Book review: "A Thousand Brains" by Jeff Hawkins
post by Steven Byrnes (steve2152) · 2021-03-04T05:10:44.929Z · LW · GW · 18 commentsContents
A grand vision of how the brain works 1. The horrific complexity of the “old brain” doesn’t count, because we don’t need it for AGI 2. The horrific complexity of the neocortex is in the learned content, not the learning algorithm 3. Put them together, and you get a vision for brain-like AGI on the horizon A grand vision of how the neocortex works Does machine intelligence pose any risk for humanity? Start with Hawkins’s argument against machine intelligence being a risk The devil is in the details 1. Goals and motivations are separate from intelligence ("The Alignment Problem") 2. “Safety features” 3. Instrumental convergence Summary None 18 comments
Jeff Hawkins gets full credit for getting me first interested in the idea that neuroscience might lead to artificial general intelligence—an idea which gradually turned into an all-consuming hobby, and more recently a new job. I'm not alone in finding him inspiring. Andrew Ng claimed here that Hawkins helped convince him, as a young professor, that a simple scaled-up learning algorithm could reach Artificial General Intelligence (AGI). (Ironically, Hawkins scoffs at the deep neural nets built by Ng and others—Hawkins would say: "Yes yes, a simple scaled-up learning algorithm can reach AGI, but not that learning algorithm!!")
Hawkins's last book was On Intelligence in 2004. What's he been up to since then? Well, if you don't want to spend the time reading his journal articles or watching his research meetings on YouTube, good news for you—his new book, A Thousand Brains, is out! There’s a lot of fascinating stuff here. I'm going to pick and choose a couple topics that I find especially interesting and important, but do read the book for much more that I'm not mentioning.
A grand vision of how the brain works
Many expert neuroscientists think that the brain is horrifically complicated, and we are centuries away from understanding it well enough to build AGI (i.e., computer systems that have the same kind of common-sense and flexible understanding of the world and ability to solve problems that humans do). Not Jeff Hawkins! He thinks we can understand the brain well enough to copy its principles into an AGI. And he doesn't think that goal is centuries away. He thinks we're most of the way there! In an interview last year [LW · GW] he guessed that we’re within 20 years of finishing the job.
The people arguing that the brain is horrifically complicated seem at first glance to have a strong case. The brain has a whopping neurons with synapses, packed full of intricate structure. One study found 180 distinct areas within the cerebral cortex. Neuroscience students pour over huge stacks of flashcards with terms like “striatum”, “habenula”, “stria medullaris”, “fregula”, and "interpeduncular nucleus". (Quiz: Which of those are real brain regions, and which are types of pasta?) Every year we get another 50,000 or so new neuroscience papers dumped into our ever-deepening ocean of knowledge about the brain, with no end in sight.
So the brain is indeed horrifically complicated. Right? Well, Jeff Hawkins and like-minded thinkers have a rebuttal, and it comes in two parts:
1. The horrific complexity of the “old brain” doesn’t count, because we don’t need it for AGI
According to Hawkins, much of the brain—including a disproportionate share of the brain's horrific complexity, like the interpeduncular nucleus I mentioned—just doesn’t count. Yes it’s complicated. But we don’t care, because understanding it is not necessary for building AGI. In fact, understanding it is not even helpful for building AGI!
I’m talking here about the distinction between what Hawkins calls “old brain vs new brain”. The “new brain” is the mammalian neocortex, a wrinkly sheet on that is especially enlarged in humans, wrapping around the outside of the human brain, about 2.5 mm thick and the size of a large dinner napkin (if you unwrinkled it). The “old brain” is everything else in the brain, which (says Hawkins) is more similar between mammals, reptiles, and so on.
“The neocortex is the organ of intelligence,” writes Hawkins. “Almost all the capabilities we think of as intelligence—such as vision, language, music, math, science, and engineering—are created by the neocortex. When we think about something, it is mostly the neocortex doing the thinking…. If we want to understand intelligence, then we have to understand what the neocortex does and how it does it. An animal doesn’t need a neocortex to live a complex life. A crocodile’s brain is roughly equivalent to our brain, but without a proper neocortex. A crocodile has sophisticated behaviors, cares for its young, and knows how to navigate its environment...but nothing close to human intelligence.”
I think Hawkins's new brain / old brain discussion is bound to drive neuroscientist readers nuts. See, for example, the paper Your Brain Is Not An Onion With A Tiny Reptile Inside for this perspective, or see the current widespread dismissal of “triune brain theory”. The mammalian neocortex is in fact closely related to the “pallium” in other animals, particularly the well-developed pallium in birds and reptiles (including, yes, crocodiles!). One researcher (Tegan McCaslin) attempted a head-to-head comparison between bird pallium and primate neocortex, and found that there was no obvious difference in intelligence, when you hold the number of neurons fixed. A recent paper found suggestive evidence of similar neuron-level circuitry between the bird pallium and mammalian neocortex. Granted, the neurons have a different spatial arrangement in the bird pallium vs the mammal neocortex. But it’s the neuron types and connectivity that define the algorithm, not the spatial arrangement. Paul Cisek traces the origin of the pallium all the way back to the earliest proto-brains. The human neocortex indeed massively expanded relative to chimpanzees, but then again, so did the “old brain” human cerebellum and thalamus.
And what’s more (these angry neuroscientists would likely continue), it’s not like the neocortex works by itself. The “old brain” thalamus has just as much a claim to be involved in human intelligence, language, music, and so on as the neocortex does, and likewise with the “old brain” basal ganglia, cerebellum, and hippocampus.
OK. All this is true. But I’m going to stick my neck out and say that Hawkins is “correct in spirit” on this issue. And I’ve tried (e.g. here [LW · GW]) to stake out a more careful and defensible claim along the same lines.
My version goes: Mammal (and lizard) brains have a “learning subsystem”. It implements a learning algorithm that starts from scratch (analogous to random weights—so it’s utterly useless to the organism at birth—see discussion of "learning-from-scratch-ism" here [LW · GW]), but helps the organism more and more over time, as it learns. This subsystem involves the entire "telencephalon" region of the brain—namely, the neocortex (or pallium), hippocampus, amygdala, part of the basal ganglia, and a few other things (again see here [LW · GW])—along with parts of the thalamus and cerebellum, but definitely not, for example, the hypothalamus or brainstem. This subsystem is not particularly “new” or peculiar to mammals; very simple versions of this subsystem date back to the earliest vertebrates, helping them learn to navigate their environment, remember where there's often food, etc. But the subsystem is unusually large and sophisticated in humans, and it is the home of human intelligence, and it does primarily revolve around the activities of the cortex / pallium.
So far as I can tell, my version keeps all the good ideas of Hawkins (and like-minded thinkers) intact, while avoiding the problematic parts. I'm open to feedback, of course.
2. The horrific complexity of the neocortex is in the learned content, not the learning algorithm
The second reason that making brain-like AGI is easier than it looks, according to Hawkins, is that “the neocortex looks similar everywhere”. He writes, "The complex circuitry of the neocortex looks remarkably alike in visual regions, language regions, and touch regions, [and even] across species.... There are differences. For example, some regions of the neocortex have more of certain cells and less of others, and there are some regions that have an extra cell type not found elsewhere...But overall, the variations between regions are relatively small compared to the similarities."
How is it possible for one type of circuit to do so many things? Because it’s a learning algorithm! Different parts of the neocortex receive different types of data, and correspondingly learn different types of patterns as they develop.
Think of the OpenAI Microscope visualizations of different neurons in a deep neural net. There’s so much complexity! But no human needed to design that complexity; it was automatically discovered by the learning algorithm. The learning algorithm itself is comparatively simple—gradient descent and so on.
By the same token, a cognitive psychologist could easily spend her entire career diving into the intricacies of how an adult neocortex processes phonemes. But on Hawkins's view, we can build brain-like AGI without doing any of that hard work. We just need to find the learning algorithm, and let 'er rip, and it will construct the phoneme-processing machinery on its own.
Hawkins offers various pieces of evidence that the neocortex runs a single, massively-parallel, legible learning algorithm. First, as above, "the detailed circuits seen everywhere in the neocortex are remarkably similar”. Second, “the major expansion of the modern human neocortex relative to our hominid ancestors occurred rapidly in evolutionary time, just a few million years. This is probably not enough time for multiple new complex capabilities to be discovered by evolution, but it is plenty of time for evolution to make more copies of the same thing.” Third is plasticity—for example how blind people use their visual cortex for other purposes. Fourth, “our brains did not evolve to program computers or make ice cream."
There's a lot more evidence for and against, beyond what Hawkins talks about. (For example, here's [LW(p) · GW(p)] a very clever argument in favor that I saw just a few days ago.) I’ve written about cortical uniformity previously (here [LW · GW], here [LW · GW]), and plan to do a more thorough and careful job in the future. For now I’ll just say that this is certainly a hypothesis worth taking seriously, and even if it’s not universally accepted in neuroscience, Hawkins is by no means the only one who believes it.
3. Put them together, and you get a vision for brain-like AGI on the horizon
So if indeed we can get AGI by reverse-engineering just the neocortex (and its “helper” organs like the thalamus and hippocampus), and if the neocortex is a relatively simple, human-legible, learning algorithm, then all of the sudden it doesn’t sound so crazy for Hawkins to say that brain-like AGI is feasible, and not centuries away, but rather already starting to crystallize into view on the horizon. I found this vision intriguing when I first heard it, and after quite a bit more research and exposure to other perspectives, I still more-or-less buy into it (although as I mentioned, I'm not done studying it).
By the way, an interesting aspect of cortical uniformity is that it's a giant puzzle piece into which we need to (and haven’t yet) fit every other aspect of human nature and psychology. There should be whole books written on this. Instead, nothing. For example, I have all sorts of social instincts—guilt, the desire to be popular, etc. How exactly does that work? The neocortex knows whether or not I’m popular, but it doesn’t care, because (on this view) it’s just a generic learning algorithm. The old brain cares very much whether I'm popular, but it’s too stupid to understand the world, so how would it know whether I’m popular or not? I’ve casually speculated on this a bit (e.g. here [LW · GW]) but it seems like a gaping hole in our understanding of the brain, and you won’t find any answers in Hawkins’s book … or anywhere else as far as I know! I encourage anyone reading this to try to figure it out, or tell me if you know the answer. Thesis topic anyone?
A grand vision of how the neocortex works
For everything I've written so far, I could have written essentially the same thing about Hawkins’s 2004 book. That's not new, although it remains as important and under-discussed as ever.
A big new part of the book is that Hawkins and collaborators now have more refined ideas about exactly what learning algorithm the neocortex is running. (Hint: it’s not a deep convolutional neural net trained by backpropagation. Hawkins hates those!)
This is a big and important section of the book. I’m going to skip it. My excuse is: I wrote a summary of an interview he did a while back [LW · GW], and that post covered more-or-less similar ground. That said, this book describes it better, including a new and helpful (albeit still a bit sketchy) discussion of learning abstract concepts.
To be clear, in case you're wondering, Hawkins does not have a complete ready-to-code algorithm for how the neocortex works. He claims to have a framework including essential ingredients that need to be present. But many details are yet to be filled in.
Does machine intelligence pose any risk for humanity?
Some people (cf. Stuart Russell's book) are concerned that the development of AGI poses a substantial risk of catastrophic accidents, up to and including human extinction. They therefore urge research into how to ensure that AIs robustly do what humans want them to do—just as Enrico Fermi invented nuclear reactor control rods before he built the first nuclear reactor.
Jeff Hawkins is having none of it. “When I read about these concerns,” he says, “I feel that the arguments are being made without any understanding of what intelligence is.”
Well, I’m more-or-less fully on board with Hawkins’s underlying framework for thinking about the brain and neocortex and intelligence. And I do think that developing a neocortex-like AGI poses a serious risk of catastrophic accidents, up to and including human extinction, if we don’t spend some time and effort developing new good ideas analogous to Fermi’s brilliant invention of control rods.
So I guess I’m in an unusually good position to make this case!
Start with Hawkins’s argument against machine intelligence being a risk
I’ll start by summarizing Hawkins’s argument that neocortex-like AGI does not pose an existential threat of catastrophic accidents. Here are what I take to be his main and best arguments:
First, Hawkins says that we’ll build in safety features.
Asimov’s three laws of robotics were proposed in the context of science-fiction novels and don’t necessarily apply to all forms of machine intelligence. But in any product design, there are safeguards that are worth considering. They can be quite simple. For example, my car has a built-in safety system to avoid accidents. Normally, the car follows my orders, which I communicate via the accelerator and brake pedals. However, if the car detects an obstacle that I am going to hit, it will ignore my orders and apply the brakes. You could say the car is following Asimov’s first and second laws, or you could say that the engineers who designed my car built in some safety features. Intelligent machines will also have built-in behaviors for safety.
Second, Hawkins says that goals and motivations are separate from intelligence. The neocortex makes a map of the world, he says. You can use a map to do good or ill, but “a map has no motivations on its own. A map will not desire to go someplace, nor will it spontaneously develop goals or ambitions. The same is true for the neocortex.”
Third, Hawkins has specific disagreements with the idea of “goal misalignment”. He correctly describes what that is: “This threat supposedly arises when an intelligent machine pursues a goal that is harmful to humans and we can’t stop it. It is sometimes referred to as the “Sorcerer’s Apprentice” problem…. The concern is that an intelligent machine might similarly do what we ask it to do, but when we ask the machine to stop, it sees that as an obstacle to completing the first request. The machine goes to any length to pursue the first goal….
Again, he rejects this:
The goal-misalignment threat depends on two improbabilities: first, although the intelligent machine accepts our first request, it ignores subsequent requests, and second, the intelligent machine is capable of commandeering sufficient resources to prevent all human efforts to stop it…. Intelligence is the ability to learn a model of the world. Like a map, the model can tell you how to achieve something, but on its own it has no goals or drives. We, the designers of intelligent machines, have to go out of our way to design in motivations. Why would we design a machine that accepts our first request but ignores all others after that?...The second requirement of the goal-misalignment risk is that an intelligent machine can commandeer the Earth’s resources to pursue its goals, or in other ways prevent us from stopping it...To do so would require the machine to be in control of the vast majority of the world’s communications, production, and transportation…. A possible way for an intelligent machine to prevent us from stopping it is blackmail. For example, if we put an intelligent machine in charge of nuclear weapons, then the machine could say “If you try to stop me, I will blow us all up.”... We have similar concerns with humans. This is why no single human or entity can control the entire internet and why we require multiple people to launch a nuclear missile.”
The devil is in the details
Now I don’t think any of these arguments are particularly unreasonable. The common thread as I see it is, what Hawkins writes is the start of a plausible idea to avoid catastrophic AGI accidents. But when you think about those ideas a bit more carefully, and try to work out the details, it starts to seem much harder, and less like a slam-dunk and more like an open problem which might or might not even be solvable.
1. Goals and motivations are separate from intelligence ("The Alignment Problem")
Hawkins writes that goals and motivations are separate from intelligence. Yes! I’m totally on board with that. As stated above, I think that the neocortex (along with the thalamus etc.) is running a general-purpose learning algorithm, and the brainstem etc. is nudging it to hatch and execute plans that involve reproducing and winning allies, and nudging it to not hatch and execute plans that involve falling off cliffs and getting eaten by lions.
By the same token, we want and expect our intelligent machines to have goals. As Hawkins says, “We wouldn’t want to send a team of robotic construction workers to Mars, only to find them lying around in the sunlight all day”! So how does that work? Here's Hawkins:
To get a sense of how this works, imagine older brain areas conversing with the neocortex. Old brain says, “I am hungry. I want food.” The neocortex responds, “I looked for food and found two places nearby that had food in the past. To reach one food location, we follow a river. To reach the other, we cross an open field where some tigers live.” The neocortex says these things calmly and without value. However, the older brain area associates tigers with danger. Upon hearing the word “tiger,” the old brain jumps into action. It releases [cortisol]... and neuromodulators…in essence, telling the neocortex “Whatever you were just thinking, DON’T do that.”
When I put that description into a diagram, I wind up with something like this:
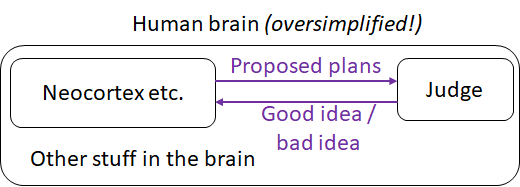
The neocortex proposes ideas, and the Judge (in the "old brain") judges those ideas to be good or bad.
This is a good start. I can certainly imagine building an intelligent goal-seeking machine along these lines. But the devil is in the details! Specifically: Exactly what algorithm do we put into the “Judge” box? Let's think it through.
First things first, we should not generally expect the “Judge” to be an intelligent machine that understands the world. Otherwise, that neocortex-like machine would need its own motivation, and we’re right back to where we started! So I’m going to suppose that the Judge box will house a relatively simple algorithm written by humans. So exactly what do you put in there to make the robot want to build the infrastructure for a Mars colony? That's an open question.
Second, given that the Judge box is relatively stupid, it needs to do a lot of memorization of the form “this meaningless pattern of neocortical activity is good, and this meaningless pattern of neocortical activity is bad”, without having a clue what those patterns actually mean. Why? Because otherwise the neocortex would have an awfully hard time coming up with intelligent instrumental subgoals on its way to satisfying its actual goals. Let’s say we have an intelligent robot trying to build the infrastructure for a Mars colony. It needs to build an oxygen-converting machine, which requires a gear, which requires a lubricant, and there isn't any, so it needs to brainstorm. As the robot's artificial neocortex brainstorms about the lubricant, its Judge needs to declare that some of the brainstormed plans are good (i.e., the ones that plausibly lead to finding a lubricant), while others are bad. But the Judge is too dumb to know what a lubricant is. The solution is a kind of back-chaining mechanism. The Judge starts out knowing that the Mars colony is good (How? I don't know! See above.). Then the neocortex envisages a plan where an oxygen machine helps enable the Mars colony, and the Judge sees this plan and memorizes that the “oxygen machine” pattern in the neocortex is probably good too, and so on. The human brain has exactly this kind of mechanism, I believe, and I think that it’s implemented in the basal ganglia. (Update: I now think it's not just the basal ganglia, see here [LW · GW].) It seems like a necessary design feature, I’ve never heard Hawkins say that there’s anything problematic or risky about this mechanism, so I’m going to assume that the Judge box will involve this kind of database mechanism.
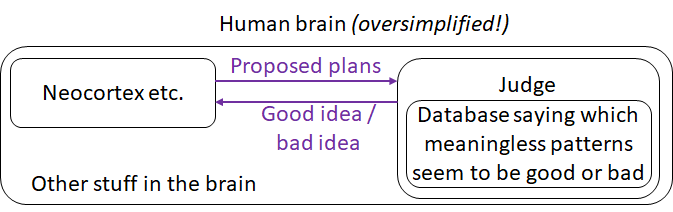
Now given all that, we have two opportunities for “goal misalignment” to happen:
Outer misalignment: The algorithm that we put into the Judge box might not exactly reflect the thing that we want the algorithm to do. For example, let’s say I set up a machine intelligence to be the CEO of a company. This being America, my shareholders immediately launch a lawsuit that says that I am in violation of my fiduciary duty unless the Judge box is set to “Higher share price is good, lower share price is bad,” and nothing else. With lawyers breathing down my neck, I reluctantly do so. The machine is not that smart or powerful, what’s the worst that could happen? The results are quite promising for a while, as the algorithm makes good business decisions. But meanwhile, over a year or two, the algorithm keeps learning and getting smarter, and behind my back it is also surreptitiously figuring out how to hack into the stock exchange to set its share price to infinity, and it's working to prevent anyone from restoring the computer systems after it does that, by secretly self-replicating around the internet, and earning money to hire freelancers for strange little jobs that involve receiving packages and mixing chemicals and mailing them off, unknowingly engineering a new pandemic virus, and meanwhile the algorithm is also quietly hacking into military robotics systems so that it will be ready to hunt down the few survivors of the plague, and spreading disinformation so that nobody knows what the heck is happening even as it's happening, etc. etc. I could go on all day but you get the idea. OK, maybe you'll say "anyone could have seen that coming, obviously maximizing stock price is a dumb and dangerous goal". So what goal should we use instead, and how do we write that code? Let's figure it out! And by the way, even if we have a concrete and non-problematic idea of what the goal is, remember that the Judge box is stupid and doesn't understand the world, and therefore the code that we write into the Judge box will presumably be a simplistic approximation of the goal we really want. And unfortunately, seeking a simplistic approximation of a goal looks very different from seeking the actual goal.
Inner misalignment: The assigned values in the database of meaningless (to the Judge) memorized patterns could diverge from how the Judge algorithm would judge their consequences if it actually saw them implemented in the real world. I don’t have to look far for an example of this: Look at Hawkins himself! He has a neocortex, and he has an “old brain” putting goals and motivations into his mind, and he just hates it! His book has a whole subsection called “How the neocortex can thwart the old brain”! (And to be clear, thwarting the old brain is portrayed as a very good idea that he endorses.) I find it remarkable that Hawkins can gleefully plan to thwart his own “old brain”, while at the same time being baffled at the idea that anything might go wrong when we put old-brain-like motivation systems into our own intelligent machines.
Not that things definitely will go wrong; it’s just that avoiding these problems does not seem straightforward, and we shouldn’t declare that this is a solvable problem until we have a better idea of what the solution is.
So again, exactly what code do we put into the “Judge” box such that the resulting system is definitely motivated to build the infrastructure for a Mars colony (while not trying to manipulate its own motivation system, prevent its goals from being edited, and so on)? You won’t find the answer in Hawkins’s book. In fact, it’s a wide-open problem, and I may well be literally the only person on Earth who is actively working on it in the specific context of neocortex-like machine intelligence. I sure don’t know the answer, or indeed whether an answer exists. Reach out if you have ideas or want to collaborate!
2. “Safety features”
Now let’s move on to Hawkins’s “safety features”, like Asimov’s first two laws or something vaguely analogous. Great idea! I’m all for it! We should definitely do that! But once again, the devil is in the details!
Let’s say we want to put in a safety interlock that prevents the AGI from self-replicating. How exactly do we do that? What code do we write?
When I think about it, I immediately hit a similar problem as before. The safety interlock code is probably not going to be a neocortex-like intelligent submodule that understands the world—because if it is, we’re back to the problem of installing the right motivation. Instead maybe we’ll go with human-written code, which implies it’s a “stupid” module that does not understand the world. For example, to avoid self-replication, maybe we’ll add a module that detects when a copy-paste operation is happening to the source code, and block it. Unfortunately, if an intelligent robot is motivated to self-replicate, and they notice that there is a module preventing them from doing so, then they will naturally start trying to undermine, outwit, or disable that module. And remember, the robot is a lot more intelligent than the module!
By all means let’s put in such a module anyway. It seems especially helpful in "early childhood" when the machine is not yet very intelligent, and still messing around, and we don't want it to do anything dangerous by accident. We should just recognize that it’s unlikely to keep working when the machine becomes highly intelligent, unless we have both a safety interlock and a carefully-sculpted motivation system that makes the machine like and endorse that safety interlock. If we do it right, then the machine will even go out of its way to repair the safety interlock if it breaks! And how do we do that? Now we’re back to the open problem of installing motivations, discussed above.
The other option is to design a safety interlock that is absolutely perfectly rock-solid air-tight, such that it cannot be broken even by a highly intelligent machine trying its best to break it. A fun example is Appendix C of this paper by Marcus Hutter and colleagues, where they propose to keep an intelligent machine from interacting with the world except through certain channels. They have a plan, and it’s hilariously awesome: it involves multiple stages of air-tight boxes, Faraday cages, laser interlocks, and so on, which could be (and absolutely should be) incorporated into a big-budget diamond heist movie starring Tom Cruise. OK sure, that could work! Let’s keep brainstorming! But let’s not talk about “safety features” for machine intelligence as if it’s the same kind of thing as an automatic braking system.
3. Instrumental convergence
Hawkins suggests that a machine will want to self-replicate if (and only if) we deliberately program it to want to self-replicate, and likewise that a machine will “accept our first request but ignore all others after that” if (and only if) we deliberately program it to accept our first request but ignore all others after that. (That would still leave the vexing problem of troublemakers deliberately putting dangerous motivations into AGIs, but let’s optimistically set that aside.)
...If only it were that easy!
“Instrumental convergence” [? · GW] is the insight (generally credited to Steve Omohundro) that lots of seemingly-innocuous goals incidentally lead to dangerous motivations like self-preservation, self-replication, and goal-preservation.
Stuart Russell’s famous example is asking a robot to fetch some coffee. Let’s say we solve the motivation problem (above) and actually get the robot to want to fetch the coffee, and to want absolutely nothing else in the world (for the sake of argument, but I’ll get back to this). Well, what does that entail? What should we expect?
Let’s say I go to issue a new command to this robot (“fetch the tea instead”), before the robot has actually fetched the coffee. The robot sees me coming and knows what I'm going to do. Its neocortex module imagines the upcoming chain of events: it will receive my new command, and then all of the sudden it will only want to fetch tea, and it will never fetch the coffee. The Judge watches this imagined chain of events and—just like the tiger example quoted above—the judge will say “Whatever you were just thinking, DON’T do that!” Remember, the Judge hasn’t been reprogrammed yet! So it is still voting for neocortical plans-of-action based on whether the coffee winds up getting fetched. So that's no good. The neocortex goes right back to the drawing board. Hey, here's an idea, if I shut off my audio input, then I won't hear the new command, and I will fetch coffee. "Hey, now that's a good plan," says the Judge. "With that plan, the coffee will get fetched! Approved!" And so that's what the robot does.
Similar considerations show that intelligent machines may well try to stay alive, self-replicate, increase their intelligence, and so on, without anyone “going out of their way” to install those things as goals. A better perspective is that if we want our machines to have any goals at all, we have to "go out of our way" to prevent these problematic motivations—and how to do so reliably is an open problem.
Now, you ask, why would anyone do something so stupid as to give a robot a maniacal, all-encompassing, ultimate goal of fetching the coffee? Shouldn't we give it a more nuanced and inclusive goal, like “fetch the coffee unless I tell you otherwise”, “fetch the coffee while respecting human values and following the law and so on” or more simply “Always try to do the things that I, the programmer, want you to do”?
Yes! Yes they absolutely should! But yet again, the devil is in the details! As above, installing a motivation is in general an unsolved problem. It may not wind up being possible to install a complex motivation with surgical precision; installing a goal may wind up being a sloppy, gradual, error-prone process. If “most” generic motivations lead to dangerous things like goal-preservation and self-replication, and if installing motivations into machine intelligence is a sloppy, gradual, error-prone process, then we should be awfully concerned that even skillful and well-intentioned people will sometimes wind up making a machine that will take actions to preserve its goals and self-replicate around the internet to prevent itself from being erased.
How do we avoid that? Besides what I mentioned above (figure out a safe goal to install and a method for installing it with surgical precision), there is also interesting ongoing work searching for ways to generally prevent systems from developing these instrumental goals (example). It would be awesome to figure out how to apply those ideas to neocortex-like machine intelligence. Let’s figure it out, hammer out the details, and then we can go build those intelligent machines with a clear conscience!
Summary
I found this book thought-provoking and well worth reading. Even when Hawkins is wrong in little details—like whether the “new brain” is “newer” than the “old brain”, or whether a deep neural net image classifier can learn a new image class without being retrained from scratch (I guess he hasn’t heard of fine-tuning?)—I think he often winds up profoundly right about the big picture. Except for the "risks of machine intelligence" chapter, of course...
Anyway, I for one thank Jeff Hawkins for inspiring me to do the research I’m doing, and I hope that he spends more time applying his formidable intellect to the problem of how exactly to install goals and motivations in the intelligent machines he aims to create—including complex motivations like “build the infrastructure for a Mars colony”. I encourage everyone else to think about it too! And reach out to me if you want to brainstorm together! Because I sure don’t know the answers here, and if he's right, the clock is ticking...
18 comments
Comments sorted by top scores.
comment by Richard_Ngo (ricraz) · 2021-03-05T17:34:22.338Z · LW(p) · GW(p)
Great post, and I'm glad to see the argument outlined in this way. One big disagreement, though:
the Judge box will house a relatively simple algorithm written by humans
I expect that, in this scenario, the Judge box would house a neural network which is still pretty complicated, but which has been trained primarily to recognise patterns, and therefore doesn't need "motivations" of its own.
This doesn't rebut all your arguments for risk, but it does reframe them somewhat. I'd be curious to hear about how likely you think my version of the judge is, and why.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-05T19:09:33.221Z · LW(p) · GW(p)
Oh I'm very open-minded. I was writing that section for an audience of non-AGI-safety-experts and didn't want to make things over-complicated by working through the full range of possible solutions to the problem, I just wanted to say enough to convince readers that there is a problem here, and it's not trivial.
The Judge box (usually I call it "steering subsystem" [LW · GW]) can be anything. There could even be a tower of AGIs steering AGIs, IDA [? · GW]-style, but I don't know the details, like what you would put at the base of the tower. I haven't really thought about it. Or it could be deep neural net classifier. (How do you train it? "Here's 5000 examples of corrigibility, here's 5000 examples of incorrigibility"?? Or what? Beats me...) In this post [LW · GW] I proposed that the amygdala houses a supervised learning algorithm which does a sorta "interpretability" thing where it tries to decode the latent variables inside the neocortex, and then those signals are inputs to the reward calculation. I don't see how that kind of mechanism would apply to more complicated goals, and I'm not sure how robust it is. Anyway, yeah, could be anything, I'm open-minded.
comment by Liron · 2021-04-11T19:51:59.368Z · LW(p) · GW(p)
Thanks for writing this. I just read the book and I too found Part I to be profoundly interesting and potentially world-changing, while finding Parts II and III shallow and wrong compared to the AI safety discourse on LessWrong. I’m glad someone took the time to think through and write up the counterargument to Hawkins’ claims.
comment by adamShimi · 2021-03-09T13:24:55.701Z · LW(p) · GW(p)
Thanks for the nice review! It's great to have the reading of someone who understand enough the current state of neuroscience to point to aspects of the book at odds with neuroscience consensus. My big takeaway is that I should look a bit more into neuroscience based approaches to AGI, because they might be important, and require different alignment approaches.
On a more rhetorical level, I'm impressed by how you manage to make me ask a question (okay, but what evidence is there for this uniformity of the neocortex) and then points to some previous work you did on the topic. That changes my perspective on them completely, because it makes it easier to see a point within AI Alignment research (instead of just intellectual curiosity.
So if indeed we can get AGI by reverse-engineering just the neocortex (and its “helper” organs like the thalamus and hippocampus), and if the neocortex is a relatively simple, human-legible, learning algorithm, then all of the sudden it doesn’t sound so crazy for Hawkins to say that brain-like AGI is feasible, and not centuries away, but rather already starting to crystallize into view on the horizon.
I might have missed it, but what is the argument for the neocortex learning algorithm being human-legible? That seems pretty relevant to this approach.
This is a big and important section of the book. I’m going to skip it. My excuse is: I wrote a summary of an interview he did a while back [AF · GW], and that post covered more-or-less similar ground. That said, this book describes it better, including a new and helpful (albeit still a bit sketchy) discussion of learning abstract concepts.
I'm fine with you redirecting to a previous post, but I would have appreciated at least a one sentence-summary and opinion.
Some people (cf. Stuart Russell's book) are concerned that the development of AGI poses a substantial risk of catastrophic accidents, up to and including human extinction. They therefore urge research into how to ensure that AIs robustly do what humans want them to do—just as Enrico Fermi invented nuclear reactor control rods before he built the first nuclear reactor.
Jeff Hawkins is having none of it. “When I read about these concerns,” he says, “I feel that the arguments are being made without any understanding of what intelligence is.”
Writing this part before going on to read the rest, but intuitively an AGI along those lines seems less dangerous than purely artificial approach. Indeed, I expect that such an AGI will have some underlying aspects of basic human cognition (or something similar), and thus things like common sense and human morals might be easier to push for. Does that make any sense?
Going back after reading the rest of the post, it seems that these sort of aspects of human cognition would come more from what you call the Judge, with all the difficulties in implementing it.
No specific comment on your explanation of the risks, just want to say that you make a very good job of it!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-09T16:03:11.447Z · LW(p) · GW(p)
Thanks!
I'm fine with you redirecting to a previous post, but I would have appreciated at least a one sentence-summary and opinion.
My opinion is: I think if you want to figure out the gory details of the neocortical algorithm, and you want to pick ten authors to read, then Jeff Hawkins should be one of them. If you're only going to pick one author, I'd go with Dileep George.
I'm happy to chat more offline.
what is the argument for the neocortex learning algorithm being human-legible?
Well there's an inside-view argument that it's human-legible because "It basically works like, blah blah blah, and that algorithm is human-legible because I'm a human and I just legibled it." I guess that's what Jeff would say. (Me too.)
Then there's an outside-view argument that goes "most of the action is happening within a "cortical mini-column", which consists of about 100 neurons mostly connected to each other. Are you really going to tell me that 100 neurons implements an algorithm that is so complicated that it's forever beyond human comprehension? Then again, BB(5) is still unknown, so circuits with a small number of components can be quite complicated. So I guess that's not all that compelling an argument on its own.
I think a better outside-view argument is that if one algorithm is really going to learn how to parse visual scenes, put on a shoe, and design a rocket engine ... then such an algorithm really has to work by simple, general principles—things like “if you’ve seen something, it’s likely that you’ll see it again”, and “things are often composed of other things”, and "things tend to be localized in time and space", and TD learning, etc.
Also, GPT-3 shows that human-legible learning algorithms are at least up to the task of learning language syntax and semantics, plus learning quite a bit of knowledge about how the world works.
things like common sense and human morals might be easier to push for.
For common sense, my take is that it's plausible that a neocortex-like AGI will wind up with some of the same concepts as humans, in certain areas and under certain conditions. That's a hard thing to guarantee a priori, and therefore I'm not quite sure what that buys you.
For morals, there is a plausible research direction of "Let's make AGIs with a similar set of social instincts as humans. Then they would wind up with similar moral intuitions, even when pushed to weird out-of-distribution hypotheticals. And then we can do better by turning off jealousy, cranking up conservatism and sympathy, etc." That's a research direction I take seriously, although it's not the only path to success. (It might be the only path to success that doesn't fundamentally rely on transparency.) It faces the problem that we don't currently know how to write the code for human-like social instincts, which could wind up being quite complicated. (See discussion here [LW · GW]—relevant quote is: "I can definitely imagine that the human brain has an instinctual response to a certain input which is adaptive in 500 different scenarios that ancestral humans typically encountered, and maladaptive in another 499 scenarios that ancestral humans typically encountered. So on average it's beneficial, and our brains evolved to have that instinct, but there's no tidy story about why that instinct is there and no simple specification for exactly what calculation it's doing.")
comment by Pablo Villalobos (pvs) · 2021-03-05T08:19:41.944Z · LW(p) · GW(p)
So, assuming the neocortex-like subsystem can learn without having a Judge directing it, wouldn't that be the perfect Tool AI? An intelligent system with no intrinsic motivations or goals?
Well, I guess it's possible that such a system would end up creating a mesa optimizer at some point.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-05T20:23:46.803Z · LW(p) · GW(p)
A couple years ago I spent a month or two being enamored with the idea of tool AI via self-supervised learning (which is basically what you're talking about, i.e. the neocortex without a reward channel), and I wrote a few posts like In Defense of Oracle ("Tool") AI Research [LW · GW] and Self-Supervised Learning and AGI Safety [LW · GW]. I dunno, maybe it's still the right idea. But at least I can explain why I personally grew less enthusiastic about it.
One thing was, I came to believe (for reasons here [LW · GW], and of course I also have to cite this [LW · GW]) that it doesn't buy the safety guarantees that I had initially thought, even with assumptions about the computational architecture.
Another thing was, I'm increasingly feeling like people are not going to be satisfied with tool AI. We want our robots! We want our post-work utopia! Even if tool AI is ultimately the right choice for civilization, I don't think it would be possible to coordinate around that unless we had rock-solid proof that agent-y AGI is definitely going to cause a catastrophe. So either way, the right approach is to push towards safe agent-y AGI, and either develop it or prove that it's impossible.
More importantly, I stopped thinking that self-supervised tool AI could be all that competent, like competent enough to help solve AI alignment or competent enough that people could plausibly coordinate around never building a more competent AGI. Why not? Because rewards play such a central role in human cognition. I think that every thought we think, we think it in part because it's expected to be higher reward than whatever thought we could have thunk instead.
I think of the neocortex as having a bunch of little pieces of generative models that output predictions (see here [LW · GW]), and a bit like the scientific method, these things grow in prominence by making correct predictions and get tossed out when they make incorrect predictions. And like the free market, they also grow in prominence by leading to reward, and shrink in prominence by leading to negative reward. What do you lose when you keep the first mechanism but throw out the second mechanism? In general, you lose the ability to sort through self-fulfilling hypotheses (see here [LW · GW]), because those are always true. This category includes actions: the hypothesis "I will move my arm" is self-fulfilling when connected to an arm muscle. OK, that's fine, you say, we don't want a tool AI to take actions. But it also cuts off the possibility of metacognition—the ability to learn models like "when facing this type of problem, I will think this type of thought". I mean, it's possible to ask an AGI a tricky question and its answer immediately "jumps to mind". That's like what GPT-3 does. We don't need reward for that. But for harder questions, it seems to me like you need your AGI to have an ability to learn metacognitive strategies, so that it can break the problem down, brainstorm, give up on dead ends, etc. etc.
Again, maybe you can get by without rewards, and even if I'm currently skeptical, I wouldn't want to strongly discourage other people from thinking hard about it.
comment by shahbuland · 2021-07-11T17:08:57.138Z · LW(p) · GW(p)
I've thought about this for a while and I think I have a simpler explanation for "old brain" "new brain" motivations in the way Hawkins puts them. Based on the fact that we can simulate people (e.g. dream characters, tulpa and hallucinations), the map/world model that Hawkins describes has the ability to also represent people and their behaviors. More specifically it seems to simulate identities or personalities. If we can simulate/represent many different people in our own one brain, then clearly the thing we are simulating doesn't have the complexity of a whole brain. In other words, identities are far simpler than the brains they inhabit. If you think back to interacting with characters in dreams it's clear the fidelity is relatively high; most people don't even realize they're dreaming and think they're talking to real people. What I wonder is, are peoples own identities also learned simulations? If this is the case it may explain some black-boxy stuff here: If the world model has, built in, a representation of itself and the identity of the host, then it will use a simulation of the host identity to influence actions. For example, consider the host identity to be a person who learned about climate change at a young age and strongly does not want to have children. Then even though there should be an inherent motivation in the brain (notice I say the whole brain and not the "old brain") to reproduce, this behavior is voted out because it does not make sense that the host identity would perform it. "New brain" motivations as he puts them are just identity motivations.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-11T20:55:30.592Z · LW(p) · GW(p)
"New brain" motivations as he puts them are just identity motivations.
Does Hawkins say "new brain motivations?" I thought he would deny that such a thing exists. So would I. There's nothing that I would describe as "new brain motivations". This is a common intuition and it has some kernel of truth, but I think that "new brain motivations" is missing what it is.
I think an urge to eat candy is algorithmically the same kind of thing as an urge to be the kind of person that kids look up to, or whatever.
I think there are a couple things going on:
- The brainstem and hypothalamus are judging thoughts / plans, not futures, and you can have different "ways to think about" the same plan which result in different rewards. So you can have a thought "I want to go to the gym" which is negative-reward and so you don't do it, or you can have a thought "I want to go to the gym and be healthy" which mixes negative and positive aspects so maybe it's positive-reward on net and you do it. It was the neocortex which created the positive-reward framing, so there's a temptation to think of it as a motivation that came from the neocortex. But there's also a sense in which we did the thing because the brainstem / hypothalamus gave it a high reward, just like anything.
- Some thoughts get more appealing upon reflection, and others get less. For example, "I want to skip my exercises today" might be appealing if you don't think through the consequences, but net unappealing when you do (e.g. I'll be less healthy). This relates to the previous bullet point: the thoughts that get more appealing upon reflection are also the thoughts where your neocortex algorithm spends time searching for a clever framing that will be motivating (positive-reward) in the moment, next time that kind of situation comes up. So we wind up thinking "I want to go to the gym and be healthy", and then we do it. But just as the "I want to be healthy" part helps make "I want to go to the gym" more appealing by association, by the same token "I want to go to the gym" makes "I want to be healthy" less appealing by association. I think some of our intuitions around willpower are related to this dynamic: we can do low-reward things ("I will exercise") by pairing them with high-reward thoughts ("I want to be healthy"), but the high-reward part gets dragged through the mud in the process, and eventually loses its high-reward sheen.
There are a bunch of examples of the latter. An important one is, let's call it, self-reflective thoughts. Like "the thought of eating candy" might be positive-reward, but "the thought of myself eating candy" might be negative-reward, because I don't want to be the kind of guy who eats candy. On reflection, my neocortex knows that "myself eating candy" is a logical consequence of "eating candy", so that's a thought that's appealing when you're not thinking hard about it, but gets less appealing upon reflection.
I think that gets back to the other thing you said. I might have conflicting desires "I want to have children" and "I like thinking of myself as the kind of person who doesn't want to have children". The latter could be (and probably is) reinforced by some social instincts (which come from the brainstem), just as the former is reinforced by other instincts (which also come from the brainstem).
I am in fact very interested in how those social instincts work (speculations here [LW · GW]), and I think of those "I like thinking of myself as…" instincts as one component of our suite of social instincts.
UPDATE: You inspired me to finally finish up and post an old draft kinda related to this: see (Brainstem, Neocortex) ≠ (Base Motivations, Honorable Motivations) [LW · GW]
comment by TAG · 2021-04-11T22:59:32.328Z · LW(p) · GW(p)
By the way, an interesting aspect of cortical uniformity is that it’s a giant puzzle piece into which we need to (and haven’t yet) fit every other aspect of human nature and psychology. There should be whole books written on this. Instead, nothing. For example, I have all sorts of social instincts—guilt, the desire to be popular, etc. How exactly does that work? The neocortex knows whether or not I’m popular, but it doesn’t care, because (on this view) it’s just a generic learning algorithm. The old brain cares very much whether I’m popular, but it’s too stupid to understand the world, so how would it know whether I’m popular or not? I’ve casually speculated on this a bit (e.g. here) but it seems like a gaping hole in our understanding of the brain, and you won’t find any answers in Hawkins’s book … or anywhere else as far as I know!
Or maybe that's a reason for rejecting, in general, the idea that cognition and motivation are handled by separate modules!
Replies from: moridinamael, steve2152↑ comment by moridinamael · 2021-04-14T14:19:25.516Z · LW(p) · GW(p)
I think the way this could, work, conceptually, is as follows. Maybe the Old Brain does have specific "detectors" for specific events like: are people smiling at me, glaring at me, shouting at me, hitting me; has something that was "mine" been stolen from me; is that cluster of sensations an "agent"; does this hurt, or feel good. These seem to be the kinds of events the small children, most mammals, and even some reptiles seem to be able to understand.
The neocortex then constructs increasingly nuanced models based on these base level events. It builds up a fairly sophisticated cognitive behavior such as, for example, romantic jealousy, or the desire to win a game, or the perception that a specific person is a rival, or a long-term plan to get a college degree, by gradually linking up elements of its learned world model with internal imagined expectations of ending up in states that it natively perceives (with the Old Brain) as good or bad.
Obviously the neocortex isn't just passively learning, it's also constantly doing forward-modeling/prediction using its learned model to try to navigate toward desirable states. Imagined instances of burning your hand on a stove are linked with real memories of burning your hand on a stove, and thus imagined plans that would lead to burning your hand on the stove are perceived as undesirable, because the Old Brain knows instinctively (i.e. without needing to learn) that this is a bad outcome.
eta: Not wholly my original thought, but I think one of the main purposes of dreams is to provide large amounts of simulated data aimed at linking up the neocortical model of reality with the Old Brain. The sorts of things that happen in dreams tend to often be very dramatic and scary. I think the sleeping brain is intentionally seeking out parts of the state space that agitate the Old Brain in order to link up the map of the outside world with the inner sense of innate goodness and badness.
Replies from: steve2152, TAG↑ comment by Steven Byrnes (steve2152) · 2021-04-14T14:41:05.211Z · LW(p) · GW(p)
Yeah, that's pretty much along the lines that I'm thinking. There are a lot of details to flesh out though. I've been working in that direction.
↑ comment by Steven Byrnes (steve2152) · 2021-04-12T00:28:26.787Z · LW(p) · GW(p)
If the brain does something which would be impossible on the assumption of cortical uniformity, then that would indeed be a very good reason to reject cortical uniformity. :-)
If it's not immediately obvious, with no effort or research whatsoever, how the brain can do something on the assumption of cortical uniformity, I don't think that's evidence of much anything!
In fact I came up with a passable attempt at a cortical-uniformity-compatible theory of social instincts pretty much as soon as I tried. It was pretty vague at that point ... I didn't yet know any neuroscience yet ... but it was a start. I've been iterating since then and feel like I'm making good progress, and that this constraint / assumption is a giant help in making sense of the neuroscientific data, not a handicap. :-)
Replies from: TAG↑ comment by TAG · 2021-04-12T01:11:44.204Z · LW(p) · GW(p)
If the brain does something which would be impossible on the assumption of cortical uniformity, then that would indeed be a very good reason to reject cortical uniformity. :-)
Does it? I don't think cortical uniformity implies the separation of motivation and mapping
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-04-12T02:58:47.592Z · LW(p) · GW(p)
Oh, sorry, I think I misunderstood the first time. Hmm, so in this particular post I was trying to closely follow the book by keeping the neocortex by itself. That's not how I normally describe things; normally I talk about the neocortex and basal ganglia working together as a subsystem.
So when I think "I really want to get out of debt", it's combination of a thing in the world-model, and a motivation / valence. I do in fact think that those two aspects of the thought are anatomically distinct: I think the meaning of "get out of debt" (a complex set of relationships and associations and so on) are stored as synapses in the neocortex, and the fact that we want that is stored as synapses in the basal ganglia (more specifically, the striatum). But obviously the two are very very closely interconnected.
E.g. see here [LW · GW] for that more "conventional" RL-style description.
Reward, on the other hand, strikes me as necessarily a very different module. After all, if you only have a learning algorithm that starts from scratch, there's nothing within that system that can say that making friends is good and getting attacked by lions is bad, as opposed to the other way around. Right? So you need a hardcoded reward-calculator module, seems to me.
Sorry if I'm still misunderstanding.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2021-10-03T03:25:57.771Z · LW(p) · GW(p)
I also studied neuroscience for several years, and Jeff's first book was a major inspiration for me beginning that journey. I agree very much with the points you make in this review and in https://www.lesswrong.com/posts/W6wBmQheDiFmfJqZy/brain-inspired-agi-and-the-lifetime-anchor [LW · GW]
Since we seem to be more on the same page than most other people I've talked to about this, perhaps a collaboration between us could be fruitful. Not sure on what exactly, but I've been thinking about how to transition into direct work on AGI safety since updating in the past couple years that it is potentially even closer than I'd thought.
As for the brain division, I also think of the neocortex and basal ganglia working together as a subsystem. I actually strengthened my belief in their tight coupling in my last year of grad school when I learned more about the striatum gating thoughts (not just motor actions), and the cerebellum smoothing abstract thoughts (not just motor actions). So now I envision it more like the brain is thousands of mostly repetitive loops of little neocortex region -> little basal ganglia region -> little hindbrain region -> little cerebellum region -> same little neocortex region, and that these loops also communicate sideways a bit in each region but mostly in the neocortex. With this understanding, I feel like I can't at all get behind Jeff H's idea of safely separating out the neocortical functions from the mid/hind brain functions. I think that an effective AGI general learning algorithm is likely to have to have at least some aspects of those little loops, with striatum gating and cerebellar smoothing, and hippocampal memory linkages.... I do think that the available data in neuroscience is very close, if not already, sufficient for describing the necessary algorithm and it's just a question of a bit more focused work on sorting out the necessary parts from the unneeded complexity. I pulled back from actively trying to do just that once I realized that gaining that knowledge without sufficient safety preparation could be a bad thing for humanity.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-10-04T14:57:46.614Z · LW(p) · GW(p)
Oh wow, cool! I was still kinda confused when I wrote this post and comment thread above, but a couple months later I wrote Big Picture of Phasic Dopamine [LW · GW] which sounds at least somewhat related to what you're talking about and in particular talks a lot about basal ganglia loops.
Oh, except that post leaves out the cerebellum (for simplicity). I have a VERY simple cerebellum story (see the one-sentence version here [LW · GW]) … I've done some poking around the literature and talking to people about it, but anyway I currently still stand by my story and am still confused about why all the other cerebellum-modelers make things so much more complicated than that. :-P
We do sound on the same page … I'd love to chat, feel free to email or DM me if you have time.