Against evolution as an analogy for how humans will create AGI
post by Steven Byrnes (steve2152) · 2021-03-23T12:29:56.540Z · LW · GW · 25 commentsContents
Background Defining “The Evolution Analogy for AGI Development”: Three ingredients A biological analogy I like much better: The “genome = code” analogy A motivating question: Two visions for how brain-like AGI would come to be 1. A couple outside-view arguments Outside view #1: How biomimetics has always worked Outside view #2: How learning algorithms have always been developed In general, which algorithms are a good fit for automated design (= design by learning algorithm), and which algorithms are a good fit for human design? Possible objections to the learning-algorithm-outside-view argument 2. Split into cases based on how the algorithm comes to understand the world Case 1: “Intelligence Via Online Learning”—The inner algorithm cannot build an ever-expanding web of knowledge & understanding by itself, but it can do so in conjunction with the outer algorithm Cases 2-5: After training, the inner algorithm by itself (i.e. without the outer algorithm's involvement) can build an ever-expanding web of knowledge & understanding Cases 2-3: The inner algorithm, by itself, builds an ever-expanding web of knowledge & understanding from scratch Case 2: Outer algorithm starts the inner algorithm from scratch, lets it run all the way to AGI-level performance, then edits the algorithm and restarts it from scratch Case 3: While the inner algorithm can build up knowledge from scratch, during development we try to preserve the “knowledge” data structure where possible, carrying it over from one version of the inner algorithm to the next Cases 4-5: The inner algorithm cannot start from scratch—it needs to start with a base of preexisting knowledge & understanding. But then can expand that knowledge arbitrarily far by itself. Case 4: The inner algorithm’s starting knowledge base is directly built by humans. Case 5: The inner algorithm’s starting knowledge base is built by the outer algorithm. 3. Computational efficiency: the inner algorithm can run efficiently only to the extent that humans (and the compiler toolchain) generally understand what it’s doing But first: A digression into algorithms and their low-level implementations Back to the main argument None 25 comments
Background
When we do Deep Reinforcement Learning to make a PacMan-playing AI (for example), there are two algorithms at play: (1) the “inner” algorithm (a.k.a. “policy”, a.k.a. “trained model”) is a PacMan-playing algorithm, which looks at the pixels and outputs a sequence of moves, and (2) the “outer” algorithm is a learning algorithm, probably involving gradient descent, which edits the “inner” PacMan-playing algorithm in a way that tends to improve it over time.
Likewise, when the human brain evolved, there were two algorithms at play: (1) the “inner” algorithm is the brain algorithm, which analyzes sensory inputs, outputs motor commands, etc., and (2) the “outer” algorithm is Evolution By Natural Selection, which edits the brain algorithm (via the genome) in a way that tends to increase the organism’s inclusive genetic fitness.
There’s an obvious parallel here: Deep RL involves a two-layer structure, and evolution involves a two-layer structure.
So there is a strong temptation to run with this analogy, and push it all the way to AGI. According to this school of thought, maybe the way we will eventually build AGI is by doing gradient descent (or some other optimization algorithm) and then the inner algorithm (a.k.a. trained model) will be an AGI algorithm—just as evolution designed the generally-intelligent human brain algorithm.
I think this analogy / development model is pretty often invoked by people thinking about AGI safety. Maybe the most explicit discussion is the one in Risks From Learned Optimization [LW · GW] last year.
But I want to argue that the development of AGI is unlikely to happen that way.
Defining “The Evolution Analogy for AGI Development”: Three ingredients
I want to be specific about what I’m arguing against here. So I define the Evolution Analogy For AGI Development as having all 3 of the following pieces:
- “Outer + Inner”: The analogy says that we humans will write and run an “outer algorithm” (e.g. gradient descent), which runs an automated search process to find an “inner algorithm” (a.k.a. “trained model”).
- …Analogous to how evolution is an automated search that discovered the human brain algorithm.
- (If you’ve read Risks From Learned Optimization [LW · GW] you can mentally substitute the words “base & mesa” for “outer & inner” respectively; I’m using different words because I'm thinking of “base & mesa” as something very specific, and I want to talk more broadly.)
- “Outer As Lead Designer”: The analogy says that the outer algorithm is doing the bulk of the “real design work”. So I am not talking about something like a hyperparameter search or neural architecture search, where the outer algorithm is merely adjusting a handful of legible adjustable parameters in the human-written inner algorithm code. Instead, I’m talking about a situation where the outer algorithm is really doing the hard work of figuring out fundamentally what the inner algorithm is and how it works, and meanwhile humans stare at the result and scratch their head and say "What on earth is this thing doing?" For example, the inner algorithm could internally have an RL submodule doing tree search, yet the humans have no idea that there's any RL going on, or any tree search going on, or indeed have any idea how this thing is learning anything at all in the first place.
- …Analogous to how evolution designed the human brain algorithm 100% from scratch.
- “Inner As AGI”: The analogy says that “The AGI” is identified as the inner algorithm, not the inner and outer algorithm working together. In other words, if I ask the AGI a question, I don’t need the outer algorithm to be running in the course of answering that question.
- ...Analogous to how, if you ask a human a question, they don’t reply “Ooh, that’s a hard question, hang on, let me procreate a few generations and then maybe my descendents will be able to help you!”
I want to argue that AGI will not be developed in a way where all three of these ingredients are present.
…On the other hand, I am happy to argue that AGI will be developed in a way that involves only two of these three ingredients!
- What if the “Outer As Lead Designer” criterion does not apply? Then (as mentioned above) we’re talking about things like automated hyperparameter search or neural architecture search, which edit a handful of adjustable parameters (number of layers, learning rate, etc.) within a human-designed algorithm. Well, I consider it totally plausible that those kinds of search processes will be part of AGI development. Learning algorithms (and planning algorithms, etc.) inevitably have adjustable parameters that navigate tradeoffs in the design space. And sometimes the best way to navigate those tradeoffs is to just try running the thing! Try lots of different settings and find what works best empirically—i.e., wrap it in an outer-loop optimization algorithm. Again, I don't count this as a victory for the evolution analogy, because the inner algorithm is still primarily designed by a human, and is legible to humans.
- What if the “Inner As AGI” criterion does not apply? Then the outer algorithm is an essential part of the AGI’s operating algorithm. I definitely see that as plausible—indeed likely—and this is how I think of within-lifetime human learning. Much more on this in a bit—see “Intelligence via online learning” below. If this is in fact the path to AGI, then we wind up with a different biological analogy…
A biological analogy I like much better: The “genome = code” analogy
Human intelligence | Artificial intelligence |
| Human genome | GitHub repository with all the PyTorch code for training and running the PacMan-playing agent |
| Within-lifetime learning | Training the PacMan-playing agent |
| How an adult human thinks and acts | Trained PacMan-playing agent |
Note that evolution is not in this picture: its role has been usurped by the engineers who wrote the PyTorch code. This is intelligent design, not evolution!
A motivating question: Two visions for how brain-like AGI would come to be
I’m trying to make a general argument in this post, but here is a concrete example to keep in mind.
As discussed here [LW · GW], I see the brain as having a “neocortex subsystem” that runs a particular learning algorithm—one which takes in sensory inputs and reward inputs, constructs a predictive world-model, and takes foresighted actions that tend to lead to high rewards. Then there is a different subsystem that (among many other things) calculates those rewards I just mentioned.
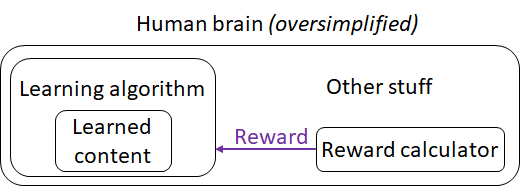
Maybe we'll make an AGI that has some resemblance to this system. Actually, I should be more specific: Maybe we'll make an AGI with this general structure, in which the learning algorithm component has some principles in common with the human brain's learning algorithm component. (The “reward calculator” and “other stuff” will obviously not be human-brain-like in any detail—unless we're doing whole-brain-emulation which is a different topic—since AGIs don't need to regulate their heart rate, or to have instinctive reactions to big hairy spiders, etc.)
Now, assuming that we make an AGI that has some resemblance to this system, consider two scenarios for how that happens:
- The scenario I don’t consider likely is where an automated search discovers both the neocortex subsystem learning algorithm and the reward calculator, tangled together into a big black box, with the programmer having no idea of how that algorithm is structured or what it's doing.
- The scenario I do consider likely is where humans design something like the neocortex subsystem learning algorithm by itself, using "the usual engineering approach" (see below)—trying to figure out how the learning algorithm is supposed to work, writing code, testing and iterating, etc. And then, in this scenario, the humans probably by-and-large ignore the rest of the brain, including the reward calculation, and they just insert their own reward function (and/or other "steering systems [LW · GW]"), starting with whatever is easy and obvious, and proceeding by trial-and-error or whatever, as they try to get this cool new learning algorithm do the things they want it to do. (Much more on this scenario in a forthcoming post.)
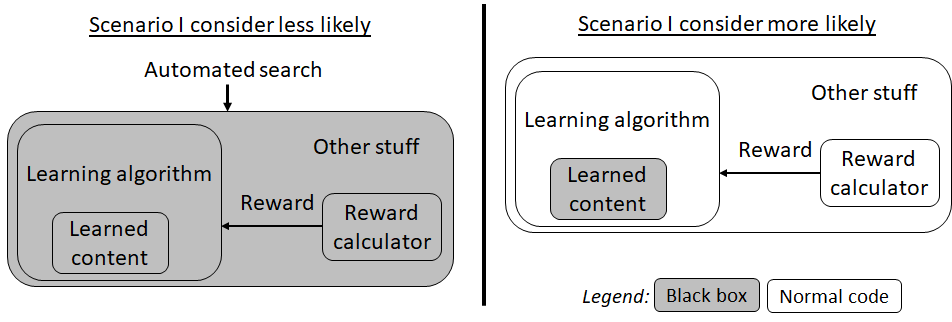
In the remainder of the post I’ll go over three reasons suggesting that the first scenario would be much less likely than the second scenario. First I’ll offer a couple outside-view arguments. Second I’ll work through the various possibilities for how the training and episode lengths would work. Third I’ll argue that the tangled-together black box in the first scenario would run with a horrific (I expect many orders of magnitude) performance penalty compared to the second scenario, due to neither the programmers nor the compiler toolchain having visibility into the black box. (I’m talking here about a run-time performance penalty. So this is on top of the computational costs of the original automated search that designed the black box.)
(I also have a very-inside-view argument—that the second scenario is already happening and well on its way to completion—but I won’t get into that, it’s more speculative and outside the scope of this post.)
Anyway, comparing these two scenarios, I have no idea which of them would make it easier or harder to develop Safe And Beneficial AGI. (There are very difficult inner alignment problems in both cases [LW · GW]—more on which in a forthcoming post.) But they are different scenarios, and I want us to be putting more effort into planning for whichever one is likelier to happen! I could be wrong here. Let’s figure it out!
1. A couple outside-view arguments
Now that we’re done with the background section, we’re on to the first of my three arguments against the evolution analogy: invoking a couple outside views [? · GW].
Outside view #1: How biomimetics has always worked
Here’s a typical example. Evolution has made wing-flapping animals. Human engineers wanted to make a wing-flapping flying machine. What those engineers did not do was imitate evolution by, say, running many generations of automated search over body plans and behaviors in a real or simulated environment and rewarding the ones that flew better. What they did do was to take, let’s call it, “the usual engineering approach”. That involves some combination of (1) trying to understand how wing-flapping animals fly, (2) trying to understand aerodynamics and the principles of flight more generally, (3) taking advantage of any available tools and techniques, (4) trial-and-error, (5) hypothesis-driven testing and iteration, etc. etc.
By the same token, Evolution has made human-level intelligence. Human engineers want to make human-level-intelligent machines. Just like the paragraph above, I expect them to take “the usual engineering approach”. That involves some combination of (1) trying to understand how human intelligence works, (2) trying to understand the nature of intelligence and intelligent algorithms more generally, (3) taking advantage of any available tools and techniques, (4) trial-and-error, (5) hypothesis-driven testing and iteration, etc. etc.
More examples along the same lines: (A) When people first started to build robots, they were inspired by human and animal locomotion, and they hooked up actuators and hinges etc. to make moving machines. There was no evolution-like outer-loop automated search process involved. (B) The Wright Brothers were inspired by, and stealing ideas from, soaring birds. There was no evolution-like outer-loop automated search process involved. (C) “Artificial photosynthesis” is an active field of research trying to develop systems that turn sunlight directly into chemical fuels. None of the ongoing research threads, to my knowledge, involve an evolution-like outer-loop automated search process (except very for narrow questions, like what molecule to put in a particular spot within the human-designed overall architecture). You get the idea.
Outside view #2: How learning algorithms have always been developed
As described above, I expect AGI to be a learning algorithm—for example, it should be able to read a book and then have a better understanding of the subject matter. Every learning algorithm you’ve ever heard of—ConvNets, PPO, TD learning, etc. etc.—was directly invented, understood, and programmed by humans. None of them were discovered by an automated search over a space of algorithms. Thus we get a presumption that AGI will also be directly invented, understood, and programmed by humans.
(Update: Admittedly, you can say "the GPT-3 trained model (inner algorithm) is a learning algorithm", in the sense that it has 96 layers, and it sorta "learns" things in earlier layers and "applies that knowledge" in later layers. And that was developed by an automated search. I don't count that because I don't think this type of "learning algorithm" is exactly the right type of learning algorithm that will be sufficient for AGI by itself; see discussion of GPT-3 in a later section, and also elaboration in my comment here [LW(p) · GW(p)].)
In general, which algorithms are a good fit for automated design (= design by learning algorithm), and which algorithms are a good fit for human design?
When we wanted to label images using a computer, we invented a learning algorithm (ConvNet + SGD) that looks at a bunch of images and gradually learns how to label images. By the same token, when we want to do human-level cognitive tasks with a computer, I claim that we'll invent a learning algorithm that reads books and watches movies and interacts and whatever else, and gradually learns how to do human-level cognitive tasks.
Why not go one level up and invent a learning algorithm that will invent a learning algorithm that will gradually learn how to do human-level cognitive tasks? (Or a learning algorithm that will invent a learning algorithm that will invent a learning algorithm that will…)
Indeed, on what principled grounds can I say "Learning algorithms are a good way to develop image classification algorithms", but also say "Learning algorithms are a bad way to develop learning algorithms?"
My answer is that, generically, automated design (= design by learning algorithm) is the best way to build algorithms that are (1) not computationally intensive to run (so we can easily run them millions of times), and (2) horrifically complicated (so that human design is intractable).
So image classification algorithms are a perfect fit for automated design (= design by learning algorithm). They’re easy to run—we can run a ConvNet image classifier model thousands of times a second, no problem. And they’re horrifically complicated, because they need logic that captures the horrific object-level complexity of the world, like the shape and coloration of trucks.
Whereas learning algorithms themselves are a terrible fit for automated design. They are famously computationally expensive—people often run learning algorithms for weeks straight on a heavy-duty supercomputer cluster. And they are not horrifically complicated. They fundamentally work by simple, general principles—things like gradient descent, and “if you’ve seen something, it’s likely that you’ll see it again”, and “things are often composed of other things”, and "things tend to be localized in time and space", etc.
So in all respects, learning algorithms seem to be a natural fit for human design and a bad fit for automated design, while image classifiers are the reverse.
Possible objections to the learning-algorithm-outside-view argument
Objection: Learning a learning algorithm is not unheard of—it’s a thing! Humans do it when they take a course on study strategies. Machines do it in meta-learning ML papers.
Response: For the human example, yes, humans can learn meta-cognitive strategies which in turn impact future learning. But learning algorithms always involve an interaction between the algorithm itself and what-has-been-learned-so-far. Even gradient descent takes a different step depending on the current state of the model-in-training. See the “Inner As AGI” criterion near the top for why this is different from the thing I’m arguing against.
For meta-learning in ML, see the “Outer as lead designer” criterion near the top. I’m not a meta-learning expert, but my understanding is that meta-learning papers are not engaged in the radical project of designing a learning algorithm from scratch—where we just have no idea what the learning algorithm’s operating principles are. Rather, the meta-learning work I’ve seen is in the same category as hyperparameter search and neural architecture search, in that we take a human-designed learning algorithm, in which there are some adjustable parameters, and the meta-learning techniques are about using learning algorithms to adjust those parameters. Maybe there are exceptions, but if so, those efforts have not led to state-of-the-art results, tellingly. (At least, not that I know of.) For example, if you read the AlphaStar paper, you see a rather complicated learning algorithm—it involved supervised learning, pointer networks, TD(λ), V-trace, UPGO, and various other components—but every aspect of that learning algorithm was written by humans, except maybe for the values of some adjustable parameters.
Objection: If you can make AGI by combining a legible learning algorithm with a legible reward function, why haven't AI researchers done so yet? Why did Evolution take billions of years to make a technological civilization?
Response: I think we don't have AGI today for the same reason we didn't have GPT-3 in 2015: In 2015, nobody had invented Transformers yet, let alone scaled them up. Some learning algorithms are better than others; I think that Transformers were an advance over previous learning algorithms, and by the same token I expect that yet-to-be-invented learning algorithms will be an advance over Transformers.
Incidentally, I think GPT-3 is great evidence that human-legible learning algorithms are up to the task of directly learning and using a common-sense world-model. I’m not saying that GPT-3 is necessarily directly on the path to AGI [LW · GW]; instead I’m saying, How can you look at GPT-3 (a simple learning algorithm with a ridiculously simple objective) and then say, “Nope! AGI is way beyond what human-legible learning algorithms can do! We need a totally different path!”?
As for evolution, an AGI-capable learning algorithm can reach AGI but certainly doesn't have to; it depends on the reward function and hyperparameters (including model size, i.e. size of the neocortex / pallium), and environment. One aspect of the environment is a culture full of ideas, which was a massive chicken-and-egg problem for early humans—early humans had no incentive to share ideas if no one was listening, and early humans had no incentive to absorb ideas if no one was saying them. AGI programmers do not face that problem.
Objection: Reasoning is special. Where does the capacity to reason come from, if not a separate outer-loop learning algorithm?
Response: I don’t think reasoning is special. See System 2 as working-memory augmented System 1 reasoning [LW · GW]. I think an RL algorithm can learn to do a chain of reasoning in the same way as it learns to do a sequence of actions.
2. Split into cases based on how the algorithm comes to understand the world
To proceed further, I need to be a bit more specific.
There’s a certain capability, where an algorithm takes unstructured input data (e.g. sensory inputs) and uses it to build and expand a common-sense model of the world, rich with concepts that build on other concepts in a huge and ever-expanding web of knowledge. This capability is part of what we expect and demand from an AGI. We want to be able to ask it a very difficult question, on a topic it hasn’t considered before—maybe a topic nobody has ever thought about before!—and have the AGI develop an understanding of the domain, and the relevant considerations, and create a web of new concepts for thinking about that domain, and so on.
Let’s assume, following the evolution analogy, that there's an outer algorithm that performs an automated search for an inner algorithm. The two cases are: (A) The inner algorithm (once trained) can do this knowledge-building thing by itself, without any real-time intervention from the outer algorithm; or (B) it can’t, but the inner and outer algorithm working together do have this capability (as in online learning, within-lifetime human learning, etc.—and here there isn’t necessarily an outer-vs-inner distinction in the first place). I’ll subdivide (A) into four subcases, and end up with 5 cases total.
Just as a teaser:
- If we exactly reproduce the process of evolution of the human brain, with evolution as the outer layer and the human brain as the inner layer, then we’re in Case 2 below.
- If you believe AGI will be developed along the lines of the “genome = code” analogy I endorsed above, then we’re in Case 1 below.
- If there’s any scenario where the evolution analogy would work well, I think it would probably be Case 5 below. I’ll argue that Case 5 is unlikely to happen, but I suppose it’s not impossible.
OK, now let’s go through the cases.
Case 1: “Intelligence Via Online Learning”—The inner algorithm cannot build an ever-expanding web of knowledge & understanding by itself, but it can do so in conjunction with the outer algorithm
As mentioned near the top, I’m defining “evolution analogy” to exclude this case, because humans can acquire new understanding without needing to wait many centuries to create new generations of humans that can be further selected by evolution.
But within-lifetime human learning is in this category. We have an outer algorithm (our innate learning algorithm) which does an automated search for an inner algorithm (set of knowledge, ideas, habits of thought, etc.). But the inner algorithm by itself is not sufficient for intelligence; the outer algorithm is actively editing it, every second. After all, in order to solve a problem—or even carry on a conversation!—you're constantly updating your database of knowledge and ideas in order to keep track of what's going on. Your inner algorithm by itself would be like an amnesiac! (Admittedly, even splitting things up into outer / inner is kinda unhelpful here.)
Anyway, I think this kind of system is a very plausible model for what AGI will look like.
Let’s call this case “intelligence via online learning”. Online learning is when a learning algorithm comes across data sequentially, and learns from each new datapoint, forever, both in training and deployment.
Now, there’s a boring version of "online learning is relevant for AGIs" (see e.g. here [LW · GW]), which I’m not talking about. It goes like this: “Of course AGI will probably use online learning. I mean, we have all these nice unsupervised learning techniques—one is predictive learning (a.k.a. “self-supervised learning”), another is TD learning, another is amplification [? · GW] (and related things like chunking, memoization, etc.), and so on. You can keep using these techniques in deployment, and then your AGI will keep getting more capable. So why not do that? You might as well!”
That’s not wrong, but that’s also not what I’m talking about. I’m talking about the case where I ask my AGI a question, it chugs along from time t=0 to t=10 and then gives an answer, and where the online-learning that it did during time 0<t<5 is absolutely critical for the further processing that happens during time 5<t<10.
This is how human learning works, but definitely not how, say, GPT-3 works. It’s easy to forget just how different they are! Consider these two scenarios:
- During training, the AGI comes across two contradictory expectations (e.g. "demand curves usually slope down" & "many studies find that minimum wage does not cause unemployment"). The AGI updates its internal models to a more nuanced and sophisticated understanding that can reconcile those two things. Going forward, it can build on that new knowledge.
- During deployment, the exact same thing happens, with the exact same result.
In the Intelligence-Via-Online-Learning paradigm (for example, human learning), there's no distinction; both of these are the same algorithm doing the same thing. Specifically, there is no algorithmic distinction between "figuring things out in the course of learning something" vs "figuring things out to solve a new problem".
Whereas in the evolution-analogy paradigm, these two cases would be handled by two totally different algorithmic processes—"outer algorithm editing the inner algorithm" during training and "inner algorithm running on its own" during deployment. We have to solve the same problem twice! (And not just any problem … this is kinda the core problem of AGI!) Solving the problem twice seems harder and less likely than solving it once, for reasons I'll flesh out more in a later section.
Cases 2-5: After training, the inner algorithm by itself (i.e. without the outer algorithm's involvement) can build an ever-expanding web of knowledge & understanding
Cases 2-3: The inner algorithm, by itself, builds an ever-expanding web of knowledge & understanding from scratch
As discussed above, I put the evolution-of-a-human-brain example squarely in this category: I think that all of a human’s “web of knowledge and understanding” is learned within a lifetime, although there are innate biases to look for some types of patterns rather than others (analogous to how a ConvNet will more easily learn localized, spatially-invariant patterns, but it still has to learn them). If it’s not “all” of a human’s knowledge that's learned within a lifetime, then it’s at least “almost all”—the entire genome is <1GB (only a fraction of which can possibly encode “knowledge”), while there are >100 trillion synapses in the neocortex.
(Updated to add: Oops, sorry, there’s a highly-uncertain adjustment to get from “number of synapses in an adult brain” to “stored information in an adult brain”; as a stupid example, if you put 100 trillion synapses in a perfectly regular grid, then you’re not storing any information at all. Anyway, I think even with extremely conservative assumptions, the “almost all” claim goes through, but I’ll omit further discussion, since this is getting off-topic. Thanks Aysja for the correction.)
Case 2: Outer algorithm starts the inner algorithm from scratch, lets it run all the way to AGI-level performance, then edits the algorithm and restarts it from scratch
Assuming we use the simple, most-evolution-like approach, each episode (= run of the inner algorithm) has to be long enough to build a common-sense world-model from scratch.
How long are those episodes in wall-clock time? I admit, there is no law of physics that says that a machine can’t learn a human-level common-sense world-model, from scratch, within 1 millisecond. But given that it takes many years for a human brain to do so—despite that brain having a supercomputer-equivalent brain (maybe)—and given that the early versions of an AGI algorithm would presumably be just barely working at all, I think it’s a reasonably safe bet that it would at least weeks or months of wall-clock time per episode, and I would not be at all surprised if it took more than a year.
If that’s right, then developing this AGI algorithm will not look like evolution or gradient descent. It would look like a run-and-debug loop, or a manual hyperparameter search. It seems highly implausible that the programmers would just sit around for months and years and decades on end, waiting patiently for the outer algorithm to edit the inner algorithm, one excruciatingly-slow step at a time. I think the programmers would inspect the results of each episode, generate hypotheses for how to improve the algorithm, run small tests, etc.
In fact, with such a slow inner algorithm, there’s really no other choice. On human technological development timescales, the outer algorithm is not going to get many bits of information—probably not enough to design, from scratch, a new learning algorithm that the programmers would never have thought of. (By contrast, for example, the AlphaStar outer algorithm leveraged many gigabytes of information— agent steps—to design the inner algorithm.) Instead, if there is an outer algorithm at all, it would merely be tuning hyperparameters within a highly constrained space of human-designed learning algorithms, which is the best you can do with only dozens of bits of information.
Case 3: While the inner algorithm can build up knowledge from scratch, during development we try to preserve the “knowledge” data structure where possible, carrying it over from one version of the inner algorithm to the next
Back to the other possibility. Maybe we won’t restart the inner algorithm from scratch every time we edit it, since it’s so expensive to do so. Instead, maybe once in a while we’ll restart the algorithm from scratch (“re-initialize to random weights” or something analogous), but most of the time, we’ll take whatever data structure holds the AI’s world-knowledge, and preserve it between one version of the inner algorithm and its successor. Doing that is perfectly fine and plausible, but again, the result doesn’t look like evolution; it looks like a hyperparameter search within a highly-constrained class of human-designed algorithms. Why? Because the world-knowledge data structure—a huge part of how an AGI works!—needs to be designed by humans and inserted into the AGI architecture in a modular way, for this approach to be possible at all.
Cases 4-5: The inner algorithm cannot start from scratch—it needs to start with a base of preexisting knowledge & understanding. But then can expand that knowledge arbitrarily far by itself.
Case 4: The inner algorithm’s starting knowledge base is directly built by humans.
Well, just as in Case 3 above, this case does not look like evolution, it looks like a hyperparameter search within a highly-constrained class of human-designed algorithms, because humans are (by assumption) intelligently designing the types of data structures that will house the AGI’s knowledge, and that immediately and severely constrains how the AGI works.
Case 5: The inner algorithm’s starting knowledge base is built by the outer algorithm.
Just to make sure we’re on the same page here, the scenario we’re talking about right now is that the outer algorithm builds an inner algorithm which has both a bunch of knowledge and understanding about the world and a way to open-endedly expand that knowledge. So when you turn on the inner algorithm, it already has a good common-sense understanding of the world, and then you give the inner algorithm a new textbook, or a new problem to solve, and let the algorithm run for an hour, and at the end it will come out knowing a lot more than it started. For example, GPT-3 has at least part of that—the outer algorithm built an inner algorithm which has a bunch of knowledge and understanding about the world. The inner algorithm can do some amount of figuring things out, although I would say that it cannot open-endedly expand its knowledge without the involvement of the outer algorithm (i.e., fine-tuning on new information), if for no other reason than the finite context window.
As mentioned above, I do not think that there’s any precedent in nature for a Case-5 algorithm—I think [LW · GW] that humans and other animals start life with various instincts and capabilities (some very impressive!), but literally zero “knowledge” in the usual sense of that term (i.e. an interlinking web of concepts that relate to each other and build on each other and enable predictions and planning). But of course a Case-5-type inner algorithm is not fundamentally impossible. As an existence proof, consider the algorithm that goes: “Start with this snapshot of an adult brain, and run it forward in time”.
And again, since we’re searching for an evolution analogy (and not just a low-dimensional hyperparameter search), the assumption is that the inner algorithm builds new knowledge using principles that the programmer does not understand.
There are a couple reasons that I’m skeptical that this will happen.
First, there’s a training problem. Let’s say we give our inner algorithm the task of “read this biology textbook and answer the quiz questions”. There are two ways that the inner algorithm could succeed:
- After training, the inner algorithm could start up in a state where it already understands the contents of the textbook.
- The inner algorithm could successfully learn the contents of the textbook within the episode.
By assumption, here in Case 5, we want both these things to happen. But they seem to be competing: The more that the inner algorithm knows at startup, the less incentive it has to learn. Well, it’s easy enough to incentivize understanding without incentivizing learning: just make the inner algorithm answer the quiz questions without having access to the textbook. (That’s the GPT-3 approach.) But how do you incentivize learning without incentivizing understanding? Whatever learning task you give the inner algorithm, the task is always made easier by starting with a better understanding of the world, right?
Evolution solved that problem by being in Case 2, not Case 5. As above, the genome encodes little if any of a human’s world-knowledge. So insofar as the human brain has an incentive to wind up understanding the world, it has to learn. You could say that there’s regularization (a.k.a. “Information funnel”) in the human brain algorithm—the genome can’t initialize the brain with terabytes of information. We could, by the same token, use regularization to force the inner algorithm here to learn stuff instead of already knowing it. But again, we’re talking about Case 5, so we need the inner algorithm to turn on already knowing terabytes of information about the world. So what do you do? I have a hard time seeing how it would work, although there could be strategies I’m not thinking of.
Second, there’s a “solving the problem twice” issue. As mentioned above, in Case 5 we need both the outer and the inner algorithm to be able to do open-ended construction of an ever-better understanding of the world—i.e., we need to solve the core problem of AGI twice with two totally different algorithms! (The first is a human-programmed learning algorithm, perhaps SGD, while the second is an incomprehensible-to-humans learning algorithm. The first stores information in weights, while the second stores information in activations, assuming a GPT-like architecture.)
I think the likeliest thing is that programmers would succeed at getting an outer algorithm capable of ever-better understanding of the world, but because of the training issue above, have trouble getting the inner algorithm to do the same—or realize that they don’t need to. Instead they would quickly pivot to the strategy of keeping the outer algorithm involved and in the loop while using the system, and not just while training. This is Case 1 above (“Intelligence Via Online Learning”). So for example, I don’t think GPT-N will lead to an AGI [LW · GW], but if I’m wrong, then I expect to be wrong because it has a path to AGI following Case 1, not Case 5.
Anyway, none of these are definitive arguments that Case 5 won’t happen. And if it does, then the evolution analogy would plausibly be OK after all. So this is probably the weakest link of this section of the blog post, and where I expect the most objections, which by the way I’m very interested to hear.
3. Computational efficiency: the inner algorithm can run efficiently only to the extent that humans (and the compiler toolchain) generally understand what it’s doing
But first: A digression into algorithms and their low-level implementations
Let's consider two identical computers running two different trained neural net models of the same architecture—for example, one runs a GPT model trained to predict English words, and the other runs a GPT model trained to predict image pixels. Or maybe one runs a Deep Q Network trained to play Pong and the other runs a Deep Q Network trained to play Space Invaders.
Now, look at the low-level operations that these two computers’ processors are executing. (As a concrete example: here is a random example list of a certain chip’s low-level processor instructions; which of those instructions is the computer executing right now?) You’ll see that the two computers are doing more-or-less exactly the same thing all the time. Both computers are using exactly 1347 of their 2048 GPU cores. Oh hey, now both computers are copying a set of 32 bits from SRAM to DRAM. And now both computers are multiplying the bits in register 7 by the bits in register 49, and storing the result in register 6. The bits in those registers are different on the two computers, but the operation is the same. OK, not literally every operation is exactly the same—for example, maybe the neural net has ReLU activation functions, so there’s a “set bits to zero” processor instruction that only occurs about half the time, and often one computer will execute that set-to-zero instruction when the other doesn’t. But it's awfully close to identical!
By contrast, if you look up close at one computer calculating a Fast Fourier Transform (FFT), and compare it to a second computer doing a Quicksort, their low-level processing will look totally different. One computer might be doing a 2's complement while the other is fetching data from memory. One computer might be parallelizing operations across 4 CPU cores while the other is running in a single thread. Heck, one computer might be running an algorithm on its GPU while the other is using its CPU!
So the upshot of the above is: When running inference with two differently-trained neural net models of the same architecture, the low-level processing steps are essentially the same, whereas when running FFT vs quicksort, the low-level processing steps are totally different.
Why is that? And why does it matter?
The difference is not about the algorithms themselves. I don't think there's any sense in which two different GPT trained models are fundamentally "less different" from each other than the quicksort algorithm is from the FFT algorithm. It's about how we humans built the algorithms. The FFT and quicksort started life as two different repositories of source code, which the compiler then parsed and transformed into two different execution strategies. Whereas the two different GPT trained models started life as one repository of source code for “a generic GPT trained model”, which the compiler then parsed into a generic execution strategy—a strategy that works equally well for every possible GPT trained model, no matter what the weights are.
To see more clearly that this is not about the algorithms themselves, let's do a swap!
Part 1 of the swap: Is it possible to have one computer calculating an FFT while another does quicksort, yet the processors are doing essentially the same low-level processing steps in the same order? The answer is yes—but when we do this, the algorithms will run much slower than before, probably by many orders of magnitude! Here’s an easy strategy: we write both the FFT and the quicksort algorithms in the form of two different inputs to the same Universal Turing Machine, and have both our computers simulate the operation of that Turing machine, step by step along the simulated memory tape. Now each computer is running exactly the same assembly code, and executing essentially the same processor instructions, yet at the end of the day, one is doing an FFT and the other is doing a quicksort.
Part 2 of the swap: Conversely, is it possible to have each of two computers run a different trained model of the same neural net architecture, yet the two computers are doing wildly different low-level processing? …And in the process they wind up running their algorithms many orders of magnitude faster than the default implementation? This is the exact reverse of the above. And again the answer is yes! Let's imagine a "superintelligent compiler" that can examine any algorithm, no matter how weirdly obfuscated or approximated, and deeply understand what it’s doing, and then rewrite it in a sensible, efficient way, with appropriate system calls, parallelization, data structures, etc. A “superintelligent compiler” could look at the 3 trillion weights of a giant RNN, and recognize that this particular trained model is in fact approximating a random access memory algorithm in an incredibly convoluted way … and then the superintelligent compiler rewrites that algorithm to just run on a CPU and use that chip's actual RAM directly, and then it runs a billion times faster, and more accurately too!
So in summary: the reason that differently-trained neural nets use essentially the same low-level processing steps is not necessarily because the same low-level processing steps are the best and most sensible way to implement those algorithms, but rather it’s because we don’t have a "superintelligent compiler" that can look at the trillion weights of a giant trained RNN and then radically refactor the algorithm to use more appropriate processor instructions and parallelization strategies, and to move parts of the algorithm from GPU to CPU where appropriate, etc. etc. And I don’t expect this to change in the future—at least not before we have AGI.
Back to the main argument
The moral of the previous subsection is that if you search over a Turing-complete space of algorithms—for example large RNNs—you can find any possible algorithm, but you will not find most of those algorithms implemented in a compute-efficient way.
For example, vanilla RNNs mostly involve multiplying matrices.
If your inner algorithm needs a RAM, and the programmers didn’t know that, well maybe the outer algorithm will jerry rig an implementation of RAM that mostly involves multiplying matrices. But that implementation will be a whole lot less computationally efficient than just using the actual RAM built into your chip.
And if your inner algorithm needs to sort a list, and the programmers didn’t know that, well maybe the outer algorithm will jerry rig an implementation of a list-sorting algorithm that mostly involves multiplying matrices. But that implementation will be a whole lot less computationally efficient than the usual approach, where a list-sorting algorithm is written in normal code, and then humans and compilers can work together to create a sensible low-level implementation strategy that takes advantage of the fact that your chip has blazing-fast low-level capabilities to compare binary numbers and copy bit-strings and so on.
Still other times, the inner algorithm really does just need to multiply matrices! Or it needs to do something that can be efficiently implemented in a way that mostly involves multiplying matrices. And then that’s great! That part of the algorithm will run very efficiently! For example, did you know that the update rule for a certain type of Hopfield network happens to be equivalent to the attentional mechanism of a Transformer layer? So if your outer algorithm is looking for an algorithm that involves updating a Hopfield network, and you’re using a Transformer architecture for the inner algorithm, then good news for you, the inner algorithm is going to wind up with a very computationally-efficient implementation!
OK. So let’s say there are two projects trying to make AGI:
- One project is motivated by the evolution analogy. They buy tons of compute to do a giant automated search for inner learning algorithms (which then run by themselves).
- The other project is also searching for an inner learning algorithm, but using human design, i.e. trying to figure out what data structures and operations and learning rules are most suitable for AGI.
…Then my claim in this section is that the second team would have an advantage that if they succeed in finding that inner algorithm, their version will run faster than the first team’s, possibly by orders of magnitude. This is a run-time speed advantage, i.e. it comes on top of the additional advantage of not needing tons of compute to find the inner algorithm in the first place.
(You can still argue that the first team will win despite this handicap because humans are just not smart enough to design a learning algorithm that will learn itself all the way to AGI, so the second team is doomed. That’s not what I think, as discussed above, but that’s a different topic. Anyway, hopefully we can agree that this is at least one consideration in favor of the second team.)
I think this argument will carry more weight for you if you think that an AGI-capable learning algorithm needs several modular subsystems that do different types of calculations. That's me—I’m firmly in that camp! For example, I mentioned AlphaStar above—it has LSTMs, self-attention, scatter connections, pointer networks, supervised learning, TD(λ), V-trace, UPGO, interface code connecting to the Starcraft executable, and so on. What are the odds that a single one-size-fits-all low-level processing strategy can do all those different types of calculations efficiently? I think that some of the necessary components would turn out to be a terrible fit, and would wind up bottlenecking the whole system.
I think of the brain like that too—oversimplifying a bit, there's probabilistic program inference & self-supervised learning (involving neocortex & thalamus), reinforcement learning (basal ganglia), replay learning (hippocampus), supervised learning (amygdala), hardcoded input classifiers (tectum), memoization (cerebellum), and so on—and each is implemented by arranging different types of neurons into different types of low-level circuits. I think each of these modules is there for sensible and important design reasons, and therefore I expect that most or all of these modules will be part of a future AGI. Programmers have proven themselves quite capable of building learning algorithms with all those components; and if they do so, it would wind up with an efficient low-level execution strategy. Maybe an automated search could discover a monolithic black box containing all those different types of calculations, but if it did, again, it would be very unlikely to be able to run them efficiently, within the constraints of its predetermined, one-size-fits-all, low-level processing strategy.
Thanks to Richard Ngo & Daniel Kokotajlo for critical comments on a draft.
25 comments
Comments sorted by top scores.
comment by gwern · 2021-03-24T15:55:32.256Z · LW(p) · GW(p)
As described above, I expect AGI to be a learning algorithm—for example, it should be able to read a book and then have a better understanding of the subject matter. Every learning algorithm you’ve ever heard of—ConvNets, PPO, TD learning, etc. etc.—was directly invented, understood, and programmed by humans. None of them were discovered by an automated search over a space of algorithms. Thus we get a presumption that AGI will also be directly invented, understood, and programmed by humans.
For a post criticizing the use of evolution for end to end ML, this post seems to be pretty strawmanish and generally devoid of any grappling with the Bitter Lesson, end-to-end principle, Clune's arguments for generativity and AI-GAs program to soup up self-play for goal generation/curriculum learning, or any actual research on evolving better optimizers, DRL, or SGD itself... Where's Schmidhuber, Metz, or AutoML-Zero? Are we really going to dismiss PBT evolving populations of agents in the AlphaLeague just 'tweaking a few human-legible hyperparameters'? Why isn't Co-Reyes et al 2021 an example of evolutionary search inventing TD-learning which you claim is absurd and the sort of thing that has never happened?
Replies from: steve2152, ricraz, adamShimi↑ comment by Steven Byrnes (steve2152) · 2021-03-25T02:30:01.337Z · LW(p) · GW(p)
Thanks for all those great references!
My current thinking is: (1) Outer-loop meta-learning is slow, (2) Therefore we shouldn't expect to get all that many bits of information out of it, (3) Therefore it's a great way to search for parameter settings in a parameterized family of algorithms, but not a great way to do "the bulk of the real design work", in the sense that programmers can look at the final artifact and say "Man, I have no idea what this algorithm is doing and why it's learning anything at all, let alone why it's learning things very effectively".
Like if I look at a trained ConvNet, it's telling me: Hey Steve, take your input pixels, multiply them by this specific giant matrix of numbers, then add this vector, blah blah , and OK now you have a vector, and if the first entry of the vector is much bigger than the other entries, then you've got a picture of a tench. I say "Yeah, that is a picture of a tench, but WTF just happened?" (Unless I'm Chris Olah.) That's what I think of when I think of the outer loop doing "the bulk of the real design work".
By contrast, when I look at Co-Reyes, I see a search for parameter settings (well, a tree of operations) within a parametrized family of primarily-human-designed algorithms—just what I expected. If I wanted to run the authors' best and final RL algorithm, I would start by writing probably many thousands of lines of human-written code, all of which come from human knowledge of how RL algorithms should generally work ("...the policy is obtained from the Q-value function using an ε-greedy strategy. The agent saves this stream of transitions...to a replay buffer and continually updates the policy by minimizing a loss function...over these transitions with gradient descent..."). Then, to that big pile of code, I would add one important missing ingredient—the loss function L—containing at most 104 bits of information (if I calculated right). This ingredient is indeed designed by an automated search, but it doesn't have a lot of inscrutable complexity—the authors have no trouble writing down L and explaining intuitively why it's a sensible choice. Anyway, this is a very different kind of thing than the tench-discovery algorithm above.
Did the Co-Reyes search "invent" TD learning? Well, they searched over a narrow (-element) parameterized family of algorithms that included TD learning in it, and one of their searches settled on TD learning as a good option. Consider how few algorithms is algorithms out of the space of all possible algorithms. Isn't it shocking that TD learning was even an option? No, it's not shocking, it's deliberate. The authors already knew that TD learning was good, and when they set up their search space, they made sure that TD learning would be part of it. ("Our search language...should be expressive enough to represent existing algorithms..."). I don't find anything about that surprising!
I feel like maybe I was projecting a mood of "Outer-loop searches aren't impressive or important". I don't think that! As far as I know, we might be just a few more outer-loop searches away from AGI! (I'm doubtful, but that's a different story. Anyway it's certainly possible.) And I did in fact write that I expect this kind of thing to be probably part of the path to AGI. It's all great stuff, and I didn't write this blog post because I wanted to belittle it. I wrote the blog post to respond to the idea I've heard that, for example, we could plausibly wind up with an AGI algorithm that's fundamentally based on reinforcement learning with tree search, but we humans are totally oblivious to the fact that the algorithm is based on reinforcement learning with tree search, because it's an opaque black box generating its own endogenous reward signals and doing RL off that, and we just have no idea about any of this. It takes an awful lot of bits to build that inscrutable a black box, and I don't think outer-loop meta-learning can feasibly provide that many bits of design complexity, so far as I know. (Again I'm not an expert and I'm open to learning.)
any grappling with the Bitter Lesson
I'm not exactly sure what you think I'm saying that's contrary to Bitter Lesson. My reading of "Bitter lesson" is that it's a bad idea to write code that describes the object-level complexity of the world, like "tires are black" or "the queen is a valuable chess piece", but rather we should write learning algorithms that learn the object-level complexity of the world from data. I don't read "Bitter Lesson" as saying that humans should stop trying to write learning algorithms. Every positive example in Bitter Lesson is a human-written learning algorithm.
Take something like "Attention Is All You Need" (2017). I think of it as a success story, exactly the kind of research that moves forward the field of AI. But it's an example of humans inventing a better learning algorithm. Do you think that "Attention Is All You Need" not part of the path to AGI, but rather a step forward in the wrong direction? Is "Attention Is All You Need" the modern version of "yet another paper with a better handcrafted chess-position-evaluation algorithm"? If that's what you think, well, you can make that argument, but I don't think that argument is "The Bitter Lesson", at least not in any straightforward reading of "Bitter Lesson", AFAICT...
It would also be a pretty unusual view, right? Most people think that the invention of transformers is what AI progress looks like, right? (Not that there's anything wrong with unusual views, I'm just probing to make sure I correctly understand the ML consensus.)
↑ comment by Richard_Ngo (ricraz) · 2021-03-25T13:58:51.995Z · LW(p) · GW(p)
I personally found this post valuable and thought-provoking. Sure, there's plenty that it doesn't cover, but it's already pretty long, so that seems perfectly reasonable.
I particularly I dislike your criticism of it as strawmanish. Perhaps that would be fair if the analogy between RL and evolution were a standard principle in ML. Instead, it's a vague idea that is often left implicit, or else formulated in idiosyncratic ways. So posts like this one have to do double duty in both outlining and explaining the mainstream viewpoint (often a major task in its own right!) and then criticising it. This is most important precisely in the cases where the defenders of an implicit paradigm don't have solid articulations of it, making it particularly difficult to understand what they're actually defending. I think this is such a case.
If you disagree, I'd be curious what you consider a non-strawmanish summary of the RL-evolution analogy. Perhaps Clune's AI-GA paper? But from what I can tell opinions of it are rather mixed, and the AI-GA terminology hasn't caught on.
comment by paulfchristiano · 2021-03-23T15:33:13.662Z · LW(p) · GW(p)
Outside view #1: How biomimetics has always worked
It seems like ML is different from other domains in that it already relies on incredibly massive automated search, with massive changes in the quality of our inner algorithms despite very little change in our outer algorithms. None of the other domains have this property. So it wouldn't be too surprising if the only domain in which all the early successes have this property is also the only domain in which the later successes have this property.
Outside view #2: How learning algorithms have always been developed
I don't think this one is right. If your definition of learning algorithm is the kind of thing that is "able to read a book and then have a better understanding of the subject matter" then it seems like you would be classifying the model learned by GPT-3 as a learning algorithm, since it can read a 1000 word article and then have a better understanding of the subject matter that it can use to e.g. answer questions or write related text.
It seems like your definition of "learning algorithm" is "an algorithm that humans understand," and then it's kind of unsurprising that those are the ones designed by humans. Or maybe it's something about the context size over which the algorithm operates (in which case it's worth engaging with the obvious trend extrapolation of learned transformers operating competently over longer and longer contexts) or the quality of the learning it performs?
Overall I think I agree that progress in meta-learning over the last few years has been weak enough, and evidence that models like GPT-3 perform competent learning on the inside, that it's been a modest update towards longer timelines for this kind of fully end-to-end approach. But I think it's pretty modest, and as far as I can tell the update is more like "would take more like 10^33 operations to produce using foreseeable algorithms rather than 10^28 operations" than "it's not going to happen."
3. Computational efficiency: the inner algorithm can run efficiently only to the extent that humans (and the compiler toolchain) generally understand what it’s doing
I don't think the slowdown is necessarily very large, though I'm not sure exactly what you are claiming. In particular, you can pick a neural network architecture that maps well onto the most efficient hardware that you can build, and then learn how to use the operations that can be efficiently carried out in that architecture. You can still lose something but I don't think it's a lot.
You could ask the question formally in specific computational models, e.g. what's the best fixed homogeneous circuit layout we can find for doing both FFT and quicksort, and how large is the overhead relative to doing one or the other? (Obviously for any two algorithms that you want to simulate the overhead will be at most 2x, so after finding something clean that can do both of them you'd want to look at a third algorithm. I expect that you're going to be able to do basically any algorithm that anyone cares about with <<10x overhead.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-23T16:38:03.947Z · LW(p) · GW(p)
Thanks!
ML is different from other domains in that it already relies on incredibly massive automated search, with massive changes in the quality of our inner algorithms despite very little change in our outer algorithms.
Yeah, sure, maybe. Outside views only go so far :-)
I concede that even if an evolution-like approach was objectively the best way to build wing-flapping robots, probably those roboticists would not think to actually do that, whereas it probably would occur to ML researchers.
(For what it's worth—and I don't think you were disagreeing with this—I would like to emphasize that there have been important changes in outer algorithms too, like the invention of Transformers, BatchNorm, ResNets, and so on, over the past decade, and I expect there to be more such developments in the future. This is in parallel with the ongoing work of scaling-up-the-algorithms-we've-already-got, of course.)
you would be classifying the model learned by GPT-3 as a learning algorithm, since it can read a 1000 word article and then have a better understanding of the subject matter that it can use to e.g. answer questions or write related text.
I agree that there's a sense in which, as GPT-3 goes through its 96 layers, you could say it's sorta "learning things" in earlier layers and "applying that knowledge" in later layers. I actually had a little discussion of that in an earlier version that I cut out because the article was already very long, and I figured I was already talking in detail about my thoughts on GPT-3 in the subsequent section, with the upshot that I don't see the GPT-3 trained model as belonging to the category of "the right type of learning algorithm to constitute an AGI by itself" (i.e. without some kind of fine-tuning-as-you-go system) (see "Case 5"). I put a little caveat back in. :-D
(See also: my discussion comment on this page about GPT-3 [LW(p) · GW(p)])
I don't think the slowdown is necessarily very large, though I'm not sure exactly what you are claiming. In particular, you can pick a neural network architecture that maps well onto the most efficient hardware that you can build, and then learn how to use the operations that can be efficiently carried out in that architecture. ... You could ask the question formally in specific computational models
Suppose that the idea of tree search had never occurred to any human, and someone programs a learning algorithm with nothing remotely like tree search in it, and then the black box has to "invent tree search". Or the black box has to "invent TD learning", or "invent off-policy replay learning", and so on. I have a hard time imagining this working well.
Like, for tree search, you need to go through this procedure where you keep querying the model, keep track of where you're at, play through some portion of an imaginary game, then go back and update the model at the end. Can a plain LSTM be trained in such a way that it will start internally doing something equivalent to tree search? If so, how inefficient will it be? That's where I'm assuming "orders of magnitude". It seems to me that a plain LSTM isn't doing the right type of operations to run a tree search algorithm, except in the extreme case that looks something like "a plain LSTM emulating a Turing machine that's doing tree search".
Likewise with replay learning—you need to store an unstructured database with a bunch of play-throughs, and then go back and replay them and learn from them when appropriate. Can a plain LSTM do that? Sure, it's Turing-complete, it can do anything. But a plain LSTM is not the right kind of computation to be storing a big unstructured database of play-throughs and then replaying them when appropriate and learning from the replays.
I agree that this could be investigated in more detail, for example by asking how badly a plain LSTM architecture would struggle to implement something equivalent to tree search, or off-policy replay learning, or TD learning, or whatever.
Then someone might object: Well, this is an irrelevant example, we're not going to be using a plain LSTM as our learning algorithm. We haven't been using plain LSTMs for years! We will use new and improved architectures. At least that's what I would say! And that leads me to the idea that we'll get AGI via people making better learning algorithms, just like people have been making better learning algorithms for years.
The problem would be solved by doing an automated search over assembly code, but I don't think that's feasible.
comment by Richard_Ngo (ricraz) · 2021-03-25T13:23:52.874Z · LW(p) · GW(p)
there’s a “solving the problem twice” issue. As mentioned above, in Case 5 we need both the outer and the inner algorithm to be able to do open-ended construction of an ever-better understanding of the world—i.e., we need to solve the core problem of AGI twice with two totally different algorithms! (The first is a human-programmed learning algorithm, perhaps SGD, while the second is an incomprehensible-to-humans learning algorithm. The first stores information in weights, while the second stores information in activations, assuming a GPT-like architecture.)
Cross-posting a (slightly updated) comment I left on a draft of this document:
I suspect that this is indexed too closely to what current neural networks look like. I see no good reason why the inner algorithm won't eventually be able to change the weights as well, as in human brains. (In fact, this might be a crux for me - I agree that the inner algorithm having no ability to edit the weights seems far-fetched).
So then you might say that we've introduced a disanalogy to evolution, because humans can't edit our genome.
But the key reason I think that RL is roughly analogous to evolution is because it shapes the high-level internal structure of a neural network in roughly the same way that evolution shapes the high-level internal structure of the human brain, not because there's a totally strict distinction between levels.
E.g. the thing RL currently does, which I don't expect the inner algorithm to be able to do, is make the first three layers of the network vision layers, and then a big region over on the other side the language submodule, and so on. And eventually I expect RL to shape the way the inner algorithm does weight updates, via meta-learning.
You seem to expect that humans will be responsible for this sort of high-level design. I can see the case for that, and maybe humans will put in some modular structure, but the trend has been pushing the other way. And even if humans encode a few big modules (analogous to, say, the distinction between the neocortex and the subcortext), I expect there to be much more complexity in how those actually work which is determined by the outer algorithm (analogous to the hundreds of regions which appear across most human brains).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-29T12:59:29.583Z · LW(p) · GW(p)
Thanks for cross-posting this! Sorry I didn't get around to responding originally. :-)
E.g. the thing RL currently does, which I don't expect the inner algorithm to be able to do, is make the first three layers of the network vision layers, and then a big region over on the other side the language submodule, and so on. And eventually I expect RL to shape the way the inner algorithm does weight updates, via meta-learning.
For what it's worth, I figure that the neocortex has some number (dozens to hundreds, maybe 180 like your link says, I dunno) of subregions that do a task vaguely like "predict data X from context Y", with different X & Y & hyperparameters in different subregions. So some design work is obviously required to make those connections. (Some taste of what that might look like in more detail is maybe Randall O'Reilly's vision-learning model.) I figure this is vaguely analogous to figuring out what convolution kernel sizes and strides you need in a ConvNet, and that specifying all this is maybe hundreds or low thousands but not millions of bits of information. (I don't really know right now, I'm just guessing.) Where will those bits of information come from? I figure, some combination of:
- automated neural architecture search
- and/or people looking at the neuroanatomy literature and trying to copy ideas
- and/or when the working principles of the algorithm are better understood, maybe people can just guess what architectures are reasonable, just like somebody invented U-Nets by presumably just sitting and thinking about what's a reasonable architecture for image segmentation, followed by some trial-and-error tweaking.
- and/or some kind of dynamic architecture that searches for learnable relationships and makes those connections on the fly … I imagine a computer would be able to do that to a much greater extent than a brain (where signals travel slowly, new long-range high-bandwidth connections are expensive, etc.)
If I understand your comment correctly, we might actually agree on the plausibility of the brute force "automated neural architecture search" / meta-learning case. …Except for the terminology! I'm not calling it "evolution analogy" because the final learning algorithm is mainly (in terms of information content) human-designed and by-and-large human-legible. Like, maybe humans won't have a great story for why the learning rate is 1.85 in region 72 but only 1.24 in region 13...But they'll have the main story of the mechanics of the algorithm and why it learns things. (You can correct me if I'm wrong.)
comment by Rohin Shah (rohinmshah) · 2021-03-23T18:01:43.382Z · LW(p) · GW(p)
I feel like I didn't really understand what you were trying to get at here, probably because you seem to have a detailed internal ontology that I don't really get yet. So here's some random disagreements, with the hope that more discussion leads me to figure out what this ontology actually is.
A biological analogy I like much better: The “genome = code” analogy
This analogy also seems fine to me, as someone who likes the evolution analogy
In the remainder of the post I’ll go over three reasons suggesting that the first scenario would be much less likely than the second scenario.
The first scenario strikes me as not representative of what at least I believe about AGI development, despite the fact that I agree with analogies to evolution. If by "learning algorithm" you mean things like PPO or supervised learning, then I don't expect those to be black box. If by "learning algorithm" you mean things like "GPT-3's few-shot learning capabilities", then I do expect those to be black box.
In your second scenario, where does stuff like "GPT-3's few-shot learning capabilities" come in? Are you expecting that those don't exist, or are they learned algorithms, or are they part of the learned content? My guess is you'd say "learned content", in which case I'd say that the analogy to evolution is "natural selection <-> learning algorithm, human brain <-> learned content". (Yes, the human brain can be further split into another "learning algorithm" and "what humans do"; I do think that will be a disanalogy with evolution, but it doesn't seem that important.)
As described above, I expect AGI to be a learning algorithm—for example, it should be able to read a book and then have a better understanding of the subject matter. Every learning algorithm you’ve ever heard of—ConvNets, PPO, TD learning, etc. etc.—was directly invented, understood, and programmed by humans.
GPT-3 few-shot learning? Or does that not count as a learning algorithm? What do you think is a learning algorithm? If GPT-3 few-shot learning doesn't count, then how do you expect that our current learning algorithms will get to the sample efficiency that humans seem to have?
By the same token, when we want to do human-level cognitive tasks with a computer, I claim that we'll invent a learning algorithm that reads books and watches movies and interacts and whatever else, and gradually learns how to do human-level cognitive tasks.
Seems right, except for the "invent" part. Even for humans it doesn't seem right to say that the brain's equivalent of backprop is the algorithm that "reads books and watches movies" etc, it seems like backprop created a black-box-ish capability of "learning from language" that we can then invoke to learn faster.
Incidentally, I think GPT-3 is great evidence that human-legible learning algorithms are up to the task of directly learning and using a common-sense world-model. I’m not saying that GPT-3 is necessarily directly on the path to AGI; instead I’m saying, How can you look at GPT-3 (a simple learning algorithm with a ridiculously simple objective) and then say, “Nope! AGI is way beyond what human-legible learning algorithms can do! We need a totally different path!”?
I'm totally with you on this point and I'm now confused about why I seem to disagree with you so much.
Maybe it's just that when people say "learning algorithms" you think of "PPO, experience replay, neural net architectures", etc and I think "all those things, but also the ability to read books, learn by watching and imitating others, seek out relevant information, etc" and your category doesn't include GPT-3 finetuning ability whereas mine does?
(Though then I wonder how you can justify "I claim that we'll invent a learning algorithm that reads books and watches movies and interacts and whatever else")
I’m talking about the case where I ask my AGI a question, it chugs along from time t=0 to t=10 and then gives an answer, and where the online-learning that it did during time 0<t<5 is absolutely critical for the further processing that happens during time 5<t<10.
This is how human learning works, but definitely not how, say, GPT-3 works.
Huh? GPT-3 few-shot learning is exactly "GPT-3 looks at a few examples in order, and then spits out an answer, where the processing it did to 'understand' the few examples was crucial for the processing that then spit out an answer".
You might object that GPT-3 is a Transformer and so is actually looking at all of the examples all at the same time, so this isn't an instance of what you mean. I think that's mostly a red herring -- I'd predict you'd see very similar behavior from a GPT-3 that was trained in a recurrent way, where it really is like viewing things in sequence.
For example, I mentioned AlphaStar above—it has LSTMs, self-attention, scatter connections, pointer networks, supervised learning, TD(λ), V-trace, UPGO, interface code connecting to the Starcraft executable, and so on.
This doesn't feel central, but I'd note that OpenAI Five on the other hand was PPO + shaped reward + architecture design + hyperparameter tuning and that's about it. (I find it weird that I'm arguing for more simplicity relative to you, but that is what I feel there.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-23T19:06:59.439Z · LW(p) · GW(p)
Thanks!
A lot of your comments are trying to relate this to GPT-3, I think. Maybe things will be clearer if I just directly describe how I think about GPT-3.
The evolution analogy (as I'm defining it) says that “The AGI” is identified as the inner algorithm, not the inner and outer algorithm working together. In other words, if I ask the AGI a question, I don’t need the outer algorithm to be running in the course of answering that question. Of course the GPT-3 trained model is already capable of answering "easy" questions, but I'm thinking here about "very hard" questions that need the serious construction of lots of new knowledge and ideas that build on each other. I don't think the GPT-3 trained model can do that by itself.
Now for GPT-3, the outer algorithm edits weights, and the inner algorithm edits activations. I am very impressed about the capabilities of the GPT-3 weights, edited by SGD, to store an open-ended world model of greater and greater complexity as you train it more and more. I am not so optimistic that the GPT-3 activations can do that, without somehow transferring information from activations to weights. And not just for the stupid reason that it has a finite training window. (For example, other transformer models have recurrency.)
Why don't I think that the GPT-3 trained model is just as capable of building out an open-ended world-model of ever greater complexity using activations not weights?
For one thing, it strikes me as a bit weird to think that there will be this centaur-like world model constructed out of X% weights and (100-X)% activations. And what if GPT comes to realize that one of its previous beliefs is actually wrong? Can the activations somehow act as if they're overwriting the weights? Just seems weird. How much information content can you put in the activations anyway? I don't know off the top of my head, but much less than the amount you can put in the weights.
When I think of the AGI-hard part of "learning", I think of building a solid bedrock of knowledge and ideas, such that you can build new ideas on top of the old ideas, in an arbitrarily high tower. That's the part that I don't think GPT-3 inner algorithm (trained model) by itself can do. (The outer algorithm obviously does it.) Again, I think you would need to somehow transfer information from the activations to the weights, maybe by doing something vaguely like amplification, if you were to make a real-deal AGI from something like GPT-3.
My human brain analogy for GPT-3: One thing we humans do is build a giant interconnected predictive world-model by editing synapses over the course of our lifetimes. Another thing we do is flexibly combine the knowledge and ideas we already have, on the fly, to make sense of a new input, including using working memory and so on. Don't get me wrong, this is a really hard and impressive calculation, and it can do lots of things—I think it amounts to searching over this vast combinatorial space of compositional probabilistic generative models (see analysis-by-synthesis discussion here [LW · GW], or also here [LW · GW]). But it does not involve editing synapses. It's different. You've never seen nor imagined a "banana hat" in your life, but if you saw one, you would immediately understand what it is, how to manipulate it, roughly how much it weighs, etc., simply by snapping together a bunch of your existing banana-related generative models with a bunch of your existing hat-related generative models into some composite which is self-consistent and maximally consistent with your visual inputs and experience. You can do all that and much more without editing synapses.
Anyway, my human brain analogy for GPT-3 is: I think the GPT-3 outer algorithm is more-or-less akin to editing synapses, and the GPT-3 inner algorithm is more-or-less akin to the brain's inference-time calculation (...but if humans had a more impressive working memory than we actually do).
The inference-time calculation is impressive but only goes so far. You can't learn linear algebra without editing synapses. There's just too many new concepts built on top of each other, and too many new connections to be learned.
If you were to turn GPT-3 into an AGI, the closest version consistent with my current expectations would be that someone took the GPT-3 trained model but somehow inserted some kind of online-learning mechanism to update the weights as it goes (again, maybe amplification or whatever). I'm willing to believe that something like that could happen, and it would not qualify as "evolution analogy" by my definition.
Even for humans it doesn't seem right to say that the brain's equivalent of backprop is the algorithm that "reads books and watches movies" etc, it seems like backprop created a black-box-ish capability of "learning from language" that we can then invoke to learn faster.
Learning algorithms always involve an interaction between the algorithm itself and what-has-been-learned-so-far, right? Even gradient descent takes a different step depending on the current state of the model-in-training. Again see the “Inner As AGI” criterion near the top for why this is different from the thing I’m arguing against. The "learning from language" black box here doesn't go off and run on its own; it learns new things using by editing synapses according to the synapse-editing algorithm hardwired into the genome.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-23T21:20:28.911Z · LW(p) · GW(p)
Thanks, this was helpful in understanding in where you're coming from.
When I think of the AGI-hard part of "learning", I think of building a solid bedrock of knowledge and ideas, such that you can build new ideas on top of the old ideas, in an arbitrarily high tower.
I don't feel like humans meet this bar. Maybe mathematicians, and even then, I probably still wouldn't agree. Especially not humans without external memory (e.g. paper). But presumably such humans still count as generally intelligent.
Anyway, my human brain analogy for GPT-3 is: I think the GPT-3 outer algorithm is more-or-less akin to editing synapses, and the GPT-3 inner algorithm is more-or-less akin to the brain's inference-time calculation (...but if humans had a more impressive working memory than we actually do).
Seems reasonable.
The inference-time calculation is impressive but only goes so far. You can't learn linear algebra without editing synapses. There's just too many new concepts built on top of each other, and too many new connections to be learned.
I think this makes sense in the context of humans but not in the context of AI (if you say weights = synapses). It seems totally plausible to give AI systems an external memory that they can read to / write from, and then you learn linear algebra without editing weights but with editing memory. Alternatively, you could have a recurrent neural net with a really big hidden state, and then that hidden state could be the equivalent of what you're calling "synapses".
The "learning from language" black box here doesn't go off and run on its own; it learns new things using by editing synapses according to the synapse-editing algorithm hardwired into the genome.
This feels analogous to "the AGI doesn't go and run on its own, it operates by changing values in RAM according to the assembly language interpreter hardwired into the CPU chip". Like, it's true, but it seems like it's operating at the wrong level of abstraction.
Once you've reached the point of creating schools and courses, and using spaced repetition and practice exercises, you probably don't want to be thinking in terms of "this is all stuff that's been done by the synapse-editing algorithm hardwired into the genome", you've shifted to a qualitatively new kind of learning.
----
It seems like a central crux here is:
Is it possible to build a reasonably efficient AGI that doesn't autonomously edit its weights after training?
(By AGI here I mean something about as capable as humans on a variety of tasks.)
Caveats on my "yes" position:
- I wouldn't be that surprised if in practice it turns out that continually editing the weights even at deployment time is the most efficient thing to do, but I would be surprised if the difference is many orders of magnitude.
- I do expect that we will continue to update AGI systems via editing weights in training loops, even after deployment. But this will be more like an iterative train-deploy-train-deploy cycle where each deploy step lasts e.g. days or more, rather than editing weights all the time (as with humans).
↑ comment by Steven Byrnes (steve2152) · 2021-03-24T14:44:22.996Z · LW(p) · GW(p)
Thanks again, this is really helpful.
I don't feel like humans meet this bar.
Hmm, imagine you get a job doing bicycle repair. After a while, you've learned a vocabulary of probably thousands of entities and affordances and interrelationships (the chain, one link on the chain, the way the chain moves, the feel of clicking the chain into place on the gear, what it looks like if a chain is loose, what it feels like to the rider when a chain is loose, if I touch the chain then my finger will be greasy, etc. etc.). All that information is stored in a highly-structured way in your brain (I think some souped-up version of a PGM, but let's not get into that), such that it can grow to hold a massive amount of information while remaining easily searchable and usable. The problem with working memory is not capacity per se, it's that it's not stored in this structured, easily-usable-and-searchable way. So the more information you put there, the more you start getting bogged down and missing things. Ditto with pen and paper, or a recurrent state, etc.
I find it helpful to think about our brain's understanding as lots of subroutines running in parallel. (Kaj calls these things "subagents" [? · GW], I more typically call them "generative models" [LW · GW], Kurzweil calls them "patterns", Minsky calls this idea "society of mind", etc.) They all mostly just sit around doing nothing. But sometimes they recognize a scenario for which they have something to say, and then they jump in and say it. So in chess, there's a subroutine that says "If the board position has such-and-characteristics, it's worthwhile to consider moving the pawn." The subroutine sits quietly for months until the board has that position, and then it jumps in and injects its idea. And of course, once you consider moving the pawn, that brings to mind a different board position, and then new subroutines will recognize them, jump in, and have their say, etc.
Or if you take an imperfect rule, like "Python code runs the same on Windows and Mac", the reason we can get by using this rule is because we have a whole ecosystem of subroutines on the lookout for exceptions to the rule. There's the main subroutine that says "Yes, Python code runs the same on Windows and Mac." But there's another subroutine that says "If you're sharing code between Windows and Mac, and there's a file path variable, then it's important to follow such-and-such best practices". And yet another subroutine is sitting around looking for the presence of system library calls in cross-platform code, etc. etc.
That's what it looks like to have knowledge that is properly structured and searchable and usable. I think that's part of what the trained transformer layers are doing in GPT-3—checking whether any subroutines need to jump in and start doing their thing (or need to stop, or need to proceed to their next step (when they're time-sequenced)), based on the context of other subroutines that are currently active.
I think that GPT-3 as used today is more-or-less restricted to the subroutines that were used by people in the course of typing text within the GPT-3 training corpus. But if you, Rohin, think about your own personal knowledge of AI alignment, RL, etc. that you've built up over the years, you've created countless thousands of new little subroutines, interconnected with each other, which only exist in your brain. When you hear someone talking about utility functions, you have a subroutine that says "Every possible policy is consistent with some utility function!", and it's waiting to jump in if the person says something that contradicts that. And of course that subroutine is supported by hundreds of other little interconnected subroutines with various caveats and counterarguments and so on.
Anyway, what's the bar for an AI to be an AGI? I dunno, but one question is: "Is it competent enough to help with AI alignment research?" My strong hunch is that the AI wouldn't be all that helpful unless it's able to add new things to its own structured knowledge base, like new subroutines that say "We already tried that idea and it doesn't work", or "This idea almost works but is missing such-and-such ingredient", or "Such-and-such combination of ingredients would have this interesting property".
Hmm, well, actually, I guess it's very possible that GPT-3 is already a somewhat-helpful tool for generating / brainstorming ideas in AI alignment research. Maybe I would use it myself if I had access! I should have said "Is it competent enough to do AI alignment research". :-D
I agree that your "crux" is a crux, although I would say "effective" instead of "efficient". I think the inability to add new things to its own structured knowledge base is a limitation on what the AI can do, not just what it can do given a certain compute budget.
This feels analogous to "the AGI doesn't go and run on its own, it operates by changing values in RAM according to the assembly language interpreter hardwired into the CPU chip". Like, it's true, but it seems like it's operating at the wrong level of abstraction.
Hmm, the point of this post is to argue that we won't make AGI via a specific development path involving the following three ingredients, blah blah blah. Then there's a second step: "If so, then what? What does that imply about the resulting AGI?" I didn't talk about that; it's a different issue. In particular I am not making the argument that "the algorithm's cognition will basically be human-legible", and I don't believe that.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-24T16:14:50.763Z · LW(p) · GW(p)
All of that sounds reasonable to me. I still don't see why you think editing weights is required, as opposed to something like editing external memory.
(Also, maybe we just won't have AGI that learns by reading books, and instead it will be more useful to have a lot of task-specific AI systems with a huge amount of "built-in" knowledge, similarly to GPT-3. I wouldn't put this as my most likely outcome, but it seems quite plausible.)
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2021-03-25T12:57:12.796Z · LW(p) · GW(p)
It seems totally plausible to give AI systems an external memory that they can read to / write from, and then you learn linear algebra without editing weights but with editing memory. Alternatively, you could have a recurrent neural net with a really big hidden state, and then that hidden state could be the equivalent of what you're calling "synapses".
I agree with Steve that it seems really weird to have these two parallel systems of knowledge encoding the same types of things. If an AGI learned the skill of speaking english during training, but then learned the skill of speaking french during deployment, then your hypotheses imply that the implementations of those two language skills will be totally different. And it then gets weirder if they overlap - e.g. if an AGI learns a fact during training which gets stored in its weights, and then reads a correction later on during deployment, do those original weights just stay there?
I do expect that we will continue to update AGI systems via editing weights in training loops, even after deployment. But this will be more like an iterative train-deploy-train-deploy cycle where each deploy step lasts e.g. days or more, rather than editing weights all the time (as with humans).
Based on this I guess your answer to my question above is "no": the original fact will get overridden a few days later, and also the knowledge of french will be transferred into the weights eventually. But if those updates occur via self-supervised learning, then I'd count that as "autonomously edit[ing] its weights after training". And with self-supervised learning, you don't need to wait long for feedback, so why wouldn't you use it to edit weights all the time? At the very least, that would free up space in the short-term memory/hidden state.
For my own part I'm happy to concede that AGIs will need some way of editing their weights during deployment. The big question for me is how continuous this is with the rest of the training process. E.g. do you just keep doing SGD, but with a smaller learning rate? Or will there be a different (meta-learned) weight update mechanism? My money's on the latter. If it's the former, then that would update me a bit towards Steve's view, but I think I'd still expect evolution to be a good analogy for the earlier phases of SGD.
Maybe we just won't have AGI that learns by reading books, and instead it will be more useful to have a lot of task-specific AI systems with a huge amount of "built-in" knowledge, similarly to GPT-3.
If this is the case, then that would shift me away from thinking of evolution as a good analogy for AGI, because the training process would then look more like the type of skill acquisition that happens during human lifetimes. In fact, this seems like the most likely way in which Steve is right that evolution is a bad analogy.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-25T15:53:31.917Z · LW(p) · GW(p)
If an AGI learned the skill of speaking english during training, but then learned the skill of speaking french during deployment, then your hypotheses imply that the implementations of those two language skills will be totally different. And it then gets weirder if they overlap - e.g. if an AGI learns a fact during training which gets stored in its weights, and then reads a correction later on during deployment, do those original weights just stay there?
Idk, this just sounds plausible to me. I think the hope is that the weights encode more general reasoning abilities, and most of the "facts" or "background knowledge" gets moved into memory, but that won't happen for everything and plausibly there will be this strange separation between the two. But like, sure, that doesn't seem crazy.
I do expect we reconsolidate into weights through some outer algorithm like gradient descent (and that may not require any human input). If you want to count that as "autonomously editing its weights", then fine, though I'm not sure how this influences any downstream disagreement.
Similar dynamics in humans:
- Children are apparently better at learning languages than adults; it seems like adults are using some different process to learn languages (though probably not as different as editing memory vs. editing weights)
- One theory of sleep is that it is consolidating the experiences of the day into synapses, suggesting that any within-day learning is not relying as much on editing synapses.
Tbc, I also think explicitly meta-learned update rules are plausible -- don't take any of this as "I think this is definitely going to happen" but more as "I don't see a reason why this couldn't happen".
In fact, this seems like the most likely way in which Steve is right that evolution is a bad analogy.
Fwiw I've mostly been ignoring the point of whether or not evolution is a good analogy. If you want to discuss that, I want to know what specifically you use the analogy for. For example:
- I think evolution is a good analogy for how inner alignment issues can arise.
- I don't think evolution is a good analogy for the process by which AGI is made (if you think that the analogy is that we literally use natural selection to improve AI systems).
It seems like Steve is arguing the second, and I probably agree (depending on what exactly he means, which I'm still not super clear on).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-25T16:26:00.357Z · LW(p) · GW(p)
- I think evolution is a good analogy for how inner alignment issues can arise.
- I don't think evolution is a good analogy for the process by which AGI is made (if you think that the analogy is that we literally use natural selection to improve AI systems).
Yes this post is about the process by which AGI is made, i.e. #2. (See "I want to be specific about what I’m arguing against here."...) I'm not sure what you mean by "literal natural selection", but FWIW I'm lumping together outer-loop optimization algorithms regardless of whether they're evolutionary or gradient descent or downhill-simplex or whatever.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-23T13:42:28.806Z · LW(p) · GW(p)
Note that evolution is not in this picture: its role has been usurped by the engineers who wrote the PyTorch code. This is intelligent design, not evolution!
IMO you should put evolution in the picture, as another part of the analogy! :) Make a new row at the top, with "Genomes evolving over millions of generations on a planet, as organisms with better combinations of genes outcompete others" on the left and "Code libraries evolving over thousands of days in an industry, as software/ANN's with better code outcompete (in the economy, in the academic prestige competition, in the minds of individual researchers) others" on the right. (Or some shortened version of that)
comment by Anon User (anon-user) · 2021-03-23T16:40:24.387Z · LW(p) · GW(p)
It seems you are actually describing a 3-algorithm stack view for both the human and AGI. For human, there is 1) evolution working on the genome level, there is 2) long-term brain development / learning, and there is 3) the brain solving a particular task. Relatively speaking, evolution (#1) works on much smaller number much more legible parameters than brain development (#2). So if we use some sort of genetic algorithm for optimizing AGI meta-parameters, then we'd get a very stack that is very similar in style. And in any case we need to worry about "base" optimizer used in the AGI version of #1+#2 producing an unaligned mesa-optimizer for AGI version of the #3 algorithm.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-23T17:01:58.142Z · LW(p) · GW(p)
I agree that "optimizing AGI meta-parameters" is parallel to evolution in my preferred analogy (see "genome = code"), and I agree that that's a thing we will probably do. I don't count it as "evolution analogy" because most of the design work was by a human, and tweaking a handful of human-legible parameters like learning rates and neural architectures does not significantly reduce the human-legibility of the whole algorithm. I agree about unaligned mesa-optimizers. This is not a "We don't need to worry about AGI safety" article. In fact I have a "Why we're doomed" article draft in preparation! I'll probably post it in the next week or two :-) The mesa-optimizers I'm worried about are of the form discussed here [LW · GW]. In terms of the brain, you can have an inner alignment problem where "outer" is evolution and "inner" is the whole brain, OR you can have an inner alignment problem where "outer" is the brainstem and "inner" is the neocortex learning algorithm, more or less. I'm concerned about the latter. I don't think it's an easier problem, just different. Again, hang on for that forthcoming post.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-23T14:44:05.632Z · LW(p) · GW(p)
Incidentally, I think GPT-3 is great evidence that human-legible learning algorithms are up to the task of directly learning and using a common-sense world-model. I’m not saying that GPT-3 is necessarily directly on the path to AGI [AF · GW]; instead I’m saying, How can you look at GPT-3 (a simple learning algorithm with a ridiculously simple objective) and then say, “Nope! AGI is way beyond what human-legible learning algorithms can do! We need a totally different path!”?
I think the response would be, "GPT-3 may have learned an awesome general common-sense world-model, but it took 300,000,000 tokens of training to do so. AI won't be transformative until it can learn quickly/data-efficiently. (Or until we have enough compute to train it slowly/inefficiently on medium or long-horizon tasks, which is far in the future.)"
What would you say to that?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-23T15:17:44.858Z · LW(p) · GW(p)
Good question!
A kinda generic answer is: (1) Transformers were an advance over previous learning algorithms, and by the same token I expect that yet-to-be-invented learning algorithms will be an advance over Transformers; (2) Sample-efficient learning is AFAICT a hot area that lots of people are working on; (3) We do in fact actually have impressively sample-efficient algorithms even if they're not as well-developed and scalable as others at the moment—see my discussion of analysis-by-synthesis [LW · GW]; (4) Given that predictive learning offers tons of data, it's not obvious how important sample-efficiency is.
More detailed answer: I agree that in the "intelligence via online learning" paradigm I mentioned, you really want to see something once and immediately commit it to memory. Hard to carry on a conversation otherwise! The human brain has two main tricks for this (that I know of).
- There's a giant structured memory (predictive world-model) in the neocortex, and a much smaller unstructured memory in the hippocampus, and the latter is basically just an auto-associative memory (with a pattern separator to avoid cross-talk) that memorizes things. Then it can replay it when appropriate. And just like replay learning in ML, or like doing multiple passes through your training data in ML, relevant information can gradually transfer from the unstructured memory to the structured one by repeated replays.
- Because the structured memory is in the analysis-by-synthesis paradigm [LW · GW] (i.e. searching for a generative model that matches the data), it inherently needs less training data, because its inductive biases are a closer match to reality. It's a harder search problem to build the right generative model when you're learning, and it's a harder search problem to find the right generative model at inference time, but once you get it, it generalizes better and takes you farther. For example, you can "train on no data whatsoever"—just stare into space for a while, thinking about the problem, and wind up learning something new. This is only possible because you have a space of generative models, so you can run internal experiments. How's that for sample efficiency?!
AlphaStar and GPT-3 don't do analysis-by-synthesis—well, they weren't designed to do it, although my hunch [LW · GW] is that GPT-3 is successful by doing it to a limited extent (this may be related to the Hopfield network thing). But we do have algorithms at an earlier stage of development / refinement / scaling-up that are based on those principles, and they are indeed very highly sample-efficient, and in the coming years I expect that they'll be used more widely in AI.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-24T13:29:53.354Z · LW(p) · GW(p)
To make sure I understand: you are saying (a) that our AIs are fairly likely to get significantly more sample-efficient in the near future, and (b) even if they don't, there's plenty of data around.
I think (b) isn't a good response if you think that transformative AI will probably need to be human brain sized and you believe the scaling laws and you think that short-horizon training won't be enough. (Because then we'll need something like 10^30+ FLOP to train TAI, which is plausibly reachable in 20 years but probably not in 10. That said, I think short-horizon training might be enough.
I think (a) is a good response, but it faces the objection: Why now? Why should we expect sample-efficiency to get dramatically better in the near future, when it has gotten only very slowly better in the past? (Has it? I'm guessing so, maybe I'm wrong?)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-23T14:56:10.241Z · LW(p) · GW(p)
Maybe we won’t restart the inner algorithm from scratch every time we edit it, since it’s so expensive to do so. Instead, maybe once in a while we’ll restart the algorithm from scratch (“re-initialize to random weights” or something analogous), but most of the time, we’ll take whatever data structure holds the AI’s world-knowledge, and preserve it between one version of the inner algorithm and its successor. Doing that is perfectly fine and plausible, but again, the result doesn’t look like evolution; it looks like a hyperparameter search within a highly-constrained class of human-designed algorithms. Why? Because the world-knowledge data structure—a huge part of how an AGI works!—needs to be designed by humans and inserted into the AGI architecture in a modular way, for this approach to be possible at all.
Does it though? In "crystal nights" [LW · GW] I described an AI-by-evolution scenario in which the ability to copy chunks of learned brain into your offspring is in the toolkit/genome for evolution to use if it wants. It sounds like you are saying this wouldn't work, but I don't see why.
EDIT: Also, the "Amp(GPT-7)" [LW · GW] story seems to me to be an example of your Case 4 or Case 5 maybe, while also being an example of the evolutionary analogy being correct (see: the final step, where we evolve the chinese room bureaucracies).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-03-23T17:20:48.475Z · LW(p) · GW(p)
Hmm, if you don't know which bits are the learning algorithm and which are the learned content, and they're freely intermingling, then I guess you could try randomizing different subsets of the bits in your algorithm, and see what happens, or something, and try to figure it out. This seems like a computationally-intensive and error-prone process, to me, although I suppose it's hard to know. Also, which is which could be dynamic, and there could be bits that are not cleanly in either category. If you get it wrong, then you're going to wind up updating the knowledge instead of the learning algorithm, or get bits of the learning algorithm that are stuck in a bad state but you're not editing them because you think they're knowledge. I dunno. I guess that's not a disproof, but I'm going to stick with "unlikely".
With enough compute, can't rule anything out—you could do a blind search over assembly code! I tend to think that more compute-efficient paths to AGI are far likelier to happen than less compute-efficient paths to AGI, other things equal, because the less compute that's needed, the faster you can run experiments, and the more people are able to develop and experiment with the algorithms. Maybe one giant government project can do a blind search over assembly code, but thousands of grad students and employees can run little experiments in less computationally expensive domains.