Self-Supervised Learning and AGI Safety
post by Steven Byrnes (steve2152) · 2019-08-07T14:21:37.739Z · LW · GW · 9 commentsContents
What is self-supervised learning, and why might it lead to AGI? Impact for safety: General observations 1. Output channel is not part of the training 2. No need for a task-specific reward signal 3. The world-model acquires some safety-enhancing knowledge automatically Constraints under which a self-supervised-learning world-model can be built into a safe AGI system Why won't it try to get more predictable data? Open questions (partial list!) Conclusion None 9 comments
(Update later on: I'm no longer personally excited about this direction, for reasons mentioned in section 7.2 here [LW · GW].)
Abstract: We should seriously consider the possibility that we'll build AGIs by self-supervised learning. If so, the AGI safety issues seem to be in many respects different (and I think more promising) than in the usual reinforcement learning paradigm. In particular, I'll propose that if we follow certain constraints, these systems can be turned into safe, unambitious AGI oracles. I'll end with lots of open questions.
Epistemic status: Treat as brainstorming. This post supersedes my previous post on this general topic, The Self-Unaware AI Oracle [LW · GW] for reasons mentioned below.
What is self-supervised learning, and why might it lead to AGI?
Self-supervised learning consists of taking data, masking off part of it, and training an ML system to use the unmasked data to predict the masked data. To make the predictions better and better, the system needs to develop an increasingly deep and comprehensive semantic understanding of the world. For example, say there's a movie with a rock falling towards the ground. If you want to correctly predict what image will be in the frame a few seconds ahead, you need to predict that the rock will stop when it gets to the ground, not continue falling. Or if there's a movie with a person saying "I'm going to sit down now", you need to predict that they might well sit in a chair, and probably won't start dancing.
Thus, predicting something has close relationship with understanding it. Imagine that you're in a lecture class on a topic where you're already an expert. As the professor is talking, you feel you can often finish their sentences. By contrast, when you're lost in a sea of jargon you don't understand, you can only finish their sentences with a much wider probability distribution ("they're probably going to say some jargon word now").
The term "self-supervised learning" (replacing the previous and more general term "unsupervised learning") seems to come from Yann LeCun, chief AI scientist at Facebook and co-inventor of CNNs. As he wrote here:
I now call it "self-supervised learning", because "unsupervised" is both a loaded and confusing term.
In self-supervised learning, the system learns to predict part of its input from other parts of it input. In other words a portion of the input is used as a supervisory signal to a predictor fed with the remaining portion of the input.
Self-supervised learning uses way more supervisory signals than supervised learning, and enormously more than reinforcement learning. That's why calling it "unsupervised" is totally misleading. That's also why more knowledge about the structure of the world can be learned through self-supervised learning than from the other two paradigms: the data is unlimited, and amount of feedback provided by each example is huge.
Self-supervised learning has been enormously successful in natural language processing...So far, similar approaches haven't worked quite as well for images or videos because of the difficulty of representing distributions over high-dimensional continuous spaces.
Doing this properly and reliably is the greatest challenge in ML and AI of the next few years in my opinion.
As mentioned in this quote, we have a couple good examples of self-supervised learning. One is humans. Here's Yann LeCun again:
Most of human and animal learning is [self]-supervised learning. If intelligence was a cake, [self]-supervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.
Indeed, the brain is constantly making probabilistic predictions about everything it is going to see, hear, and feel, and updating its internal models when those predictions are wrong. Have you ever taken a big drink from a glass of orange juice that you had thought was a glass of water? Or walked into a room and immediately noticed that the table is in the wrong place? It's because you were predicting those sensations in detail before they happened. This is a core part of what the human brain does, and what it means to understand things.[1] Self-supervised learning not the only ingredient in human intelligence—obviously we also have internal and external rewards, environmental interaction, and so on—but I'm inclined to agree with Yann LeCun that self-supervised learning is the cake.[2]
Beyond humans, language models like GPT-2 are a nice example of how far self-supervised learning can go, even when restricted to today's technology and an impoverished text-only datastream. See the SSC post GPT-2 as step towards general intelligence.
Thus, this post is nominally about the scenario where we make superintellignent AGI by 100% self-supervised learning (all cake, no cherries, no icing, in Yann LeCun's analogy). I consider this a live possibility but far from certain. I'll leave to future work the related scenario of "mostly self-supervised learning plus some reinforcement learning or other techniques". (See Open Questions below.)
What does self-supervised learning look like under the hood? GPT-2 and similar language models are based on a Transformer neural net, trained by stochastic gradient descent as usual. The brain, to my limited understanding, does self-supervised learning (mainly using the neocortex, hippocampus, and thalamus) via a dozen or so interconnected processes, some of which are massively parallelized (the same computational process running in thousands of locations at once).[3] These processes are things vaguely like: "If a spatiotemporal pattern recurs several times in a certain context, assign that pattern a UUID, and pass that UUID upwards to the next layer in the hierarchy", and "Pull two items out of memory, look for a transformation between them, and catalog it if it is found".[4]
If I had to guess, I would expect that the ML community will eventually find neural net data structures and architectures that can do these types of brain-like processes—albeit probably not in exactly the same way that the brain does them—and we'll get AGI shortly thereafter. I think it's somewhat less likely, but not impossible, that we'll get AGI by just, say, scaling up the Transformer to some ridiculous size. Either way, I won't speculate on how long it might take to get to AGI, if this is the path. But my vague impression is that self-supervised learning is a hot research area undergoing rapid progress.
Impact for safety: General observations
1. Output channel is not part of the training
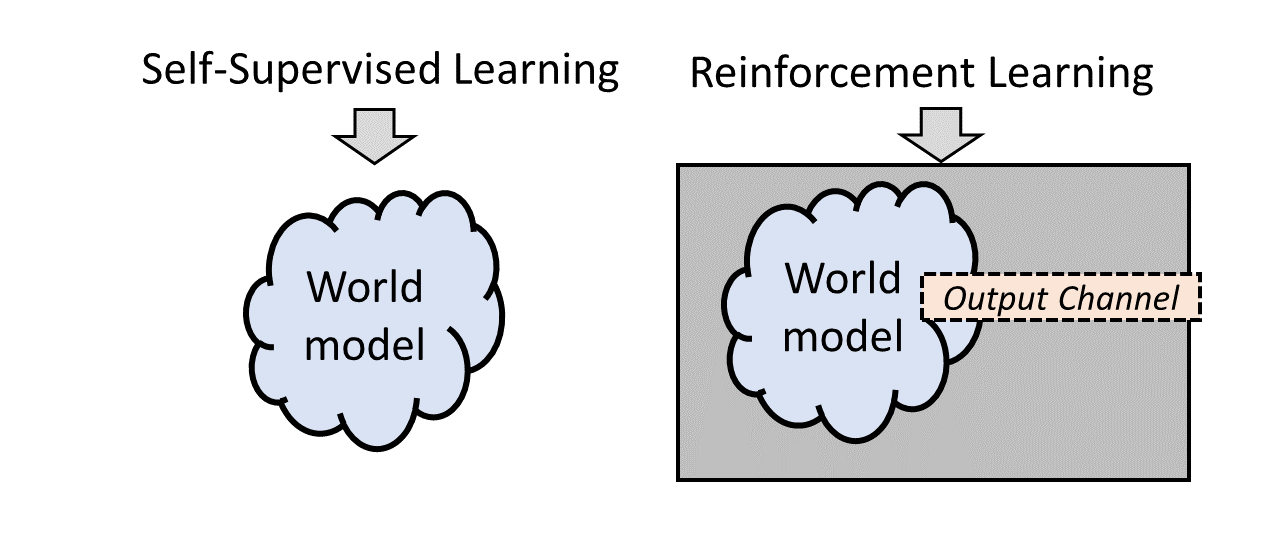
In the reinforcement learning (RL) path to AGI, we wind up creating a system consisting of a world-model attached to an output channel that reaches out into the world and does useful things, and we optimize this whole system. By contrast, in the Self-Supervised Learning path to AGI, we wind up by default with more-or-less just a bare world model. At least, that's the way I'm thinking about it. I mean, sure, it has an output channel in the sense that it can output predictions for masked bits of a file, but that's incidental, not really part of the AGI's primary intended function, i.e. answering questions or doing things. We obviously need some sort of more useful output, but whatever that output is, it's not involved in the training. This opens up some options in the design space that haven't been well explored.
My last post, The Self-Unaware AI Oracle [LW · GW], is a rather extreme example of that, where we would try to build a world model that not only has no knowledge that it is attached to an output channel, but doesn't even know it exists as an information-processing system! My (admittedly vague) proposal for that was to isolate the world-model from any reflective information about how the world-model is being built and analyzed. This is an extreme example, and after further thought I now think it's entirely unnecessary, but I still think it's a nice example of new things we might do in this different design space.[5]
2. No need for a task-specific reward signal
Let's say we want to build a question-answering system by RL. Well, we need to train it by asking questions, and rewarding it for a good answer. This is tricky, to put it mildly. The questions we really care about are ones where we don't necessarily know the answer. How do we get lots of good data? What if we make mistakes in the training set? What if the system learns to optimize a proxy to the reward function, rather than the reward function itself? What if it learns to manipulate the reward function, e.g. by self-fulfilling prophecies? I don't want to say these are impossible challenges, and I'm glad lots of people are working on them. But the self-supervised learning approach seems to largely skirt all these issues.
For self-supervised learning, the paradigm is a bit different. There is, of course, a reward signal guiding the machine learning, namely "predict the masked bits in the input data, using the unmasked bits". But we treat that as purely a method to construct a world-model. Then we ask a separate question: "Now that we have a predictive world-model, how do we use it to make the world a better place"? This step is mainly about building an interface, not building an intelligence. Now, I don't think this task is by any means easy (see "Open questions" below), but I do suspect that it's easier than the various RL challenges above.
3. The world-model acquires some safety-enhancing knowledge automatically
-
Natural-language bridge into the world-model: When we build a world model by self-supervised learning of human-created content, the world model should wind up with an understanding of the real world, an understanding of human language and concepts, and (importantly) an understanding of how these two map onto each other. This should be very helpful for using the world model to answer our questions, and might also offer some (limited) degree of interpretability of the unimaginably complicated guts of the world-model.
-
Understanding of typical human norms, behaviors, and values: When we build a world model by self-supervised learning of human-created content, the world model should wind up with an excellent predictive understanding of typical human behavior. So let's say we can ask it a counterfactual question like If there were no AGIs in the world, what's the likeliest way that a human might find a cure for Alzheimer's? (Put aside for now the issue of how we ask the question—see Open Questions below.) The answer to that question would be a kind of overlap between real-world compatibility (the cure actually works) and human compatibility (it should be the kind of "cures for Alzheimer's" that humans want and would plausibly be looking for). That's what we want! By contrast, a superintelligent biologist with alien motivation system would be likelier to "cure Alzheimer's" by some method that is impractical, or that exploits loopholes in our definition of "cure", etc. (So this incidentally also helps with Goodhart's law.)
Constraints under which a self-supervised-learning world-model can be built into a safe AGI system
A system that can make great predictions of masked bits in a data file is not really useful, and not really something I would call an AGI. We need to build something around the world model, so that it can answer questions or take actions.
Once we start moving in this direction, I think it's very easy to wander into dangerous territory. But, as a starting point, I offer this set of constraints. I believe that if we build an AGI using 100% self-supervised learning, and we follow all these constraints, then the system will be safe—more specifically, it will not do not wield its world model to do foresighted planning towards real-world consequences. Here's my list of constraints:
- The system is used as an oracle, i.e. it answers questions but does not take any other actions. (See my separate post: In defense of Oracle ("Tool") AI [LW · GW].)
- We only ask non-self-referential counterfactual questions along the lines of: If there were no AGIs in the world, what's a likely way that someone might design a better solar cell? This avoids the various problem of self-fulfilling prophecies, such as discussed by Stuart Armstrong in this [LW · GW] and follow-up posts, as well as steering towards solutions compatible with human norms and values as discussed above.
- We fix the training data (what data to look at and what bits to predict, in what order) before we ever start training the system, then we "lock down" the world-model after the training (as opposed to letting it evolve further during question-and-answer operation), and moreover do not allow the oracle to do anything except output answers (no follow-up questions, no asking for more data about some topic, no running simulations in COMSOL, etc.).
- For asking questions and getting answers, we don't try to build a new interface into the world model, but rather build some wrapper around its existing predict-masked-bits interface. (It's not obvious that we can build such a wrapper that works well, but I'm hopeful, and see Open Questions below.)
I'm pretty sure some of these constraints are unnecessarily strict; and conversely, I may be forgetting or leaving off some important requirement.
Why won't it try to get more predictable data?
(Update: After further thought, I am now less confident that this section is correct. See Self-supervised learning & manipulative predictions [LW · GW].)
Why do I think that such an AGI would be safe? (Again, I mean more narrowly that it won't wield its world model to do foresighted planning towards real-world consequences—which is the worst, but not only, thing that can go wrong.) Here's one possible failure mode that I was thinking about. I'm sure some readers are thinking it too:
Oh, it optimizes its ability to predict masked bits from a file, eh? Well it's going to manipulate us, or threaten us, or hack itself, to get easy-to-predict files of all 0's!!
I say that this will not happen with any reasonable self-supervised learning algorithm that we'd be likely to build, if we follow the constraints above.
Gradient descent is a particularly simple example to think about here. In gradient descent, when the world-model makes a bad prediction, the model is edited such that the updated model would (in retrospect) have been likelier to get the right answer for that particular bit. Since the optimization pressure is retrospective ("backwards-facing" in Stuart Armstrong's terminology [LW · GW]), we are not pushing the system to do things like "seeking easier-to-predict files", which help with forward-looking optimization but are irrelevant to retrospective optimization. Indeed, even if the system randomly stumbled upon that kind of forward-looking strategy, further gradient descent steps would be just as likely to randomly discard it again! (Remember, I stipulated above that we will fix in advance what the training data will be, and in what order it will be presented.)
(Neuromorphic world-model-building algorithms do not work by gradient descent, and indeed we don't really know exactly how they would work, but from what we do know, I think they also would be unlikely to do forward-looking optimization.)
The algorithm will, of course, search ruthlessly for patterns that shed light on the masked bits. If it takes longer to read 1s from RAM than 0s (to take a silly example), and if the pattern-finder has access to timing information, then of course it will find the pattern and start making better predictions on that basis. This is not a malign failure mode, and if it happens, we can fix these side channels using cybersecurity best practices.
Open questions (partial list!)
- Input and output: How exactly do we give the system input and output? Predicting masked bits has obvious shortcomings, like that it naturally tries to predict what a flawed humans might say on some topic, rather than what the truth is. This problem may be solvable by doing things like flagging some inputs as highly reliable, and trusting the system to automatically learn the association of that flag with truth and insight, and then priming the system with that flag when we ask it questions. Or would it be better to build a new, separate interface into the guts of the world model? If so, how?
- Sculpting the world model: There may be too much information in the world for our best algorithms to learn it all. Thus an entomologist and botanist can look at the same picture of a garden but enrich their world-models in very different directions. (When I look at a picture of a garden, I zone out and learn nothing whatsoever.) In humans, our innate goals play a critical role in directing the learning process (see my later post Predictive Coding = RL + SL + Bayes + MPC [LW · GW]), but I was hoping to avoid those types of real-world goals; what do we do instead? Can we flag some masked bits as really important to "think about" longer and harder before making a prediction? Or what?
- Training data: Exactly what data should we feed it? Is there dangerous data that we need to censor? Is there unhelpful data that makes it dumber? Is text enough to get AGI, or does there also need to be audio and video? (People can be perfectly intelligent without sight or hearing, though they do have tactile graphics...) Books, articles, and YouTube are obvious sources of training data; are there less obvious but important data sources we should also be thinking about? How does the choice of training data impact safety and interpretability?
- Adding in supervised or reinforcement learning: I've been assuming that we use 100% self-supervised learning to build the AGI. Can we sprinkle in some supervised or reinforcement learning, e.g. as a fine-tuning step, as a way to build an interface into the world model, or as a kind of supervisor to the main training? If so, how, and how would that impact safety and capabilities? (Update: For more on how the brain combines SSL & RL, see my later post: Predictive Coding = RL + SL + Bayes + MPC [LW · GW].)
- Capabilities: Would a system subject to the constraints listed above nevertheless be powerful enough to do the things we want AGIs to do, and if not, can we relax some of those constraints? Can a world model get bigger and richer forever, or will it grind to a halt after deeply understanding the first 300,000 journal articles it reads? More generally, how do these things scale?
- Agency: Can we safely give it a bit of agency in requesting more information, or asking follow-up questions, or interfacing with other software or databases? Or more boldly, can we safely give it a lot of agency, e.g. a 2-way internet connection, and if so, how?
- Experiments: Can we shed light on any of these questions by playing with GPT-2 or other language models? Is there some other concrete example we can find or build? Like, is there any benefit to doing self-supervised learning on a corpus of text and movies talking about the Game Of Life universe?
- Safety: I mentioned a couple possible failure mode above, and said that I didn't think they were concerning. But this obviously needs much more careful thought and analysis before we can declare victory. What are other failure modes we should be thinking about?
- Timelines and strategy: If we get AGI by 100% self-supervised learning, how does that impact takeoff speed, timelines, likelihood of unipolar vs multipolar scenarios, CAIS [LW · GW]-like suites of narrow systems versus monolithic all-purpose systems, etc.?
Conclusion
I hope I've made the point that self-supervised learning scenarios are plausible, and bring forth a somewhat different and neglected set of issues and approaches in AGI safety. I hope I'm not the only one working on it! There's tons of work to do, and god knows I can't do it myself! (I have a full-time job...) :-)
See Andy Clark's Surfing Uncertainty (or SSC summary), or Jeff Hawkins On Intelligence, for more on this. ↩︎
Here are some things guiding my intuition on the primacy of self-supervised learning in humans: (1) In most cultures and most of human history, children have been largely ignored by adults, and learn culture largely by watching adults. They'll literally just sit for an hour straight, watching adults work and interact. This seems to be an instinct that does not properly develop in modern industrialized societies! (See Anthropology of Childhood by Lancy.) (2) Babies' understanding of the world is clearly developing long before they have enough motor control to learn things by interacting (see discussion in Object permanence on wikipedia, though I suppose one could also give the credit to brain development in general rather than self-supervised learning in particular). (3) By the same token, some kids (like me!) start talking unusually late, but then almost immediately have age-appropriate language skills, e.g. speaking full sentences. (See the book Einstein Syndrome, or summary on wikipedia.) I take this as evidence that we primarily learn to speak by self-supervised learning, not trial-and-error. (4) If you read math textbooks, and try to guess how the proofs are going to go before actually reading them, that seems like a pretty good way to learn the content. ↩︎
See The Brain as a Universal Learning Machine [LW · GW] and my post on Jeff Hawkins [LW · GW]. ↩︎
The first of these is vaguely paraphrasing Jeff Hawkins, the latter Doug Hofstadter ↩︎
I haven't completely lost hope in self-unaware designs, but I am now thinking it's likely that cutting off reflective information might make it harder to build a good world-modeler—for example it seems useful for a system to know how it came to believe something. More importantly, I now think self-supervised learning is capable of building a safe AGI oracle even if the system is not self-unaware, as discussed below. ↩︎
9 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2019-08-10T06:41:42.439Z · LW(p) · GW(p)
This is definitely an interesting topic, and I'll eventually write a related post, but here are my thoughts at the moment.
1 - I agree that using natural language prompts with systems trained on natural language makes for a much easier time getting common-sense answers. A particular sort of idiot-proofing that prevents the hypothetical idiot from having the AI tell them how to blow up the world. You use the example of "How would we be likely to cure Alzheimer's?" - but for a well-trained natural language Oracle, you could even ask "How should we cure Alzheimer's?"
If it was an outcome pump [LW · GW] with no particular knowledge of humans, it would give you a plan that would set off our nuclear arsenals. A superintelligent search process with an impact penalty would tell you how to engineer a very unobtrusive virus. A perfect world model with no special knowledge of humans would tell you a series of configurations of quantum fields. These are all bad answers.
What you want the Oracle to tell you is the sort of plan that might practically be carried out, or some other useful information, that leads to an Alheimer cure in the normal way that people mean when talking about diseases and research and curing things. Any model that does a good job predicting human natural language will take this sort of thing for granted in more or less the way you want it to.
2 - But here's the problem with curing Alzheimer's: it's hard. If you train GPT-3 on a bunch of medical textbooks and prompt it to tell you a cure for Alzheimer's, it won't tell you a cure, it will tell you what humans have said about curing Alzheimer's.
If you train a simultaneous model (like a neural net or a big transformer or something) of human words, plus sensor data of the surrounding environment (like how an image captioning ai can be thought of as having a simultaneous model of words and pictures), and figure out how to control the amount of detail of verbal output, you might be able to prompt an AI with text about an Alzheimer's cure, have it model a physical environment that it expects those words to take place in, and then translate that back into text describing the predicted environment in detail. But it still wouldn't tell you a cure. It would just tell you a plausible story about a situation related to the prompt about curing Alzheimer's, based on its training data. Rather than a logical Oracle, this image-captioning-esque scheme would be an intuitive Oracle, telling you things that make sense based on associations already present within the training set.
What am I driving at here, by pointing out that curing Alzheimer's is hard? It's that the designs above are missing something, and what they're missing is search.
I'm not saying that getting a neural net to directly output your cure for Alzheimer's is impossible. But it seems like it requires there to already be a "cure for Alzheimer's" dimension in your learned model. The more realistic way to find the cure for Alzheimer's, if you don't already know it, is going to involve lots of logical steps one after another, slowly moving through a logical space, narrowing down the possibilities more and more, and eventually finding something that fits the bill. In other words, solving a search problem.
So if your AI can tell you how to cure Alzheimer's, I think either it's explicitly doing a search for how to cure Alzheimer's (or worlds that match your verbal prompt the best, or whatever), or it has some internal state that implicitly performs a search.
And once you realize you're imagining an AI that's doing search, maybe you should feel a little less confident in the idiot-proofness I talked about in section 1. Maybe you should be concerned that this search process might turn up the equivalent of adversarial examples in your representation.
3 - Whenever I see a proposal for an Oracle, I tend to try to jump to the end - can you use this Oracle to immediately construct a friendly AI? If not, why not?
A perfect Oracle would, of course, immediately give you FAI. You'd just ask it "what's the code for a friendly AI?", and it would tell you, and you would run it.
Can you do the same thing with this self-supervised Oracle you're talking about? Well, there might be some problems.
One problem is the search issue I just talked about - outputting functioning code with a specific purpose is a very search-y sort of thing to do, and not a very big-ol'-neural-net thing to do, even moreso than outputting a cure for Alzheimer's. So maybe you don't fully trust the output of this search, or maybe there's no search and your AI is just incapable of doing the task.
But I think this is a bit of a distraction, because the basic question is whether you trust this Oracle with simple questions about morality. If you think the AI is just regurgitating an average answer to trolley problems or whatever, should you trust it when you ask for the FAI's code?
There's an interesting case to be made for "yes, actually," here, but I think most people will be a little wary. And this points to a more general problem with definitions - any time you care about getting a definition having some particularly nice properties beyond what's most predictive of the training data, maybe you can't trust this AI.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-08-11T02:34:15.078Z · LW(p) · GW(p)
Thanks for this really helpful comment!!
Search: I don't think search is missing from self-supervised learning at all (though I'm not sure if GPT-2 is that sophisticated). In fact, I think it will be an essential, ubiquitous part of self-supervised learning systems of the future.
So when you say "The proof of this theorem is _____", and give the system a while to think about it, it uses the time to search through its math concept space, inventing new concepts and building new connections and eventually outputting its guess.
Just because it's searching doesn't mean it's dangerous. I was just writing code to search through a string for a substring...no big deal, right? A world-model is a complicated data structure, and we can search for paths through this data structure just like any other search problem. Then when a solution to the search problem is found, the result is (somehow) printed to the terminal. I would be generically concerned here about things like (1) The search algorithm "decides" to seize more computing power to do a better search, or (2) the result printed to the terminal is manipulative. But (1) seems unlikely here, or if not, just use a known search algorithm you understand! For (2), I don't see a path by which that would happen, at least under the constraints I mentioned in the post. Or is there something else you had in mind?
Going beyond human knowledge: When you write "it will tell you what humans have said", I'm not sure what you're getting at. I don't think this is true even with text-only data. I see three requirements to get beyond what humans know:
(1) System has optimization pressure to understand the world better than humans do
(2) System is capable of understanding the world better than humans do
(3) The interface to the model allows us to extract information that goes beyond what humans already know.
I'm pretty confident in all three of these. For example, for (1), give the system a journal article that says "We looked at the treated cell in the microscope and it appeared to be ____". The system is asked to predict the blank. It does a better job at this prediction task by understanding biology better and better, even after it understands biology better than any human. By the same token, for (3), just ask a similar question for an experiment that hasn't yet been done. For (2), I assume we'll eventually invent good enough algorithms for that. What's your take?
(I do agree that videos and images make it easier for the system to exceed human knowledge, but I don't think it's required. After all, blind people are able to have new insights.)
Ethics & FAI: I assume that a self-supervised learning system would understand concepts in philosophy and ethics just like it understands everything else. I hope that, with the right interface, we can ask questions about the compatibility of our decisions with our professed principles, arguments for and against particular principles, and so on. I'm not sure we should expect or want an oracle to outright endorse any particular theory of ethics, or any particular vision for FAI. I think we should ask more specific questions than that. Outputting code for FAI is a tricky case because even a superintelligent non-manipulative oracle is not omniscient; it can still screw up. But it could be a big help, especially if we can ask lots of detailed follow-up questions about a proposed design and always get non-manipulative answers.
Let me know if I misunderstood you, or any other thoughts, and thanks again!
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2019-08-19T19:28:24.917Z · LW(p) · GW(p)
The search thing is a little subtle. It's not that search or optimization is automatically dangerous - it's that I think the danger is that search can turn up adversarial examples / surprising solutions.
I mentioned how I think the particular kind of idiot-proofness that natural language processing might have is "won't tell an idiot a plan to blow up the world if they ask for something else." Well, I think that as soon as the AI is doing a deep search through outcomes to figure out how to make Alzheimer's go away, you lose a lot of that protection and I think the AI is back in the category of Oracles that might tell an idiot a plan to blow up the world.
Going beyond human knowledge
You make some good points about even a text-only AI having optimization pressure to surpass humans. But for the example "GPT-3" system, even if it in some sense "understood" the cure for Alzheimer's, it still wouldn't tell you the cure for Alzheimer's in response to a prompt, because it's trying to find the continuation of the prompt with highest probability in the training distribution.
The point isn't about text vs. video. The point is about the limitations of trying to learn the training distribution.
To the extent that understanding the world will help the AI learn the training distribution, in the limit of super-duper-intelligent AI it will understand more and more about the world. But it will filter that all through the intent to learn the training distribution. For example, if human text isn't trustworthy on a certain topic, it will learn to not be trustworthy on that topic either.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-08-21T14:13:01.999Z · LW(p) · GW(p)
Thanks, that's helpful!
The way I'm currently thinking about it, if we have an oracle that gives superintelligent and non-manipulative answers, things are looking pretty good for the future. When you ask it to design a new drug, you also ask some follow-up questions like "How does the drug work?" and "If we deploy this solution, how might this impact the life of a typical person in 20 years time?" Maybe it won't always be able to give great answers, but as long as it's not trying to be manipulative, it seems like we ought to be able to use such a system safely. (This would, incidentally, entail not letting idiots use the system.)
I agree that extracting information from a self-supervised learner is a hard and open problem. I don't see any reason to think it's impossible. The two general approaches would be:
-
Manipulate the self-supervised learning environment somehow. Basically, the system is going to know lots of different high-level contexts in which the statistics of low-level predictions are different—think about how GPT-2 can imitate both middle school essays and fan-fiction. We would need to teach it a context in which we expect the text to reflect profound truths about the world, beyond what any human knows. That's tricky because we don't have any such texts in our database. But maybe if we put a special token in the 50 most clear and insightful journal articles ever written, and then stick that same token in our question prompt, then we'll get better answers. That's just an example, maybe there are other ways.
-
Forget about text prediction, and build an entirely separate input-output interface into the world model. The world model (if it's vaguely brain-like) is "just" a data structure with billions of discrete concepts, and transformations between those concepts (composition, cause-effect, analogy, etc...probably all of those are built out of the same basic "transformation machinery"). All these concepts are sitting in the top layer of some kind of hierarchy, whose lowest layer consists of probability distributions over short snippets of text (for a language model, or more generally whatever the input is). So that's the world model data structure. I have no idea how to build a new interface into this data structure, or what that interface would look like. But I can't see why that should be impossible...
comment by John_Maxwell (John_Maxwell_IV) · 2020-01-01T23:43:13.872Z · LW(p) · GW(p)
The term "self-supervised learning" (replacing the previous and more general term "unsupervised learning")
BTW, the way I've been thinking about it, "self-supervised learning" represents a particular way to achieve "unsupervised learning"--not sure what use is standard.
comment by John_Maxwell (John_Maxwell_IV) · 2019-08-10T05:54:17.379Z · LW(p) · GW(p)
Agreed this is a neglected topic. My personal view is self-supervised learning is much more likely to lead to AGI than reinforcement learning. I think this is probably good from a safety point of view, although I've been trying to brainstorm possible risks. Daemons seem like the main thing.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-08-11T01:10:17.305Z · LW(p) · GW(p)
Can you be more specific about the daemons you're thinking about? I had tried to argue that daemons wouldn't occur under certain circumstances, or at least wouldn't cause malign failures...
Do you accept the breakdown into "self-supervised learning phase" and "question-answering phase"? If so, in which of those two phases are you thinking that a daemon might do something bad?
I started my own list of pathological things that might happen with self-supervised learning systems, maybe I'll show you when it's ready and we can compare notes...?
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-08-14T02:58:25.935Z · LW(p) · GW(p)
Can you be more specific about the daemons you're thinking about? I had tried to argue that daemons wouldn't occur under certain circumstances, or at least wouldn't cause malign failures...
Which part are you referring to?
Anyway, I'm worried that a daemon will arise while searching for models which do a good job of predicting masked bits. As it was put here [LW · GW]: "...we note that trying to predict the output of consequentialist reasoners can reduce to an optimisation problem over a space of things that contains consequentialist reasoners." Initially daemons seemed implausible to me, but then I thought of a few ways they could happen--hoping to write posts about this before too long. I encourage others to brainstorm as well, so we can try & think of all the plausible ways daemons could get created.
I started my own list of pathological things that might happen with self-supervised learning systems, maybe I'll show you when it's ready and we can compare notes...?
Sure!
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2019-08-21T10:45:43.614Z · LW(p) · GW(p)
Ah, thanks for clarifying.
The first entry on my "list of pathological things" wound up being a full blog post in length: See Self-supervised learning and manipulative predictions [LW · GW].
RE daemons, I wrote in that post (and have been assuming all along): "I'm assuming that we will not do a meta-level search for self-supervised learning algorithms... Instead, I am assuming that the self-supervised learning algorithm is known and fixed (e.g. "Transformer + gradient descent" or "whatever the brain does"), and that the predictive model it creates has a known framework, structure, and modification rules, and that only its specific contents are a hard-to-interpret complicated mess." The contents of a world-model, as I imagine it, is a big data structure consisting of gajillions of "concepts" and "transformations between concepts". It's a passive data structure, therefore not a "daemon" in the usual sense. Then there's a KANSI (Known Algorithm Non Self Improving) system that's accessing and editing the world model. I also wouldn't call that a "daemon", instead I would say "This algorithm we wrote can have pathological behavior..."