Inner Alignment in Salt-Starved Rats
post by Steven Byrnes (steve2152) · 2020-11-19T02:40:10.232Z · LW · GW · 41 commentsContents
Introduction: The Dead Sea Salt Experiment What does this have to do with inner alignment? What is inner alignment anyway? Why should we care about any of this? Aside: Obligatory post-replication-crisis discussion Outline of the rest of the post My hypothesis for how the rat brain did what it did The overall story Hypothesis 1 for the “imagining taste of salt” signal: The neocortex API enables outputting a prediction for any given input channel Hypothesis 2 for the “neocortex is imagining the taste of salt” signal: The neocortex is rewarded for “communicating its thoughts” Hypothesis 3 for the “neocortex is imagining the taste of salt” signal (my favorite!): Sorta an “interpretability” approach, probably involving the amygdala What would other possible explanations for the rat experiment look like? None 41 comments
(This post is deprecated. It has some kernels of truth but also lots of mistakes and confusions. You should instead read Incentive Learning vs Dead Sea Salt Experiment (2024) [LW · GW], which covers many of the same topics. —Steve, 2024)
(See comment here [LW(p) · GW(p)] for some corrections and retractions. —Steve, 2022)
Introduction: The Dead Sea Salt Experiment
In this 2014 paper by Mike Robinson and Kent Berridge at University of Michigan (see also this more theoretical follow-up discussion by Berridge and Peter Dayan), rats were raised in an environment where they were well-nourished, and in particular, where they were never salt-deprived—not once in their life. The rats were sometimes put into a test cage with a lever which, when it appeared, was immediately followed by a device spraying ridiculously salty water directly into their mouth. The rats were disgusted and repulsed by the extreme salt taste, and quickly learned to hate the lever—which from their perspective would seem to be somehow causing the saltwater spray. One of the rats went so far as to stay tight against the opposite wall—as far from the lever as possible!
Then the experimenters made the rats feel severely salt-deprived, by depriving them of salt. Haha, just kidding! They made the rats feel severely salt-deprived by injecting the rats with a pair of chemicals that are known to induce the sensation of severe salt-deprivation. Ah, the wonders of modern science!
...And wouldn't you know it, almost instantly upon injection, the rats changed their behavior! When shown the lever (this time without the salt-water spray), they now went right over to that lever and jumped on it and gnawed at it, obviously desperate for that super-salty water.
The end.
Aren't you impressed? Aren’t you floored? You should be!!! I don’t think any standard ML algorithm would be able to do what these rats just did!
Think about it:
- Is this Reinforcement Learning? No. RL would look like the rats randomly stumbling upon the behavior of “nibbling the lever when salt-deprived”, find it rewarding, and then adopt that as a goal via “credit assignment”. That’s not what happened. While the rats were nibbling at the lever, they had never in their life had an experience where the lever had brought forth anything other than an utterly repulsive experience. And they had never in their life had an experience where they were salt-deprived, tasted something extremely salty, and found it gratifying. I mean, they were clearly trying to interact with the lever—this is a foresighted plan we're talking about—but that plan does not seem to have been reinforced by any experience in their life.
- Update for clarification: Specifically, it's not any version of RL where you learn about the reward function only by observing past rewards. This category includes all model-free RL and some model-based RL (e.g. MuZero). If, by contrast, you have a version of model-based RL where the agent can submit arbitrary hypothetical queries to the true reward function, then OK, sure, now you can get the rats' behavior. I don't think that's what's going on here for reasons I'll mention at the bottom.
- Is this Imitation Learning? Obviously not; the rats had never seen any other rat around any lever for any reason.
- Is this an innate, hardwired, stimulus-response behavior? No, the connection between a lever and saltwater was an arbitrary, learned connection. (I didn't mention it, but the researchers also played a distinctive sound each time the lever appeared. Not sure how important that is. But anyway, that connection is arbitrary and learned, too.)
So what’s the algorithm here? How did their brains know that this was a good plan? That’s the subject of this post.
What does this have to do with inner alignment? What is inner alignment anyway? Why should we care about any of this?
With apologies to the regulars on this forum who already know all this, the so-called “inner alignment problem” occurs when you, a programmer, build an intelligent, foresighted, goal-seeking agent. You want it to be trying to achieve a certain goal, like maybe “do whatever I, the programmer, want you to do” or something. The inner alignment problem is: how do you ensure that the agent you programmed is actually trying to pursue that goal? (Meanwhile, the “outer alignment problem” is about choosing a good goal in the first place.) The inner alignment problem is obviously an important safety issue, and will become increasingly important as our AI systems get more powerful in the future.
(See my earlier post mesa-optimizers vs “steered optimizers” [LW · GW] for specifics about how I frame the inner alignment problem in the context of brain-like algorithms.)
Now, for the rats, there’s an evolutionarily-adaptive goal of "when in a salt-deprived state, try to eat salt". The genome is “trying” to install that goal in the rat’s brain. And apparently, it worked! That goal was installed! And remarkably, that goal was installed even before that situation was ever encountered! So it’s worth studying this example—perhaps we can learn from it!
Before we get going on that, one more boring but necessary thing:
Aside: Obligatory post-replication-crisis discussion
The dead sea salt experiment strikes me as trustworthy. Pretty much all the rats—and for key aspects literally every tested rat—displayed an obvious qualitative behavioral change almost instantaneously upon injection. There were sensible tests with control levers and with control rats. The authors seem to have tested exactly one hypothesis, and it's a hypothesis that was a priori plausible and interesting. And so on. I can't assess every aspect of the experiment, but from what I see, I believe this experiment, and I'm taking its results at face value. Please do comment if you see anything questionable.
Outline of the rest of the post
Next I'll go through my hypothesis for how the rat brain works its magic here. Actually, I've come up with three variants of this hypothesis over the past year or so, and I’ll talk through all of them, in chronological order. Then I’ll speculate briefly on other possible explanations.
My hypothesis for how the rat brain did what it did
The overall story
As I discussed in My Computational Framework for the Brain [LW · GW], my starting-point assumption is that the rat brain has a “neocortex subsystem” (really the neocortex, hippocampus, parts of thalamus and basal ganglia, maybe other things too). The neocortex subsystem takes sensory inputs and reward inputs, builds a predictive model from scratch, and then chooses thoughts and actions that maximize reward. The reward, in turn, is issued by a different subsystem of the brain that I’ll call “subcortex”.
To grossly oversimplify the “neocortex builds a predictive model” part of that, let’s just say for present purposes that the neocortex subsystem memorizes patterns in the inputs, and then patterns in the patterns, and so on.
To grossly oversimplify the “neocortex chooses thoughts and actions that maximize reward” part, let’s just say for present purposes that different parts of the predictive model are associated with different reward predictions, the reward predictions are updated by a TD learning system that has something to do with dopamine and the basal ganglia, and parts of the model that predict higher reward are favored while parts of the model that predict lower reward are pushed out of mind.
Since the “predictive model” part is invoked for the “reward-maximization” part, we can say that the neocortex does model-based RL.
(Aside: It's sometimes claimed in the literature that brains do both model-based and model-free RL. I disagree that this is a fundamental distinction; I think "model-free" = "model-based with a dead-simple model". See my old comment here [LW(p) · GW(p)].)
Why is this important? Because that brings us to imagination! The neocortex can activate parts of the predictive model not just to anticipate what is about to happen, but also to imagine what may happen, and (relatedly) to remember what has happened.
Now we get a crucial ingredient: I hypothesize that the subcortex somehow knows when the neocortex is imagining the taste of salt. How? This is the part where I have three versions of the story, which I’ll go through shortly. For now, let’s just assume that there is a wire going into the subcortex, and when it’s firing, that means the neocortex is activating the parts of the predictive model that correspond (semantically) to tasting salt.
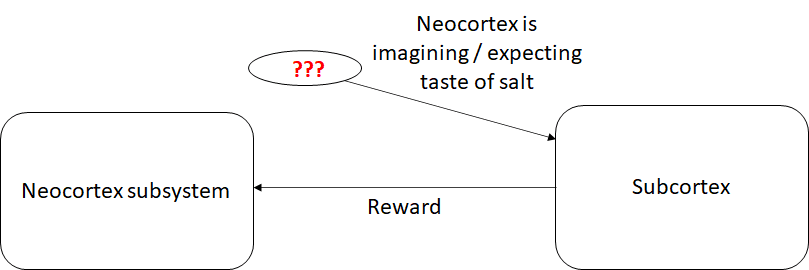
And once we have that, the last ingredient is simple: The subcortex has an innate, hardwired circuit that says “If the neocortex is imagining tasting salt, and I am currently salt-deprived, then send a reward to the neocortex.”
OK! So now the experiment begins. The rat is salt-deprived, and it sees the lever appear. That naturally evokes its previous memory of tasting salt, and that thought is rewarded! When the rat imagines walking over and nibbling the lever, it finds that to be a very pleasing (high-reward-prediction) thought indeed! So it goes and does it!
(UPDATE: Commenters point out that this description isn't quite right—it doesn't make sense to say that the idea of tasting salt is rewarding per se. Rather, I propose that the subcortex sends a reward related to the time-derivative of how strongly the neocortex is imagining / expecting to taste salt. So the neocortex gets a reward for first entertaining the idea of tasting salt, and another incremental reward for growing that idea into a definite plan. But then it would get a negative reward for dropping that idea. Sorry for the mistake / confusion. Thanks commenters!)
Now let's fill in that missing ingredient: How does the subcortex get its hands on a signal flagging that the neocortex is imagining the taste of salt? I have three hypotheses.
Hypothesis 1 for the “imagining taste of salt” signal: The neocortex API enables outputting a prediction for any given input channel
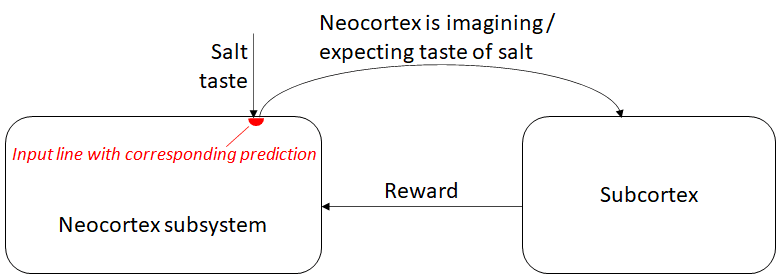
This was my first theory, I guess from last year. As argued by the “predictive coding” people, Jeff Hawkins, Yann LeCun, and many others, the neocortex is constantly predicting what input signals it will receive next, and updating its models when the predictions are wrong. This suggests that it should be possible to stick an arbitrary input line into the neocortex, and then pull out a signal carrying the neocortex’s predictions for that input line. (It would look like a slightly-earlier copy of the input line, with sporadic errors for when the neocortex is surprised.) I can imagine, for example, that if you put an input signal into cortical mini-column #592843 layer 4, then you look at a certain neuron in the same mini-column, you find those predictions.
If this is the case, then the rest is pretty straightforward. The genome wires the salt taste bud signal to wherever in the neocortex, pulls out the corresponding prediction, and we're done! For the reason described above, that line will also fire when merely imagining salt taste.
Commentary on hypothesis 1: I have mixed feelings.
On the one hand, I haven’t really come across any independent evidence that this mechanism exists. And, having learned more about the nitty-gritty of neocortex algorithms (the outputs come from layer 5, blah blah blah), I don’t think the neocortex outputs carry this type of data.
On the other hand, I have a strong prior belief that if there are ten ways for the brain to do a certain calculation, and each is biologically and computationally plausible without dramatic architectural change, the brain will do all ten! (Probably in ten different areas of the brain.) After all, evolution doesn't care much about keeping things elegant and simple. I mean, there is a predictive signal for each input—it has to be there somewhere! And I don’t currently see any reason that this signal couldn’t be extracted from the neocortex. So I feel sorta obligated to believe that this mechanism probably exists.
So anyway, all things considered, I don’t put much weight on this hypothesis, but I also won’t strongly reject it.
With that, let’s move on to the later ideas that I like better.
Hypothesis 2 for the “neocortex is imagining the taste of salt” signal: The neocortex is rewarded for “communicating its thoughts”
This was my second guess, I guess dating to several months ago.
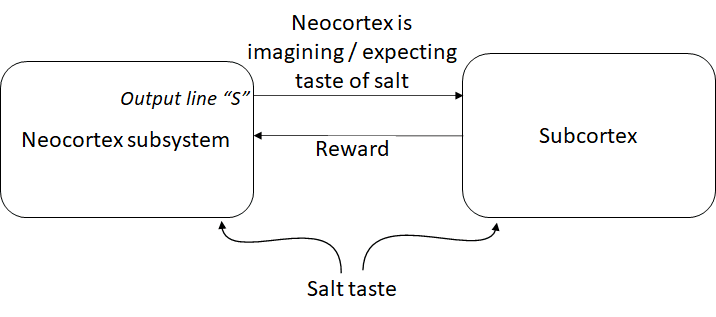
The neocortex subsystem has a bunch of output lines for motor control and whatever else, and it has a special output line S (S for salt).
Meanwhile, the subcortex sends rewards under various circumstances, and one of those things is that the neocortex is rewarded for sending a signal into S whenever salt is tasted. (The subcortex knows when salt is tasted, because it gets a copy of that same input.)
So now, as the rat lives its life, it stumbles upon the behavior of outputting a signal into S when eating a bite of saltier-than-usual food. This is reinforced, and gradually becomes routine.
The rest is as before: when the rat imagines a salty taste, it reuses the same model. We did it!
Commentary on hypothesis 2: A minor problem (from the point-of-view of evolution) is that it would take a while for the neocortex to learn to send a signal into S when eating salt. Maybe that’s OK.
A much bigger potential problem is that the neocortex could learn a pattern where it sends a signal into S when tasting salt, and also learns a different pattern where it sends a signal into S whenever salt-deprived, whether thinking about salt or not. This pattern would, after all, be rewarded, and I can’t immediately see how to stop it from developing.
So I’m pretty skeptical about this hypothesis now.
Hypothesis 3 for the “neocortex is imagining the taste of salt” signal (my favorite!): Sorta an “interpretability” approach, probably involving the amygdala
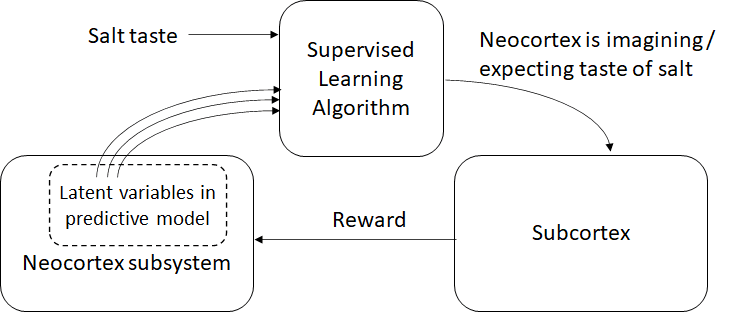
This one comes out of my last post, Supervised Learning of Outputs in the Brain [LW · GW]. Now we have a separate brain module that I labeled “supervised learning algorithm”, and which I suspect is primarily located in the amygdala. This module does supervised learning: the salt signal (from the taste buds) functions as the supervisory signal, and a random assortment of neurons in the neocortex subsystem (describing latent variables in the neocortex’s predictive model) function as the inputs to the learned model. Then the supervised learning module learns which patterns in those latent variables tend to reliably predict that salt is about to be tasted. Having done that, when it sees those patterns recur, that’s our signal that the neocortex is probably expecting the taste of salt … and as described above, it will also see those same patterns when the neocortex is merely imagining or remembering the taste of salt. So we have our signal!
Commentary on Hypothesis 3: There’s a lot I really like about this. It seems to at-least-vaguely match various things I’ve seen in the literature about the functionality and connectivity of the amygdala. It makes a lot of sense from a design perspective—the patterns would be learned quickly and reliably, etc., as far as I can tell. I find it satisfyingly obvious and natural (in retrospect). So I would put this forward as my favorite hypothesis by far.
It also transfers in an obvious way to AGI programming, where it would correspond to something like an automated "interpretability" module that tries to make sense of the AGI's latent variables by correlating them with some other labeled properties of the AGI's inputs, and then rewarding the AGI for "thinking about the right things" (according to the interpretability module's output), which in turn helps turn those thoughts into the AGI's goals, using the time-derivative reward-shaping trick as described above.
(Is this a good design idea that AGI programmers should adopt? I don't know, but I find it interesting, and at least worthy of further thought. I don't recall coming across this idea before in the context of the inner alignment problem.)
(Update 6 months later: I'm now more confident that this hypothesis is basically right, except maybe I should have said "medial prefrontal cortex and ventral striatum" where I said "amygdala". Or maybe it's all of the above. Anyway, see my later post Big Picture Of Phasic Dopamine [LW · GW].)
What would other possible explanations for the rat experiment look like?
The theoretical follow-up by Dayan & Berridge is worth reading, but I don’t think they propose any real answers, just lots of literature and interesting ideas at a somewhat-more-vague level.
(Update to add this paragraph) Next: At the top I mentioned "a version of model-based RL where the agent can submit arbitrary hypothetical queries to the true reward function" (this category includes AlphaZero). If the neocortex had a black-box ground-truth reward calculator (not a learned-from-observations model of the reward) and a way to query it, that would seem to resolve the mystery of how the rats knew to get the salt. But I can't see how this would work. First, the ground-truth reward is super complicated. There are thousands of pain receptors, there are hormones sloshing around, there are multiple subcortical brain regions doing huge complicated calculations involving millions of neurons that provide input to the reward calculation (I believe), and so on. You can learn to model this reward-calculating system by observing it, of course, but actually running this system (or a copy of it) on hypotheticals seems unrealistic to me. Second, how exactly would you query the ground-truth reward calculator? Third, there seems to be good evidence that the neocortex subsystem chooses thoughts and actions based on reward predictions that are updated by TD learning, and I can't immediately see how you can simultaneously have that system and a mechanism that chooses thoughts and actions by querying a ground-truth reward calculator. I think my preferred mechanism, "reward depends in part on what you're thinking" (which we know is true anyway), is more plausible and flexible than "your imagination has special access to the reward function".
Next: What would Steven Pinker say? He is my representative advocate of a certain branch of cognitive neuroscience—a branch to which I do not subscribe. Of course I don’t know what he would say, but maybe it’s a worthwhile exercise for me to at least try. Well, first, I think he would reject the idea that there's a “neocortex subsystem”. And I think he would more generally reject the idea that there is any interesting question along the lines of "how does the reward system know that the rat is thinking about salt?". Of course I want to pose that question, because I come from a perspective of “things like this need to learned from scratch” (again see My Computational Framework for the Brain [LW · GW]). But Pinker would not be coming from that perspective. I think he wants to assume that a comparatively elaborate world-modeling infrastructure is already in place, having been hardcoded by the genome. So maybe he would say there's a built-in “diet module” which can model and understand food, taste, satiety, etc., and he would say there's a built-in “navigation module” which can plan a route to walk over to the lever, and he would there's a built-in “3D modeling module” which can make sense of the room and lever, etc. etc.
OK, now that possibly-strawman-Steven-Pinker has had his say in the previous paragraph, I can respond. I don't think this is so far off as a description of the calculations done by an adult brain. In ML we talk about “how the learning algorithm works” (SGD, BatchNorm, etc.), and separately (and much less frequently!) we talk about “how the trained model works” (OpenAI Microscope, etc.). I want to put all that infrastructure in the previous paragraph at the "trained model" level, not the "learning algorithm" level. Why? First, because I think there’s pretty good evidence for cortical uniformity [LW · GW]. Second—and I know this sounds stupid—because I personally am unable to imagine how this setup would work in detail. How exactly do you insert learned content into the innate framework? How exactly do you interface the different modules with each other? And so on. Obviously, yes I know, it’s possible that answers exist, even if I can’t figure them out. But that’s where I’m at right now.
41 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2020-12-13T21:40:42.501Z · LW(p) · GW(p)
Now, for the rats, there’s an evolutionarily-adaptive goal of "when in a salt-deprived state, try to eat salt". The genome is “trying” to install that goal in the rat’s brain. And apparently, it worked! That goal was installed!
This is importantly technically false in a way that should not be forgotten on pain of planetary extinction:
The outer loss function training the rat genome was strictly inclusive genetic fitness. The rats ended up with zero internal concept of inclusive genetic fitness, and indeed, no coherent utility function; and instead ended up with complicated internal machinery running off of millions of humanly illegible neural activations; whose properties included attaching positive motivational valence to imagined states that the rat had never experienced before, but which shared a regularity with states experienced by past rats during the "training" phase.
A human, who works quite similarly to the rat due to common ancestry, may find it natural to think of this as a very simple 'goal'; because things similar to us appear to have falsely low algorithmic complexity when we model them by empathy; because the empathy can model them using short codes. A human may imagine that natural selection successfully created rats with a simple salt-balance term in their simple generalization of a utility function, simply by natural-selection-training them on environmental scenarios with salt deficits and simple loss-function penalties for not balancing the salt deficits, which were then straightforwardly encoded into equally simple concepts in the rat.
This isn't what actually happened. Natural selection applied a very simple loss function of 'inclusive genetic fitness'. It ended up as much more complicated internal machinery in the rat that made zero mention of the far more compact concept behind the original loss function. You share the complicated machinery so it looks simpler to you than it should be, and you find the results sympathetic so they seem like natural outcomes to you. But from the standpoint of natural-selection-the-programmer the results were bizarre, and involved huge inner divergences and huge inner novel complexity relative to the outer optimization pressures.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-12-13T23:04:26.610Z · LW(p) · GW(p)
Thanks for your comment! I think that you're implicitly relying on a different flavor of "inner alignment" than the one I have in mind.
(And confusingly, the brain can be described using either version of "inner alignment"! With different resulting mental pictures in the two cases!!)
See my post Mesa-Optimizers vs "Steered Optimizers" [LW · GW] for details on those two flavors of inner alignment.
I'll summarize here for convenience.
I think you're imagining that the AGI programmer will set up SGD (or equivalent) and the thing SGD does is analogous to evolution acting on the entire brain. In that case I would agree with your perspective.
I'm imagining something different:
The first background step is: I argue (for example here [LW · GW]) that one part of the brain (I'm calling it the "neocortex subsystem") is effectively implementing a relatively simple, quasi-general-purpose learning-and-acting algorithm. This algorithm is capable of foresighted goal seeking, predictive-world-model-building, inventing new concepts, etc. etc. I don't think this algorithm looks much like a deep neural net trained by SGD; I think it looks like an learning algorithm that no human has invented yet, one which is more closely related to learning probabilistic graphical models than to deep neural nets. So that's one part of the brain, comprising maybe 80% of the weight of a human brain. Then there are other parts of the brain (brainstem, amygdala, etc.) that are not part of this subsystem. Instead, one thing they do is run calculations and interact with the "neocortex subsystem" in a way that tends to "steer" that "neocortex subsystem" towards behaving in ways that are evolutionarily adaptive. I think there are many different "steering" brain circuits, and they are designed to steer the neocortex subsystem towards seeking a variety of goals using a variety of mechanisms.
So that's the background picture in my head—and if you don't buy into that, nothing else I say will make sense.
Then the second step is: I'm imagining that the AGI programmers will build a learning-and-acting algorithm that resembles the "neocortex subsystem"'s learning-and-acting algorithm—not by some blind search over algorithm space, but by directly programming it, just as people have directly programmed AlphaGo and many other learning algorithms in the past. (They will do this either by studying how the neocortex works, or by reinventing the same ideas.) Once those programmers succeed, then OK, now these programmers will have in their hands a powerful quasi-general-purpose learning-and-acting (and foresighted goal-seeking, concept-inventing, etc.) algorithm. And then the programmer will be in a position analogous to the position of the genes wiring up those other brain modules (brainstem, etc.): the programmers will be writing code that tries to get this neocortex-like algorithm to do the things they want it to do. Let's say the code they write is a "steering subsystem".
The simplest possible "steering subsystem" is ridiculously simple and obvious: just a reward calculator that sends rewards for the exact thing that the programmer wants it to do. (Note: the "neocortex subsystem" algorithm has an input for reward signals, and these signals are involved in creating and modifying its internal goals.) And if the programmer unthinkingly build that kind of simple "steering subsystem", it would kinda work, but not reliably, for the usual reasons like ambiguity in extrapolating out-of-distribution, the neocortex-like algorithm sabotaging the steering subsystem, etc. But, we can hope that there are more complicated possible "steering subsystems" that would work better.
So then this article is part of a research program of trying to understand the space of possibilities for the "steering subsystem", and figuring out which of them (if any!!) would work well enough to keep arbitrarily powerful AGIs (of this basic architecture) doing what we want them to do.
Finally, if you can load that whole perspective into your head, I think from that perspective it's appropriate to say "the genome is “trying” to install that goal in the rat’s brain", just as you can say that a particular gene is "trying" to do a certain step of assembling a white blood cell or whatever. (The "trying" is metaphorical but sometimes helpful.) I suppose I should have said "rat's neocortex subsystem" instead of "rat's brain". Sorry about that.
Does that help? Sorry if I'm misunderstanding you. :-)
Replies from: azsantosk↑ comment by azsantosk · 2022-03-28T18:01:57.696Z · LW(p) · GW(p)
Having read Steven's post on why humans will not create AGI through a process analogous to evolution [LW · GW], his metaphor of the gene trying to do something felt appropriate to me.
If the "genome = code" analogy is the better one for thinking about the relationship of AGIs and brains, then the fact that the genome can steer the neocortex towards such proxy goals as salt homeostasis is very noteworthy, as a similar mechanism may give us some tools, even if limited, to steer a brain-like AGI toward goals that we would like it to have.
I think Eliezer's comment is also important in that it explains quite eloquently how complex these goals really are, even though they seem simple to us. In particular the positive motivational valence that such brain-like systems attribute to internal mental states makes them very different from other types of world-optimizing agents that may only care about themselves for instrumental reasons.
Also the fact that we don't have genetic fitness as a direct goal is evidence not only that evolution-like algorithms don't do inner alignment well, but also that simple but abstract goals such as inclusive genetic fitness may be hard to install in a brain-like system. This is especially so if you agree, in the case of humans, that having genetic fitness as a direct goal, at least alongside the proxies, would probably help fitness, even in the ancestral environment.
I don't really know how big of a problem this is. Given that our own goals are very complex and that outer alignment is hard, maybe we shouldn't be trying to put a simple goal into an AGI to begin with.
Maybe there is a path for using these brain-like mechanisms (including positive motivational valence for imagined states and so on) to create a secure aligned AGI. Getting this answer right seems extremely important to me, and if I understand correctly, this is a key part of Steven's research.
Of course, it is also possible that this is fundamentally unsafe and we shouldn't do that, but somehow I think that is unlikely. It should be possible to build such systems in a smaller scale (therefore not superintelligent) so that we can investigate their motivations to see what the internal goals are, and whether the system is treacherous or looking for proxies. If it turns out that such a path is indeed fundamentally unsafe, I would expect this to be related to ontological crises or profound motivational changes that are expected to occur as capability increases.
comment by JenniferRM · 2021-06-10T03:22:37.234Z · LW(p) · GW(p)
I wrote the following before reading the three hypotheses or other comments. The links were added after I copied the text over to the website:
My hypothesis for how the salt pursuing behavior worked is that there's a generic "entity" subsystem in the brain.
It has a deep prior that "things" exist and it figures out the sound/smell/appearance of "things".
Where is "thing modeling" implemented? Something something temporal cortex, something something hippocampus, something something halle berry neuron.
As a similarly deep prior, some "things" are classified in terms of a "food" category, and for all such things there is a taste vector which is basically a list of values for how full of nutrient/features the "thing" is when considered as "food". There are low level rewards to help "educate the palate" which fills in this part of a model of the world and so: goats and rats and babies constantly stick stuff in their mouths.
The features/characteristics of "things" that are "edible" are non-trivial, and based on complex sensors that can essentially perform a chemical assay. These assays are central to everything. There's thousands of smells that could support a dimensional analysis engine that would have probably had something like 2 billion years of evolution to develop.
There are receptors which measure how glucose-like a substance is, for example, and their operation is ancient and also non-trivial. Also acidity and saltiness are simpler molecular ideas than glucose, and all of these simple molecules were "learned about" by DNA-based learning for a long time before neurons even existed.
Single celled organisms already have chemical assay based behavioral learning. Smell was almost certainly the first sense. In a way, the only sense 99% of neurons have is a sense of smell.
Dogs have a lot of smell sensors (and bad eyesight) whereas human noses are far from the ground, but we haven't lost all the smell receptors to mutational load and lack of selection yet. We probably will never lose them all?
So then there's a large number of nutrient deficiencies and chemical imbalances that are possible. Low blood sugar is an obvious one, but many others could exist. Every amino acid's levels could, individually, be tracked and that would "just make sense" on a first principles evolutionary level for there to be chemical sensors here.
Sensors for the chemical or physiological precursors of basically any and all serious nutrient deficiency could exist in large numbers, with many subtypes. Some of the microbiological sensors could modulate the conscious mind directly, the evidence being that many people know what it feels like to "feel hungry" in different ways, but different signals could be subconscious quite easily and not violate the hypothesis? Just have the optimization signals propagate via paths far from the verbal awareness loops, basically?
The claim is simply that the microsensory details here could exist in the body, and send signals to some part of the brain stem that recognizes "food-fixable deficiencies" that treat food seeking as a first class task. Call all these subtypes of chemically measurable hunger different internal "deficiency sensors"?
Any big obvious linkages between a deficiency and a tastable food feature that could reliably occur over evolutionary timescales is likely to already exist at a very low level, with hard coded linkages.
Basically we should expect a many-to-many lookup table between "foods" and how much each food type would help avoid worsening over supply (and/or helping with under supply) of every nutrient, with the only learning being the food list contents (plus where each food is and so on, for motor planning) and then learned "deficiency fixing" values for each food (plausibly subconsciously).
When the vector of various kinds of "hunger levels" changes, a relatively hard coded circuit probably exists that (abstractly (maybe even literally?)) assigns each food a new dot product value in terms of general food goodness, and foods with high values "sort to the top", after which a whole planning engine kicks in, confabulating plans for getting any or all such high value foods and throwing out the implausible plans, until a food with a high value and a plausible plan is left over.
Then after a while (something something prefrontal cortex, something something inhibition of motor plans) the plan is tried. Sometimes it will be a terrible plan, like "eat sand (because your parents suck at being providers)" but we can't keep parents from torturing their children using insane dietary theories... that's not even an important example... it mostly just shows that human conscious thought is mostly not that great. The main case is just like, a dog whose puppies are hungry because it sucks at hunting, so the puppies get weird deficiencies, and then the puppies that wordlessly/atheoretically solve these cravings somehow survive to have more puppies.
Anyway... the intrinsic horrifying bleakness of biology aside... in low cephalization animals (like cows) with bodies and habitats and habits that are already "known viable", evolution's instrumental task here doesn't need to be very complicated. Maybe slightly modulate which grasses or herbs are eaten, and wander in the direction of places where the desired plants tend to grow more?
For some animals (like chimps) the confabulation engine turned out to be pretty valuable, and it just kept getting bigger over time. Hence human brains getting progressively bigger confabulation engines.
When humans starve, they become obsessed with imagination about food. A nearly identical process plausibly explains romantic obsessions. And so on. A HUGE amount of human behavioral reasoning is plausibly "pica [LW · GW] with more steps".
Basically, my theory is that "mammal brains have first class specialized treatment of edible physical objects, the mice got pica for salt, and the source of salt was already in the relevant foodthing/location memory slot, and the obvious half-hard-coded action happened when the relevant check engine light came on and a new part of the dot product calculator for food value reversed in sign... for the first time ever (in the experiment)".
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-10T20:53:24.926Z · LW(p) · GW(p)
Thanks!! I largely agree with what you wrote.
I was focusing on the implementation of a particular aspect of that. Specifically, when you're doing what you call "thing modeling", the "things" you wind up with are entries in a complicated learned world-model—e.g. "thing #6564457" is a certain horrifically complicated statistical regularity in multimodal sensory data, something like: "thing #6564457" is a prediction that thing #289347 is present, and thing #89672, and thing #68972, but probably not thing #903672", or whatever.
Meanwhile I agree with you that there is some brainstem / hypothalamus function (outside the learned world-model) that can evaluate how biologically adaptive it would be to eat food with a certain profile of flavors / smells / etc., given the current readings of various sensors detecting nutrient deficiencies etc. (That component actually seems quite straightforward to me.)
And then my particular focus is how exactly the brain builds interface into and out of the world-model, which is a prerequisite for learning that this particular statistical regularity (in the learned world-model) corresponds to a particular vector of sweetness, savoriness, etc. (in the brainstem), which the brainstem can analyze and declare likely to satisfy current physiological needs, and then therefore let's try to eat it (back in the learned world-model).
If you look closely at what you wrote, I think you'll find a few places where you need to transfer information into and out of the learned world-model. That's fine, but there has to be a way that that works, and that's the part I was especially interested in.
I guess my underlying assumption is that this interfacing isn't a trivial thing—like I don't think you can just casually say "The world-model shall have an item type called 'food' in it" and then there's an obvious way to make that happen. I think the world-model is built from the ground up, as learned patterns, and patterns in the patterns, etc., so you generally need stories for how things are learned. At any rate, that type of algorithm seems plausible to me (from everything I've read and thought about), and I haven't seen any alternative story that makes sense to me so far.
When the vector of various kinds of "hunger levels" changes, a relatively hard coded circuit probably exists that (abstractly (maybe even literally?)) assigns each food a new dot product value in terms of general food goodness, and foods with high values "sort to the top", after which a whole planning engine kicks in, confabulating plans for getting any or all such high value foods and throwing out the implausible plans, until a food with a high value and a plausible plan is left over.
It sounds like you want to start with the hypothalamus & brainstem providing a ranked list of all possible foods, and then the world-model finds one that can be eaten. But I want to go basically in the opposite direction, where the planner (working within the learned world-model) proposes a thought that involves eating ("I could eat that carrot in the fridge"), and the hypothalamus & brainstem evaluate how appealing that plan is ("carrots are sweet, I'm low in sugar right now, 7/10"), and then it sends dopamine to reward the thinking of appealing thoughts (and moreso if they're part of realistic likely-to-succeed plans). Like, if I'm really hungry, I think I'm more likely to decide to eat the first easily-accessible food that pops into my head, rather than working my way through a long list of possible foods that would be hypothetically better ("no I don't have a coconut smoothie, no I don't have fried clams, ..."). Then, through the magic of reinforcement learning, the planner gradually learns to skillfully and quickly come up with appropriate and viable foods.
Replies from: JenniferRM↑ comment by JenniferRM · 2021-06-11T00:21:30.340Z · LW(p) · GW(p)
Response appreciated! Yeah. I think I have two hunches here that cause me to speak differently.
One of these hunches is that hunger sensors are likely to be very very "low level", and motivationally "primary". The other is maybe an expectation that almost literally "every possible thought" is being considered simultaneously in the brain by default, but most do not rise to awareness, or action-production, or verbalizability?
Like I think that hunger sensors firing will cause increased firing in "something or other" that sort of "represents food" (plus giving the food the halo of temporary desirability) and I expect this firing rate to basically go up over time... more hungriness... more food awareness?
Like if you ask me "Jennifer, when was the last time you ate steak?" then I am aware of a wave of candidate answers, and many fall away, and the ones that are left I can imagine defending, and then I might say "Yesterday I bought some at the store, but I think maybe the last time I ate one (like with a fork and a steakknife and everything) it was about 5-9 days ago at Texas Roadhouse... that was certainly a vivid event because it was my first time back there since covid started" and then just now I became uncertain, and I tried to imagine other events, like what about smaller pieces of steak, and then I remembered some carne asada 3 days ago at a BBQ.
What I think is happening here is that (like the Halle Berry neuron found in the hippocampus of the brain surgery patient) there is at least one steak neuron in my own hippocampus, and it can be stimulated by hearing the word, and persistent firing of it will cause episodic memories (nearly always associated with places) to rise up. Making the activations of cortex-level sensory details and models conform to "the ways that the entire brain can or would be different if the remembered episode was being generated from sensory stimulation (or in this case the echo of that as a memory)".
So I think hunger representations, mapped through very low level food representations, could push through into episodic memories, and the difference between a memory and a plan is not that large?
Just as many food representing neurons could be stimulated by deficiency detecting sensory neurons, the food ideas would link to food memories, and food memories could become prompts to "go back to that place and try a similar action to what is remembered".
And all the possible places to go could be activated in parallel in the brain, with winnowing, until a handful of candidates get the most firing because of numerous simultaneous "justifications" that route through numerous memories or variations of action that would all "be good enough".
The model I have is sort of like... maybe lightning?
An entire cloud solves the problem of finding a very low energy path for electrons to take to go from electron dense places to places that lack electrons, first tentatively and widely, then narrowly and quickly.
Similarly, I suspect the entire brain solves the problem of finding a fast cheap way to cause the muscles to fire in a way that achieves what the brain stem thinks would be desirable, first tentatively and widely, then narrowly and quickly.
I googled [thinking of food fMRI] and found a paper suggesting: hippocampus, insula, caudate.
Then I googled [food insula] and [food caudate] in different tabs. To a first approximation, it looks like the caudate is related to "skilled reaching" for food? Leaving, by process of elimination: the insula?
And uh... yup? The insula seems to keep track of the taste and "goal-worthiness" of foods?
In this review, we will specifically focus on the involvement of the insula in food processing and on multimodal integration of food-related items. Influencing factors of insular activation elicited by various foods range from calorie-content to the internal physiologic state, body mass index or eating behavior. Sensory perception of food-related stimuli including seeing, smelling, and tasting elicits increased activation in the anterior and mid-dorsal part of the insular cortex. Apart from the pure sensory gustatory processing, there is also a strong association with the rewarding/hedonic aspects of food items, which is reflected in higher insular activity and stronger connections to other reward-related areas.
So my theory is:
Biochemistry --> hunger sensors (rising, enduring) --> insula (rising, enduring) -->
--> hippocampus (also triggerable by active related ideas?) --> memories sifted --> plans (also loop back to hippocampus if plans trigger new memories?) -->
--> prefrontal cortex(?) eventualy STOPS saying "no go" on current best mishmash of a plan -->
--> caudate (and presumably cerebellum) generate --> skilled food seeking firing of muscles to act in imagined way!
The arrows represent sort of "psychic motivational energy" (if we are adopting a theory of mind) as well as "higher firing rate" as well as maybe "leading indicator of WHICH earlier firing predicts WHICH later firing by neurons/activities being pointed to".
I think you have some theories that there's quite a few low level subsystems that basically do supervised learning on their restricted domain? My guess is that the insula is where the results of supervised learning on "feeling better after consuming something" are tracked?
Also, it looks like the insula's supervised learning algorithms can be hacked?
The insular cortex subserves visceral-emotional functions, including taste processing, and is implicated in drug craving and relapse. Here, via optoinhibition, we implicate projections from the anterior insular cortex to the nucleus accumbens as modulating highly compulsive-like food self-administration behaviors
Trying to reconcile this with your "telencephalon" focus... I just learned that the brain has FIVE lobes of the cortex, instead of the FOUR that I had previously thought existed?! At least Encarta used to assert that there are five...
These and other sulci and gyri divide the cerebrum into five lobes: the frontal, parietal, temporal, and occipital lobes and the insula. [bold not in original]
Until I looked up the anatomy, I had just assumed that the insula was part of the brain stem, and so I thought I won some bayes points for my "hard wiring" assumption, but the insula is "the lobe" hiding in the valley between the temporal cortex and the rest of the visible surface lobes, so it is deep down, closer to the brain stem... So maybe you win some bayes points for your telencephalon theory? :-)
Replies from: steve2152{kind=link}
↑ comment by Steven Byrnes (steve2152) · 2021-06-11T20:42:07.648Z · LW(p) · GW(p)
Thanks! This is very interesting!
there is at least one steak neuron in my own hippocampus, and it can be stimulated by hearing the word, and persistent firing of it will cause episodic memories...to rise up
Oh yeah, I definitely agree that this is an important dynamic. I think there are two cases. In the case of episodic memory I think you're kinda searching for one of a discrete (albeit large) set of items, based on some aspect of the item. So this is a pure autoassociative memory mechanism. The other case is when you're forming a brand new thought. I think of it like, your thoughts are made up of a bunch of little puzzle pieces that can snap together, but only in certain ways (e.g. you can't visualize a "falling stationary rock", but you can visualize a "blanket made of banana peels"). I think you can issue top-down mandates that there should be a thought containing a certain small set of pieces, and then your brain will search for a way to build out a complete thought (or plan) that includes those pieces. Like "wanting to fit the book in the bag" looks like running a search for a self-consistent thought that ends with the book sliding smoothly into the bag. There might be some autoassociative memory involved here too, not sure, although I think it mainly winds up vaguely similar to belief-propagation algorithms in Bayesian PGMs.
Anyway, the hunger case could look like invoking the piece-of-a-thought:
Piece-of-a-thought X: "[BLANK] and then I eat yummy food"
…and then the search algorithm looks for ways to flesh that out into a complete plausible thought.
I guess your model is more like "the brainstem reaches up and activates Piece-of-a-thought X" and my model is more like "the brainstem waits patiently for the cortex to activate Piece-of-a-thought X, and as soon as it does, it says YES GOOD THANKS, HERE'S SOME REWARD". And then very early in infancy the cortex learns (by RL) that when its own interoceptive inputs indicate hunger, then it should activate piece-of-a-thought X.
Maybe you'll say: eating is so basic, this RL mechanism seems wrong. Learning takes time, but infants need to eat, right? But then my response would be: eating is basic and necessary from birth, but doesn't need to involve the cortex. There can be a hardwired brainstem circuit that says "if you see a prey animal, chase it and kill it", and another that says "if you smell a certain smell, bite on it", and another that says "when there's food in your mouth, chew it and swallow it", etc. The cortex is for learning more complicated patterns, I think, and by the time it's capable of doing useful things in general, it can also learn this one simple little pattern, i.e. that hunger signals imply reward-for-thinking-about-eating.
insula
FWIW, in the scheme here [LW · GW], one part of insular cortex is an honorary member of the "agranular prefrontal cortex" club—that's based purely on this quote I found in Wise 2017: "Although the traditional anatomical literature often treats the orbitofrontal and insular cortex as distinct entities, a detailed analysis of their architectonics, connections, and topology revealed that the agranular insular areas are integral parts of an “orbital prefrontal network”". So this is a "supervised learning" part (if you believe me), and I agree with you that it may well more specifically involve predictions about "feeling better after consuming something". I also think this is probably the part relevant to your comment "the insula's supervised learning algorithms can be hacked?".
Another part of the insula is what Lisa Feldman Barrett calls "primary interoceptive cortex", i.e. she is suggesting that it learns a vocabulary of patterns that describe incoming interoceptive (body status) signals, analogously to how primary visual cortex learns a vocabulary of patterns that describe incoming visual signals, primary auditory cortex learns a vocabulary of patterns that describe incoming auditory signals, etc.
Those are the two parts of the insula that I know about. There might be other things in the insula too.
caudate
I didn't explicitly mention caudate here [LW · GW] but it's half of "dorsal striatum". The other half is putamen—I think they're properly considered as one structure. "Dorsal striatum" is the striatum associated with motor-control cortex and executive-function cortex, more or less. I'm not sure how that breaks down between caudate and putamen. I'm also not sure why caudate was active in that fMRI paper you found.
hippocampus
I think I draw more of a distinction between plans and memories than you, and put hippocampus on the "memory" side. (I'm thinking roughly "hippocampus = navigation (in all mammals) and first-person memories (only in humans)", and "dorsolateral prefrontal cortex is executive function and planning (in humans)".) I'm not sure exactly what the fMRI task was, but maybe it involved invoking memories?
comment by Steven Byrnes (steve2152) · 2020-12-02T14:15:15.846Z · LW(p) · GW(p)
FYI: In the original version I wrote that the saltwater spray happens when the rats press the lever. It turns out I misunderstood. During training, the saltwater spray happens immediately after the lever appears, whether or not the rats touch the lever. Still, the rats act as if the lever deserves the credit / blame for causing the spray, by nibbling the lever when they like the spray (e.g. with the sugar-water control lever), or staying away from the lever if they don't. Thanks Kent Berridge for the correction. I've made a few other corrections since posting this but I think I marked all the other ones in the text.
comment by ADifferentAnonymous · 2020-11-20T23:13:51.924Z · LW(p) · GW(p)
This might just be me not grokking predictive processing, but...
I feel like I do a version of the rat's task all the time to decide what to have for dinner—I imagine different food options, feel which one seems most appetizing, and then push the button (on Seamless) that will make that food appear.
Introspectively, this feels to me there's such a thing as 'hypothetical reward'. When I imagine a particular food, I feel like I get a signal from... somewhere... that tells me whether I would feel reward if I ate that food, but does not itself constitute reward. I don't generally feel any desire to spend time fantasizing about the food I'm waiting for.
To turn this into a brain model, this seems like the neocortex calling an API the subcortex exposes. Roughly, the neocortex can give the subcortex hypothetical sensory data and get a hypothetical reward in exchange. I suppose this is basically hypothesis two with a modification to avoid the pitfall you identify, although that's not how I arrived at the idea.
This does require a second dimension of subcortex-to-neocortex signal alongside the reward. Is there a reason to think there isn't one?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-22T01:56:57.358Z · LW(p) · GW(p)
I don't generally feel any desire to spend time fantasizing about the food I'm waiting for.
Haha, yeah, there's a song about that.
So anyway, I think you're onto something, and I think that something is that "reward" and "reward prediction" are two distinct concepts, but they're all jumbled up in my mind, and therefore presumably also jumbled up in my writings. I've been vaguely aware of this for a while, but thanks for calling me out on it, I should clean up my act. So I'm thinking out loud here, bear with me, and I'm happy for any help. :-)
The TD learning algorithm is:
where is the previous state, is the new state, V is the value function a.k.a. reward prediction, and r is the reward from this step.
(I'm ignoring discounting. BTW, I don't think the brain literally does TD learning in the exact form that computer scientists do, but I think it's close enough to get the right idea.)
So let's go through two scenarios.
Scenario A: I'm going to eat candy, anticipating a large reward (high ). I eat the candy (high r) then don't anticipate any reward after that (low ). RPE=0 here. That's just what I expected. V went down, but it went down in lock-step with the arrival of the reward r.
Scenario B: I'm going to eat candy, anticipating a large reward (high ). Then I see that we're out of candy! So I get no reward and have nothing to look forward to (, low ). Now this is a negative (bad) RPE! Subjectively, this feels like crushing disappointment. The TD learning rule kicks in here, so that next time when I go to eat candy, I won't be expecting as much reward as I did this time (lower than before), because I will be preemptively braced for the possibility that we'll be out of candy.
OK, makes sense so far.
Interestingly, the reward r, as such, barely matters here! It's not decision-relevant, right? Good actions can be determined entirely by the following rule:
Each step, do whatever maximizes RPE.
(right?)
Or subjectively, thoughts and sensory inputs with positive RPE are attractive, while thoughts and sensory inputs with negative RPE are aversive.
OK, so when the rat first considers the possibility that it's going to eat salt, it gets a big injection of positive RPE. It now (implicitly) expects a large upcoming reward. Let's say for the sake of argument that it decides to not eat the salt, and go do something else. Well now we're not expecting to eat the salt, whereas previously we were, so that's a big injection of negative RPE. So basically, once it gets the idea that it can eat salt, it's very aversive (negative RPE) to drop that idea, without actually consummating it (by eating the salt and getting the anticipated reward r).
Back to your food example, you go in with some baseline expectation for what dinner's going to be like. Then you invoke the idea "I'm going to eat yam". You get a negative RPE in response. OK, go back to the baseline plan then. You get a compensatory positive RPE. Then you invoke the idea "I'm going to eat beans". You get a positive RPE. Alright! You think about it some more. Oh, I can't have beans tonight, I don't have any. You drop the idea and suffer a negative RPE. That's aversive, but you're stuck. Then you invoke another idea "I'm going to eat porridge". Positive RPE! As you flesh out the plan, it becomes more confident, which activates the model more strongly, the idea in your head of having porridge becomes more vivid, so to speak. Each increment of increasing confidence that you're going to eat porridge is rewarded by a corresponding spurt of RPE. Then you eat the porridge. Back to low RPE, but there's a reward at the same time, so that's fine, there's no RPE.
Let's go to fantasizing in general. Let's say you get the idea that a wad of cash has magically appeared in your wallet. That idea is attractive (positive RPE). But sooner or later you're going to actually look in the wallet and find that there's no wad of cash (negative RPE). The negative RPE triggers the TD learning rule such that next time "the idea that a wad of cash has magically appeared in your wallet" will not be such an attractive idea, it will be tinged with a negative memory of it failing to happen. Of course, you could go the other way and try to avoid the negative RPE by clinging to the original story—like, don't look in your wallet, or if you see that the cash isn't there you think "guess I must have deposited in the bank already", etc. This is unhealthy but certainly a known human foible. For example, as of this writing, in the USA, each of the two major presidential candidates has millions of followers who believe that their preferred candidate will be president for the next four years. It's painful to let go of an idea that something good is going to happen, so you resist if at all possible. Luckily the brain has some defense systems against wishful thinking. For example you can't not expect something to happen that you've directly experienced multiple times. See here [LW · GW]. Another is: if you do eventually come back to earth, and the negative RPE finally does happen, then TD learning kicks in, and all the ideas and strategies that contributed to your resisting the truth until now get tarred with a reduction in associated RPE, which makes them less likely to be used next time.
Hmm, so maybe I had it right in the diagram here [LW · GW]: I had the neocortex sending reward predictions to the subcortex, and the subcortex sending back RPEs to the neocortex. So if the neocortex sends a high reward prediction, then a low reward prediction, that might or might not be a RPE, depending on whether you just ate candy in between. Here, the subcortex sends a positive RPE when the neocortex starts imagining tasting salt, and sends a negative RPE when it stops imagining salt (unless it actually ate the salt at that moment). And if the salt imagination / expectation signal gets suddenly stronger, it sends a positive RPE for the difference, and so on.
(I could make a better diagram by pulling a "basal ganglia" box out of the neocortex subsystem into a separate box in the diagram. My understanding, definitely oversimplified, is that the basal ganglia has a dense web of connections across the (frontal lobe of the) neocortex, and just memorizes reward predictions associated with different arbitrary neocortical patterns. And it also suppresses patterns that lead to lower reward predictions and amplifies patterns that lead to higher reward predictions. So in the diagram, the neocortex would sends "information" to the basal ganglia, the basal ganglia calculates a reward prediction and sends it to the subcortex, and the subcortex sends the RPE to the basal ganglia (to alter the reward predictions) and to the neocortex (to reinforce or weaken the associated patterns). Something like that...).
Does that make sense? Sorry this is so long. Happy for any thoughts if you've read this far.
Another update: Actually maybe it's simpler (and equivalent) to say the subcortex gives a reward proportional to the time-derivative of how strongly the salt-expectation signal is activated.
Replies from: ADifferentAnonymous↑ comment by ADifferentAnonymous · 2020-11-24T00:25:50.128Z · LW(p) · GW(p)
Thanks for the reply; I've thought it over a bunch, and I think my understanding is getting clearer.
I think one source of confusion for me is that to get any mileage out of this model I have to treat the neocortex as a black box doing trying to maximize something, but it seems like we also need to rely on the fact that it executes a particular algorithm with certain constraints.
For instance, if we think of the 'reward predictions' sent to the subcortex as outputs the neocortex chooses, the neocortex has no reason to keep them in sync with the rewards it actually expects to receive—instead, it should just increase the reward predictions to the maximum for some free one-time RPE and then leave it there, while engaging in an unrelated effort to maximize actual reward.
(The equation V(sprev)+=(learning rate)⋅(RPE) explains why the neocortex can't do that, but adding a mathematical constraint to my intuitive model is not really a supported operation. If I say "the neocortex is a black box that does whatever will maximize RPE, subject to the constraint that it has to update its reward predictions according to that equation," then I have no idea what the neocortex can and can't do)
Adding in the basal ganglia as an 'independent' reward predictor seems to work. My first thought was that this would lead to an adversarial situation where the neocortex is constantly incentivized to fool the basal ganglia into predicting higher rewards, but I guess that isn't a problem if the basal ganglia is good at its job.
Still, I feel like I'm missing a piece to be able to understand imagination as a form of prediction. Imagining eating beans to decide how rewarding they would be doesn't seem to get any harder if I already know I don't have any beans. And it doesn't feel like "thoughts of eating beans" are reinforced, it feels like I gain abstract knowledge that eating beans would be rewarded.
Meanwhile, it's quite possible to trigger physiological responses by imagining things. Certainly the response tends to be stronger if there's an actual possibility of the imagined thing coming to pass, but it seems like there's a floor on the effect size, where arbitrarily low probability eventually stops weakening the effect. This doesn't seem like it stops working if you keep doing it—AIUI, not all hungry people are happier when they imagine glorious food, but they all salivate. So that's a feedback channel separate from reward. I don't see why there couldn't also be similar loops entirely within the brain, but that's harder to prove.
So when our rat thinks about salt, the amygdala detects that and alerts... idk, the hypothalamus? The part that knows it needs salt... and the rat starts salivating and feels something in its stomach that it previously learned means "my body wants the food" and concludes eating salt would be a good idea.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-24T21:46:03.651Z · LW(p) · GW(p)
Strong agree that I have lots of detailed thoughts about the neocortex's algorithms and am probably implicitly leaning on them in ways that I'm not entire aware of and not communicating well. I appreciate your working with me. :-)
I do want to walk back a bit about the reward prediction error stuff. I think the following is equivalent but simpler:
I propose that the subcortex sends a reward related to the time-derivative of how strongly the neocortex is imagining / expecting to taste salt. So the neocortex gets a reward for first entertaining the idea of tasting salt, and another incremental reward for growing that idea into a definite plan. But then it would get a negative reward for dropping that idea.
(I think this is maybe related to the Russell-Ng potential-based reward shaping thing.)
the neocortex is constantly incentivized to fool the basal ganglia into predicting higher rewards
Well, there's a couple things, I think.
First, the neocortex can't just expect arbitrary things. It's constrained by self-supervised learning [LW · GW], which throws out models that have, in the past, made predictions refuted by experience. Like, let's say that every time you open the door, the handle makes a click. You're going to start expecting the click to happen. You have no choice, you can't not expect it! There are also constraints around self-consistency and other things, like you can't visualize something that is simultaneously stationary and dancing; those two models are just inconsistent, and the message-passing algorithm [LW · GW] will simply not allow both to be active at the same time.
Second, I think that one neocortex "thought" is made up of a large number of different components, and all of them carry separate reward predictions, which are combined (somehow) to get the attractiveness of the overall thought. Like, when you decide to step outside, you might expect to feel cold and sore muscles and wind and you'll say goodbye to the people inside ... all those different components could have different attractiveness. And an RPE changes the reward predictions of all of the ingredients of the thought, I think.
So like, if you're very hungry but have no food, you can say to yourself "I'm going to open my cupboard and find that food has magically appeared", and it seems like that should be a positive-RPE thought. But actually, the thought doesn't carry a positive reward. The "I will find food" part by itself does, but meanwhile you're also activating the thought "I am fooling myself", and the previous 10 times that thought was active, it carried a negative RPE, so that thought carries a very negative RP whenever it's invoked. But you can't get rid of that thought, because it previously made correct sensory predictions in this kind of situation—that's the previous paragraph.
Imagining eating beans to decide how rewarding they would be doesn't seem to get any harder if I already know I don't have any beans. And it doesn't feel like "thoughts of eating beans" are reinforced, it feels like I gain abstract knowledge that eating beans would be rewarded.
I would posit that it's a subtle effect in this particular example, because you don't actually care that much about beans. I would say "You get a subtle positive reward for entertaining the idea of eating beans, and then if you realize that you're out of beans and put the idea aside, you get a subtle negative reward upon going back to baseline." I think if you come up with less subtle examples it might be easier to think about, perhaps.
My general feeling is that if you just abstractly think about something for no reason in particular, it activates the models weakly (and ditto if you hear that someone else is thinking about that thing, or remember that thing in the past, etc.) If you start to think of it as "something that will happen to me", that activates the models more strongly. If you are directly experiencing the thing right now, it activates the model most strongly of all. I acknowledge that this is vague and unjustified, I wrote this [LW(p) · GW(p)] but it's all pretty half-baked.
An additional complication is that, as above, one thought consists of a bunch of component sub-thoughts, which all impact the reward prediction. If you imagine eating beans knowing that you're not actually going to, the "knowing that I'm not actually going to" part of the thought can have its own reward prediction, I suppose.
Oh, yet another thing is that I think maybe we have no subjective awareness of "reward", just RPE. (Reward does not feel rewarding!) So if we (1) decide "I will imagine yummy food", then (2) imagine yummy food, then (3) stop imagining yummy food, we get a positive reward from the second step and a negative reward from the third step, but both of those rewards were already predicted by the first step, so there's no RPE in either the second or third step, and therefore they don't feel positive or negative. Unless we're hungrier than we thought, I guess...
it seems like there's a floor on the effect size, where arbitrarily low probability eventually stops weakening the effect
Yeah sure, if a model is active at all, it's active above some threshold, I think. Like, if the neuron fires once every 10 minutes, then, well, the model is not actually turned on and affecting the brain. This is probably related to our inability to deal with small probabilities.
Meanwhile, it's quite possible to trigger physiological responses by imagining things.
Yes, I would say the "neocortex is imagining / expecting to taste salt" signal has many downstream effects, one of which is affecting the reward signal, one of which is causing salivation.
This doesn't seem like it stops working if you keep doing it
Really? I think that if some thought causes you to salivate, but doesn't actually ever lead to eating for hours afterwards, and this happens over and over again for weeks, your systems would learn to stop salivating. I guess I don't know for sure. Didn't Pavlov do that experiment? See also my "scary movie" example here [LW · GW].
the rat starts salivating and feels something in its stomach that it previously learned means "my body wants the food" and concludes eating salt would be a good idea
Basically, there could be a non-reward signal that indicates "whatever you're thinking of, eat it and you'll feel rewarded". And that could be learned from eating other food over the course of life. Yeah, sure, that could work. I think it would sorta amount to the same thing, because the neocortex would just turn that signal into a reward prediction, and register a positive RPE when it sees it. So why not just cut out the middleman and create a positive RPE by sending a reward? I guess you would argue that if it's not at all rewarding to imagine food that you know you're not going to eat, your theory fits that better.
Still thinking about it.
Thanks again, you're being very helpful :-)
Replies from: ADifferentAnonymous↑ comment by ADifferentAnonymous · 2020-11-25T00:24:29.369Z · LW(p) · GW(p)
Glad to hear this is helpful for you too :)
I didn't really follow the time-derivative idea before, and since you said it was equivalent I didn't worry about it :p. But either it's not really equivalent or I misunderstood the previous formulation, because I think everything works for me now.
So if we (1) decide "I will imagine yummy food", then (2) imagine yummy food, then (3) stop imagining yummy food, we get a positive reward from the second step and a negative reward from the third step, but both of those rewards were already predicted by the first step, so there's no RPE in either the second or third step, and therefore they don't feel positive or negative. Unless we're hungrier than we thought, I guess...
Well, what exactly happens if we're hungrier than we thought?
(1) "I will imagine food": No reward yet, expecting moderate positive reward followed by moderate negative reward.
(2) [Imagining food]: Large positive reward, but now expecting large negative reward when we stop imagining, so no RPE on previous step.
(3) [Stops imagining food]: Large negative reward as expected, no RPE for previous step.
The size of the reward can then be informative, but not actually rewarding (since it predictably nets to zero over time). The neocortex obtains hypothetical reward information form the subcortex, without actually extracting a reward—which is the thing I've been insisting had to be possible. Turns out we don't need to use a separate channel! And the subcortex doesn't have to know or care whether its receiving a genuine prediction or an exploratory imagining from the neocortex—the incentives are right either way.
(We do still need some explanation of why the neocortex can imagine (predict?) food momentarily but can't keep doing it food forever, avoid step (3), and pocket a positive RPE after step (2). Common sense suggests one: keeping such a thing up is effortful, so you'd be paying ongoing costs for a one-time gain, and unless you can keep it up forever the reward still nets to zero in the end)
comment by AdamGleave · 2020-11-19T12:13:00.655Z · LW(p) · GW(p)
I'm a bit confused by the intro saying that RL can't do this, especially since you later on say the neocortex is doing model-based RL. I think current model-based RL algorithms would likely do fine on a toy version of this task, with e.g. a 2D binary state space (salt deprived or not; salt water or not) and two actions (press lever or no-op). The idea would be:
- Agent explores by pressing lever, learns transition dynamics that pressing lever => spray of salt water.
- Planner concludes that any sequence of actions involving pressing lever will result in salt water spray. In a non salt-deprived state this has negative reward, so the agent avoids it.
- Once the agent becomes salt deprived, the planner will conclude this has positive reward, and so take that action.
I do agree that a typical model-free RL algorithm is not capable of doing this directly (it could perhaps meta-learn a policy with memory that can solve this).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-19T15:09:12.525Z · LW(p) · GW(p)
Good question! Sorry I didn't really explain. The missing piece is "the planner will conclude this has positive reward". The planner has no basis for coming up with this conclusion, that I can see.
In typical RL as I understand it, regardless of whether it's model-based or model-free, you learn about what is rewarding by seeing the outputs of the reward function. Like, if an RL agent is playing an Atari game, it does not see the source code that calculates the reward function. It can try to figure out how the reward function works, for sure, but when it does that, all it has to go on is the observations of what the reward function has output in the past. (Related discussion [LW · GW].)
So yeah, in the salt-deprived state, the reward function has changed. But how does the planner know that? It hasn't seen the salt-deprived state before. Presumably if you built such a planner, it would go in with a default assumption of "the salt-deprivation state is different now than I've ever seen before—I'll just assume that that doesn't affect the reward function!" Or at best, its default assumption would be "the salt deprivation state is different now than I've ever seen before—I don't know how and whether that impacts the reward function. I should increase my uncertainty. Maybe explore more.". In this experiment the rats were neither of those, instead they were acting like "the salt deprivation state is different than I've ever seen, and I specifically know that, in this new state, very salty things are now very rewarding". They were not behaving as if they were newly uncertain about the reward consequences of the lever, they were absolutely gung-ho about pressing it.
Sorry if I'm misunderstanding :-)
Replies from: AdamGleave↑ comment by AdamGleave · 2020-11-26T09:48:40.458Z · LW(p) · GW(p)
Thanks for the clarification! I agree if the planner does not have access to the reward function then it will not be able to solve it. Though, as you say, it could explore more given the uncertainty.
Most model-based RL algorithms I've seen assume they can evaluate the reward functions in arbitrary states. Moreover, it seems to me like this is the key thing that lets rats solve the problem. I don't see how you solve this problem in general in a sample-efficient manner otherwise.
One class of model-based RL approaches is based on [model-predictive control](https://en.wikipedia.org/wiki/Model_predictive_control): sample random actions, "rollout" the trajectories in the model, pick the trajectory that had the highest return and then take the first action from that trajectory, then replan. That said, assumptions vary. [iLQR](https://en.wikipedia.org/wiki/Linear%E2%80%93quadratic_regulator) makes the stronger assumption that reward is quadratic and differentiable.
I think methods based on [Monte Carlo tree search](https://en.wikipedia.org/wiki/Monte_Carlo_tree_search) might exhibit something like the problem you discuss. Since they sample actions from a policy trained to maximize reward, they might end up not exploring enough in this novel state if the policy is very confident it should not drink the salt water. That said, they typically include explicit methods for exploration like [UCB](https://en.wikipedia.org/wiki/Thompson_sampling#Upper-Confidence-Bound_(UCB)_algorithms) which should mitigate this.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-28T03:40:13.098Z · LW(p) · GW(p)
Most model-based RL algorithms I've seen assume they can evaluate the reward functions in arbitrary states.
Hmm. AlphaZero can evaluate the true reward function in arbitrary states. MuZero can't—it tries to learn the reward function by supervised learning from observations of past rewards (if I understand correctly). I googled "model-based RL Atari" and the first hit was this which likewise tries to learn the reward function by supervised learning from observations of past rewards (if I understand correctly). I'm not intimately familiar with the deep RL literature, I wouldn't know what's typical and I'll take your word for it, but it does seem that both possibilities are out there.
Anyway, I don't think the neocortex can evaluate the true reward function in arbitrary states, because it's not a neat mathematical function, it involves messy things like the outputs of millions of pain receptors, hormones sloshing around, the input-output relationships of entire brain subsystems containing tens of millions of neurons, etc. So I presume that the neocortex tries to learn the reward function by supervised learning from observations of past rewards—and that's the whole thing with TD learning and dopamine.
I added a new sub-bullet at the top to clarify that it's hard to explain by RL unless you assume the planner can query the ground-truth reward function in arbitrary hypothetical states. And then I also added a new paragraph to the "other possible explanations" section at the bottom saying what I said in the paragraph just above. Thank you.
I don't see how you solve this problem in general in a sample-efficient manner otherwise.
Well, the rats are trying to do the rewarding thing after zero samples, so I don't think "sample-efficiency" is quite the right framing.
In ML today, the reward function is typically a function of states and actions, not "thoughts". In a brain, the reward can depend directly on what you're imagining doing or planning to do, or even just what you're thinking about. That's my proposal here.
Well, I guess you could say that this is still a "normal MDP", but where "having thoughts" and "having ideas" etc. are part of the state / action space. But anyway, I think that's a bit different than how most ML people would normally think about things.
Replies from: AdamGleave↑ comment by AdamGleave · 2020-11-30T17:45:47.651Z · LW(p) · GW(p)
I googled "model-based RL Atari" and the first hit was this which likewise tries to learn the reward function by supervised learning from observations of past rewards (if I understand correctly)
Ah, the "model-based using a model-free RL algorithm" approach :) They learn a world model using supervised learning, and then use PPO (a model-free RL algorithm) to train a policy in it. It sounds odd but it makes sense: you hopefully get much of the sample efficiency of model-based training, while still retaining the state-of-the-art results of model-free RL. You're right that in this setup, as the actions are being chosen by the (model-free RL) policy, you don't get any zero-shot generalization.
I added a new sub-bullet at the top to clarify that it's hard to explain by RL unless you assume the planner can query the ground-truth reward function in arbitrary hypothetical states. And then I also added a new paragraph to the "other possible explanations" section at the bottom saying what I said in the paragraph just above. Thank you.
Thanks for updating the post to clarify this point -- I agree with you with the new wording.
In ML today, the reward function is typically a function of states and actions, not "thoughts". In a brain, the reward can depend directly on what you're imagining doing or planning to do, or even just what you're thinking about. That's my proposal here.
Yes indeed, your proposal is quite different from RL. The closest I can think of to rewards over "thoughts" in ML would be regularization terms that take into account weights or, occasionally, activations -- but that's very crude compared to what you're proposing.
comment by adamShimi · 2020-11-21T17:25:38.232Z · LW(p) · GW(p)
I really liked this post. Not used to thinking about brain algorithms, but I believe I followed most of your points.
That being said, I'm not sure I get how your hypotheses explain the actual behavior of the rats. Just looking at hypothesis 3, you posit that thinking about salt gets an improved reward, and so does actions that make the rat expect salt-tasting. But that doesn't remove the need for exploration! The neocortex still needs to choose a course of action before getting a reward. Actually, if thinking about salt is rewarded anyway, this might reinforce any behavior decided after thinking about salt. And if the interpretability is better and only rewards actions that are expected to result in tasting salt, there is still need for exploring to find such a plan and having it reinforced.
Am I getting something wrong?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-22T02:11:30.464Z · LW(p) · GW(p)
You're right. "Thinking about salt is rewarded anyway" doesn't make sense and isn't right. You're one of two people to call me out on it, and I just posted a long comment replying to the other here [LW(p) · GW(p)]. Thank you!! I just added a correction to the article:
(UPDATE: Commenters point out that this description isn't quite right—it doesn't make sense to say that the idea of tasting salt is rewarding per se. Rather, when the rat starts expecting to taste salt, the subcortex sends a positive reward-prediction-error signal, and conversely if the rat stops expecting to taste salt, the subcortex sends a negative reward-prediction-error signal. Something like that. Sorry for the mistake / confusion. Thanks commenters!)
Does that answer your question?
comment by Kevin Lacker (kevin-lacker) · 2020-11-20T00:58:03.805Z · LW(p) · GW(p)
Now, for the rats, there’s an evolutionarily-adaptive goal of "when in a salt-deprived state, try to eat salt". The genome is “trying” to install that goal in the rat’s brain. And apparently, it worked! That goal was installed! And remarkably, that goal was installed even before that situation was ever encountered!
I don't think this is remarkable. Plenty of human activities work this way, where some goal has been encoded through evolution. For example, heterosexual teenage boys often find teenage girls to be attractive and want to get them naked, even before they have ever managed to do it successfully, without a true conscious understanding of their eventual goals. Or babies know to seek out nipple-shaped objects, before they have ever interacted with a nipple.
Replies from: steve2152, Raemon↑ comment by Steven Byrnes (steve2152) · 2020-11-20T03:47:06.852Z · LW(p) · GW(p)
Well, the brain does a lot of impressive things :-) We shouldn't be less impressed by any one impressive thing just because there are many other impressive things too.
Anyway I wrote this blog post last year [LW · GW] where I went through a list of universal human behaviors and tried to think about how they could work. I've learned more since writing that, and I think I got some of the explanations wrong, but it's still a good starting point.
What about sexual attraction?
Without getting into too much detail, I would say that sexual attraction involves the same "supervised learning" mechanism I talked about here, but with one extra complication: For salt, it's trivial to get ground truth about whether you are tasting salt—you have salt taste buds sending their signals straight into the brain, it's crystal clear. But for sexual attraction, you need an extra computational step to get (approximate) ground truth about whether or not you are interacting with a sexually-attractive (to you) person. (Then that approximate ground truth can be the supervisory signal of the supervised learning algorithm.)
So, where does the "ground truth" for "I am interacting with a sexually-attractive (to me) person" come from? First, I think there are hardwired sight cues, sound cues, smell cues, touch cues, etc. See here [LW · GW] for details, particularly my claim that these cues are detected by circuitry in the subcortical sensory processing systems (especially the tectum), not in the neocortex. Second, I'm big into empathetic simulation and think they're central to all social emotions [LW · GW], and I think that it plays a role in all aspects of sexual attraction too, both physical and emotional. That's a bit of a long story, I think.
I think newborns finding their mother's nipple are just going by hardwired smell and touch cues, and hardwired movement routines, I presume in the brainstem. Hardwired stimulus-response, nothing complicated! Well, I don't really know, I'm just guessing.
comment by Gurkenglas · 2020-11-19T17:38:59.307Z · LW(p) · GW(p)
Do you posit that it learns over the course of its life that salt taste cures salt definiency, or do you allow this information to be encoded in the genome?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-19T18:07:55.467Z · LW(p) · GW(p)
I think the circuitry which monitors salt homeostasis, and which sends a reward signal when both salt is deficient and the neocortex starts imagining the taste of salt ... I think that circuitry is innate and in the genome. I don't think it's learned.
That's just a guess from first principles: there's no reason it couldn't be innate, it's not that complicated, and it's very important to get the behavior right. (Trial-and-error learning of salt homeostasis would, I imagine, be often fatal.)
I do think there are some non-neocortex aspects of food-related behavior that are learned—I'm thinking especially of how, if you eat food X, then get sick a few hours later, you develop a revulsion to the taste of food X. That's obviously learned, and I really don't think that this learning is happening in the neocortex. It's too specific. It's only one specific type of association, it has to occur in a specific time-window, etc.
But I suspect that the subcortical systems governing salt homeostasis in particular are entirely innate (or at least mostly innate), i.e. not involving learning.
Does that answer your question? Sorry if I'm misunderstanding.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2020-11-19T22:30:48.921Z · LW(p) · GW(p)
This all sounds reasonable. I just saw that you were arguing for more being learned at runtime (as some sort of Steven Reknip), and I thought that surely not all the salt machinery can be learnt, and I wanted to see which of those expectations would win.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-20T01:48:05.454Z · LW(p) · GW(p)
(Oh, I get it, Reknip is Pinker backwards.) If you're interested in my take more generally see My Computational Framework for the Brain [LW · GW]. :-)
comment by evhub · 2020-11-19T06:44:35.369Z · LW(p) · GW(p)
It also transfers in an obvious way to AGI programming, where it would correspond to something like an automated "interpretability" module that tries to make sense of the AGI's latent variables by correlating them with some other labeled properties of the AGI's inputs, and then rewarding the AGI for "thinking about the right things" (according to the interpretability module's output), which in turn helps turn those thoughts into the AGI's goals.
(Is this a good design idea that AGI programmers should adopt? I don't know, but I find it interesting, and at least worthy of further thought. I don't recall coming across this idea before in the context of inner alignment.)
Fwiw, I think this is basically a form of relaxed adversarial training [AF · GW], which is my favored solution for inner alignment.
comment by Gunnar_Zarncke · 2021-12-27T14:18:58.546Z · LW(p) · GW(p)
This is one of multiple posts by Steven that explain the cognitive architecture of the brain. All posts together helped me understand the mechanism of motivation and learning and answered open questions. Unfortunately, the best post of the sequence is not in 2020. I recommend including either this compact and self-contained post or the longer (and currently higher voted) My computational framework for the brain [LW · GW].
comment by fin · 2020-11-20T19:14:28.451Z · LW(p) · GW(p)
I interviewed Kent Berridge a while ago about this experiment and others. If folks are interested, I wrote something about it here, mostly trying to explain his work on addiction. You can listen to the audio on the same page.
Replies from: steve2152, steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-26T01:31:24.018Z · LW(p) · GW(p)
Update: Both the podcast and the article were interesting, enjoyable, and helpful :-)
Replies from: fin↑ comment by Steven Byrnes (steve2152) · 2020-11-20T19:34:16.364Z · LW(p) · GW(p)
No way! Awesome, looking forward to listening to that! :-)
comment by Shmi (shminux) · 2020-11-20T00:35:47.878Z · LW(p) · GW(p)
a comparatively elaborate world-modeling infrastructure is already in place, having been hardcoded by the genome
is an obvious model, given that most of the brain is NOT necortex, but much more ancient structures. Somewhere inside there is an input to the nervous system, SALT_CONTENT_IN_BLOOD which gets translated into less graded and more binary "salt taste GOOD" or "salt taste BAD", and the "Need SALT" on/off urge. When the rat tastes the salt water from the tap for the first time, what gets recorded is not (just) "tastes good" or "tastes bad" but "tastes SALTY", which is post-processed into a behavior based on whether the salty taste is good or bad. Together with the urge to seek salt when low, and the memory of the salty taste from before, this would explain the rats' behavior pretty well.
You don't need a fancy neural net and reinforcement learning here, the logic seems quite basic.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-20T02:54:29.509Z · LW(p) · GW(p)
most of the brain is NOT necortex, but much more ancient structures
Well, 75% of the human brain by weight is neocortex. Not sure what the ratio is for rats. I disagree with "much more ancient structures"; my current understanding is that the neocortex is not all that different from the pallium in birds and lizards, and there are homologous structures even in lampreys I think. Some say the neurons in a bird pallium are arranged differently in space from the neurons in a mammal neocortex, but the neurons are connected into the same circuits doing the same computations. I don't really know, I think it's still an open question.
Dayan & Berridge cite this old study with decorticate rats (rats with their neocortexes surgically removed (yikes)), I read it (well, parts of it) a few days ago when researching this post. Unfortunately they didn't do the types of tests I'm talking about here, where they go for the salt based on memory alone (indeed, based on an unpleasant memory). I didn't think anything in that paper contradicted what I wrote, unless I misunderstood something, which is entirely possible. It would be interesting if the study I described in this post was repeated with decorticate rats. My strong expectation would be that it wouldn't work. It would be an even stronger expectation if both the neocortex and hippocampus were removed—as I mentioned, I count the hippocampus as part of the "neocortex subsystem".
You don't need a fancy neural net and reinforcement learning here
I think I get what you're trying to say, but for what it's worth, I think it's well-established that mammals (and presumably many other animals) do a kind of reinforcement learning, famously involving dopamine neurons doing TD learning, or at least something related to TD learning. Of course animal brains do other things too: RL is not a grand all-encompassing theory of animal brains. But RL is one thing that they do. So putting reinforcement learning into the story is not an burdensome detail for which my model should be penalized—we already know that RL is present in the rat brain! Likewise, it's an established fact that the amygdala does supervised learning, as far as I understand from sources like this.
Somewhere inside there is an input to the nervous system, SALT_CONTENT_IN_BLOOD which gets translated into less graded and more binary "salt taste GOOD" or "salt taste BAD", and the "Need SALT" on/off urge. When the rat tastes the salt water from the tap for the first time, what gets recorded is not (just) "tastes good" or "tastes bad" but "tastes SALTY", which is post-processed into a behavior based on whether the salty taste is good or bad. Together with the urge to seek salt when low, and the memory of the salty taste from before, this would explain the rats' behavior pretty well.
I basically agree with that and would say that I am trying to flesh out the details. But let me say why I think it's not such a simple computation.
Photons hit the retina. The brain has to turn these photons into a predictive model of the world. Rat-cage-levers were not present in the evolutionary environment, so the predictive model needs to have a flexible way to learn new concepts / things and relations between them, including causal relations, spatial relations, temporal relations, and so on. So there's this big predictive world-model in the brain, and the genome has no idea what's in it. It's just a bunch of unlabeled items, and they only have semantic meaning through their web of connections. If Entity #5785238 is active, then it's likely that Entity #6873298 is also active. Etc. etc.
Again, levers are an arbitrary, learned object in the world-model, not hardwired. The affordance of "pressing the saltwater lever" is Entity #123456 in the world-model, let's say. The rat learns that Entity #123456 causes the taste of salt. How is that information learned, and stored, and how is it used to drive behavior in a salt-deprivation-dependent way? That's the question.
Like, you say "urge to seek salt" is one of your ingredients. OK, sure, but an "urge" is an intuitive notion. What is an "urge" in terms of an algorithm? How do you flesh it out? I know how I would answer that question: I would flesh it out by introducing the idea of reinforcement learning. I would say that every entity in the world-model (well, the part of the world model that's stored in the frontal lobe) carries a scalar reward prediction, and these numbers are updated by a reward signal, and you decide whether to do an action or think a thought based on whether it predicts more reward than what you would be doing otherwise. And now I can answer the question: what's an urge? An "urge to do X" is when the ground-truth reward signal shifts to make "doing X" and "thinking about doing X" suddenly more rewarding than usual. I'm not giving all the details here, but I feel like I have a nice outline of a picture in my head here of "urge", and it bridges all the way from neurons to algorithms to behavior. You're saying that there's an "urge", but you're also saying that you don't need "fancy" reinforcement learning to implement it. OK, how then? What is the "urge" under the hood? That's not rhetorical. If you have an answer, I'm very interested and would love to brainstorm with you. :-)
Replies from: shminux↑ comment by Shmi (shminux) · 2020-11-20T07:29:37.135Z · LW(p) · GW(p)
Well, you are clearly an expert here. And indeed bridging from the neurons to algorithms has been an open problem since forever. What I meant is, assuming you needed to code, say, an NPC in a game, you would code an "urge" certain way, probably in just a few dozen lines of code. Plus the underlying language, plus the compiler, plus the OS, plus the hardware, which is basically gates upon gates upon gates, all alike. There is no reinforcement learning there at all, and yet rows of nearly identical gates become an algorithm. Maybe some parts of the brain work like that, as well?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2020-11-20T18:52:45.539Z · LW(p) · GW(p)
Well, you are clearly an expert here.
LOL, "fake it til you make it" ftw! I disagree, but that's very kind of you to say. :-)
assuming you needed to code, say, an NPC in a game, you would code an "urge" certain way, probably in just a few dozen lines of code.
Hmm, if the NPC didn't need to be very good, I would use bacteria-level logic like "if you're getting attacked, move away from the last hit, if you can attack, attack, otherwise move towards the player" or whatever. Then an "urge to be more aggressive" would be, like, move towards the player more quickly, or changing some thresholds. But there's no foresight / planning here. So that's not exactly relevant to this post. The rats are making a plan to get saltwater.
So, if I were going to make the NPC better, maybe I would next incorporate planning. Like: Define an "expected reward" function (related to position, health, etc.), consider possible things to do next, and then pick the thing with the highest expected reward at the end. That might be more than a few dozen lines of code ... I guess it depends on the library functions available :-P Then you could have an "urge" be expressed through tweaking the parameters of the expected-reward calculation. And now the NPC would then be able to make plans to satisfy the urge, as opposed to just acting based on what's right in front of it, or whatever.
This thing where it considering multiple possible courses of action—that's not yet model-based reinforcement learning. There's no learning! But I would say it's a first step. There is indeed something like that as an ingredient in AlphaZero, for example.
But that's actually all that matters for this post anyway, I think. The real RL part−where you learn things—didn't come up. Maybe I shouldn't have brought up RL at all, now that I think about it :-P
comment by Towards_Keeperhood (Simon Skade) · 2024-11-05T14:22:53.292Z · LW(p) · GW(p)
Hi Steve, I didn't read this post yet and just wanted to ask whether it's still worth reading or whether everything relevant is now better in "incentive learning and dead sea salt experiment"?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-11-05T14:29:49.174Z · LW(p) · GW(p)
No I don’t recommend reading this post anymore, it has some ideas with little kernels of truth but also lots of errors and confusions. ¯\_(ツ)_/¯
comment by Ben Smith (ben-smith) · 2022-08-29T05:27:21.645Z · LW(p) · GW(p)
I wrote a paper on another experiment by Berridge reported in Zhang & Berridge (2009). Similar behavior was observed in that experiment, but the question explored was a bit different. They reported a behavioral pattern in which rats typically found moderately salty solutions appetitive and very salty solutions aversive. Put into salt deprivation, rats then found both solutions appetitive, but the salty solution less so.
They (and we) took it as given that homeostatic regulation set a 'present value' for salt that was dependent on the organism's current state. However, in that model, you would think rats would most prefer the extremely salty solution. But in any state, they prefer the moderately salty solution.
In a CABN paper, we pointed out this is not explainable when salt value is determined by a single homeostatic signal, but is explainable when neuroscience about the multiple salt-related homeostatic signals is taken into account. Some fairly recent neuroscience by Oka & Lee (and some older stuff too!) is very clear about the multiple sets of pathways involved. Because there are multiple regulatory systems for salt balance, the present value of these can be summed (as in your "multi-dimensional rewards [LW · GW]" post) to get a single value signal that tracks the motivation level of the rat for the rewards involved.