Predictive coding = RL + SL + Bayes + MPC
post by Steven Byrnes (steve2152) · 2019-12-10T11:45:56.181Z · LW · GW · 8 commentsContents
8 comments
(Update much later (2021-06): I put in some minor updates and retractions below. Also, if I were writing this today I would probably have framed it as "here's how I disagree with predictive coding" rather than "here's a version of predictive coding that I like". Also, wherever you see "predictive coding" below, read "predictive processing"—at the time that I wrote this, I didn't understand the difference, and used the wrong one. By the way, I wrote this near the very earliest stages of my learning about the brain. Having learned a lot more since then, I guess I'm not too embarrassed by what I wrote here, but there are certainly lots of little things I would describe differently now.)
I was confused and skeptical for quite a while about some aspects of predictive coding—and it's possible I'm still confused—but after reading a number of different perspectives on brain algorithms, the following picture popped into my head and I felt much better:
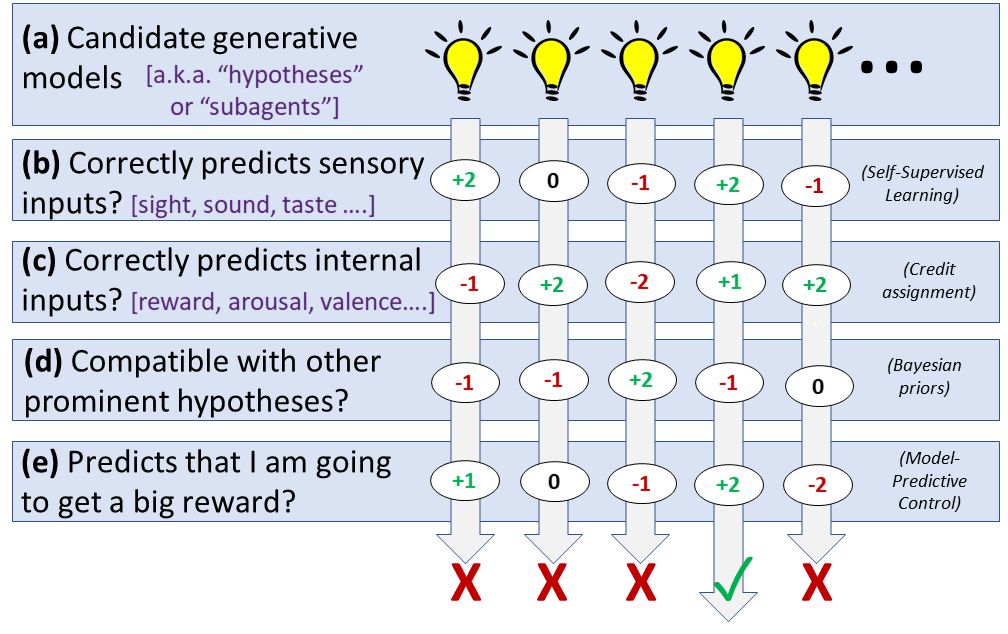
This is supposed to be a high-level perspective on how the neocortex[1] builds a predictive world-model and uses it to choose appropriate actions. (a) We generate a bunch of generative models in parallel, which make predictions about what's going on and what's going to happen next, including what I am doing and will do next (i.e., my plans). The models gain "prominence" by (b) correctly predicting upcoming sensory inputs; (c) correctly predicting other types of input information coming into the neocortex like tiredness, hormonal signals, hunger, warmth, pain, pleasure, reward, and so on; (d) being compatible with other already-prominent models; (e) predicting that a large reward signal is coming, which as discussed in my later article Inner Alignment in the Brain [LW · GW], includes things like predicting that my goals will be fulfilled with minimal effort, I'll be eating soon if I'm hungry, I'll be sleeping soon if I'm tired, I'll avoid pain, and so on. Whatever candidate generative model winds up the most "prominent" wins, and determines my beliefs and actions going forward.
(Note on terminology: I'm calling these things "generative models" in all cases. Kurzweil calls them "patterns". They're also sometimes called "hypotheses", especially in the context of passive observation (e.g. "that thing I see is a bouncy ball"). Or they're called "subagents"[2], especially in the context of self-prediction (e.g. "I am about to eat").
Before we get to details, I need to apologize for the picture being misleading:
-
First, I drew (b,c,d,e) as happening after (a), but really some of these (especially (d) I think) work by affecting which models get considered in the first place. (More generally, I do not want to imply that a,b,c,d,e correspond to exactly five distinct neural mechanisms, or anything like that. I'm just going for a functional perspective in this post.)
-
Second (and relatedly), I depicted it as if we simply add up points for (b-e), but it's certainly not linear like that. I think at least some of the considerations effectively get vetoes. For example, we don't generally see a situation where (e) is so positive that it simply outvotes (b-d), and thus we spend all day checking our wallet expecting to find it magically filled with crisp $1000 bills. (Much more about wishful thinking below.) (Update much later: Yeah, I think (e) is implemented by a very different mechanism involving different parts of the brain than (a-d)—see here [AF · GW]—and indeed I think that (b-d) more-or-less get a veto.)
-
Third, at the bottom I drew one generative model being the "winner". Things like action plans and conscious attention [LW · GW] do in fact have a winner-take-all dynamic because, for example, we don't want to be sending out muscle commands for both walking and sitting simultaneously.[3] But in general, lower-ranked models are not thrown out; they linger, with their prominence growing or shrinking as more evidence comes in.
Anyway, the picture above tells a nice story:
(b) is self-supervised learning[4], i.e. learning from prediction. Process (b) simply votes against generative models when they make incorrect predictions. This process is where we get the vast majority of the information content we need to build a good predictive world-model. Note that there doesn't seem to be any strong difference in the brain between (i) actual experiences, (ii) memory recall, and (iii) imagination—process (b) will vote for or against models when presented with any of those three types of "evidence". (I think they vote much more strongly in case (i) though.)
(c) is credit assignment, i.e. learning what aspects of the world cause good or bad things to happen to us, so that we can make good decisions. Each generative model makes claims about what is the cause of subcortex-provided informational signals [LW · GW] (analogous to "reward" in RL)—information signals that say we're in pain, or eating yummy food, or exhausted, or scared, etc. These claims cash out as predictions that can prove right or wrong, thus either supporting or casting doubt on that model. Thus our internal models say that "cookies are yummy", corresponding to a prediction that, if we eat one, we'll get a "yummy" signal from some ancient reptilian part of our brain.
(d) is Bayesian priors. I doubt we do Bayesian updating in a literal mathematical sense, but we certainly do incorporate prior beliefs into our interpretation of new evidence. I'm claiming that the mechanism for this is "models gain prominence by being compatible with already-prominent models". What is an "already-prominent model"? One that has previously been successful in this same process I'm describing here, especially if in similar contexts, and super-especially if in the immediate past. Such models function as our priors. And what does it mean for a new model to be "compatible" with these prior models? Well, a critical fact about these models is that they snap together like Legos, allowing hierarchies, recursion, composition, analogies, casual relationships, and so on. (Thus, I've never seen a rubber wine glass, but I can easily create a mental model of one by gluing together some of my rubber-related generative models with some of my wine-glass-related generative models.) Over time we build up these super-complicated and intricate Rube Goldberg models, approximately describing our even-more-complicated world. I think a new model is "compatible" with a prior one when (1) the new model is almost the same as the prior model apart from just one or two simple edits, like adding a new bridging connection to a different already-known model; and/or (2) when the new model doesn't make predictions counter to the prior one, at least not in areas where the prior one is very precise and confident.[5] Something like that anyway, I think...
(e) is Model-Predictive Control. If we're hungry, we give extra points to a generative model that says we're about to get up and eat a snack, and so on. This works in tandem with credit assignment (process (c)), so if we have a prominent model that giving speeches will lead to embarrassment, then we will subtract points from a new model that we will give a speech tomorrow, and we don't need to run the model all the way through to the part where we get embarrassed. I like Kaj Sotala's description here: "mental representations...[are] imbued with a context-sensitive affective gloss"—in this case, the mental representation of "I will give a speech" is infused with a negative "will lead to embarrassment" vibe, and models lose points for containing that vibe. It's context-sensitive because, for example, the "will lead to feeling cold" vibe could be either favorable or unfavorable depending on our current body temperature. Anyway, this framing makes a lot of sense for choosing actions, and amounts to using control theory to satisfy our innate drives. But if we're just passively observing the world, this framework is kinda problematic...
(e) is also wishful thinking. Let's say someone gives us an unmarked box with a surprise gift inside. According to the role of (e) in the picture I drew, if we receive the box when we're hungry, we should expect to find food in the box, and if we receive the box when we're in a loud room, we should expect to find earplugs in the box, etc. Well, that's not right. Wishful thinking does exist, but it doesn't seem so inevitable and ubiquitous as to deserve a seat right near the heart of human cognition. Well, one option is to declare that one of the core ideas of Predictive Coding theory—unifying world-modeling and action-selection within the same computational architecture—is baloney. But I don't think that's the right answer. I think a better approach is to posit that (b-d) are actually pretty restrictive in practice, leaving (e) mainly as a comparitively weak force that can be a tiebreaker between equally plausible models. In other words, passive observers rarely if ever come across multiple equally plausible models for what's going on and what will happen next; it would require a big coincidence to balance the scales so precisely. But when we make predictions about what we ourselves will do, that aspect of the prediction is a self-fulfilling prophecy, so we routinely have equally plausible models...and then (e) can step in and break the tie.
More general statement of situations where (e) plays a big role: Maybe "self-fulfilling" is not quite the right terminology for when (e) is important; it's more like "(e) is most important in situations where lots of models are all incompatible, yet where processes (b,c,d) never get evidence to support one model over the others." So (e) is central in choosing action-selection models, since these are self-fulfilling, but (e) plays a relatively minor role in passive observation of the world, since there we have (b,c) keeping us anchored to reality (but (e) does play an occasional role on the margins, and we call it "wishful thinking"). (e) is also important because (b,c,d) by themselves leave this whole process highly under-determined: walking in a forest, your brain can build a better predictive model of trees, of clouds, of rocks, or of nothing at all; (e) is a guiding force that, over time, keeps us on track building useful models for our ecological niche.
One more example where (e) is important: confabulation, rationalization, etc. Here's an example: I reach out to grab Emma's unattended lollipop because I'm hungry and callous, but then I immediately think of an alternate model, in which I am taking the lollipop because she probably wants me to have it. The second model gets extra points from the (e) process, because I have an innate drive to conform to social norms, be well-regarded and well-liked, etc. Thus the second model beats the truthful model (that I grabbed the lollipop because I was hungry and callous). Why can't the (b) process detect and destroy this lie? Because all that (b) has to go on is my own memory, and perniciously, the second model has some influence over how I form the memory of grabbing the lollipop. It has covered its tracks! Sneaky! So I can keep doing this kind of thing for years, and the (b) process will never be able to detect and kill this habit of thought. Thus, rationalization winds up more like action selection, and less like wishful thinking, in that it is pretty much ubiquitous and central to cognition.[6]
Side note: Should we lump (d-e) together? When people describe Predictive Coding theory, they tend to lump (d-e) together, to say things like "We have a prior that, when we're hungry, we're going to eat soon." I am proposing that this lumping is not merely bad [LW(p) · GW(p)] pedagogy, but is actually conflating together two different things: (d) and (e) are not inextricably unified into a single computational mechanism. (I don't think the previous sentence is obvious, and I'm not super-confident about it.) (Update later on: yeah they're definitely different, see here [AF · GW].) By the same token, I'm uncomfortable saying that minimizing prediction error is a fundamental operating principle of the brain; I want to say that processes (a-e) are fundamental, and minimizing prediction error is something that arguably happens as an incidental side-effect.
Well, that's my story, it seems to basically makes sense, but that could just be my (e) wishful thinking and (e) rationalization talking. :-)
(Update May 2020: The traditional RL view would be that there's a 1-dimensional signal called "reward" that drives process (e). When I first wrote this, I was still confused about whether that was the right way to think about the brain, and thus I largely avoided the term "reward" in favor of less specific things. After thinking about it more—see inner alignment in the brain [LW · GW], I am now fully on board with the traditional RL view; process (e) is just "We give extra points to models that predict that a large reward signal is coming". Also, I replaced "hypotheses" with "generative models" throughout, I think it's a better terminology.) (Update June 2021: Better discussion of "reward" here [AF · GW].)
The neocortex is 75% of the human brain by weight, and centrally involved in pretty much every aspect of human intelligence (in partnership with the thalamus and hippocampus). More about the neocortex in my previous post [LW · GW] ↩︎
See Jan Kulveit's Multi-agent predictive minds and AI alignment [LW · GW], Kaj Sotala's Multiagent models of mind sequence [? · GW], or of course Marvin Minsky and many others. ↩︎
I described conscious attention and action plans as "winner-take-all" in the competition among models, but I think it's somewhat more complicated and subtle than that. I also think that picking a winner is not a separate mechanism from (b,c,d,e), or at least not entirely separate. This is a long story that's outside the scope of this post. ↩︎
I have a brief intro to self-supervised learning at the beginning of Self-Supervised Learning and AGI Safety [LW · GW] ↩︎
Note that my picture at the top shows parallel processing of models, but that's not quite right; in order to see whether two prominent models are making contradictory predictions, we need to exchange information between them. ↩︎
See The Elephant in the Brain etc. ↩︎
8 comments
Comments sorted by top scores.
comment by MaxRa · 2020-10-21T09:54:13.132Z · LW(p) · GW(p)
That's super fascinating. I've dabbled a bit in all of those parts of your picture and seeing them put together like this feels really illuminating. I'd wish some predictive coding researcher would be so kind to give it a look, maybe somebody here knows someone?
During reading, I was a bit confused about the set of generative models or hypotheses. Do you have an example how this could concretely look like? For example, when somebody tosses me an apple, is there a generative model for different velocities and weights, or one generative model with an uncertainty distribution over those quantities? In the latter case, one would expect another updating-process acting "within" each generative model, right?
Replies from: steve2152, MaxRa↑ comment by Steven Byrnes (steve2152) · 2020-10-21T13:36:55.210Z · LW(p) · GW(p)
Thanks!
I'd wish some predictive coding researcher would be so kind to give it a look, maybe somebody here knows someone?
Yeah, I haven't had the time or energy to start cold-emailing predictive coding experts etc. Well, I tweet this article at people now and then :-P Also, I'm still learning, the picture is in flux, and in particular I still can't really put myself in the head of Friston, Clark, etc. so as to write a version of this that's in their language and speaks to their perspective.
During reading, I was a bit confused about the set of generative models or hypotheses. Do you have an example how this could concretely look like? For example, when somebody tosses me an apple, is there a generative model for different velocities and weights, or one generative model with an uncertainty distribution over those quantities? In the latter case, one would expect another updating-process acting "within" each generative model, right?
I put more at My Computational Framework for the Brain [LW · GW], although you'll notice that I didn't talk about where the generative models come from or their exact structure (which is not entirely known anyway). Three examples I often think about would be: the Dileep George vision model, the active dendrite / cloned HMM sequence learning story (biological implementation by Jeff Hawkins, algorithmic implementation by Dileep George) (note that neither of these have reward), and maybe (well, it's not that concrete) also my little story about moving your toe [LW · GW].
I would say that the generative models are a consortium of thousands of glued-together mini-generative-models, maybe even as much as one model per cortical column, which are self-consistent in that they're not issuing mutually-contradictory predictions (often because any given mini-model simply abstains from making predictions about most things). Some of the mini-model pieces stick around a while, while other pieces get thrown out and replaced constantly, many times per second, either in response to new sensory data or just because the models themselves have time-dependence. Like if someone tosses you an apple, there's a set of models (say, in language and object-recognition areas) that really just mean "this is an apple" and they're active the whole time, while there are other models (say, in a sensory-motor area) that say "I will reach out in a certain way and catch the apple and it will feel like this when it touches my hand)", and some subcomponents of the latter one keep getting edited or replaced as you watch the apple and update your belief about its trajectory. I think "edited or replaced" is the right way to think about it—both can happen—but I won't say more because now this is getting into low-level gory details that are highly uncertain anyway. :-P
Replies from: MaxRa↑ comment by MaxRa · 2020-10-22T10:03:22.093Z · LW(p) · GW(p)
Thanks a lot for the elaboration!
in particular I still can't really put myself in the head of Friston, Clark, etc. so as to write a version of this that's in their language and speaks to their perspective.
Just a sidenote, one of my profs is part of the Bayesian CogSci crowd and was fairly frustrated with and critical of both Friston and Clark. We read one of Friston's papers in our journal club and came away thinking that Friston is reinventing a lot of wheels and using odd terms for known concepts.
For me, this paper by Sam Gershman helped a lot in understanding Friston's ideas, and this one by Laurence Aitchison and Máté Lengyel was useful, too.
I would say that the generative models are a consortium of thousands of glued-together mini-generative-models
Cool, I like that idea, I previously thought about the models as fairly separated and bulky entities, that sounds much more plausible.
↑ comment by MaxRa · 2020-10-21T09:57:08.035Z · LW(p) · GW(p)
As a (maybe misguided) side comment, model sketches like yours make me intuitively update for shorter AI timelines, because they give me a sense of a maturing field of computational cognitive science. Would be really interested in what others think about that.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-10-21T13:43:09.722Z · LW(p) · GW(p)
I think I'm in a distinct minority on this forum, maybe a minority of 1, in thinking that there's more than 50% chance that studying and reverse-engineering neocortex algorithms will be the first way we get AGI. (Obviously I'm not the only one in the world with this opinion, just maybe the only one on this forum.)
I think there's a good outside-view argument, namely this is an active field of research, and at the end of it, we're all but guaranteed to have AGI-capable algorithms, unlike almost any other research program.
I think there's an even stronger (to me) inside-view argument, in which cortical uniformity [LW · GW] plays a big role, because (1) if one algorithm can learn languages and image-processing and calculus, that puts a ceiling on the level of complexity and detail within that algorithm, and (2) my reading of the literature makes me think that we already understand the algorithm at least vaguely, and the details are starting to crystallize into view on the horizon ... although I freely acknowledge that this might just be the Dunning-Kruger talking. :-)
Replies from: MaxRa↑ comment by MaxRa · 2020-10-22T09:40:26.457Z · LW(p) · GW(p)
That's really interesting, I haven't thought about this much, but it seems very plausible and big if true (though I am likely biased as a Cognitive Science student). Do you think this might be turned into a concrete question to forecast for the Metaculus crowd, i.e. "Reverse-engineering neocortex algorithms will be the first way we get AGI"? The resolution might get messy if an org like DeepMind, with their fair share of computational neuroscientists, will be the ones who get there first, right?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-10-23T11:16:49.636Z · LW(p) · GW(p)
Yeah I think it would be hard to pin down. Obviously AGI will resemble neocortical algorithms in some respects, and obviously it will be different in some respects. For example, the neocortex uses distributed representations, deep neural nets use distributed representations, and the latter was historically inspired by the former, I think. And conversely, no way AGI will have synaptic vesicles! In my mind this probabilistic programming system with no neurons - https://youtu.be/yeDB2SQxCEs - is "more like the neocortex" than a ConvNet, but that's obviously just a particular thing I have in mind, it's not an objective assessment of how brain-like something is. Maybe a concrete question would be "Will AGI programmers look back on the 2010s work of people like Dileep George, Randall O'Reilly, etc. as being an important part of their intellectual heritage, or just 2 more of the countless thousands of CS researchers?" But I dunno, and I'm not sure if that's a good fit for Metaculus anyway.
comment by Gordon Seidoh Worley (gworley) · 2019-12-10T20:49:31.467Z · LW(p) · GW(p)
Side note: Should we lump (d-e) together?
Or more generally, should we lump all of these levels together or not?
On the one hand, I think yes, because I think the same basic mechanism is at work (homeostatic feedback loop).
On the other hand, no, because those loops are wired together in different ways in different parts of the brain to do different things. I draw my model of what the levels are from the theory of dependent origination but other theories are possible, and maybe we can eventually get some thoroughly grounded in empirical neuroscience.