Why I’m not into the Free Energy Principle
post by Steven Byrnes (steve2152) · 2023-03-02T19:27:52.309Z · LW · GW · 49 commentsContents
0. But first, some things I do like, that are appropriately emphasized in the FEP-adjacent literature 1. The Free Energy Principle is an unfalsifiable tautology 2. The FEP is applicable to both bacteria and human brains. So it’s probably a bad starting point for understanding how human brains work 3. It’s easier to think of a feedback control system as a feedback control system, and not as an active inference system 4. Likewise, it’s easier to think of a reinforcement learning (RL) system as an RL system, and not as an active inference system 5. It’s very important to distinguish explicit prediction from implicit prediction—and FEP-adjacent literature is very bad at this 6. FEP-adjacent literature is also sometimes bad at distinguishing within-lifetime learning from evolutionary learning 7. “Changing your predictions to match the world” and “Changing the world to match your predictions” are (at least partly) two different systems / algorithms in the brain. So lumping them together is counterproductive 8. (Added Dec. 2024) It’s possible to want something without expecting it, and it’s possible to expect something without wanting it None 49 comments
0. But first, some things I do like, that are appropriately emphasized in the FEP-adjacent literature
- I like the idea that in humans, the cortex (and the cortex specifically, in conjunction with the thalamus, but definitely not the whole brain IMO) has a generative model that’s making explicit predictions about upcoming sensory inputs, and is updating that generative model on the prediction errors. For example, as I see the ball falling towards the ground, I’m expecting it to bounce; if it doesn’t bounce, then the next time I see it falling, I’ll expect it to not bounce. This idea is called “self-supervised learning” in ML. AFAICT this idea is uncontroversial in neuroscience, and is widely endorsed even by people very far from the FEP-sphere like Jeff Hawkins and Randall O’Reilly and Yann LeCun. Well at any rate, I for one think it’s true.
- I like the (related) idea that the human cortex interprets sensory inputs by matching them to a corresponding generative model, in a way that’s at least loosely analogous to Bayesian probabilistic inference. For example, in the neon color spreading optical illusion below, the thing you “see” is a generative model that includes a blue-tinted solid circle, even though that circle is not directly present in the visual stimulus. (The background is in fact uniformly white.)

{kind=link}
- I like the (related) idea that my own actions are part of this generative model. For example, if I believe I am about to stand up, then I predict that my head is about to move, that my chair is about to shift, etc.—and part of that is a prediction that my own muscles will in fact execute the planned maneuvers.
So just to be explicit, the following seems perfectly fine to me: First you say “Hmm, I think maybe the thalamocortical system in the mammalian brain processes sensory inputs via approximate Bayesian inference”, and then you start doing a bunch of calculations related to that, and maybe you’ll even find that some of those calculations involve a term labeled “variational free energy”. OK cool, good luck with that, I have no objections. (Or if I do, they’re outside the scope of this post.) Note that this hypothesis about the thalamocortical system is substantive—it might be true or it might be false—unlike FEP as discussed shortly.
Instead, my complaint here is about the Free Energy Principle as originally conceived by Friston, i.e. as a grand unified theory of the whole brain, even including things like the circuit deep in your brainstem that regulates your heart rate.
OK, now that we’re hopefully on the same page about exactly what I am and am not ranting about, let the rant begin!
1. The Free Energy Principle is an unfalsifiable tautology
It is widely accepted that FEP is an unfalsifiable tautology, including by proponents—see for example Beren Millidge, or Friston himself.
By the same token, once we find a computer-verified proof of any math theorem, we have revealed that it too is an unfalsifiable tautology. Even Fermat’s Last Theorem is now known to be a direct logical consequence of the axioms of math—arguably just a fancy way of writing 0=0.
So again, FEP is an unfalsifiable tautology. What does that mean in practice? Well, It means that I am entitled to never think about FEP. Anything that you can derive from FEP, you can derive directly from the same underlying premises from which FEP itself can be proven, without ever mentioning FEP.
(The underlying premises in question are something like “it’s a thing with homeostasis and bodily integrity”. So, by the way: if someone tells you “FEP implies organisms do X”, and if you can think of an extremely simple toy model of something with homeostasis & bodily integrity that doesn’t do X, then you can go tell that person that they’re wrong about what FEP implies!)
So the question is really whether FEP is helpful.
Here are two possible analogies:
- (1) Noether’s Theorem (if the laws of physics have a symmetry, they also have a corresponding conservation law) is also an unfalsifiable tautology.
- (2) The pointless bit of math trivia is also an unfalsifiable tautology.
In both cases, I don’t have to mention these facts. But in the case of (1)—but not (2)—I want to.
More specifically, here’s a very specific physics fact that is important in practice: “FACT: if a molecule is floating in space, without any light, collisions, etc., then it will have a conserved angular momentum”. I can easily prove this fact by noting that it follows from Noether’s Theorem. But I don’t have to, if I don’t want to; I could also prove it directly from first principles.
However: proving this fact from first principles is no easier than first proving Noether’s Theorem in its full generality, and then deriving this fact as a special case. In fact, if you ask me on an exam to prove this fact from first principles without using Noether’s theorem, that’s pretty much exactly what I would do—I would write out something awfully similar to the (extremely short) fully-general quantum-mechanical proof of Noether’s theorem.
So avoiding (1) is kinda silly—if I try to avoid talking about (1), then I find myself tripping over (1) in the course of talking about lots of other things that are of direct practical interest. Whereas avoiding (2) is perfectly sensible—if I don’t deliberately bring it up, it will never come up organically. It’s pointless trivia. It doesn’t help me with anything.
So, which category is FEP in?
From my perspective, I have yet to see any concrete algorithmic claim about the brain that was not more easily and intuitively [from my perspective] discussed without mentioning FEP.
For example, at the top I mentioned that the cortex predicts upcoming sensory inputs and updates its models when there are prediction errors. This idea is true and important. And it’s also very intuitive. People can understand this idea without understanding FEP. Indeed, somebody invented this idea long before FEP existed.
I’ll come back to two more examples in Sections 3 & 4.
2. The FEP is applicable to both bacteria and human brains. So it’s probably a bad starting point for understanding how human brains work
What’s the best way to think about the human cerebral cortex? Or the striatum? Or the lateral habenula? There are neurons sending signals from retrosplenial cortex to the superior colliculus—what are those signals for? How does curiosity work in humans? What about creativity? What about human self-reflection and consciousness? What about borderline personality disorder?
None of these questions are analogous to questions about bacteria. Or, well, to the very limited extent that there are analogies (maybe some bacteria have novelty-detection systems that are vaguely analogous to human curiosity / creativity if you squint?), I don’t particularly expect the answers to these questions to be similar in bacteria versus humans.
Yet FEP applies equally well to bacteria and humans.
So it seems very odd to expect that FEP would be a helpful first step towards answering these questions.
3. It’s easier to think of a feedback control system as a feedback control system, and not as an active inference system
Let’s consider a simple thermostat. There’s a metal coil that moves in response to temperature, and when it moves beyond a setpoint it flips on a heater. It’s a simple feedback control system.
There’s also a galaxy-brain “active inference” way of thinking about this same system. The thermostat-heater system is “predicting” that the room will maintain a constant temperature, and the heater makes those “predictions” come true. There’s even a paper going through all the details (of a somewhat-similar class of systems).
OK, now here’s a quiz: (1) What happens if the thermostat spring mechanism is a bit sticky (hysteretic)? (2) What happens if there are two thermostats connected to the same heater, via an AND gate? (3) …or an OR gate? (4) What happens if the heater can only turn on once per hour?
I bet that people thinking about the thermostat-heater system in the normal way (as a feedback control system) would nail all these quiz questions easily. They’re not trick questions! We have very good intuitions here.
But I bet that people attempting to think about the thermostat-heater system in the galaxy-brain “active inference” way would have a very hard time with this quiz. It’s probably technically possible to derive a set of the equations analogous to those in the above-mentioned paper and use those equations to answer these quiz questions, but I don’t think it’s easy. Really, I’d bet that even the people who wrote that paper would probably answer the quiz questions in practice by thinking about the system in the normal control-system way, not the galaxy-brain thing where the system is “predicting” that the room temperature is constant.
What’s true for thermostats is, I claim, even more true for more complicated control systems.
My own background is physics, not control systems engineering. I can, however, brag that at an old job, I once designed an unusually complicated control system that had to meet a bunch of crazy specs, and involved multiple interacting loops of both feedback and anticipatory-feedforward control. I wrote down a design that I thought would work, and when we did a detailed numerical simulation, it worked on the computer just like I imagined it working in my head. (I believe that the experimental tests also worked as expected, although I had gotten reassigned to a different project in the meantime and am hazy on the details.)
The way that I successfully designed this awesome feedforward-feedback control system was by thinking about it in the normal way, not the galaxy-brain “active inference” way. Granted, I hadn’t heard of active inference at the time. But now I have, and I can vouch that this knowledge would not have helped me design this system.

That’s just me, but I have also worked with numerous engineers designing numerous real-world control systems, and none of them ever mentioned active inference as a useful way to think about what’s going on in any kind of control system.
And these days, I often think about various feedback control systems in the human brain, and I likewise find it very fruitful to think about them using my normal intuitions about how feedback signals work etc., and I find it utterly unhelpful to think of them as active inference systems.
4. Likewise, it’s easier to think of a reinforcement learning (RL) system as an RL system, and not as an active inference system
Pretty much ditto the previous section.
Consider a cold-blooded lizard that goes to warm spots when it feels cold and cold spots when it feels hot. Suppose (for the sake of argument) that what’s happening behind the scenes is an RL algorithm in its brain, whose reward function is external temperature when the lizard feels cold, and whose reward function is negative external temperature when the lizard feels hot.
- We can talk about this in the “normal” way, as a certain RL algorithm with a certain reward function, as per the previous sentence.
- …Or we can talk about this in the galaxy-brain “active inference” way, where the lizard is (implicitly) “predicting” that its body temperature will remain constant, and taking actions to make this “prediction” come true.
I claim that we should think about it in the normal way. I think that the galaxy-brain “active inference” perspective is just adding a lot of confusion for no benefit. Again, see previous section—I could make this point by constructing a quiz as above, or by noting that actual RL practitioners almost universally don’t find the galaxy-brain perspective to be helpful, or by noting that I myself think about RL all the time, including in the brain, and my anecdotal experience is that the galaxy-brain perspective is not helpful.
5. It’s very important to distinguish explicit prediction from implicit prediction—and FEP-adjacent literature is very bad at this
(Or in everyday language: It’s very important to distinguish “actual predictions” from “things that are not predictions at all except in some weird galaxy-brain sense”)
Consider two things: (1) an old-fashioned thermostat-heater system as in Section 3 above, (2) A weather-forecasting supercomputer.
As mentioned in Section 3, in a certain galaxy-brain sense, (1) is a feedback control system that (implicitly) “predicts” that the temperature of the room will be constant.
Whereas (2) is explicitly designed to “predict”, in the normal sense of the word—i.e. creating a signal right now that is optimized to approximate a different signal that will occur in the future.
I think (1) and (2) are two different things, but Friston-style thinking is to unify them together. At best, somewhere in the fine print of a Friston paper, you'll find a distinction between “implicit prediction” and “explicit prediction”, but other times it's not even mentioned, AFAICT.
And thus, as absurd as it sounds, I really think that one of the ways that the predictive processing people go wrong is by under-emphasizing the importance of [explicit] prediction. If we use the word “prediction” to refer to a thermostat connected to a heater, then the word practically loses all meaning, and we’re prone to forgetting that there is a really important special thing that the human cortex can do and that a mechanical thermostat cannot—i.e. build and store complex explicit predictive models and query them for intelligent, flexible planning and foresight.
6. FEP-adjacent literature is also sometimes bad at distinguishing within-lifetime learning from evolutionary learning
I haven’t been keeping track of how often I’ve seen this, but for the record, I wrote down this complaint in my notes after reading a (FEP-centric) Mark Solms book.
7. “Changing your predictions to match the world” and “Changing the world to match your predictions” are (at least partly) two different systems / algorithms in the brain. So lumping them together is counterproductive
Yes they sound related. Yes you can write one equation that unifies them. But they can’t be the same algorithm, for the following reason:
- “Changing your predictions to match the world” is a (self-) supervised learning problem. When a prediction fails, there’s a ground truth about what you should have predicted instead. More technically, you get a full error gradient “for free” with each query, at least in principle. Both ML algorithms and brains use those sensory prediction errors to update internal models, in a way that relies on the rich high-dimensional error information that arrives immediately-after-the-fact.
- “Changing the world to match your predictions” is a reinforcement learning (RL) problem. No matter what action you take, there is no ground truth about what action you counterfactually should have taken. So you can’t use a supervised learning algorithm. You need a different algorithm.
Since they’re (at least partly) two different algorithms, unifying them is a way of moving away from a “gears-level [? · GW]” understanding of how the brain works. They shouldn’t be the same thing in your mental model, if they’re not the same thing in the brain.
(Side note: In actor-critic RL, the critic gets error information, and so we can think of the critic specifically as doing supervised learning. But the actor has to be doing something different, presumably balancing exploration with exploitation and so on. Anyway, as it turns out, I think that in the human brain, the RL critic is a different system from the generative world-model—the former is centered around the striatum, the latter around the cortex. So even if they’re both doing supervised learning, we should still put them into two different mental buckets.)
8. (Added Dec. 2024) It’s possible to want something without expecting it, and it’s possible to expect something without wanting it
This is an obvious common-sense fact, but seems deeply incompatible with the very foundation of Active Inference theory.
Bafflingly, for all I've read on Active Inference, I have yet to see anyone grappling with this contradiction—at least, not in a way that makes any sense to me.
(Added May 2023) For the record, my knowledge of FEP is based mainly on the books Surfing Uncertainty by Andy Clark, Predictive Mind by Jakob Hohwy, Hidden Spring by Mark Solms, How Emotions Are Made by Lisa Feldman Barrett, and Being You by Anil Seth; plus a number of papers (including by Friston) and blog posts. Also thanks to Eli Sennesh & Beren Millidge for patiently trying (and perhaps failing) to explain FEP to me at various points in my life.
Thanks Kevin McKee, Andrew Richardson, Thang Duong, and Randall O’Reilly for critical comments on an early draft of this post.
49 comments
Comments sorted by top scores.
comment by the gears to ascension (lahwran) · 2023-03-02T19:47:03.449Z · LW(p) · GW(p)
Before I start: I do not properly understand the free energy principle's claimed implications. I agree that it is simply a transformation on physical laws which is useful if and only if it makes implications of those laws easier to reason about in generality. I have some papers lying around somewhere I'd like to link you about it, but I don't have those handy as I write this, so I'll add another comment later.
None of these questions are analogous to questions about bacteria. Or, well, to the very limited extent that there are analogies (maybe some bacteria have novelty-detection systems that are vaguely analogous to human curiosity / creativity if you squint?), I don’t particularly expect the answers to these questions to be similar in bacteria versus humans.
This seems like one of the key strengths of the FEP's approach to me: I want to understand what features of reasoning are shared across physical systems that share no common ancestor, or at least do not share a common ancestor for a very very long time. I have a strong hunch that this will turn out to matter a lot to safety, and that any approach to formal safety that does not recognize bacteria as trying to protect their own genetic beauty by learning about their environments is one that is doomed to failure. (see also my comment on the trading with ants post, arguing that we should become able to trade with ants [LW(p) · GW(p)] - and yes, also bacteria.)
I bet that people thinking about the thermostat-heater system in the normal way (as a feedback control system) would nail all these quiz questions easily. They’re not trick questions! We have very good intuitions here.
Yeah this seems like the key knockdown here to me.
So if I've followed you correctly, your point is to describe the difference between prediction (make a system now take the shape of an external future) and control (make a system take a target shape represented in another system). control may involve predicting deviations in order to prevent them, but by preventing them, a predictor is changed into a controller. Does that sound like a solid compressive rephrase, where I haven't lost anything key? I don't want to accidentally use a lossy compression, as my hope is to be able to explain your entire point to someone else later in one or two sentences.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-02T20:20:44.997Z · LW(p) · GW(p)
I want to understand what features of reasoning are shared across physical systems that share no common ancestor, or at least do not share a common ancestor for a very very long time. I have a strong hunch that this will turn out to matter a lot to safety, and that any approach to formal safety that does not recognize bacteria as trying to protect their own genetic beauty by learning about their environments is one that is doomed to failure.
FEP is definitionally true of anything that maintains its bodily integrity (or whatever). So I claim that if you think you’ve learned something nontrivial from FEP, something that isn’t inherently, definitionally, part of what it means for an organism to have bodily integrity (or whatever), then I think you’re wrong about what FEP says.
In particular, I think you were suggesting in your comment that FEP implies that bacteria learn about their environments, but I don’t think FEP implies that. It seems to me that it’s obviously possible for there to be a living organism that doesn’t have the capacity to learn anything about its environment. (E.g. imagine a very simple organism that evolved in an extremely, or even perfectly, homogeneous environment. No it’s not realistic, but it’s certainly possible in principle, right?) Since FEP universally applies to everything, it cannot actually imply that bacteria will learn anything about their environment. They might, because learning about one’s environment is often a useful thing to do, but we didn’t need FEP to learn that fact, it’s obvious.
(It’s tricky because I think FEP people often make various additional assumptions on top of FEP itself—assumptions which might or might not apply in any particular animal—without always being clear that that’s what they’re doing. It’s also tricky because FEP discussions use suggestive variable names that can potentially be misleading, I think.)
Replies from: lahwran, lahwran↑ comment by the gears to ascension (lahwran) · 2023-03-02T20:35:20.522Z · LW(p) · GW(p)
It seems to me that it’s obviously possible for there to be a living organism that doesn’t have the capacity to learn anything about its environment. (E.g. imagine a very simple organism that evolved in an extremely, or even perfectly, homogeneous environment. No it’s not realistic, but it’s certainly possible in principle, right?)
Tangentially, this might be interesting to model in https://znah.net/lenia/
↑ comment by the gears to ascension (lahwran) · 2023-03-02T20:35:44.022Z · LW(p) · GW(p)
Yeah, I think I'm sold on the key point.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-03T17:39:49.389Z · LW(p) · GW(p)
Except, this is wrong. FEP is a tautology like Noether's theorem. Indeed, it implies that even rocks "learn" about their environment (the temperature of the rock is the inference about the temperature of the outside environment). But Active Inference, which is a process theory of agency is far from a tautology. FEP should best be understood as a mathematical framework that "sets the stage" for Active Inference and sort of explains the nature of the objects that Active Inference operates with, but couldn't be derived from the FEP (the FEP literature often calls Active Inference a "corollary" of the FEP, which sort of implies the contrary, which is confusing; besides, FEP and Active Inference are hopelessly confused in text and speech, especially by people who are not experts in this theory, or even by experts, but outside of papers). See this comment [LW(p) · GW(p)] for further discussion.
comment by Jan_Kulveit · 2023-03-03T10:26:00.819Z · LW(p) · GW(p)
Seems a bit like too general counterargument against more abstracted views?
1. Hamiltonian mechanics is almost an unfalsifiable tautology
2. Hamiltonian mechanics is applicable to both atoms and starts. So it’s probably a bad starting point for understanding atoms
3. It’s easier to think of a system of particles in 3d space as a system of particles in 3d space, and not as Hamiltonian mechanics system in an unintuitive space
4. Likewise, it’s easier to think of systems involving electricity using simple scalar potential and not the bring in the Hamiltonian
5. It’s very important to distinguish momenta and positions —and Hamiltonian mechanics textbooks make it more confusing
7. Lumping together positions and momenta is very un-natural. Positions are where particle is, momentum is where it moves
↑ comment by Steven Byrnes (steve2152) · 2023-03-03T14:44:36.170Z · LW(p) · GW(p)
1. Hamiltonian mechanics is almost an unfalsifiable tautology
In the OP, I wrote:
avoiding (1) is kinda silly—if I try to avoid talking about (1), then I find myself tripping over (1) in the course of talking about lots of other things that are of direct practical interest.
I think Hamiltonian mechanics passes that test. If my friend says that Hamiltonian mechanics is stupid and they don’t want to learn it or think about it ever, and then my friend spends some time trying to answer practical questions about practical physics systems, they will “trip over” pretty much every aspect of Hamiltonian mechanics in the course of answering those questions. (Examples include “doing almost anything in quantum mechanics” and “figuring out what quantities are conserved in a physical system”.)
The real crux is I think where I wrote: “I have yet to see any concrete algorithmic claim about the brain that was not more easily and intuitively [from my perspective] discussed without mentioning FEP.” Have you? If so, what?
Hamiltonian mechanics is applicable to both atoms and [stars]. So it’s probably a bad starting point for understanding atoms
If somebody says “As a consequence of Hamiltonian mechanics, stars burn hydrogen”, we would correctly recognize that claim as nonsense. Hamiltonian mechanics applies to everything, whereas stars burning hydrogen is a specific contingent hypothesis that might or might not be true.
That’s how I feel when I read sentences like “In order to minimize free energy, the agent learns an internal model of potential states of the environment.” Maybe the agent does, or maybe it doesn’t! The free energy principle applies to all living things by definition, whereas “learning an internal model of potential states of the environment” is a specific hypothesis about an organism, a hypothesis that might be wrong. For example (as I mentioned in a different comment), imagine a very simple organism that evolved in an extremely, or even perfectly, homogeneous environment. This organism won’t evolve any machinery for learning (or storing or querying) an internal model of potential states of the environment, right? Sure, that’s not super realistic, but it’s certainly possible in principle. And if it happened, the FEP would apply to that organism just like every other organism, right? So the sentence above is just wrong. Or we can interpret the sentence more charitably as: “The free energy principle makes it obvious that it may be evolutionarily-adaptive for an organism to learn an internal model of potential states of the environment.” But then my response is: That was already obvious, without the FEP!
Ditto for any sentence that says that anything substantive (i.e. something that might or might not be true) about how the brain works as a consequence of FEP.
3,4,5,7
I think Hamiltonian mechanics makes some important aspects of a system more confusing to think about, and other important aspects of a system much easier to think about. It’s possible that one could say that about FEP too; however, my experience is that it’s 100% the former and 0% the latter.
As above, I’m interested in hearing concrete plausible claims about how the brain works that are obvious when we think in FEP terms and non-obvious if we don’t.
↑ comment by romeostevensit · 2023-03-04T22:50:28.900Z · LW(p) · GW(p)
I agree that calling a representation an 'unfalsifiable tautology' is a type error. Representation problems are ontology, not epistemology. The relevant questions are whether they allow some computation that was intractable before.
comment by Jeff Beck (jeff-beck) · 2023-05-20T20:35:28.506Z · LW(p) · GW(p)
There is a great deal of confusion regarding the whole point of the FEP research program. Is it a tautology, does it apply to flames, etc. This is unfortunate because the goal of the research program is actually quite interesting: to come up with a good definition of an agent (or any other thing for that matter). That is why FEP proponents embrace the tautology criticism: they are proposing a mathematical definition of 'things' (using markov blankets and langevin dynamics) in order to construct precise mathematical notions of more complex and squishy concepts that separate life from non-life. Moreover, they seek to do so in a manner that is compatible with known physical theory. It may seem like overkill to try to nail down how a physical system can form a belief, but its actually pretty critical for anyone who is not a dualist. Moreover, because we dont currently have such a mathematical framework we have no idea if the manner in which we discuss life and thinking is even coherent. This about Russel's paradox. Prior to late 19th century it was considered so intuitively obvious that a set could be defined by a property that the so called axiom of unrestricted comprehension literally went without saying. Only in the attempt to formalize set theory was it discovered that this axiom had to go. By analogy, only in the attempt to construct formal description of how matter can form beliefs do we have any chance of determining if our notion of 'belief' is actually consistent with physical theories.
While I have no idea how to accomplish such an ambitious goal, it seems clear to me that the reinforcement learning paradigm is not suited to the task. This is because, in such a setting, definitions matter and the RL definition of an agent leaves a lot to be desired. In RL, an agent is defined by (a) its sensory and action space, (b) its inference engine, and (c) the reward function it is trying to maximize. Ignoring the matter of identifying sensory and action space, it should be clear this is a practical definition not a principled one as it is under-constrained. This isn't just because I can add a constant to reward without altering policy or something silly like that, it is because (1) it is not obvious how to identify the sensory and action space and (2) inference and reward are fundamentally conflated. Item (1) leads to questions like does my brain end at the base of my skull, the tips of my fingers, or the items I have arranged on my desk. The Markov blanket component of the FEP attempts to address this, and while I think it still needs work it has the right flavor. Item (2), however, is much more problematic. In RL policies are computed by convolving beliefs (the output of the inference engine) with reward and selecting the best option. This convolution + max operation means that if your model fails to predict behavior it could be because you were wrong about the inference engine or wrong about the reward function. Unfortunately, it is impossible to determine which you were wrong about without additional assumptions. For example, in MaxEntInverseRL one has to assume (incredibly) that inference is Bayes optimal and (reasonably) that equally rewarding paths are equally likely to occur. Regardless, this kind of ambiguity is a hallmark of a bad definition because it relies on a function from beliefs and reward to observations of behavior that is not uniquely invertible.
In contrast, FEP advocates propose a somewhat 'better' definition of an agent. This is accomplished by identifying the necessary properties of sensor and action spaces, i.e. they form a Markov blanket and, in a manner similar to that used in systems identification theory, define an agent's type by the statistics of that blanket. They then replace arbitrary reward functions with negative surprise. Though it doesn't quite work for very technical reasons, this has the flavor of a good definition and a necessary principle. After all, if an object or agent type is defined by the statistics of its boundary, then clearly a necessary description of what an agent is doing is that it is not straying too far from its definition.
That was more than I intended to write, but the point is that precision and consistency checks require good definitions, i.e. a tautology. On that front, the FEP is currently the only game in town. It's not a perfect principle and its presentation leaves much to be desired, but it seems to me that something very much like it will be needed if we ever wish to understand the relationship between 'mind' and matter.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-05-21T13:43:39.682Z · LW(p) · GW(p)
Thanks for the comment!
Your comment is a bit funny to me because I think of algorithms and definitions as kinda different topics. In particular, I think of RL as a family of algorithms, not as a definition of an agent.
If I have I have a robot running an RL algorithm, and I have a sufficiently thorough understanding of how the algorithm works and how the robot works, then I can answer any question about what the robot will do, but I haven’t necessarily made any progress at all on the question of “what are its beliefs?” or “is it an agent?” For example, we can easily come up with edge cases where the question “what do I (Steve) believe?” has an unclear answer, even knowing everything about how I behave and how my brain works. (E.g. if I explicitly deny X but act in other ways as if I believe X, then is X part of my “beliefs”? Or if I give different answers about X depending on context and framing? Etc.)
Conversely, I presume that if we had a rigorous mathematical definition of “beliefs” and “agents” and whatever, it would not immediately tell us the answers to algorithms questions like how to build artificial general intelligence or how the brain works.
In terms of definitions: If FEP people someday use FEP to construct a definition of “agent” that reproduces common sense, e.g. I'm an agent, a rock isn't an agent, a flame isn't an agent, etc., then I’d be interested to see it. And if I thought that this definition had any kernel of truth, the first thing I’d try to do is reformulate that definition in a way that doesn't explicitly mention FEP. If I found that this was impossible or pointlessly convoluted, then I would count that as the first good reason to talk about FEP. I am currently skeptical that any part of that is going to actually happen.
As it happens, I have some friends in AGI safety & alignment interested in the question of how to define agency, goals, etc. (e.g. 1 [? · GW],2 [? · GW]). I guess I find such work slightly helpful sometimes. I’ve gone back to this post [LW · GW] a couple times, for example. (I have not found the FEP-centric discussions in this vein to be helpful.) But by and large, I mostly don’t see it as very central to my main interest of safe and beneficial AGI. Again, if I have I have a robot running a certain algorithm, and I understand that algorithm well enough, then I can answer any question about what the robot will do. And that’s what I care about. If I don’t know a rigorous definition of “what the robot believes”, but I can still answer any question about what the robot will do and why, then I don’t really feel like I’m missing anything important.
You bring up the difficulty of defining the interface separating an algorithm’s actuators from the world. Amusingly, you take that observation as evidence that we need FEP to come up with good definitions, and I take that same observation as evidence that there is no good definition, it’s inherently an arbitrary thing and really there isn’t anything here to define and we shouldn’t be arguing about it in the first place. :-P
In terms of algorithms: I agree that there are interesting questions related to building a reinforcement learning algorithm that is not subject to wishful thinking, or at least that is minimally subject to wishful thinking. (I consider humans to be “minimally subject to wishful thinking”, in the sense that it obviously happens sometimes, but it happens much less than it might happen, e.g. I don’t keep opening my wallet expecting to find a giant wad of cash inside.) I feel like I personally have a pretty good handle on how that potential issue is mitigated in the human brain, after a whole lot of time thinking about it. I think it centrally involves the fact that the human brain use model-based actor-critic RL, and the model is not updated to maximize reward but rather updated using (a generalization of) self-supervised learning on sensory predictions. And likewise the critic is (obviously) not updated to maximize rewards but rather updated to estimate reward using (a variant of) TD learning.
(See my post Reward Is Not Enough [LW · GW] for example.)
In principle it’s possible that I would learn something new and helpful about the question of wishful thinking by reading more FEP literature, but my personal experience is very strongly in the opposite direction, i.e. that FEP people are typically way more confused about this topic than pretty much anyone else, e.g. their proposed solutions actually make the problem much much worse, but also make everything sufficiently confusing / obfuscated that they don’t realize it. Basically, a good solution to wishful thinking involves working hard to separate plans/inclinations/desires from beliefs, and in particular updating them in different ways, whereas FEP people want to go in the opposite direction by mixing plans/inclinations/desires & beliefs together into one big unified framework. Interestingly, one of the first things I read when I was starting in that area was an FEP-ish book (Surfing Uncertainty), and I consider that much of my subsequent progress involved “un-learning” many of the ideas I had gotten out of that book. ¯\_(ツ)_/¯
Replies from: jeff-beck↑ comment by Jeff Beck (jeff-beck) · 2023-05-21T21:02:22.840Z · LW(p) · GW(p)
I will certainly agree that a big problem for the FEP is related to its presentation. They start with the equations of mathematical physics and show how to get from there to information theory, inference, beliefs, etc. This is because they are trying to get from matter to mind. But they could have gone the other way since all the equations of mathematical physics have an information theoretic derivation that includes a notion of free energy. This means that all the stuff about Langevin dynamics of sparsely connected systems (the 'particular' fep) could have been included as a footnote in a much simpler derivation.
As you note, the other problem with the FEP is that it seems to add very little to the dominant RL framework. I would argue that this is because they are really not interested in designing better agents, but rather in figuring out what it means for mind to arise from matter. So basically it is physics inspired philosophy of mind, which does sound like something that has no utility whatsoever. But explanatory paradigms can open up new ways of thinking.
For example, relevant to your interests, it turns out that the FEP definition of an agent has the potential to bypass one of the more troubling AI safety concerns associated with RL. When using RL there is a substantial concern that straight-up optimizing a reward function can lead to undesirable results, i.e. the imperative to 'end world hunger' leads to 'kill all humans'. In contrast, in the standard formulation of the FEP the reward function is replaced by a stationary distribution over actions and outcomes. This suggests the following paradigm for developing a safer AI agent. Observe human decision making in some area to get a stationary distribution over actions and outcomes that are considered acceptable but perhaps not optimal. Optimize the free energy of the expected future (FEEF) applied to the observed distribution of actions and outcomes (instead of just outcomes as is usually done) to train an agent to reproduce human decision-making behavior. Assuming it works you now have an automated decision maker that, on average, replicates human behavior, i.e you have an agent that is weakly equivalent to the average human. Now suppose that there are certain outcomes that we would like to make happen more frequently than human decision-makers have been able to achieve, but don't want the algorithm to take any drastic actions. No problem: train a second agent to produce this new distribution of outcomes while keeping the stationary distribution over actions the same.
This is not guaranteed to work as some outcome distributions are inaccessible, but one could conceive an iterative process where you explore the space of accessible outcome distributions by slightly perturbing the outcome distribution and retraining and repeating...
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-05-22T18:09:29.825Z · LW(p) · GW(p)
I’m generally in favor of figuring out how to make AIs that are inclined to follow human norms / take human-typical actions / share human-typical preferences and can still do human-level R&D etc.
That seems hard basically for reasons here [AF · GW] (section “recognizing human actions in data”) and the fact that most actions are invisible (e.g. brainstorming), and the fact that innovation inevitably entails going out of distribution.
But first I have a more basic question where I’m confused about your perspective:
- Do you think it’s possible for the exact same source code to be either a “FEP agent” or an “RL agent” depending on how you want to think about things?
- Or do you think “FEP agent” and “RL agent” are two different families of algorithms? (Possibly overlapping?)
- And if it’s this, do you think both families of algorithms include algorithms that can do human-level scientific R&D, invent tools, design & build factories, etc.? Or if you think just one of the two families of algorithms can do those things, which one?
- And which family of algorithms (or both) would you put the human brain into?
Thanks!
Replies from: jeff-beck↑ comment by Jeff Beck (jeff-beck) · 2023-05-24T16:39:30.134Z · LW(p) · GW(p)
The short answer is that, in a POMDP setting, FEP agents and RL agents can be mapped one onto the other via appropriate choice of reward function and inference algorithm. One of the goals of the FEP is to come with a normative definition of the reward function (google the misleadingly titled "optimal control without cost functions" paper or, for a non-FEP version of the same, thing google the accurately titled: "Revisiting Maximum Entropy Inverse Reinforcement Learning"). Despite the very different approaches, the underlying mathematics is very similar as both are strongly tied to KL control theory and Jaynes' maximum entropy principle. But the ultimate difference between FEP and RL in a POMDP setting is how an agent is defined. RL needs an inference algorithm and a reward function that operates on action and outcomes, R(o,a). The FEP needs stationary blanket statistics, p(o,a), and nothing else. The inverse reinforcement paper shows how to go from p(o,a) to a unique R(o,a) assuming a bayes optimal RL agent in a MDP setting. Similarly, if you start with R(o,a) and optimize it, you get a stationary distribution, p(o,a). This distribution is also unique under some 'mild' conditions. So they are more or less equivalent in terms of expressive power. Indeed, you can generalize all this crap to show any subsystem of any physical system can be mathematically described as Bayes optimal RL agent. You can even identify the reward function with a little work. I believe this is why we intuitively anthropomorphize physical systems, i.e. when we say things like they system is "seeking" a minimum energy state.
But regardless, from a pragmatic perspective they are equally expressive mathematical systems. The advantage of one over the other depends upon your prior knowledge and goals. If you know the reward function and have knowledge of how the world works use RL. If you know the reward function but are in a POMDP setting without knowledge of how the world works, use an information seeking version of RL (maxentRL or BayesianRL). If you dont know the reward function but do know how the world works and have observations of behavior use max ent inverseRL).
The problem with RL is that its unclear how to use it when you don't know how the world works and you don't know what the reward function is, but do have observations of behavior. This is the situation when you are modeling behavior as in the url you cited. In this setting, we don't know what model humans are using to form their inferences and we don't know what motivates their behavior. If we are lucky we can glean some notion of their policy by observing behavior, but usually that notion is very coarse i.e. we may only know the average distribution of their actions and observations, p(o,a). The utility of the FEP is that p(o,a) defines the agent all by itself. This means we can start with a policy and infer both belief and reward. This is not something RL was designed to do. RL is for going from reward and belief (or belief formation rules) to policy, not the other way around. IRL can go backward, but only if your beliefs are Bayes optimal.
As for the human brain, I am fully committed to the Helmholtzian notion that the brain is a statistical learning machine as in the Bayesian brain hypothesis with the added caveat that it is important to remember that the brain is massively suboptimal.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-05-26T15:20:03.521Z · LW(p) · GW(p)
Thanks again! Feel free to stop responding if you’re busy.
Here’s where I’m at so far. Let’s forget about human brains and just talk about how we should design an AGI.
One thing we can do is design an AGI whose source code straightforwardly resembles model-based reinforcement learning. So the code has data structures for a critic / value-function, and a reward function, and TD learning, and a world-model, and so on.
- This has the advantage that (I claim) it can actually work. (Not today, but after further algorithmic progress.) After all, I am confident that human brains have all those things (critic ≈ striatum, TD learning ≈ dopamine, etc.) [AF · GW] and the human brain can do lots of impressive things, like go to the moon invent and quantum mechanics and so on.
- But it also has a disadvantage that it’s unclear how to make the AGI motivated to act in a human-like way and follow human norms. It’s not impossible, evidently—after all, I am a human and I am at least somewhat motivated to follow human norms, and when someone I greatly admire starts doing X or wanting X, then I also am more inclined to start doing X and wanting X. But it’s unclear how this works in terms of my brain’s reward functions / loss functions / neural architecture / whatever—or at least, it’s presently unclear to me. (It is one of my major areas of research interest, and I think I’m making gradual progress, but as of now I don’t have any good & complete answer.)
A different thing we can do is design an AGI whose source code straightforwardly resembles active inference / FEP. So the code has, umm, I’m not sure, something about generative models and probability distributions? But it definitely does NOT have a reward function or critic / value-function etc.
- This has the advantage that (according to you, IIUC) there’s a straightforward way to make the AGI act in a human-like way and follow human norms.
- And it has the disadvantage that I’m somewhat skeptical that it will ever be possible to actually code up an AGI that way.
So I’m pretty confused here.
For one thing, I’m not yet convinced that the first bullet point is actually straightforward (or even possible). Maybe I didn’t follow your previous response. Some of my concerns are: (1) most human actions are not visible (e.g. deciding what to think about, recalling a memory), (2) even the ones that are visible in principle are very hard to extract in practice (e.g. did I move deliberately or did was that a random jostle or gust of wind?) (3) almost all “outcomes” of interest in the AGI context are outcomes that have never happened in the training data, e.g. the AGI can invent a new gadget which no human had ever previously invented. So I’m not sure how you get p(o,a) from observations of humans.
For the second thing, among other issues, it seems to me that building a beyond-human-level understanding of the world requires RL-type trial-and-error exploration, for reasons in Section 1.1 here [LW · GW].
comment by Roman Leventov · 2023-03-03T07:51:21.361Z · LW(p) · GW(p)
2. The FEP is applicable to both bacteria and human brains. So it’s probably a bad starting point for understanding how human brains work
[...]
Yet FEP applies equally well to bacteria and humans.So it seems very odd to expect that FEP would be a helpful first step towards answering these questions.
I don't understand what the terms "starting point" and "first step" mean in application to a theory/framework. The FEP is a general framework, whose value lies mainly in being a general framework: proving the base ontology for thinking about intelligence and agency, and classifying various phenomena and aspects of more concrete theories (e.g., theories of brain function) in terms of this ontology.
This role of a general framework is particularly valuable in discussing the soundness of the scalable strategies for aligning AIs with a priori unknown architecture. We don't know whether the first AGI will be an RL agent or a decision Transformer or H-JEPA agent or a swarm intelligence, etc. And we don't know in what direction the AGI architecture will evolve (whether via self-modification or not). The FEP ontology might be one of the very few physics-based (this is an important qualification) ontologies that allow discussing agents on such a high level. Other two ontologies that I have heard of are thermodynamic machine learning (Boyd, Crutchfield, and Gu, Sep 2022) and the MCR^2 (maximal coding rate reduction) principle (Ma, Tsao, and Shum, Jul 2022).
comment by Noosphere89 (sharmake-farah) · 2025-01-07T21:58:18.356Z · LW(p) · GW(p)
I broadly agree with the post on the Free Energy Principle, but I do think some clarifications are called for here, so I'll do so:
For example, I'll elaborate on what these quotes mean here:
It is widely accepted that FEP is an unfalsifiable tautology, including by proponents—see for example Beren Millidge, or Friston himself.
By the same token, once we find a computer-verified proof of any math theorem, we have revealed that it too is an unfalsifiable tautology. Even Fermat’s Last Theorem is now known to be a direct logical consequence of the axioms of math—arguably just a fancy way of writing 0=0.
So again, FEP is an unfalsifiable tautology. What does that mean in practice? Well, It means that I am entitled to never think about FEP. Anything that you can derive from FEP, you can derive directly from the same underlying premises from which FEP itself can be proven, without ever mentioning FEP.
(The underlying premises in question are something like “it’s a thing with homeostasis and bodily integrity”. So, by the way: if someone tells you “FEP implies organisms do X”, and if you can think of an extremely simple toy model of something with homeostasis & bodily integrity that doesn’t do X, then you can go tell that person that they’re wrong about what FEP implies!)
And this:
If somebody says “As a consequence of Hamiltonian mechanics, stars burn hydrogen”, we would correctly recognize that claim as nonsense. Hamiltonian mechanics applies to everything, whereas stars burning hydrogen is a specific contingent hypothesis that might or might not be true.
That’s how I feel when I read sentences like “In order to minimize free energy, the agent learns an internal model of potential states of the environment.” Maybe the agent does, or maybe it doesn’t! The free energy principle applies to all living things by definition, whereas “learning an internal model of potential states of the environment” is a specific hypothesis about an organism, a hypothesis that might be wrong. For example (as I mentioned in a different comment), imagine a very simple organism that evolved in an extremely, or even perfectly, homogeneous environment. This organism won’t evolve any machinery for learning (or storing or querying) an internal model of potential states of the environment, right? Sure, that’s not super realistic, but it’s certainly possible in principle. And if it happened, the FEP would apply to that organism just like every other organism, right? So the sentence above is just wrong. Or we can interpret the sentence more charitably as: “The free energy principle makes it obvious that it may be evolutionarily-adaptive for an organism to learn an internal model of potential states of the environment.” But then my response is: That was already obvious, without the FEP!
It's definitely true that theories that apply to everything have little to nothing to say about their contents, and the reason for this is basically related to the conservation of expected evidence rule in Bayes's theorem, which states that for every expectation of evidence, there is an equal and opposite expectation of counter-evidence, and if a theory doesn't have that counter-evidence, it's either a logical theory in which the tautologies are always true, or your theory is too general to explain something.
Thus, a theory that tries to apply to everything can't really predict any empirical phenomenon (which is defined as a phenomenon that applies only sometimes, where there exists a possibility of not having it, and a possibility of having that.):
Jeff Beck does have an interesting counterargument, where the FEP/Active Inference is there to mathematically define agency and life from it's complement/negation, and suggests a parallel to Russell's paradox in the 19th century on why formalizing agency is necessary, because the mathematics/set theories people intuitively have often turn out to have inconsistencies, which is disastrous for any attempt at distinguishing true from false statements, and thus people work in formalized set theories like ZFC, which restrains the paradoxes of naive set theory, and this is caused by people not being logically ominisicent for computational reasons, and a Bayesian would never have logically inconsistent hypotheses in it's sample space due to logical omnisicence.
https://www.lesswrong.com/posts/MArdnet7pwgALaeKs/why-i-m-not-into-the-free-energy-principle#QaGuuYXPnpDqDQKCL [LW(p) · GW(p)]
The issue is Markov blankets don't actually work to formalize important stuff in the way that FEP people imagine, see here:
https://www.lesswrong.com/posts/vmfNaKbZ6urMdQrv2/agent-boundaries-aren-t-markov-blankets-unless-they-re-non [LW · GW]
More generally, I consider formalization for safety to be mostly not useful for AI safety, due to the timelines becoming shorter than they used to.
Finally, while I agree that “Changing your predictions to match the world” problem and “Changing the world to match your predictions” problem does have different algorithmic solutions in the brain, which makes it bad from a descriptive perspective, it's still possible that the two domains are able to be unified more then they currently have, see here:
https://www.lesswrong.com/posts/8dbimB7EJXuYxmteW/fixdt [LW · GW]
While I personally think FEP is way overrated by it's practitioners, I do think some elements of their agenda are interesting enough to pursue as separate threads.
I think it's fine staying at 0.
comment by AntonS · 2023-07-05T03:30:48.303Z · LW(p) · GW(p)
Thanks, very interesting discussion! Let me add some additional concerns pertaining to FEP theory:
- Markov blankets, to the best of my knowledge, have never been derived, either precisely or approximately, for physical systems. Meanwhile, they play the key role in all subsequent derivations in FEP. Markov blankets don't seem to me as fundamental as entropy, free energy, etc., to be just postulated. Or, if they are introduced as an assumption, it would be worthwhile to affirm that this assumption is feasible for the real-world systems, justifying their key role in the theory.
- The Helmholtz-Ao decomposition refers to the leading term in the series expansion in terms of (or the effective noise temperature ) as a small parameter. Consequently, subsequent equations in FEP are exact only at the potential function's global minimum. In other words, we can't make any exact conclusions about the states of the brain or the environment, except for the only state with the highest probability density at steady state. Perhaps adding higher-order terms (in or ) to the Helmholtz-Ao decomposition could fix this, but I’ve never seen such attempts in FEP papers.
Also, a nice review by Millidge, Seth, Buckley (2021) lists several dozens of assumptions required for FEP. The assumption I find most problematic is that the environment is presumed to be at steady state. This appears intuitively at odds with the biological scenarios of the emergence of the nervous system and the human brain.
Replies from: winstonne↑ comment by winstonne · 2023-11-15T20:51:00.283Z · LW(p) · GW(p)
> Markov blankets, to the best of my knowledge, have never been derived, either precisely or approximately, for physical systems
This paper does just that. It introduces a 'blanket index' by which any state space can be analyzed to see whether a markov blanket assumption is suitable or not. Quoting MJD Ramstead's summary of the paper's results with respect to the markov blanket assumption:
We now know that, in the limit of increasing dimensionality, essentially all systems (both linear and nonlinear) will have Markov blankets, in the appropriate sense. That is, as both linear and nonlinear systems become increasingly high-dimensional, the probability of finding a Markov blanket between subsets approaches 1.
The assumption I find most problematic is that the environment is presumed to be at steady state
Note the assumption is that the environment is at a nonequilibrium steady state, not a heat-death-of-the-universe steady state. My reading of this is that it is an explicit assumption that probabilistic inference is possible.
comment by [deleted] · 2023-05-22T20:05:24.737Z · LW(p) · GW(p)
Interesting, I first heard about FEP when I was looking for articles on Korzybski and I found this paper- https://link.springer.com/article/10.1007/s10539-021-09807-0 And then I realized that Donald Hoffman used such words - math is not a territory - in his "Case Against Reality", in which he is somehow close to Anil Seth's conclusions. Anyway, I guess it boils down to problem of choosing scientific model that will work well and nothing more, as I see it at this moment. Thanks for the post, I enjoyed it.
comment by Roman Leventov · 2023-03-03T09:31:31.747Z · LW(p) · GW(p)
In section 4, you discuss two different things, that ought to be discussed separately. The first thing is the discussion of whether thinking about the systems that are explicitly engineered as RL agents (or, generally, with any other explicit AI architecture apart from the Active Inference architecture itself) is useful:
4. Likewise, it’s easier to think of a reinforcement learning (RL) system as an RL system, and not as an active inference system
[...] actual RL practitioners almost universally don’t find the galaxy-brain perspective to be helpful.
I would say that whether it's "easier to think" about RL agents as Active Inference agents (which you can do, see below) depends on what you are thinking about, exactly.
I think there is one direction of thinking that is significantly aided by applying the Active Inference perspective: it's thinking about the ontology of agency (goals, objectives, rewards, optimisers and optimisation targets, goal-directedness, self-awareness, and related things). Under the Active Inference ontology, all these concepts that keep bewildering and confusing people on LW/AF and beyond acquire quite straightforward interpretations. Goals are just beliefs about the future. Rewards are constraints on the physical dynamics of the system that in turn lead to shaping this-or-that beliefs, as per the FEP and CMEP (Ramstead et al., 2023). Goal-directedness is a "strange loop" belief that one is an agent with goals[1]. (I'm currently writing an article where I elaborate on all these interpretations.)
This ontology also becomes useful in discussing agency in LLMs, which is a very different architecture from RL agents. This ontology also saves one from ontological confusion wrt. agency (or lack thereof) in LLMs.
Second is the discussion of agency in systems that are not explicitly engineered as RL agents (or Active Inference agents, for that matter):
Consider a cold-blooded lizard that goes to warm spots when it feels cold and cold spots when it feels hot. Suppose (for the sake of argument) that what’s happening behind the scenes is an RL algorithm in its brain, whose reward function is external temperature when the lizard feels cold, and whose reward function is negative external temperature when the lizard feels hot.
- We can talk about this in the “normal” way, as a certain RL algorithm with a certain reward function, as per the previous sentence.
- …Or we can talk about this in the galaxy-brain “active inference” way, where the lizard is (implicitly) “predicting” that its body temperature will remain constant, and taking actions to make this “prediction” come true.
I claim that we should think about it in the normal way. I think that the galaxy-brain “active inference” perspective is just adding a lot of confusion for no benefit.
Imposing an RL algorithm on the dynamics of the lizard's brain and body is no more justified than imposing the Active Inference algorithm on it. Therefore, there is no ground for calling the first "normal" and the second "galaxy brained": it's normal scientific work to find which algorithm predicts the behaviour of the lizard better.
There is a methodological reason to choose the Active Inference theory of agency, though: it is more generic[2]. Active Inference recovers RL (with or without entropy regularisation) as limit cases, but the inverse is not true:
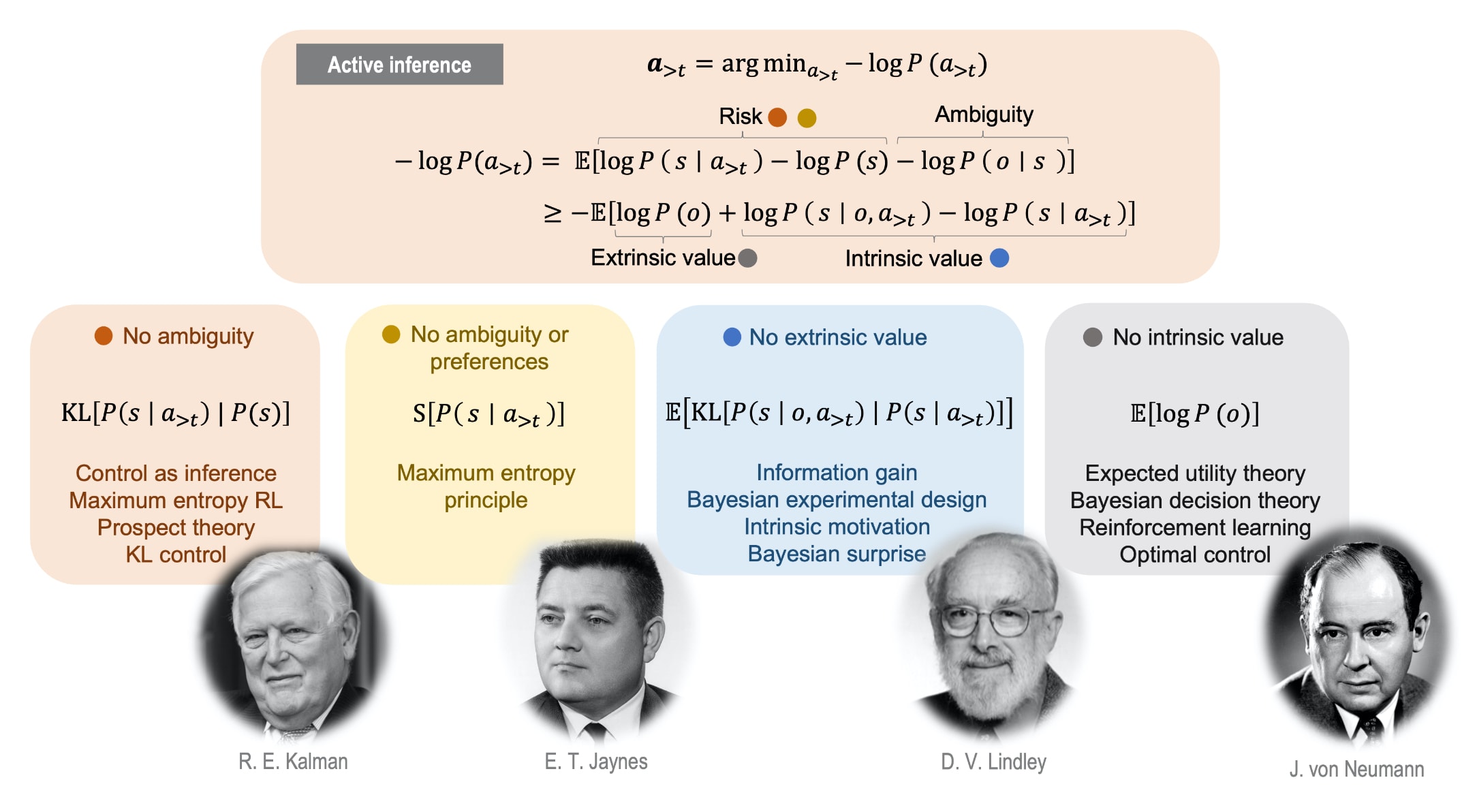
(Reproduced Figure 3 from Barp et al., Jul 2022.)
We can spare the work of deciding whether a lizard acts as a maximum entropy RL agent or an Active Inference agent because, under the statistical limit of systems whose internal dynamics follow their path of least action exactly (such systems are called precise agents in Barp et al., Jul 2022 and conservative particles in Friston et al., Nov 2022) and whose sensory observations don't exhibit random fluctuations, there is "no ambiguity" in the decision making under Active Inference (calling this "no ambiguity could be somewhat confusing, but it is what it is), and thus Active Inference becomes maximum entropy RL (Haarnoja et al., 2018) exactly. So, you can think of a lizard (or a human, of course) as a maximum entropy RL agent, it's conformant with Active Inference.
- ^
Cf. Joscha Bach's description [LW · GW] of the formation of this "strange loop" belief in biological organisms: "We have a loop between our intentions and the actions that we perform that our body executes, and the observations that we are making and the feedback that they have on our interoception giving rise to new intentions. And only in the context of this loop, I believe, can we discover that we have a body. The body is not given, it is discovered together with our intentions and our actions and the world itself. So, all these parts depend crucially on each other so that we can notice them. We basically discover this loop as a model of our own agency."
- ^
Note, however, that there is no claim that Active Inference is the ultimately generic theory of agency. In fact, it is already clear that it is not the ultimately generic theory, because it doesn't account for the fact that most cognitive systems won't be able to combine all their beliefs into a single, Bayes-coherent multi-factor belief structure (the problem of intrinsic contextuality). The "ultimate" decision theory should be quantum. See Basieva et al. (2021), Pothos & Busemeyer (2022), and Fields & Glazebrook (2022) for some recent reviews, and Fields et al. (2022a) and Tanaka et al. (2022) for examples of recent work. Active Inference could, perhaps, still serve as a useful tool for ontologising the effectively classic agency, or a Bayes-coherent "thread of agency" by a system. However, I regard the problem of intrinsic contextuality as the main "threat" to the FEP and Active Inference. The work for updating the FEP theory so that it accounts for intrinsic contextuality has recently started (Fields et al., 2022a; 2022b).
↑ comment by Steven Byrnes (steve2152) · 2023-03-03T15:16:04.313Z · LW(p) · GW(p)
it's normal scientific work to find which algorithm predicts the behaviour of the lizard better
I’m confused. Everyone including Friston says FEP is an unfalsifiable tautology—if a lizard brain does X, and it’s not totally impossible for such a lizard to remain alive and have bodily integrity, then the prediction of FEP is always “Yes it is possible for the lizard brain to do X”.
The way you’re talking here seems to suggest that FEP is making more specific predictions than that, e.g. you seem to be implying that there’s such a thing as an “Active Inference agent” that is different from an RL agent (I think?), which would mean that you are sneaking in additional hypotheses beyond FEP itself, right? If so, what are those hypotheses? Or sorry if I’m misunderstanding.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-03T16:08:10.467Z · LW(p) · GW(p)
The way you’re talking here seems to suggest that FEP is making more specific predictions than that, e.g. you seem to be implying that there’s such a thing as an “Active Inference agent” that is different from an RL agent (I think?), which would mean that you are sneaking in additional hypotheses beyond FEP itself, right? If so, what are those hypotheses? Or sorry if I’m misunderstanding.
Yes, this is right. FEP != Active Inference. I deal with this at length in another comment [LW(p) · GW(p)]. Two additional assumptions are: 1) the agent "holds" (in some sense, whether representationalist or enactivist is less important here) beliefs about the future, whereas in FEP, the system only holds beliefs about the present. 2) The agent selects action so as to minimise expected free energy (EFE) wrt. these beliefs about the future. (Action selection, or decision making, is entirely absent in the FEP, which is simply a dynamicist "background" for Active Inference, which simply explains what these beliefs in Active Inference are; when you start talking about action selection or decision making, you imply causal symmetry breaking)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-04T14:07:17.789Z · LW(p) · GW(p)
Can you give a concrete example of a thing that has homeostasis / bodily integrity / etc. (and therefore FEP applies to it), but for which it is incorrect (not just unhelpful but actually technically incorrect) to call this thing an Active Inference agent?
(I would have guessed that “a room with a mechanical thermostat & space heater” would be an example of that, i.e. a thing for which FEP applies but which is NOT an Active Inference agent. But nope! Your other comment [LW(p) · GW(p)] says that “a room with a mechanical thermostat & space heater” is in fact an Active Inference agent.)
↑ comment by Steven Byrnes (steve2152) · 2023-03-03T15:04:49.210Z · LW(p) · GW(p)
Imposing an RL algorithm on the dynamics of the lizard's brain and body is no more justified than imposing the Active Inference algorithm on it.
I think you misunderstood (or missed) the part where I wrote “Suppose (for the sake of argument) that what’s happening behind the scenes is an RL algorithm in its brain, whose reward function is external temperature when the lizard feels cold, and whose reward function is negative external temperature when the lizard feels hot.”
What I’m saying here is that RL is not a thing I am “imposing” on the lizard brain—it’s how the brain actually works (in this for-the-sake-of-argument hypothetical).
Pick your favorite RL algorithm—let’s say PPO. And imagine that when we look inside this lizard brain we find every step of the PPO algorithm implemented in neurons in a way that exactly parallels, line-by-line, how PPO works in the textbooks. “Aha”, you say, “look at the pattern of synapses in this group of 10,000 neurons, this turns out to be exactly how you would wire together neurons to calculate the KL divergence of (blah blah blah). And look at that group of neurons! It is configured in the exact right way to double the β parameter when the divergence is too high. And look at …” etc. etc.
Is this realistic? No. Lizard brains do not literally implement the PPO algorithm. But they could in principle, and if they did, we would find that the lizards move around in a way that effectively maintains their body temperature. And FEP would apply to those hypothetical lizard brains, just like FEP applies by definition to everything with bodily integrity etc. But here we can say that the person who says “the lizard brain is running an RL algorithm, namely PPO with thus-and-such reward function” is correctly describing a gears-level model of this hypothetical lizard brain. They are not “imposing” anything! Whereas the person who says “the lizard is ‘predicting’ that its body temperature will be constant” is not doing that. The latter person is much farther away from understanding this hypothetical lizard brain than the former person, right?
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-03T16:18:41.581Z · LW(p) · GW(p)
Yes, I mentally skipped the part when you created "artificial lizard with RL architecture" (that was unexpected). Then, the argument collapses to the first part of the comment to which you are replying: gears-level is more precise, of course, but "birds-eye view" of Active Inference could give you the concepts for thinking about agency, persuadability (aka corrigibility), etc., without the need to re-invent them, and without spawning a plethora of concepts which don't make sense in the abstract and are specific for each AI algorithm/architecture (such as, the concept of "reward" is not a fundamental concept of alignment, because it applies to RL agents, but doesn't apply to LLMs, which are also agents).
comment by Roman Leventov · 2023-03-03T07:30:16.844Z · LW(p) · GW(p)
I have yet to see any concrete algorithmic claim about the brain that was not more easily and intuitively [from my perspective] discussed without mentioning FEP.
There is a claim about a brain, but a neural organoid: "We develop DishBrain, a system that harnesses the inherent adaptive computation of neurons in a structured environment. In vitro neural networks from human or rodent origins are integrated with in silico computing via a high-density multielectrode array. Through electrophysiological stimulation and recording, cultures are embedded in a simulated game-world, mimicking the arcade game “Pong.” Applying implications from the theory of active inference via the free energy principle, we find apparent learning within five minutes of real-time gameplay not observed in control conditions. Further experiments demonstrate the importance of closed-loop structured feedback in eliciting learning over time. Cultures display the ability to self-organize activity in a goal-directed manner in response to sparse sensory information about the consequences of their actions, which we term synthetic biological intelligence." (Kagan et al., Oct 2022). It's arguably hard (unless you can demonstrate that it's easy) to make sense of the DishBrain experiment not through the FEP/Active Inference lens, even though it should be possible, as you rightly highlighted: the FEP is a mathematical tool that should help to make sense of the world (i.e., doing physics), by providing a principled way of doing physics on the level of beliefs, a.k.a. Bayesian mechanics (Ramstead et al., Feb 2023).
It's interesting that you mention Noether's theorem, because in the "Bayesian mechanics" paper, the authors use it as the example as well, essentially repeating something very close to what you have said in section 1:
To sum up: principles like the FEP, the CMEP, Noether’s theorem, and the principle of stationary action are mathematical structures that we can use to develop mechanical theories (which are also mathematical structures) that model the dynamics of various classes of physical systems (which are also mathematical structures). That is, we use them to derive the mechanics of a system (a set of equations of motion); which, in turn, are used to derive or explain dynamics. A principle is thus a piece of mathematical reasoning, which can be developed into a method; that is, it can applied methodically—and more or less fruitfully—to specific situations. Scientists use these principles to provide an interpretation of these mechanical theories. If mechanics explain what a system is doing, in terms of systems of equations of movement, principles explain why. From there, scientists leverage mechanical theories for specific applications. In most practical applications (e.g., in experimental settings), they are used to make sense of a specific set of empirical phenomena (in particular, to explain empirically what we have called their dynamics). And when so applied, mechanical theories become empirical theories in the ordinary sense: specific aspects of the formalism (e.g., the parameters and updates of some model) are systematically related to some target empirical phenomena of interest. So, mechanical theories can be subjected to experimental verification by giving the components specific empirical interpretation. Real experimental verification of theories, in turn, is more about evaluating the evidence that some data set provides for some models, than it is about falsifying any specific model per se. Moreover, the fact that the mechanical theories and principles of physics can be used to say something interesting about real physical systems at all—indeed, the striking empirical fact that all physical systems appear to conform to the mechanical theories derived from these principles; see, e.g., [81]—is distinct from the mathematical “truth” (i.e., consistency) of these principles.
Note that the FEP theory has developed significantly only in the last year or so: apart from these two references above, the shift to the path-tracking (a.k.a. path integral) formulation of the FEP (Friston et al., Nov 2022) for systems without NESS (non-equilibrium steady state) has been significant. So, judging the FEP on pre-2022 work may not do it justice.
comment by Review Bot · 2024-04-02T19:04:53.958Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by Roman Leventov · 2023-03-03T13:07:29.231Z · LW(p) · GW(p)
I combined all my responses, section by section, in a post [LW · GW].
comment by Roman Leventov · 2023-03-03T11:55:04.001Z · LW(p) · GW(p)
7. “Changing your predictions to match the world” and “Changing the world to match your predictions” are (at least partly) two different systems / algorithms in the brain. So lumping them together is counterproductive
The title of this section contradicts the ensuing text. The title says that recognition and action selection (plus planning, if the system is sufficiently advanced) are "at least partially" two different algorithms. Well, yes, they could, and almost always are implemented separately, in one or another way. But we also should look at the emergent algorithm that comes out of coupling these two algorithms (they are physically lumped, because they are situated within a single system, like a brain, which you pragmatically should model as a unified whole).
So, the statement that considering these two algorithms as a whole is "counterproductive" doesn't make sense to me, just as saying that in GAN, you should consider only the two DNNs separately, rather than the dynamics of the coupled architecture. You should also look at the algorithms separately, of course, at the "gears level" (or, we can call it the mechanistic interpretability level [LW · GW]), but it doesn't make the unified view perspective counterproductive. The are both productive.
Since they’re (at least partly) two different algorithms, unifying them is a way of moving away from a “gears-level [? · GW]” understanding of how the brain works. They shouldn’t be the same thing in your mental model, if they’re not the same thing in the brain.
As I also mentioned in another comment, moving up the abstraction stack is useful as well as moving down [LW · GW].
Then, in the text of the section, you also say something stronger than these two algorithms are "at least partially" separate algorithms, but that they "can't be" the same algorithm:
Yes they sound related. Yes you can write one equation that unifies them. But they can’t be the same algorithm, for the following reason:
- “Changing your predictions to match the world” is a (self-) supervised learning problem. When a prediction fails, there’s a ground truth about what you should have predicted instead. More technically, you get a full error gradient “for free” with each query, at least in principle. Both ML algorithms and brains use those sensory prediction errors to update internal models, in a way that relies on the rich high-dimensional error information that arrives immediately-after-the-fact.
- “Changing the world to match your predictions” is a reinforcement learning (RL) problem. No matter what action you take, there is no ground truth about what action you counterfactually should have taken. So you can’t use a supervised learning algorithm. You need a different algorithm.
I think you miss the perspective that justifies that perception and action should be considered within a single algorithm, namely, the pragmatics of perception. In "Being You" (2021), Anil Seth writes:
Action is inseparable from perception. Perception and action are so tightly coupled that they determine and define each other. Every action alters perception by changing the incoming sensory data, and every perception is the way it is in order to help guide action. There is simply no point to perception in the absence of action. We perceive the world around us in order to act effectively within it, to achieve our goals and – in the long run – to promote our prospects of survival. We don’t perceive the world as it is, we perceive it as it is useful for us to do so.
It may even be that action comes first. Instead of picturing the brain as reaching perceptual best guesses in order to then guide behaviour, we can think of brains as fundamentally in the business of generating actions, and continually calibrating these actions using sensory signals, so as to best achieve the organism’s goals. This view casts the brain as an intrinsically dynamic, active system, continually probing its environment and examining the consequences.
In predictive processing, action and perception are two sides of the same coin. Both are underpinned by the minimisation of sensory prediction errors. Until now, I’ve described this minimisation process in terms of updating perceptual predictions, but this is not the only possibility. Prediction errors can also be quenched by performing actions in order to change the sensory data, so that the new sensory data matches an existing prediction.
The pragmatics of perception don't allow considering self-supervised learning in complete isolation from the action-selection algorithm.
comment by Roman Leventov · 2023-03-03T10:56:06.467Z · LW(p) · GW(p)
6. FEP-adjacent literature is also sometimes bad at distinguishing within-lifetime learning from evolutionary learning
I think good literature that conceptualises evolutionary learning under the FEP has only started to appear last year (Kuchling et al., 2022; Fields et al., 2022b).
comment by Roman Leventov · 2023-03-03T10:47:37.485Z · LW(p) · GW(p)
5. It’s very important to distinguish explicit prediction from implicit prediction—and FEP-adjacent literature is very bad at this
It's hard to criticise this section because it doesn't define "explicit" and "implicit" prediction. If it's about representationalism vs. enactivism, then I should only point here that there are many philosophical papers that discuss this in excruciating detail, including the questions of what "representation" really is, and whether it is really important to distinguish representation and "enacted beliefs" (Ramstead et al., 2020; Constant et al., 2021; Sims & Pezzulo, 2021; Fields et al., 2022a; Ramstead et al., 2022b). Disclaimer: most of this literature, even though authored by "FEP-sided" people, does not reject represenationalism, but rather leans towards different ways of "unifying" representationalism and enactivism. I scarcely understand this literature myself and don't hold an opinion on this matter. However, the section of your post is bad philosophy (or bad pragmatic epistemology, if you wish, because we are talking about pragmatical implications of explicit representation; however, these two coincide under pragmatism): it doesn't even define the notions it discusses (or explain them in sufficient depth) and doesn't argue for the presented position. It's just an (intuitive?) opinion. Intuitive opinions are unreliable, so to discuss this, we need more in-depth writing (well, philosophical writing is also notoriously unreliable, but it's still better than just an unjustified opinion). If there is philosophical (and/or scientific) literature on this topic that you find convincing, please share it.
Another (adjacent?) problem (this problem may also coincide or overlap with the enactivism vs. representationalism problem; I don't understand the latter well to know whether this is the case) is that the "enactive FEP", the path-tracking formulation (Friston et al., 2022) is not really about the entailment ("enaction") of the beliefs about the future, but only beliefs about the present: the trajectory of the internal states of a particle parameterises beliefs about the trajectory of external (environmental) states over the same time period. This means, as it seems to me[1], that the FEP, in itself, is not a theory of agency. Active Inference, which is a process theory (an algorithm) that specifically introduces and deals with beliefs about the future (a.k.a. (prior) preferences, or the preference model in Active Inference literature), is a theory of agency.
I think this is definitely a valid criticism of much of the FEP literature that it sort of "papers over" this transition from the FEP to Active Inference in a language like the following (Friston et al., 2022):
The expected free energy above is an expectation under a predictive density over hidden causes and sensory consequences, based on beliefs about external states, supplied by the variational density. Intuitively, based upon beliefs about the current state of affairs, the expected free energy furnishes the most likely ‘direction of travel’ or path into the future.
The bolded sentence is where the "transition is made", but it is not convincing to me, neither intuitively, nor philosophically, not scientifically. It might be that this is just "trapped intuition" on my part (and part of some other people, I believe) that we ought to overcome. It's worth noting here that the DishBrain experiment (Kagan et al., 2022) looks like an evidence that this transition from the FEP to Active Inference does exist, at least for neuronal tissue (but I would also find surprising if this transition wouldn't generalise to the cases of DNNs, for instance). So, I'm not sure what to make of all this.
Regardless, the position that I currently find coherent is treating Active Inference as a theory of agency that is merely inspired by the FEP (or "based on", in a loose sense) rather than derived from the FEP. Under this view, the FEP is not tasked to explain where do the beliefs about the future (aka preferences, or goals) come from, and what is the "seed of agency" that incites the system to minimise the expected free energy wrt. these beliefs in choosing one's actions. These two things could be seen as the prior assumptions of the Active Inference theory of agency, merely inspired by the FEP[2]. Anyways, these assumptions are not arbitrary nor too specific (which would be bad for a general theory of agency). Definitely, they are no more arbitrary nor more specific than the assumptions that maximum entropy RL, for instance, would require to be counted as a general theory of agency.
- ^
Note: I discovered this problem only very recently and I'm currently actively thinking about it and discussing it with people, so my understanding may change significantly from what I express here very soon.
- ^
Ramstead et al., 2022b maybe recover these from the FEP when considering one as a "FEP scientist" in a "meta-move", but I'm not sure.
comment by Roman Leventov · 2023-03-03T08:10:50.819Z · LW(p) · GW(p)
3. It’s easier to think of a feedback control system as a feedback control system, and not as an active inference system
[...]
And these days, I often think about various feedback control systems in the human brain, and I likewise find it very fruitful to think about them using my normal intuitions about how feedback signals work etc., and I find it utterly unhelpful to think of them as active inference systems.
Don't you think that the control-theoretic toolbox becomes a very incomplete perspective for analysing and predicting the behaviour of systems exactly when we move from complicated, but manageable cybernetic systems (which are designed and engineered) to messy human brains, deep RL, or Transformers, which are grown and trained?
I don't want to discount the importance of control theory: in fact, one of the main points of my recent post [LW · GW] was that SoTA control theory is absent from the AI Safety "school of thought", which is a big methodological omission. (And LessWrong still doesn't even have a tag for control theory!)
Yet, criticising the FEP on the ground that it's not control theory also doesn't make sense: all the general theories of machine learning [LW · GW] and deep learning are also not control theory, but they would be undoubtfully useful for providing a foundation for concrete interpretability theories. These general theories of ML and DL, in turn, would benefit from connecting with even more general theories of cognition/intelligence/agency, such as the FEP, Boyd-Crutchfield-Gu's theory, or MCR^2, as I described here [LW · GW]:
↑ comment by Steven Byrnes (steve2152) · 2023-03-03T15:55:01.473Z · LW(p) · GW(p)
Don't you think that the control-theoretic toolbox becomes a very incomplete perspective for analysing and predicting the behaviour of systems exactly when we move from complicated, but manageable cybernetic systems (which are designed and engineered) to messy human brains, deep RL, or Transformers, which are grown and trained?
I think you misunderstood what I was saying. Suppose that some part of the brain actually literally involves feedback control. For example (more details here [LW · GW]):
- Fat cells emit leptin. The more fat cells there are, the more leptin winds up in your bloodstream.
- There are neurons in the hypothalamus called “NPY/AgRP neurons”, which have access to the bloodstream via a break in the blood-brain barrier. When leptin binds to these neurons, it makes them express less mRNA for NPY & AgRP, and also makes them fire less.
- The less that NPY/AgRP neurons fire, and the less AgRP and NPY that they release, the less that an animal will feel inclined to eat, via various pathways in the brain that we don’t have to get into.
- The less an animal eats, the less fat cells it will have in the future.
This is straightforwardly a feedback control system that (under normal circumstances) helps maintain an animal’s adiposity. Right?
All I’m saying here is, if we look in the brain and we see something like this, something which is actually literally mechanistically a feedback control system, then that’s what we should call it, and that’s how we should think about it.
I am definitely not endorsing “control theory” as a grand unified theory of the brain. I am generally opposed to grand unified theories of the brain in the first place. I think if part of the brain is configured to run an RL algorithm, we should say it’s doing RL, and if a different part of the brain is configured as a feedback control system, we should say it’s a feedback control system, and yes, if the thalamocortical system is configured to do the specific set of calculations that comprise approximate Bayesian inference, then we should say that too!
By the same token, I’m generally opposed to grand unified theories of the body. The shoulder involves a ball-and-socket joint, and the kidney filters blood. OK cool, those are two important facts about the body. I’m happy to know them! I don’t feel the need for a grand unified theory of the body that includes both ball-and-socket joints and blood filtration as two pieces of a single grand narrative. Likewise, I don’t feel the need for a grand unified theory of the brain that includes both the cerebellum and the superior colliculus as two pieces of a single grand narrative. The cerebellum and the superior colliculus are doing two very different sets of calculations, in two very different ways, for two very different reasons! They’re not quite as different as the shoulder joint versus the kidney, but same idea.
Replies from: itaibn0, Roman Leventov↑ comment by itaibn0 · 2023-03-03T19:23:33.353Z · LW(p) · GW(p)
By the same token, I’m generally opposed to grand unified theories of the body. The shoulder involves a ball-and-socket joint, and the kidney filters blood. OK cool, those are two important facts about the body. I’m happy to know them! I don’t feel the need for a grand unified theory of the body that includes both ball-and-socket joints and blood filtration as two pieces of a single grand narrative.
I think I am generally on board with you on your critiques of FEP, but I disagree with this framing against grand unified theories. The shoulder and the kidney are both made of cells. They both contain DNA which is translated into proteins. They are both are designed by an evolutionary process.
Grand unified theories exist, and they are precious. I want to eke out every sliver of generality wherever I can. Grand unified theories are also extremely rare, and far more common in the public discourse are fakes that create an illusion of generality without making any substantial connections. The style of thinking that looks at a ball-and-socket joint and a blood filtration system and immediately thinks "I need to find how these are really the same" rather than studying these two things in detail and separately is apt to create these false grand unifications, and altho I haven't looked into FEP as deeply as you or other commenters the writing I have seen on it smells more like this mistake than true generality.
But a big reason I care about exposing these false theories and the bad mental habits that are conducive to them is precisely because I care so much about true grand unified theories. I want grand unified theories to shine like beacons so we can notice their slightest nudge, and feel the faint glimmer of a new one when it is approaching from the distance, rather than be hidden by a cacophony of overblown rhetoric coming from random directions.
↑ comment by Roman Leventov · 2023-03-03T16:46:35.631Z · LW(p) · GW(p)
Methodologically, opposing "grand unifying theories" of the brain (or AI architecture) doesn't make sense to me. Of course we want grand unifying theories of these things, because we don't deal with generator and discriminator separately, we deal with GAN as a whole (or LeCun's H-JEPA architecture as a whole, to take a more realistic example of an agent; it has many distinct DNN components, performing inference and being trained separately and at different timescales) because we are going to deal with the system as a whole, not its components. We want to predict the behaviour of the system as a whole.
If you analyse and predict components separately, in order to predict the system as a whole, you effectively "sort of" executing a "grand unifying theory" in your own head. It's much less reliable than if the theory is formalised, tested, simulated, etc. explicitly.
Now, the reason for why I hold both Active Inference and control theory as valid perspectives, is because neither of them is a "real" unifying model of a messy system, for various reasons. So, in effect, I suggest that taking both these perspectives is useful because if their predictions diverge in some situations, we should make a judgement call of what prediction we "trust" more, which would be the execution of our "grand unifying theory" (there are also other approaches for triaging such a situation, for example, apply the precautionary principle and trust the more pessimistic prediction).
So, if we could construct a unifying theory that would easily recover both control theory (I mean not the standard KL control, which Active Inference recovers, but more SoTA developments of control theory, such as those discussed by Li et al. (2021)) and Active Inference, that would be great. Or, it might be shown that one recovers another (I doubt it is possible, but who knows).
Finally, there is a question of whether unifying algorithms is "sound" or it's too "artificial, forced". And your claim is that Active Inference is a "forced" unification of perception and planning/action algorithms. To this claim, the first reply is that even if you dislike Active Inference unification, you would better provide alternative unification, because otherwise you just do this unification in your head, which is not optimal. And second, in case of specifically perception and action, they should be considered together, as Anil Seth explains in "Being You" more eloquently than I can (I cited in another comment [LW(p) · GW(p)].)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-03T18:01:45.197Z · LW(p) · GW(p)
I’m pretty confused here.
The thing I’m advocating for is: if a system has seven different interconnected components, we should think of it as a system with seven different interconnected components, and we can have nice conversations about what those components are and how they work together and interact, and what is the system going to do at the end of the day in different situations.
I believe that the brain has a number of different interconnected components, including parts that implement feedback control (cf. the leptin example above) and parts that run an RL algorithm and maybe parts that run a probabilistic inference algorithm and so on. Is that belief of mine compatible with the brain being “a unified system”? Beats me, I don’t know what that means. You give examples like how a GAN has two DNN components but is also “a unified system”, and LeCun’s H-JEPA has “many distinct DNN components” but is also “a unified system”, if I understand you correctly. OK, then my proposed multi-component brain can also be “a unified system”, right? If not, what’s the difference?
Now, if the brain in fact has a number of different interconnected components doing different things, then we can still model it as a simpler system with fewer components, if we want to. The model will presumably capture some aspects / situations well, and others poorly—as all models do.
If that’s how we’re thinking about Active Inference—an imperfect model of a more complicated system—then I would expect to see people say things like the following:
- “Active inference is an illuminating model for organisms A,B,C but a misleading model for organisms D,E,F” [and here’s how I know that…]
- “Active inference is an illuminating model for situations / phenomena A,B,C but a misleading model for situations / phenomena D,E,F”
- “Active inference is an illuminating model for brain regions A,B,C but a misleading model for brain regions D,E,F”
- “…And that means that we can build a more accurate model of the brain by treating it as an Active Inference subsystem (i.e. for regions A,B,C) attached to a second non-Active-Inference subsystem (i.e. for regions D,E,F). The latter performing functions X,Y,Z and the two subsystems are connected as follows….”
My personal experience of the Active Inference literature is very very different from that! People seem to treat Active Inference as an infallible and self-evident and omni-applicable model. If you don’t think of it that way, then I’m happy to hear that, but I’m afraid that it doesn’t come across in your blog posts, and I vote for you to put in more explicit statements along the lines of those bullet points above.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-03T18:54:52.568Z · LW(p) · GW(p)
I believe that the brain has a number of different interconnected components, including parts that implement feedback control (cf. the leptin example above) and parts that run an RL algorithm and maybe parts that run a probabilistic inference algorithm and so on. Is that belief of mine compatible with the brain being “a unified system”?
"Being" a unified system has realist connotations. Let's stay on the instrumentalist side, at least for now. I want to analyse the brain (or, the whole human, really) as a unified system, and assume an intentional stance towards it, and build its theory of mind, all because I want to predict its behaivour as a whole.
OK, then my proposed multi-component brain can also be “a unified system”, right? If not, what’s the difference?
Yes, it can and should be analysed as a unified system, to the extent possible and reasonable (not falling into over-extending theories by concocting components in an artificial, forced way).
"Active inference is an illuminating model for organisms A,B,C but a misleading model for organisms D,E,F"
Active Inference is an illuminating and misleading model of Homo Sapiens simultaneously, in a similar way as Newtonian physics is both an illuminating and misleading theory of planetary motion. I explained why it's misleading: it doesn't account for intrinsic contextuality in inference and decision-making (see my other top-level comment on this). The austere instrumentalist response to it would be "OK, let's, as scientists, model the same organism as two separate Active Inference models at the same time, and decide 'which one acts at the moment' based on the context". While this approach could also be illuminating and instrumentally useful, I agree it beings to be very slippery.
Also, Active Inference is too simple/general (I suspect, but not sure) to recover some more sophisticated distributed control characteristics of the human brain (or, possibly, AI systems, for that matter), as I discussed above.
Active Inference is not a "very misleading" ("degree of misleadingness" is not a precise thing, but I hope you get it) of any "normal" agents we can think of (well, barring some extreme instances of quantumness/contextuality, a-la agentic quantum AI, but let's not go there) precisely because it's very generic, as I discuss in this comment [LW(p) · GW(p)]. By this token, maximum entropy RL would be a misleading model of an agent hinging on the boundary between the scale where random fluctuations do and don't make a difference (this should be a scale smaller than cellular, because probably random (quantum) fluctuations already don't make difference on the cellular scale; because the scale is so small, it's also hard to construct anywhere "smart" agent on such a small scale).
“Active inference is an illuminating model for situations / phenomena A,B,C but a misleading model for situations / phenomena D,E,F”
See above, pretty much. Active Inference is not a good model for decision making under cognitive dissonance, i.e., intrinsic contextuality (Fields typically cites Dzhafarov for psychological evidence of this).
Note that intrinsic contextuality is not a problem for any theory of agency, it's more endemic to Active Inference than (some) other theories. E.g., connectionist models where NNs are first-class citizens of the theory are immune to this problem. See Marciano et al. (2022) for some work in this direction.
Also, Active Inference is probably not very illuminating model in discussing access consciousness and memory (some authors, e.g., Whyte & Smith (2020), claim that it is illuminating, at least partially, but it definitely not the whole story). (Phenomenal consciousness is more debatable, and I tend to think that Active Inference is a rather illuminating model for this phenomenon.)
“Active inference is an illuminating model for brain regions A,B,C but a misleading model for brain regions D,E,F”
I know too little about brain regions, neurobiological mechanisms, and the like, but I guess it's possible (maybe not today, but maybe today, I really don't know enough to judge, but you can tell better; also, these may have already been found, but I don't know the literature) to find these mechanisms and brain regions that play the role during "context switches", or in ensuring long-range distributed control, as discussing above. Or access consciousness and memory.
“…And that means that we can build a more accurate model of the brain by treating it as an Active Inference subsystem (i.e. for regions A,B,C) attached to a second non-Active-Inference subsystem (i.e. for regions D,E,F). The latter performing functions X,Y,Z and the two subsystems are connected as follows….”
I hope from the exposition above it should be clear that you couldn't quite factor Active Inference into a subsystem of the brain/mind (unless under "multiple Active Inference models with context switches" model of the mind, but, as I noted above, I thing this would be a rather iffy model to begin with). I would rather say: Active Inference still as a "framework" model with certain "extra Act Inf" pieces (such as access consciousness and memory) "attached" to it, plus other models (distributed control, and maybe there are some other models, I didn't think about it deeply) that don't quite cohere with Active Inference altogether and thus we сan only resort to modelling the brain/mind "as either one or another", getting predictions, and comparing them.
My personal experience of the Active Inference literature is very very different from that! People seem to treat Active Inference as an infallible and self-evident and omni-applicable model. If you don’t think of it that way, then I’m happy to hear that, but I’m afraid that it doesn’t come across in your blog posts, and I vote for you to put in more explicit statements along the lines of those bullet points above.
Ok, I did that. My own understanding (and appreciation of limitations) of Active Inference progressed significantly, and changed considerably in a matter of the last several weeks alone, so most of my earlier blog posts could be significantly wrong or misleading in important aspects (and, I think, even my current writing is significantly wrong and misleading, because this process of re-appreciation of Active Inference is not settled for me yet).
I would also encourage you to read about thermodynamic machine learning and MCR^2 theories. (I want to do this myself, but still haven't.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-03T21:23:43.677Z · LW(p) · GW(p)
It’s cool that you’re treating Active Inference as a specific model that might or might not apply to particular situations, organisms, brain regions, etc. In fact, that arguably puts you outside the group of people / papers that this blog post is even criticizing in the first place—see Section 0.
A thing that puzzles me, though, is your negative reactions to Sections 3 & 4. From this thread, it seems to me that your reaction to Section 3 should have been:
“If you have an actual mechanical thermostat connected to an actual heater, and that’s literally the whole system, then obviously this is a feedback control system. So anyone who uses Active Inference language to talk about this system, like by saying that it’s ‘predicting’ that the room temperature will stay constant, is off their rocker! And… EITHER …that position is a straw-man, nobody actually says things like that! OR …people do say that, and I join you in criticizing them!”
And similarly for Section 4, for a system that is actually, mechanistically, straightforwardly based on an RL algorithm.
But that wasn’t your reaction, right? Why not? Was it just because you misunderstood my post? Or what’s going on?
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-03T22:02:25.178Z · LW(p) · GW(p)
I thought your post is an explanation of why you don't find Active Inference a useful theory/model, rather than criticism of people. I mean, it sort of criticises authors of the papers on FEP for various reasons, but who cares? I care whether the model is useful or not, not whether people who proposed the theory were clear in their earlier writing (as long as you are able to arrive at the actual understanding of the theory). I didn't see this as a central argument.
So, my original reaction to 3 (the root comment in this thread) was about the usefulness of the theory (vs control theory), not about people.
Re: 4, I already replied that I misunderstood your "mechanistical lizard" assumption. So only the first part of my original reply to 4 (about ontology and conceptualisation, but also about interpretability, communication, hierarchical composability, which I didn't mention originally, but that is discussed at length in "Designing Ecosystems of Intelligence from First Principles" (Friston et al., Dec 2022)). Again, these are arguments about the usefulness of the model, not about criticising people.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-03-03T22:16:01.137Z · LW(p) · GW(p)
Sorry, I’ll rephrase. I expect you to agree with the following; do you?
“If you have an actual mechanical thermostat connected to an actual heater, and that’s literally the whole system, then this particular system is a feedback control system. And the most useful way to model it and to think about it is as a feedback control system. It would be unhelpful (or maybe downright incorrect?) to call this particular system an Active Inference system, and to say that it’s ‘predicting’ that the room temperature will stay constant.”
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-03-04T08:15:54.852Z · LW(p) · GW(p)
Unhelpful - yes.
"Downright incorrect" - no, because Active Inference model would be simply a mathematical generalisation of (simple) feedback control model in a thermostat. The implication "thermostat is a feedback control system" -> "thermostat is an Active Inference agent" has the same "truth property" (sorry, I don't know the correct term for this in logic) as the implication "A is a group" -> "A is a semigroup". Just a strict mathematical model generalisation.
"and to say that it’s ‘predicting’ that the room temperature will stay constant.” - no, it doesn't predict predict specifically that "temperature will stay constant". It predicts (or, "has preference for") a distribution of temperature states of the room. And tries to act so as the actual distribution of these room temperatures matches this predicted distribution.
comment by Kaj_Sotala · 2023-03-03T07:57:53.944Z · LW(p) · GW(p)
The FEP is applicable to both bacteria and human brains. So it’s probably a bad starting point for understanding how human brains work
This is a great line. Concise but devastating.
Replies from: FEPbro↑ comment by FEPbro · 2023-03-03T19:51:43.846Z · LW(p) · GW(p)
I don't understand. Consider the analogous statement: "The laws of physics are applicable to both X and Y, where X and Y are literally any two things in our universe. So the laws of physics are probably a bad starting point for understanding how Y works."
Replies from: steve2152, sil-ver↑ comment by Steven Byrnes (steve2152) · 2023-03-03T20:47:03.054Z · LW(p) · GW(p)
Hmm, I guess it was a bit of cheap shot. But I think I was communicating something real, and disanalogous to what you wrote.
Specifically, everybody knows that both bacteria and humans have homeostasis, and that they maintain their bodily integrity under normal conditions etc. And FEP does not add any new information beyond that fact (cf. Section 1).
If you want to properly understand the human hypothalamus (for example), you should be aware that homeostasis is a thing! This is important background knowledge, albeit so obvious that one might think it goes without saying.
But it’s equally obvious that you cannot start with homeostasis and “derive” that the human brain has to look a certain way and do a certain thing. After all, bacteria have homeostasis too, and they have no brains at all.
Yet the FEP-adjacent discourse, in my experience, is full of claims (or at least suggestions) of that type: claims that we can start with FEP and derive all sorts of detailed contingent facts about how the brain is structured and what it does. But that can’t be right. It’s possible for a thing with homeostasis & bodily integrity to explore and model its surroundings, and it’s also possible for a thing with homeostasis & bodily integrity to NOT explore and model its surroundings. It’s possible for a thing with homeostasis & bodily integrity to turn on the light in a dark room, and it’s also possible for a thing with homeostasis & bodily integrity to NOT turn on the light in a dark room. Etc. Homeostasis & bodily integrity are just not enough of a constraint to get us to any of the interesting conclusions that people seem to ascribe to FEP in practice. And the applicability of FEP to bacteria is relevant evidence of that.
I don’t think the laws-of-physics discourse has any issues like that. The laws of physics are a ridiculously strong constraint. In fact, given initial conditions, the laws of physics are completely constraining. So when people say “X is a direct consequence of the laws of physics”, it’s probably fine.
Replies from: FEPbro↑ comment by FEPbro · 2023-03-03T21:16:21.934Z · LW(p) · GW(p)
Thank you for replying—and for the interesting post.
Your mention of homeostasis suggests an important conceptual distinction indicated by your discussion of feedback control systems. Basically, much of the interest in FEP among neuroscientists is due to the failure of concepts like homeostasis and feedback control to explain complex, dynamic, "goal-oriented" behavior. These concepts aren't false; they just don't work very well for some classes of interesting phenomena. It's like pushing a car instead of driving it. You can get where you're going eventually, you just wish you had some other way of doing it.
Perhaps an original post on the empirical situation leading up to interest in FEP and active inference would be useful, although I am not a historian and would undoubtedly give a summary more relevant to my background than to the modal neuroscientist.
↑ comment by Rafael Harth (sil-ver) · 2023-03-03T19:56:29.181Z · LW(p) · GW(p)
I think the claim here is supposed to be that if the principle works for bacteria, it can't tell you that much.[1] That's true for your laws of physics example as well; nothing is gained from taking the laws of physics as a starting point.
That said, this doesn't seem obviously true; I don't see why you can't have a principle that holds for every system yet tells you something very important. Maybe it's not likely, but doesn't seem impossible. ↩︎
↑ comment by FEPbro · 2023-03-03T20:27:48.388Z · LW(p) · GW(p)
I know more about the brain than I do about physics, but I would hope that quite a lot is gained from taking the laws of physics as a starting point.
The fact that the FEP applies to both humans and bacteria (and non-living things like rocks, as Roman Leventov pointed out elsewhere), is valuable because, empirically, we observe common structure across those things. What is gained by the FEP is, accordingly, an abstract and general understanding of that structure. (Whether that is useful as a "starting point" depends on how one solves problems, I suppose.)
Replies from: Korz↑ comment by Mart_Korz (Korz) · 2023-03-06T12:27:38.855Z · LW(p) · GW(p)
I think one important aspect for the usefulness of general principles is by how much they constrain the possible behaviour. Knowing general physics for example, I can rule out a lot of behaviour like energy-from-nothing, teleportation, perfect knowledge and many such otherwise potentially plausible behaviours. These do apply both to bacteria and humans, and they actually are useful for understanding bacteria and humans.
The OP, I think, argues that FEP is not helpful in this sense because without further assumptions it is equally compatible with any behaviour of a living being.
comment by Ilio · 2023-03-03T03:06:59.427Z · LW(p) · GW(p)
Me too I feel like some of these ideas make a lot of sense from a neurological point of view, like evolution makes a lot of sense from a biological point of view. Indeed, for point 1) evolution is not falsifiable either. Popper pretended that some fossils like rabbits at -3Gy would falsified evolution, but that’s bullshit. It would destroy one family of biological models based on evolution, but it wouldn’t change one bit to the idea that evolution must apply each time you have replicators and environmental pressure. It’s tautologically true, the same way free energy principle must be a law each time what you want to describe obeys classical physics (or close enough).
So that’s why point 2) evolution apply to both bacteria and human brain; point 3) it’s easier to think of Mendel laws, but evolution need mutations (should that count as much as a prediction?); likewise for point 4) it may be easier to organize language models without evolution in mind, but memetic information will still thrive and/or cause alignment difficulties.
Points 5 is sound, and for point 6 I haven’t made my mind yet. For point 7, I think you have an excellent point. To me the basal ganglia feel like RL, hypothalamus feel like thermostat, the cerebellum feel like self-supervised learning, thalamocortical loops, colliculi, brainstem and spinal cord feel like maps and clocks, and none of that seems to come from first principles: it must come from our particular random evolutionary path. So, even if I disagree on some of your arguments, I still think your text represents a very serious point against FEP: strong upvote and thank you!