AI, timelines, and existential risk Differences between actual neurons and artifical neural networks (ANNs) Non-proximal synapses and recognizing time-based patterns Binary weights, sparse representations Learning and synaptogenesis Vision processing My conclusions for AGI safety None 24 comments
I just listened to AI podcast: Jeff Hawkins on the Thousand Brain Theory of Intelligence, and read some of the related papers. Jeff Hawkins is a theoretical neuroscientist; you may have heard of his 2004 book On Intelligence. Earlier, he had an illustrious career in EECS, including inventing the Palm Pilot. He now runs the company Numenta, which is dedicated to understanding how the human brain works (especially the neocortex), and using that knowledge to develop bio-inspired AI algorithms.
In no particular order, here are some highlights and commentary from the podcast and associated papers.
Every part of the neocortex is running the same algorithm
The neocortex is the outermost and most evolutionarily-recent layer of the mammalian brain. In humans, it is about the size and shape of a dinner napkin (maybe 1500cm²×3mm), and constitutes 75% of the entire brain. Jeff wants us to think of it like 150,000 side-by-side "cortical columns", each of which is a little 1mm²×3mm tube, although I don't think we're supposed to the "column" thing too literally (there's no sharp demarcation between neighboring columns).
When you look at a diagram of the brain, the neocortex has loads of different parts that do different things—motor, sensory, visual, language, cognition, planning, and more. But Jeff says that all 150,000 of these cortical columns are virtually identical! Not only do they each have the same types of neurons, but they're laid out into the same configuration and wiring and larger-scale structures. In other words, there seems to be "general-purpose neocortical tissue", and if you dump visual information into it, it does visual processing, and if you connect it to motor control pathways, it does motor control, etc. He said that this theory originated with Vernon Mountcastle in the 1970s, and is now widely (but not universally) accepted in neuroscience. The theory is supported both by examining different parts of the brain under the microscope, and also by experiments, e.g. the fact that congenitally blind people can use their visual cortex for non-visual things, and conversely he mentioned in passing some old experiment where a scientist attached the optic nerve of a lemur to a different part of the cortex and it was able to see (or something like that).
Anyway, if you accept that premise, then there is one type of computation that the neocortex does, and if we can figure it out, we'll understand everything from how the brain does visual processing to how Einstein's brain invented General Relativity.
To me, cortical uniformity seems slightly at odds with the wide variety of instincts we have, like intuitive physics, intuitive biology, language, and so on. Are those not implemented in the neocortex? Are they implemented as connections between (rather than within) cortical columns? Or what? This didn't come up in the podcast. (ETA: I tried to answer this question in my later post, Human instincts, Symbol grounding, and the blank-slate neocortex [LW · GW].)
(See also previous LW discussion at: The brain as a universal learning machine, 2015 [LW · GW])
Grid cells and displacement cells
Background: Grid cells for maps in the hippocampus
Grid cells, discovered in 2005, help animals build mental maps of physical spaces. (Grid cells are just one piece of a complicated machinery, along with "place cells" and other things, more on which shortly.) Grid cells are not traditionally associated with the neocortex, but rather the entorhinal cortex and hippocampus. But Jeff says that there's some experimental evidence that they're also in the neocortex, and proposes that this is very important.
What are grid cells? Numenta has an educational video here. Here's my oversimplified 1D toy example (the modules can also be 2D). I have a cortical column with three "grid cell modules". One module consists of 9 neurons, one has 10 neurons, and the third has 11. As I stand in a certain position in a room, one neuron from each of the three modules is active - let's say the active neurons right now are , , and for some integers . When I take a step rightward, are each incremented by 1; when I take a step leftward, they're each decremented by 1. The three modules together can thus keep track of 990 unique spatial positions (cf. Chinese Remainder Theorem).
With enough grid cell modules of incommensurate size, scale-factor, and (in 2D) rotation, the number of unique representable positions becomes massive, and there is room to have lots of entirely different spaces (each with their own independent reference frame) stored this way without worrying about accidental collisions.
So you enter a new room. Your brain starts by picking a point in the room and assigns it a random (in my toy 1D example), and then stores all the other locations in the room in reference to that. Then you enter a hallway. As you turn your attention to this new space, you pick a new random and build your new hallway spatial map around there. So far so good, but there's a missing ingredient: the transformation from the room map to the hallway map, especially in their areas of overlap. How does that work? Jeff proposes (in this paper) that there exist what he calls "displacement cells", which (if I understand it correctly) literally implement modular arithmetic for the grid cell neurons in each grid cell module. So—still in the 1D toy example—the relation between the room map and the hall map might be represented by three displacement cell neurons (one for each of the three grid cell modules), and the neurons are wired up such that the brain can go back and forth between the activations
So if grid cell #2 is active, and then displacement cell #5 turns on, it should activate grid cell #7=5+2. It's kinda funny, but why not? We just put in a bunch of synapses that hardcode each entry of an addition table—and not even a particularly large one.
(Overall, all the stuff about the detailed mechanisms of grid cells and displacement cells comes across to me as "Ingenious workaround for the limitations of biology", not "Good idea that AI might want to copy", but maybe I'm missing something.)
New idea: Grid cells for "maps" of objects and concepts in the neocortex
Anyway, Jeff theorizes that this grid cell machinery is not only used for navigating real spaces in the hippocampus but also navigating concept spaces in the neocortex.
Example #1: A coffee cup. We have a mental map of a coffee cup, and you can move around in that mental space by incrementing and decrementing the (in my 1D toy example).
Example #2: A coffee mug with a picture on it. Now, we have a mental map of the coffee mug, and a separate mental map of the picture, and then a set of displacement cells describe where the picture is in relation to the coffee cup. (This also includes relative rotation and scale, which I guess are also part of this grid cell + displacement cell machinery somehow, but he says he hasn't worked out all the details.)
Example #3: A stapler, where the two halves move with respect to each other. This motion can be described by a sequence of displacement cells ... and conveniently, neurons are excellent at learning temporal sequences (see below).
Example #4: Logarithms. Jeff thinks we have a reference frame for everything! Every word, every idea, every concept, everything you know has its own reference frame, in at least one of your cortical columns and probably thousands of them. Then displacement cells can encode the mathematical transformations of logarithms, and the relations between logarithms and other concepts, or something like that. I tried to sketch out an example of what he might be getting at in the next section below. Still, I found that his discussion of abstract cognition was a bit sketchier and more confusing than other things he talked about. My impression is that this is an aspect of the theory that he's still working on.
"Thousand brains" theory
(See also Numenta educational video.) His idea here is that every one of the 150,000 "cortical columns" in the brain (see above) has the whole machinery with grid cells and displacement cells, reference frames for gazillions of different objects and concepts, and so on.
A cortical column that gets input from the tip of the finger is storing information and making predictions about what the tip of the finger will feel as it moves around the coffee cup. A cortical column in the visual cortex is storing information and making predictions about what it will see in its model of the coffee cup. And so on. If you reach into a box, and touch it with four fingers, each of those fingers is trying to fit its own data into its own model to learn what the object is, and there's a "voting" mechanism that allows them to reach agreement on what it is.
So I guess if you're doing a math problem with a logarithm, and you're visually imagining the word "log" floating to the other side of the equation and turning into an "exp", then there's a cortical column in your visual cortex that "knows" (temporal sequence memory) how this particular mathematical transformation works. Maybe the other cortical columns don't "know" that that transformation is possible, but can find out the result via the voting mechanism.
Or maybe you're doing the same math problem, but instead of visualizing the transformation, instead you recite to yourself the poem: "Inverse of log is exp". Well, then this knowledge is encoded as the temporal sequence memory in some cortical column of your auditory cortex.
There's a homunculus-esque intuition that all these hundreds of thousands of models need to be brought together into one unified world model. Neuroscientists calls this the "sensor fusion" problem. Jeff denies the whole premise. Thousands of different incomplete world models, plus a voting mechanism, is all you need; there is no unified world model.
Is the separate world model for each cortical column an "Ingenious workaround for the limitations of biology" or a "Good idea that AI should copy"? On the one hand, clearly there's some map between the concepts in different cortical columns, so that voting can work. That suggests that we can improve on biology by having one unified world model, but with many different coordinate systems and types of sensory prediction associated with each entry. On the other hand, maybe the map between entries of different columns' world models is not a nice one-to-one map, but rather some fuzzy many-to-many map. Then unifying it into a single ontology might be fundamentally impossible (except trivially, as a disjoint union). I'm not sure. I guess I should look up how the voting mechanism is supposed to work.
Human-level AI, timelines, and existential risk
Jeff's goal is to "understand intelligence" and then use it to build intelligent machines. He is confident that this is possible, and that the machines can be dramatically smarter than humans (e.g. thinking faster, more memory, better at physics and math, etc.). Jeff thinks the hard part is done—he has the right framework for understanding cortical algorithms, even if there are still some details to be filled in. Thus, Jeff believes that, if he succeeds at proselytizing his understanding of brain algorithms to the AI community (which is why he was doing that podcast), then we should be able to make machines with human-like intelligence in less than 20 years.
Near the end of the podcast, Jeff emphatically denounced the idea of AI existential risk, or more generally that there was any reason to second-guess his mission of getting beyond-human-level intelligence as soon as possible. However, he appears to be profoundly misinformed about both what the arguments are for existential risk and who is making them. Ditto for Lex, the podcast host.
Differences between actual neurons and artifical neural networks (ANNs)
Non-proximal synapses and recognizing time-based patterns
He brought up his paper Why do neurons have thousands of synapses?. Neurons have anywhere from 5 to 30,000 synapses. There are two types. The synapses near the cell body (perhaps a few hundred) can cause the neuron to fire, and these are most similar to the connections in ANNs. The other 95% are way out on a dendrite (neuron branch), too far from the neuron body to make it fire, even if all 95% were activated at once! Instead, what happens is if you have 10-40 of these synapses that all activate at the same time and are all very close to each other on the dendrite, it creates a "dendritic spike" that goes to the cell body and raises the voltage a little bit, but not enough to make the cell fire. And then the voltage goes back down shortly thereafter. What good is that? If the neuron is triggered to fire (due to the first type of synapses, the ones near the cell body), and has already been prepared by a dendritic spike, then it fires slightly sooner, which matters because there are fast inhibitory processes, such that if a neuron fires slightly before its neighbors, it can prevent those neighbors from firing at all.
So, there are dozens to hundreds of different patterns that the neuron can recognize—one for each close-together group of synapses on a dendrite—each of which can cause a dendritic spike. This allows networks of neurons to do sophisticated temporal predictions, he says: "Real neurons in the brain are time-based prediction engines, and there's no concept of this at all" in ANNs; "I don't think you can build intelligence without them".
Another nice thing about this is that a neuron can learn a new pattern by forming a new cluster of synapses out on some dendrite, and it won't alter the neuron's other behavior—i.e., it's an OR gate, so when that particular pattern is not occurring, the neuron behaves exactly as before.
Binary weights, sparse representations
Another difference: "synapses are very unreliable"; you can't even assign one digit of precision to their connection strength. You have to think of it as almost binary. By contrast, I think most ANN weights are stored with at least ~2 and more often 7 decimal digits of precision.
Related to this, "the brain works on sparse patterns". He mentioned his paper How do neurons operate on sparse distributed representations? A mathematical theory of sparsity, neurons and active dendrites. He came back to this a couple times. Apparently in the brain, at any given moment, ~2% of neurons are firing. So imagine a little subpopulation of 10,000 neurons, and you're trying to represent something with a population code of sets of 200 of these neurons. First, there's an enormous space of possibilities (). Second, if you pick two random sets-of-200, their overlap is almost always just a few. Even if you pick millions of sets, there won't be any pair that significantly overlaps. Therefore a neuron can "listen" for, say, 15 of the 200 neurons comprising X, and if those 15 all fire at once, that must have been X. The low overlap between different sets also gives the system robustness, for example to neuron death. Based on these ideas, they recently published this paper advocating for sparseness in image classifier networks, which sounds to me like they're reinventing neural network pruning, but maybe it's slightly different, or at least better motivated.
Learning and synaptogenesis
According to Jeff, the brain does not learn by changing the strength of synapses, but rather by forming new synapses (synaptogenesis). Synaptogenesis takes about an hour. How does short-term memory work faster than that? There's something called "silent synapses", which are synapses that don't release neurotransmitters. Jeff's (unproven) theory is that short-term memory entails the conversion of silent synapses into active synapses, and that this occurs near-instantaneously.
Vision processing
His most recent paper has this image of image processing in the visual cortex:
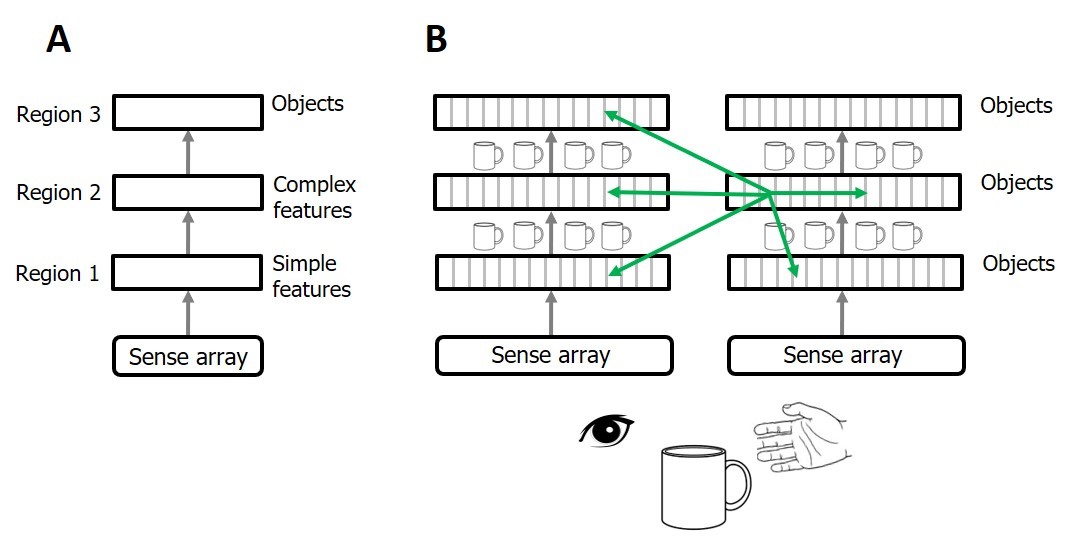
As I understand it, the idea is that every part of the field of view is trying to fit what it's looking at into its own world model. In other words, when you look at a cup, you shouldn't be thinking that the left, center, and right parts of the field-of-view are combined together and then the whole thing is recognized as a coffee cup, but rather that the left part of the field-of-view figures out that it's looking at the left side of the coffee cup, the center part of the field-of-view figures out that it's looking at the center of the coffee cup, and the right part of the field-of-view figures out that it's looking at the right side of the coffee cup. This process is facilitated by information exchange between different parts of the field-of-view, as well as integrating the information that a single cortical column sees over time as the eye or coffee cup moves. As evidence, they note that there are loads of connections in the visual cortex that are non-hierarchical (green arrows). Meanwhile, the different visual areas (V1, V2, etc.) are supposed to operate on different spatial scales, such that a faraway cup of coffee (taking up a tiny section of your field-of-view) might be recognized mainly in V1, while a close-up cup of coffee (taking up a larger chunk of your field-of-view) might be recognized mainly in V4, or something like that.
Maybe this has some profound implications for building CNN image classifiers, but I haven't figured out what exactly they would be, other than "Maybe try putting in a bunch of recurrent, non-hierarchical, and/or feedback connections?"
My conclusions for AGI safety
Jeff's proud pursuit of superintelligence-as-fast-as-possible is a nice reminder that, despite the mainstreaming of AGI safety over the past few years, there's still a lot more advocacy and outreach work to be done. Again, I'm concerned not so much about the fact that he disagrees with arguments for AGI existential risks, but rather that he (apparently) has never even heard the arguments for AGI existential risks, at least not from any source capable of explaining them correctly.
As for paths and timelines: I'm not in a great position to judge whether Jeff is on the right track, and there are way too many people who claim to understand the secrets of the brain for me to put a lot of weight on any one of them being profoundly correct. Still, I was pretty impressed, and I'm updating slightly in favor of neuromorphic AGI happening soon, particularly because of his claim that the whole neocortex is more-or-less cytoarchitecturally uniform.
Finally, maybe the most useful thing I got out of this is fleshing out my thinking about what an AGI's world model might look like.
Jeff is proposing that our human brain's world models are ridiculously profligate in the number of primitive entries included. Our world models don't just have one entry for "shirt", but rather separate entries for wet shirt, folded shirt, shirt-on-ironing-board, shirt-on-floor, shirt-on-our-body, shirt-on-someone-else's-body, etc. etc. etc. After all, each of those things is associated with a different suite of sensory predictions! In fact, it's even more profligate than that: Really, there might be an entry for "shirt on the floor, as it feels to the center part of my left insole when I step on it", and an entry for "my yellow T-shirt on the floor, as it appears to the rod cells in my right eye's upper peripheral vision". Likewise, instead of one entry for the word "shirt", there are thousands of them in the various columns of the auditory cortex (for the spoken word), and thousands more in the columns of the visual cortex (for the written word). To the extent that there's any generic abstract concept of "shirt" in the human brain, it would probably be some meta-level web of learned connections and associations and transformations between all these different entries.
If we build an AI which, like the human brain, has literally trillions of primitive elements in its world model, it seems hopeless to try to peer inside and interpret what it's thinking. But maybe it's not so bad? Let's say some part of cortical column #127360 has 2000 active neurons at some moment. We can break that down into 10 simultaneous active concepts (implemented as sparse population codes of 200 neurons each), and then for each of those 10, we can look back at the record of what was going on the first time that code ever appeared. We can look at the connections between that code and columns of the language center, and write down all those words. We can look at the connections between that code and columns of the visual cortex, and display all those images. Probably we can figure out more-or-less what that code is referring to, right? But it might take 1000 person-years to interpret one second of thought by a human-brain-like AGI! (...Unless we have access to an army of AI helpers, says the disembodied voice of Paul Christiano....) Also, some entries of the world model might be just plain illegible despite our best efforts, e.g. the various neural codes active in Ed Witten's brain when he thinks about theoretical physics.
24 comments
Comments sorted by top scores.
comment by moridinamael · 2019-07-15T20:16:13.431Z · LW(p) · GW(p)
Thanks for writing this up, it helps to read somebody else's take on this interview.
My thought after listening to this talk is that it's even worse ("worse" from an AI Risk perspective) than Hawkins implies because the brain relies on one or more weird kludges that we could probably easily improve upon once we figured out what those kludges are doing and why they work.
For example, let's say we figured out that some particular portion of a brain structure or some aspect of a cortical column is doing what we recognize as Kalman filtering, uncertainty quantification, or even just correlation. Once we recognize that, we can potentially write our next AIs so that they just do that explicitly instead of needing to laboriously simulate those procedures using huge numbers of artificial neurons.
I have no idea what to make of this quote from Hawkins, which jumped to me when I was listening and which you also pulled out:
"Real neurons in the brain are time-based prediction engines, and there's no concept of this at all" in ANNs; "I don't think you can build intelligence without them".
We've had neural network architectures with a time component for many many years. It's extremely common. We actually have very sophisticated versions of them that intrinsically incorporate concepts like short-term memory. I wonder if he somehow doesn't know this, or if he just misspoke, or if I'm misunderstanding what he means.
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-07-16T00:24:48.850Z · LW(p) · GW(p)
We've had neural network architectures with a time component for many many years. It's extremely common. We actually have very sophisticated versions of them that intrinsically incorporate concepts like short-term memory. I wonder if he somehow doesn't know this, or if he just misspoke, or if I'm misunderstanding what he means.
I assume you're talking about LSTMs and similar. I think you are misunderstanding what he means. I assumed he was referring to this:
If the neuron is triggered to fire (due to the first type of synapses, the ones near the cell body), and has already been prepared by a dendritic spike, then it fires slightly sooner, which matters because there are fast inhibitory processes, such that if a neuron fires slightly before its neighbors, it can prevent those neighbors from firing at all.
In other words, the analogy here might not be LSTMs, but a multithreaded program where race conditions are critical to its operation :(
EDIT: Maybe not, actually; I missed this part: "This allows networks of neurons to do sophisticated temporal predictions". My new guess is that he's referring to predictive processing. I assume self-supervised learning is the analogous concept in ML.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-07-16T15:24:05.116Z · LW(p) · GW(p)
Hmm, it's true that a traditional RNN can't imitate the detailed mechanism, but I think it can imitate the overall functionality. (But probably in a computationally inefficient way—multiple time-steps and multiple nodes.) I'm not 100% sure.
comment by John_Maxwell (John_Maxwell_IV) · 2019-07-16T00:19:03.677Z · LW(p) · GW(p)
Is the separate world model for each cortical column an "Ingenious workaround for the limitations of biology" or a "Good idea that AI should copy"?
In machine learning, one technique for training an ensemble is to give each model in your ensemble a different subset of the features you have available. (Well known as a component of one of the most successful ML algorithms.) So I think it already has been copied. BTW, results from different models in an ensemble are usually combined using a voting mechanism.
Re: sparseness--"sparse representation theory" is apparently a thing, and it looks really cool. At some point I want to take this course on EdX.
Near the end of the podcast, Jeff emphatically denounced the idea of AI existential risk, or more generally that there was any reason to second-guess his mission of getting beyond-human-level intelligence as soon as possible. However, he appears to be profoundly misinformed about both what the arguments are for existential risk and who is making them—almost as if he learned about the topic by reading Steven Pinker or something. Ditto for Lex, the podcast host.
Maybe we can get an AI safety person to appear on the podcast.
Jeff is proposing that our human brain's world models are ridiculously profligate in the number of primitive entries included. Our world models don't just have one entry for "shirt", but rather separate entries for wet shirt, folded shirt, shirt-on-ironing-board, shirt-on-floor, shirt-on-our-body, shirt-on-someone-else's-body, etc. etc. etc.
Shower thought: If the absent-minded professor stereotype is true, maybe it's because the professor's brain has repurposed so much storage space that these kind of "irrelevant" details are now being abstracted away. This could explain why learning more stuff doesn't typically cause you to forget things you already know: You are forgetting stuff, it's just irrelevant minutiae.
We can break that down into 10 simultaneous active concepts (implemented as sparse population codes of 200 neurons each)
Maybe thoughts which appear out of nowhere are the neurological equivalent of collisions in a bloom filter.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2019-07-16T12:35:31.407Z · LW(p) · GW(p)
Interesting, thanks!
Thinking of the cortical columns as models in an ensemble... Have ML people tried ensemble models with tens of thousands of models? If so, are they substantially better than using only a few dozen? If they aren't, then why does the brain need so many?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-07-16T15:16:07.365Z · LW(p) · GW(p)
According to A Recipe for Training NNs, model ensembles stop being helpful at ~5 models. But that's when they all have the same inputs and outputs. The more brain-like thing is to have lots of models whose inputs comprise various different subsets of both the inputs and the other models' outputs.
...But then, you don't really call it an "ensemble", you call it a "bigger more complicated neural architecture", right? I mean, I can take a deep NN and call it "six different models, where the output of model #1 is the input of model #2 etc.", but no one in ML would say that, they would call it a single six-layer model...
comment by Connor Leahy (NPCollapse) · 2019-08-07T15:42:24.898Z · LW(p) · GW(p)
Great writeup, thanks!
To add to whether or not kludge and heuristics are part of the theory, I've asked the Numenta people in a few AMAs about their work, and they've made clear they are working solely on the neocortex (and the thalamus), but the neocortex isn't the only thing in the brain. It seems clear that the kludge we know from the brain is still present, just maybe not in the neocortex. Limbic or other areas could implement kludge style shortcuts which could bias what the more uniform neocortex learns or outputs. Given my current state of knowledge of neuroscience, the most likely interpretation of this kind of research is that the neocortex is a kind of large unsupervised world model that is connected to all kinds of other hardcoded, RL or other systems, which all in concert produce human behavior. It might be similar to Schmidhuber's RNNAI idea, where a RL agent learns to use an unsupervised "blob" of compute to achieve its goals. Something like this is probably happening in the brain since, at least as far as Numenta's theories go, there is no reinforcement learning going on in the neocortex, which seems to contradict how humans work overall.
comment by Hazard · 2020-06-17T19:37:49.385Z · LW(p) · GW(p)
Great post!
Example #4: Logarithms. Jeff thinks we have a reference frame for everything! Every word, every idea, every concept, everything you know has its own reference frame, in at least one of your cortical columns and probably thousands of them. Then displacement cells can encode the mathematical transformations of logarithms, and the relations between logarithms and other concepts, or something like that. I tried to sketch out an example of what he might be getting at in the next section below. Still, I found that his discussion of abstract cognition was a bit sketchier and more confusing than other things he talked about. My impression is that this is an aspect of the theory that he's still working on.
George Lakoff's whole shtick is this! He's a linguist, so he frames it in terms of metaphors; "abstract concepts are understood via metaphors to concrete spatial/sensory/movement domains". His book "Where Mathematics Comes From" is a in depth exploration of trying to show how various mathematical concepts ground out in mashups of physical metaphors.
Jeff's ideas seem like they would be the neurological backing to Lakoff's more conceptual analysis. Very cool connection!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-06-17T19:52:43.226Z · LW(p) · GW(p)
Ooh, sounds interesting, thanks for the tip!
Hofstadter also has a thing maybe like that when he talks about "analogical reasoning".
Replies from: Hazardcomment by Douglas_Knight · 2019-08-10T20:21:28.071Z · LW(p) · GW(p)
How does this compare to what he was saying in 2004? Has he changed his mind about the brain or about AI? Maybe these things about the brain are foundational and we shouldn't expect him to change his mind, but surely his beliefs about AI should have changed.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-08-11T00:53:06.146Z · LW(p) · GW(p)
I did actually read his 2004 book (after writing this post), and as far as I can tell, he doesn't really seem to have changed his mind about anything, except details like "What exactly is the function of 5th-layer cortical neurons?" etc.
In particular, his 2004 book gave the impression that artificial neural nets would not appreciably improve except by becoming more brain-like. I think most neutral observers would say that we've had 15 years of astounding progress while stealing hardly any ideas from the brain, so maybe understanding the brain isn't required. Well, he doesn't seem to accept that argument. He still thinks the path forward is brain-inspired. I guess his argument would be that today's artifical NN's are neat but they don't have the kind of intelligence that counts, i.e. the type of understanding and world-model creation that the neocortex does, and that they won't get that kind of intelligence except by stealing ideas from the neocortex. Something like that...
comment by linkhyrule5 · 2019-08-17T00:29:02.806Z · LW(p) · GW(p)
I'd like to point out that technically speaking, basically all neural nets are running the exact same code: "take one giant matrix, multiply it by your input vector; run an elementwise function on the result vector; pass it to the next stage that does the exact same thing." So part 1 shouldn't surprise us too much; what learns and adapts and is specialized in a neural net isn't the overall architecture or logic, but just the actual individual weights and whatnot.
Well, it *does* tell us that we might be overthinking things somewhat -- that there might be One True Architecture for basically every task, instead of using LSTM's for video and CNNs for individual pictures and so on and so forth -- but it's not something that I can't see adding up to normality pretty easily.
comment by George3d6 · 2020-12-12T07:08:41.591Z · LW(p) · GW(p)
Oh God, a few quick points:
- Require some proof of knowledge of the people you pay attention to. At least academic success, but ideally market success. This guy has been peddling his ideas for over 10 years with no results or buy in.
- His conception of the ML field is distorted, in that for his points to stand one has to ignore the last 10-20 years of RNN R&D.
- Even assuming he made a more sophisticated point, there's hardly any reason to believe brain designs are the pinecle of efficiency, indeed they likely aren't, but building digital circuits or quantum computers via evolution might require too much slack.
↑ comment by ESRogs · 2020-12-13T07:17:51.379Z · LW(p) · GW(p)
Oh God, a few quick points:
I don't like this way of beginning comments. Just make your substantive criticism without the expression of exasperation.
(I'm having a little trouble putting into words exactly why this bothers me. Is it wrong to feel exasperated? No. Is it wrong to express it? No. But this particular way of expressing it feels impolite and uncharitable to me.
I think saying, "I think this is wrong, and I'm frustrated that people make this kind of mistake", or something like that, would be okay -- you're expressing your frustration, and you're owning it.
But squeezing that all into just, "Oh God" feels too flippant and dismissive. It feels like saying, "O geez, I can't believe you've written something so dumb. Let me correct you..." which is just not how I want us to talk to each other on this forum.)
Replies from: George3d6↑ comment by George3d6 · 2020-12-13T11:41:31.322Z · LW(p) · GW(p)
Yeah, bad choice of words in hindsight, especially since I was criticizing the subject of the article, not necessarily its contents.
But now there's 2 comments which are in part reacting to the way my comment opens up, so by editing it I'd be confusing any further reader of this discussion if ever there was one.
So I think it's the lesser of two evils to leave it as is.
↑ comment by Steven Byrnes (steve2152) · 2020-12-12T21:13:20.979Z · LW(p) · GW(p)
Require some proof of knowledge of the people you pay attention to. At least academic success, but ideally market success.
Sure, I mean, that's not a bad idea for people who won't or can't use their judgment to sort good ideas from bad, but I don't think that applies to me in this case. I mean, it's not like Jeff Hawkins is a fringe crackpot or anything, I think his papers get at least as many citations as your average university neuroscience professor, and I think his book was pretty influential and well-regarded, and he interacts regularly with university neuroscientists who seem to take his ideas seriously and aren't ashamed to be interacting with him, etc. I certainly don't take his ideas as gospel truth! And I never did. In this post I tried to relay some of his ideas without endorsing them. If I were writing this article today (18 months later), I would have and express a lot more opinions, including negative ones.
His conception of the ML field is distorted
Strong agree. He doesn't really know any ML, and seems to struggle with other algorithms too. He's one of the people who say "Intelligence is obviously impossible unless we faithfully copy the brain, duh", which I don't agree with.
I do think there's an argument that more neocortex-like algorithms in general, and the knowledge gained from scientists studying the neocortex in particular, will turn out to be very relevant to eventual AGI development, even moreso than, say, GPT-3. I myself made that argument here [LW · GW]. But it's a complicated and uncertain argument, especially since deep neural nets can interface with pretty much any other data structure and algorithm and people still call it a success for deep neural nets. ("Oh, causal models are important? OK, let's put causal models into PyTorch...")
That said, I don't think his sequence memory thing is quite like an RNN. You should really read Dileep George's papers about sequence memory rather than Jeff Hawkins's, if you have an ML background and don't care about dendritic spikes and whatnot. Dileep George calls the algorithm "cloned hidden Markov model", and seems to get nice results. He can train it either by MAP (maximum a posteriori) or by SGD. I don't know if it's won any benchmarks or anything, but it's a perfectly respectable and practical algorithm that is different from RNNs, as far as I can tell.
there's hardly any reason to believe brain designs are the pinecle of efficiency, indeed they likely aren't
I think one can make an argument (and again I did here [LW · GW]) that certain aspects of brain designs are AGI-relevant, but it has to be argued, not assumed from some a priori outside-view, like Jeff Hawkins does. I certainly don't expect our future AGIs to have firing neurons, but I do think (>50%) that they will involve components that resemble some higher-level aspects of brain algorithms, either by direct bio-inspiration or by converging to the same good ideas.
Replies from: George3d6↑ comment by George3d6 · 2020-12-13T06:37:25.021Z · LW(p) · GW(p)
I don't particularly disagree with anything you said here, my reaction was more related towards the subject of the article than the article itself.
Well, I deeply disagree with the idea of using reason to judge the worth of an idea, I think as a rule of thumb that's irrational, but that's not really relevant.
Anyway, HMMs are something I was unaware on, I just skimmed the george d paper and it looks interesting, the only problem is that it's compared with what I'd call a "2 generations" old lang model in the form of char RNN.
I'd actually be curious in trying to replicate those experiments and use the occasion to bench against some aiayn models. I'll do my own digging beforehand, but since you're familiar with this area it seems, any clue if there's some follow-up work to this that I should be focusing on instead ?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-13T10:51:27.880Z · LW(p) · GW(p)
I strongly suspect that cloned hidden Markov model is going to do worse in any benchmark where there's a big randomly-ordered set of training / tasting data, which I think is typical for ML benchmarks. I think its strength is online learning and adapting in a time-varying environment (which of course brains need to do), e.g. using this variant. Even if you find such a benchmark, I still wouldn't be surprised if it lost to DNNs. Actually I would be surprised if you found any benchmark where it won.
I take (some) brain-like algorithms seriously for reasons that are not "these algorithms are proving themselves super useful today". Vicarious's robots might change that, but that's not guaranteed. Instead there's a different story which is "we know that reverse-engineered high-level brain algorithms, if sufficiently understood, can do everything humans do, including inventing new technology etc. So finding a piece of that puzzle can be important because we expect the assembled puzzle to be important, not because the piece by itself is super useful."
Replies from: George3d6↑ comment by George3d6 · 2020-12-13T11:38:35.355Z · LW(p) · GW(p)
The point of benchmarking something is not to see if it's "better" necessarily, but to see how much worst it is.
For example, a properly tuned FCNN will almost always beat a gradient booster at a mid-sized (say < 100,000 features once you bucketize your numbers, since a GB will require that, and OHE your categories and < 100,000 samples) problem.
But gradient boosting has many other advantages around time, stability, ease of tuning, efficient ways of fitting on both CPUs and GPUs, more tradeoffs flexibility between compute and memory usage, metrics for feature importance, potentially faster inference time logic and potentially easier to train online (though both are arguable and kind of besides the point, they aren't the main advantages).
So really, as long as benchmark tell me a gradient booster is usually just 2-5% worst than a finely tuned FCNN on this imaginary set of "mid-sized" tasks, I'd jump at the option to never use FCNNs here again, even if the benchmarks came up seemingly "against" them.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-13T12:19:54.187Z · LW(p) · GW(p)
Interesting!
I guess I should add: an example I'm slightly more familiar with is anomaly detection in time-series data. Numenta developed the "HTM" brain-inspired anomaly detection algorithm (actually Dileep George did all the work back when he worked at Numenta, I've heard). Then I think they licensed it into a system for industrial anomaly detection ("the machine sounds different now, something may be wrong"), but it was a modular system, so you could switch out the core algorithm, and it turned out that HTM wasn't doing better than the other options. This is a vague recollection, I could be wrong in any or all details. Numenta also made an anomaly detection benchmark related to this, but I just googled it and found this criticism. I dunno.
comment by Raemon · 2020-12-13T05:39:49.229Z · LW(p) · GW(p)
This post has an interesting position of "I feel like I got a lot out of it, and that it has impacted my overall view on AGI", but... when I try to articulate why, exactly, I don't think I could. I don't actually even remember most of Hawkin's theory (mostly I just remember "every part of the neocortex is running the same algorithm.")
I feel okay about being the first person to nominate it, but probably would like the second nominator to be someone who actually understood it and thought it was important.
This post does seem useful simply as distillation work, whether or not the ideas here are actually central to AGI.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-13T10:56:41.202Z · LW(p) · GW(p)
I decline. Thanks though.