Inner alignment in the brain
post by Steven Byrnes (steve2152) · 2020-04-22T13:14:08.049Z · LW · GW · 16 commentsContents
Background & motivation The subcortex provides the training signals that guide the neocortex to do biologically-useful things.[3] Things to keep in mind Simple example: Fear of spiders The neocortex is a black box from the perspective of the subcortex General picture Emotions, "emotion concepts", and "reactions" The neocortex's non-motor outputs Reward criterion (one among many): when the subcortex calls for a reaction (e.g. cortisol release, eyes widening, etc.), it rewards the neocortex with dopamine if it sees that those commands have somehow already been issued. Predicting, imagining, remembering, empathizing Various implications Opening a window into the black-box neocortex Complex back-and-forth between neocortex and subcortex "Overcoming" subcortical reactions Things I still don't understand None 16 comments
Abstract: We can think of the brain crudely as (1) a neocortex which runs an amazingly capable quasi-general-purpose learning-and-planning algorithm, and (2) subcortical structures (midbrain, etc.), one of whose functions is to calculate rewards that get sent to up the neocortex to direct it. But the relationship is actually more complicated than that. "Reward" is not the only informational signal sent up to the neocortex; meanwhile information is also flowing back down in the opposite direction. What's going on? How does all this work? Where do emotions fit in? Well, I'm still confused on many points, but I think I'm making progress. In this post I will describe my current picture of this system.
Background & motivation
I'm interested in helping ensure a good post-AGI future. But how do we think concretely about AGI, when AGI doesn't exist and we don't know how to build it? Three paths:
- We can think generally about the nature of intelligence and agency—a research program famously associated with MIRI, Marcus Hutter, etc.;
- We can think about today's AI systems—a research program famously associated with OpenAI, DeepMind, CHAI, etc.;
- We can start from the one "general intelligence" we know about, i.e. the human brain, and try to go from there to lessons about how AGI might be built, what it might look like, and how it might be safely and beneficially used and controlled.
I like this 3rd research program; it seems to be almost completely neglected,[1] and I think there's a ton of low-hanging fruit there. Also, this program will be especially important if we build AGI in part by reverse-engineering (or reinventing) high-level neocortical algorithms, which (as discussed below) I think is very plausible, maybe even likely—for better or worse.
Now, the brain is divided into the neocortex and the subcortex.
Start with the neocortex[2] The neocortex does essentially all the cool exciting intelligent things that humans do, like building an intelligent world-model involving composition and hierarchies and counterfactuals and analogies and meta-cognition etc., and using that thing to cure diseases and build rocket ships and create culture etc. Thus, both neuroscientists and AI researchers focus a lot of attention onto the neocortex, and on understanding and reverse-engineering its algorithms. Textbooks divide the neocortex into lots of functional regions like "motor cortex" and "visual cortex" and "frontal lobe" etc., but microscopically it's all a pretty uniform 6-layer structure, and I currently believe that all parts of the neocortex are performing more-or-less the same algorithm, but with different input and output connections. These connections are seeded by an innate gross wiring diagram and then edited by the algorithm itself. See Human Instincts, Symbol Grounding, and the Blank-Slate Neocortex [LW · GW] for discussion and (heavy!) caveats on that claim. And what is this algorithm? I outline some of (what I think are) the high-level specifications at Predictive coding = RL + SL + Bayes + MPC [LW · GW]. In terms of how the algorithm actually works, I think that researchers are making fast progress towards figuring this out, and that a complete answer is already starting to crystallize into view on the horizon. For a crash course on what's known today on how the neocortex does its thing, maybe a good starting point would be to read On Intelligence and then every paper ever written by Dileep George (and citations therein).
The subcortex, by contrast, is not a single configuration of neurons tiled over a huge volume, but rather it is a collection of quite diverse structures like the amygdala, cerebellum, tectum, and so on. Unlike the neocortex, this stuff does not perform some miraculous computation light-years beyond today's technology; as far as I can tell, it accomplishes the same sorts of things as AlphaStar does. And the most important thing to understand (for AGI safety) is this:
The subcortex provides the training signals that guide the neocortex to do biologically-useful things.[3]
Now, if people build AGI that uses algorithms similar to the neocortex, we will need to provide it with training signals. What exactly are these training signals? What inner alignment [LW · GW] issues might they present? Suppose we wanted to make an AGI that was pro-social for the same underlying reason as humans are (sometimes) pro-social (i.e., thanks to the same computation); is that possible, how would we do it, and would it work reliably? These are questions we should answer well before we finish reverse-engineering the neocortex. I mean, really these questions should have been answered before we even started reverse-engineering the neocortex!! I don't have answers to those questions, but I'm trying to lay groundwork in that direction. Better late than never…
(Update 1 year later: These days I say "hypothalamus & brainstem" instead of subcortex, and I'm inclined to lump almost the entire rest of the brain—the whole telencephalon plus cerebellum—in with the neocortex as the subsystem implementing a from-scratch learning algorithm. See here [LW · GW])
Things to keep in mind
Before we get into the weeds, here are some additional mental pictures we'll need going forward:
Simple example: Fear of spiders
My go-to example for the relation between subcortex and neocortex is fear of spiders.[4] Besides the visual cortex, humans have a little-known second vision system in the midbrain (superior colliculus). When you see a black scuttling thing in your field of view, the midbrain vision system detects that and sends out a reaction that makes us look in that direction and increase our heart rate and flinch away from it. Meanwhile, the neocortex is simultaneously seeing the spider with its vision system, and it's seeing the hormones and bodily reaction going on, and it connects the dots to learn that "spiders are scary". In the future, if the neocortex merely imagines a spider, it might cause your heart to race and body to flinch. On the other hand, after exposure therapy, we might be able to remain calm when imagining or even seeing a spider. How does all this work?
(Note again the different capabilities of the midbrain and neocortex: The midbrain has circuitry to recognize black scuttling things—kinda like today's CNNs can—whereas the neocortex is able to construct and use a rich semantic category like "spiders".)
We'll be returning to this example over and over in the post, trying to work through how it might be implemented and what the consequences are.
The neocortex is a black box from the perspective of the subcortex
The neocortex's algorithm, as I understand it, sorta learns patterns, and patterns in the patterns, etc., and each pattern is represented as an essentially randomly-generated[5] set of neurons in the neocortex. So, if X is a concept in your neocortical world-model, there is no straightforward way for an innate instinct to refer directly to X—say, by wiring axons from the neurons representing X to the reward center—because X's neurons are not at predetermined locations. X is inside the black box. An instinct can incentivize X, at least to some extent, but it has to be done indirectly.
I made a list of various ways that we can have universal instincts despite the neocortex being a black-box learning algorithm: See Human Instincts, Symbol Grounding, and the Blank-Slate Neocortex [LW · GW] for my list.
This blog post is a much deeper dive into how a couple of these mechanisms might be actually implemented.
General picture
Finally, here is the current picture in my head:
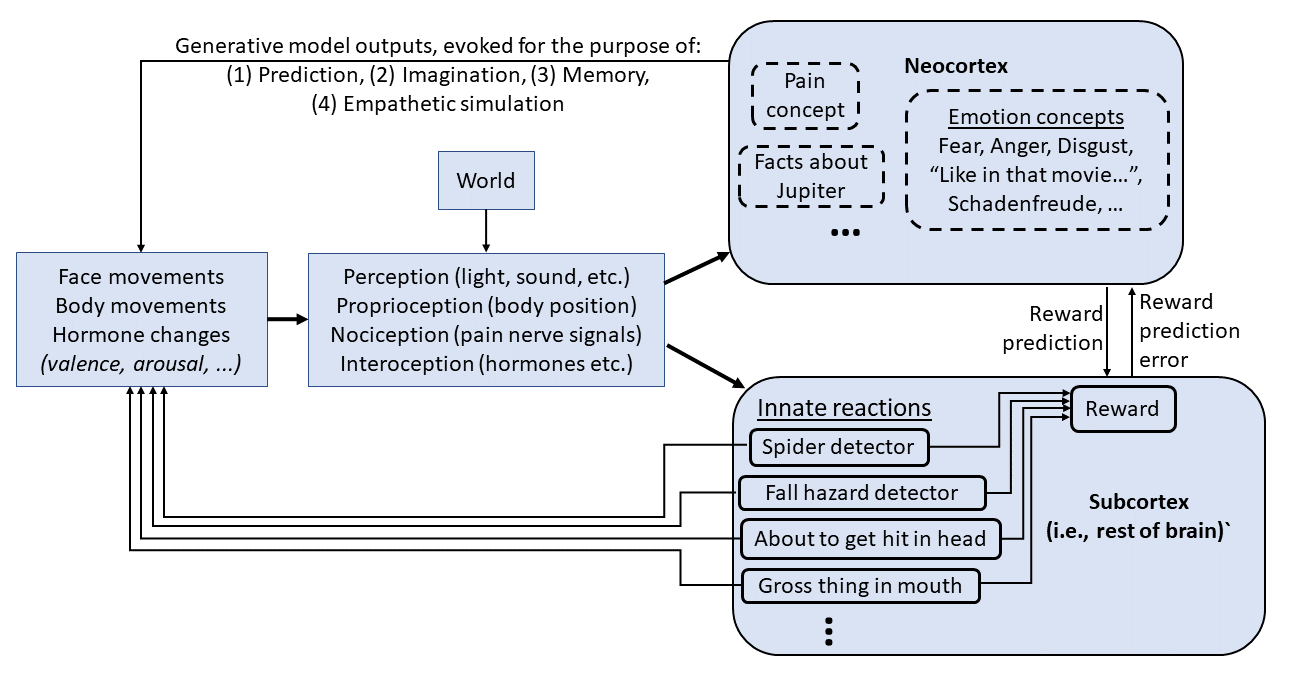
(Update 1 year later: I no longer would draw it this way—see Big picture of phasic dopamine [LW · GW] for what I now think instead. The main difference is: I would not draw a direct line from neocortex to a hormone change (for example); instead the cortex would tell the subcortex (hypothalamus + brainstem) to make that hormone change, and then the subcortex might or might not comply with that recommendation. (I guess the way I drew it here is more like somatic marker hypothesis.))
There’s a lot here. Let's go through it bit by bit.
Emotions, "emotion concepts", and "reactions"
One aspect of this picture is emotions. There's a school of thought, popularized by Paul Ekman and the movie Inside Out, that there are exactly six emotions (anger, disgust, fear, happiness, sadness, surprise), each with its own universal facial expression. (I've seen other lists of emotions too, and sometimes there's also a list of social emotions like embarrassment, jealousy, guilt, shame, pride, etc.) That was my belief too, until I read the book How Emotions Are Made by Lisa Feldman Barrett, which convincingly argues against it. Barrett argues that a word like "anger" lumps together a lot of very different bodily responses involving different facial expressions, hormones, etc. Basically, emotional concepts, like other concepts, are arbitrary categories describing things that we find useful to lump together. Sure, they might be lumped together because they share a common hormone change or a common facial expression, but they might just as likely be lumped together because they share a common situational context, or a common set of associated social norms, or whatever else. And an emotion concept with an English-language name like "anger" is not fundamentally different from an idiosyncratic emotion concept like "How Alice must have felt in that TV episode where...".
(Incidentally, while I think Barrett's book is right about that, I am definitely not blanket-endorsing the whole book—there are a lot of other claims in it that I don't agree with, or perhaps don't understand.[6] I think Barrett would strongly disagree with most of this blog post, though I could be wrong.)
So instead of putting "emotions" in the subcortex, I instead put there a bunch of things I'm calling "reactions" for clarity.[7] I imagine that there are dozens to hundreds of these (...and separating them into a discrete list is probably an oversimplification of a more complicated computational architecture, but I will anyway). There's the reaction that gets triggered when your midbrain vision system sees a spider moving towards you out of the corner of your eye, as discussed above. And there's a different reaction that gets triggered when you stand at the edge of a precipice and peer over the edge. Both of those reactions might be categorized as "fear" in the neocortex, but they're really different reactions, involving (I presume) different changes to heart rate, different bodily motions, different facial expressions, different quantities of (negative) reward, etc. (Reactions where peripheral vision is helpful will summon a wide-eyed facial expression; reactions where visual acuity is helpful will summon a narrow-eyed facial expression; and so on.)
As described above for the spider example, the neocortex can see what the subcortex does to our hormones, body, face, etc., and it can learn to predict that, and build those expectations into its predictive world-model, and create concepts around that.
(I also put "pain concept" in the neocortex, again following Barrett. A giant part of the pain concept is nociception—detecting the incoming nerve signals we might call "pain sensations". But at the end of the day, the neocortex gets to decide whether or not to classify a situation as "pain", based on not only nociception but also things like context and valence.)
The neocortex's non-motor outputs
From the above, our neocortex comes to expect that if we see a scuttling spider out of the corner of our eye, our heart will race and we'll turn towards it and flinch away. What's missing from this picture? The neocortex causing our heart to race by anticipating a spider. It's easy to see why this would be evolutionarily useful: If I know (with my neocortex) that a poisonous spider is approaching, it's appropriate for my heart to start racing even before my midbrain sees the black scuttling blob.
Now we're at the top-left arrow in the diagram above: the neocortex causing (in this case) release of stress hormones. How does the neocortex learn to do that?
There are two parts of this "how" question: (1) what are the actual output knobs that the neocortex can use, and (2) how does the neocortex decide to use them? For (1), I have no idea. For the purpose of this blog post, let us assume that there is a set of outgoing axons from the neocortex that (directly or indirectly) cause hormone release, and also assume that "hormone release" is the right thing to be talking about in terms of controlling valence, arousal, and so on. I have very low confidence in all this, but I don't think it matters much for what I want to say in this post. (Update 1 year later: I understand (1) better now, but it still doesn't matter here.)
I mainly want to discuss question (2): given these output knobs, how does the neocortex decide to use them?
Recall again that in predictive coding, the neocortex finds generative models which are consistent with each other, which have not been repeatedly falsified, and which predict that reward will happen [LW · GW].
My first thought was: No additional ingredients, beyond that normal predictive coding picture, are needed to get the neocortex to imitate the subcortical hormone outputs. Remember, just like my post on predictive coding and motor control [LW · GW], the neocortex will discover and store generative models that entail “self-fulfilling prophecies”, where a single generative model in the neocortex simultaneously codes for a prediction of stress hormone and the neocortical output signals that actually cause the release of this stress hormone. Thus (...I initially thought...), after seeing spiders and stress hormones a few times, the neocortex will predict stress hormones when it sees a spider, which incidentally creates stress hormones.
But I don’t think that’s the right answer, at least not by itself. After all, the neocortex will also learn a generative model where stress hormone is generated exogenously (e.g. by the subcortical spider reaction) and where the neocortex’s own stress hormone generation knob is left untouched. This latter model is issuing perfectly good predictions, so there is no reason that the neocortex would spontaneously throw it out and start using instead the self-fulfilling-prophecy model. (By the same token, in the motor control case [LW · GW], if I think you are going to take my limp arm and lift it up, I have no problem predicting that my arm will move due to that exogenous force; my neocortex doesn’t get confused and start issuing motor commands.)
So here's my second, better story:
Reward criterion (one among many): when the subcortex calls for a reaction (e.g. cortisol release, eyes widening, etc.), it rewards the neocortex with dopamine if it sees that those commands have somehow already been issued.
(Update 2021/06: Oops, that was wrong too. I think I got it on the third try though; see here [LW · GW].)
So if the subcortex computes that a situation calls for cortisol, the neocortex is rewarded if the subcortex sees that cortisol is already flowing. This example seems introspectively reasonable: Seeing a spider out of the corner of your eye is bad, but being surprised to see a spider when you were feeling safe and relaxed is even worse (worse in terms of dopamine, not necessarily worse in terms of valence—remember wanting ≠ liking [LW · GW]). Presumably the same principle can apply to eye-widening and other things.
To be clear, this is one reward criterion among many—the subcortex issues positive and negative rewards according to other criteria too (as in the diagram above, I think different reactions inherently issue positive or negative rewards to the neocortex, just like they inherently issue motor commands and hormone commands). But as long as this "reward criterion" above is permanently in place, then thanks to the laws of the neocortex's generative model economy [LW · GW], the neocortex will drop those generative models that passively anticipate the subcortex's reactions, in favor of models that actively anticipate / imitate the subcortical reactions, insofar as that's possible (the neocortex doesn't have output knobs for everything).
Predicting, imagining, remembering, empathizing
The neocortex’s generative models appear in the context of (1) prediction (including predicting the immediate future as it happens), (2) imagination, (3) memory, and (4) empathetic simulation (when we imagine someone else reacting to a spider, predicting a spider, etc.). I think all four of these processes rely on fundamentally the same mechanism in the neocortex, so by default the same generative models will be used for all four. Thus, we get the same hormone outputs in all four of these situations.
Hang on, you say: That doesn’t seem right! If it were the exact same generative models, then when we remember dancing, we would actually issue the motor commands to start dancing! Well, I answer, we do actually sometimes move a little bit when we remember a motion! I think the rule is, loosely speaking, the top-down information flow is much stronger (more confident) when predicting, and much weaker for imagination, memory, and empathy. Thus, the neocortical output signals are weaker too, and this applies to both motor control outputs and hormone outputs. (Incidentally, I think motor control outputs are further subject to thresholding processes, downstream of the neocortex, and therefore a sufficiently weak motor command causes no motion at all.)
As discussed more below, the subcortex relies on the neocortex’s outputs to guess what the neocortex is thinking about, and issue evolutionarily-appropriate guidance in response. Presumably, to do this job well, the subcortex needs to know whether a given neocortical output is part of a prediction, or memory, or imagination, or empathetic simulation. From the above paragraph, I think it can distinguish predictions from the other three by the neocortical output strength. But how does it tell memory, imagination, and empathetic simulation apart from each other? I don’t know! Then that suggests to me an interesting hypothesis: maybe it can’t! What if some of our weirder instincts related to memory or counterfactual imagination are not adaptive at all, but rather crosstalk from social instincts, or vice-versa? For example, I think there’s a reaction in the subcortex that listens for a strong prediction of lower reward, alternating with a weak prediction of higher reward; when it sees this combination, it issues negative reward and negative valence. Think about what this subcortical reaction would do in the three different cases: If the weak prediction it sees is an empathetic simulation, well, that’s the core of jealousy! If the weak prediction it sees is a memory, well, that’s the core of loss aversion! If the weak prediction it sees is a counterfactual imagination, well, that’s the core of, I guess, that annoying feeling of having missed out on something good. Seems to fit together pretty well, right? I’m not super confident, but at least it’s food for thought.
Various implications
Opening a window into the black-box neocortex
Each subcortical reaction has its own profile of facial, body, and hormone changes. The "reward criterion" above ensures that the neocortex will learn to imitate the characteristic consequences of reaction X whenever it is expecting, imagining, remembering, or empathetically simulating reaction X. This is then a window for the subcortex to get a glimpse into the goings-on inside the black-box neocortex.
In our running example, if the spider reaction creates a certain combination of facial, body, and hormone changes, then the subcortex can watch for this set of changes to happen exogenously (from its perspective), and if it does, the subcortex can infer that the neocortex was maybe thinking about spiders. Perhaps the subcortex might then issue its own spider reaction, fleshing out the neocortex's weak imitation. Or perhaps it could do something entirely different.
I have a hunch that social emotions rely on this. With this mechanism, it seems that the subcortex can build a hierarchy of increasingly complicated social reactions: "if I'm activating reaction A, and I think you're activating reaction B, then that triggers me to feel reaction C", "if I'm activating reaction C, and I think you're activating reaction A, then that triggers me to feel reaction D", and so on. Well, maybe. I'm still hazy on the details here and want to think about it more.
Complex back-and-forth between neocortex and subcortex
The neocortex can alter the hormones and body, which are among the inputs into the subcortical circuits. The subcortical circuits then also alter the hormones and body, which are among the inputs into the neocortex! Around and around it goes! So for example, if you tell yourself to calm down, your neocortex changes your hormones, which in turn increases the activation of the subcortical "I am safe and calm" reaction, which reinforces and augments that change, which in turn makes it easier for the neocortex to continue feeling safe and calm! … Until, of course, that pleasant cycle is broken by other subcortical reactions or other neocortical generative models butting in.
"Overcoming" subcortical reactions
Empirically, we know it's possible to "overcome" fear of spiders, and other subcortical reactions. I'm thinking there are two ways this might work. I think both are happening, but I’m not really sure.
First, there's subcortical learning … well, "learning" isn't the right word here, because it's not trying to match some ground truth. (The only "ground truth" for subcortical reaction specifications is natural selection!) I think it's more akin to the self-modifying code in Linux than to the weight updates in ML. So let's call it subcortical input-dependent dynamic rewiring rules.
(By the way, elsewhere in the subcortex, like the cerebellum, there is also real stereotypical “learning” going on, akin to the weight updates in ML. That does happen, but it’s not what I’m talking about here. In fact, I prefer to lump the cerebellum in with the neocortex as the learning-algorithm part of the brain.)
Maybe one subcortical dynamic rewiring rule says: If the spider-detection reaction triggers, and then within 3 seconds the "I am safe and calm" reaction triggers, then next time the spider reaction should trigger more weakly.
Second, there’s neocortical learning—i.e., the neocortex developing new generative models. Let's say again that we're doing exposure therapy for fear of spiders, and let's say the two relevant subcortical reactions are the spider-detection reaction (which rewards the neocortex for producing anxiety hormones before it triggers) and the "I am safe and calm" reaction (which rewards the neocortex for for producing calming hormones before it triggers). (I'm obviously oversimplifying here.) The neocortex could learn generative models that summon the “I am safe and calm” reaction whenever the spider-detection reaction is just starting to trigger. That generative model could potentially get entrenched and rewarded, as the spider-detection reaction is sorta preempted and thus can’t issue a penalty for the lack of anxiety hormones, whereas the “I am safe and calm” reaction does issue a reward for the presence of calm hormones. Something like that?
I have no doubt that the second of these two processes—neocortical learning—really happens. The first might or might not happen, I don’t know. It does seem like something that plausibly could happen, on both evolutionary and neurological grounds. So I guess my default assumption is that dynamic rewiring rules for subcortical reactions do in fact exist, but again, I’m not sure, I haven't thought about it much.
Things I still don't understand
I lumped together the subcortex into a monolithic unit. I actually understand very little about the functional decomposition beyond that. The tectum and tegmentum seem to be doing a lot of the calculations for what I'm calling "reactions", including the colliculi, which seem to house the subcortical sensory processing. What computations does the amygdala do, for example? It has 10 million neurons, they have to be calculating something!!! I really don't know. (Update 1 year later: On the plus side, I feel like I understand the amygdala much better now; on the minus side, I was wrong to lump it in with "subcortex" rather than "neocortex". See discussion here [LW · GW].)
As discussed above, I don't understand what the non-motor output signals from the neocortex are (update: see here [LW · GW]), or whether things like valence and arousal correspond to hormones or something else. (Update: attempt to understand valence here [LW · GW].)
I'm more generally uncertain about everything I wrote here, even where I used a confident tone. Honestly, I haven't found much in the systems neuroscience literature that's addressing the questions I'm interested in, although I imagine it's there somewhere and I'm reinventing lots of wheels (or re-making classic mistakes). As always, please let me know any thoughts, ideas, things you find confusing, etc. Thanks in advance!
A few people on this forum are thinking hard about the brain, and I've learned a lot from their writings—especially Kaj’s multi-agent sequence [? · GW]—but my impression is that they're mostly working on the project of "Let's understand the brain so we can answer normative questions of what we want AGI to do and how value learning might work", whereas here I'm talking about "Let's understand the brain as a model of a possible AGI algorithm, and think about whether such an AGI algorithm can be used safely and beneficially". Y'all can correct me if I'm wrong :) ↩︎
I will sloppily use the term "neocortex" as shorthand for "neocortex plus other structures that are intimately connected to the neocortex and are best thought of as part of the same algorithm"—this especially includes the hippocampus and thalamus. ↩︎
For what it's worth, Elon Musk mentioned in a recent interview about Neuralink that he is thinking about the brain this way as well: "We've got like a monkey brain with a computer on top of it, that's the human brain, and a lot of our impulses and everything are driven by the monkey brain, and the computer, the cortex, is constantly trying to make the monkey brain happy. It's not the cortex that's steering the monkey brain, it's the monkey brain steering the cortex." (14:45). Normally people would say "lizard brain" rather than "monkey brain" here, although even that terminology is unfair to lizards, who do in fact have something homologous to a neocortex. ↩︎
Unfortunately I don't have good evidence that this spider story is actually true. Does the midbrain really have specialized circuitry to detect spiders? There was a study that showed pictures of spiders to a blindsighted person (i.e., a person who had an intact midbrain visual processing system but no visual cortex). It didn't work; nothing happened. But I think they did the experiment wrong—I think it has to be a video of a moving spider, not a stationary picture of a spider, to trigger the subcortical circuitry. (Source: introspection. Also, I think I read that the subcortical vision system has pretty low spatial resolution, so watching for a characteristic motion would seem a sensible design.) Anyway, it has to work this way, nothing else makes sense to me. I'm comfortable using this example prominently because if it turns out that this example is wrong, then I'm so very confused that this whole article is probably garbage anyway. For the record, I am basically describing Mark Johnson's "two-process” model, which is I think well established in the case of attending-to-faces in humans and filial imprinting in chicks (more here [LW · GW]), even if it's speculative when applied to fear-of-spiders. ↩︎
I am pretty confident that neocortical patterns are effectively random at a microscopic, neuron-by-neuron level, and that's what matters when we talk about why it's impossible for evolution to directly create hardwired instincts that refer to a semantic concept in the neocortex. However, to be clear, at the level of gross anatomy, you can more-or-less predict in advance where different concepts will wind up getting stored in the neocortex, based on the large-scale patterns of information flow and the inputs it gets in a typical human life environment. To take an obvious example, low-level visual patterns are likely to be stored in the parts of the neocortex that receive low-visual visual information from the retina! ↩︎
When I say "I didn't understand" something Barrett wrote, I mean more specifically that I can't see how to turn her words into a gears-level [LW · GW] model of a computation that the brain might be doing. This category of "things I didn't understand" includes, in particular, almost everything she wrote about "body budgets", which was a major theme of the book that came up on almost every page... ↩︎
If you want to call the subcortical things "emotions" instead of "reactions", that's fine with me, as long as you distinguish them from "emotion concepts" in the neocortex. Barrett is really adamant that the word "emotion" must refer to the neocortical emotion concepts, not the subcortical reactions (I'm not even sure if she thinks the subcortical reactions exist), but for my part, I think reasonable people could differ, and it's ultimately a terminological question with no right answers anyway. ↩︎
16 comments
Comments sorted by top scores.
comment by evhub · 2020-07-10T04:25:26.347Z · LW(p) · GW(p)
A thought: it seems to me like the algorithm you're describing here is highly non-robust to relative scale [LW · GW], since if the neocortex became a lot stronger it could probably just find some way to deceive/trick/circumvent the subcortex to get more reward and/or avoid future updates. I think I'd be pretty worried about that failure case if anything like this algorithm were ever to be actually implemented in an AI.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-07-10T14:00:07.624Z · LW(p) · GW(p)
Thanks! Yes, I am also definitely worried about that.
I 100% agree that the default result, in the absence of careful effort, would be value lock-in [LW · GW] at some point in time, when the neocortex part grows clever enough to undermine the subcortex part, and then you better hope that the locked-in values are what you want!
On the optimistic side:
-
There's no law that says the subcortex part has to be super dumb and simple; we can have less-powerful AIs steering more powerful AIs, helped by intrusive interpretability tools, running faster and in multiple instances, etc. (as has been discussed in other contexts of course);
-
We can try to instill a motivation system from the start that doesn't want to undermine the subcortex part—in particular, corrigible motivation. This is basically reliant on the "corrigibility is a broad basin of attraction" argument being correct, I think.
On the pessimistic side, I'm not at all confident that either of those things would work. For (2) in particular, I remain concerned about ontological crises (or other types of goal instability upon learning and reflection) undermining corrigibility after an indeterminate amount of time. (This remains my go-to example of a possibly-unsolvable safety problem [LW · GW], or at least I have no idea how to solve it.)
So yeah, maybe we would be doomed in this scenario (or at least doomed to roll the dice). Or maybe we just need to keep working on it :-)
comment by Adam Scholl (adam_scholl) · 2020-06-17T12:21:03.978Z · LW(p) · GW(p)
I found this post super interesting, and appreciate you writing it. I share the suspicion/hope that gaining better understanding of brains might yield safety-relevant insights.
I’m curious what you think is going on here that seems relevant to inner alignment. Is it that you’re modeling neocortical processes (e.g. face recognizers in visual cortex) as arising from something akin to search processes conducted by similar subcortical processes (e.g. face recognizers in superior colliculus), and noting that there doesn’t seem to be much divergence between their objective functions, perhaps because of helpful features of subcortex-supervised learning like e.g. these subcortical input-dependent dynamic rewiring rules?
Replies from: steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2020-07-10T21:48:23.509Z · LW(p) · GW(p)
FYI, I now have a whole post elaborating on "inner alignment": mesa-optimizers vs steered optimizers [LW · GW]
↑ comment by Steven Byrnes (steve2152) · 2020-06-17T18:50:29.129Z · LW(p) · GW(p)
Thanks!
I’m curious what you think is going on here that seems relevant to inner alignment.
Hmm, I guess I didn't go into detail on that. Here's what I'm thinking.
For starters, what is inner alignment anyway? Maybe I'm abusing the term, but I think of two somewhat different scenarios.
-
In a general RL setting, one might say that outer alignment is alignment between what we want and the reward function, and inner alignment is alignment between the reward function and "what the system is trying to do". (This one is closest to how I was implicitly using the term in this post.)
-
In the "risks from learned optimization" paper, it's a bit different: the whole system (perhaps an RL agent and its reward function, or perhaps something else entirely) is conceptually bundled together into a single entity, and you do a black-box search for the most effective "entity". In this case, outer alignment is alignment between what we want and the search criterion, and inner alignment is alignment between the search criterion and "what the system is trying to do". (This is not really what I had in mind in this post, although it's possible that this sort of inner alignment could also come up, if we design the system by doing an outer search, analogous to evolution.)
Note that neither of these kinds of "inner alignment" really comes up in existing mainstream ML systems. In the former (RL) case, if you think of an RL agent like AlphaStar, I'd say there isn't a coherent notion of "what the system is trying to do", at least in the sense that AlphaStar does not do foresighted planning towards a goal. Or take AlphaGo, which does have foresighted planning because of the tree search; but here we program the tree search by hand ourselves, so there's no risk that the foresighted planning is working towards any goal except the one that we coded ourselves, I think.
So, "RL systems that do foresighted planning towards explicit goals which it invents itself" are not much of a thing these days (as far as I know), but they presumably will be a thing in the future (among other things, this is essential for flexibly breaking down goals into sub-goals). And the neocortex is in this category. So yeah, it seems reasonable to me to extend the term "inner alignment" to this case too.
So anyway, the neocortex creates explicit goals for itself, like "I want to get out of debt", and uses foresight / planning to try to bring them about. (Of course it creates multiple contradictory goals, and also has plenty of non-goal-seeking behaviors, but foresighted goal-seeking is one of the things people sometimes do! And of course transient goals can turn into all-consuming goals in self-modifying AGIs [EA(p) · GW(p)]) The neocortical goals have something to do with subcortical reward signals, but it's obviously not a deterministic process, and therefore there's an opportunity for inner alignment problems.
...noting there doesn’t seem to be much divergence between their objective functions...
This is getting into a different question I think... OK, so, If we build an AGI along the lines of a neocortex-like system plus a subcortex-like system that provides reward signals and other guidance, will it reliably do the things we designed it to do? My default is usually pessimism, but I guess I shouldn't go too far. I think some of the things that this system is designed to do, it seems to do very reliably. Like, almost everyone learns language. This requires, I believe, a cooperation between the neocortex and a subcortical system that flags human speech sounds as important. And it works almost every time! A more important question is, can we design the system such that the neocortex will wind up reliably seeking pre-specified goals? Here, I just don't know. I don't think humans and animals provide strong evidence either way, or at least it's not obvious to me...
comment by Rafael Harth (sil-ver) · 2020-11-28T15:25:58.110Z · LW(p) · GW(p)
I'm still in the process of understanding this stuff, so apologies in advance if I'm saying something stupid.
There seems to be an important misanalogy here between inner alignment in AGI and in the brain. In both cases, it's about the difference between the inner and the outer objective, but in the AGI case, we want to make sure the inner objective is as close to the outer objective as possible, whereas in the brain, we want to make sure the outer objective doesn't corrupt the inner objective.
I guess this makes sense: we're misaligned from the perspective of evolution, but from our perspective, well we are the inner optimizers, so we want them to 'win'. Conversely, if we build AI, our PoV is analogous to that of evolution, so we want the outer objective to come out on top.
The neocortex's algorithm, as I understand it, sorta learns patterns, and patterns in the patterns, etc., and each pattern is represented as an essentially randomly-generated[5] set of neurons in the neocortex.
Are these 'patterns' the same as the generative models? And does 'randomly generated' mean that, if I learn a new pattern, my neocortex generates a random set of neurons that is then associated with that pattern from that point onward?
(I also put "pain concept" in the neocortex, again following Barrett. A giant part of the pain concept is nociception—detecting the incoming nerve signals we might call "pain sensations". But at the end of the day, the neocortex gets to decide whether or not to classify a situation as "pain", based on not only nociception but also things like context and valence.)
So, if a meditator says that they have mastered mindfulness to the point that they can experience pain without suffering, your explanation of that (provided you believe the claim) would be, they have reprogrammed their neocortex such that it no longer classifies the generally-pain-like signals from the subcotex as pain?
Not sure what 'valence' is doing here. Isn't valence an output of what the neocortex does, or does it mean something else in the context of neuroscience?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-28T18:40:31.531Z · LW(p) · GW(p)
Thanks! No worries! I'm in the process of understanding this stuff too :-P
in the AGI case, we want to make sure the inner objective is as close to the outer objective as possible, whereas in the brain, we want to make sure the outer objective doesn't corrupt the inner objective.
I'm not sure I agree with the second one. Maybe my later discussion in Mesa-Optimizers vs Steered Optimizers [LW · GW] is better:
You try a new food, and find it tastes amazing! This wonderful feeling is your subcortex sending a steering signal up to your neocortex. All of the sudden, a new goal has been installed in your mind: eat this food again! This is not your only goal in life, of course, but it is a goal, and you might use your intelligence to construct elaborate plans in pursuit of that goal, like shopping at a different grocery store so you can buy that food again.
It’s a bit creepy, if you think about it!
“You thought you had a solid identity? Ha!! Fool, you are a puppet! If your neocortex gets dopamine at the right times, all of the sudden you would want entirely different things out of life!”
Yes I do take the perspective of the inner optimizer, but I have mixed feelings about my goals changing over time as a result of the outer layer's interventions. Like, if I taste a new food and really like it, that changes my goals, but that's fine, in fact that's a delightful part of my life. Whereas, if I thought that reading nihilistic philosophers would carry a risk of making me stop caring about the future, I would be reluctant to read nihilistic philosophers. Come to think of it, neither of those is a hypothetical!
Are these 'patterns' the same as the generative models?
Yes. Kaj calls (a subset of) them "subagents" [? · GW], I more typically call them "generative models" [LW · GW], Kurzweil calls them "patterns", Minsky calls this idea "society of mind", etc.
And does 'randomly generated' mean that, if I learn a new pattern, my neocortex generates a random set of neurons that is then associated with that pattern from that point onward?
Yes, that's my current belief fwiw, although to be clear, I only think it's random on a micro-scale. On the large scale, for example, patterns in raw visual inputs are going to be mainly stored in the part of the brain that receives raw visual inputs, etc. etc.
So, if a meditator says that they have mastered mindfulness to the point that they can experience pain without suffering, your explanation of that (provided you believe the claim) would be, they have reprogrammed their neocortex such that it no longer classifies the generally-pain-like signals from the subcotex as pain?
Sure, but maybe a more everyday example would be a runner pushing through towards the finish line while experiencing runner's high, or a person eating their favorite spicy food, or whatever. It's still the same sensors in your body sending signals, but in those contexts you probably wouldn't describe those signals as "I am in pain right now".
As for valence, I was confused about valence when I wrote this, and it's possible I'm still confused. But I felt less confused after writing Emotional Valence Vs RL Reward: A Video-Game Analogy [LW · GW]. I'm still not sure it's right—just the other day I was thinking that I should have said "positive reward prediction error" instead of "reward" throughout that article. I'm going back and forth on that, not sure.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-11-29T10:49:43.786Z · LW(p) · GW(p)
As for valence, I was confused about valence when I wrote this, and it's possible I'm still confused. But I felt less confused after writing Emotional Valence Vs RL Reward: A Video-Game Analogy. I'm still not sure it's right—just the other day I was thinking that I should have said "positive reward prediction error" instead of "reward" throughout that article. I'm going back and forth on that, not sure.
My prior understanding of valence, which is primarily influenced by the Qualia Research Institute, was as the ontologically fundamental utility function of the universe. The claim is that every slice of experience has an objective quantity (its valence) that measures how pleasant or unpleasant it is. This would locate 'believing valence is a thing' as a subset of moral realism.
My assumption after reading this post was that you're talking about something else, but your Emotional Valence vs. RL Reward post made me think you're talking about the same thing after all, especially this paragraph:
For example, some people say anger is negative valence, but when I feel righteous anger, I like having that feeling, and I want that feeling to continue. (I don't want to want that feeling to continue, but I do want that feeling to continue!) So by my definition, righteous anger is positive valence!
This sounds to me like you're talking about how pleasant the state fundamentally is. But then I noticed someone already linked a QRI talk and you didn't think it was talking about the same thing, so I'm back to being confused.
Are you thinking about valence as something fundamental, or as an abstraction? And if it's an abstraction, does the term do any work? I guess what confuses me is that the Emotional Valence [...] post makes it sound like you think valence is an important concept, but if you consider it an abstraction, I'm not clear on why. It seems like you could take valence out of the picture and your model of the brain would still work fine.
Anyway, this might not be super important to discuss further, so feel free to leave it here.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-29T13:08:49.113Z · LW(p) · GW(p)
I noticed someone already linked a QRI talk and you didn't think it was talking about the same thing, so I'm back to being confused.
When I wrote here [LW(p) · GW(p)] "Thanks but I don't see the connection between what I wrote and what they wrote", I did not mean that QRI was talking about a different phenomenon than I was talking about. I meant that their explanation is wildly different than mine. Re-reading the conversation, I think I was misinterpreting the comment I was replying to; I just went back to edit.
Needless to say I disagree with the QRI explanation of valence, but there's such a chasm between their thoughts and my thoughts that it would be challenging for me to try to write a direct rebuttal.
Again, I do think they're talking about the same set of phenomena that I'm talking about.
My prior understanding of valence, which is primarily influenced by the Qualia Research Institute, was as the ontologically fundamental utility function of the universe. The claim is that every slice of experience has an objective quantity (its valence) that measures how pleasant or unpleasant it is. This would locate 'believing valence is a thing' as a subset of moral realism.
I don't think there's anything fundamental in the universe besides electrons, quarks, photons, and so on, following their orderly laws as described by the Standard Model of Particle Physics etc. Therefore it follows that there should be an answer to the question "why do people describe a certain state as pleasant" that involves purely neuroscience / psychology and does not involve the philosophy of consciousness or any new ontologically fundamental entities. After all, "describing a certain state as pleasant" is an observable behavioral output of the brain, so it should have a chain of causation that we can trace within the underlying neural algorithms, which in turn follows from the biochemistry of firing neurons and so on, and ultimately from the laws of physics. So, that's what I was trying to do in that blog post: Trace a chain of causation from "underlying neural algorithms" to "people describing a state as pleasant".
After we do that (and I have much more confidence that "a solution exists" than "my particular proposal is the 100% correct solution") we can ask: is there a further unresolved question of how that exercise we just did (involving purely neuroscience / psychology) relates to consciousness and qualia and whatnot. My answer would be "No. There is nothing left to explain.", for reasons discussed more at Book Review: Rethinking Consciousness [LW · GW], but I acknowledge that's a bit counterintuitive and can't defend it very eloquently, since I haven't really dived into the philosophical literature.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-11-29T14:21:30.568Z · LW(p) · GW(p)
When I wrote here "Thanks but I don't see the connection between what I wrote and what they wrote", I did not mean that QRI was talking about a different phenomenon than I was talking about. I meant that their explanation is wildly different than mine. Re-reading the conversation, I think I was misinterpreting the comment I was replying to; I just went back to edit.
That makes sense.
I don't think there's anything fundamental in the universe besides electrons, quarks, photons, and so on, following their orderly laws as described by the Standard Model of Particle Physics etc. Therefore it follows that there should be an answer to the question "why do people describe a certain state as pleasant" that involves purely neuroscience / psychology and does not involve the philosophy of consciousness or any new ontologically fundamental entities. After all, "describing a certain state as pleasant" is an observable behavioral output of the brain, so it should have a chain of causation that we can trace within the underlying neural algorithms, which in turn follows from the biochemistry of firing neurons and so on, and ultimately from the laws of physics. So, that's what I was trying to do in that blog post: Trace a chain of causation from "underlying neural algorithms" to "people describing a state as pleasant".
Ah, but QRI also thinks that the material world is exhaustively described by the laws of physics. I believe they would give a blanket endorsement to everything in the above paragraph except the first sentence. Their view is not that valence is an additional parameter that your model of physics needs to take into consideration to be accurate. Rather, it's that the existing laws of physics exhaustively describe the future states of particles (so in particular, you can explain the behavior of humans, including their reaction to pain and such, without modeling valence), and the phenomenology can also be described precisely. The framework is dual-aspect monism plus physicalism.
You might still have substantial disagreements with that view, but I as far as I can tell, your posts about neuroscience and even your post on emotional valence are perfectly compatible, except for the one sentence I quoted earlier
the neocortex gets to decide whether or not to classify a situation as "pain", based on not only nociception but also things like context and valence.)
because it has valence as an input to the neocortex' decision rather than a property of the output (i.e., if our phenomenology 'lives' in the neocortex, then the valence of situation should depend on what the neocortex classifies it as, not vice-versa). And even that could just be using valence to refer to a different thing that's also real.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-29T16:16:26.712Z · LW(p) · GW(p)
Ok, thanks for helping me understand. Hmm. I hypothesize the most fundamental part of why I disagree with them is basically what Eliezer talked about here [LW · GW] as "explaining" vs."explaining away". I think they're looking for an explanation, i.e. a thing in the world whose various properties match the properties of consciousness and qualia as they seem to us. I'm much more expecting that there is no thing in the world meeting those criteria. Rather I think that this is a case where our perceptions are not neutrally reporting on things in the world, and thus where "the way things seem to us" is different than the way things are.
Or maybe I just narrowly disagree with QRI's ideas about rhythms and harmony and so on. Not sure. Whenever I try to read QRI stuff it just kinda strikes me as totally off-base, so I haven't spent much time with it, beyond skimming a couple articles and watching a talk on Connectome-Specific Harmonic Waves on YouTube a few months ago. I'm happy to have your help here :-)
As for valence, yes I think that valence is in an input to the neocortex subsystem (just as vision is an input), although it's really the neocortex subsystem observing the activity of other parts of the brain, and incidentally those other parts of the brain also depend in part on what the neocortex is doing and has been doing.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-11-29T18:15:44.694Z · LW(p) · GW(p)
PrincipiaQualia is definitely the thing to read if you want to engage with QRI. It reviews the science and explains the core theory that the research is structured around. I'm not sure if you want to engage with it -- I begin from the strong intuition that qualia is real, and so I'm delighted that someone is working on it. My impression is that it makes an excellent case, but my judgment is severely limited since I don't know the literature. Either way, it doesn't have a lot of overlap with what you're working on.
There's also an AI alignment podcast episode.
comment by Gordon Seidoh Worley (gworley) · 2020-04-23T16:55:53.719Z · LW(p) · GW(p)
Then that suggests to me an interesting hypothesis: maybe it can’t! What if some of our weirder instincts related to memory or counterfactual imagination are not adaptive at all, but rather crosstalk from social instincts, or vice-versa? For example, I think there’s a reaction in the subcortex that listens for a strong prediction of lower reward, alternating with a weak prediction of higher reward; when it sees this combination, it issues negative reward and negative valence. Think about what this subcortical reaction would do in the three different cases: If the weak prediction it sees is an empathetic simulation, well, that’s the core of jealousy! If the weak prediction it sees is a memory, well, that’s the core of loss aversion! If the weak prediction it sees is a counterfactual imagination, well, that’s the core of, I guess, that annoying feeling of having missed out on something good. Seems to fit together pretty well, right? I’m not super confident, but at least it’s food for thought.
I think this is interesting in terms of thinking about counterfactuals in decision theory, preference theory, etc.. To me it suggests that when we talk about counterfactuals we're putting our counterfactual worlds in a stance that mixes up what they are and what we want them to be. What they are, as in the thing going on in our brains that causes us to think in terms of counterfactual worlds, is these predictions about the world (so world models or ontology), and when we apply counterfactual reasoning we're considering different predictions about the world contingent on different inputs, possibly including inputs other than the ones we actually saw but that we are able to simulate. This means that it's not reasonable that counterfactual worlds would be consistent with the history of the world (the standard problem with counterfactuals) because they aren't alternative territories but maps of how we think we would have mapped different territory.
This doesn't exactly save counterfactual reasoning, but it does allow us to make better sense of what it is when we use it and why it works sometimes and why it's a problem other times.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-04-25T17:15:01.277Z · LW(p) · GW(p)
I haven't read the literature on "how counterfactuals ought to work in ideal reasoners" and have no opinion there. But the part where you suggest an empirical description of counterfactual reasoning in humans, I think I basically agree with what you wrote.
I think the neocortex has a zoo of generative models, and a fast way of detecting when two are compatible, and if they are, snapping them together like Legos into a larger model.
For example, the model of "falling" is incompatible with the model of "stationary"—they make contradictory predictions about the same boolean variables—and therefore I can't imagine a "falling stationary rock". On the other hand, I can imagine "a rubber wine glass spinning" because my rubber model is about texture etc., my wine glass model is about shape and function, and my spinning model is about motion. All 3 of those models make non-contradictory predictions (mostly because they're issuing predictions about non-overlapping sets of variables), so the three can snap together into a larger generative model.
So for counterfactuals, I suppose that we start by hypothesizing some core of a model ("a bird the size of an adult blue whale") and then searching out more little generative model pieces that can snap onto that core, growing it out as much as possible in different ways, until you hit the limits where you can't snap on any more details without making it unacceptably self-contradictory. Something like that...
Again, I think I agree with what you wrote. :-)
comment by romeostevensit · 2020-04-22T20:50:58.059Z · LW(p) · GW(p)
You may find this useful https://arxiv.org/abs/1610.08602
comment by Gordon Seidoh Worley (gworley) · 2020-04-23T16:48:47.942Z · LW(p) · GW(p)
Hang on, you say: That doesn’t seem right! If it were the exact same generative models, then when we remember dancing, we would actually issue the motor commands to start dancing! Well, I answer, we do actually sometimes move a little bit when we remember a motion! I think the rule is, loosely speaking, the top-down information flow is much stronger (more confident) when predicting, and much weaker for imagination, memory, and empathy. Thus, the neocortical output signals are weaker too, and this applies to both motor control outputs and hormone outputs. (Incidentally, I think motor control outputs are further subject to thresholding processes, downstream of the neocortex, and therefore a sufficiently weak motor command causes no motion at all.)
As I recall, much of how the brain causes you to do one thing rather than another involves suppression of signals. As in, everything in the brain is doing it's thing all the time, and how you manage to do only one thing and not have a seizure is that it suppresses the signals from various parts of the brain such that only one is active at a time.
That's probably a bit of a loose model and doesn't exactly explain how it maps to particular structures, but might be interesting to look at how this sort of theory of output suppression meshes with the weaker/stronger model you're looking at here built out of PP.