"AI and Compute" trend isn't predictive of what is happening
post by alexlyzhov · 2021-04-02T00:44:46.671Z · LW · GW · 16 commentsContents
16 comments
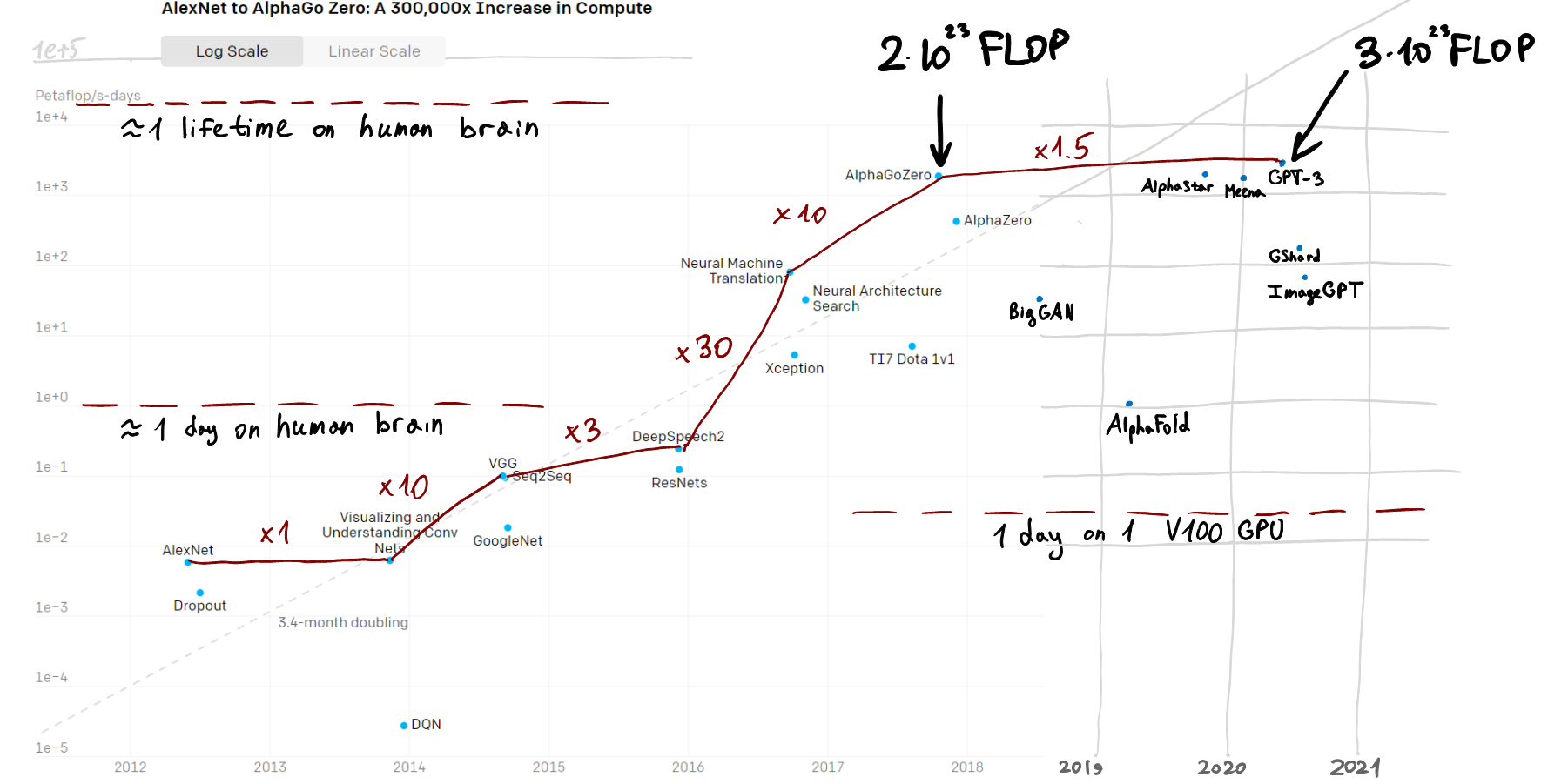
(open in a new tab to view at higher resolution)
In May 2018 (almost 3 years ago) OpenAI published their "AI and Compute" blogpost where they highlighted the trend of increasing compute spending on training the largest AI models and speculated that the trend might continue into the future. This note is aimed to show that the trend has ended right around the moment of OpenAI publishing their post and doesn't hold up anymore.
On the above image, I superimposed the scatter plot from OpenAI blogpost and my estimates of compute required for some recent large and ambitious ML experiments. To the best of my knowledge (and I have tried to check for this), there haven't been any experiments that required more compute than those shown on the plot.
The main thing shown here is that less than one doubling of computational resources for the largest training occured in the 3-year period between 2018 and 2021, compared to around 10 doublings in the 3-year period between 2015 and 2018. This seems to correspond to a severe slowdown of computational scaling.
To stay on the trend line, we currently would need an experiment requiring roughly around 100 times more compute than GPT-3. Considering that GPT-3 may have costed between $5M and $12M and accelerators haven't vastly improved since then, such an experiment would now likely cost $0.2B - $1.5B.
16 comments
Comments sorted by top scores.
comment by alexlyzhov · 2021-04-02T00:49:02.886Z · LW(p) · GW(p)
My calculation for AlphaStar: 12 agents * 44 days * 24 hours/day * 3600 sec/hour * 420*10^12 FLOP/s * 32 TPUv3 boards * 33% actual board utilization = 2.02 * 10^23 FLOP which is about the same as AlphaGo Zero compute.
For 600B GShard MoE model: 22 TPU core-years = 22 years * 365 days/year * 24 hours/day * 3600 sec/hour * 420*10^12 FLOP/s/TPUv3 board * 0.25 TPU boards / TPU core * 0.33 actual board utilization = 2.4 * 10^21 FLOP.
For 2.3B GShard dense transformer: 235.5 TPU core-years = 2.6 * 10^22 FLOP.
Meena was trained for 30 days on a TPUv3 pod with 2048 cores. So it's 30 days * 24 hours/day * 3600 sec/hour * 2048 TPUv3 cores * 0.25 TPU boards / TPU core * 420*10^12 FLOP/s/TPUv3 board * 33% actual board utilization = 1.8 * 10^23 FLOP, slightly below AlphaGo Zero.
Image GPT: "iGPT-L was trained for roughly 2500 V100-days" - this means 2500 days * 24 hours/day * 3600 sec/hour * 100*10^12 * 33% actual board utilization = 6.5 * 10^9 * 10^12 = 6.5 * 10^21 FLOP. There's no compute data for the largest model, iGPT-XL. But based on the FLOP/s increase from GPT-3 XL (same num of params as iGPT-L) to GPT-3 6.7B (same num of params as iGPT-XL), I think it required 5 times more compute: 3.3 * 10^22 FLOP.
BigGAN: 2 days * 24 hours/day * 3600 sec/hour * 512 TPU cores * 0.25 TPU boards / TPU core * 420*10^12 FLOP/s/TPUv3 board * 33% actual board utilization = 3 * 10^21 FLOP.
AlphaFold: they say they trained on GPU and not TPU. Assuming V100 GPU, it's 5 days * 24 hours/day * 3600 sec/hour * 8 V100 GPU * 100*10^12 FLOP/s * 33% actual GPU utilization = 10^20 FLOP.
Replies from: Bucky, robirahman, Jsevillamol↑ comment by Bucky · 2021-04-02T08:17:55.317Z · LW(p) · GW(p)
A previous calculation [LW(p) · GW(p)] on LW gave 2.4 x 10^24 for AlphaStar (using values from the original alphastar blog post) which suggested that the trend was roughly on track.
The differences between the 2 calculations are (your values first):
Agents: 12 vs 600
Days: 44 vs 14
TPUs: 32 vs 16
Utilisation: 33% vs 50% (I think this is just estimated in the other calculation)
Do you have a reference for the values you use?
Replies from: alexlyzhov, teradimich↑ comment by alexlyzhov · 2021-04-03T02:02:22.817Z · LW(p) · GW(p)
I appreciate questioning of my calculations, thanks for checking!
This is what I think about the previous avturchin calculation: I think that may have been a misinterpretation of DeepMind blogpost. In the blogpost they say "The AlphaStar league was run for 14 days, using 16 TPUs for each agent". But I think it might not be 16 TPU-days for each agent, it's 16 TPU for 14/n_agent=14/600 days for each agent. And 14 days was for the whole League training where agent policies were trained consecutively. Their wording is indeed not very clear but you can look at the "Progression of Nash of AlphaStar League" pic. You can see there that, as they say, "New competitors were dynamically added to the league, by branching from existing competitors", and that the new ones drastically outperform older ones, meaning that older ones were not continuously updated and were only randomly picked up as static opponents.
From the blogpost: "A full technical description of this work is being prepared for publication in a peer-reviewed journal". The only publication about this is their late-2019 Nature paper linked by teradimich here which I have taken the values from. They have upgraded their algorithm and have spent more compute in a single experiment by October 2019. 12 agents refers to the number of types of agents and 600 (900 in the newer version) refers to the number of policies. About the 33% GPU utilization value - I think I've seen it in some ML publications and in other places for this hardware, and this seems like a reasonable estimate for all these projects, but I don't have sources at hand.
Replies from: teradimich↑ comment by teradimich · 2021-04-03T09:01:14.669Z · LW(p) · GW(p)
Probably that:
When we didn’t have enough information to directly count FLOPs, we looked GPU training time and total number of GPUs used and assumed a utilization efficiency (usually 0.33)
↑ comment by teradimich · 2021-04-02T11:11:50.097Z · LW(p) · GW(p)
This can be useful:
We trained the league using three main agents (one for each StarCraft race), three main exploiter agents (one for each race), and six league exploiter agents (two for each race). Each agent was trained using 32 third-generation tensor processing units (TPUs) over 44 days
↑ comment by Robi Rahman (robirahman) · 2023-12-01T17:32:41.211Z · LW(p) · GW(p)
Correction: AlphaStar used 6*10^22 FLOP, not 2*10^23. You have mixed up TPU chips and TPU boards.
↑ comment by Jsevillamol · 2021-07-21T10:25:25.627Z · LW(p) · GW(p)
What is the GShard dense transformer you are referring to in this post?
Replies from: alexlyzhov↑ comment by alexlyzhov · 2021-07-23T23:22:21.093Z · LW(p) · GW(p)
It should be referenced here in Figure 1: https://arxiv.org/pdf/2006.16668.pdf
comment by alexlyzhov · 2021-04-03T14:37:23.536Z · LW(p) · GW(p)
gwern has recently remarked that one cause of this is supply and demand disruptions and this may be a temporary phenomenon in principle.
comment by Jsevillamol · 2021-08-16T14:31:18.973Z · LW(p) · GW(p)
One more question: for the BigGAN which model do your calculations refer to?
Could it be the 256x256 deep version?
Replies from: alexlyzhov↑ comment by alexlyzhov · 2021-08-19T18:08:21.415Z · LW(p) · GW(p)
Ohh OK I think since I wrote "512 TPU cores" it's 512x512, because in Appendix C here https://arxiv.org/pdf/1809.11096.pdf they say it corresponds to 512x512.
Replies from: Jsevillamol↑ comment by Jsevillamol · 2021-08-20T09:20:29.092Z · LW(p) · GW(p)
Deep or shallow version?
Replies from: alexlyzhov↑ comment by alexlyzhov · 2021-08-21T22:58:36.595Z · LW(p) · GW(p)
"Training takes between 24 and 48 hours for most models"; I assumed both are trained within 48 hours (even though this is not precise and may be incorrect).
comment by [deleted] · 2021-04-04T04:34:49.667Z · LW(p) · GW(p)
Assuming that prices haven't improved, what money has someone made to pay for the first 5-12 million dollar tab?
For AI to take off it has to pay for itself. It very likely will but this requires deployment of highly profitable, working applications.