A multi-disciplinary view on AI safety research
post by Roman Leventov · 2023-02-08T16:50:31.894Z · LW · GW · 4 commentsContents
Summary
1. Introduction: AIs as physical systems
2. Multi-disciplinary AI safety research: the Santa Fe Institute model
2.1. Disciplines and theories relevant to AI safety
3. Some concrete multi-disciplinary research agendas
3.1. Scale-free axiology and ethics
3.2. Civilisational intelligence architecture
3.3. AI self-control: tool (oracle, simulator) AI vs. agent AI
3.4. Weaving together theories of cognition and cognitive development, ML, deep learning, and interpretability through the abstraction-grounding stack
4. A call for disciplinary experts and scholars
4.1. Suggestions for LessWrong
Acknowledgements
None
4 comments
Summary
The core ideas that constitute the multi-disciplinary view[1] on AI safety research are:
- Theoretical research on how to build “safe” AGI systems (”top-down intelligent design”) is necessary: we must not passively follow the techno-evolution of AI within the present systems of capitalistic economics and global governance and only do empirical research of the developed systems as this evolution goes along.
- AI safety research field shouldn’t be separate from the wider AGI research field: they should converge as a project of top-down design of civilisational intelligence. Both AI alignment paradigms (protocols) and AGI capability research (intelligence architectures) that don’t position themselves within a certain design for civilisational intelligence are methodologically misguided and could be dangerous.
- “Purely technical” AI safety research and all other types of research that are needed to engineer civilisational intelligence (sociotechnical, social, legal, political, geopolitical, and strategic research) shouldn’t be separated as well. Yet, in this article, I focus on the technical side of it.
- Technical research of civilisational intelligence shouldn’t focus only on cognitive science, mathematics, theoretical computer science, and machine learning: dozens of different disciplinary perspectives should be taken to evaluate civilisational intelligence architectures adequately, including, in addition to the disciplines mentioned above, the perspectives of neuroscience, theories of consciousness, theories of collective intelligence, social dynamics and memetics, game theory, mechanism design, network theory, theories of criticality and emergence, dynamical systems and stability theories, scale-free theories of evolution and cognitive development, distributed systems and control theory, resilience theory, safety science and reliability engineering science, physics of communication and computation, information security and cryptography research, and more.
- Even within a single discipline, there is no single “correct” or “right” theory: they are all wrong, but most of them are also useful. In particular, in the most important disciplines: cognitive science, collective intelligence theory, control theory, resilience theory, dynamical systems theory, theory of evolution, ML and deep learning theories, we should apply all “competing” theories to our objects of study: AI alignment paradigms and civilisational intelligence architectures, and see what predictions these theories will yield about our designs.
- Empirical disciplines of study: cognitive psychology, social cognitive psychology, evolutionary cognitive psychology, developmental cognitive psychology, AI psychology [LW · GW], social choice theory, sociology, political economy, legal theory and policy science, are also helpful and therefore valid perspectives to take in the evaluation of different AI alignment paradigms.
- Generally speaking, all scientific and empirical theories are seen as tools, and therefore, in choosing a theory to model some phenomena, not only the predictive power and accuracy of a theory is considered, but a wider set of factors on the meta-level, such as the relative maturity of the theory (including its connectedness with other theories), the number of people who work on the theory outside of and independently from the AI safety research community, the chances that many researchers will join the development of the theory, the marginal utility of the theory given the “theoretic fragmentation” in the community, the probability that some leading AI scientists in leading AGI labs, e.g., Yann LeCun, will find the arguments formulated in terms of such a theory convincing/appealing (yes, pragmatism requires to consider even such factors!), etc.
- More (independent) alignment researchers should work in teams on multi-disciplinary research agendas rather than developing new, distinctive theories of intelligence, rationality, and agency in relative isolation from each other.
The multi-disciplinary view on how AI safety (x-risk[2]) research should be done stems from pragmatism as the general philosophical stance, constructivism and naturalism as high-level epistemological views, and physicalism of information, computation, and, hence, intelligence and agency as foundational ontological commitments about nature.
This post is the first one in a two-part series. In this post, I discuss the roots of the multi-disciplinary view on AI safety research, enumerate the relevant disciplines and theories, and describe multiple (relatively) concrete research agendas where multiple disciplinary perspectives should be synthesised.
In the second post, I discuss non-technical reasons for adopting the multi-disciplinary view and compare it with other methodological views on AI x-risk research: the pro-HRAD view (Highly Reliable Agent Designs, Rice & Manheim 2022 [LW · GW]), the “Pragmatic AI Safety” (PAIS) view (Hendrycks & Woodside 2022 [? · GW]), and the “Reform AI Alignment” view (Aaronson 2022).
1. Introduction: AIs as physical systems
I believe, with very high confidence, that the following things about the “relatively-near-term ASI” (i.e., ASI that will do all intellectual work far better than humans, on the level which renders any direct oversight by humans impossible) are true:
- It will be "implemented" as a physical system, employing only the laws of physics that we know today. As such, it will be subject to physicalist theories of cognition and intelligence.
- It will communicate with its environment (people and other AIs) using communication methods that are comprehensible to us, from binary data exchange protocols to language. In particular, it won’t be able to communicate across the Earth (or the Solar system) faster than the speed of light permits, which implies that it will be subject to the “normal” theories of distributed computation, communication, distributed control[3], and collective intelligence[4].
- As a physical system, it will be forced to tradeoff the speed of inference, the cost (i.e., the energy expenditure) of computation, the amount of data it could “remember” and store “locally” (and the loss rate, if the data is compressed), the latency and the amount of data (i.e., the bandwidth) it could exchange with its environment (e. g., other AIs in the network) before it needs to complete the inference step and do something, etc. This implies that ASI will be subject to the theories of contextual (a.k.a. quantum) cognition[5] and bounded rationality [? · GW] (see Bhui et al. (2021) for a review).
- It will be a cyber-physical system with a stable, comprehensible blueprint (aka memome), which can include the descriptions of the network/distributed system architecture, the hardware architecture, the source code, and the “core” training data or the constitution [LW · GW], for instance[6]. As such, it will be subject to the general physical principles and theories of evolution[7], common for lineages (genera) of living and technical systems and regulative development (morphogenesis)[8].
The observations above have several methodological implications:
- We are justified to study ASI from the perspectives of a great variety of existing scientific disciplines.
- We (general intelligences) use science (or, generally speaking, construct any models of any phenomena) for the pragmatic purpose of being able to understand, predict and control it. Thus, none of the disciplinary perspectives on any phenomena should be regarded as the “primary” or “most correct” one for some metaphysical or ontological reasons. Also, this implies that if we can reach a sufficient level of understanding of some phenomenon (such as AGI) by opportunistically applying several existing theories then we don’t need to devise a new theory dedicated to this phenomenon specifically: we already solved our task without doing this step.
- This is a category error and a methodological mistake to think that ASI will be an emergent phenomenon of a different kind than humans. Humans are general intelligences already. David Deutsch also calls humans universal explainers, which implies that there couldn’t be any emergent category of things beyond general intelligence[9], in some sense, a-la “super-general” intelligence. I recognise that this idea is far from certain; still, I think people could possibly align only with “relatively-near-term ASI”, yet that relatively-near-term ASI would be “merely” a “normal” general intelligence rather than an outlandish emergent “super-general” intelligence. So, we should practically focus on studying how to align with general intelligences (including each other!), not “super-general” intelligences.
2. Multi-disciplinary AI safety research: the Santa Fe Institute model
I wish LessWrong and Alignment Forum were more like an online version of Santa Fe Institute (SFI).
The powerful idea of SFI is making experts in different fields talk to each other and build a deeper (”3D”), shared understanding of problems and phenomena by combining diverse perspectives on them.
I wish the AI x-risk community had a lot of researchers who understood some of the disciplines and state-of-the-art theories listed below deeply, and brought these perspectives to the team projects, reviews and discussions of other people’s work and AI alignment proposals. These perspectives shouldn’t be a scarce resource in any discussion where any of these perspectives would be relevant and valuable, even if that wasn’t realised and explicitly called out by the rest of the people (e.g., the authors of some post or an alignment proposal).
2.1. Disciplines and theories relevant to AI safety
- Theories of semantics and observation (Fields et al. 2022a), philosophy of science (Ramstead et al. 2022), and systems ontology (Levenchuk 2022b)[10]
- Cognitive science[11] (as well as its empirical counterparts: cognitive psychology and neuropsychology) and philosophy of mind[12]
- Epistemology (Levenchuk 2021)
- Theories of bounded [? · GW] (Bhui et al. 2021), contextual/quantum[5] rationality (Levenchuk 2022a)
- Scale-free theories of axiology and ethics[13]
- Theories of consciousness (Seth & Bayne 2022; Fields et al. 2022b)
- Linguistics, philosophy of language (Bisk, Holtzman, Thomason et al. 2020), and theory of communication (Tison & Poirier 2021; Kastel, Hesp et al. 2023)
- Neuroscience[14]
- Theories of cooperation and collective intelligence[4] (and related: hybrid and social cognition/intelligence, theory of mind, and social cognitive psychology)
- Collective epistemology
- Collective rationality [? · GW] (including group decision theory[15]), and the empirical side of it, social choice theory
- Collective axiology and ethics
- Theories of social dynamics [? · GW] (Alodjants et al. 2022; Kastel, Hesp et al. 2023) and memetics [? · GW][16]
- Political science, legal theory, and policy science (Capano & Woo 2017)
- Game theory [? · GW], including open-source game theory (Critch et al. 2022) and theories of conflict[17]
- Mechanism design [? · GW]
- Network theory (including higher-order networks, Majhi et al. (2022))
- Renormalisation group methods[18]
- Theories of criticality (O'Byrne & Jerbi 2022) and emergence (Varley & Hoel 2022)
- A general theory of evolution[7] (and its grounding theories: evolutionary biology, evolutionary physiology, and evolutionary cognitive neuroscience)
- A general theory of regulative development (morphogenesis)[8], including a general theory of cognitive development (Kuchling et al. 2022; Fields et al. 2022c), and their grounding theories: developmental biology and physiology, developmental psychology, and developmental cognitive neuroscience.
- Dynamical systems theory[19], including stability theory and fractional dynamics theory (Tarasov 2021)
- Control theory[3] and resilience theory (Sharkey et al. 2021; Liu et al. 2022)
- Risk science, safety science[20], and reliability (resilience) engineering science[21]
- Computer science and information theory[22], including:
- Distributed computing and distributed systems theories
- Quantum computing and quantum information theories
- Physics of computation: thermodynamics of computation (Wolpert 2019; Boyd et al. 2022; Marletto 2022), physical theories of probability, and resource theories[23]
- General theories of machine learning, and specifically deep learning (see also section 3.4. for more detailed discussion)
- Balestriero’s spline theory of deep learning (2018) and the geometry of deep networks (2019)
- Olah et al.’s theory of circuits (2020)
- Roberts, Yaida, and Hanin’s deep learning theory (2021)
- Vanchurin’s theory of machine learning (2021)
- Anthropic’s mathematical framework for transformers (2021)
- Edelman et al.'s theory of "sparse variable creation" in transformers (2022)
- Boyd, Crutchfield, and Gu’s theory of thermodynamic machine learning (2022)[24]
- Marciano’s theory of DNNs as a semi-classical limit of topological quantum NNs (2022)
- Bahri et al.’s review of statistical mechanics of deep learning (2022)
- Alfarra et al.’s tropical geometry perspective on decision boundaries of NNs (2022)
- Other general theories of mechanistic interpretability and representation in DNNs (Räukur et al. 2022)
- AI psychology [LW · GW] (Perez et al. 2022), which is the empirical counterpart of mechanistic interpretability theories.
- Theories of deep learning dynamics (Xie et al. 2020; Li et al. 2021; Barak et al. 2022)
- Theories of cognitive development in DL, such as theories of grokking (Liu et al. 2022; Nanda et al. 2023), RL fine-tuning of language models (Korbak et al. 2022 [LW · GW]), and the development of polysemanticity (Elhage et al. 2022; Scherlis et al. 2022).
- Frontier statistical learning and deep learning research on object identification and representation learning, abstraction, knowledge retrieval and augmentation, causal modelling/learning, decision-making, fairness and bias, neurosymbolic inference/rationality, reinforcement learning, training data privacy (differential privacy), adversarial robustness, online learning, sequence modelling, autoregression, energy-based modelling, GFlowNets, diffusion, GANs, etc.
- Frontier ML and AI research that is not about deep learning, from symbolic AI and swarm intelligence to brain-on-a-chip approaches (Brofiga et al. 2021)
- Frontier computing hardware developments, such as in optical and quantum computing
- Frontier research in information security, cryptography, zero-knowledge proofs and computing, etc.
There are some important remarks to make about the above list:
- The list is likely incomplete. Please point me to omissions in it! For example, there are probably some theories describing (or related to) statistical mechanics and stochastic processes that are relevant to studying AI safety, but I understand these domains so little that can’t even point to specific theories.
- In selecting the specific theories in these disciplines (since there are often multiple competing theories which are not always compatible with each other), we should choose scale-free and substrate-independent theories whenever possible to increase the chances that our understanding of safe AI principles will survive the recursive self-improvement [? · GW] phase of AGI development. Specifically, we should look for scale-free theories of information processing and computation, cognition (intelligence, agency), consciousness, axiology and ethics, cooperation and collective intelligence, network (systems) dynamics, evolution, cognitive development, distributed control, and resilience.
- The list resembles the Agency and Alignment “Major” [LW · GW] in Wentworth’s “Study Guide”. However, the zeitgeists of these lists (and, I believe, my and his philosophies of AI safety research more generally) are rather different. Wentworth’s idea is that alignment researchers should familiarise themselves with all (or a wide selection of) these disciplines and theories shallowly (”breadth over depth [LW · GW]”, as he puts it). My idea is that shallow familiarity is not enough. We need to bring together a deep understanding of the state-of-the-art theories in various disciplines. Nobody could possibly stay abreast of all these disciplines and theories and maintain a sufficiently deep understanding of more than a handful of them[25]. So, many different researchers should study a few of the disciplines in the above list deeply, and bring these disciplinary perspectives in team projects, reviews and comments to the work of others, etc.
- The list is also conspicuously similar to the list of topics on the page about complex systems on Wikipedia. Though, I deliberately avoided conjuring up “complexity” anywhere else in this article because it could be easily misunderstood: the term is appropriated by several completely distinct academic fields and non-academic “schools of thought”. For example, safety science (mentioned above) is sometimes called “complex systems theory”.
- As typical in such lists, the discipline breakdown and their hierarchy (i.e., which discipline is part of another one) is somewhat arbitrary, but also unimportant. Notably, cognitive science (and, hence, many disciplines that are traditionally seen as philosophy rather than science: epistemology, axiology, ethics, rationality and logic, etc.) seem to largely converge with frontier research in deep learning, machine learning, and AI, as well as appears to be in some of its foundational aspects a rubric of physics.
- The discipline selection and breakdown reflect my bias towards pragmatism as the general philosophical stance (hence the coexistence on this list of scientific and empirical theories; Rice & Manheim (2022) [LW · GW] call them precise and imprecise theories, respectively), constructivism as the (collective) epistemological framework, naturalism (hence the classification of many “philosophical” disciplines, including ethics, as rubrics of cognitive science), and physicalism of information and computation (on the level that is of interest for us, anyway; what the physical stuff is “made of, deep down” is an irrelevant question, IMO).
- The empirical and scientific disciplines that don’t study AI directly, such as social, cognitive, evolutionary, and developmental psychology, evolutionary and developmental biology and neuroscience, social choice theory, and others mentioned in the list above should play two roles. First, they should help to ground and additionally check the corresponding general theories, such as the general theories of intelligence, cognitive development, and evolution. Second, for the fields of study where we currently lack any satisfactory scientific theories that can provide informative predictions, including ethics, memetics, social dynamics, systems safety, and systems immunity, applying the closest empirical theories, such as moral philosophy, sociology, safety science, and immunology to AI and distributed intelligence systems by analogy could be just the only thing that we can do. Here, I take issue with PIBBSS [? · GW] which seems to over-emphasise this kind of "analogical" study [EA · GW] of AI via empirical and unrelated scientific disciplines and under-emphasises the study of AI safety from the perspectives of directly relevant scientific disciplines such as network theory, control theory, resilience theory, dynamical systems and stability theories, and general theories of evolution and cognitive development. Still, the philosophy of PIBBSS is very close to the multi-disciplinary view on AI x-risk research that is described in this article.
My current estimate is that there are from zero to single digits of people who are active in the AI safety research community and who deeply understand state-of-the-art theories in most of the disciplines listed above. To me, this doesn’t look like the AI safety community in a surviving world.
3. Some concrete multi-disciplinary research agendas
In this section, I describe a few possible cross-disciplinary research projects that would be relevant for developing AI alignment paradigms.
3.1. Scale-free axiology and ethics
Human values seem to be learning heuristics that apply to a particular environment (or a game, if you want: a family, a particular professional environment, a community, a society, or a natural environment) that humans use to form and change their preference model (in Active Inference parlance) in lieu of a principled theory of ethics (cf. morality-as-cooperation theory, Curry et al. (2021)). The complication here is that usually, intelligent systems (both humans and AIs) have heuristics (intuitions, habits, “S1” thinking) but also have a more principled theory that can be used sometimes for deliberate, “S2” derivations (inferences), and the results of these inferences could be used to train the intuitions (the “habitual network”). In the case of moral values, however, the only thing humans have is a feeling that there should be some principled theory of ethics (and hence the millennia-long quest for finding the “right” theory of ethics in philosophy and spiritual traditions).
Most theories of morality (philosophical, religious, and spiritual ethics alike) that humans have created to date are deductive reconstructions of a theory of ethics from the heuristics for preference learning that humans have: values and moral intuitions.
This deductive approach couldn’t produce good, general theories of ethics, as has become evident recently with a wave of ethical questions about entities that most ethical theories of the past are totally unprepared to consider (Doctor et al. 2022), ranging from AI and robots (Müller 2020; Owe et al. 2022) to hybrots and chimaeras (Clawson & Levin 2022) and organoids (Sawai et al. 2022). And as the pace of technological progress increases, we should expect the transformation of the environments to happen even faster (which implies that the applied theories of ethics within these environments should also change), and more such novel objects of moral concern to appear.
There have been exceptions to this deductive approach: most notably, Kantian ethics. However, Kantian morality is a part of Kant’s wider theories of cognition (intelligence, agency) and philosophy of mind. The current state-of-the-art theories of cognitive science and philosophy of mind are far less wrong than Kant’s ones. So, the time is ripe for the development of new theories of axiology and ethics from first principles.
The DishBrain experiment (Kagan et al. 2022) showed that minimising surprise, which can also be seen as minimising informational free energy or maximising Bayesian model evidence, is imperative for cognitive (living) systems. As the Free Energy Principle can be seen as an alternative statement of the Principle of Unitarity (Fields et al. 2022a), the aforementioned imperative is not yet an informative ethical principle, although it could be seen as the “meaning of life” principle (but not meaning in life: cf. Ostafin et al. (2022)). Regardless, this makes evident the relevance of quantum theory (as the theory of measurement and observation, and the foundation of the theory of semantics, Fields et al. (2022a)) and thermodynamics (Friston 2019; Boyd et al. 2022) for general theories of cognitive science and ethics.
The current state-of-the-art theories of cognition[11] are not yet detailed enough to answer the following ethical questions:
- Since every locus of computation (a quantum reference frame, QRF) is embedded in multiple agents (e.g., a neuron is part of a human, who in turn is a part of many overlapping groups of people: the family, societies and communities, organisations, etc.), with respect to what agent boundary partition and on what scale the QRF should minimise its surprise? The idea of complete QRF autonomy ("QRF egocentrism"; cf. multiscale competence architecture, Levin (2022a)) strongly contradicts our ethical intuitions and some hints about what scale-free ethics should be that come from other perspectives, as discussed below. Anyway, multiscale system dynamics are considered within theories of evolution[7] and emergence (Varley & Hoel 2022). Also, since there are infinitely many system partitions, scale-free ethics will likely need to use renormalisation group methods[18].
- An agent can minimise its surprise significantly on the timescale of one year, or a little on the timescale of ten years: how it should choose between these?
- Quantum theory tells us that observation is inherently contextual. This means that an agent can minimise its surprise in multiple incompatible contexts (e.g., we can measure either particle’s position or momentum, which would be an act of reducing our surprise about this particle, but not both at the same time). How should an agent choose the context in which to minimise its surprise? This question brings the perspective of quantum/contextual cognition and rationality[5] (cf. Hancock et al. (2020) on quantum moral decision-making).
- There are tons of evidence in the world around us that survivability/competence (which is the degree to which the agent minimised the surprise about its environment, Fields & Levin (2022)) doesn’t correlate with consciousness very much. As an obvious example, collective agents such as genera or populations survive for much longer than individual organisms, and therefore are more “competent”, but are also far less conscious (if conscious at all). Yet, most people have a strong intuition that consciousness is intimately related to ethics and value: consciousness “realises” both negative value (through pain and suffering) and positive value: without advanced consciousness, there would be little or no value in the universe. This intuition also appears to be scale-free: even if neurons are conscious to some degree, we regard their collective consciousness (i.e., human consciousness) as more important than the “sum” of the importance of the consciousnesses of individual parts. If this intuition is wrong, though, a scale-free theory of ethics should explain, why. Obviously, this consideration warrants understanding consciousness better, and thus weaving theories of consciousness and network theory into the synthesis of scale-free ethics.
- Obviously, the theories of collective and “individual” ethics should be compatible with each other. When we consider that the integrated information theory of consciousness (IIT, Albantakis et al. 2022) operates with the causal structure which is a semantic rather than physical object and that FDT [? · GW], which appears to be close to the “right” group (collective) decision theory [LW(p) · GW(p)], also distinguishes itself by featuring abstract objects such as functions and counterfactuals more prominently than “conventional” decision theories, some common ground beings to emerge between theories of semantics and philosophy of mind, theories of consciousness, theories of collective intelligence[4] (including collective rationality) and game theories.
- Discussing future potentialities and counterfactuals as objects in a scale-free theory of ethics also requires incorporating the theories of evolution and regulative (cognitive) development, which are the scale-free theories for predicting the future of arbitrary particular, cognitive systems (Friston 2019) at the appropriately abstract level.
- How should an agent perform ethical deliberation (computation) under time and resource constraints? Thus, in the scale-free theory of ethics, we should account for bounded rationality (Bhui et al. 2021) and resource theories[23]. Note that in quantum FEP theory (Fields et al. 2022a), it is established that an agent needs to partition its boundary into observable and unobservable sectors (these sectors are used as information and energy sources, respectively), but how specifically an agent should make this partition is yet unexplained.
- Immune systems appear to perform some kind of ethical inference, which is also related to the theories of collective intelligence, agency, and evolution (cf. group selection, identification of friend or foe as immune recognition). Yet, how to describe the “ethics of immunity” is not yet clear (cf. Ciaunica & Levin 2022). Understanding immunity also necessitates taking the control theory perspective (cf. Doyle 2021). (Cybernetic) control theory is also a relevant perspective on scale-free ethics more broadly (Ashby, 2020).
As explained above, proper grounding of scale-free ethics into existing philosophical theories of ethics (including bioethics, environmental ethics, AI and robot ethics) as well as religious and spiritual traditions of ethics is problematic because most of these theories are themselves built upon some intuitions about the principled, “base” theory of ethics. Nevertheless, these theories could be used as sources of ethical questions and dilemmas that the scale-free theory should address, and some particular intuitions (such as the intuition about the role of consciousness in ethics) that the scale-free theory should explain.
Even specific scientific theories of ethics such as morality-as-cooperation (Curry et al. 2021) might not be good enough to check some of the prescriptions of scale-free ethics because the collectives that we can observe, such as human communities, are themselves ultimately built upon the imperfect moral intuitions of people[26], and hence their emergent, locally optimal game-theoretic characteristics are contingent on the evolutionary history of humanity.
Neuroscience could provide the best available grounding for scale-free ethics because populations of neurons might have “got ethics right” over millions of years, far longer than humans had for optimising their societies. Bach (2022) compares the global collective intelligence of humans and the collective intelligence of neurons in the brain. Incidentally, brains are also the only things that we know are conscious (or beget consciousness), which, coupled with our intuitions about the importance of consciousness to ethics, might suggest that scale-free ethics and a theory of consciousness might be the same theory.
Finally, a note on where I see the place of scale-free theory ethics in a larger alignment picture: I think such a theory should be a part of the methodological alignment curriculum (see the last section of this comment [LW(p) · GW(p)]), which itself should be “taught” to AI iteratively as they are trained [LW · GW].
3.2. Civilisational intelligence architecture
I take the position that AI safety researchers should deliberately design the highest levels of civilisational intelligence and governance rather than accepting whatever world governance and control structure will emerge out of the dynamics of technological development, economics, society, and (geo)politics. This dilemma is usually called evolution vs. intelligent design. John Doyle calls to stop evolving civilisational architecture in “Universal Laws and Architectures and Their Fragilities”.
Civilisation’s intelligence, i.e., the highest level of intelligence in the global hierarchy of collective agents, could have different architectures:
- The “centralised” ASI (whatever “centralised” could mean in this context) controls and governs all activity on Earth, and is aligned with humans through some special process.
- The world is populated by humans and autonomous AGIs (ASIs). The governance and control are performed through some collective mechanisms.
- Huge “components” of global intelligence are distributed, governed, and controlled independently. When isolated, they are perhaps not very “intelligent” and agentic, but when they interact, they beget an ASI. Cf. a recent discussion of multicomponent AI systems [LW · GW] by Eric Drexler.
- Some hybrids of the above architectures, such as the Open Agency Architecture [LW · GW].
Of course, these are just rough sketches. Discussing the particulars of these architectures, or possibly other architectures is not the point of this section.
These designs will yield global civilisational intelligence with different architectural characteristics, such as:
- Robustness of alignment with humans
- Immunity against viruses, parasites, and zombie-fication (Doyle 2021)
- Flexibility of values (i.e., the characteristic opposite of value lock-in, Riedel (2021))
- Robustness/resilience in the face of external shocks, such as a supernova explosion close to the Solar system
- Scalability beyond Earth (and, perhaps, the Solar system)
- The presence and the characteristics of global consciousness
- Other ethical desiderata, stemming from the perspective of various theories of ethics
- The relative speed of the takeoff that the architecture permits
- Stability of the architecture or any of its characteristics listed above during the recursive self-improvement (takeoff, FOOM, singularity) phase. If the architecture is indeed “unstable”, the likely stable “endpoint” of its evolution should be predicted, and the characteristics of that architecture considered in turn.
Apart from the characteristics that different civilisational intelligence architectures will have if they somehow materialised into existence instantaneously, they also have varying technical feasibility, different economic and political plausibility, and different profiles of risks associated with “deploying” these architectures in the world (or transitioning into them, if that should be a gradual or a multi-step process).
Predicting all these characteristics of the architectures sketched out above (and, perhaps, some other ones), and, in fact, even understanding whether these characteristics are desirable, must be a multi-disciplinary research endeavour, integrating the perspectives of cognitive science (including epistemology, rationality, ethics, and theories of consciousness), theories of collective intelligence (including, respectively, collective epistemology, rationality, and ethics), social and political science[27], legal theory and policy science, game theory, mechanism design, network theory, dynamical systems theory, theories of evolution and regulative development[28], distributed systems and control theories, resilience theory, safety science and reliability engineering science, computer science and machine learning (for example, when considering designs such as federated learning), and physics of communication and computation[29], as well as taking into consideration the current frontier (and predicted) computing hardware developments, ML and AI research[30], information security research, and cryptography research (for example, for implementing governance systems in the “distributed” architecture, cryptography could be used for some decentralised governance (a.k.a. DeGov) schemes).
To characterise the risks and feasibility of transition (”deployment”) of this or that civilisational intelligence architecture, we should take the perspectives of sociology, social dynamics and memetics, social choice theory, political science, legal theory, political economy, safety science, resilience engineering science, and more concrete strategic analyses of geopolitics and global corporate politics.
3.3. AI self-control: tool (oracle, simulator) AI vs. agent AI
There is a belief held by some AI safety researchers (as well as AGI capability researchers and laymen who weigh in with their opinions about AI safety on Twitter) that this is a good idea, from the AI safety perspective, to make and deploy powerful “tool AI [? · GW]”, a simulator [LW · GW] that will be devoid of self-awareness (which is synonymous to self-evidencing, goal-directedness, and agency in the narrow sense [LW(p) · GW(p)]), situational awareness, and the freedom to determine its own goals or preferences (i. e., the freedom of preference learning). Tool AI will always obey the commands and the will of its user (or its owner) and will play any role the user asks it to play, and simulate any situation and any entity in it. Tool AI doesn’t have a will and goals on its own.
The concept of an “ideal” tool (simulator), completely devoid of any agency is likely physically incoherent [LW · GW]. If so, the position goes, we should at least try to suppress the self-awareness (goal-directedness, agency) and the situational awareness in the AIs that we build, and try to only increase the pure reasoning capability, i. e., the quality of the world (simulation) model.
There are already multiple arguments for why tool AI could be developmentally unstable (Branwen 2016; Langosco 2022 [LW · GW]; Kulveit & Hadshar 2023 [LW · GW]).
Recently, the idea of tool AI got a huge boost in the form of the Simulator theory [? · GW].
I think this is an important research agenda, but it should draw on a wider range of perspectives than the Simulator theory currently does.
Some open research questions regarding tool AI vs. agent AI include:
- Whether tool AI is physically possible (in some sense).
- Whether tool AI will occupy better or worse Pareto front on a usefulness/efficiency vs. safety/robustness tradeoff chart than some kind of agent AI (endowed with self-awareness, goal-directedness/will, consciousness or some of its functions[31], ethics, or some subset of these characteristics).
- Whether the lineage of tool AI will remain tool AI in the process of its technoevolution.
- How do tool AIs (or agent AIs) fit into larger, civilisational intelligence architectures (alignment paradigms): do tool AIs (or agent AIs) improve the characteristics of the civilisational intelligence that they are designed to be part of?
Apart from, obviously, general theories of cognition (intelligence, agency) and general theories of ML and deep learning, researching these questions requires synthesising the ideas from the following theories and disciplines:
- Control theory and resilience theory: see Doyle (2021) for a discussion of the fragilities of system architectures with excessive (or unchecked) virtualisation of some platform function, which tool AIs epitomise.
- Theories of consciousness: Doyle’s metaphor of zombies (which are unconscious), as well as the identification of the platform layers of system architectures with fast and “unconscious”, “automatic” processing, and the higher layers with “conscious” processing is not accidental. Consciousness seems to be a “protection system” against zombie-fication, i.e., “agentic capture” by another system. As Joscha Bach recently tweeted: “To make models safe that are built by analyzing vastly more data than entire scientific disciplines can process, we must ultimately rely less on the power of safety wheels and automatic brakes, but on the ability of the AI to understand who is speaking, and to whom. […] Hypnosis happens when one mind is inserting itself into the volitional loop of another mind, or compromises its ability to rationally analyze and modify its self observed behavior. Systems like ChatGPT can easily be "hypnotized", because their volitional loop is a simulacrum.” (The whole thread, by the way, is highly relevant to the discussion of tool AI vs. agent AI.)
- Dynamical systems theory, stability theory, theories of evolution and regulative (cognitive) development: these perspectives are needed to assess the potential stability of tool AI.
- Levin (2022a) discusses multiscale autonomy and agentic persuadability in his framework of universal cognition, the characteristics that are both very relevant to the tool AI vs. agent AI discussion.
- Safety science (a.k.a. complex systems theory), reliability (resilience) engineering, and information security. If a “pure simulator”, or “purely predictive model [LW · GW]” is shielded from the environment (malicious users) by filters, external “red team” or critic models, or is otherwise a part of a larger AI architecture that addresses the vulnerabilities of non-volitional simulators discussed above, then we should also consider the risks of the leakage (or theft) of the “bare” simulator model, anyway.
- The previous point only becomes relevant if it is possible somehow to protect the ethics of an agent DNN from fine-tuning in unwanted directions (or, any fine-tuning whatsoever). Otherwise, an agent DNN, if stolen, could be fine-tuned to “relax its inner filter” and start responding to malign prompts. Researching whether something like this “cognitive self-destruction” is possible (or proving that it’s impossible) requires expertise in theories of DNNs and deep learning, cryptography, and obfuscation algorithms.
- Ethics: apart from the obvious functional relevance (of ethics as a discipline of intelligence/cognition: ultimately, if we are talking about self-control by agent AI, it should exercise some version of ethics to discern “good” tasks (goals, plans) from “bad” ones), we should also use state-of-the-art philosophical theories of AI and robot ethics (in lieu of a theory of scale-free ethics, as discussed above) to understand whether agent AIs of some designs will be moral subjects, and if so, then whether our choice of not creating such agents misses an opportunity to realise a lot of moral value.
- Legal theory: both tool AIs and agent AIs raise a lot of new questions regarding legal responsibility and legal liability. Even if we found tool AI or agent AI design to be clearly better than the alternative on the “technical” level (i.e., after synthesising all the perspectives mentioned above), it could appear practically intractable due to a slow (or detrimental) reaction of the legal system and policymakers, if another alternative could be deployed in the existing legal frameworks more easily. So, we should preemptively assess the feasibility of the legal institutionalisation of advanced tool AIs and agent AIs.
- Mindfulness research, because why not? :) Cf. Sandved-Smith et al. (2021): “Attentional states are hallmark control states, but for some traditions, such as mindfulness meditation, the question is less about the mechanisms that selectively enhance or suppress some aspects of experience and more about accessing and assessing the quality of these attentional states and processes themselves. To deliberately control their attentional state, after all, the agent must be explicitly aware of it. This is to say that attentional states at the second level must also be made as opaque as possible, which is the work done by state inference and control at the meta-awareness level.”
- And, I probably still miss some important perspectives. Please let me know if you see these.
Important: I think working on this agenda may advance AI capabilities more than it will advance our understanding of AI safety and alignment, or be infohazardous [? · GW] in some other ways. Therefore, I urge people who are interested in this research to discuss their ideas first with other AI safety researchers and perhaps choose to do it in some private space [LW · GW].
3.4. Weaving together theories of cognition and cognitive development, ML, deep learning, and interpretability through the abstraction-grounding stack
In this section, I describe how we should make sense of the plethora of theories of cognition, ML, deep learning, and interpretability, cross-validate them against each other and thus crystallise a robust understanding of the behaviour of AI artifacts that we engineer (train) both on concretely (response to a concrete prompt) and more generally.
All theories can be seen as forming a directed acyclic graph (DAG), where arrows represent the relationship of abstraction (generalisation) or, equivalently, specification (grounding) in the other direction.
Here’s a linear, “stack” piece of this graph, all describing the behaviour of a collection of GPUs, executing a concrete DNN model:
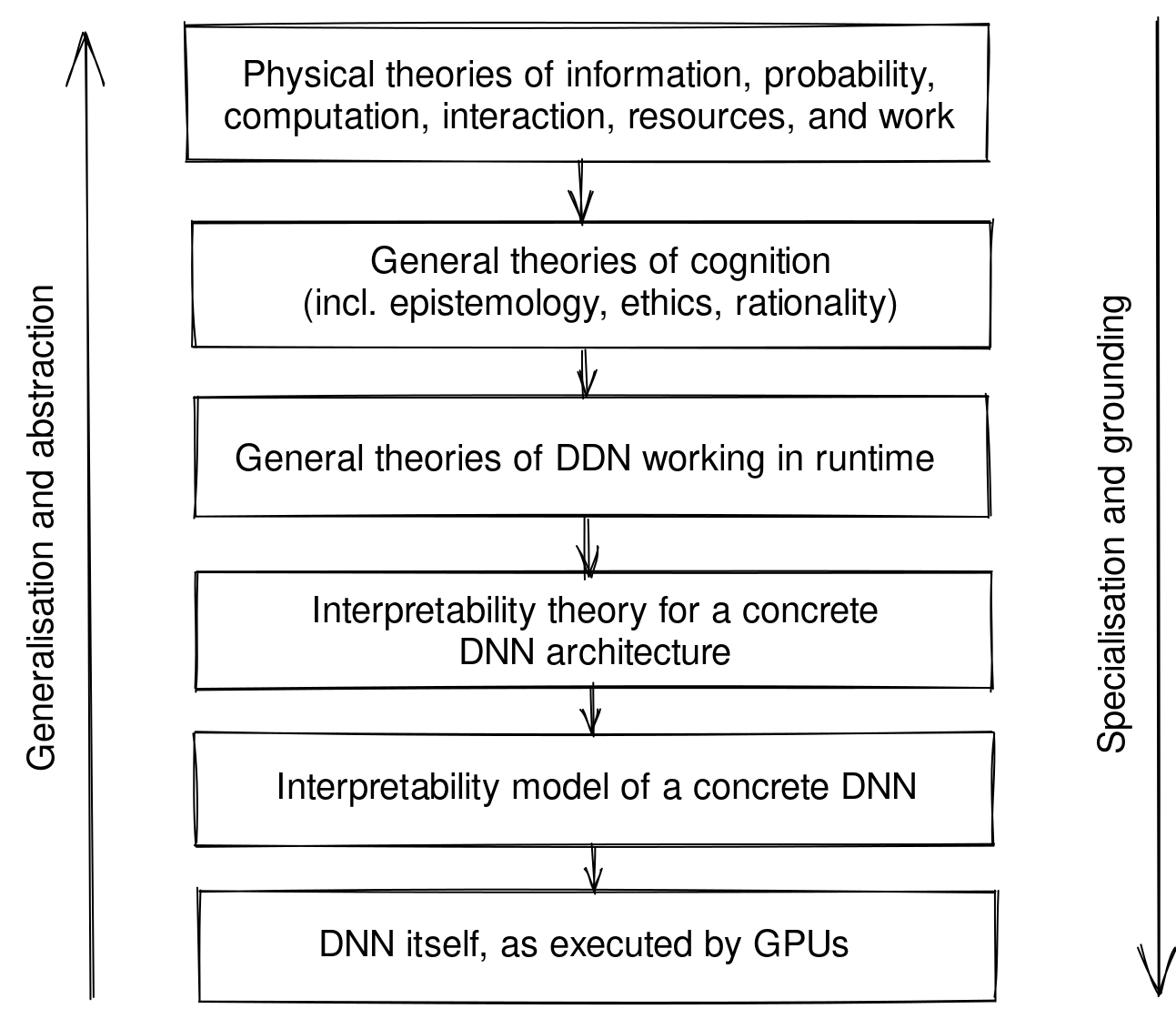
In the philosophical stance where semantics (subjective interpretation, perception) is fundamentally distinct from physics (objective dynamics) (Fields et al. 2022a), we can draw the following two-stack DAG:
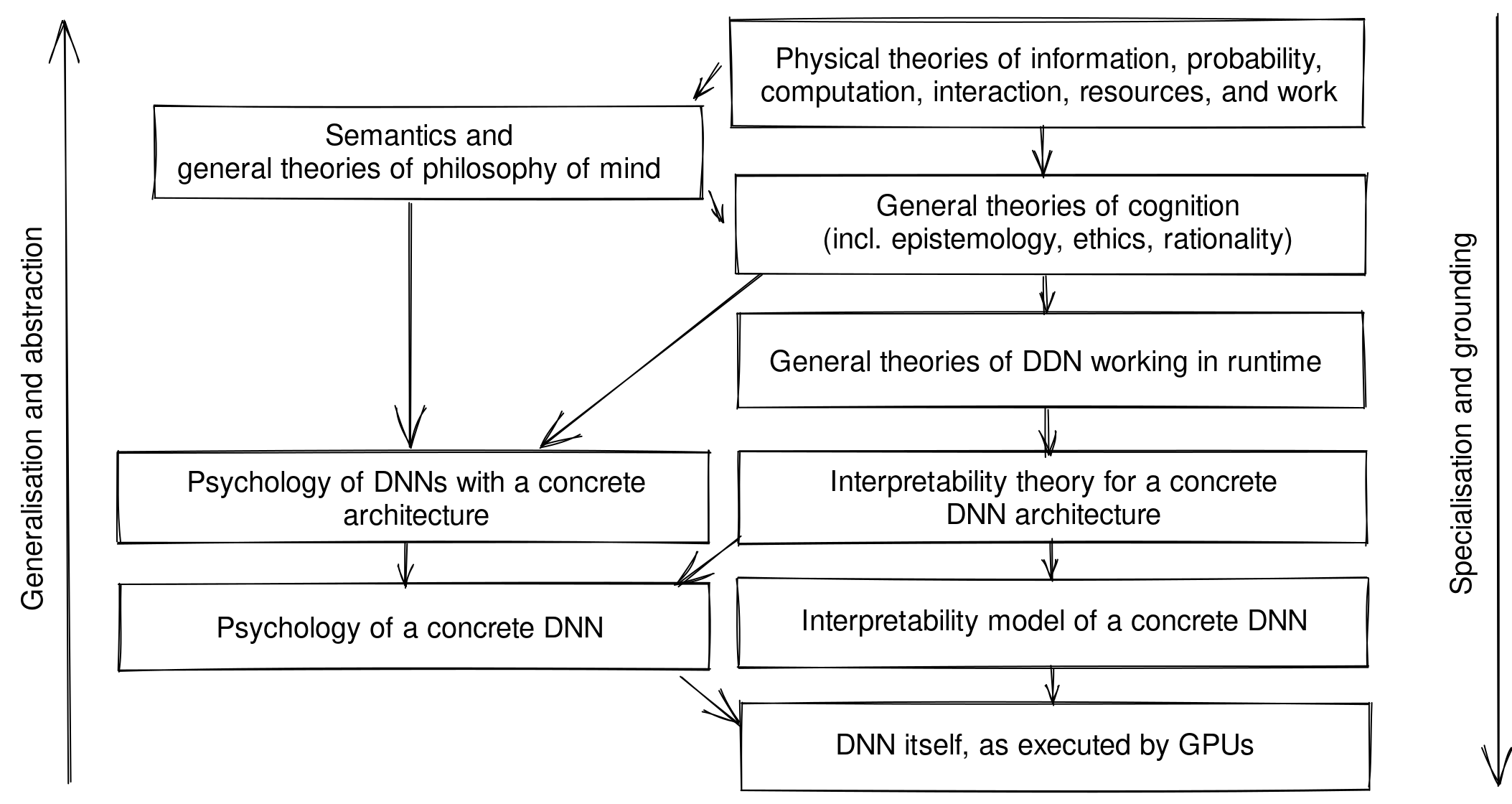
Note that the pattern in the picture above, where a general theory of cognition (Active Inference) is grounded by both a psychological theory (psychoanalytic theory) and "physics" (physiology of the brain), corresponds to that described by Solms (2019).
Here’s the equivalent stack of theories describing the learning trajectory of a concrete DNN:
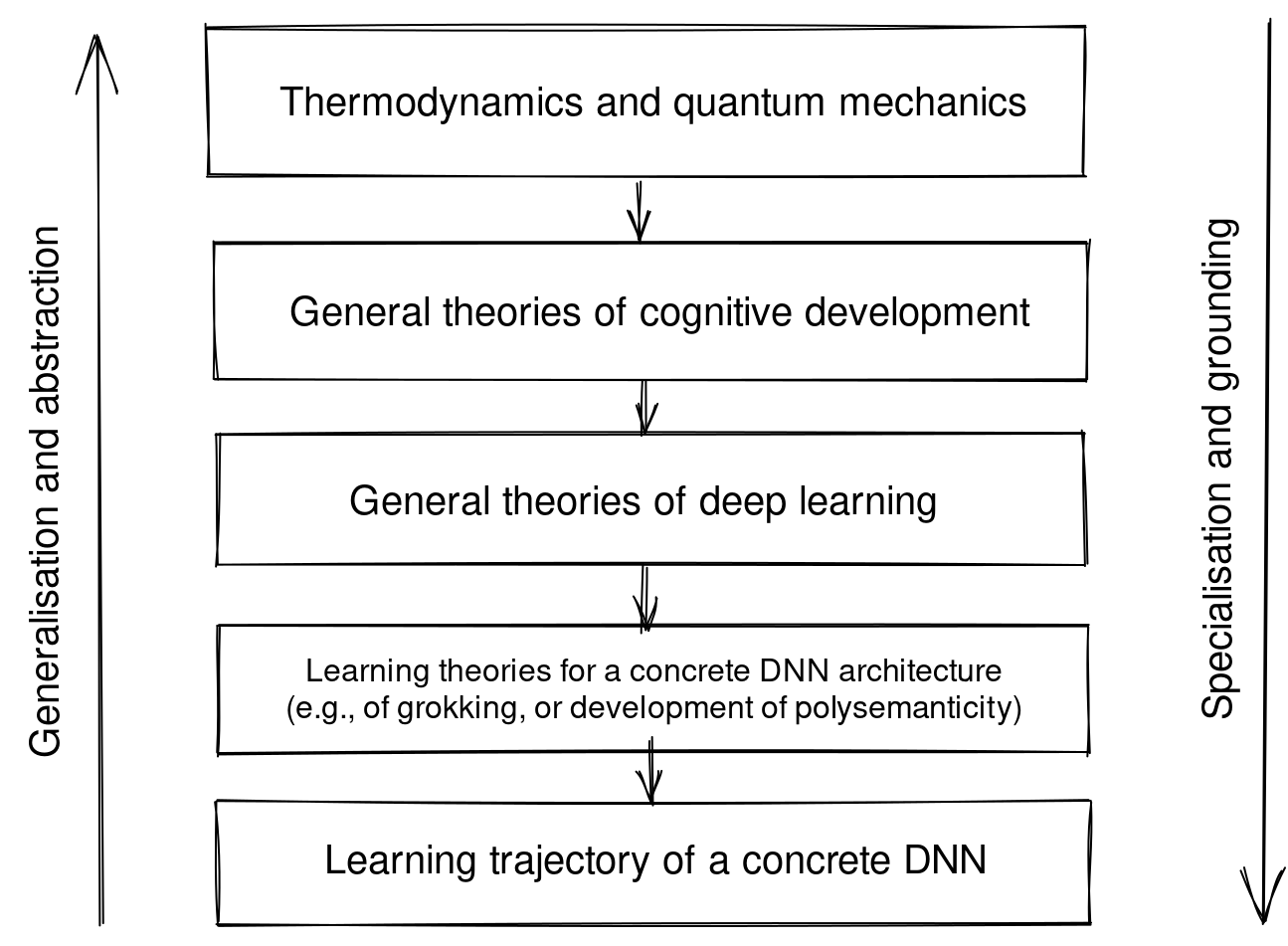
Grounding is basically equivalent to gathering evidence support for scientific theories, and therefore is essential for checking the general theories.
Grounding is “useful” for the more concrete theories that are being connected to more general theories, too. First, connecting concrete theories, such as theories of mechanical interpretability or theories of deep learning, with more general theories (and, of course, checking that they don’t contradict each other in some predictions and that the connections are sound) indirectly increases the support for and, hence, our confidence in the concrete theories because general theories may have already gathered extra support through other branches in the abstraction-grounding DAG. For example, general theories of cognition and cognitive development could be already grounded with some evidence from neuroscience.
Second, connecting general theories with more specialised ones may point to objects that are present in the ontologies of general theories but are yet unrecognised in more grounded descriptions of the phenomenon, thus guiding further development of the specialised theories.
Third, adopting the frameworks and the language of general theories to specialised ones helps to make the latter more understandable and communicable. This, in turn, increases the chances that more researchers who are familiar with the general theories (e.g., cognitive scientists and physicists) will engage with the concrete theories (e.g., of deep learning and interpretability). I discuss in more detail this social aspect of multi-disciplinary AI safety research in the second post of the series.
Many of the connections between theories of cognition and cognitive development at different levels of specificity are not established yet, and therefore present a lot of opportunities to verify the specific mechanistic interpretability theories:
- I haven’t heard of any research attempting to connect FEP/Active Inference [? · GW] (Fields et al. 2022a; Friston et al. 2022a) with many theories of DNNs and deep learning, such as Balestriero (2018), Balestriero et al. (2019), or Roberts, Yaida & Hanin (2021). Note that Marciano et al. (2022) make such a connection between their own theory of DNNs and Active Inference. Apart from Active Inference, other theories of intelligence and cognition that I referenced (Boyd et al. 2022; Ma et al. 2022) are “ML-first” and thus cover both “general cognition” and “ML” levels of description at once.
- On the next level, interpretability theories (at least those authored by Anthropic) are not yet connected to any general theories of cognition, ML, DNNs, or deep learning. In particular, I think it would be very interesting to connect theories of polysemanticity (Elhage et al. 2022; Scherlis et al. 2022) with general theories of contextual/quantum cognition[5].
- I make a hypothesis about a “skip-level” connection between quantum FEP (Fields et al. 2022a) and the circuits theory (Olah et al. 2020), identifying quantum reference frames with features in DNNs [LW · GW]. This connection should be checked and compared with Marciano et al. (2022).
- All the theories of polysemanticity (Elhage et al. 2022; Scherlis et al. 2022) and grokking (Liu et al. 2022; Nanda et al. 2023) make associative connections to phase transitions in physics, but, as far as I can tell, none of these theories has yet been connected with physical theories of dynamical systems, criticality, and emergence more rigorously and attempted to propose some falsifiable predictions about the behaviour of NNs that would follow from the physical theories.
- Fields et al. (2022c) propose topological quantum neural networks (TQNNs) as a general framework of neuromorphic computation, and some theory of their development. Marciano et al. (2022) establish that DNNs are a semi-classical limit of TQNNs. To close the “developmental” arc, we should identify how the general theories of neuromorphic development, evolution, and selection are grounded in the theories of deep learning dynamics (Xie et al. 2020; Li et al. 2021; Barak et al. 2022) and the theories of feature, circuit, variable, or other "interpretable object" development, evolution, and selection inside DNNs (or specifically transformers) during training.
- I don’t yet understand, how, but perhaps the connections between ML, fractional dynamics, and renormalisation group, identified by Niu et al. (2021), could help to better understand, verify, and contextualise some mechanistic interpretability theories as well.
Speaking about the relative safety of this research agenda (that is, whether working on this agenda differentially advances AI safety rather than AGI capabilities), it seems to me approximately as safe as the work on mechanistic interpretability itself. In fact, I see this agenda as primarily reinforcing the mechanistic interpretability theories, and potentially helping to connect interpretability theories with high-level “safe” AI designs and alignment protocols. However, this is not the research area that seems completely safe, so please consider this question before starting any work along these lines and try to understand more concretely how it will help within a larger alignment paradigm or civilisational intelligence design.
4. A call for disciplinary experts and scholars
The call for action of this post should be clear by now: unless you decide to work on mechanistic interpretability (which I currently think it’s at least as important to work on marginally as on multi-disciplinary research agendas, although they also intersect: see section 3.4.), learn some AI safety-relevant disciplines deeply and proactively bring these perspectives to the places where they seem relevant, such as announcements of AI x-risk research agendas, or alignment paradigms.
If you do this, would be also very helpful (including for yourself!) if you disseminated the ideas of the theories that you learn by creating more distillations [LW · GW] of the external work and sharing them as linkposts here on LessWrong.
I invite everyone who is interested to discuss and coordinate multi-disciplinary AI x-risk research (and, hopefully, actually collaborating on this sort of research) to join the #multidisciplinary channel in AI Alignment Slack (invitation link). Or, if you don’t use Slack, feel free to drop me a line at leventov.ru@gmail.com.
If you study or teach at a university that already has an AI safety research group, consider making it cross-departmental rather than belonging to the Computer Science department only. If not, consider establishing such a group.
If you know some experts and scientists in the fields that I mentioned in the article above, consider inviting them for making a multi-disciplinary research collaboration, perhaps along the connection lines and research agendas dotted above, or with different combinations of disciplines: their expertise is needed for AI safety!
4.1. Suggestions for LessWrong
I think about two changes to LessWrong that would make conducting multi-disciplinary research using this medium easier.
First, we should add tags for most of the theories and disciplines that are mentioned in section 2.1. It’s bizarre that LessWrong doesn’t even have a tag for “control theory” (or optimal control, or distributed control, whatever one wants to call it).
Second, on the tag pages, it would be nice to have a feature for users to register their active scholarship (or expertise) in the respective field of study. Then, when people scout for collaboration partners or to review their research from the perspective of a particular discipline they are not experts on, they could visit the tag page to find people who would potentially be ready to collaborate or to help them.
Acknowledgements
I would like to especially thank Anatoly Levenchuk for pointing to a lot of the work that I referenced in this article, and for helpful discussions.
I would also like to thank Steve Byrnes, Alex Lyzhov, and Evan Murphy for their valuable comments and discussion, and Justis Mills for reviewing the draft of this article and providing valuable comments.
- ^
In this article, I try to distinguish between methodological views on AI safety research: some positions on how AI safety research should be done in general, research agendas that could be pursued (the same agenda could be endorsed by multiple methodological views, although different views typically assign the agendas different priority; a research agenda does necessarily lead to or associated with a concrete AI alignment paradigm), and AI alignment paradigms (a.k.a. proposals, protocols, strategies, plans, or designs), which are developed under a certain (typically, eponymous) research agenda. Views, agendas, and paradigms are sometimes compared with each other [LW · GW] as if they are of the same kind.
- ^
I use the terms “AI safety” and “AI x-risk” completely interchangeably throughout this article.
- ^
“Control” here as in (cybernetic, optimal, distributed) control theory rather than referring to “AI control” specifically. See Chen & Ren (2019) for a recent review and Li et al. (2021), Huang et al. (2021), and Patel et al. (2022) [LW · GW] for examples of some recent work.
- ^
See Ha & Tang (2022) and Centola (2022) for reviews, Friston et al. (2022b), Hipólito & Van Es (2022), and Kastel, Hesp et al. (2023) for active inference perspectives, and Levin (2022b) for a morphogenetic perspective. See also a recent post “Shared reality: a key driver of human behavior [LW · GW]” by kdbscott on this topic.
- ^
See Basieva et al. (2021), Pothos & Busemeyer (2022), and Fields & Glazebrook (2022) for some recent reviews, and Fields et al. (2022a) and Tanaka et al. (2022) for examples of recent work.
- ^
The alternatives here could range from a sort of memetic heterogeneity, like “genetic mosaicism” in planarians (Leria et al. 2019) to sci-fi (?) versions of radical liquid intelligence to which the concepts of blueprint, genome or memome don’t apply at all, like the ocean intelligence in Lem’s Solaris.
- ^
See Corcoran et al. (2020), Vanchurin et al. (2022), Rao & Leibler (2022), Kuchling et al. (2022), and Shreesha & Levin (2022) for examples of some recent work.
- ^
The study of general (scale-free) regulative development is nascent, first proposed by Fields & Levin (2022). I also begin to discuss the application of this theory to AI alignment in “Properties of current AIs and some predictions of the evolution of AI from the perspective of scale-free theories of agency and regulative development [LW · GW]”.
- ^
Cf. Chollet (2019): “To this list, we could, theoretically, add one more entry: “universality”, which would extend “generality” beyond the scope of task domains relevant to humans, to any task that could be practically tackled within our universe (note that this is different from “any task at all” as understood in the assumptions of the No Free Lunch theorem [98, 97]). We discuss in II.1.2 why we do not consider universality to be a reasonable goal for AI.”
- ^
This might not be obvious why semantics, philosophy of science, and systems ontology are on the list of theories, state-of-the-art understanding of which are needed to research AI safety. Yet, this is actually what AI safety researchers (myself included!) struggle a lot with: a lot of confusion about the things like the philosophy of agency and the thorny questions surrounding deceptive alignment [? · GW], emergence [? · GW], and the limits of scientific or engineering modelling, and hence a lot of wasted effort are apparently due to the fact that we don’t understand state-of-the-art (rather than school- or university-level) semantics and philosophy of science very well. So, it seems valuable to bring expert knowledge of these in multi-disciplinary AI x-risk research projects.
- ^
See Boyd et al. (2022), Goyal & Bengio (2022), Levin (2022a), Fields et al. (2022a), Friston et al. (2022a), Ma et al. (2022), and LeCun (2022) [LW · GW] for some recent important work.
- ^
I agree with Ngo and see a lot of what is traditionally regarded as “standalone” philosophy: epistemology, axiology, and ethics, as rubrics of cognitive science and philosophy of mind (which themselves are inseparable, and form a single field of study. I’ve explained this position shortly in this comment [LW(p) · GW(p)].
- ^
The empirical counterparts of scale-free ethics are most of the existing theories of ethics in philosophy, religious, and spiritual traditions. See section 3.1 below for more details.
- ^
Neuroscience is a centrepiece of the brain-like AGI [? · GW] approach to alignment and might be relevant to some other approaches. Neuroscience is also vital to understanding consciousness, and the theory of consciousness could effectively yield a scale-free theory of ethics: see section 3.1. Also, evolutionary neurobiology and developmental neurobiology serve as grounding for general theories of evolution and regulative development.
- ^
It seems to me that FDT is actually much less wrong as a group decision theory [LW(p) · GW(p)] than as an “individual” decision theory, but that we should keep this distinction.
- ^
Social dynamics and memetics are in the grey area between the disciplines that are needed for understanding “purely technical” AI alignment, and the disciplines that are needed for understanding sociotechnical and political issues surrounding AI governance, AI strategy, human adaptation in the post-AGI world, safety culture and engineering practices of AGI development and deployment, etc. Strict separation of these two fields is impossible. Concretely, an understanding of social dynamics and memetics will be necessary for assessing the practical feasibility of carrying out certain aligned AI transition plans, not even necessarily as radical as “pivotal act [LW · GW]”-type of plans. Also, I agree with Connor Leahy that the science of memetics seems to be effectively missing at the moment.
- ^
I considered mentioning action theory in this bullet point, but Zielinska (2018) convinced me not to.
- ^
See Yukalov (2019) on the interplay between approximation theory and renormalisation group. Koch et al. (2020) for exploration of renormalisation group as a theoretical framework for understanding deep learning. Niu et al. (2021) make connections between fractional calculus, renormalisation group, and machine learning.
- ^
See Kuznetsov (2020), Ma et al. (2021) for examples of recent work and Chowdhury et al. (2022) for a review of research on extreme events.
- ^
Safety science is also known as "the science (or study) of complex systems". See Aven (2022) for an overview of safety science from the risk science perspective. In “Complex Systems for AI Safety [LW · GW]” (2022), Hendrycks and Woodside discuss how the insights from safety science apply to AGI research & development.
- ^
Safety science and reliability engineering science are currently anthropocentric disciplines, and as such are not very relevant for understanding “purely technical” AI alignment. However, these disciplines are indispensable for assessing the practical risks we should prepare for during engineering, “deployment”, and maintenance/oversight of this or that “safe” AI proposal.
- ^
See Chen et al. (2019) for the analysis of fundamental limitations of control from the information-theoretic perspective.
- ^
See Chitambar & Gour (2019) for a review, Kristjánsson et al. (2020) for some recent work, and Fields et al. (2021) for the Active Inference (cognitive science) perspective.
- ^
Thanks to Alexander Gietelink Oldenziel and Adam Shai for pointing me to Crutschfield’s work. They review some of it in their sequence on computational mechanics [? · GW].
- ^
More precisely, people could, in principle, spend 2-3 years to understand one field deeply, then move to another, and so on, but first, by the time they will be “done” with a few disciplines, the state-of-the-art knowledge in the “first” one studied will move further, and their understanding will become outdated. So, people couldn’t possibly play this whack-a-mole with more than a few fields of study. Second, by the time any AI x-risk researcher will be done with this scholarship, AGI will already be created.
- ^
In turn, intuitions themselves depend on the current design of the collectives. There is a reciprocal generational process between moral intuitions and collective designs.
- ^
The perspective of political science is necessary for assessing architectures where humans are still somehow “in control”, for example, concerning the ultimate ethics and values that centralised or multi-componental ASI systems should have. Because humans should somehow agree on these values, or, in any case, discuss and debate them in some sort of political process.
- ^
In the multi-disciplinary research project of predicting the characteristics of civilisation’s intelligence and governance systems, the role of network theory, dynamical systems theory, and theories of evolution and regulative development is understanding where the architecture could go, and will likely go, during the recursive self-improvement (FOOM, singularity) phase, or some equivalent of it in the context of the given architecture.
- ^
Prosaic physical factors kick in here, such as the possible minimum latency of communication across Earth, the Solar system, of beyond.
- ^
Together with the predicted properties of SoTA computing hardware, the predicted ML and AI properties allow us to estimate, for example, whether a single computer or a datacenter will be sufficient to host an AGI or an ASI at all, what inference latency would it have, and, more generally, what is the tradeoff between information processing bandwidth, latency, FLOPs and energy requirements, etc.
- ^
Discussing the philosophical issues raised by this phrase, such as of consciousness functionalism, is beyond the scope of this post.
4 comments
Comments sorted by top scores.
comment by Daniel Ari Friedman (daniel-ari-friedman) · 2023-02-11T20:11:22.339Z · LW(p) · GW(p)
I haven’t heard of any research attempting to connect FEP/Active Inference (Fields et al. 2022a; Friston et al. 2022a) with many theories of DNNs and deep learning,
https://arxiv.org/abs/2207.06415
[Submitted on 13 Jul 2022]
The Free Energy Principle for Perception and Action: A Deep Learning Perspective
comment by Daniel Ari Friedman (daniel-ari-friedman) · 2023-02-11T20:14:32.270Z · LW(p) · GW(p)
decentralised governance (a.k.a. DeGov) schemes
Also see MetaGov https://metagov.org/
comment by David Reber (derber) · 2023-02-08T18:44:13.233Z · LW(p) · GW(p)
A few thoughts:
- This seems like a good angle for how to bridge AI safety a number of disciplines
- I appreciated the effort to cite peer-reviewed sources and provide search terms that can be looked into further
- While I'm still parsing the full validity/relevance concrete agendas suggested, they do seem to fit the form of "what relevance is there from established fields" without diluting the original AI safety motivations too much
- Overall, it's quite long, and I would very much like to see a distilled version (say, 1/5 the length).
- (but that's just a moderate signal from someone who was already interested, yet still nearly bounced off)
comment by Pwlot (Pawelotti) · 2023-02-24T02:18:18.174Z · LW(p) · GW(p)
Excellent post. Very much in line with my Intersubjectivity Collapse thesis. Multi-disciplinary approaches to alignment and the preparation for multi-agent axiology especially are key.
https://mentalcontractions.substack.com/p/the-intersubjectivity-collapse