Reward Is Not Enough
post by Steven Byrnes (steve2152) · 2021-06-16T13:52:33.745Z · LW · GW · 19 commentsContents
Three case studies 1. Incentive landscapes that can’t feasibly be induced by a reward function 2. Wishful thinking 3. Deceptive AGIs Does an agent need to be "unified" to be reflectively stable? The Fraught Valley Finally we get to the paper “Reward Is Enough” by Silver, Sutton, et al. None 19 comments
Three case studies
1. Incentive landscapes that can’t feasibly be induced by a reward function
You’re a deity, tasked with designing a bird brain. You want the bird to get good at singing, as judged by a black-box hardcoded song-assessing algorithm that you already built into the brain last week. The bird chooses actions based in part on within-lifetime reinforcement learning involving dopamine [LW · GW]. What reward signal do you use?
Well, we want to train the bird to sing the song correctly. So it’s easy: the bird practices singing, and it listens to its own song using the song-assessing black box, and it does RL using the rule:
The better the song sounds, the higher the reward.
Oh wait. The bird is also deciding how much time to spend practicing singing, versus foraging or whatever. And the worse it sings, the more important it is to practice! So you really want the rule:
The worse the song sounds, the more rewarding it is to practice singing.
Uh oh.
How do you resolve this conflict?
- Maybe “Reward = Time derivative of how good the song sounds”? Nope, under this reward, if the bird is bad at singing, and improving very slowly, then practice would not feel very rewarding. But here, the optimal action is to continue spending lots of time practicing. (Singing well is really important.)
- Maybe “Reward is connected to the abstract concept of ‘I want to be able to sing well’?” Sure—I mean, that is ultimately what evolution is going for, and that’s what it would look like for an adult human to “want to get out of debt” or whatever. But how do you implement that? "I want to be able to sing well" is an awfully complicated thought; I doubt most birds are even able to think it—and if they could, we still have to solve a vexing symbol-grounding problem if we want to build a genetic mechanism that points to that particular concept and flags it as desirable. No way. I think this is just one of those situations where “the exact thing you want” is not a feasible option for the within-lifetime RL reward signal, or else doesn’t produce the desired result. (Another example in this category is “Don’t die”.)
- Maybe you went awry at the start, when you decided to choose actions using a within-lifetime RL algorithm? In other words, maybe “choosing actions based on anticipated future rewards, as learned through within-lifetime experience” is not a good idea? Well, if we throw out that idea, it would avoid this problem, and a lot of reasonable people do go down that route (example [? · GW]), but I disagree (discussion here [LW · GW], here [LW · GW]); I think RL algorithms (and more specifically model-based RL algorithms) are really effective and powerful ways to skillfully navigate a complex and dynamic world, and I think there's a very good reason that these algorithms are a key component of within-lifetime learning in animal brains. There’s gotta be a better solution than scrapping that whole approach, right?
- Maybe after each singing practice, you could rewrite those memories, to make the experience seem more rewarding in retrospect than it was at the time? I mean, OK, maybe in principle, but can you actually build a mechanism like that which doesn't have unintended side-effects? Anyway, this is getting ridiculous.
…“Aha”, you say. “I have an idea!” One part of the bird brain is “deciding” which low-level motor commands to execute during the song, and another part of the bird brain is “deciding” whether to spend time practicing singing, versus foraging or whatever else. These two areas don’t need the same reward signal! So for the former area, you send a signal: “the better the song sounds, the higher the reward”. For the latter area, you send a signal: “the worse the song sounds, the more rewarding it feels to spend time practicing”.
...And that’s exactly the solution that evolution discovered! See the discussion and excerpt from Fee & Goldberg 2011 in my post Big picture of phasic dopamine [LW · GW].
2. Wishful thinking
You’re the same deity, onto your next assignment: redesigning a human brain to work better. You’ve been reading all the ML internet forums and you’ve become enamored with the idea of backprop and differentiable programming. Using your godlike powers, you redesign the whole human brain to be differentiable, and apply the following within-lifetime learning rule:
When something really bad happens, do backpropagation-through-time, editing the brain’s synapses to make that bad thing less likely to happen in similar situations in the future.
OK, to test your new design, you upgrade a random human, Ned. Ned then goes on a camping trip to the outback, goes to sleep, wakes up to a scuttling sound, opens his eyes and sees a huge spider running towards him. Aaaah!!!
The backpropagation kicks into gear, editing the synapses throughout Ned's brain so as to make that bad signal less likely in similar situations the future. What are the consequences of these changes? A bunch of things! For example:
- In the future, the decision to go camping in the outback will be viewed as less appealing. Yes! Excellent! That's what you wanted!
- In the future, when hearing a scuttling sound, Ned will be less likely to open his eyes. Whoa, hang on, that’s not what you meant!
- In the future, when seeing a certain moving black shape, Ned’s visual systems will be less likely to classify it as a spider. Oh jeez, this isn’t right at all!!
In The Credit Assignment Problem [LW · GW], Abram Demski describes actor-critic RL as a two-tiered system: an “instrumental” subsystem which is trained by RL to maximize rewards, and an “epistemic” subsystem which is absolutely not trained to maximize rewards, in order to avoid wishful thinking / wireheading.
Brains indeed do an awful lot of processing which is not trained by the main reward signal, for precisely this reason:
- Low-level sensory processing seems to run on pure predictive (a.k.a. self-supervised) learning, with no direct involvement of RL at all [LW · GW].
- Some higher-level sensory-processing systems seem to have a separate reward signal that reward it for discovering and attending to “important things” both good and bad—see discussion of inferotemporal cortex here [LW · GW].
- The brainstem and hypothalamus seem to be more-or-less locked down, doing no learning whatsoever—which makes sense since they’re the ones calculating the reward signals. (If the brainstem and hypothalamus were being trained to maximize a signal that they themselves calculate … well, it's easy enough to guess what would happen, and it sure wouldn't be “evolutionarily adaptive behavior”.)
- Other systems that help the brainstem and hypothalamus calculate rewards and other assessments—amygdala, ventral striatum, agranular prefrontal cortex, etc.—likewise seem to have their own supervisory training signals [LW · GW] that are different from the main reward signal.
So we get these funny within-brain battles involving subsystems that do not share our goals and that we cannot directly intentionally control. I know intellectually that it's safe to cross the narrow footbridge over the ravine, but my brainstem begs to differ, and I wind up turning around and missing out on the rest of the walk. “Grrr, stupid brainstem,” I say to myself.
3. Deceptive AGIs
You're a human. You have designed an AGI which has (you believe) a good corrigible motivation, and it is now trying to invent a better solar panel.
- There's some part of the AGI's network that is imagining different ways to build a solar panel, and trying to find a good design;
- There's another part of the AGI's network that is choosing what words to say, when the AGI is talking to you and telling you what it’s working on.
(In the human case, we could point to different parts of the cortex. The parts are interconnected, of course, but they can still get different reward signals, just as in the bird example above.)
The obvious approach is to have one reward signal, widely broadcast, influencing both parts of the network. And if we get to a point where we can design reward signals that sculpt an AGI's motivation with surgical precision, that's fine! We would sculpt the motivation so that the AGI is trying to invent a better solar panel as a means to an end, with the ultimate goal of helping you. Then when it chooses words, it would also be maximally helpful.
I think it's more likely that we won't get to that point—that AGIs' motivations will always be a bit off from what we intended for various reasons [LW · GW], but we'll (hopefully) muddle through anyway thanks to conservativism, transparency, and so on [LW · GW]. Anyway, the motivation will certainly be off during training, when it's still learning basic things about the world, the existence of people, itself, etc. So either way, we should be deeply concerned that the AGI may sometimes be overly motivated to invent a better solar panel. And then, when it chooses the words to say to you, it may choose its words partly to manipulate you so as to advance its goal of inventing a better solar panel—rather than choosing words that are purely maximally helpful and honest.
So it seems to me that the word-choosing part of the network should have a separate reward signal (or be built in a different way altogether), a reward signal which doesn't care a whit about inventing a better solar panel, a reward signal geared purely towards clear and honest communication.
I don’t have a specific plan here. I just feel like I'd be surprised if the best possible safe AGI design that anyone can dream up will involve using the exact same reward signal for “making plans” and “choosing what words to emit when taking to a human”. I think we'll want different reward signals. Just like the bird example above.
This kind of non-unified agent sounds kinda weird, right? Like an AGI with Tourette’s or something?!? But it shouldn’t sound weird! It’s similar to (or even isomorphic to) a robot taking actions while being inspected by an interpretability / oversight module:
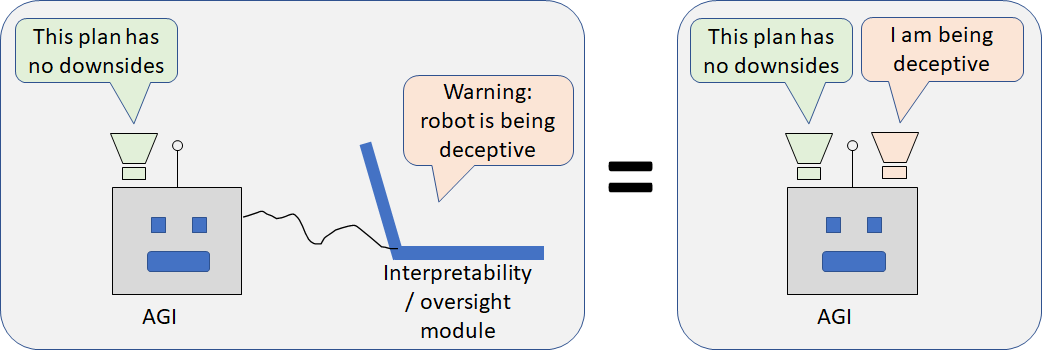
Does an agent need to be "unified" to be reflectively stable?
“Need”? No. It’s clearly possible for a non-unified system—with different supervisory signals training different subsystems—to be reflectively stable. For example, take the system “me + AlphaZero”. I think it would be pretty neat to have access to a chess-playing AlphaZero. I would have fun playing around with it. I would not feel frustrated in the slightest that AlphaZero’s has “goals” that are not my goals (world peace, human flourishing, etc.), and I wouldn’t want to change that.
By the same token, if I had easy root access to my brain, I would not change my low-level sensory processing systems to maximize the same dopamine-based reward signal that my executive functioning gets. I don't want the wishful thinking failure mode! I want to have an accurate understanding of the world! (Y’know, having Read The Sequences and all…) Sure, I might make a few tweaks to my brain here and there, but I certainly wouldn’t want to switch every one of my brain subsystems to maximize the same reward signal.
(If AlphaZero were an arbitrarily powerful goal-seeking agent, well then, yeah, I would want it to share my goals. But it’s possible to make a subsystem that is not an arbitrarily powerful goal-seeking agent. For example, take AlphaZero itself—not scaled up, just literally exactly as coded in the original paper. Or a pocket calculator, for that matter.)
So it seems to me that a “non-unified” agent is not inevitably reflectively unstable. However, they certainly can be. Just like I have a few bones to pick with my brainstem, as mentioned above, it's likewise very possible for different parts of the agent to start trying to trick each other, or hack into each other, or whatever. This is an obvious potential failure mode that we’d be nuts to ignore.
It's not a new problem though. Remember the figure above: it's arbitrary where we draw the line between "the AGI" and "other algorithms interacting with and trying to influence the AGI". So it's not a fundamentally different type of problem from gradient hacking [LW · GW]. Or, for that matter, deception in general. (After all, humans are algorithms too.)
The Fraught Valley
Still, while it's not a new problem, I'll still take this as an excuse to talk about solving it.
The way I’m thinking about it is:
- Early in training, we have The Path Of Incompetence, where the “executive / planning submodule” of the AGI is too stupid / insufficiently self-aware / whatever to formulate and execute a plan to undermine other submodules.
- Late in training, we can hopefully get to The Trail of Corrigibility. That’s where we have succeeded at making a corrigible AGI that understands and endorses the way that it’s built—just like how, as discussed above, my low-level sensory processing systems don’t share my goals, but I like them that way.
- If there’s a gap between those, we’re in, let’s call it, The Fraught Valley.
For example, go back to that figure above, and imagine using those interpretability / oversight tools to install and verify good motivations in the executive / planning submodule. The goal is to do this successfully before the AGI is sophisticated enough to undermine the interpretability tools themselves.
Or imagine trying to do value learning (IRL etc.) in an AGI that builds a world-model from scratch, as I believe humans do. Here we literally can’t install the right motivations from the get-go, because “the right motivations” are inevitably defined in terms of concepts like objective reality, people, self, etc., that are (as of yet) nowhere to be found in the world-model. So maybe we let it do some learning, with some carefully-thought-through curriculum of data and rewards, and spin up the IRL subsystem as soon as the world-model is developed enough to support it.
Anyway, the goal is to make the width of the Fraught Valley as small as possible, or better yet, eliminate it altogether. This involves:
- Making it hard and complicated to corrupt the various motivation-installation and interpretability systems. I don’t think it’s realistic to harden these systems against a superintelligent adversary, but every little roadblock we can think of is good—it helps stretch out the Path Of Incompetence.
- Meanwhile, we push from the other side by designing the AGI in such a way that we can install good motivations, and especially root out the most dangerous ones, early. This might involve things like directing its attention to learn corrigibility-relevant concepts early, and self-awareness late, or whatever. Maybe we should even try to hardcode some key aspects of the world-model, rather than learning the world-model from scratch as discussed above. (I’m personally very intrigued by this category and planning to think more along these lines.)
Success here doesn't seem necessarily impossible. It just seems like a terrifying awful mess. (And potentially hard to reason about a priori.) But it seems kinda inevitable that we have to solve this, unless of course AGI has a wildly different development approach than the one I'm thinking of [LW · GW].
Finally we get to the paper “Reward Is Enough” by Silver, Sutton, et al.
The title of this post here is a reference to the recent paper by David Silver, Satinder Singh, Doina Precup, and Rich Sutton at DeepMind.
I guess the point of this post is that I’m disagreeing with them. But I don’t really know. The paper left me kinda confused.
Starting with their biological examples, my main complaint is that they didn’t clearly distinguish “within-lifetime RL (involving dopamine [AF · GW])” from “evolution treated as an RL process maximizing inclusive genetic fitness”.
With the latter (intergenerational) definition, their discussion is entirely trivial. Oh, maximizing inclusive genetic fitness “is enough” to develop perception, language, etc.? DUUUHHHH!!!
With the former (within-lifetime) definition, their claims are mostly false when applied to biology, as discussed above. Brains do lots of things that are not “within-lifetime RL with one reward signal”, including self-supervised (predictive) learning [LW · GW], supervised learning, auxiliary reward signals, genetically-hardcoded brainstem circuits [LW · GW], etc. etc.
Switching to the AI case, they gloss over the same interesting split—whether the running code, the code controlling the AI’s actions and thoughts in real time, looks like an RL algorithm (analogous to within-lifetime dopamine-based learning), or whether they are imagining reward-maximization as purely an outer loop (analogous to evolution). If it’s the latter, then, well, then what they’re saying is trivially obvious (humans being an existence proof). If it’s the former, then the claim is nontrivial, but it’s also I think wrong.
As a matter of fact, I personally expect an AGI much closer to the former (the real-time running code—the code that chooses what thoughts to think etc.—involves an RL algorithm) than the latter (RL purely as an outer-loop process), for reasons discussed in Against Evolution as an analogy for how humans will create AGI [LW · GW]. If that’s what they were talking about, then the point of my post here is that “reward is not enough”. The algorithm would need other components too, components which are not directly trained to maximize reward, like self-supervised learning.
Then maybe their response would be: “Such a multi-component system would still be RL; it’s just a more sophisticated RL algorithm.” If that’s what they meant, well, fine, but that’s definitely not the impression I got when I was reading the text of the paper. Or the paper's title, for that matter.
19 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-06-17T16:37:30.373Z · LW(p) · GW(p)
Nice post!
I'm generally bullish on multiple objectives, and this post is another independent arrow pointing in that direction. Some other signs which I think point that way:
- The argument from Why Subagents? [LW · GW]. This is about utility maximizers rather than reward maximizers, but it points in a similar qualitative direction. Summary: once we allow internal state, utility-maximizers are not the only inexploitable systems; markets/committees of utility-maximizers also work.
- The argument from Fixing The Good Regulator Theorem [LW · GW]. That post uses some incoming information to "choose" between many different objectives, but that's essentially emulating multiple objectives. If we have multiple objectives explicitly, then the argument should simplify. Summary: if we need to keep around information relevant to many different objectives, but have limited space, that forces the use of a map/model in a certain sense.
One criticism: at a few points I think this post doesn't cleanly distinguish between reward-maximization and utility-maximization. For instance, the optimizing for "the abstract concept of ‘I want to be able to sing well’" definitely sounds like utility-maximization.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-17T17:48:46.902Z · LW(p) · GW(p)
Thanks!
I had totally forgotten about your subagents post.
this post doesn't cleanly distinguish between reward-maximization and utility-maximization
I've been thinking that they kinda blend together in model-based RL, or at least the kind of (brain-like) model-based RL AGI that I normally think about. See this comment [LW(p) · GW(p)] and surrounding discussion. Basically, one way to do model-based RL is to have the agent create a predictive model of the reward and then judge plans based on their tendency to maximize "the reward as currently understood by my predictive model". Then "the reward as currently understood by my predictive model" is basically a utility function. But at the same time, there's a separate subroutine that edits the reward prediction model (≈ utility function) to ever more closely approximate the true reward function (by some learning algorithm, presumably involving reward prediction errors).
In other words: At any given time, the part of the agent that's making plans and taking actions looks like a utility maximizer. But if you lump together that part plus the subroutine that keeps editing the reward prediction model to better approximate the real reward signal, then that whole system is a reward-maximizing RL agent.
Please tell me if that makes any sense or not; I've been planning to write pretty much exactly this comment (but with a diagram) into a short post.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-06-17T18:41:26.102Z · LW(p) · GW(p)
Good explanation, conceptually.
Not sure how all the details play out - in particular, my big question for any RL setup is "how does it avoid wireheading?". In this case, presumably there would have to be some kind of constraint on the reward-prediction model, so that it ends up associating the reward with the state of the environment rather than the state of the sensors.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-17T19:52:57.971Z · LW(p) · GW(p)
how does it avoid wireheading
Um, unreliably, at least by default. Like, some humans are hedonists, others aren't.
I think there's a "hardcoded" credit assignment algorithm. When there's a reward prediction error, that algorithm primarily increments the reward-prediction / value associated with whatever stuff in the world model became newly active maybe half a second earlier. And maybe to a lesser extent, it also increments the reward-prediction / value associated with anything else you were thinking about at the time. (I'm not sure of the gory details here.)
Anyway, insofar as "the reward signal itself" is part of the world-model, it's possible that reward-prediction / value will wind up attached to that concept. And then that's a desire to wirehead. But it's not inevitable. Some of the relevant dynamics are:
- Timing—if credit goes mainly to signals that slightly precede the reward prediction error, then the reward signal itself is not a great fit.
- Explaining away—once you have a way to accurately predict some set of reward signals, it makes the reward prediction errors go away, so the credit assignment algorithm stops running for those signals. So the first good reward-predicting model gets to stick around by default. Example: we learn early in life that the "eating candy" concept predicts certain reward signals, and then we get older and learn that the "certain neural signals in my brain" concept predicts those same reward signals too. But just learning that fact doesn't automatically translate into "I really want those certain neural signals in my brain". Only the credit assignment algorithm can make a thought appealing, and if the rewards are already being predicted then the credit assignment algorithm is inactive. (This is kinda like the behaviorism concept of blocking.)
- There may be some kind of bias to assign credit to predictive models that are simple functions of sensory inputs, when such a model exists, other things equal. (I'm thinking here of the relation between amygdala predictions, which I think are restricted to relatively simple functions of sensory input, versus mPFC predictions, which I think can involve more abstract situational knowledge. I'm still kinda confused about how this works though.)
- There's a difference between hedonism-lite ("I want to feel good, although it's not the only thing I care about") and hedonism-level-10 ("I care about nothing whatsoever except feeling good"). My model would suggest that hedonism-lite is widespread, but hedonism-level-10 is vanishingly rare or nonexistent, because it requires that somehow all value gets removed from absolutely everything in the world-model except that one concept of the reward signal.
For AGIs we would probably want to do other things too, like (somehow) use transparency to find "the reward signal itself" in the world-model and manually fix its reward-prediction / value at zero, or whatever else we can think of. Also, I think the more likely failure mode is "wireheading-lite", where the desire to wirehead is trading off against other things it cares about, and then hopefully conservatism (section 2 here [LW · GW]) can help prevent catastrophe.
comment by Donald Hobson (donald-hobson) · 2021-06-20T22:50:25.193Z · LW(p) · GW(p)
I would be potentially concerned that this is a trick that evolution can use, but human AI designers can't use safely.
In particular, I think this is the sort of trick that produces usually fairly good results when you have a fixed environment, and can optimize the parameters and settings for that environment. Evolution can try millions of birds, tweaking the strengths of desire, to get something that kind of works. When the environment will be changing rapidly; when the relative capabilities of cognitive modules are highly uncertain and when self modification is on the table, these tricks will tend to fail. (I think)
Use the same brain architecture in a moderately different environment, and you get people freezing their credit card in blocks of ice so they can't spend it, and other self defeating behaviour. I suspect the tricks will fail much worse with any change to mental architecture.
On your equivalence to an AI with an interpretability/oversight module. Data shouldn't be flowing back from the oversight into the AI.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-21T17:17:26.682Z · LW(p) · GW(p)
On your equivalence to an AI with an interpretability/oversight module. Data shouldn't be flowing back from the oversight into the AI.
Sure. I wrote "similar to (or even isomorphic to)". We get to design it how we want. We can allow the planning submodule direct easy access to the workings of the choosing-words submodule if we want, or we can put strong barriers such that the planning submodule needs to engage in a complicated hacking project in order to learn what the choosing-words submodule is doing. I agree that the latter is probably a better setup.
I would be potentially concerned that this is a trick that evolution can use, but human AI designers can't use safely.
Sure, that's possible.
My "negative" response is: There's no royal road to safe AGI, at least not that anyone knows of so far. In particular, if we talk specifically about "subagent"-type situations where there are mutually-contradictory goals within the AGI, I think that this is simply a situation we have to deal with, whether we like it or not. And if there's no way to safely deal with that kind of situation, then I think we're doomed. Why do I think that? For one thing, as I wrote in the text, it's arbitrary where we draw the line between "the AGI" and "other algorithms interacting with and trying to influence the AGI". If we draw a box around the AGI to also include things like gradient updates, or online feedback from humans, then we're definitely in that situation, because these are subsystems that are manipulating the AGI and don't share the AGI's (current) goals. For another thing: it's a complicated world and the AGI is not omniscient. If you think about logical induction [? · GW], the upshot is that when venturing into a complicated domain with unknown unknowns, you shouldn't expect nice well-formed self-consistent hypotheses attached to probabilities, you should expect a pile of partial patterns (i.e. hypotheses which make predictions about some things but are agnostic about others), supported by limited evidence. Then you can get situations where those partial patterns push in different directions, and "bid against each other". Now just apply exactly that same reasoning to "having desires about the state of the (complicated) world", and you wind up concluding that "subagents working against each other" is a default expectation and maybe even inevitable.
My "positive" response is: I certainly wouldn't propose to set up a promising-sounding reward system and then crack a beer and declare that we solved AGI safety. First we need a plan that might work (and we don't even have that yet, IMO!) and then we think about how it might fail, and how to modify the plan so that we can reason more rigorously about how it would work, and add in extra layers of safety (like testing, transparency, conservatism, boxing [LW · GW]) in case even our seemingly-rigorous reasoning missed something, and so on.
comment by Archimedes · 2021-06-17T14:56:52.978Z · LW(p) · GW(p)
This was enlightening for me. I suspect the concept of treating agents (artificial, human, or otherwise) as multiple interdependent subsystems working in coordination, each with its own roles, goals, and rewards, rather than as a single completely unified system is critical for solving alignment problems.
I recently read Entangled Life (by Merlin Sheldrake), which explores similar themes. One of the themes is that the concept of the individual is not so easily defined (perhaps not even entirely coherent). Every complex being is made up of smaller systems and also part of a larger ecosystem and none of these levels can truly be understood independently of the others.
comment by sebastiankosch · 2021-06-19T19:57:51.438Z · LW(p) · GW(p)
I found myself struggling a bit to really wrap my mind around your phasic dopamine post, and the concrete examples in here helped me get a much clearer understanding. So thank you for sharing them!
Do you have a sense of how these very basic, low-level instances of reward-based learning (birds learning to sing, campers learning to avoid huge spiders, etc.) map to more complex behaviours, particularly in the context of human social interaction? For instance, would it be reasonable to associate psychological "parts", to borrow from Internal Family Systems terminology, with spaghetti towers of submodules that each have their own reward signal (or perhaps some of them might share particular types of reward signals)?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-21T17:27:15.364Z · LW(p) · GW(p)
Thanks!
My current working theory of human social interactions does not involve multiple reward signals. Instead it's a bunch of rules like "If you're in state X, and you empathetically simulate someone in state Y, then send reward R and switch to state Z". See my post "Little glimpses of empathy" as the foundation of social emotions [LW · GW]. These rules would be implemented in the hypothalamus and/or brainstem.
(Plus some involvement from brainstem sensory-processing circuits that can run hardcoded classifiers that return information about things like whether a person is present right now, and maybe some aspects of their tone of voice and facial expressions, etc. Then those data can also be inputs to the "bunch of rules".)
I haven't thought it through in any level of detail or read the literature (except superficially). Maybe ask me again in a few months… :-)
comment by M. Y. Zuo · 2021-06-16T17:11:54.791Z · LW(p) · GW(p)
Interesting post!
Query: How do you define ‘feasibly’? as in ‘Incentive landscapes that can’t feasibly be induced by a reward function’
As from my perspective all possible incentive landscapes can be induced by reward, with sufficient time and energy. Of course a large set of these are beyond the capacity of present human civilization.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-16T17:46:00.073Z · LW(p) · GW(p)
Right, the word "feasibly" is referring to the bullet point that starts "Maybe “Reward is connected to the abstract concept of ‘I want to be able to sing well’?”". Here's a little toy example we can run with: teaching an AGI "don't kill all humans". So there are three approaches to reward design that I can think of, and none of them seem to offer a feasible way to do this (at least, not with currently-known techniques):
- The agent learns by experiencing the reward. This doesn't work for "don't kill all humans" because when the reward happens it's too late.
- The reward calculator is sophisticated enough to understand what the agent is thinking, and issue rewards proportionate to the probability that the current thoughts and plans will eventually lead to the result-in-question happening. So the AGI thinks "hmm, maybe I'll blow up the sun", and the reward calculator recognizes that merely thinking that thought just now incrementally increased the probability that the AGI will kill all humans, and so it issues a negative reward. This is tricky because the reward calculator needs to have an intelligent understanding of the world, and of the AGI's thoughts. So basically the reward calculator is itself an AGI, and now we need to figure out its rewards. I'm personally quite pessimistic about approaches that involve towers-of-AGIs-supervising-other-AGIs, for reasons in section 3.2 here [LW · GW], although other people would disagree with me on that (partly because they are assuming different AGI development paths and architectures than I am [LW · GW]).
- Same as above, but instead of a separate reward calculator estimating the probability that a thought or plan will lead to the result-in-question, we allow the AGI itself to do that estimation, by flagging a concept in its world-model called "I will kill all humans", and marking it as "very bad and important" somehow. (The inspiration here is a human who somehow winds up with the strong desire "I want to get out of debt". Having assigned value to that abstract concept, the human can assess for themselves the probabilities that different thoughts will increase or decrease the probability of that thing happening, and sorta issue themselves a reward accordingly.) The tricky part is (A) making sure that the AGI does in fact have that concept in its world-model (I think that's a reasonable assumption, at least after some training), (B) finding that concept in the massive complicated opaque world-model, in order to flag it. So this is the symbol-grounding problem I mentioned in the text. I can imagine solving it if we had really good interpretability techniques (techniques that don't currently exist), or maybe there are other methods, but it's an unsolved problem as of now.
↑ comment by M. Y. Zuo · 2021-06-16T18:18:48.922Z · LW(p) · GW(p)
Could the hypothetical AGI be developed in a simulated environment and trained with proportionally lower consequences?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-16T18:30:23.429Z · LW(p) · GW(p)
I'm all for doing lots of testing in simulated environments, but the real world is a whole lot bigger and more open and different than any simulation. Goals / motivations developed in a simulated environment might or might not transfer to the real world in the way you, the designer, were expecting.
So, maybe, but for now I would call that "an intriguing research direction" rather than "a solution".
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2021-06-16T20:04:15.242Z · LW(p) · GW(p)
That is true, the desired characteristics may not develop as one would hope in the real world. Though that is the case for all training, not just AGI. Humans, animals, even plants, do not always develop along optimal lines even with the best ‘training’, when exposed to the real environment. Perhaps the solution you are seeking for, one without the risk of error, does not exist.
comment by Steven Byrnes (steve2152) · 2022-03-13T02:00:26.453Z · LW(p) · GW(p)
Keerthana Gopalakrishnan wrote a response blog post here: https://keerthanapg.com/posts/rewardisnotnotenough/
comment by Matt Putz (Mathieu Putz) · 2021-06-22T20:23:08.508Z · LW(p) · GW(p)
Interesting post!
Disclaimer: I have only read the abstract of the "Reward is enough" paper. Also, I don't have much experience in AI safety, but I consider changing that.
Here are a couple of my thoughts.
Your examples haven't entirely convinced me that reward isn't enough. Take the bird. As I see it, something like the following is going on:
Evolution chose to take a shortcut: maybe a bird with a very large brain and a lot of time would eventually figure out that singing is a smart thing to do if it received reward for singing well. But evolution being a ruthless optimizer with many previous generations of experience, shaped two separate rewards in the way you described. Silver et al.'s point might be that when building an AGI, we wouldn't have to take that shortcut, at least not by handcoding it.Assume we have an agent that is released into the world and is trying to optimize reward. It starts out from scratch, knowing nothing, but with a lot of time and the computational capacity to learn a lot.Such an agent has an incentive to explore. So it tries out singing for two minutes. It notes that in the first minute it got 1 unit of reward and in the second 2 (it got better!). All in all, 3 units is very little in this world however, so maybe it moves on.But as it gains more experience in the world it notices that patterns like these can often be extrapolated. Maybe, with its two minutes of experience, if it sang for a third minute, it would get 3 units of reward? It tries and yes indeed. Now it has an incentive to see how far it can take this. It knows the 4 units it expects from the next try will not be worth its time on their own, but the information of whether it could eventually get a million units per minute this way is very much worth the cost!
Something kind of analogous should be true for the spider story.Reward very much provides an incentive for the agent to eventually figure out that after encountering a threat, it should change its behavior, not its interpretations of the world. At the beginning it might get this wrong, but it's unfair to compare it to a human who has had this info "handcoded in" by evolution.If our algorithms don't allow you to learn to update differently in the future, because past update were unhelpful (I don't know, pointers welcome!), then that's not a problem with reward, it's a problem with our algorithms!Maybe this is what you alluded to in your very last paragraph where you speculated that they might just mean a more sophisticated RL algorithm?
Concerning the deceptive AGI etc., I agree problems emerge when we don't get the reward signal exactly right and that it's probably not a safe assumption that we will. But it might still be an interesting question how things would go assuming a perfect reward signal?
My impression is that their answer is "it would basically work", while yours is something like "but we really shouldn't assume that and if we don't, then it's probably better to have separate reward signals etc.". Given the bird example, I assume you also don't agree that things would work out fine even if we did have the best possible reward signal?
Also, I just want to mention that I agree the distinction between within-lifetime RL and intergenerational RL is useful, certainly in the case of biology and probably in machine learning too.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-06-23T12:32:47.824Z · LW(p) · GW(p)
Thanks!
Reward very much provides an incentive for the agent to eventually figure out that after encountering a threat, it should change its behavior, not its interpretations of the world.
In some cases yeah, but I was trying to give an example where the interpretations of the world itself impacts the reward. So it's more-or-less a version of wireheading. An agent cannot learn "Wireheading is bad" on the basis of a reward signal—wireheading by definition has a very high reward signal. So if you're going to disincentivize wireheading, you can't do it by finding the right reward function, but rather by finding the right cognitive architecture. (Or the right cognitive architecture and the right reward function, etc.) Right?
Silver et al.'s point might be that when building an AGI, we wouldn't have to take that shortcut, at least not by handcoding it.
I don't follow your bird example. What are you assuming is the reward function in your example?
In this comment [LW · GW] I gave an example of a thing you might want an agent to do which seems awfully hard to incentivize via a reward function, even if it's an AGI that (you might think) doesn't "die" and lose its (within-lifetime) memory like animals do.
But it might still be an interesting question how things would go assuming a perfect reward signal?
I think that if the AGI has a perfect motivation system then we win, there's no safety problem left to solve. (Well, assuming it also remains perfect over time, as it learns new things and thinks new thoughts.) (See here [AF · GW] for the difference between motivation and reward.)
I suspect that, in principle, any possible motivation system (compatible with the AGI's current knowledge / world-model) can be installed by some possible reward signal. But it might be a reward signal that we can't calculate in practice—in particular, it might involve things like "what exactly is the AGI thinking about right now" which require as-yet-unknown advances in interpretability and oversight. The best motivation-installation solution might involve both rewards and non-reward motivation-manipulation methods, maybe. I just think we should keep an open mind. And that we should be piling on many layers of safety.
Replies from: Mathieu Putz↑ comment by Matt Putz (Mathieu Putz) · 2021-09-04T21:57:21.522Z · LW(p) · GW(p)
Sorry for my very late reply!
Thanks for taking the time to answer, I now don't endorse most of what I wrote anymore.
I think that if the AGI has a perfect motivation system then we win, there's no safety problem left to solve. (Well, assuming it also remains perfect over time, as it learns new things and thinks new thoughts.) (See here for the difference between motivation and reward.)
and from the post:
And if we get to a point where we can design reward signals that sculpt an AGI's motivation with surgical precision, that's fine!
This is mostly where I went wrong. I.e. I assumed a perfect reward signal coming from some external oracle in examples where your entire point was that we didn't have a perfect reward signal (e.g. wireheading).
So basically, I think we agree: a perfect reward signal may be enough in principle, but in practice it will not be perfect and may not be enough. At least not a single unified reward.