Why Subagents?
post by johnswentworth · 2019-08-01T22:17:26.415Z · LW · GW · 48 commentsContents
Preference Representation and Weak Utility Preference By Committee Path-Dependence Applications & Speculations Conclusion None 48 comments
The justification for modelling real-world systems as “agents” - i.e. choosing actions to maximize some utility function - usually rests on various coherence theorems [LW · GW]. They say things like “either the system’s behavior maximizes some utility function, or it is throwing away resources” or “either the system’s behavior maximizes some utility function, or it can be exploited” or things like that. Different theorems use slightly different assumptions and prove slightly different things, e.g. deterministic vs probabilistic utility function, unique vs non-unique utility function, whether the agent can ignore a possible action, etc.
One theme in these theorems is how they handle “incomplete preferences”: situations where an agent does not prefer one world-state over another. For instance, imagine an agent which prefers pepperoni over mushroom pizza when it has pepperoni, but mushroom over pepperoni when it has mushroom; it’s simply never willing to trade in either direction. There’s nothing inherently “wrong” with this; the agent is not necessarily executing a dominated strategy, cannot necessarily be exploited, or any of the other bad things we associate with inconsistent preferences. But the preferences can’t be described by a utility function over pizza toppings.
In this post, we’ll see that these kinds of preferences are very naturally described using subagents. In particular, when preferences are allowed to be path-dependent, subagents are important for representing consistent preferences. This gives a theoretical grounding for multi-agent models of human cognition.
Preference Representation and Weak Utility
Let’s expand our pizza example. We’ll consider an agent who:
- Prefers pepperoni, mushroom, or both over plain cheese pizza
- Prefers both over pepperoni or mushroom alone
- Does not have a stable preference between mushroom and pepperoni - they prefer whichever they currently have
We can represent this using a directed graph:
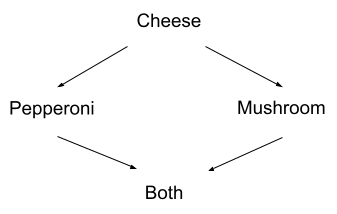
The arrows show preference: our agent prefers B over A if (and only if) there is a directed path from A to B along the arrows. There is no path from pepperoni to mushroom or from mushroom to pepperoni, so the agent has no preference between them. In this case, we’re interpreting “no preference” as “agent prefers to keep whatever they have already”. Note that this is NOT the same as “the agent is indifferent”, in which case the agent is willing to switch back and forth between the two options as long as the switch doesn’t cost anything.
Key point: there is no cycle in this graph. If the agent’s preferences are cyclic, that’s when they provably throw away resources, paying to go in circles. As long as the preferences are acyclic, we call them “consistent”.
Now, at this point we can still define a “weak” utility function by ignoring the “missing” preference between pepperoni and mushroom. Here’s the idea: a normal utility function says “the agent always prefers the option with higher utility”. A weak utility function says: “if the agent has a preference, then they always prefer the option with higher utility”. The missing preference means we can’t build a normal utility function, but we can still build a weak utility function. Here’s how: since our graph has no cycles, we can always order the nodes so that the arrows only go forward along the sorted nodes - a technique called topological sorting. Each node’s position in the topological sort order is its utility. A small tweak to this method also handles indifference.

(Note: I’m using the term “weak utility” here because it seems natural; I don’t know of any standard term for this in the literature. Most people don’t distinguish between these two interpretations of utility.)
When preferences are incomplete, there are multiple possible weak utility functions. For instance, in our example, the topological sort order shown above gives pepperoni utility 1 and mushroom utility 2. But we could just as easily swap them!
Preference By Committee
The problem with the weak utility approach is that it treats the preference between pepperoni and mushroom as unknown - depending on which possible utility we pick, it could go either way. It’s pretending that there’s some hidden preference there which we simply don’t know. But there are real systems where the preference is not merely unknown, but a real preference to stay in the current state.
For example, maybe our pizza-agent is actually a committee which must unanimously agree to any proposed change. One member prefers pepperoni to no pepperoni, regardless of mushrooms; the other prefers mushrooms to no mushrooms, regardless of pepperoni. This committee is not exploitable and does not throw away resources, nor does it have any hidden preference between pepperoni and mushrooms. Viewed as a black box, its “true” preference between pepperoni and mushrooms is to keep whichever it currently has.
In fact, it turns out that we can represent any consistent preferences by a committee requiring unanimous agreement.
The key idea here is called order dimension. We want to take our directed acyclic graph of preferences, and stick it into a multidimensional space so that there is an arrow from A to B if-and-only-if B is higher along all dimensions. Each dimension represents the utility of one subagent on the committee; that subagent approves a change only if the change does not decrease the subagent’s utility. In order for the whole committee to approve a change, the trade must increase (or leave unchanged) the utilities of all subagents. The minimum number of agents required to make this work - the minimum number of dimensions required - is the order dimension of the graph.
For instance, our pizza example has order dimension 2. We can draw it in a 2-dimensional space like this:
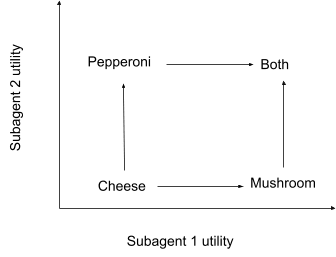
Note that, if there are infinitely many possibilities, then the order dimension can be infinite - we may need infinitely many agents to represent some preferences. But as long as the possibilities are finite, the order dimension will be as well.
Path-Dependence
So far, we’ve interpreted “missing” preferences as “agent prefers to stay in current state”. One important reason for that interpretation is that it’s exactly what we need in order to handle path-dependent preferences.
In practice, path-dependent preferences mostly matter for systems with “hidden state”: internal variables which can change in response to the system’s choices. A great example of this is financial markets: they’re the ur-example of efficiency and inexploitability, yet it turns out that a market does not have a utility function in general (economists call this “nonexistence of a representative agent”). The reason is that the distribution of wealth across the market’s agents functions as an internal hidden variable. Depending on what path the market follows, different internal agents end up with different amounts of wealth, and the market as a whole will hold different portfolios as a result - even if the externally-visible variables, i.e. prices, end up the same.
Most path-dependence results from some hidden state directly, but even if we don’t know the hidden state, we can always add hidden state in order to model path-dependence. Whenever future preferences differ based on how the system reached the current state, we just split the state into two states - one for each possibility. Then we repeat, until we have a full set of states with path-independent preferences between them. These new states are “full” states of the system; from outside, some of them look the same.
An example: suppose I prefer New York to Boston if I just came from DC, but Boston to New York if I just came from Philadelphia.
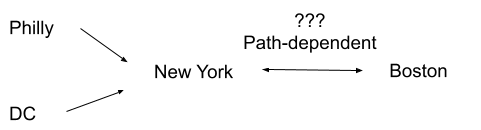
We can represent that with hidden state:
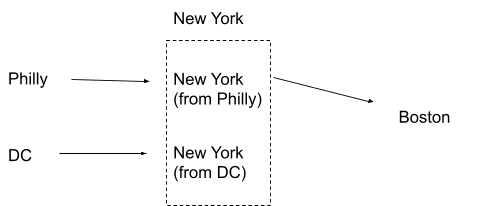
We now have two separate hidden internal nodes, which both correspond to the same externally-visible state “New York”.
Now the key piece: there is no way to get to the “New York (from Philly)” node directly from the “New York (from DC)” node. The agent does not, and cannot, have a preference between these two nodes. Analogously, a market cannot have a preference between two different wealth distributions - the subagents who comprise a market will never spontaneously decide to redistribute their wealth amongst themselves. They always “prefer” (or “decide”) to stay in whatever state they’re currently in.
This is why we need to understand incomplete preferences in order to handle path-dependent preferences: hidden state creates situations where the agent “prefers” to stay in whatever state they’re in.
Now we can easily model the system using subagents exactly as we did for incomplete preferences. We have a directed preference graph between full states (including hidden state), it needs to be acyclic to avoid throwing away resources, so we can find a set of subagents to represent the preferences. In the case of a market, this is just the subagents which comprise the market: they’ll take a trade if it does not decrease the utility of any subagent. (Note, however, that the same externally-visible trade can correspond to multiple possible internal state changes; the subagents will take the trade if any of the possible internal state changes are non-utility-decreasing for all of them. For a market, this means they can trade amongst themselves in response to the external trade in order to make everyone happy.)
Applications & Speculations
We’ve just argued that a system with consistent preferences can be modelled as a committee of utility-maximizing agents. How does this change our interpretation and predictions of the world?
First and foremost: the subagents argument is a generalization of the standard acyclic preferences argument. Anytime we might want to use the acyclic preferences argument, but there’s no reason for the system to be path-independent, we can apply the subagents argument instead. In practice, we usually expect systems to be efficient/inexploitable because of some selection pressure (evolution, market competition, etc) - and that selection pressure usually doesn’t care about path dependence in and of itself.
Main takeaway: pretty much anywhere we’d use an agent with a utility function to model something, we can apply the subagents argument and use a committee of agents with utility functions instead. In particular, this is a good replacement for "weak" utility functions.
Humans are a particularly interesting example. We’d normally use the acyclic preferences argument (among other arguments) to argue that humans approximate utility-maximizers in most situations. But there’s no particular reason to assume path-independence; indeed, human behavior looks highly path-dependent [? · GW]. So, apply the subagents argument. Hypothesis: human behavior approximates the choices of a committee of utility-maximizing agents in most situations.
Sound familiar [? · GW]? The subagents argument offers a theoretical basis for the idea that humans have lots of internal subagents, with competing wants and needs, all constantly negotiating with each other to decide on externally-visible behavior.
In principle, we could test this hypothesis more rigorously. Lots of people think of AI “learning what humans want” by asking questions or offering choices or running simulations. Personally, I picture an AI taking in a scan of a full human connectome, then directly calculating the embedded preferences. Someday, this will be possible. When the AI solves those equations, do we expect it to find a single generic optimizer embedded in the system, approximately optimizing some “utility”? Or do we expect to find a bunch of separate generic optimizers, approximately optimizing several different “utilities”, and negotiating with each other? Probably neither picture is complete yet, but I’d bet the second is much closer to reality.
Conclusion
Let’s recap:
- The acyclic preferences argument is the easiest entry point for efficiency/inexploitability-implies-utility-maximization theorems, but it doesn’t handle lots of important things, including path dependence.
- Markets, for example, are efficient/inexploitable but can’t be represented by a utility function. They have hidden internal state - the distribution of wealth over agents - which makes their preferences path-dependent.
- The subagents argument says that any system with deterministic, efficient/inexploitable preferences can be represented by a committee of utility-maximizing agents - even if the system has path-dependent or incomplete preferences.
- That means we can substitute committees in many places where we currently use utilities. For instance, it offers a theoretical foundation for the idea that human behavior is described by many negotiating subagents.
One big piece which we haven’t touched at all is uncertainty. An obvious generalization of the subagents argument is that, once we add uncertainty (and a notion of efficiency/inexploitability which accounts for it), an efficient/inexploitable path-dependent system can be represented by a committee of Bayesian utility maximizers. I haven’t even started to tackle that conjecture yet; it’s a wide-open problem.
48 comments
Comments sorted by top scores.
comment by johnswentworth · 2020-12-17T18:43:52.529Z · LW(p) · GW(p)
What's the type signature of goals?
The type signature of goals is the overarching topic to which this post contributes. It can manifest in a lot of different ways in specific applications:
- What's the type signature of human values?
- What structure types should systems biologists [LW · GW] or microscope AI [LW · GW] researchers look for in supposedly-goal-oriented biological or ML systems?
- Will AI be "goal-oriented", and what would be the type signature of its "goal"?
If we want to "align AI with human values", build ML interpretability tools, etc, then that's going to be pretty tough if we don't even know what-kind-of-thing we're looking for. When we don't know what-kind-of-things we're talking about, our analysis risks being completely confused - like trying to subtract 3 from "cookie", or measure the angular momentum of life satisfaction.
The traditional go-to answer for these type signatures is "expected utility over world-states": we have a "utility function" mapping world-states (inputs) to real numbers (outputs), and we average utility values over some distribution on world-states.
This go-to answer feels confused, in multiple ways, both in theory and in practice. On the theory side, this review [LW(p) · GW(p)] outlines some problems. On the practice side, "Why Subagents?" mentions that markets are not expected utility maximizers, Kaj's sequence [? · GW] talks about many of the ways in which humans seem to be made of subagents rather than one monolithic utility maximizer, and of course there are also other problems which aren't about subagents.
What Part Of The Problem Do Subagents Address?
What are the inputs to human values, and what are the outputs? That's a reasonable formulation of the type-signature question, in the context of human values.
I consider the "utility function on world-states" answer confused on both parts of the question - inputs and outputs. Subagents address half of that problem: the outputs half. "Why Subagents?" argues that the outputs should be, not one real number, but a set of real numbers, representing the utilities of subagents.
(The other half of the problem - inputs to values - I consider harder, and it's the inputs part which is involved in the most "conceptually difficult" problems of alignment. My current best answer is that the inputs to human values are latent variables in a human's world-model. This provides a clean and intuitive formalization of hairy conceptual/philosophical problems in alignment; see here [LW · GW] for more on that.)
Dangling Threads
There's still a lot of dangling threads. On the theory side, "Why Subagents?" only talks about deterministic preferences, which is dramatically easier than the probabilistic version we really care about. Ideally, we'd like a coherence theorem [LW · GW]. On the empirical side, we'd really like to know if there are subagents embedded in e.g. trained neural networks or bacteria. These empirical investigations will eventually be the real test, but we probably need more work on theory side before we're ready for the empirical component. Subagents are only half of the type signature, and it's a coherence theorem (or something analogous) which would tell us how to look for these structures embedded in real-world systems.
comment by riceissa · 2019-09-17T23:04:01.388Z · LW(p) · GW(p)
When I initially read this post, I got the impression that "subagents = path-dependent/incomplete DAG". After working through more examples, it seems like all the work is being done by "committee requiring unanimous agreement" rather than by the "subagents" part.
Here are the examples I thought about:
- Same as the mushroom/pepperoni situation, with the same two agents, but now each side can retaliate/hijack the rest of the mind if it doesn't get what it wants. For example, if it starts at pepperoni, the mushroom-preferring agent will hijack the rest of the mind to remove the pepperoni, ending up at cheese. But if the agent starts at the "both" node, it will stay there (because both agents are satisfied). The preference relation can be represented as with an extra arrow from . This is still a DAG, and it's still incomplete (in the sense that we can't compare pepperoni vs mushroom) but it's no longer path-dependent, because no matter where we start, we end up at cheese or "both" (I am assuming that toppings-removal can always be done, whereas acquiring new toppings can't).
- Same as the previous example, except now only the mushroom-preferring agent can retaliate/hijack (because the pepperoni-preferring agent is weak or nice). Now the preferences are . This is still a DAG, but now the preferences are total, so we can also view it as a (somewhat weird) single agent. A realistic example of this is given by Andrew Critch, where pepperoni=work, cheese=burnout (i.e. neither work nor friendship), mushroom=friendship, and both=friendship-and-work.
- A modified version of the Zyzzx Prime planet by Scott Alexander. Now whenever we start out at pepperoni, the pepperoni-preferring agent becomes stupid/weak, and loses dominance, so now there are edges from pepperoni to mushroom and "both". (And similarly, mushroom points to both pepperoni and "both".) Now we no longer have a DAG because of the cycle between pepperoni and mushroom.
It seems like when people talk about the human mind being composed of subagents, the deliberation process is not necessarily "committee requiring unanimous agreement", so the resulting preference relations cannot necessarily be represented using path-dependent DAGs.
It also seems like the general framework of viewing systems as subagents (i.e. not restricting to "committee requiring unanimous agreement") is broad enough that it can basically represent any kind of directed graph. On one hand, this is suspicious (if everything can be viewed as a bunch of subagents, then maybe the subagents framework isn't adding anything after all). On the other hand, this suggests that claims of subagents are not really about the resulting behavior/preference ordering of the system, but rather about the internal dynamics of the system.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-09-18T00:26:51.321Z · LW(p) · GW(p)
I definitely agree that most of the work is being done by the structure in which the subagents interact (i.e. committee requiring unanimous agreement) rather than the subagents themselves. That said, I wouldn't get too hung up on "committee requiring unanimous agreement" specifically - there are structures which behave like unanimous committees but don't look like a unanimous committee on the surface, e.g. markets. In a market, everyone has a veto, but each agent only cares about their own basket of goods - they don't care if somebody else' basket changes.
In the context of humans, one way to interpret this post is that it predicts that subagents in a human usually have veto power over decisions directly touching on the thing they care about. This sounds like a pretty good model of, for example, humans asked about trade-offs between sacred values.
comment by Scott Garrabrant · 2019-09-03T00:07:36.791Z · LW(p) · GW(p)
Not sure if you've seen it, but this paper by Critch and Russell might be relevant when you start thinking about uncertainty.
comment by Thomas Kwa (thomas-kwa) · 2022-07-01T03:37:28.895Z · LW(p) · GW(p)
Note that the particular form of "nonexistence of a representative agent" John mentions is an original result that's not too difficult to show informally, but hasn't really been written down formally either here or in the economics literature.
Ryan Kidd and I did an economics literature review a few weeks ago for representative agent stuff, and couldn't find any results general enough to be meaningful. We did find one paper that proved a market's utility function couldn't be of a certain restricted form, but nothing about proving the lack of a coherent utility function in general. A bounty also hasn't found any such papers.
comment by Donald Hobson (donald-hobson) · 2019-08-02T12:38:47.675Z · LW(p) · GW(p)
Suppose you offer to pay a penny to swap mushroom for pepperoni, and then another penny to swap back. This agent will refuse, failing to money pump you.
Suppose you offer the agent a choice between pepperoni or mushroom, when it currently has neither. Which does it choose? If it chooses pepperoni, but refuses to swap mushroom for pepperoni then its decisions depend on how the situation is framed. How close does it have to get to the mushroom before they "have" mushroom and refuse to swap? Partial preferences only make sense when you don't have to choose between unordered options.
We could consider the agent to have a utility function with a term for time consistency, they want the pizza in front of them at times 0 and 1 to be the same.
Replies from: Kaj_Sotala, johnswentworth↑ comment by Kaj_Sotala · 2019-08-07T10:06:43.142Z · LW(p) · GW(p)
If it chooses pepperoni, but refuses to swap mushroom for pepperoni then its decisions depend on how the situation is framed. How close does it have to get to the mushroom before they "have" mushroom and refuse to swap?
Relevant example [LW · GW].
I previously suggested [? · GW] that revealing the two options as equivalent will bring the two subagents into a standstill, requiring some third factor to help decide. Which seems close to what happens if I introspect on what happens if I'm offered a choice between two foods that I think are equally good - I just decide at random or go by e.g. some force of habit that provides a slight starting point bias [? · GW].
↑ comment by johnswentworth · 2019-08-02T15:59:45.701Z · LW(p) · GW(p)
Good question. Let's talk about analogous choices for a market, since that's a more realistic system, and then we can bring it back to pizza.
In a market, partial preferences result from hidden state. There is never a missing preference between externally-visible states (i.e. the market's aggregate portfolio). However, the market could have a choice between two hidden states: given one aggregate trade, the market could implement it two different ways, resulting in different wealth distributions. For instance, if I offer the market $5000 for 5 shares of AAPL, then those 5 shares can come from any combination of the internal agents holding AAPL, and the $5000 can be distributed among them in many different ways. This means the market's behavior is underspecified: there are multiple possible solutions for its behavior. Economists call the set of possible solutions the "contract curve". Usually, additional mechanics are added to narrow down the possible behavior - most notably the Law of One Price, the strongest form of which gives locally-unique solutions for the market's behavior. For real markets, Law of One Price is an approximation, and the exact outcome will depend on market microstructure: market making, day trading, and so forth.
Now let's translate this back to the original question about pizza.
Short answer: the preferences don't specify which choice the system takes when offered mushroom or pepperoni. It depends on internal structure of the system, which the preferences abstract away. And that's fine - as the market example shows, there are real-world examples where that abstraction is still useful. Additionally, for real-world cases of interest, the underspecified choices will usually be between hidden states, so the underspecified behavior will itself be "hidden" - it will only be externally-visible via path-dependence of later preferences.
comment by tailcalled · 2022-11-16T19:30:29.933Z · LW(p) · GW(p)
This post has a lot of implications. But I feel like one of them might be underrated: Utilitarianism is wrong? I'm not sure if I'm reading too much into it, but I feel like implicitly this post demolishes utilitarianism as usually understood.
We might think of utilitarianism as relying on a few simple intuitive moral arguments like "the point of morality is to make people better off"... as well as relying on the assumption that morality is path-independent. This is the key assumption that this post brings to life. And I feel like if you challenged people on whether morality is path-independent, then the assumption would be "obviously not".
Whenever I've seen people people discussing whether utilitarianism is correct, I've been linking them to this post. So I would be curious if you agree with the assessment that this is a strong challenge to utilitarianism.
I think it's also interesting, because it suggests that we should think of morality in terms of subagents. Obviously there's a few different ways of going about that, but one thing I've been playing with recently is to think of morality as a sort of renormalization of individual preferences in large-scale groups. That is, you can take as input the preferences of all individual people or something, and then you can try and derive a small set of subagents that approximately represent their preference ordering.
Replies from: donald-hobson, Raemon, sharmake-farah↑ comment by Donald Hobson (donald-hobson) · 2022-12-25T00:43:54.145Z · LW(p) · GW(p)
This post is describing a style of agent that can exist. Whether or not they are coherent is arguable. You could say "sure, that type of agent is coherent. But I happen to be an agent with totally ordered preferences. " Or you could say, "I as a whole act according to a committee of utilitarianism and personal hedonism".
Utilitarianism, on some abstract level, can only ever be a fact about the sort of agent you (or other people) are or want to be. There are arguments of "if you aren't utilitarian, then ..." but some agents are fine with "...". It is a specific human trait to see this argument, decide that "..." is bad and act utilitarian.
↑ comment by Raemon · 2022-11-16T19:42:40.315Z · LW(p) · GW(p)
I think this is probably right, but I also think the sequences generally made a solid case for that from a few different angles, so it was already pretty established on LW by the time this post came out.
Replies from: DanielFilan↑ comment by DanielFilan · 2022-12-27T18:43:56.249Z · LW(p) · GW(p)
Huh, I don't remember that. What's an example post that makes such a case?
Replies from: Raemon↑ comment by Raemon · 2022-12-27T19:15:48.424Z · LW(p) · GW(p)
Here are some ones that feel relevant. (This was me searching for posts where Eliezer is criticizing having "one great moral principle" that you could give an AI, which is a major theme. One major point of the sequences is that morality is quite complicated)
https://www.lesswrong.com/s/fqh9TLuoquxpducDb/p/NnohDYHNnKDtbiMyp [? · GW]
https://www.lesswrong.com/posts/4ARaTpNX62uaL86j6/the-hidden-complexity-of-wishes [LW · GW]
https://www.lesswrong.com/posts/RFnkagDaJSBLDXEHs/heading-toward-morality [LW · GW]
Replies from: DanielFilan↑ comment by DanielFilan · 2022-12-28T07:14:02.622Z · LW(p) · GW(p)
The arguments here sound like "morality is actually complex, and you shouldn't oversimplify it". But utilitarianism is pretty complex, in the relevant sense, so this kind of fails to land for me.
Replies from: Raemon↑ comment by Raemon · 2022-12-28T07:27:35.697Z · LW(p) · GW(p)
Hmm. What do you mean by "complex in the relevant sense?". The two obvious things you might call complex are "the part where you figure out to estimate a person's utility in the first place, and aggregate that across people", and "the part where in practice you need all kinds of complex rules of thumb or brute force evaluation of second-order consequences."
The former seems legit "hard", I guess, but sorta seems like a one-shot upfront scientific/philosophical problem that isn't that hard. (I realize it's, like, unsolved after decades of relevant work, but, idk, still, doesn't seem fundamentally confusing to me?). Is this what you meant by "relevant sense?"
The second seems complex in some sense, but seems sorta like how AlphaGo can figure out complex Go strategy given the simple task of "play go against yourself a bunch". And it seemed like the sequences were arguing against this sort of thing being that easy.
Also I guess depends what sort of utilitarianism you mean, but note:
https://www.lesswrong.com/posts/synsRtBKDeAFuo7e3/not-for-the-sake-of-happiness-alone [LW · GW]
I dunno if there's a "not for the sake of aggregate preference utility (alone)", but I felt like the sequences were arguing (albeit indirectly) that this was still more complex than you (generic you) were probably imagining.
Replies from: DanielFilan↑ comment by DanielFilan · 2023-01-08T22:22:10.029Z · LW(p) · GW(p)
I mean the former: like, whatever "utility" is is not a simple thing to define in terms of things we have a handle on ("pleasurable mental states" does not count as a simple definition), and even if you allow yourself access to standard language about mental states I don't think it's so easy (e.g. there are a bunch of different sorts of mental states that might fall under the broad umbrella of "pleasure").
I do agree that "not for the sake of happiness alone" argues against utilitarianism.
↑ comment by Noosphere89 (sharmake-farah) · 2022-11-22T02:28:30.511Z · LW(p) · GW(p)
In my ontology, there is no such thing as morality being right or wrong in any sense, so I don't understand why this is an implication of this post.
Replies from: tailcalled↑ comment by tailcalled · 2022-11-22T18:19:59.363Z · LW(p) · GW(p)
Well I guess you should stay out of moral discussions then.
comment by Thomas Kwa (thomas-kwa) · 2022-04-21T21:45:51.357Z · LW(p) · GW(p)
This post makes two different points:
- Path-dependent preferences are not necessarily incoherent in practice. Therefore, the expected-utility-related coherence theorems are too strong. The correct selection theorems for agents actually generated by base optimizers will be some weaker notion than expected utility maximization.
- Path-dependent preferences are well-described by subagents. One particularly strong reason for this is the subagents argument: that subagents are sufficient to describe any path-dependent consistent preferences.
To decide whether subagents are the right model, I think we need both
- additional arguments for the niceness of subagents: how many subagents are required to represent path-dependent agents in practice? Are there reasons why subagents should arise from the selection process instead of a single EU maximizer?
- to investigate other possible models for path-dependent consistent behavior. Maybe one such model is a utility function with some explicit path-dependence term, though there are probably better ones I haven't thought of.
↑ comment by Thomas Kwa (thomas-kwa) · 2022-04-30T17:40:21.427Z · LW(p) · GW(p)
The number of subagents required to represent a partial preference ordering is the order dimension of the poset. If it's not in the number of states, this would be bad for the subagents hypothesis! There are exponentially many possible states of the world, and superlogarithmic order dimension would mean agents have a number of subagents superlinear in the number of atoms in the world. So what are the order dimensions of posets we care about? I found the following results with a brief search:
- The order dimension of a poset is less than or equal to its width (the size of the largest set of pairwise incomparable elements). Source.
- This doesn't seem like a useful upper bound. If you have two sacred values, lives and beauty, then there are likely to be arbitrarily many incomparable states on the lives-beauty Pareto frontier, but the order dimension is two.
- This paper finds the following bounds for order dimension of a random poset (defined by taking all edges in a random graph with n vertices where each edge has probability p, orienting them, then taking the transitive closure). If , the following result holds almost surely:
- where .
- The order dimension of a random poset decreases as p increases. We should expect agents in the real world to have reasonably high , since refusing to make a large proportion of trades is probably bad for reward.
- If , then
- If , then
- If , we have
- This is still way too many subagents (~sqrt of number of atoms in the world) to actually make sense as e.g. a model of humans, but at least it can physically fit in an agent.
- Of course, this is just a heuristic argument, and if partial preference orderings in real life have some special structure, the conclusion might differ.
↑ comment by Nora Belrose (nora-belrose) · 2022-06-05T18:02:09.086Z · LW(p) · GW(p)
Of course, this is just a heuristic argument, and if partial preference orderings in real life have some special structure, the conclusion might differ.
Hmm I may be missing something here, but I suspect that "partial preference orderings in real life have some special structure" in the relevant sense, is very likely true. Human preferences don't appear to be a random sample from the set of all possible partial orders over "world states" (or more accurately, human models of worlds).
First of all, if you model human preferences as a vector-valued utility function (i.e. one element of the vector per subagent) it seems that it has to be continuous, and probably Lipschitz, in the sense that we're limited in how much we can care about small changes in the world state. There's probably some translation of this property into graph theory that I'm not aware of.
Also, it seems like there's one or a handful of preferred factorizations [LW · GW] of our world model into axes-of-value, and different subagents will care about different factors/axes. More specifically, it appears that human preferences have a strong tendency to track the same abstractions that we use for empirical prediction of the world; as John says, human values are a function of humans' latent variables [LW · GW]. If you stop believing that souls and afterlives exist as a matter of science, it's hard to continue sincerely caring about what happens to your soul after you die. We also don't tend to care about weird contrived properties with no explanatory/predictive power like "grue" (green before 1 January 2030 and blue afterward).
To the extent this is the case, it should dramatically– exponentially, I think– reduce the number of posets that are really possible and therefore the number of subagents needed to describe them.
comment by Morgan_Rogers · 2021-10-26T14:26:39.778Z · LW(p) · GW(p)
The example you give has a pretty simple lattice of preferences, which lends itself to illustrations but which might create some misconceptions about how the subagent model should be formalized. For example, in your example you assume that the agents' preferences are orthogonal (one cares about pepperoni, the other about mushrooms, and each is indifferent to the opposite direction), the agents have equal weighting in the decision-making, the lattice is distributive... Compensating for these factors, there are many ways that a given 'weak utility' can be expressed in terms of subagents. I'm sure there are optimization questions that follow here, about the minimum number of subagents (dimensions) needed to embed a given weak-utility function (partially ordered set), and about when reasonable constraints such as orthogonality of subagents can be imposed. There are also composition questions: how does a committee of agents with subagents behave?
comment by habryka (habryka4) · 2020-12-15T06:16:04.250Z · LW(p) · GW(p)
This post felt like it took a problem that I was thinking about from 3 different perspectives and combined them in a way that felt pretty coherent, though I am fully sure how right it gets it. Concretely, the 3 domains I felt it touched on were:
- How much can you model human minds as consistent of subagents?
- How much can problems with coherence theorems be addressed by modeling things as subagents?
- How much will AI systems behave like consisting of multiple subagents?
All three of these feel pretty important to me.
comment by Bucky · 2019-08-02T21:28:00.482Z · LW(p) · GW(p)
Imagine a second agent which has the same preferences but an anti-status-quo preference between mushroom and pepperoni.
This would be exploitable by a third agent who is able to compare mushroom and pepperoni but assigns equal utilities to both. However the original agent described in the OP would not be able to exploit agent 2 (if agent 1's status-quo bias is larger than agent 2's anti-status-quo bias), so agent 3 dominates agent 1 in terms of performance.
Over multiple dimensions agent 3 becomes much more complex than agent 1. Having a status quo bias makes sense as a way to avoid being exploited whilst also being less computationally expensive than tracking or calculating every preference ordering.
Assuming agent 2 is rare, the loss incurred by not being able to exploit others is small.
comment by Zack_M_Davis · 2021-08-06T04:18:24.653Z · LW(p) · GW(p)
a real preference to stay in the current state [...] financial markets[ are] the ur-example of efficiency and inexploitability, yet it turns out that a market does not have a utility function in general [...] hidden state creates situations where the agent "prefers" to stay in whatever state they're in.
Wait, does this help solve the problem of fully updated deference?!
My summary: one of the reasons to expect AI to be dangerous by default is that smart agents are coherent, coherent agents are expected utility maximizers [LW · GW], and sufficiently powerful expected utility maximizers destroy everything in their path: even if you're my best friend in the whole actually-existing world, if I'm sufficiently powerful, I'm still going to murder you and use your atoms to build my best friend across all possible worlds.
This would seem to sink alignment schemes of the form "Just make the AI uncertain about the correct utility function, and have it ask us questions—and let us modify it if necessary—when it's not sure." Becuase if it's sufficiently powerful, it'll just disassemble our brains to figure out how we would have responded to questions, without letting us modify it. (Which would be fine if the value-loading problem were already completely solved—disassemble us now and resurrect us after it's done turning off all those negentropy-wasting stars—but you'd want to be very sure of that, first.)
But if the "coherent agents are expected utility maximizers" part isn't true because state-dependent preferences are still coherent in the relevant sense, doesn't deference/corrigibility potentially become a lot easier? In some sense, you just ("just") need one of the subagents on the committee to veto all plans that prevent us from hitting the Off switch ... right?
Replies from: johnswentworth↑ comment by johnswentworth · 2021-08-06T05:39:23.003Z · LW(p) · GW(p)
I mean... the subagent who vetos all the "prevent human from hitting the Off switch" plans must itself be a utility-maximizer, so we have to be able to write a utility-maximizer which wants to not-block the off switch anyway.
If you want a hot take on fully updated deference, I'd recommend reading The Pointers Problem [LW · GW], then considering how various AI architectures would handle uncertainty in their own objective-pointers.
comment by Kaj_Sotala · 2020-12-02T13:03:41.421Z · LW(p) · GW(p)
The "many decisions can be thought of as a committee requiring unanimous agreement" model felt intuitively right to me, and afterwards I've observed myself behaving in ways which seem compatible with it, and thought of this post.
Replies from: jbkjr↑ comment by jbkjr · 2021-07-17T11:54:12.821Z · LW(p) · GW(p)
Wouldn't decisions about e.g. which objects get selected and broadcast to the global workspace be made by a majority or plurality of subagents? "Committee requiring unanimous agreement" feels more like what would be the case in practice for a unified mind, to use a TMI term. I guess the unanimous agreement is only required because we're looking for strict/formal coherence in the overall system, whereas e.g. suboptimally-unified/coherent humans with lots of akrasia can have tug-of-wars between groups of subagents for control.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2021-07-17T18:17:28.517Z · LW(p) · GW(p)
The way I'd think of it, it's not that you literally need unanimous agreement, but that in some situations there may be subagents that are strong enough to block a given decision. And then if you only look at the subagents that are strong enough to exert a major influence on that particular decision (and ignore the ones either who don't care about it or who aren't strong enough to make a difference), it kind of looks like a committee requiring unanimous agreement.
It gets a little handwavy and metaphorical but so does the concept of a subagent. :)
Replies from: jbkjr↑ comment by jbkjr · 2021-07-17T18:40:30.901Z · LW(p) · GW(p)
The way I'd think of it, it's not that you literally need unanimous agreement, but that in some situations there may be subagents that are strong enough to block a given decision.
Ah, I think that makes sense. Is this somehow related to the idea that the consciousness is more of a "last stop for a veto from the collective mind system" for already-subconsciously-initiated thoughts and actions? Struggling to remember where I read this, though.
It gets a little handwavy and metaphorical but so does the concept of a subagent.
Yeah, considering the fact that subagents are only "agents" insofar as it makes sense to apply the intentional stance (the thing we'd like to avoid having to apply to the whole system because it seems fundamentally limited) to the individual parts, I'm not surprised. It seems like it's either "agents all the way down" or abandon the concept of agency altogether (although posing that dichotomy feels like a suspicious presumption of agency, itself!).
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2019-09-09T14:04:27.700Z · LW(p) · GW(p)
Thanks, this is really cool!
I'm a bit concerned about this sort of thing: "The subagents argument offers a theoretical basis for the idea that humans have lots of internal subagents, with competing wants and needs, all constantly negotiating with each other to decide on externally-visible behavior."
A worry I have about the standard representation theorems is that they prove too much; if everything can be represented as having a utility function, then maybe it's not so useful to talk about utility functions. Similarly now I worry: I thought when people talked about subagent theories of mind, they meant something substantial by this--not merely that the mind has incomplete (though still acyclic) preferences!
Replies from: johnswentworth↑ comment by johnswentworth · 2019-09-10T17:39:15.552Z · LW(p) · GW(p)
Not sure if you've ever taken a class on electricity & magnetism, but one of the central notions is the conservative vector field - electric fields being the standard example. You take an electron, and drag it around the electric field. Sometimes you'll have to push it against the field, sometimes the field will push it along for you. You add up all the energy spent pushing (or energy extracted when the field pushes it for you), and find an interesting result: the energy spent moving the electron from point A to point B is completely independent of the path taken. Any two paths from A to B will require exactly the same energy expenditure.
That's a pretty serious constraint on the field - the vast majority of possible vector fields are not conservative.
It's also exactly the same constraint as a utility function: a vector field is conservative if-and-only-if it is acyclic, in the sense of having zero circulation around any closed curve. Indeed, this means that conservative vector fields can be viewed as utility functions: the field itself is the gradient of a "utility function" (called the potential field), and it accepts any local "trade" which increases utility - i.e. moving an electron up the gradient of the utility function. Conversely, if we have preferences represented by local preferences in a (finite-dimensional) vector space, then we can summarize those preferences with a utility function if-and-only-if the field is conservative.
My point is: acyclicity is a major constraint on a system's behavior. It is definitely not the case that "everything can be represented as having a utility function".
Now, there is a separate piece to your concern: when people talk about subagent theories of mind, they think that the brain is actually implemented using subagents, not merely behaving in a manner equivalent to having subagents. It's a variant of the behavior vs architecture question [LW · GW]. In this case, we can partially answer the question: subagent architectures have a relative advantage over most non-subagent architectures in that the subagent architectures won't throw away resources via cyclic preferences, whereas most of the non-subagent architectures will. The only non-subagent architectures which don't throw away resources are those whose behavior just so happens to be equivalent to subagents.
If a system with a subagent architecture is evolving, then it will mostly be exploring different configurations of subagents - so any configuration it explores will at least not throw away resources. On the other hand, with a non-subagent architecture, we'd expect that there's some surface in configuration space which happens to implement agent-like behavior, and any changes which move off that surface will throw away at least some resources - and any single-nucleotide change is likely to move off the surface. In other words, a subagent architecture is more likely to have a nice evolutionary path from wherever it starts to the maximum-fitness design, whereas a non-subagent architecture may not have such a smooth path. As an evolutionary analogue to the behavior vs architecture question, I'd conjecture: subagent-like behavior generally won't evolve without subagent-like architecture, because it's so much easier to explore efficient designs within a subagent architecture.
comment by Ben Pace (Benito) · 2019-09-01T21:24:04.918Z · LW(p) · GW(p)
Curated - great explanation of some key technical ideas, tying together some applied rationality with the theoretical rationality.
comment by jbkjr · 2021-07-17T09:55:58.936Z · LW(p) · GW(p)
The arrows show preference: our agent prefers A to B if (and only if) there is a directed path from A to B along the arrows.
Shouldn't this be "iff there is a directed path from B to A"? E.g. the agent prefers pepperoni to cheese, so there is a directed arrow from cheese to pepperoni.
Replies from: johnswentworth↑ comment by johnswentworth · 2021-07-17T12:27:56.615Z · LW(p) · GW(p)
Nice catch, thanks.
comment by romeostevensit · 2019-09-09T16:17:15.348Z · LW(p) · GW(p)
One thing I don't understand about cycles is that they seem fine as long as you have a generalized cycle detector and a single instance of a cycle getting generated is fine because the losses from one (or a few) rounds is small. I guess people think of utility functions as fixed normally, but this sort of rolls in fixed point/convergence intuitions into the problem formulation.
One frame is that utility functions as a formalism are just an extension of the great rationality debate.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-09-16T18:01:06.894Z · LW(p) · GW(p)
If we have a cycle detector which prevents cycling, then we don't have true cycles. Indeed, that would be an example of a system with internal state: the externally-visible state looks like it cycles, but the full state never does - the state of the cycle detector changes.
So this post, as applied to cycle-detectors, says: any system which detects cycles and prevents further cycling can be represented by a committee of utility-maximizing agents.
comment by Gordon Seidoh Worley (gworley) · 2019-08-02T17:30:00.107Z · LW(p) · GW(p)
With regards to path dependence and partial preferences, a certain amount of this feels like the model simply failing to fully capture the preference on the first go. That is, preferences are conditional, i.e. they are conditioned on the environment in which they are embedded, and the sense in which there is partiality and path dependence issues seems to me to arise entirely from partial specification, not the preference being partial itself. Thus I have to wonder, why pursue models that deal with partial preferences and their issues rather than trying to build better models of preferences that better capture the full complexity of preferences?
To a certain extent it feels to me like with partial preferences we're trying to hang on to some things that were convenient about older models while dealing with the complexities of reality they failed to adequately model, rather than giving up our hope to patch the old models and look for something better suited to what we are trying to model (yes, I'm revealing my own preference here for new models based on what we learned from old models instead of incrementally improving old models).
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-02T18:53:08.080Z · LW(p) · GW(p)
I recommend thinking about the market example. The difficulty for markets is not that the preferences are "conditioned on the environment"; exactly the opposite. The problem is that the preferences are conditional on internal state; they can't be captured only by looking at the external environment.
For examples like pepperoni vs mushroom pizza, where we're just thinking about partial preferences directly, it's reasonable to say that the problem is partial specification. Presumably the system does something when it has to choose between pepperoni and mushroom - see Donald Hobson's comment for more on that. But path dependence is a different beast. Once we start thinking about internal state and path dependence, partial preferences are no longer just due to partial specification - they're due to the system having internal variables which it doesn't "want" to change.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2019-08-02T20:07:44.201Z · LW(p) · GW(p)
The problem is that the preferences are conditional on internal state; they can't be captured only by looking at the external environment.
I think I wasn't clear enough about what I meant. I mean to question specifically why excluding such so-called "internal" state is the right choice. Yes, it's difficult and inconvenient to work with that which we cannot externally observe, but I think much of the problem is that our models leave this part of the world out because it can't be easily observed with sufficient fidelity (yet). The division between internal and external is somewhat arbitrary in that it exists at the limit of our observation powers, not generally as a natural limit of the system independent of our knowledge of it, so I question whether it makes sense to then allow that limit to determine the model we use, rather than stepping back and finding a way to make the model larger such that it can include the epistemological limits that create partial preferences as a consequence rather than being ontologically basic to the model.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-02T21:17:35.472Z · LW(p) · GW(p)
Ah, that makes more sense. There's several answers; the main answer is that the internal/external division is not arbitrary.
First: at least for coherence-type theorems, they need to work for any choice of system which satisfies the basic type signature (i.e. the environment offers choices, the system "decides" between them, for some notion of decision). The theorem has to hold regardless of where we draw the box. On the other hand, you could argue that some theorems are more useful than others and therefore we should draw our boxes to use those theorems - even if it means fewer "systems" qualify. But then we can get into trouble if there's a specific system we want to talk about which doesn't qualify - e.g. a human.
Second: in this context, when we talk about "internal" variables, that's not an arbitrary modelling choice - the "external" vs "internal" terminology is hiding a functionally-important difference. Specifically, the "external" variables are anything which the system chooses between, anything we could offer in a trade. It's not about the limits of observation, it's about the limits of trade or tradeoffs or choices. The distribution of wealth within a market is "internal" not because we can't observe it (to a large extent we can), but because it's not something that the market itself is capable of choosing, even in principle.
Now, it may be that there are other things in the external world which the market can't make choice about as a practical matter, like the radius of the moon. But if it somehow became possible to change the radius of the moon, then there's no inherent reason why the market can't make a choice on that - as opposed to the internal wealth distribution, where any choice would completely break the market mechanism itself.
That leads into a third answer: think of the "internal" variables as gears, pieces causally involved in making the decision. The system as a whole can have preferences over the entire state of the external world, but if it has preferences about the gears which are used to make decisions... well, then we're going to end up in a self-referential mess. Which is not to say that it wouldn't be useful to think about such self-referential messes; it would be an interesting embedded agency problem.
comment by Xodarap · 2019-10-09T21:03:51.084Z · LW(p) · GW(p)
This can be formalized in the following sense:
1. Suppose your set of values are lattice-ordered, and
2. Suppose they admit some sort of group structure that preserves this ordering: if you prefer apples to oranges, then you prefer two apples to two oranges, and so forth.
Then:
1. As long as you don't have "infinitely" good outcomes, your preferences can be represented by a utility function.
2. If you have "infinitely" good outcomes, your preferences can be represented by a set of agents, each of which has a utility function, and your overall preference is equivalent to these subagents "unanimously agreeing".
The former claim is due to Holders theorem, and the latter is a result of the Hahn embedding theorem. I wrote a little bit more about this here.
↑ comment by johnswentworth · 2019-10-09T21:26:53.885Z · LW(p) · GW(p)
Wouldn't the Hahn embedding theorem result in a ranking of the subagents themselves, rather than requiring unanimous agreement? Whichever subagent corresponds to the "largest infinities" (in the sense of ordinals) makes its choice, the choice of the next agent only matters if that first subagent is indifferent, and so on down the line.
Anyway, I find the general idea here interesting. Assuming a group structure seems unrealistic as a starting point, but there's a bunch of theorems of the form "any abelian operation with properties X, Y, Z is equivalent to real/vector addition", so it might not be an issue.
Replies from: Xodarapcomment by gjm · 2019-08-03T13:17:57.786Z · LW(p) · GW(p)
Consider a pizza-eating agent with the following "grass is always greener on the other side of the fence" preference: it has no "initial" preference between toppings but as soon as it has one it realises it doesn't like it and then prefers all other not-yet-tried toppings to the one it's got (and to others it's tried).
There aren't any preference cycles here -- if you give it mushroom it then prefers pepperoni, but having switched to pepperoni it then doesn't want to switch back to mushroom. If our agent has no opinion about comparisons between all toppings it's tried, and between all toppings it hasn't tried, then there are no outright inconsistencies either.
Can you model this situation in terms of committees of subagents? Can you do it without requiring an unreasonably large number of subagents?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-03T17:07:09.882Z · LW(p) · GW(p)
Those are consistent path-dependent preferences, so they can be modeled by a committee of subagents by the method outlined in the post. It would require something like states, I think, one for each current topping times each possible set of toppings tried already. Off the top of my head, I'm not sure how many dimensions it would require, but you can probably figure it out by trying a few small examples.
That said, the right way to model those particular preferences is to introduce uncertainty and Bayesian reasoning. The "hidden state" in this case is clearly information the agent has learned about each topping.
This raises another interesting question: can we just model all path-dependent preferences by introducing uncertainty? What subset can be modeled this way? Nonexistence of a representative agent for markets suggests that we can't always just use uncertainty, at least without changing our interpretations of "system" or "preference" or "state" somewhat. On the other hand, in some specific cases it is possible to interpret the wealth distribution in a market as a probability distribution in a mixture model - log utilities let us do this, for instance. So I'd guess that there's some clever criteria that would let us tell whether a committee/market with given utilities can be interpreted as a single Bayesian utility maximizer.