Fun with +12 OOMs of Compute
post by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-01T13:30:13.603Z · LW · GW · 86 commentsContents
Or: Big Timelines Crux Operationalized The hypothetical Question One: In this hypothetical, what sorts of things could AI projects build? My tentative answers: OmegaStar: Amp(GPT-7): Crystal Nights: Skunkworks: Neuromorph: Question Two: In this hypothetical, what’s the probability that TAI appears by end of 2020? OK, here’s why all this matters None 87 comments
Or: Big Timelines Crux Operationalized
What fun things could one build with +12 orders of magnitude of compute? By ‘fun’ I mean ‘powerful.’ This hypothetical is highly relevant to AI timelines, for reasons I’ll explain later.
Summary (Spoilers):
I describe a hypothetical scenario that concretizes the question “what could be built with 2020’s algorithms/ideas/etc. but a trillion times more compute?” Then I give some answers to that question. Then I ask: How likely is it that some sort of TAI would happen in this scenario? This second question is a useful operationalization of the (IMO) most important, most-commonly-discussed timelines crux [? · GW]: “Can we get TAI just by throwing more compute at the problem?” I consider this operationalization to be the main contribution of this post; it directly plugs into Ajeya’s timelines model and is quantitatively more cruxy than anything else I know of. The secondary contribution of this post is my set of answers to the first question: They serve as intuition pumps for my answer to the second, which strongly supports my views on timelines.
The hypothetical
In 2016 the Compute Fairy visits Earth and bestows a blessing: Computers are magically 12 orders of magnitude faster! Over the next five years, what happens? The Deep Learning AI Boom still happens, only much crazier: Instead of making AlphaStar for 10^23 floating point operations, DeepMind makes something for 10^35. Instead of making GPT-3 for 10^23 FLOPs, OpenAI makes something for 10^35. Instead of industry and academia making a cornucopia of things for 10^20 FLOPs or so, they make a cornucopia of things for 10^32 FLOPs or so. When random grad students and hackers spin up neural nets on their laptops, they have a trillion times more compute to work with. [EDIT: Also assume magic +12 OOMs of memory, bandwidth, etc. All the ingredients of compute.]
For context on how big a deal +12 OOMs is, consider the graph below, from ARK. It’s measuring petaflop-days, which are about 10^20 FLOP each. So 10^35 FLOP is 1e+15 on this graph. GPT-3 and AlphaStar are not on this graph, but if they were they would be in the very top-right corner.

Question One: In this hypothetical, what sorts of things could AI projects build?
I encourage you to stop reading, set a five-minute timer, and think about fun things that could be built in this scenario. I’d love it if you wrote up your answers in the comments!
My tentative answers:
Below are my answers, listed in rough order of how ‘fun’ they seem to me. I’m not an AI scientist so I expect my answers to overestimate what could be done in some ways, and underestimate in other ways. Imagine that each entry is the best version of itself, since it is built by experts (who have experience with smaller-scale versions) rather than by me.
OmegaStar:
In our timeline, it cost about 10^23 FLOP to train AlphaStar. (OpenAI Five, which is in some ways more impressive, took less!) Let’s make OmegaStar like AlphaStar only +7 OOMs bigger: the size of a human brain.[1] [? · GW] [EDIT: You may be surprised to learn, as I was, that AlphaStar has about 10% as many parameters as a honeybee has synapses! Playing against it is like playing against a tiny game-playing insect.]
Larger models seem to take less data to reach the same level of performance, so it would probably take at most 10^30 FLOP to reach the same level of Starcraft performance as AlphaStar, and indeed we should expect it to be qualitatively better.[2] [? · GW] So let’s do that, but also train it on lots of other games too.[3] [? · GW] There are 30,000 games in the Steam Library. We train OmegaStar long enough that it has as much time on each game as AlphaStar had on Starcraft. With a brain so big, maybe it’ll start to do some transfer learning, acquiring generalizeable skills that work across many of the games instead of learning a separate policy for each game.
OK, that uses up 10^34 FLOP—a mere 10% of our budget. With the remainder, let’s add some more stuff to its training regime. For example, maybe we also make it read the entire internet and play the “Predict the next word you are about to read!” game. Also the “Predict the covered-up word” and “predict the covered-up piece of an image” and “predict later bits of the video” games.
OK, that probably still wouldn’t be enough to use up our compute budget. A Transformer that was the size of the human brain would only need 10^30 FLOP to get to human level at the the predict-the-next-word game according to Gwern [LW(p) · GW(p)], and while OmegaStar isn’t a transformer, we have 10^34 FLOP available.[4] [? · GW] (What a curious coincidence, that human-level performance is reached right when the AI is human-brain-sized! Not according to Shorty [LW · GW].)
Let’s also hook up OmegaStar to an online chatbot interface, so that billions of people can talk to it and play games with it. We can have it play the game “Maximize user engagement!”
...we probably still haven’t used up our whole budget, but I’m out of ideas for now.
Amp(GPT-7):
Let’s start by training GPT-7, a transformer with 10^17 parameters and 10^17 data points, on the entire world’s library of video, audio, and text. This is almost 6 OOMs more params and almost 6 OOMs more training time than GPT-3. Note that a mere +4 OOMs of params and training time is predicted to reach near-optimal performance at text prediction and all the tasks [LW · GW] thrown at GPT-3 in the original paper; so this GPT-7 would be superhuman at all those things, and also at the analogous video and audio and mixed-modality tasks.[5] [? · GW] Quantitatively, the gap between GPT-7 and GPT-3 is about twice as large as the gap between GPT-3 and GPT-1, (about 25% the loss GPT-3 had, which was about 50% the loss GPT-1 had) so try to imagine a qualitative improvement twice as big also. And that’s not to mention the possible benefits of multimodal data representations.[6] [? · GW]
We aren’t finished! This only uses up 10^34 of our compute. Next, we let the public use prompt programming to make a giant library of GPT-7 functions, like the stuff demoed here and like the stuff being built here, only much better because it’s GPT-7 instead of GPT-3. Some examples:
- Decompose a vague question into concrete subquestions
- Generate a plan to achieve a goal given a context
- Given a list of options, pick the one that seems most plausible / likely to work / likely to be the sort of thing Jesus would say / [insert your own evaluation criteria here]
- Given some text, give a score from 0 to 10 for how accurate / offensive / likely-to-be-written-by-a-dissident / [insert your own evaluation criteria here] the text is.
And of course the library also contains functions like “google search” and “Given webpage, click on X” (remember, GPT-7 is multimodal, it can input and output video, parsing webpages is easy). It also has functions like “Spin off a new version of GPT-7 and fine-tune it on the following data.” Then we fine-tune GPT-7 on the library so that it knows how to use those functions, and even write new ones. (Even GPT-3 can do basic programming, remember. GPT-7 is much better.)
We still aren’t finished! Next, we embed GPT-7 in an amplification scheme — a “chinese-room bureaucracy” [LW · GW] of calls to GPT-7. The basic idea is to have functions that break down tasks into sub-tasks, functions that do those sub-tasks, and functions that combine the results of the sub-tasks into a result for the task. For example, a fact-checking function might start by dividing up the text into paragraphs, and then extract factual claims from each paragraph, and then generate google queries designed to fact-check each claim, and then compare the search results with the claim to see whether it is contradicted or confirmed, etc. And an article-writing function might call the fact-checking function as one of the intermediary steps. By combining more and more functions into larger and larger bureaucracies, more and more sophisticated behaviors can be achieved. And by fine-tuning GPT-7 on examples of this sort of thing, we can get it to understand how it works, so that we can write GPT-7 functions in which GPT-7 chooses which other functions to call. Heck, we could even have GPT-7 try writing its own functions! [7] [? · GW]
The ultimate chinese-room bureaucracy would be an agent in its own right, running a continual OODA loop of taking in new data, distilling it into notes-to-future-self and new-data-to-fine-tune-on, making plans and sub-plans, and executing them. Perhaps it has a text file describing its goal/values that it passes along as a note-to-self — a “bureaucracy mission statement.”
Are we done yet? No! Since it “only” has 10^17 parameters, and uses about six FLOP per parameter per token, we have almost 18 orders of magnitude of compute left to work with.[8] [? · GW] So let’s give our GPT-7 uber-bureaucracy an internet connection and run it for 100,000,000 function-calls (if we think of each call as a subjective second, that’s about 3 subjective years). Actually, let’s generate 50,000 different uber-bureaucracies and run them all for that long. And then let’s evaluate their performance and reproduce the ones that did best, and repeat. We could do 50,000 generations of this sort of artificial evolution, for a total of about 10^35 FLOP.[9 [? · GW]] [? · GW]
Note that we could do all this amplification-and-evolution stuff with OmegaStar in place of GPT-7.
Crystal Nights:
(The name comes from an excellent short story.)
Maybe we think we are missing something fundamental, some unknown unknown, some special sauce [AF · GW] that is necessary for true intelligence that humans have and our current artificial neural net designs won’t have even if scaled up +12 OOMs. OK, so let’s search for it. We set out to recapitulate evolution.
We make a planet-sized virtual world with detailed and realistic physics and graphics. OK, not perfectly realistic, but much better than any video game currently on the market! Then, we seed it with a bunch of primitive life-forms, with a massive variety of initial mental and physical architectures. Perhaps they have a sort of virtual genome, a library of code used to construct their bodies and minds, with modular pieces that get exchanged via sexual reproduction (for those who are into that sort of thing). Then we let it run, for a billion in-game years if necessary!
Alas, Ajeya estimates it would take about 10^41 FLOP to do this, whereas we only have 10^35.[10] [? · GW] So we probably need to be a million times more compute-efficient than evolution. But maybe that’s doable. Evolution is pretty dumb, after all.
- Instead of starting from scratch, we can can start off with “advanced” creatures, e.g. sexually-reproducing large-brained land creatures. It’s unclear how much this would save but plausibly could be at least one or two orders of magnitude, since Ajeya’s estimate assumes the average creature has a brain about the size of a nematode worm’s brain.[11] [? · GW]
- We can grant “magic traits” to the species that encourage intelligence and culture; for example, perhaps they can respawn a number of times after dying, or transfer bits of their trained-neural-net brains to their offspring. At the very least, we should make it metabolically cheap to have big brains; no birth-canal or skull should restrict the number of neurons a species can have! Also maybe it should be easy for species to have neurons that don’t get cancer or break randomly.
- We can force things that are bad for the individual but good for the species, e.g. identify that the antler size arms race is silly and nip it in the bud before it gets going. In general, more experimentation/higher mutation rate is probably better for the species than for the individual, and so we could speed up evolution by increasing the mutation rate. We can also identify when a species is trapped in a local optima and take action to get the ball rolling again, whereas evolution would just wait until some climactic event or something shakes things up.
- We can optimise for intelligence instead of ability to reproduce, by crafting environments in which intelligence is much more useful than it was at any time in Earth’s history. (For example, the environment can be littered with monoliths that dispense food upon completion of various reasoning puzzles. Perhaps some of these monoliths can teach English too, that’ll probably come in handy later!) Think about how much faster dog breeding is compared to wolves evolving in the wild. Breeding for intelligence should be correspondingly faster than waiting for it to evolve.
- There are probably additional things I haven’t thought of that would totally be thought of, if we had a team of experts building this evolutionary simulation with 2020’s knowledge. I’m a philosopher, not an evolutionary biologist!
Skunkworks:
What about STEM AI [LW · GW]? Let’s do some STEM. You may have seen this now-classic image:

These antennas were designed by an evolutionary search algorithm. Generate a design, simulate it to evaluate predicted performance, tweak & repeat. They flew on a NASA spacecraft fifteen years ago, and were massively more efficient and high-performing than the contractor-designed antennas they replaced. Took less human effort to make, too.[12] [? · GW]
This sort of thing gets a lot more powerful with +12 OOMs. Engineers often use simulations to test designs more cheaply than by building an actual prototype. SpaceX, for example, did this for their Raptor rocket engine. Now imagine that their simulations are significantly more detailed, spending 1,000,000x more compute, and also that they have an evolutionary search component that auto-generates 1,000 variations of each design and iterates for 1,000 generations to find the optimal version of each design for the problem (or even invents new designs from scratch.) And perhaps all of this automated design and tweaking (and even the in-simulation testing) is done more intelligently by a copy of OmegaStar trained on this “game.”
Why would this be a big deal? I’m not sure it would be. But take a look at this list of strategically relevant technologies and events and think about whether Skunkworks being widely available would quickly lead to some of them. For example, given how successful AlphaFold 2 has been, maybe Skunkworks could be useful for designing nanomachines. It could certainly make it a lot easier for various minor nations and non-state entities to build weapons of mass destruction, perhaps resulting in a vulnerable world.
Neuromorph:
According to page 69 of this report, the Hodgkin-Huxley model of the neuron is the most detailed and realistic (and therefore the most computationally expensive) as of 2008. [EDIT: Joe Carlsmith, author of a more recent report, tells me there are more detailed+realistic models available now] It costs 1,200,000 FLOP per second per neuron to run. So a human brain (along with relevant parts of the body, in a realistic-physics virtual environment, etc.) could be simulated for about 10^17 FLOP per second.
Now, presumably (a) we don’t have good enough brain scanners as of 2020 to actually reconstruct any particular person’s brain, and (b) even if we did, the Hodgkin-Huxley model might not be detailed enough to fully capture that person’s personality and cognition.[13] [? · GW]
But maybe we can do something ‘fun’ nonetheless: We scan someone’s brain and then create a simulated brain that looks like the scan as much as possible, and then fills in the details in a random but biologically plausible way. Then we run the simulated brain and see what happens. Probably gibberish, but we run it for a simulated year to see whether it gets its act together and learns any interesting behaviors. After all, human children start off with randomly connected neurons too, but they learn.[14] [? · GW]
All of this costs a mere 10^25 FLOP. So we do it repeatedly, using stochastic gradient descent to search through the space of possible variations on this basic setup, tweaking parameters of the simulation, the dynamical rules used to evolve neurons, the initial conditions, etc. We can do 100,000 generations of 100,000 brains-running-for-a-year this way. Maybe we’ll eventually find something intelligent, even if it lacks the memories and personality of the original scanned human.
Question Two: In this hypothetical, what’s the probability that TAI appears by end of 2020?
The first question was my way of operationalizing “what could be built with 2020’s algorithms/ideas/etc. but a trillion times more compute?”
This second question is my way of operationalizing “what’s the probability that the amount of computation it would take to train a transformative model using 2020’s algorithms/ideas/etc. is 10^35 FLOP or less?”
(Please ignore thoughts like “But maybe all this extra compute will make people take AI safety more seriously” and “But they wouldn’t have incentives to develop modern parallelization algorithms if they had computers so fast” and “but maybe the presence of the Compute Fairy will make them believe the simulation hypothesis?” since they run counter to the spirit of the thought experiment.)
Remember, the definition of Transformative AI is “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”
Did you read those answers to Question One, visualize them and other similarly crazy things that would be going on in this hypothetical scenario, and think “Eh, IDK if that would be enough, I’m 50-50 on this. Seems plausible TAI will be achieved in this scenario but seems equally plausible it wouldn’t be.”
No! … Well, maybe you do, but speaking for myself, I don’t have that reaction.
When I visualize this scenario, I’m like “Holyshit all five of these distinct research programs seem like they would probably produce something transformative within five years and perhaps even immediately, and there are probably more research programs I haven’t thought of!”
My answer is 90%. The reason it isn’t higher is that I’m trying to be epistemically humble and cautious, account for unknown unknowns, defer to the judgment of others, etc. If I just went with my inside view, the number would be 99%. This is because I can’t articulate any not-totally-implausible possibility in which OmegaStar, Amp(GPT-7), Crystal Nights, Skunkworks, and Neuromorph and more don’t lead to transformative AI within five years. All I can think of is things like “Maybe transformative AI requires some super-special mental structure which can only be found by massive blind search, so massive that the Crystal Nights program can’t find it…” I’m very interested to hear what people whose inside-view answer to Question Two is <90% have in mind for the remaining 10%+. I expect I’m just not modelling their views well and that after hearing more I’ll be able to imagine some not-totally-implausible no-TAI possibilities. My inside view is obviously overconfident. Hence my answer of 90%.
Poll: What is your inside-view answer to Question Two, i.e. your answer without taking into account meta-level concerns like peer disagreement, unknown unknowns, biases, etc.
Bonus: I’ve argued elsewhere [AF · GW] that what we really care about, when thinking about AI timelines, is AI-induced points of no return. I think this is likely to be within a few years [LW · GW] of TAI, and my answer to this question is basically the same as my answer to the TAI version, but just in case:
OK, here’s why all this matters
Ajeya Cotra’s excellent timelines forecasting model is built around a probability distribution over “the amount of computation it would take to train a transformative model if we had to do it using only current knowledge.”[15] [? · GW] (pt1p25) Most of the work goes into constructing that probability distribution; once that’s done, she models how compute costs decrease, willingness-to-spend increases, and new ideas/insights/algorithms are added over time, to get her final forecast.
One of the great things about the model is that it’s interactive; you can input your own probability distribution and see what the implications are for timelines. This is good because there’s a lot of room for subjective judgment and intuition [EA(p) · GW(p)] when it comes to making the probability distribution.
What I’ve done in this post is present an intuition pump, a thought experiment that might elicit in the reader (as it does in me) the sense that the probability distribution should have the bulk of its mass by the 10^35 mark.
Ajeya’s best-guess distribution has the 10^35 mark as its median, roughly. As far as I can tell, this corresponds to answering “50%” to Question Two.[16] [? · GW]
If that’s also your reaction, fair enough. But insofar as your reaction is closer to mine, you should have shorter timelines than Ajeya did when she wrote the report.
There are lots of minor nitpicks I have with Ajeya’s report, but I’m not talking about them; instead, I wrote this, which is a lot more subjective and hand-wavy. I made this choice because the minor nitpicks don’t ultimately influence the answer very much, whereas this more subjective disagreement is a pretty big crux [? · GW].[17] [? · GW] Suppose your answer to Question 2 is 80%. Well, that means your distribution should have 80% by the 10^35 mark compared to Ajeya’s 50%, and that means that your median should be roughly 10 years earlier than hers, all else equal: 2040-ish rather than 2050-ish.[18] [? · GW]
I hope this post helps focus the general discussion about timelines. As far as I can tell, the biggest crux for most people is something like “Can we get TAI just by throwing more compute at the problem?” Now, obviously we can get TAI just by throwing more compute at the problem, there are theorems about how neural nets are universal function approximators etc., and we can always do architecture search to find the right architectures. So the crux is really about whether we can get TAI just by throwing a large but not too large amount of compute at the problem… and I propose we operationalize “large but not too large” as “10^35 FLOP or less.”[19] [? · GW] I’d like to hear people with long timelines explain why OmegaStar, Amp(GPT-7), Crystal Nights, SkunkWorks, and Neuromorph wouldn’t be transformative (or more generally, wouldn’t cause an AI-induced PONR) [AF · GW]. I’d rest easier at night if I had some hope along those lines.
This is part of my larger investigation into timelines commissioned by CLR. Many thanks to Tegan McCaslin, Lukas Finnveden, Anthony DiGiovanni, Connor Leahy, and Carl Shulman for comments on drafts. Kudos to Connor for pointing out the Skunkworks and Neuromorph ideas. Thanks to the LW team (esp. Raemon) for helping me with the formatting.
86 comments
Comments sorted by top scores.
comment by nostalgebraist · 2023-01-11T18:42:39.876Z · LW(p) · GW(p)
This post provides a valuable reframing of a common question in futurology: "here's an effect I'm interested in -- what sorts of things could cause it?"
That style of reasoning ends by postulating causes. But causes have a life of their own: they don't just cause the one effect you're interested in, through the one causal pathway you were thinking about. They do all kinds of things.
In the case of AI and compute, it's common to ask
- Here's a hypothetical AI technology. How much compute would it require?
But once we have an answer to this question, we can always ask
- Here's how much compute you have. What kind of AI could you build with it?
If you've asked the first question, you ought to ask the second one, too.
The first question includes a hidden assumption: that the imagined technology is a reasonable use of the resources it would take to build. This isn't always true: given those resources, there may be easier ways to accomplish the same thing, or better versions of that thing that are equally feasible. These facts are much easier to see when you fix a given resource level, and ask yourself what kinds of things you could do with it.
This high-level point seems like an important contribution to the AI forecasting conversation. The impetus to ask "what does future compute enable?" rather than "how much compute might TAI require?" influenced my own view of Bio Anchors, an influence that's visible in the contrarian summary at the start of this post.
I find the specific examples much less convincing than the higher-level point.
For the most part, the examples don't demonstrate that you could accomplish any particular outcome applying more compute. Instead, they simply restate the idea that more compute is being used.
They describe inputs, not outcomes. The reader is expected to supply the missing inference: "wow, I guess if we put those big numbers in, we'd probably get magical results out." But this inference is exactly what the examples ought to be illustrating. We already know we're putting in +12 OOMs; the question is what we get out, in return.
This is easiest to see with Skunkworks, which amounts to: "using 12 OOMs more compute in engineering simulations, with 6 OOMs allocated to the simulations themselves, and the other 6 to evolutionary search." Okay -- and then what? What outcomes does this unlock?
We could replace the entire Skunkworks example with the sentence "+12 OOMs would be useful for engineering simulations, presumably?" We don't even need to mention that evolutionary search might be involved, since (as the text notes) evolutionary search is one of the tools subsumed under the category "engineering simulations."
Amp suffers from the same problem. It includes two sequential phases:
- Training a scaled-up, instruction-tuned GPT-3.
- Doing an evolutionary search over "prompt programs" for the resulting model.
Each of the two steps takes about 1e34 FLOP, so we don't get the second step "for free" by spending extra compute that went unused in the first. We're simply training a big model, and then doing a second big project that takes the same amount of compute as training the model.
We could also do the same evolutionary search project in our world, with GPT-3. Why haven't we? It would be smaller-scale, of course, just as GPT-3 is smaller scale than "GPT-7" (but GPT-3 was worth doing!).
With GPT-3's budget of 3.14e23 FLOP, we could to do a GPT-3 variant of AMP with, for example,
- 10000 evaluations or "1 subjective day" per run (vs "3 subjective years")
- population and step count ~1600 (vs ~50000), or two different values for population and step count whose product is 1600^2
100,000,000 evaluations per run (Amp) sure sounds like a lot, but then, so does 10000 (above). Is 1600 steps "not enough"? Not enough for what? (For that matter, is 50000 steps even "enough" for whatever outcome we are interested in?)
The numbers sound intuitively big, but they have no sense of scale, because we don't know how they relate to outcomes. What do we get in return for doing 50000 steps instead of 1600, or 1e8 function evaluations instead of 1e5? What capabilities do we expect out of Amp? How does the compute investment cause those capabilities?
The question "What could you do with +12 OOMs of Compute?" is an important one, and this post deserves credit for raising it.
The concrete examples of "fun" are too fun for their own good. They're focused on sounding cool and big, not on accomplishing anything. Little would be lost if they were replaced with the sentence "we could dramatically scale up LMs, game-playing RL, artificial life, engineering simulations, and brain simulations."
Answering the question in a less "fun," more outcomes-focused manner sounds like a valuable exercise, and I'd love to read a post like that.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-15T04:22:47.699Z · LW(p) · GW(p)
Thanks for this thoughtful review! Below are my thoughts:
--I agree that this post contributes to the forecasting discussion in the way you mention. However, that's not the main way I think it contributes. I think the main way it contributes is that it operationalizes a big timelines crux & forcefully draws people's attention to it. I wrote this post after reading Ajeya's Bio Anchors report carefully many times, annotating it, etc. and starting several gdocs with various disagreements. I found in doing so that some disagreements didn't change the bottom line much, while others were huge cruxes. This one was the biggest crux of all, so I discarded the rest and focused on getting this out there. And I didn't even have the energy/time to really properly argue for my side of the crux--there's so much more I could say!--so I contented myself with having the conclusion be "here's the crux, y'all should think and argue about this instead of the other stuff."
--I agree that there's a lot more I could have done to argue that OmegaStar, Amp(GPT-7), etc. would be transformative. I could have talked about scaling laws, about how AlphaStar is superhuman at Starcraft and therefore OmegaStar should be superhuman at all games, etc. I could have talked about how Amp(GPT-7) combines the strengths of neural nets and language models with the strengths of traditional software. Instead I just described how they were trained, and left it up to the reader to draw conclusions. This was mainly because of space/time constraints (it's a long post already; I figured I could always follow up later, or in the comments. I had hoped that people would reply with objections to specific designs, e.g. "OmegaStar won't work because X" and then I could have a conversation in the comments about it. A secondary reason was infohazard stuff -- it was already a bit iffy for me to be sketching AGI designs on the internet, even though I was careful to target +12 OOMs instead of +6; it would have been worse if I had also forcefully argued that the designs would succeed in creating something super powerful. (This is also a partial response to your critique about the numbers being too big, too fun -- I could have made much the same point with +6 OOMs instead of +12 (though not with, say, +3 OOMs, those numbers would be too small) but I wanted to put an extra smidgen of distance between the post and 'here's a bunch of ideas for how to build AGI soon.')
Anyhow, so the post you say you would love to read, I too would love to read. I'd love to write it as well. It could be a followup to this one. That said, to be honest I probably don't have time to devote to making it, so I hope someone else does instead! (Or, equally good IMO, would be someone writing a post explaining why none of the 5 designs I sketched would work. Heck I think I'd like that even more, since it would tell me something I don't already think I know.)
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-18T13:06:04.978Z · LW(p) · GW(p)
Update: After talking to various people, it appears that (contrary to what the poll would suggest) there are at least a few people who answer Question 2 (all three variants) with less than 80%. In light of those conversations, and more thinking on my own, here is my current hot take on how +12 OOMs could turn out to not be enough:
1. Maybe the scaling laws will break. Just because GPT performance has fit a steady line across 5 orders of magnitude so far (or whatever) doesn't mean it will continue for another 5. Maybe it'll level off for some reason we don't yet understand. Arguably this is what happened with LSTMs? Anyhow, for timelines purposes what matters is not whether it'll level off by the time we are spending +12 OOMs of compute, but rather more like whether it will level off by the time we are spending +6 OOMs of compute. I think it's rather unlikely to level off that soon, but it might. Maybe 20% chance. If this happens, then probably Amp(GPT-7) and the like wouldn't work. (80%?) The others are less impacted, but maybe we can assume OmegaStar probably won't work either. Crystal Nights, SkunkWorks, and Neuromorph... don't seem to be affected by scaling laws though. If this were the only consideration, my credence would be something like 15% chance that Crystal Nights and OmegaStar don't work, and then independently, maybe 30% chance that none of the others work too, for a total of 95% answer to Question Two... :/ I could fairly easily be convinced that it's more like a 40% chance instead of 15% chance, in which case my answer is still something like 85%... :(
2. Maybe the horizon length framework plus scaling laws really will turn out to be a lot more solid than I think. In other words, maybe +12 OOMs is enough to get us some really cool chatbots and whatnot but not anything transformative or PONR-inducing; for those tasks we need long-horizon training... (Medium-horizons can be handled by +12 OOMs). Unsurprisingly to those who've read my sequence on takeoff and takeover, I do not think this is very plausible; I'm gonna say something like 10%. (Remember it has to not just apply to standard ML stuff like OmegaStar, but also to amplified GPT-7 and also to Crystal Nights and whatnot. It has to be basically an Iron Law of Learning.) Happily this is independent of point 1 though so that makes for total answer to Q2 of something more like 85%
3. There's always unknown unknowns. I include "maybe we are data-limited" in this category. Or maybe it turns out that +12 OOMs is enough, and actually +8 OOMs is enough, but we just don't have the industrial capacity or energy production capacity to scale up nearly that far in the next 20 years or so. I prefer to think of these things as add-ons to the model that shift our timelines back by a couple years, rather than as things that change our answer to Question Two. Unknown unknowns that change our answer to Question Two seem like, well, the thing I mentioned in the text--maybe there's some super special special sauce that not even Crystal Nights or Neuromorph can find etc. etc. and also Skunkworks turns out to be useless. Yeah... I'm gonna put 5% in this category. Total answer to Question Two is 80% and I'm feeling pretty reasonable about it.
4. There's biases. Some people I talked to basically said "Yeah, 80%+ seems right to me too, but I think we should correct for biases and assume everything is more difficult than it appears; if it seems like it's very likely enough to us, that means it's 50% likely enough." I don't currently endorse this, because I think that the biases pushing in the opposite direction--biases of respectability, anti-weirdness, optimism, etc.--are probably on the whole stronger. Also, the people in the past who used human brain milestone to forecast AI seem to have been surprisingly right, of course it's too early to say but reality really is looking exactly like it should look if they were right...
5. There's deference to the opinions of others, e.g. AI scientists in academia, economists forecasting GWP trends, the financial markets... My general response is "fuck that." If you are interested I can say more about why I feel this way; ultimately I do in fact make a mild longer-timelines update as a result of this but I do so grudgingly. Also, Roodman's model actually predicts 2037, not 2047 [? · GW]. And that's not even taking into account how AI-PONR will probably be a few years beforehand! [? · GW]
So all in all my credence has gone down from 90% to 80% for Question Two, but I've also become more confident that I'm basically correct, that I'm not the crazy one here. Because now I understand the arguments people gave, the models people have, for why the number might be less than 80%, and I have evaluated them and they don't seem that strong.
I'd love to hear more thoughts and takes by the way, if you have any please comment!
Replies from: abramdemski, abramdemski↑ comment by abramdemski · 2021-04-18T13:30:18.836Z · LW(p) · GW(p)
So, how does the update to the AI and compute trend [LW · GW] factor in?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-18T21:34:57.824Z · LW(p) · GW(p)
It is irrelevant to this post, because this post is about what our probability distribution over orders of magnitude of compute should be like. Once we have said distribution, then we can ask: How quickly (in clock time) will we progress through the distribution / explore more OOMs of compute? Then the AI and compute trend, and the update to it, become relevant.
But not super relevant IMO. The AI and Compute trend was way too fast to be sustained, people at the time even said so. This recent halt in the trend is not surprising. What matters is what the trend will look like going forward, e.g. over the next 10 years, over the next 20 years, etc.
It can be broken down into two components: Cost reduction and spending increase.
Ajeya separately estimates each component for the near term (5 years) and for the long-term trend beyond.
I mostly defer to her judgment on this, with large uncertainty. (Ajeya thinks costs will halve every 2.5 years, which is slower than the 1.5 years average throughout all history, but justifiable given how Moore's Law is said to be dying now. As for spending increases, she thinks it will take decades to ramp up to trillion-dollar expenditures, whereas I am more uncertain and think it could maybe happen by 2030 idk.)
I feel quite confident in the following claim: Conditional on +6 OOMs being enough with 2020's ideas, it'll happen by 2030. Indeed, conditional on +8 OOMs being enough with 2020's ideas, I think it'll probably happen by 2030. If you are interested in more of my arguments for this stuff, I have some slides I could share slash I'd love to chat with you about this! :)
Replies from: abramdemski↑ comment by abramdemski · 2021-04-30T16:42:19.093Z · LW(p) · GW(p)
If the AI and compute trend is just a blip, then doesn't that return us to the previous trend line in the graph you show at the beginning, where we progress about 2 ooms a decade? (More accurately, 1 oom every 6-7 years, or, 8 ooms in 5 decades.)
Ignoring AI and compute, then: if we believe +12 ooms in 2016 means great danger in 2020, we should believe that roughly 75 years after 2016, we are at most four years from the danger zone.
Whereas, if we extrapolate the AI-and-compute trend, +12 ooms is like jumping 12 years in the future; so the idea of risk by 2030 makes sense.
So I don't get how your conclusion can be so independent of AI-and-compute.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-10-30T14:10:41.821Z · LW(p) · GW(p)
Sorry, somehow I missed this. Basically, the answer is that we definitely shouldn't just extrapolate out the AI and compute trend into the future, and Ajeya's and my predictions are not doing that. Instead we are assuming something more like the historic 2 ooms a decade trend, combined with some amount of increased spending conditional on us being close to AGI/TAI/etc. Hence my conditional claim above:
Conditional on +6 OOMs being enough with 2020's ideas, it'll happen by 2030. Indeed, conditional on +8 OOMs being enough with 2020's ideas, I think it'll probably happen by 2030.
If you want to discuss this more with me, I'd love to, how bout we book a call?
↑ comment by abramdemski · 2021-04-18T13:22:16.492Z · LW(p) · GW(p)
Arguably this is what happened with LSTMs?
Is there a reference for this?
Replies from: gwern, daniel-kokotajlo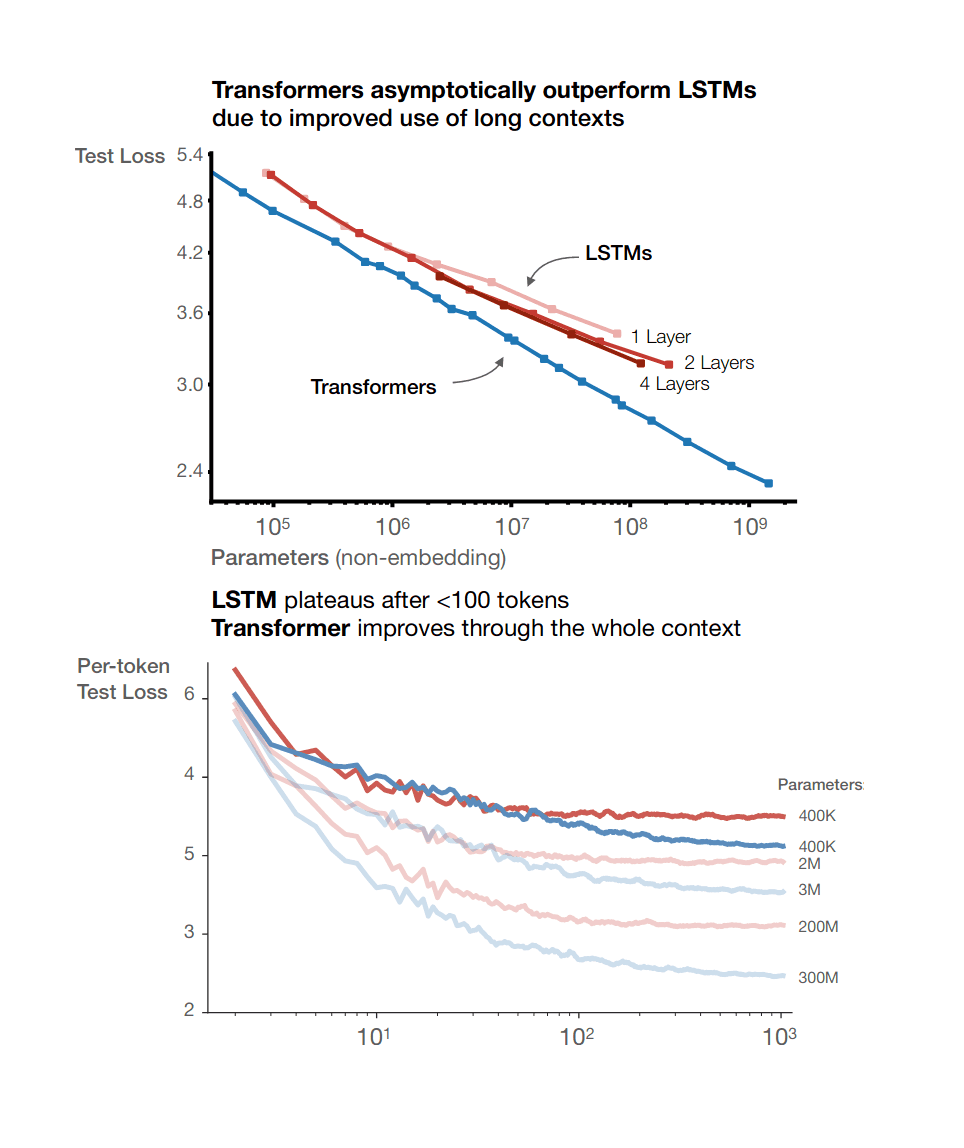{kind=link}
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-18T21:26:25.572Z · LW(p) · GW(p)
What Gwern said. :) But I don't know for sure what the person I talked to had in mind.
comment by Rohin Shah (rohinmshah) · 2021-03-05T16:55:54.426Z · LW(p) · GW(p)
I feel like if you think Neuromorph has a good chance of succeeding, you need to explain why we haven't uploaded worms yet. For C. elegans, if we ran 302 neurons for 1 subjective day (= 8.64e4 seconds) at 1.2e6 flops per neuron, and did this for 100 generations of 100 brains, that takes a mere 3e17 flops, or about $3 at current costs.
(And this is very easy to parallelize, so you can't appeal to that as a reason this can't be done.)
(It's possible that we have uploaded worms in the 7 years since that blog post was written, though I would have expected to hear about it if so.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-05T17:20:33.342Z · LW(p) · GW(p)
Good question! Here's my answer:
--I think Neuromorph has the least chance of succeeding of the five. Still more than 50% though IMO. I'm not at all confident in this.
--Neuromorph =/= an attempt to create uploads. I would be extremely surprised if the resulting AI was recognizeably the same person as was scanned. I'd be mildly surprised if it even seemed human-like at all, and this is conditional on the project working. What I imagine happening conditional on the project working is something like: After a few generations of selection, we get brains that "work" in more or less the way that vanilla ANN's work, i.e. the brains seem like decently competent RL agents (of human-brain size) at RL tasks, decently competent transformers at language modelling, etc. So, like GPT-5 or so. But there would still be lots of glitches and weaknesses and brittleness. But then with continued selection we get continued improvement, and many (though not nearly all) of the tips & tricks evolution had discovered and put into the brain (modules, etc.) are rediscovered. Others are bypassed entirely as the selection process routes around them and finds new improvements. At the end we are left with something maybe smarter than a human, but probably not, but competent enough and agenty enough to be transformative. (After all, it's faster and cheaper than a human.)
From the post you linked:
If this doesn't count as uploading a worm, however, what would? Consider an experiment where someone trains one group of worms to respond to stimulus one way and another group to respond the other way. Both groups are then scanned and simulated on the computer. If the simulated worms responded to simulated stimulus the same way their physical versions had, that would be good progress. Additionally you would want to demonstrate that similar learning was possible in the simulated environment.
Yeah, Neuromorph definitely won't be uploading humans in that sense.
Suzuki et. al. (2005) [2] ran a genetic algorithm to learn values for these parameters that would give a somewhat realistic worm and showed various wormlike behaviors in software.
This might already qualify as success for what I'm interested in, depending on how "wormlike" the behaviors are. I haven't looked into this.
--I used to think our inability to upload worms was strong evidence against any sort of human uploading happening anytime soon. However, I now think it's only weak evidence. This is because, counterintuitively, worms being small makes them a lot harder to simulate. Notice how each worm has exactly 302 neurons, and their locations and connections are the same in each worm. That means the genes are giving extremely precise instructions, micro-managing how each neuron works. I wouldn't be at all surprised if each one of those 302 neurons has code specific to it in particular, that makes it act differently from all the others. By contrast, humans simply have far too many neurons for this to be possible. The genes must be instructing the neurons at a higher level than that.
--Have we actually tried the massive search method I recommended in Neuromorph? I don't know, I haven't looked at the literature, but I wouldn't be that surprised if the researchers are trying to "get it right" rather than "merely make it work." Maybe they would read this discussion and be like "Oh yeah we could totally just throw a ton of compute at it and find some parameter settings for something that looks somewhat like a worm, that is similarly competent at all wormy tasks. But what would be the point? It wouldn't teach us anything about how worms work, and it wouldn't help us upload humans."
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-05T19:34:31.300Z · LW(p) · GW(p)
Neuromorph =/= an attempt to create uploads.
My impression is that the linked blog post is claiming we haven't even been able to get things that are qualitatively as impressive as a worm. So why would we get things that are qualitatively as impressive as a human? I'm not claiming it has to be an upload.
This is because, counterintuitively, worms being small makes them a lot harder to simulate.
I could believe this (based on the argument you mentioned) but it really feels like "maybe this could be true but I'm not that swayed from my default prior of 'it's probably as easy to simulate per neuron'".
Also if it were 100x harder, it would cost... $300. Still super cheap.
Have we actually tried the massive search method I recommended in Neuromorph?
That's what the genetic algorithm is? It probably wasn't run with as 3e17 flops, since compute was way more expensive then, but that's at least evidence that researchers do in fact consider this approach.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-05T20:12:16.435Z · LW(p) · GW(p)
At this point I guess I just say I haven't looked into the worm literature enough to say. I can't tell from the post alone whether we've neuromorphed the worm yet or not.
"Qualitatively as impressive as a worm" is a pretty low bar, I think. We have plenty of artificial neural nets that are much more impressive than worms already, so I guess the question is whether we can make one with only 302 neurons that is as impressive as a worm... e.g. can it wriggle in a way that moves it around, can it move away from sources of damage and towards sources of food, etc. idk, I feel like maybe at this point we should make bets or something, and then go read the literature and see who is right? I don't find this prospect appealing but it seems like the epistemically virtuous thing to do.
I do feel fairly confident that on a per-neuron basis worms are much harder than humans to simulate. My argument seems solid enough for that conclusion, I think. It's not solid enough to mean that you are wrong though -- like you said, a 100x difference is still basically nothing. And to be honest I agree that the difference probably isn't much more than that; maybe 1000x or something. That's computational expense, though; qualitative difficulty is another matter. If you recall from my post about birds & planes, my position is not that simulating/copying nature is easy; rather it's that producing something that gets the job done is easy, or at least in expectation easier than a lot of people seem to think, because the common argument that it's hard is bogus etc. etc. This whole worm-uploading project seems more like "simulating/copying nature" to me, whereas the point of Neuromorph was to try to lazily/cheaply copy some things from nature and then make up the rest in whatever way gets the job done.
What do you imagine happening, in the hypothetical, when we run the Neuromorph project? Do you imagine it producing gibberish eternally? If so, why -- wouldn't you at least expect it to do about as well as a transformer or regular RL agent or whatever of comparable size? Do you imagine that it does about that well, but not significantly better, even after all the artificial evolution? I guess that seems somewhat plausible to me, but less than 50% likely. I'm very unsure of this of course, and am updating downwards in light of your pushback.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-05T22:44:21.135Z · LW(p) · GW(p)
idk, I feel like maybe at this point we should make bets or something, and then go read the literature and see who is right? I don't find this prospect appealing but it seems like the epistemically virtuous thing to do.
Meh, I don't think it's a worthwhile use of my time to read that literature, but I'd make a bet if we could settle on an operationalization and I didn't have to settle it.
What do you imagine happening, in the hypothetical, when we run the Neuromorph project?
I mostly expect that you realize that there were a bunch of things that were super underspecified and they don't have obvious resolutions, and if you just pick a few things then nothing happens and you get gibberish eternally, and if you search over all the underspecified things you run out of your compute budget very quickly. Some things that might end up being underspecified:
- How should neurons be connected to each other? Do we just have a random graph with some average degree of connections, or do we need something more precise?
- How are inputs connected to the brain? Do we just simulate some signals to some input neurons, that are then propagated according to the physics of neurons? How many neurons take input? How are they connected to the "computation" neurons?
- To what extent do we need to simulate other aspects of the human body that affect brain function? Which hormone receptors do we / don't we simulate? For the ones we do simulate, how do we determine what their inputs are? Or do we have to simulate an entire human body (would be way, way more flops)?
- How do we take "random draws" of a new brain? Do we need to simulate the way that DNA builds up the brain during development?
- Should we build brains that are like that of a human baby, or a human adult, given that the brain structure seems to change between these?
I'm not saying any of these things will be the problem. I'm saying that there will be some sort of problem like this (probably many such problems), that I'm probably not going to find reasoning from my armchair. I also wouldn't really change my mind if you had convincing rebuttals to each of them, because the underlying generator is "there are lots of details; some will be devilishly difficult to handle; you only find those by actually trying to solve the problem and running headfirst into those details". You'd either have to argue against the underlying generator, or actually do the thing and demonstrate it was feasible.
(Btw, I have similar feelings about the non-Neuromorph answers too; but "idk I'm not really compelled by this" didn't seem like a particularly constructive comment.)
I do feel fairly confident that on a per-neuron basis worms are much harder than humans to simulate. My argument seems solid enough for that conclusion, I think.
Idk, here are a few ways it could be wrong:
- Most of the effect of DNA is on things that are not the brain, so the effect you mention is tiny. (This doesn't make it wrong, just uninteresting.)
- Most of the effect of DNA in worms is in deciding the number + structure of the neurons, which we already know and can hardcode in our simulation. However, in humans, DNA doesn't determine number + structure of neurons, and instead it somehow encodes priors about the world, which we don't know and can't hardcode in our simulation.
- Worms are small enough and simple enough that it's fine to just have one type of neuron (e.g. perhaps all neurons are the same length, which affects their function), whereas this isn't true for human brains (e.g. we need to try multiple variations on the lengths of neurons).
Again, I don't particularly think any of these are true, it's more like I start with massive uncertainty when attempting to reason about such a complex system, and an armchair argument is usually only going to slightly shift me within that massive uncertainty. (And as a general heuristic, the cleverer it is, the less it shifts me.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-06T09:38:55.693Z · LW(p) · GW(p)
(Btw, I have similar feelings about the non-Neuromorph answers too; but "idk I'm not really compelled by this" didn't seem like a particularly constructive comment.)
On the contrary, I've been very (80%?) surprised by the responses so far -- in the Elicit poll, everyone agrees with me! I expected there to be a bunch of people with answers like "10%" and "20%" and then an even larger bunch of people with answers like "50%" (that's what I expected you, Ajeya, etc. to chime in and say). Instead, well, just look at the poll results! So, even a mere registering of disagreement is helpful.
That said, I'd be interested to hear why you have similar feelings about the non-Neuromorph answers, considering that you agreed with the point I was making in the birds/brains/etc. post [LW · GW]. If we aren't trying to replicate the brain, but just to do something that works, yes there will be lots of details to work out, but what positive reason do you have to think that the amount of special sauce / details is so high that 12 OOMs and a few years isn't enough to find it?
I mostly expect that you realize that there were a bunch of things that were super underspecified and they don't have obvious resolutions, and if you just pick a few things then nothing happens and you get gibberish eternally, and if you search over all the underspecified things you run out of your compute budget very quickly.
Interesting. This conflicts with something I've been told about neural networks, which is that they "want to work." Seems to me that more likely than eternal gibberish is something that works but not substantially better than regular ANN's of similar size. So, still better than GPT-3, AlphaStar, etc. After all, those architectures are simple enough that surely something similar is in the space of things that would be tried out by the Neuromorph search process?
I think the three specific ways my claim about worms could be wrong are not very plausible:
Sure, most of the genes don't code neuron stuff. So what? Sure, maybe the DNA mostly contents itself with specifying number + structure of neurons, but that's just a rejection of my claim, not an argument against it. Sure, maybe it's fine to have just one type of neuron if you are so simple -- but the relevant metric is not "number of types" but "number of types / number of neurons." And the size of the human genome limits that fraction to "something astronomically tiny" for humans, whereas for worms it could in principle go all the way up to 1.
I'm more sympathetic to your meta-level skepticism though.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-06T19:01:42.871Z · LW(p) · GW(p)
That said, I'd be interested to hear why you have similar feelings about the non-Neuromorph answers, considering that you agreed with the point I was making in the birds/brains/etc. post. If we aren't trying to replicate the brain, but just to do something that works, yes there will be lots of details to work out, but what positive reason do you have to think that the amount of special sauce / details is so high that 12 OOMs and a few years isn't enough to find it?
The positive reason is basically all the reasons given in Ajeya's report? Like, we don't tend to design much better artifacts than evolution (currently), the evolution-designed artifact is expensive, and reproducing it using today's technology looks like it could need more than 12 OOMs.
I don't think the birds/brains/etc post contradicts this reason, as I said before [LW(p) · GW(p)] (and you seemed to agree).
Replies from: nathan-helm-burger, daniel-kokotajlo↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-12T06:04:45.418Z · LW(p) · GW(p)
Ok, as a former neuroscientist who has spent a lot of years (albeit not recent ones) geeking out about, downloading, and playing with various neural models, I'd like to add to this discussion. First, the worm stuff seems overly detailed and focused on recreating the exact behavior rather than 'sorta kinda working like a brain should'. A closer, more interesting project to look at (but still too overly specific) is the Blue Brain project [ https://www.epfl.ch/research/domains/bluebrain/ ]. Could that work with 12 more OOMs of compute? I feel quite confident it could, with no additional info. But I think you could get there with a lot less than 12 OOMs if you took a less realistic, more functional project like Nengo [ https://www.nengo.ai/ ]. Nengo is a brain simulation that can already do somewhat interesting stuff at boring 2019 levels of compute. If you gave it GPT-3 levels of compute, I bet it would be pretty awesome.
And beyond that, neuroscientists have been obsessively making separate little detailed computer models of their tiny pieces of specialized knowledge about the brain since the 1980s at least, here's some links [ https://compneuroweb.com/database.html ]. There are archives of hundreds of such models, open source and available for download. Each one with a subtly different focus, painstakingly confirmed to be accurate about the tiny piece of the picture it was designed to model. With enough compute it would be easy to brute force search over these and over BlueBrain to see if anything was useful to the base Nengo model. I played with a bunch of such models back around 2012-2015.
And of course, there's Numenta [ https://numenta.com ]. A bit more abstract than Nengo, a bit more efficient. The researchers have put more work into distilling out just what they believe to be the critical components of the human cortex. I've been following their work for over 20 years now, since Jeff's first book got me into neuroscience in the first place. I agree with some of their distillations, not all of them, but generally feel like they've got some workable ideas that just hasn't been given the oomph they need to really shine.
If I had just 4 OOMs to work with, I'd start with Numenta, and bring in a few more details from Nengo. If I had 9 OOMs, I'd go straight to Nengo. If I had 12 OOMs, I'd go full BlueBrain.
edit: I no longer endorse these super rough estimates of compute. I did some research and estimation and put the results here: https://www.lesswrong.com/posts/5Ae8rcYjWAe6zfdQs/what-more-compute-does-for-brain-like-models-response-to [LW · GW]
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-04-12T12:57:37.591Z · LW(p) · GW(p)
(I know ~nothing about any of this, so might be misunderstanding things greatly)
12 OOMs is supposed to get us human-level AGI, but BlueBrain seems to be aiming at a mouse brain? "It takes 12 OOMs to get to mouse-level AGI" seems like it's probably consistent with my positions? (I don't remember the numbers well enough to say off the top of my head.) But more fundamentally, why 12 OOMs? Where does that number come from?
From a brief look at the website, I didn't immediately see what cool stuff Nengo could do with 2019 levels of compute, that neural networks can't do. Same for Numenta.
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-13T03:54:07.848Z · LW(p) · GW(p)
Blue Brain does actually have a human brain model waiting in the wings, it just tries to avoid mentioning that. A media-image management thing. I spent the day digging into your question about OOMs, and now have much more refined estimates. Here's my post: https://www.lesswrong.com/posts/5Ae8rcYjWAe6zfdQs/what-more-compute-does-for-brain-like-models-response-to [LW · GW]
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-06T22:07:03.535Z · LW(p) · GW(p)
Hmmm, it seems we aren't on the same page. (The argument sketch you just made sounds to me like a collection of claims which are either true but irrelevant, or false, depending on how I interpret them.) I'll go back and reread Ajeya's report (or maybe talk to her?) and then maybe we'll be able to get to the bottom of this. Maybe my birds/brains/etc. post directly contradicts something in her report after all.
comment by Donald Hobson (donald-hobson) · 2021-03-01T19:22:46.672Z · LW(p) · GW(p)
That crystal nights story. As I was reading it, it was like a mini Eliezer in my brain facepalming over and over.
Its clear that the characters have little idea how much suffering they caused, or how close they came to destroying humanity. It was basically luck that pocket universe creation caused a building wrecking explosion, not a supernova explosion. Its also basically luck that the Phites didn't leave some nanogoo behind them. You still have a hyperrapid alien civ on the other side of that wormhole. One with known spacewarping tech, and good reason to hate you, or just want to stop you trying the same thing again, or to strip every last bit of info about their creation from human brains. How long until they invade?
This feels like an idiot who is playing with several barely subcritical lumps of uranium, and drops one on their foot.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-01T20:55:18.613Z · LW(p) · GW(p)
comment by nostalgebraist · 2023-01-10T20:10:10.579Z · LW(p) · GW(p)
uses about six FLOP per parameter per token
Shouldn't this be 2 FLOP per parameter per token, since our evolutionary search is not doing backward passes?
On the other hand, the calculation in the footnote seems to assume that 1 function call = 1 token, which is clearly an unrealistic lower bound.
A "lowest-level" function (one that only uses a single context window) will use somewhere between 1 and tokens. Functions defined by composition over "lowest-level" functions, as described two paragraphs above, will of course require more tokens per call than their constituents.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-01-13T03:14:44.330Z · LW(p) · GW(p)
Thanks for checking my math & catching this error!
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:08:17.490Z · LW(p) · GW(p)
Footnotes
Replies from: daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo, daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:14:01.032Z · LW(p) · GW(p)
[1] AlphaStar was 10^8 parameters, ten times smaller than a honeybee brain. I think this puts its capabilities in perspective. Yes, it seemed to be more of a heuristic-executor than a long-term planner, because it could occasionally be tricked into doing stupid things repeatedly. But the same is true for insects.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:09:32.060Z · LW(p) · GW(p)
[18] Quick calculation: Suppose we take Ajeya’s best-guess distribution and modify it by lowering the part to the right of 10^35 and raising the part to the left of 10^35, until the 10^35 mark is the 80-percentile mark instead of the 50-percentile mark. And suppose we do this raising and lowering in a “distribution-preserving way,” i.e. the shape of the curve before the 10^35 mark looks exactly the same, it’s just systematically bigger. In other words, we redistribute 30 percentage points of probability mass from above 10^35 to below, in proportion to how the below-10^35 mass is already distributed.
Well, in this case, then 60% of the redistributed mass should end up before the old 30% mark. (Because the 30% mark is 60% of the mass prior to the old median, the 10^35 mark.) And 60% of 30 percentage points is 18, so that means +18 points added before the old 30% mark. This makes it the new 48% mark. So the new 48% mark should be right where the old 30% mark is, which is (eyeballing the spreadsheet) a bit after 2040, 10 years sooner. (Ajeya’s best guess median is a bit after 2050.) This is, I think, a rather conservative estimate of how cruxy this disagreement is.
First, my answer to Question Two is 0.9, not 0.8, and that’s after trying to be humble and whatnot. Second, this procedure of redistributing probability mass in proportion to how it is already distributed produces an obviously silly outcome, where there is a sharp drop-off in probability at the 10^35 mark. Realistically, if you are convinced that the answer to Question Two is 0.8 (or whatever) then you should think the probability distribution tapers off smoothly, being already somewhat low by the time the 80th-percentile mark at 10^35 is reached.
Thus, realistically, someone who mostly agrees with Ajeya but answers Question Two with “0.8” should have somewhat shorter timelines than the median-2040-ish I calculated
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:13:51.236Z · LW(p) · GW(p)
[2] This is definitely true for Transformers (and LSTMs I think?), but it may not be true for whatever architecture AlphaStar uses. In particular some people I talked to worry that the vanishing gradients problem might make bigger RL models like OmegaStar actually worse. However, everyone I talked to agreed with the “probably”-qualified version of this claim. I’m very interested to learn more about this.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:13:38.629Z · LW(p) · GW(p)
[3] To avoid catastrophic forgetting, let’s train OmegaStar on all these different games simultaneously, e.g. it plays game A for a short period, then plays game B, then C, etc. and loops back to game A only much later.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:13:25.962Z · LW(p) · GW(p)
[4] Lukas Finnveden points out that Gwern’s extrapolation is pretty weird. Quoting Lukas: “Gwern takes GPT-3's current performance on lambada; assumes that the loss will fall as fast as it does on "predict-the-next-word" (despite the fact that the lambada loss is currently falling much faster!) and extrapolates current performance (without adjusting for the expected change in scaling law after the crossover point) until the point where the AI is as good as humans (and btw we don't have a source for the stated human performance)
I'd endorse a summary more like “If progress carries on as it has so far, we might just need ~1e27 FLOP to get to mturk-level of errors on the benchmarks closest to GPT-3's native predict-the-next-word game. Even if progress on these benchmarks slowed down and improved at the same rate as GPT-3's generic word-prediction abilities, we'd expect it to happen at ~1e30 FLOP for the lambada benchmark."
All that being said, Lukas’ own extrapolation [LW · GW] seems to confirm the general impression that GPT’s performance will reach human-level around the same time its size reaches brain-size: “Given that Cotra’s model’s median number of parameters is close to my best guess of where near-optimal performance is achieved, the extrapolations do not contradict the model’s estimates, and constitute some evidence for the median being roughly right.”↩︎ [LW · GW]
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:13:03.914Z · LW(p) · GW(p)
[5] One might worry that the original paper had a biased sample of tasks. I do in fact worry about this. However, this paper tests GPT-3 on a sample of actual standardized tests used for admission to colleges, grad schools, etc. and GPT-3 exhibits similar performance (around 50% correct), and also shows radical improvement over smaller versions of GPT.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:12:52.333Z · LW(p) · GW(p)
[6] In theory (and maybe in practice too, given how well the new pre-training paradigm is working? See also e.g. this paper) it should be easier for the model to generalize and understand concepts since it sees images and videos and hears sounds to go along with the text.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:12:13.237Z · LW(p) · GW(p)
[7] GPT-3 has already been used to write its own prompts, sorta. See this paper and look for “metaprompt.” Also, this paper demonstrates the use of stochastic gradient descent on prompts to evolve them into better versions.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:11:58.865Z · LW(p) · GW(p)
[8] Thanks to Connor Leahy for finding this source for me.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:11:47.571Z · LW(p) · GW(p)
[9] 50,000 x 50,000 x 100,000,000 x 10^17 x 6 = 1.5x10^35
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:11:32.811Z · LW(p) · GW(p)
[10] Bostrom and Shulman have an earlier estimate with wide error bars: 10^38 - 10^51 FLOP. See page 6 and multiply their FLOPS range by the number of seconds in a year.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:11:23.475Z · LW(p) · GW(p)
[11] Well, we’d definitely start with small brains and scale up, but we’d make sure to spend only a fraction of our overall compute on small brains. From the report, page 25 of part 3: "the number of FLOP/s contributed by humans is (~7e9 humans) * (~1e15 FLOP/s / person) = ~7e24. The human population is vastly larger now than it was during most of our evolutionary history, whereas it is likely that the population of animals with tiny nervous systems has stayed similar. This suggests to me that the average ancestor across our entire evolutionary history was likely tiny and performed very few FLOP/s. I will assume that the “average ancestor” performed about as many FLOP/s as a nematode and the “average population size” was ~1e21 individuals alive at a given point in time. This implies that our ancestors were collectively performing ~1e25 FLOP every second on average over the ~1 billion years of evolutionary history."
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:11:12.068Z · LW(p) · GW(p)
[12] See page 4 of this paper. Relevant quote: “Originally the ST5 mission managers had hired a contractor to design and produce an antenna for this mission. Using conventional design practices the contractor produced a quadrifilar helix antenna (QHA). In Fig. 3 we show performance comparisons of our evolved antennas with the conventionally designed QHA on an ST5 mock-up. Since two antennas are used on each spacecraft – one on the top and one on the bottom – it is important to measure the overall gain pattern with two antennas mounted on the spacecraft. With two QHAs 38% efficiency was achieved, using a QHA with an evolved antenna resulted in 80% efficiency, and using two evolved antennas resulted in 93% efficiency.
Since the evolved antenna does not require a phasing circuit, less design and fabrication work is required, and having fewer parts may result in greater reliability. In terms of overall work, the evolved antenna required approximately three person-months to design and fabricate whereas the conventional antenna required approximately five months. Lastly, the evolved antenna has more uniform coverage in that it has a uniform pattern with only small ripples in the elevations of greatest interest (40◦ − 80◦ ). This allows for reliable performance as the elevation angle relative to the ground changes.”
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:10:43.121Z · LW(p) · GW(p)
[13] So, no Ems, basically. Probably.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:10:32.576Z · LW(p) · GW(p)
[14] I mean, definitely not completely random. But I said we’d fill in the details in a random-but-biologically-plausible way. And children simply have far too many neurons for genes to say much about how they connect to each other. Whatever unknowns there are about about how the neurons connect, we can make that part of what’s being optimized by our hundred-thousand-generation search process. The size of the search space can’t be that big, because there isn’t that much space in the human genome to encode any super-complicated instructions. I guess at this point we should start talking about Ajeya’s Genome Anchor idea. I admit I’m out of my depth here.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:10:21.097Z · LW(p) · GW(p)
[15] Since later I talk about how I disagree with Ajeya, I want to make super clear that I really do think her report is excellent. It’s currently the best writing on timelines that I know of. When people ask me to explain my timelines, I say “It’s like Ajeya’s, except…"
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:10:06.942Z · LW(p) · GW(p)
[16] I think this because I’ve looked at the probability distribution she gives on page 34 of part 3 of her report and 35 OOMs of floating point operations seems to be the median. I had to do this by measuring with a ruler and doing some eyeballing, so it’s probably not exactly correct, but I’d be surprised if the true answer is more than 55% or less than 45%. As a sanity check, Ajeya has 7 buckets in which her credence is distributed, with 30% in a bucket with median 34.5 OOMs, and 35% in buckets with higher medians, and 35% in buckets with lower medians. (But the lower buckets are closer to 35 than the higher buckets, meaning their tails will be higher than 35 more than the higher bucket’s tails will be lower than 35.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:09:52.608Z · LW(p) · GW(p)
[17] Example: One nitpick I have is that Ajeya projects that the price of compute for AI will fall more slowly than price-performance Moore’s Law, because said law has faltered recently. I instead think we should probably model this uncertainty, with (say) a 50% chance of Moore continuing and a 50% chance of continued slowdown. But even if it was a 100% chance of Moore continuing, this would only bring forward Ajeya’s median timeline to 2045-ish! (At least, according to my tinkering with her spreadsheet)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-04T21:08:51.188Z · LW(p) · GW(p)
[19] I recommend trying out different numbers depending on who is in the conversation. For conversations in which everyone assigns high credence to the 10^35 version, it may be more fruitful to debate the 10^29 version, since 10^29 FLOP is when GPT-7 surpasses human level at text prediction (and is also superhuman at the other tests we’ve tried) according to the scaling laws and performance trends [LW · GW], I think.
For conversations where everyone has low credence in the 10^35 version, I suggest using the 10^41 version, since 10^41 FLOP is enough to recapitulate evolution without any shortcuts.
comment by George3d6 · 2021-03-02T07:15:42.891Z · LW(p) · GW(p)
The aliens seem to have also included with their boon:
- Cheap and fast eec GPU RAM with minute electricity consumptions
- A space time disruptor that allows you to have CMOS transistors smaller than electrons to serve as the L1&L2
- A way of getting rid of electron tunneling at a very small scale
- 12 OOMs better SSDs and fiber optic connections and cures for the host of physical limitations plaguing mere possibility of those 2.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-02T08:15:49.293Z · LW(p) · GW(p)
I did say it was magic. :D
comment by Zach Stein-Perlman · 2022-12-02T00:00:09.153Z · LW(p) · GW(p)
The ideas in this post greatly influence how I think about AI timelines, and I believe they comprise the current single best way to forecast timelines.
A +12-OOMs-style forecast, like a bioanchors-style forecast, has two components:
- an estimate of (effective) compute over time (including factors like compute getting cheaper and algorithms/ideas getting better in addition to spending increasing), and
- a probability distribution on the (effective) training compute requirements for TAI (or equivalently the probability that TAI is achievable as a function of training compute).
Unlike bioanchors, a +12-OOMs-style forecast answers #2 by considering various kinds of possible transformative AI systems and using some combination of existing-system performance, scaling laws, principles, miscellaneous arguments, and inside-view intuition to estimate how much compute they would require. Considering the "fun things" that could be built with more compute lets us use more inside-view knowledge than bioanchors-style analysis, while not committing to a particular path to TAI like roadmap-style analysis would.
In addition to introducing this forecasting method, this post has excellent analysis of some possible paths to TAI.
comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-03-02T03:16:57.500Z · LW(p) · GW(p)
I only read the prompt.
But I want to say: that much compute would be useful for meta-learning/NAS/AIGAs, not just scaling up DNNs. I think that would likely be a more productive research direction. And I want to make sure that people are not ONLY imagining bigger DNNs when they imagine having a bunch more compute, but also imagining how it could be used to drive fundamental advances in ML algos, which could plausibly kick of something like recursive self-improvement (even in DNNs are in some sense a dead end).
↑ comment by Anthony DiGiovanni (antimonyanthony) · 2021-07-02T01:34:48.844Z · LW(p) · GW(p)
Something I'm wondering, but don't have the expertise in meta-learning to say confidently (so, epistemic status: speculation, and I'm curious for critiques): extra OOMs of compute could overcome (at least) one big bottleneck in meta-learning, the expense of computing second-order gradients. My understanding is that most methods just ignore these terms or use crude approximations, like this, because they're so expensive. But at least this paper found some pretty impressive performance gains from using the second-order terms.
Maybe throwing lots of compute at this aspect of meta-learning would help it cross a threshold of viability, like what happened for deep learning in general around 2012. I think meta-learning is a case where we should expect second-order info to be very relevant to optimizing the loss function in question, not just a way of incorporating the loss function's curvature. In the first paper I linked, the second-order term accounts for how the base learner's gradients depend on the meta-learner's parameters. This seems like an important feature of what their meta-learner is trying/supposed to do, i.e., use the meta-learned update rule to guide the base learner - and the performance gains in the second paper are evidence of this. (Not all meta-learners have this structure, though, and MAML apparently doesn't get much better when you use Hessians. Hence my lack of confidence in this story.)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-02T08:55:32.380Z · LW(p) · GW(p)
Interesting, could you elaborate? I'd love to have a nice, fleshed-out answer along those lines to add to the five I came up with. :)
Replies from: capybaralet↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-03-02T21:15:11.436Z · LW(p) · GW(p)
Sure, but in what way?
Also I'd be happy to do a quick video chat if that would help (PM me).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-03T14:49:52.314Z · LW(p) · GW(p)
Well, I've got five tentative answers to Question One in this post. Roughly, they are: Souped-up AlphaStar, Souped-up GPT, Evolution Lite, Engineering Simulation, and Emulation Lite. Five different research programs basically. It sounds like what you are talking about is sufficiently different from these five, and also sufficiently promising/powerful/'fun', that it would be a worthy addition to the list basically. So, to flesh it out, maybe you could say something like "Here are some examples of meta-learning/NAS/AIGA in practice today. Here's a sketch of what you could do if you scaled all this up +12 OOMs. Here's some argument for why this would be really powerful."
Replies from: capybaralet↑ comment by David Scott Krueger (formerly: capybaralet) (capybaralet) · 2021-03-05T13:50:07.483Z · LW(p) · GW(p)
There's a ton of work in meta-learning, including Neural Architecture Search (NAS). AIGA's (Clune) is a paper that argues a similar POV to what I would describe here, so I'd check that out.
I'll just say "why it would be powerful": the promise of meta-learning is that -- just like learned features outperform engineered features -- learned learning algorithms will eventually outperform engineered learning algorithms. Taking the analogy seriously would suggest that the performance gap will be large -- a quantitative step-change.
The upper limit we should anchor on is fully automated research. This helps illustrate how powerful this could be, since automating research could easily give many orders of magnitude speed up (e.g. just consider the physical limitation of humans manually inputting information about what experiment to run).
An important underlying question is how much room there is for improvement over current techniques. The idea that current DL techniques are pretty close to perfect (i.e. we've uncovered the fundamental principles of efficient learning (associated view: ...and maybe DNNs are a good model of the brain)) seems too often implicit in some of the discussions around forecasting and scaling. I think it's a real possibility, but I think it's fairly unlikely (~15%, OTTMH). The main evidence for it is that 99% of published improvements don't seem to make much difference in practice/at-scale.
Assuming that current methods are roughly optimal has two important implications:
- no new fundamental breakthroughs needed for AGI (faster timelines)
- no possible acceleration from fundamental algorithmic breakthroughs (slower timelines)
comment by theme_arrow · 2021-03-02T06:41:04.768Z · LW(p) · GW(p)
Really interesting post, I appreciate the thought experiment. I have one comment on it related to the Crystal Nights and Skunkworks sections, based on my own experience in the aerospace world. There are lots of problems that I deal with today where the limiting factor is the existence of high-quality experimental data (for example, propellant slosh dynamics in zero-g). This has two implications:
- For the "Crystal Nights" example, I think that our current ability to build virtual worlds that are useful for evolutionarily creating truly transformative AIs may be more limited than you might think. A standard physics simulation-based environment is likely to not be that good a map of the real world. And a truly "bottom-up" simulation environment that recreated physics by simulating down at the molecular level would require a few orders of magnitude more computing power (and may run into similar issues with fidelity training data for modeling molecular interactions, though alphafold is evidence that this is not as great a limitation).
- For the "Skunkworks" example, I think that you may run into similar problems where the returns to more computing power are greatly limited by the fidelity of the training data.
Now if fidelity of training data was the only thing holding Google et al. from making trillions off of AI in this world, there would be a very strong push to gather the necessary data. But that kind of work in the physical world tends to move more slowly and could well push the timelines required for these two applications past the 4-year mark. I couldn't find similar objections to the other three.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-02T08:28:12.499Z · LW(p) · GW(p)
Thanks! Yeah, I basically agree with you overall that Skunkworks could be undermined by our lack of understanding of real-physics dynamics. We certainly wouldn't be able to create perfectly accurate simulations even if we threw all 35 OOMs at the problem. The question is whether the simulations would be accurate enough to be useful. My argument is that since we already have simulations which are accurate enough to be useful, adding +12 OOMs should lead to simulations which are even more useful. But useful enough to lead to crazy transformative stuff? Yeah, I don't know.
For Crystal Nights, I'm more 'optimistic.' The simulation doesn't have to be accurate at all really. It just has to be complex enough, in the right sort of ways. If you read the Crystal Nights short story I linked, it involves creating a virtual world and evolving creatures in it, but the creators don't even try to make the physics accurate; they deliberately redesign the physics to be both (a) easier to compute and (b) more likely to lead to intelligent life evolving.
Replies from: theme_arrow↑ comment by theme_arrow · 2021-03-03T05:59:18.016Z · LW(p) · GW(p)
Your comment about Crystal Nights makes sense. I guess humans have evolved in a word based on one set of physical laws, but we're general purpose intelligences that can do things like play videogames really well even when the game's physics don't match the real world's.
comment by lsusr · 2021-03-02T03:36:03.676Z · LW(p) · GW(p)
I like how these ideas are falsifiable, in the sense that that they have clear performance success criteria. It is possible to evaluate whether we hit these milestones (if we do so before a increase). I also like how it addresses several different potential directions for AI development instead of just scaling today's most popular architectures.
comment by Borasko · 2021-03-02T01:50:31.645Z · LW(p) · GW(p)
This was really interesting to read. I'm still pretty new to the AI space so I don't know how this compares to our current FLOP usage. Assuming our current course of computing power doesn't change, how long is the timeline to get to 10^34 FLOP of computing power?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-02T09:13:26.186Z · LW(p) · GW(p)
Well, it's 12 OOMs more than our current FLOP usage. ;) Ajeya's report is excellent and contains the best and most thorough answers to your questions I think. If I recall correctly, she projects that the price of compute will drop in half every 2.5 years on average, and that algorithmic/efficiency improvements will have a similar effect. And then there's a one-time boost of up to +5 OOMs that we get from just spending a lot more. So she projects we get to (the equivalent of) +12 OOMs around 2050. Personally, I think the price of compute will drop a bit faster in the next ten years, and the algorithmic improvements will be a bit better too in the near term. But I'm very uncertain about that and mostly just defer to her judgment.
Replies from: Boraskocomment by hippke · 2021-03-06T10:48:41.149Z · LW(p) · GW(p)
At the Landauer kT limit [LW · GW], you need kWh to perform your FLOPs. That's 10,000x the yearly US electricity production. You'd need a quantum computer or a Dyson sphere to solve that problem.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-06T13:09:06.418Z · LW(p) · GW(p)
Either that, or magic. :D
Replies from: vascoamaralgrilo↑ comment by Vasco Grilo (vascoamaralgrilo) · 2023-11-06T18:34:41.975Z · LW(p) · GW(p)
Hi there,
Assuming 10^6 [LW · GW] bit erasures per FLOP (as you did [LW · GW]; which source are you using?), one only needs 8.06*10^13 kWh (= 2.9*10^(-21)*10^(35+6)/(3.6*10^6)), i.e. 2.83 (= 8.06*10^13/(2.85*10^13)) times global electricity generation in 2022, or 18.7 (= 8.06*10^13/(4.30*10^12)) times the one generated in the United States.
comment by Caridorc Tergilti (caridorc-tergilti) · 2021-03-03T19:18:08.963Z · LW(p) · GW(p)
Consider Stockfish + NN searches 25 moves ahead on modern hardware. Considering a branching factor of 10 this means Stockfish +12oom will see 37 moves ahead. Some games last less then 37 moves. This is really cool indeed
Replies from: Archimedes↑ comment by Archimedes · 2021-03-05T01:05:55.819Z · LW(p) · GW(p)
With AB pruning, the branching factor is closer to 2 for Stockfish.
comment by nim · 2021-03-01T16:28:21.046Z · LW(p) · GW(p)
More than 5mins, because it's fun, but:
For convenience I shall gloss this "12 orders of magnitude' thing to "suddenly impossibly fast".
Are there energy and thermal implications here? If we did 12 orders of magnitude more computation for what it costs today, we could probably only do it underwater at a hydroelectric damn. Things, both our devices and eventually the rest of the atmosphere, would get much warmer.
Disk and memory are now our bottlenecks for everything that used to be compute-intensive. We probably set algorithms to designing future iterations which can be built on existing machinery, and end up with things that work great but are even further into incomprehensibility than current iterations. There's a link out there where they had a computer design a thing on an FPGA and it ended up with an isolated bit of "inoperative" circuitry which the design failed to work without; expect a whole lot more of this kind of magic.
Socially, RIP all encryption from before the compute fairy arrived, and most from shortly afterwards. It'll be nice to be able to easily break back into old diaries that I encrypted and lost the keys to, but that's about the most ethical possible application and it's still not great.
Socio-politically, imagine if deep fakes just suddenly appeared in like 2000. Their reception would be very different from what it is today because today we have a sort of memetic herd immunity -- there exists a "we" for "we know things at or below a certain quality or plausibility could be fakes". 'We' train our collective System 1 on a pattern of reacting to probable-fakes a certain way, even though the fakes can absolutely fool someone without those patterns. Letting a technology grow up in an environment with pressures from those who want to use it for "evil" and those who want to prevent that from happening shapes the tech, in a way that a sudden massive influx of computing power would not have time to be shaped by.
Programming small things by writing tests and then having your compiler search for a program that passes all the tests gets a lot more feasible. Thus, "small" computers (phone, watch, microwave, newish refrigerator, recent washing machine) can be tweaked into "doing more things", which in practice will probably mean observing us and trying to do something useful with that data. Useful to whom? Well, that depends. Computers still do what humans ask them to, and I am unconvinced that we can articulate what we collectively mean by "general intelligence" well enough to ask even an impossibly fast machine for it. We could hook it up to some biofeedback and say "make the system which makes me the most excited/frightened/interested", but isn't that the faster version of what video games already are?
Replies from: daniel-kokotajlo, sanil↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-01T16:45:59.247Z · LW(p) · GW(p)
I forgot about memory! I guess I should have just said "Magically 12 OOMs cheaper" instead of "magically 12 OOMs faster" though that's a bit weirder to imagine.
↑ comment by sanil · 2023-01-14T06:03:33.884Z · LW(p) · GW(p)
Why limit ourselves to our planet? 12 OOMs is well within reason if we were a type 2 civilization and had access to all the energy from our sun (our planet as a whole only receives 1/10^10 of it).
Encryption wouldn't really be an issue - we can simply tune our algorithms to use slightly more complicated assumptions. After all, one can just pick a problem that scales as O(10^(6n)), where n could for example be secret key length. If you have 12 orders of magnitude more compute, just make your key 2 times larger and you still have your cryptography.
Thought of how small computers (phones etc) would scale also came to me. Basically, with 12 OOMs every phone becomes a computer powerful enough to train something as complicated as GPT-3. Everyone could carry their own personalized GPT-3 model with them. Actually, this is another way to improve AI performance - reduce the amount of things it needs to model. Training a personalized model specific for one problem would be cheaper and require less parameters/layers to get useful results.
Basically, we would be able to put a "small" specialized model with power like that of GPT-3 on every microcontroller.
You mentioned deep fakes. But with this much compute, why not "deepfake" brand new networks from scratch? Doing such experiments right now is expensive since they roughly quadruple the amount of computational resources needed to achieve this "second order" training mode.
Theoretically, there's nothing preventing one from constructing a network that can assemble new networks based on training parameters. This meta-network could take into account network structure that it "learned" from training smaller models for other applications in order to generate new models with order of magnitude less parameters.
As an analogy, compare the amount of data a neural network needs to learn to differentiate between cats and dogs vs the amount of data a human needs to learn the same thing. Human only needs a couple of examples, while neural networks needs dozens of hundreds of examples just to learn the concept of shapes and topology.
comment by JakubK (jskatt) · 2023-02-09T18:21:05.281Z · LW(p) · GW(p)
I think it's worth noting Joe Carlsmith's thoughts on this post, available starting on page 7 of Kokotajlo's review of Carlsmith's power-seeking AI report (see this EA Forum post [EA · GW] for other reviews).
Replies from: daniel-kokotajloJC: I do think that the question of how much probability mass you concentrate on APS-AI by 2030 is helpful to bring out – it’s something I’d like to think more about (timelines wasn’t my focus in this report’s investigation), and I appreciate your pushing the consideration.
I read over your post on +12 OOMs, and thought a bit about your argument here. One broad concern I have is that it seems like rests a good bit (though not entirely) on a “wow a trillion times more compute is just so much isn’t it” intuition pump about how AI capabilities scale with compute inputs, where the intuition has a quasi-quantitative flavor, and gets some force from some way in which big numbers can feel abstractly impressive (and from being presented in a context of enthusiasm about the obviousness of the conclusion), but in fact isn’t grounded in much. I’d be interested, for example, to see how this methodology looks if you try running it in previous eras without the benefit of hindsight (e.g., what % do you want on each million-fold scale up in compute-for-the-largest-AI-experiment). That said, maybe this ends up looking OK in previous eras too, and regardless, I do think this era is different in many ways: notably, getting in the range of various brain-related biological milestones, the many salient successes (which GPT-7 and OmegaStar extrapolate from), and the empirical evidence of returns to ML-style scaling. And I think the concreteness of the examples you provide is useful, and differentiating from mere hand-waves at big numbers.
Those worries aside, here’s a quick pass at some probabilities from the exercise, done for “2020 techniques” (I’m very much making these up as I go along, I expect them to change as I think more).
A lot of the juice, for me, comes from GPT-7 and Omegastar as representatives of “short and low-end-of-medium-to-long horizon neural network anchors”, which seem to me the most plausible and the best-grounded quantitatively.
- In particular, I agree that if scaling up and fine-tuning multi-modal short-horizon systems works for the type of model sizes you have in mind, we should think that less than 1e35 FLOPs is probably enough – indeed, this is where a lot of my short-timelines probability comes from. Let’s say 35% on this.
- It’s less clear to me what AlphaStar-style training of a human-brain-sized system on e.g. 30k consecutive Steam Games (plus some extra stuff) gets you, but I’m happy to grant that 1e35 FLOPs gives you a lot of room to play even with longer-horizon forms of training and evolution-like selection. Conditional on the previous bullet not working (which would update me against the general compute-centric, 2020-technique-enthusiast vibe here), let’s say another 40% that this works, so out of a remaining 65%, that’s 26% on top.
- I’m skeptical of Neuromorph (I think brain scanning with 2020 tech will be basically unhelpful in terms of reproducing useful brain stuff that you can’t get out of neural nets already, so whether the neuromorph route works is ~entirely correlated with whether the other neural net routes work), and Skunkworks (e.g., extensive search and simulation) seems like it isn’t focused on APS-systems in particular and does worse on a “why couldn’t you have said this in previous areas” test (though maybe it leads to stuff that gets you APS systems – e.g., better hardware). Still, there’s presumably a decent amount of “other stuff” not explicitly on the radar here. Conditional on previous bullet points not working (again, an update towards pessimism), probability that “other stuff” works? Idk… 10%? (I’m thinking of the previous, ML-ish bullets as the main meat of “2020 techniques.”) So that would be 10% of a remaining 39%, so ~4%.
So overall 35%+26%+4% =~65% on 1e35 FLOPs gets you APS-AI using “2020 techniques” in principle? Not sure how I’ll feel about this on more reflection + consistency checking, though. Seems plausible that this number would push my overall p(timelines) higher (they’ve been changing regardless since writing the report), which is points in favor of your argument, but it also gives me pause about ways the exercise might be distorting. In particular, I worry the exercise (at least when I do it) isn’t actually working with a strong model of how compute translates into concrete results, or tracking other sources of uncertainty and/or correlation between these different paths (like uncertainty about brain-based estimates, scaling-centrism, etc – a nice thing about Ajeya’s model is that it runs some of this uncertainty through a monte carlo).
OK, what about 1e29 or less? I’ll say: 25%. (I think this is compatible with a reasonable degree of overall smoothness in distributing my 65% across my OOMs).
In general, though, I’d also want to discount in a way that reflects the large amount of engineering hassle, knowledge build-up, experiment selection/design, institutional buy-in, other serial-time stuff, data collection, etc required for the world to get into a position where it’s doing this kind of thing successfully by 2030, even conditional on 1e29 being enough in principle (I also don’t take $50B on a single training run by 2030 for granted even if in worlds where 1e29 is enough, though I grant that WTP could also go higher). Indeed, this kind of thing in general makes the exercise feel a bit distorting to me. E.g., “today’s techniques” is kind of ambiguous between “no new previously-super-secret sauce” and “none of the everyday grind of figuring out how to do stuff, getting new non-breakthrough results to build on and learn from, gathering data, building capacity, recruiting funders and researchers, etc” (and note also that in the world you’re imagining, it’s not that our computers are a million times faster; rather, a good chunk of it is that people have become willing to spend much larger amounts on gigantic training runs – and in some worlds, they may not see the flashy results you’re expecting to stimulate investment unless they’re willing to spend a lot in the first place). Let’s cut off 5% for this.
So granted the assumptions you list about compute availability, this exercise puts me at ~20% by 2030, plus whatever extra from innovations in techniques we don’t think of as covered via your 1-2 OOMs of algorithmic improvement assumption. This feels high relative to my usual thinking (and the exercise leaves me with some feeling that I’m taking a bunch of stuff in the background for granted), but not wildly high.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-02-09T19:26:29.064Z · LW(p) · GW(p)
Great point, thanks for linking this!
I think 65% that +12 OOMs would be enough isn't crazy. I'm obviously more like 80%-90%, and therein lies the crux. (Fascinating that such a seemingly small difference can lead to such big downstream differences! This is why I wrote the post.)
If you've got 65% by +12, and 25% by +6, as Joe does, where is your 50% mark? idk maybe it's at +10?
So, going to takeoffspeeds.com, and changing the training requirements parameter to +10 OOMs more than GPT-3 (so, 3e33) we get the following:
So, I think it's reasonable to say that Joe's stated credences here roughly imply 50% chance of singularity by 2033.
comment by sanil · 2023-01-13T10:39:30.202Z · LW(p) · GW(p)
Very interesting question!
My observations:
- 12 OOMs is a lot
- 12 OOMs is like comparing computational capacity of someone who just started learning arithmetics to a computer that an average person could obtain
- You mainly focused on modern AI approaches and how they would scale. With 12 OOMs, it's possible that other approaches would be used. See galactic algorithms for example.
- It might be useful to look at this through the lens of computational complexity. Here's a table of expected speedups:
| Problem Complexity | Scaling |
|---|---|
| O(log(n)) | 10^10¹² |
| O(n), O(n log(n)) | 10^12 |
| O(n^2) | 10^6 |
| O(n^3) | 10^4 |
| O(n^4) | 10^3 |
| O(n^6) | 10^2 |
| O(n^12) | 10 |
| O(10^n) | 12 |
Hence, we should expect exponentially complex brute force problems to perform 10 times better. With this, you'd only need 1 year to simulate something that would have taken 10 years. Quite nice for problems like quantum material design and computational biology.
On the other hand, neural networks are far more simple in terms of computation. A generous upper bound is O(n^5) for training and prediction. So if you spend a little more on compute, and get 13 OOMs speedup (just get 10 of those magical machines instead of 1), you should expect to be able to train neural networks 1000 times faster. What previously took you a week, now takes you a mere 10 minutes.
Aside: There is a problem here. O(n^5) is still slow. In part this is because biological brains work on different principles than digital computers. Neural networks are simple mathematically, but they were not designed for digital computers. It's a simulation, and those are always slower than a real thing. Hence, I'd expect TAI to happen once this architecture mismatch would be fixed.
Furthermore, there are a lot of things that are swept under the rug when you imagine that compute (and everything related) is simply scaled 12 OOMs. For example, not all problems are parallelizable (though intelligence is - after all, biological neurons don't need to wait until others have updated their state). Similarly, different problems might have different memory complexity.
This is why we have seen success in using specialized hardware for neural network training and execution.</Aside>
Now, improved run times would give you more freedom to tweak and experiment with meta parameters - adjusting network architecture, automatically categorizing all possible quantum materials and DNA sequence expressions. What would have taken you 100 years would now only take 10 years. That's quite transformative. As a bonus, now such "100 years projects" would be able to fit into one's research career. Not that different from current experiments in nuclear physics. This should open quite a lot of possibilities which we simply don't have access to now.
Actually, this gives me an idea. The reason we can have such long-running and expensive projects like say LHC is that we have a clear theory of what we expect to get and what energies we need for that. If we were close to getting TAI (or any other computationally expensive product) and would know that, we would be able to collect funds to construct machine that would be "LHC of TAI".
comment by Zach Stein-Perlman · 2022-09-21T16:16:56.664Z · LW(p) · GW(p)
- How would something like OmegaStar be transformative?
- How would something like GPT-7 be transformative?
(I think your kind of thinking is currently the best way to do timelines, and I buy that we could very likely do fun stuff with +12 OOMs, but I don't understand through what mechanism these systems would be transformative, and this seems really important to think about carefully so we can determine other probabilities, like the probability that a GPT-style system/bureaucracy with 10^30 FLOP would be transformative.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-09-22T01:06:12.414Z · LW(p) · GW(p)
I think OmegaStar and Amp(GPT-7) would be APS-AI -- advanced, planning, strategically aware. (Defined in the Carlsmith report). I think they'd be capable of playing the training game [LW · GW] and deceiving humans into thinking they are aligned/trustworthy and/or incapable of doing truly dangerous things. I think they'd probably have powerbase ability. [LW · GW]
As for economic impact, I think they'd be able to automate a significant fraction of the economy and in particular accelerate AI R&D significantly. (Once they and variations of them and things they built were suitably deployed widely, that is.)
This is just a brief answer of course, I imagine you want more -- but could you perhaps explain which part of the above you disagree with and why?
↑ comment by Zach Stein-Perlman · 2022-09-22T18:42:59.491Z · LW(p) · GW(p)
Thanks very much!
I don't really disagree-- I just feel uncertain. I'd struggle to tell a story about how (e.g.) OmegaStar could "automate a significant fraction of the economy" or "accelerate AI R&D significantly" or take control of a leading AI lab (powerbase ability). To be more precise, I feel deeply uncertain about how agent-y OmegaStar would be, how capable it would be, and the kinds of actions that it could use to take over (if it wanted to and was sufficiently capable).
I can't think of much written on this. I think it could be a great use of your time to write about how AI systems based on game-playing or token-prediction could be economically important, be important to AI R&D, and have powerbase ability, as well as what signs we might see along the way. (This might easily fit into a continuation of What 2026 looks like [LW · GW], or maybe not.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-09-22T19:22:49.401Z · LW(p) · GW(p)
I agree this is something I could do that would be valuable, I just haven't prioritized it alas. I did say I wanted to write the sequel to that story at some point...
I encourage other people to think about it too. I suggest reasoning as follows: (1) What skills/properties would combine to create APS-AI? Agency, reasoning, situational awareness... maybe persuasion, deception, hacking... etc. (2) Does the training process of OmegaStar or whatever incentivize the growth of those skills? That is, does the net developing those skills help it to perform better in that training process, get reinforced, etc.? (3) Is the model big enough that it could in principle come to develop those skills? (4) Is the model trained long enough that it likely will in practice come to have those skills?
comment by Dirichlet-to-Neumann · 2021-03-06T23:05:21.033Z · LW(p) · GW(p)
The crystal nights story is pretty good but it stabbed my willing suspension of disbelief right in whatever is its vital organ when the Phites casually and instantly begin manipulating matter in the outside world at the speed of their simulation. Real physical experimentation has a lot of trial-and-error processes as you try to get your parameters to the optimal position - no amount of a priori explicit knowledge will enable you to avoid slowly building up your tacit knowledge.
Replies from: gwern↑ comment by gwern · 2021-03-07T00:36:16.631Z · LW(p) · GW(p)
One man's a priori is another man's a posteriori, one might say; there are many places one can acquire informative priors... Learning 'tacit knowledge' can be so fast as to look instantaneous. An example here would be OA's Dactyl hand: it learns robotic hand manipulation in silico, using merely a model simulating physics, with a lot of randomization of settings to teach it to adapt on the fly, to whatever new model it finds itself in. This enables it to, without ever once training on an actual robot hand (only simulated ones), successfully run on an actual robot hand after seconds of adaptation. Another example might be PILCO: it can learn your standard "Cartpole" task within just a few trials by carefully building a Bayesian model and picking maximally informative experiments to run. (Cartpole is quite difficult for a human, incidentally, there's an installation of one in the SF Exploratorium, and I just had to try it out once I recognized it. My sample-efficiency was not better than PILCO.) Because the Phites have all that computation and observations of the real world, they too can do similar tricks, and who knows what else we haven't thought of.
comment by [deleted] · 2021-03-02T19:48:57.781Z · LW(p) · GW(p)
Here is the reason I am skeptical as to the outcome.
Hear me out a little bit. Suppose you can in fact build a 'brain like' model. Except, the brain is not one gigantic repeating neural network, it has many distinct regions where nature has made the rules slightly different for a reason. Nature can't actually encode too much complexity by default as there is so little space in genomes, but it obviously encodes quite a bit or we wouldn't see complex starter instincts for living beings.
But we just have 12 OOMs of compute, we don't have the knowledge how to code up these thousands of regions, and we don't have a detailed enough scan of a formerly living patient's brain to emulate all the regions yet.
So you have to take shortcuts, cram in some 'brain like' neural network on top of a wobbly structure, and then what? What inputs are you feeding these brains in a box? What sort of environment do they have to develop intelligence in? Why do they need intelligence, what motivation system is giving them feedback to develop it?
I don't dispute that more compute will help, or that AI is possible, or if we had more compute there would be napkin estimates that showed AI was imminently possible and mass crash programs that would pop up everywhere. Just it's not as simple as getting more compute - we have a lot of it now, maybe enough if it what we have gets utilized more efficiently - we have to develop all the rest of the pieces.
These functional subsystems that wake up the rest of the brain, that give rewards, that give starter reflexes - they aren't simple and they have to be debugged and made well defined. Or you get trash. Nature developed them over hundreds of millions of years and reused them over and over, it's why we see so many behavior similarities with our mammalian cousins.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-03-03T14:55:48.843Z · LW(p) · GW(p)
Thanks for the pushback! I agree that if we are trying to copy the human brain, it's not clear that +12 OOMs would be enough. I had my Neuromorph project to illustrate this.
However, (a) this might not be as hard as it sounds [LW · GW], and (b) there are other ways to TAI besides trying to copy the human brain.
Replies from: None↑ comment by [deleted] · 2021-03-04T03:00:17.338Z · LW(p) · GW(p)
Oh I don't think we need 12 OOMs. Maybe 2. I don't think most of the electrical details have any net effect you can't model a simpler and equally good way. I was pointing out that the brain is a system, your argument is like saying if we had the hardware for a game console we would therefore get the benefit of the most amazing games the hardware can support.
This isn't true, once we have sufficiently capable hardware someone will have to build up algorithms that exhibit intelligence one layer at a time. Well, starting with existing work.
comment by ChristianKl · 2022-04-14T16:26:29.966Z · LW(p) · GW(p)
When it comes to training a neural net, both training the neural net and then actually running it costs compute. Are those increased costs similar between different methods?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-04-14T19:21:18.663Z · LW(p) · GW(p)
IDK, probably not? I didn't try to estimate inference costs.
comment by zeshen · 2022-09-23T11:25:19.173Z · LW(p) · GW(p)
Very minor thing but I was confused for a while when you say end of 2020, I thought of it as the year instead of the decade (2020s).
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-09-23T13:21:20.598Z · LW(p) · GW(p)
It was the year, your original interpretation was correct. Key thing to notice: The question is asking about a hypothetical situation in which we magically get lots more compute 5 years before 2020, and then asks what happens by end of 2020 in that hypothetical.
Replies from: zeshen