Incentive Learning vs Dead Sea Salt Experiment
post by Steven Byrnes (steve2152) · 2024-06-25T17:49:01.488Z · LW · GW · 1 commentsContents
1. Background context 2. Two seemingly-contradictory experiments 2.1 “Dead Sea Salt Experiment”[3] 2.2: “Instrumental Incentive Learning” experiment 2.3 Why these two experiments seem contradictory 3. My model 3.1 Background 3.2 The Steering Subsystem (hypothalamus & brainstem) has the innate, genetically-hardwired circuits that say whether specific visceral predictions are motivating or demotivating in light of physiological state 3.3 Two pathways for revaluation: valence predictions and visceral predictions 3.3.1 Revaluation pathway 1: Change-of-physiological-state leads to different Thought Assessor outputs 3.3.2 Revaluation pathway 2: Change-of-physiological-state leads to the Steering Subsystem emitting a different response to the same set of visceral predictions from the Thought Assessors. 3.4 Back to those two experiments above 4. Various factors that may affect the extent to which revaluation does or doesn’t occur 4.1 Visceral predictions generally go rapidly to zero when there’s time, distraction, and/or indirection before the outcome (to a much greater extent than valence predictions) 4.1.1 Evidence that timing is very relevant 4.1.2 Proposal: super-steep “discount rate” for visceral predictions, less so for valence predictions Everyday example to illustrate this graph: 4.2 Different visceral predictions can be different 4.3 Overtraining / habits are relevant too 4.4 The way that the Thought Assessors (especially valence prediction) generalizes from prior life experience is a whole can of worms 4.4.1 Example 4.4.2 Background on “generalization” 4.4.3 Dead Sea Salt experiment revisited 4.5 Upshot: even granting my theoretical framework, experimental results can still be a big pain to interpret 5. Bonus: Some comments on how my model differs from some stuff in the neuro/psych literature 5.1 The literature distinction between “Pavlovian versus instrumental conditioning” is kinda related to my division of Thought Assessors into valence-prediction versus visceral-prediction 5.1.1 General discussion part 1: Pavlovian 5.1.2 General discussion part 2: Instrumental conditioning 5.1.3 Case study: Dickinson & Nicholas 1983 5.2 Two complaints about the terms “model-based” or “outcome-directed” as used in the literature 5.2.1 “Model-based” / “outcome-directed” squashes together two things that I see as profoundly different, namely (A) innate “business logic” in the Steering Subsystem versus (B) planning via a learned world-model in the cortex 5.2.2 “Model-based” / “outcome-directed” splits up two things that I see as the same kind of thing: learned habits and outcome-oriented plans 5.3 My “valence function learning and generalization” discussion is very similar to Dickinson & Balleine’s “Hedonic Interface Theory” None 1 comment
(Target audience: People both inside and outside neuroscience & psychology. I tried to avoid jargon.)
1. Background context
One of my interests is the neuroscience of motivation. This is a topic I care about for the same obvious reason as everyone else: to gain insight into how to control the motivations of future superintelligent brain-like Artificial General Intelligence [? · GW].
(Wait, you’re telling me that there are other reasons people care about the neuroscience of motivation? Huh. No accounting for taste, I guess.)
Part of the neuropsychology-of-motivation literature is a few related phenomena variously called “incentive learning”, “retasting”, “devaluation”, and “revaluation”. In the experiments of interest here:
- You change something about an animal’s homeostatic state (e.g. its level of hunger),
- …And you see whether the animal accounts for that change in its behavior (e.g. whether it tries to get food).
For example, my own children, despite many years of experience, are very shaky on this learning task. After skipping a meal, they get grumpy rather than hungry, and when they finally sit down and take a bite, they’re shocked, shocked, to find how much they were craving it.
Anyway, there is a massive literature on these phenomena. You won’t learn any practical parenting tips, alas, but you can learn lots of random things like ‘what happens to revaluation if we block the activity of neurotransmitter X in macaque brain region Y?’. And there are intriguing contrasts, where the animal does or doesn’t adapt its behavior to its physiological state in two situations that seem generally pretty similar. The title of this post is an example—I’ll go over it in Section 2.
People do these studies out of the (reasonable) expectation that they will help illuminate the nuts-and-bolts of how homeostatic needs connect to actions, decisions, and desires. But unfortunately, there’s a generic problem: it’s hard to go backwards from observed behaviors to how brain algorithms generated those behaviors. You basically need to already have a good theoretical framework. My spicy opinion is that most people in the field don’t, and that they fill in that gap by grasping for salient but unhelpful concepts.
In some cases, these unhelpful concepts are borrowed from AI—e.g., “model-based RL versus model-free RL” is a salient partitioning for AI practitioners, whether or not it’s relevant for the brain (see §5.2). In other cases, these concepts are borrowed from experimental psychology practice—e.g., “Pavlovian versus operant conditioning”[1] is a profoundly important distinction for the experimentalist … but that doesn’t necessarily mean it’s an important distinction for the rat!! (See §5.1.)
Well, I have a theoretical framework! It’s the one pictured here [LW · GW], which I’ll go over below. So the goal of this post is to offer an overview of how to think about incentive learning and related phenomena from that perspective.
I won’t comprehensively survey the incentive learning literature, and I also won’t particularly try to convince you that my theoretical framework is right and others are wrong. After all, in a field like neuroscience, understanding a hypothesis and its consequences is 99%+ of the work. Compared to that, if you have several plausible hypotheses and are trying to find the correct one, it’s a walk in the park!
Quick summary of the rest of the article:
- Section 2 motivates and introduces the topic by presenting two experimental results which seem to contradict each other: the “dead sea salt experiment” of Robinson & Berridge, and the “instrumental incentive learning” experiment of Dickinson & Balleine.
- Section 3 presents my big-picture model of decision-making in the brain, and how that interacts with incentive learning, revaluation, etc.
- Section 4 lists some factors that do or don’t affect whether revaluation happens, within my framework.
- Section 5 is kind of an appendix tailored towards people with neuro / psych backgrounds, listing a few notions in the literature and how they relate to my own models.
(Obligatory post-replication-crisis discussion in footnote→[2].)
2. Two seemingly-contradictory experiments
2.1 “Dead Sea Salt Experiment”[3]
In this 2014 paper by Mike Robinson and Kent Berridge at University of Michigan (see also this more theoretical follow-up discussion by Berridge and Peter Dayan), rats were raised in an environment where they were well-nourished, and in particular, where they were never salt-deprived—not once in their life. The rats were sometimes put into a test cage, in which sometimes a little stick[4] would pop out of a wall, along with a sound. Whenever that happened, it was immediately followed by a device spraying ridiculously salty water directly into the rat’s mouth. The rats were disgusted and repulsed by the extreme salt taste, and quickly started treating the stick’s appearance as an aversive event. (From their perspective, the stick was to blame for the saltwater spray, or a reminder of it, or associated with it, or something.) One of the rats went so far as to stay tight against the opposite wall—as far from the stick as possible!
Then the experimenters made the rats feel severely salt-deprived, by depriving them of salt. Haha, just kidding! They made the rats feel severely salt-deprived by injecting the rats with a pair of chemicals that are known to induce the sensation of severe salt-deprivation. (Ah, the wonders of modern science!)
...And wouldn't you know it, almost instantly upon injection, the rats changed their behavior! When the stick popped out (this time without the salt-water spray), they now went right over to that stick and jumped on it and gnawed at it, obviously very excited about what was happening.
2.2: “Instrumental Incentive Learning” experiment
The classic version of the experiment is described in a 2002 review article by Anthony Dickinson and Bernard Balleine, citing earlier work by the same authors.
The experiment is a bit complicated, so to make it easier to follow, I’ll start with the headline conclusion: In this experiment, rats had to learn through direct experience that drinking sugar-water is especially satisfying when you’re thirsty. In the absence of this direct experience, they behave as if they don’t realize that.
Here are more details (omitting various control experiments):
In “training”, rats were put in a cage. They were free to press a lever which would give them sugar-water, and they could also pull a chain which would give them food pellets.
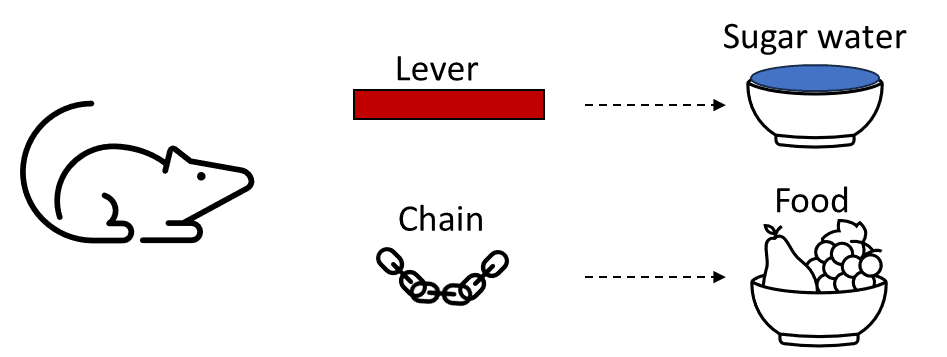
Importantly, the rats were hungry during this training process.
Then during the test, the rats were not hungry but rather thirsty. They were put back in the test chamber, this time with the chain and lever disconnected (so they didn’t do anything). The rats periodically pulled the chain and pressed the lever, evidently hoping that maybe this time they’d get the goodies. But interestingly, despite being thirsty, they didn’t press the sugar-water lever any more often than they pulled the food-pellet chain.
In a separate experiment, a different set of rats first had “pretraining sessions”. There was no lever or chain, but food pellets and sugar-water showed up sporadically. One subgroup of rats did the pretraining sessions hungry, and had the same results as the paragraph above. The other subgroup did the pretraining sessions thirsty—and for them, during the test sessions, they pressed the sugar-water lever much more than they pulled the food-pellet chain.
Thus, as above, the interpretation is: these rats had to learn through direct experience that drinking sugar-water is especially satisfying when you’re thirsty. The other rats had no idea.
2.3 Why these two experiments seem contradictory
- In the Dead Sea Salt experiment, the rats acted as if they knew that saltwater-when-salt-deprived is especially satisfying, despite never having had such an experience.
- In the Instrumental Incentive Learning experiment, the rats acted as if they did not know that sugar-water-when-thirsty is especially satisfying, unless they had previously had such an experience.
3. My model
As I mentioned in the intro, I’m going to ignore the (substantial) existing theoretical discussion in the literature (I’ll talk about it a bit in §5 below), and just talk through how I would explain these two experiments.
3.1 Background
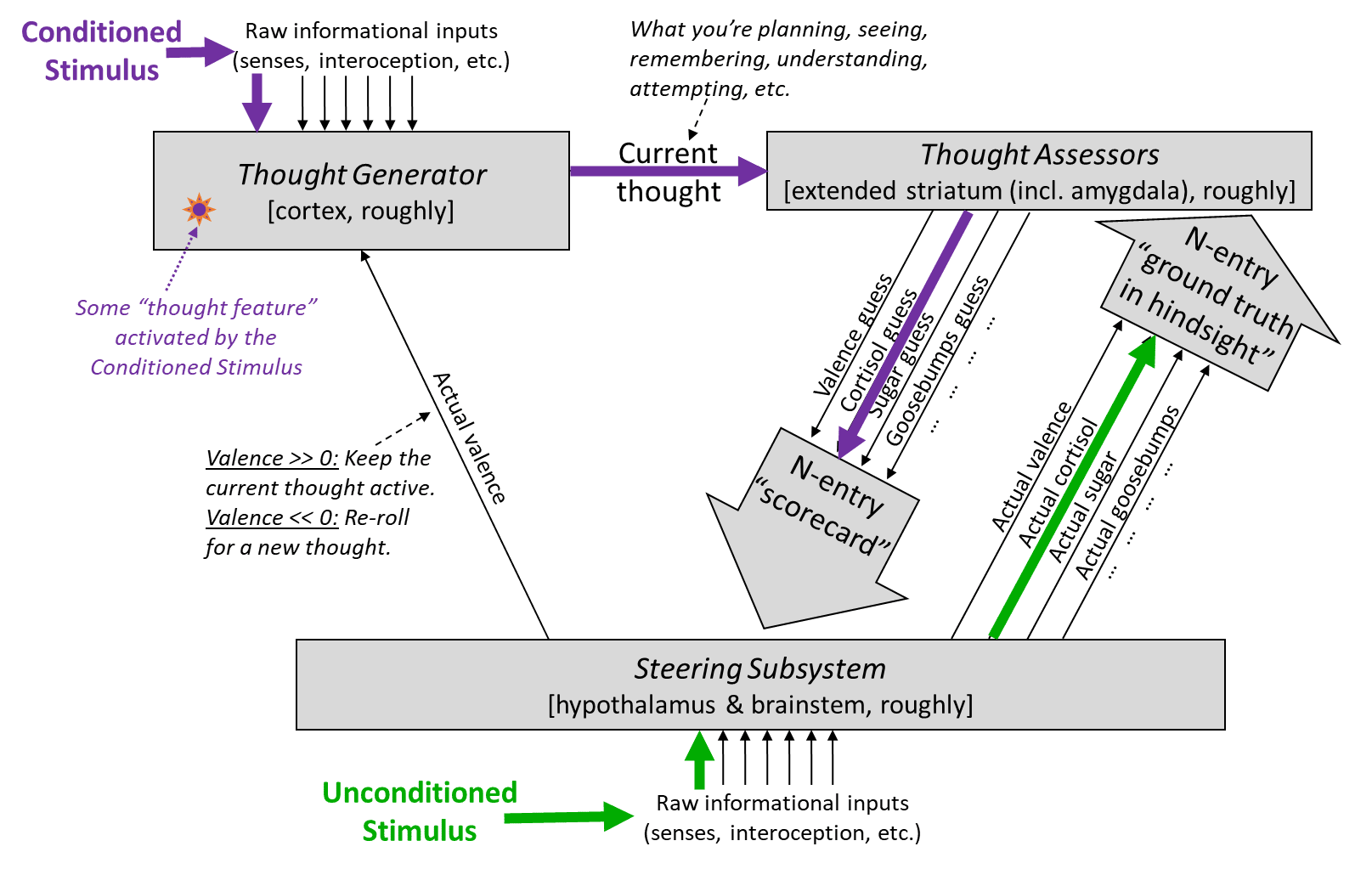
You can get the gist of my thinking from the following diagram (and for much more detail, see Posts 2 through 6 here [? · GW]):
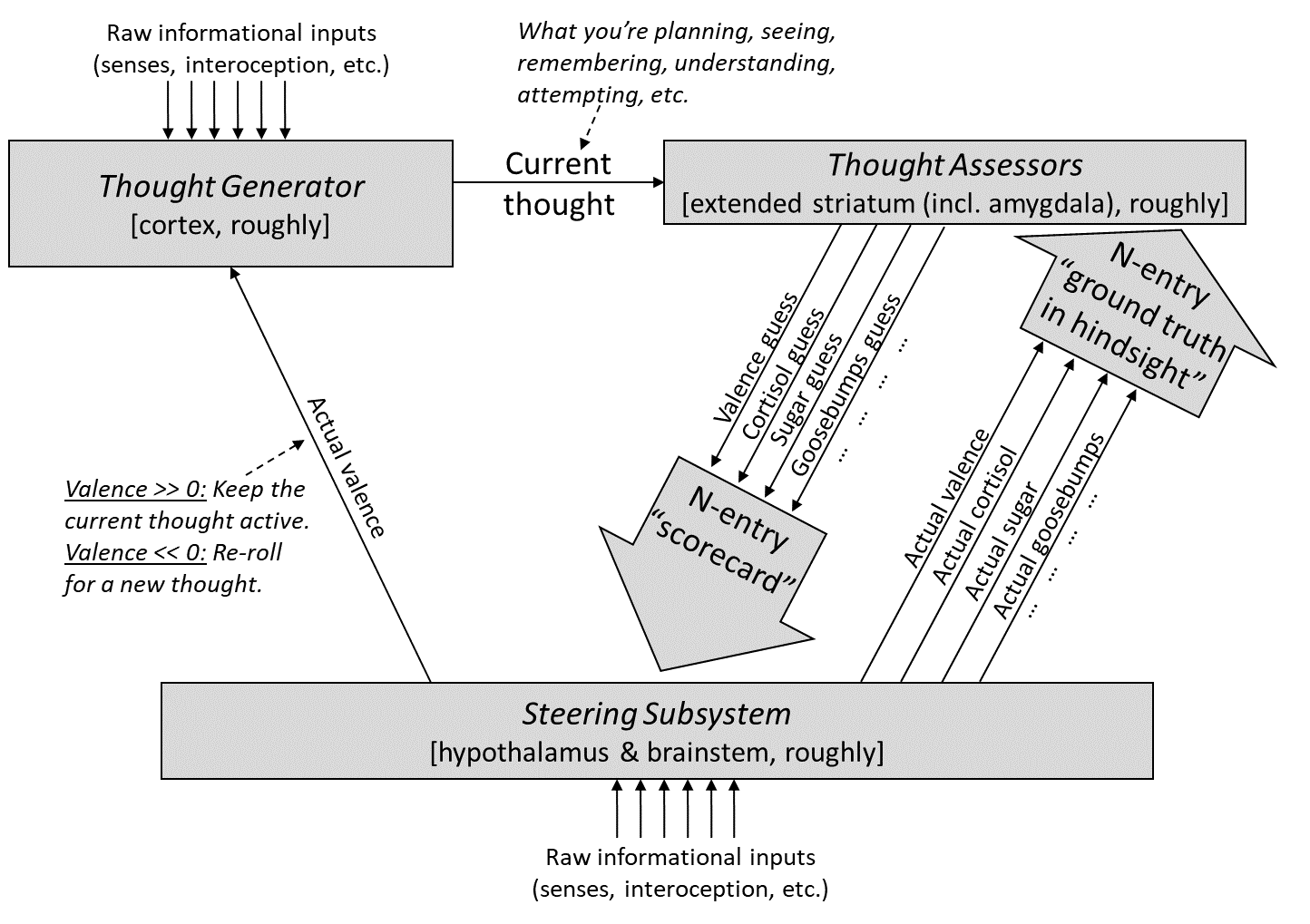
The “Thought Assessors” box in the top right corresponds anatomically to (more-or-less) the “extended striatum”, which by Larry Swanson’s accounting includes the caudate, putamen, nucleus accumbens (NAc),[5] lateral septum (LS), part of the amygdala, and a few other odds and ends. Here I’ll call out one aspect of the above diagram:
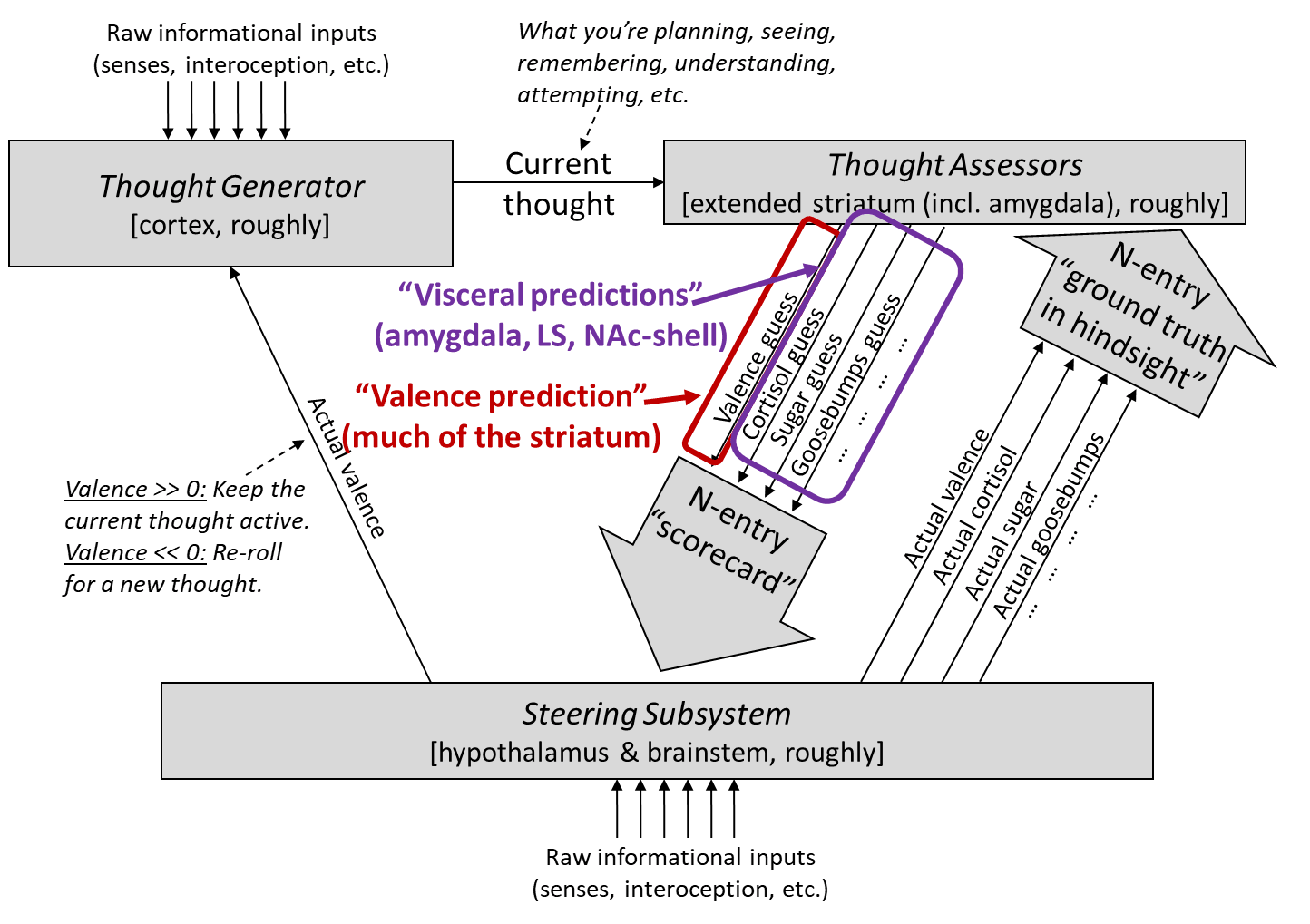
Although I used equally-sized downward arrows for the Thought Assessors when making my diagram, that’s actually a bit misleading:
- The “will lead to reward” / “valence [? · GW] prediction” arrow (red box) seems to singularly encompass a substantial fraction (maybe 20% in rodents?) of the entire extended striatum
- The hundreds of other arrows (purple box), which I’ll call “visceral predictions”, seem to add up to a relatively small area of the extended striatum, namely part of the extended amygdala, part of the lateral septum, and part of the nucleus accumbens shell, more or less. So each of those individual visceral prediction arrows is built from just a tiny fraction of a percent of the total area of the extended striatum.
(The other 75%-ish of the extended striatum is in neither category, and off-topic for this post; I talk about them briefly in §1.5.6 of my valence series [LW · GW].)
Elaborating on the red-circled “valence prediction” signal:
- I have a whole series [LW · GW] spelling out what “valence” is and why it’s centrally important in the brain. (Note that I’m using the term “valence” in a very specific way described in that series, and that it’s generally more related to motivation than pleasure.)
- In actor-critic reinforcement learning terms, I think of this red-circled signal as the “critic”, a.k.a. “value function”.
- In psychology terms, this red-circled signal is a short-term predictor [LW · GW] of upcoming valence [LW · GW]. That valence—i.e., the actual valence, as opposed to the valence prediction—is different: it’s drawn in twice in the above diagram, as the upward arrows with the labels “actual valence”. However, their relationship is a bit subtle: the predicted valence can impact the actual valence, including in some cases determining it entirely. See discussion of “defer-to-predictor mode” in general here [? · GW], and in the more specific case of valence here [LW · GW].
- In computational-level terms, this red-circled signal is more-or-less an estimate of “how things are going in life, in general, based on everything I know, including what I’m doing and planning right now”—see my normative discussion here [LW · GW] & here [LW · GW].
3.2 The Steering Subsystem (hypothalamus & brainstem) has the innate, genetically-hardwired circuits that say whether specific visceral predictions are motivating or demotivating in light of physiological state
Consider a possible circuit in a rat’s brain that somehow encodes the rule “if I’m salt-deprived, then eating salt is good”, in an innate way, i.e. as a result of specific “business logic” [LW · GW] encoded in the genome. Such a circuit evidently exists, based on the Dead Sea Salt experiment. And it’s no surprise that it does exist—salt deficiency can be fatal, so this is not the kind of thing that we want to be learning purely via trial-and-error experience!
For reasons discussed here [LW · GW], on my models, this innate circuit has to be in the Steering Subsystem [LW · GW] (hypothalamus & brainstem). See green text in this figure:
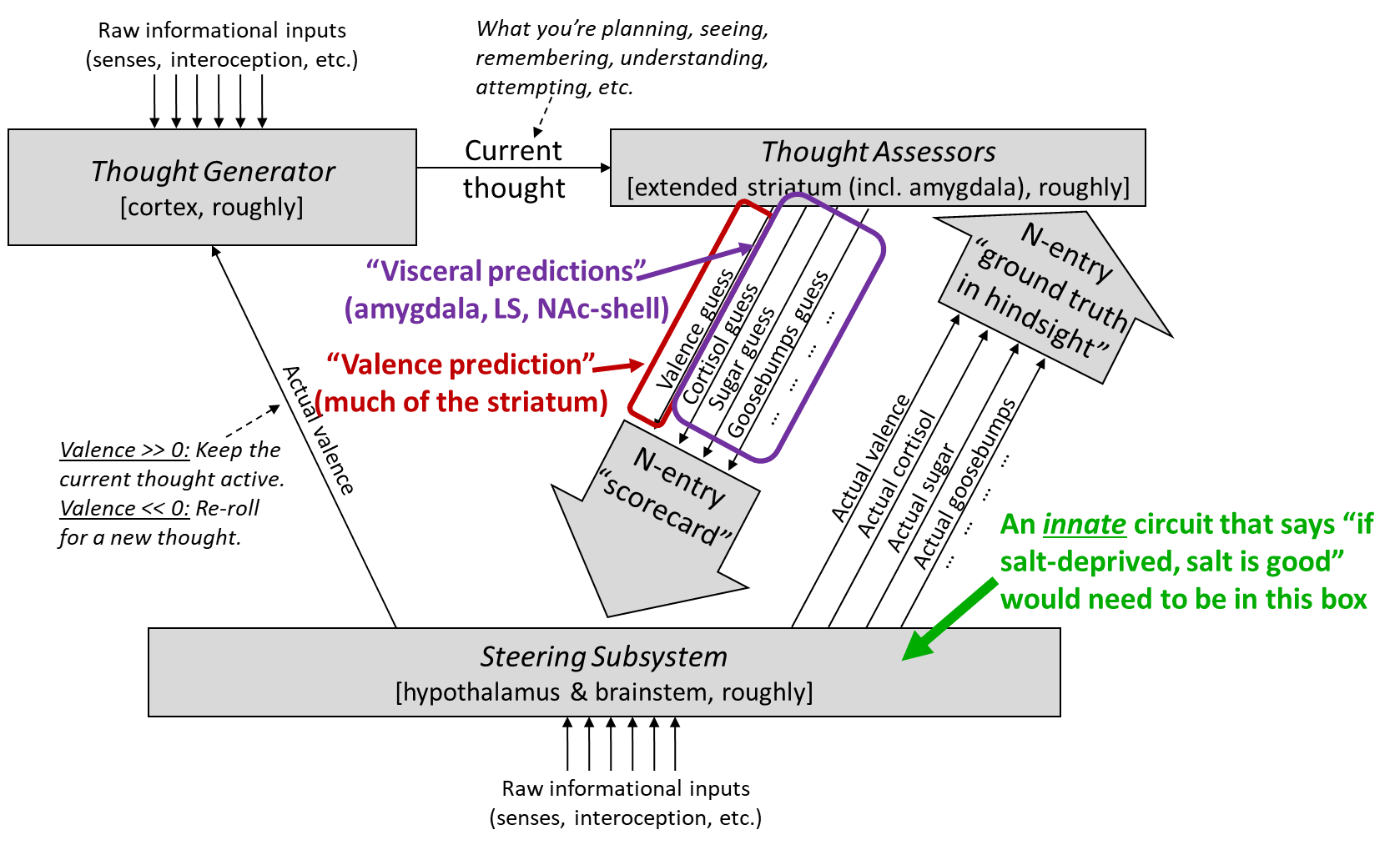
(Ditto for an innate circuit that says “if I’m thirsty, then drinking water is good”, and so on.)
Why does that matter? Because the Steering Subsystem is (more-or-less) [LW · GW] a bunch of interconnected, hardwired, innate reaction circuits. Yes, animals have a rich, flexible, constantly-changing, and forward-looking understanding of the world, but this understanding is not in their Steering Subsystem, and in fact their Steering Subsystem has a quite limited and inflexible window into it. Indeed, for our purposes,[6] the only information that the Steering Subsystem has about the future is via the Thought Assessor predictions.
3.3 Two pathways for revaluation: valence predictions and visceral predictions
Now let’s say we change the rat’s physiological state somehow—we make it hungry, thirsty, salt-deprived, whatever. And suppose that the rat now starts responding differently in anticipation of food / drink / whatever in a way, in a sensible and adaptive way. If that happens, there are two (non-mutually-exclusive) stories for how it happened:
3.3.1 Revaluation pathway 1: Change-of-physiological-state leads to different Thought Assessor outputs
(I’ll focus on the valence predictor for simplicity, since I think that one is typically most important in this context. But note that one could tell a similar story for any of the visceral predictors as well.)
Recall that the valence prediction is the output of a learning algorithm, trained from the past history of actual valence:

So basically, things will be motivating if they seem (to the animal) to be similar to things that were motivating in the past. (More on this in §4.4 below.)
Anyway, let’s go back to the instrumental incentive learning experiment cited above. What’s happening during thirsty “pretraining” is that the valence predictor learns the following rule:
- If a thought involves feelings-of-thirst interoceptive inputs,
- …and the same thought also involves drinking-sugar-water semantic / perceptual inputs,
- …that thought will be assigned positive valence by the Steering Subsystem.
It learns this rule from direct experience.
Then later on, during training, the rat learns that, if it presses the lever, it should expect to drink sugar water afterwards. (This is an update to its world-model a.k.a. Thought Generator, not a change in its Thought Assessors.)
Then finally, during testing, the rat sometimes looks at the lever and an idea pops into its head: “maybe I’ll press the lever and then go get sugar water”. Meanwhile, this whole time, it is experiencing feelings-of-thirst interoceptive inputs. So, per the learned rule above, the valence predictor outputs a guess that whatever this thought is, it’s a great plan (very high valence). And then that valence prediction in turn leads to the actual valence being very positive as well (cf. “defer-to-predictor mode” [LW · GW]). Finally, by basic properties of valence [LW · GW], the rat actually does it.
3.3.2 Revaluation pathway 2: Change-of-physiological-state leads to the Steering Subsystem emitting a different response to the same set of visceral predictions from the Thought Assessors.
This, I claim, is what’s happening in the dead sea salt experiment. Regardless of whether or not the rats are salt-deprived, their Thought Assessors are emitting the same visceral predictions—I guess something related to an expectation of imminent salt, which might trigger salivation etc.
However, when the rats are in a salt-deprived physiological state, their Steering Subsystem issues a different response to those same set of visceral predictions—most importantly for our purposes, it issues a positive-valence signal.[7]
3.4 Back to those two experiments above
Going back to §2 above, both the Dead Sea Salt experiment and the Instrumental Incentive Learning experiment were set up such that Pathway 1 would be blocked—the Thought Assessors are trained during previous life experience, and nothing in that dataset would allow them to infer the relevance of physiological state is relevant.[8]
So then the thing we learn is:
There were relevant visceral predictions indicating an expectation of salt in the Dead Sea Salt experiment.[9]
- There were not relevant visceral predictions indicating an expectation of thirst-quenching in the Instrumental Incentive Learning experiment.
(Why the difference? See next section!)
In the latter (Instrumental Incentive Learning) case, the lack of response from non-pre-trained rats reflects a funny situation in terms of the Learning Subsystem / Steering Subsystem dichotomy [LW · GW]:
- The rat brain has information reflecting the fact that drinking-sugar-water-when-thirsty is especially good—but that information is not in the Learning Subsystem, but rather implicit in the innate wiring of the Steering Subsystem.
- The rat brain has information reflecting the fact that drinking-sugar-water is expected in the near future—but that information is in the Learning Subsystem, and is not being communicated to the Steering Subsystem.
So the necessary information for physiologically-appropriate actions is all in the brain somewhere, but it’s partitioned between the two subsystems in a way that preempts connecting the dots.
4. Various factors that may affect the extent to which revaluation does or doesn’t occur
(I say “the extent to which”, not “whether”, because it’s generally a continuum, not a binary. For example, an animal can have a nonzero but very weak motivation to do something in the absence of incentive learning.)
In order to relate the general considerations of §3 to experimental results, we need to talk about the circumstances under which the relevant visceral predictions do or don’t get to the Steering Subsystem. That depends on a lot of things, so let’s dive in.
4.1 Visceral predictions generally go rapidly to zero when there’s time, distraction, and/or indirection before the outcome (to a much greater extent than valence predictions)
In the Dead Sea Salt experiment, the stick would pop out of the wall and the sound would play for 8 seconds, and then the stick would retract, the sound would stop, and the saltwater would at that same instant spray in the rat’s mouth.[10]
In the Instrumental Incentive Learning experiment, the rat had to press the lever (or pull the chain) to grant access to the food magazine[11] (or water magazine), then walk over to the magazine, open its flap, and start eating (or drinking).
So one possibility is that this is the difference: incentive learning is unnecessary for immediate expectations, but is necessary for more distant expectations, and even just a few extra steps and a few extra seconds is enough to get into the “distant” bucket.
4.1.1 Evidence that timing is very relevant
As described in the Dickinson & Balleine 2002 review, even in the first instrumental incentive learning study, the experimenters astutely noticed that they were accidentally running two instrumental incentive learning experiments, not one. The intended experiment involved rats pulling on a chain or lever to gain access to the food or water magazine. The unintended experiment involved the rats subsequently opening the flap of the magazine to get at the food or drink behind it.
If you think about it, both of these “experiments” are perfectly valid instrumental learning tasks. And yet, as it turned out, they gave different results! The chain-pulling / lever-pushing did require incentive learning, but the flap-opening didn’t—the flap-opening was more like the Dead Sea Salt experiment. Here’s the relevant quote:
In his initial incentive learning study, Balleine (1992) reported that flap opening, unlike lever pressing and chain pulling, did not require an incentive learning experience for motivational control and was directly affected by shifts in food deprivation. In other words, there was a motivational dissociation between the two responses. Rats that had been trained hungry but not received incentive learning pressed the lever frequently but did not enter the magazine when tested sated in extinction. The corresponding animals that were nondeprived during training pressed [the lever] slowly but [they] frequently entered the magazine when tested hungry.
To restate more intuitively: There were rats that had only had access to the food-access lever when super-hungry. Naturally, they learned that pressing the food-access lever was an awesome idea. Then they were shown the lever again while very full. They enthusiastically pressed the lever as before. But they did not enthusiastically open the food magazine. Instead (I imagine), they pressed the lever, then started off towards the now-accessible food magazine, then when they got close, they stopped and said to themselves, “Yuck, wait, I’m not hungry at all, this is not appealing, what am I even doing right now??”. (We’ve all been there, right?) And then they turned back without ever opening the flap. And then a bit later they lost their train of thought, and said to themselves, “Ooh, the lever! I remember that! I should press it, it was great!” And repeat. Vice-versa for a different set of rats who had only pressed the lever when full, and then were offered it when hungry.
The above result could be a consequence of the magazine flap smelling like food, rather than related to the time-delay and distraction per se. But in a later (1995) paper, the experimentalists dove into this effect more systematically and deliberately, and confirmed that indeed incentive learning had a slight impact on almost-immediate consequences and a bigger impact on more-distant consequences.
Some broader context also lends support to the idea that “immediate vs distant expectations” is highly relevant and thus an a priori plausible hypothesis for the observed discrepancy:
In particular, in Pavlovian experiments, I believe it’s well-known that if there is a gap between the end of the conditioned stimulus (e.g. light) and the start of the unconditioned stimulus (e.g. electric shock), then the animal learns the association much more weakly, even at the scale of mere seconds. (Relevant keyword: “trace conditioning”.) And I imagine that the learning is weaker still if other potentially-distracting things are going on during that gap
This insight knowledge has flowed from Pavlov into common practice via clicker training. If you’ve ever clicker-trained your pet, you’ll know that the delay between the animal’s action and its consequence, even at the scale of fractions of a second, is not a trivial detail but rather an absolutely central aspect of the experimental design.
4.1.2 Proposal: super-steep “discount rate” for visceral predictions, less so for valence predictions
(I put scare-quotes around “discount rates” because I don’t think the brain’s time-discounting mechanism is at all similar to the one in ML. But at a vague qualitative level, for present purposes, I think the term “discount rate” is good enough—it’s conveying the right general idea.)
Using the same color scheme as above, here’s a proposal:
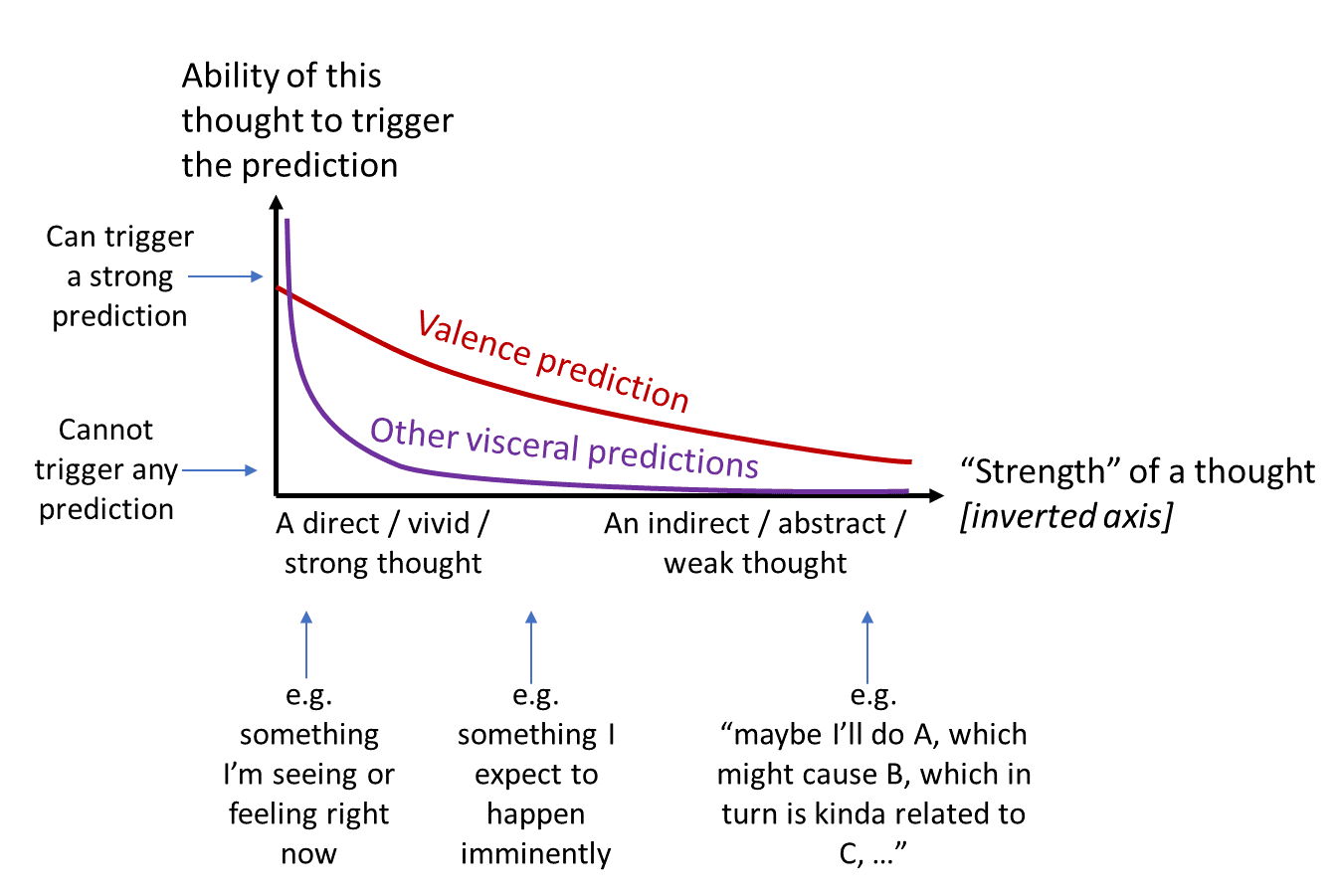
Everyday example to illustrate this graph:
- Start with an example near the left side of the graph. I tell you that your crush is about to walk into the room and ask you out, in 3… 2… 1… and then they enter the room. Now, this is a direct / vivid / strong thought—the idea of dating your crush is real and happening right now in front of your very eyes. This situation has a very strong effect on both the valence of your thoughts, and visceral reactions like racing heart, goosebumps, blushing, and so on.
- Now let’s jump to the right side of the graph. Your crush has told you that they’re interested in dating you, but first you need to get a real job. And now it’s two months later, and you’re spell-checking a cover letter. The valence associated with the dream of dating your crush has propagated through these many steps of indirection, all the way backwards from the imagined future blissful romance to the current tedious cover-letter spell-checking. (After all, you wouldn’t be pressing the spell-check button, if pressing the button had no appeal / positive valence whatsoever.) But the visceral reactions have not propagated through these many steps of indirection—pressing the spell-check button does not call forth any heart-racing, goosebumps, blushing, etc.
Here’s another example, this one from Anthony Dickinson’s own life (see his 2010 book chapter). Anthony went to Sicily on holiday, ate a watermelon in the afternoon, then drank too much wine and threw up that evening. His vomiting triggered conditioned taste aversion for the watermelon—but he didn’t “know” that at the time. The next morning, he got thirsty again and set off in search of watermelon. It was only once he got very close to the watermelon stalls, where he could see the watermelons, that he felt any nausea at all. It progressed all the way to gagging when he put watermelon in his mouth. The takeaway is: the distant, abstract prospect of watermelon was able to trigger the valence-predicting Thought Assessor, but was not able to noticeably trigger the nausea-predicting visceral Thought Assessor. On the other hand, the immediate expectation of watermelon did trigger visceral predictions.
(Of course, once he had tasted the watermelon and gagged, that’s an unpleasant experience, and hence this experience updates Anthony’s valence-predicting Thought Assessor to treat watermelon as demotivating. And the valence Thought Assessor is much better at responding to distant and abstract expectations. So after that morning experience (i.e., incentive learning), Anthony wouldn’t even start walking towards the watermelon stalls.)
Thus, I claim, the valence predictor is designed to propagate more strongly into distant, indirect, and uncertain consequences, compared to the other “visceral” predictors. That seems at least vaguely in keeping with my earlier claim that the brain dedicates orders of magnitude more processing power to the valence prediction than to any of the hundreds of visceral predictions.
(Interestingly, there are in fact experiments where the rat needs to press a lever then walk over to the magazine, but where the rats nevertheless immediately change their behavior in a physiologically-appropriate way without incentive learning. See §5.1.3 below for an example and how I would explain it.)
4.2 Different visceral predictions can be different
This is obvious, but visceral predictions of salt-flavor / salivation, and visceral predictions of disgust-reactions, and visceral predictions of I’m-about-to-drink, etc., can all be different from each other. They can be easier or harder to learn, they can generalize in different ways, they can have different effective “time-discounting” per the previous subsection, and they can have different downstream consequences once they get to the Steering Subsystem. I fully expect that some experimental contrasts can be explained this way. For example, this kind of thing would be an alternate (not mutually exclusive with §4.1 above) explanation for the contrast between the Dead Sea Salt experiment and the Instrumental Incentive Learning experiment—the former involved salt and salt-deprivation, the other involved sugar-water and thirst. This could of course be checked experimentally, and I think the literature shows that the Instrumental Incentive Learning result stays the same if you switch it to salt. But in general, we should keep these kinds of hypotheses in mind.
4.3 Overtraining / habits are relevant too
The Thought Assessors are assessing a thought. Thoughts can involve actions, and thoughts can involve expected consequences, or both. For example, if I’m walking to the shelf to get a piece of candy, the thing happening in my head is an outcome-related thought “I’m walking over to get the candy”. As it happens, one part of this thought (“I’m walking over…”) has no particular appeal to me. But that’s fine. The other part of the thought (“…to get the candy”) is very motivating. So the valence of the overall thought is positive, and I will do it.
However, upon “overtraining” (a huge number of repetitions of a behavior), positive or negative valence can travel from a consequence to the preceding action, by TD learning, as discussed here [LW · GW] and illustrated by the following picture:
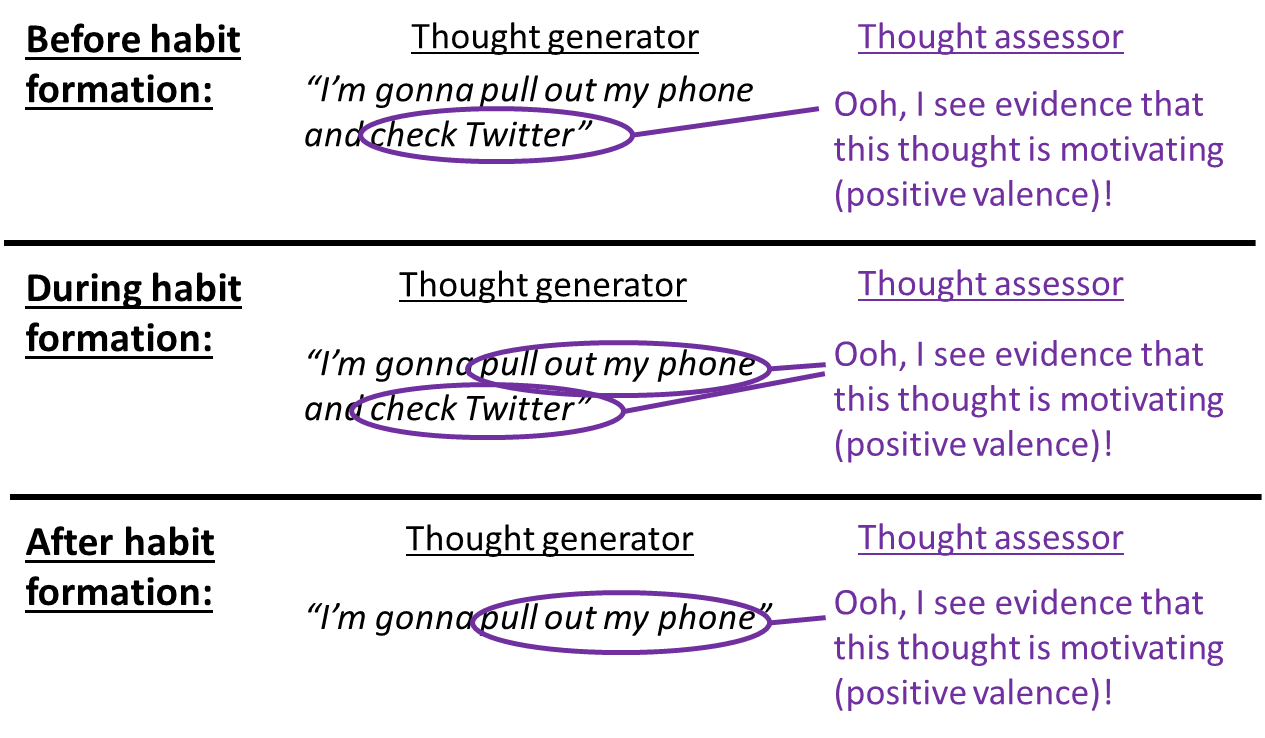
In the case mentioned above, if I have walked to the shelf to get candy enough times in the past, I might find myself walking to the shelf without even realizing why. I don’t have to be thinking of the candy, because the thought “I’m walking to the shelf” can summon positive valence all by itself.
Well in any case, it’s natural and expected that the phenomena under discussion here (incentive learning, retasting, devaluation, revaluation) can manifest differently depending on whether the rat is in habit-mode (the rat is thinking about its actions but not their consequences) or outcome-mode (the rat is thinking about both its actions and its consequences). For example, Dickinson & Balleine 2010 cite Adams 1982 as an early demonstration of the fact “that overtraining can render instrumental responding impervious to outcome devaluation”—i.e., if the rat starts really liking (assigning positive valence to) the idea of pressing the lever, in and of itself, without really having the consequences in mind (i.e., represented in the Thought Generator), then it will do so even when it ought to know that the consequences have shifted to something it doesn’t care about.
4.4 The way that the Thought Assessors (especially valence prediction) generalizes from prior life experience is a whole can of worms
As mentioned in §3.3.1, things will be motivating if they seem (to the animal) to be similar to things that were motivating in the past.
However, the word “similar” is hiding a lot of complexity—indeed, much of animal intelligence, and even human intelligence, consists of sorting out what situations / actions / thoughts are or aren’t “similar”!
4.4.1 Example
Here’s a fun example from Dickinson & Balleine 2002, where generalization determines the necessity of incentive learning. They say that Shipley & Colwill 1996 failed to reproduce the Instrumental Incentive Learning result of §2.2 above, but only because they used more dilute sugar-water. (Indeed, Dickinson & Balleine reproduced this failure-to-reproduce—i.e. they too found instant revaluation when they used more dilute sugar-water.)
Their hypothesized explanation is as follows: Maybe sufficiently dilute sugar-water basically tastes like regular water, from the rats’ perspective. And the rats had previously drunk regular water when thirsty, lots of times in the course of their normal upbringing. So the incentive-learning was already complete, long before the experiment started.
4.4.2 Background on “generalization”
For readers who are familiar with ML but not psych: “Generalization” (in this context) loosely corresponds to “If we gradient-update a function V via the labeled datapoint “V(X) is supposed to be Y”, then we are also incidentally, simultaneously, updating V such that V(X’) ≈ Y, for any inputs X’ that are sufficiently close to X in terms of their latent representation.”
In this case, V is the valence predictor (or in principle, V could be any other Thought Assessor too), X is a thought, and Y is the predicted valence of that thought.
In the dilute-sugar-water case mentioned above, the rats learned from life experience that V(the thought of drinking pure water when thirsty) >> 0, and this turned out to generalize to V(the thought of drinking dilute sugar-water when thirsty) >> 0, but it did not generalize to V(the thought of drinking concentrated sugar-water when thirsty) >> 0.
4.4.3 Dead Sea Salt experiment revisited
My guess is that the dead sea salt experiment involved visceral predictions, and that’s the story I told above, but I’m not even sure of that! Alternatively, it could have just been their valence prediction function successfully generalizing from prior life experience.
After all, in the course of their normal upbringing, the rats were never salt-deprived—or so the experimentalists say! But isn’t it likely that the rats were slightly salt-deprived now and then, over the course of their prior upbringing? And the experimentalists assure us that the rats had never before in their life tasted a very strong salt flavor while salt-deprived, but surely some bits of their feed had a slight salty flavor! So that gives us another hypothesis: maybe the rats’ valence functions successfully generalized from prior life experience to guess the general rule that saltwater-while-salt-deprived is good.
That’s not my main guess, based on different experiments. But it’s definitely a hypothesis worth checking.
4.5 Upshot: even granting my theoretical framework, experimental results can still be a big pain to interpret
I gave a couple examples above where you can accept my theoretical framework but still not know the underlying explanation for a particular experimental result. In particular, a priori, either or both of the time-delay / distraction issue (§4.1) and the salt-water-versus-sugar-water distinction (§4.2) could explain the requirement of incentive learning in the §2.2 experiment; and even the salt-water experiment on its own could in principle involve either of the two revaluation pathways of §3.3 (see §4.4.3).
By the same token, when I come upon some study of monkeys responding or not responding to devaluation when their left orbitofrontal cortex and right amygdala are simultaneously deactivated (or whatever), I can usually list off a bunch of rather different hypotheses for what’s going on. It takes a lot of work to narrow it down.
In fact, in practice, I don’t put incentive learning / devaluation / revaluation experiments very high on my list of best ways to learn useful things about the brain. They’re annoyingly indirect. By contrast, easier-to-interpret sources of information include tracer studies (which neurons connect to which neurons and how), stimulation or lesion studies (what does the animal do if you stimulate or destroy such-and-such neurons), evolutionary homologies and embryology (if two regions are evolutionarily and embryologically related, then maybe they’re running a similar algorithm), and of course thinking about algorithms and behavior.
5. Bonus: Some comments on how my model differs from some stuff in the neuro/psych literature
5.1 The literature distinction between “Pavlovian versus instrumental conditioning” is kinda related to my division of Thought Assessors into valence-prediction versus visceral-prediction
5.1.1 General discussion part 1: Pavlovian
Start with Pavlovian conditioning. In my framework, visceral Thought Assessors are functions whose output is a scalar, and whose input is a “thought” (a high-dimensional object which includes not only direct sensory inputs but also where you are, what you’re doing, and everything else in your mental world). Each of these functions is built by supervised learning from past life experience.
The relation to Pavlovian terminology is as follows:
| Literature | My model | |
| “Pavlovian conditioning” | ≈ | “A visceral Thought Assessor has been updated by supervised learning.” |
| “Unconditioned stimulus” | ≈ | “A situation where, when you put a rat in that situation, it triggers an innate behavior program stored in the rat’s Steering Subsystem (hypothalamus & brainstem), where this happens directly via the Steering Subsystem’s own sensory processing systems [LW · GW], without the Learning Subsystem (cortex, amygdala, etc.) [LW · GW] playing a central role. Incidentally, this triggering will then send ground truth signals that update the visceral-prediction Thought Assessors via supervised learning.” |
| “Conditioned stimulus” | ≈ | “A situation where, when you put the rat in that situation, the rat reliably has thoughts involving a thought-feature / world-model latent variable / pattern of cortical activation F, where there’s a visceral Thought Assessor which has previously learned to send a visceral prediction upon seeing F.” |
So yes, there’s a relationship between my model and the standard literature framework. But, on my model, the literature framework is somewhat misleading and unhelpful for two (related) reasons:
First, the literature framework emphasizes external situations (“stimuli” that experimentalists can see and control), whereas mine emphasizes internal thoughts (what the rat is thinking about, a.k.a. thought-features / latent variables / patterns-of-active-neurons in the rat’s Thought Generator / world-model / cortex.)
I understand where people were coming from—we inherited this terminology from behaviorism, and it’s a natural starting point for describing experiments (since it’s hard to read rat minds). Moreover, I suspect that neuro / psych people would protest that they’re perfectly well aware of the obvious fact that visceral reactions are proximally triggered by thoughts rather than “stimuli”. But still, I think the terminology we use exerts a strong pull on the kinds of hypotheses we entertain, and I think people are still being manipulated by the zombie remnants of 1950s behaviorism, more than they’d like to believe.
Anyway, in my framework, it’s thought-features, not situations, that get tagged by Thought Assessors as evidence of an imminent visceral reactions—see my intuitive discussion in §9.3.1 here [LW · GW].
Of course, external situations impact and constrain internal thoughts: if I’m sitting at my desk, then I can’t sincerely believe that I’m scuba diving. Or for a more experimentally-relevant example, if a loud sound suddenly starts, then that sound is going to impact my Thought Generator, in a way that I might describe in words as “I hear a sound!”. The sound will relatedly have an obvious and reproducible imprint on the pattern of neural activation in my auditory cortex—an imprint that my Thought Assessors (e.g. amygdala) can then learn to recognize.
Given that, why am I harping on the distinction? Because internal thoughts can also include things that are not straightforwardly driven by external stimuli. Which brings us to my next point:
Second, in my framework, a rat’s plans, actions, and expectations are all thought-features too—just as much as the thought-features connected to hearing a sound. For example, if I get up to open the window, then there’s a thought in my head to the effect of “I’m getting up to open the window right now”. That’s a thought in my Thought Generator, and therefore it is perfectly allowable for any of those related thought-features to get picked up by Thought Assessors as evidence relevant to the latter’s prediction task.
Does this apply to rats too? Yes! Tons of experiments show that ideas can pop into a rat’s head—e.g. “maybe I’ll go to the left”—just as ideas can pop into a human’s head.
Now, as it turns out, when rats are thinking of non-immediate consequences of their plans-of-action, those thought-features tend not to trigger strong visceral predictions, thanks to the time-discounting issue in §4.1. (They can trigger strong valence predictions.) …But that fact is kinda incidental rather than fundamental, and it might also be somewhat less true for monkeys and humans than for rats. I think some discussions in the literature go wrong by making much too big a deal out of this incidental, contingent observation, and incorrectly elevating it to a profound bedrock principle of their theoretical framework. That brings us to:
5.1.2 General discussion part 2: Instrumental conditioning
My view, as in §3 above, is that, in addition to the visceral-prediction Thought Assessors, there’s also the all-important valence-prediction Thought Assessor. (See my Valence series [LW · GW].) Now, as above, some thoughts are not action-oriented, e.g. “I’m hearing a sound”. Other thoughts are action-oriented—e.g. “I’m gonna open the window”. The latter kind of thought often also incorporates the consequences of an action—e.g. when I think “I’m gonna open the window”, I might be visualizing a future world in which the window has now been opened.
If an action-oriented thought has positive valence, then we’ll actually do that action, and if not, we won’t. That’s my model. So I think that instrumental conditioning experiments mostly revolve around valence predictions, whereas Pavlovian conditioning experiments mostly revolve around visceral predictions.
But that correspondence (i.e., (instrumental, Pavlovian) ↔ (valence predictions, visceral predictions)) isn’t perfect. In particular, voluntary actions require positive valence (coming up from the Steering Subsystem), but they don’t strictly require positive valence predictions (coming down from the valence Thought Assessor). Alternatively, the Steering Subsystem can issue positive valence based on visceral predictions—cf. “Pathway 2”, §3.3.2 above.
For example, maybe the rat has the idea “I’m gonna mate right now”, and then that idea triggers visceral predictions, and then those visceral predictions trigger positive valence, and so then the rat will proceed to mate, even if it’s never mated before.
Now, there’s a distinction in the literature between instrumental and non-instrumental contingencies. In my framework, this distinction—or at least, the way people talk about it—strikes me as kinda foreign, or abstruse, or trivial, or something, I’m not sure.
Here’s an example: if you put food at the end of a hallway, and rats run down the hallway to get to the food, is that “instrumental” behavior? I would give the obvious answer: “Yeah duh!”. But if you read the literature, this is treated as a dubious claim! In his 1983 book, Nicholas Mackintosh mentions (among other things) the following two pieces of purported counterevidence. First, various experiments such as Gonzalez & Diamond 1960 find that if rats walk down a hallway to an empty goal-box, and then later they’re put directly into the same goal-box when it’s full of food, then next time they’re in the hallway they’ll run down the hallway fast to get the goal-box. He describes this result as: “a classical contingency between goal-box and food is sufficient to cause rats to run down an alley to the goal-box before any instrumental contingency can take hold”. Second, he mentions a devious experiment from Logan 1960 where rats would only get food if they arrived after a certain amount of time; alas, the over-excited rats ran too fast ≳50% of the time.
In my view, what’s happening in both cases is: rats think there might be food at the end of a hallway, and that thought is highly motivating (positive valence), so they run to go get it. This running deserves to be called “instrumental” if anything does—the rats are imagining a possible future course-of-action and its consequences, liking what they see, and then doing it. Again, we now have abundant direct evidence from neuroscience that rats are capable of this. And if that doesn’t fit the technical psych definition of “instrumental” for whatever reason, then, well, so much the worse for technical psych definition of “instrumental”!
Anyway, I’ll now go through an example more relevant to the subject of this post.
5.1.3 Case study: Dickinson & Nicholas 1983
Anthony Dickinson and colleagues did an experiment in 1983 (original, later review article summary), reproducing and extending a 1968 experiment by Krickhaus & Wolf. In it, the rats had to walk over to the drink magazine, but nevertheless their behavior was immediately responsive to physiological state without incentive learning. This one used the salt protocol—the drink magazine had salt-water, and the rats were made to feel severely salt-deprived.
I had claimed above (§4.1) that the delay between pressing the lever and walking to the magazine was evidently too long to allow visceral predictions to propagate backwards from the drinking to the lever. Is this experiment counterevidence?
The possible answer “yes” is not a crazy idea a priori—the time-discounting is presumably a matter of degree, not binary. However, the authors did some brilliant follow-up experiments that suggest that the answer is approximately “no”—the visceral reactions don’t get connected to the idea of pressing the lever. So what’s going on? Let’s dive in.
I’ll greatly oversimplify the setup and controls. Let’s just say: In “training”, the rats were put in a cage with two doors. Behind the left door is saltwater, and behind the right door is pure water. For one group of rats, the left door opens spontaneously sometimes, while the right door opens when the rat presses the lever. For the other group of rats, it’s the opposite: the right door opens spontaneously sometimes, while the left door opens when the rat presses the lever. The experiment is set up such that the two doors open equally often in aggregate.
Then during the test, the lever was disconnected, the doors sealed shut, and the rats injected with chemicals to make them feel severely salt-deprived. Here’s the remarkable result: those two groups of rats pressed the lever the same amount! But this amount was still sensitive to the fact that they were salt-deprived, and to the number of times they had been exposed to the saltwater during training.
Here’s the explanation I would offer.
After training, the visceral reactions are not particularly associated with pressing the lever, in the rat’s mind, because of the time-delay issue as discussed in §4.1 above. It just takes too long to walk to the magazine. Instead, the visceral expectation-of-salt reaction is triggered by just being in the cage! After all, during training, being-in-the-cage was associated with the saltwater with zero seconds of delay.
So during the test, the rat is just hanging out in the cage, and maybe especially looking at the door, and that triggers a weak visceral expectation-of-salt, which in turn prompts the Steering Subsystem to issue positive valence—in essence, the brainstem says to the cortex / Thought Generator: “whatever you’re thinking of doing right now, hey, go for it, it’s probably a great idea!” So then the rat gets excited and does … something. And some fraction of the time, the thing it does is to press the lever. After all, that’s a salient action that might well pop into the rat’s head (Thought Generator)—it’s an obvious outlet for the rat’s free-floating feelings of motivation.

Again, since there’s no specific association between pressing-the-lever and visceral-expectation-of-salt, there’s really no reason we should expect the two groups of rats to press the lever at different rates. We should, however, generically expect the rats to be pressing the lever more when they’re salt-deprived. We should also expect more lever-presses when the salt was tasted more during training—that would lead to a stronger visceral expectation of salt. And that’s what the experiments showed.
5.2 Two complaints about the terms “model-based” or “outcome-directed” as used in the literature
My foil for this section is the paper “Model-based and model-free Pavlovian reward learning: Revaluation, revision, and revelation” by Dayan & Berridge (2014). (If that paper isn’t a central representative of “the literature”, then oops, let me know and I’ll retitle this section.)
5.2.1 “Model-based” / “outcome-directed” squashes together two things that I see as profoundly different, namely (A) innate “business logic” in the Steering Subsystem versus (B) planning via a learned world-model in the cortex
As described in this post [LW · GW], “business logic” is a software engineering term to refer to parts of source code that more-or-less directly implement specific, real-world, functional requirements: “IF the company has offices in Texas, THEN attach form SR008-04X”. By the same token, the genome directly builds a ton of innate “business logic” circuitry into the Steering Subsystem (hypothalamus and brainstem) that do specific, adaptive things: “IF I’m fertile, THEN increase my sex drive.” Or in the case at hand: “IF I’m salt-deprived, AND I have an imminent visceral expectation that I’m about to taste salt, THEN issue positive valence etc.” If you zoom in on (especially) the hypothalamus, you find this kind of logic everywhere—I go through a real-life example (“NPY/AgRP neurons” in the hypothalamus) here [LW · GW].
Meanwhile, on the other side of the brain, the cortex (and thalamus etc.) are doing within-lifetime learning of a predictive, generative world-model. By the time I’m an adult, I can query this cortical world-model to get useful predictions like “If I jump in the lake, then I’m gonna be cold and wet and my cell phone will stop working.”
In my preferred terminology, the thing the cortex does is a bona fide “model”, whereas the innate Steering Subsystem circuity is not.
I suppose there’s no point arguing over terminology. But if you insist on calling both of those things “models”, let’s at least be clear that they are about as different as can possibly be. They’re in different parts of the brain; one is built by a within-lifetime learning algorithm [LW · GW] while the other is innate; they each involve very different types of neurons interacting in very different ways; one is actually making predictions about the future while the other is only “making predictions” in an abstruse metaphorical sense [LW · GW].
5.2.2 “Model-based” / “outcome-directed” splits up two things that I see as the same kind of thing: learned habits and outcome-oriented plans
I talked about habit-formation above—see §4.3. The Dayan & Berridge paper cited above describes habits as “model-free”. And I don’t like that.
From my perspective: if a thought pops into my head to go to the store to buy candy, that thought is an activation state of my world-model. If a thought pops into my head to bite my nails right now, that thought is an activation state of my world-model too! As long as the Thought Generator is involved (i.e. voluntary behavior), I say it’s model-based. The cortex is always modeling. That’s just what the cortex does. See “cortical uniformity” [LW · GW]—if any part of the cortex is learning a generative world-model (which is surely the case) then one should strongly presume that the entire cortex is learning a generative world-model. The generative world-model can model what will happen in the distant future, and it can also model what I’m doing right now and in the immediate future. It can also (optionally) model both at once including how they relate. And (given positive valence) it can make all these things happen. It’s a very impressive world-model! We should give it more credit!
To be clear, I do like the distinction between voluntary actions (e.g. talking) and involuntary actions (e.g. crying). That’s a sharp and important distinction in my framework. (I think this might be related to “two-process learning theory” in the old psych literature? Not sure.) Some notes on that:
- We can pin down this distinction by saying that the voluntary actions happen if and only if the idea of doing them is positive-valence, while involuntary actions can happen regardless of their valence. Involuntary actions are associated with innate behavioral programs stored in the Steering Subsystem (for example, there are a bunch in the brainstem periaqueductal gray).
- Be careful not to confuse “voluntary” with “ego-syntonic”—see my handy chart here [LW · GW].
- Confusingly, you can voluntarily control “involuntary” actions to a degree—e.g., many people can cry on demand. But that happens via “tricking” your visceral Thought Assessors (see discussion in §6.3.3 here [? · GW]), rather than through the direct motor outputs of the Thought Generator.[12]
5.3 My “valence function learning and generalization” discussion is very similar to Dickinson & Balleine’s “Hedonic Interface Theory”
If any readers are trying to compare my discussion of how the valence predictor Thought Assessor learns and generalizes (cf. §3.3.1 and §4.4) with Dickinson & Balleine’s “Hedonic Interface Theory”, I think they basically agree, but to really understand the correspondence you would need to also read my Appendix A of my valence series [LW · GW] explaining how I think hedonic tone / pleasure connects to valence. The short version of that is: hedonic tone / pleasure plays a “ground truth” role for the valence predictor, analogous to how unconditioned stimuli like shocks play a “ground truth” role for the visceral predictors.
(Thanks Patrick Butlin for first informing me that “incentive learning” exists way back when. Thanks Anthony Dickinson for carefully reading, and devastatingly criticizing, an early draft of this post with a somewhat different thesis. Thanks also to Linda Linsefors, Cameron Berg, Seth Herd, Tom Hazy, and Patrick Butlin for critical comments on earlier drafts.)
- ^
Terminology: In a Pavlovian (a.k.a. classical) conditioning experiment, something happens to a rat (e.g. it gets electrocuted) at some random time, independent of what the rat is doing. In an operant (a.k.a. instrumental) conditioning experiment, the rat does something (e.g. presses a lever), and then it has some consequence (e.g. it gets electrocuted).
- ^
Most of my key sources are from the 1980s or earlier (or much earlier), generally predating the flood of crappy psychology papers. I’m also mostly relying on the work of Anthony “Tony” Dickinson, whose papers strike me as exceedingly fastidious—he might do an experiment that suggests some interesting result, and then immediately do seventeen more control experiments to rule out every possible alternative explanation. Moreover, the interesting results were generally very obviously above noise (as opposed to p=0.0499)—e.g., one group of rats might press a lever twice as often as the other group. And at least some of the key results have been reproduced by multiple labs anyway.
- ^
The description in this section is mostly self-plagiarized from an ancient blog post I wrote [LW · GW].
- ^
In the Dead Sea Salt paper they call it a “lever”, but I’m calling it a “stick” in this post, because I want to follow common non-technical usage in which a “lever” is “a stick that does something when you pull it”, whereas the Dead Sea Salt Experiment “stick” does not do anything except sit there. (The experiment is “Pavlovian”, not “instrumental”, see previous footnote.)
- ^
Fun fact (details here): There’s no sharp line between the putamen and caudate, nor between the caudate and (core side of the) nucleus accumbens. It’s just one big structure that got split up into three terms by confused early neuroscientists. (There’s likewise a smooth transition between nucleus accumbens shell and lateral septum, and so on.) In fact, the brilliant neuroanatomist Lennart Heimer was against calling it the “nucleus accumbens” in the first place—it’s not a “nucleus”, he wrote, so we should just call it the “accumbens”!
- ^
As in the bottom of the diagram, the Steering Subsystem also has access to “raw informational inputs”. Those would be relevant if, for example, the rat could smell the food before getting to it. That could be applicable in certain cases, but I think all the specific experiments I’ll mention here had control experiments appropriate to rule out that factor.
- ^
Side-note: From an ecological perspective, Pavlovian experiments are pretty weird—the rats are doing nothing in particular, and then all of the sudden something happens to them. Like, under ecological circumstances, a rat might be overcome by fear when it sees an incoming bird, or a rat might be flooded with pain when it walks into a cactus, etc. And then the rat’s brain algorithms are set up to generally build in the right associations and take sensible actions, both now and in the future—e.g., don’t walk into cactuses. But in a Pavlovian experiment, there is no sensible action—the rat just gets randomly zapped or sprayed or whatever no matter what it does—and thus the rats wind up doing something somewhat random—cf. the distinction between “sign-tracking” and “goal-tracking” rats. See also §5.1.3.
- ^
One should be very cautious in making claims that a rat couldn’t possibly deduce something from its previous life experience—see §4.4.1 below on “accidental” incentive learning earlier in life.
- ^
However, see §4.4.3 for an alternative hypothesis.
- ^
Methodological details are in the original paper’s supplemental information. If you’re wondering why I’m treating this as “0-second delay” instead of “8-second delay”, I claim that the rat is generalizing from “what it’s thinking after the sound has already been on for 7.99 seconds” to “what it’s thinking after the sound has just turned on”—see §4.4 below.
- ^
“Magazine” is a standard term in the context of rat experiments—here’s a google image search for “rat experiment food magazine”.
- ^
More specifically, in my view, “voluntary” control corresponds to cortex layer 5PT output signals coming out of any of the cortical areas wherein those signals are trained by the “main” a.k.a. “success-in-life” RL signals [LW · GW] related to valence—as opposed to outputs from other parts of the cortex, or from the striatum, amygdala, hypothalamus, brainstem, etc.
1 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2024-06-28T11:58:49.211Z · LW(p) · GW(p)
I feel like there's gotta be several different "time constants" for valence/viscera prediction, and I'm not totally clear on when you're talking about which.
- A time constant in a learning algorithm that's similar to temporal credit assignment. E.g. If I get a ground truth signal (by tasting salt, say) maybe credit assignment says that everything I did/felt in the last half-second (for a "time constant" of 0.5s I guess) gets treated as predictive of salt, with some decay and potential extra massaging such that the most immediately proximal thoughts are associated strongest.
- Very similar to #1, a time constant in a learning algorithm that's similar to td learning. E.g. If I predict salt, everything I did in the last half-second gets treated as predictive of salt.
- A learning speed of #s 1 or 2 in practice. E.g. if there's a button that releases a lever, and pulling the lever dispenses salt water into my mouth, maybe my salt predictor pretty quickly learns to predict salt when I'm thinking about the lever, and only more slowly learns to predict salt when I'm thinking about the button. The rate at which this predictive power propagates back through time could be different between environments, and between predicting salt vs. valence.
- A time constant in the eventual product of a learning algorithm such as #1 or #2. E.g. maybe thinking about the button from the previous example never becomes as predictive of salt as thinking about the lever, and if you introduce a time delay between the button and the lever the predictive power of the button gets weaker as the time delay increases.
- A sort of "time constant" that's really more of a measure of generalization power / ability to assign predictions to complicated thoughts. E.g. if my salt predictor is small and can't do complicated computation, maybe it can only ever learn to fire when I'm really obviously about to get salt, while the larger valence predictor can quickly learn to fire on multi-step plans to do good things. This might just be a different way of looking at a major cause of #4.
- A time constant for predictions as a function of the world model's own internal time stamps. E.g. If I imagine going to the store and buying some salty crackers in an hour, maybe I salivate less than if I imagine going to the store and buying some salty crackers in 2 minutes, because my thought-assessors are actually using my model's internal representation of time to help predict how much salt to expect.