Big picture of phasic dopamine
post by Steven Byrnes (steve2152) · 2021-06-08T13:07:43.192Z · LW · GW · 22 commentsContents
Summary / Table of Contents Backstory: Dopamine and TD learning on computers and in animals Reward Prediction Errors (RPEs), and Temporal Difference (TD) learning The Schultz dopamine experiments Some wrinkles in the story The cortico-basal ganglia-thalamo-cortical loop The loop The telencephalon: simpler than it looks, and full of loops Cortex-like part of the loops Striatum-like part of the loops Pallidum-like part of the loops Telencephalic “learning-from-scratch-ism” Telencephalic uniformity? Nah, let’s call it “family resemblance” Toy loop model “Context” in the striatum value function Three categories of dopamine signals Overview: why heterogeneous dopamine? Dopamine category #1: RPE for “Success-In-Life Reward” Dopamine category #2: RPE for “local” sub-circuit rewards Example 2A: Birds teaching themselves to sing by RL Example 2B: Animals teaching themselves to move smoothly and efficiently by RL Example 2C: Visual attention Dopamine category #3: Supervised Learning (SL) error signals Finally, the “prediction” part of reward prediction error Zooming back out: lessons for Artificial General Intelligence (AGI) safety None 22 comments
(Update Jan. 2023: This article has important errors. I am leaving it as-is in case people want to see the historical trail of me gradually making progress. Most of the content here is revised and better-explained in my later post series Intro to Brain-Like AGI Safety [? · GW], see especially Posts 5 [AF · GW] and 6 [AF · GW]. Anyway, I still think that this post has lots of big kernels of truth, and that my updates since writing it have mostly been centered around how that big picture is implemented in neuroanatomy. More detail in this comment [LW(p) · GW(p)].)
Target audience: Everyone, particularly (1) people in ML/AI, and (2) people in neuroscience. I tried hard to avoid jargon and prerequisites. You can skip the parts that you find obvious.
Context: I’m trying to make sense of dopamine in the brain—and decision-making and motivation more generally. This post is me playing with ideas; expect errors and omissions (and then tell me about them!).
This post is a bit long; I’m worried no one will read it. So in a shameless attempt to draw you in, here’s a Drake meme...

(Thanks Adam Marblestone, Trenton Bricken, Beren Millidge, Connor Leahy, Jeroen Verharen, Ben Smith, Adam Shimi, and Jessica Mollick for helpful suggestions and criticisms.)
Summary / Table of Contents
- I’ll start by briefly reviewing the famous 1990s story relating the role of dopamine in the brain to the “TD learning” algorithm.
- Then I’ll switch over to the “cortico-basal ganglia-thalamo-cortical loop” (“loop” for short), a circuit intimately related to dopamine learning and inference.
- I’ll go over a theory that the entire telencephalon region of the brain (which includes neocortex, hippocampus, amygdala, basal ganglia, and more) has a coherent overall architecture, with these loops being the key unifying element, and I’ll relate that idea to some bigger-picture ideas about within-lifetime learning vs instinctive behaviors.
- I’ll offer a toy model of how the loops work.
- I’ll suggest that there are three more specific categories of what these loops are doing in the brain, with different dopamine signals in each case:
- Reinforcement learning loops, where the “reward function” is the thing we all expect (yummy food is good, electric shocks are bad, etc.);
- Reinforcement learning loops, but with a different “reward function”, one narrowly tailored to a particular subsystem;
- Supervised learning loops, for example to train some loop in the amygdala to fire whenever it’s an appropriate time to flinch.
- Then I’ll suggest that the way we get from “reward” to “reward prediction error” (as needed in the learning algorithm) is via one of those supervised learning loops, tasked with predicting the upcoming reward. And in particular (following Randall O’Reilly’s “PVLV” model) I’ll suggest that in fact no part of the brain is doing TD learning after all!
- Finally—and inevitably, given my job—at the end I’ll discuss some takeaways for the Artificial General Intelligence Control Problem.
Backstory: Dopamine and TD learning on computers and in animals
Reward Prediction Errors (RPEs), and Temporal Difference (TD) learning
If you haven’t read The Alignment Problem by Brian Christian, then you should. Great book! I’ll wait.
…Welcome back! As you now know (if you didn’t already), Temporal Difference (TD) learning (wiki) is a reinforcement learning algorithm invented by Richard Sutton in the 1980s. Let’s say you’re playing a game with a reward. As you go through, you keep track of a value function, a.k.a. “expected sum of future rewards”. (I’m ignoring time-discounting for simplicity.)
How do you know the expected future reward? After all, predictions are hard. So you start with a random function or constant function or whatever as your value function, and update it from experience to make it more and more accurate. For example, maybe you seem to be in a very bad chess position, with the queen exposed in the center of the board. Then you make a move, and then your opponent makes a move, and then all of the sudden you’re in a very very good position! Well, hmm, maybe your old position, with the exposed queen, wasn’t quite as bad as you thought!! So next time you’re in a similar situation, you’ll be a bit more optimistic about things—i.e., you now assign that position a higher value.
That’s an example of a positive reward prediction error (RPE). The general formula for RPE in TD learning is:
Reward Prediction Error = RPE = [(Reward just now) + (Value now)] – (Previous value)
...and this RPE is used to update the previous value.
So that’s TD learning. If you keep iterating, the value function converges to the desired “value = time-integral of expected future rewards”.
The Schultz dopamine experiments
Now in the 1980s-90s, Wolfram Schultz did some experiments on monkeys, while measuring the activity of dopamine neurons in the midbrain.
I’ll pause here to help the non-neuroscientists follow along. In the midbrain (part of the brainstem) are two neighboring regions called “VTA” and “SNc”. In these regions you find the inputs and cell bodies (dendrites and somas) of almost all the dopamine-emitting neurons in the brain. These neurons’ axons (output lines) then generally exit the midbrain and go off to various distant regions of the brain, and that’s where they dump their dopamine.
Anyway, Schultz found (among other things) three intriguing results:
- When he gave the monkeys yummy juice at an unexpected time, there was a burst of dopamine.
- After he trained the monkeys to expect yummy juice right after a light flash, there was a burst of dopamine at the light, and not at the juice.
- When he then presented the light but surprisingly omitted the expected juice, there was negative dopamine release (compared to baseline) at the time when there normally would have been juice.
Peter Dayan and Read Montegue saw the connection: All three of these results are perfectly consistent with dopamine being the RPE signal of a TD learning algorithm! This became a celebrated and widely-cited 1997 paper, and a cornerstone of much neuroscience research since.
Oh, one more terminology side note:
- “Phasic dopamine” vs “Tonic dopamine”: The dopamine signal has some steady (slowly-varying) level, and it also has periodic divergences up or down from that level. “Tonic” is the former, “Phasic” is the latter. The reward prediction error (RPE)-like signal is generally found in phasic dopamine. The role of tonic dopamine remains (even) more controversial than phasic. For my part, I don’t think tonic and phasic are that different—I’m rather fond of the very simple idea that tonic is more-or-less a rolling average of phasic—but I’m not sure, and that’s a whole separate can of worms. In this post I’m only going to talk about phasic dopamine. Well, I’ll also talk about a subset of dopamine neurons that have weird patterns of current, such that I’m not sure they even have a phasic / tonic distinction.
Some wrinkles in the story
There are a number of wrinkles suggesting that there’s more to the story than simple TD learning:
- While the dopamine signals agree with the TD learning predictions in Wolfram Schultz’s experiments above, there are lots of other situations where the dopamine neurons are doing something different from what TD would do. For example, in the light-then-juice experiment, before training there's dopamine at the juice, and after training there's dopamine at the light but not at the juice. What about during training? Well if this were TD learning, dopamine-at-the-light should go up in perfect synchrony with dopamine-at-the-juice going down to baseline. But in experiments, they’re not synchronized; the former happens faster than the latter. This is just one example; more are in Mollick et al. 2020.
- I talked about “phasic dopamine” as a monolithic thing, but really there are lots of dopamine neurons, and they are not a homogeneous group! My impression is that there’s a big subset of these neurons whose signaling seems to match RPE, but there are also various subpopulations that seem to be doing other things. There even seem to be some dopamine neurons that fire at aversive experiences! (ref)
- TD learning is a learning algorithm (hence the name!), but dopamine seems to be related to motivation as well as learning—for example, “after forebrain dopamine depletion, animals will cease to actively search for food (and eventually starve to death), but they will still consume food when it is placed in their mouth” (ref). What's the deal with that?
To make sense of these facts, and much more, let’s dive deeper into how the brain is built and what different parts are doing!
The cortico-basal ganglia-thalamo-cortical loop
The loop
Dopamine is closely related to a circuit called the cortico-basal ganglia-thalamo-cortical loop. I’ll just call it “loop” for short.
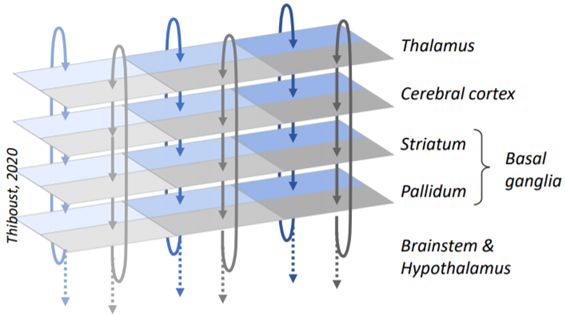
A classic 1986 paper found that a bunch of brain circuitry consists of these loops, running in parallel, following a path from cortex to basal ganglia (striatum then pallidum) to thalamus and then back to where it started. (If you’re not familiar with the neuroanatomy terms here, that’s fine, I’ll get back to them.)
(Side note to appease the basal ganglia nerds: This loop is real, and it’s important, but I’m leaving out various other branches and supporting circuitry needed to make it work—see the frankly terrifying Fig. 6 here. I’ll get back to that below, but basically this simplified picture of the loop will be good enough to get us through this post.)
What are these loops doing? That’s going to be a big theme of this blog post. I’ll get back to it.
Where are these loops? All over the telencephalon. And what is the telencephalon? Read on:
The telencephalon: simpler than it looks, and full of loops
The telencephalon (aka “cerebrum”) is one of ~5 major divisions of the brain, differentiating itself from the rest of the brain just a few weeks into human embryonic development. The telencephalon is especially important in “smart” animals, comprising 87% of total brain volume in humans (ref), 79% in chimps (ref), 77% in certain parrots, 51% in chickens, 45% in crocodiles, and just 22% in frogs (ref). The human telencephalon consists of the neocortex (“the home of human intelligence”, more-or-less), some non-“neo” cortex areas like the hippocampus (classified as “allocortex”, more on which below), as well as the basal ganglia, the amygdala, and various more obscure bits and bobs. It seems at first glance that “telencephalon” is just a big grab-bag of miscellaneous brain parts—i.e., a category that only embryologists have any reason to care about. At least, that was my working assumption. ...Until now!
It turns out, when people peered into the telencephalon, they found a unifying structure hidden beneath! The breakthrough, as far as I can tell, was Swanson 2000. I learned about it mainly from the excellent book The Evolution of Memory Systems by Murray, Wise, Graham. (Or see this shorter paper by the same authors with the relevant bit.)
It turns out that there’s a remarkable level of commonality across these superficially-different structures. The amygdala is actually a bunch of different substructures, some of which look like cortex, and others that look like striatum. There’s a thing called the “lateral septum” whose neurons and connectivity are such that it looks like “the striatum of the hippocampus”. And practically everything is organized into those neat parallel loops through cortex-like, striatum-like, and pallidum-like layers!
Cortex-like part of the loops | Hippo- | Amygdala [basolateral part] | Piriform cortex | Ventromedial prefrontal cortex | Motor & “planning” cortex |
|---|---|---|---|---|---|
Striatum-like part of the loops | Lateral septum | Amygdala [central part] | Olfactory tubercle | Ventral striatum | Dorsal striatum |
Pallidum-like part of the loops | Medial septum | Substantia innominata | Ventral pallidum | Globus pallidus |
The entire telencephalon—neocortex, hippocampus, amygdala, everything—can be divided into cortex-like structures, striatum-like structures, and pallidum-like structures. If two structures are in the same column in this table, that means they’re wired together into cortico-basal ganglia-thalamo-cortical loops. This table is incomplete and oversimplified; for a better version see Fig. 4 here.
So many loops! Loops all over the place! Are all those different loops doing the same type of calculation? Let’s take that as a hypothesis to explore, and see how far we get. (Preview: I’m actually going to argue that the loops are not all doing the exact same calculation, but that they’re similar—variations on a theme.)
Telencephalic “learning-from-scratch-ism”
I’ve previously written (here [LW · GW]) about, um, let’s call it, “neocortical learning-from-scratch-ism”. That’s the idea that the neocortex starts out totally useless to the organism—outputting fitness-improving signals no more often than chance—until it starts learning things. In particular, if this idea is right, then all adaptive neonatal behavior is driven by other parts of the brain, especially the brainstem and hypothalamus. That idea doesn't sound so crazy after you learn that the brainstem has its own whole parallel sensory-processing system (in the midbrain), and its own motor-control system, and so on. (Example: apparently the mouse has a brainstem bird-detecting circuit wired directly to a brainstem running-away circuit.) In that previous article [LW · GW] I called this idea “blank slate neocortex”, which in retrospect was probably an unnecessarily confusing and clickbaity terminology. Here’s a pair of alternate framings that maybe makes the idea seem a bit less wild:
- How you should think about learning-from-scratch-ism (if you’re an ML reader): Think of a deep neural net initialized with random weights. Its neural architecture might be simple or might be incredibly complicated, it doesn't matter. And it certainly has an inductive bias that makes it learn certain types of patterns more easily than other types of patterns. But it still has to learn them! If its weights are initially random, then it's initially useless, and gets gradually more useful with training data. The idea here is that the neocortex is likewise “initialized from random weights” (or something equivalent).
- How you should think about learning-from-scratch-ism (if you’re a neuroscience reader): Think of a memory-related system, like the hippocampus. The ability to form memories is a very helpful ability for an organism to have! …But it ain’t helpful at birth!! You need to accumulate memories before you can use them! My proposal is that the neocortex is in the same category—a kind of memory module. It’s a very special kind of memory module, one which can learn and remember a super-complex web of interconnected patterns, and which comes with powerful querying features, and which can even query itself in recurrent loops, and so on. But still, it’s a form of memory, and hence starts out useless, and gets progressively more useful to the organism as it accumulates learned content.
OK, so I’ve already been a “neocortical learning-from-scratch-ist” since, like, last year. And from what little I know about the hippocampus, I think of it as a thing that stores memories (whether temporarily or permanently, I’m not sure), so I’ve always been a “hippocampal learning-from-scratch-ist” too. The striatum is another part of the telencephalon, and as soon as I started reading and thinking about its functional role (see below), I felt like it’s probably also a learning-from-scratch component.
...I seem to be sensing a pattern here...
Oh what the hell. Maybe I should be a learning-from-scratch-ist about the whole frigging telencephalon. So again, that would be the claim that the whole telencephalon starts out totally useless to the organism—outputting fitness-improving signals no more often than chance—until it starts learning things within the animal’s lifetime.
Incidentally, I’m also a cerebellum learning-from-scratch-ist (see my post here [AF · GW]). So I guess I would propose that as much as 96% of the human brain by volume is “learning from scratch”—pretty much everything but the hypothalamus and brainstem. Sounds like a pretty radical claim, right? ...Until you think, ‘Hang on, isn't the information capacity of the brain like 10,000× larger than the information content of the genome? So maybe that’s not a radical claim! Maybe I should be saying to myself, "Only 96%??"
Anyway, I haven’t dug (much) into the evidence for or against telencephalic learning-from-scratch-ism, and I'm not sure what other thinkers think. But I’m taking it as a working assumption—a hypothesis to explore.
...And I’m already finding it a very fruitful hypothesis! In particular, I was not previously thinking about the amygdala in a learning-from-scratch-ism framework. And then when I tried, everything kinda clicked into place immediately! Well, at least, compared to how confused I was before. I’ll discuss that below.
Telencephalic uniformity? Nah, let’s call it “family resemblance”
So that was learning-from-scratch-ism. Separately, I’ve also previously written about “neocortical uniformity” (e.g. here [LW · GW], here [LW · GW])—the hypothesis that every part of the neocortex is more-or-less running the same learning-and-inference algorithm in parallel. To be clear, if this idea is correct at all, then it definitely comes with two big caveats: (1) the learning algorithm has different “hyperparameters” in different places, and (2) the neocortex is seeded with an innate gross wiring diagram that brings together different information streams that have learnable and biologically-important relationships (ML people can think of it as loosely analogous to a neural architecture).
So anyway, if “neocortical uniformity” is the idea that every part of the neocortex is running a more-or-less similar learning algorithm, then I guess “telencephalic uniformity” would say that not only the whole neocortex but also the hippocampus, the cortex-ish part of the amygdala, etc. are doing that same algorithm too. And likewise that all the striatum-like stuff is running a "common striatal algorithm", and so on.
Do I believe that? To a first approximation:
- I will not say the word “uniformity”. It’s much too strong. In particular, neocortex tissue has more neuron-layers than does allocortex, and I’m inclined to guess that those extra layers are supporting different and richer ways to interconnect the different entries in the memory. Or something.
- I do expect that the different types of cortex have at least something in common. Variations on a theme, say.
- No comment on how uniform the striatum layer is, or the pallium layer. I haven’t looked into it.
Instead of “uniformity” for the cortex layer, maybe I’ll go with “family resemblance”. They are, after all, literally family. Like, we mammals have that 6-layer-neocortex-vs-3-layer-allocortex distinction I mentioned, but our ancestors probably just had uniform allocortex architecture everywhere (and most modern reptiles still do) (ref). (Birds independently evolved a different modification of the allocortex, with a functionally-similar end result, I think.)
(Fun fact: The “basolateral complex” of the amygdala is apparently neither allocortex nor neocortex per se, but rather a bottom layer of neocortex that peeled off from the rest! Not sure whether it's just detached spatially while still being wired up as a traditional layer 6B, or whether its current wiring is now wholly unrelated to its historical roots, or what. The claustrum is also in this category, incidentally. See Swanson 1998 & 2000.)
Toy loop model
Finally, let’s get back to the cortico-basal ganglia-thalamo-cortical loop. What is it for? Here’s the toy model currently in my head. It has two parts, inference (what to do right now) and learning (editing the connections so that future inference steps give better answers). Here they are:
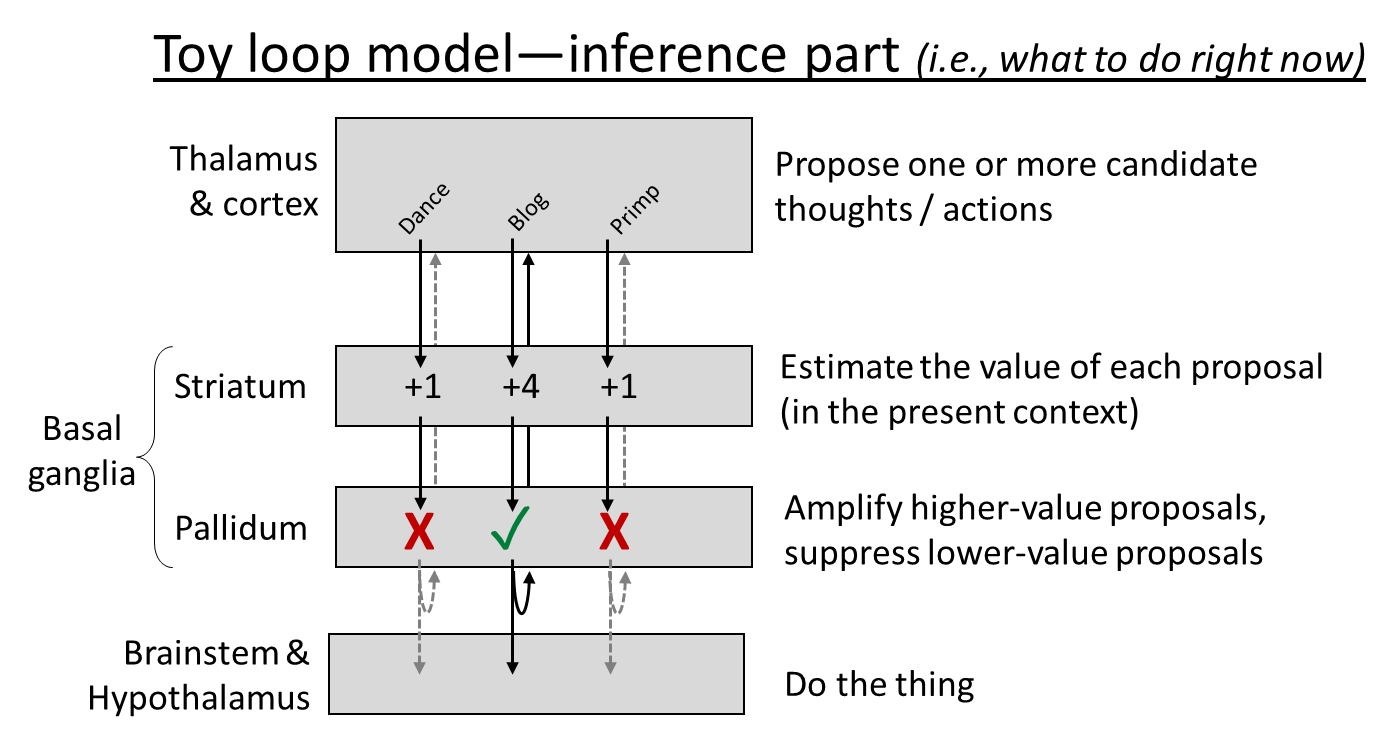
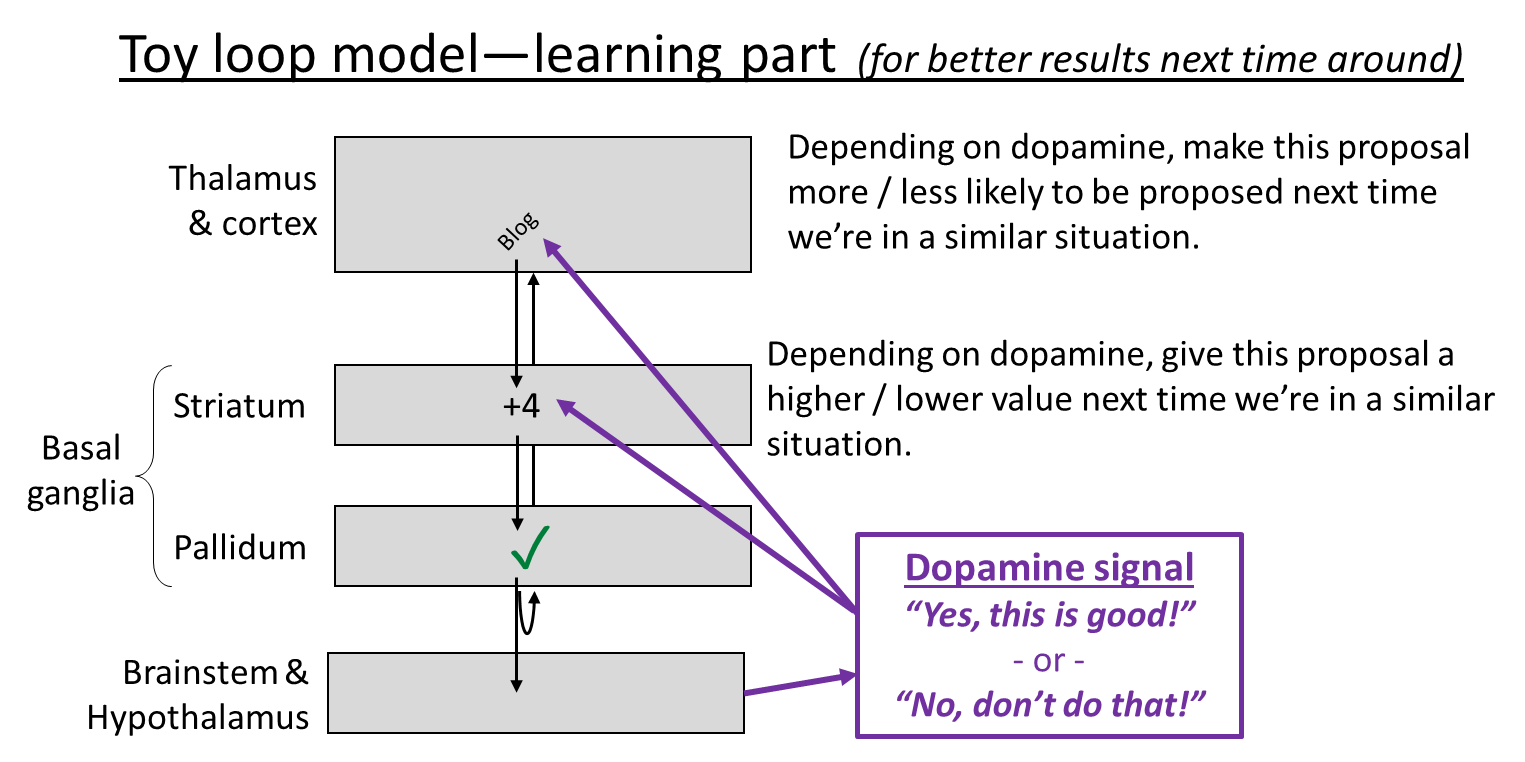
I make no pretense to originality here, and this model is obviously oversimplified, but it’s serving me well so far. So, print these pictures out, tattoo them on your eyelids, whatever, because I’ll be going back to these over and over for the rest of this blog post.
Here is some discussion and nuances to go along with the toy loop model:
- Consistent with the experimental data, I put dopamine-induced learning into both the cortex and the striatum. Why should the algorithm work that way? Here’s an example. Let’s say you’re walking past an alleyway, and it occurs to you “Oh hey, there’s a new ice cream shop down that alleyway!” This is a very very good thought! Cha-ching, dopamine! And specifically…
- Dopamine-in-the-cortex edits the within-cortex connections such that next time you see the alley, the thought of the ice cream shop is more likely to immediately pop into your head. Basically, your cortex starts to learn the sequence “see the alley and then think about the ice cream shop” just like it learned the sequence “twinkle twinkle little star”.
- Dopamine-in-the-striatum edits the cortex-to-striatum connections such that, next time the cortex starts activating that thought about the ice cream shop (in a similar context as now), that thought will be amplified, and hence will be likelier to fight its way up to conscious awareness.
- (Isn’t that redundant? Well, yes, it is kinda redundant! I suspect that there are lots of boring technical reasons that the algorithm works better when both of these mechanisms are active, rather than just one of them. But in terms of the really big picture, I think we should lump these two mechanisms together, and say they’re two ways of doing the same thing.)
- For ML people: dopamine-in-the-cortex is kinda like policy learning, and dopamine-in-the-striatum is kinda like value function learning, I think.
- I’m using “dopamine” as a shorthand here, as there are also non-dopamine neurons mixed in with the dopamine neurons, going along the same paths. Without having looked into it, my default assumption is that this is a boring implementation detail—that they’re all communicating similar information, and that on the receiving side, different circuits are designed to work with different neurotransmitters.
- The third layer of the diagram, “pallidum”, is of course not to be confused with “pallium”, which is more-or-less a term for cortex in non-mammals—so “pallium” would be the top layer of the diagram. You could go nuts, right?
- Speaking of pallidum, I labeled it as “Amplify higher-value proposals, suppress lower-value proposals.” I do think the algorithm may really be that simple, but the brain implementation absolutely is not!—it involves a bunch of different pathways and cross-connections between the loops, to keep the activations balanced and normalized and whatnot. I’m pretty hazy on how this works in detail; I guess this is related to the “direct & indirect pathways through the basal ganglia”. Here’s a friendly video introduction.
- I didn’t draw it in, but the loop circuit has direct connections from each of the top three layers to the bottom layer. (Swanson 2000 says the cortex-to-bottom connection is “excitatory”, the striatum-to-bottom connection is “inhibitory”, and the pallidum-to-bottom connection is “disinhibitory”.) Again, I don’t think this is important from a high-level algorithm perspective, it’s just an implementation detail. (This is one of many reasons that those crazy brain wiring diagrams are so crazy.)
- To be clear, this diagram is not all the learning algorithms in this part of the brain, just the learning algorithm specifically related to these loops. There are other learning algorithms too, in particular predictive learning within the cortex & thalamus, which I won't talk about here.
- By the same token, there’s a lot more complexity in the inference algorithm than this loop part I’m talking about here, because the cortex’s job (“propose one or more candidate thoughts / actions”) can (and does) involve a very complicated within-cortex proposal-discovery algorithm, which is outside the scope of this post.
- I put dopamine into the learning diagram but not the inference diagram. But really I think it plays an important role on the inference side too, even if I didn’t draw it. See figure below. That part is why (if I understand correctly) blocking dopamine receptors produces immediate motivational effects in laboratory experiments; it doesn’t only impact long-term learning.

“Context” in the striatum value function
The “value function” calculated by the striatum is not as simple as a database with one entry for each possible thing to do. Among other things, it’s bound to be context-dependent. Singing in the shower is good, singing in the library is bad.
Here’s a real example. In Fee & Goldberg 2011, they studied zebra finches learning to sing their song (it’s a lovely song by the way, here’s a video). I have to pause here to warn that bird papers are annoying because practically every part of the bird telencephalon has a different name from the corresponding part of the mammal telencephalon. Anyway, if you look at Figure 4B, “HVC” (some part of the cortex) is providing high-level context—what song am I singing and how far along am I in that song? Meanwhile “LMAN” (a different part of the cortex) seems to be lower-level: if I understand correctly, it holds a catalog of sounds that the bird knows how to make, and how to make them. Then we have the enigmatically-named “Area X”, which is part of the striatum. This HVC signal is widely broadcasting its context signal into Area X, while meanwhile LMAN is making narrow, topographic connections to Area X, which then loop back to the exact same part of LMAN. Thus the bird can learn that making a certain sound is high-value in some specific part of the song, but low-value in a different part of the song.
This context idea is reflected in the relative sizes of different parts of the basal ganglia:
One of the remarkable features of [basal ganglia] organization is the massive convergence at every level from cortex to [striatum neurons] to pallidal neurons, and to thalamic neurons that project back to cortex…. In rats, roughly three million [striatum neurons] converge onto only 30,000 pallidal output neurons and subsequently onto a similar number of thalamic neurons .... In humans, a similarly massive convergence from >100 million [striatum neurons] to <50,000 pallidal neurons is reported…. In the context of our model, the reason for this convergence becomes apparent. If the role of Area X [=striatum] is to bias the variable activity of LMAN [=low-level motor cortex] neurons, then the feedback from DLM [=pallidum] to LMAN requires only as many channels as LMAN contains. In contrast, [striatum neurons] in Area X evaluate the performance of each LMAN channel separately at each moment in the song, which requires many more neurons. (Fee & Goldberg 2011)

Three categories of dopamine signals
Overview: why heterogeneous dopamine?
You’ll note that my toy loop model above avoids the term “reward”. It’s too specific. Go back and look at the diagram with an open mind. What is the dopamine signal signaling? Here’s the most general pattern:
A positive phasic dopamine signal tells a cortico-basal ganglia-thalamo-cortical loop to be more active next time we’re in a similar situation. A negative phasic dopamine signal tells a loop to be less active next time we’re in a similar situation.
My proposal is that this pattern is valid for all loops, but nevertheless different parts of the telencephalon use different dopamine signals to do different things. Remember, as I mentioned above, we already know that there isn’t just one dopamine signal.
I currently see three categories of (phasic) dopamine signals. I’ll list them here, then go through them one-by-one in the next subsections: (1) Reward Prediction Error (RPE) for what I’ll call the Success-In-Life Reward, the classic kind of “reward” that we intuitively think about, i.e. an approximation of how well the organism is maximizing its inclusive genetic fitness; (2) RPE for local rewards specific to certain circuits—e.g. negative dopamine specifically to motor output brain areas when a motor action is poorly executed; (3) supervised learning error signals—e.g. if you get whacked in the head, then there’s a hardcoded circuit that says “you should have flinched”, and that signal can train a loop that specifically triggers a flinch reaction.
Analogy: You did a multiple-choice test, and then later the teacher hands it back:
- If the only thing the teacher wrote on it was a grade at the top (“B+ overall”), that’s like category #1, Success-In-Life Reward.
- If the teacher gives grades for one or more sub-sections (“B- on the first page of questions, A- on the second page of questions...”), that’s like category #2, local rewards to sub-circuits.
- If the teacher tells you what any of the correct answers were (“You circled (B) on question #72, but the right answer was (D)”) then that’s like category #3, supervised learning.
My discussion here will be a bit in the tradition of (and inspired by) Marblestone, Wayne, Kording 2016, in the sense that I’m arguing that part of the brain is running a learning algorithm, with different training signals used in different areas. The big difference is that I want to focus on the dopamine signals, whereas they focused on acetylcholine signals. (I think acetylcholine mainly controls learning rate [LW · GW], so it’s not directly a training signal.) Also, as mentioned above, I’m not telling the whole “different training signals in different places” story in this post; the other part of that story is predictive (a.k.a. self-supervised) learning, in which different parts of the cortex are trained to predict different things. But that learning algorithm is not related to the loops, and it’s not related to dopamine, and it’s outside the scope of this post. (It’s related to how the cortex “selects proposals”.)
Dopamine category #1: RPE for “Success-In-Life Reward”
Start with the classic, stereotypical kind of reward, the reward that says “pain is bad” and “social approval is good” and so on. By and large, this reward should be some kind of heuristic approximation to the time-derivative of the organism’s inclusive genetic fitness. I’ll call it “Success-In-Life Reward”, to distinguish it from other reward functions that we’ll discuss in the next section.
Where does that reward signal come from? My short answer is: the hypothalamus and brainstem calculate it, on the basis of things like pain inputs (bad!), sweet taste inputs (good!), hunger inputs (bad!), and probably hundreds of other things. Boy, I would give anything for the complete exact formula for Success-In-Life Reward! Like, it’s not literally “The Meaning Of Life”, but it might be the closest thing that neuroscience can get us. I’ll get back to this later.
You said “Reward Prediction Error” (RPE); where do the “predictions” come from? Hold that thought, we’re not ready to answer it yet, but I’ll get back to it in a later section.
Why is this particular reward function useful? Because parts of the telencephalon are “deciding what to do” in a general way. Should you go out in the rain or stay inside? Should you eat the cheese now or save it for later? If the animal is to learn to make systematically good decisions of this type, then we need the decisions to be made by a learning algorithm trained to maximize “Success-In-Life Reward”. So I especially expect this reward function to be used for parts of the brain making high-level decisions involving cross-domain tradeoffs.
Those areas include, I think, at least some parts of “granular prefrontal cortex” (don’t worry if you don’t know what that means) and the hippocampus. These areas are both making decisions involving cross-domain tradeoffs. Like in humans, the former is the place that “decides” to bring to consciousness the idea “I’m gonna roast some vegetables!” (out of all possible ideas that could have been brought to consciousness instead). And the hippocampus is the place that “decides” to bring to consciousness the idea “I’m gonna turn right at the fork to go to the farmstand!” (out of all possible navigation-related ideas that could have been brought to consciousness instead). Something like that, maybe, for example.
Dopamine category #2: RPE for “local” sub-circuit rewards
Think about the Millenium Falcon, with Han Solo in the gun turret while Chewbacca is up front piloting. Chewbacca’s steering could be perfect while Han’s aim is terrible, or vice-versa. If they have to share a single training signal, then the signal will be noisier for each of them—for example, sometimes Han will do a bad job, but still get a high score because Chewy did unusually well, and then Han will internalize that wrong message. This isn’t necessarily the end of the world—I imagine that, if you do it right, the noise will average away, and they’ll eventually learn the right thing—but the learning process may be slower. So I figure that if it’s possible to allocate credit and blame for performance variation between Han and Chewy, they would probably learn faster.
By the same token, your own body is a lumbering contraption controlled by thousands of dials and knobs in the brain, and different parts of your cortex are in control of different parts of this system. If the brain can allocate credit, and thus send different rewards to different areas, then I imagine that it will.
(Side note 1: I imagine that some ML readers are instinctively recoiling here: "Nooooo, The Bitter Lesson says that we'll get the best results by using end-to-end performance as the one and only input to our learning algorithm!" Well readers, if you want to think about animals, I think you'll need to put a bit more emphasis on "learning fast" and a bit less emphasis on “asymptotic performance”, compared to what you’re used to. After all, Pac-Man can keep learning after getting eaten, but an animal brain can't—well, not usually. So you gotta learn fast!)
(Side note 2: Backpropagation (and its more-biologically-plausible cousins) can allocate credit automatically. However, they require error gradients to do so. In supervised (or self-supervised) learning, that’s fine: we get an error gradient each query. But here we’re talking about reinforcement learning, where error gradients are harder to come by, as discussed in a later section.)
Example 2A: Birds teaching themselves to sing by RL
Here’s the clearest example I’ve seen in the literature:
For example, we recently identified song-related auditory error signals in dopaminergic neurons of the songbird ventral tegmental area (VTA).... We discovered that only a tiny fraction (<15%) of VTA dopamine neurons project to the vocal motor system - yet these were the ones that encoded vocal reinforcement signals. The majority of VTA neurons which project to other parts of the motor system did not encode any aspect of song or singing-related error. —Murdoch 2018 describing a result from Gadagkar 2016
Got that? Birds have an innate tendency to sing, and they learn to sing well by listening to themselves, and doing RL guided by whether the song “sounds right”, as judged by some other part of the brain (I suspect the tectum, in the brainstem). And those specific dopamine feedback signals, the ones that say whether the song sounds good, go only to the singing-related-motor-control part of the bird brain. Makes sense to me!
Example 2B: Animals teaching themselves to move smoothly and efficiently by RL
This is more speculative, but seems to me that it should be feasible for some part of the brain to send a higher “reward” to a motor control loop when motion is rapid and energy-efficient and low-strain, and a lower “reward” when it isn’t. So I would assume that the “reward” going to low-level motor control loops should narrowly reflect the muscle’s energy expenditure, speed, strain, or whatever other metrics are biologically relevant.
(Some of you might be thinking here: What a stupid idea! If the reward is really like that, then the low-level motor control loops will gradually learn to do nothing whatsoever. That’s extremely rapid and energy-efficient and low-strain! Well, again, I'm hiding a lot of complexity behind the "propose candidate actions" part of my toy loop model above. If I’m not mistaken, the within-cortex dynamics will ensure that if a lower-level motor sequence isn't compatible with advancing the currently-active higher-level plan, then it won't get proposed in the first place!)

What of the literature? Schultz 2019 cites evidence for heterogeneous dopamine that goes along with larger movements, but not concise, stereotyped movements. That fits my theory pretty well: concise, stereotyped movements are more likely to use exactly the expected amount of energy and speed (and hence produce no motor-loop RPEs), whereas larger movements are likely to have some idiosyncratic differences in energy & speed compared to expectations (and hence produce positive or negative motor-loop RPEs). Moreover, the movement-related dopamine is heterogeneous, which is expected if some muscles are using slightly more energy than typical while others are using slightly less. Then my hypothesis would be that these movement-associated dopamine signals go specifically to brain areas associated with low-level motor control, but I haven’t yet found literature either for or against that.
Example 2C: Visual attention
Recently I wrote a post Is RL involved in sensory processing? [LW · GW], and was pretty weirded out when an astute reader told me that there was a non-frontal-lobe region of neocortex that had complete loops—namely inferotemporal cortex (IT) (ref). I was weirded out because I was thinking of the cortico-basal ganglia loops as part of an algorithm for choosing among multiple viable options—like what action to take, or what thought to think. Those choices tend to be made in the frontal lobe. IT, by contrast, is the home of visual object recognition, which I would think should not be a “choice”: Whatever the object is, that’s the right answer! So it seems like it calls for predictive (self-supervised) learning, not the loop algorithm.
Then I came across another weird thing! When the IT loops hit the striatum, that region is called “tail of the caudate”, and it’s one of the five regions flagged in a recent paper as an “aversion hot spot in the dopamine system”—i.e., it has elevated dopamine after bad things happen (when we traditionally expect low dopamine). The other four “aversion hot spot” regions, incidentally, are exactly the regions that I’ll talk about in the next section (dopamine for supervised learning of autonomic reactions), so that makes sense. But the IT loops need a different explanation.
So here’s my theory: IT is helping “choose” what object to attend to, within the visual field. If there’s a lion ready to pounce, almost perfectly hidden in the grass, and IT directs attention in a way that makes the subtle form of the lion visible ... well, seeing the lion is highly scary and aversive, so the high-level planner gets negative dopamine. But IT did the right thing here! Cha-ching, dopamine for IT! This sets up a kinda adversarial dynamic—IT focuses on anything in the visual field that might be dangerous or exciting, as judged by a different part of the brain, and the latter in turn then gets to hone its judgment on lots of edge-cases. This quasi-adversarial dynamic is good and healthy, and I think consistent with lived experience.

Dopamine category #3: Supervised Learning (SL) error signals
The fundamental difference between supervised learning and reinforcement learning is that in supervised learning, there’s a ground truth about “what you should have done”, and in the latter, there’s a ground truth about how successful some action was, but no specific advice about how to make it better. (Or in ML terminology, SL gets a loss gradient from each query, while RL doesn’t.)
I talked about this previously in Supervised Learning of Outputs in the Brain [AF · GW]. I got some details wrong but I stand by the big picture I offered there. In particular, I think there are certain categories of telencephalon “outputs” for which the brainstem & hypothalamus can generate a “ground truth” after the fact about whether that output should have fired. For example, if you get whacked by a projectile, then your brainstem & hypothalamus can deduce that you should have flinched a moment earlier.
I think “outputs for which a ground truth error signal is available after the fact” include “autonomic outputs”, “neuroendocrine outputs”, and “neurosecretory outputs”, but not “neuromuscular outputs”. I’m quite unsure that I’m drawing the line in the right place here—in fact, I don’t know what half those terms mean—but for the purposes of this blog post I’ll just use the term “autonomic outputs” as a stand-in for this whole category.
While SL is different from RL, if you go back to the Toy Loop Model above, you’ll see that it works for both, with only minor modifications:
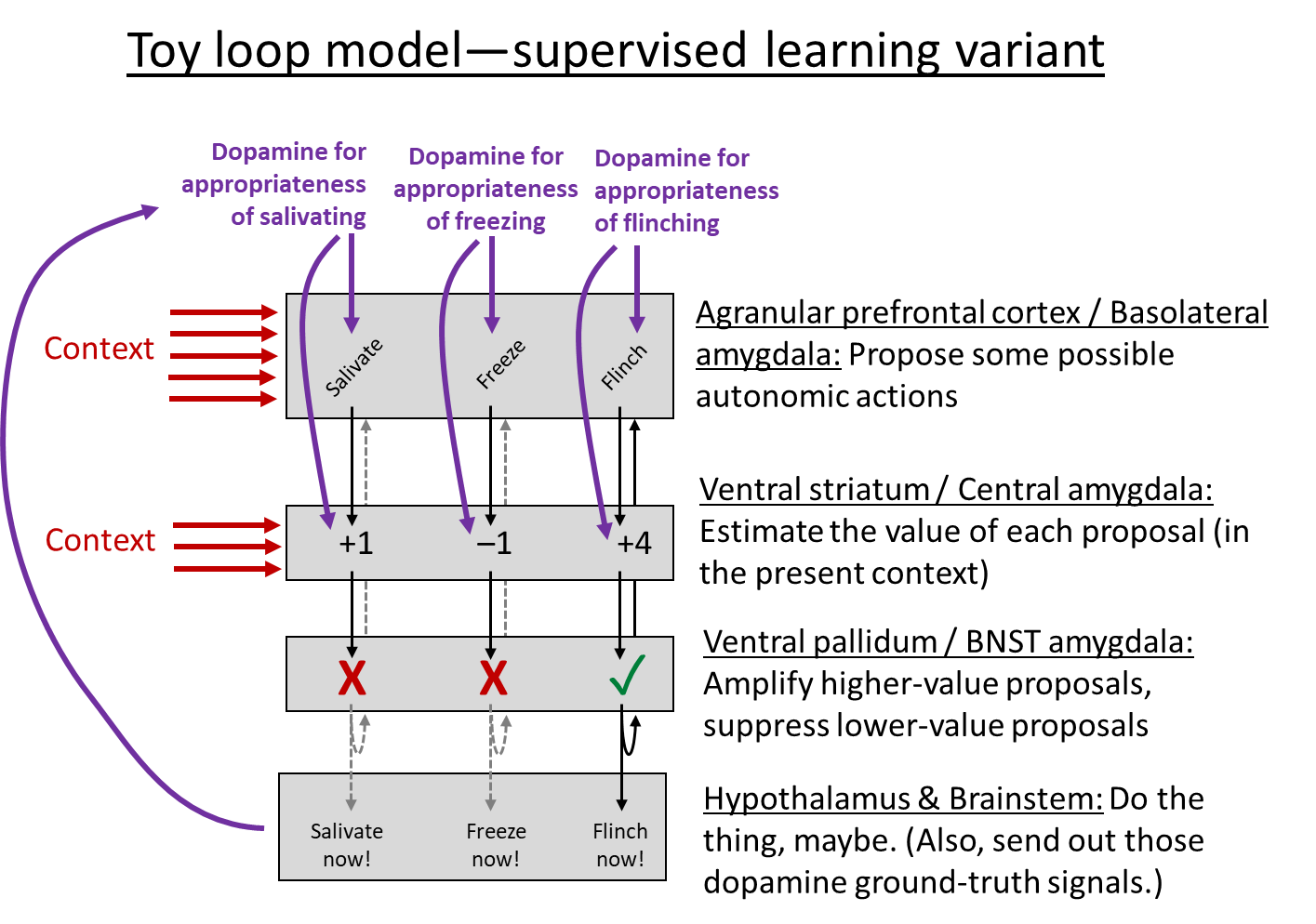
Some comments on this:
- Where are these SL loops? I think they're in two places in the telencephalon:
- Amygdala loops. As mentioned above, the amygdala has cortex-like parts and striatum-like parts. Then the pallidum-like part is the catchily-named “Bed Nuclei of the Stria Terminalis” (BNST), which is sometimes lumped into the so-called “extended amygdala”. I note that the amygdala is “neither a structural nor a functional unit”, and therefore I’m open to the possibility that supervised learning is really only happening in a subset of the amygdala, or that it spills out into neighboring structures, or whatever.
- Agranular prefrontal cortex + Ventral striatum loops. “Agranular” here means “missing layer 4 (out of the 6 neocortical layers)”. Layer 4 is the one that processes inputs, so “agranular cortex” is an output region (see here). This region of cortex is also called (roughly) “medial prefrontal cortex” or “ventromedial prefrontal cortex”, and also spills into cingulate and insular areas. (I admit I’m hazy on the anatomy here). Agranular prefrontal cortex is a universal component of mammalian brains, whereas granular prefrontal cortex is a primate innovation (Wise 2017).
- My sense right now is that these two regions are mostly or entirely overlapping in their suite of autonomic outputs, but I'm not sure—I’ll get back to that below.
- Neuron-level differences between SL loops & RL loops: I think there are some low-level learning rule changes you need to make to get from the RL version to the SL version. For example, if a loop was not recently active, but does get dopamine exposure, should it be more or less active in similar situations in the future? I think it’s “more” for SL, and “less” for RL. So presumably you need different dopamine receptors and plasticity mechanisms and whatnot.
- ...And there does indeed seem to be evidence for this!
- “[Dopamine] neurons in medial posterior VTA...selectively project to the [ventral striatum], medial prefrontal cortex..., and basolateral amygdala.... These “non-conventional” VTA [dopamine] neurons had no or only very little Ih [current] and also did not exhibit typical action potential waveforms and firing patterns.” (Lammel et al. 2014)
- ...So basically, there’s a subpopulation of dopamine neurons that tend to fire different types of signals than the rest of them, and this subpopulation is almost exactly those that go to the places I’m claiming are doing SL not RL. This is very encouraging! Maybe I’m on the right track!
- ...And there does indeed seem to be evidence for this!
- Architecture-level differences between SL & RL loops: In the SL case, we need probably many dozens of small “zones”, one for each innate autonomic reaction (recoiling, flinching, glaring, freezing, sweating, laughing, Duchenne-smiling, etc. etc.). And we need a corresponding number of different dopamine signals, each going into the corresponding zone.
- As for “different zones for different outputs”, I think that’s uncontroversial. In the amygdala case, see this creepy 1967 experiment stimulating the amygdalas of anesthetized cats. Different parts of the amygdala induced various actions including "sniffing reaction...reaction of alertness or attention...Strongly aggressive behavior or a defensive reaction...licking, swallowing...salivation, urination...turning the head to the side..." In the agranular prefrontal cortex case, see Wise 2017—electrically stimulating it leads to various actions including “[bristling]; pupillary dilation; and changes in blood pressure, respiratory rate, and heart rate”. In a different experiment, researchers fiddling with ventral striatum managed to induce vomiting, shivering, and ejaculation.
- As for “different dopamine signals for each different output zone”, well, I haven’t found particularly great evidence for or against this idea, at least not so far. But I did already mention the study listing five parts of the brain where researchers have found dopamine enhancement during aversive experiences. I already covered one of those five above (“Example 2C” section.) The other four send dopamine into more-or-less exactly the regions that I claim are doing SL (medial prefrontal cortex, ventral striatum, cortex-like amygdala, and striatum-like amygdala) . This makes sense because some of the autonomic reactions are appropriate for aversive experiences—like freezing, raising your heart rate, and so on. Other autonomic reactions are of course not appropriate at aversive experiences—like smiling and relaxing. But I don’t think that paper is claiming that those entire regions are getting extra dopamine at aversive experiences, just that there was enhanced dopamine activity somewhere in those regions.
- Here’s one thing my diagram leaves out: Mollick et al. 2020 suggests an “opponent processing” thing, which I guess looks like having both a “Flinch” loop and a “Don’t Flinch” loop side-by-side. This is more subtle than it sounds: almost every situation is a good time not to flinch, so how do you train the “Don’t Flinch” loop? Mollick suggests a neat little trick: the “Don’t Flinch” loop learning algorithm is turned off entirely unless the “Flinch” loop is active. So it’s really learning “Wait Actually Don’t Flinch Even Though There Might Seem To Be A Reason To Flinch”, which is specific enough to be learnable. I didn’t draw this opponent-process thing into my diagram above, partly because the diagram would be too crowded and hard to read, and partly because I’m a bit confused about some details of how it would fit in. Anyway, read Mollick for details. The opponent-processing thing is necessary to explain some aspects of animal experiments, like “rapid reacquisition” and “renewal”. From an algorithmic performance perspective, imagine learning “lions are scary” and then learning “lions in cages are not scary”. We want to be able to learn the latter without unlearning the former. And in an unfamiliar context, we want to still treat lions as scary by default.
- Here as elsewhere, “context” is just a big collection of whatever possibly-relevant signals exist anywhere in the brain. The algorithm then sifts through all those in search of any that are predictive, as discussed in my old post here [AF · GW]. I think that one contribution to the intimidating complexity of those brain flow diagram thingies is that the brain is pretty profligate in pulling in lots of random signals from all over the place, to use as context lines. (To be clear, there is also “context” in the RL version of the toy loop model above, I just left it out of my earlier diagram for simplicity.)
- As in the general toy loop model, having both the cortex and the striatum layer is a bit redundant in principle, but presumably helps the algorithm work better. In particular, I think that the existence of two layers of selection is somehow related to the fact that animals have “second-order conditioning” but very little “third-order conditioning” (ref).
- In the bottom layer of my diagram, I wrote “Do the thing, maybe”. What’s with the “maybe”? Well, the hypothalamus and brainstem are simultaneously getting suggestions for which autonomic reactions to execute from the amygdala, the agranular prefrontal cortex, and the hippocampus. Meanwhile, it’s also doing its own calculations related to sensory inputs (e.g. in the superior colliculus) and things like how hungry you are. It weighs all those things together and decides what to do, I presume using an innate (non-learned) algorithm.
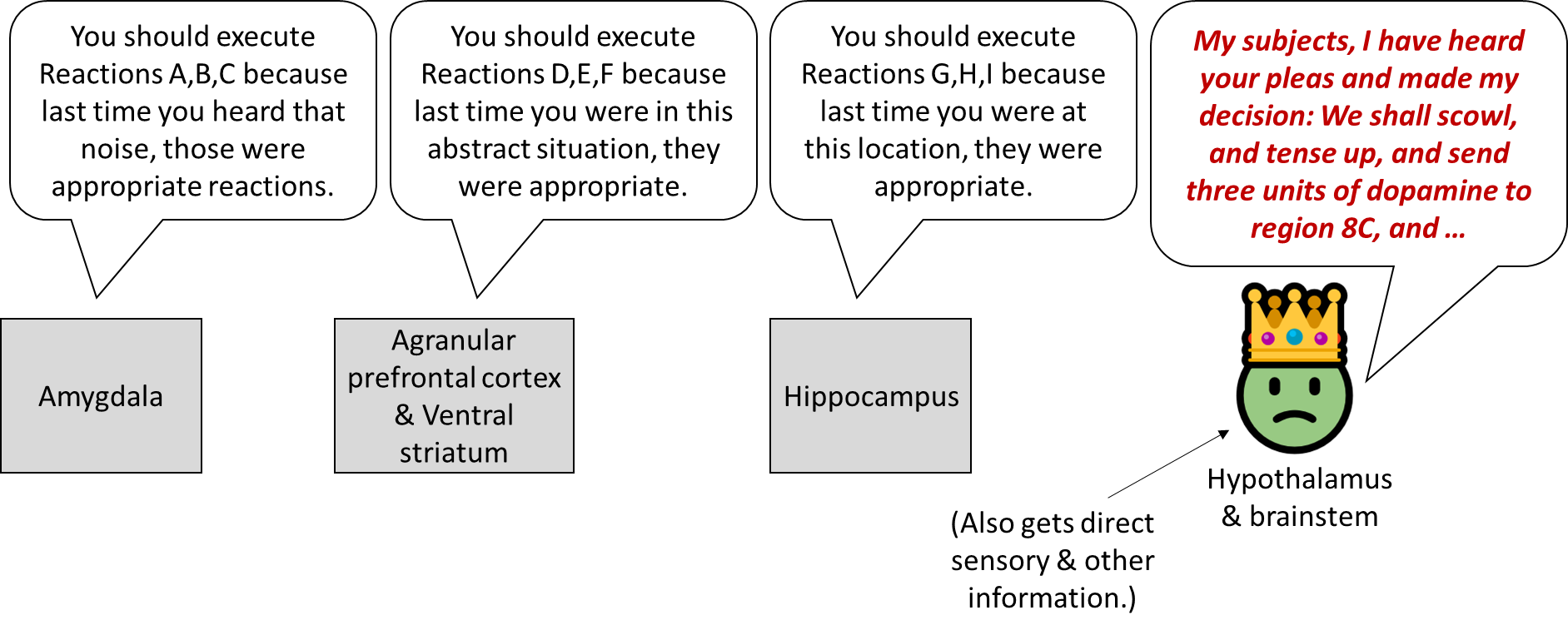
(The hippocampus is in that diagram, sending autonomic output suggestions to the hypothalamus, but I don’t think the hippocampus involves the kind of supervised learning loop that I’m discussing here. I think it uses a different mechanism—like, the hippocampus stores a bunch of locations, and each is tagged with the autonomic outputs that have previously happened at that location, and that’s what it suggests. So, basically, more like a lookup table.)
I admit I’m pretty hazy on the details here—like, if there’s an amygdala loop for releasing cortisol, and if there’s also an agranular prefrontal cortex loop for releasing cortisol, then how exactly are they related? I made a suggestion in my diagram above, but that might not be right, or might not be the whole story.
As an example of my confusion in this area, S.M., a person supposedly missing her whole amygdala and nothing else, seems to have more-or-less lost the ability to have (and to understand in others) negative emotions, but not positive emotions. But AFAICT the amygdala can trigger both positive- and negative-emotion-related autonomic outputs! Weird.
Finally, the “prediction” part of reward prediction error
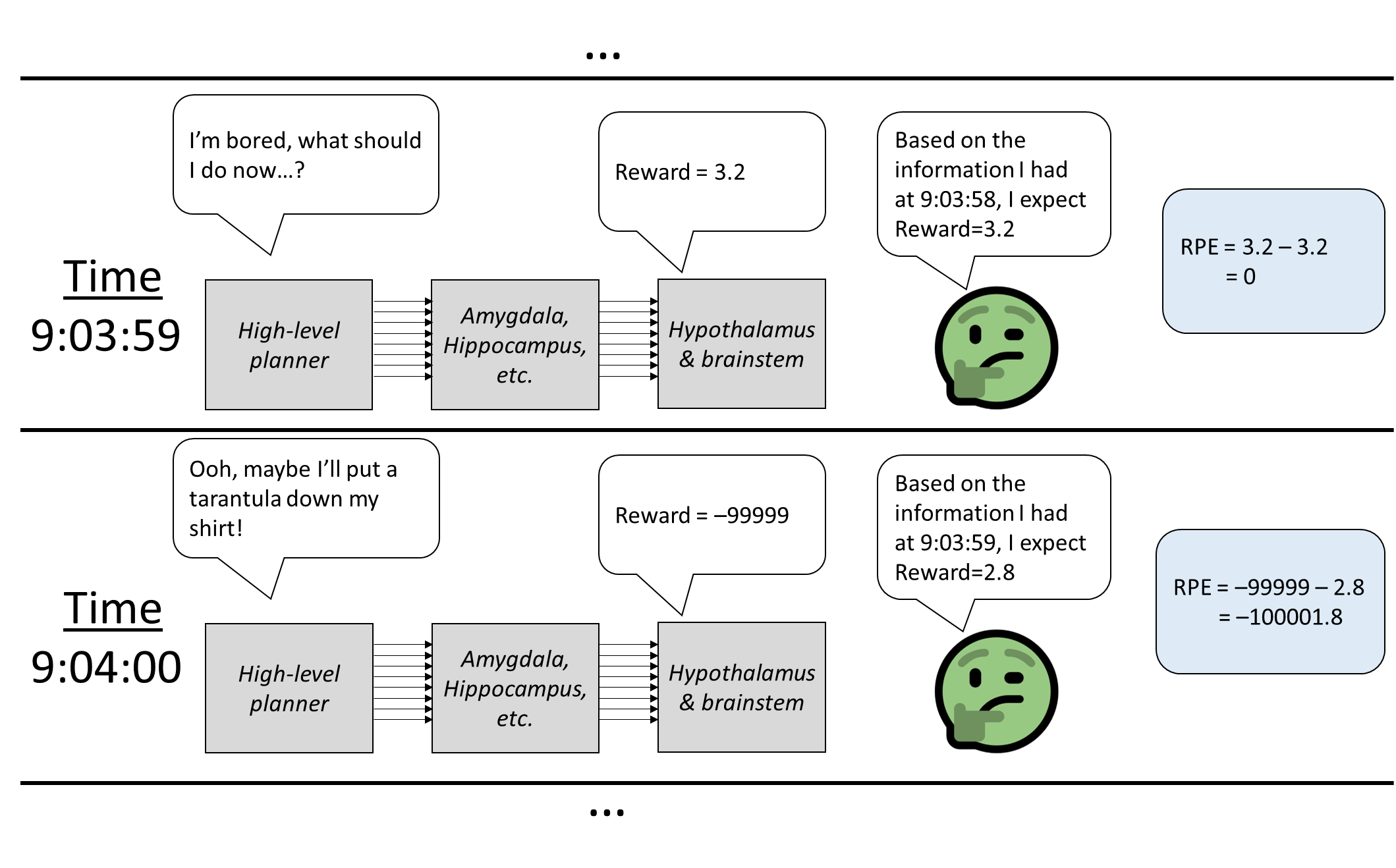
Now that we’ve covered the RL loops and the SL loops, we’re finally ready to tackle the reward prediction error! And it’s easy! See figure and caption. Some comments on that:
- Based on how this dopamine signal is generated, we can generally be pretty confident that the dopamine is signaling something good or bad that happened specifically in the previous 1 second (or whatever the reward forecast interval is). This is very useful information, because the dopamine-related learning rules can assign credit / blame for activity in that same interval.
- The “predictor” is a neocortex circuit, and I presume that we can build a reward-prediction model just as complex as anything else in our world-model. This is important because traditional step-by-step TD learning has a bunch of shortcomings involving, for example, rewards that arrive early (if the brain used traditional TD, then after getting an early reward, then there would be negative dopamine at the old reward time!), or rewards that arrive after variable intervals, or distractions between stimulus and reward, etc. (Further discussion) Animals don’t have those problems because they can build a better reward-prediction model, one involving persistent state variables, learned hierarchical sequences, time-dependence, and so on.
- There’s a recent set of experiments showing that dopamine neurons do something like “distributional reinforcement learning”. In my framework, we can explain those results by having a bunch of reward prediction loops, each with different supervised learning hyperparameters, such that the various loops span the range from “very optimistic reward prediction” to “unbiased reward prediction” to “very pessimistic reward prediction”. All these loops together give a reward prediction probability distribution, rather than just a point estimate. And these different prediction loops can then feed signals into different dopamine neurons. Honestly, I bet that every other supervised learning loop is set up that way too—e.g., that the amygdala answers the question “how appropriate would it be to freeze in terror right now?” with a bunch of loops sampling a probability distribution.
- My proposal here is heavily inspired by Randall O’Reilly & colleagues’ “PVLV” (pronounced “Pavlov”, hahaha) model (original version, most recent version). That said, I think my version wound up rather different, and I’m not sure whether they would endorse this. See supplement [LW · GW] for more discussion. My proposal also wound up reassuringly similar to a Steve Grossberg model, I think—again, see supplement [LW · GW].
- I think you can do this thing for any of the various "rewards" that the hypothalamus calculates—most famously the “Success-In-Life Reward” approximating the time-derivative of inclusive genetic fitness (Dopamine Category #1 above), but also potentially the sub-circuit rewards (Dopamine Category #2 above). Not sure that actually happens, but it's possible.
- Fun fact: Punishments create dopamine pauses even when they’re fully expected (ref). How does that happen? Easy: for example, maybe there’s a limit on how negative the reward prediction is allowed to go. Or maybe (as in Mollick) negative reward predictions get multiplied by a scale-factor, like 0.9 or whatever. More to the point, why does that happen? I figure, at the end of the day, negative dopamine means “No, don’t do that!”—as in my toy loop model. If things are bad enough—e.g. life-threatening—it’s plausibly always fitness-improving to treat the status quo plan as unacceptable, even in the face of growing evidence that the alternatives are even worse. After all, on the current trajectory, you know for sure that you’re doomed. Call it an “evolutionary prior” that “This just can’t be the best option; there’s gotta be something better!”, maybe.
- Side tangent: There’s an annoying paradox that: (1) In RL, there’s no “zero of reward”, you can uniformly add 99999999 to every reward signal and it makes no difference whatsoever; (2) In life, we have a strong intuition that experiences can be good, bad, or neutral; (3) ...Yet presumably what our brain is doing has something to do with RL! That “evolutionary prior” I just mentioned is maybe relevant to that? Not sure … food for thought ...
- While the system as a whole does a passable imitation of TD learning under many circumstances, no part of it is actually literally doing TD learning (!!!!!). The reward-prediction circuit here is operating on plain old supervised learning—i.e. outputting expected next-timestep reward, without any involvement of “expected future rewards”. (I’m following the PVLV model in rejecting TD learning in favor of something closer to the Rescorla-Wagner model.) If there’s no TD learning, then how on earth do we wind up with a time-integral of reward? Well, we basically don’t! Humans are absolute rubbish at calculating a time-integral of reward—see the Peak-End Rule! OK, so how do we weigh decisions that will involve both pleasant and unpleasant aspects at different times? The snarky answer is “poorly”. A better answer is: If “Going to the restaurant” involves both a scary drive and a yummy meal, then after a few times, entertaining the plan will activate both the “this will be scary” supervised learning loop and the “this will be yummy” supervised learning loop. Then the hypothalamus and brainstem can see both aspects and give an appropriate overall assessment. The best answer of all is: “This is a great question that deserves more discussion than I’m going to give here.” :-P
Zooming back out: lessons for Artificial General Intelligence (AGI) safety
Of course for me, everything is always ultimately about AGI safety, and so is this post. Let’s go back to “telencephalic learning-from-scratch-ism” above—and let’s gingerly set aside the possibility that that hypothesis is totally false….
Anyway, there’s a learning algorithm in our brain. It’s initialized from random weights (or something equivalent). It gets various input signals including sensory inputs, dopamine and other signals from the hypothalamus & brainstem system, and so on. You run the code for some number of years, and bam, that learning algorithm has built a competent, self-aware agent full of ideas, plans, goals, habits, and so on.
Now, sooner or later (no one knows when) we’ll learn to build “AGI”—by which I mean, for example, an AI system that could have written this entire blog post much better than me. And here’s one specific way we could get this kind of AGI: We could code up a learning algorithm similar to the one in the telencephalon, and give it the appropriate input signals, run it for some period of time, and there’s our AGI.
Why not?
- Maybe the telencephalon-like learning algorithm is too complicated for humans to figure out? Well, sure, maybe. I do certainly imagine that the “neural architecture” equivalent of the telencephalon is rather complicated—there may be as many as hundreds of little regions connected in a particular way, for example. But on the other hand, we have ever-improving neuroanatomy databases, and we have automated “neural architecture search” that can fill in any gaps by brute force trial-and-error. And we have experts all over the world digging into the exact operating principles of the learning algorithms in question.
- Maybe an appropriate training environment (sensory data etc.) is unavailable? I find that hard to believe. We can easily steep an AI system in human cultural artifacts (like books and movies) and give it lots of human interactions, if that were essential (which I don’t think it is anyway). Are you an “embodied cognition” advocate? Well, we can give the AI a robot body if we want, not to mention the ability to take various possible “virtual actions”.
- Maybe the algorithms in the other parts of the brain—especially the hypothalamus and brainstem—are too complicated for humans to figure out, but without those algorithms sending up the right dopamine and other signals, the telencephalon-like learning algorithm can't properly do its thing? Well, yes and no …
…I do think the innate hypothalamus-and-brainstem algorithm is kinda a big complicated mess, involving dozens or hundreds of things like snake-detector circuits, and curiosity, and various social instincts, and so on. And basically nobody in neuroscience, to my knowledge, is explicitly trying to reverse-engineer this algorithm. I wish they would! I would absolutely encourage neuroscientists to push it upwards on their research priority list. But the way things look right now, I'm pessimistic that we’ll have made much progress on that, at least not by the time we have telencephalon-like learning algorithms coded up and working better and better.
So then we’re at the scenario I wrote about in My AGI Threat Model: Misaligned Model-Based RL Agent [AF · GW]: we will know how to make a “human-level-capable” learning algorithm, but we won’t know how to send it reward and other signals that sculpt the learning algorithm into having human-like instincts and drives and goals. So researchers will mess around with different simple reward functions—as researchers are wont to do—and they’ll wind up training superhuman AGIs with radically nonhuman drives and goals, and they’ll have no reliable techniques to set, or change, or even know what the AGIs’ goals are. You can read that post [AF · GW]. I do not think that scenario will end well. I think it will end in catastrophe! The solution, I think, is to do focused research on what the reward function (and other signals) should be—perhaps modified from the human hypothalamus and brainstem algorithm, or else designed from scratch.
So what was the point of me writing this blog post? I wanted to better understand the telencephalon learning algorithm’s “API”. Like, what is the suite of input signals (other than sensory data) that guides this learning algorithm, and how do they work? I don’t have a complete answer yet—there are still plenty of brain connections where I don’t know what the heck they’re doing. But I think I’m making progress! And this post in particular (and work leading up to it) constitutes a noticeable change:
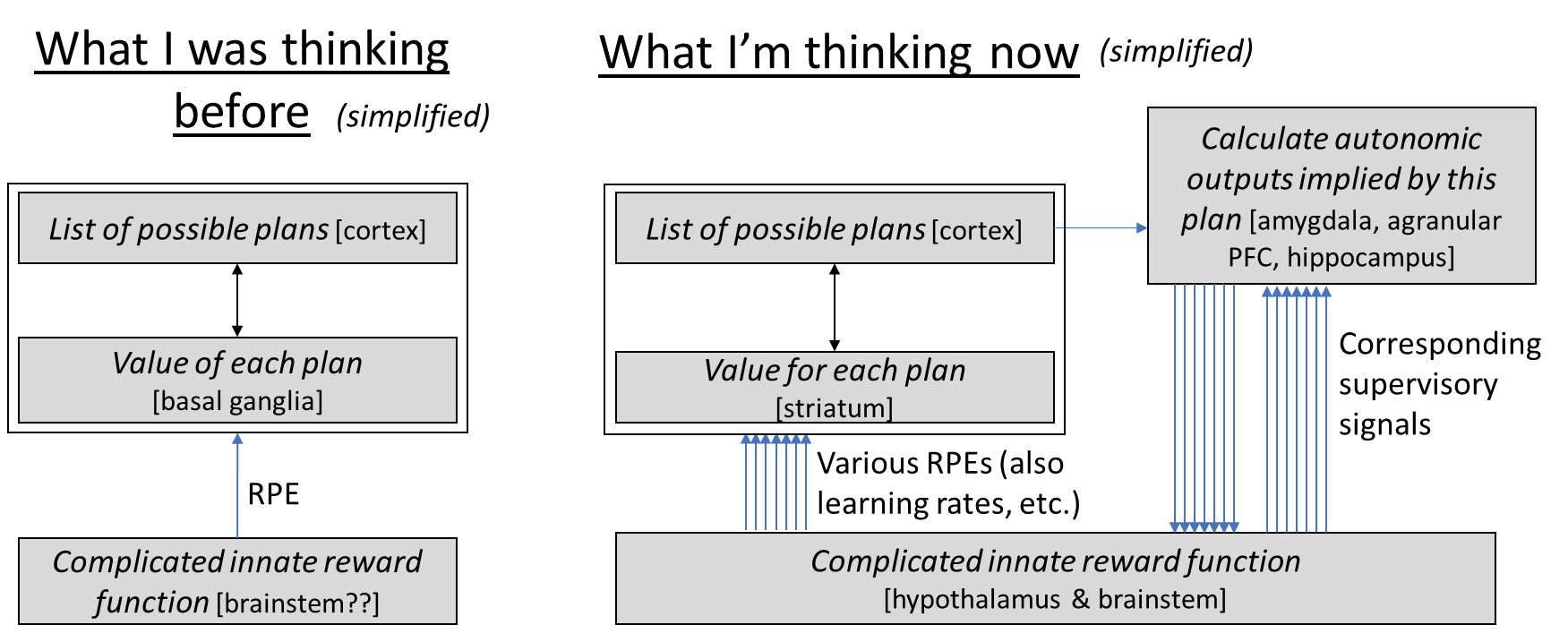
I guess the biggest change is that now I think of two ways for the brain to evaluate how good a plan is. The fast (parallelizable) way uses the striatum, and helps determine which plans can rise to full attention. Then the slow (serial) but more accurate way involves the plan rising to full attention, at which point a maybe dozens-of-dimensional vector of auxiliary information about this plan’s expected consequences is calculated—if I do this plan, should I raise my heart rate? Should I salivate? Should I cringe? Etc. That auxiliary data vector gives the hypothalamus & brainstem something to work with when evaluating the plan. Regular readers of course will connect this to my earlier post Inner Alignment in Salt-Starved Rats [AF · GW], where I was relying on a mechanism like this to explain some animal experiments. Or think of the famous Iowa gambling task; here you can watch in real time (using skin conductance) as the supervised learning algorithm gradually improves the accuracy of the auxiliary data vector associated with each of two choices, until eventually the auxiliary data vector provides a clear enough signal to guide decision-making.
Update: see also follow-up A model of decision-making in the brain (the short version) [LW · GW], where I put this diagram:
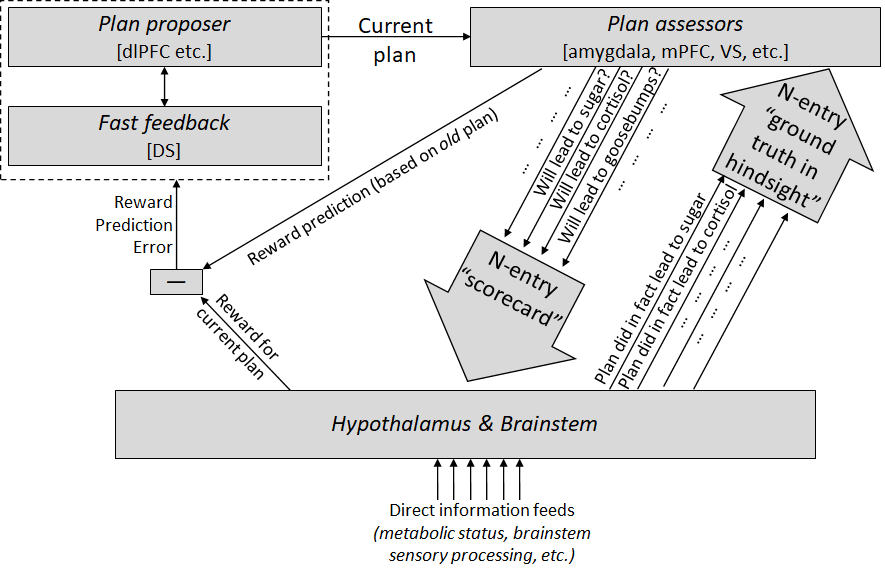
Like, I was thinking I should use this terminology:
- Cached value function is the result when the striatum evaluates a plan, in order to make sure that only especially promising plans can rise to attention;
- Actual value function is the result when the plan does rise to attention, and generates an auxiliary data vector of its corresponding autonomic outputs (“this plan would entail salivating and shivering”), and then the hypothalamus & brainstem evaluates it and sends up dopamine corresponding to its judgment (“well I’m hungry, so any plan involving salivation sounds pretty good!”);
- Reward function is the result when the plan is actually executed and the hypothalamus & brainstem get to see how it goes, including via direct sensory input to the brainstem.
These are listed in increasing order of, um, “fidelity” to the “intentions” of the innate hypothalamus & brainstem algorithm—and consequently the information tends to flow in the opposite direction, from third bullet to second to first. So “cached value function” is trained to imitate “actual value function”, and “actual value function” is ultimately reliant on information flowing from “reward function”. (I'm not sure this terminology is quite right, and also note that there isn't a sharp line between "actual value function" and "reward function".)
Anyway, when we think about how to control AGIs, the idea of “auxiliary data vectors” seems like an awfully important thing to keep in mind! What kinds of auxiliary data can we use to better understand and control our future telencephalon-like-learning-algorithm AGIs, and where do we get the ground truth to train the auxiliary-data-calculating subsystems? Umm, beats me [AF · GW], but it seems like an important question, and I’m still thinking about it, and let me know if you have any ideas.
Likewise, the hypothalamus and brainstem can output multiple region-specific RPEs, not just one. (They probably output various hyperparameter-modulating signals too.) Once again, our future telencephalon-like-learning-algorithm AGI will likewise also presumably be trained by sending different RPEs to different sub-networks. We’re the programmers, so we get to decide exactly what RPEs go to what sub-networks. Is there a scheme like that which will help keep our powerful AGIs reliably under human control? Once again, beats me [AF · GW], but I’m still thinking about it. And you can too! I’m probably the only person on earth being paid to think specifically about how to safely control telencephalon-like-learning-algorithm AGIs, and god knows I’m not gonna figure it out myself, I’m in way the hell over my head.
(If thinking directly about how to control futuristic powerful AGIs isn’t your cup of tea—and I admit it would be a tough sell on your next NIH grant application—at least let’s reverse-engineer “The Human Reward Function”, i.e. that innate hypothalamus & brainstem algorithm I keep talking about. That’s a conventional neuroscience research program, and it definitely helps the cause! Like, try writing down the part of the reward function that leads to jealousy. I don't think it's obvious! Remember, you’re not allowed to directly use common-sense concepts as ingredients in the reward function; the function needs to be built entirely out of information that the hypothalamus and brainstem have access to.)
(This post has a supplement here [LW · GW]. Please leave comments at the lesswrong crosspost, or email me.)
22 comments
Comments sorted by top scores.
comment by Dalcy (Darcy) · 2023-08-03T10:18:04.500Z · LW(p) · GW(p)
What are the errors in this essay? As I'm reading through the Brain-like AGI sequence I keep seeing this post being referenced (but this post says I should instead read the sequence!)
I would really like to have a single reference post of yours that contains the core ideas about phasic dopamine rather than the reference being the sequence posts (which is heavily dependent on a bunch of previous posts; also Post 5 and 6 feels more high-level than this one?)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-08-03T14:34:23.552Z · LW(p) · GW(p)
I think that if you read the later Intro to Brain-Like AGI Safety series [? · GW], then the only reason you might want to read this post (other than historical interest) is that the section “Dopamine category #2: RPE for “local” sub-circuit rewards” is talking about a topic that was omitted from Intro to Brain-Like AGI Safety (for brevity).
For example, practically everything I said about neuroanatomy in this post is at least partly wrong and sometimes very wrong. (E.g. the “toy loop model” diagrams are pretty bad.) The “Finally, the “prediction” part of reward prediction error” section has a very strange proposal for how RPE works; I don’t even remember why I ever believed that.
The main strengths of the post are the “normative” discussions: why might supervised learning be useful? why might more than one reward signal be useful? etc. I mostly stand by those. I also stand by “learning from scratch” being a very useful concept, and elaborated on it much more later [LW · GW].
comment by Michaël Trazzi (mtrazzi) · 2021-06-09T07:44:52.625Z · LW(p) · GW(p)
Awesome post! I happen to also have tried to distill links between RPE and phasic dopamine in the "Prefrontal Cortex as a Meta-RL System" of this blog.
In particular I reference this paper on DL in the brain & this other one for RL in the brain. Also, I feel like the part 3 about links between RL and neuro of the RL book is a great resource for this.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-09T14:42:04.695Z · LW(p) · GW(p)
Thanks!
If you Ctrl-F the post you'll find my little paragraph on how my take differs from Marblestone, Wayne, Kording 2016.
I haven't found "meta-RL" to be a helpful way to frame either the bandit thing or the follow-up paper relating it to the brain, more-or-less for reasons here [LW(p) · GW(p)], i.e. that the normal RL / POMDP expectation is that actions have to depend on previous observations—like think of playing an Atari game—and I guess we can call that "learning", but then we have to say that a large fraction of every RL paper ever is actually a meta-RL paper, and more importantly I just don't find that thinking in those terms leads me to a better understanding of anything, but whatever, YMMV.
I don't agree with everything in the RL book chapter but it's still interesting, thanks for the link.
Replies from: mtrazzi↑ comment by Michaël Trazzi (mtrazzi) · 2021-06-09T14:50:30.431Z · LW(p) · GW(p)
Right I just googled Marblestone and so you're approaching it with the dopamine side and not the acetylcholine. Without debating about words, their neuroscience paper is still at least trying to model the phasic dopamine signal as some RPE & the prefrontal network as an LSTM (IIRC), which is not acetylcholine based. I haven't read in detail this post & the one linked, I'll comment again when I do, thanks!
comment by MadHatter · 2021-06-09T04:45:36.993Z · LW(p) · GW(p)
This was an amazing article, thank you for posting it!
- Side tangent: There’s an annoying paradox that: (1) In RL, there’s no “zero of reward”, you can uniformly add 99999999 to every reward signal and it makes no difference whatsoever; (2) In life, we have a strong intuition that experiences can be good, bad, or neutral; (3) ...Yet presumably what our brain is doing has something to do with RL! That “evolutionary prior” I just mentioned is maybe relevant to that? Not sure … food for thought ...
The above isn't quite true in all senses in all RL algorithms. For example, in policy gradient algorithms (http://www.scholarpedia.org/article/Policy_gradient_methods for a good but fairly technical introduction) it is quite important in practice to subtract a baseline value from the reward that is fed into the policy gradient update. (Note that the baseline can be and most profitably is chosen to be dynamic - it's a function of the state the agent is in. I think it's usually just chosen to be V(s) = max Q(s,a).) The algorithm will in theory converge to the right value without the baseline, but subtracting the baseline speeds convergence up significantly. If one guesses that the brain is using a policy-gradients-like algorithm, a similar principle would presumably apply. This actually dovetails quite nicely with observed human psychology - good/bad/neutral is a thing, but it seems to be defined largely with respect to our expectation of what was going to happen in the situation we were in. For example, many people get shitty when it turns out they aren't going to end up having sex that they thought they were going to have - so here the theory would be that the baseline value was actually quite high (they were anticipating a peak experience) and the policy gradients update will essentially treat this as an aversive stimulus, which makes no sense without the existence of the baseline.
It's closer to being true of Q-learning algorithms, but here too there is a catch - whatever value you assign to never-before-seen states can have a pretty dramatic effect on exploration dynamics, at least in tabular environments (i.e. environments with negligible generalization). So here too one would expect that there is a evolutionarily appropriate level of optimism to apply to genuinely novel situations about which it is difficult to form an a priori judgment, and the difference between this and the value you assign to known situations is at least probably known-to-evolution.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-09T15:07:06.535Z · LW(p) · GW(p)
That's interesting, thanks!
good/bad/neutral is a thing, but it seems to be defined largely with respect to our expectation of what was going to happen in the situation we were in.
I agree that this is a very important dynamic. But I also feel like, if someone says to me, "I keep a kitten in my basement and torture him every second of every day, but it's no big deal, he must have gotten used to it by now", I mean, I don't think that reasoning is correct, even if I can't quite prove it or put my finger on what's wrong. I guess that's what I was trying to get at with that "evolutionary prior" comment: maybe there's a hardcoded absolute threshold such that you just can't "get used to" being tortured, and set that as your new baseline, and stop actively disliking it? But I don't know, I need to think about it more, there's also a book I want to read on the neuroscience of pleasure and pain, and I've also been meaning to look up what endorphins do to the brain. (And I'm happy to keep chatting here!)
I don't have a full explanation of comparing-to-baseline. At first I was gonna say "it's just the reward-prediction-error thing I described: if you expect candy based on your beliefs at 5:05:38, and then you no longer expect candy based on your beliefs at 5:05:39, then that's a big negative reward prediction error. (Because the reward-predictor makes its prediction based on slightly-stale brain status information.) But that doesn't explain why maybe we still feel raw about it 3 minutes later. Maybe it's like, you had this active piece-of-a-thought "I'm gonna get candy", but it's contradicted by the other piece-of-a-thought "no I'm not", but that appealing piece-of-a-thought "I'm gonna get candy" keeps popping back up for a while, and then keeps getting crushed by reality, and the net result is a bad feeling. Or something? I dunno.
Oh, I think there's also a thing where the brainstem can force the high-level planner to think about a certain thing; like if you get poked on the shoulder it's kinda impossible to ignore. I think I have an idea of what mechanism is involved here … involving acetylcholine and how specific and confident the top-down predictions are, I'm hoping to write this up soon … That might be relevant too. Like if you're being tortured then you can't think about anything else, because of this mechanism. Then that would be like an objective sense in which you can't get used to a baseline of torture the way you can get used to other things.
comment by Charlie Steiner · 2021-06-09T23:16:26.406Z · LW(p) · GW(p)
One thing that strikes me as odd about this model is that it doesn't have the blessing of dimensionality - each plan is one loop, and evaluating feedback to a winning plan just involves feedback to one loop. When it's general reward we can simplify this with just rewarding recent winning plans, but in some places it seems like you do imply highly specific feedback, for which you need N feedback channels to give feedback on ~N possible plans. The "blessing of dimensionality" kicks in when you can use more diverse combinations of a smaller number of feedback channels to encode more specific feedback.
Maybe what seems to be specific feedback is actually a smaller number of general types? Like rather than specific feedback to snake-fleeing plans or whatever, a broad signal (like how Success-In-Life Reward is a general signal rewarding whatever just got planned) could be sent out that means "whatever the amygdala just did to make the snake go away, good job" (or something). Note that I have no idea what I'm talking about.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-10T01:27:21.370Z · LW(p) · GW(p)
Right, so I'm saying that the "supervised learning loops" get highly specific feedback, e.g. "if you get whacked in the head, then you should have flinched a second or two ago", "if a salty taste is in your mouth, then you should have salivated a second or two ago", "if you just started being scared, then you should have been scared a second or two ago", etc. etc. That's the part that I'm saying trains the amygdala and agranular prefrontal cortex.
Then I'm suggesting that the Success-In-Life thing is a 1D reward signal to guide search in a high-dimensional space of possible thoughts to think, just like RL. In this case, it's not "each plan is one loop", because there's a combinatorial explosion of possible thoughts you can think, and there are not enough loops for that. (It also wouldn't work because for pretty much every thought you think, you've never thought that exact thought before—like you've never put on this particular jacket while humming this particular song and musing about this particular upcoming party...) Instead I think compositionality is involved, such that one plan / thought can involve many simultaneous loops.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2021-06-10T04:49:18.137Z · LW(p) · GW(p)
How does the section of the amygdala that a particular dopamine neuron connects to even get trained to do the right thing in the first place? It seems like there should be enough chance in connections that there's really only this one neuron linking a brainstem's particular output to this specific spot in the amygdala - it doesn't have a whole bundle of different signals available to send to this exact spot.
SL in the brain seems tricky because not only does the brainstem have to reinforce behaviors in appropriate contexts, it might have to train certain outputs to correspond to certain behaviors in the first place, all with only one wire to each location! Maybe you could do this with a single signal that means both "imitate the current behavior" and also "learn to do your behavior in this context"? Alternatively we might imagine some separate mechanism for of priming the developing amygdala to start out with a diverse yet sensible array of behavior proposals, and the brainstem could learn what its outputs correspond to and then signal them appropriately.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-10T14:24:47.129Z · LW(p) · GW(p)
I'm proposing that (1) the hypothalamus has an input slot for "flinch now", (2) VTA has an output signal for "should have flinched", (3) there is a bundle of partially-redundant side-by-side loops (see the "probability distribution" comment) that connect specifically to both (1) and (2), by a genetically-hardcoded mechanism.
I take your comment to be saying: Wouldn't it be hard for the brain to orchestrate such a specific pair of connections across a considerable distance?
Well, I'm very much not an expert on how the brain wires itself up. But I think there's gotta be some way that it can do things like that. I feel like those kinds of feats of wiring are absolutely required for all kinds of reasons. Like, I think motor cortex connects directly to spinal hand-control nerves, but not foot-control nerves. How do the output neurons aim their paths so accurately, such that they don't miss and connect to the foot nerves by mistake? Um, I don't know, but it's clearly possible. "Molecular signaling" or something, I guess?
Alternatively we might imagine some separate mechanism for of priming the developing amygdala to start out with a diverse yet sensible array of behavior proposals, and the brainstem could learn what its outputs correspond to and then signal them appropriately.
Hmm, one reasonable (to me) possibility along these lines would be something like: "VTA has 20 dopamine output signals, and they're guided to wind up spread out across the amygdala, but not with surgical precision. Meanwhile the corresponding amygdala loops terminate in an "input zone" of the lateral hypothalamus, but not to any particular spot, instead they float around unsure of exactly what hypothalamus "entry point" to connect to. And there are 20 of these intended "entry points" (collections of neurons for flinching, scowling, etc.). OK, then during embryonic development, the entry-point neurons are firing randomly, and that signal goes around the loop—within the hypothalamus and to VTA, then up to the amygdala, then back down to that floating neuron. Then Hebbian learning—i.e. matching the random code—helps the right loop neuron find its way to the matching hypothalamus entry point."
I'm not sure if that's exactly what you're proposing, but that seems like a perfectly plausible way for the brain to orchestrate these connections during embryonic development. I do have a hunch that this isn't what happens, that the real mechanism is "molecular signaling" instead. But like I said, I'm not an expert, and I certainly wouldn't be shocked to learn that the brain embryonic wiring mechanism involves this kind of thing where it closes a loop by sending a random code around the loop and Hebbian-learning the final connection.
Replies from: JenniferRM↑ comment by JenniferRM · 2021-07-19T23:37:09.545Z · LW(p) · GW(p)
I enjoy that you have an algorithm which presumes the existence of some hypothetical mechanism, whereas researchers in labs have been elucidating these mechanisms for years without any necessarily coherent vision of agentic architectures <3
I think there's gotta be some way that it can do things like that. I feel like those kinds of feats of wiring are absolutely required for all kinds of reasons. Like, I think motor cortex connects directly to spinal hand-control nerves, but not foot-control nerves. How do the output neurons aim their paths so accurately, such that they don't miss and connect to the foot nerves by mistake? Um, I don't know, but it's clearly possible. "Molecular signaling" or something, I guess?
Its like you don't know about keywords like "growth cone" or "chemotaxis" or attempts to visualize chemoattractant gradients!
One of the main idioms of brain wiring is basically for axon tips to do chemotaxis (often through various way stations, in sequence) and then if they find the right home base they notice and "decide" to survive, and otherwise they commit suicide and have to be cleaned up (probably to save on neural metabolic demands? and/or to reduce noise?) but then it seems like maybe there are numerous similar systems all kind of working in parallel, each with little details like the "homotopic connections" between each spot in one hemisphere and its rough cognate in the other hemisphere, through the corpus callosum?
The normal way it works, I think, is for people to get the big picture wiring diagram by simply looking, and then do biochemistry and so on, and then back their way into vague hunches about what algorithms could be consistent with such diagrams and mechanisms? You seem to be going in "algorithms first" instead :-)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-20T14:05:04.567Z · LW(p) · GW(p)
Thanks!! And thanks for the wiring references! Such intricate complexity everywhere you look! Sometimes I wonder "how is there so much to say about neuroscience that we can write 50,000 neuroscience papers each year, year after year?", and then I see stuff like this and say "Oh, that's how." :-P
comment by buckithed · 2022-12-30T15:36:33.808Z · LW(p) · GW(p)
I haven't read the entire thing yet, so maybe I am missing something, but isn't the globus pallidus inhibitory? In this you stated that it amplifies signals. there should be a path from the cortex to the subthalamic nucleus that where the globus pallidus shuts down the idea fed to striatum. I like to think of the striatum as the dad, and the globus pallidus as the mom. Then the cortex is the idea that the kids(thalamus) come up with. The dad and mom both see the idea, and the mom always says no, unless the dad convinces her to do the thing. The globus pallidus internal can also send the thalamus to time out to suppress new ideas.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-01-03T15:39:56.627Z · LW(p) · GW(p)
My main answer is that the “toy loop model”s here are pretty bad and shouldn’t be taken literally. I have an updated discussion here [? · GW] (posts 5-6 mostly), but even that has some issues; I made more progress in the last six months that I haven’t written up yet.
I’m more confident in the “‘Context’ in the striatum value function” section here. The convergence of many striatal neurons onto few “final answer” neurons (in both pallidum and SNr) seems pretty central to me. Kinda vaguely like the striatum is the final hidden layer, and pallidum / SNr / whatever neurons are “heads”, in a loose ML analogy.
To answer your question slightly, I’m working at a pretty high level (Marr’s “algorithm level”, I suppose) here. It’s possible to have a signal which is best thought of as exciting something, but is actually implemented by an inhibitory connection. For example, it could be “disinhibitory” (inhibiting an inhibitor). Swanson 2000 does indeed claim that pallidum-to-brainstem signals are disinhibitory, specifically by inhibiting the inhibitory striatum-to-brainstem signals.
But anyway, yeah, I would read this post as kinda “early attempt” rather than correct. A lot of the details are very much wrong. I’ll make the top-note more prominent.
comment by Vaniver · 2021-07-24T16:00:40.350Z · LW(p) · GW(p)
But in experiments, they’re not synchronized; the former happens faster than the latter.
This has the effect of incentivizing learning, right? (A system that you don't yet understand is, in total, more rewarding than an equally yummy system that you do understand.) So it reminds me of exploration in bandit algorithms, which makes sense given the connection to motivation.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-26T02:25:01.529Z · LW(p) · GW(p)
Hmm, I guess I mostly disagree because:
- I see this as sorta an unavoidable aspect of how the system works, so it doesn't really need an explanation;
- You're jumping to "the system will maximize sum of future rewards" but I think RL in the brain is based on "maximize rewards for this step right now" (…and by the way "rewards for this step right now" implicitly involves an approximate assessment of future prospects.) See my comment "Humans are absolute rubbish at calculating a time-integral of reward".
- I'm all for exploration, value-of-information, curiosity, etc., just not involving this particular mechanism.
↑ comment by Vaniver · 2021-07-26T05:54:12.590Z · LW(p) · GW(p)
I guess my sense is that most biological systems are going to be 'package deals' instead of 'cleanly separable' as much as possible--if you already have a system that's doing learning, and you can tweak that system in order to get something that gets you some of the benefits of a VoI framework (without actually calculating VoI), I expect biology to do that.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-26T12:04:00.199Z · LW(p) · GW(p)
I agree about the general principle, even if I don't think this particular thing is an example because of the "not maximizing sum of future rewards" thing.
comment by Borasko · 2021-06-08T23:11:20.672Z · LW(p) · GW(p)
Very interesting! I don't know much about the brain but I think this post did a good job of explaining the concept and showing it's importance. I wonder how the brain does this with neuroplasticity. I've read this article from MIT about researchers rewiring eye inputs to the audio processing parts of the brain. Would the hypothalamus have that hyper-prior on what eye data "looks like" and create loops and systems that could de-code that data and reintegrate it with the undamaged processing systems? Could an AI system just as easily create or re-use existing substructures within it's code? I'm too new to ML learning to know if models can add layers during deployment, or how generalizability could be made within neuro networks past training.
comment by Hoagy · 2021-06-09T13:12:16.817Z · LW(p) · GW(p)
Cheers for the post, I find the whole series fascinating.
One thing I was particularly curious about is how these 'proposals' are made. Do you have a picture of what kind of embedding is used to present a potential action?
For example, is a proposal encoded in the activations of set of neurons that are isomorphic to the motor neurons and it could then propose tightening a set of finger muscles through specific neurons? Or is the embedding jointly learned between the two in some large unstructured connection, or smaller latent space, or something completely different?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-09T14:15:59.719Z · LW(p) · GW(p)
The least-complicated case (I think) is: I (tentatively) think that the hippocampus is more-or-less a lookup table with a finite number of discrete thoughts / memories / locations / whatever (the type of content in different in different species), and a "proposal" is just "which of the discrete things should be activated right now".
A medium-difficulty case is: I think motor cortex stores a bunch of sequences of motor commands which execute different common action sequences. (I'm a believer in the Graziano theory that primary motor cortex, secondary motor cortex, supplementary motor cortex, etc. etc., are all doing the same kind of thing and should be lumped together.) The exact details of the data structures that the brain uses to store these sequences of motor commands are controversial and I don't want to get into it here…
Then the hardest case is the areas that "think thoughts", spawn new ideas, etc., all the cool stuff that leads to human intelligence. (e.g. dorsolateral prefrontal cortex I think.) Things like "I'm going to go to the store" or "what if I differentiate both sides of the equation?". Those things are clearly not isomorphic to a sequence of motor commands. It's higher-level than that. Again, the exact data structures and algorithms involved in representing and searching for these "thoughts" is a very big and controversial topic that I don't want to get into here…